1. Introduction
Change detection (CD) is a hot issue in the applications of remote sensing images, allowing for the detection of ground change features by contrasting images of the same area at different periods [
1,
2]. Due to the speedy advancement of remote sensing technologies, remote sensing image CD methods have been broadly applied in land use planning [
3,
4], illegal building investigation and handling [
5], disaster assessments [
6,
7], etc.
In the early stages of CD exploration, some handcrafted methods were proposed to solve various problems in CD. Through image differentiation [
8], change vector analysis [
9], imaging and regression analysis [
10], principal component analysis [
11], and others, they design and adjust super parameters manually and have achieved good results based on low-resolution data [
12,
13]. Nevertheless, these methods suffer from manual operations, which perform poorly when dealing with complex scenes.
In recent years, with the development of artificial intelligence technology, deep learning-based CD methods have demonstrated the advantages of being efficient, convenient, and highly automated. Currently, some CD methods employ a Siamese structure combined with semantic segmentation neural networks. CNNs possess strong capability for pixel-level feature extraction, such as Unet [
14] and ResNet [
15], the most representative semantic segmentation networks [
16,
17]. CNNs used for CD are progressing rapidly and have achieved excellent results [
18,
19,
20]. However, due to the influence of intra-class differences in ground objects, lighting conditions, seasonal changes, complex scenes, and other factors, the content in remote sensing images is diverse, making it difficult to capture crucial information solely through convolution in CNNs [
21]. Therefore, some other modules have been introduced to improve the feature distinction of CNNs, including deeper CNNs [
22], dilated convolution [
23], multi-scale feature fusion [
24], etc.
Despite the above methods achieving good results, they still fail to break away from the inherent limitations of the convolutional receptive field, they still struggle to model explicit long-range relations in space–time [
25], and the issue of internal holes in detection results often exists. On the contrary, transformers perform pretty well in handling global information and long-range input problems, suppressing the occurrence of internal holes in CD. Therefore, recent research has proposed introducing transformer structures into the CNN to improve the above problems, as the transformer can realize global modeling and reduce the occurrence of holes in change targets [
25,
26,
27,
28].
A common way to adopt the transformer structure in CNNs is to connect them [
25]. Many studies have fed shallow features extracted by the CNN into the transformer for global modeling, which could better solve the problem of internal holes in the results. But it ignores the deeper feature extraction capabilities of CNN, particularly when it comes to issues with extracting a small change target and the complete target boundaries. In addition, it has been proposed to utilize the transformer alone for feature extraction [
27,
28], using the transformer to divide the image into small image sequences for fine segmentation and suppression of omission and misdetection. Nevertheless, this method leads to coarse segmentation problems and has weak ability to capture local detail information, because only the transformer is used for feature extraction [
29]. In particular, when the features in the remote sensing image vary greatly in size and shape, such as buildings, roads, etc., the problems of the above methods will be magnified, weakening the integrity of the change information. Considering the respective characteristics of the CNN and transformer, when extracting features, combining the two would be an effective way to solve the above problems [
30]. The current methods combining the CNN and transformer mainly include superposition, full connection, etc., which have significant improvements in coarse segmentation and small target extraction problems. However, this kind of method rarely focuses on the relationship between different levels of change features, which means they need to be strengthened in the extraction of linear targets and boundary integrity.
To improve the feature extraction ability, while combining CNN and transformer structures, and strengthen the feature connections between different levels, this study proposes a full-scale connected CNN–Transformer network for the CD, which is named SUT. Considering the pros and cons of convolution and transformers and the computation volume, the proposed network consists of a one-layer CNN and three-layers integrating the CNN and transformer. Specifically, PAM [
31] is adopted to integrate the features extracted from the CNN and transformer, which uses global average pooling to reduce computational costs and can improve the capacity of the network in small target detection and boundary detection. In addition, SUT introduces full-scale skip connections from the encoder to decoder [
32,
33] to achieve the multi-directional flow of feature information and the fusion of multi-scale features, which enhances the ability to detect linear targets and complete boundaries. Finally, the change maps obtained from the decoder are aggregated through deep supervision to achieve feature fusion at a multi-level. The main contributions of the method in this article are as follows:
- (1)
A full-scale connected CNN–Transformer network (named SUT) for remote sensing images change detection is proposed, which has a strong ability to extract changed features and achieves excellent results on publicly available change datasets while maintaining concise architecture.
- (2)
The PAMCT proposed in SUT fuses the feature generated from the CNN and transformer, which not only retains the ability of the CNN to extract detailed features but also strengthens the global modeling ability of the transformer.
- (3)
The full-scale skip layer connection from the encoder to decoder is adopted to facilitate the multi-directional flow of features between various levels, enabling the network to fuse feature details at different scales, thus being conducive to detecting changed objects at different scales.
The remainder of this study is arranged as follows.
Section 2 introduces the relevant research studies. The method we designed in this article is detailed in
Section 3.
Section 4 displays the relative experiments and discussion. At last, we provide the conclusion of this study in
Section 5.
3. Methodology
A detailed principle and process details of the method are provided in this section. The overall architecture of SUT is introduced firstly. Then, detailed explanations of the various parts of network are provided. Besides, the loss function is provided.
3.1. Network Architecture
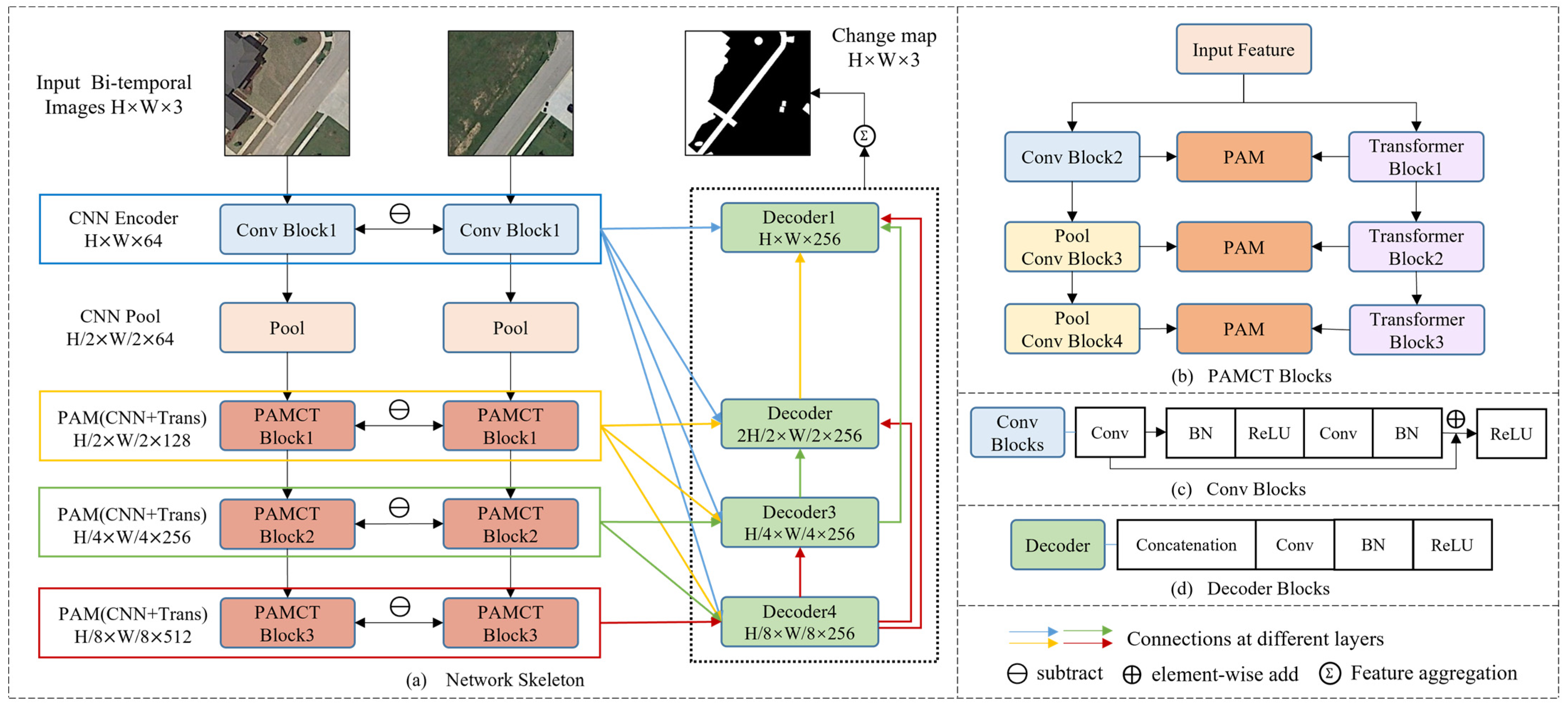
SUT is a standard U-shaped network using a Siamese structure as the encoder. The overall architecture of SUT consists of four symmetric encoders and decoders, as displayed in
Figure 1. It takes dual temporal images as inputs to the Siamese network and shares parameters to enable the dual branch encoder to focus on the same area during feature extraction. The input images are first subjected to a convolutional block and then down-sampled once, as displayed in
Figure 1c, which preserves the shallow information extracted using the CNN and reduces computational complexity. The subsequent three layers of encoders use PAM to fuse features generated from the CNN and transformer structures, fully leveraging the advantages of both structures and complementing each other, denoted as PAMCT. Here, the subtraction method is directly used to extract change maps between two Siamese branches, and the weight values are shared and connected to the decoder.
For the decoder, the inputs for each layer are four features generated in different scales. Considering the unidirectionality of information flow in the encoding process, full-scale skip connections are used to connect different levels of change maps to the decoder, which achieves multi-directional information flow and multi-scale feature fusion. Finally, SUT aggregates and classifies the outputs of each decoder layer to obtain the ultimate change features.
3.2. Encoder
Considering the computational complexity and feature extraction capability, the encoder is designed as a combination of a one-layer CNN and three-layer CNN–Transformer, as shown in
Figure 2.
There are basic blocks, such as pooling operations, up-sample, conv blocks, transformer blocks, and PAMCT, in the encoder. The pool is the maximum pooling operation, and the up-sample blocks are designed to scale the feature images extracted using the CNN and transformer blocks to the same size during computation.
In
Figure 1c, the calculation of conv blocks could be represented using Equation (1).
where
represents the input feature map of layer
and the time phase
,
represents
convolution operations,
represents batch normalization, and
represents the ReLU activation function.
3.3. Transformer Blocks
The output of the first CNN layer passes through the pooling and is inputted into the last three layers of the encoder. In the structure of the integrated CNN and transformer, the CNN also uses the conv blocks mentioned above, and the detailed transformer structure we used is displayed in
Figure 3.
Before encoding with the transformer, the input images must proceed through patch embedding to be expanded into image sequences with tokens of shape
. Here, we set
as the tokens after passing through the patch embedding, and these are calculated using Equation (2).
where
means the input images,
represents a dimensionality reduction function,
represents the weight matrixes of the deep convolution operation, and
represents the data reconstruction operation. Equation (2) actually represents data transformation in code and can be described as
, where
and
represent the image size,
is the number of channels, and
is the batch size during training.
The next module in the transformer is the self-attention module. When inputted into the self-attention module, tokens must first go through layer normalization [
57]. Then, each layer uses a linear projection to produce three vectors
Q,
K, and
V, which can be expressed using Equation (3).
where
represents the tokens of the layer,
,
, and
represent learnable parameters. Besides,
,
, and
of the same layer have the identical
dimension. After obtaining the
Q,
K, and
V vectors, self-attention can be described using Equation (4) [
47].
where
is a softmax function along the channel dimension and
is the channel dimension of the head in the
vector.
Furthermore, the core structure of the transformer is multi-head self-attention (
MSA).
MSA divides
Q,
K, and
V vectors into multiple separate heads, computes the attention coefficient of each head, and then concatenates their values. This process can be described using Equations (5) and (6).
where
is the multiple independent heads, with
taking values between 1 and
n,
represents a concatenation operation,
means a matrix for linear projection, and
is the number of heads.
We perform layer normalization on the output of
MSA and compute it through
MLP to obtain the output features of the transformer. The
MLP in the transformer mainly comprises two linear projection layers, with one of the projection transformations using the
GELU activation function [
58]. The implementation of
MLP is expressed in Equation (7).
where
and
represent learnable linear projection matrices that can expand and compress the channel dimensions of tokens.
After the process shown in
Figure 3, we can obtain the 2D feature maps
containing rich global contextual information, and it is also necessary to convert
into images that match the shape of the input images, which is the process
, in order to facilitate subsequent feature fusion between the CNN and transformer.
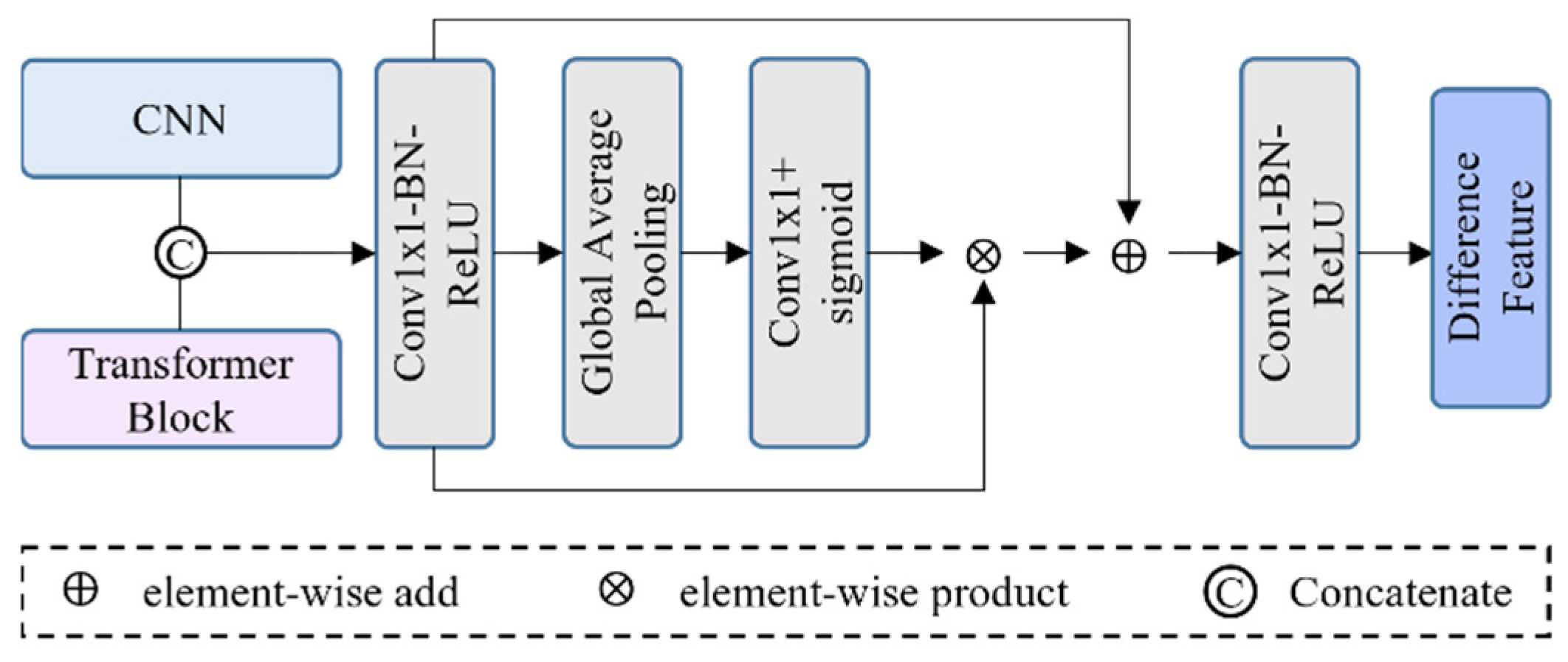
3.4. PAMCT Blocks and PAM Module
The composition of PAMCT is displayed in
Figure 1b, which is designed to fuse feature maps extracted from the CNN and transformer using the PAM [
31,
59]. The calculation process of the PAM is shown in
Figure 4.
The PAM takes the features generated from the CNN and transformer as inputs, concatenates them, and enhances the change features through channel attention. As displayed in
Figure 4, the feature maps undergo global average pooling after convolution and are activated with sigmoid, while introducing residual connections to improve performance. Finally, the PAM adopts a
convolution to obtain the output feature. The mathematical expression of the calculation process of the PAM is shown in Equations (8) and (9).
where
and
, respectively, denote the features extracted using the
k-th
layer of the CNN and transformer at time
,
denotes the concatenation operation,
denotes
convolution,
denotes batch normalization,
denotes the ReLU activation function,
denotes the global average pooling,
denotes a sigmoid function, and the output feature of PAM is
.
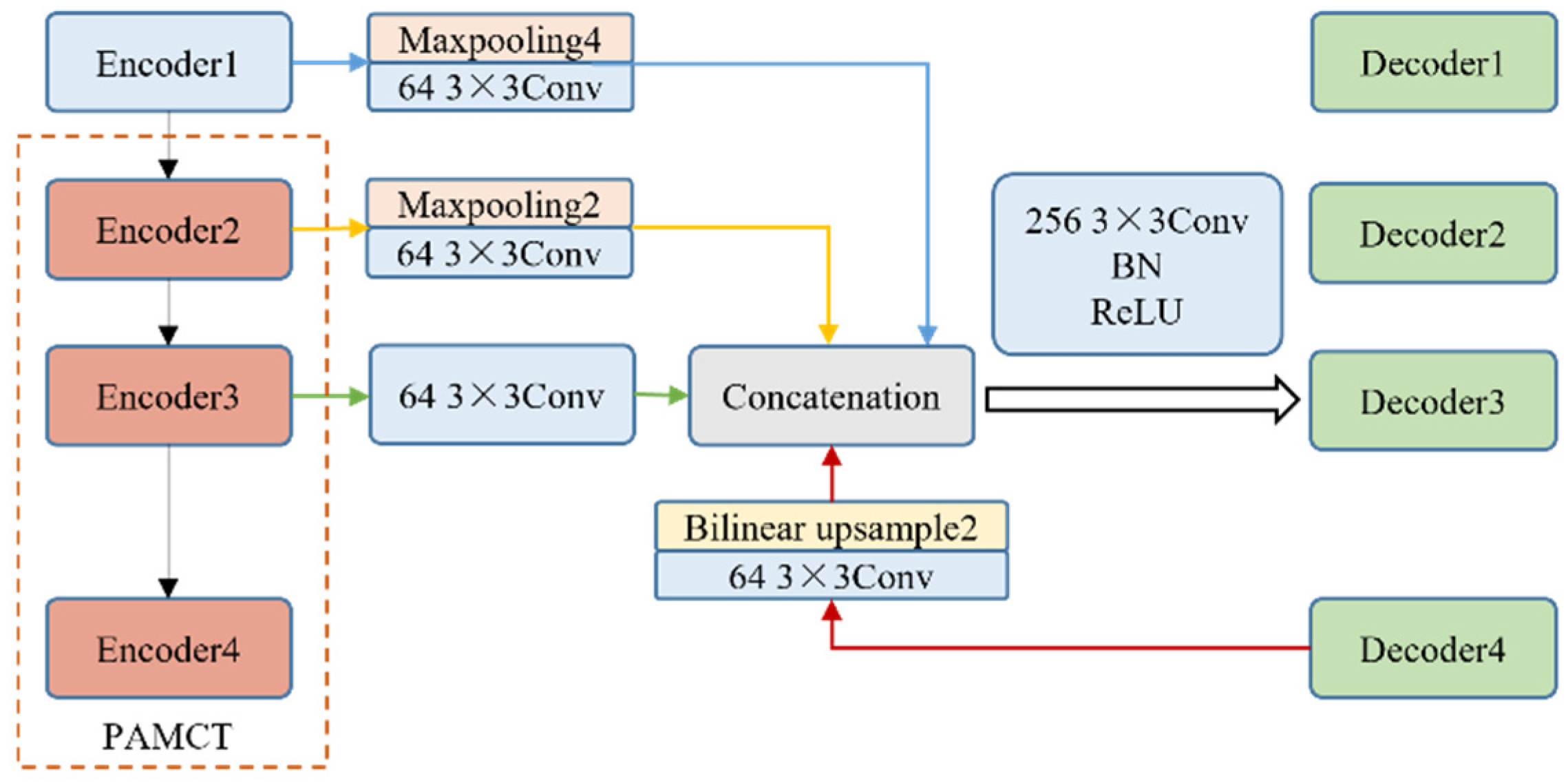
3.5. Decoder with Full-Scale Skip Connection
Currently, transformer-based networks connect the encoder and decoder layer-by-layer for inter-scale communication, resulting in unidirectional information flow and the easy loss of feature information. In response to this issue, this study was inspired by [
32,
33] and adopted full-scale skip connections to achieve multi-scale information flow in multiple directions while maintaining high-resolution and fine-grain feature representations. Considering the encoder structure and computational limitations, we adopt a four-layer decoder to achieve full-scale skip connections. The structure of the third layer decoder is taken as an example, as displayed in
Figure 5.
This process can be described as the maximum pooling of the change maps in Encoder1 and Encoder2 to the size of the change map in Encoder3, then up-sampling the output features of Decoder4 to the size of the change map in Encoder3, concatenating the above features with the change map in Encoder3, and finally fusing them through convolution to attain the output feature of Decoder3. This process can be described using Equations (10)–(12).
where
and
are the bi-temporal features of the
k-th layer
,
is the output change map of each encoder layer, and
is the absolute value difference.
means the concatenating operation,
and
denote maximum pooling with coefficients of
and
,
represents up-sampling to twice the size,
represent convolution with a
kernel,
means batch normalization, and
represents the ReLU activation function.
Other layers of decoders can be obtained using similar calculations. Last, the outputs of the decoder at different scales are fused after being deep supervised, and the final feature maps are what we need, as shown in
Figure 6.
3.6. Loss Function
In the remote sensing image change detection, the quantity of pixels that have not changed is much greater than the quantity of pixels that have changed. In this study, we adopt a mixed weighted loss function to alleviate the problem of sample imbalance. Here, we consider the mixed method of weighted cross-entropy loss [
46] and dice loss [
60], so the loss function can be expressed using Equation (13).
where
represents the weighted cross-entropy loss,
represents the dice loss, and
is the loss function we used.
Cross-entropy can be defined as Equation (14). Here, we set
as the real probability distribution,
is the predicted probability distribution, and
refers to the probability of image pixel distribution.
When the sample label is binary {0, 1},
is taken as 0 or 1,
is taken as
after softmax, and if we define
as the probability of correct the prediction, the cross-entropy can be optimized using Equation (15).
Moreover,
can use the coefficient
to show the importance of the sample in the loss, strengthening the contribution of changed pixels and reducing the contribution of unchanged pixels to the loss function, thus to some extent alleviating the sample imbalance problem, as shown in Equation (16). The coefficient
can be defined using Equation (17) [
46].
where the value of
is 0 or 1, which indicates non-changed or changed pixels, and
H and
W means the size of the change maps.
Dice loss is a metric function used to evaluate the similarity between samples. It can curb the problem of positive and negative samples being strongly imbalanced. The range of dice loss is [0, 1], and the larger the value, the more similar the samples. The calculation of dice loss can be defined using Equation (18).
4. Experimental Results and Analysis
In this section, we introduce the datasets, experimental settings, and evaluation metrics, then in detail, show the performance of SUT based on three public datasets, and compare it with the state-of-the-art methods to demonstrate its efficiency. Moreover, an ablation experiment is designed to verify the effectiveness of the blocks used in SUT.
4.1. Datasets
Three remote sensing image datasets that we used, namely CDD [
43], LEVIR-CD [
24], and WHU-CD [
61], are adopted to verify the performance of the proposed network, as shown in
Figure 7.
CDD dataset: a remote sensing image set with significant seasonal changes and various sizes of changed classes, such as buildings, roads, cars, etc. The images in this dataset are RGB images with a spatial resolution from 3 to 10 cm per pixel. And there are 16,000 pairs of dual temporal non-overlapping images of 256 × 256 pixels in size. The quantity of training, validation, and testing sets in CDD are 10,000, 3000, and 3000 pairs, respectively.
LEVIR-CD dataset: a building CD dataset collected from Texas, USA. It is an RGB image dataset with a spatial resolution of 0.5 cm per pixel. The size of the images in LEVIR-CD is pixels. There are a total of 637 pairs of images in it. The training, validation, and testing datasets are 445 pairs, 64 pairs, and 128 pairs of images, respectively. Since the image size is large, and if the image pairs are used directly for training, it would lead to excessive memory consumption. Therefore, they need to be cropped into non-overlapping image pairs of pixels in advance, and correspondingly the training, validation, and test datasets are 7120, 1024, and 2048 image pairs, respectively.
WHU-CD dataset: a city-building CD dataset with bi-temporal high-resolution (0.075 m/pixel) remote sensing images collected from the Christchurch, New Zealand, region by Wuhan University. Similarly, considering the required memory, the images in WHU-CD are cropped into non-overlapping image pairs of pixels in size, and the training, validation, and test datasets consist of 6096, 762, and 762 image pairs, respectively.
4.2. Implementation Details
All experiments in this study were carried out using the Ubuntu 22.04 operating system, with the deep learning framework of Pytorch, coded in Python, and trained, verified, and tested on the server equipped with multiple NVIDIA GeForce RTX 4090 graphics cards. In terms of the model architecture, SUT adopts a four-layer encoder, with the last three layers using a fusion structure of the CNN and transformer. And on the Siamese structure, we use subtraction to connect the dual temporal phase diagram. In addition, the sampling strategy is 1/2 of the last-layer image size in the transformer settings. In the training process based on the three datasets, the SUT network adopts Adam as the optimizer and employs a cosine annealing learning rate as the adjustment strategy, which sets the initial learning rate to 1 × 10−4 and the minimum learning rate to 1 × 10−6. In addition, all experiments set the batch size to 8, and 200 epochs are trained for each dataset.
4.3. Evaluation Metrics
The aim of CD is to detect changing and non-changing pixels, which is a binary classification problem in essence. Therefore, the following classification evaluation indicators can be used for the accuracy evaluation:
Precision,
Recall,
F1-score,
IOU, and overall accuracy (
OA). The calculation for these indicators can be described using Equations (19)–(23), where
TP means true positive,
TN means true negative,
FN means false negative, and
FP means false positive.
4.4. Comparative Methods
To verify the superior performance of our method SUT, we contrast it with some state-of-the-art methods as follows:
- (1)
FC-Siam-Diff [
39]: The network architecture is Siamese Unet. And it is a CNN-based network that uses the feature difference to generate change information from dual temporal images.
- (2)
RDPnet [
62]: It is a CNN-based network that uses an efficient training strategy to make CNNs learn from easy to hard and proposes an edge-constrained loss function to enhance the extraction of boundary details.
- (3)
Bit [
25]: It is a transformer-based network. It first extracts semantic features through CNN, then proceeds to global modeling with a transformer, strengthening the contextual information of the change features.
- (4)
ChangeFormer [
27]: The network only adopts the transformer structure and achieves CD tasks through a Siamese transformer encoder and an MLP decoder.
- (5)
SiUnet3+-CD [
33]: It is a CNN-based network using a full-scale connected Siamese Unet3+ network to extract features.
- (6)
SNUnet-CD [
46]: It uses a densely connected Siamese Unet++ network to extract change features and fuses four levels of features of different sizes using the ECAM.
- (7)
MCTnet [
30]: It considers the characteristics of the CNN and transformer and adopts the Siamese Unet structure to fuse the features extracted using the CNN and transformer through an attention mechanism.
The parameters of the above method were set based on the results of the original research. If the parameters of any method are not mentioned in the original study, we optimized them as much as possible. In addition, because the code of MCTnet and SiUnet3+-CD are not publicly available, we reproduced them ourselves.
4.5. Results and Analysis
We have trained the proposed SUT and the comparative methods based on the CDD, LEVIR-CD, and WHU-CD datasets, with their respective best results obtained from multiple training sessions being compared, and multiple cross-validation experiments were conducted based on hyperparameter settings to protect against overfitting. To highlight the importance of change information and the weakened impact of non-change information, all methods only evaluate the accuracy of change information based on the test set.
Table 1 displays the quantitative results of all methods based on the CDD dataset. The SUT method we proposed performs excellently, realizes the best results in precision (97.98%),
F1 (94.71%),
IOU (89.95%), and
OA (98.93%). The worst performance is achieved using the FE-Siam-diff network, which only adopts a simple Siamese Unet with an all-convolutional structure. It has poor feature extraction capability, making it difficult to capture the features associated with large seasonal changes. RDPnet, due to its efficient sampling strategy and edge-loss, has made strides in detecting edge features, yet it has issues with smoothing linear changing features. SNUnet-CD fully used the advantages of dense connection and the ECAM, achieving the highest recall rate, but it was not detailed enough in detecting boundary and linear targets. The SiUnet3+-CD network performs well with good quantitative indicators, demonstrating the effectiveness of full-scale skip layer connections. However, its overly complex calculations have led to missed detections based on small targets and boundary features. Although Bit and ChangeFormer have good global modeling capabilities, there are problems with the excessive smoothing of boundaries and corners. As for MCTnet lacking in linear change feature detection, it is slightly lower than SUT based on multiple evaluation indicators, and its concise structure of combining a CNN and transformer confirms the powerful performance of CNNs fused with transformers.
Figure 8 displays the visualization results of the CD on the CDD dataset as a sample. Compared with other methods, SUT performs the best in detecting contour integrity and accuracy and can effectively weaken the effects of factors, such as lighting and seasonal changes.
Table 2 shows the performance of various methods based on the LEVIR-CD dataset. SUT performs well, achieving the best results in
Precision (92.82%),
F1 (91.52%),
IOU (84.36%), and
OA (99.14%). The accuracy of FE-Siam-diff is slightly poor, and its test results often feature cavities. RDPnet still has troubles with missed and false detections, and the feature boundaries are not smooth. Due to their dense connections, SNUnet-CD and SiUnet3+-CD have quite good quantitative indicators and complete contours, but there are many small target misdetections. In addition, Bit suffers from the missed and false detection of small targets and has overly smooth contours. ChangeFormer has fewer instances of false positives but performs poorly based on edge information, making it prone to unevenness and blurriness. MCTnet performs mediocrely in building CDs, with frequent occurrences of false positives and edge blurring.
Figure 9 shows a sample of the visualization results for CD in the LEVIR-CD dataset. Upon comparing SUT with the other networks, it is not difficult to confirm that SUT can better suppress false and missed detections. It is outstanding in extracting the contour of change features, which is especially suitable for detecting regular ground change features, such as buildings.
Among the three datasets, the WHU-CD has the smallest number of samples, and the training effect is relatively unstable. After multiple training sessions, the result with a minimum loss during the iteration is used for the quantitative comparison in this experiment. As shown in
Table 3, SUT still obtains the best results in
F1 (90.61%),
IOU (82.83%), and
OA (99.26%), which has the best comprehensive performance. The best
Precision (95.84%) is obtained by Bit, which uses CNN to simply connect the transformer, making the edges smoother. However, when detecting changes in buildings with larger targets, holes are prone to occur in Bit, similar to ChangeFormer. The best
Recall (88.29%) is achieved by FE-Siam-diff, which performs well based on simple datasets with a weak seasonal effect, but with a rudimentary structure; its detection performance is not satisfactory, leading to problems of false detection. For RDPnet, it performs well in detecting large targets, but there is a problem with irregular boundaries for small targets. The calculation of SiUnet3+-CD is too complex, often missing portions when detecting large target changes in buildings. SNUnet-CD rarely misses detections, but it lacks global modeling capabilities and is prone to issues, such as false detections of small targets in the WHU-CD dataset. MCTnet may perform poorly in contour extraction due to an insufficient connection between the CNN and transformer at different scales. As shown in
Figure 10, SUT has better detection ability based on change targets of different sizes than the above methods and has smooth boundaries and regular contours.
From the experiments, it can be seen that SUT achieves the best performance based on the three datasets. The extracted results of SUT based on boundaries, linear targets, and small targets are more detailed than other methods. In addition, as the number of samples in the dataset decreases, the abovementioned advantages of SUT become more apparent.
4.6. Channel Hyperparameter Adjustment
This study takes channel dimensions in the feature map of the network as an adjustable hyperparameter. The comparative experiments mentioned above are conducted by setting the adjustable channel dimensions to 64n while retaining the original network parameters. Therefore, in order to verify that SUT can maintain its excellent performance even with a smaller channel dimension, a comparative experiment with 32 channels was conducted.
As shown in
Table 4, from the accuracy perspective, SUT also has the best comprehensive performance when using 32 channels, achieving the best
F1,
IOU, and
OA results based on all three datasets. Significantly, SUT with 32 channels is already superior to FE-Siam-diff, Bit, ChangeFormer, and SiUnet3+-CD with their optimal settings from the corresponding publications. In addition, SNUnet-CD and MCTnet are indeed better at 64 channels than SUT at 32 channels. However, when both are set to the same channel dimension, SUT performs better than SNUnet-CD and MCTnet. In summary, SUT definitely maintains good CD ability even with 32 channels and performs best among the compared networks.
4.7. Efficiency Evaluation
Furthermore, the efficiency of models also needs to be considered. Efficiency represents the computational complexity and memory cost during model training and prediction, and there is a bounded relationship between efficiency and accuracy in deep learning methods. Therefore, we compared the Parameters, Flops, and Time of the above methods, based on the input datasets using image sizes of 256 × 256 pixels and training parameter settings, shown in
Table 5. Parameters refer to the quantity of parameters used in the model, Flops refers to the calculation amount of the model, and Time means the reaction time cost of the model to deal with a single image. Apparently, SUT performs well in terms of Parameters and Flops while achieving the best overall results, and the Time is also within the reasonable range. When the channel number reaches 64, despite the performance degradation based on parameters and Flops, the effect of CD in SUT is further improved.
4.8. Ablation Studies
To demonstrate the effectiveness of the PAM fusion based on the CNN and transformer in SUT, as well as the effect of deep supervision and the Unet3+ structure, we conducted ablation experiments based on the CDD, LEVIR-CD, and WHU-CD datasets. For the sake of the comparison, we refer to the network that does not use deep supervision and the PAM as SUT-base, the network that only uses deep supervision without the PAM as SUT-sup, the network that only uses the PAM without deep supervision as SUT-PAM, the network that uses both the PAM and deep supervision as SUT-PAM-sup, and the network that uses the Unet structure with the transformer, PAM, and deep supervision as UnetT-PAM-sup.
Table 6,
Table 7 and
Table 8 display the quantitative results of these ablation experiments based on the CDD, LEVIR-CD, and WHU-CD datasets. From these tables, we can find that the best results are all achieved in SUT-PAM-sup. the results obtained by the networks with the PAM are obviously better than those of the networks without the PAM, which indicates that the PAM has a significant impact on the integration of CNN and transformer structures. In addition, the results of the networks with deep supervision show that as the number of samples in the dataset decreases, the effectiveness of deep supervision gradually improves. Moreover, when we change the backbone of the SUT from Unet3+ to Unet, it is obvious that the CD effect is not as good as the original structure.
Some example outputs of the ablation studies based on the three datasets are displayed in
Figure 11(a1–e1). Specifically, in SUT, deep supervision can suppress the occurrence of falsely detected small targets, as shown in
Figure 11(5) and (7), and reduce the problem of concave holes at the boundary of changed targets, as shown in
Figure 11(1), (8) and (9). The methods with the PAM have better performance based on linear targets and contour optimization, as shown in
Figure 11(2), (3) and (9). Furthermore, regarding corner details, the results of networks with the PAM are closer to the GT than those without the PAM. It is demonstrated that the PAM contributes to the fusion of the CNN and transformer. As shown in
Figure 11(e1) for the SUT method under the Unet architecture, comparing the results of the Unet3+ and Unet structures, it can be seen that the advantages of Unet3+ are specifically in the linear target integrity and the suppression of the misdetection of small targets. We also utilized a heatmap to visualize the results of the above ablation experiments, as shown in
Figure 11(a2–e2). Based on a thermal comparison, it can be found that SUT significantly improved feature extraction while using the PAM, Unet3+ structure, and deep supervision. We can compare
Figure 11(a2,b2) and
Figure 11(c2,d2) and find that deep supervision does have a role in optimizing the boundaries and enhances the detection of changing targets to some extent in the heat map. And when comparing
Figure 11(a2,c2) and
Figure 11(b2,d2), we can find that the results of detecting the linearly changing targets are related to whether or not the PAM structure is used, and in general, it seems that the network fusing the CNN and the transformer by the PAM performs better. As for the backbone network of Unet3+ and Unet, it is easy to see that Unet3+ has a huge advantage in detecting the changing target integrity from the heat map.
5. Conclusions
In this study, we propose a full-scale connected CNN–Transformer network named SUT for the CD of remote sensing images. The network encoder comprises a one-layer CNN and a three-layer integrated CNN and transformer. In response to the lack of global modeling abilities of CNNs, the boundary generalization of pure transformer networks, and the problem of potentially omitting small targets when CNNs are connected to transformers, this study adopts the PAM to effectively fuse CNN and transformers. Furthermore, to address the problem of detail feature loss due to inter-scale communication and one-way information flow in the existing networks that fuse CNNs and transformers, we apply full-scale skip connections for the encoder and decoder. The comparative experiments based on public datasets demonstrate the effectiveness of the proposed SUT. Specifically, it performs well in restoring the shape of changed targets, with clear and complete detailed features, such as contours, corners, and linear targets. However, the change detection effect of SUT training based on fewer samples is unsatisfactory. One of our possible future works is to adopt the weakly supervised learning to address this problem.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}