
ConCs-Fusion: A Context Clustering-Based Radar and Camera Fusion for Three-Dimensional Object Detection


Abstract
:1. Introduction
- (1)
- We propose a ConCs-Fusion network that leverages a fusion module to aggregate and redistribute features, enabling mutual assistance between the radar and camera.
- (2)
- In the fusion module, we employ transposed convolution to learn different scale features from context cluster blocks, and fuse the output features through concatenation. We then utilize the nonlinear representation capability of multi-layer perceptron (MLP) to reduce the dimensionality of fused features, thereby improving the computational efficiency of the model.
- (3)
- Extensive experiments are conducted on the nuScenes dataset and the mini_nuScenes dataset. The results on the nuScenes dataset show that our method relatively improves the nuScenes detection score (NDS) [19] by 16.97%, 26.39%, and 1.34%, compared to CenterNet, QD_3DT [20], and CenterFusion, respectively. It also relatively reduces the mean average orientation error (mAOE) by 25.29%, 3.56%, and 12.94%, compared to these methods, respectively. The experimental results demonstrate that the proposed method effectively integrates multi-modal data at the intermediate level and improves 3D object detection performance.
2. Related Works
2.1. Single-Modality 3D Object Detection Methods
2.1.1. Methods Based on Camera
2.1.2. Methods Based on LiDAR
2.1.3. Methods Based on Radar
2.2. Multi-Modality 3D Object Detection Methods
2.2.1. Methods Based on the Fusion of Radar and LiDAR
2.2.2. Methods Based on the Fusion of LiDAR and Camera
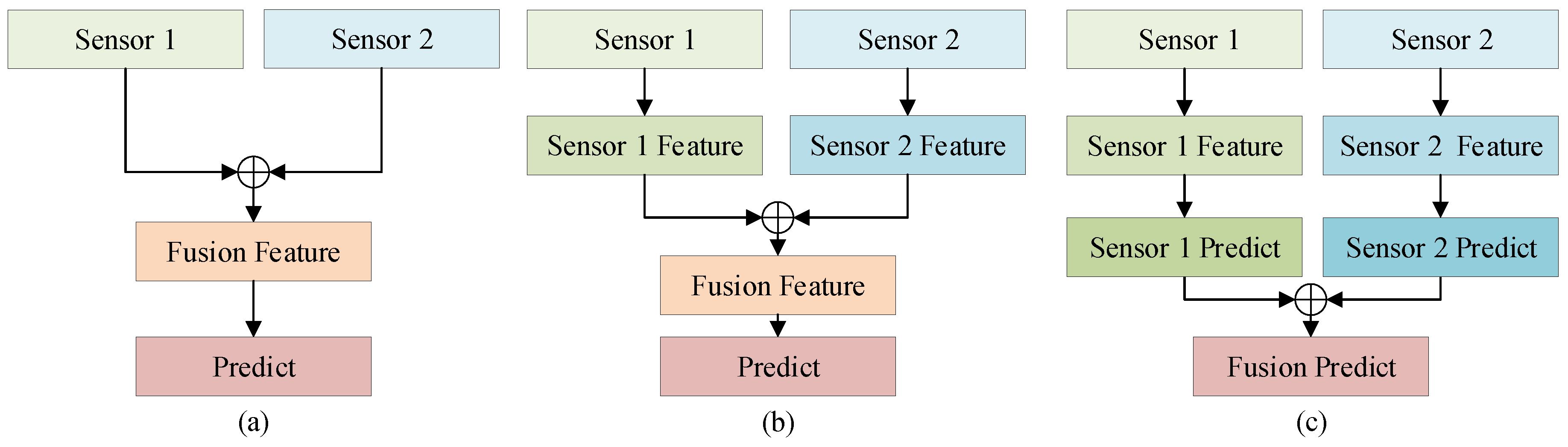
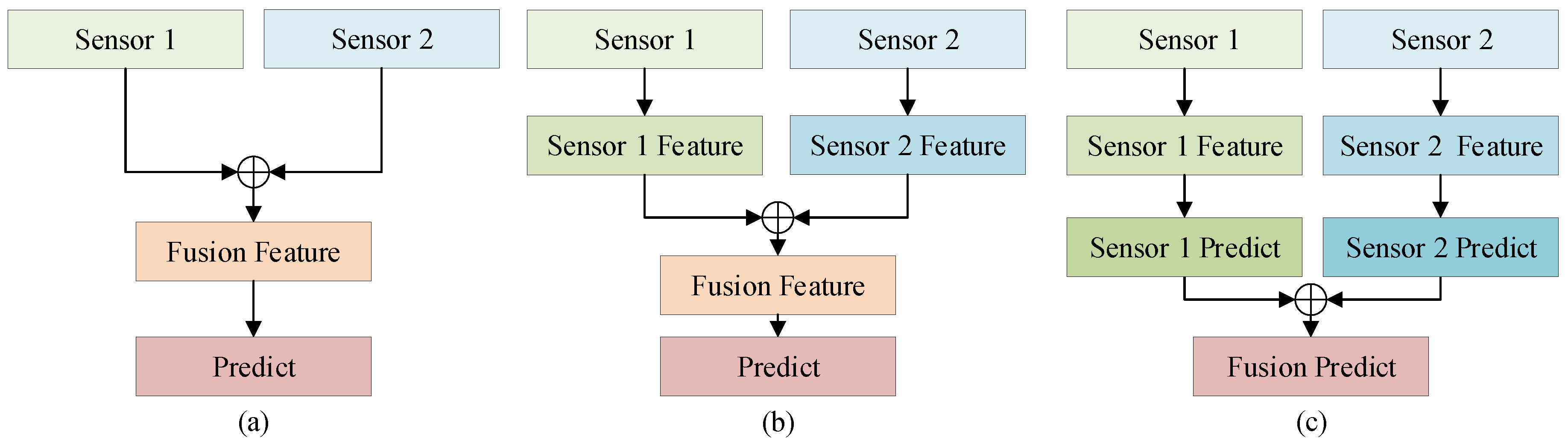
2.2.3. Methods Based on the Fusion of Radar and Camera
3. Methods
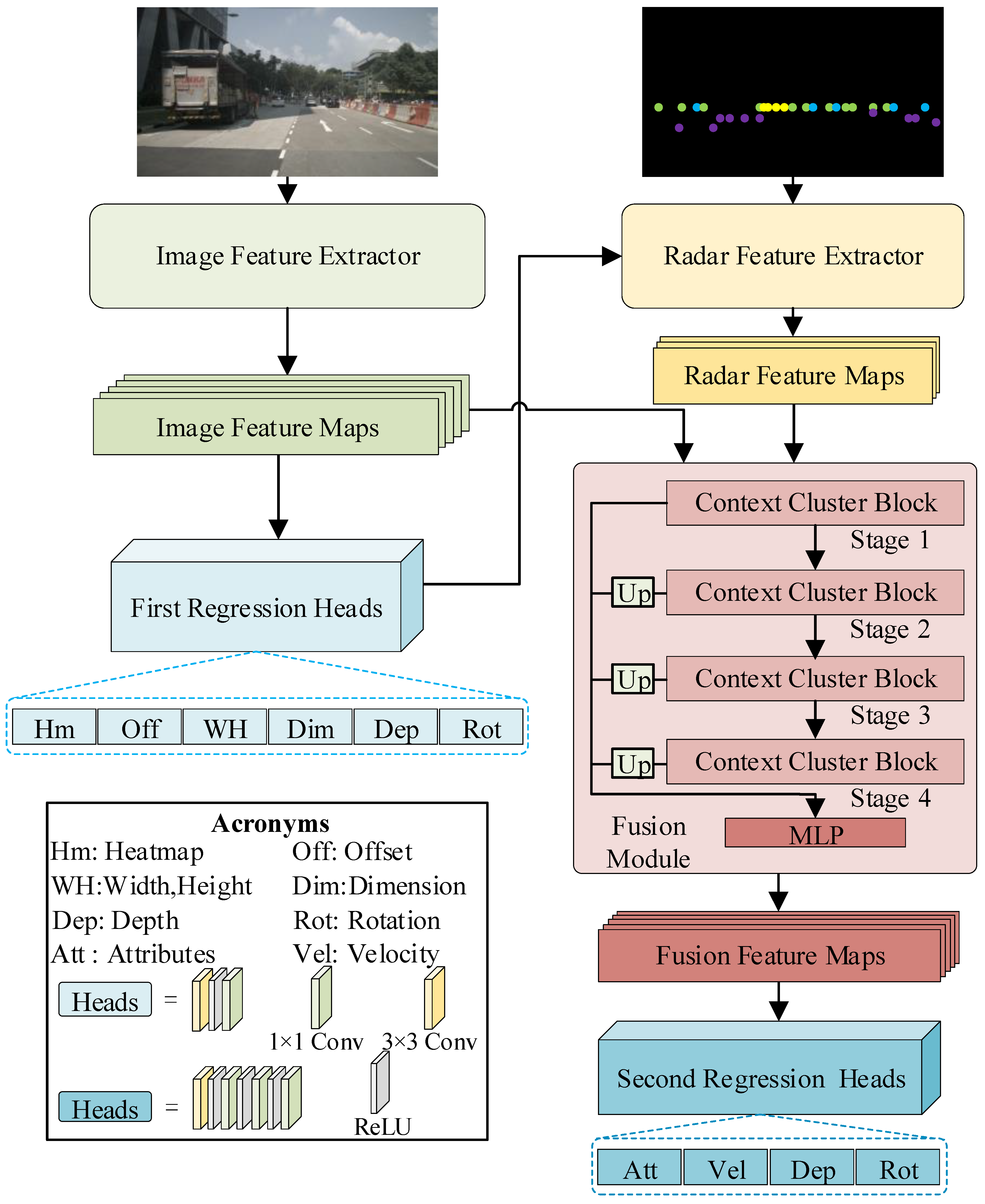
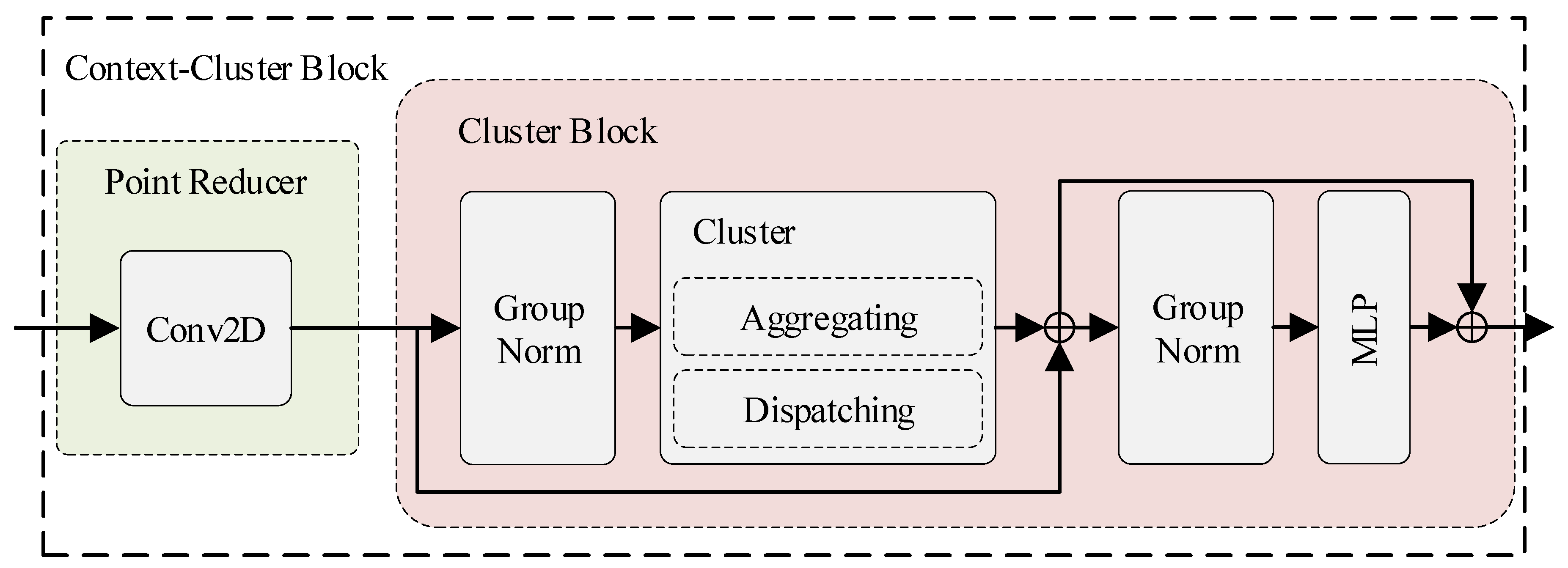
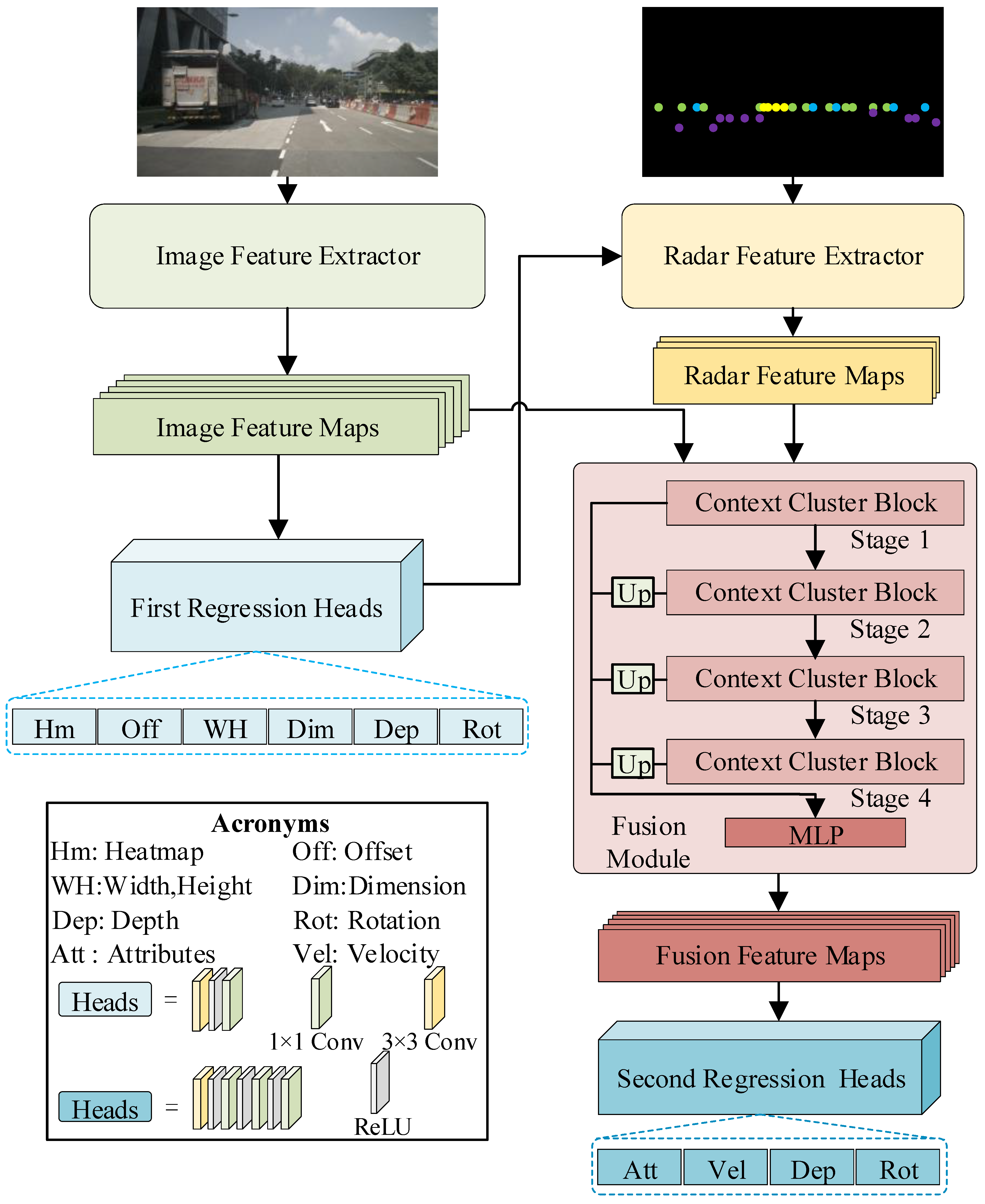
3.1. The Overall Architecture of ConCs-Fusion Network
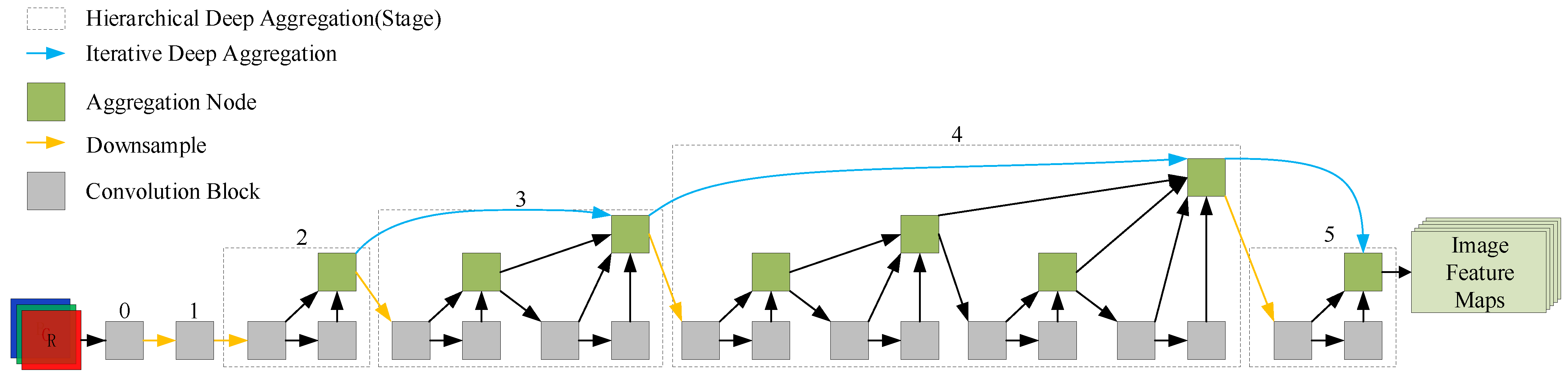
3.2. The Image Feature Extractor
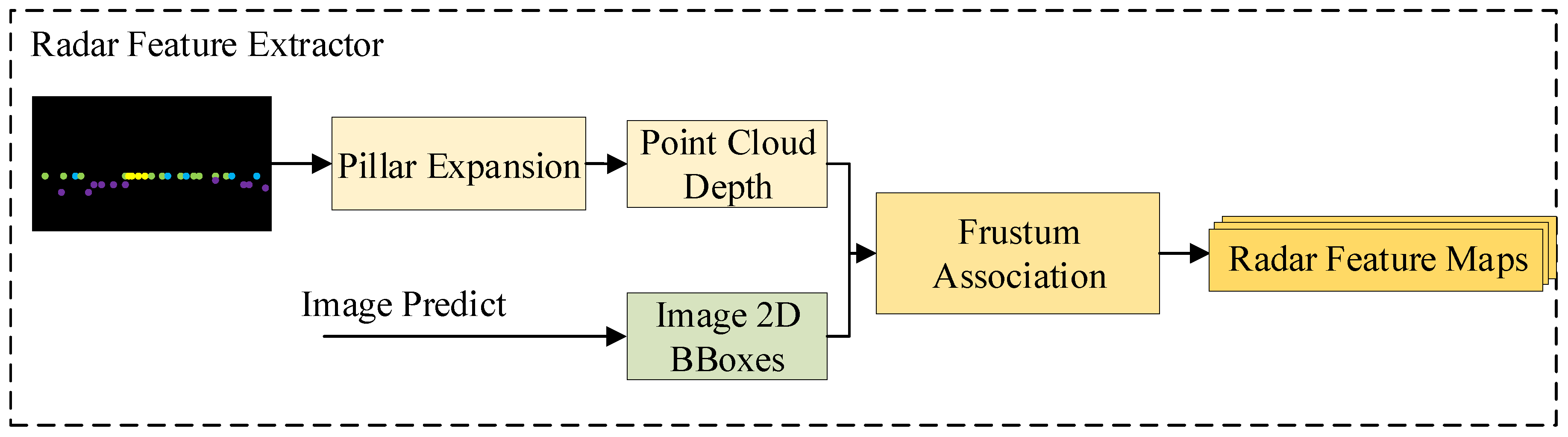
3.3. The Radar Feature Extractor
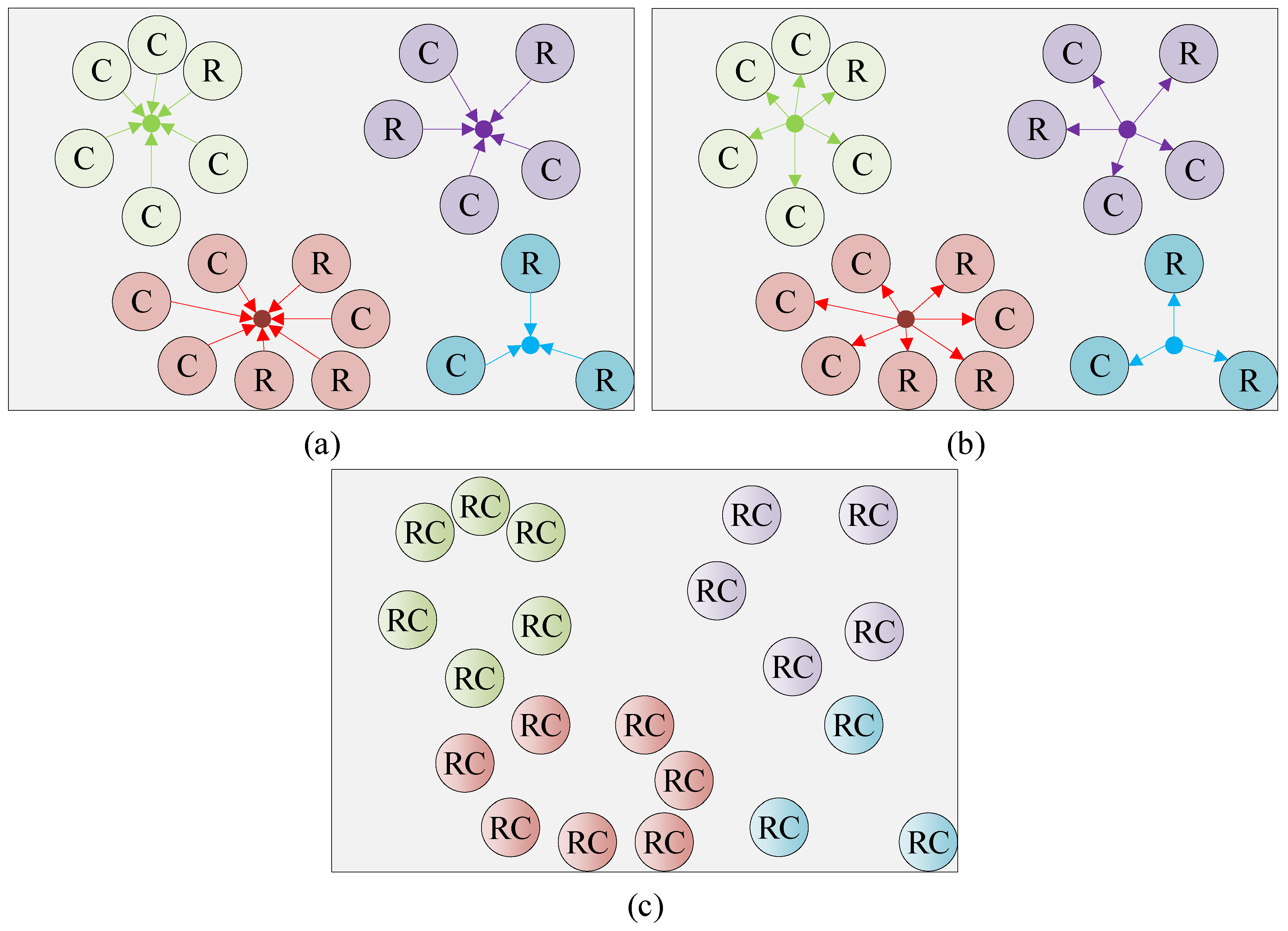
3.4. Fusion Module
3.5. Loss Functions
4. Results
4.1. Experimental Setup
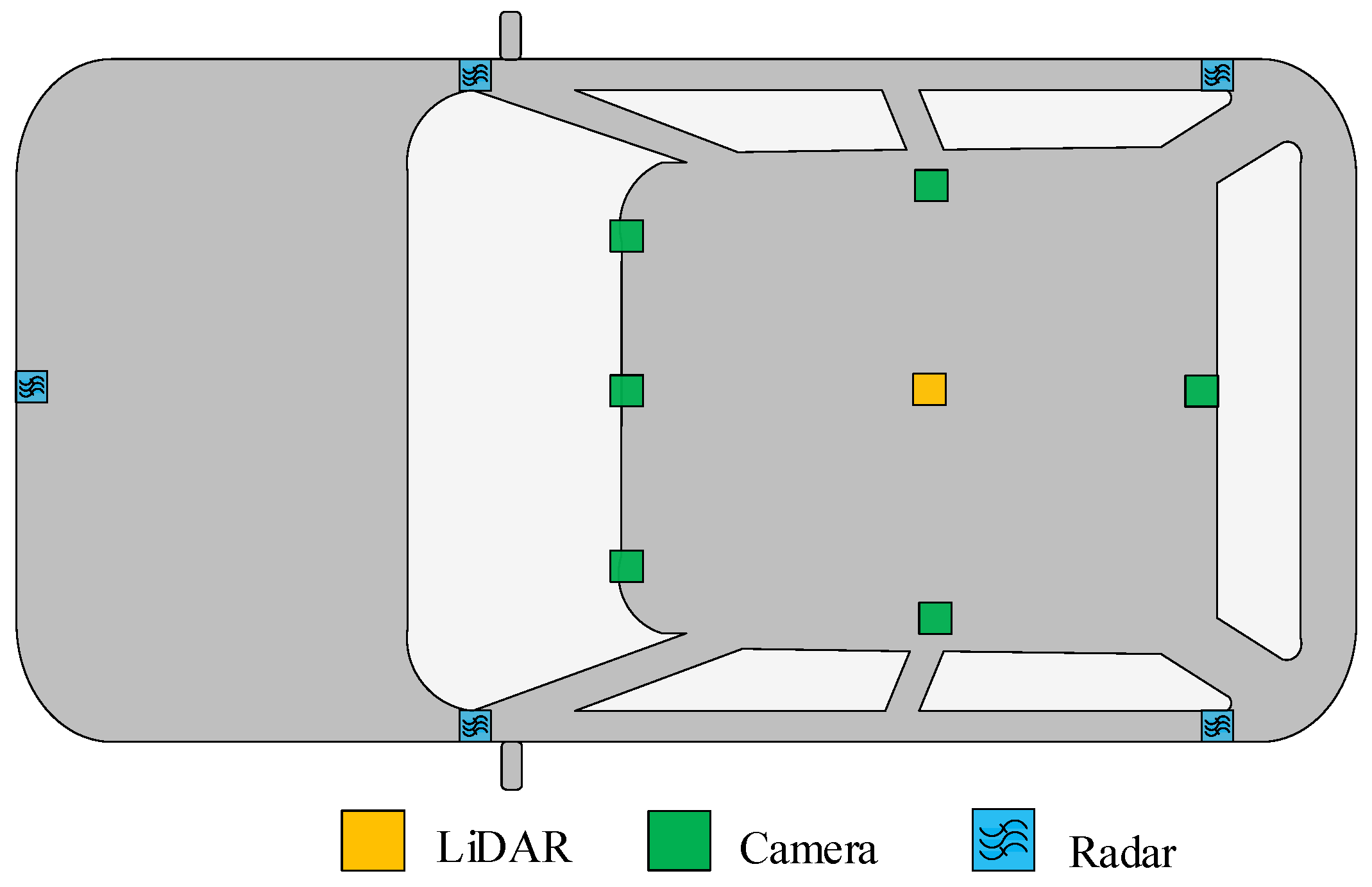
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
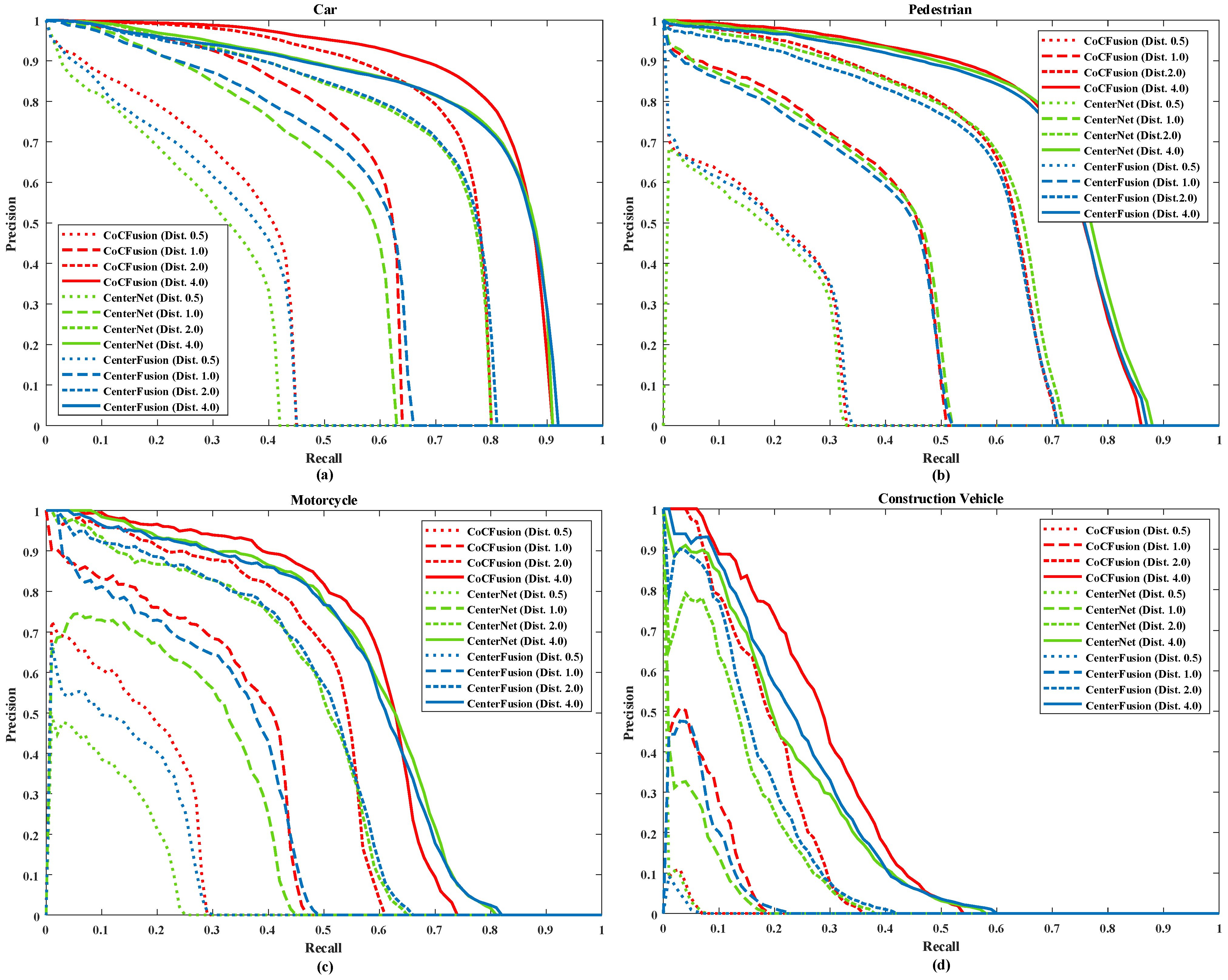
4.2. Detection Performance Evaluation
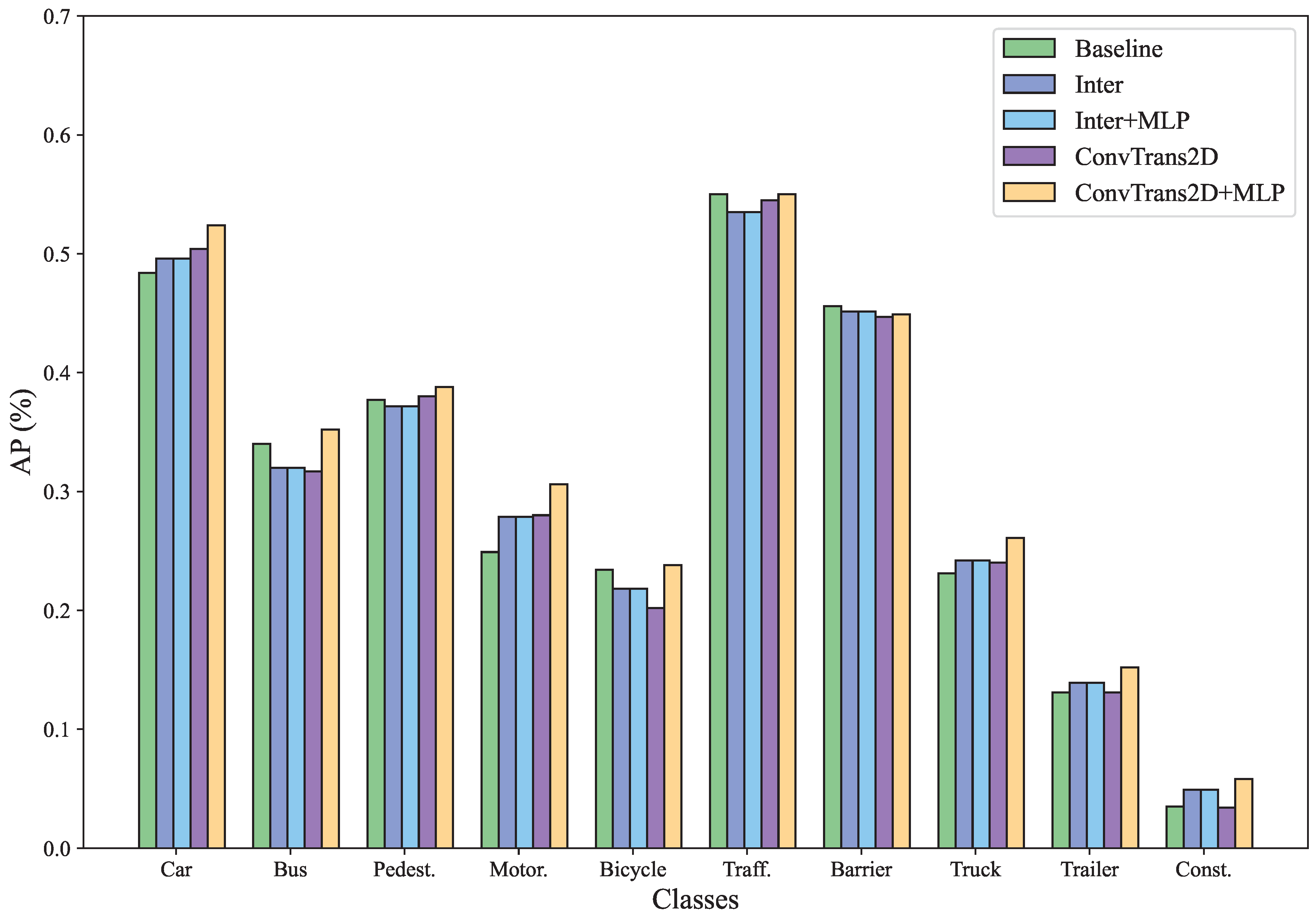
4.3. Ablation Studies
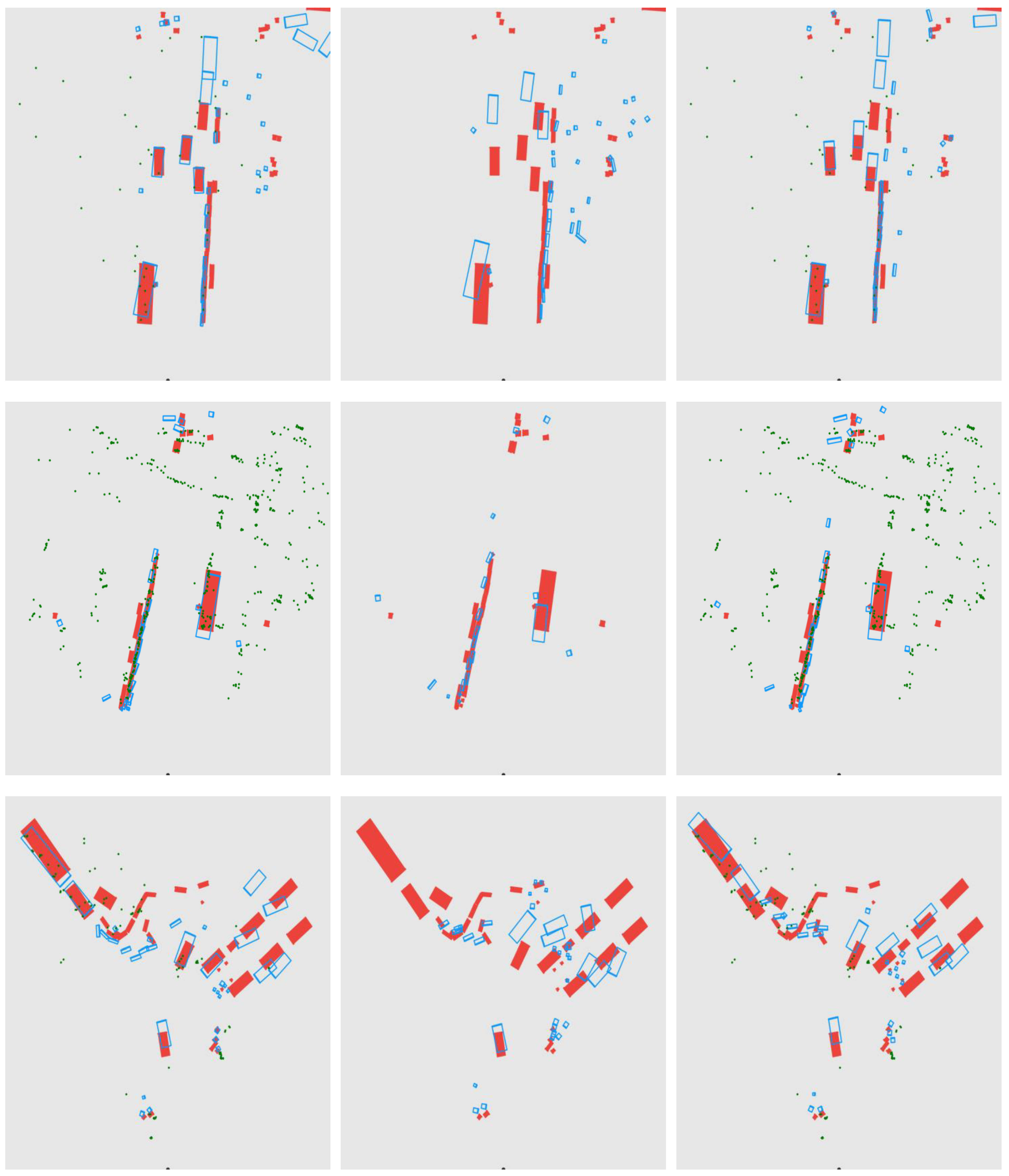
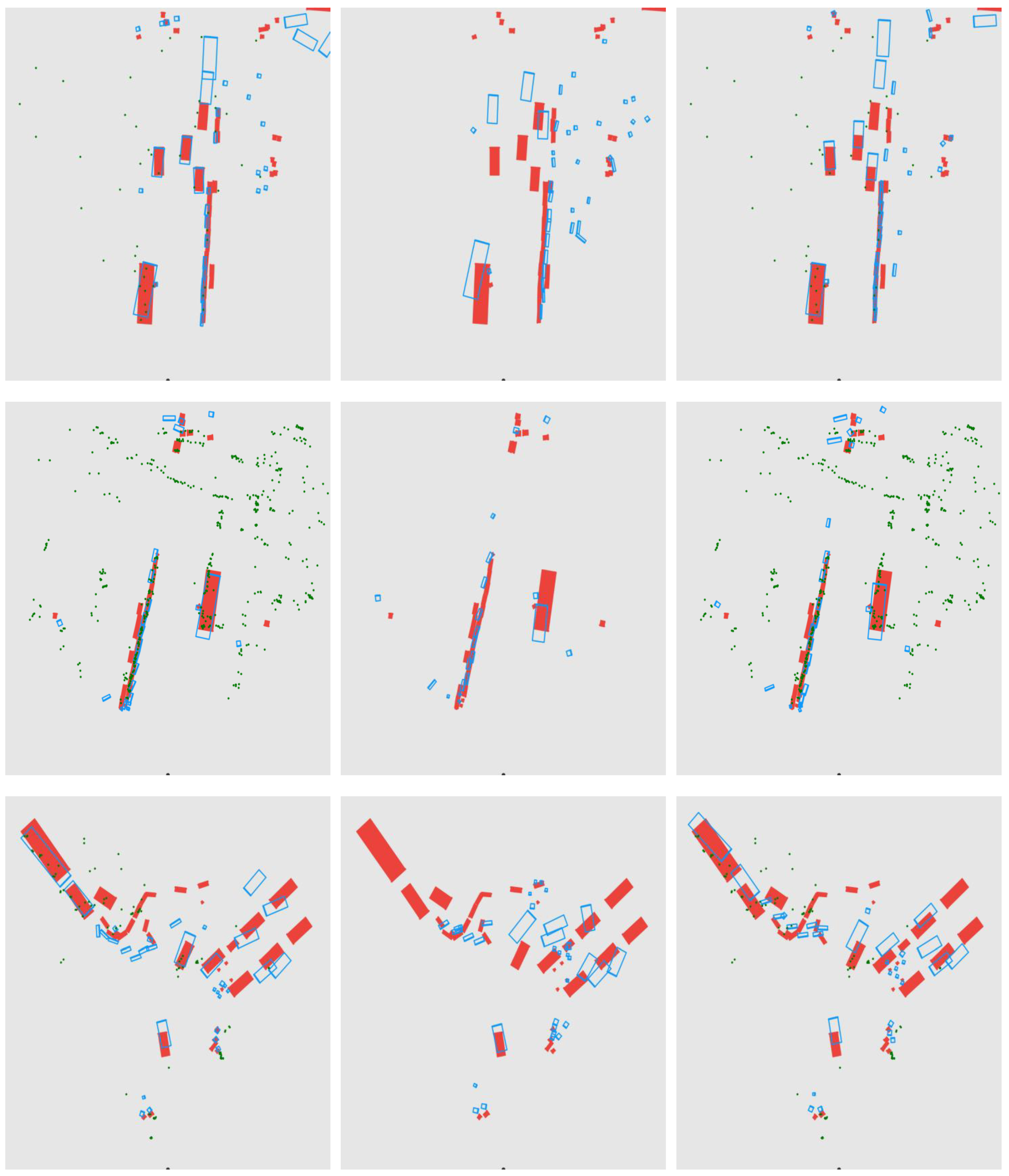
5. Qualitative Result and Discussion
5.1. Results of 3D Object Detection
5.2. BEV Results with Object Detection
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tang, Y.; He, H.; Wang, Y.; Mao, Z.; Wang, H. Multi-modality 3D object detection in autonomous driving: A review. Neurocomputing 2023, 553, 126587. [Google Scholar] [CrossRef]
- Long, Y.; Kumar, A.; Morris, D.; Liu, X.; Castro, M.; Chakravarty, P. RADIANT: Radar-Image Association Network for 3D Object Detection. Proc. AAAI Conf. Artif. Intell. 2023, 37, 1808–1816. [Google Scholar] [CrossRef]
- Park, D.; Ambruş, R.; Guizilini, V.; Li, J.; Gaidon, A. Is Pseudo-Lidar needed for Monocular 3D Object detection? In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3122–3132. [Google Scholar] [CrossRef]
- Huo, B.; Li, C.; Zhang, J.; Xue, Y.; Lin, Z. SAFF-SSD: Self-Attention Combined Feature Fusion-Based SSD for Small Object Detection in Remote Sensing. Remote Sens. 2023, 15, 3027. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. Comput. Vis. ECCV 2020 2020, 12346, 213–229. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Elaksher, A.; Ali, T.; Alharthy, A. A Quantitative Assessment of LIDAR Data Accuracy. Remote Sens. 2023, 15, 442. [Google Scholar] [CrossRef]
- Wei, Z.; Zhang, F.; Chang, S.; Liu, Y.; Wu, H.; Feng, Z. MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A Review. Sensors 2022, 22, 2542. [Google Scholar] [CrossRef] [PubMed]
- Bi, X.; Tan, B.; Xu, Z.; Huang, L. A New Method of Target Detection Based on Autonomous Radar and Camera Data Fusion; Technical report; SAE Technical Paper; SAE: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Chang, S.; Zhang, Y.; Zhang, F.; Zhao, X.; Huang, S.; Feng, Z.; Wei, Z. Spatial Attention Fusion for Obstacle Detection Using MmWave Radar and Vision Sensor. Sensors 2020, 20, 956. [Google Scholar] [CrossRef] [PubMed]
- Drews, F.; Feng, D.; Faion, F.; Rosenbaum, L.; Ulrich, M.; Gläser, C. DeepFusion: A Robust and Modular 3D Object Detector for Lidars, Cameras and Radars. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 560–567. [Google Scholar] [CrossRef]
- Nabati, R.; Qi, H. CenterFusion: Center-based Radar and Camera Fusion for 3D Object Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 1526–1535. [Google Scholar] [CrossRef]
- Kim, J.; Kim, Y.; Kum, D. Low-Level Sensor Fusion for 3D Vehicle Detection Using Radar Range-Azimuth Heatmap and Monocular Image. In Computer Vision—ACCV 2020, Proceedings of the 15th Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; Volume 12624, pp. 388–402. [Google Scholar] [CrossRef]
- Chavez-Garcia, R.O.; Burlet, J.; Vu, T.D.; Aycard, O. Frontal object perception using radar and mono-vision. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Alcala de Henares, Spain, 3–7 June 2012; pp. 159–164. [Google Scholar] [CrossRef]
- Ćesić, J.; Marković, I.; Cvišić, I.; Petrović, I. Radar and stereo vision fusion for multitarget tracking on the special Euclidean group. Robot. Auton. Syst. 2016, 83, 338–348. [Google Scholar] [CrossRef]
- Ma, X.; Zhou, Y.; Wang, H.; Qin, C.; Sun, B.; Liu, C.; Fu, Y. Image as Set of Points. arXiv 2023. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019. [Google Scholar] [CrossRef]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep Layer Aggregation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2403–2412. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and PatternRecognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar] [CrossRef]
- Hu, H.N.; Yang, Y.H.; Fischer, T.; Darrell, T.; Yu, F.; Sun, M. Monocular Quasi-Dense 3D Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 1992–2008. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Zhou, C.; Shang, G.; Wang, X.; Li, Z.; Xu, C.; Hu, K. SLAM Overview: From Single Sensor to Heterogeneous Fusion. Remote Sens. 2022, 14, 6033. [Google Scholar] [CrossRef]
- Guo, X.; Cao, Y.; Zhou, J.; Huang, Y.; Li, B. HDM-RRT: A Fast HD-Map-Guided Motion Planning Algorithm for Autonomous Driving in the Campus Environment. Remote Sens. 2023, 15, 487. [Google Scholar] [CrossRef]
- Chabot, F.; Chaouch, M.; Rabarisoa, J.; Teulière, C.; Chateau, T. Deep MANTA: A Coarse-to-Fine Many-Task Network for Joint 2D and 3D Vehicle Analysis from Monocular Image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017; pp. 1827–1836. [Google Scholar] [CrossRef]
- Wang, T.; Zhu, X.; Pang, J.; Lin, D. FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2011; pp. 913–922. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, Z.; Toth, R. SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 4289–4298. [Google Scholar] [CrossRef]
- Li, Z.; Gao, Y.; Hong, Q.; Du, Y.; Serikawa, S.; Zhang, L. Keypoint3D: Keypoint-Based and Anchor-Free 3D Object Detection for Autonomous Driving with Monocular Vision. Remote Sens. 2023, 15, 1210. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Qi, C.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar] [CrossRef]
- Wang, J.; Lan, S.; Gao, M.; Davis, L.S. InfoFocus: 3D Object Detection for Autonomous Driving with Dynamic Information Modeling. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; Volume 12355, pp. 405–420. [Google Scholar] [CrossRef]
- He, W.; Yang, X.; Wang, Y. A High-Resolution and Low-Complexity DOA Estimation Method with Unfolded Coprime Linear Arrays. Sensors 2019, 20, 218. [Google Scholar] [CrossRef] [PubMed]
- Svenningsson, P.; Fioranelli, F.; Yarovoy, A. Radar-PointGNN: Graph Based Object Recognition for Unstructured Radar Point-cloud Data. In Proceedings of the 2021 IEEE Radar Conference (RadarConf21), Atlanta, GA, USA, 7–14 May 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Meyer, M.; Kuschk, G.; Tomforde, S. Graph Convolutional Networks for 3D Object Detection on Radar Data. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 3053–3062. [Google Scholar] [CrossRef]
- Yang, B.; Guo, R.; Liang, M.; Casas, S.; Urtasun, R. RadarNet: Exploiting Radar for Robust Perception of Dynamic Objects. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; Volume 12363, pp. 496–512. [Google Scholar] [CrossRef]
- Wang, L.; Goldluecke, B. Sparse-PointNet: See Further in Autonomous Vehicles. IEEE Robot. Autom. Lett. 2021, 6, 7049–7056. [Google Scholar] [CrossRef]
- Qian, K.; Zhu, S.; Zhang, X.; Li, L.E. Robust Multimodal Vehicle Detection in Foggy Weather Using Complementary Lidar and Radar Signals. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 444–453. [Google Scholar] [CrossRef]
- Li, Y.J.; Park, J.; O’Toole, M.; Kitani, K. Modality-agnostic learning for radar-lidar fusion in vehicle detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 918–927. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D Object Detection Network for Autonomous Driving. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017; pp. 6526–6534. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015. [Google Scholar] [CrossRef]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D Proposal Generation and Object Detection from View Aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Chadwick, S.; Maddern, W.; Newman, P. Distant Vehicle Detection Using Radar and Vision. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8311–8317. [Google Scholar] [CrossRef]
- John, V.; Mita, S. RVNet: Deep Sensor Fusion of Monocular Camera and Radar for Image-Based Obstacle Detection in Challenging Environments. In Image and Video Technology, Proceedings of the 10th Pacific-Rim Symposium, PSIVT 2022, 12–14 November 2022; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 11854, pp. 351–364. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018. [Google Scholar] [CrossRef]
- Kim, Y.; Choi, J.W.; Kum, D. GRIF Net: Gated Region of Interest Fusion Network for Robust 3D Object Detection from Radar Point Cloud and Monocular Image. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10857–10864. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Barrera, A.; Guindel, C.; Beltran, J.; Garcia, F. BirdNet+: End-to-End 3D Object Detection in LiDAR Bird’s Eye View. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensors | Strengths | Limitations | |
|---|---|---|---|
| Optical Sensors | Monocular Camera | affordable and easy to deploy; intuitive understanding of object’s texture information | weak depth perception; sensitive to environmental conditions; prone to image distortion |
| LiDAR | high accuracy; providing 3D information about objects | large and expensive, vulnerable under adverse weather conditions like rain, fog, and snow | |
| Radar | capacity of detecting objects at long distances; strong adaptability in all weather conditions | false alarm rate relatively high; object information relatively abstract | |
| Method | Datasets | Modality | NDS↑ | mAP↑ | Error↓ | ||||
|---|---|---|---|---|---|---|---|---|---|
| mATE | mASE | mAOE | mAVE | mAAE | |||||
| InfoFocus | Test | L | 0.395 | 0.395 | 0.363 | 0.265 | 1.132 | 1.000 | 0.395 |
| BirdNet+ | Test | L | 0.296 | 0.245 | 0.382 | 0.253 | 0.626 | 1.766 | 1.000 |
| CenterNet | Test | C | 0.389 | 0.312 | 0.673 | 0.257 | 0.599 | 1.448 | 0.138 |
| QD_3DT | Test | C | 0.360 | 0.270 | 0.714 | 0.247 | 0.464 | 1.307 | 0.326 |
| FCOS3D | Test | C | 0.428 | 0.358 | 0.690 | 0.249 | 0.452 | 1.434 | 0.124 |
| CenterFusion | Test | R+C | 0.449 | 0.324 | 0.633 | 0.261 | 0.514 | 0.610 | 0.117 |
| Ours | Test | R+C | 0.455 | 0.323 | 0.645 | 0.262 | 0.448 | 0.599 | 0.110 |
| CenterNet | Val | C | 0.387 | 0.320 | 0.688 | 0.261 | 0.601 | 1.162 | 0.183 |
| CenterFusion | Val | R+C | 0.441 | 0.319 | 0.678 | 0.267 | 0.549 | 0.543 | 0.144 |
| Ours | Val | R+C | 0.454 | 0.329 | 0.668 | 0.262 | 0.454 | 0.570 | 0.152 |
| CenterNet | mini_Val | C | 0.323 | 0.288 | 0.726 | 0.469 | 0.711 | 1.303 | 0.298 |
| CenterFusion | mini_Val | R+C | 0.375 | 0.309 | 0.679 | 0.461 | 0.604 | 0.747 | 0.305 |
| Ours | mini_Val | R+C | 0.396 | 0.313 | 0.671 | 0.469 | 0.544 | 0.614 | 0.308 |
| Method | Datasets | Modality | mAP↑ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Car | Truck | Bus | Trailer | Const | Ped | Motor | Bic | Traff | Barrier | |||
| CenterNet | Test | C | 0.480 | 0.232 | 0.202 | 0.232 | 0.074 | 0.364 | 0.288 | 0.199 | 0.570 | 0.478 |
| CenterFusion | Test | R+C | 0.505 | 0.255 | 0.232 | 0.234 | 0.077 | 0.370 | 0.307 | 0.201 | 0.575 | 0.484 |
| Ours | Test | R+C | 0.509 | 0.256 | 0.223 | 0.232 | 0.075 | 0.370 | 0.302 | 0.207 | 0.569 | 0.484 |
| CenterNet | Val | C | 0.496 | 0.247 | 0.342 | 0.148 | 0.039 | 0.388 | 0.269 | 0.241 | 0.560 | 0.467 |
| CenterFusion | Val | R+C | 0.512 | 0.251 | 0.328 | 0.145 | 0.047 | 0.378 | 0.286 | 0.222 | 0.554 | 0.464 |
| Ours | Val | R+C | 0.526 | 0.259 | 0.345 | 0.152 | 0.058 | 0.389 | 0.313 | 0.243 | 0.551 | 0.449 |
| CenterNet | mini_Val | C | 0.494 | 0.388 | 0.481 | - | - | 0.455 | 0.295 | 0.127 | 0.632 | - |
| CenterFusion | mini_Val | R+C | 0.533 | 0.433 | 0.514 | - | - | 0.449 | 0.331 | 0.151 | 0.676 | - |
| Ours | mini_Val | R+C | 0.539 | 0.409 | 0.599 | - | - | 0.469 | 0.343 | 0.165 | 0.678 | - |
| Method | Upsample | MLP | NDS↑ | mAP↑ | Error↓ | ||||
|---|---|---|---|---|---|---|---|---|---|
| mATE | mASE | mAOE | mAVE | mAAE | |||||
| Baseline | - | - | 0.389 | 0.312 | 0.673 | 0.257 | 0.599 | 1.448 | 0.138 |
| ours | Inter | - | 0.411 | 0.285 | 0.717 | 0.270 | 0.507 | 0.699 | 0.128 |
| ours | Inter | ✓ | 0.454 | 0.320 | 0.635 | 0.264 | 0.453 | 0.596 | 0.108 |
| ours | ConvTrans2d | - | 0.450 | 0.317 | 0.644 | 0.263 | 0.468 | 0.602 | 0.107 |
| ours | ConvTrans2d | ✓ | 0.455 | 0.323 | 0.645 | 0.262 | 0.448 | 0.599 | 0.110 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, W.; Deng, Z.; Ye, Y.; Pan, P. ConCs-Fusion: A Context Clustering-Based Radar and Camera Fusion for Three-Dimensional Object Detection. Remote Sens. 2023, 15, 5130. https://doi.org/10.3390/rs15215130
He W, Deng Z, Ye Y, Pan P. ConCs-Fusion: A Context Clustering-Based Radar and Camera Fusion for Three-Dimensional Object Detection. Remote Sensing. 2023; 15(21):5130. https://doi.org/10.3390/rs15215130
Chicago/Turabian StyleHe, Wei, Zhenmiao Deng, Yishan Ye, and Pingping Pan. 2023. "ConCs-Fusion: A Context Clustering-Based Radar and Camera Fusion for Three-Dimensional Object Detection" Remote Sensing 15, no. 21: 5130. https://doi.org/10.3390/rs15215130
APA StyleHe, W., Deng, Z., Ye, Y., & Pan, P. (2023). ConCs-Fusion: A Context Clustering-Based Radar and Camera Fusion for Three-Dimensional Object Detection. Remote Sensing, 15(21), 5130. https://doi.org/10.3390/rs15215130