
Filtering in Triplet Markov Chain Model in the Presence of Non-Gaussian Noise with Application to Target Tracking



Abstract
:
1. Introduction
2. Problem Formulation
2.1. Hidden Markov Chain Model
2.2. Triplet Markov Chain Model
2.3. Triplet Kalman Filter
- 1
- ,
- 2
- ,
- 3
- ,
- 4
- .
- 5
- ,
- 6
- .
- 7
- ,
- 7
- ,
- 9
- ,
- 10
- ,
- 11
- .
3. Methods
3.1. Maximum Correntropy Triplet Kalman Filter
3.1.1. Correntropy
3.1.2. Main Result
- 1
- ,
- 2
- ,
- 3
- ,
- 4
- .
- 5
- ,
- 6
- .
- 7
- ,
- 8
- ,
- 9
- ,
- 10
- ,
- 11
- ,
- 12
- .
3.1.3. Derivation of the MCTKF
3.2. Square-Root MCTKF
- 1
- , .
- 2
- ,
- 3
- ,
- 4
- ,
- 5
- ,
- 6
- Find the square root .
- 7
- ,
- 8
- . Form the pre-array
- 9
- . Find the post-array
- 10
- ,
- 11
- ,
- 12
- ,
- 13
- . Find the post-array
- 14
- .
4. Applications
5. Results and Analysis
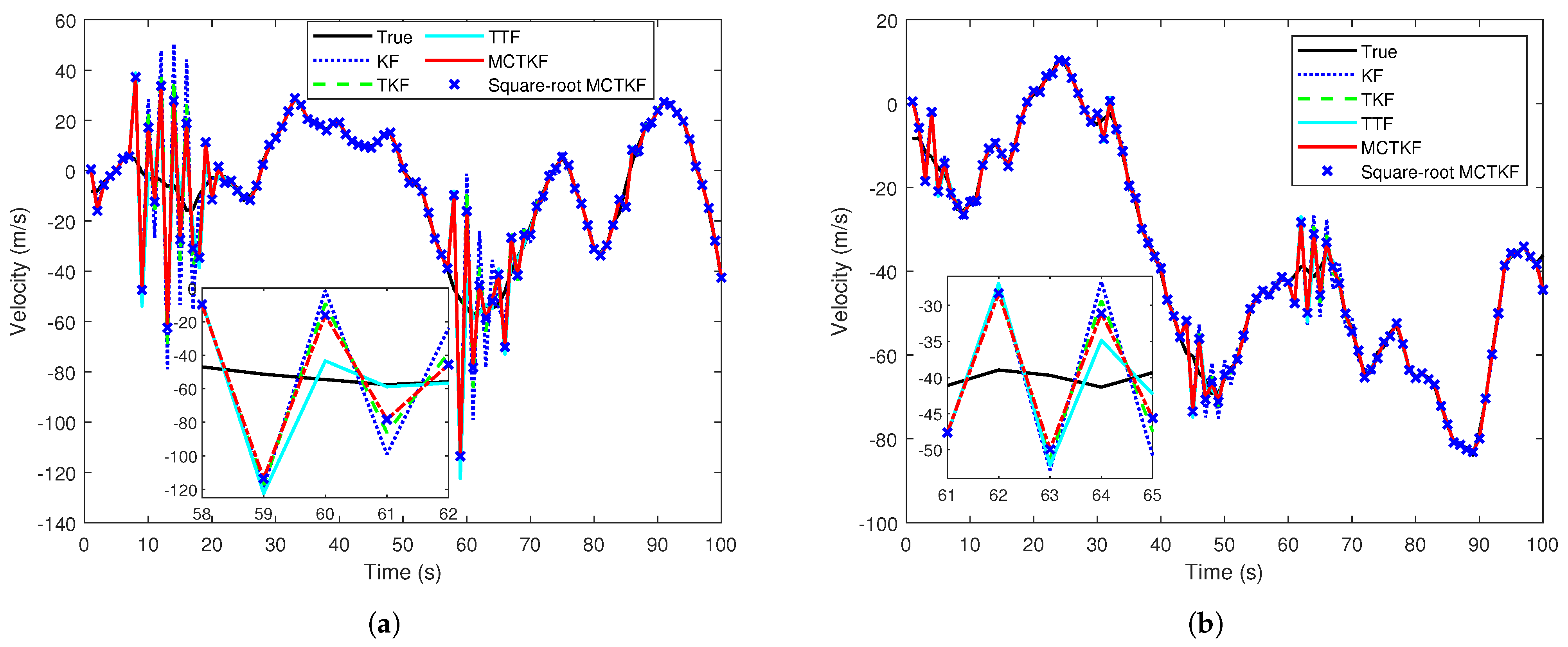
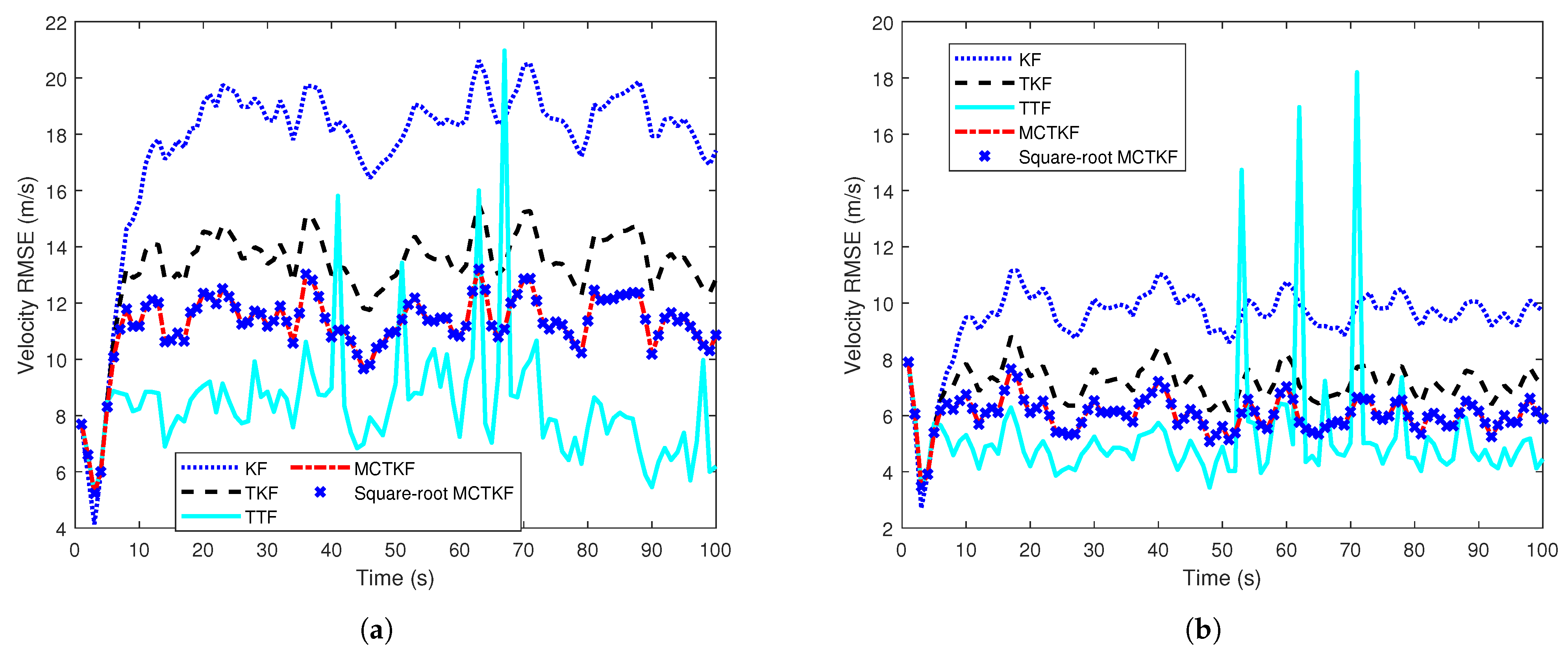
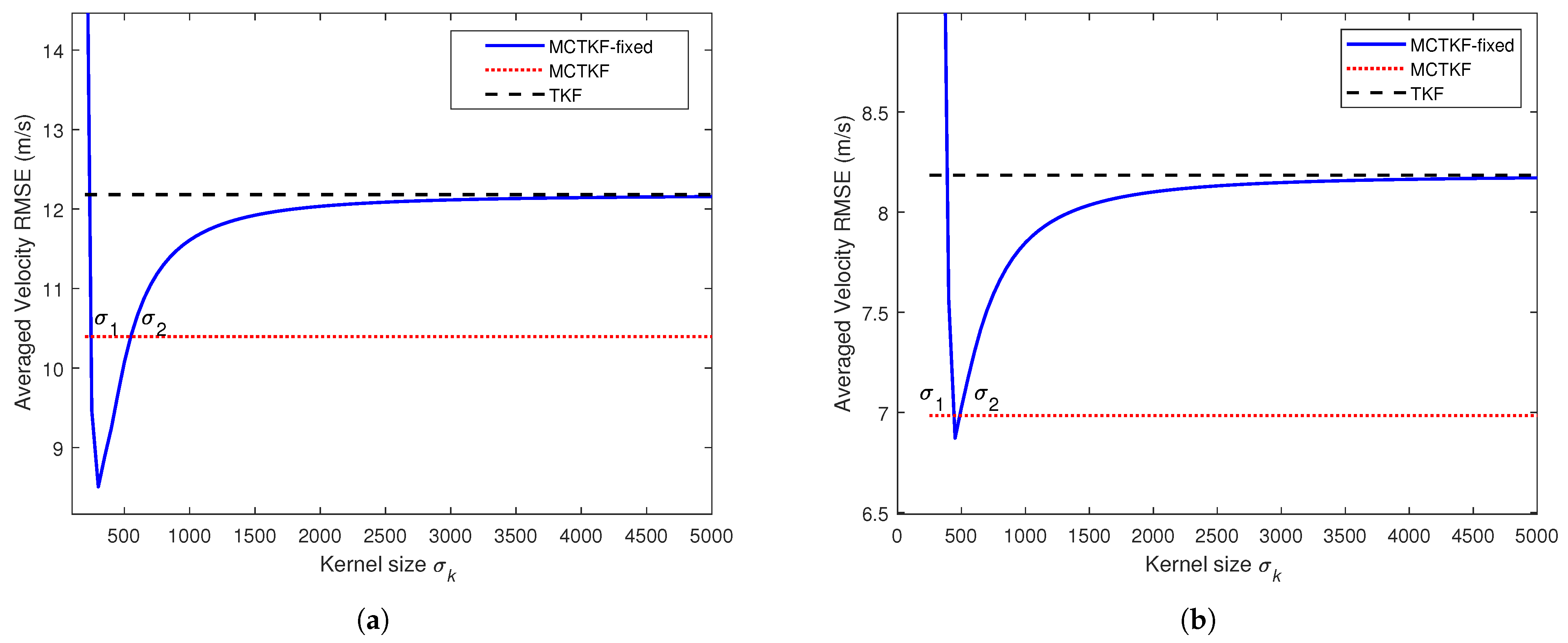
5.1. Single Target-Tracking Example with Correlated and Non-Gaussian Noise
5.2. Linear TMC Example with Round-off Error
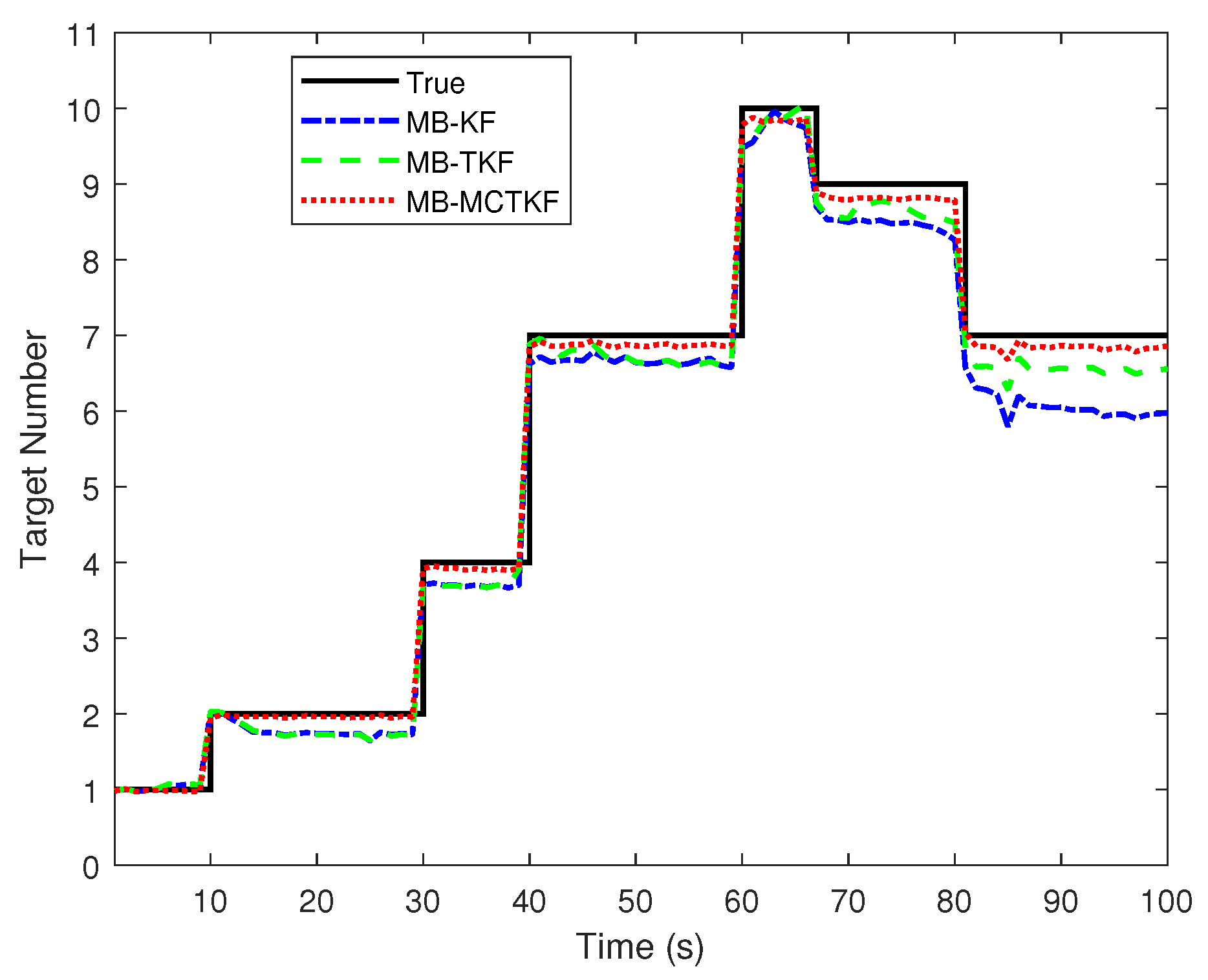
5.3. Nonlinear Bearing-Only Multi-Target Tracking Example in the Presence of Non-Gaussian Noise
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bar-Shalom, Y.; Li, X.R.; Kirubarajan, T. Estimation with Applications to Tracking and Navigation: Theory, Algorthims and Software; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Jiang, M.; Guo, S.; Luo, H.; Yao, Y.; Cui, G. A Robust Target Tracking Method for Crowded Indoor Environments Using mmWave Radar. Remote Sens. 2023, 15, 2425. [Google Scholar] [CrossRef]
- Zandavi, S.M.; Chung, V. State Estimation of Nonlinear Dynamic System Using Novel Heuristic Filter Based on Genetic Algorithm. Soft Comput. 2019, 23, 5559–5570. [Google Scholar] [CrossRef]
- Lan, J.; Li, X.R. Nonlinear Estimation Based on Conversion-Sample Optimization. Automatica 2020, 121, 109160. [Google Scholar] [CrossRef]
- Zhang, G.; Lan, J.; Zhang, L.; He, F.; Li, S. Filtering in Pairwise Markov Model with Student’s t Non-Stationary Noise with Application to Target Tracking. IEEE Trans. Signal Process. 2021, 69, 1627–1641. [Google Scholar] [CrossRef]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- An, D.; Zhang, F.; Yang, Q.; Zhang, C. Data Integrity Attack in Dynamic State Estimation of Smart Grid: Attack Model and Countermeasures. IEEE Trans. Autom. Sci. Eng. 2022, 19, 1631–1644. [Google Scholar] [CrossRef]
- Wu, W.R.; Chang, D.C. Maneuvering Target Tracking with Colored Noise. IEEE Trans. Aerosp. Electron. Syst. 1996, 32, 1311–1320. [Google Scholar]
- Saha, S.; Gustafsson, F. Particle Filtering with Dependent Noise Processes. IEEE Trans. Signal Process. 2012, 60, 4497–4508. [Google Scholar] [CrossRef]
- Li, W.; Jia, Y.; Du, J.; Zhang, J. PHD Filter for Multi-Target Tracking with Glint Noise. Signal Process. 2014, 94, 48–56. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, Y.; Li, N.; Wu, Z.; Chambers, J.A. A Novel Robust Student’s t-Based Kalman Filter. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 1545–1554. [Google Scholar] [CrossRef]
- Roth, M.; Özkan, E.; Gustafsson, F. A Student’s t Filter for Heavy Tailed Process and Measurement Noise. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 5770–5774. [Google Scholar]
- Pieczynski, W.; Desbouvries, F. Kalman Filtering Using Pairwise Gaussian Models. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2003, Hong Kong, China, 6–10 April 2003; pp. 57–60. [Google Scholar]
- Pieczynski, W. Pairwise Markov Chains. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 634–639. [Google Scholar] [CrossRef]
- Némesin, V.; Derrode, S. Robust Blind Pairwise Kalman Algorithms Using QR Decompositions. IEEE Trans. Signal Process. 2013, 61, 5–9. [Google Scholar] [CrossRef]
- Zhang, G.H.; Han, C.Z.; Lian, F.; Zeng, L.H. Cardinality Balanced Multi-target Multi-Bernoulli Filter for Pairwise Markov Model. Acta Autom. Sin. 2017, 43, 2100–2108. [Google Scholar]
- Petetin, Y.; Desbouvries, F. Bayesian Multi-Object Filtering for Pairwise Markov Chains. IEEE Trans. Signal Process. 2013, 61, 4481–4490. [Google Scholar] [CrossRef]
- Ait-El-Fquih, B.; Desbouvries, F. Kalman Filtering in Triplet Markov Chains. IEEE Trans. Signal Process. 2006, 54, 2957–2963. [Google Scholar] [CrossRef]
- Lehmann, F.; Pieczynski, W. Reduced-Dimension Filtering in Triplet Markov Models. IEEE Trans. Autom. Control 2021, 67, 605–617. [Google Scholar] [CrossRef]
- Lehmann, F.; Pieczynski, W. Suboptimal Kalman Filtering in Triplet Markov Models Using Model Order Reduction. IEEE Signal Process. Lett. 2020, 27, 1100–1104. [Google Scholar] [CrossRef]
- Petetin, Y.; Desbouvries, F. Exact Bayesian Estimation in Constrained Triplet Markov Chains. In Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Reims, France, 21–24 September 2014; pp. 1–16. [Google Scholar]
- Ait El Fquih, B.; Desbouvries, F. Kalman Filtering for Triplet Markov Chains: Applications and Extensions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, Philadelphia, PA, USA, 23–23 March 2005; Volume IV, pp. 685–688. [Google Scholar]
- Izanloo, R.; Fakoorian, S.A.; Yazdi, H.S.; Simon, D. Kalman Filtering Based on the Maximum Correntropy Criterion in The Presence of Non–Gaussian Noise. In Proceedings of the 2016 Annual Conference on Information Science and Systems (CISS), Princeton, NJ, USA, 16–18 March 2016; pp. 500–505. [Google Scholar]
- Zhu, J.; Xie, W.; Liu, Z. Student’s t-Based Robust Poisson Multi-Bernoulli Mixture Filter under Heavy-Tailed Process and Measurement Noises. Remote Sens. 2023, 15, 4232. [Google Scholar] [CrossRef]
- Bilik, I.; Tabrikian, J. MMSE-Based Filtering in Presence of Non-Gaussian System and Measurement Noise. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 1153–1170. [Google Scholar] [CrossRef]
- Shan, C.; Zhou, W.; Jiang, Z.; Shan, H. A New Gaussian Approximate Filter with Colored Non-Stationary Heavy-Tailed Measurement Noise. Digit. Signal Process. 2021, 122, 103358. [Google Scholar] [CrossRef]
- Zheng, F.; Derrode, S.; Pieczynski, W. Semi-supervised optimal recursive filtering and smoothing in non-Gaussian Markov switching models. Signal Process. 2020, 171, 107511. [Google Scholar] [CrossRef]
- Pieczynski, W. Exact Filtering in Conditionally Markov Switching Hidden Linear Models. C. R. Math. 2011, 349, 587–590. [Google Scholar] [CrossRef]
- Abbassi, N.; Benboudjema, D.; Derrode, S.; Pieczynski, W. Optimal filter approximations in conditionally Gaussian pairwise Markov switching models. IEEE Trans. Autom. Control 2014, 60, 1104–1109. [Google Scholar] [CrossRef]
- Gorynin, I.; Derrode, S.; Monfrini, E.; Pieczynski, W. Fast filtering in switching approximations of nonlinear Markov systems with applications to stochastic volatility. IEEE Trans. Autom. Control 2016, 62, 853–862. [Google Scholar] [CrossRef]
- Kotecha, J.; Djuric, P. Gaussian Sum Particle Filtering. IEEE Trans. Signal Process. 2003, 51, 2602–2612. [Google Scholar] [CrossRef]
- Liu, X.; Qu, H.; Zhao, J.; Yue, P. Maximum Correntropy Square-Root Cubature Kalman Filter with Application to SINS/GPS Integrated Systems. ISA Trans. 2018, 80, 195–202. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Pokharel, P.P.; Príncipe, J.C. Correntropy: Properties and Applications in Non–Gaussian Signal Processing. IEEE Trans. Signal Process. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, H.; Huang, H.; Ge, B. A Redundant Measurement-Based Maximum Correntropy Extended Kalman Filter for the Noise Covariance Estimation in INS/GNSS Integration. Remote Sens. 2023, 15, 2430. [Google Scholar] [CrossRef]
- Liao, T.; Hirota, K.; Wu, X.; Shao, S.; Dai, Y. A Dynamic Self-Tuning Maximum Correntropy Kalman Filter for Wireless Sensors Networks Positioning Systems. Remote Sens. 2022, 14, 4345. [Google Scholar] [CrossRef]
- Li, X.; Guo, Y.; Meng, Q. Variational Bayesian-Based Improved Maximum Mixture Correntropy Kalman Filter for Non-Gaussian Noise. Entropy 2022, 24, 117. [Google Scholar] [CrossRef]
- Chen, B.; Liu, X.; Zhao, H.; Principe, J.C. Maximum Correntropy Kalman Filter. Automatica 2017, 76, 70–77. [Google Scholar] [CrossRef]
- Kulikova, M.V. Square-Root Algorithms for Maximum Correntropy Estimation of Linear Discrete-Time Systems in Presence of Non–Gaussian Noise. Syst. Control Lett. 2017, 108, 8–15. [Google Scholar] [CrossRef]
- Liu, X.; Qu, H.; Zhao, J.; Chen, B. State Space Maximum Correntropy Filter. Signal Process. 2017, 130, 152–158. [Google Scholar] [CrossRef]
- Liu, X.; Chen, B.; Xu, B.; Wu, Z.; Honeine, P. Maximum Correntropy Unscented Filter. Int. J. Syst. Sci. 2017, 48, 1607–1615. [Google Scholar] [CrossRef]
- Gunduz, A.; Príncipe, J.C. Correntropy as A Novel Measure for Nonlinearity Tests. Signal Process. 2009, 89, 14–23. [Google Scholar] [CrossRef]
- Cinar, G.T.; Príncipe, J.C. Hidden State Estimation Using the Correntropy Filter with Fixed Point Update and Adaptive Kernel Size. In Proceedings of the The 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–6. [Google Scholar]
- Vo, B.T.; Vo, B.N.; Cantoni, A. The Cardinality Balanced Multi-Target Multi-Bernoulli Filter and Its Implementations. IEEE Trans. Signal Process. 2009, 57, 409–423. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Zhang, G.; Lian, F.; Han, C.; Chen, H.; Fu, N. Two Novel Sensor Control Schemes for Multi-Target Tracking via Delta Generalised Labelled Multi-Bernoulli Filtering. IET Signal Process. 2018, 12, 1131–1139. [Google Scholar] [CrossRef]
- Higham, N.J. Accuracy and Stability of Numerical Algorithms; SIAM: Philadelphia, PA, USA, 2002. [Google Scholar]
- Higham, N.J. Analysis of the Cholesky Decomposition of a Semi-Definite Matrix; Oxford University Press: Manchester, UK, 1990. [Google Scholar]
- Grewal, M.S.; Andrews, A.P. Kalman Filtering: Theory and Practice with MATLAB; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Kaminski, P.; Bryson, A.; Schmidt, S. Discrete Square Root Filtering: A Survey of Current Techniques. IEEE Trans. Autom. Control 1971, 16, 727–736. [Google Scholar] [CrossRef]
- Mahler, R.P. Advances in Statistical Multisource-Multitarget Information Fusion; Artech House: Norwood, MA, USA, 2014. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Addition/Subtraction and Multiplication | Matrix Inversion |
|---|---|---|
| 5 | ||
| 6 | 0 | |
| 7 | 0 | |
| 8 | 0 | |
| 9 | ||
| 10 | 0 | |
| 11 | 0 |
| Step | Addition/Subtraction and Multiplication | Matrix Inversion |
|---|---|---|
| 5 | ||
| 6 | 0 | |
| 7 | 0 | |
| 8 | ||
| 9 | 0 | |
| 10 | ||
| 11 | 0 | |
| 12 | 0 |
| Step | Addition/Subtraction and Multiplication | Matrix Inversion |
|---|---|---|
| 7 | ||
| 8 | 0 | |
| 9 | 0 | 0 |
| 10 | 0 | |
| 11 | ||
| 12 | 0 | |
| 13 | 0 | 0 |
| 14 |
| Method | Case 1: Shot Noise | Case 2: Gaussian Mixture Noise | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | CPU Time (s) | RMSE | CPU Time (s) | |||||||
| MCTKF | 2.8790 | 2.9882 | 5.7947 | 5.7867 | ||||||
| Square-root MCTKF | 2.8790 | 2.9868 | 2.8630 | 2.8635 | 5.7949 | 5.7866 | 6.0405 | 5.7510 | ||
| MB-EKF | MB-ETKF | MB-MCETKF | |
|---|---|---|---|
| CPU time (s) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Zhang, X.; Zeng, L.; Dai, S.; Zhang, M.; Lian, F. Filtering in Triplet Markov Chain Model in the Presence of Non-Gaussian Noise with Application to Target Tracking. Remote Sens. 2023, 15, 5543. https://doi.org/10.3390/rs15235543
Zhang G, Zhang X, Zeng L, Dai S, Zhang M, Lian F. Filtering in Triplet Markov Chain Model in the Presence of Non-Gaussian Noise with Application to Target Tracking. Remote Sensing. 2023; 15(23):5543. https://doi.org/10.3390/rs15235543
Chicago/Turabian StyleZhang, Guanghua, Xiqian Zhang, Linghao Zeng, Shasha Dai, Mingyu Zhang, and Feng Lian. 2023. "Filtering in Triplet Markov Chain Model in the Presence of Non-Gaussian Noise with Application to Target Tracking" Remote Sensing 15, no. 23: 5543. https://doi.org/10.3390/rs15235543
APA StyleZhang, G., Zhang, X., Zeng, L., Dai, S., Zhang, M., & Lian, F. (2023). Filtering in Triplet Markov Chain Model in the Presence of Non-Gaussian Noise with Application to Target Tracking. Remote Sensing, 15(23), 5543. https://doi.org/10.3390/rs15235543