1. Introduction
Nitrogen (N) is an indispensable element for crop biomass development [
1] and yield formation [
2], and it, as a major element, interacts at the intersection of the soil–water–air environment [
3,
4,
5,
6]. Supplying N to the crop is one of the critical soil functions [
7]; however, soil organic matter (SOM) shortages and unfavorable microclimates are among the reasons why soils often fail to provide adequate amounts of N to crops [
8,
9]. When soils are unable or limited in providing N, critically required bye crops, applying external N is a common farming practice. Traditionally, farmers assume a field is homogenously fertile, hence, apply a uniform rate N (URN) throughout the field area. Nevertheless, most agricultural soils are highly variable at spatially and temporally, which has strong impacts on crop yields and environments [
10,
11]. Applying N uniformly may exceed the crop needs in some parts of a field where soils are fertile, whereas crops may suffer from N deficiency in parts where soils are not fertile enough [
12]. Consequently, below-optimal N rates can reduce the final yield while above-optimal N rates may endanger soil and crop health. Particularly, excess use of N above crop needs can cause surface and groundwater contamination through leaching, run-off and eutrophication [
13]. Excessive N inputs can also affect air quality through N volatilization and gasification [
14] and, ultimately, cause economic loss to the farmer [
15]. Usually, N fertilizer is the most expensive farming input; nevertheless, the recent hike in N prices has made farming more expensive than ever. Therefore, the optimal application of N doses essentially requires efficient technologies, which should minimize environmental risks while maximizing N use efficiency and crop productivity.
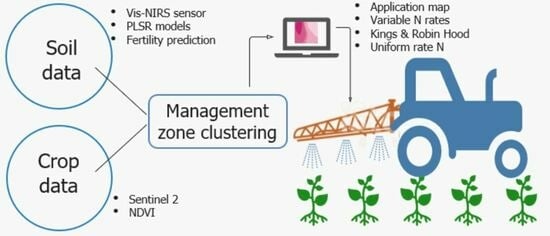
Site-specific N fertilization (SNF) has recently drawn mass attention and is a suggested technology to manage in-field variabilities by prescribing optimal but variable N doses across different parts of a field [
16]. The first step in implementing SNF is to map within-field soil and crop variations and divide the field area into several homogenous zones (known as management zones, MZs). In particular, the MZ delineation relies on the soil fertility indicators in combination with crop attributes such as crop biomass, vegetation index, greenness index and so on [
17,
18]. Ideally, MZs should consider multiple soil and crop quality indicators to map the yield potential of a field because none of the single indicators can represent the yield potential of a field or a MZ [
19,
20,
21]. Once a MZ map is available, a certain N rate is assigned to each MZ class by adjusting the usually practiced N dose by some percentages. The percentage of change depends on the degree of within-field variabilities and can be as high as 30% [
22]. Therefore, N doses can be higher and lower than the usual N rate. However, there is no scientific method to date to quantitively determine the best N rates except for two methods, i.e., Kings (KA) and Robin Hood (RHA) [
23]. The KA method recommends a high N dose for highly fertile MZs, and vice versa (feeding the rich), and RHA suggests a low N rate for highly fertile MZs, and vice versa (feeding the poor). A few SNF studies evaluated the performance of KA and RHA methods. For example, Maleki et al. [
24] reported a real-time control study of variable P application rates in maize using the RHA method. Guerrero et al. [
25] and Zhang et al. [
23] compared the KA and RHA methods for variable rate N management in winter wheat and barley and manure-based P fertilization in winter wheat by altering doses up to ±40%, respectively. Schillaci et al. [
22] tested the RHA-based SNF (SNF-RHA) for N topdressing in maize by varying N doses by up to ±30%. Most of these studies concluded that SNF-RHA is more productive and more economically efficient and environmentally sustainable than the SNF-KA and URN approaches. However, no work comparing the two SNF methods for poppy production can be found in the literature to date.
Conflicting results are often reported as well. For example, Basso et al. [
26] observed that a high-yielding zone maximized economic return and minimized environmental impacts (low N leaching) when fertilized with 90 kg N ha
−1 compared to a low-yielding zone fertilized with 30 kg N ha
−1. Not only because of this contradiction but also due to inconsistent economic prospects reported for SNF management [
27,
28], more and more studies are required to evaluate different methods for recommending variable N rates in order to confirm the benefit of SNF in different crops under different agroecological zones [
13,
26]. With this, this study is motivated to investigate and compare the two SNF treatments (SNF-KA and SNF-RHA) against URN for poppy production in Spain, the second biggest poppy-producing country in the world [
29]. Opium poppy (
Papaver somniferum L.) is usually grown for three purposes, i.e., poppy seeds, opium and alkaloids production, while seed yield can vary widely, with an average of around 2.0 t ha
−1 [
30,
31]. Commercially, poppy has multiple values in medicine (e.g., morphine), decoration (as an ornamental plant), and food, while poppy seeds are useful for making porridge, eating raw or being pressed for edible oil [
32]. Despite its large economic importance, no previous study has evaluated the agroeconomic and environmental performance of SNF in poppy production. Therefore, this study evaluates the agroeconomic and environmental impact of SNF in opium poppy production and compares the performance of KA and RHA recommendations. It hypothesizes that SNF increases poppy yield and/or reduces N application compared to URN, and that RHA is a better approach than KA from economic and environmental perspectives. The novelty of this study lies in the implementation and validation of an existing methodology of SNF technology in a new crop, i.e., in poppy for the first time. Additionally, it introduces an innovative index, the ‘Field Fertility Index’, designed to optimize the selection of an effective method for recommending variable N rates. The SNF application is based on an MZ map delineated with a multi-sensor data fusion approach that included (i) a set of soil fertility attributes estimated using an on-line soil sensor, (ii) crop normalized difference vegetation index retrieved from Sentinel-2 images and (iii) previous yield records. Finally, it compares the agro-economic and environmental benefits of SNF with URN technologies.
2. Material and Methods
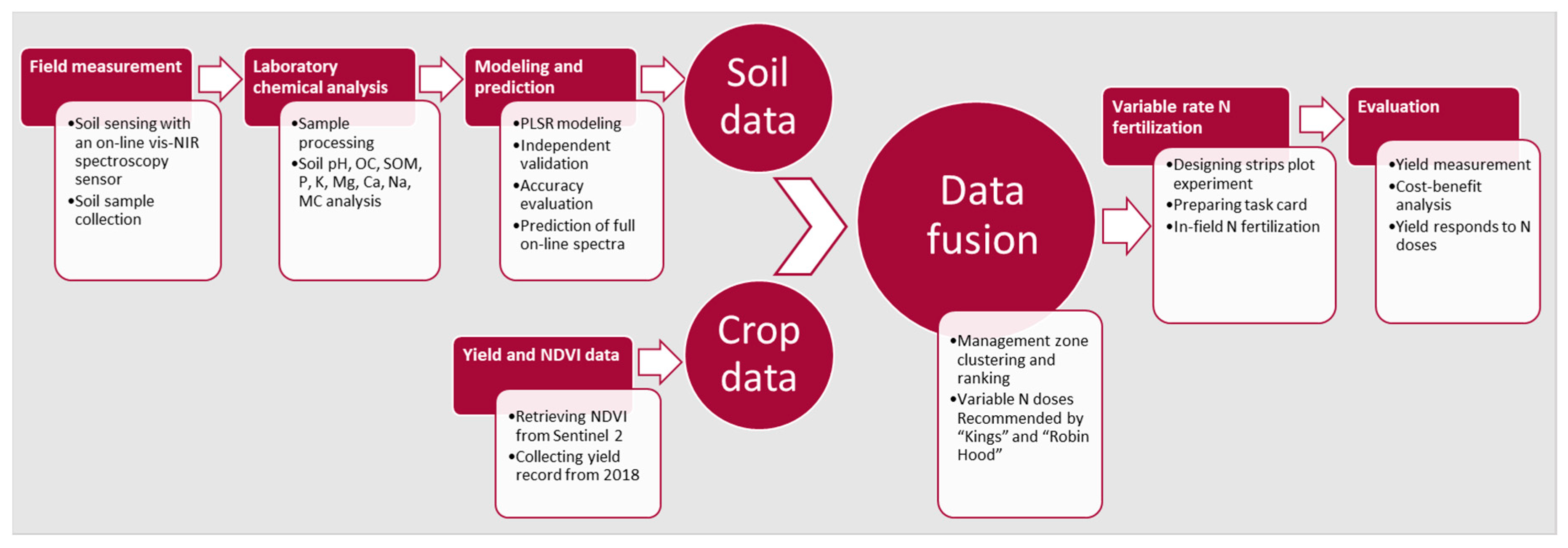
The overall methodology used in this study is illustrated in
Figure 1. The simultaneous collection of soil samples and on-line soil sensing was carried out using a mobile visible and near infrared spectroscopy (vis-NIRS) sensing platform [
33]. Soil samples were subsequently analyzed to assess soil fertility attributes, which were further used as response variables for modeling vis-NIRS data. Partial least squares regression (PLSR) models were established and validated for each soil property. These models were then used for predicting soil fertility attributes using on-line collected soil spectra. Crop normalized difference vegetation index (NDVI) data were retrieved from Sentinel-2 multispectral images, while yield data were derived from historical records from the 2018 cropping season provided by the farmer. These multi-layered datasets were passed through geostatistical analyses, including variogram modeling and kriging, to enable high-resolution spatial visualization of within-field variability. A cluster analysis was then performed using k-means clustering to establish MZ maps. Each cluster was assigned a fertility level based on yield data, soil fertility attributes and farmer knowledge of their field. The determination of variable N doses per MZ was made using two recommendation methods, namely, KA and RHA, and their performance was compared with the control uniform N dose. Cost–benefit and environmental analyses were conducted to evaluate the performance of the two proposed SNF treatments with the control UNR treatment.
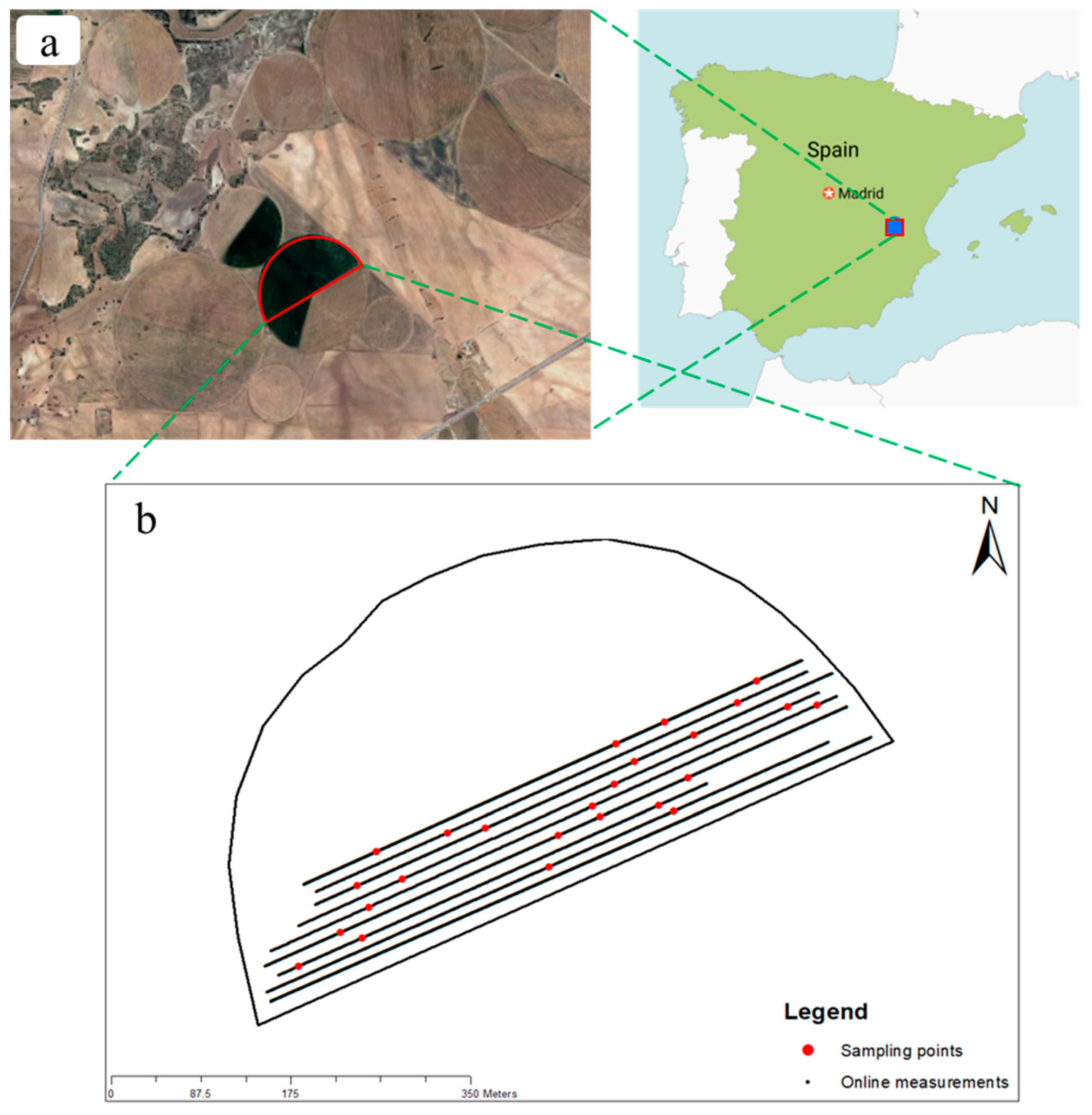
2.1. Experimental Field
The experiment was conducted in an area of about 9 ha within a 50 ha field (39°04′03.8″N, 1°40′03.5″W) at a commercial farm in Albacete, Spain, in 2021 (
Figure 2).
In Albacete, the climate is characterized by short, warm and predominantly sunny summers, while winters continue for an extended period, bringing cold temperatures, strong winds and intermittent cloud cover. Precipitation levels remain consistently low throughout the year, resulting in a dry climate. The annual temperature typically varies from 0.6 to 33 °C and is rarely below −4.5 °C or above 36.7 °C. The region experiences a semi-arid Mediterranean climate, known for its significant variations in rainfall during the crop growing season. This variability is accentuated by the limited soil water-holding capacity of the Calcaric Cambisols found in the area, which have shallow subsurface horizons at depths of around 40–80 cm. Irrigation helps in offsetting these challenges. The annual rainy season spans over 10 months, starting in late August and extending through the year until early July, with a 31-day rainfall of at least 1.25 cm per rainy day. October stands out as the wettest month, boasting an average precipitation of 3.3 cm. Particle analysis indicates that the field soil is a sandy loam. Before the year of the experiment in 2019, Garlic (Allium sativum) was grown under an irrigated system.
2.2. On-Line Soil Sensing
In the summer of 2019, spectral measurements were conducted using an on-line soil-sensing platform (
Figure 3) originally designed, developed and patented by Mouazen [
33]. This platform consists of a subsoiler affixed to a frame that is attached to the standard three-point linkage of a tractor. The subsoiler creates trenches in the soil, reaching depths of 15–20 cm, and smooths the bottom of these trenches through its downward vertical forces. An optical probe, hosted within a mild steel lens holder, is attached to the rear of the subsoiler chisel to capture soil spectra in diffuse reflectance mode from the smoothed trench bottom. To record the soil spectra, a visible and near-infrared spectrophotometer (vis-NIRS) with a detection range spanning from 305 to 1700 nm and a sampling resolution of 1 nm was used (CompactSpec from Tec5 Technology in Germany). A PTFE (polytetrafluoroethylene) disc with ≅99% reflectance and 50 mm in diameter was used as the standard reference, allowing for sensor recalibration every 30 min. A real-time kinematic global positioning system (RTK-GPS) from Trimble Navigation Ltd., based in Sunnyvale, Canada, was employed to record the precise location data of each soil spectrum. These georeferenced soil spectra were recorded at a rate of 1 Hz using a MultiSpec pro-II data logger and an acquisition system by Tec5 Technology in Germany. This equipment was integrated into a semi-rugged computer (Toughbook, Panasonic UK Ltd., Bracknell, UK). The measurement platform traversed parallel transects spaced 12 m apart (
Figure 1), maintaining an average forward speed of approximately 3.5 km h
−1. While conducting the on-line sensing, a set of 25 soil samples was randomly collected from the trench bottoms, about 20 cm deep. Concurrently, the data logger system recorded around 900 on-line spectra per hectare (ha
−1).
2.3. Laboratory Soil Analysis
The fresh soil samples underwent a cleaning process to eliminate non-soil particles, including grass, stones, stubble, roots and any other foreign materials. Subsequently, each soil sample was thoroughly mixed and reduced to 300 g using the standard coning and quartering technique. Soil pH was measured with an electrode meter after making a soil solution with distilled water followed by shaking and settling the suspension for 30 min. The available potassium (K
+), magnesium (Mg
2+), calcium (Ca
2+) and sodium (Na
+) were measured in 1 N ammonium acetate (NH
4CH
3O
2) extract with inductively coupled plasma atomic emission spectroscopy (ISO 11885 [
34]; CMA2/I/B1). Soil moisture content (MC) was measured by subjecting samples to a 24 h drying at a temperature of 105 °C. Soil phosphorus (P) and SOM were measured using the Olsen [
35] and Walkley and Black [
36] methods, respectively. Soil organic carbon (OC) was derived from SOM by dividing it by a constant of 1.724 [
37], and the ratios of K:Mg and K:Ca were calculated arithmetically.
2.4. Modeling of On-Line Measured Soil Vis-NIR Spectra
The 25 soil samples collected from the field were very limited in calibrating the vis-NIRS sensor; hence, they were merged with selected samples from an existing spectra library (
Table 1). The selection of samples was based on the data distribution similarity by projecting histogram, soil origin, type and mineralogy. To improve the signal-to-noise ratio, spectra were then pre-processed using the following steps successively: moving averaging, standard normalization, gap–segment derivatives and Savtizky-Golay filtering (
Table 1). On top of this, spectral edges were trimmed to exclude the noisy edges resulting in variable spectral ranges (350 to 1690 nm), which differed among soil properties. To correct the spectral bounce between the two detectors, namely, the visible and NIR detectors at the 1045 nm waveband, a correction method proposed by Mouazen et al. [
38] was applied. The pre-processed spectra were then randomly split into calibration (70%) and prediction (30%) datasets. Calibration involved conducting partial least squares regression (PLSR) analyses with leave-one-out cross-validation (LOOCV) on the calibration dataset. Subsequently, the resulting models were validated using the prediction dataset. An individual model was developed for MC, OC, CEC, pH, Ca, Mg, Na, P, K, SOM, Ca:Mg and K:Mg. The selection of the number of latent variables (LV) in PLSR was based on the lowest root mean square error (RMSE) in cross-validation. The predictive performance of each model was assessed using the the coefficient of determination (R
2), RMSE, the ratio of prediction to inter-quartile range (RPIQ) and the ratio of prediction to deviation (RPD). All spectral analyses, including data pre-processing and model development, were conducted using the ‘prospectr’ package by Stevens and Ramirez Lopez [
39] and the ‘pls’ package by Mevik and Wehrens [
40], both available in R CRAN.
2.5. Soil and Crop Data Collection and Mapping
After the PLSR models’ development and validation, models were used to predict each of the soil properties mentioned using the on-line soil spectra. The output of the on-line soil prediction corresponded to one dataset of each of the soil properties with DGPS coordinates. With these datasets, a high-resolution map for each predicted soil property was developed through interpolation by using the ordinary kriging method available in ArcMap (ESRI ArcGIS™ v10.7, Redlands, CA, USA). Before interpolation, semi-variogram models were fitted, whose parameters were used in the interpolation. The kriging maps were then classified into five classes, aiming at critical analyses and visualization purposes. In addition to the on-line soil data, crop NDVIs before the SNF in 2021 and yield records from 2018 were collected. The NDVI data were derived by employing a two-band combination function [
41] on the multi-band images obtained from the Sentinel-2 open data hub [
42]. These different layers of soil and crop data were used in the delineation of the MZ map, described in the following section.
2.6. Management Zone Delineation
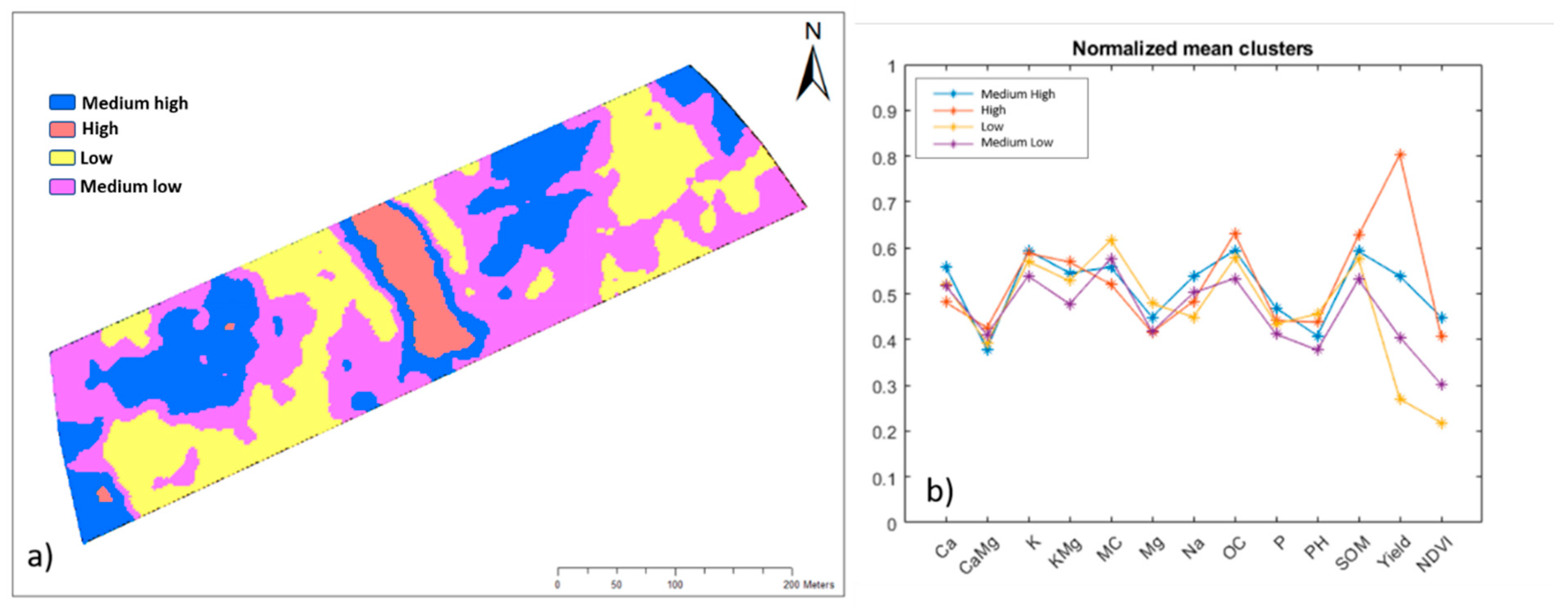
Since clustering requires the same spatial resolution data, all soil and crop maps were transferred into 5 by 5 m resolution by a raster analysis. Cell values of each raster were extracted and joined spatially to create a spatially homogenous data matrix where each pair of coordinates contained information on all variables, i.e., soil properties, NDVI and yield. The k-means clustering was developed in MATLAB software—R2019b, version 9.7.0, (MathWorks, Natick, MA, USA). This algorithm grouped the observations of the data matrix into k clusters and returned the cluster indices of each observation. It used the squared Euclidean distance metric to maximize the between-clusters distances. A normalized means cluster chart was obtained by normalizing the means of clusters of each variable used in the k-means clustering. This explored insights into each variable’s contribution to the clustering process. The optimal number of clusters was made by means of the elbow method. The ranking of the fertility of each management zone was conducted through consultation with the farmer in addition to the analysis of the historical yield data from 2018 and soil fertility for each management zone. This fertility ranking analysis thus facilitated MZ ranking as high (H), medium-high (MH), medium-low (ML) or low (L).
2.7. Variable Rate Fertilization Scheme
Farmers used to calculate N rates based on laboratory soil analyses using 1 or 2 sample ha
−1, whose output was used to calculate a N recommended rate that is homogeneous (URN) throughout the entire field area. This study adopted two SNF treatments, i.e., SNF-KA and SNF-RHA, and compared them against the URN treatment. The first SNF applied N according to the KA, e.g., feeding the rich. This was performed by recommending 40–50% more N rates to highly fertile zones (MZ-H), the usual N rate in medium fertile zones and 40–50% less in poorly fertile zones (MZ-L). If the number of MZ classes were five, then the MH fertility zone would receive 20–25% more fertilizer and the ML fertility zone would receive 20–25% less fertilizer than the URN. The second SNF adopted the RHA, which follows the opposite principle to that of the KA. N fertilizer rates of up to +50%, +25%, −25% and −50% were decided upon to ensure measurable differences allowing for comparison among treatments, i.e., URN, SNF-KA and SNF-RHA. The tested percentages were indeed subjective but agreed with farmers and local legislation. Nevertheless, previous studies have reported different N rates to evaluate crop responses to SNF [
17].
2.8. On-Field Experimental Design and Application
The map for fertilizer application was created by dividing the field into multiple parallel strips, each being 21 m wide, which corresponded to the width of the available sprayer on the farm. The stripes were superimposed onto the MZ map, leading to a variable count of individual plots within each strip. The number of plots within a strip depended on the number of MZ classes this particular strip intersected. Each strip was assigned as URN, SNF-KA or SNF-RHA treatment, and each treatment was repeated twice (
Figure 4). The N rate of each plot was determined according to URN, SNK-KA and SNF-RHA treatments as described before. A georeferenced application map (known as a task card) (
Figure 4), as machine-compatible shapefiles containing plot N doses, was created using ArcMap (ESRI ArcGIS™ v10.7, Redlands, CA, USA).
Three applications of granular N fertilizers were made using a twin-disc centrifugal spreader (Kuhn AXIS 40.2 W M EMC, KUHN, Saverne, France). In the first N application 2 days before sowing on 11th February 2021, a commercial product with 18% N concentration was applied to the URN plots at a rate of 195 kg ha−1, while in the SNF plots, doses varied according to the fertility level of a plot, between 97.5 and 292.5 kg ha−1 (±20–40%). In the second application on 9 April, 150 kg N ha−1 was applied in the URN plots and 75–225 kg N ha−1 (±25–50%) in the SNF treatments. In the third application on 5 May, a homogeneous N rate of 215 kg N ha−1 was applied across the entire field area to ensure that the required amount of N was provided to each MZ class. Other management operations, i.e., tillage, irrigation and pesticide applications, were identical across the three treatments.
2.9. Harvest and Gross Margin Analysis
On 13th of July 2021, a total of 119 yield samples were collected by harvesting poppy heads manually, and these were separated and stored in plastic bags for weighing and recording yield. At least 3 samples per plot were confirmed in order to ensure meaningful data analysis. Each sample was collected by harvesting a 1.5 m length of two central rows (0.14 m apart) covering an area of 0.21 m2 each. Gross margins and N use were analyzed considering the yield, costs of machinery hiring and N fertilizer, and market price for yield. Poppy price (930 € t−1) was directly obtained from farmers. The gross margin was calculated by subtracting the price of fertilizer and machinery hiring cost (EUR 15 ha−1) from the selling price of the yield. This type of analysis is well known as a partial budget analysis, which does not determine profitability but the ‘change in profit’ if an alternative is adopted, i.e., SNF instead of URN. Finally, a gross margin per field was simulated as if one treatment was applied throughout the entire field area. Additionally, the total amount of fertilizer applied was compared between treatments, and simulations of fertilizer use and savings per treatment were also calculated.
3. Results
3.1. Prediction Accuracy of On-Line Vis-NIRS Sensor
The developed vis-NIRS spectral models exhibited moderate to highly accurate performance in both calibration and on-line prediction (validation) of the studied soil properties (
Table 2). Generally, the calibration phase tended to produce slightly better models compared to the models in the validation phase, a trend often observed in such analyses. Notably, the accuracies of the models varied significantly across soil properties. For example, the soil pH and P models were calibrated with the highest and lowest R
2 values of 0.95 and 0.44, respectively. These same properties maintained their order in the test prediction, with slightly reduced R
2 values of 0.87 and 0.14, respectively. Furthermore, the cross-validation process resulted in an optimized and finely tuned model, with a very limited number of LV, ranging from 3 to 8. This outcome indicates an overall high stability and reliability of the spectral model, which can be confidently utilized for practical applications.
The vis-NIRS sensor demonstrated remarkable accuracy in predicting nearly all the studied soil properties, with particularly outstanding performance in estimating soil pH (R2 = 0.87, RMSE = 0.25). It was closely followed by the predictions for K (R2 = 0.76, RMSE = 0.43 meq 100 g−1), SOM and SOC (R2 = 0.74, RMSE = 1.76%). The sensor also performed well in predicting MC (R2 = 0.74, RMSE = 4.19%), Ca:Mg (R2 = 0.72, RMSE = 1.02), Mg (R2 = 0.71, RMSE = 0.94 meq 100 g−1) and Ca (R2 = 0.53, RMSE = 4.5 meq 100 g−1). However, there were certain cases where the vis-NIRS sensor did not perform as well as expected. For instance, it underperformed in predicting soil Na (R2 = 0.41, RMSE = 0.21 meq 100 g−1), K:Mg (R2 = 0.38, RMSE = 0.07) and P (R2 = 0.14, RMSE = 4.69 ppm). Overall, the on-line spectral models in the validation tests could be classified as excellent (RPD > 2.5) for pH; very good (RPD = 2.5–2.0) for K; fair (RPD = 1.8–1.4) for Ca; poor (RPD = 1.4–1.0) for P, Na and K:Mg; and good (2.0–1.8) for the remaining properties.
3.2. Within-Field Fertility Variations
Predicted soils maps illustrated substantial within-field variations, concurrently highlighting the robustness of on-line soil prediction and geostatistical interpolation (
Figure 5). Notably, spatial patterns exhibited divergence across distinct soil and crop attributes. The majority of the soil properties displayed discernible structural variations, whereas MC exhibited a more stochastic distribution. The upper-right quadrant of the field demonstrated elevated levels of fertility constituents, including pH, P, Mg, Ca and K:Mg, with a moderate enrichment of Na as well. Remarkably expansive ranges were observed in SOM (OC) and MC, explaining the necessity for advanced field management technology like SNF. The observed SOM and OC both remained within a range often recommended for optimal crop development. The field’s soil pH fell within a range indicative of a mildly alkaline nature.
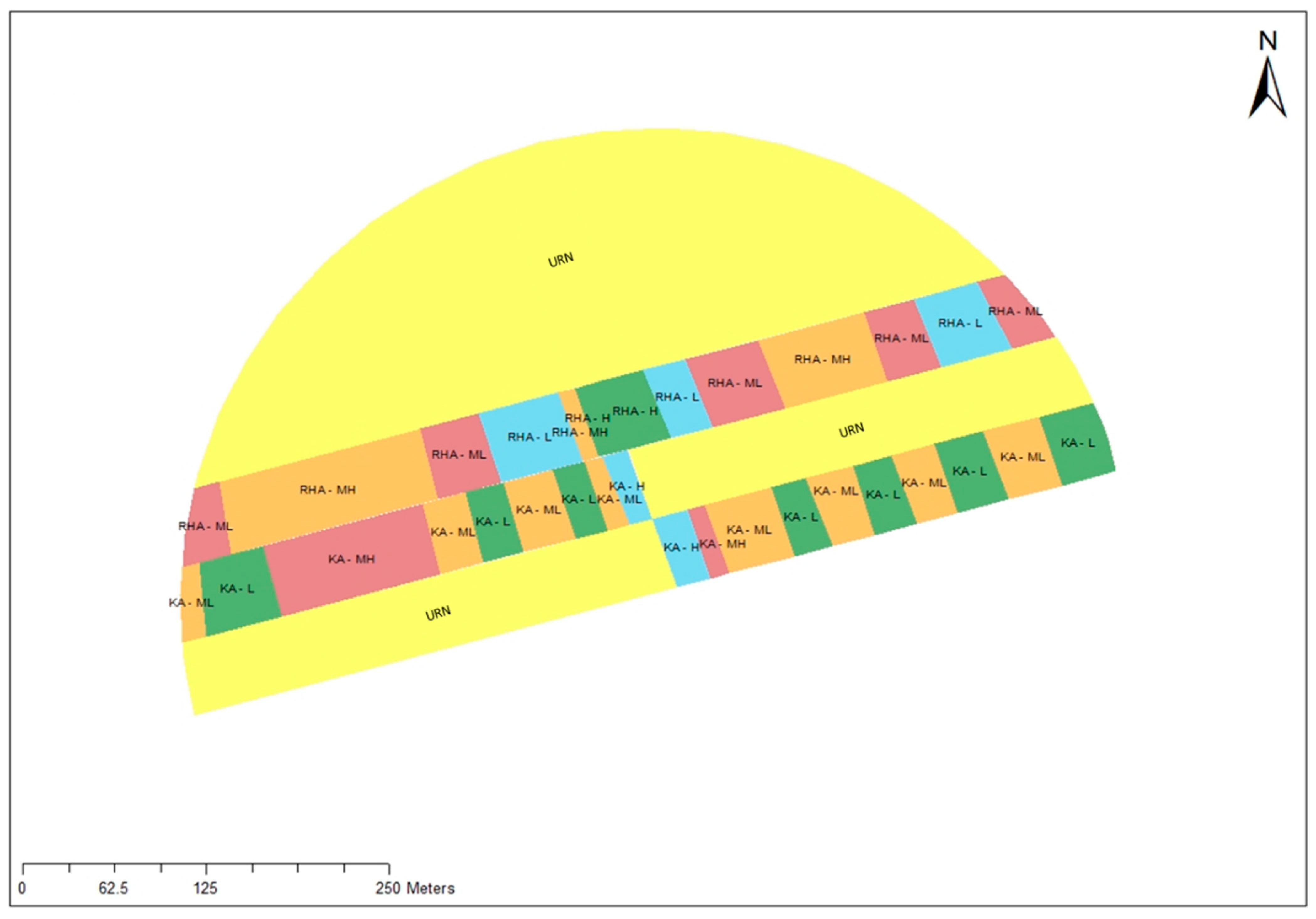
Four MZ classes, as determined by the k-means cluster analyses (
Figure 6), were categorized into different fertility levels, namely, H, MH, ML and L (
Figure 6b). This classification was based on the within-cluster soil fertility status and farmer experience and knowledge in his field. The ranking of MZ classes was also based on per cluster historical yield maps. Despite the MH fertile MZ having the highest NDVI, it did not have the highest yield, which was recorded in the MZ class H with the highest SOM (and OC), K:Mg, Ca:Mg and K contents but the second highest NDVI. The two least fertile MZ classes (ML and L) strongly agreed with their previous cropping season yield being low, which can be explained by their low fertility levels, e.g., low SOM (and OC), P, NDVI, K:Mg and K. Analyzing the spatial extent of MZ classes indicated that a small part of the experimental field of the current study was highly productive (high fertility), while the largest part was of low productivity (low fertility). Here, the authors introduce a new index called the field fertility index (FFI), which can be calculated as follows:
This FFI = 0.26 in this study, meaning that only 26% of the total study area was in a highly fertile class.
3.3. Yield Response to Variable Rates N
Yield response to variable N rates applied in different MZ classes differed across SNF treatments (
Figure 7). The N–yield response curve for the SNF-RHA treatment revealed an almost similar yield across all MZ classes fertilized with variable N doses. This indicates that the RHA equalized yield across different fertility level MZs by recommending a complementary N rate redistributed among MZ classes. The SNF-KA method illustrated a typical N–yield response curve, i.e., increasing yield with increased N doses, reaching a peak value, after which it preserved a plateau stage or declined slowly. In the least fertile MZ (L), yield dropped significantly due to the lowest N dose prescribed by the SNF-KA (b in
Figure 7), but SNF-RHA yielded much more in the L fertile MZ than the comparative zone under SNF-KA. Indeed, the yield in the MZs under SNF-RHA increased slightly with the increase in N dose to the highest level at the L fertility zone (
Figure 7). The application of high N doses increased yield of the highly fertile MZ class H under SNF-KA. However, the increased N dose in the MH zone did not lead to yield improvement in this zone compared to the ML zone. It is most important to highlight that the yield for all MZ classes for SNF-RHA was larger than that for the URN treatment, while the yields of ML, MH and H MZs for SNF-KA were higher than that for the URN treatment. Yields of both the MH and H fertile MZs for SNF-KA were slightly and clearly higher, respectively, than the corresponding MZs’ yields for SNF-RHA.
3.4. Cost–Benefit and N Use Analyses
The implementation of SNF treatments yielded an average yield enhancement compared to the URN approach, consequently resulting in a corresponding elevation in overall gross production (
Table 3). Among these treatments, SNF-RHA produced the highest average yield (2.74 t ha
−1), closely followed by SNF-KA (2.72 t ha
−1) and URN (2.64 t ha
−1). In tandem with this yield enhancement, SNF-RHA distinctly provided a more substantial revenue stream, reaching EUR 2546.3 ha
−1, surpassing both SNF-KA (EUR 2531.7 ha
−1) and URN (EUR 2454.3 ha
−1) treatments. However, SNF-KA and SNF-RHA increased gross margins almost equally by EUR 91 and 88.4 ha
−1, respectively, in comparison to URN.
Examining the amount of N used by the three different treatments revealed that SNF-KA reduced the N input applied (493.5 kg N ha−1) compared to URN (560 kg N ha−1). Conversely, SNF-RHA showcased elevated N use (577.9 kg N ha−1). The field-scale simulation showed that SFN-KA had the potential to reduce N input by 594.2 kg, while SNF-RHA was likely to increase N input by 159.9 kg within the experimental area (approximately 9 ha). Despite this fact, both SNF treatments were effective in increasing yield, while only SNF-KA reduced N input. Intriguingly, while using slightly extra N, SNF-RHA led to yield increases surpassing those in both SNF-KA and URN treatments.
4. Discussion
4.1. Spectral Models and Within-Field Fertility
The current performance accuracies (
Table 2) of vis-NIRS sensors in predicting multiple soil fertility indicators are comparable with those reported in previous studies [
20,
43,
44,
45]. The low number of LV observed in this study is in line with results reported in the literature [
46,
47,
48], which is an indication of the model’s robustness and reliability. It is worth noting that the current spectral models were developed based on the leave-one-out cross-validation criterion, and these models were validated using an independent prediction dataset. However, a recent study has raised concerns regarding the use of leave-one-out cross-validation, suggesting the use of a random subset instead [
49]. This new suggested methodology of cross-validation can be tested in the future, as the current work was conducted in 2019, much earlier than the recent suggestion became available in 2023. The closely similar accuracy observed for SOC and SOM can attributed to their direct associations. Usually, vis-NIRS is less accurate in predicting the secondary attributes (e.g., K, Na, Ca) than the primary soil attributes (e.g., OC, MC) [
43,
45], which is in line with the results obtained in the current study. Since the soil was very dry during the on-line measurement in 2018 (4–12%), high levels of noise due to vibrations may have negatively affected the spectral quality, and the quality of predictions. Despite these harsh measurement conditions, the accuracy for all properties was in the excellent to good range, except for the low prediction accuracy for P and Na. The low accuracy observed for the P and Na models can be attributed to the low MC, as it was documented that the prediction of P [
50] and Na [
45] is possible due to their covariation with soil MC- and MC-sensitive spectral bands, which are indeed not strongly featured in this study. Generally, such covariations of secondary soil properties, i.e., P, K, Mg, Na and Ca with MC in the 350–1700 nm spectral range, are attributed to the O-H absorption overtone region around 1400–1450 nm [
45]. Munnaf et al. [
45] reported that some bands can make Mg (1056 nm) and K (1158 nm) predictions possible due to the covariation with aromatic C-H absorption around 1100 nm, and that Na (1550 nm) and Mg (1510 nm) were possible to predict mainly because of the indirect association with amine N-H absorption around 1500 nm. Additionally, several bands within the visible spectral range were found to be key to predict secondary properties. For example, 456 nm and 460 nm together with 571 nm are associated with successful prediction of pH and Mg, through the possible associations with soil albedo due to soil MC and SOM. The key bands for predicting Ca were the same as those for pH prediction, and 560 nm along with 770 nm were observed to support Na prediction. Another possible reason for low accurate predictions could be the availability of a limited dataset during model development, with a critical shortfall in the sample size, as only 25 samples were collected from the specific field of study. After all, most of the current models met the criteria established by Maleki et al. [
24], requiring a model to achieve R
2 ≥ 0.70 and RPD ≥ 1.75 to be considered a reliable model for the development of site-specific applications.
Despite observing structural variability in soil fertility maps (
Figure 5), abrupt alterations observed in on-line predicted MC maps can be attributed to the highly dynamic nature of MC compared to other soil properties. Areas with high pH contents resembled Mg-, P- and Ca-rich areas, confirming the influence of those nutrients on pH. Soil P availability to crops is constrained to both alkaline and acid soils, affecting crop root development severely, primarily because P plays a pivotal role in cell division. A pH between 6 and 7.5 is often considered as an ideal soil acidity for P availability, but this was not the case in the study field, where pH was more than 8. High pH (7–8.5) also influences soil’s Mg availability. Noticeably, high variations in Ca:Mg and K:Mg maps should be given special attention in crop management decisions because of their antagonistic interactions, i.e., the presence of one can limit the availability of another [
1,
51]. Accordingly, studies recommended retaining a proper ratio of Ca
2+ to Mg
2+ prior to making a nutrient management decision and managing soil acidity through liming [
51,
52]. On the contrary, research suggested confirming an optimal level of soil Ca and Mg for best crop growth instead of altering the Ca
2+:Mg
2+ ratio [
53]. The antagonistic effect of K on Mg was reported to be stronger than the effect of Mg on K availability [
54]; however, such influences as well as balanced ratios depend on crop and soil types [
55]. Therefore, the fusion of multiple fertility indicators in the MZ delineation is the ideal option as it allows for the determination of key yield-limiting factors and thus optimizes management decisions [
56,
57].
The lack of alignment between yield and NDVI variability among MZ classes (
Figure 6) raises concerns about the reliability of using NDVI for ranking soil fertility classes, a practice often employed for making management decisions. Many studies found NDVI to have a strong correlation with crop yield [
58], hence, this was adopted in this study as a MZ proxy. The opposite suggestion was also reported, i.e., NDVI cannot be an MZ proxy directly, and the use of NDVI should be carefully interpreted [
59]. The weak correlation between NDVI and yield when encountered can be attributed to biotic and abiotic stresses at the late stages of the cropping season [
60]. Nevertheless, NDVI in the current work correlated with crop yield quite well, particularly for the H and MH fertile MZs. This suggests that relying solely on NDVI for decision making on N fertilization should be given special care, particularly regarding the selection of the best crop growth stage for NDVI data collection [
61,
62]. The use of time-series NDVI data instead of a single NDVI measurement is highly recommended [
18], although this was not the case in this study.
4.2. Influences of Site-Specific N Applications
Looking at the N–yield response curve (
Figure 7) observed for SNF-KA reveals that KA recommended a lower than necessary N dose for the poorly fertile MZ (L), which deteriorated its fertility further because of its low N mineralization potential, limiting crop growth and final yield. A yield improvement was not possible to observe even after applying an elevated N dose in the MH fertile MZ, indicating the optimal N consumption to grow marginally, but carried risks of increasing residual N accumulation in the soil and N leaching [
63]. It is worth noting that a yield–N response curve like the current one for the SNF-KA approach was possible to derive from the data reported by Guerrero et al. [
25], where SNF-KA diminished barley yields by increasing the N doses over the usual dose, and SNF-RHA led to a nearly equal yield over variable N doses. The yield response to increased N can be mediated by the increased capturing of solar radiation, which is in turn mediated by improved tillering and leaf enlargement and enhanced photosynthesis [
64]. N application amplifies crop yield, but an overdose of N can reduce yield due to lodging [
23] and foliar infections [
64].
Almost homogenous poppy yields among MZ classes under SNF-RHA treatment explain that the low fertility (L and ML) MZ classes required supplementary high N doses, whereas the highly fertile MZ classes (MH and H) did not require this, but were able to provide adequate amounts of N, allowing crops to grow optimally. This was possible for the highly fertile MZs (H and MH) due to their high potential of mineral N release by the naturally occurring soil N mineralization process [
65,
66] since both H and MH fertile MZ classes possess higher SOM than ML and L fertile MZ classes (
Figure 6). Apart from soil microclimate conditions, soil N mineralization largely depends on SOM, which can influence microbial activity and microbial biomass [
67]. This means that the H and MH fertility MZs had higher N mineralization potential under favorable soil micro-climatic conditions (e.g., temperature, pH, redox, MC, texture) than the ML and L MZ classes; however, the current study does not have sufficient data to support the quantification of N mineralization potential. It is worth noting that poppy yields can vary widely (1.5–3.0 t ha
−1) depending on the local weather conditions, cultivar used, seeding rates and inter-cultural management including N rate, irrigation and agrochemicals application, limiting a fair comparison between the yield obtained in the current work with those reported in the literature [
30,
31].
The estimated cost–benefits (
Table 3) in these studies to some extent agreed with those in the literature that site-specific fertilization increases the gross margin compared to URN for cereal crops. Guerrero et al. [
25] reported enhanced gross margins of EUR 129.27–148.78 ha
−1 and EUR 4.85–16.40 ha
−1 by SNF technology in barley and wheat, respectively. Zhang et al. [
23] observed an increase in gross margins ranging between EUR 36.32 and 40.06 ha
−1 by applying variable rate manure using the same data fusion approach as that of the current study. Another work reported a net return of EUR 15.2–24.64 ha
−1 from SNF in maize compared to URN [
12]. Recently, Munnaf et al. [
68] reported SNF to increase gross margins by EUR 43.93 ha
−1 in winter wheat production by implementing a novel map–sensor-based technology for variable rate N management.
The potential of SNF in reducing N use (
Table 3) observed in this study both partially agreed as well as contradicted to observations reported in the literature. Guerrero et al. [
25] found SNF-KA (15.22 kg N ha
−1) to increase and SNF-RHA (7.79 kg N ha
−1) to decrease N inputs in barley production; however, both SNF treatments reduced N (2.10–26.83 kg N ha
−1) compared to URN in wheat. For site-specific manure application, Zhang et al. [
23] showed that SNF-KA consumed additional N (5.21 kg N ha
−1) and P (1.63 kg N ha
−1), while SNF-RHA reduced both N (11.01 kg N ha
−1) and P (7.1 kg N ha
−1) compared to uniform rate manure application in wheat. Such conflicting findings could be due to the FFI, reflecting the proportion of highly (H and MH) fertile areas to the total area under both highly and poorly fertile zones, which is in line with what was pointed out by Pedersen and Lind [
69]. As such, most of the field area of the study field was classified as poorly fertile (ML and L fertile MZs), covering three-fourths of the total field area (FFI = 0.26). This is the reason why the RHA treatment applied high N doses for about three-quarters of the total area, leading to an increase in the average N dose, which, in turn, reduced the corresponding gross margin [
15]. Contrarily, SNF-KA applied high N doses only over a small area (in H and MH fertile MZs), leading to a reduction in N use. Generally, SNF has the potential not only to decrease N costs but also to prevent agroecosystems from N-based contamination, e.g., leaching, emission and residue [
70,
71]. Increasing gross margins and reducing environmental footprints are expected benefits of SNF, as observed in this study, at least for SNF-KA, and as reported earlier [
15,
16,
28,
72].
4.3. Possible Limitations
Despite observing a positive gross margin and poppy yield as well as a reduction in N use through the proposed SNF technology, this study acknowledges a couple of possible limitations around spectral modeling, MZ mapping, N dose calculation, the duration of the trial and economic analysis. The quality of the spectral models seemed not the best mainly because of the dry soil conditions during soil scanning in 2018. The limited number of samples collected from the study field and used in the model training allowed to use PLSR only in spectra modelling instead of intelligent learning algorithms, e.g., artificial neural networks. It is highly possible to improve vis-NIRS spectral prediction accuracy by increasing the number of observations, thus taking the benefit of using advanced machine and/or deep learning techniques. The quality of spectral predictions also determines the quality of MZ maps, which is the backbone of SNF. To develop the MZ map, several key soil fertility attributes were used in the current work, while excluding soil mineral N and clay, which are two critical soil fertility indicators for deciding upon N doses. Therefore, a future study should take clay and N information into account for MZ delineation and determining variable N doses. Variable N dose per each MZ class was based on the arbitrary percentage increase or decrease of the uniform rate N dose, which is not the optimal N dose. Ideally, N dose should be calculated as a function of soil fertility per MZ based on long-term experimental data, which were not available in this study.
The current findings relied on a single-site-year experiment, limiting the generalization of the results achieved, despite being promising, as this agronomic study was highly sensitive to weather conditions. Particularly, the amount of rainfall and temperature can largely affect the crop yield and N use efficiency. Therefore, we suggest a careful interpretation of the current agronomic, economic and environmental benefits while comparing them with existing studies as well as any future studies to come. Future work should consider several field experiments that are run for several cropping seasons to arrive at robust conclusions regarding the benefits.
The cost–benefit analysis of the current work relied on a partial budgeting method, which is indeed an acceptable economic tool due to the lack of appropriate data required to use a full-budget economic analysis, which is a more realistic analysis compared to partial budgeting. Given that the partial budget analysis showed inconsistent economic performances, this study foresees the need to use a full-budget analysis of the proposed SNF in the future.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}