3.3.1. Hyperparameter Tuning
During hyperparameter tuning, a full grid search was applied in which all possible parameter combinations were tested.
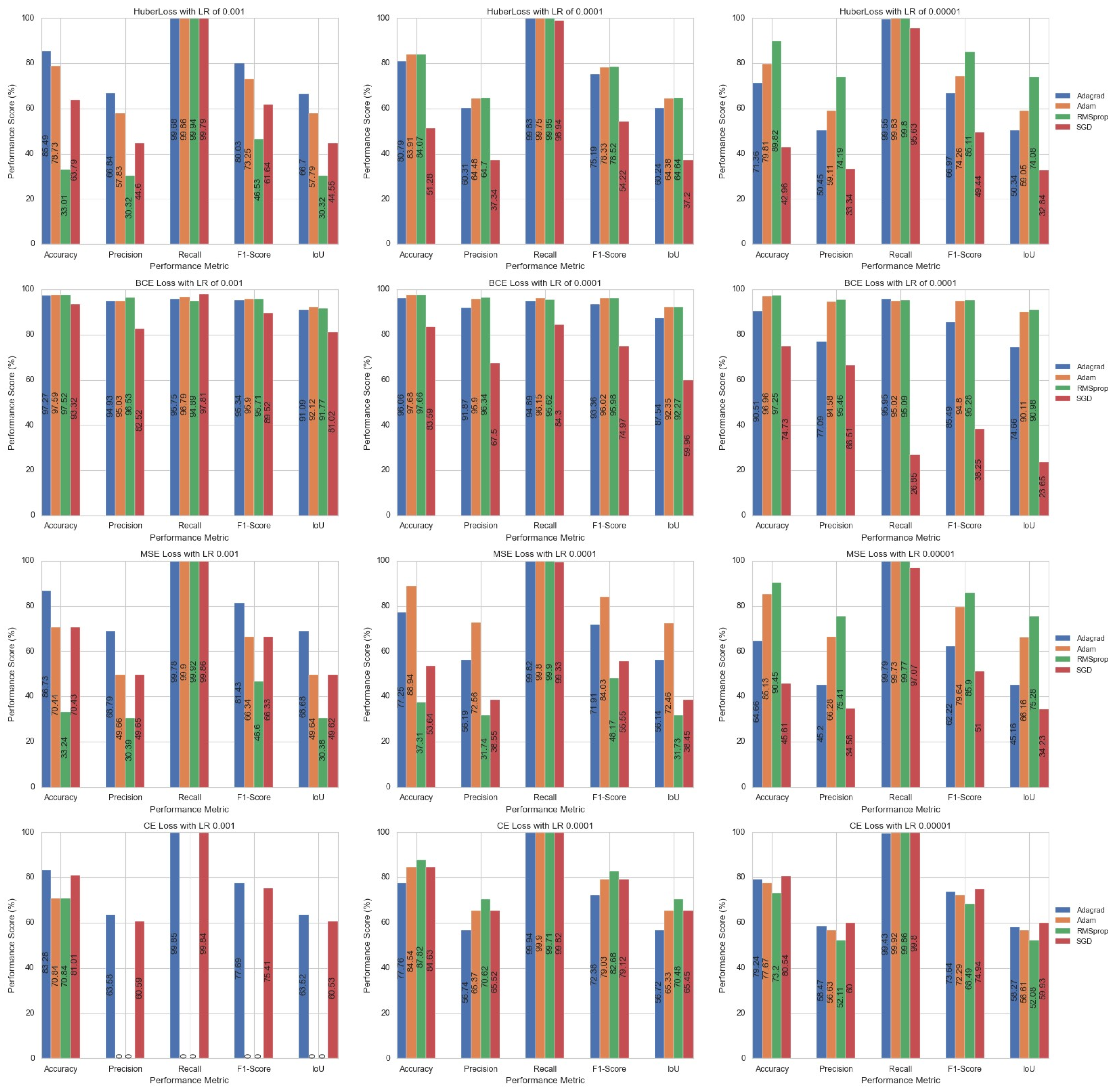
Table 3 shows the search space metrics of the grid search where four loss functions, four optimizers, three learning rates, nine batch sizes, and four stride values are defined. These parameters are chosen due to the fact that the selected combined model, DeepLabV3 ResNet101, uses pre-trained weights. Therefore, hyperparameters were selected such that the model is as fine-tuned as possible to perform image segmentation. Direct parameter changes were avoided to preserve the integrity of the pre-trained weights, which ensures that the advantage of what using said weights brings is maintained. Examples of direct parameters omitted from tuning are number of layers, pooling type, and activation function types. The goal is to tune the listed parameters available with pre-trained weights such that evaluation metrics are maximized.
The parameters’ loss function, optimizer, and learning rate were tested simultaneously. Conversely, batch size and stride parameters were tested independently and in isolation from other parameters. Additionally, an early stopping mechanism was utilized to prevent the model from overfitting to the training data. The mechanism involves evaluating the performance of model every 10 epochs using the IoU metric. The best IoU value would be checked every 10 epochs and if the IoU value for that epoch is greater than the current best IoU, then the IoU value for that particular epoch would then be the new benchmark value for future performance checks. However, if the opposite occurs where the current best IoU is greater than the IoU value for that epoch, then the model training is stopped. Lastly, a maximum of 100 epochs is used for training.
Four loss functions are selected for tuning. The Huber loss function, invented by Huber in 1964, provides robustness as it has duality in its behavior in how to treats outlier and inlier errors [
32]. According to Huber, the function will apply the squared error function (L2 loss) for error values below a particular threshold. However, if the error value is above the threshold, a scaled absolute (L1 loss) error loss function would be applied [
32]. This, therefore, means that the Huber loss function behaves like a piecewise function. The threshold is called the delta variable (
). The delta variable is the threshold for errors that are considered outliers. Furthermore, the Huber loss function is differentiable everywhere. When comparing different loss functions, it was concluded that dynamic loss functions (such as Huber loss) yielded better model performance during training regression CNN architecture [
33]. Mathematically, the function can be described as follows:
The Cross-Entropy loss (CE loss) function can be referred to as logarithmic loss. For a given set of predictions, the loss function simply averages the sum of the products of truth values (
y) and the log of the predicted values (
p) from the model.
Binary Cross-Entropy (BCE) loss is a specific variation of Cross-Entropy loss tailored for binary classification tasks, where there are only two possible classes (e.g., 0 and 1). Unlike the standard CE loss function, BCE loss calculates the error for predicting binary outcomes and is ideal for problems with binary class labels. The BCEWithLogits loss function is a combination of sigmoid and BCE loss and is numerically stable.
Here, y is the true label,
z represents the logit or the output of your model, and
is the sigmoid function which converts the logits into probabilities. The BCE loss measures the difference between the predicted probabilities and the true labels. This loss function has been successfully implemented in applications such as video segmentation to minimize motion blur. Implementation involved using BCEWithLogits function in an UNet inspired encoder–decoder network [
34]. Another study aimed to create a pix2pix Generative Adversarial Network (GAN) that can generate synthetic computerized tomography (sCT) images using positron emission tomography (PET) images [
35]. The BCEWithLogits loss function was used for both the generator and discriminator of the GAN in combination with other loss functions. The last loss function tested is the Mean Squared Error (MSE) loss function:
The MSE loss function is the squared difference between the ground truth (y) and prediction value (). Squaring the error helps the model penalize large errors. However, it should not be used with data with a sizable percentage of outliers for this reason.
The optimizers selected are the Adagrad, Adam, RMSProp, and SGD optimizers. The optimizer is responsible for backpropagation, whereby each weight is adjusted based on the error computed by the loss function. Due to backpropagation, each loss function must be differentiable as the derivative of it is found and used to adjust the weights. This means that the loss function is the objective function as it is the function that the optimizer is attempting to minimize its output. Weights are adjusted by finding the derivative of the loss function with respect to weight and subtracting that derivative value from the original weight value. To further increase the rate of the optimization to minimize the loss function’s output, the derivative value is multiplied by a factor so that the minimum is found more quickly. The multiplying factor is called the learning rate. This process continues until the minimum of the loss function is found, i.e., when the derivative of the loss function is zero and the weights can no longer be adjusted. This entire process is called Stochastic Gradient Descent (SGD). The Adagrad, Adam, and RMSProp optimizers are optimizers with adaptive learning rates. The Adaptive Gradient (Adagrad) optimizer implements an algorithm that controls proximal functions, which in turn modifies the “gradient steps of the algorithm” [
36]. The study that introduced this approach concluded that adaptive optimizers’ algorithms outperform non-adaptive algorithms [
36]. The Adagrad optimizer is known for its adaptive learning rate approach. It is, therefore, well-suited for scenarios where the characteristics of the solar PV systems in images may vary widely. Adagrad can effectively navigate complex and varied landscapes by adjusting the learning rates for each parameter individually based on their historical gradients. This can be the case with PV segmentation. The Root Mean Square Propagation (RMSProp) algorithm was used to optimize the weights in recurrent neural network (RNN) using Long Short-term Memory (LSTM) units [
37]. The model was trained to generate text sequences for handwritten text. The model was successful at both generating text as well as handwriting styles. By finding the running average of recent gradients for a particular weight, the value of that weight can be adjusted by dividing it by that average [
37]. RMSProp, like Adagrad, incorporates adaptive learning rates but it further addresses the diminishing learning rate problem. In the context of PV systems segmentation, certain features may require more nuanced adjustments during optimization. RMSProp’s ability could, therefore, be used to adaptively scale the learning rates for different parameters and lead to more efficient convergence. The Adaptive Moment Estimation (Adam) algorithm was introduced in 2014 by Kingma and Lei Ba [
38]. It is a gradient-based stochastic optimization algorithm. This algorithm requires fewer computational resources and less memory and is relatively straightforward to implement [
38]. Using the Adam optimization takes advantage of both the Adagrad and RMSProp methods. Sparse gradients and non-stationary objectives are resolved using the intricacies deployed in both the Adagrad and RMSProp methods, respectively, [
38]. Computational resources and memory efficiency are critical in the context of using large amounts of data in PV segmentation. The capability of the Adam optimizer to provide effective optimization with reduced resource requirements makes it an attractive optimizer to consider. The last optimizer to be tested is the standard SGD algorithm. This algorithm is non-adaptive, meaning that the learning rate is static. Standard SGD is a fundamental optimizer that can serve as a basis for comparison. In particular, SGD proves to be a reliable option in PV segmentation since the stability of certain features is provided for. In other words, less frequent adjustments to the learning rate are required. Due to its simplicity and stability, it serves as an important reference point for evaluating the performance of adaptive optimizers.
Three sequential learning rates are tested, each being an order of magnitude higher than its predecessor. Note that the learning rate is adjusted iteratively by multiplying factors if the optimizer is an adaptive optimizer. The magnitudes of factors depend on the selected optimizer to find the optimal adjustment value.
Batch size is the number of samples of training data inputted in the model and passes both forward and backward in the network. There is an inherent trade-off between accuracy and computational efficiency. If fast training is required, then a large batch size is preferred. However, larger batch sizes could lead to overfitting and an inaccurate model. Conversely, although a smaller batch size results in longer training times, it typically leads to higher accuracy.
Lastly, the stride of the model is tested. Stride refers to the step size over which an image is passed over by a filter (or kernel). Higher strides lead to reduce computational requirements due to smaller feature map outputs.




{kind=link}
{kind=link}
{kind=link}
{kind=link}