
A Spatial Cross-Scale Attention Network and Global Average Accuracy Loss for SAR Ship Detection


Abstract
1. Introduction
- A novel cross-scale spatial attention module is proposed, which consists of a cross-scale attention module and a spatial attention redistribution module. The former dynamically adjusts the position of network attention by combining information from different scales. The latter redistributes spatial attention to mitigate the influence of complex backgrounds and make the ship more distinctive.
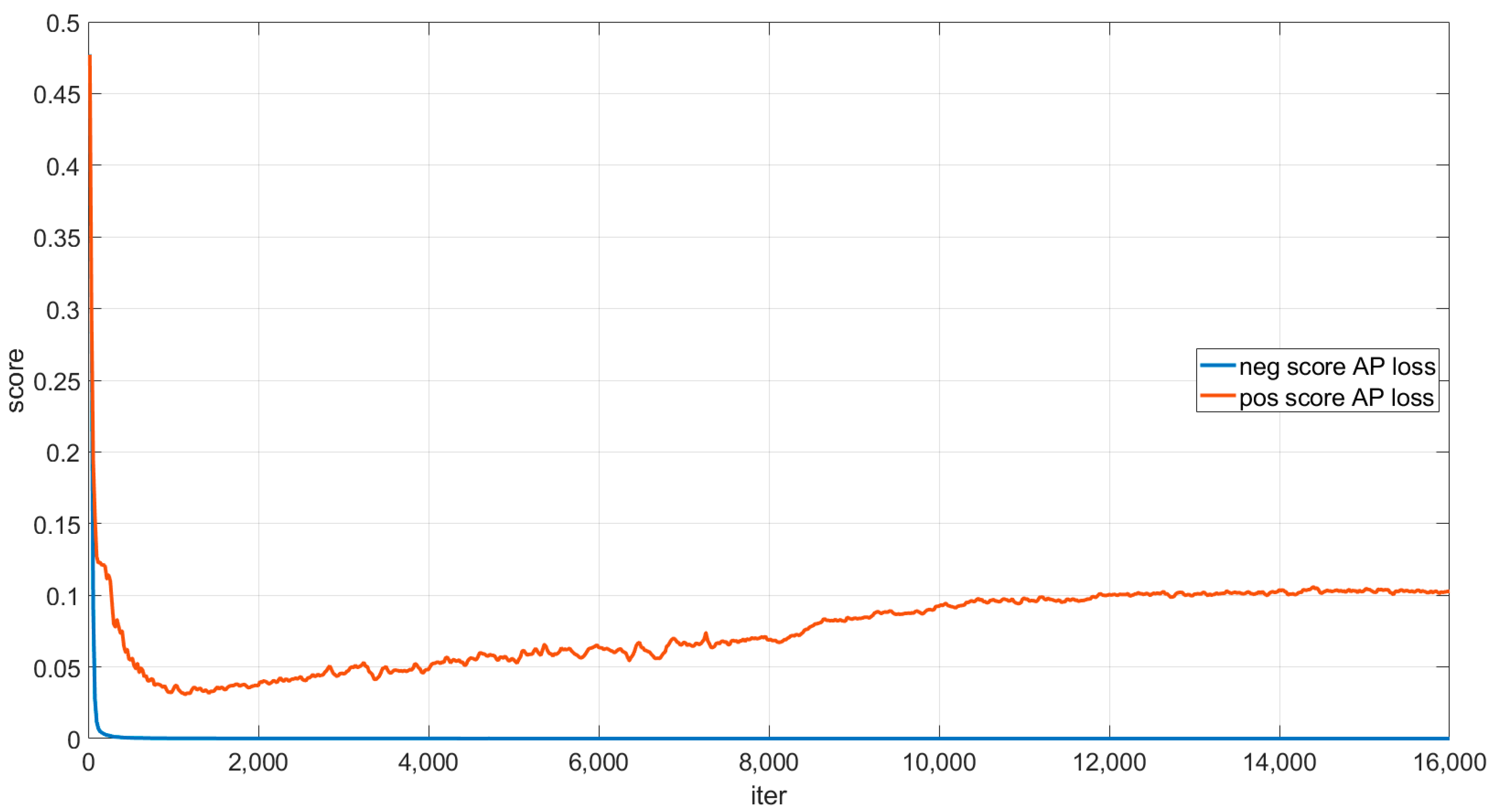
- We analyze the reasons why AP loss generates the “score shift” problem and propose a global average accuracy loss (GAP loss) to solve it. Compared to traditional methods using focus loss as the classification loss, training with GAP loss allows the network to optimize directly with the average precision (AP) as the target and to distinguish between positive and negative samples more quickly, achieving better detection results.
- We propose an anchor-free spatial cross-scale attention network (SCSA-Net) for ship detection in SAR images, which reached 98.7% AP on the SSDD, 97.9% AP on the SAR-Ship-Dataset and 95.4% AP on the HRSID, achieving state-of-the-art performance.
2. Methods
2.1. Overall Architecture of SCSA-Net
2.2. Spatial Cross-Scale Attention Module
2.2.1. Cross-Scale Attention Module
2.2.2. Spatial Attention Redistribution Module
2.3. Global Average Precision Loss
2.3.1. Average Precision Loss
2.3.2. Global Average Precision Loss
3. Experiment
3.1. Datasets
- Official-SSDD (SSDD): Currently, the SSDD [26] dataset published in 2017 is the most widely used in the SAR ship detection field. Subsequently, Zhang et al. published the updated official SSDD dataset of the SSDD dataset in 2021 [29], which corrected the wrong labels in SSDD and provided richer label formats. The official SSDD dataset contains complex backgrounds and multi-scale offshore and inshore targets. Most of the images are 500 pixels wide, and the SSDD has a variety of SAR image samples with resolutions ranging from 1 m to 15 m from different sensors of RadarSat-2, Terra SAR-X, and Sentinel-1. The average size of ships in SSDD is only ~35 × 35 pixels. In this paper, we refer to Official SSDD as SSDD for convenience.
- SAR-Ship-Dataset: SAR-Ship-Dataset was released by Wang et al. [27] in 2019. It contains 43,819 images with 256 × 256 image sizes, mainly from Sentinel-1 and Gaofen-3. SAR ships in SAR-Ship-Dataset are provided with resolutions from 5 m to 20 m, and HH, HV, VV, and VH polarizations. Same to their original reports in [27], the entire dataset is randomly divided into training (70%), validation (20%), and test dataset (10%).
- High-Resolution SAR Images Dataset (HRSID): The HRSID proposed by Wei et al. [28] is constructed by using original SAR images from the Sentinel-1B, TerraSAR-X, and TanDEM-X satellites. The HRSID contains 5604 images of 800 × 800 size and 16,951 ship targets. These images have various polarization rates, imaging modes, imaging conditions, etc. As in its original reports in [28], the ratio of the training set and the test set is 13:7 according to its default configuration files.
3.2. Evaluation Metrics
3.3. Training Details
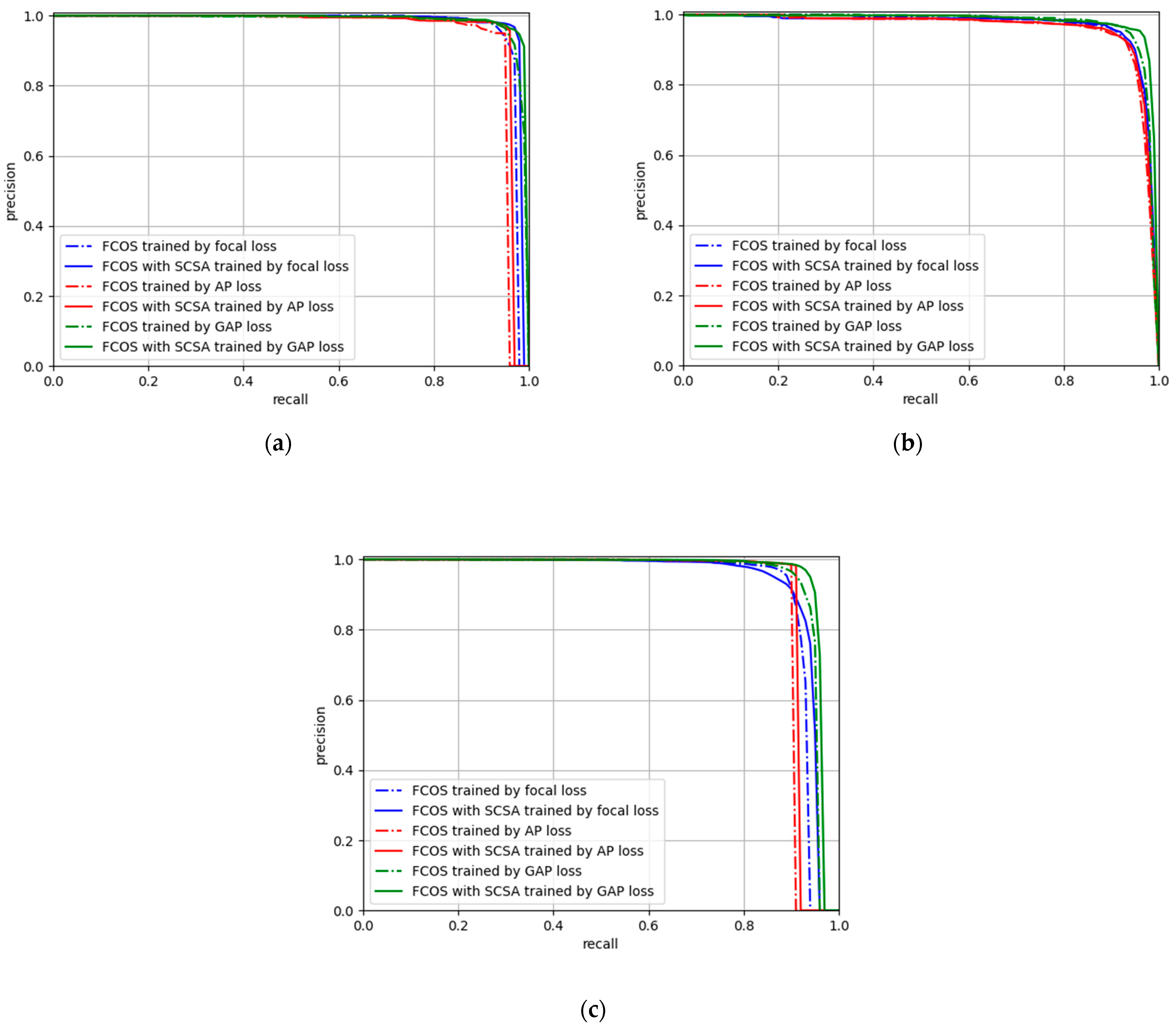
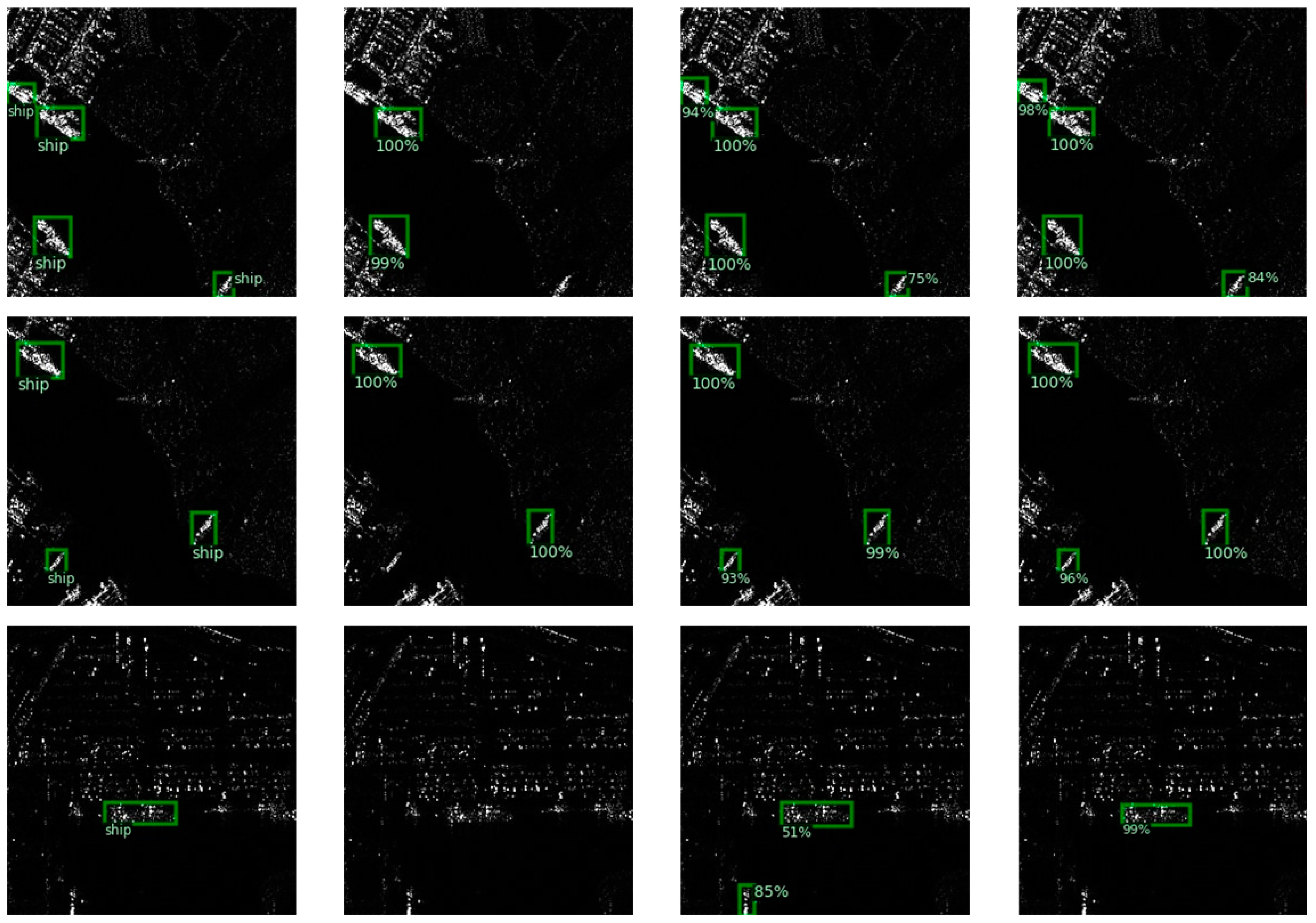
3.4. Ablation Study
3.5. Comparison with the Latest SAR Ship Detection Methods
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, P.; Xu, H.; Tian, T.; Gao, P.; Li, L.; Zhao, T.; Zhang, N.; Tian, J. SEFEPNet: Scale Expansion and Feature Enhancement Pyramid Network for SAR Aircraft Detection with Small Sample Dataset. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3365–3375. [Google Scholar] [CrossRef]
- Hong, Z.; Yang, T.; Tong, X.; Zhang, Y.; Jiang, S.; Zhou, R.; Han, Y.; Wang, J.; Yang, S.; Liu, S. Multi-Scale Ship Detection from SAR and Optical Imagery Via A More Accurate YOLOv3. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6083–6101. [Google Scholar] [CrossRef]
- Du, L.; Dai, H.; Wang, Y.; Xie, X.; Wang, Z. Target discrimination based on weakly supervised learning for high-resolution SAR images in complex scenes. IEEE Trans. Geosci. Remote Sens. 2020, 58, 461–472. [Google Scholar] [CrossRef]
- Li, X.; Li, D.; Liu, H.; Wan, J.; Chen, Z.; Liu, Q. A-BFPN: An Attention-Guided Balanced Feature Pyramid Network for SAR Ship Detection. Remote Sens. 2022, 14, 3829. [Google Scholar] [CrossRef]
- Li, S.; Fu, X.; Dong, J. Improved Ship Detection Algorithm Based on YOLOX for SAR Outline Enhancement Image. Remote Sens. 2022, 14, 4070. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Yang, K.; Zou, H. A Bilateral CFAR Algorithm for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2015, 15, 1536–1540. [Google Scholar] [CrossRef]
- Ai, J.; Yang, X.; Song, J.; Dong, Z.; Jia, L.; Zhou, F. An Adaptively Truncated Clutter-Statistics-Based Two-Parameter CFAR Detector in SAR Imagery. IEEE J. Ocean. Eng. 2018, 43, 267–279. [Google Scholar] [CrossRef]
- Dai, H.; Du, L.; Wang, Y.; Wang, Z. A Modified CFAR Algorithm Based on Object Proposals for Ship Target Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1925–1929. [Google Scholar] [CrossRef]
- Li, N.; Pan, X.; Yang, L.; Huang, Z.; Wu, Z.; Zheng, G. Adaptive CFAR Method for SAR Ship Detection Using Intensity and Texture Feature Fusion Attention Contrast Mechanism. Sensors 2022, 22, 8116. [Google Scholar] [CrossRef]
- Li, M.; Cui, X.; Chen, S. Adaptive Superpixel-Level CFAR Detector for SAR Inshore Dense Ship Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4010405. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Tang, G.; Liu, S.; Fujino, I.; Claramunt, C.; Wang, Y.; Men, S. H-YOLO: A Single-Shot Ship Detection Approach Based on Region of Interest Preselected Network. Remote Sens. 2020, 12, 4192. [Google Scholar] [CrossRef]
- Tang, G.; Zhuge, Y.; Claramunt, C.; Men, S. N-YOLO: A SAR Ship Detection Using Noise-Classifying and Complete-Target Extraction. Remote Sens. 2021, 13, 871. [Google Scholar] [CrossRef]
- Xie, F.; Lin, B.; Liu, Y. Research on the Coordinate Attention Mechanism Fuse in a YOLOv5 Deep Learning Detector for the SAR Ship Detection Task. Sensors 2022, 22, 3370. [Google Scholar] [CrossRef]
- Zhu, H.; Xie, Y.; Huang, H.; Jing, C.; Rong, Y.; Wang, C. DB-YOLO: A Duplicate Bilateral YOLO Network for Multi-Scale Ship Detection in SAR Images. Sensors 2021, 21, 8146. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019; pp. 9626–9635. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR Dataset of Ship Detection for Deep Learning under Complex Backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A High-Resolution SAR Images Dataset for Ship Detection and Instance Segmentation. IEEE Access. 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Shi, H.; Fang, Z.; Wang, Y.; Chen, L. An Adaptive Sample Assignment Strategy Based on Feature Enhancement for Ship Detection in SAR Images. Remote Sens. 2022, 14, 2238. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense Attention Pyramid Networks for Multi-Scale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X. Quad-FPN: A Novel Quad Feature Pyramid Network for SAR Ship Detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]
- Zhu, M.; Hu, G.; Li, S.; Zhou, H.; Wang, S.; Feng, Z. A Novel Anchor-Free Method Based on FCOS + ATSS for Ship Detection in SAR Images. Remote Sens. 2022, 14, 2034. [Google Scholar] [CrossRef]
- Wu, Z.; Hou, B.; Ren, B.; Ren, Z.; Wang, S.; Jiao, L. A Deep Detection Network Based on Interaction of Instance Segmentation and Object Detection for SAR Images. Remote Sens. 2021, 13, 2582. [Google Scholar] [CrossRef]
- Wang, R.; Shao, S.; An, M.; Li, J.; Wang, S.; Xu, X. Soft Thresholding Attention Network for Adaptive Feature Denoising in SAR Ship Detection. IEEE Access 2021, 9, 29090–29105. [Google Scholar] [CrossRef]
- Tian, L.; Cao, Y.; He, B.; Zhang, Y.; He, C.; Li, D. Image Enhancement Driven by Object Characteristics and Dense Feature Reuse Network for Ship Target Detection in Remote Sensing Imagery. Remote Sens. 2021, 13, 1327. [Google Scholar] [CrossRef]
- Wei, S.; Su, H.; Ming, J.; Wang, C.; Yan, M.; Kumar, D.; Shi, J.; Zhang, X. Precise and Robust Ship Detection for High-Resolution SAR Imagery Based on HR-SDNet. Remote Sens. 2020, 12, 167. [Google Scholar] [CrossRef]
- Ashish, V.; Noam, S.; Niki, P.; Jakob, U.; Llion, J.; Aidan, N.G.; Lukasz, K.; Illia, P. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chen, K.; Li, J.; Lin, W.; See, J.; Wang, J.; Duan, L.; Chen, Z.; He, C.; Zou, J. Towards Accurate One-Stage Object Detection With AP-Loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5119–5127. [Google Scholar]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and Excitation Rank Faster R-CNN for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 751–755. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baseline | Different Settings of SCSA-Net | |||||
|---|---|---|---|---|---|---|
| Focal loss | √ | √ | ||||
| AP loss | √ | √ | ||||
| GAP loss | √ | √ | ||||
| SCSA | √ | √ | √ | |||
| SSDD | 96.5 | 94.5 | 98.0 | 97.2 | 95.5 | 98.7 |
| SAR-Ship-Dataset | 96.1 | 95.4 | 97.0 | 96.3 | 95.8 | 97.9 |
| HRSID | 92.0 | 89.9 | 94.2 | 93.2 | 90.9 | 95.4 |
| Different Settings of SCSA Module | ||||
|---|---|---|---|---|
| √ | √ | |||
| √ | √ | |||
| SSDD | 98.475 | 98.571 | 98.591 | 98.745 |
| SAR-Ship-Dataset | 97.571 | 97.758 | 97.766 | 97.882 |
| HRSID | 95.046 | 95.203 | 95.230 | 95.392 |
| Methods | AP | |
|---|---|---|
| Two-stage | Faster R-CNN [13] | 90.8 |
| SER Faster R-CNN [40] | 91.5 | |
| ISASDNet+r50 [34] | 95.4 | |
| ISASDNet+r101 [34] | 96.8 | |
| STANet-50+FPN [35] | 95.7 | |
| Mask-RCNN(OCIE-DFR-RFE) [36] | 92.1 | |
| One-stage | ResNet-50+Quad-FPN [32] | 96.6 |
| YOLOV3 (OCIE-DFR-RFE) [36] | 68.8 | |
| ASAFE [30] | 95.2 | |
| A-BFPN [4] | 96.8 | |
| HR-SDNet [37] | 89.4 | |
| Unnamed method * [33] | 98.4 | |
| ours | 98.7 |
| Methods | AP | |
|---|---|---|
| Two-stage | Faster R-CNN [13] | 91.7 |
| SER Faster R-CNN [40] | 92.2 | |
| ISASDNet+r50 [34] | 95.3 | |
| ISASDNet+r101 [34] | 95.8 | |
| One-stage | ResNet-50+Quad-FPN [32] | 94.4 |
| HR-SDNet [37] | 92.3 | |
| ours | 97.9 |
| Methods | AP | |
|---|---|---|
| Two-stage | Faster R-CNN [13] | 80.7 |
| SER Faster R-CNN [40] | 81.5 | |
| One-stage | ResNet-50+Quad-FPN [32] | 90.9 |
| HR-SDNet [37] | 85.9 | |
| ours | 95.4 |
| Backbone (ResNet-50) | FPN | SCSA Module | Class-Box Subnet | Total Param(M) | FPS | |
|---|---|---|---|---|---|---|
| Param(M) | 23.45 | 3.87 | 9.61 | 4.74 | - | - |
| FCOS | √ | √ | √ | 32.06 | 30 | |
| SCSA-Net | √ | √ | √ | √ | 41.67 | 22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Liu, Y.; Qu, L.; Cai, J.; Fang, J. A Spatial Cross-Scale Attention Network and Global Average Accuracy Loss for SAR Ship Detection. Remote Sens. 2023, 15, 350. https://doi.org/10.3390/rs15020350
Zhang L, Liu Y, Qu L, Cai J, Fang J. A Spatial Cross-Scale Attention Network and Global Average Accuracy Loss for SAR Ship Detection. Remote Sensing. 2023; 15(2):350. https://doi.org/10.3390/rs15020350
Chicago/Turabian StyleZhang, Lili, Yuxuan Liu, Lele Qu, Jiannan Cai, and Junpeng Fang. 2023. "A Spatial Cross-Scale Attention Network and Global Average Accuracy Loss for SAR Ship Detection" Remote Sensing 15, no. 2: 350. https://doi.org/10.3390/rs15020350
APA StyleZhang, L., Liu, Y., Qu, L., Cai, J., & Fang, J. (2023). A Spatial Cross-Scale Attention Network and Global Average Accuracy Loss for SAR Ship Detection. Remote Sensing, 15(2), 350. https://doi.org/10.3390/rs15020350