
Deep Object Detection of Crop Weeds: Performance of YOLOv7 on a Real Case Dataset from UAV Images

 , , , ,
, , , ,  and
and 
Abstract

1. Introduction
- Construct a comprehensive dataset of chicory plants (CPs) and make it public [34], consisting of 3373 UAV-based RGB images acquired from multi-flight and different field conditions labeled to provide essential training data for weed detection with a DL object-oriented approach;
- Investigate and evaluate the performance of a YOLOv7 object detector model for weed identification and detection and then compare it with previous versions;
- Analyze the impact of data augmentation techniques on the evaluation of YOLO family models.
2. Related Work
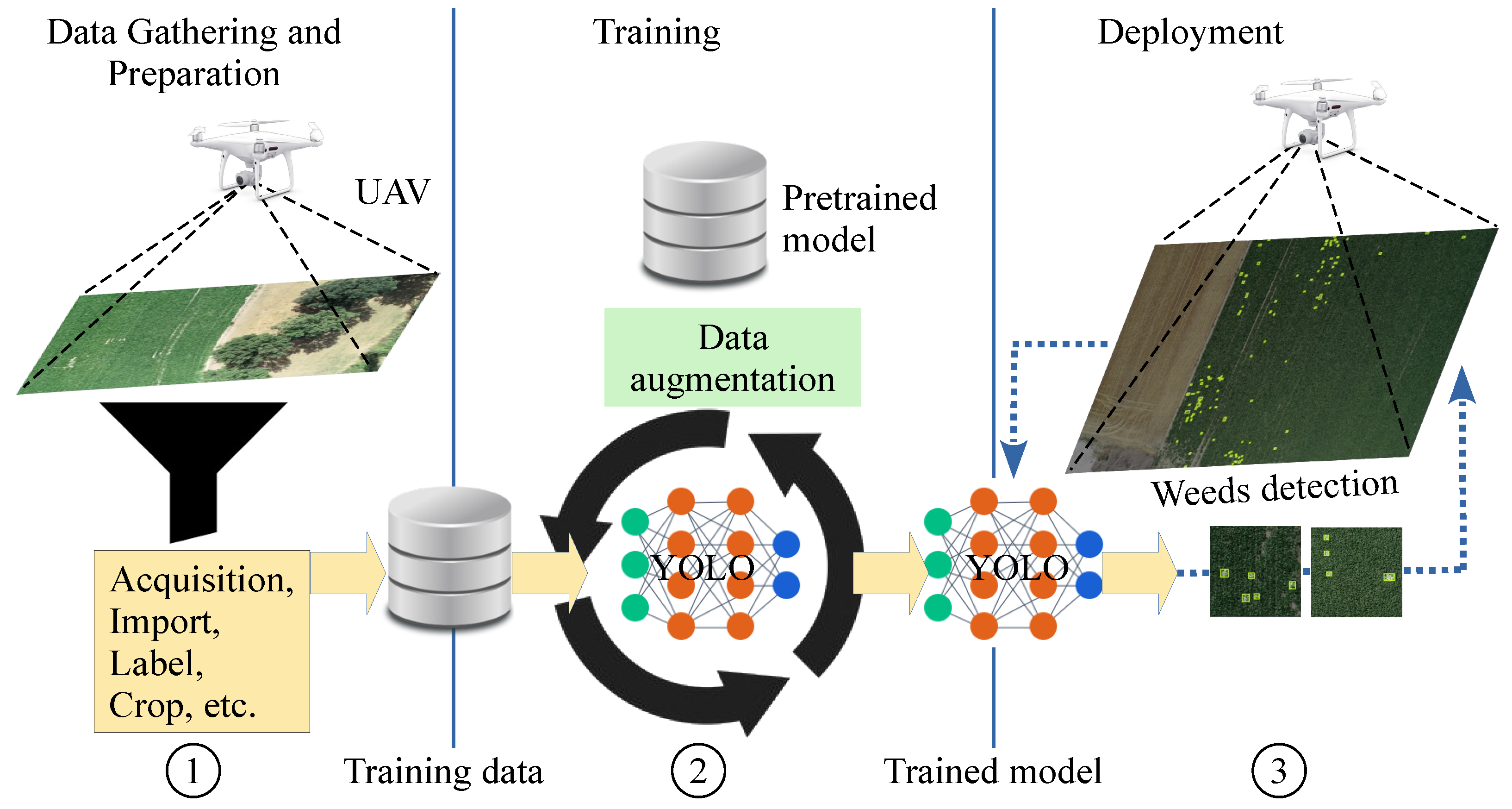
3. Methodology
3.1. You Only Look Once v7
3.1.1. Extended Efficient Layer Aggregation Network (EELAN)
3.1.2. Compound Model Scaling for Concatenation-Based Models
3.1.3. Planned Reparameterized Convolution
3.1.4. Coarseness for Auxiliary Loss and Fineness for Lead Loss
3.2. Models and Parameters
4. Dataset
4.1. Lincoln Beet (LB) Dataset
4.2. Chicory Plant (CP) Dataset
5. Results
Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Young, S.L. Beyond precision weed control: A model for true integration. Weed Technol. 2018, 32, 7–10. [Google Scholar] [CrossRef]
- Barnes, E.; Morgan, G.; Hake, K.; Devine, J.; Kurtz, R.; Ibendahl, G.; Sharda, A.; Rains, G.; Snider, J.; Maja, J.M.; et al. Opportunities for robotic systems and automation in cotton production. AgriEngineering 2021, 3, 339–362. [Google Scholar] [CrossRef]
- Pandey, P.; Dakshinamurthy, H.N.; Young, S.N. Frontier: Autonomy in Detection, Actuation, and Planning for Robotic Weeding Systems. Trans. ASABE 2021, 64, 557–563. [Google Scholar] [CrossRef]
- Bauer, M.V.; Marx, C.; Bauer, F.V.; Flury, D.M.; Ripken, T.; Streit, B. Thermal weed control technologies for conservation agriculture—A review. Weed Res. 2020, 60, 241–250. [Google Scholar] [CrossRef]
- Kennedy, H.; Fennimore, S.A.; Slaughter, D.C.; Nguyen, T.T.; Vuong, V.L.; Raja, R.; Smith, R.F. Crop signal markers facilitate crop detection and weed removal from lettuce and tomato by an intelligent cultivator. Weed Technol. 2020, 34, 342–350. [Google Scholar] [CrossRef]
- Van Der Weide, R.; Bleeker, P.; Achten, V.; Lotz, L.; Fogelberg, F.; Melander, B. Innovation in mechanical weed control in crop rows. Weed Res. 2008, 48, 215–224. [Google Scholar] [CrossRef]
- Lamm, R.D.; Slaughter, D.C.; Giles, D.K. Precision weed control system for cotton. Trans. ASAE 2002, 45, 231. [Google Scholar]
- Chostner, B. See & Spray: The next generation of weed control. Resour. Mag. 2017, 24, 4–5. [Google Scholar]
- Gerhards, R.; Andújar Sanchez, D.; Hamouz, P.; Peteinatos, G.G.; Christensen, S.; Fernandez-Quintanilla, C. Advances in site-specific weed management in agriculture—A review. Weed Res. 2022, 62, 123–133. [Google Scholar] [CrossRef]
- Chen, D.; Lu, Y.; Li, Z.; Young, S. Performance evaluation of deep transfer learning on multi-class identification of common weed species in cotton production systems. Comput. Electron. Agric. 2022, 198, 107091. [Google Scholar] [CrossRef]
- Olsen, A.; Konovalov, D.A.; Philippa, B.; Ridd, P.; Wood, J.C.; Johns, J.; Banks, W.; Girgenti, B.; Kenny, O.; Whinney, J.; et al. DeepWeeds: A multiclass weed species image dataset for deep learning. Sci. Rep. 2019, 9, 1–12. [Google Scholar] [CrossRef]
- Suh, H.K.; Ijsselmuiden, J.; Hofstee, J.W.; van Henten, E.J. Transfer learning for the classification of sugar beet and volunteer potato under field conditions. Biosyst. Eng. 2018, 174, 50–65. [Google Scholar] [CrossRef]
- Espejo-Garcia, B.; Mylonas, N.; Athanasakos, L.; Fountas, S.; Vasilakoglou, I. Towards weeds identification assistance through transfer learning. Comput. Electron. Agric. 2020, 171, 105306. [Google Scholar] [CrossRef]
- Dyrmann, M.; Karstoft, H.; Midtiby, H.S. Plant species classification using deep convolutional neural network. Biosyst. Eng. 2016, 151, 72–80. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Glenn, J. What Is YOLOv5? 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 December 2022).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Gao, J.; French, A.P.; Pound, M.P.; He, Y.; Pridmore, T.P.; Pieters, J.G. Deep convolutional neural networks for image-based Convolvulus sepium detection in sugar beet fields. Plant Methods 2020, 16, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, A.; Saraswat, D.; Aggarwal, V.; Etienne, A.; Hancock, B. Performance of deep learning models for classifying and detecting common weeds in corn and soybean production systems. Comput. Electron. Agric. 2021, 184, 106081. [Google Scholar] [CrossRef]
- Sharpe, S.M.; Schumann, A.W.; Boyd, N.S. Goosegrass detection in strawberry and tomato using a convolutional neural network. Sci. Rep. 2020, 10, 1–8. [Google Scholar] [CrossRef]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Lu, Y.; Young, S. A survey of public datasets for computer vision tasks in precision agriculture. Comput. Electron. Agric. 2020, 178, 105760. [Google Scholar] [CrossRef]
- Mylonas, N.; Malounas, I.; Mouseti, S.; Vali, E.; Espejo-Garcia, B.; Fountas, S. Eden library: A long-term database for storing agricultural multi-sensor datasets from uav and proximal platforms. Smart Agric. Technol. 2022, 2, 100028. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, Y.; Zhao, B.; Kang, X.; Ding, Y. Review of weed detection methods based on computer vision. Sensors 2021, 21, 3647. [Google Scholar] [CrossRef]
- Salazar-Gomez, A.; Darbyshire, M.; Gao, J.; Sklar, E.I.; Parsons, S. Towards practical object detection for weed spraying in precision agriculture. arXiv 2021, arXiv:2109.11048. [Google Scholar]
- Gallo, I.; Rehman, A.U.; Dehkord, R.H.; Landro, N.; La Grassa, R.; Boschetti, M. Weed Detection by UAV 416a Image Dataset—Chicory Crop Weed. 2022. Available online: https://universe.roboflow.com/chicory-crop-weeds-5m7vo/weed-detection-by-uav-416a/dataset/1 (accessed on 1 December 2022).
- Lottes, P.; Khanna, R.; Pfeifer, J.; Siegwart, R.; Stachniss, C. UAV-based crop and weed classification for smart farming. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3024–3031. [Google Scholar]
- Gao, J.; Liao, W.; Nuyttens, D.; Lootens, P.; Vangeyte, J.; Pižurica, A.; He, Y.; Pieters, J.G. Fusion of pixel and object-based features for weed mapping using unmanned aerial vehicle imagery. Int. J. Appl. Earth Obs. Geoinf. 2018, 67, 43–53. [Google Scholar] [CrossRef]
- Lottes, P.; Behley, J.; Milioto, A.; Stachniss, C. Fully convolutional networks with sequential information for robust crop and weed detection in precision farming. IEEE Robot. Autom. Lett. 2018, 3, 2870–2877. [Google Scholar] [CrossRef]
- Le, V.N.T.; Apopei, B.; Alameh, K. Effective plant discrimination based on the combination of local binary pattern operators and multiclass support vector machine methods. Inf. Process. Agric. 2019, 6, 116–131. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Sa, I.; Chen, Z.; Popović, M.; Khanna, R.; Liebisch, F.; Nieto, J.; Siegwart, R. weednet: Dense semantic weed classification using multispectral images and mav for smart farming. IEEE Robot. Autom. Lett. 2017, 3, 588–595. [Google Scholar] [CrossRef]
- Jin, X.; Che, J.; Chen, Y. Weed identification using deep learning and image processing in vegetable plantation. IEEE Access 2021, 9, 10940–10950. [Google Scholar] [CrossRef]
- Milioto, A.; Lottes, P.; Stachniss, C. Real-time semantic segmentation of crop and weed for precision agriculture robots leveraging background knowledge in CNNs. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2229–2235. [Google Scholar]
- Lottes, P.; Stachniss, C. Semi-supervised online visual crop and weed classification in precision farming exploiting plant arrangement. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5155–5161. [Google Scholar]
- Etienne, A.; Ahmad, A.; Aggarwal, V.; Saraswat, D. Deep Learning-Based Object Detection System for Identifying Weeds Using UAS Imagery. Remote Sens. 2021, 13, 5182. [Google Scholar] [CrossRef]
- Peteinatos, G.G.; Reichel, P.; Karouta, J.; Andújar, D.; Gerhards, R. Weed identification in maize, sunflower, and potatoes with the aid of convolutional neural networks. Remote Sens. 2020, 12, 4185. [Google Scholar] [CrossRef]
- Bah, M.D.; Hafiane, A.; Canals, R. Deep learning with unsupervised data labeling for weed detection in line crops in UAV images. Remote Sens. 2018, 10, 1690. [Google Scholar] [CrossRef]
- Di Cicco, M.; Potena, C.; Grisetti, G.; Pretto, A. Automatic model based dataset generation for fast and accurate crop and weeds detection. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5188–5195. [Google Scholar]
- Espejo-Garcia, B.; Mylonas, N.; Athanasakos, L.; Vali, E.; Fountas, S. Combining generative adversarial networks and agricultural transfer learning for weeds identification. Biosyst. Eng. 2021, 204, 79–89. [Google Scholar] [CrossRef]
- Dwyer, J. Quickly Label Training Data and Export To Any Format. 2020. Available online: https://roboflow.com/annotate (accessed on 1 December 2022).
- Chien, W. YOLOv7 Repositry with all Instruction. 2022. Available online: https://github.com/WongKinYiu/yolov7 (accessed on 1 December 2022).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13039–13048. [Google Scholar]
- Jensen, P.K. Survey of Weeds in Maize Crops in Europe; Dept. of Integral Pest Management, Aarhus University: Aarhus, Denmark, 2011. [Google Scholar]
- Image Augmentation in Roboflow. Available online: https://docs.roboflow.com/image-transformations/image-augmentation (accessed on 1 August 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Optimizers | Adam |
| Learning rate | Adam = |
| Momentum | 0.98 |
| Learning decay | |
| Pretrained | MS COCO dataset |
| Number of epochs | 300 |
| Parameters | YOLOvF | SSD |
|---|---|---|
| Optimizers | SGD | SGD |
| Learning rate | 0.12 | 0.002 |
| Momentum | 0.9 | 0.9 |
| Learning decay | 0.0001 | 0.0005 |
| Pretrained | resnet50-caffe | COCO |
| Number of epochs | 300 | 300 |
| LB Dataset | CP Dataset | |
|---|---|---|
| Number of images | 4402 | 3373 |
| Number of bounding boxes | 39,246 | 12,113 |
| Average weeds per picture | 5.190 | 3.561 |
| Total number of weeds | 22,847 | 12,113 |
| Number of sugar beets | 16,399 | N/A |
| Model | Backbone | mAP Score | mAP Suger | mAP Weed |
|---|---|---|---|---|
| YOLOv7 | DN-53 | 61.0 | 74.1 | 48.0 |
| YOLOv5m | DN-53 | 51.0 | 67.5 | 34.6 |
| YOLOv4 | DN-53 | 41.2 | 59.5 | 23.0 |
| YOLOv3 | DN-53 | 50.4 | 66.3 | 34.6 |
| F-RCNN | R-50 FPN | 42.4 | 62.2 | 22.6 |
| F-RCNN | R-101 FPN | 42.2 | 62.2 | 22.3 |
| F-RCNN | Rx-101 FPN | 43.2 | 62.8 | 23.6 |
| SSD | VGG-16 Bi-Real | 37.4 | 54 | 20.8 |
| Class | Images | Labels | P | R | mAP@.5 | mAP@.5:.95 |
|---|---|---|---|---|---|---|
| All | 501 | 1180 | 7.83 | 0.000847 | 5.31 | 5.31 |
| Weeds | 501 | 1180 | 7.83 | 0.000847 | 5.31 | 5.31 |
| Model | Precision | Recall | mAP@ 0.5 Score | mAP@0.5:0.95 Score |
|---|---|---|---|---|
| YOLOv7-tiny | 57.6 | 58.3 | 55.8 | 17.9 |
| YOLOv7m | 55.2 | 60.9 | 56.3 | 18.5 |
| YOLOv7-x | 59.3 | 58.1 | 56.6 | 18.5 |
| YOLOv7-w6 | 55.3 | 62.1 | 56.5 | 18.5 |
| YOLOv7-e6 | 59.2 | 57.0 | 56.0 | 17.9 |
| YOLOv7-e6e | 57.1 | 58.8 | 55.3 | 18.1 |
| YOLOv7-d6 | 61.3 | 54.8 | 55.0 | 18.1 |
| Models | Backbone | Recall | mAP Weed |
|---|---|---|---|
| YOLOv7 | DarkNet-53 | 58.1 | 56.6 |
| YOLOv3 | DarkNet-53 | 31.3 | 22.18 |
| YOLOvF | R-50-C5 | 54.6 | 24.97 |
| SSD | VGG16 | 75.3 | 23.74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gallo, I.; Rehman, A.U.; Dehkordi, R.H.; Landro, N.; La Grassa, R.; Boschetti, M. Deep Object Detection of Crop Weeds: Performance of YOLOv7 on a Real Case Dataset from UAV Images. Remote Sens. 2023, 15, 539. https://doi.org/10.3390/rs15020539
Gallo I, Rehman AU, Dehkordi RH, Landro N, La Grassa R, Boschetti M. Deep Object Detection of Crop Weeds: Performance of YOLOv7 on a Real Case Dataset from UAV Images. Remote Sensing. 2023; 15(2):539. https://doi.org/10.3390/rs15020539
Chicago/Turabian StyleGallo, Ignazio, Anwar Ur Rehman, Ramin Heidarian Dehkordi, Nicola Landro, Riccardo La Grassa, and Mirco Boschetti. 2023. "Deep Object Detection of Crop Weeds: Performance of YOLOv7 on a Real Case Dataset from UAV Images" Remote Sensing 15, no. 2: 539. https://doi.org/10.3390/rs15020539
APA StyleGallo, I., Rehman, A. U., Dehkordi, R. H., Landro, N., La Grassa, R., & Boschetti, M. (2023). Deep Object Detection of Crop Weeds: Performance of YOLOv7 on a Real Case Dataset from UAV Images. Remote Sensing, 15(2), 539. https://doi.org/10.3390/rs15020539