1. Introduction
Semantic segmentation of large-scale point cloud scenes is a crucial task in 3D computer vision, serving as the core capability for machines to comprehend the 3D world. It has found extensive applications in autonomous driving [
1,
2], robotics [
3,
4], and augmented reality [
5,
6]. In particular, deep learning has made striking breakthroughs in computer vision over the past few years. Enabling reliable semantic parsing of point cloud data using deep neural networks has become an emerging hot research direction and attracted wide interest [
7]. Unlike 2D images, 3D point clouds are intrinsically sparse and irregularly scattered in a continuous 3D space. They are unstructured in nature and often at a massive scale. These unique properties impose difficulties in directly adopting convolution operations, which have been the mainstay for 2D image analysis [
8,
9]. In recent years, convolutional networks (CNNs) [
10,
11,
12] and Transformer [
13,
14,
15] architectures have led to striking advances in semantic parsing of 2D visual data. However, efficiently learning discriminative representations from disordered 3D point sets using deep neural networks, especially at large-scale indoor scenes, remains a challenging open problem.
Abundant methods have explored the comprehension of 3D point clouds and obtained decent performance. In order to leverage convolutional neural networks (CNNs) for point cloud analysis, one category of approaches [
16,
17,
18,
19] first transforms the 3D points into discrete representations such as voxels, before applying CNN models to extract high-dimensional features. Another line of work [
9,
20,
21,
22,
23], pioneered by PointNet [
8], directly processes points in the native continuous space. Through alternating steps of grouping and aggregation, PointNet-style models are able to capture multi-scale contextual information from unordered 3D point sets. However, most of these existing methods concentrate on aggregating local feature representations but do not explicitly model long-range dependencies, which have been shown to be vital for capturing contextual information from distant spatial locations [
24].
Transformers [
25] based on self-attention come naturally with the ability to model long-range dependencies, and the permutation and cardinality invariance of self-attention in Transformers make them inherently suitable for point cloud processing. Recently, inspired by the transformer’s remarkable success [
13,
14,
15,
26,
27,
28] in the 2D image domain, a number of studies [
29,
30,
31,
32] have investigated adapting Transformer architectures to process unstructured 3D point sets. Engel et al. [
29] proposed a kind of point transformer algorithm, which incorporates standard self-attention to extract global features for capturing point relationships and shape information in the 3D space. Guo et al. [
31] presented offset-attention that computes the offset difference between self-attention features and input features in an element-wise manner. Concurrently, a spectrum of scholars have explored embedding self-attention modules in diverse point cloud tasks, witnessing noteworthy successes as showcased in works like [
30,
33]. Despite the promising advancements in point cloud transformers, a clear limitation persists. These models need to generate expansive attention maps due to the use of conventional self-attention mechanisms, placing a high computational complexity (quadratic) and consuming a huge number of GPU memory. This methodology, while rigorous, becomes implausible when scaling up to expansive 3D point cloud datasets, thereby hindering large-scale modeling pursuits.
Furthermore, in an effort to aggregate localized neighborhood information from point clouds, Zhao et al. [
30] introduced another kind of point transformer algorithm, which establishes local vector attention within neighboring point sets. Guo et al. [
31] proposed the use of neighbor embedding strategies to enhance point embedding. The PointSwin, as presented by Jiang et al. [
34], employs self-attention based on a sliding window to capture local details from point clouds. While the two point transformers, PCT and the PointSwin, have achieved significant advancements, certain challenges continue to hinder their efficiency and performance. These methods fall short of establishing attention across features of different scales, which is crucial for 3D visual tasks [
35]. For instance, a large indoor scene often encompasses both smaller instances (such as chairs and lamps) and larger objects (like tables). Recognizing and understanding the relationships between these entities necessitates a multi-scale attention mechanism. Moreover, when delving into large-scale scene point clouds, an optimal blend of both coarse-grained and fine-grained features becomes pivotal [
36]. Coarse-grained features present a bird’s eye view, providing a general overview of the scene, whereas fine-grained ones are key in identifying and interpreting small details. Integrating both these feature dimensions can significantly amplify the potential and accuracy of point cloud semantic segmentation, particularly in heterogeneous and complex scenarios.
In addressing the challenges discussed previously, we present a novel dual-branch block named the Regional-to-Local Point-Voxel Transformer Block (R2L Point-Voxel Transformer Block), specifically engineered for the semantic segmentation of large-scale indoor point cloud scenes. This block is designed to effectively capture both coarse-grained regional and fine-grained local features within large-scale indoor point cloud senses with linear computational complexity. Our method has two key components, including a voxel-based regional self-attention for coarse-grained features modeling and a window-based point-voxel self-attention for fine-grained features learning and multi-scale feature fusion. More specifically, we first spatially partition the raw point clouds into non-overlapping cubes, termed “windows”, following the concept similar to that of the Swin Transformer [
14]. Then, we voxelize the point clouds using a window size unit and establish a hash table [
37] between the points and voxels. Voxel-based regional self-attention is subsequently applied among the nearest neighboring voxels to obtain coarse-grained features. Finally, the aggregated voxels serving as special “points” participate in the window-based point-voxel self-attention with their corresponding points to obtain fine-grained features. The voxel-based regional self-attention achieves information interaction between different windows while aggregating voxel features. Meanwhile, the window-based point-voxel self-attention not only focuses on learning fine-grained local features, but also captures high-level voxel information, enabling multi-scale feature fusion by treating voxels as specialized points.
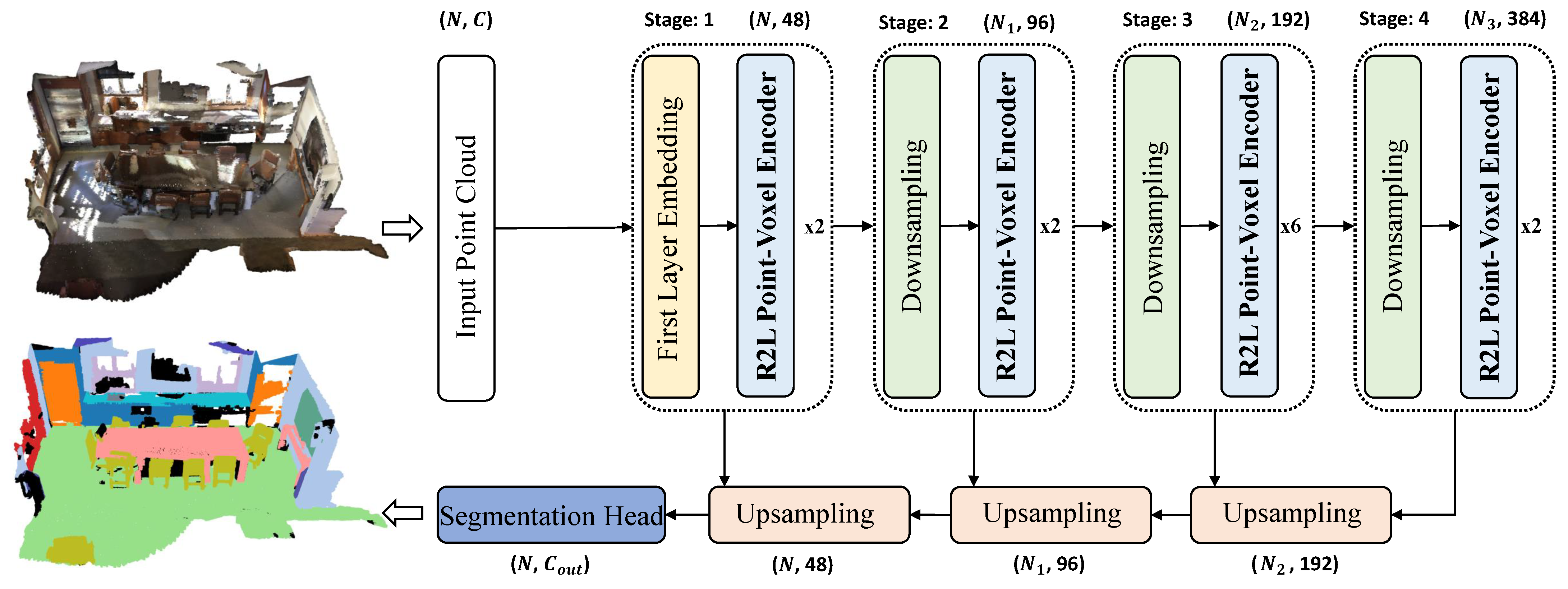
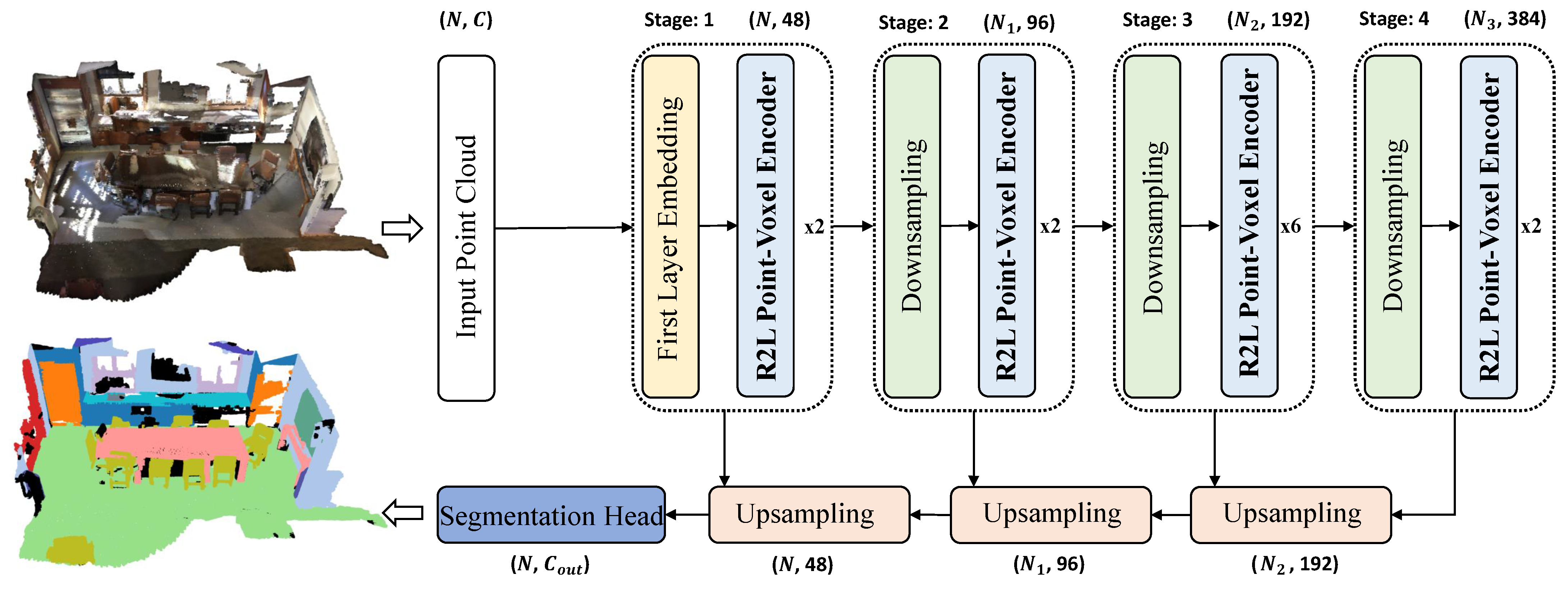
Building upon the R2L Point-Voxel Transformer Block, we propose a network for large-scale indoor point cloud semantic segmentation, named RegionPVT (Regional-to-Local Point-Voxel Transformer), as depicted in
Figure 1. We conducted experiments on two publicly available large-scale indoor point cloud scene datasets, S3DIS [
38] and ScanNet v2 [
39]. Our results are not only competitive with but also surpass state-of-the-art benchmarks, achieving mIoUs of 71.0% and 73.6% respectively. Compared to our baseline, Swin3d (without shifted window) [
40], there is a 1.6 percentage point enhancement of mIoU on the S3DIS dataset. Additionally, in comparison to voxel-based approaches (Fast Point Transformer [
32], MinkowskiNet [
19]), we observed mIoU improvements of 0.9 and 5.6 percentage points, respectively. In the subsequent sections, we delve deeper into the details of our proposed large-scale indoor point cloud semantic segmentation network.
3. Material and Methods
In this section, we first briefly introduce the datasets used for the evaluation of our proposed model in
Section 3.1. Then, we present the detailed network architecture of our model in
Section 3.2. Subsequently, we describe the baselines and evaluation metrics employed in our experiments in
Section 3.3. Finally, we present the implementation details of our approach in
Section 3.4.
3.1. Datasets
We conducted experiments and evaluations of our proposed method on two publicly available indoor point cloud datasets: S3DIS [
38] and ScanNet v2 [
39]. Both datasets are large-scale because they occupy a large 3D space and include a large number of sample points.
S3DIS. The S3DIS dataset [
38], commonly used for point cloud semantic segmentation, consists of 271 room scans across 6 areas from 3 buildings, covering approximately 6020 square meters in total. The spaces exhibit varying functionalities, architectures, and interior designs, primarily including offices, corridors, and restrooms. Each room contains 0.5–2.5 million points. The points are annotated with semantic labels from 13 categories (
Table 1) and have 3D coordinates and color attributes. Following previous works [
22,
30,
41,
43], we used Areas 1, 2, 3, 4, and 6 for training, and Area 5 for evaluation. Our method was tested on Area 5.
ScanNet V2. We used the second official version of ScanNet [
39], comprising 1513 room scans. Some rooms were captured by different sensors, resulting in point clouds with per-point semantic labels from 20 categories (
Table 2). Following common practices [
20,
22,
41,
53], our model employed per-point coordinate and RGB color as input features for this 20-class 3D semantic segmentation task. We used 1201 samples to train our model and set aside 312 samples to validate its performance. The prediction results for the official test set, which had a sample size of 100 with all semantic labels publicly unavailable, were obtained from the model that performed the best on the validation set and were ultimately submitted to the officials for the test results due to the strict submission of ScanNet online test benchmark, where each method can be only tested once.
3.2. Methods
The 3D indoor scene semantic segmentation network we propose, titled Regional-to-Local Point-Voxel Transformer (RegionPVT), fundamentally adopts a pyramid U-Net architecture comprising an encoder and a decoder, as depicted in
Figure 1. This architecture encompasses an initial point embedding layer, a Regional-to-Local Point-Voxel Transformer Encoder Block (R2L Point-Voxel Transformer Encoder Block), a tokenization module for both points and voxels and modules for both downsampling and upsampling. Specifically, for the initial point embedding, we employ KPConv [
41] to extract the local spatial features of the points. Within the point and voxel tokenization module, we first partition the point cloud scene spatially into non-overlapping cubic regions. Each cube is treated as a window, with every point within it regarded as a local token for the window-based point-voxel self-attention computation. For voxel tokenization, each window is considered as a voxel, and points within are voxelized. As network depth increases, to balance the computational consumption and achieve feature maps at varied resolutions, we incorporate a downsampling procedure. Before progressing to the subsequent stage, the channel dimensions on local tokens (akin to CNNs) are doubled, while the spatial resolution is quartered. For upsampling, we resort to common trilinear interpolation techniques used in point cloud analysis. Each layer of the encoder communicates with its corresponding decoder via skip connections. The Regional-to-Local Point-Voxel Transformer Encoder consists of two primary components: a window-based point-voxel attention layer based on local points within the same window and its corresponding regional token and a voxel-based regional attention layer based on local regional voxels. Given its pyramid structure, our RegionPVT can generate multi-scale features for point clouds, making it easily adaptable for broader visual applications like object detection, point cloud classification, part segmentation, and more, not just limited to indoor point cloud semantic segmentation.
In the following sections, we delve into the detailed composition of RegionPVT’s encoder and decoder modules.
Section 3.2.1 introduces the proposed Voxel-based Regional Self-Attention mechanism.
Section 3.2.2 presents the Window-based Point-Voxel Self-Attention mechanism.
Section 3.2.3 describes the complete Regional-to-Local Point-Voxel Transformer Encoder. Finally,
Section 3.2.4 explains the downsampling and upsampling layers employed in our model’s encoder–decoder architecture.
3.2.1. Voxel-Based Regional Self-Attention
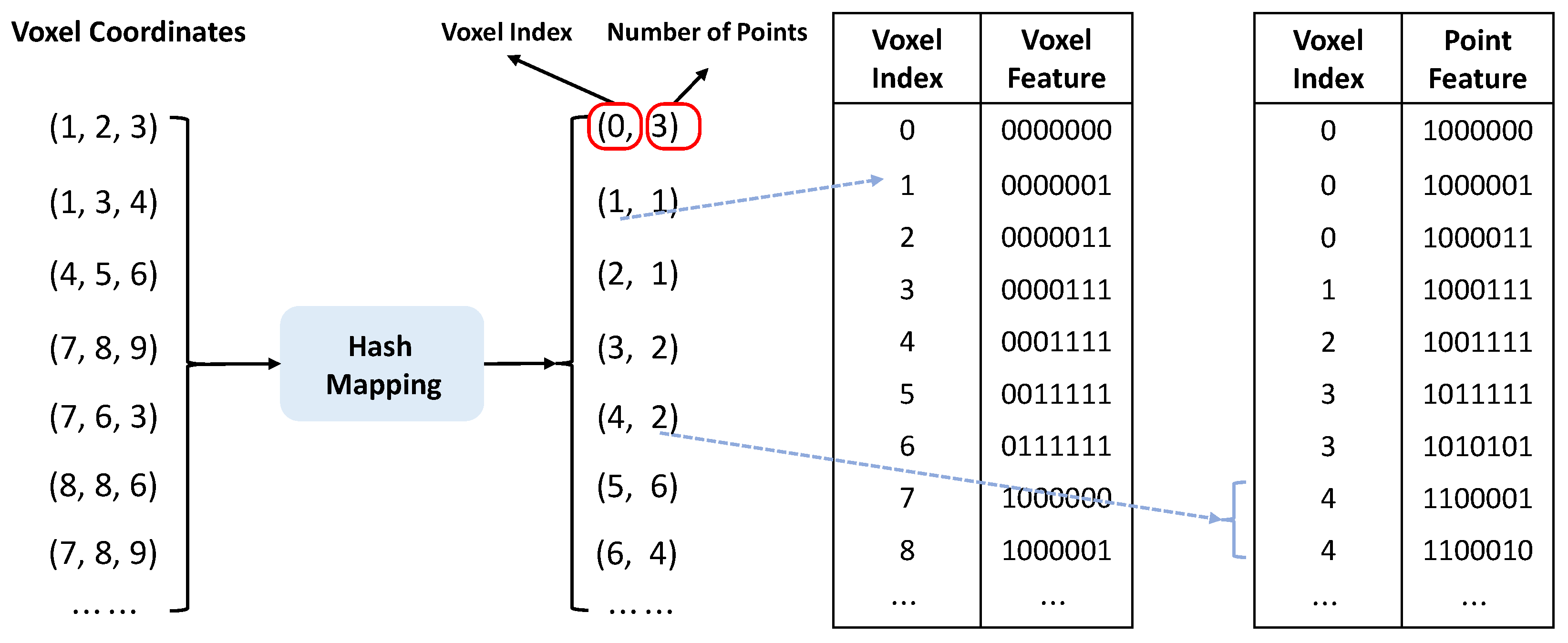
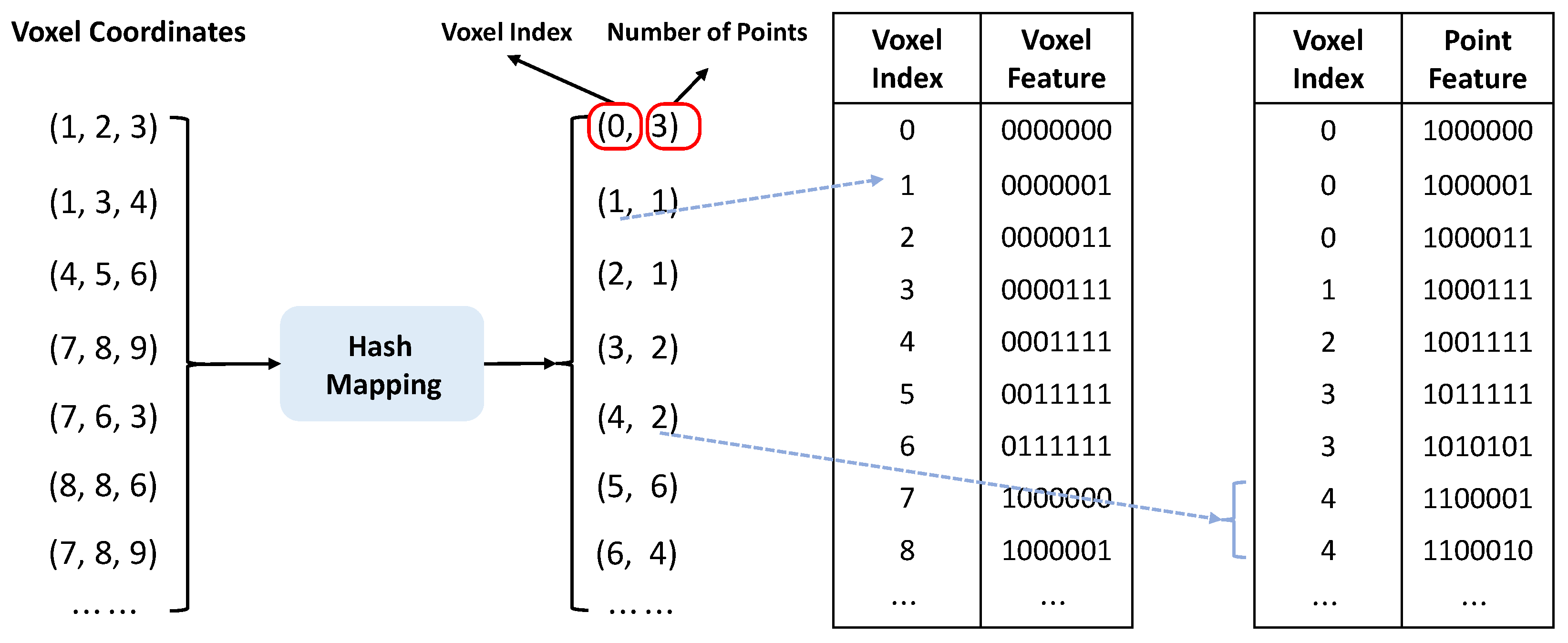
In the framework of point-based local window multi-head self-attention, point clouds are divided into non-overlapping windows based on their spatial coordinates. For every individual window, self-attention computations are performed for its contained points, enabling the capture of local feature relationships within the 3D point cloud. Conversely, with our voxel-based regional self-attention approach, point clouds are voxelized in accordance with the window sizes. Subsequently, a hash mapping is established between the voxels and their associated point cloud segments within the respective windows as shown in
Figure 2. Then, the regional self-attention is carefully calculated for every voxel, incorporating insights from its k-nearest neighboring voxels, which highlights the regional feature interplay on a voxel level within the 3D point clouds. It is worth mentioning that the advanced hash mapping method speeds up the process of finding neighboring voxels, doing so with an
complexity. Meanwhile, the point-based methods [
8,
30,
43] require constructing neighbors using a search for the
k-nearest neighbors [
54], a process with a complexity of
, which can be quite slow when working with large sets of point clouds. Moreover, a crucial feature of our voxel splitting method is its accuracy; it only focuses on valid voxels, ensuring that each voxel contains at least one point from the point clouds.
Specifically, for the voxel-based regional self-attention mechanism, the input point cloud is denoted as
. Here,
represents the spatial coordinates of the
nth point, while
encapsulates the inherent features of
, such as color, normal vectors, and so forth. In alignment with methodologies presented in [
32,
55], the point cloud is voxelized via the ensuing process:
Initially, we employ an encoding layer
to positionally encode the point cloud coordinates, encoding them into a high-dimensional space
. This encoding aims to mitigate information loss during the voxelization process. We denote this as:
where
represents the set of point indices within the
ith voxel. Subsequently, our voxel feature can be defined as follows
:
where ⊕ represents the concatenation operation of a vector,
is an operator with permutation-invariant properties, such as taking the
. In our experiment setting, we employ the
operation.
We formally represent the voxelization of the input point cloud, denoted as , by the tuple . In this context, M is the number of voxels, specifies the spatial coordinate of the ith voxel. The feature associated with this voxel is given by . Additionally, , which represents the centroid of the ith voxel, is computed as an average of the points within it: .
In our approach, the voxel-based regional self-attention mechanism ingests the input
and efficiently employs a hash table, which aids in identifying the k-nearest neighbors for each voxel. Here, the regional neighbor indices for
are represented as
. Given this setup, the self-attention calculation at the voxel level, focusing on
, is elegantly captured by equation
In the context of this equation, denotes the resultant feature. The functions and stand for linear projection layers of the input feature. Lastly, acts as a position encoding function, introducing spatial contextual awareness into the self-attention mechanism.
Complexity Analysis. To conclude, let us delve into the computational complexity associated with our voxel-based regional self-attention mechanism. Considering that the number of neighbor indices denoted by
in Equation (
3) stands at
k, and post voxelization, the voxel count totals to
M, the computational overhead for our voxel-based regional self-attention becomes
. Given that
k is invariant, the overall complexity scales linearly. Such a linear scaling greatly alleviates the computational demands typically associated with the Transformer’s self-attention operation, making our approach both efficient and resource conservative.
3.2.2. Window-Based Point-Voxel Self-Attention
A traditional Transformer block is fundamentally composed of a multi-head attention module complemented by a feed-forward network (FFN). The global self-attention mechanism in such a setup poses a computational challenge as its complexity grows quadratically with the increment in the number of input tokens. When processing point clouds with tens of thousands of points used as direct input, this results in a memory overhead of
(
N being the total count of input points), making it practically unworkable. In alignment with the methodologies outlined in [
34,
40], we adopt local window-based multi-head self-attention to learn fine-grained point representations while maintaining cross-scale information exchange.
To effectively leverage the inherent structure of 3D spatial data, we spatially segment the 3D space into distinct, non-overlapping cubic regions, termed “windows”. Every point within the 3D point cloud landscape is associated with a specific window, determined by its spatial coordinates. Within each of these windows, multi-head self-attention operates in isolation. As a result, when computing the attention map for a given query point, only the neighboring points within its designated window and the associated voxel token (which can be thought of as a unique “point token”) are considered. This contrasts with global self-attention, which typically involves all input points. Such window-centric partitioning markedly streamlines computational demands. Importantly, our method does not merely zone in on high-resolution local features. It also weaves in voxel-level insights, ensuring a rich interplay of features across multiple scales. Given the inherent sparsity and irregular distribution of point clouds, the points each window houses can fluctuate. For the
tth window, let us represent the count of its encapsulated points as
. Defining the number of attention heads as
and the dimension of each head as
, we can infer that the dimension
is associated with the points in the
tth window and its corresponding voxel token, or, more precisely,
and
. For our window-based point-voxel self-attention scheme, the input can be succinctly denoted as
. To elucidate further, the application of the point-voxel multi-head self-attention mechanism on the
tth window is formulated as follows:
The matrices and of dimensions are derived from the input features using three separate linear transformations. Here, · symbolizes the dot product operation between vectors and . The attention score matrix, represented as , has dimensions of . From this, the aggregated feature matrix with dimensions is obtained. These features are then linearly transformed to yield the output feature matrix , which is of size .
In Vision Transformers (ViT) tailored for 2D imagery, empirical studies have continually emphasized the indispensable role of positional encodings within the Transformer’s architecture. When transposed to 3D Transformers, though the spatial coordinates of the point cloud are inherently woven into the feature learning process, there is a risk that nuanced positional cues could be masked or even jettisoned as the network delves deeper. It is worth noting that, unlike the uniformly arrayed pixels in 2D imagery, 3D points exist within a vastly more intricate, continuous spatial configuration. This innate complexity amplifies the challenges when capitalizing on the
positional coordinates of these point clouds. To more astutely harness this spatial information within our 3D Transformer, we integrated the contextual relative position encoding strategy delineated in the stratified transformer—refer to [
40] for a comprehensive exploration.
Complexity Analysis. To wrap things up, let us distill the computational complexity inherent to the window-based point-voxel multi-head self-attention mechanism. The expressions from (
4) through (
8) detail the multi-head self-attention operations pertinent to a singular window. Given an average point cloud count of
m within each window, the computational intricacy of this window-based approach is presented as
, with
m being substantially smaller than
N. In a comparative light, this is a marked decline from the
complexity endemic to a global multi-head self-attention, effectuating a considerable attenuation in the computational demands of the Transformer block.
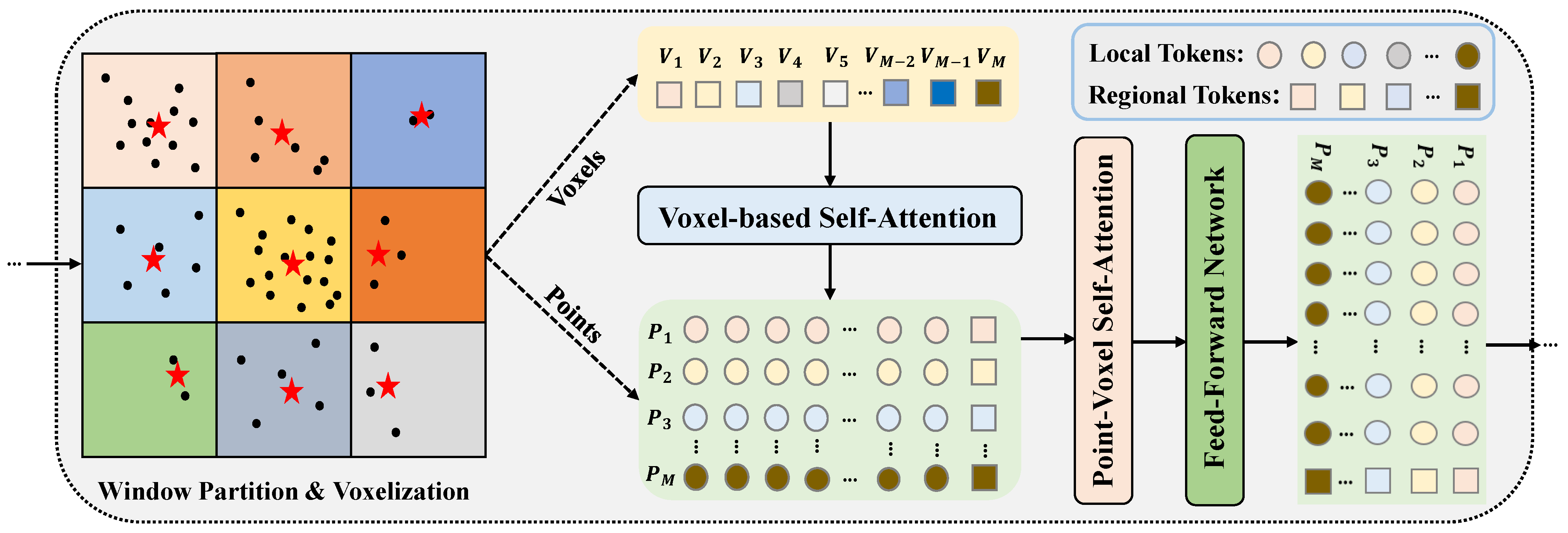
3.2.3. Regional-to-Local Point-Voxel Transformer Encoder
Our proposed Region-to-Local (R2L) Point-Voxel Transformer Encoder, as illustrated in
Figure 3, consists of an R2L point-voxel attention and a feed-forward network (FFN). Specifically, in the R2L point-voxel attention domain, the Voxel-based Regional Self-Attention (RSA) first conducts self-attention computation on all regional tokens, effectively learning regional information at the voxel level. Subsequently, the Local Window-based Point-Voxel Self-Attention (LSA) employs local tokens associated with regional tokens to grasp local characteristics. The participation of the corresponding regional tokens in the LSA computation infuses more extensive regional insights, enabling interaction across different windows and thereby broadening the receptive field. Within the R2L point-voxel encoder, both RSA and LSA utilize Multihead Self-Attention (MSA) tailored for distinct input tokens. Ultimately, an FFN layer is incorporated for feature enhancement. Furthermore, we integrate layer normalization (LN) and residual connections within the conventional Transformer encoder. Given the input of the network’s
dth layer, consisting of regional tokens (voxels)
and local tokens (points)
, the R2L Point-Voxel Transformer Encoder can be articulated as
where
denotes the spatial index associated with a regional token,
i serves as the local token index within the
tth window. The variable
represents the number of local tokens present in that window. The input to the LSA,
, incorporates both a regional token and its associated local tokens, facilitating the exchange of information between the regional and local tokens. On the other hand, the outputs
and
can be extracted from
, similarly to the top right expression in Equation (9).
The RSA facilitates the exchange of information across local regional tokens, encompassing the voxel level coarse-grained context of the point cloud scene. On the other hand, the LSA integrates features among tokens within a spatial region (i.e., points within a window and their corresponding voxels), encompassing both regional tokens (voxel tokens) and local tokens (point tokens). Since the regions are divided by non-overlapping windows, the RSA is also designed to exchange information among these regions where the LSA takes one regional token and then combines with it the local tokens in the same region. In this setup, all local tokens are still capable of obtaining broader regional information while maintaining focus on their local neighbors. With these two attentions, the R2L can effectively and efficiently exchange information among all regional and local tokens. The self-attention mechanism of regional tokens aims to extract higher-level details, serving as a bridge for local token information to transition between regions. Conversely, the R2L point-voxel attention focuses on local contextual information with one regional token.
Complexity Analysis. Given a point cloud input encompassing
N points, where each window, on average, contains
m points, and the voxel-based regional self-attention engages with
k neighboring entities, the computational intricacy for this self-attention can be outlined as
. Meanwhile, the complexity for the window-based point-voxel self-attention stands at
. Therefore, the collective computational complexity for the R2L Point-Voxel Transformer encoder can be delineated as
. Notably, given that
, the overall complexity simplifies to
. This figure is substantially more favorable compared to the
complexity found with global self-attention in some existing methods [
29,
56]. Furthermore, the proposed R2L Point-Voxel Transformer encoder enables capturing both fine-grained local and larger regional details. By prioritizing local feature learning, it significantly reduces computational complexity, enhances efficiency, and is highly memory efficient.
3.2.4. Downsampling and Upsampling Layer
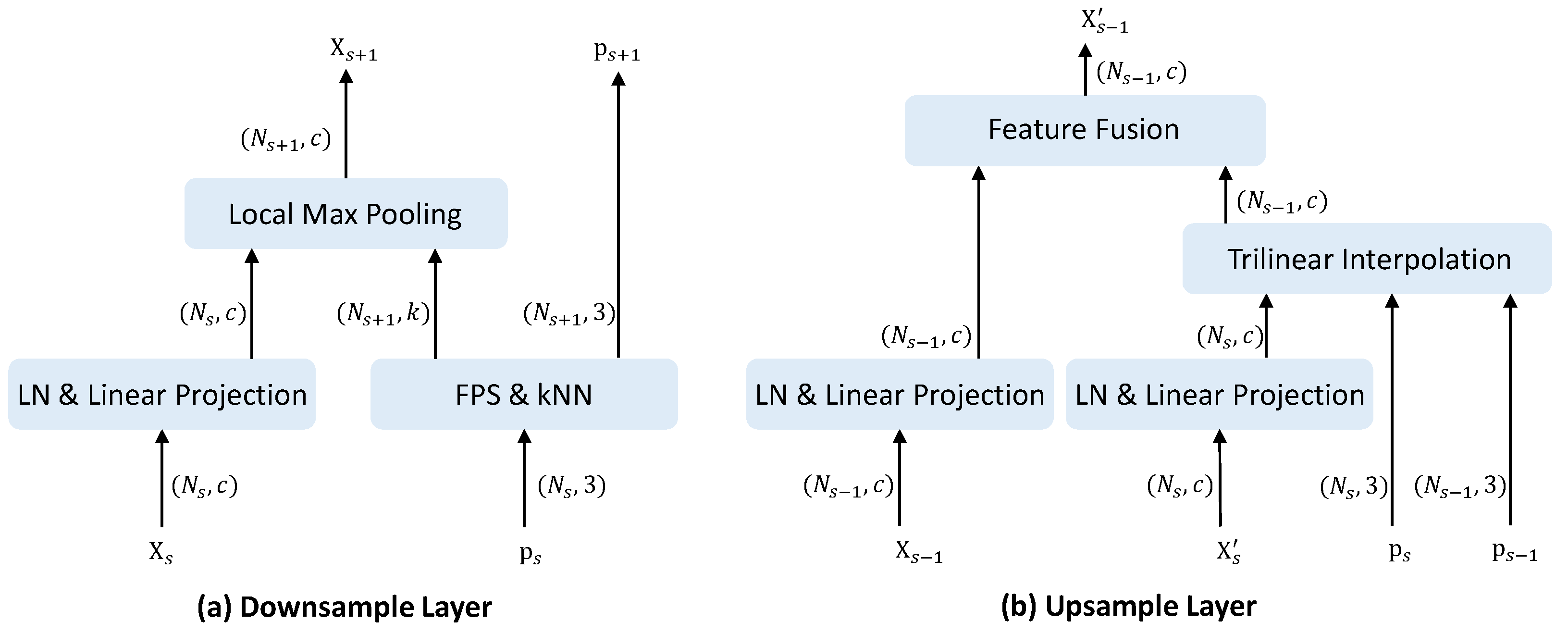
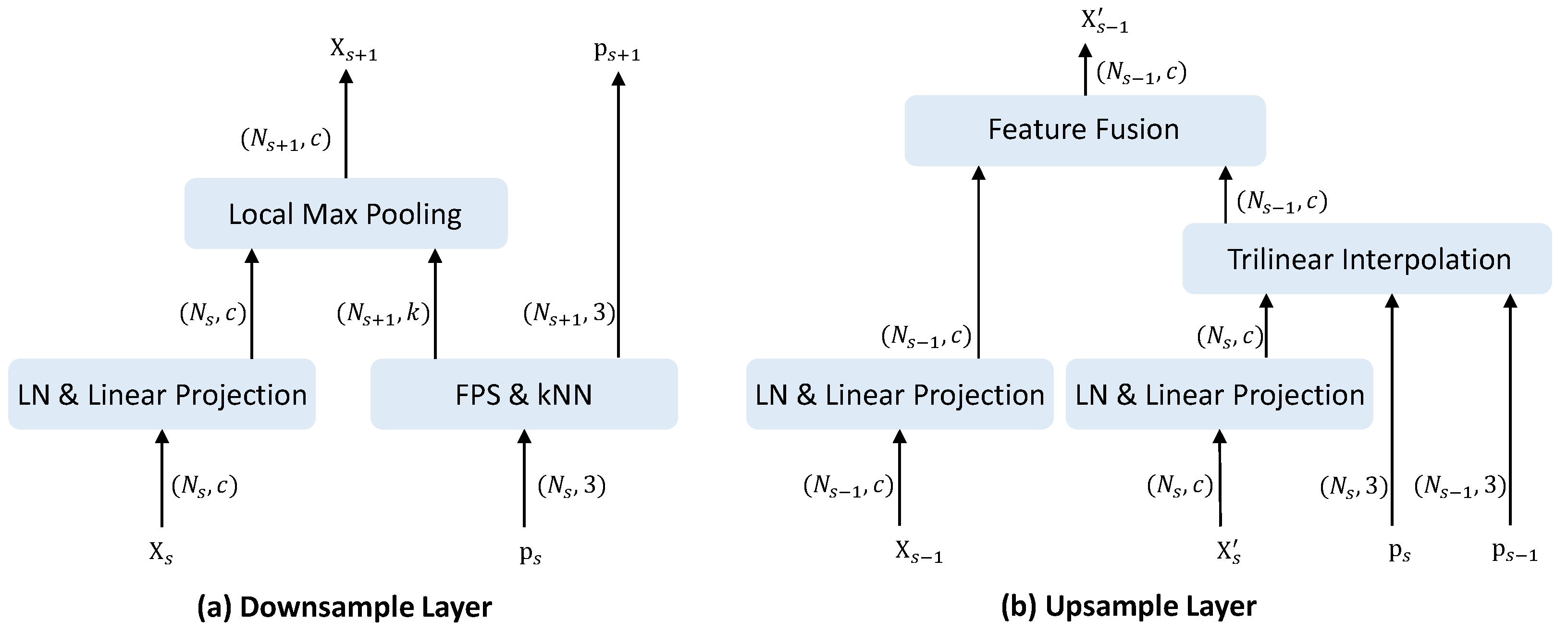
Following previous methods [
8,
9,
22,
30], the downsampling layer depicted in
Figure 4a operates as follows: The input coordinates
are first passed to the FPS and kNN module for sampling and grouping. The farthest point sampling (FPS) is applied to obtain the centroid points
. Next, the kNN search is performed on the original points to acquire the grouping indices
. The number of centroids after downsampling is a quarter of the original, i.e.,
. In parallel, the input features
are fed into a layer normalization and linear projection layer. Finally, local max-pooling is conducted over the groups to aggregate the projected features, outputting the downsampled features
.
Figure 4b shows the upsampling layer. The decoder features
are first projected with layer normalization and a linear layer. Interpolation is then performed between the current coordinates
and prior
. The encoder features
from the previous stage undergo layer normalization and linear transformation. These features are summed by the feature fusion module to produce the decoded output
.
3.3. Baseline and Evaluation Metrics
In our evaluation, we rigorously compared our network model against an array of state-of-the-art methods across two datasets. For the S3DIS dataset, we selected a range of methods to compare with our network model, including PointNet [
8], SegCloud [
57], PointCNN [
20], SPGraph [
58], PAT [
59], PointWeb [
42], GACNet [
60], SegGCN [
61], MinkowskiNet [
19], PAConv [
43], KPConv [
41], PatchFormer [
35], CBL [
62], FastPointTransformer [
32], PointTransformer [
30], PointNeXt-XL [
22], and Swin3d [
40].
Meanwhile, for the ScanNet v2 dataset, our comparisons were made against PointNet++ [
9], 3DMV [
63], PanopticFusion [
64], PointCNN [
20], PointConv [
53], JointPointBased [
65], PointASNL [
56], SegGCN [
61], RandLA-Net [
21], KPConv [
41], JSENet [
66], FusionNet [
46], SparseConvNet [
18], MinkowskiNet [
19], PointTransformer [
30], PointNeXt-XL [
22], and FastPointTransformer [
32].
Our comparative analysis was comprehensive, encompassing a wide range of methodologies: point-based techniques (e.g., PointTransformer [
30] and PointNeXt-XL [
22]), voxel-based approaches (such as MinkowskiNet [
19] and FastPointTransformer [
32]), and hybrid strategies that seamlessly integrate voxels and points (like PatchFormer [
35]). An in-depth discussion on the evaluations and consequential results is elaborated in the subsequent
Section 4.1.
In assessing the efficacy of our advanced network, we resort to three vital metrics, each capturing a distinct aspect of the model’s predictive prowess: Mean Classwise Intersection over Union (mIoU), Mean of Classwise Accuracy (mAcc), and Overall Pointwise Accuracy (OA). These metrics collectively provide a robust evaluation, ensuring a comprehensive assessment of our proposed model against ground truths.
3.4. Implementation Details
In
Figure 1, we present the central architecture of our 3D semantic segmentation network. Inputs to our model included both the
coordinates and the
color values. We initialized the feature dimension at 48, with the number of attention heads set to 3. Notably, both these parameters were doubled with every subsequent downsampling layer. For the S3DIS dataset, we constructed a network comprising four stages, delineated by block depths of
. Meanwhile, for the ScanNet v2 dataset, the architecture encompassed five stages characterized by block depths of
.
In our experimental setup for both the S3DIS and ScanNet v2 datasets, we utilized a server powered by an Intel(R) Xeon(R) E5-2650 v4 @ 2.20GHz × 40 CPU, accompanied by 4 Tesla V100 16G GPUs, 200 GB RAM, CUDA 10.2, and cuDNN v7. Specifically for the S3DIS dataset, the model was trained for 76,500 iterations using the AdamW [
67] optimizer. The initial learning rate was determined at 0.006, with a batch size of 8, and we employed the cross-entropy loss as the optimization metric. Following common practice [
30,
43], the raw input point clouds were grid-sampled at an initial size of 0.04 m. The training phase saw the input point count restricted to 80,000, while the testing phase employed the entire raw point cloud. Notably, the starting window size was 0.16 m, doubling after each downsampling layer. Data augmentation for S3DIS encompassed z-axis rotation, scaling, jittering, and color dropout.
When transitioning to the ScanNet v2 experiments, our model was trained across 600 epochs, with weight decay, batch size, and grid sampling configured to 0.1, 8, and 0.02m, respectively. The training phase retained a ceiling of 120,000 input points and an initial window size of 0.1 m. Data augmentation, beyond random jitter, mirrored the S3DIS approach. To streamline the training process and conserve GPU memory across both datasets, we leveraged PyTorch’s native Automatic Mixed Precision (AMP). Furthermore, any other training parameters remained consistent between both datasets.
4. Results and Discussion
In this section, we first exhibit the detailed results on S3DIS and ScanNet v2, with comparisons to other state-of-the-art methods in
Section 4.1. Subsequently, we provide ablation experiments to analyze the efficacy of the key components within our proposed model design in
Section 4.2. Finally, we discuss the computational requirements that our model needed in
Section 4.3.
4.1. Evaluation
We conduct a rigorous comparison of our innovative approach with contemporary cutting-edge semantic segmentation techniques. In accordance with previous study [
8,
9,
20,
21,
22,
30,
41,
43,
53], we report the OA, mAcc, and mIoU on Area 5 of S3DIS dataset, while for the ScanNet v2 dataset, we report the validation set mIoU (Val mIoU) and the online test set mIoU (Test mIoU) for a fair comparison. Results related to various evaluation metrics for the S3DIS and ScanNet v2 datasets are clearly laid out in
Table 3 and
Table 4. For a deeper dive into class-specific performances, one can refer to
Table 5 and
Table 6. It is noteworthy that our approach achieves top-tier performance on both of these challenging large-scale 3D indoor point cloud datasets.
On the S3DIS dataset, the performance of our proposed method significantly surpasses that of other approaches. It exceeds our baseline—Swin3d without shift (69.4% mIoU)—by 1.6 percentage points in mIoU. When compared with the shifted version of Swin3d (70.1% mIoU), our model still demonstrates a 0.9 percentage point improvement in mIoU. Furthermore, relative to other methods, our approach achieves state-of-the-art levels for both OA and mAcc. Specifically, our method outperforms voxel-based methods like MinkowskiNet and Fast Point Transformer by 5.6 and 0.9 percentage points in mIoU, respectively. When compared to point-based methods like PointTransformer and PointNeXt-XL, we observe improvements of 0.6 and 0.5 percentage points in mIoU, respectively. This improvement is attributed to the introduction of our voxel branch with self-attention. Features from the voxel level offer a broader receptive field for point-based self-attention, bolstering information exchange between different windows and consequently enhancing dense point prediction accuracy.
Regarding the ScanNet v2 dataset, our method’s validation of mIoU again surpasses that of voxel-based methods like MinkowskiNet and Fast Point Transformer, with improvements of 1.0 and 1.1 percentage points in mIoU, respectively. When set against point-based techniques, namely PointTransformer and PointNeXt-XL, we observe advantages of 2.6 and 1.7 percentage points in mIoU. Contrary to the performance uplift of MinkowskiNet on the S3DIS dataset, the improvement of our method on the Scannet v2 dataset is not as pronounced. This difference relates to the dataset sparsity levels. As the ScanNet v2 dataset is sparser than S3DIS, there is less information loss during voxelization. For denser data, the voxelization process inevitably incurs a higher loss of information, which allows excelling of voxel-based methods like MinkowskiNet on sparser datasets. However, our approach consistently achieves outstanding results on both datasets due to our fusion of voxel and point multi-scale information, coupled with our region-to-local encoder module.
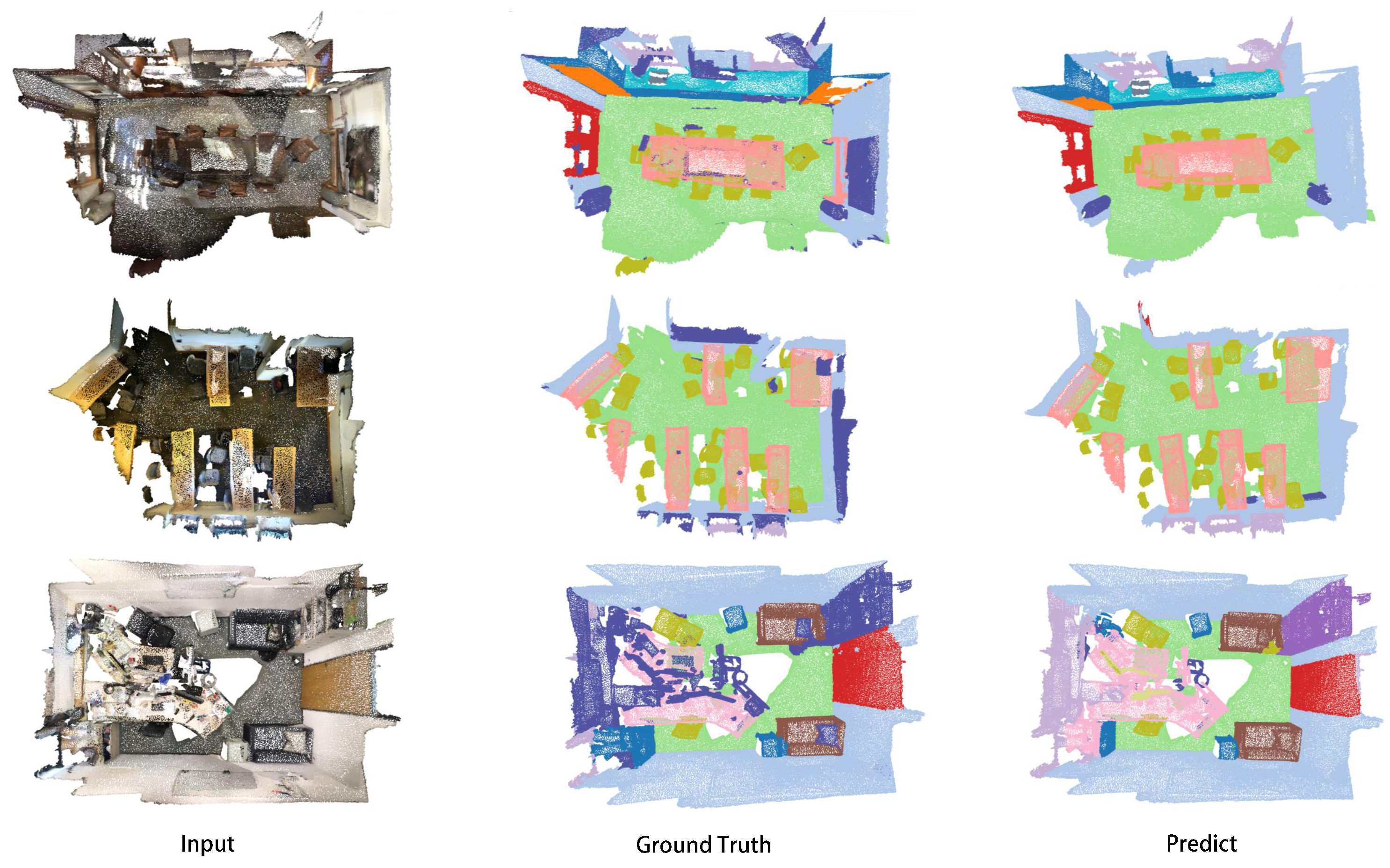
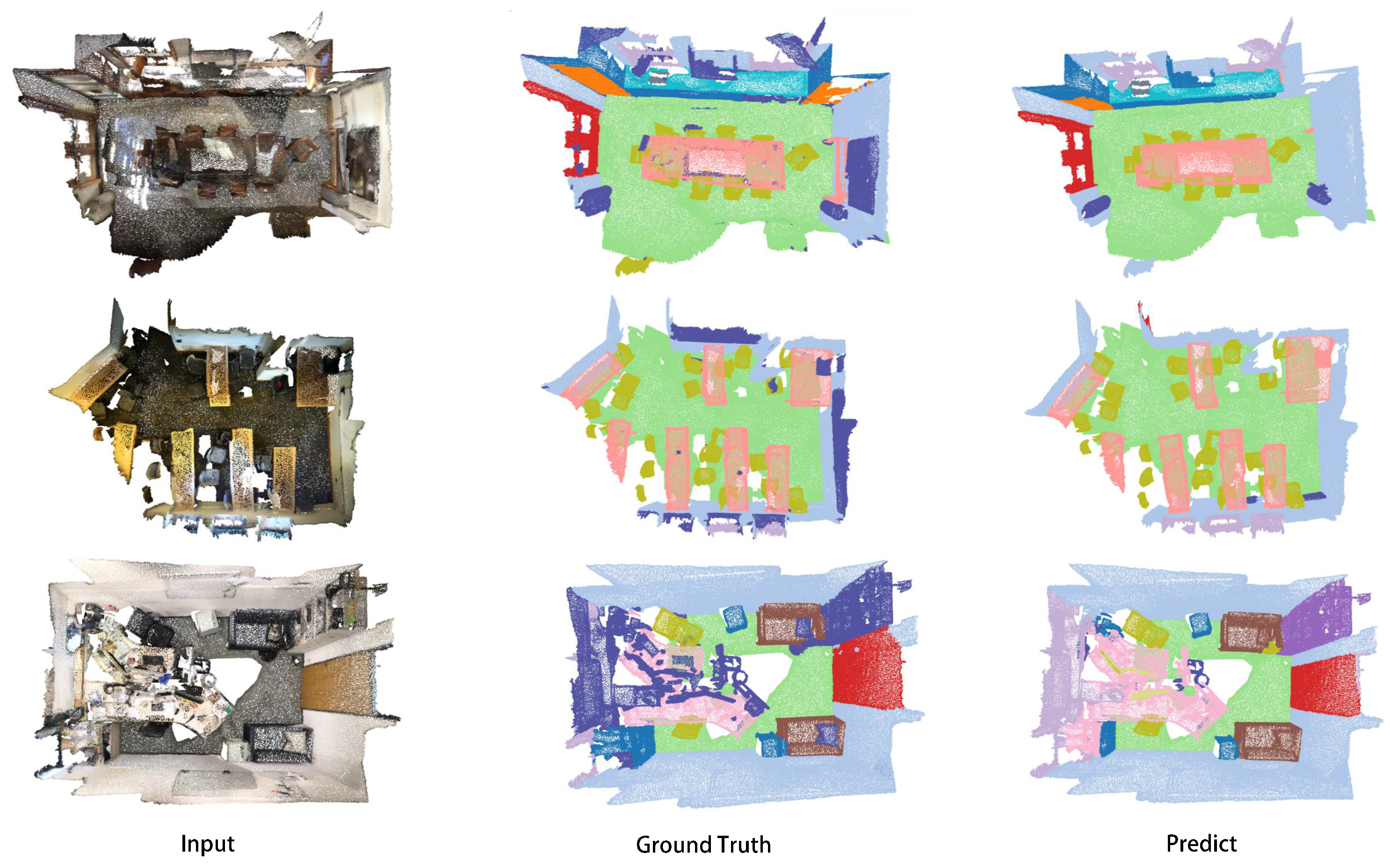
Qualitative visualization results on the test datasets can be seen in
Figure 5 and
Figure 6. The left column showcases the network’s input point cloud, the central column represents the actual input labels, and the right column depicts predictions from our network. As the figures illustrate, our network can adeptly predict every point cloud, aligning well with the Ground Truth, whether on dense datasets like S3DIS or sparser ones like ScanNet v2.
4.2. Ablation Study
To thoroughly validate the efficacy of each main component in our proposed RegionPVT model, we conducted extensive ablation experiments focused on two main aspects—the main components of our model and the skip connections within the voxel branch. The ablation study was performed on S3DIS to enable fair comparison, strengthen result credibility, and improve experimental efficiency.
4.2.1. Model Design
To underscore the individual and combined significance of each main component in our proposed RegionPVT model, we meticulously performed ablation studies.
Table 7 furnishes a detailed breakdown of these experiments. Spanning from Exp.I through IV, we progressively enhanced the model, initiating with the foundational Local Window-based Point-Voxel Self-Attention (LSA), subsequently integrating the Contextual Relative Position Encoding (CRPE), followed by the inclusion of Voxel-based Regional Self-Attention (RSA), culminating with the integration of Voxel Position Encoding (VPE).
The results demonstrate consistent mIoU improvement as more components were added, validating the efficacy of each module. Introducing CRPE and VPE in Exp.II and Exp.IV lead to gains of 1.1 and 0.5 percentage points, respectively, showing the importance of positional encoding for the large-scale point cloud semantic segmentation task. The largest jump emerged from adding RSA, improving mIoU by two percentage points in Exp. III. This highlighted the pivotal role of RSA in semantic understanding, enabled by the coarse-grained regional features it provides. The RSA module not only incorporated a broader context, but also enhanced information interaction among different windows. Overall, the local window-based self-attention, voxel positional encoding, and particularly the voxel-based regional self-attention each contributed collectively to the performance, demonstrating that the proposed components are well-designed and integrate synergistically within the RegionPVT framework for point cloud segmentation.
4.2.2. Skip Connections in Voxel Branch
In
Table 8, we investigated the influence of integrating skip connections within the voxel branch. In this configuration, regional tokens passed to the subsequent stage are derived from the preceding stage’s regional tokens which were processed via the R2L Point-Voxel Transformer encoder and then voxel-downsampled. This approach contrasts with the method of receiving tokens from the local tokens of the previous stage, which are first downsampled, followed by voxelization. The results showcased in
Table 8 reveal that the performance of RegionPVT equipped with voxel-branch skip connections trails that of the RegionPVT variant devoid of such connections. We theorize this discrepancy arises because our voxel resolution is rather compact, where a single window epitomizes one voxel. With the expansive dimensions of our regional windows across four stages—namely [0.16 m, 0.32 m, 0.64 m, 1.28 m]—further voxel downsampling intensifies their sparsity, engendering pronounced feature attrition. Some windows in ensuing stages find themselves devoid of corresponding regional tokens, which curtails effective information exchange, culminating in a performance decline. To counteract this, we gravitate towards solely downsampling the points, ensuring that the subsequent stage’s regional tokens stem from the voxelized points.
4.3. Computational Requirements Analysis
As depicted in
Table 9, we offer a comprehensive comparison of Floating Point Operations (FLOPs), model parameters (Params), and Memory consumption against several state-of-the-art (SOTA) methods. Our evaluation criteria strictly adhere to the methodology proposed by PAConv [
43], basing our measurements on an input of 4096 points and a batch size of one within the S3DIS dataset.
Amongst the compared methods, our model achieved the highest performance, registering a mIoU of 71.0%. This underscores the superiority of our approach. Notably, even as our approach concurrently learns both coarse-grained regional and fine-grained local features, it remains computationally efficient. With 1.8 G FLOPs, our model’s computational complexity is slightly higher compared to PointTransformer [
30], yet substantially lower than KPConv [
41] and PosPool [
72]. This suggests that our model is capable of delivering exceptional performance without a huge increase in computational overhead. In terms of model parameters, our approach utilizes 9.5 M parameters, making it more compact than KPConv and PosPool, even though it is slightly larger than PointTransformer. Nonetheless, given the improvement in performance, this trade-off is considered reasonable. Most importantly, our model excels in memory efficiency. With a consumption of just 1.7 GB, our model stands out as the most memory efficient amongst all listed, highlighting its potential value in memory-constrained deployment scenarios.
In summary, our method strikes a harmonious balance between high performance and computational efficiency. It ensures the economical use of memory and parameters while setting new benchmarks for the large-scale indoor point cloud semantic segmentation task.
5. Conclusions
In this work, we introduced a novel Regional-to-Local Point-Voxel Transformer (RegionPVT), which captures both regional and local features within indoor 3D point cloud scenes effectively for the semantic segmentation task. The proposed method tackles computational and memory consumption challenges of multi-scale feature learning in large-scale indoor point cloud scenes by facilitating a voxel-based regional self-attention and a window-based voxel-point self-attention. The former efficiently captures broad, coarse-grained regional features, and the latter delves deep, enabling the extraction of fine-grained local details. The combined effect of these modules not only helps with multi-scale feature fusion, but also strengthens information exchange across different windows. By embedding a regional token within each window, our window-based self-attention concurrently facilitates the breadth of regional insights and the depth of local features, thus achieving a harmonious blend of scale and detail.
More importantly, our RegionPVT stands out by finding just the right balance between the performance and computational requirements. It adeptly learns both regional and local features while maintaining computational and memory efficiency—a balance often sought but seldom achieved in the domain. Our extensive empirical evaluations on S3DIS and ScanNet v2 datasets underscore RegionPVT’s prowess. Not only does it outperform hybrid and voxel-based methods, but it also shows competitive results compared with point-based counterparts, all the while using much less memory.
Also, our method has some limitations. Although we achieved satisfying results in terms of performance, computational complexity, and memory consumption, the training process of our approach is relatively slower compared to that of previous methods. Moreover, we only verified our method on two indoor scene datasets, leaving its applicability to larger-scale outdoor scene datasets yet to be further explored. In the future, we will attempt to optimize our model using advanced CUDA operators to enhance inference speed, while also testing its performance on a more diverse range of large-scale point cloud scene datasets. Furthermore, global structural information is crucial for feature point localization and overall understanding in 3D scene comprehension tasks. Efficient learning of global information will be a worthy area of exploration.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}