

A Downscaling Methodology for Extracting Photovoltaic Plants with Remote Sensing Data: From Feature Optimized Random Forest to Improved HRNet



Abstract
:1. Introduction
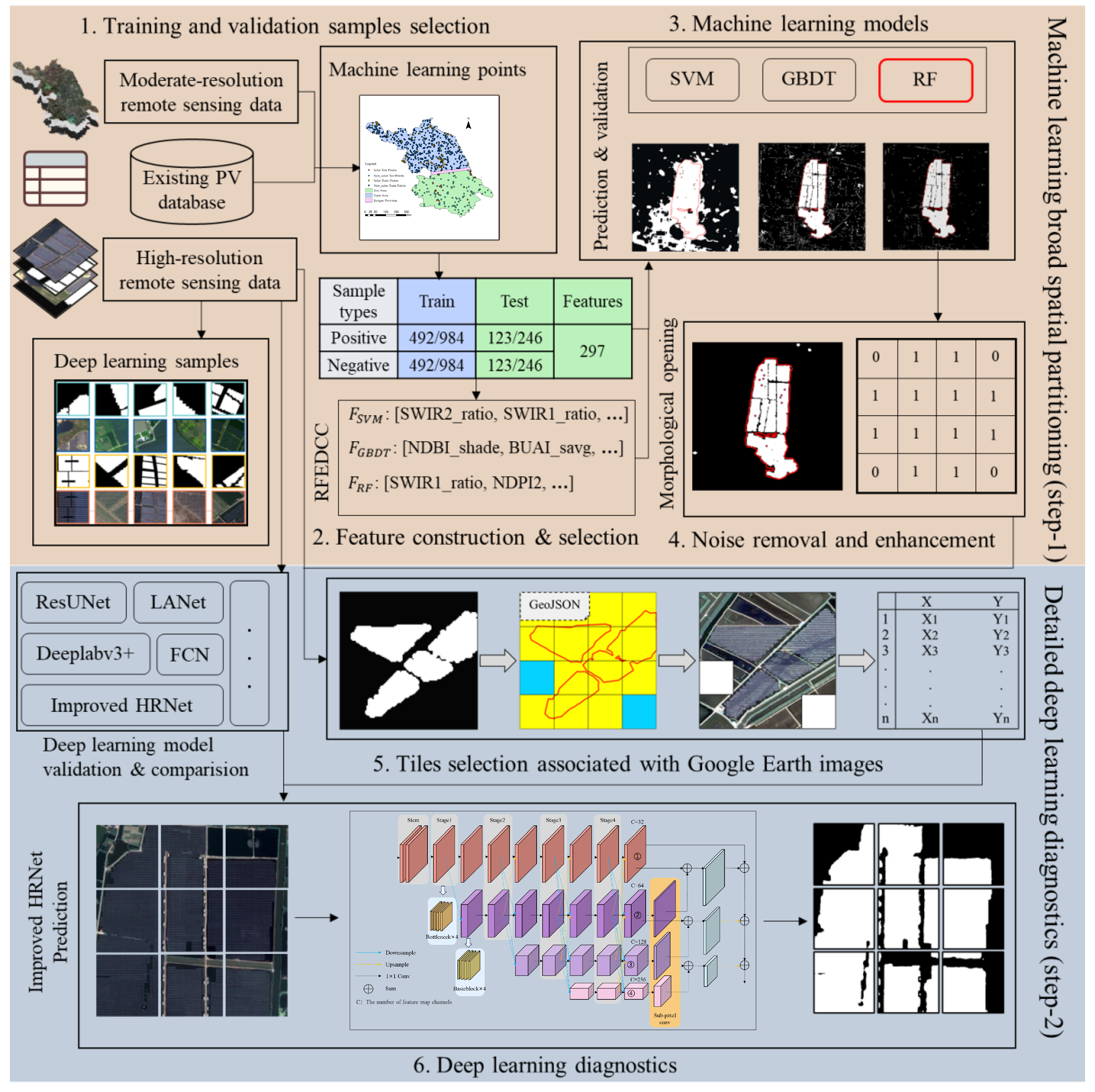
2. Materials and Methodology
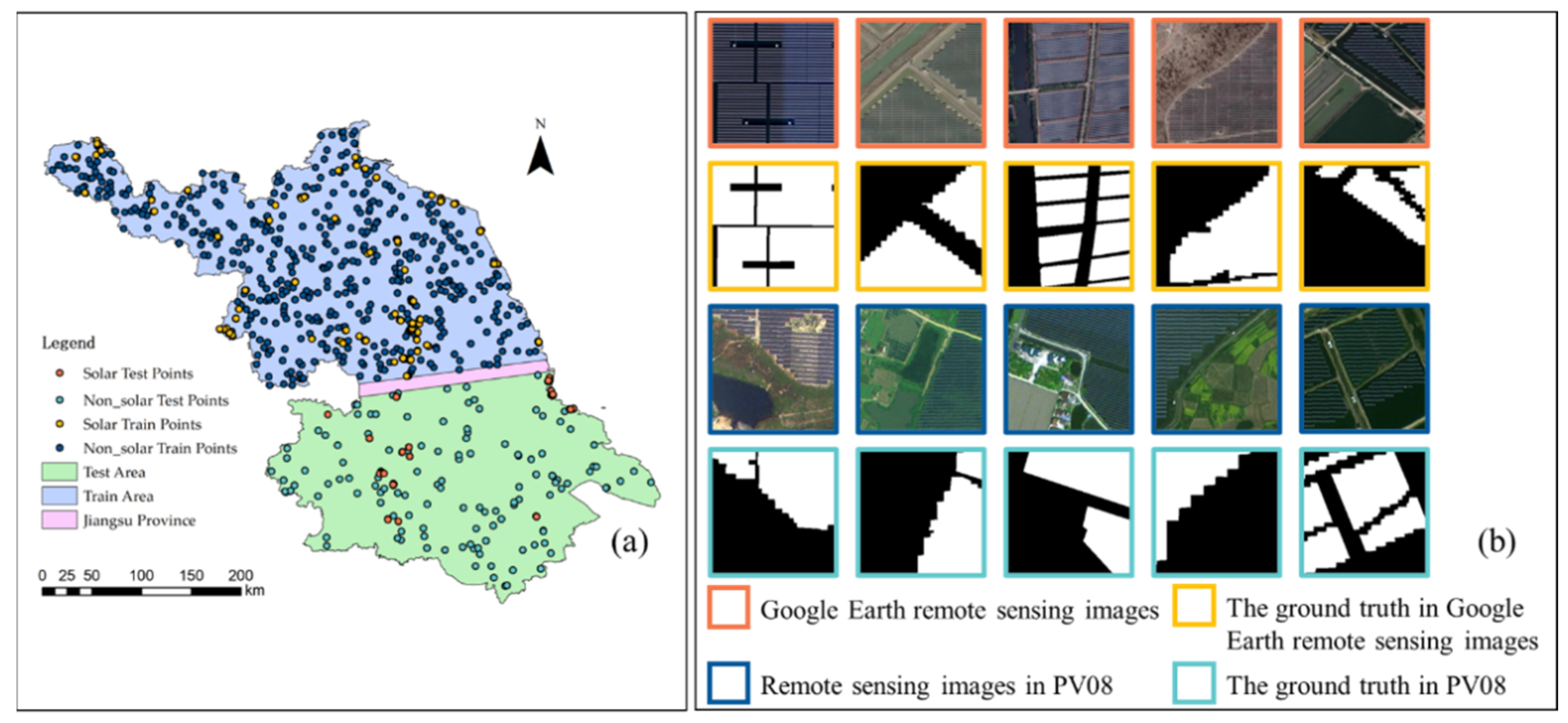
2.1. Training and Validation Samples Selection
2.2. Feature Construction and Selection
- Step-1 Machine Learning-based Recursive Feature Elimination (RFE):
- Step-2 Distance Correlation Coefficient-based Feature Elimination:
- Step-3 Iteration Validation and Selection:
2.3. Machine Learning Models
- Random Forest (RF): RF is a commonly-used machine learning algorithm trade-marked by Leo Breiman and Adele Cutler, which combines the output of multiple decision trees to vote for a single result [44]. In this study, the number of decision trees is set to 71, and the Gini index is used to evaluate feature importance.
- Gradient Boosting Decision Tree (GBDT): GBDT has strong robustness and interpretability, which uses a loss function to optimize the model in steps of shrinkage [45]. In this study, the number of decision trees and the shrinkage are set to 127 and 0.005, respectively. The least absolute deviation loss function is used.
- Support Vector Machine (SVM): SVM constructs a hyper-plane to maximize the distance between different classes [46]. In this study, the linear kernel is used to reduce the computational effort, and the regularization coefficient in SVM is set to 1 to improve the generalization ability.
2.4. Noise Removal and Enhancement
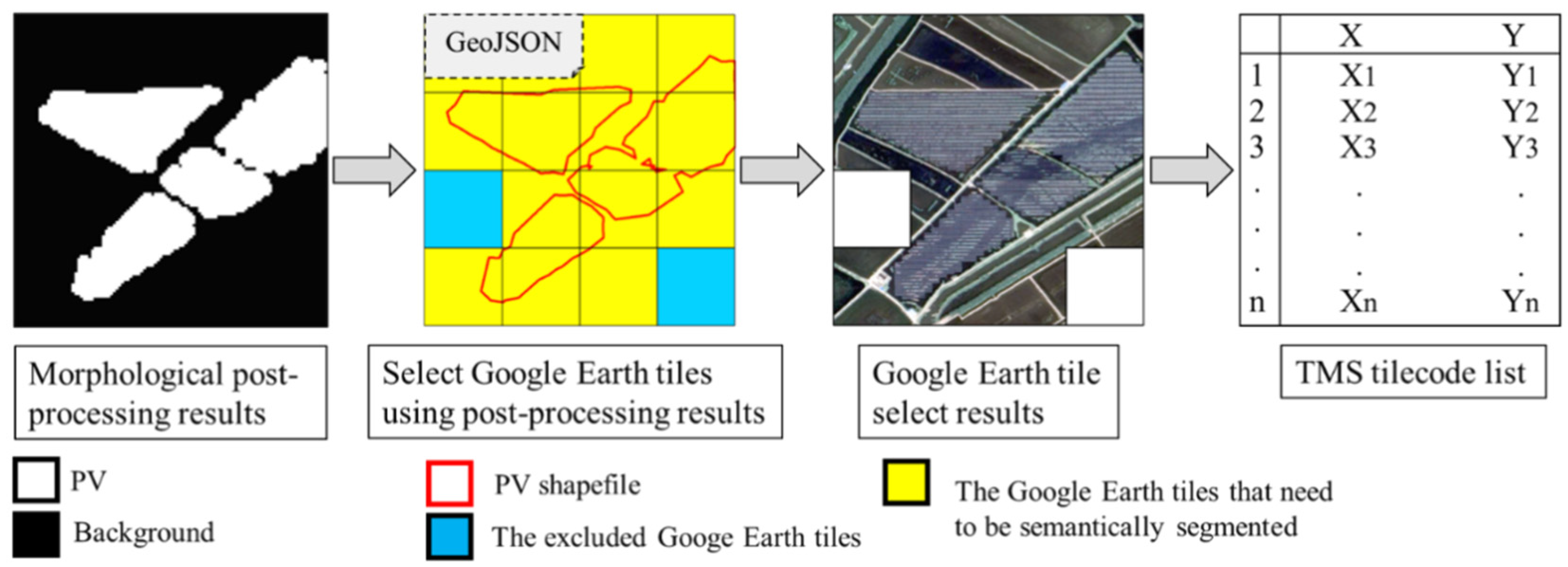
2.5. Tiles Selection associated with Google Earth Images
2.6. Deep Learning Diagnostics
2.7. Methodology and Result Evaluation
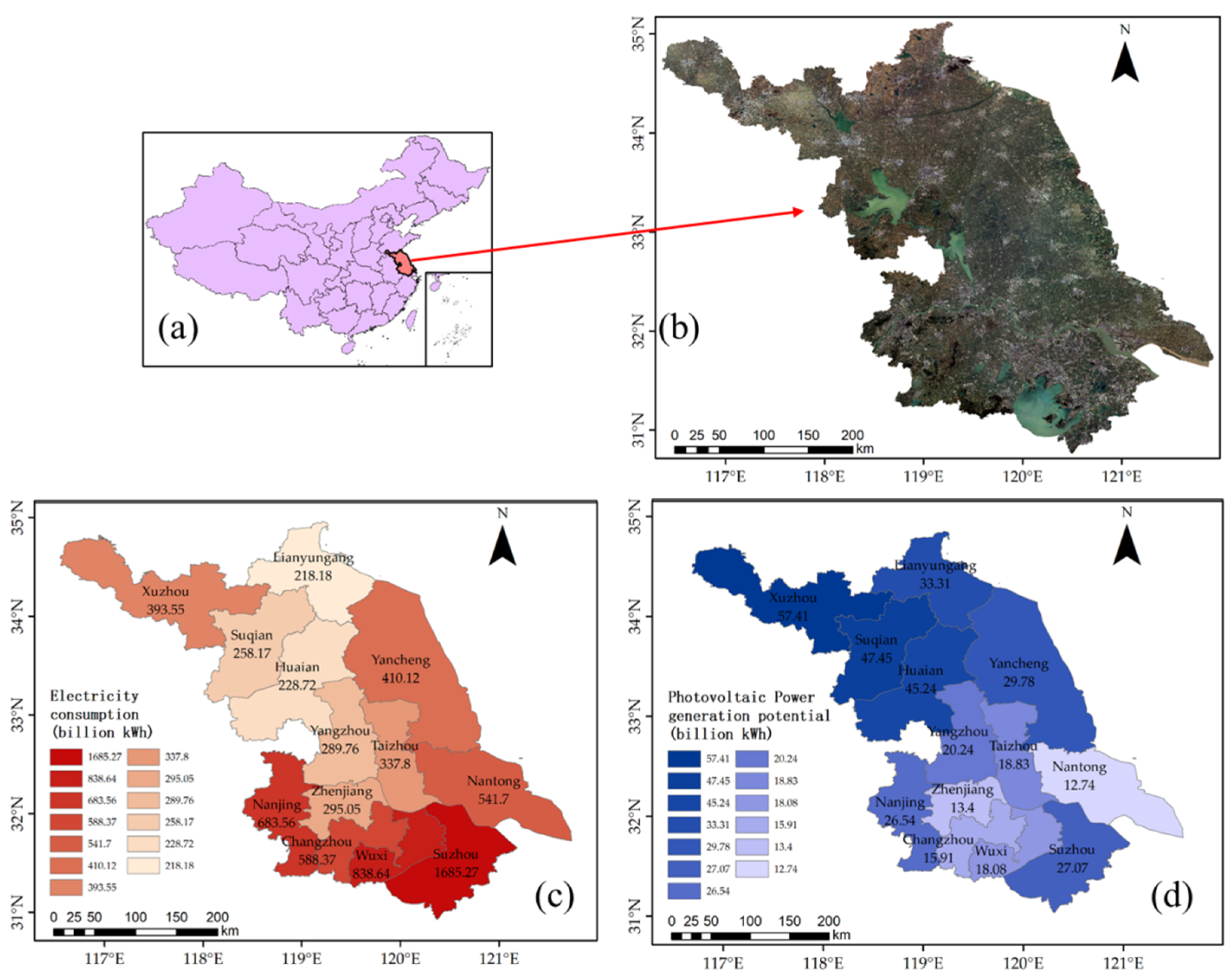
3. Applications over Highly Urbanized Regions
- Moderate-resolution satellite data: For the whole Jiangsu province, 80 tiles of Sentinel-1 Ground Range Detected SAR products (VV/VH) with a spatial resolution of 10 m × 10 m and 189 tiles of Sentinel2 L2A product with spatial resolutions of 10 m, 20 m, and 60 m are used for the first step machine learning broad spatial partitioning. Note that data from 04/01/2022 to 06/30/2022 with cloud coverage of less than 1% are selected for further GEE-based de-clouding, median filtering, mosaic, and cropping.
- DEM: Shuttle Radar Topography Mission (SRTM) obtained from NASA [55] with a spatial resolution of 30 m is used.
- High-resolution satellite data: Google Earth images (level 18, a mosaic dataset of Pleiades-1 and WorldView-3) with red, green, and blue bands and a spatial resolution of 0.54 m are acquired from the Google Earth API for the second step of the detailed deep learning diagnostics.
- PV observations: The GPPD database was updated in June 2021. It records 1318 (115) PV power stations globally (in Jiangsu Province) and is used to derive training and testing samples for both machine-learning and deep-learning models. PV08 data set provides regional PV observations obtained from GaoFen-2 and BJ-2 satellites with a spatial resolution of 0.8 m, which will be used for adding additional training samples for enhancing the generalization of the improved HRNet methodology. Kruitwagen’s PV dataset provides 221 PV plants with confidence level A, which will be compared with results from this two-step methodology.
3.1. Training and Validation Samples over Jiangsu Province
3.2. Machine Learning Broad Spatial Partitioning
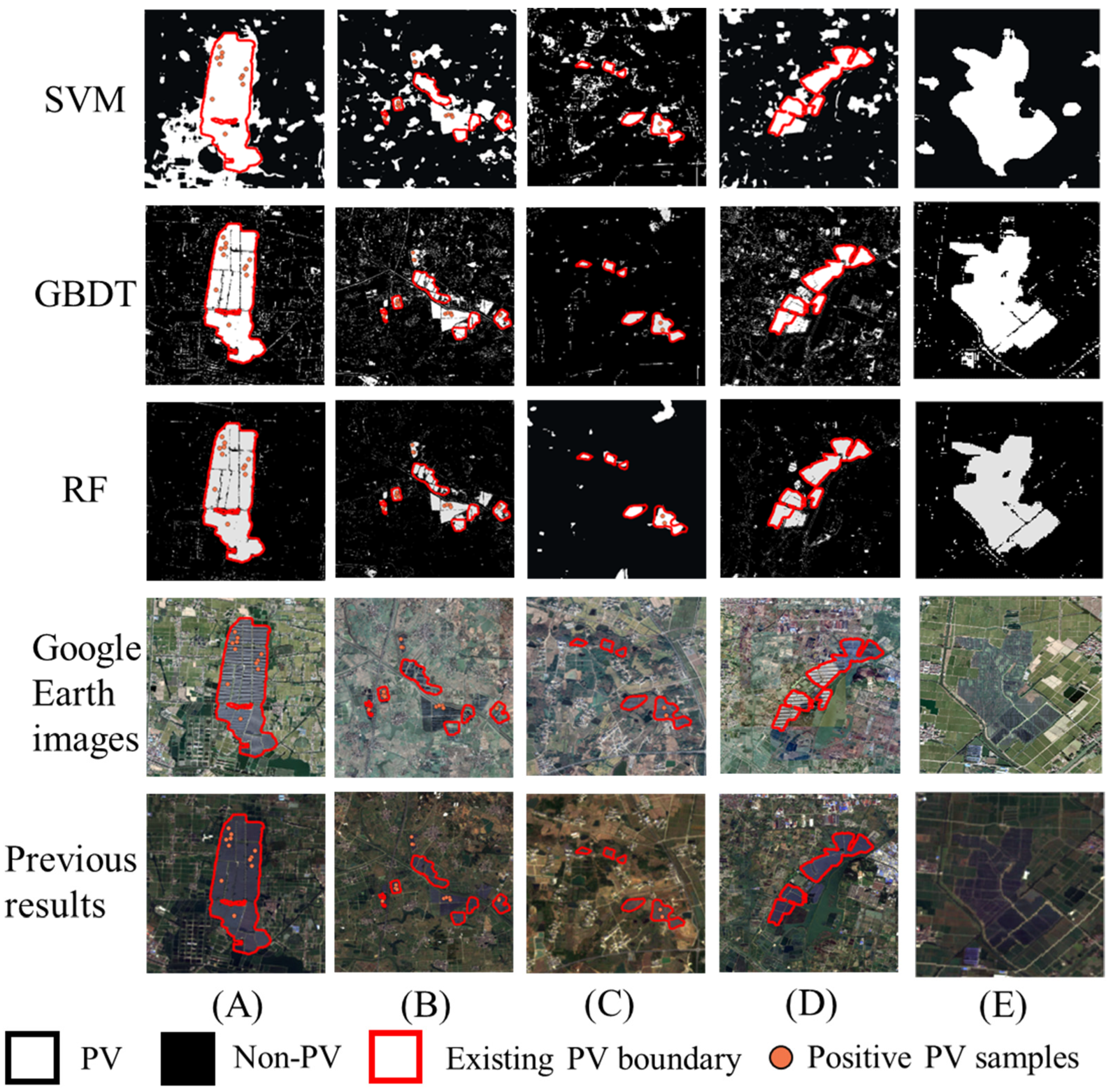
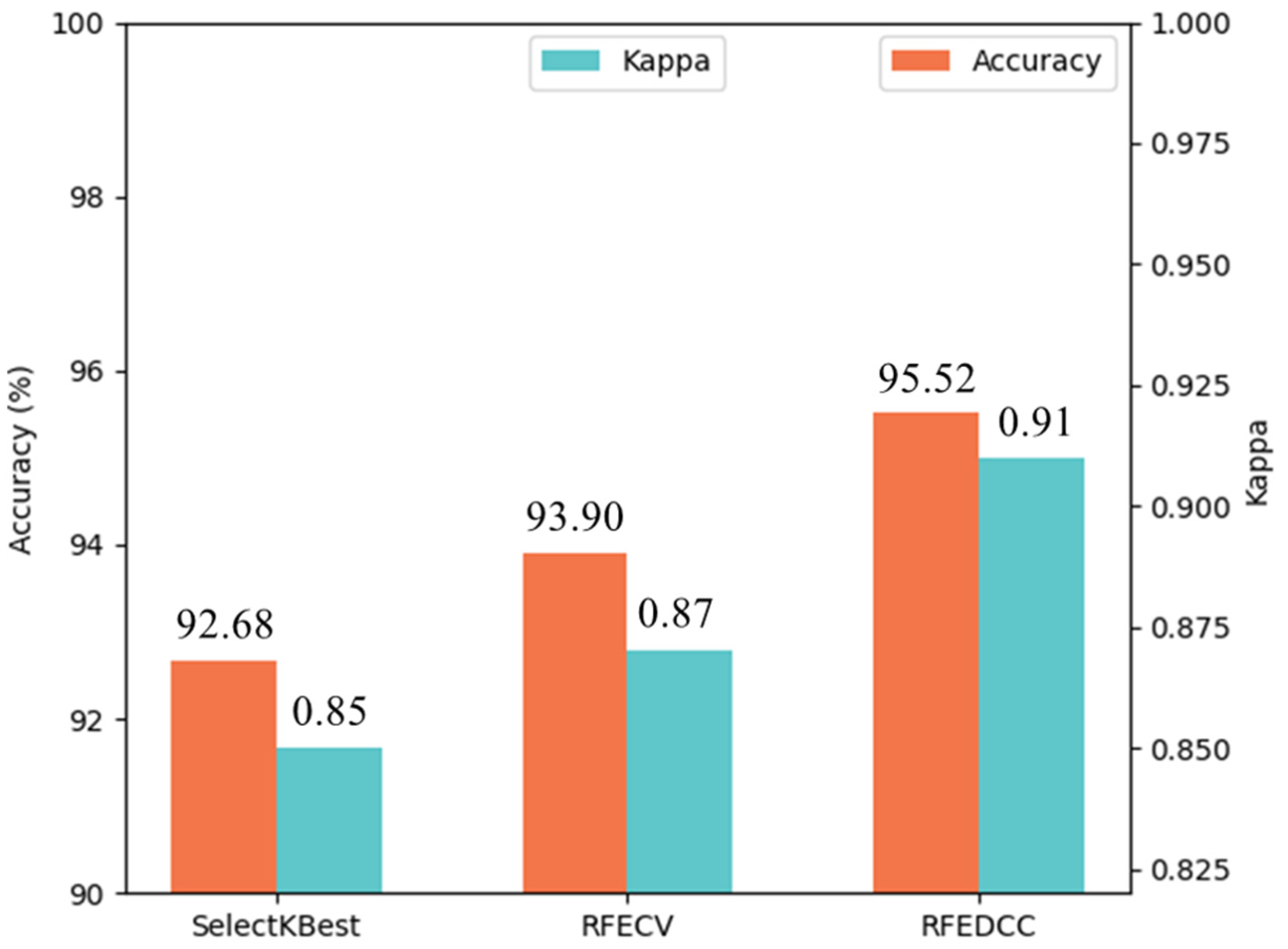
- Statistically, results from RF showed the highest overall accuracy (OA) and the highest Kappa value (OA = 95.52%, Kappa = 0.91) compared with results from GBDT (OA = 92.27%, Kappa = 0.84) and SVM (OA = 91.86%, Kappa = 0.83). PV detection results from RF have the highest UApv (95.16%), and background detection results have the highest PAnon-pv (95.12%). That is, RF is a better choice in both PV detection and noise removal. Although GBDT and SVM may extract similar PV plants as RF (PApv and UAnon-pv values ~96%), GBDT and SVM lack the ability to remove noise from the background (see UApv and PAnon-pv less than 90%). Compared with GBDT and SVM, RF uses unbiased estimation for the generalization error and has better generalization. The training data may contain noise, and RF can resist model overfitting, effectively reducing noise interference, so its results are better than GBDT and SVM.
- Spatially, machine learning broad spatial partitioning from three ML models indicates that missing PV plants in observation data could be diagnosed by those three ML models. However, SVM would be the last choice in PV detection due to the overwhelming noise and unclear detected edges (see 1st row), followed by GBDT with clear boundaries and less noise (see 2nd row), and RF provides even better edges and the best noise suppression (see 3rd row).
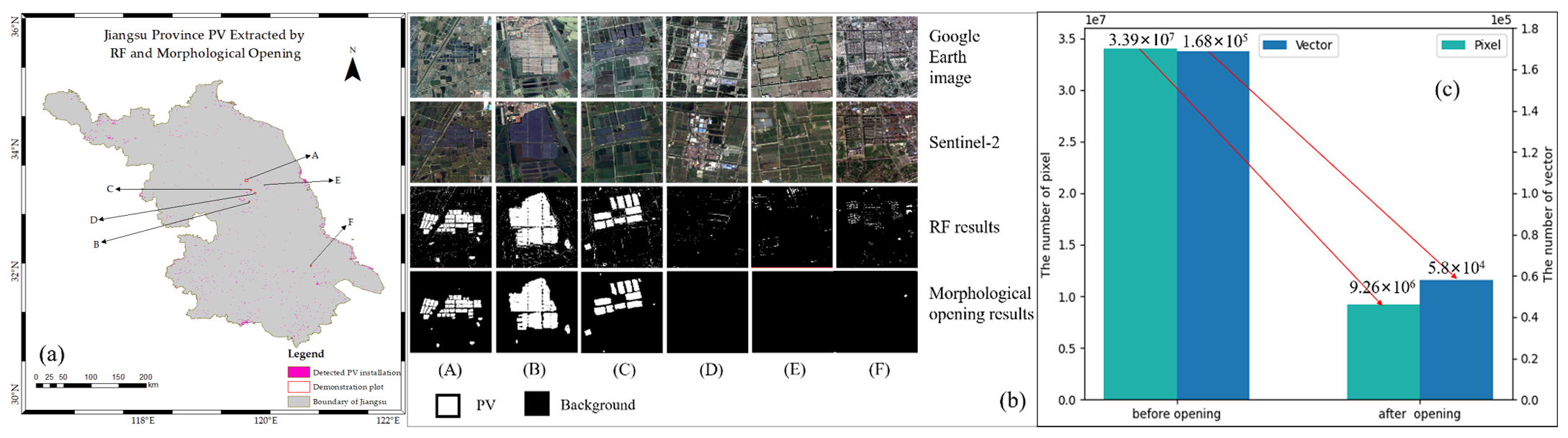
3.3. Morphological Processing
3.4. Deep Learning Model Comparison
- Selected deep learning models indicate similar evaluation values in terms of Precision and Recall, which means out of all the predicted PV plant pixels, a similar amount (greater than around 95%) are PV plant pixels. Meanwhile, out of all the ground truth PV plants, the models predict a similar amount (greater than 95%) as PV plant pixel, except U2-Net.
- Selected deep learning models indicate an obvious difference in the evaluation metrics IoU, which measures the overlapped percentage between the predicted results and the ground truth. Compared with commonly used deep learning models, HRNet deep learning diagnostics shows the best performance in terms of evaluation metrics of F1-score (around 96.51%) and IoU (around 93.26%).
- By integrating sub-pixel convolution, the improved HRNet methodology indicates an improved evaluation value in F1-score (by around 0.23%) and IoU (by around 0.42%). This is because the sub-pixel convolution mitigates the information loss caused by upsampling and thus improves the model performance.
- Extra PV observations (PV08) are added as training samples applied to the improved HRNet methodology, which helps model performance with the highest evaluation metrics value of F1-score (around 96.95%) and IoU (around 94.08%) and with the highest stability in terms of a low standard deviation (F1-score: 0.03%, IoU: 0.06%).
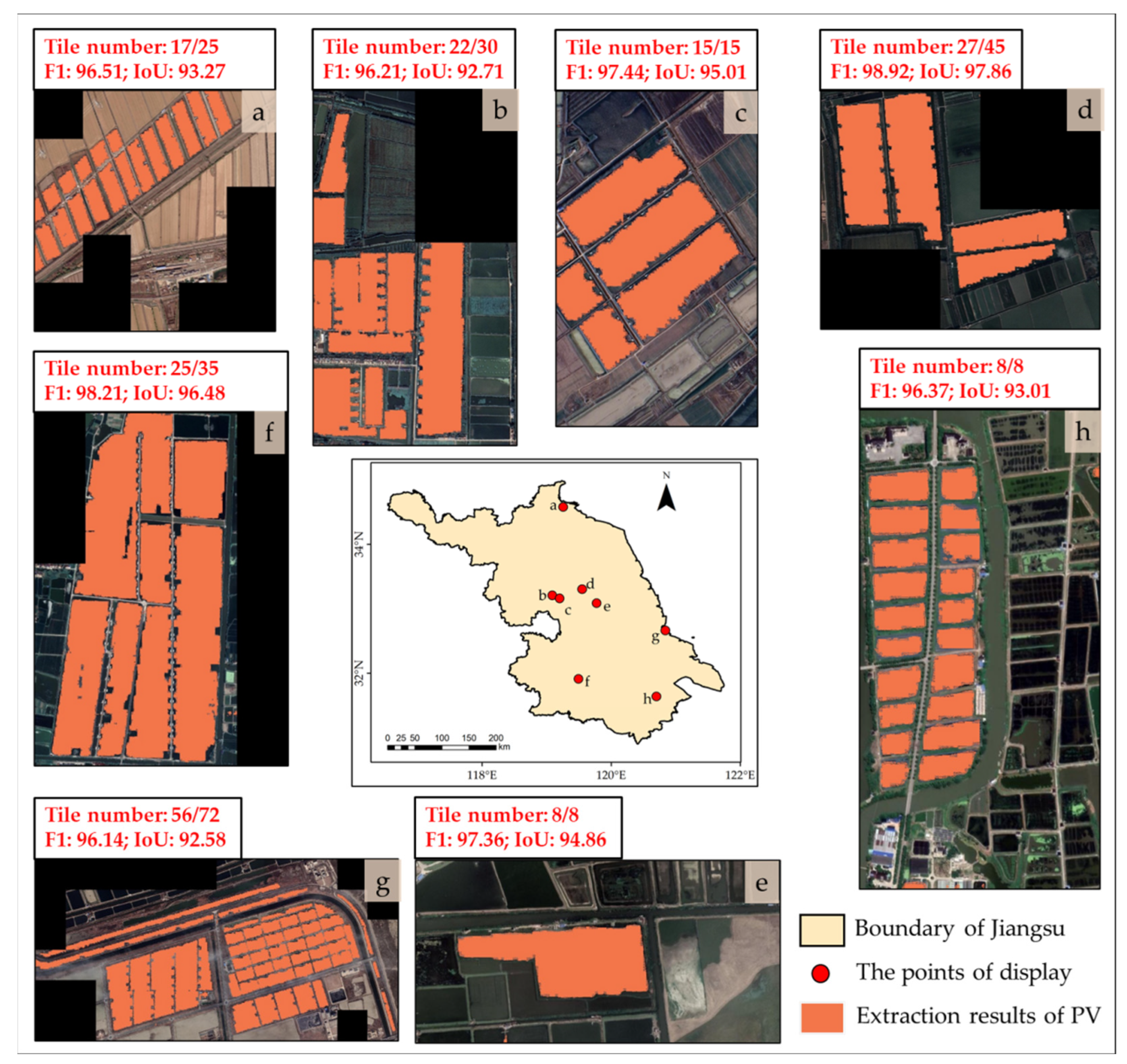
3.5. Detailed Deep Learning Diagnostics
4. Discussion
4.1. Comparison of Different Feature Selection Methods
4.2. The Effectiveness of Adding Nighttime Light Data
4.3. Consistency with Existing PV Database and a Time Consumption Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | SVM | GBDT | RF |
|---|---|---|---|
| 1 | SWIR1_ratio | SWIR1_ratio | SWIR1_ratio |
| 2 | SWIR2_ratio | B2_asm | NDPI |
| 3 | NDBI_savg | NDPI | B6 |
| 4 | Elevation | NDBI_savg | NDBI_savg |
| 5 | B8A | B6 | NDBI |
| 6 | MNDWI_savg | B5_savg | B7 |
| 7 | B8A_shade | B5 | B6_savg |
| 8 | NDBI_shade | B2_shade | B2_asm |
| 9 | NDPI2 | Elevation | NIR_ratio |
| 10 | B12 | B7 | B5 |
| 11 | B2_idm | BUAI_savg | B2_ent |
| 12 | B5 | NDBI_shade | NDPI2 |
| 13 | MNDWI | SWIR2_ratio | B12_dvar |
| 14 | B4 | B6_imcorr1 | B2_sent |
| 15 | B7 | B2_savg | B8A_savg |
| 16 | B2 | NDBI_corr | B8 |
| 17 | B8A_savg | B8_corr | BUAI |
| 18 | NDBI | NIR_ratio | B8_savg |
| 19 | MNDWI_asm | B8 | BUAI_savg |
| 20 | B2_ent | NDBI | NDVI_savg |
| Texture Name | Full Name | Description |
|---|---|---|
| _asm | Angular Second Moment | Measures the number of repeated pairs |
| _contrast | Contrast | Measures the local contrast of an image |
| _corr | Correlation | Measures the correlation between pairs of pixels |
| _var | Variance | Measures how spread out the distribution of gray levels is |
| _idm | Inverse Difference Moment | Measures the homogeneity |
| _savg | Sum Average | — |
| _svar | Sum Variance | |
| _sent | Sum Entropy | |
| _ent | Entropy | Measures the randomness of a grey-level distribution |
| _dvar | Difference variance | — |
| _dent | Difference entropy | |
| _imcorr1 | Information Measure of Corr. 1 | |
| _imcorr2 | Information Measure of Corr. 2 | |
| _diss | Dissimilarity | |
| _inertia | Inertia | |
| _shade | Cluster Shade | |
| _prom | Cluster prominence |
References
- The World’s Energy Problem. Available online: https://ourworldindata.org/worlds-energy-problem (accessed on 13 August 2023).
- Singh, G.K. Solar power generation by PV (photovoltaic) technology: A review. Energy 2013, 53, 1–13. [Google Scholar]
- Timilsina, G.R.; Kurdgelashvili, L.; Narbel, P.A. Solar energy: Markets, economics and policies. Renew. Sustain. Energy Rev. 2012, 16, 449–465. [Google Scholar] [CrossRef]
- Abdin, Z.; Alim, M.A.; Saidur, R.; Islam, M.R.; Rashmi, W.; Mekhilef, S.; Wadi, A. Solar energy harvesting with the application of nanotechnology. Renew. Sustain. Energy Rev. 2013, 26, 837–852. [Google Scholar] [CrossRef]
- China Energy Portal. Available online: https://chinaenergyportal.org/2021-q2-pv-installations-utility-and-distributed-by-province/ (accessed on 13 August 2023).
- Okoye, C.O.; Solyalı, O. Optimal sizing of stand-alone photovoltaic systems in residential buildings. Energy 2017, 126, 573–584. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Thoreau, R.; Achard, V.; Risser, L.; Berthelot, B.; Briottet, X. Active learning for hyperspectral image classification: A comparative review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 256–278. [Google Scholar] [CrossRef]
- Rangarajan, A.K.; Whetton, R.L.; Mouazen, A.M. Detection of fusarium head blight in wheat using hyperspectral data and deep learning. Expert Syst. Appl. 2022, 208, 118240. [Google Scholar] [CrossRef]
- Chen, Z.; Kang, Y.; Sun, Z.; Wu, F.; Zhang, Q. Extraction of Photovoltaic Plants Using Machine Learning Methods: A Case Study of the Pilot Energy City of Golmud, China. Remote Sens. 2022, 14, 2697. [Google Scholar] [CrossRef]
- Zhang, H.; Tian, P.; Zhong, J.; Liu, Y.; Li, J. Mapping Photovoltaic Panels in Coastal China Using Sentinel-1 and Sentinel-2 Images and Google Earth Engine. Remote Sens. 2023, 15, 3712. [Google Scholar] [CrossRef]
- Xia, Z.; Li, Y.; Chen, R.; Sengupta, D.; Guo, X.; Xiong, B.; Niu, Y. Mapping the rapid development of photovoltaic power stations in northwestern China using remote sensing. Energy Rep. 2022, 8, 4117–4127. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Wang, J.; Liu, J.; Li, L. Detecting Photovoltaic Installations in Diverse Landscapes Using Open Multi-Source Remote Sensing Data. Remote Sens. 2022, 14, 6296. [Google Scholar] [CrossRef]
- Zhao, H.; Yin, Z. Remote Sensing Extraction of Photovoltaic Panels in Desert Areas Based on Feature Optimization. In Proceedings of the 2022 15th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 5–7 November 2022; pp. 1–6. [Google Scholar]
- Plakman, V.; Rosier, J.; van Vliet, J. Solar park detection from publicly available satellite imagery. GISci. Remote Sens. 2022, 59, 462–481. [Google Scholar] [CrossRef]
- Cui, W.; Wang, F.; He, X.; Zhang, D.; Xu, X.; Yao, M.; Wang, Z.; Huang, J. Multi-scale semantic segmentation and spatial relationship recognition of remote sensing images based on an attention model. Remote Sens. 2019, 11, 1044. [Google Scholar] [CrossRef]
- Venkatesh, B.; Anuradha, J. A review of feature selection and its methods. Cybern. Inf. Technol. 2019, 19, 3–26. [Google Scholar] [CrossRef]
- Jianxun, W.; Xin, C.; Weicheng, J.; Li, H.; Junyi, L.; Haigang, S. PVNet: A novel semantic segmentation model for extracting high-quality photovoltaic panels in large-scale systems from high-resolution remote sensing imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 119, 103309. [Google Scholar]
- Jie, Y.; Yue, A.; Liu, S.; Huang, Q.; Chen, J.; Meng, Y.; Deng, Y.; Yu, Z. Photovoltaic power station identification using refined encoder–decoder network with channel attention and chained residual dilated convolutions. J. Appl. Remote Sens. 2020, 14, 016506. [Google Scholar] [CrossRef]
- Pérez-González, A.; Jaramillo-Duque, Á.; Cano-Quintero, J.B. Automatic boundary extraction for photovoltaic plants using the deep learning U-net model. Appl. Sci. 2021, 11, 6524. [Google Scholar] [CrossRef]
- Jie, Y.; Ji, X.; Yue, A.; Chen, J.; Deng, Y.; Chen, J.; Zhang, Y. Combined multi-layer feature fusion and edge detection method for distributed photovoltaic power station identification. Energies 2020, 13, 6742. [Google Scholar] [CrossRef]
- Su, B.; Du, X.; Mu, H.; Xu, C.; Li, X.; Chen, F.; Luo, X. FEPVNet: A Network with Adaptive Strategies for Cross-Scale Mapping of Photovoltaic Panels from Multi-Source Images. Remote Sens. 2023, 15, 2469. [Google Scholar] [CrossRef]
- Zhu, R.; Guo, D.; Wong, M.S.; Qian, Z.; Chen, M.; Yang, B.; Chen, B.; Zhang, H.; You, L.; Heo, J. Deep solar PV refiner: A detail-oriented deep learning network for refined segmentation of photovoltaic areas from satellite imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 116, 103134. [Google Scholar] [CrossRef]
- Chen, Q.; Li, X.; Zhang, Z.; Zhou, C.; Guo, Z.; Liu, Z.; Zhang, H. Remote sensing of photovoltaic scenarios: Techniques, applications and future directions. Appl. Energy 2023, 333, 120579. [Google Scholar] [CrossRef]
- Malof, J.M.; Collins, L.M.; Bradbury, K.; Newell, R.G. A deep convolutional neural network and a random forest classifier for solar photovoltaic array detection in aerial imagery. In Proceedings of the 2016 IEEE International Conference on Renewable Energy Research and Applications (ICRERA), Birmingham, UK, 20–23 November 2016; pp. 650–654. [Google Scholar]
- Kruitwagen, L.; Story, K.; Friedrich, J.; Byers, L.; Skillman, S.; Hepburn, C. A global inventory of photovoltaic solar energy generating units. Nature 2021, 598, 604–610. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III 18; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Yu, J.; Wang, Z.; Majumdar, A.; Rajagopal, R. DeepSolar: A machine learning framework to efficiently construct a solar deployment database in the United States. Joule 2018, 2, 2605–2617. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Ge, F.; Wang, G.; He, G.; Zhou, D.; Yin, R.; Tong, L. A Hierarchical Information Extraction Method for Large-Scale Centralized Photovoltaic Power Plants Based on Multi-Source Remote Sensing Images. Remote Sens. 2022, 14, 4211. [Google Scholar] [CrossRef]
- Fan, L.; Chen, D.; Fu, C.; Yan, Z. Statistical downscaling of summer temperature extremes in northern China. Adv. Atmos. Sci. 2013, 30, 1085–1095. [Google Scholar] [CrossRef]
- Wilby, R.L.; Wigley, T.; Conway, D.; Jones, P.; Hewitson, B.; Main, J.; Wilks, D. Statistical downscaling of general circulation model output: A comparison of methods. Water Resour. Res. 1998, 34, 2995–3008. [Google Scholar] [CrossRef]
- Xu, Z.; Han, Y.; Tam, C.-Y.; Yang, Z.-L.; Fu, C. Bias-corrected CMIP6 global dataset for dynamical downscaling of the historical and future climate (1979–2100). Sci. Data 2021, 8, 293. [Google Scholar] [CrossRef] [PubMed]
- Zha, Y.; Gao, J.; Ni, S. Use of normalized difference built-up index in automatically mapping urban areas from TM imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Li, W. Study on Extraction Methods of Impervious Surface Information Extraction from Urban Area Using Remote Sensing. Master’s Thesis, North University of China, Taiyuan, China, 2013. [Google Scholar]
- Wang, S. Application of Machine Learning Method in Remote Sensing Extraction of Photovoltaic Power Plants. Master’s Thesis, Jiangsu Normal University, Xuzhou, China, 2018. [Google Scholar]
- Wang, S.; Zhang, L.; Zhu, S.; Ji, L.; Chai, Q.; Shen, Y.; Zhang, R. Multi-invariant Feature Combined Photovoltaic Power Plants Extraction Using Multi-temporal Landsat 8 OLI Imagery. Bull. Surv. Mapp. 2018, 11, 46–52. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef]
- Ji, C.; Bachmann, M.; Esch, T.; Feilhauer, H.; Heiden, U.; Heldens, W.; Hueni, A.; Lakes, T.; Metz-Marconcini, A.; Schroedter-Homscheidt, M. Solar photovoltaic module detection using laboratory and airborne imaging spectroscopy data. Remote Sens. Environ. 2021, 266, 112692. [Google Scholar] [CrossRef]
- Zhang, M.; Du, J.; Luo, J.; Nie, B.; Xiong, W.; Liu, M.; Zhao, S. Research on Feature Selection of Multi-Objective Optimization. Comput. Eng. Appl. 2023, 59, 23–32. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Van Horebeek, J.; Tapia-Rodriguez, E. The approximation of a morphological opening and closing in the presence of noise. Signal Process. 2001, 81, 1991–1995. [Google Scholar] [CrossRef]
- Tile Map Service Specification. Available online: https://wiki.osgeo.org/wiki/Tile_Map_Service_Specification (accessed on 5 June 2023).
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Shamshiri, R.; Eide, E.; Høyland, K.V. Spatio-temporal distribution of sea-ice thickness using a machine learning approach with Google Earth Engine and Sentinel-1 GRD data. Remote Sens. Environ. 2022, 270, 112851. [Google Scholar] [CrossRef]
- Electricity Consumption of the Whole Society in Jiangsu Province by Region in 2021. Available online: http://stats.jiangsu.gov.cn/2022/nj09/nj0910.htm (accessed on 5 August 2023).
- Jiang, H.; Yao, L.; Lu, N.; Qin, J.; Liu, T.; Liu, Y.; Zhou, C. Multi-resolution dataset for photovoltaic panel segmentation from satellite and aerial imagery. Earth Syst. Sci. Data 2021, 13, 5389–5401. [Google Scholar] [CrossRef]
- Global Power Plant Database. Available online: https://datasets.wri.org/dataset/globalpowerplantdatabase (accessed on 20 June 2023).
- Farr, T.G.; Rosen, P.A.; Caro, E.; Crippen, R.; Duren, R.; Hensley, S.; Kobrick, M.; Paller, M.; Rodriguez, E.; Roth, L. The shuttle radar topography mission. Rev. Geophys. 2007, 45, RG2004. [Google Scholar] [CrossRef]
- Zhang, X.; Cheng, B.; Chen, J.; Liang, C. High-resolution boundary refined convolutional neural network for automatic agricultural greenhouses extraction from gaofen-2 satellite imageries. Remote Sens. 2021, 13, 4237. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local attention embedding to improve the semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]
- Wu, J.; Zheng, D.; Wu, Z.; Song, H.; Zhang, X. Prediction of Buckwheat Maturity in UAV-RGB Images Based on Recursive Feature Elimination Cross-Validation: A Case Study in Jinzhong, Northern China. Plants 2022, 11, 3257. [Google Scholar] [CrossRef]

| Types | Attributes | Details | Method |
|---|---|---|---|
| Remote Sensing Observations | Reflectance | — | — |
| Polarization | |||
| DEM | |||
| Remote Sensing Retrieves | Remote Sensing Index | NDBI [35] | |
| NDVI [36] | |||
| MNDWI [37] | |||
| BUAI [38] | |||
| NDPI [39] | |||
| NDPI2 [39] | |||
| NIR_ratio [40] | |||
| SWIR1_ratio [40] | |||
| SWIR2_ratio [40] | |||
| Texture [41] | — | glcmTexture() function in GEE (kernel size = 8) | |
| Geographical Characteristics | Slope, Aspect, Hillshade. | ee.Terrain.slope(), ee.Terrain.aspect(), and ee.Terrain.hillshade() function in GEE |
| Model | Parameter Setting | Number of Selected Features | Detailed Features |
|---|---|---|---|
| SVM | decisionProcedure = ’Voting’, svmType = ’C_SVC’, KernelType = ’LINEAR’, const = 1. | 11 | SWIR1_ratio, SWIR2_ratio, Elevation, B8A, MNDWI_savg, B8A_shade, NDBI_shade, B12, B2_idm, B2, MNDWI_asm. |
| GBDT | numberOfTrees = 127, shrinkage = 0.005, seed = 42, loss = ’LeastAbsoluteDeviation’. | 15 | SWIR1_ratio, B2_asm, NDPI, B6, B5_savg, B5, B2_shade, Elevation, BUAI_savg, NDBI_shade, SWIR2_ratio, B6_imcorr1, B2_savg, NDBI_corr, B8_corr. |
| RF | numberOfTrees = 71, critertion = ‘gini’, seed = 42. | 8 | SWIR1_ratio, NDPI, B6, B2_asm, B5, NDPI2, B12_dvar, BUAI_savg. |
| Model | OA (%) | Kappa | UAnon-pv (%) | PAnon-pv (%) | UApv (%) | PApv (%) |
|---|---|---|---|---|---|---|
| SVM | 91.86 | 0.83 | 96.39 | 86.99 | 88.14 | 96.74 |
| GBDT | 92.27 | 0.84 | 95.61 | 88.61 | 89.39 | 95.93 |
| RF | 95.52 | 0.91 | 95.91 | 95.12 | 95.16 | 95.93 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) |
|---|---|---|---|---|---|
| FCN8S [57] | 95.98 ± 0.18 | 94.92 ± 0.21 | 95.34 ± 0.57 | 95.13 ± 0.23 | 90.17 ± 0.42 |
| ResUNet34 [58] | 96.88 ± 0.12 | 96.85 ± 0.57 | 95.53 ± 0.47 | 96.18 ± 0.14 | 92.65 ± 0.25 |
| Deeplabv3+ [59] | 96.73 ± 0.16 | 95.39 ± 0.34 | 96.73 ± 0.51 | 96.05 ± 0.21 | 92.41 ± 0.36 |
| U2-Net [60] | 93.01 ± 1.56 | 95.65 ± 0.34 | 86.97 ± 3.88 | 91.07 ± 2.18 | 83.65 ± 3.64 |
| LANet [61] | 96.22 ± 0.13 | 95.41 ± 0.48 | 95.42 ± 0.31 | 95.41 ± 0.15 | 91.22 ± 0.28 |
| HRNet [49] | 97.12 ± 0.16 | 96.32 ± 0.15 | 96.71 ± 0.31 | 96.51 ± 0.21 | 93.26 ± 0.37 |
| Ours | 97.31 ± 0.09 | 96.33 ± 0.21 | 97.14 ± 0.32 | 96.74 ± 0.11 | 93.68 ± 0.21 |
| Ours+ | 97.47 ± 0.03 | 96.45 ± 0.06 | 97.45 ± 0.04 | 96.95 ± 0.03 | 94.08 ± 0.06 |
| Radius (km) | Intensity Threshold (nanoWatts/sr/cm2) | |||
|---|---|---|---|---|
| 3 (%) | 4 (%) | 5 (%) | 6 (%) | |
| 10 | 1.30/√ | 2.51/× | 4.05/× | 6.98/× |
| 15 | 0.31/√ | 0.49/√ | 0.97/√ | 1.82/× |
| 20 | 0.05/√ | 0.06/√ | 0.12/√ | 0.45/× |
| Reference Database | Number of PV | Detection | Detection Rate (%) |
|---|---|---|---|
| GPPD | 115 | 112 | 92.31 |
| Kruitwagen et al., 2021 [27] | 221 | 204 | 97.39 |
| Method | Number of Tiles (all) | Number of Tiles (selected) | Time Consumption |
|---|---|---|---|
| DL | 3,405,795 | — | 309.7 min |
| Ours Method | 3,405,795 | 94,020 | 15.2 min |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Cai, D.; Chen, L.; Yang, L.; Ge, X.; Peng, L. A Downscaling Methodology for Extracting Photovoltaic Plants with Remote Sensing Data: From Feature Optimized Random Forest to Improved HRNet. Remote Sens. 2023, 15, 4931. https://doi.org/10.3390/rs15204931
Wang Y, Cai D, Chen L, Yang L, Ge X, Peng L. A Downscaling Methodology for Extracting Photovoltaic Plants with Remote Sensing Data: From Feature Optimized Random Forest to Improved HRNet. Remote Sensing. 2023; 15(20):4931. https://doi.org/10.3390/rs15204931
Chicago/Turabian StyleWang, Yinda, Danlu Cai, Luanjie Chen, Lina Yang, Xingtong Ge, and Ling Peng. 2023. "A Downscaling Methodology for Extracting Photovoltaic Plants with Remote Sensing Data: From Feature Optimized Random Forest to Improved HRNet" Remote Sensing 15, no. 20: 4931. https://doi.org/10.3390/rs15204931
APA StyleWang, Y., Cai, D., Chen, L., Yang, L., Ge, X., & Peng, L. (2023). A Downscaling Methodology for Extracting Photovoltaic Plants with Remote Sensing Data: From Feature Optimized Random Forest to Improved HRNet. Remote Sensing, 15(20), 4931. https://doi.org/10.3390/rs15204931