
MSFANet: Multi-Scale Strip Feature Attention Network for Cloud and Cloud Shadow Segmentation



Abstract
:1. Introduction
2. Methodology
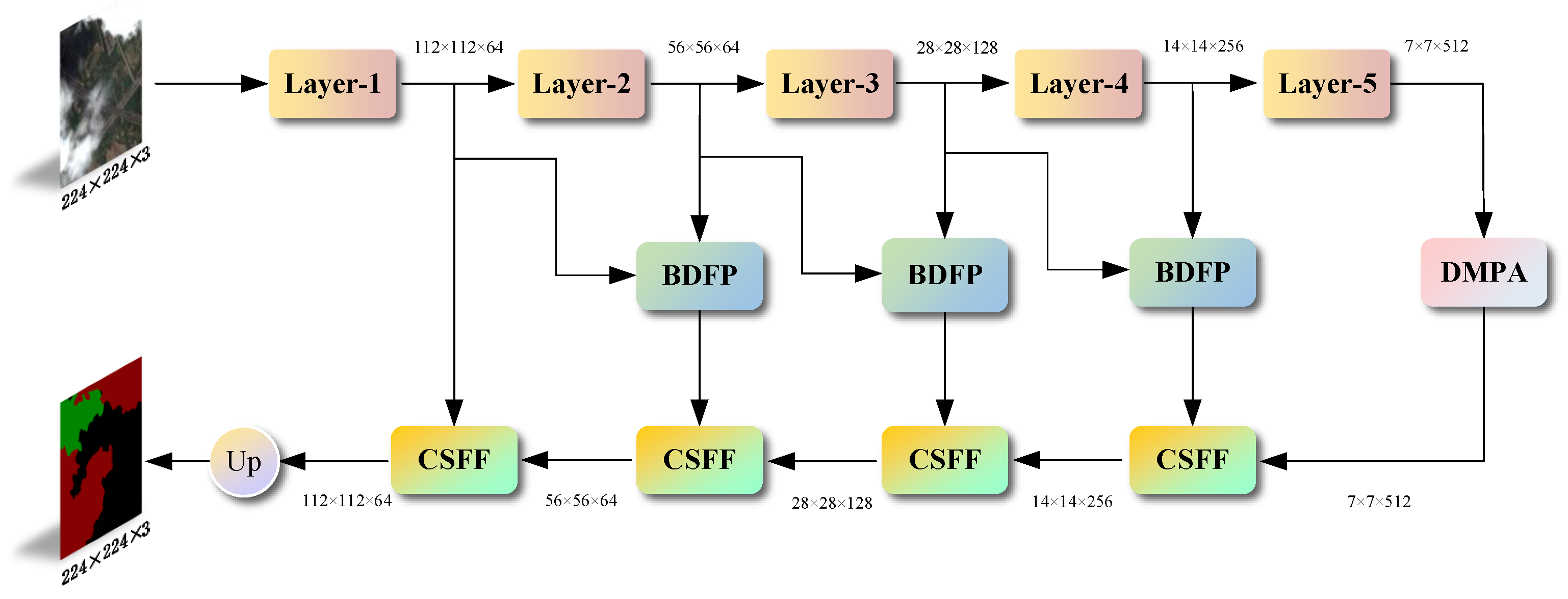
2.1. Network Architecture
2.2. Backbone
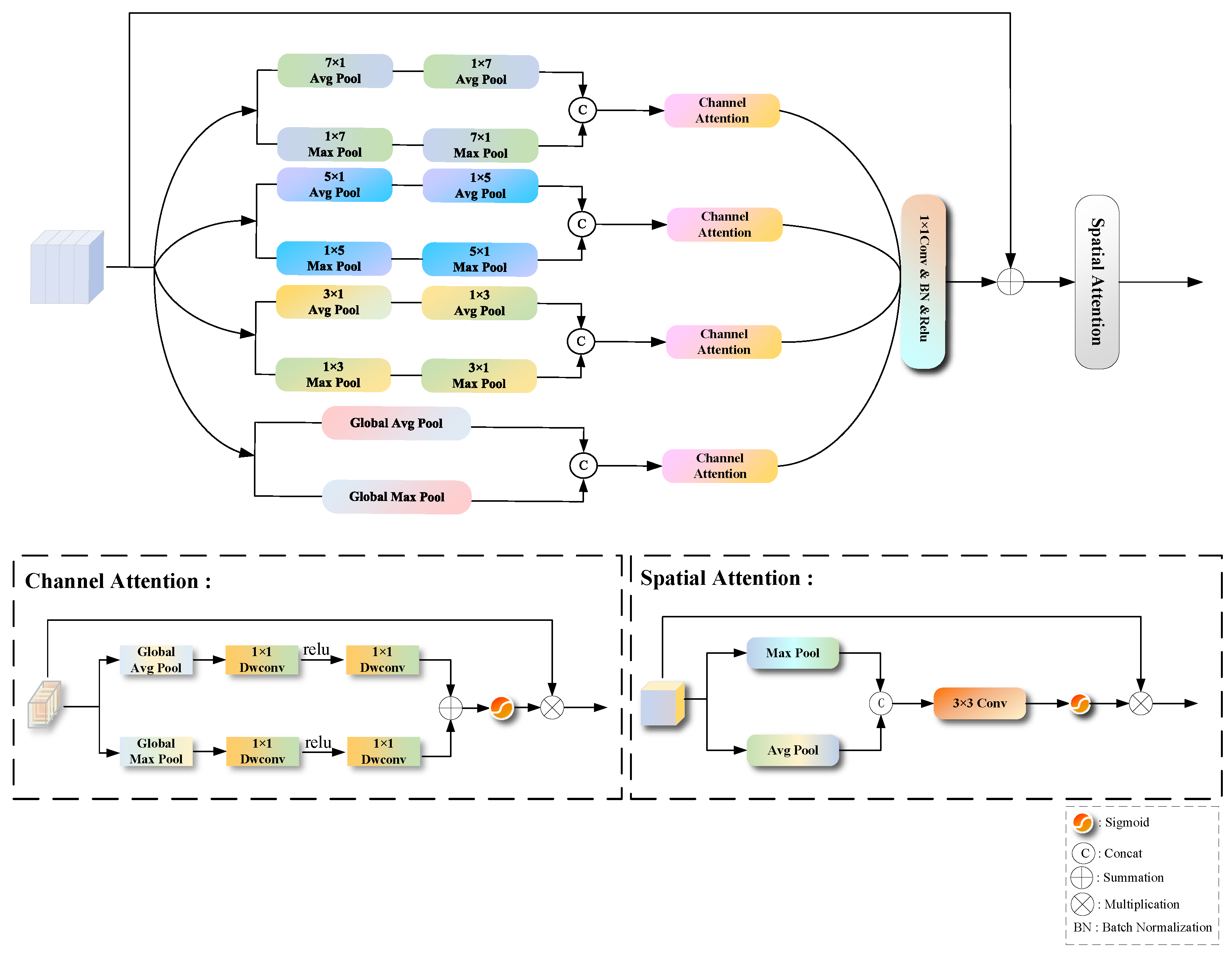
2.3. Deep-Layer Multi-Scale Pooling Attention Module (DMPA)
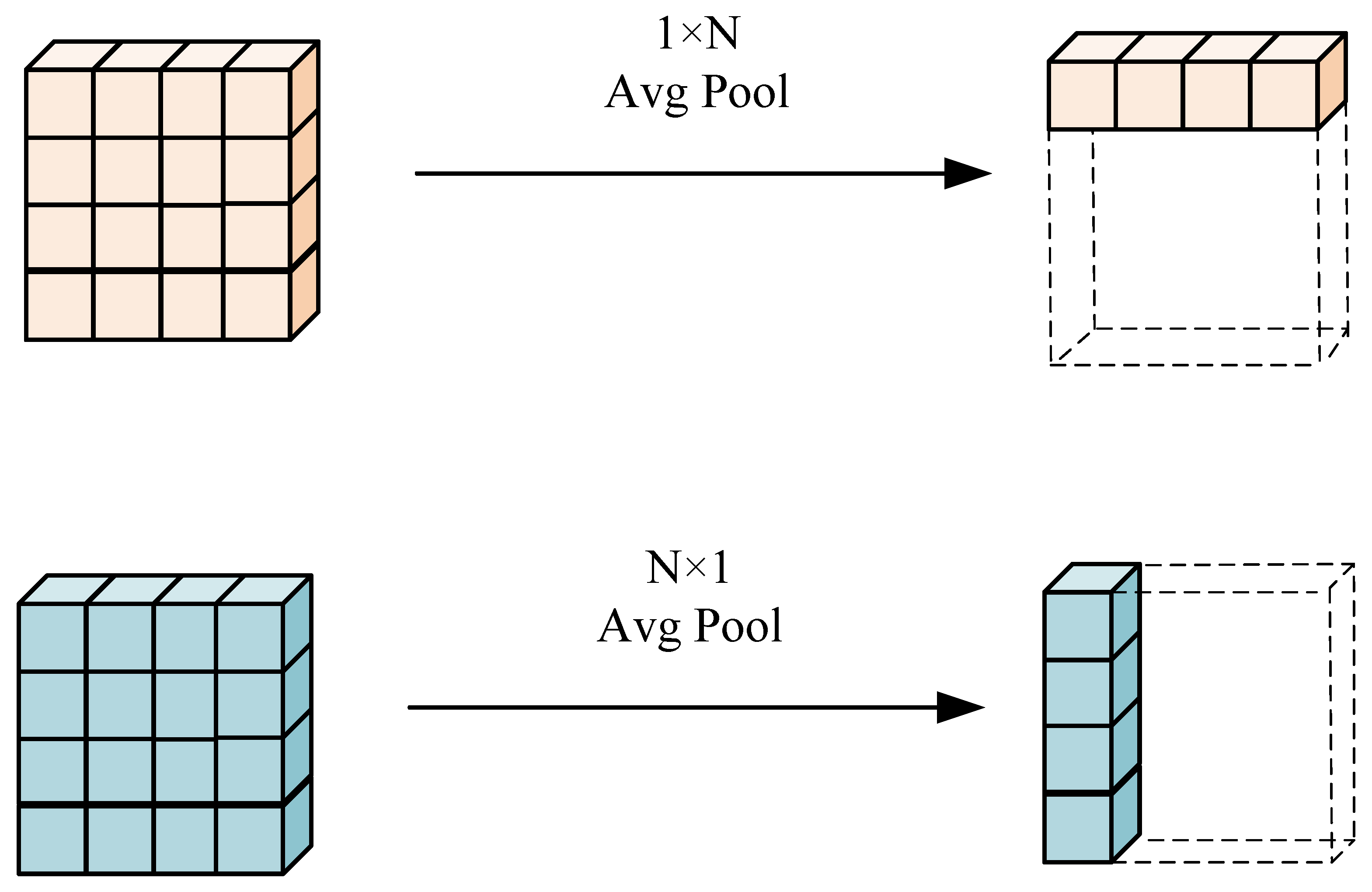
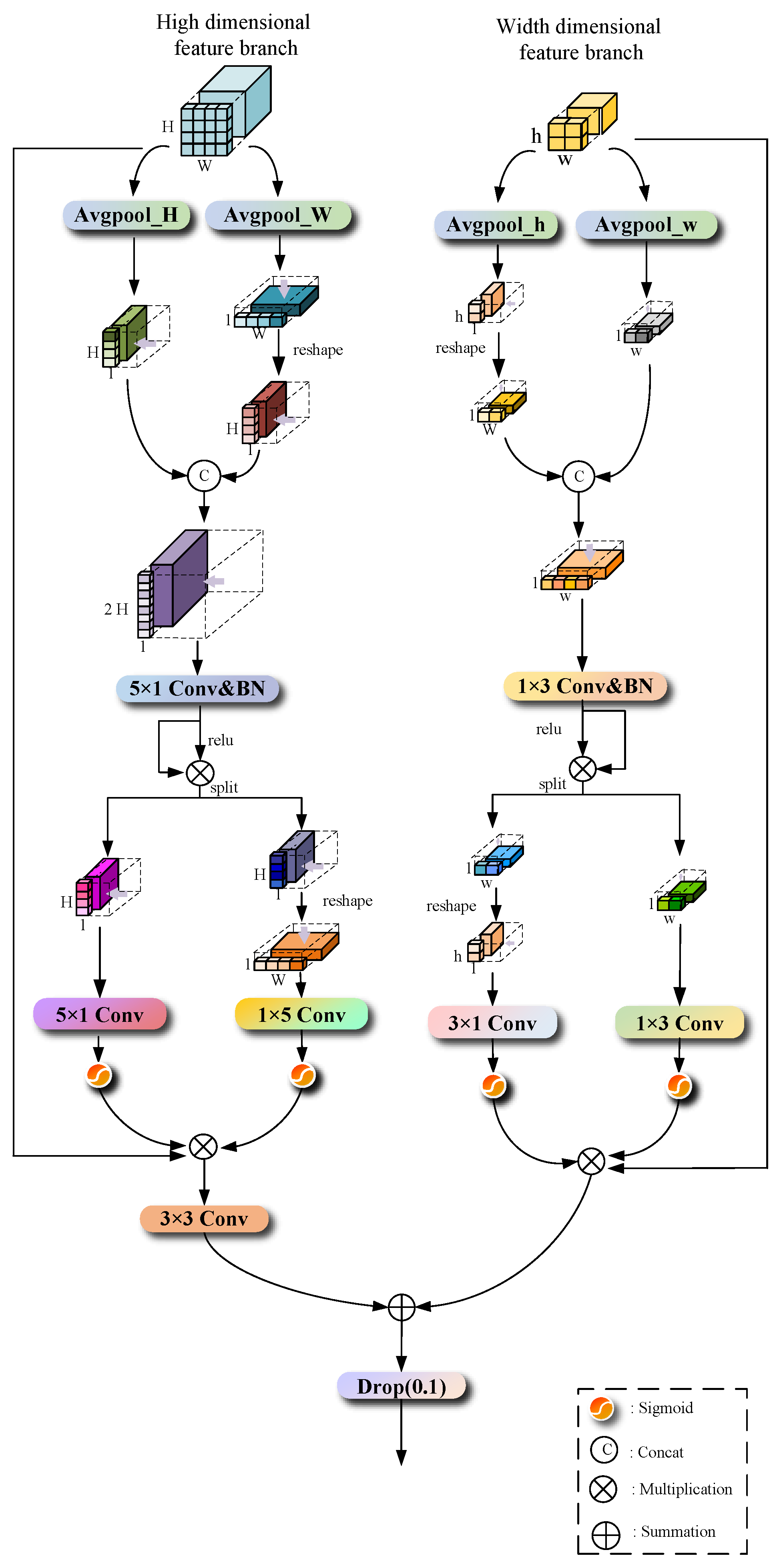
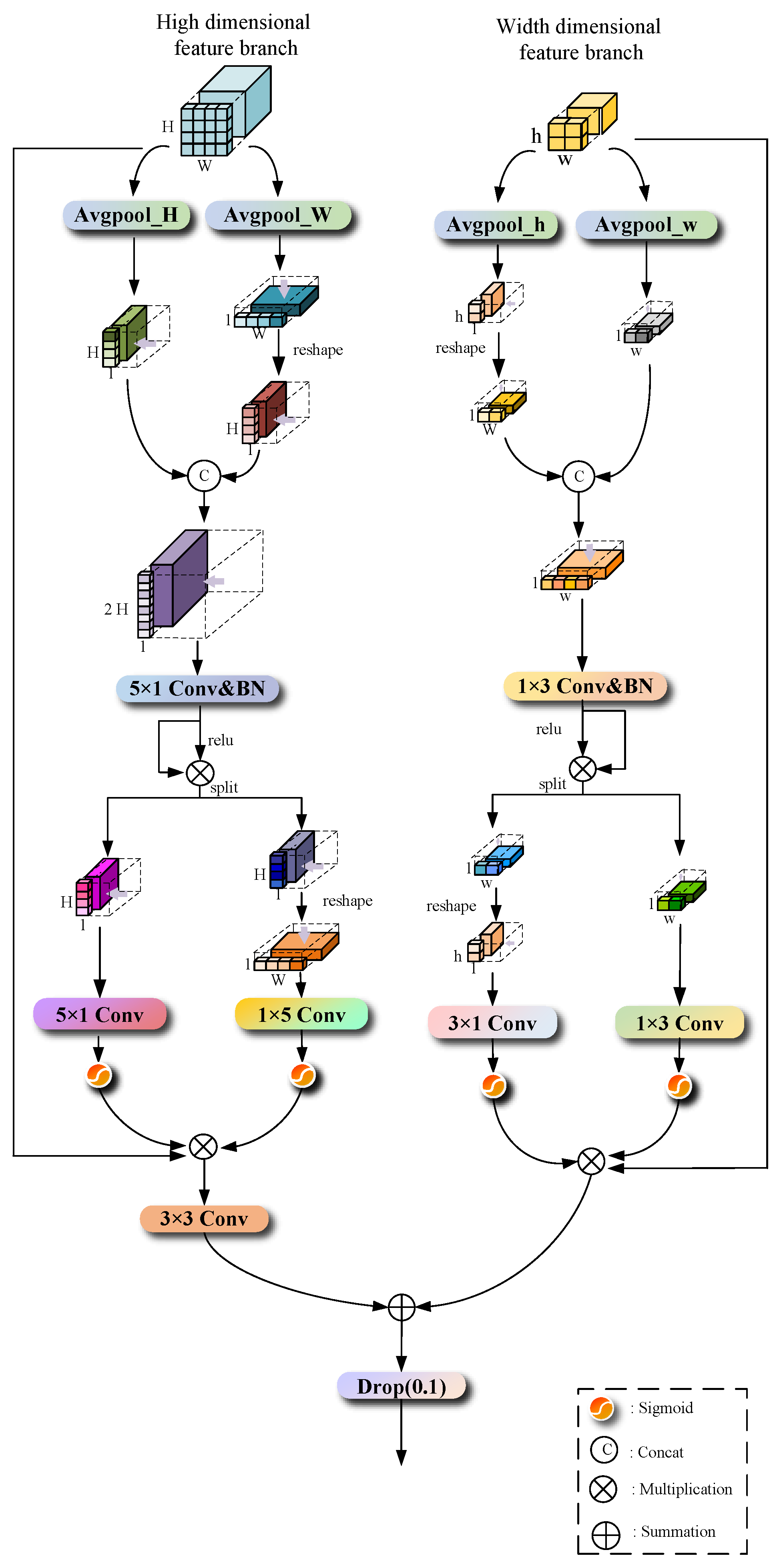
2.4. Boundary Detail Feature Perception Module (BDFP)
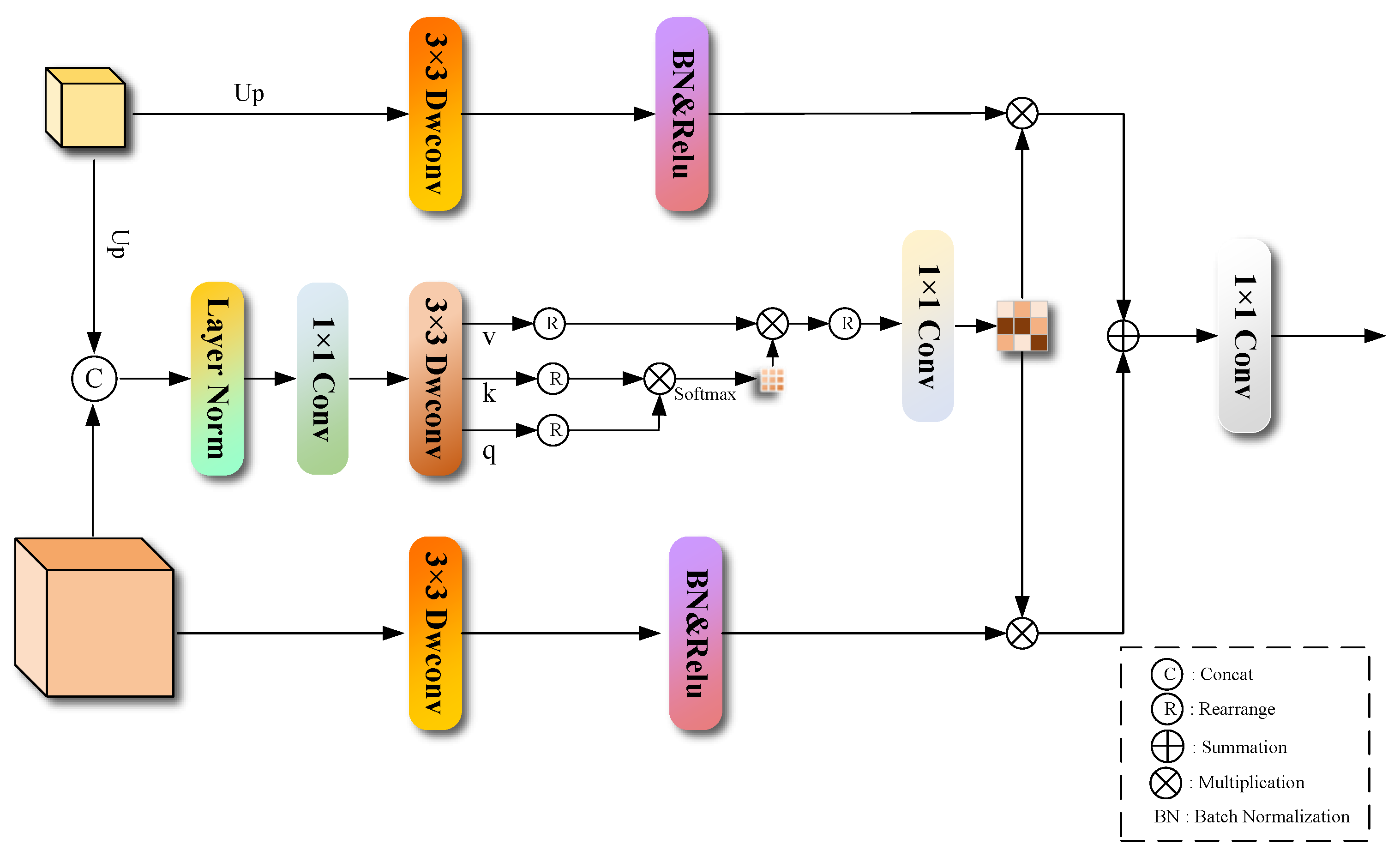
2.5. Cross-Layer Self-Attention Feature Fusion Module (CSFF)
3. Experiment
3.1. Dataset
3.1.1. Cloud and Cloud Shadow Datasets
3.1.2. HRC_WHU Dataset
3.1.3. SPARCS Dataset
3.2. Experimental Details
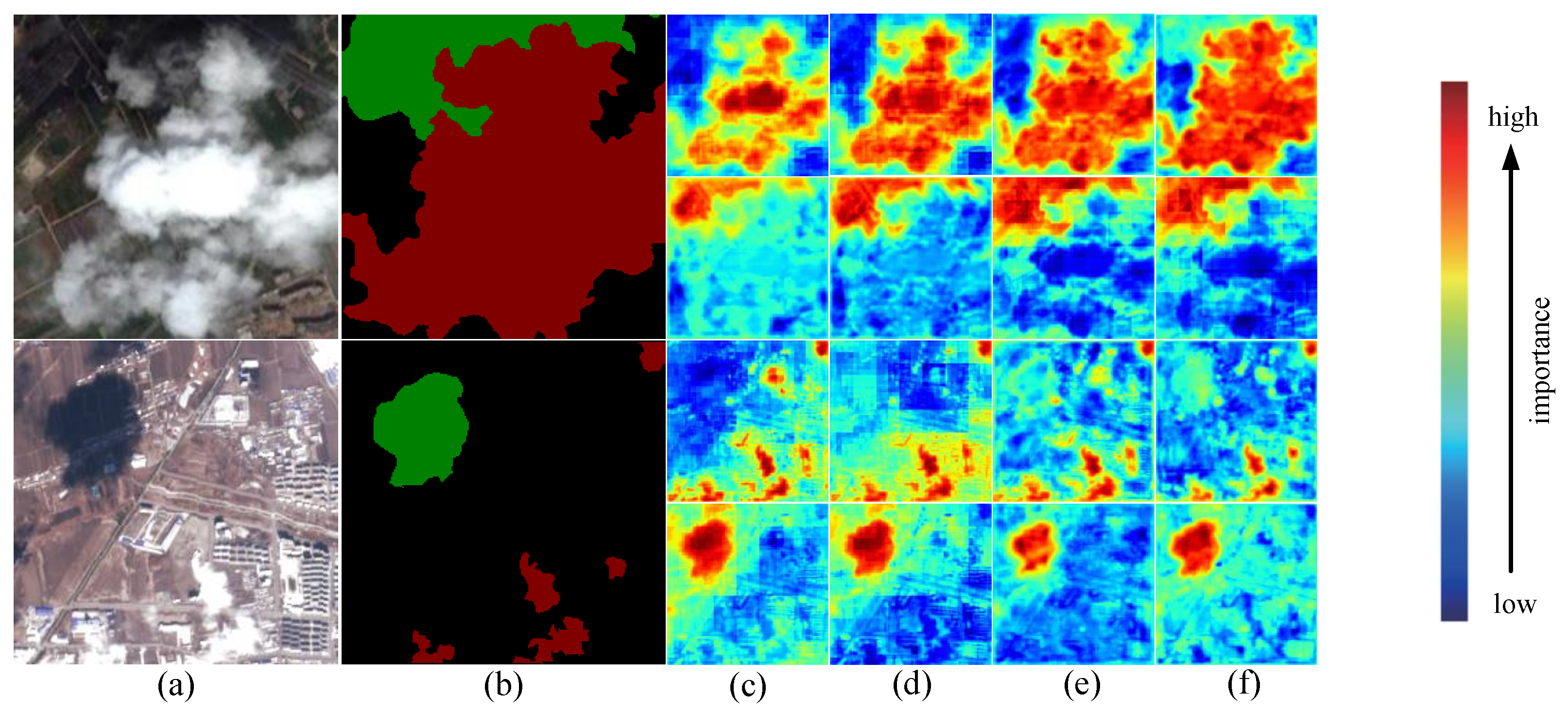
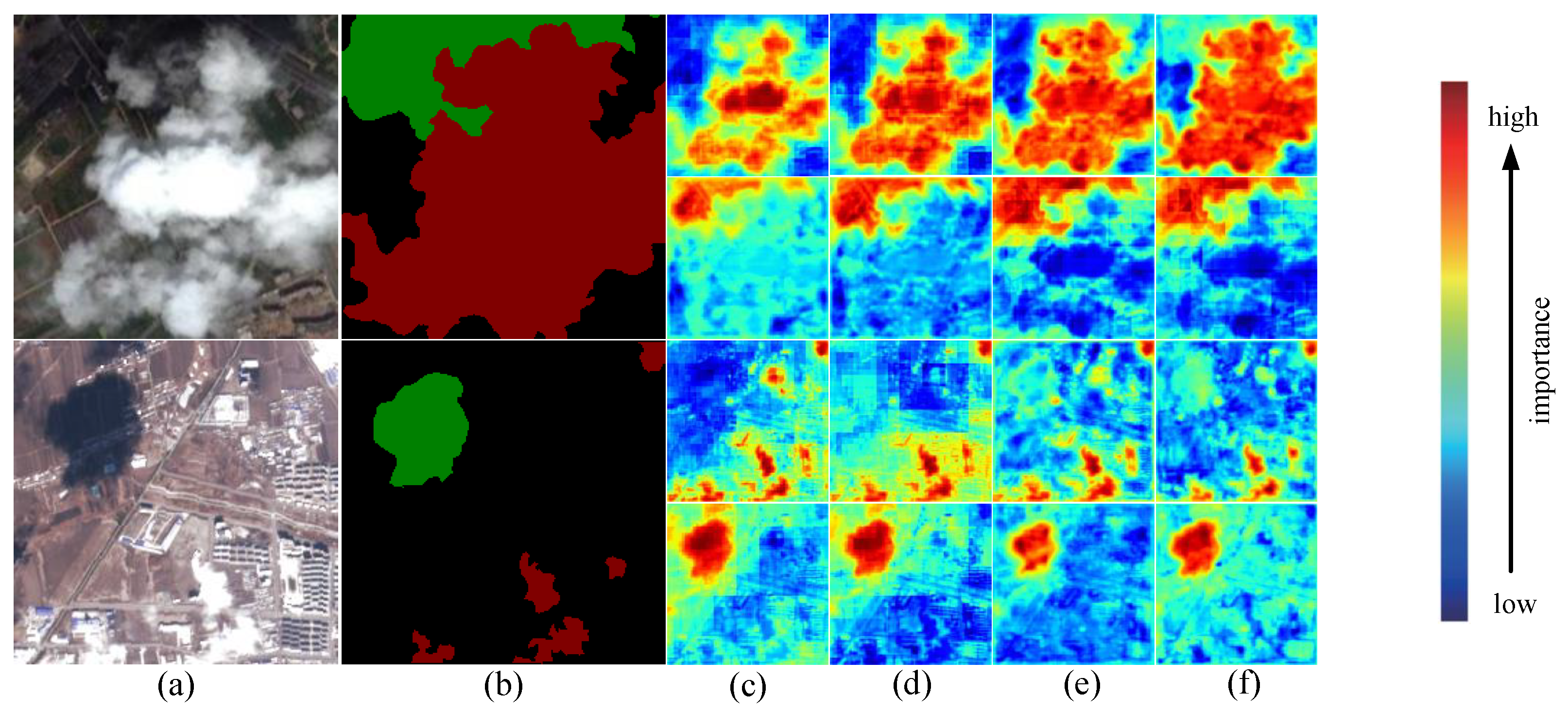
3.3. Ablation Experiment
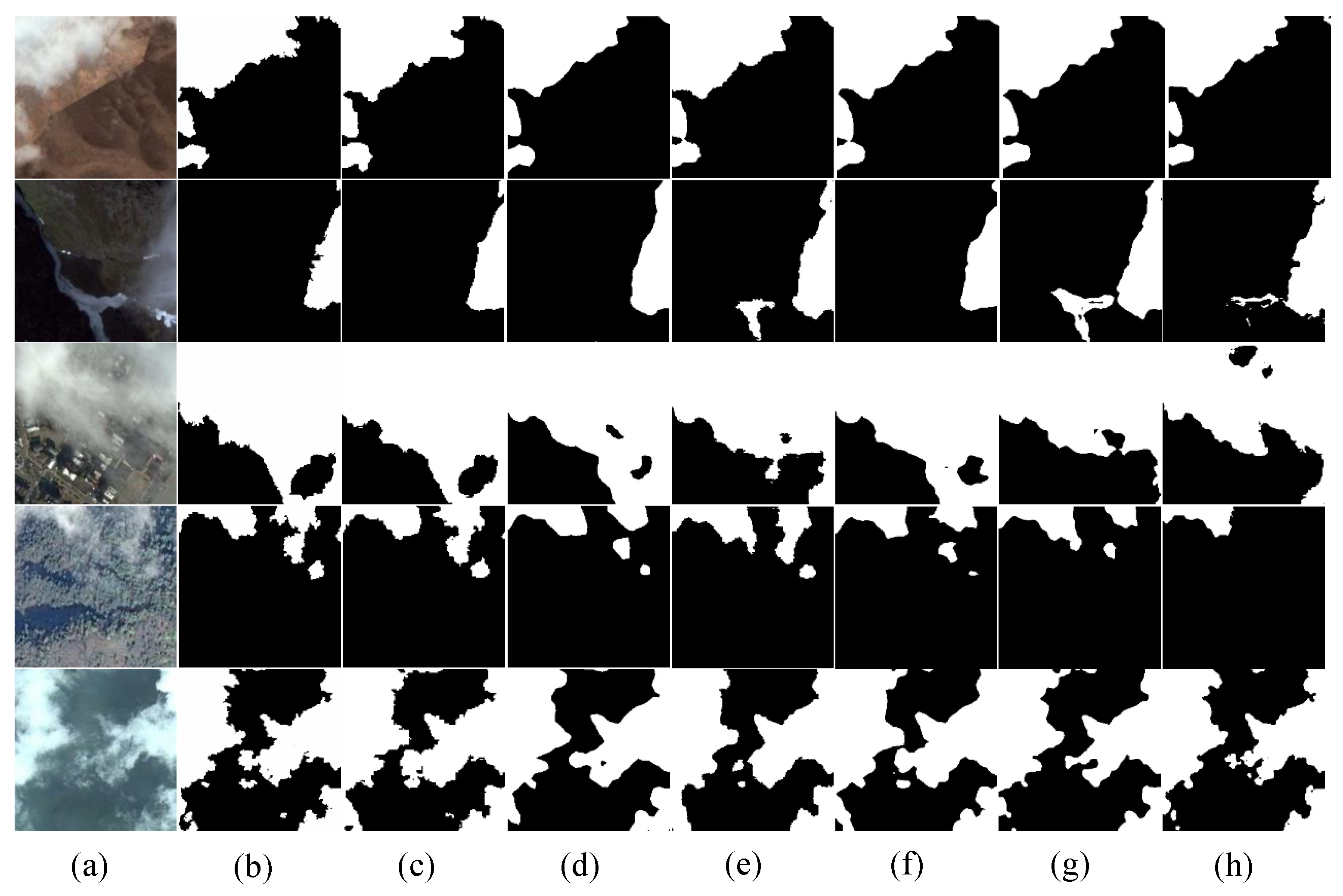
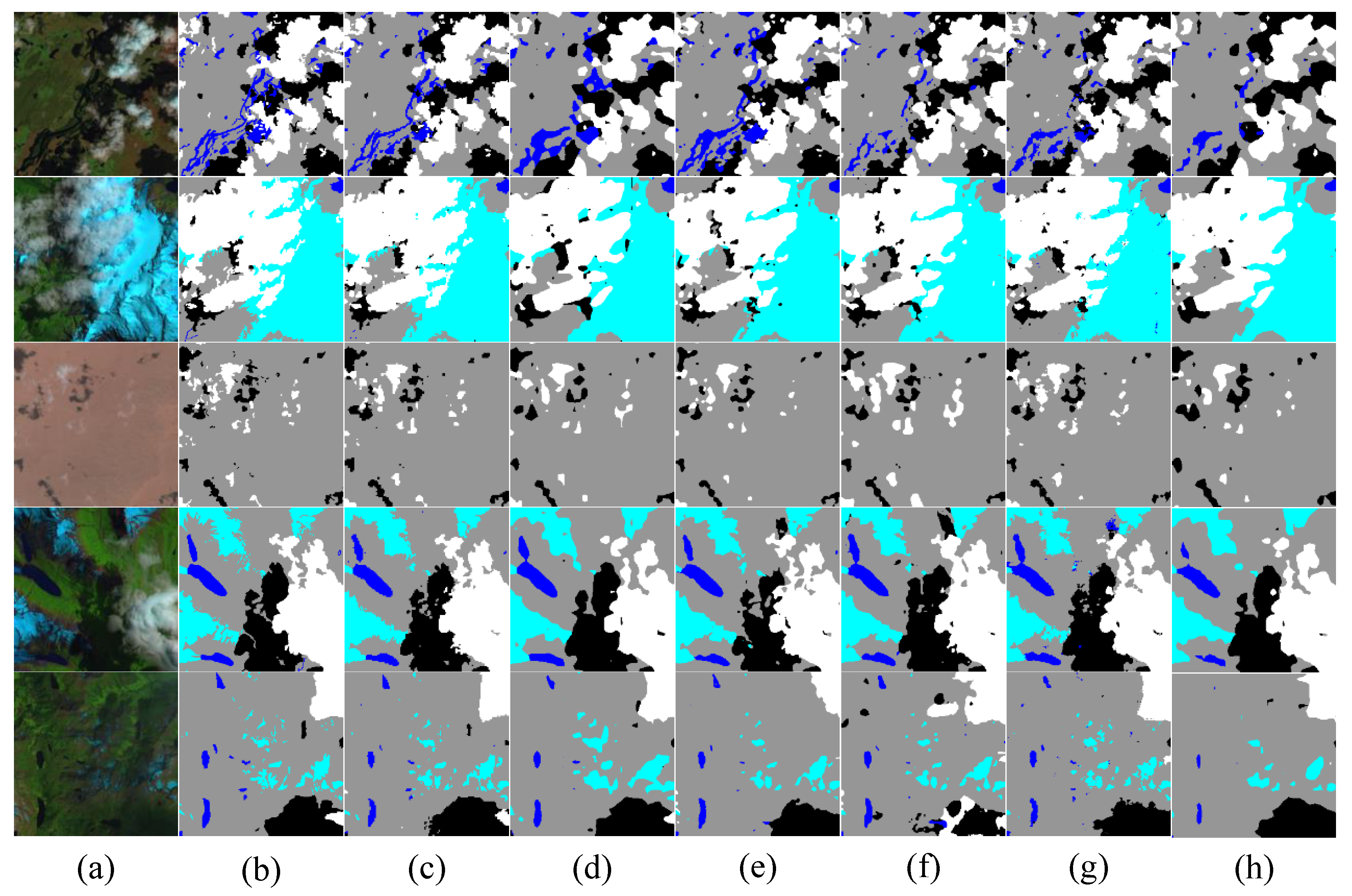
3.4. Comparative Testing of Cloud and Cloud Shadow Datasets
3.5. Generalization Experiment of HRC_WHU Dataset
3.6. Generalization Experiment of SPARCS Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Rossow, W.B.; Lacis, A.A.; Oinas, V.; Mishchenko, M.I. Calculation of radiative fluxes from the surface to top of atmosphere based on ISCCP and other global data sets: Refinements of the radiative transfer model and the input data. J. Geophys. Res. Atmos. 2004, 109, D19. [Google Scholar] [CrossRef]
- Goodman, A.; Henderson-Sellers, A. Cloud detection and analysis: A review of recent progress. Atmos. Res. 1988, 21, 203–228. [Google Scholar] [CrossRef]
- Pankiewicz, G. Pattern recognition techniques for the identification of cloud and cloud systems. Meteorol. Appl. 1995, 2, 257–271. [Google Scholar] [CrossRef]
- Oishi, Y.; Ishida, H.; Nakamura, R. A new Landsat 8 cloud discrimination algorithm using thresholding tests. Int. J. Remote Sens. 2018, 39, 9113–9133. [Google Scholar] [CrossRef]
- Luo, Y.; Trishchenko, A.P.; Khlopenkov, K.V. Developing clear-sky, cloud and cloud shadow mask for producing clear-sky composites at 250-meter spatial resolution for the seven MODIS land bands over Canada and North America. Remote Sens. Environ. 2008, 112, 4167–4185. [Google Scholar] [CrossRef]
- Main-Knorn, M.; Pflug, B.; Louis, J.; Debaecker, V.; Müller-Wilm, U.; Gascon, F. Sen2Cor for sentinel-2. In Proceedings of the Image and Signal Processing for Remote Sensing XXIII. International Society for Optics and Photonics, Warsaw, Poland, 11–13 September 2017; Volume 10427, p. 1042704. [Google Scholar]
- Hutchison, K.D.; Mahoney, R.L.; Vermote, E.F.; Kopp, T.J.; Jackson, J.M.; Sei, A.; Iisager, B.D. A geometry-based approach to identifying cloud shadows in the VIIRS cloud mask algorithm for NPOESS. J. Atmos. Ocean. Technol. 2009, 26, 1388–1397. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Ji, H.; Xia, M.; Zhang, D.; Lin, H. Multi-Supervised Feature Fusion Attention Network for Clouds and Shadows Detection. ISPRS Int. J. Geo-Inf. 2023, 12, 247. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhang, X.; Yu, W.; Pun, M.O. Multilevel deformable attention-aggregated networks for change detection in bitemporal remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4003–4012. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Zhang, Y.; Guindon, B.; Cihlar, J. An image transform to characterize and compensate for spatial variations in thin cloud contamination of Landsat images. Remote Sens. Environ. 2002, 82, 173–187. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for remote sensing images by the fusion of multi-scale convolutional features. arXiv 2018, arXiv:1810.05801. [Google Scholar]
- Hughes, M.J.; Hayes, D.J. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef]
- Hughes, M. L8 SPARCS Cloud Validation Masks; US Geological Survey: Sioux Falls, SD, USA, 2016.
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. 2017. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 14 August 2023).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Qu, Y.; Xia, M.; Zhang, Y. Strip pooling channel spatial attention network for the segmentation of cloud and cloud shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- Xia, M.; Qu, Y.; Lin, H. PANDA: Parallel asymmetric network with double attention for cloud and its shadow detection. J. Appl. Remote Sens. 2021, 15, 046512. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, D.; Xia, M.; Qian, M.; Chen, B. LCDNet: Light-Weighted Cloud Detection Network for High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4809–4823. [Google Scholar] [CrossRef]
- Xia, M.; Wang, T.; Zhang, Y.; Liu, J.; Xu, Y. Cloud/shadow segmentation based on global attention feature fusion residual network for remote sensing imagery. Int. J. Remote Sens. 2021, 42, 2022–2045. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3684–3692. [Google Scholar]
- Pang, K.; Weng, L.; Zhang, Y.; Liu, J.; Lin, H.; Xia, M. SGBNet: An ultra light-weight network for real-time semantic segmentation of land cover. Int. J. Remote Sens. 2022, 43, 5917–5939. [Google Scholar] [CrossRef]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Zhang, L.; Zhang, L. Artificial intelligence for remote sensing data analysis: A review of challenges and opportunities. IEEE Geosci. Remote Sens. Mag. 2022, 10, 270–294. [Google Scholar] [CrossRef]
- Estes, J.E.; Sailer, C.; Tinney, L.R. Applications of artificial intelligence techniques to remote sensing. Prof. Geogr. 1986, 38, 133–141. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Background | South to North | West to East |
|---|---|---|
| Water | 30°53′4.48″N to 31°35′46.19″N | 119°47′34.52″E to 120°49′43.81″E |
| Water, City | 31°20′1.32″N to 31°46′25.27″N | 117°27′46.75″E to 117°58′1.24″E |
| City | 32°19′56.28″N to 33°26′13.11″N | 120°28′46.49″E to 121°38′22.05″E |
| Vegetation | 26°47′38.87″N to 27°58′2.12″N | 107°19′35.11″E to 109°32′55.19″E |
| Wasteland | 29°52′53.25″N to 30°45′46.22″N | 88°10′12.45″E to 89°18′10.76″E |
| Wasteland | 41°2′27.26″N to 41°52′47.26″N | 91°54′25.23″E to 92°3′53.14″E |
| Methods | MIoU (%) |
|---|---|
| ResNet18 | 92.34 |
| Resnet18 + BDFP | 92.55 |
| Resnet18 + BDFP + CSFF | 93.20 |
| Resnet18 + BDFP + CSFF + DMPA | 93.70 |
| Methods | PA(%) | MPA(%) | F1(%) | FWIoU(%) | MIoU(%) | Time(ms) |
|---|---|---|---|---|---|---|
| Swin_Transformer [30] | 96.10 | 95.33 | 92.97 | 92.53 | 90.93 | 16.98 |
| UNet [12] | 96.13 | 95.53 | 92.92 | 92.57 | 90.96 | 3.26 |
| DenseAspp [31] | 96.22 | 95.13 | 93.37 | 92.76 | 91.21 | 15.03 |
| DeepLabv3plus [14] | 96.32 | 95.65 | 93.33 | 92.92 | 91.41 | 9.50 |
| SGBNet [32] | 96.39 | 95.44 | 93.53 | 93.06 | 91.51 | 7.93 |
| PADANet [27] | 96.44 | 95.55 | 93.63 | 93.16 | 91.66 | 9.45 |
| FCN8s [11] | 96.46 | 95.51 | 93.71 | 93.21 | 91.71 | 2.97 |
| SP_CSANet [26] | 96.48 | 95.61 | 93.70 | 93.24 | 91.76 | 16.45 |
| BiseNetv2 [33] | 96.55 | 96.07 | 93.66 | 93.34 | 91.92 | 7.29 |
| PVT [34] | 96.60 | 95.64 | 93.49 | 93.46 | 92.00 | 12.83 |
| LCDNet [28] | 96.67 | 96.04 | 93.96 | 93.58 | 92.19 | 6.35 |
| CloudNet [29] | 96.69 | 96.11 | 93.99 | 93.61 | 92.24 | 5.21 |
| ENet [35] | 96.74 | 95.84 | 94.05 | 93.72 | 92.33 | 1.69 |
| PSPNet [13] | 96.80 | 96.45 | 94.06 | 93.80 | 92.47 | 7.96 |
| MSFANet | 97.34 | 96.84 | 95.15 | 94.83 | 93.70 | 2.55 |
| 97.04 | 96.46 | 94.67 | 94.28 | 93.07 | 2.97 | |
| 97.12 | 96.55 | 94.79 | 94.42 | 93.22 | 7.96 | |
| 97.74 | 97.34 | 95.88 | 95.59 | 94.65 | 2.55 |
| Methods | PA(%) | MPA(%) | F1(%) | FWIoU(%) | MIoU(%) |
|---|---|---|---|---|---|
| FCN8s | 93.30 | 93.03 | 89.98 | 87.48 | 87.06 |
| Swin_Transformer | 93.64 | 93.06 | 90.55 | 88.11 | 87.59 |
| UNet | 93.95 | 93.85 | 90.89 | 88.60 | 88.27 |
| PVT | 94.23 | 93.96 | 91.32 | 89.11 | 88.73 |
| DeepLabv3plus | 94.33 | 94.05 | 91.48 | 89.23 | 88.92 |
| SGBNet | 94.32 | 94.30 | 91.41 | 89.25 | 88.96 |
| LCDNet | 94.51 | 94.36 | 91.71 | 89.59 | 89.27 |
| DenseAspp | 94.53 | 94.44 | 91.74 | 89.64 | 89.33 |
| CloudNet | 94.61 | 94.40 | 91.88 | 89.79 | 89.45 |
| BiseNetv2 | 94.64 | 94.60 | 91.88 | 89.82 | 89.53 |
| ENet | 94.66 | 94.63 | 91.91 | 89.86 | 89.57 |
| SP_CSANet | 94.72 | 94.53 | 92.03 | 89.98 | 89.65 |
| PADANet | 94.73 | 94.56 | 92.05 | 90.01 | 89.69 |
| PSPNet | 94.74 | 94.66 | 92.02 | 89.99 | 89.70 |
| MSFANet | 95.35 | 95.25 | 92.95 | 91.12 | 90.85 |
| ine | 93.93 | 93.90 | 90.85 | 88.56 | 88.24 |
| 95.09 | 94.83 | 92.45 | 90.54 | 90.29 | |
| 95.75 | 95.52 | 93.70 | 91.87 | 91.55 |
| Methods | PA(%) | MPA(%) | F1(%) | FWIoU(%) | MIoU(%) |
|---|---|---|---|---|---|
| SGBNet | 89.50 | 82.15 | 78.89 | 81.92 | 73.42 |
| DenseAspp | 90.22 | 81.42 | 80.74 | 83.61 | 74.69 |
| BiseNetv2 | 90.44 | 83.98 | 80.64 | 83.30 | 75.49 |
| ENet | 91.36 | 86.22 | 81.87 | 84.74 | 77.46 |
| DeepLabv3plus | 91.30 | 86.09 | 82.39 | 84.56 | 77.75 |
| Swin_Transformer | 91.63 | 87.23 | 82.07 | 85.00 | 77.79 |
| PSPNet | 91.67 | 85.90 | 82.93 | 85.21 | 77.96 |
| PADANet | 91.57 | 85.55 | 82.95 | 85.15 | 78.02 |
| PVT | 92.02 | 88.02 | 83.76 | 85.74 | 79.65 |
| CloudNet | 92.42 | 86.90 | 84.43 | 86.41 | 79.67 |
| LCDNet | 92.29 | 88.18 | 83.94 | 86.14 | 79.86 |
| FCN8s | 92.33 | 87.48 | 84.31 | 86.32 | 79.95 |
| SP_CSANet | 92.74 | 87.27 | 84.67 | 86.98 | 80.10 |
| UNet | 92.59 | 88.04 | 84.77 | 86.73 | 80.51 |
| MSFANet | 92.84 | 88.94 | 85.62 | 87.07 | 81.66 |
| 91.91 | 86.06 | 83.50 | 85.58 | 78.48 | |
| 92.50 | 87.58 | 84.59 | 86.63 | 80.29 | |
| 93.17 | 89.35 | 86.07 | 87.57 | 82.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, K.; Dai, X.; Xia, M.; Weng, L.; Hu, K.; Lin, H. MSFANet: Multi-Scale Strip Feature Attention Network for Cloud and Cloud Shadow Segmentation. Remote Sens. 2023, 15, 4853. https://doi.org/10.3390/rs15194853
Chen K, Dai X, Xia M, Weng L, Hu K, Lin H. MSFANet: Multi-Scale Strip Feature Attention Network for Cloud and Cloud Shadow Segmentation. Remote Sensing. 2023; 15(19):4853. https://doi.org/10.3390/rs15194853
Chicago/Turabian StyleChen, Kai, Xin Dai, Min Xia, Liguo Weng, Kai Hu, and Haifeng Lin. 2023. "MSFANet: Multi-Scale Strip Feature Attention Network for Cloud and Cloud Shadow Segmentation" Remote Sensing 15, no. 19: 4853. https://doi.org/10.3390/rs15194853
APA StyleChen, K., Dai, X., Xia, M., Weng, L., Hu, K., & Lin, H. (2023). MSFANet: Multi-Scale Strip Feature Attention Network for Cloud and Cloud Shadow Segmentation. Remote Sensing, 15(19), 4853. https://doi.org/10.3390/rs15194853