
Self-Supervised Convolutional Neural Network Learning in a Hybrid Approach Framework to Estimate Chlorophyll and Nitrogen Content of Maize from Hyperspectral Images




Abstract
:1. Introduction
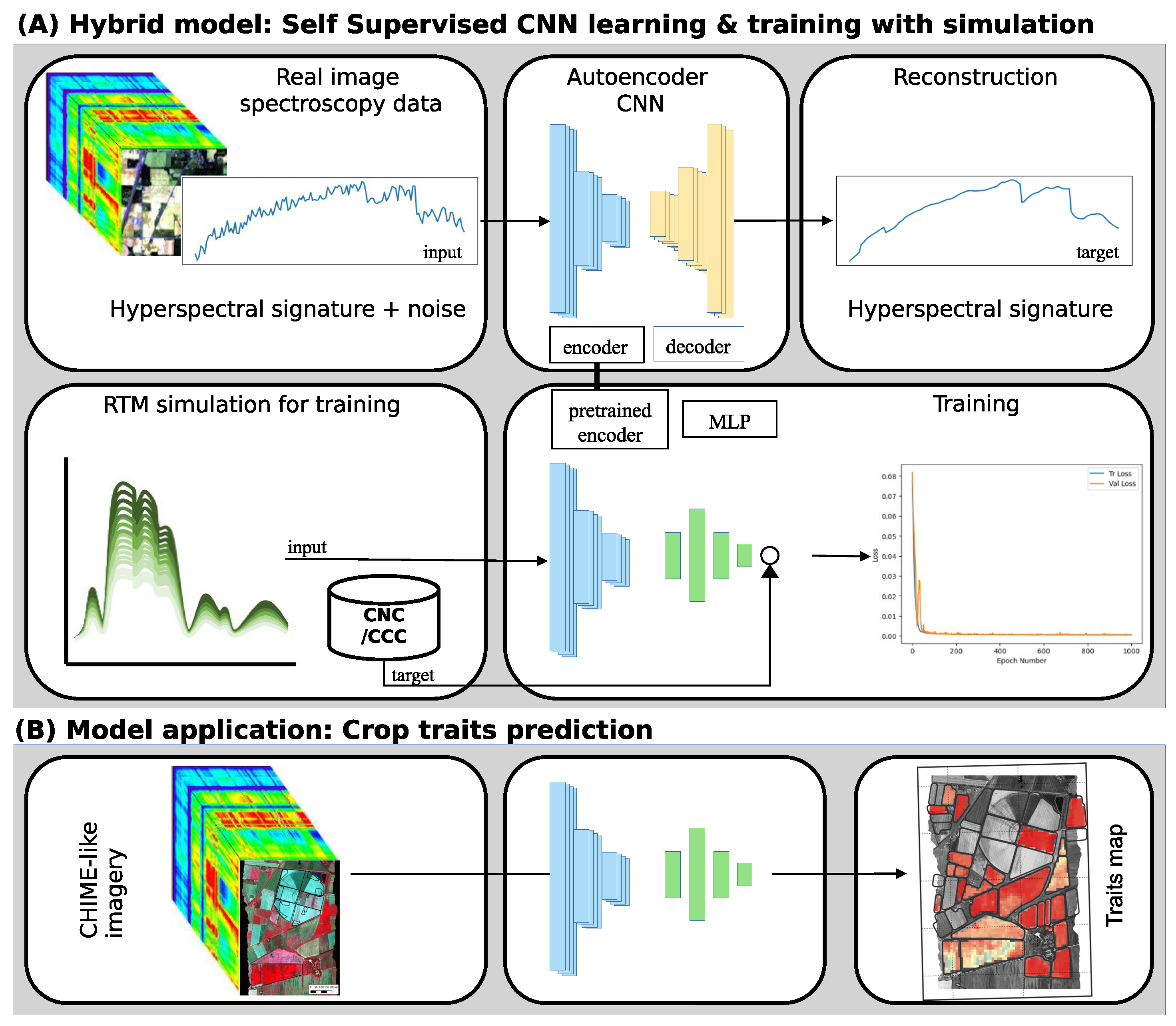
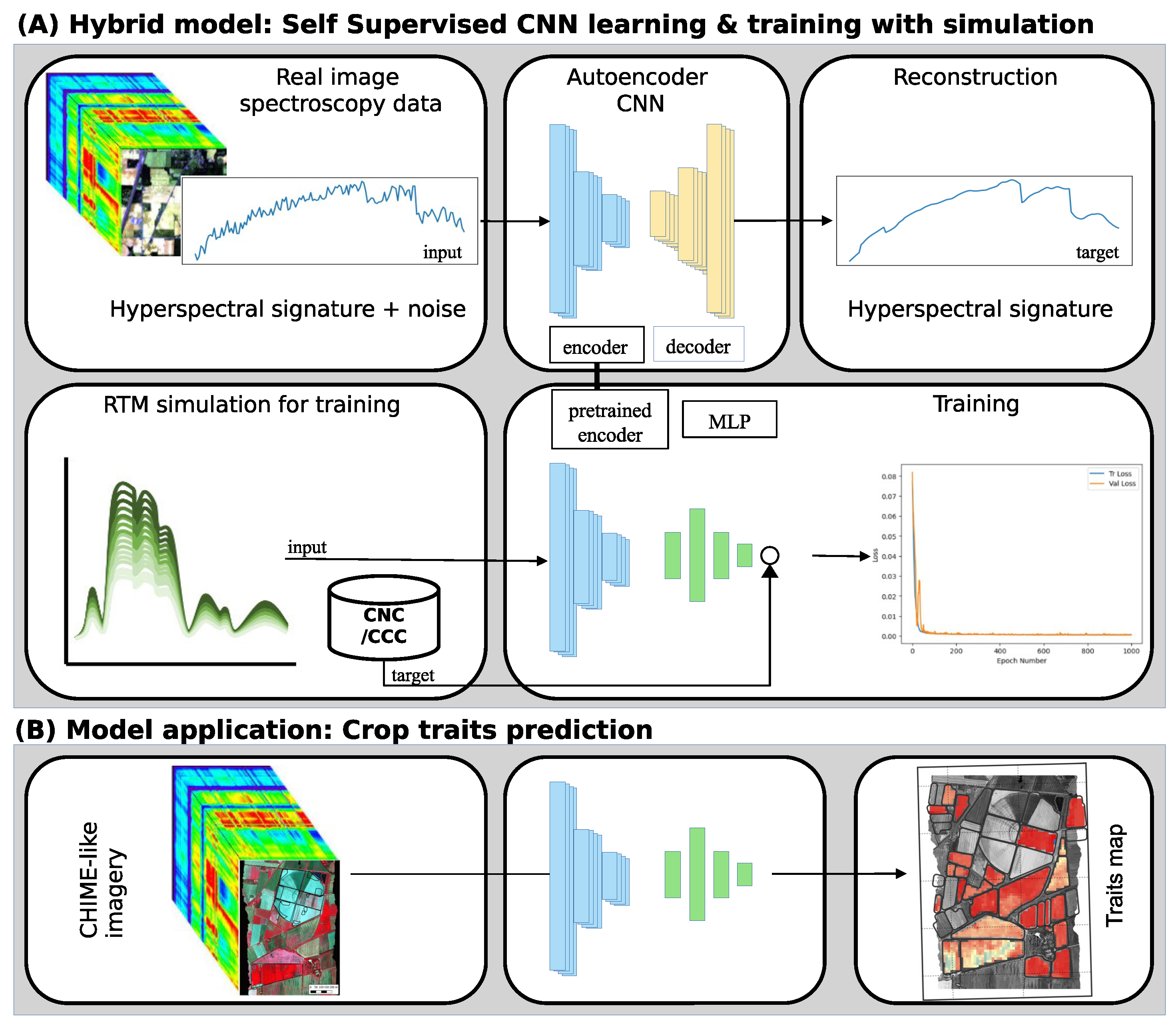
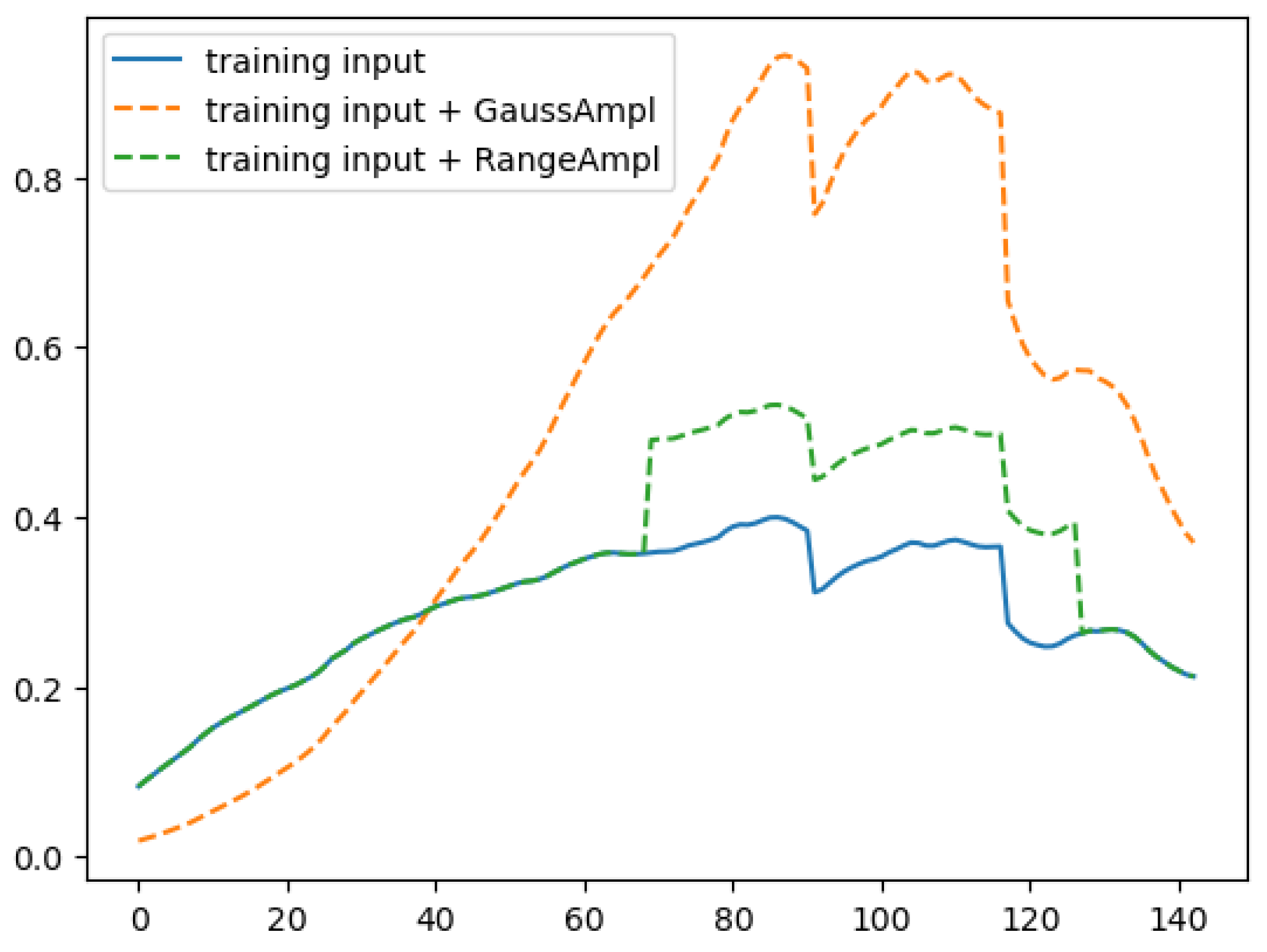
- SSL is a machine learning paradigm that utilizes unlabeled data to learn valuable representations and supervisory signals, in our case, without human-annotated labels. The objective is to investigate how SSL methods can process unlabeled hyperspectral data, effectively capturing spectral correlations and exploiting them on simulated data to learn how to retrieve crop traits.
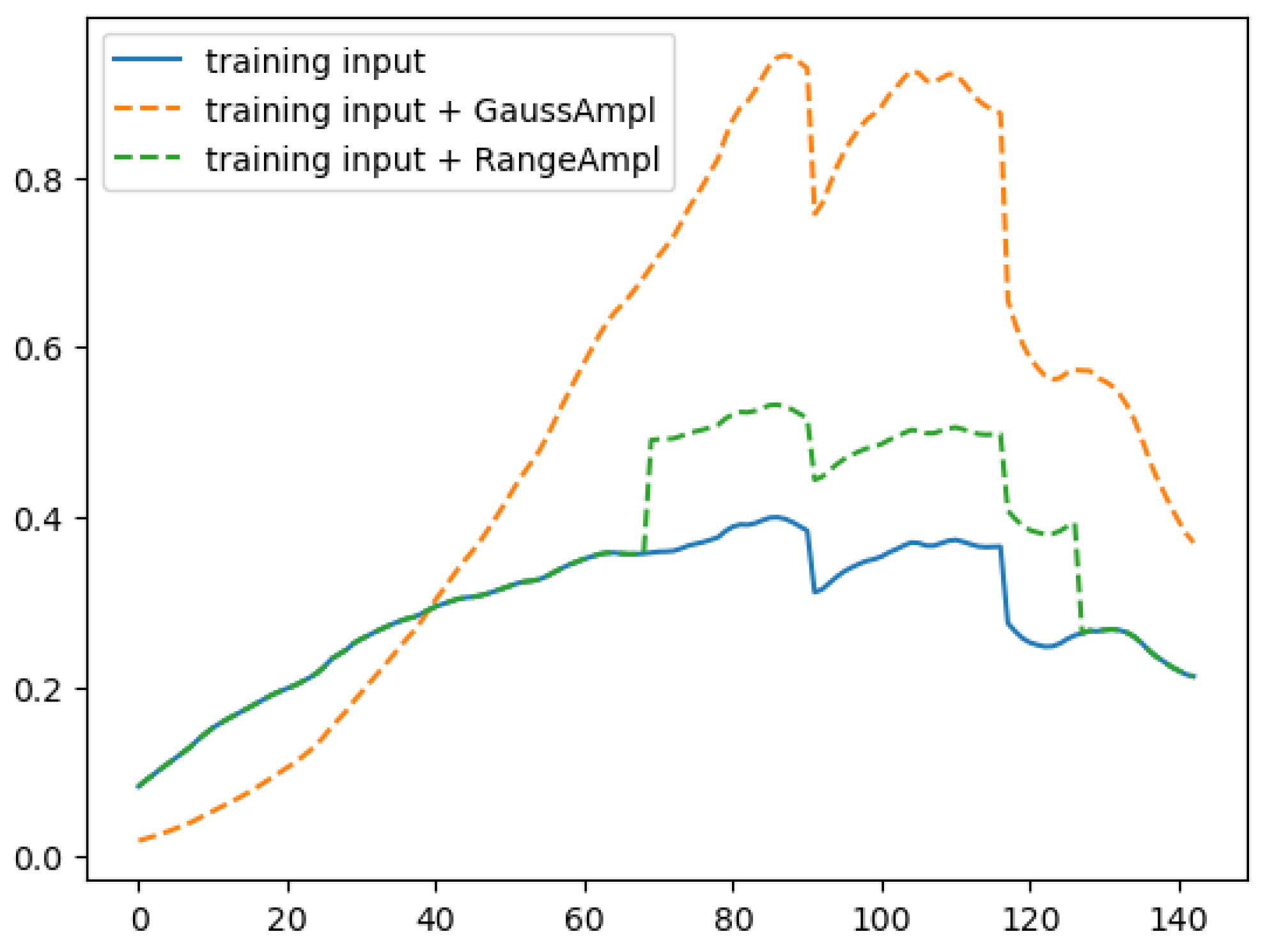
- For this purpose, the study proposes an innovative two-step SSL learning method consisting of pre-training and further training procedures. In the first stage, a convolutional neural network (CNN) for de-noising is trained using pairs of noisy and clean images. In the second stage, the pre-trained network is utilized to identify the spectral correlation between latent features and crop traits.
- The effectiveness of the proposed two-stage learning method in estimating CCC and CNC in maize crops from hyperspectral images is evaluated. The objective is to demonstrate the predictive capabilities and accuracy of the proposed technique in estimating these crop traits using hyperspectral images. The performance is compared with other proposed results to better assess the obtained results.
- With our results, we demonstrate the effectiveness of the proposed approach in accurately estimating CCC and CNC and its potential for advancing the monitoring and management of maize crop productivity and ecosystem health based on satellite data.
2. Related Work
3. Methodology
3.1. Autoencoder
3.2. Convolutional Neural Network
3.3. Multi-Layer Perceptron
4. Datasets
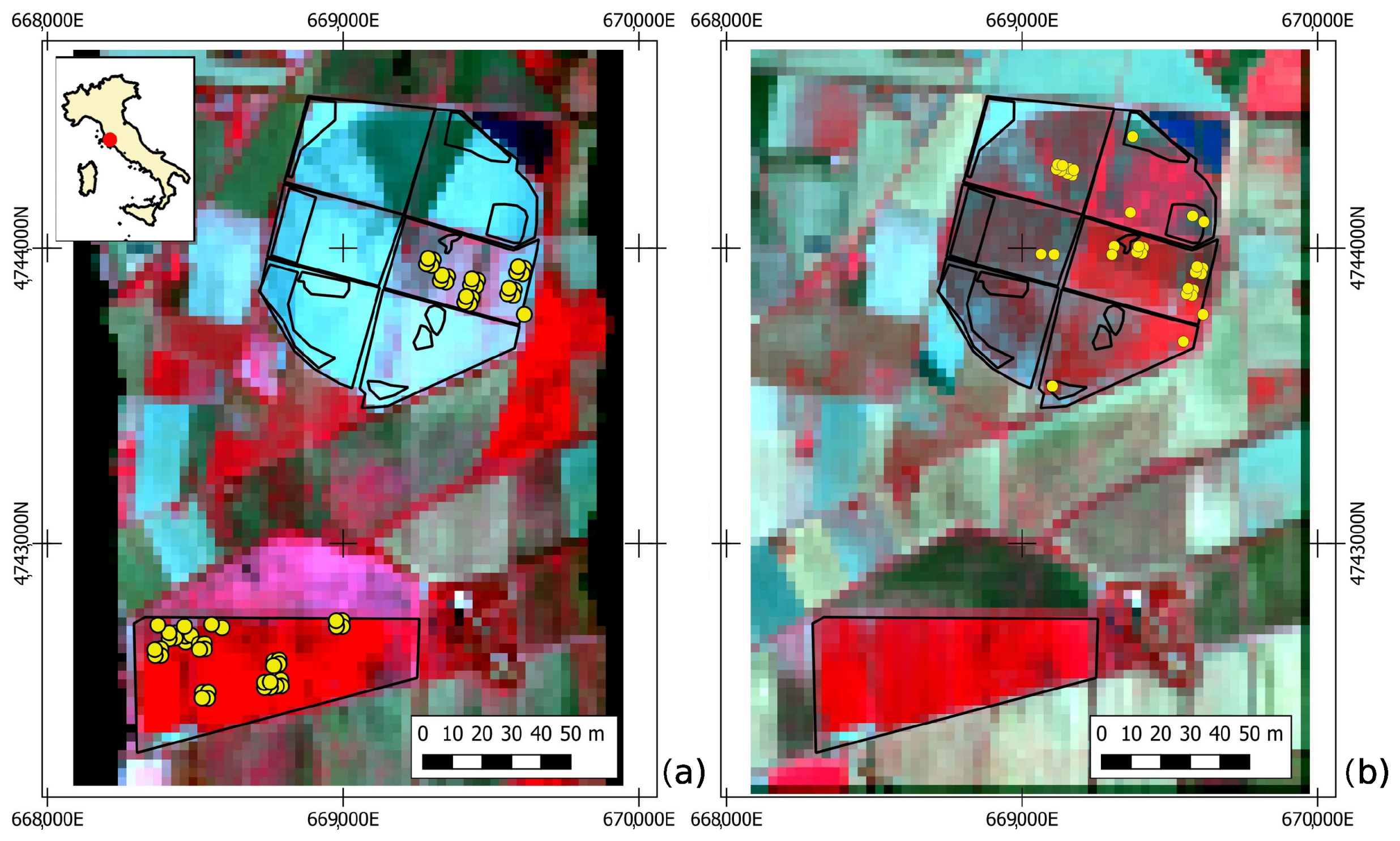
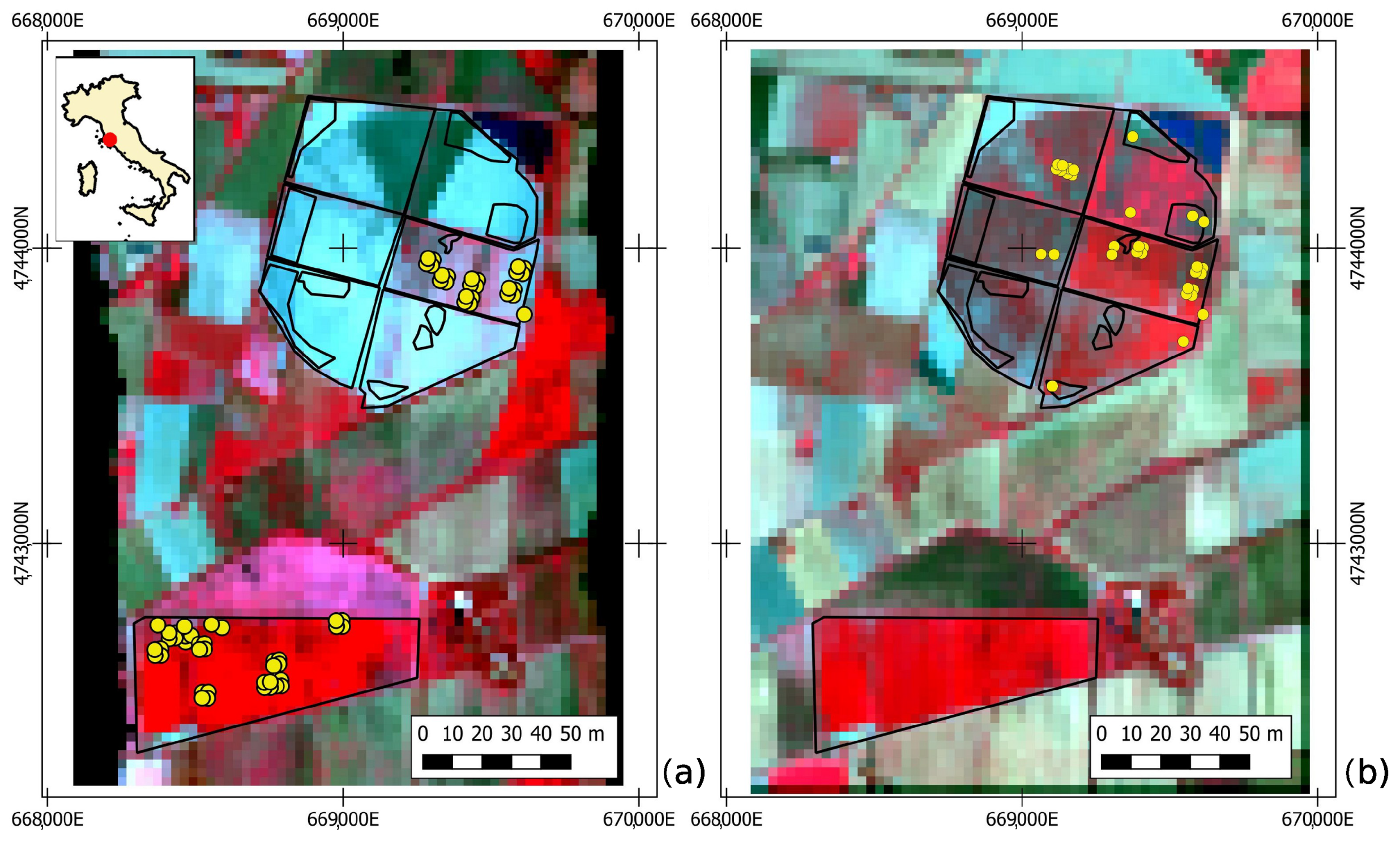
4.1. Study Area and Field Campaigns
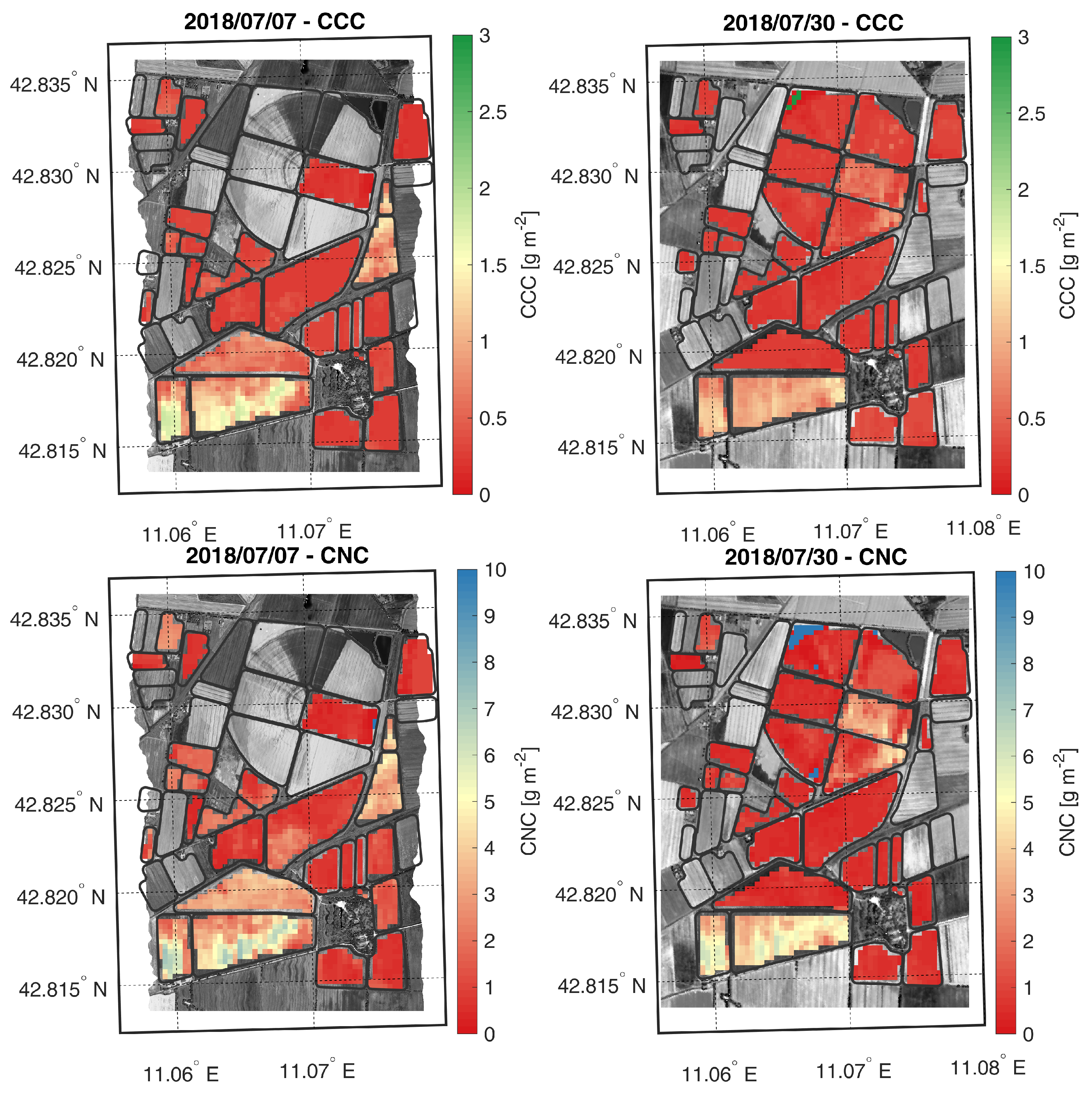
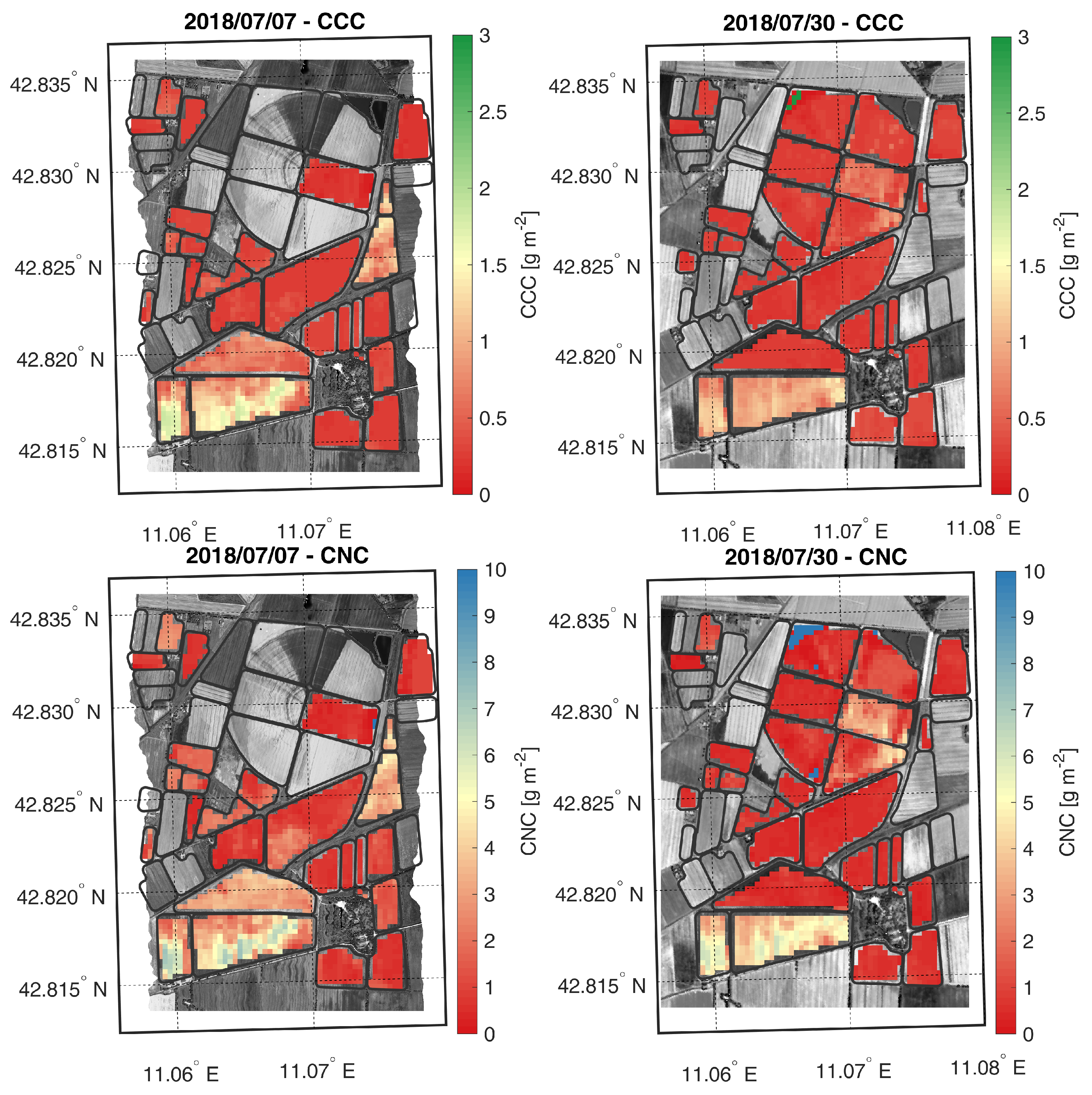
4.2. Earth Observation Dataset
4.3. Simulated Reflectances and Crop Traits Dataset
5. Experiments, Results and Discussion
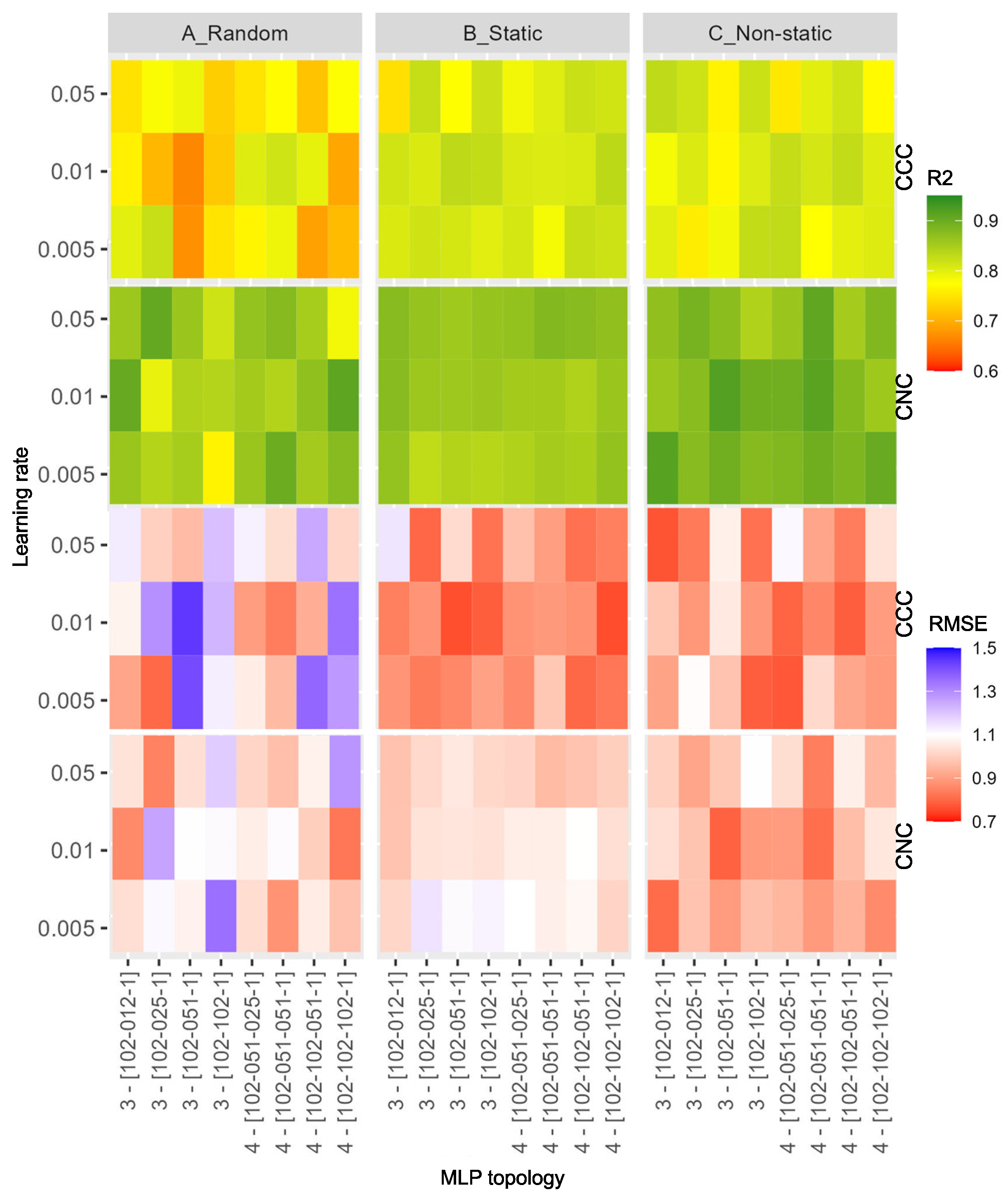
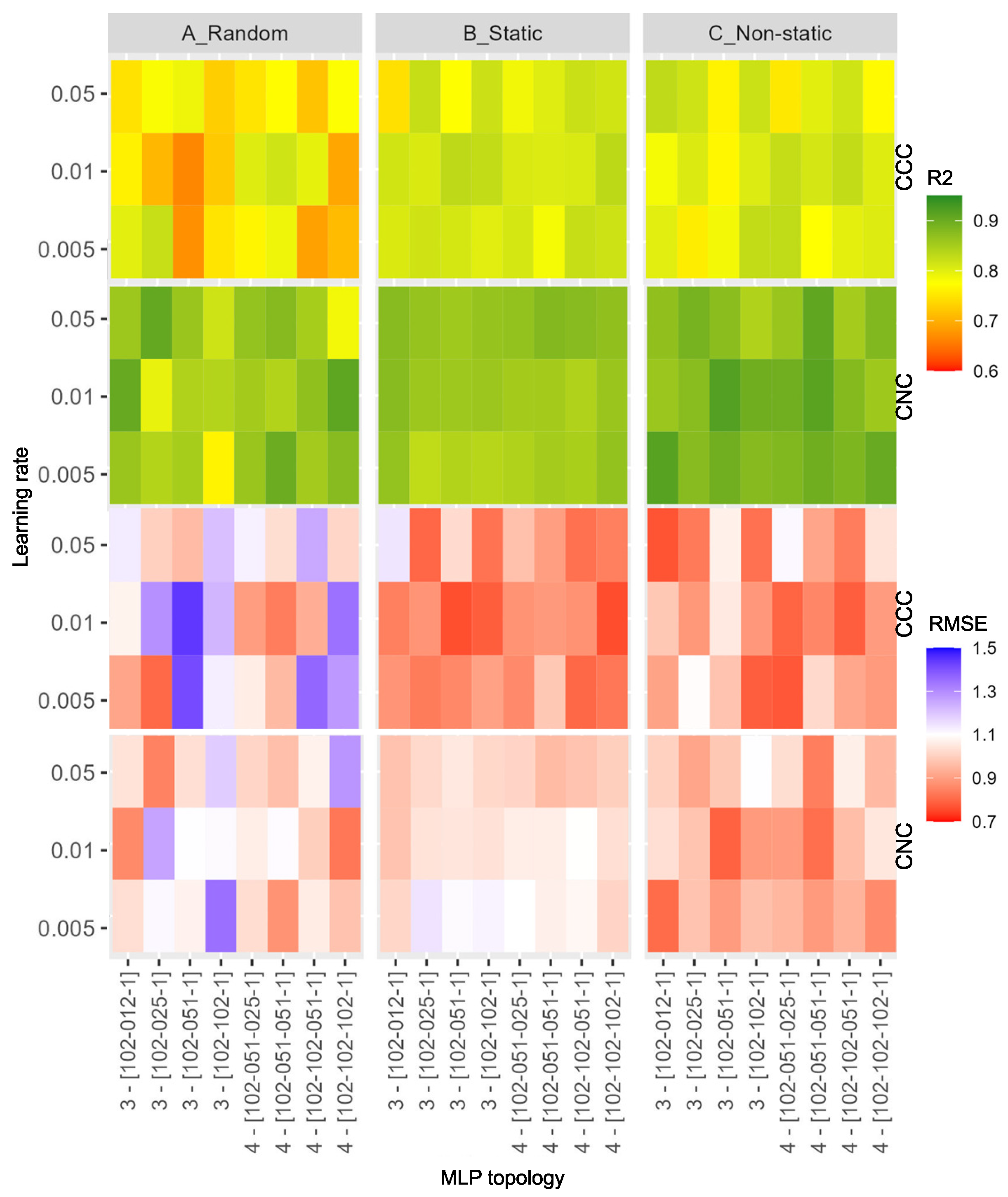
- In the first group, to evaluate the self-supervised approach, we fixed the autoencoder topology and compared a large set of different MLP configurations combined with different encoder initializations. An ablation study was also conducted;
- In the second group of experiments, to assess the performance of the proposed solution with a standard features extraction approach, the accuracies of MLP estimations using features extracted from the Encoder were compared with those extracted by a Principal Component Analysis (PCA) with different configurations;
- Finally, a comparison with a previously published result is also presented.
5.1. Metrics
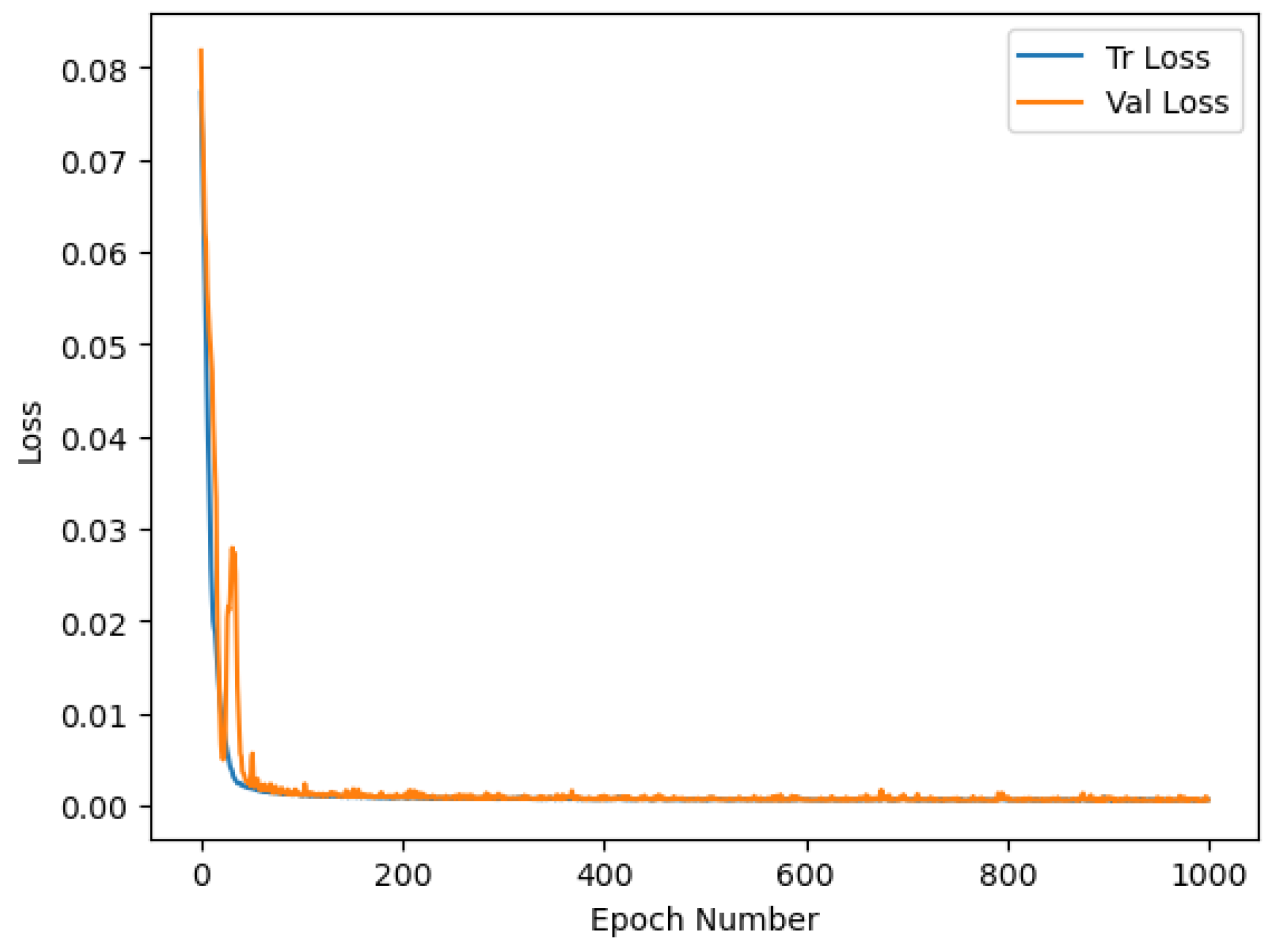
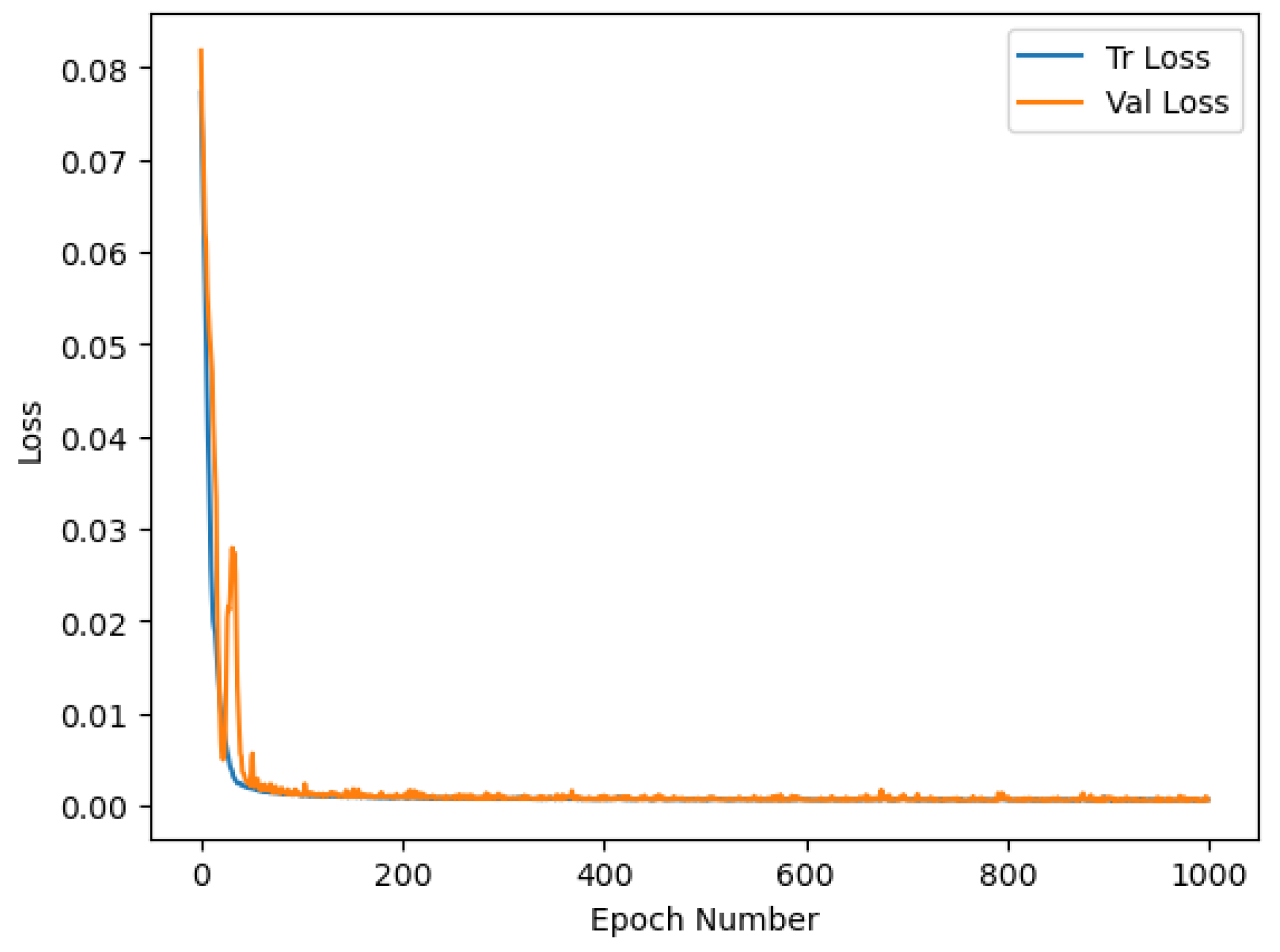
5.2. Autoencoder Model
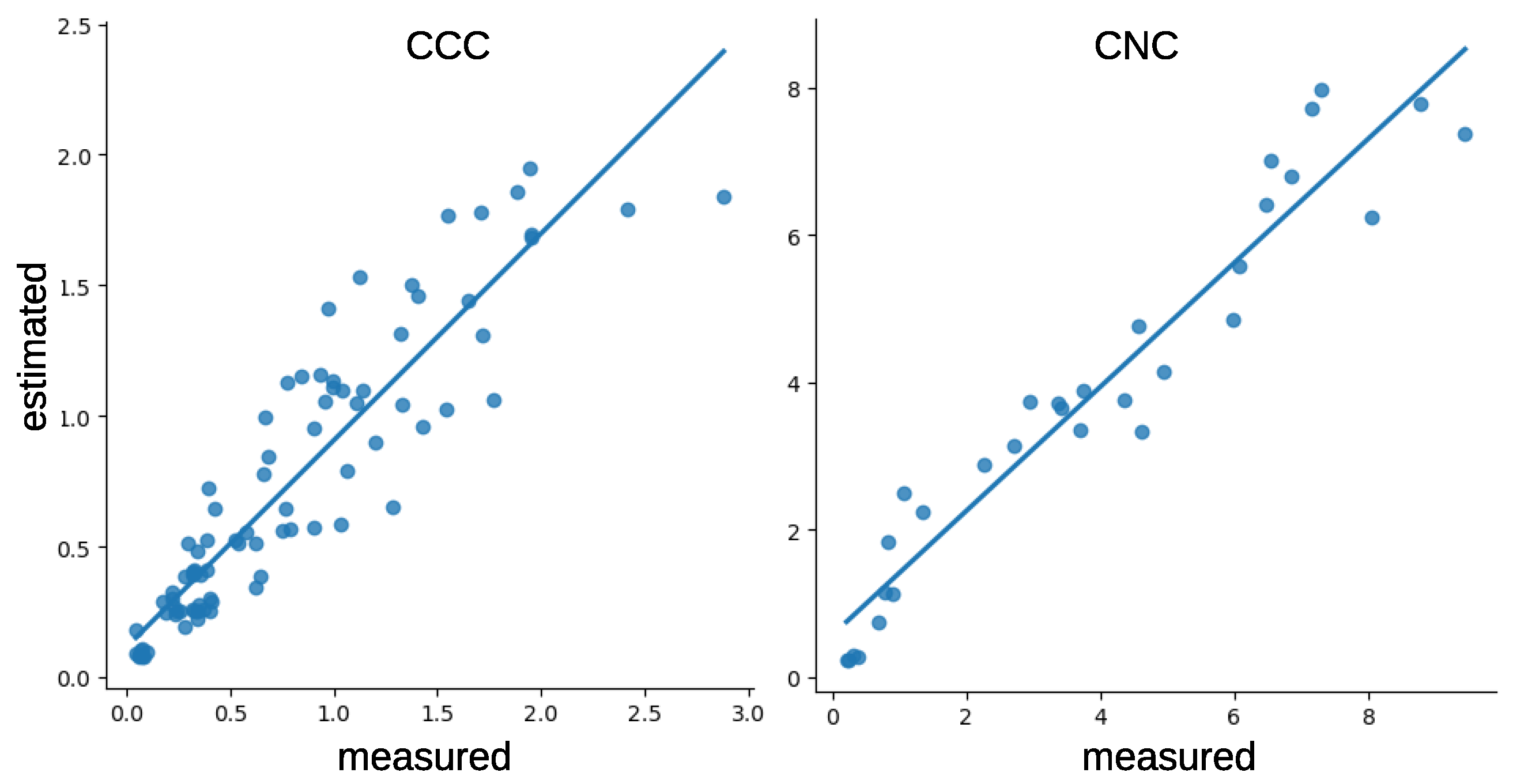
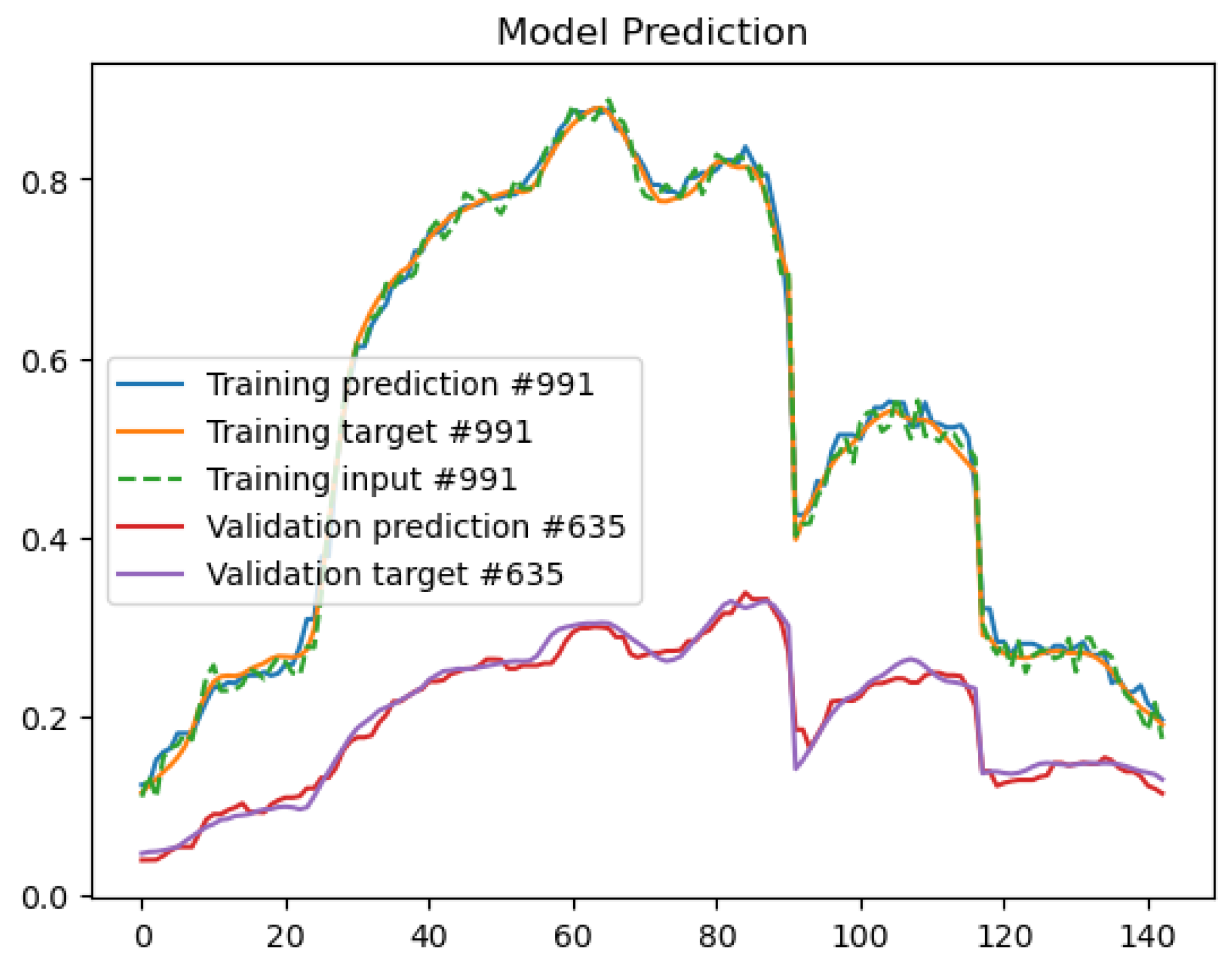
5.3. Model for Regression
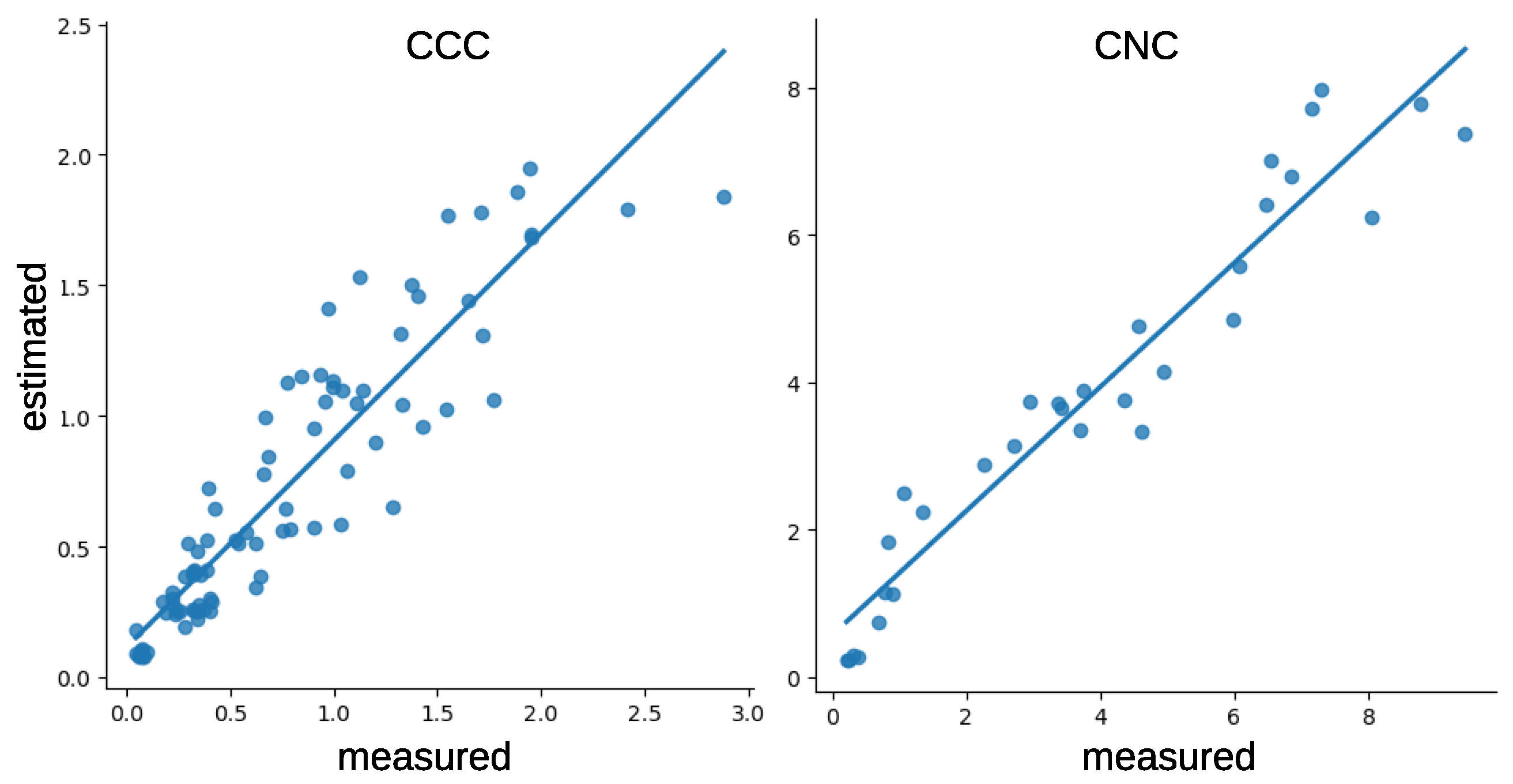
5.4. Comparisons
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Herrmann, I.; Bdolach, E.; Montekyo, Y.; Rachmilevitch, S.; Townsend, P.A.; Karnieli, A. Assessment of maize yield and phenology by drone-mounted superspectral camera. Precis. Agric. 2020, 21, 51–76. [Google Scholar] [CrossRef]
- Sun, Q.; Chen, L.; Zhang, S.; Gu, X.; Zhou, J.; Gu, L.; Zhen, W. Estimation of Canopy Nitrogen Density of Lodging Maize Via UAV-Based Hyperspectral Images. SSRN 4364605. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4364605 (accessed on 1 May 2023).
- Zhang, X.; Han, L.; Sobeih, T.; Lappin, L.; Lee, M.A.; Howard, A.; Kisdi, A. The Self-Supervised Spectral–Spatial Vision Transformer Network for Accurate Prediction of Wheat Nitrogen Status from UAV Imagery. Remote Sens. 2022, 14, 1400. [Google Scholar] [CrossRef]
- Herrmann, I.; Berger, K. Remote and proximal assessment of plant traits. 2021. [Google Scholar]
- Colaço, A.F.; Bramley, R.G. Do crop sensors promote improved nitrogen management in grain crops? Field Crop. Res. 2018, 218, 126–140. [Google Scholar] [CrossRef]
- Munnaf, M.A.; Haesaert, G.; Van Meirvenne, M.; Mouazen, A. Site-specific seeding using multi-sensor and data fusion techniques: A review. Adv. Agron. 2020, 161, 241–323. [Google Scholar]
- Wang, J.; Shen, C.; Liu, N.; Jin, X.; Fan, X.; Dong, C.; Xu, Y. Non-destructive evaluation of the leaf nitrogen concentration by in-field visible/near-infrared spectroscopy in pear orchards. Sensors 2017, 17, 538. [Google Scholar] [CrossRef] [PubMed]
- Berger, K.; Verrelst, J.; Féret, J.B.; Wang, Z.; Wocher, M.; Strathmann, M.; Danner, M.; Mauser, W.; Hank, T. Crop nitrogen monitoring: Recent progress and principal developments in the context of imaging spectroscopy missions. Remote Sens. Environ. 2020, 242, 111758. [Google Scholar] [CrossRef]
- Imani, M.; Ghassemian, H. An overview on spectral and spatial information fusion for hyperspectral image classification: Current trends and challenges. Inf. Fusion 2020, 59, 59–83. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Shi, P.; Wang, Y.; Xu, J.; Zhao, Y.; Yang, B.; Yuan, Z.; Sun, Q. Rice nitrogen nutrition estimation with RGB images and machine learning methods. Comput. Electron. Agric. 2021, 180, 105860. [Google Scholar] [CrossRef]
- Qiu, Z.; Ma, F.; Li, Z.; Xu, X.; Ge, H.; Du, C. Estimation of nitrogen nutrition index in rice from UAV RGB images coupled with machine learning algorithms. Comput. Electron. Agric. 2021, 189, 106421. [Google Scholar] [CrossRef]
- Verrelst, J.; Malenovskỳ, Z.; Van der Tol, C.; Camps-Valls, G.; Gastellu-Etchegorry, J.P.; Lewis, P.; North, P.; Moreno, J. Quantifying vegetation biophysical variables from imaging spectroscopy data: A review on retrieval methods. Surv. Geophys. 2019, 40, 589–629. [Google Scholar] [CrossRef] [PubMed]
- Féret, J.B.; Berger, K.; de Boissieu, F.; Malenovský, Z. PROSPECT-PRO for estimating content of nitrogen-containing leaf proteins and other carbon-based constituents. Remote Sens. Environ. 2021, 252, 112173. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 21–27 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Güldenring, R.; Nalpantidis, L. Self-supervised contrastive learning on agricultural images. Comput. Electron. Agric. 2021, 191, 106510. [Google Scholar] [CrossRef]
- Chiu, M.T.; Xu, X.; Wei, Y.; Huang, Z.; Schwing, A.G.; Brunner, R.; Khachatrian, H.; Karapetyan, H.; Dozier, I.; Rose, G.; et al. Agriculture-vision: A large aerial image database for agricultural pattern analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR2020, Seattle, WA, USA, 13–19 June 2020; pp. 2828–2838. [Google Scholar]
- Olsen, A.; Konovalov, D.A.; Philippa, B.; Ridd, P.; Wood, J.C.; Johns, J.; Banks, W.; Girgenti, B.; Kenny, O.; Whinney, J.; et al. DeepWeeds: A multiclass weed species image dataset for deep learning. Sci. Rep. 2019, 9, 2058. [Google Scholar] [CrossRef]
- Marszalek, M.L.; Saux, B.L.; Mathieu, P.P.; Nowakowski, A.; Springer, D. Self-supervised learning–A way to minimize time and effort for precision agriculture? arXiv 2022, arXiv:2204.02100. [Google Scholar] [CrossRef]
- Yue, J.; Fang, L.; Rahmani, H.; Ghamisi, P. Self-supervised learning with adaptive distillation for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Liu, Z.; Han, X.H. Deep self-supervised hyperspectral image reconstruction. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–20. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Chen, Y.; Yu, H.; Qin, T. Adaptive memory networks with self-supervised learning for unsupervised anomaly detection. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Zhao, R.; An, L.; Tang, W.; Qiao, L.; Wang, N.; Li, M.; Sun, H.; Liu, G. Improving chlorophyll content detection to suit maize dynamic growth effects by deep features of hyperspectral data. Field Crop. Res. 2023, 297, 108929. [Google Scholar] [CrossRef]
- Yin, C.; Lv, X.; Zhang, L.; Ma, L.; Wang, H.; Zhang, L.; Zhang, Z. Hyperspectral UAV Images at Different Altitudes for Monitoring the Leaf Nitrogen Content in Cotton Crops. Remote Sens. 2022, 14, 2576. [Google Scholar] [CrossRef]
- Wang, X.; Yang, N.; Liu, E.; Gu, W.; Zhang, J.; Zhao, S.; Sun, G.; Wang, J. Tree Species Classification Based on Self-Supervised Learning with Multisource Remote Sensing Images. Appl. Sci. 2023, 13, 1928. [Google Scholar] [CrossRef]
- Xie, X.; Wang, Y.; Li, Q. S 3 R: Self-supervised Spectral Regression for Hyperspectral Histopathology Image Classification. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2022: 25th International Conference, Singapore, 18–22 September 2022; Proceedings, Part II. Springer: Berlin/Heidelberg, Germany, 2022; pp. 46–55. [Google Scholar]
- Candiani, G.; Tagliabue, G.; Panigada, C.; Verrelst, J.; Picchi, V.; Rivera Caicedo, J.P.; Boschetti, M. Evaluation of hybrid models to estimate chlorophyll and nitrogen content of maize crops in the framework of the future CHIME mission. Remote Sens. 2022, 14, 1792. [Google Scholar] [CrossRef] [PubMed]
- Bank, D.; Koenigstein, N.; Giryes, R. Autoencoders. arXiv 2020, arXiv:2003.05991. [Google Scholar]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Morisette, J.T.; Baret, F.; Privette, J.L.; Myneni, R.B.; Nickeson, J.E.; Garrigues, S.; Shabanov, N.V.; Weiss, M.; Fernandes, R.A.; Leblanc, S.G.; et al. Validation of global moderate-resolution LAI products: A framework proposed within the CEOS land product validation subgroup. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1804–1817. [Google Scholar] [CrossRef]
- Weiss, M.; Baret, F.; Smith, G.; Jonckheere, I.; Coppin, P. Review of methods for in situ leaf area index (LAI) determination: Part II. Estimation of LAI, errors and sampling. Agric. For. Meteorol. 2004, 121, 37–53. [Google Scholar] [CrossRef]
- Jonckheere, I.; Fleck, S.; Nackaerts, K.; Muys, B.; Coppin, P.; Weiss, M.; Baret, F. Review of methods for in situ leaf area index determination: Part I. Theories, sensors and hemispherical photography. Agric. For. Meteorol. 2004, 121, 19–35. [Google Scholar] [CrossRef]
- Rascher, U.; Alonso, L.; Burkart, A.; Cilia, C.; Cogliati, S.; Colombo, R.; Damm, A.; Drusch, M.; Guanter, L.; Hanus, J.; et al. Sun-induced fluorescence–a new probe of photosynthesis: First maps from the imaging spectrometer HyPlant. Glob. Chang. Biol. 2015, 21, 4673–4684. [Google Scholar] [CrossRef]
- Rossini, M.; Nedbal, L.; Guanter, L.; Ač, A.; Alonso, L.; Burkart, A.; Cogliati, S.; Colombo, R.; Damm, A.; Drusch, M.; et al. Red and far red Sun-induced chlorophyll fluorescence as a measure of plant photosynthesis. Geophys. Res. Lett. 2015, 42, 1632–1639. [Google Scholar] [CrossRef]
- Cogliati, S.; Rossini, M.; Julitta, T.; Meroni, M.; Schickling, A.; Burkart, A.; Pinto, F.; Rascher, U.; Colombo, R. Continuous and long-term measurements of reflectance and sun-induced chlorophyll fluorescence by using novel automated field spectroscopy systems. Remote Sens. Environ. 2015, 164, 270–281. [Google Scholar] [CrossRef]
- Siegmann, B.; Alonso, L.; Celesti, M.; Cogliati, S.; Colombo, R.; Damm, A.; Douglas, S.; Guanter, L.; Hanuš, J.; Kataja, K.; et al. The high-performance airborne imaging spectrometer HyPlant—From raw images to top-of-canopy reflectance and fluorescence products: Introduction of an automatized processing chain. Remote Sens. 2019, 11, 2760. [Google Scholar] [CrossRef]
- Verhoef, W. Light scattering by leaf layers with application to canopy reflectance modeling: The SAIL model. Remote Sens. Environ. 1984, 16, 125–141. [Google Scholar] [CrossRef]
- Verhoef, W.; Jia, L.; Xiao, Q.; Su, Z. Unified Optical-Thermal Four-Stream Radiative Transfer Theory for Homogeneous Vegetation Canopies. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1808–1822. [Google Scholar] [CrossRef]
- Weiss, M.; Baret, F. S2ToolBox Level 2 Products: LAI, FAPAR, FCOVER, v1.1 ed.; Institut National de la Recherche Agronomique (INRA): Avignon, France, 2016. [Google Scholar]
- Ranghetti, M.; Boschetti, M.; Ranghetti, L.; Tagliabue, G.; Panigada, C.; Gianinetto, M.; Verrelst, J.; Candiani, G. Assessment of maize nitrogen uptake from PRISMA hyperspectral data through hybrid modelling. Eur. J. Remote. Sens. 2022, 1–17. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Out. Shape | Param |
|---|---|---|
| Encoder | ||
| Conv1d (1, 24) | [−1, 24, 143] | 96 |
| ReLU | [−1, 24, 143] | 0 |
| Conv1d (24, 24) | [−1, 24, 143] | 1752 |
| BatchNorm1d | [−1, 24, 143] | 48 |
| ReLU | [−1, 24, 143] | 0 |
| MaxPool1d | [−1, 24, 71] | 0 |
| Conv1d (24, 12) | [−1, 12, 71] | 876 |
| ReLU | [−1, 12, 71] | 0 |
| Conv1d (12, 12) | [−1, 12, 71] | 444 |
| BatchNorm1d | [−1, 12, 71] | 24 |
| ReLU | [−1, 12, 71] | 0 |
| MaxPool1d | [−1, 12, 35] | 0 |
| Conv1d (12, 6) | [−1, 6, 35] | 222 |
| ReLU | [−1, 6, 35] | 0 |
| MaxPool1d | [−1, 6, 17] | 0 |
| Decoder | ||
| Conv1d (6, 12) | [−1, 12, 17] | 228 |
| ReLU | [−1, 12, 17] | 0 |
| Interpolate | [−1, 12, 57] | 0 |
| Conv1d(12, 24) | [−1, 24, 57] | 888 |
| ReLU | [−1, 24, 57] | 0 |
| Interpolate | [−1, 24, 115] | 0 |
| Conv1d (24, 1) | [−1, 1, 115] | 73 |
| ReLU | [−1, 1, 115] | 0 |
| Interpolate | [−1, 1, 143] | 0 |
| MLP for regression | ||
| Flatten | [−1, 102] | 0 |
| Linear (102, 51) | [−1, 51] | 5253 |
| BatchNorm1d | [−1, 51] | 102 |
| Dropout | [−1, 51] | 0 |
| ReLU | [−1, 51] | 0 |
| Linear (51, 1) | [−1, 1] | 52 |
| Date | Lines | Tot. Length | Tot. Area | Swath | GSD |
|---|---|---|---|---|---|
| 7 July 2018 | 6 | ∼7 km | ∼18 km | 400 m | 1 m |
| 30 July 2018 | 4 | ∼8 km | ∼20 km | 1800 m | 4.5 m |
| Param. | Description | Unit | Range 1 | |||
|---|---|---|---|---|---|---|
| PROSPECT-PRO | N | Structural parameter | - | Normal | 1.4 | 0.14 |
| Cab | Chlorophyll content 2 | g cm | Normal | 41.5 | 8.8 | |
| Ccx | Carotenoid content 2 | g cm | Normal | 7.32 | 1.5 | |
| Canth | Anthocyanin content | g cm | Normal | 0.0 | 0.0 | |
| Cbp | Brown pigment content | g cm | Normal | 0.0 | 0.0 | |
| Cw | Water content 2 | mg cm | Normal | 12.92 | 1.91 | |
| Cp | Protein content 2 | g cm | Uniform | 0.0 | 0.001 | |
| CBC | Carbon-Based Constituents | g cm | Uniform | 0.003 | 0.006 | |
| 4SAIL | ALA | Average Leaf Angle 2 | ° | Normal | 49.0 | 4.9 |
| LAI | Leaf Area Index 2 | m m | Normal | 1.77 | 1.4 | |
| HOT | Hot spot parameter | m m | Normal | 0.01 | 0.001 | |
| SZA | Solar Zenith Angle 2 | ° | Uniform | 26 | 30 | |
| OZA | Observer Zenith Angle | ° | Uniform | 0 | 0 | |
| RAA | Relative Azimuth Angle | ° | Uniform | 0 | 0 | |
| BG | Soil Spectra 2 | - | Uniform | 2 | 4 | |
| FE | ML | VAR | R2 | RMSE |
|---|---|---|---|---|
| Encoder | MLP | CCC | 0.8318 | 0.2490 |
| PCA | MLP | CCC | 0.8275 | 0.2521 |
| PCA | GPR | CCC | 0.79 | 0.38 |
| PCA | GPR-AL | CCC | 0.88 | 0.21 |
| Encoder | MLP | CNC | 0.9186 | 0.7908 |
| PCA | MLP | CNC | 0.8861 | 0.9351 |
| PCA | GPR | CNC | 0.84 | 1.10 |
| PCA | GPR-AL | CNC | 0.93 | 0.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gallo, I.; Boschetti, M.; Rehman, A.U.; Candiani, G. Self-Supervised Convolutional Neural Network Learning in a Hybrid Approach Framework to Estimate Chlorophyll and Nitrogen Content of Maize from Hyperspectral Images. Remote Sens. 2023, 15, 4765. https://doi.org/10.3390/rs15194765
Gallo I, Boschetti M, Rehman AU, Candiani G. Self-Supervised Convolutional Neural Network Learning in a Hybrid Approach Framework to Estimate Chlorophyll and Nitrogen Content of Maize from Hyperspectral Images. Remote Sensing. 2023; 15(19):4765. https://doi.org/10.3390/rs15194765
Chicago/Turabian StyleGallo, Ignazio, Mirco Boschetti, Anwar Ur Rehman, and Gabriele Candiani. 2023. "Self-Supervised Convolutional Neural Network Learning in a Hybrid Approach Framework to Estimate Chlorophyll and Nitrogen Content of Maize from Hyperspectral Images" Remote Sensing 15, no. 19: 4765. https://doi.org/10.3390/rs15194765
APA StyleGallo, I., Boschetti, M., Rehman, A. U., & Candiani, G. (2023). Self-Supervised Convolutional Neural Network Learning in a Hybrid Approach Framework to Estimate Chlorophyll and Nitrogen Content of Maize from Hyperspectral Images. Remote Sensing, 15(19), 4765. https://doi.org/10.3390/rs15194765