1. Introduction
Afghanistan supplies more than 80% of the world’s opiates. Changes in Afghan opiate production have far-reaching consequences for trafficking activities and the flow of illicit money as well as for the high dependency users of heroin and opium. Understanding and monitoring opiate production in the country is therefore of great importance for the international community and the United Nations Office on Drugs and Crime (UNODC) conducts annual opium cultivation and production surveys [
1].
The relationship between land use and poppy cultivation is critical for monitoring the dynamics of opium poppy cultivation, and thus for evaluating and developing effective counter narcotics policy to reduce opium production. In the main opium provinces of Afghanistan, the availability of agricultural land is strongly correlated to opium cultivation, making up-to-date and accurate information on agricultural land a requirement for efficient monitoring [
2]. The land used for cultivating opium poppy can fluctuate strongly from year to year and is driven by many socio-economic and agro-economic factors, such as water and resource availability, land rotation and agricultural expansion [
3,
4]. For example, access to solar-powered pumps and fertilisers have enabled some poppy farmers to relocate to former desert areas, increasing the total area of land available for opium poppy cultivation in Helmand, one of the main cultivating Provinces, resulting in an unprecedented increase in opium cultivation in the 2010s [
5].
Satellite imagery can be used to map agricultural land as it provides a synoptic view of the landscape that can be timed to coincide with the presence of crops. The UNODC uses a combination of digital classification and visual image-interpretation of Landsat-8 Operational Land Imager (OLI) data, supplemented with Sentinel-2 and very-high resolution imagery (VHR), to create an agricultural mask, or agmask, that defines the sampling frame for their annual survey of opium production in Afghanistan [
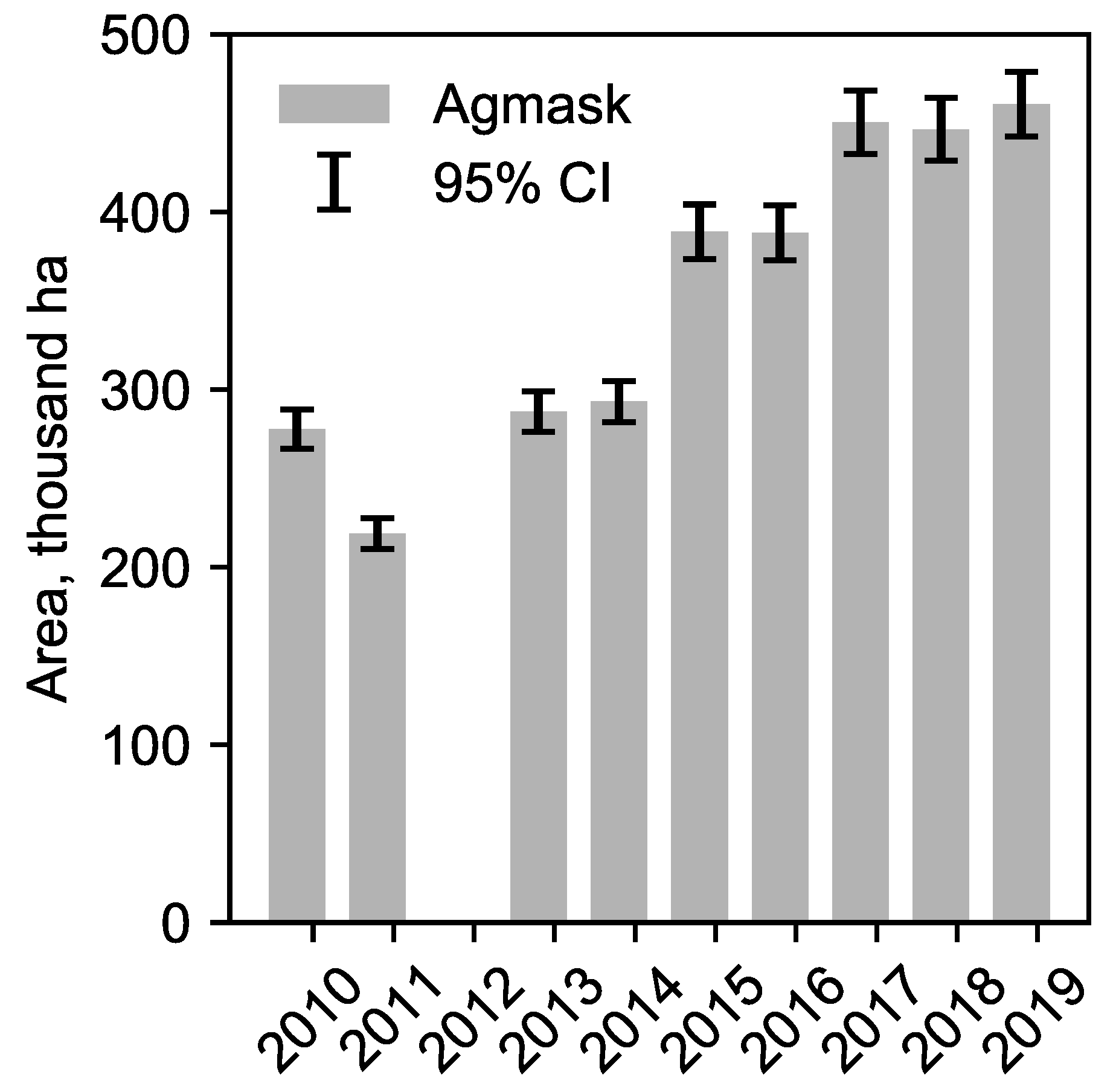
2]. This methodology is time consuming and resource intensive, making the creation of an annual map impractical. Instead a pragmatic approach of adding new areas of agriculture on an ad-hoc basis is taken, with each year’s agmask largely based on the previous year. This results in a conservative agmask, that tends to over-estimate the agricultural land that can used for opium poppy cultivation. While this avoids underestimation of opium poppy caused by the omission of potential land, it reduces the efficiency of the sample used for obtaining VHR satellite imagery, collected for estimating the area under opium poppy cultivation, and does not capture the inter-annual changes in agricultural land.
Recent work has shown the potential to produce accurate and timely agricultural land classification from satellite imagery using convolutional neural networks (CNNs) [
6,
7]. These deep learning models differ from conventional pixel- and object-based approaches in that they can be trained across multiple years of image data using transfer learning: where a pre-trained model is fine tuned using new labelled image data from a much smaller dataset than was used to train the original model. Ref. [
6] found that transfer learning in Afghanistan’s Helmand Province between years required 75% less labelled data than models trained from scratch (no prior training), with improved overall accuracy (>94%).
An explanation for the improvement in model accuracy with fine tuning is that each image-specific dataset contains a subset of all possible observations, so as more data becomes available the model gets better at extrapolating, or generalising, to unknown instances as they are more likely to fall within the distribution of the training data [
8]. The challenge is creating the large amounts of labelled data required to train the model to the required accuracy [
9]. Utilising datasets that already exist would reduce the need for costly and time consuming image labelling and provide a broader set of training examples. However, these historical data are likely to be from a range of different sensors, some of which are no longer operating, and the resulting models would need to accurately classify image data from the latest Earth Observations (EO) programmes. The difficulty in leveraging historical data is the inherent radiometric and atmospheric differences between image acquisitions, which means, in general, different images require different analysis and models, especially for supervised classification [
10].
In this paper, we investigate the characteristics of agricultural land in Afghanistan that span different image datasets and use this new knowledge to train a generalised deep learning model to classify new (or archive) images, without the need for any further training, to achieve fully automated mapping. The generalised model is used to map the evolution of agricultural land in Helmand Province, including hindcasting, on Landsat and Sentinel-2 data from 1999 to 2019. The ability of the model to generalise to other geographical areas is tested in Farah and Nangarhar Provinces with no additional training. The novelty in this work is the creation of a model trained using images and historical labelled data from different satellite sensors over time, which can be used to classify images from any medium resolution image.
2. Materials and Methods
A generalised model for agricultural land classification was developed using historical labelled image data at medium resolution (∼30 m). First, to optimise preprocessing of inputs for transfer learning, the contribution of shape, texture, and spectral image features to agricultural land classification were investigated, along with different approaches to standardising image pixel values. Second, we trained a CNN year-on-year with dense and sparse datasets between 2007 and 2017 for use as a generalised classifier of agricultural land from medium resolution images. This generalised model was then used to map the yearly changes in agricultural land in Helmand Province from 2017 to 2019, and in two other provinces, with no further training. The individual steps are detailed in the following subsections.
2.1. Study Area
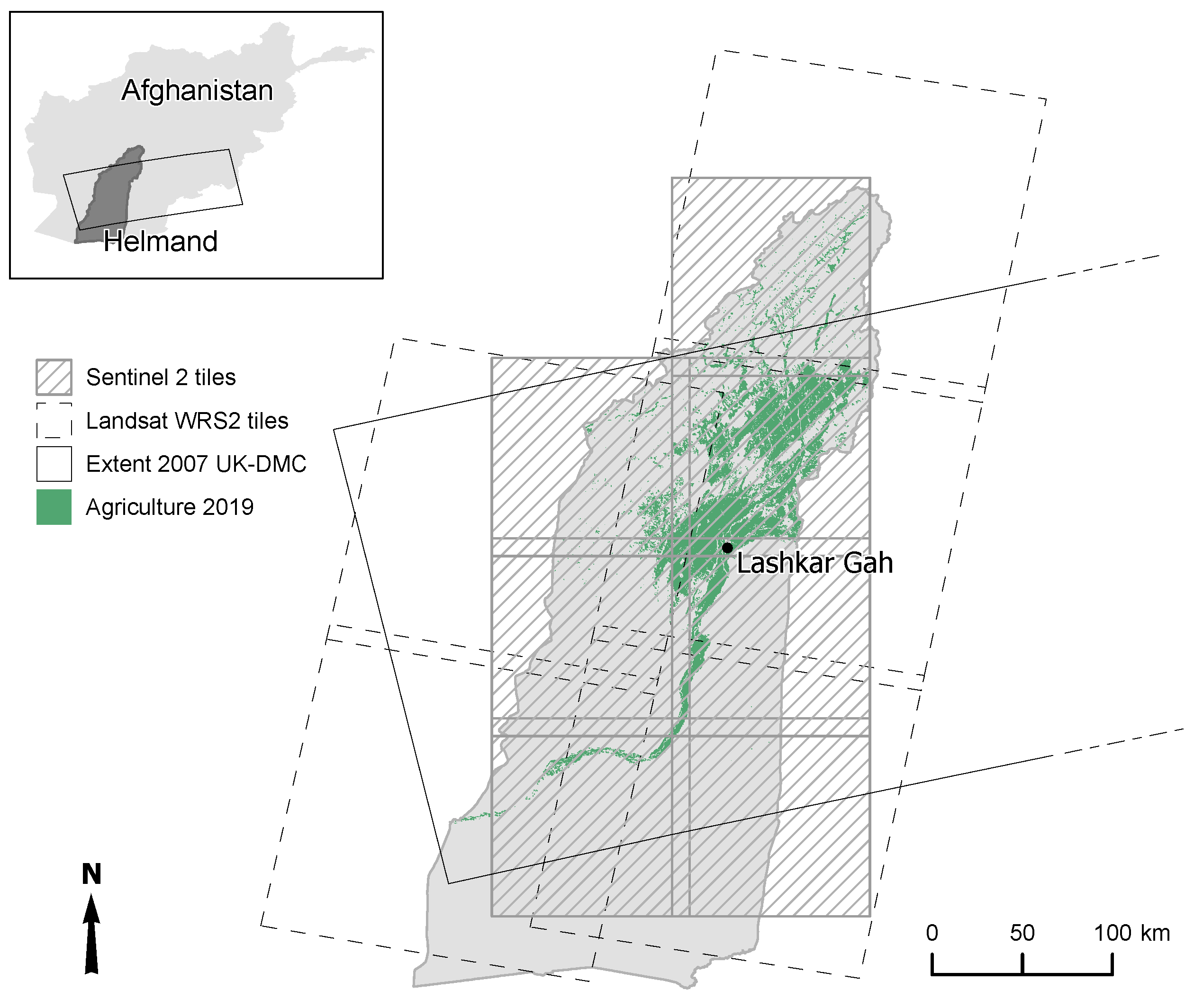
The study area is Helmand Province in the south of Afghanistan (
Figure 1), which is the largest opium producing province in Afghanistan with an estimated 109,778 ha grown in 2021, accounting for 60% of national opium cultivation [
11]. The majority of the Province is desert plain with the main area of cultivation in the Helmand river valley. There are areas of natural vegetation (needle leaved trees and shrubs) in the mountainous north of the Province. The agricultural landscape is dominated by irrigated crops of poppy and wheat but also includes fruit trees, vineyards, and rain-fed crops in lowland and highland areas [
12]. Agriculture is reliant on snowpack melt to supply sufficient groundwater for irrigation, with water availability one of the main drivers for changes in agricultural area [
4,
13].
2.2. Model Training and Evaluation Datasets
Labels for training and evaluation of the models were created from existing maps of agricultural land for Helmand Province using a targeted training strategy [
6]. Labelled datasets of active agricultural land and orthorectified Disaster Monitoring Constellation (DMC) images, with near-infrared (NIR, 0.76 to 0.90 µm), red (R, 0.63 to 0.69 µm), and green (G, 0.52 to 0.62 µm) bands at 32 m spatial resolution for 2007 and 2009 (
Table 1) were taken from opium poppy cultivation surveys detailed in [
3].
Input images from each year were split into individual image chips, or patches, using a non-overlapping 256 × 256 pixel grid. The chip size was chosen so samples would easily fit within memory on a NVIDIA Quadro K2200 graphics card during training. Chips containing vegetation not classified as agriculture in the agmasks were identified using a simple threshold of Normalised Difference Vegetation Index (NDVI) (
), calculated at the image level using the Otsu method [
14]. All chips with no vegetation were discarded, as the majority of chips contain no agriculture and the background class is well represented in the remaining agricultural chips. The selected chips were then ordered according to proportion of agriculture and split into a 75% training and 25% validation set by drawing every fourth chip from the ordered set, resulting in 415 training samples and 137 validation samples for each year.
Agricultural masks for Helmand Province from 2015 to 2017 were obtained from the UNODC. These agmasks differ from the 2007 to 2009 data as they represent the potential agricultural area for that year, including any fallow areas, and define the area-frame for the UNODC’s annual opium survey [
15]. Image datasets for the UNODC labels were selected for model development (2009 Landsat-5) and transfer learning (Landsat-5 & 8 and Sentinel-2a) from cloud-free scenes as close as possible to the peak in the first vegetation cycle [
16] and paired with the agmasks (
Table 1). Multiple images for each year were used because of differences in peak opium biomass (approximately 1–2 weeks) between the north and south of the province [
3]. Landsat-5 and Landsat-8 OLI images were downloaded from the United States Geological Survey Earth Explorer as level-1A top-of-atmosphere reflectance and Sentinel-2a images from The Copernicus Open Access Hub. Bands for each image were then stacked into false colour near-infrared composites (FCC) to match the bands of the DMC. Samples for training and evaluation were selected using the same sampling strategy as the 2008 and 2009 DMC data.
Each sample comprised an image FCC chip and labels on the same pixel grid (i.e., one label per pixel). The sampling strategy was found to be efficient during training compared to using all the data or a purely random sample as the examples were drawn from a balanced sample containing a higher number of natural vegetation pixels—the main source of confusion.
2.3. Deep Fully-Convolutional Neural Network
Fully-convolutional neural networks are a subset of deep learning models that are well suited for use with satellite imagery. Their main advantage is that inference takes place at the pixel level, without any flattening of the data, as input pixels are path-connected to the output classification [
17]. In practice, this means that models can be trained and evaluated on images of different dimensions, with image size limited to the available memory on a Graphical Processing Unit (GPU), and the relationships between adjacent pixels are maintained.
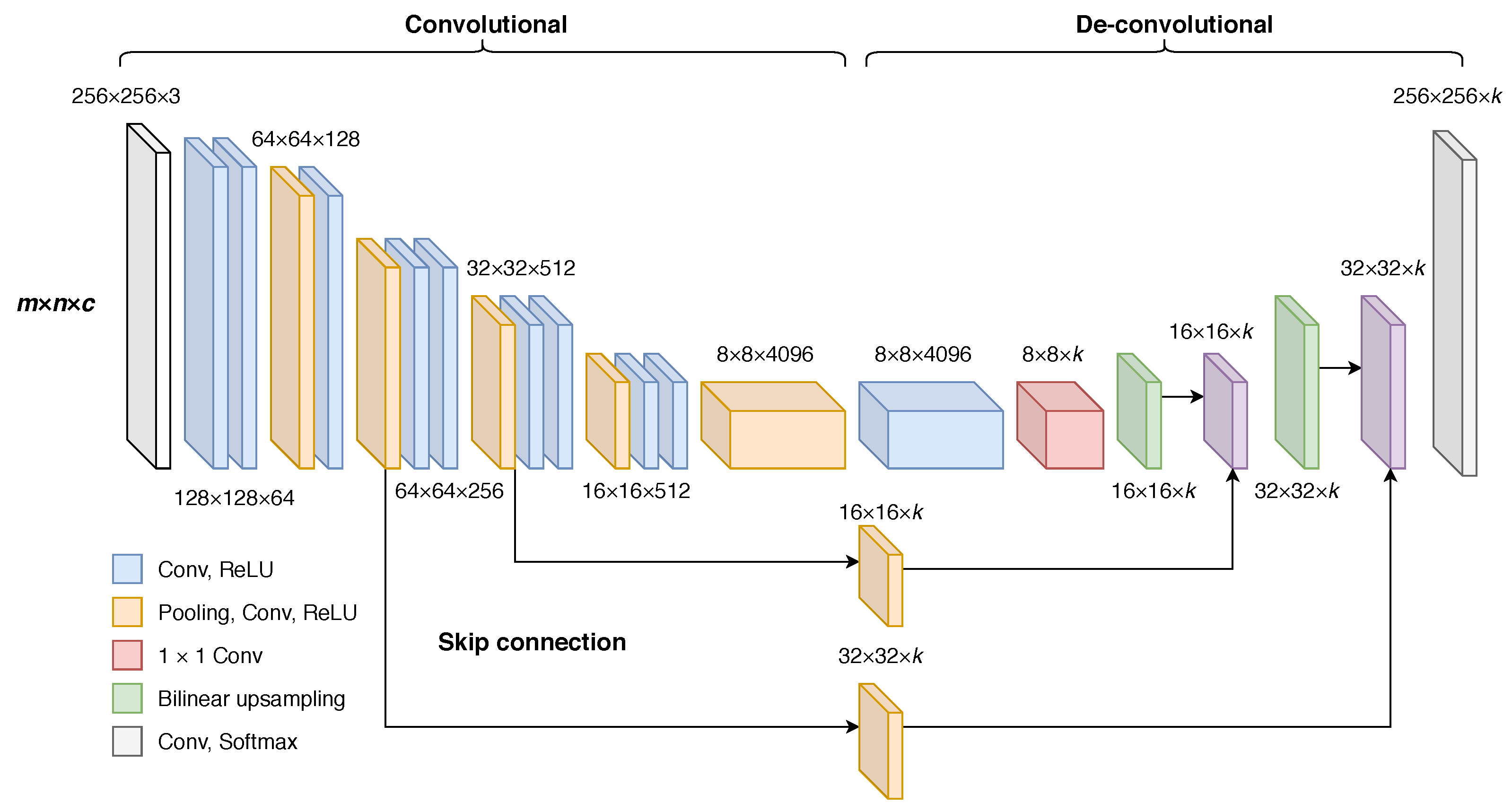
Fully Convolutional Network 8 (FCN-8) of [
17] was selected for this study because of its relative simplicity and the performance of U-Net type CNN architectures for semantic segmentation of satellite image data [
18]. The network is built up of convolutional layers, where each layer can be though of as a kernel operation using filter weights
k of shape
, with width
m, height
n and depth
c. Starting with the input image, each subsequent layer with pixel vector
, at location
, is computed from the previous layer (
) by
where
f is a matrix multiplication and the offsets
, along with the stride
s, map the input spatial region, known as the receptive field. Pooling layers down-sample inputs to encode complex relationships between pixels, with an increasing number of features (dimension
c) at the expense of spatial resolution (
). The deeper layers are up-sampled back to the 2D dimensions of the input using de-convolutional layers. Information from preceding layers is fused with the up-sampled layers using skip connections that add finer spatial information to the dense output. Scoring takes place before fusing to reduce the depth of the layer to the number of output classes (
Figure 2).
FCN-8 model code (available at
https://github.com/dspix/deepjet (accessed on 2 August 2023)) written for TensorFlow [
20] was used for all experiments within the open source Anaconda Python distribution [
21]. Convolutional layer weights were randomly initialised and up-sampling layer weights initialised as bilinear filters as suggested in [
17]. All models were trained on a NVIDIA Quadro K2200 GPU. The cross entropy loss between the model predictions and labels was summed across the spatial dimensions at each training step and gradients optimised using Adam [
22] with a learning rate of 10
. To avoid over-fitting a 50% dropout rate was applied to layers 6 and 7 and model training was stopped after 50 epochs. This was found by experiment to be long enough for the training loss to stabilise without an increase in the validation loss, which would indicate over-fitting of the model.
2.4. Image Features for Agricultural Land Classification and Input Standardisation
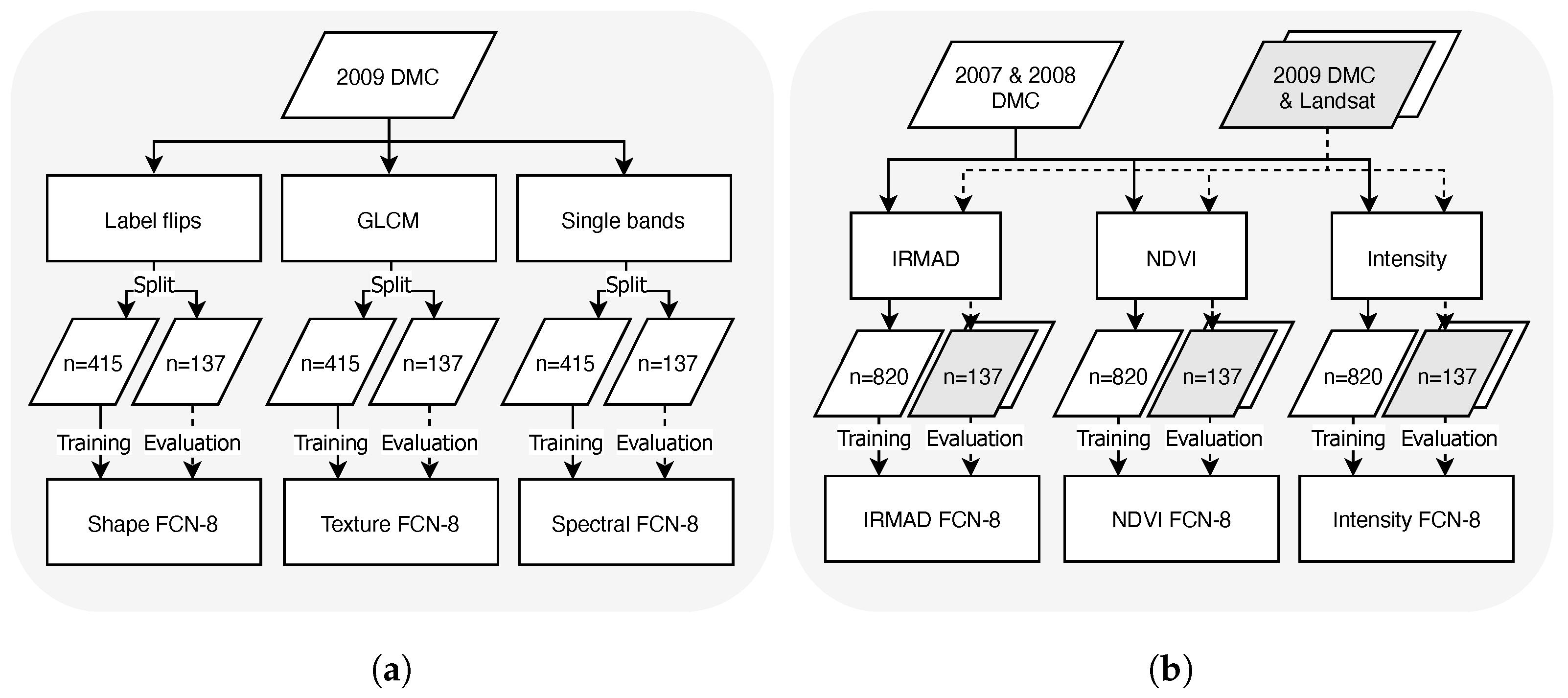
Image features and image standardisation were investigated in order to optimise transfer learning of the generalised model from the variable sources of input data (
Figure 3). Isolating the individual effect of spectral reflectance, textural or spatial patterns, and shape on model accuracy is complex as these features are combined by the convolutional layers of the FCN-8. The approach taken was to create sets of the 2009 training data (number of samples,
n = 415), using DMC Level 1A image chips, with the feature of interest extracted to train separate models (steps shown in
Figure 3a). The individual models were evaluated on the 2009 validation samples (
n = 137) from the targeted sample strategy.
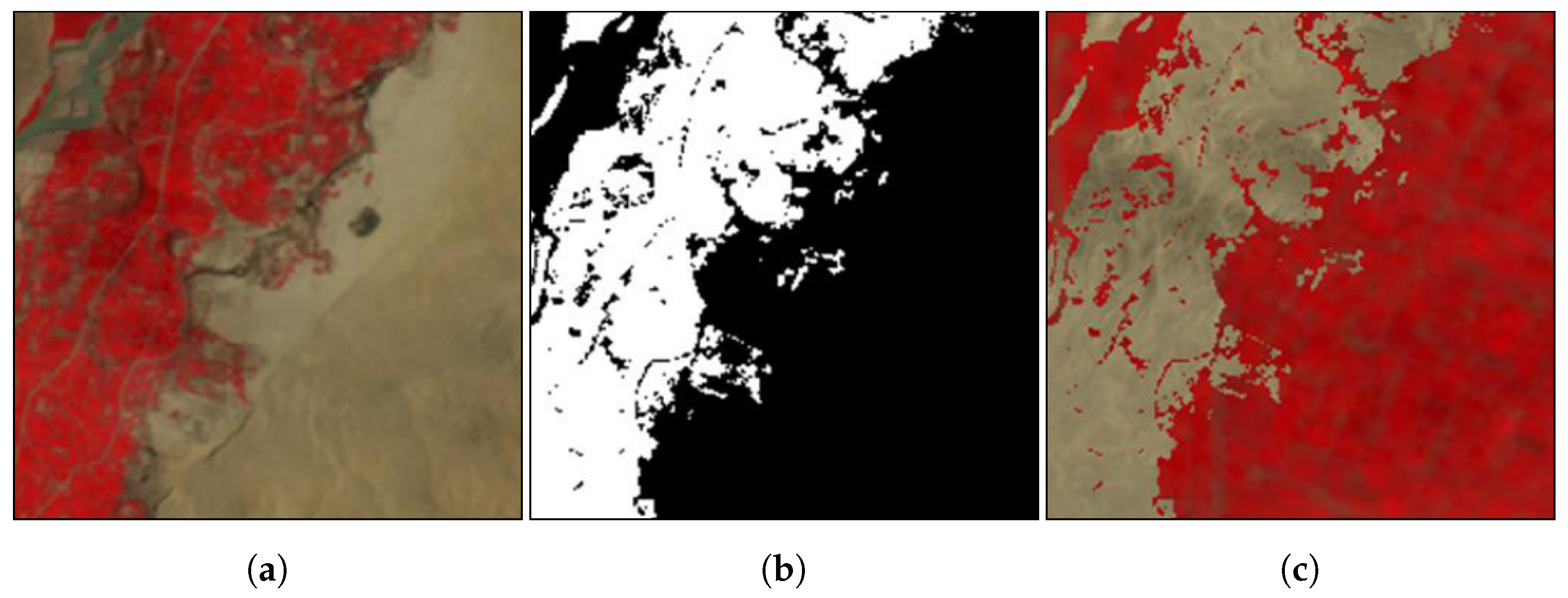
The model for the shape was trained on a synthetic dataset created using a similar method to that in [
23], where input images were modified by randomly switching the pixel values to those of the another class. The reasoning behind the approach is that if pixel values within an object are no longer related to the class label, the CNN can only learn to separate classes based on the shape of objects. The 2009 training samples were ordered based on the proportion of agriculture, and in every other sample the pixels were swapped to those from the other class (
Figure 4). Replacement pixels were taken from samples with 100% background and 100% agriculture, selected randomly. The combined synthetic and Level-1A samples were used to train an FCN-8 model over 50 epochs.
Textural components were extracted by applying a grey-level co-occurrence matrix (GLCM) to the sample images [
24]. The textural metrics with the greatest variance, homogeneity, entropy and correlation, were used as a three band input (
Figure 5), in place of the FCC, for each sample to train an FCN-8 model over 50 epochs, with:
where
is the probability of column
i and row
j values occurring in adjacent pixels using the fixed kernel window of the GLCM,
is the mean, and
is the standard deviation [
25].
Separating spectral features from their texture was not possible while maintaining the size of the input sample images. Instead, FCN-8 models were trained on sample sets of single band inputs (
Figure 6) from the FCC over 50 epochs and compared to the models trained on isolated features of texture. The difference in accuracy between the individual band models and the previous texture models was attributed to the effect of spectral information.
Standardisation of input data was investigated for minimising the variation in measured surface reflectance caused by atmospheric, topographic and illumination differences between images. This is an important, and often overlooked, source of spatial and temporal variation in image pixels used for deep learning. Four approaches were selected: (1) Top of Atmosphere (TOA) reflectance calibration (Level-1A), (2) Iteratively Reweighted Multivariate Alteration Detection (IR-MAD), (3) pixel intensity, and (4) NDVI. Image data for Landsat and Sentinel were downloaded as pre-processed Level-1A and DMC images were pre-calibrated to TOA using:
where
is the spectral reflectance,
is the spectral radiance,
is the Earth–Sun distance,
is the mean solar exo-atmospheric spectral irradiance and
is the solar zenith.
IR-MAD is a radiometric transform for extracting invariant pixels from two images to determine normalization coefficients (slope, intercept) from orthogonal regression, described fully in [
26]. The approach uses Canonical Correlation Analysis (CCA) to find the vector coefficients (
a and
b) that maximise the variance of the difference between two
N-dimension images (
F and
G). The MAD variates (
M) are constructed from the paired differences of the transformed images
and
:
The probability of change (
Z) can be estimated from the sum of the squares of the standardised MAD variates:
where
is the standard deviation. Invariant pixels between both images can then be extracted using a 95% threshold of no-change.
Sets of standardised image samples were created from the 2007 and 2008 DMC images for training individual FCN-8 models for each approach (
Figure 7) and validated on DMC and Landsat-5 images from 2009 (steps shown in
Figure 3b). For the IR-MAD normalised set, images were resampled to the same 32 m pixel grid and normalised to a target DMC image from 27 April 2007 using code from [
27] (available at
https://github.com/mortcanty/CRCPython (accessed on 2 August 2023)). Image chips were then extracted at the sample locations for model training (
n = 820). Validation samples (
n = 137) were extracted from 2009 DMC and Landsat-5 images, and were normalised using the same target DMC image. No Landsat-5 data were used in training this model.
NDVI and intensity sets were created from the Level-1A samples, with pixel intensity calculated as the weighted sum of the spectral image bands. Individual models were trained using the same 2007 and 2008 sample locations and validated on 2009 DMC and Landsat-5 images, again with no Landsat-5 data used during training.
2.5. Building a Generalised Model with Dense and Sparse Labels
A generalised model was developed by transfer learning across multiple yearly datasets from DMC and Landsat-8 using a combination of dense and sparsely labelled samples. All images were first pre-processed to standardise inputs using IR-MAD normalisation, detailed in
Section 2.4. The first step in model development was training a base model using the densely labelled DMC data from 2008 to 2009 and the targeted sample strategy. The model was then fine tuned on Landsat-8 OLI imagery used by the UNODC from 2015 to 2019 in the creation of their potential agmask. This cumulative training strategy was designed to replicate a process of year-on-year fine tuning of the model.
Labelling the Landsat-8 image data was problematic as the UNODC agmasks contain land not in production within the current year that would be labelled as agriculture in the images. Manual editing of the samples from the 2015 UNODC potential mask was carried out to remove areas not in production and check consistency with the DMC agmasks. A random subset of 25% of the 273 training samples were used to fine tune the base model, as suggested by Hamer et al. [
6], and were validated using a hold out set of 91 samples.
A sparse labelling procedure was trialed for fine tuning the model on the 2016 and 2017 UNODC data to investigate if non-contiguous blocks of pixels within the samples could be used for training. New areas of agriculture for each year were isolated from the agmasks by intersection to ensure only active agriculture was included in the agricultural class. The data was labelled as new agriculture, background or unknown using the agmask from the year of training and the previous year. A new layer was then added to the sample to weight the cost function, setting new agriculture and the background class to 1 and all other pixels to 0, in a similar approach used to balance samples in Long et al. [
17]. Samples containing no new agriculture (>1%) were removed from the training sets. The same validation sample locations (
n = 91) were used for evaluating the generalised model for 2015 to 2017, with fallow areas edited out manually. Model accuracy was evaluated before and after fine tuning over 50 epochs and on Sentinel-2 images from 2017 with no further training.
2.6. Image Timing
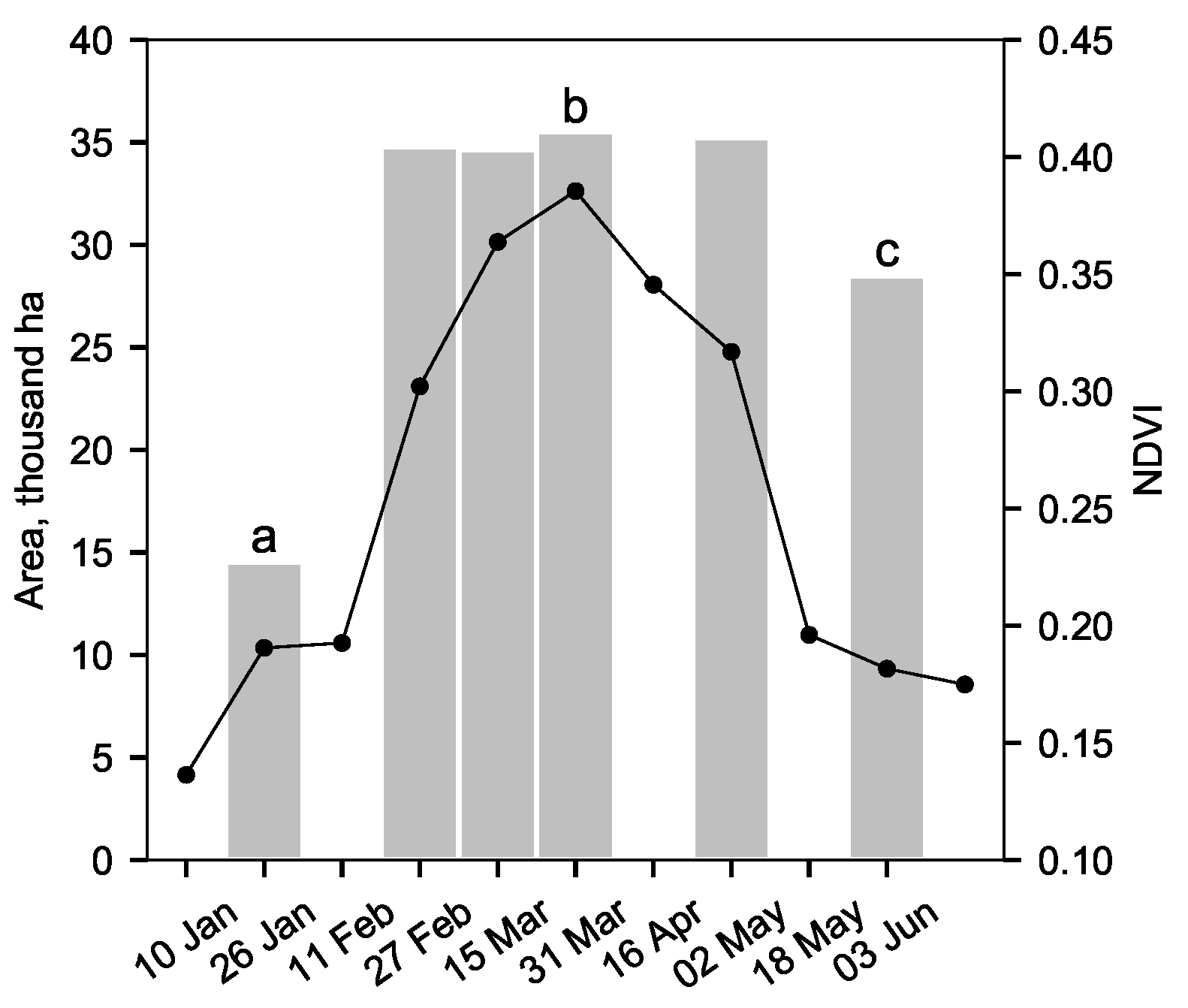
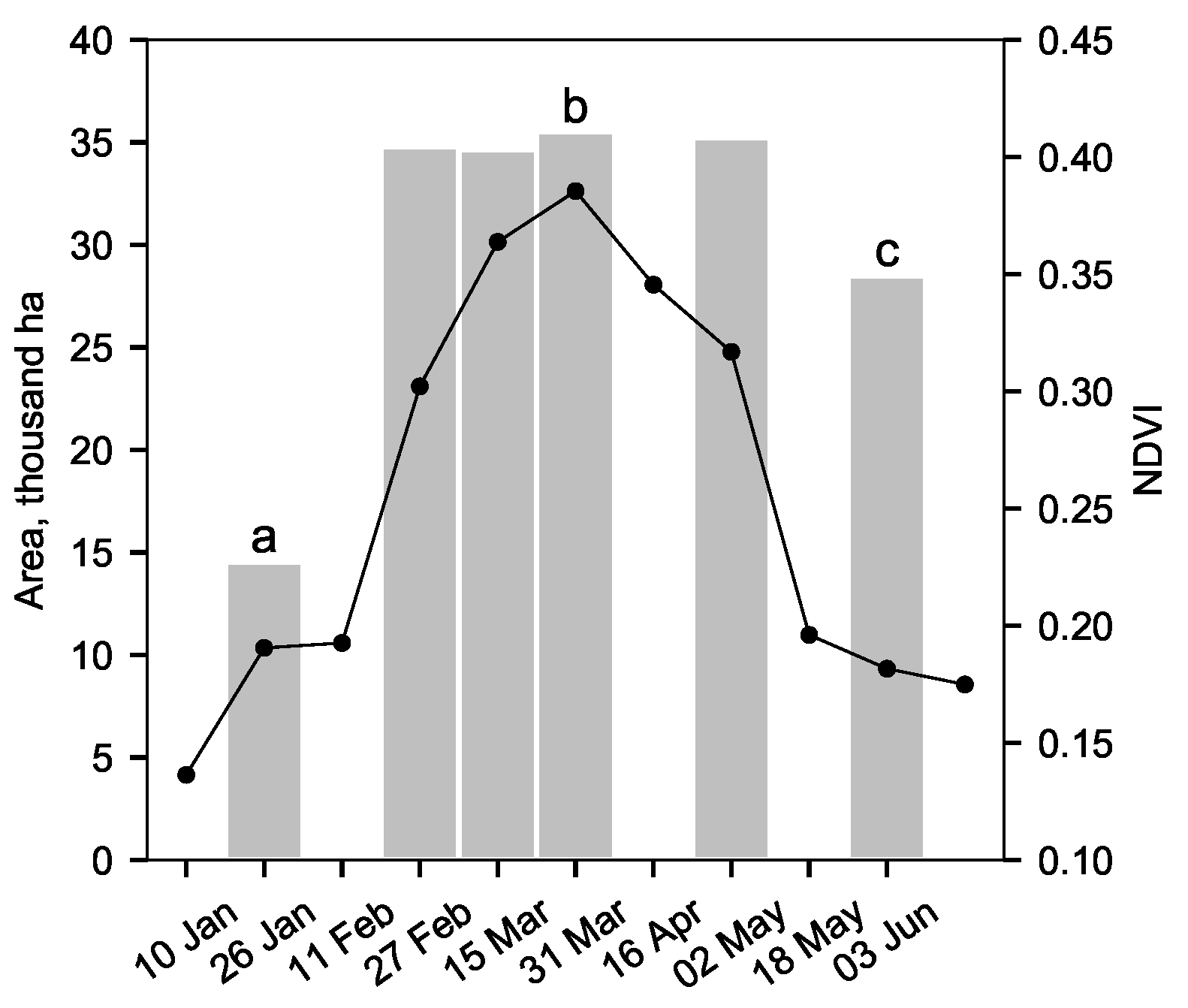
The effect of image timing on classification was investigated to determine the operational time-window for image collection, which is an important operational parameter for the generalised model as it defines the earliest point in the growth cycle that accurate information on agricultural land can be collected for the current year. A time series of largely cloud-free Landsat-8 images from 2015 were selected that covered the first crop growth cycle in Helmand, from January to June (
Table 1). Each input image was normalised to the target DMC image from 2009 using invariant pixels identified automatically using IR-MAD and was then classified using the FCN-8 model, fine tuned up to 2015 (see
Section 2.5). The area of agriculture within the same set of cloud-free 2015 validation samples (
n = 91) was calculated for each classified image.
Crop phenology for the same period was estimated from a time series of NDVI Landsat-8 OLI images from Google Earth Engine. The mean NDVI was calculated for each time point within the agricultural area of the samples at the maximum extent for 2015 (31 March image).
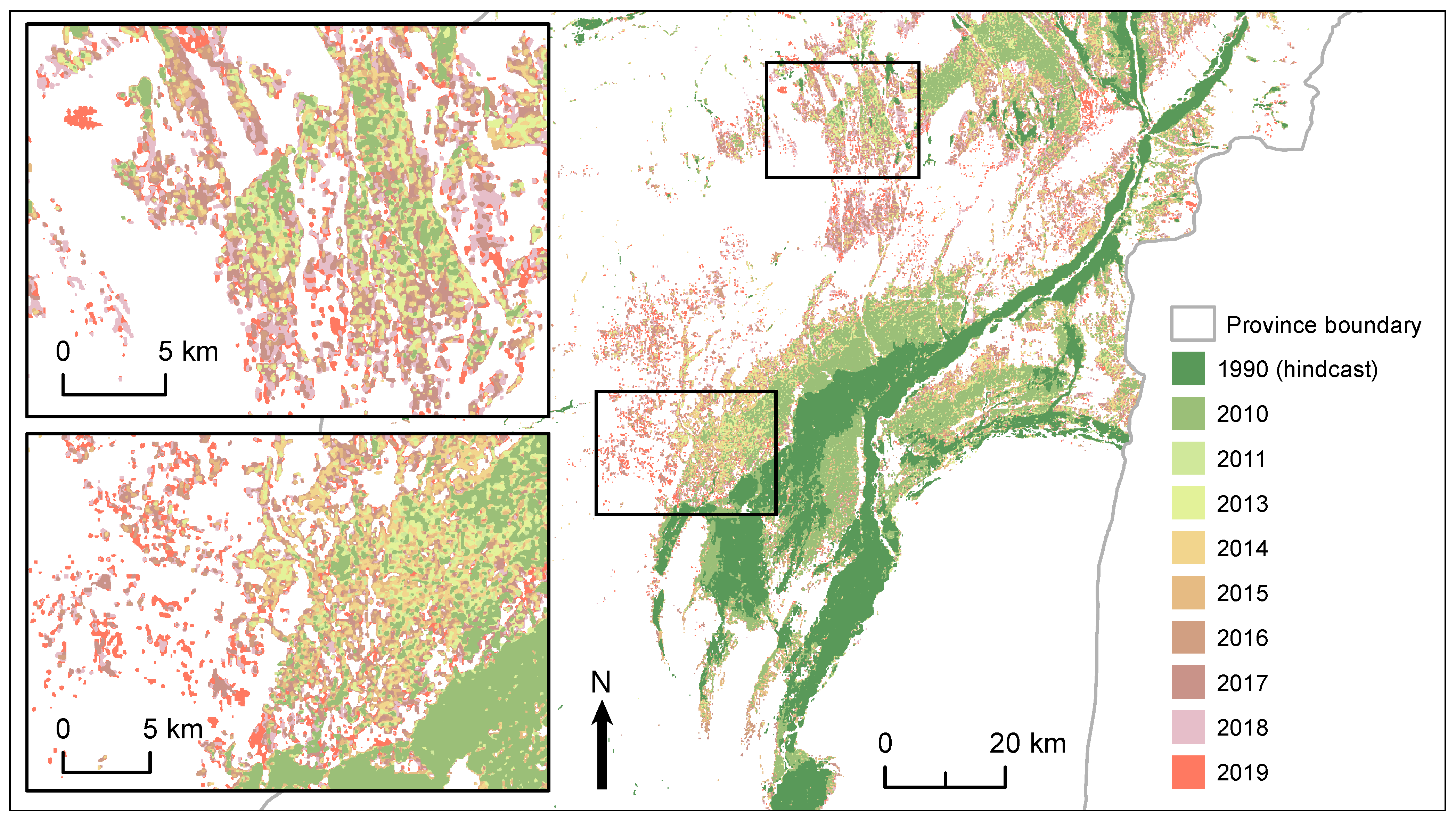
2.7. Land Use Change in Helmand Province
The generalised FCN-8 model developed in
Section 2.5 was used to classify agricultural land in Helmand Province to map the spatial and temporal variation in land under cultivation (active agriculture) each year between 2010 and 2019. Medium resolution cloud-free images from Landsat or Sentinel-2a for each year were selected at dates close to the peak in vegetation activity (
Table 2) and processed to standardised reflectance using IR-MAD (see
Section 2.4). No suitable images were available for 2012 because of the limited acquisitions during the decommission period of Landsat-5. Sentinel-2 imagery was resampled to the same resolution as Landsat imagery (30 m) for consistency in reporting total agricultural area and comparison over the time-series.
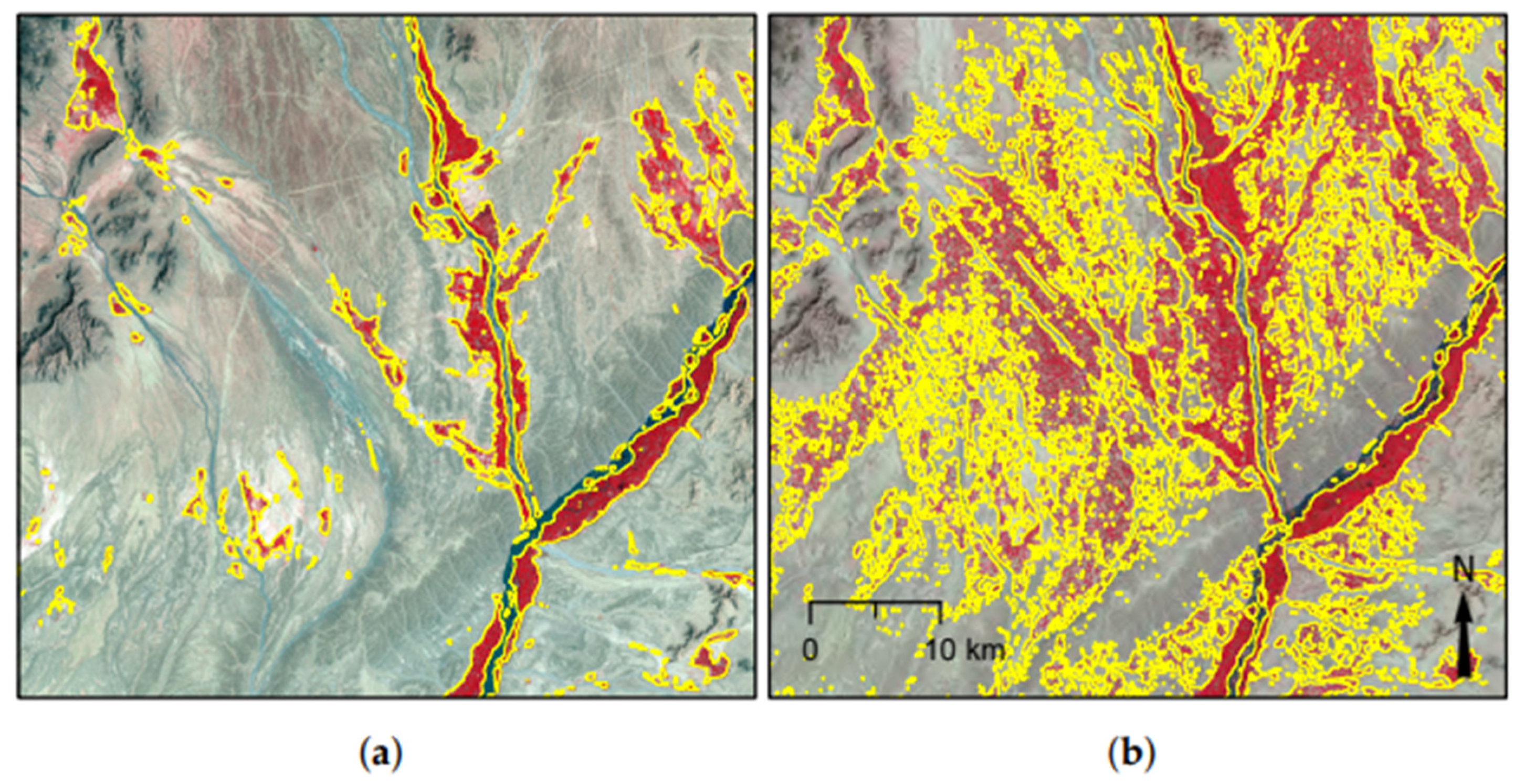
2.8. Hindcasting and Application in Other Areas
The generalised FCN-8 model was tested on imagery well outside the temporal range of the training data in Helmand Province, and outside the geographical range of the training data in Farah and Nangarhar Provinces. The model was hindcast, defined as the use of a model to re-create past conditions, on a Landsat-5 image collected on 18 April 1990, calibrated to reflectance using IR-MAD (
Section 2.4) with no further training. The Farah and Nangarhar images were the same DMC scenes used to create the original 2008 agmasks collected on 5 April 2008 and 22 March 2008, respectively. The images were calibrated to TOA reflectance and classified using the generalised model. The classification accuracy was evaluated against a random 10% sample of pixels from the existing agricultural masks for 2008, which were created using the same manual process as the historical Helmand agmasks. Again no further training took place.
2.9. Model Validation
Land cover classification accuracy was assessed using the hold-out validation samples as reference data to calculate standard accuracy metrics at the pixel level. Overall accuracy (OA) is the number of correctly classified pixels in comparison to the reference data and widely adopted within remote sensing [
28]:
where
is number of pixels predicted as class
i belonging to class
i and
is the total number of pixels belonging to class
i in the reference data.
Producer accuracy (PA) is the percentage of correctly classified pixels within each class in the evaluation data (omission errors in the classification), also known as recall for positive cases [
29],
where
is the number of pixels predicted as class
j belonging to class
i.
User accuracy (UA) is the mapping accuracy for each class (commission errors in the classification), also known as precision for positive cases [
29],
The agreement between predicted and reference pixels in overlapping regions was assessed using the frequency-weighted Intersection over Union (fwIoU) [
30]:
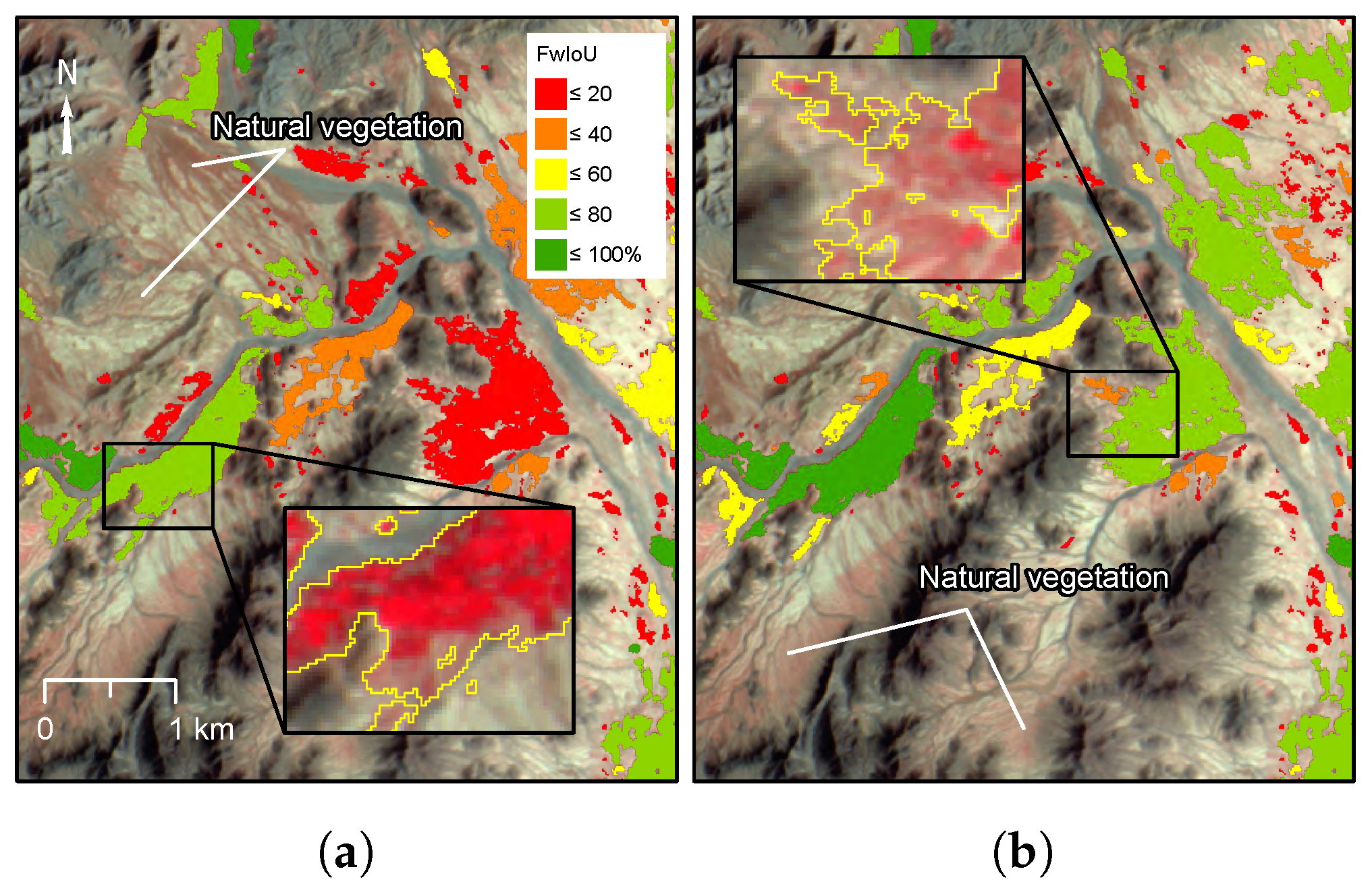
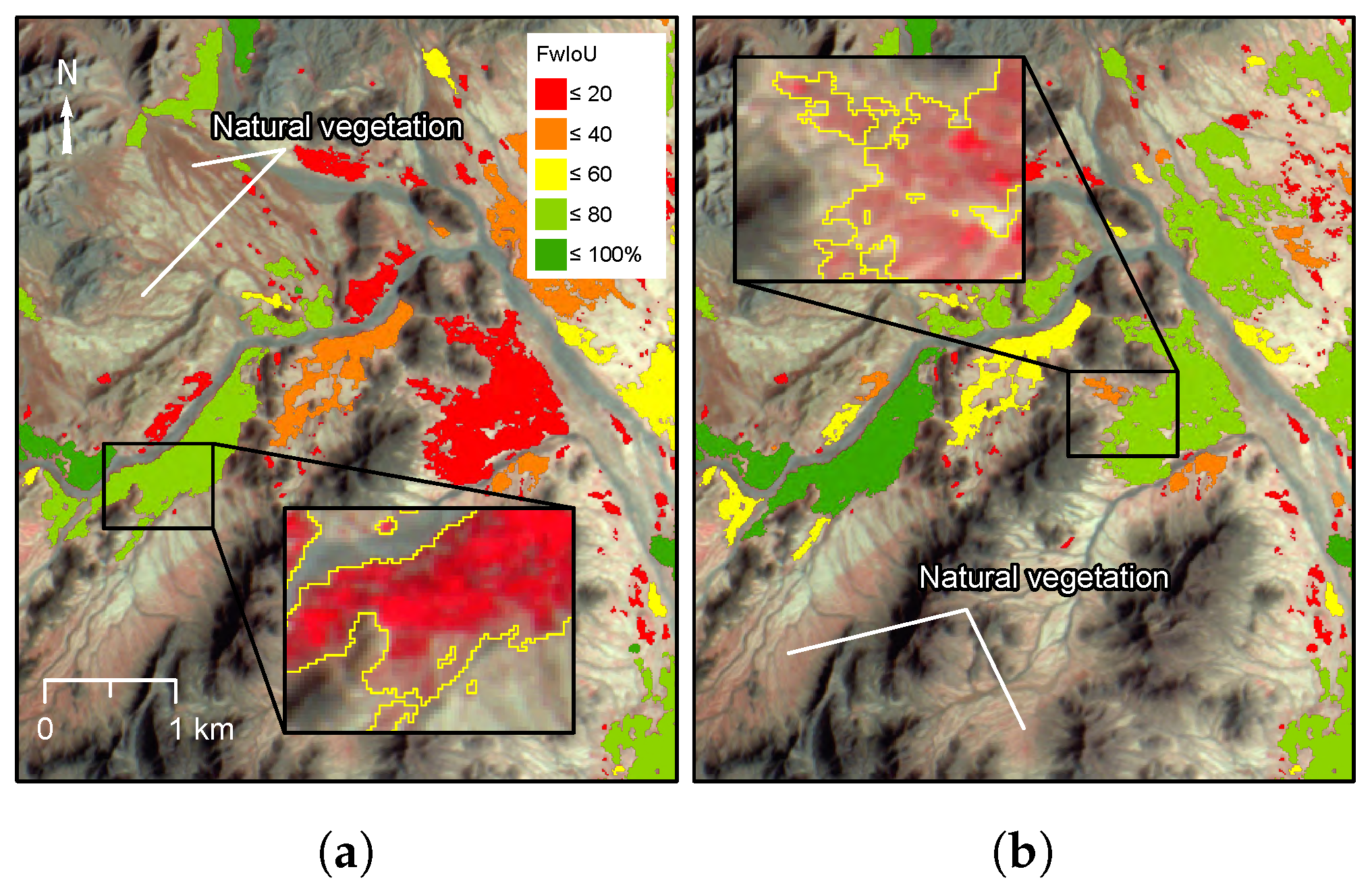
A new method for mapping fwIoU at the level of individual objects was developed to assess how agreement varied spatially and with object size. Individual objects, defined as any region with more than one connected pixel, were first subset from the reference agricultural masks. Each object was matched to zero or more objects in the classified output by intersection. FwIoU was then calculated and for each set of matching objects within the bounding box of the reference object in order to map agreement in overlap of agriculture between the classified and reference data.
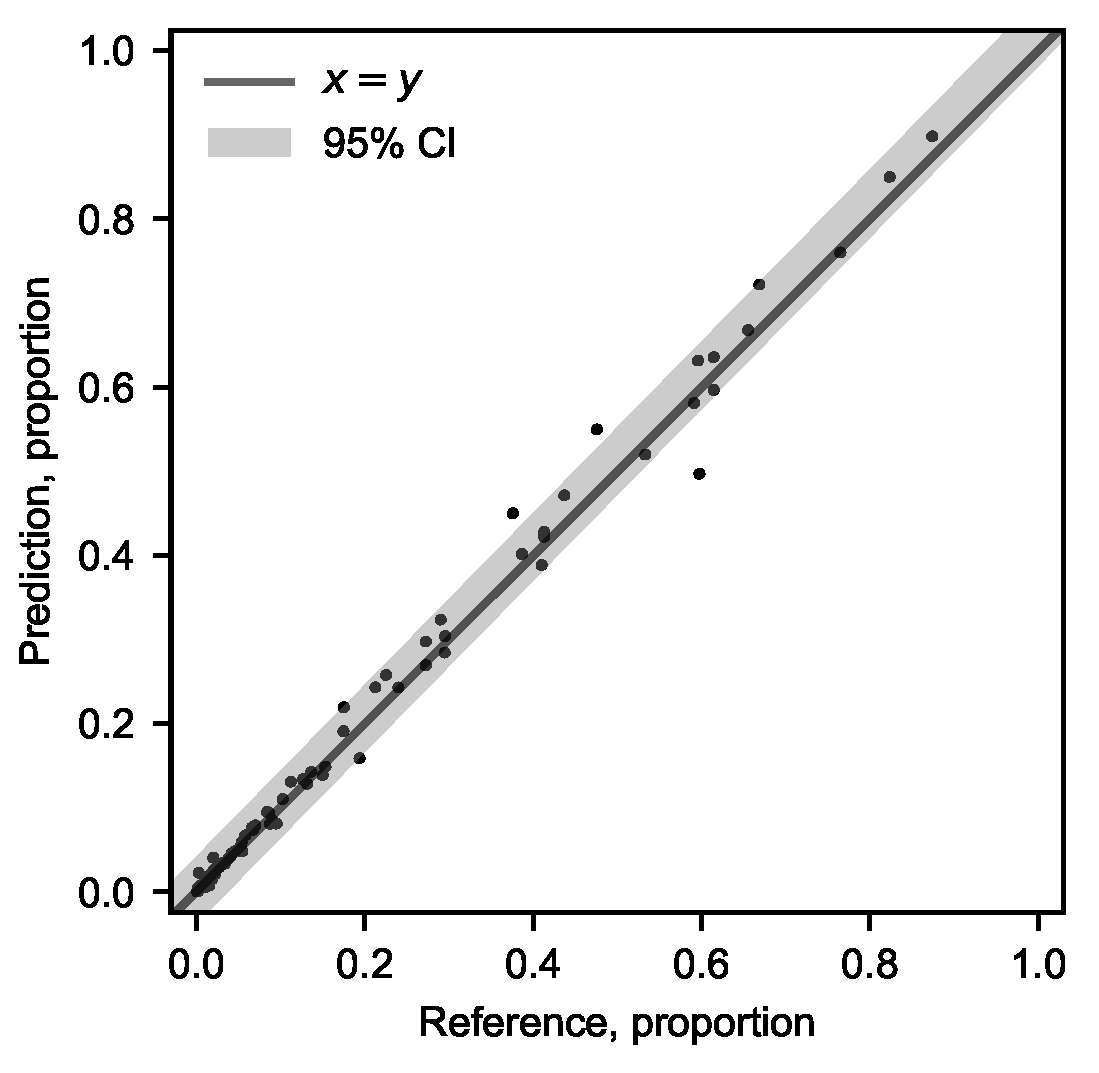
The confidence of agricultural land prediction from the generalised FCN-8 model was calculated as
where
is the proportion of agriculture in the validation sample
i with mean
,
is the model prediction for the validation sample
i,
is the critical value from a t-distribution,
is the fitted value at
from orthogonal least squares regression, and
n is the number of samples.
is mean square error of the prediction,
The kappa coefficient [
31], used to assess aclassifier performance devoid of chance agreement, was not calculated in this study as there is disagreement on its use relating to assumptions of randomness in validation data [
29,
32,
33].
4. Discussion
There are major limitations to overcome in order to create a robust model that is capable of classifying the latest satellite image into an accurate map of land-cover. These are caused by the radiometric and atmospheric differences between images, alongside the natural variation in environmental conditions that affect growth and phenology [
34,
35]. The improved performance of CNNs and deep learning over other machine learning approaches, such as Random Forest, is attributed to their ability to efficiently encode the contextual information that is less affected by changes in absolute pixel values [
6,
36]. Our results show that the textural features related to agricultural land use are consistent between images at medium resolution and alone can reach an overall classification accuracy of 73% for images collected in different years (see
Table 3). This explains why the FCN-8 model is able to separate natural vegetation from agricultural land even though the spectral response of the land-cover at the pixel level is similar at medium resolution. However, the highest classification accuracy (>95%) was achieved using the full three-band image (NIR, R, G), which combines spatial and spectral image features.
It is interesting to note that shape plays no role in the classification (OA of 53%). This is perhaps not surprising, as the appearance of agricultural areas in medium resolution imagery is not distinct. At higher resolutions, features such as the shape of field parcels would be visible to the model and expected to play a greater role in discrimination of agricultural land, as can be demonstrated in segmentation of objects in natural photography [
17].
Transforming images into a lower number of input features was investigated as a way to standardise the input to the FCN and to reduce the complexity. Models using NDVI or single-band intensity resulted in lower classification accuracy (1–2%) compared to using the three band image, suggesting that there is data loss when reducing the number of bands. Conversely, expanding the number of input dimensions into the short-wave infrared could improve the classification but was not investigated in this study as there were only three bands in the DMC imagery used to train the model between 2007 and 2009. One approach for adding spectral information to the model would be to initialise extra input dimensions for the short-wave bands from Landsat-8 and Sentinel-2 using weights cloned from other input layers during transfer learning. Further work is needed to understand the input features that are diagnostics of land-cover and land use classes and to take advantage of the full range of spectral data to build more efficient models.
The input data for FCNs are normalised to maintain consistency in colour values and reduce variability. Normalisation will also stabilise and speed up model convergence during training [
37]. For 8-bit natural photography, which FCN models were originally developed for, this is normally done by scaling and centring the values using the mean and variance of the whole dataset. This approach is not ideal for EO data as images will typically have different dynamic range and the distribution of spectral response will vary with landscape. In this study we used reflectance, which reduces the sensor and illumination effects and scales the input appropriately for use in the FCN while preserving the spectral properties of the image.
The effect of further normalisation of the TOA, using IR-MAD to match radiometry based on invariant pixels, can be seen as an improvement in classification at the edges of marginal agriculture, where a small change in value can switch a pixel between the agricultural or non-agricultural class. These differences have a small effect on the overall accuracy in Helmand Province, as the majority of the land used for agriculture has a distinct boundary because of irrigation features. However, in other areas or for wider applications without such clear delineations, like mosaic classes or transitions between complex classes, standardising image radiometry will have a significant effect on the ability of FCN models to generalise.
Relative normalisation was used instead of an absolute radiometric calibration with an atmospheric model as no in-situ measurements, or approximations for historical images, are required and potential differences in sensor-calibration can be avoided [
38]. IR-MAD has also been shown to reduce variability in retrieval of surface parameters compared to absolute correction [
39]. Absolute atmospheric correction is worth investigation going forward as it will remove the need for reference images and any potential distortions in temporal patterns [
40].
The FCN’s ability to be trained through transfer learning makes it well suited to developing a generalised model across image sensors from existing datasets. Firstly, the model can be trained from a much broader range of examples as training takes place incrementally, while the model from the previous step is maintained. Secondly, the ability to fine tune using a much smaller dataset means that any manual labelling effort is reduced once a base model has been trained. The use of sparse data, where training samples contain unlabelled (unknown) areas instead of spatially dense labels, means data from a wider range of sources can be used for training and fine tuning.
Single-date images were used instead of multi-temporal data as classification has to work in near real-time throughout the season. The model was found to be robust to changes in image acquisition date up to 2 months either side of the peak in vegetation activity, measured using NDVI. This is an important consideration for operational use as obtaining information on land use early in the season can improve the efficiency of the UNODC’s opium survey, either by reducing the size of the sample frame in areas that are not active, or extending sampling into new areas. Early warnings of changes are also invaluable for directing resources to investigate new trends in opium production within the same season. Tracking the development of agriculture in near real-time using the generalised model is timely and efficient as all steps in the classification pipeline can be automated and inference is fast.
A small bias in classification is visible in larger blocks of agriculture that contain many gaps between fields parcels. This is caused by the loss of resolution that at takes place during the resampling and de-convolution steps in the FCN-8 model. This is a limitation of the model and leads to generalisation in areas of high complexity at the boundary between agriculture and the background land-cover. Further research into model refinement using the full spatial resolution of Sentinel-2 (10 m) is recommended to reduce this effect and improve the resolution of the mapping.
Boundary generalisation may also be caused by differences in the original image interpretations used for labelling. While quality control using cross-checking was undertaken in the production of these historical data, there are differing levels of uncertainty, especially in more complex areas where considerably more effort is required to fully digitise boundaries.
Mapping using the generalised model provides much greater insight into the annual variation in land use compared to the potential agmask, which is the result of adding new areas to an existing map. Important changes related to water availability, salinity and the consistency of irrigated areas reveal information that can be used to investigate the links between opium production, water use, and food security. Mapping the active area can also be used to validate that well-driven expansion into the desert is increasing the overall area of land, and the overall demand for irrigation water, and is not a shift in the location of production. Going further back in time by hindcasting the model also reveals how areas have seen significant growth in agricultural production since the 1990s (
Figure 15).
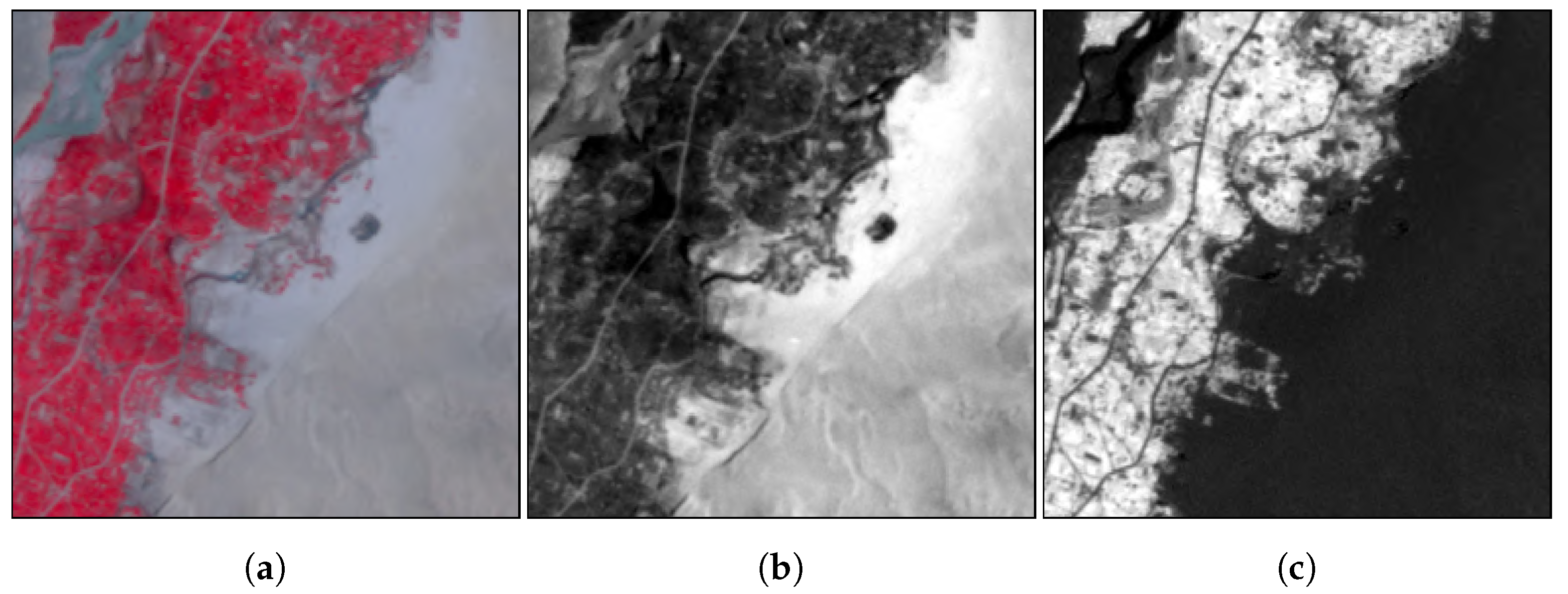
Our results show that the ability of the model to generalise is directly linked to the landscapes encountered during training. In Farah and Nangarhar the classified agricultural area was consistent with manual interpretation in the main growing areas and narrow ribbon valleys that follow rivers into more mountainous areas. The classified area contained a number of false positives as the terrain within the images varied in appearance from the original Helmand training data. In Nangarhar there were larger areas of confusion linked to distinct tree-covered uplands. Use of the generalised model in new areas is an improvement over manual methods and supervised classification approaches based on the analysis of single images, because of the much reduced effort of collecting additional training data for fine tuning. For example, digitising additional samples in problem areas would require minimal manual work to produce an accurate map compared to producing a province-level agmask from scratch. One suggested improvement is to identify those areas in the output with lower classification confidence for further fine tuning, taking the approach closer to a self-learning system.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}