
Noisy Remote Sensing Scene Classification via Progressive Learning Based on Multiscale Information Exploration


Abstract
:
1. Introduction
- We propose a specialized network (i.e., MIEN) and a specific learning algorithm (i.e., PLA) to effectively address the challenges posed by noisy labels in RS scene classification tasks. Combining them, not only can the significant features be mined from RS scenes, but also the adverse effects caused by noisy labels can be whittled down.
- To fully explore the contents within RS scenes, TAMSFM is developed, which fuses the different immediate features learned by ResNet18 in an interactive self-attention manner. This way, the local, multiscale, and intra-/inter-level global information hidden in RS scenes can be mined.
- MIEN is designed as a dual-branch structure to mitigate the influence of noisy samples at the network architecture level. Two branches have the same sub-networks, i.e., ResNet18 embedded with TAMSFM. MIEN can instinctively discover the possible noisy RS scenes through the different parameter updating schemes and the temporal information-aware parameter-transmitting strategy.
- PLA contains three consecutive steps, i.e., DNL, APL, and ESL, to further whittle noisy samples’ impacts and improve the classification results. After applying them to MIEN orderly, the comprehensive relations between RS scenes and their annotations can be learned. Thus, the behavior of MIEN can be guaranteed, even if some RS scenes are misannotated.
2. Related Work
2.1. RS Scene Classification
2.2. RS Scene Classification with Noisy Labels
3. Materials
3.1. Data Set Description
3.2. Evaluation Metrics
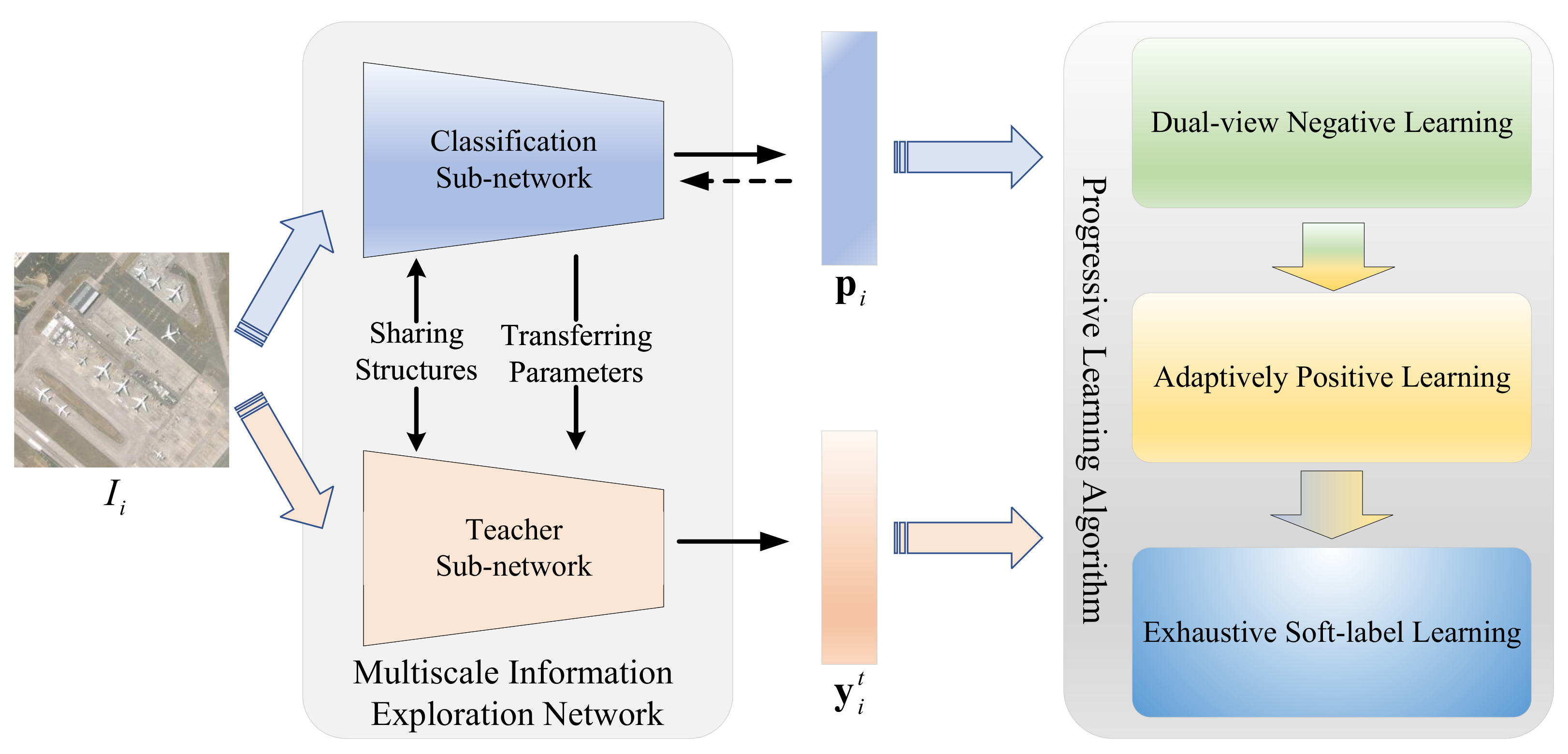
4. Proposed Method
4.1. Preliminaries
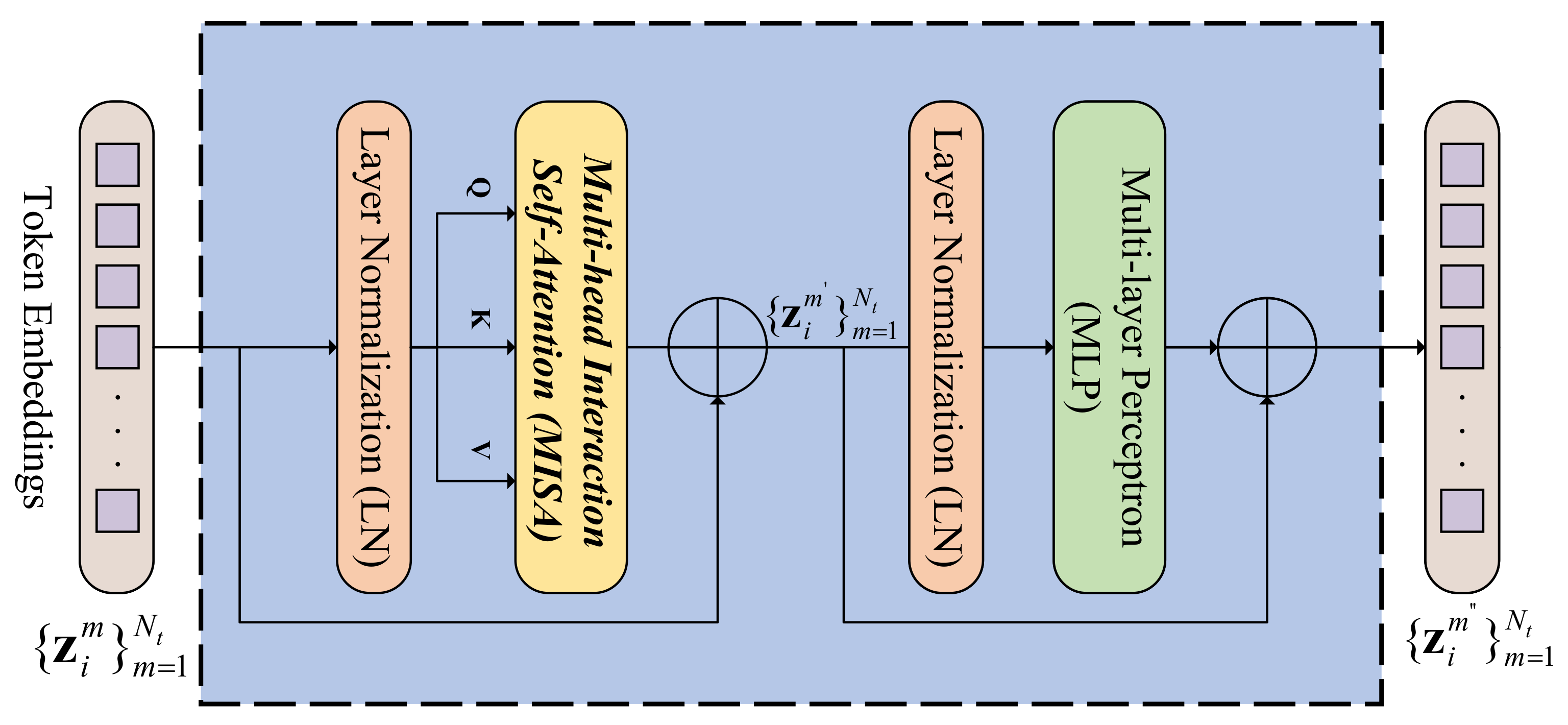
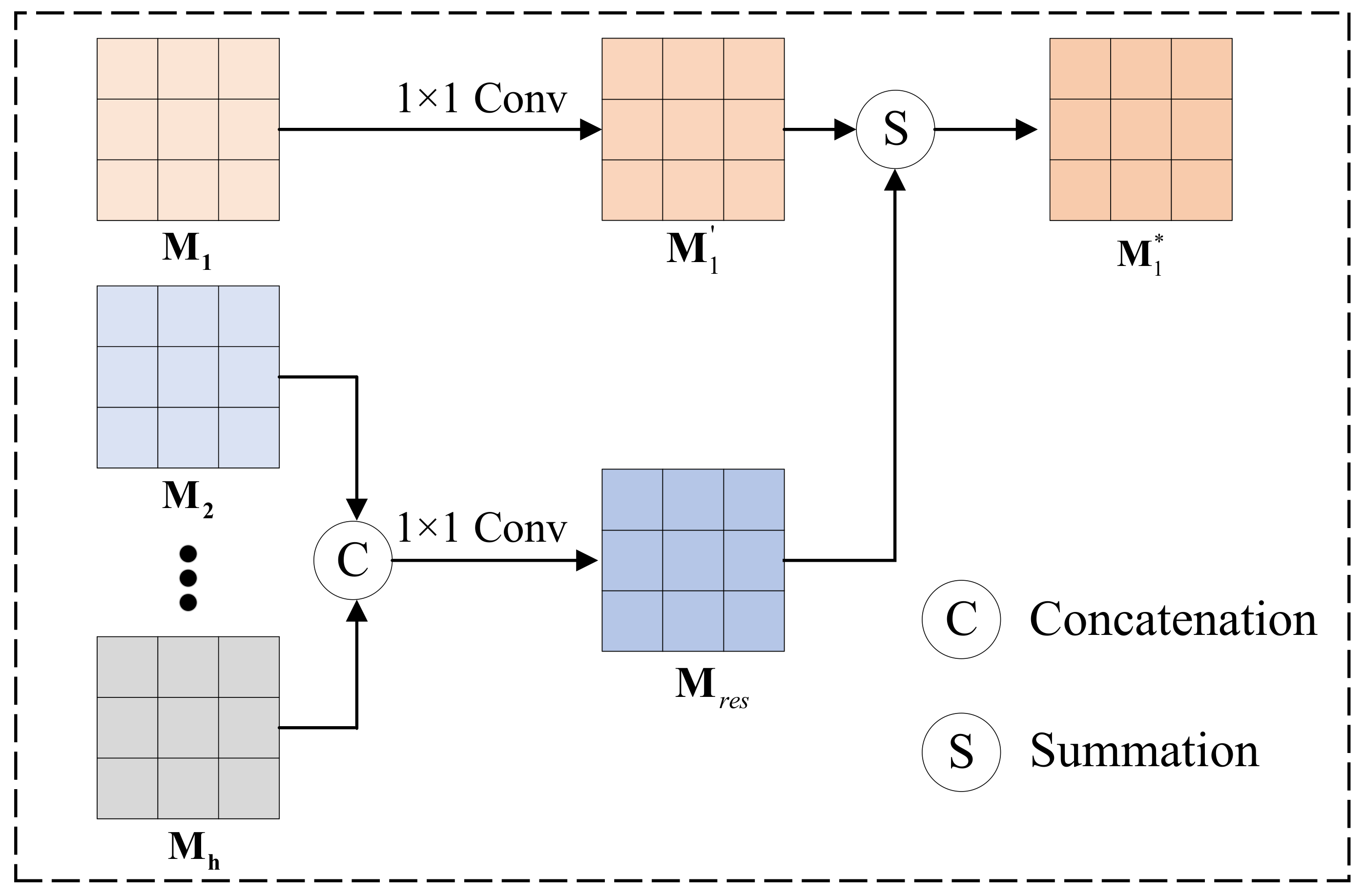
4.2. Multiscale Information Exploration Network
4.2.1. Classification Sub-Network
4.2.2. Teacher Sub-Network
4.3. Progressive Learning Algorithm
4.3.1. Dual-View Negative-Learning Stage
4.3.2. Adaptively Positive-Learning Stage
4.3.3. Exhaustive Soft-Label Learning
5. Results
5.1. Experiment Settings
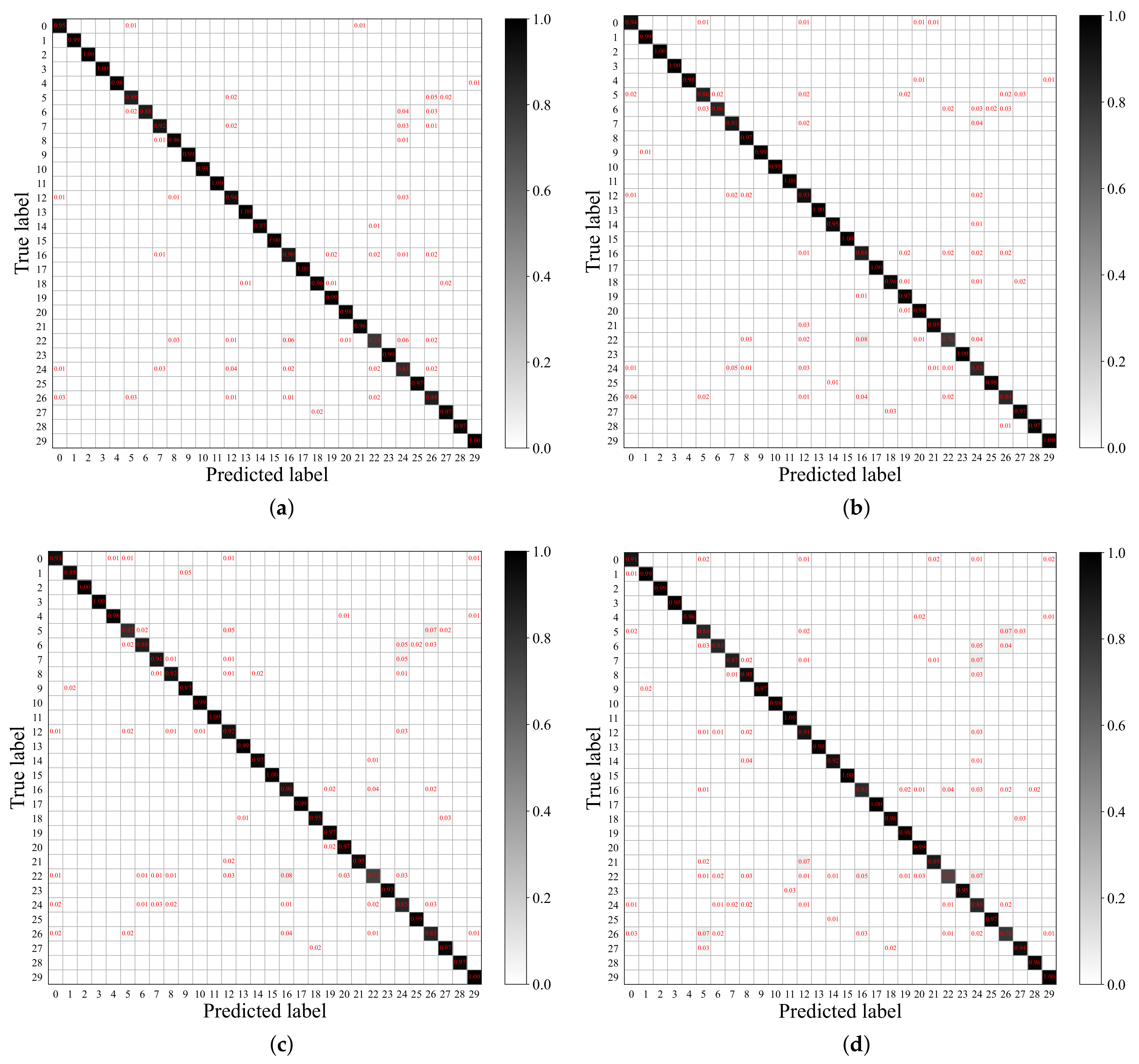
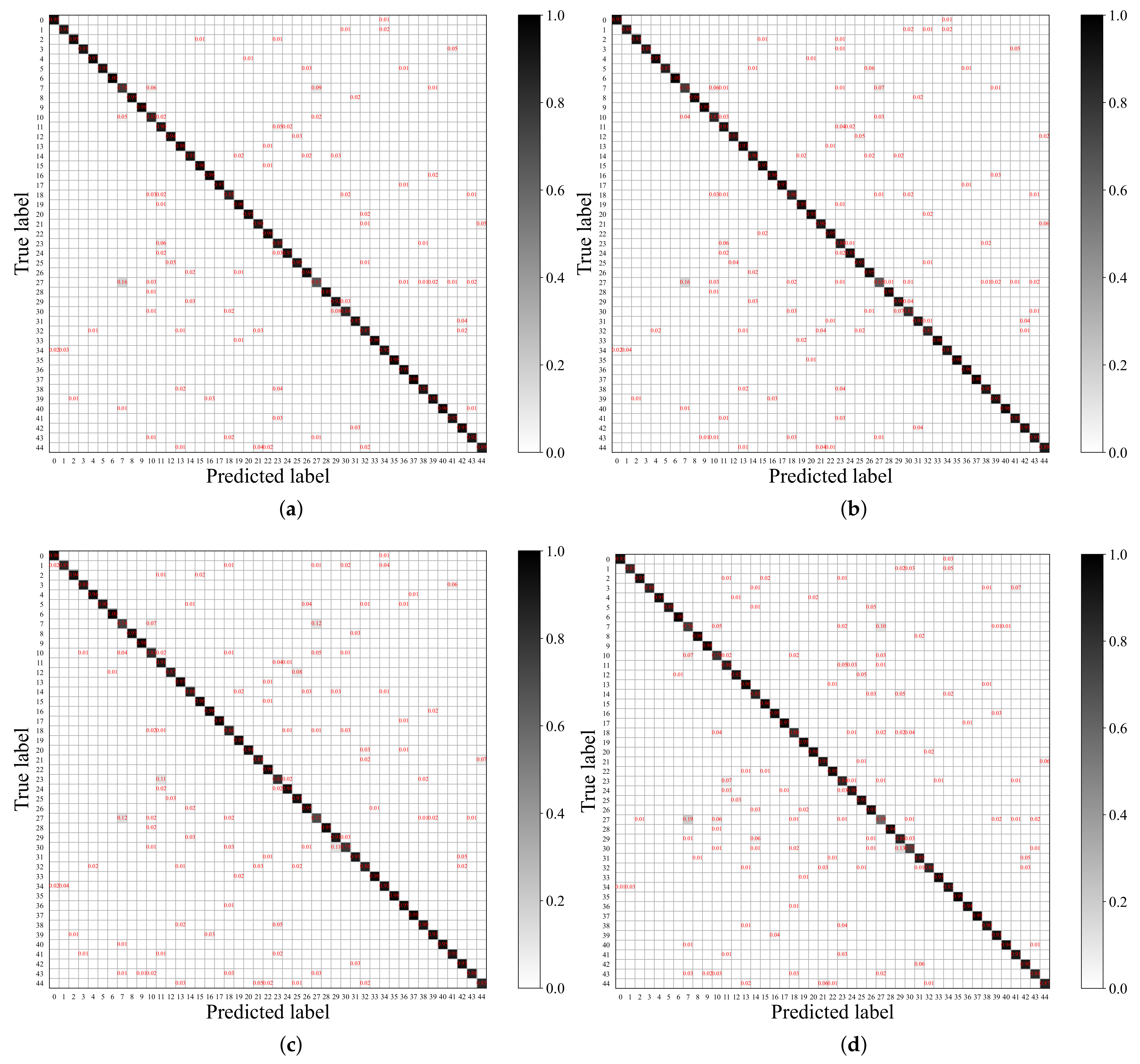
5.2. Comparison with Existing Methods
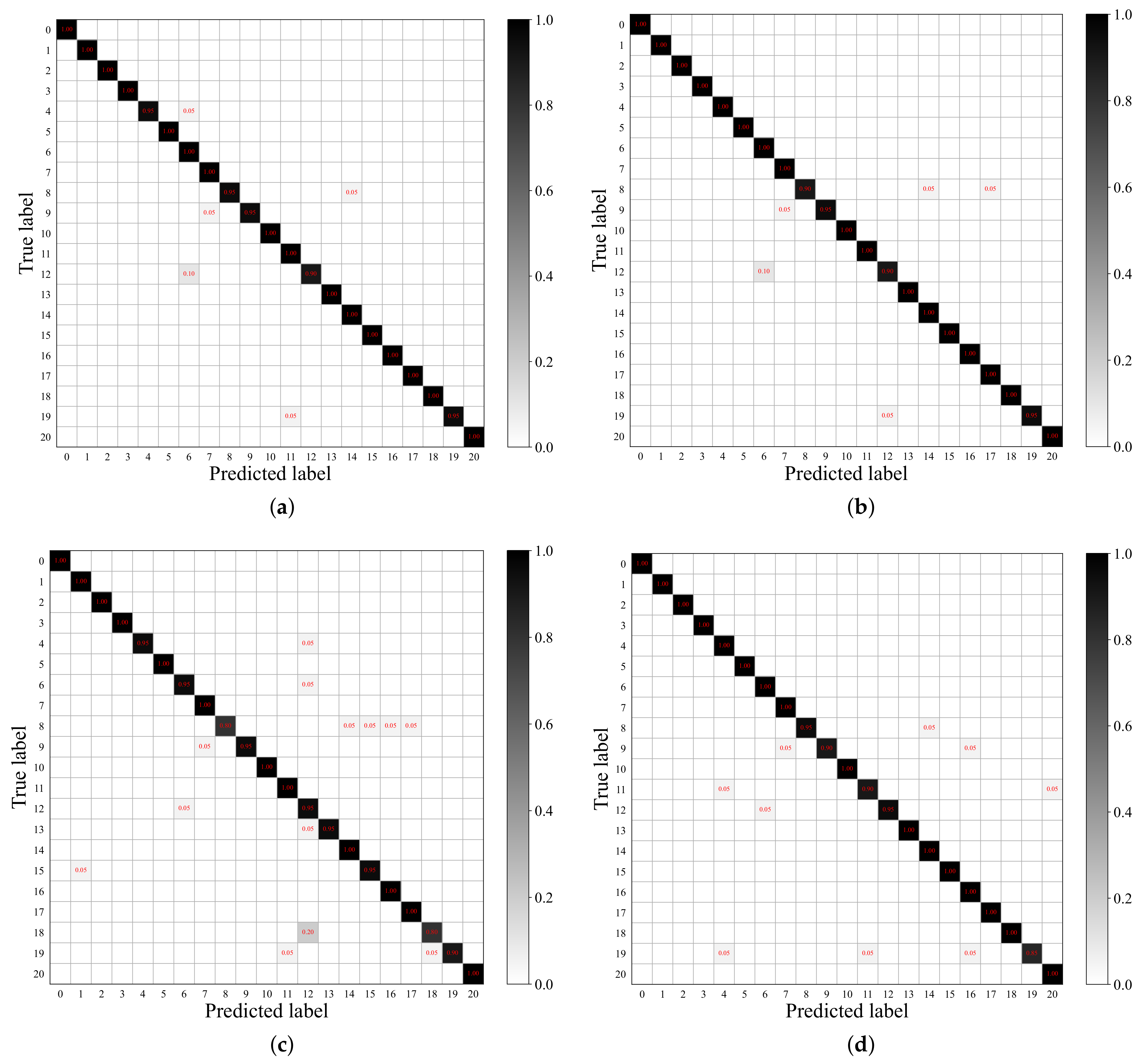
5.2.1. Results on UCM21
5.2.2. Results on AID30
5.2.3. Results on NWPU45
5.3. Ablation Study
5.3.1. Effectiveness of MIEN
- Net-1: Classification Sub-network without TAMSFM;
- Net-2: Classification Sub-network;
- Net-3: Classification and Teacher Sub-networks.
5.3.2. Effectiveness of PLA
5.4. Sensitivity Analysis
5.5. Comparison with Other Classification Models
5.6. Time Costs
6. Discussion
6.1. Similar Work Comparison
6.2. Advantages, Weaknesses, and Future Works
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Zhang, L. Artificial Intelligence for Remote Sensing Data Analysis: A review of challenges and opportunities. IEEE Geosci. Remote Sens. Mag. 2022, 10, 270–294. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Tang, X.; Yang, Y.; Ma, J.; Cheung, Y.M.; Liu, C.; Liu, F.; Zhang, X.; Jiao, L. Meta-hashing for remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5615419. [Google Scholar] [CrossRef]
- Xue, J.; Zhao, Y.; Liao, W.; Chan, J.C.W. Nonlocal low-rank regularized tensor decomposition for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5174–5189. [Google Scholar] [CrossRef]
- Tang, X.; Meng, F.; Zhang, X.; Cheung, Y.M.; Ma, J.; Liu, F.; Jiao, L. Hyperspectral image classification based on 3-D octave convolution with spatial–spectral attention network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2430–2447. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Y.; Zhang, Y.; Zhong, L.; Wang, J.; Chen, J. DKDFN: Domain Knowledge-Guided deep collaborative fusion network for multimodal unitemporal remote sensing land cover classification. ISPRS J. Photogramm. Remote Sens. 2022, 186, 170–189. [Google Scholar] [CrossRef]
- Provost, F.; Michéa, D.; Malet, J.P.; Boissier, E.; Pointal, E.; Stumpf, A.; Pacini, F.; Doin, M.P.; Lacroix, P.; Proy, C.; et al. Terrain deformation measurements from optical satellite imagery: The MPIC-OPT processing services for geohazards monitoring. Remote Sens. Environ. 2022, 274, 112949. [Google Scholar] [CrossRef]
- De Vroey, M.; De Vendictis, L.; Zavagli, M.; Bontemps, S.; Heymans, D.; Radoux, J.; Koetz, B.; Defourny, P. Mowing detection using Sentinel-1 and Sentinel-2 time series for large scale grassland monitoring. Remote Sens. Environ. 2022, 280, 113145. [Google Scholar] [CrossRef]
- Zhao, Y.Q.; Yang, J. Hyperspectral image denoising via sparse representation and low-rank constraint. IEEE Trans. Geosci. Remote Sens. 2014, 53, 296–308. [Google Scholar] [CrossRef]
- Liu, S.; Bai, X.; Zhu, G.; Zhang, Y.; Li, L.; Ren, T.; Lu, J. Remote estimation of leaf nitrogen concentration in winter oilseed rape across growth stages and seasons by correcting for the canopy structural effect. Remote Sens. Environ. 2023, 284, 113348. [Google Scholar] [CrossRef]
- Gómez-Chova, L.; Tuia, D.; Moser, G.; Camps-Valls, G. Multimodal classification of remote sensing images: A review and future directions. Proc. IEEE 2015, 103, 1560–1584. [Google Scholar] [CrossRef]
- Chi, M.; Plaza, A.; Benediktsson, J.A.; Sun, Z.; Shen, J.; Zhu, Y. Big data for remote sensing: Challenges and opportunities. Proc. IEEE 2016, 104, 2207–2219. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Zhang, B.; Wu, Y.; Zhao, B.; Chanussot, J.; Hong, D.; Yao, J.; Gao, L. Progress and challenges in intelligent remote sensing satellite systems. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1814–1822. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Veit, A.; Alldrin, N.; Chechik, G.; Krasin, I.; Gupta, A.; Belongie, S. Learning from noisy large-scale datasets with minimal supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 839–847. [Google Scholar]
- Han, B.; Tsang, I.W.; Chen, L.; Celina, P.Y.; Fung, S.F. Progressive stochastic learning for noisy labels. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5136–5148. [Google Scholar] [CrossRef]
- Algan, G.; Ulusoy, I. Image classification with deep learning in the presence of noisy labels: A survey. Knowl. Based Syst. 2021, 215, 106771. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Zhu, Z. Error-Tolerant Deep Learning for Remote Sensing Image Scene Classification. IEEE Trans. Cybern. 2021, 51, 1756–1768. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.; Fernandez-Beltran, R.; Duan, P.; Kang, X.; Plaza, A.J. Robust normalized softmax loss for deep metric learning-based characterization of remote sensing images with label noise. IEEE Trans. Geosci. Remote Sens. 2020, 59, 8798–8811. [Google Scholar] [CrossRef]
- Li, J.; Huang, X.; Chang, X. A label-noise robust active learning sample collection method for multi-temporal urban land-cover classification and change analysis. ISPRS J. Photogramm. Remote Sens. 2020, 163, 1–17. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Tang, X.; Ma, Q.; Zhang, X.; Liu, F.; Ma, J.; Jiao, L. Attention consistent network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2030–2045. [Google Scholar] [CrossRef]
- Yang, Y.; Tang, X.; Cheung, Y.M.; Zhang, X.; Jiao, L. SAGN: Semantic-Aware Graph Network for Remote Sensing Scene Classification. IEEE Trans. Image Process. 2023, 32, 1011–1025. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Ning, C.; Zhou, H. Enhanced feature pyramid network with deep semantic embedding for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7918–7932. [Google Scholar] [CrossRef]
- Liu, C.; Ma, J.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Deep hash learning for remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3420–3443. [Google Scholar] [CrossRef]
- Chen, J.; Huang, H.; Peng, J.; Zhu, J.; Chen, L.; Tao, C.; Li, H. Contextual information-preserved architecture learning for remote-sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602614. [Google Scholar] [CrossRef]
- Bi, Q.; Qin, K.; Zhang, H.; Xia, G.S. Local semantic enhanced convnet for aerial scene recognition. IEEE Trans. Image Process. 2022, 30, 6498–6511. [Google Scholar] [CrossRef]
- Guo, N.; Jiang, M.; Gao, L.; Li, K.; Zheng, F.; Chen, X.; Wang, M. HFCC-Net: A Dual-Branch Hybrid Framework of CNN and CapsNet for Land-Use Scene Classification. Remote Sens. 2023, 15, 5044. [Google Scholar] [CrossRef]
- Tang, X.; Lin, W.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. Class-Level Prototype Guided Multiscale Feature Learning for Remote Sensing Scene Classification With Limited Labels. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5622315. [Google Scholar] [CrossRef]
- Li, X.; Shi, D.; Diao, X.; Xu, H. SCL-MLNet: Boosting Few-Shot Remote Sensing Scene Classification via Self-Supervised Contrastive Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5801112. [Google Scholar] [CrossRef]
- Peng, C.; Li, Y.; Jiao, L.; Shang, R. Efficient convolutional neural architecture search for remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6092–6105. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef] [PubMed]
- Lin, H.; Cheng, X.; Wu, X.; Shen, D. Cat: Cross attention in vision transformer. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo, Taipei, China, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Huang, X.; Bi, N.; Tan, J. Visual Transformer-Based Models: A Survey. In Proceedings of the International Conference on Pattern Recognition and Artificial Intelligence, Xiamen, China, 23–25 September 2022; pp. 295–305. [Google Scholar]
- Ma, J.; Li, M.; Tang, X.; Zhang, X.; Liu, F.; Jiao, L. Homo–Heterogenous Transformer Learning Framework for RS Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2223–2239. [Google Scholar] [CrossRef]
- Lv, P.; Wu, W.; Zhong, Y.; Du, F.; Zhang, L. SCViT: A Spatial-Channel Feature Preserving Vision Transformer for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4409512. [Google Scholar] [CrossRef]
- Tang, X.; Li, M.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. EMTCAL: Efficient Multiscale Transformer and Cross-Level Attention Learning for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5626915. [Google Scholar] [CrossRef]
- Xu, K.; Deng, P.; Huang, H. Vision transformer: An excellent teacher for guiding small networks in remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5618715. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, Z.; Yu, J.G.; Zhang, Y. Learning deep cross-modal embedding networks for zero-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10590–10603. [Google Scholar] [CrossRef]
- Zhou, L.; Liu, Y.; Zhang, P.; Bai, X.; Gu, L.; Zhou, J.; Yao, Y.; Harada, T.; Zheng, J.; Hancock, E. Information bottleneck and selective noise supervision for zero-shot learning. Mach. Learn. 2023, 112, 2239–2261. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, D.; Wang, Y.; Lin, D.; Zhang, J. Generative adversarial networks for zero-shot remote sensing scene classification. Appl. Sci. 2022, 12, 3760. [Google Scholar] [CrossRef]
- Pradhan, B.; Al-Najjar, H.A.; Sameen, M.I.; Tsang, I.; Alamri, A.M. Unseen land cover classification from high-resolution orthophotos using integration of zero-shot learning and convolutional neural networks. Remote Sens. 2020, 12, 1676. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, J.; Shi, H.; Ge, Z.; Yu, Q.; Cao, G.; Li, X. Agreement and Disagreement-Based Co-Learning with Dual Network for Hyperspectral Image Classification with Noisy Labels. Remote Sens. 2023, 15, 2543. [Google Scholar] [CrossRef]
- Zheng, G.; Awadallah, A.H.; Dumais, S. Meta label correction for noisy label learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 11053–11061. [Google Scholar]
- Tu, B.; Kuang, W.; He, W.; Zhang, G.; Peng, Y. Robust learning of mislabeled training samples for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5623–5639. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, Z.; Zhang, S.; Song, F.; Zhang, G.; Zhou, Q.; Lei, T. Remote sensing image scene classification with noisy label distillation. Remote Sens. 2020, 12, 2376. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Zhu, Z. Learning deep networks under noisy labels for remote sensing image scene classification. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3025–3028. [Google Scholar]
- Kang, J.; Fernandez-Beltran, R.; Kang, X.; Ni, J.; Plaza, A. Noise-tolerant deep neighborhood embedding for remotely sensed images with label noise. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2551–2562. [Google Scholar] [CrossRef]
- Li, Q.; Chen, Y.; Ghamisi, P. Complementary learning-based scene classification of remote sensing images with noisy labels. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8021105. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Miao, W.; Geng, J.; Jiang, W. Multigranularity Decoupling Network With Pseudolabel Selection for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5603813. [Google Scholar] [CrossRef]
- Xu, Q.; Shi, Y.; Yuan, X.; Zhu, X.X. Universal Domain Adaptation for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4700515. [Google Scholar] [CrossRef]
- Yang, Y.; Tang, X.; Zhang, X.; Ma, J.; Liu, F.; Jia, X.; Jiao, L. Semi-Supervised Multiscale Dynamic Graph Convolution Network for Hyperspectral Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022. early access. [Google Scholar] [CrossRef]
- Lu, X.; Sun, H.; Zheng, X. A feature aggregation convolutional neural network for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7894–7906. [Google Scholar] [CrossRef]
- Wang, X.; Duan, L.; Ning, C. Global context-based multilevel feature fusion networks for multilabel remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11179–11196. [Google Scholar] [CrossRef]
- Li, J.; Socher, R.; Hoi, S.C. Dividemix: Learning with noisy labels as semi-supervised learning. arXiv 2020, arXiv:2002.07394. [Google Scholar]
- Tan, C.; Xia, J.; Wu, L.; Li, S.Z. Co-learning: Learning from noisy labels with self-supervision. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, China, 20–24 October 2021; pp. 1405–1413. [Google Scholar]
- Li, S.; Xia, X.; Ge, S.; Liu, T. Selective-supervised contrastive learning with noisy labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 316–325. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Kim, Y.; Yim, J.; Yun, J.; Kim, J. Nlnl: Negative learning for noisy labels. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 101–110. [Google Scholar]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning from noisy labels with deep neural networks: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8135–8153. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.; Sugiyama, M. Co-teaching: Robust training of deep neural networks with extremely noisy labels. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018 2018; Volume 31. [Google Scholar]
- Wang, Y.; Ma, X.; Chen, Z.; Luo, Y.; Yi, J.; Bailey, J. Symmetric cross entropy for robust learning with noisy labels. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 322–330. [Google Scholar]
- Ma, X.; Huang, H.; Wang, Y.; Romano, S.; Erfani, S.; Bailey, J. Normalized loss functions for deep learning with noisy labels. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 6543–6553. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 568–578. [Google Scholar]
- Wang, X.; Duan, L.; Ning, C.; Zhou, H. Relation-attention networks for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 15, 422–439. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NR | SCE [73] | NCE [74] | RCE [73] | Mixup [75] | NLNL [67] | CMR-NLD [50] | t-RNSL [22] | NTDNE [53] | RS-COCL [54] | Res-PLA (Ours) | MIEN-PLA (Ours) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 94.47 | 93.80 | 97.18 | 93.80 | 97.19 | 90.23 | 96.19 | 96.00 | 98.19 | 98.33 | 98.81 |
| 0.2 | 91.32 | 90.95 | 95.99 | 88.42 | 96.42 | 89.09 | 95.82 | 95.66 | 97.09 | 97.62 | 98.42 |
| 0.3 | 83.56 | 83.57 | 93.67 | 81.47 | 95.33 | 88.80 | 94.52 | 94.37 | 96.19 | 96.99 | 97.42 |
| 0.4 | 75.37 | 75.80 | 87.18 | 73.76 | 94.52 | 88.57 | 91.14 | 91.04 | 95.90 | 96.19 | 96.80 |
| NR | SCE [73] | NCE [74] | RCE [73] | Mixup [75] | NLNL [67] | CMR-NLD [50] | t-RNSL [22] | NTDNE [53] | RS-COCL [54] | Res-PLA (Ours) | MIEN-PLA (Ours) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 91.36 | 91.39 | 94.95 | 92.13 | 94.34 | 85.10 | 95.01 | 94.77 | 95.09 | 95.22 | 95.72 |
| 0.2 | 86.66 | 86.82 | 93.62 | 89.56 | 93.58 | 84.09 | 94.52 | 94.31 | 94.53 | 95.14 | 95.27 |
| 0.3 | 78.48 | 78.58 | 91.07 | 82.27 | 92.54 | 83.05 | 92.69 | 92.66 | 94.00 | 94.74 | 94.81 |
| 0.4 | 71.07 | 70.99 | 88.23 | 77.79 | 91.48 | 82.04 | 91.30 | 91.04 | 93.11 | 93.36 | 93.44 |
| NR | SCE [73] | NCE [74] | RCE [73] | Mixup [75] | NLNL [67] | CMR-NLD [50] | t-RNSL [22] | NTDNE [53] | RS-COCL [54] | Res-PLA (Ours) | MIEN-PLA (Ours) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 84.23 | 86.56 | 88.87 | 85.65 | 89.37 | 78.63 | 88.35 | 86.25 | 90.62 | 92.00 | 92.35 |
| 0.2 | 78.28 | 82.15 | 86.59 | 82.13 | 88.62 | 77.72 | 86.96 | 84.77 | 89.69 | 91.33 | 91.70 |
| 0.3 | 69.59 | 74.75 | 84.62 | 74.19 | 88.20 | 76.14 | 85.35 | 83.27 | 89.15 | 90.88 | 90.97 |
| 0.4 | 61.21 | 66.52 | 77.97 | 67.17 | 86.67 | 75.63 | 82.76 | 82.00 | 87.99 | 89.77 | 89.88 |
| NR | Nets | Data Set | ||
|---|---|---|---|---|
| UCM | AID | NWPU | ||
| 0.1 | Net-1 | 98.38 | 95.06 | 90.64 |
| Net-2 | 98.47 | 95.22 | 91.28 | |
| Net-3 | 98.81 | 95.72 | 92.35 | |
| 0.2 | Net-1 | 97.28 | 94.38 | 89.88 |
| Net-2 | 97.75 | 94.71 | 91.07 | |
| Net-3 | 98.42 | 95.27 | 91.70 | |
| 0.3 | Net-1 | 96.47 | 94.12 | 89.56 |
| Net-2 | 96.70 | 94.38 | 90.43 | |
| Net-3 | 97.42 | 94.81 | 90.97 | |
| 0.4 | Net-1 | 95.61 | 92.98 | 88.09 |
| Net-2 | 95.90 | 93.27 | 88.42 | |
| Net-3 | 96.80 | 93.44 | 89.88 | |
| TAMSFM-V | TAMSFM-E | TAMSFM-S | TAMSFM-P | TAMSFM | |
|---|---|---|---|---|---|
| UCM21 | 98.42 | 98.71 | 98.57 | 98.47 | 98.81 |
| AID30 | 95.25 | 95.70 | 95.62 | 95.44 | 95.72 |
| NWPU45 | 92.30 | 92.33 | 92.33 | 92.31 | 92.35 |
| NR | Experiments | DNL | APL | ESL | Data Set | ||
|---|---|---|---|---|---|---|---|
| UCM | AID | NWPU | |||||
| 0.1 | Experiment-1 | × | × | × | 94.28 | 93.12 | 89.56 |
| Experiment-2 | ✓ | × | × | 94.76 | 93.31 | 89.78 | |
| Experiment-3 | ✓ | ✓ | × | 98.57 | 95.24 | 91.64 | |
| Experiment-4 | ✓ | ✓ | ✓ | 98.81 | 95.72 | 92.35 | |
| 0.2 | Experiment-1 | × | × | × | 89.04 | 89.62 | 85.32 |
| Experiment-2 | ✓ | × | × | 89.52 | 90.14 | 85.51 | |
| Experiment-3 | ✓ | ✓ | × | 98.10 | 94.74 | 91.21 | |
| Experiment-4 | ✓ | ✓ | ✓ | 98.42 | 95.27 | 91.70 | |
| 0.3 | Experiment-1 | × | × | × | 84.52 | 84.55 | 80.57 |
| Experiment-2 | ✓ | × | × | 85.23 | 84.96 | 80.92 | |
| Experiment-3 | ✓ | ✓ | × | 97.00 | 94.62 | 90.56 | |
| Experiment-4 | ✓ | ✓ | ✓ | 97.42 | 94.81 | 90.97 | |
| 0.4 | Experiment-1 | × | × | × | 73.57 | 76.24 | 73.14 |
| Experiment-2 | ✓ | × | × | 74.04 | 76.48 | 73.23 | |
| Experiment-3 | ✓ | ✓ | × | 96.43 | 93.16 | 88.52 | |
| Experiment-4 | ✓ | ✓ | ✓ | 96.80 | 93.44 | 89.88 | |
| MIEN-E | MIEN-S | MIEN-A | MIEN-R | MIEN (Ours) | |
|---|---|---|---|---|---|
| UCM21 | 98.81 | 98.75 | 98.62 | 98.67 | 98.81 |
| AID30 | 95.74 | 95.64 | 95.58 | 95.60 | 95.72 |
| NWPU45 | 92.42 | 92.32 | 92.12 | 92.03 | 92.35 |
| GFLOPs | 4.24 | 4.33 | 15.35 | 6.96 | 2.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, X.; Du, R.; Ma, J.; Zhang, X. Noisy Remote Sensing Scene Classification via Progressive Learning Based on Multiscale Information Exploration. Remote Sens. 2023, 15, 5706. https://doi.org/10.3390/rs15245706
Tang X, Du R, Ma J, Zhang X. Noisy Remote Sensing Scene Classification via Progressive Learning Based on Multiscale Information Exploration. Remote Sensing. 2023; 15(24):5706. https://doi.org/10.3390/rs15245706
Chicago/Turabian StyleTang, Xu, Ruiqi Du, Jingjing Ma, and Xiangrong Zhang. 2023. "Noisy Remote Sensing Scene Classification via Progressive Learning Based on Multiscale Information Exploration" Remote Sensing 15, no. 24: 5706. https://doi.org/10.3390/rs15245706
APA StyleTang, X., Du, R., Ma, J., & Zhang, X. (2023). Noisy Remote Sensing Scene Classification via Progressive Learning Based on Multiscale Information Exploration. Remote Sensing, 15(24), 5706. https://doi.org/10.3390/rs15245706