1. Introduction
Change detection in remote sensing is a significant and challenging task that involves identifying differences in land cover or land surface using multi-temporal images of the same geospatial area [
1]. It is widely used across various applications, including agricultural land use activities, urban planning, and disaster assessment [
2,
3,
4]. Over the past decade, deep learning has revolutionized remote sensing applications, encompassing tasks like image fusion, land cover classification, and object detection [
5,
6,
7,
8,
9]. This revolution has spurred a surge of interest among researchers in integrating deep learning methodologies into change detection tasks, leading to substantial scholarly endeavors [
10,
11,
12,
13]. Existing deep-learning-based methods for change detection mainly focus on binary change detection (BCD), which generates a binary change map where 0 and 1 correspond to unchanged and changed regions, respectively, by inputting a pair of registered bi-temporal images. However, BCD solely pinpoints areas of change, lacking the ability to furnish comprehensive “from–to” change type information, which limits their broader applicability. Consequently, the research focus has shifted towards semantic change detection (SCD), which represents an emerging research frontier [
12,
13,
14,
15]. SCD not only identifies altered regions, but also provides specific “from–to” change-type details extracted from bi-temporal remote sensing images.
There are mainly two paradigms for SCD: the direct-classification method and the post-classification method. In the direct-classification approach, each change type is treated as an independent class and predicted using semantic segmentation [
16,
17,
18,
19,
20]. However, this method has two drawbacks: (1) the number of change types increases quadratically with the number of land cover classes, leading to class-imbalance problems and greater training sample requirements; (2) overlaying land cover maps can produce excessively fragmented regions, often overlooked [
21]. Thus, the post-classification method is increasingly favored for SCD [
22,
23,
24,
25]. Seen from a perspective other than the direct-classification method, SCD can be decomposed into semantic segmentation and binary change detection tasks. The post-classification method typically employs two identical semantic segmentation branches and a binary change detection branch to predict land cover maps and a binary change map, respectively. The SCD results are then derived by multiplying these outputs. However, most post-classification methods treat the two semantic segmentation branches independently, disregarding the change relationship, a crucial prior knowledge, during land cover map prediction.
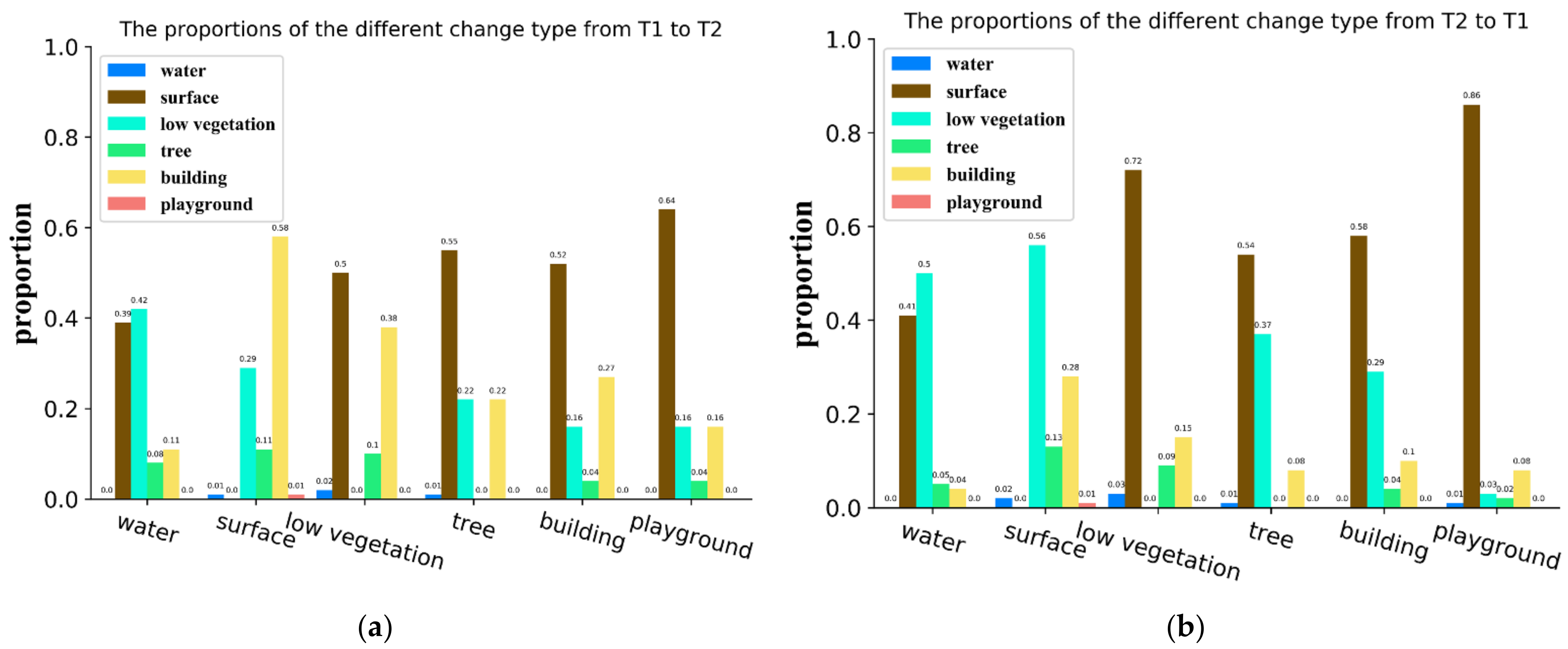
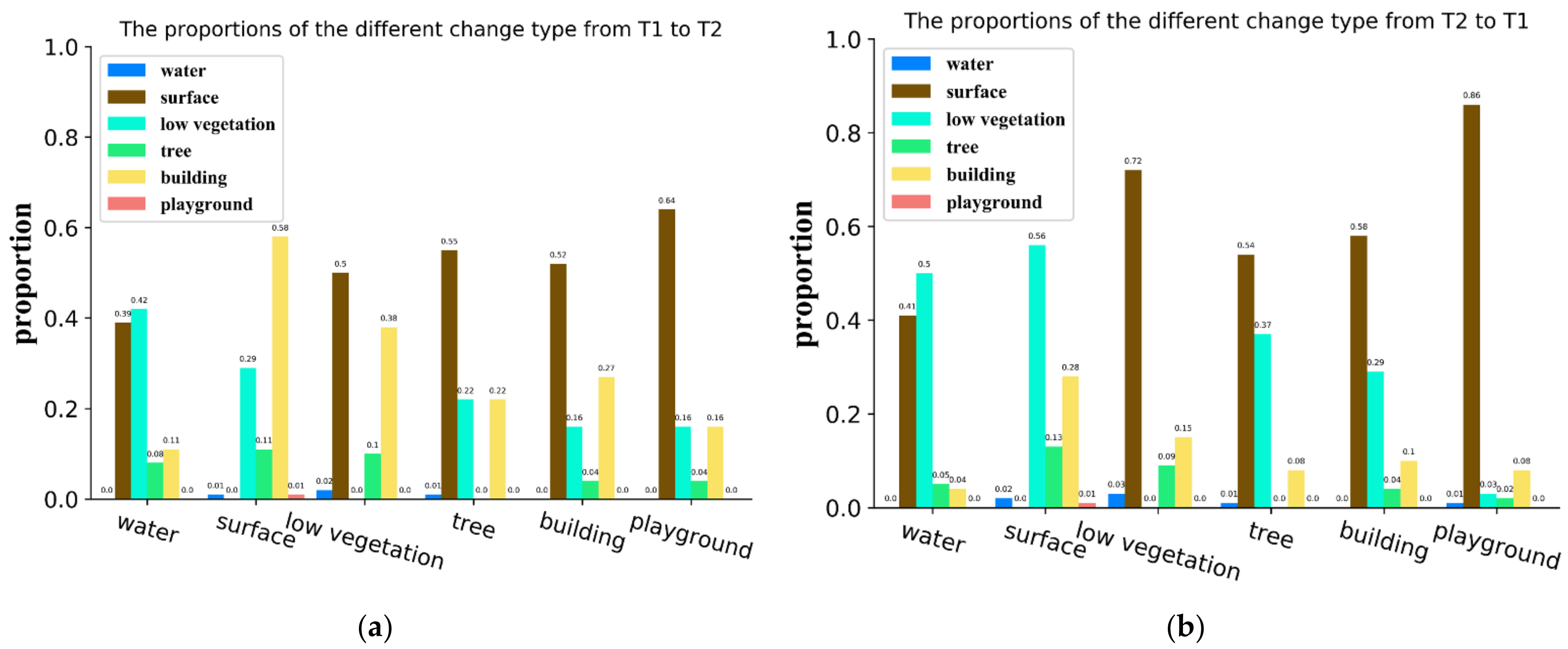
This paper contends that considering change relationships can enhance the performance of the semantic segmentation branch within post-classification methods. Land cover changes, unless triggered by abrupt natural events, follow certain patterns due to factors like urban planning. These patterns are defined as change relationships in this paper. We conducted a statistical analysis of different “from–to” change types based on the SECOND dataset [
22], depicted in
Figure 1, revealing inconsistent change-type probabilities and, consequently, change relationships among land cover classes. For instance,
Figure 1a indicates that pixels classified as water in T1 (image taken at the 1st timestamp) transform to low vegetation (42%) more often than to trees (8%) in T2 (image taken at the 2nd timestamp). This underscores the value of the change relationship as an auxiliary predictor for land cover classes. Notably, the change relationship is bidirectional, as evident in
Figure 1a,b. We interpret the change relationship from T1 to T2 as a probability distribution representing the shift from one land cover class to others. Conversely, the change relationship from T2 to T1 signifies the probability distribution of other land cover classes “transitioning into” a specific category. While temporal relationships have proven effective in multi-temporal image land cover class and video semantic segmentation [
26,
27,
28,
29], the method described earlier only considers one-way temporal relationships.
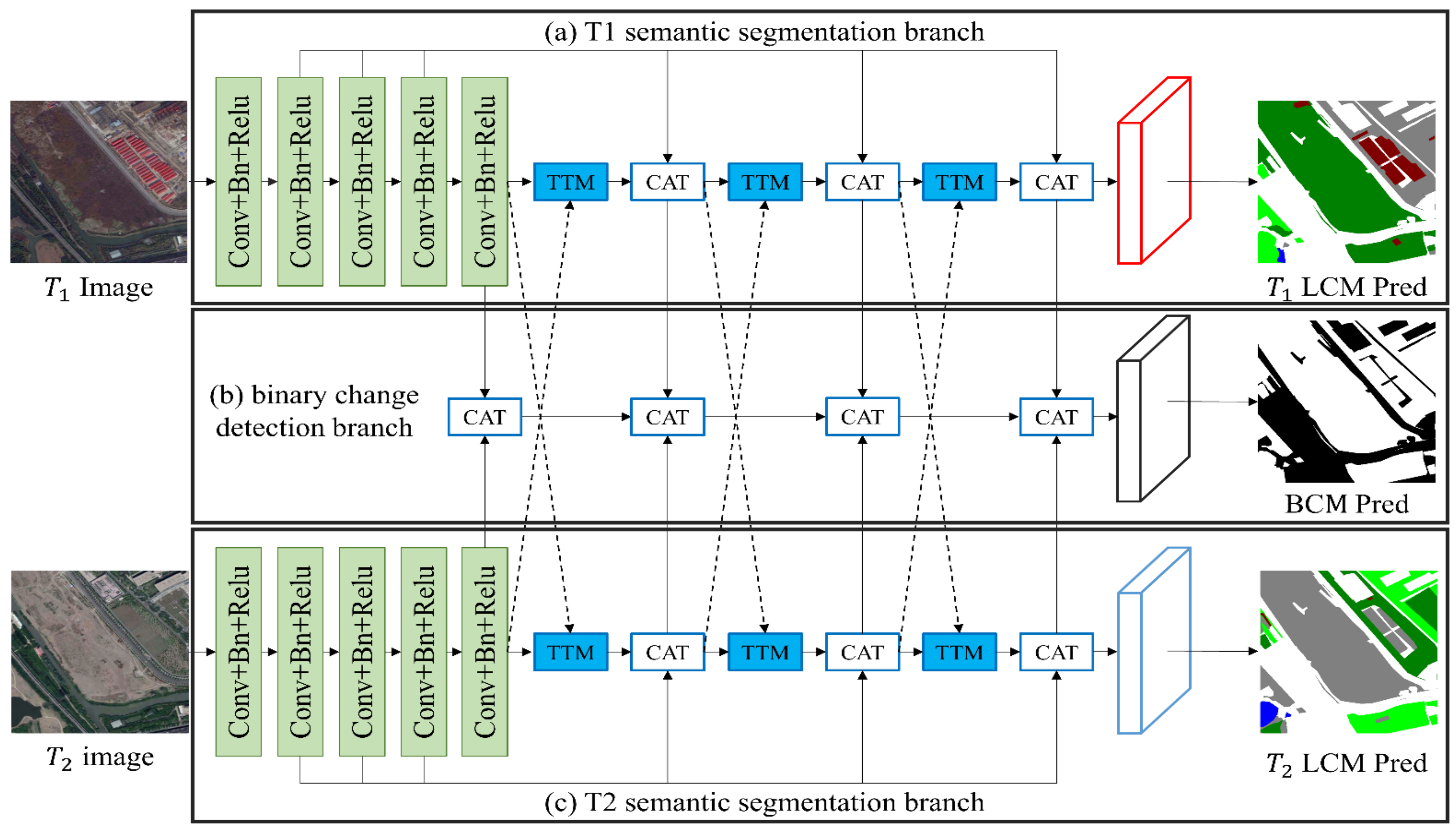
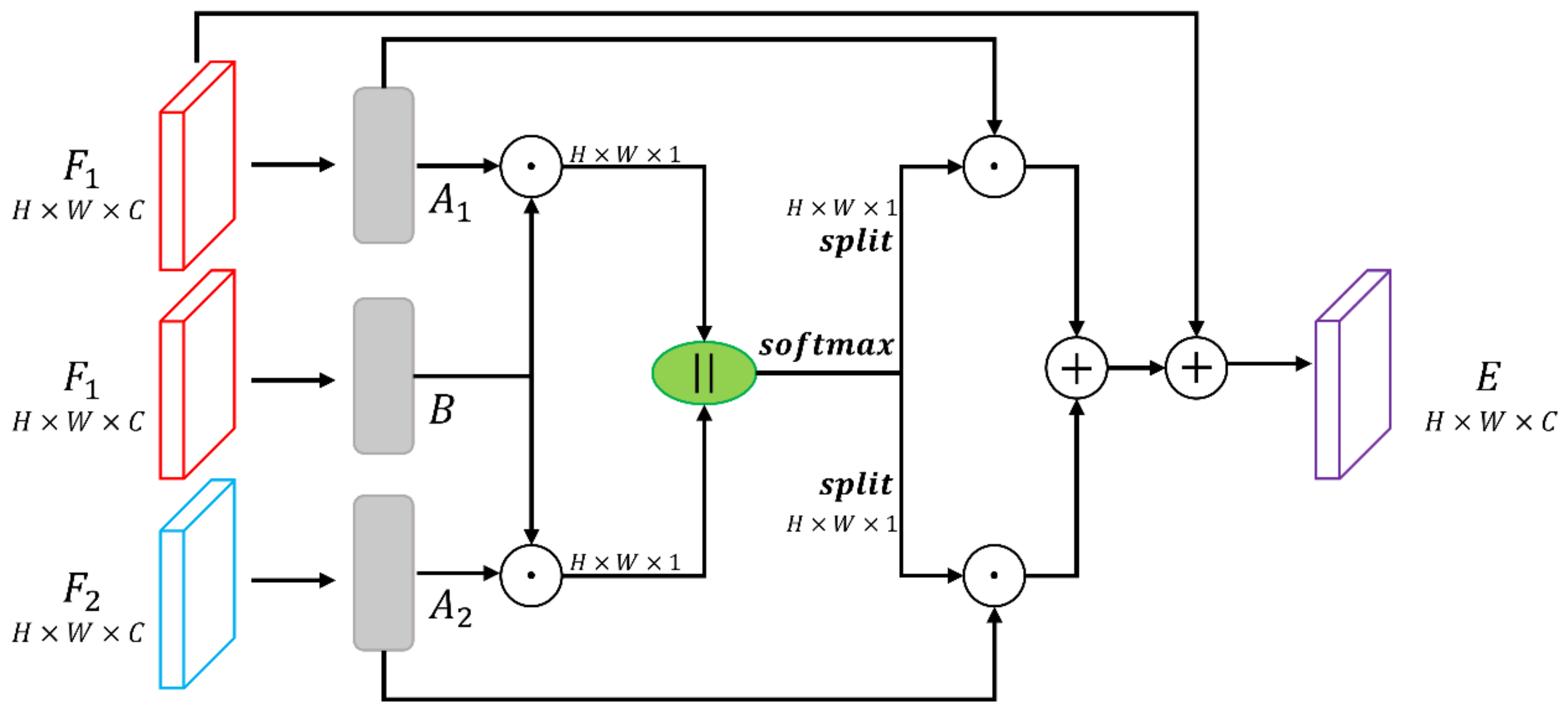
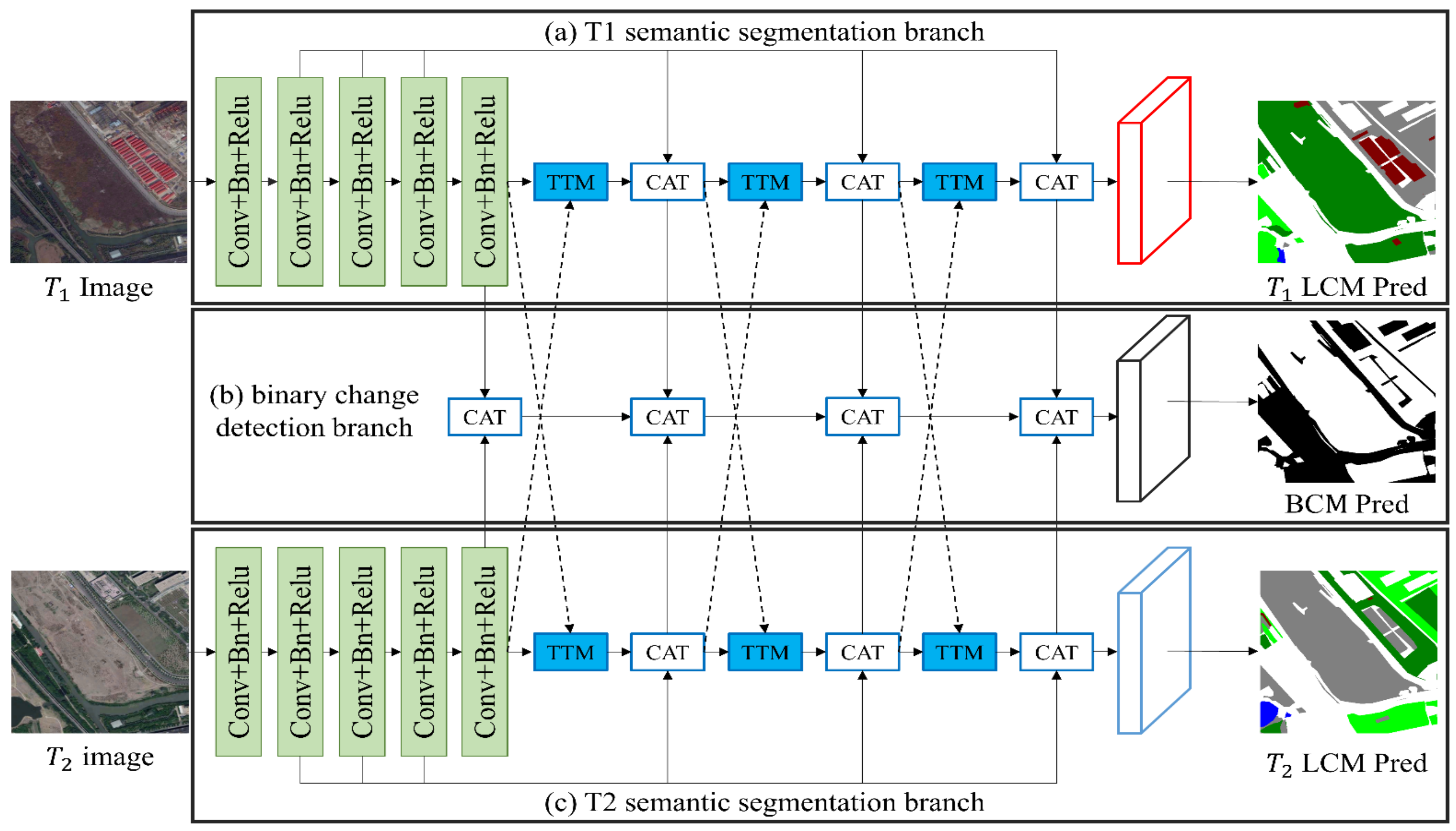
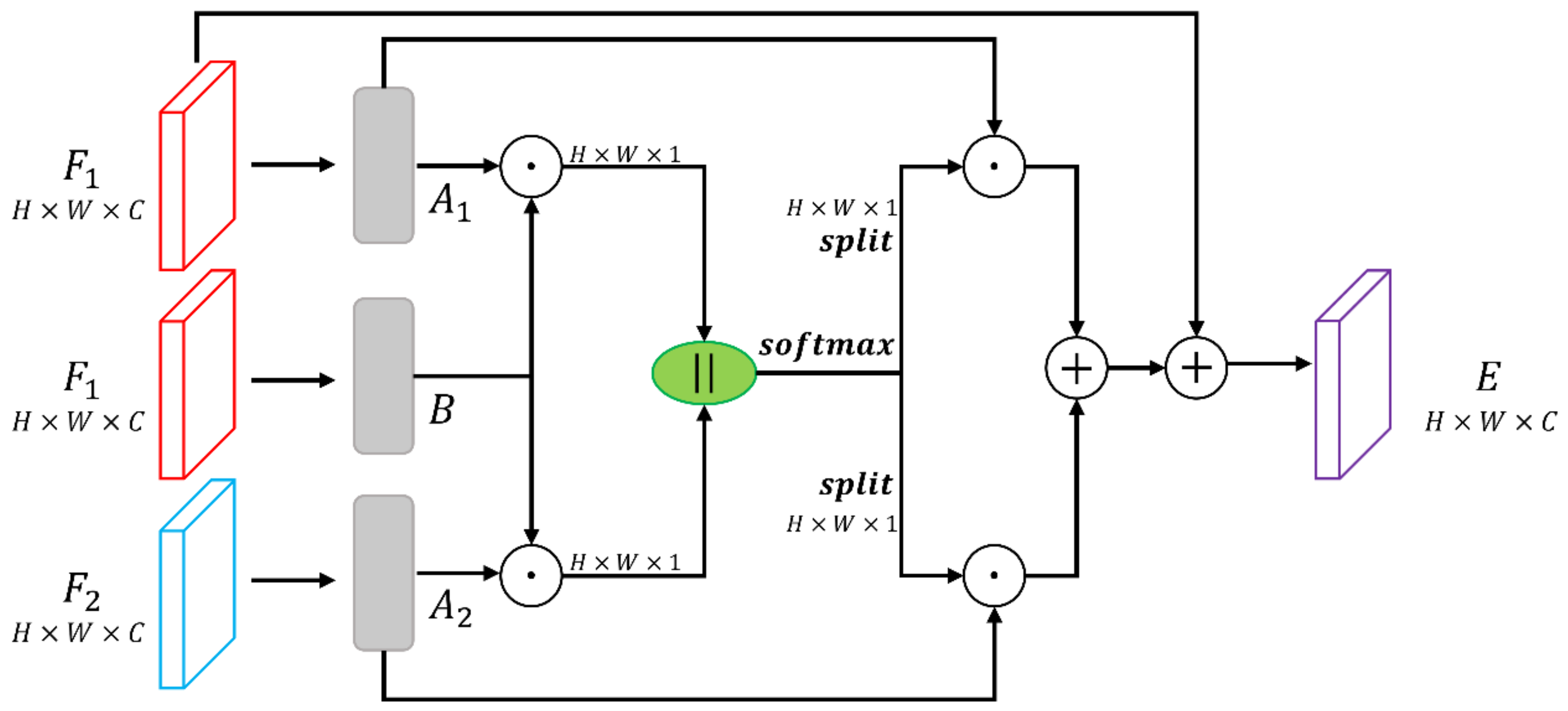
Building on the concept of change relationships in semantic change detection, we introduce the Temporal-Transform Module (TTM), inspired by spatial self-attention mechanisms [
30,
31,
32]. TTM captures these relationships bidirectionally by evaluating feature similarities across temporal images. It enhances features in each temporal image by selectively integrating them with others, boosting mutual improvement. TTM can be seamlessly integrated into post-classification networks, enhancing performance without significant computational burden. Moreover, we present the Temporal-Transform Network (TTNet) founded on TTM for SCD, delineated in
Figure 2. TTNet comprises three key components: two semantic segmentation branches (depicted in
Figure 2a,c) and a binary change detection branch (
Figure 2b). Each semantic segmentation branch, equipped with the feature pyramid decoder, incorporates three TTM layers to link the other semantic segmentation branch and capture bidirectional change relationships.
The contributions of this study are summarized as follows:
We identify a two-way change relationship between “from-to” change types and analyze its significance in the semantic change detection task, deepening our comprehension of semantic change detection.
Grounded in the concept of change relationships, we introduce the innovative Temporal-Transform Module to dynamically model these relationships, amplifying the discriminative capacity of feature maps.
Integrating several TTMs into the semantic segmentation branch, augmented by the feature pyramid decoder, we devise a fresh Temporal-Transform Network for SCD. TTNet encompasses twin semantic segmentation branches and a binary change detection branch, predicting two land cover maps and a binary change map.
Comprehensive experiments and analyses affirm the effectiveness of our approach, with comparisons showcasing TTNet’s superior performance on the SEONCD dataset in comparison to several benchmark methods.
4. Experiment and Analysis
4.1. Dataset and Metric
The benchmark dataset chosen for our experiments is the SECOND dataset [
22].
Figure 4 presents several samples from the SECOND dataset. This dataset encompasses 4662 pairs of aerial images with spatial resolutions varying from 0.5 m to 3 m. It is further divided into training and testing subsets, with 2968 pairs allocated for training and 1694 pairs for testing. Each sample comprises two images from distinct time phases and corresponding land cover classification labels. Each image is sized at 512 × 512 pixels, with pixel-wise annotations belonging to one of the 7 classes (no change, water, surface, low vegetation, tree, building, and playground). Considering that only 2968 sample pairs from the SECOND dataset were available for training, we allocated 2000 and 968 sample pairs for training and testing, respectively. To gauge performance, we employed the mean Intersection over Union (mIoU) metric.
4.2. Implementation Details
Our method and benchmark methods were implemented using the PyTorch framework. We employed the Adam optimizer with a batch size of 8 for network optimization over 80 epochs. The initial learning rate was set to and was adjusted to after 50 epochs. Data augmentation techniques included random horizontal and vertical flips, scaling between 1 and 2, and random rotations at 0, 90, 180, and 270 degrees. All experiments were conducted on a single Tesla P40 GPU under consistent settings. The TTM utilized 1 × 1 convolutional layers with 256 output channels.
4.3. Benchmark Methods
To assess the effectiveness of our proposed method, we conducted a comprehensive comparison with six prominent benchmark methods designed for semantic change detection. These methods include:
HRSCD.str1 [
24]: This method employs a direct comparison strategy for land cover maps. It trains a network to generate the LCMs of bi-temporal images and then compares these maps pixel by pixel to derive the semantic change maps.
HRSCD.str2 [
24]: This approach adopts a direct semantic change detection strategy, treating each change type as a distinct and independent class. For instance, a pixel transitioning from water to surface is labeled as class A. This transforms the SCD problem into a semantic segmentation task.
HRSCD.str3 [
24]: Using a different approach, this method predicts the LCMs and the BCM separately. It employs two semantic segmentation branches to predict the LCMs of the bi-temporal images, while the binary change detection branch predicts the BCM.
HRSCD.str4 [
24]: Similar in architecture to HRSCD.str3, this method differentiates itself by fusing features from the encoder of the semantic segmentation branches during the BCM prediction.
Deeplab v3+ [
41]: This approach replaces the semantic segmentation branch of HRSCD.str4 with Deeplab v3+, a model utilizing an Atrous Spatial Pyramid Pooling (ASPP) module with different rates to capture spatial contextual information.
PSPNet [
42]: In this method, the semantic segmentation branch of HRSCD.str4 is substituted with PSPNet. PSPNet employs a multi-scale pyramid pooling module (PPM) to capture scene context in the spatial dimension.
4.4. Comparison with Benchmark Methods
In our comparison with benchmark methods, we present results for both semantic change detection and semantic segmentation. The semantic change detection results are obtained using the predicted binary change map from the binary change detection branch, allowing for an evaluation of the overall method performance. Moreover, to specifically showcase the effectiveness of the Temporal-Transform Module in enhancing the semantic segmentation branch, we also present semantic segmentation results based on labeled binary change maps. This approach eliminates the influence of the binary change detection branch.
4.4.1. Assessment of Semantic Change Detection
Quantitative Analysis:
Table 1 showcases the quantitative outcomes of semantic change detection for TTNet in comparison with six benchmark methods on the SECOND dataset. The optimal performance is highlighted in bold. From the table, it is evident that TTNet achieves the highest performance in terms of mIoU and per-class semantic IoU, excluding the “no change” class. HRSCD.str1, HRSCD.str2, and HRSCD.str3 exhibit the lowest mIoU, all falling below 40%. By incorporating land cover label information into the binary change detection branch, HRSCD.str4 achieves a notable mIoU of 43.45%, marking an 8.15% improvement. In contrast, PSPNet, which emphasizes capturing spatial context, marginally improves mIoU by 0.91%, while Deeplab v3+ slightly reduces mIoU by 0.47%. This indicates that the stability of capturing spatial context for SCD is uncertain. In stark comparison, TTNet, which focuses on capturing change relationships, enhances mIoU by 2.46% compared to HRSCD.str4. These quantitative results underscore the remarkable performance of TTNet in semantic change detection.
4.4.2. Assessment of Semantic Segmentation
To provide further insight into TTNet’s superior performance, we initially present the outcomes of binary change detection in
Table 2. Subsequently, we present the quantitative results for semantic segmentation obtained by multiplying the predicted land cover maps with the labeled binary change map, as showcased in
Table 3. It is important to note that HRSCD.str2, due to its direct-classification method, is excluded from
Table 2 and
Table 3.
Quantitative Analysis: Analyzing the initial three rows of
Table 3, we observe that HRSCD.str1 and HRSCD.str3 yield similar semantic segmentation outcomes as HRSCD.str4. While, referring to
Table 2, it becomes evident that HRSCD.str4 attains a significantly improved mIoU of 70.28%, marking an enhancement of 21.97% and 6.69% over HRSCD.str1 and HRSCD.str3 in terms of binary change detection outcomes, respectively. This highlights that the integration of semantic segmentation branch features into the binary change detection branch notably enhances binary change map predictions.
In the last four rows of
Table 2, the binary change detection branch displays a fairly consistent performance among the four methods, with TTNet achieving the highest mIoU of 70.51% and the lowest being 70.13% (a gap of 0.38%). Conversely, it is worth noting that the performance variations within the semantic segmentation branch among these methods become evident when referring to
Table 3. When compared to HRSCD.str4 and PSPNet, TTNet stands out by enhancing the mIoU from 61.46% and 62.18% to 65.36%. This contrast in semantic mIoU significantly widens to 5.34% when compared to Deeplab v3+.
These outcomes indicate that TTNet’s enhanced performance in semantic change detection arises from its improved semantic segmentation accuracy. This is primarily attributed to TTNet’s utilization of TTM to comprehend the change relationships within bi-temporal images. This understanding of change relationships assists the model in identifying altered regions and characterizing their change types, thereby mitigating issues of un-detection and mis-detection.
4.4.3. Visualization Comparison
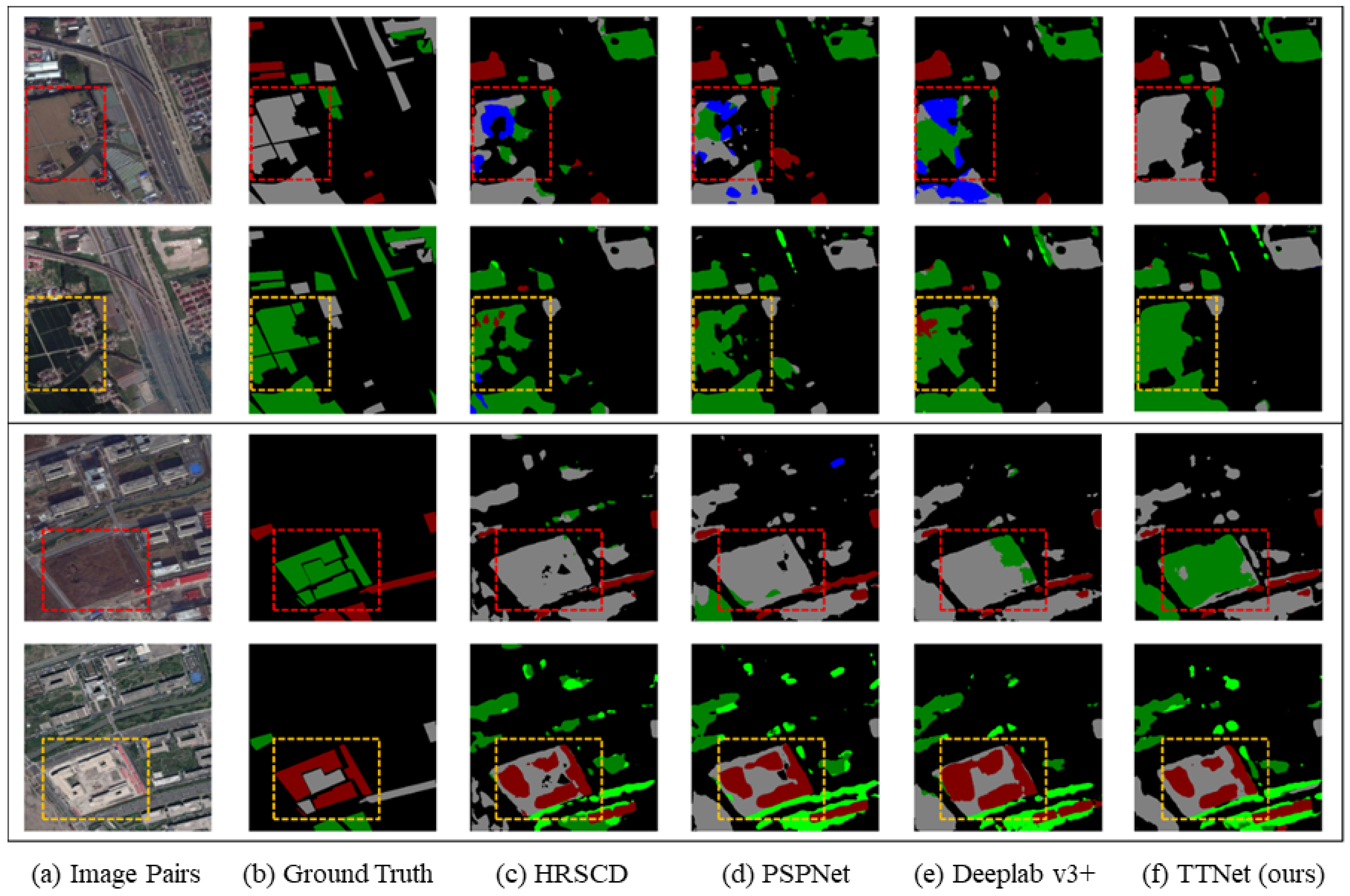
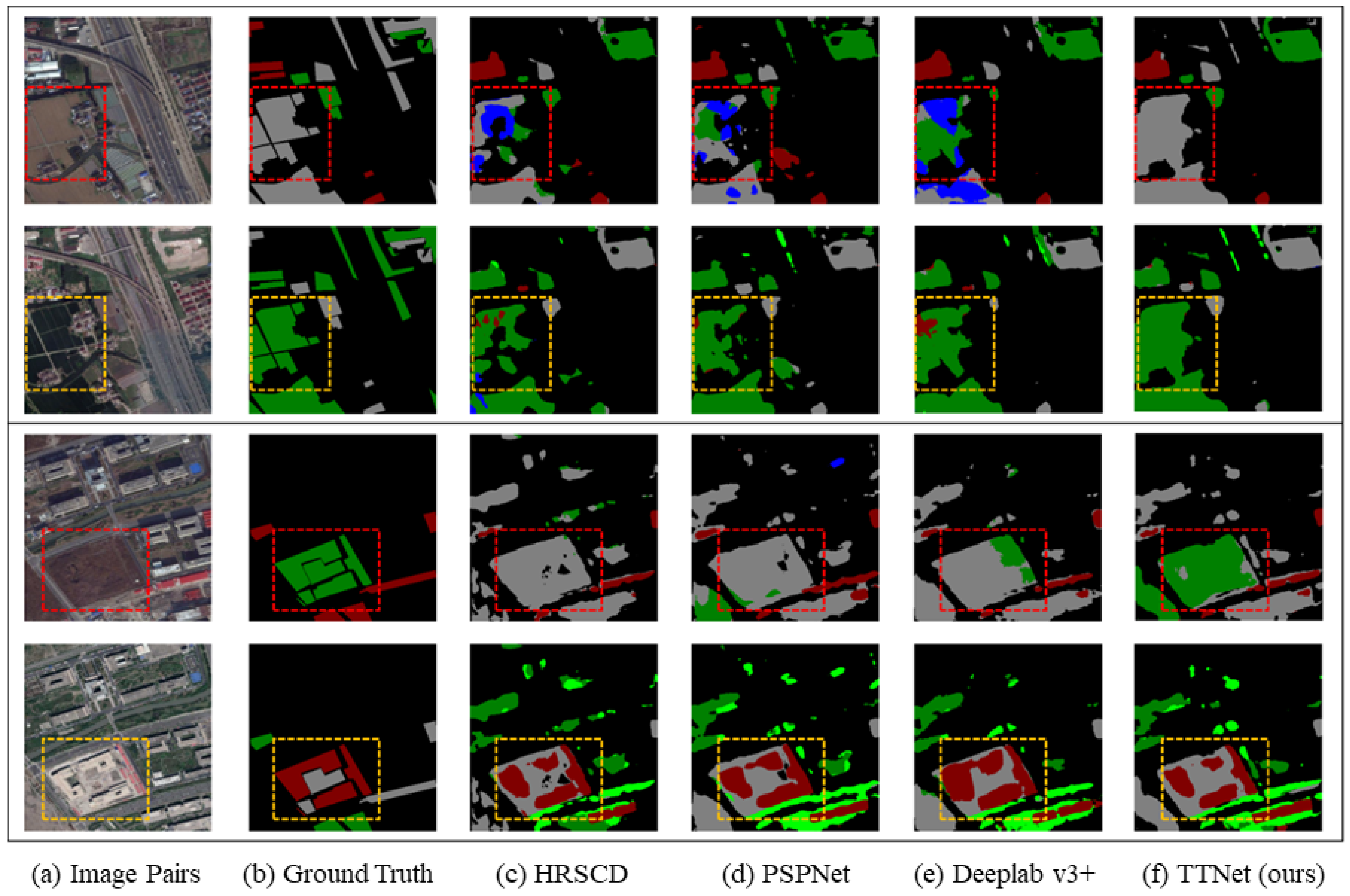
Figure 5 and
Figure 6 offer a visual comparison of the un-detection and mis-detection problems, respectively, based on the predicted binary change map. Meanwhile,
Figure 7 and
Figure 8 provide visualization comparison results based on the labeled binary change map. Across all these visualizations, it is evident that the proposed TTNet outperforms the six benchmark methods.
In
Figure 5 and
Figure 7, the benchmark methods exhibit significant un-detection issues, particularly in cases where the spectral features of change regions bear resemblance. Notably, HRSCD.str4 exhibits shortcomings in identifying certain conspicuous change types, such as the “surface-to-building” change and “low vegetation-to-water” transition. Even with spatial context information capture, PSPNet and Deeplab v3+ still struggle with un-detection problems. In contrast, TTNet significantly mitigates un-detection problems even when dealing with similar spectral features in bi-temporal images.
Moreover, all benchmark methods encounter mis-detection problems when the spectral features of change regions diverge. As observed in
Figure 6 and
Figure 8, HRSCD.str4 inaccurately predicts surface as water or vegetation. This misclassification is more pronounced in PSPNet and Deeplab v3+, suggesting that context information might introduce noise in bi-temporal semantic segmentation. TTNet effectively curbs the influence of noise by learning the change relationship between bi-temporal images, accurately determining the current land cover class of change regions.
4.5. Ablation Study
To comprehensively analyze and discuss the performance of our proposed method, with a specific emphasis on exploring why certain TTM configurations outperform others, we have conducted several ablation studies. These studies are designed to delve into critical aspects such as the insertion positions, architectural design, and weight-sharing mechanisms of the TTM, aiming to analyze the rationale behind TTM configurations and their strategic placement within the model architecture.
4.5.1. Positions for TTM Insertion
To assess the impact of inserting the TTM at different layers, we experiment with placing the TTM at various stages within the decoder of the semantic segmentation branch. We conduct comparisons across seven different network configurations: TTNet.baseline, TTNet.TTM2, TTNet.TTM3, TTNet.TTM4, TTNet.TTM42, TTNet.TTM43, and TTNet.TTM432. Similar to
Section 4.4, we present the results of this ablation study for different TTM insertion positions, considering both the predicted and labeled binary change maps. These results are detailed in
Table 4 and
Table 5, which evaluate the performance of both semantic change detection and semantic segmentation, respectively.
Starting with the overall performance of semantic change detection, the results in
Table 4 show that TTNet.baseline attains a 44.43% mIoU. Then, we progressively incorporate the TTM along the decoder’s top-down pathway after
, and
. It can be observed that TTNet.TTM4 and TTNet.TTM43 achieve 44.85% mIoU and 44.97% mIoU, respectively, thus enhancing TTNet.baseline by 0.42% and 0.54%. By introducing TTM across all feature layers, TTNet.TTM432 achieves the most favorable outcome at 45.91%, elevating TTNet.baseline by 1.48%. Furthermore, applying TTM to HRSCD.str4 increases mIoU to 44.76, resulting in a 1.31% enhancement over the basic HRSCD.str4.
Next, we explore TTM’s impact on the performance of the semantic segmentation branch. As detailed in
Table 5, TTNet.TTM432 outperforms all other network configurations, showcasing a remarkable 65.36% mIoU and a significant 3.08% enhancement over TTNet.baseline. Notably, TTNet.TTM42 and TTNet.TTM43 also contribute improvements of 2.38% and 2.41%, respectively. Similarly, the inclusion of TTM in HRSCD.str4 leads to a 3.41% enhancement in mIoU. This observation is further supported by the visual comparison examples presented in
Figure 9 and
Figure 10, where TTNet.TTM432 effectively mitigates issues of un-detection and mis-detection.
In summary, the consistent improvement trend observed in both label-based and prediction-based experimental results, as depicted in
Table 4 and
Table 5, underlines TTM’s capacity to achieve enhanced outcomes by capturing change relationships and displaying robust generalization performance.
Furthermore, the above ablation studies show that the TTNet.TTM 432 configuration outperforms others. As shown in
Table 4 and
Table 5, inserting TTM only after
or
yields negative impacts. This phenomenon can likely be attributed to the absence of comprehensive guidance from high-level semantic information.
, with its broader receptive field and richer semantic features, appears to play a pivotal role. Skipping
and directly placing TTM after
or
might introduce noise due to the lack of substantial semantic context in the corresponding phase’s features. Consequently, this could lead to a degradation in TTM’s performance. This interpretation gains further substantiation from the observations in rows 5 and 6 of both
Table 4 and
Table 5. The noticeable improvements in TTNet.TTM42 and TTNet.TTM43 upon inserting TTM after
underscore the irreplaceable role of high-level semantic information in effectively capturing change relationships.
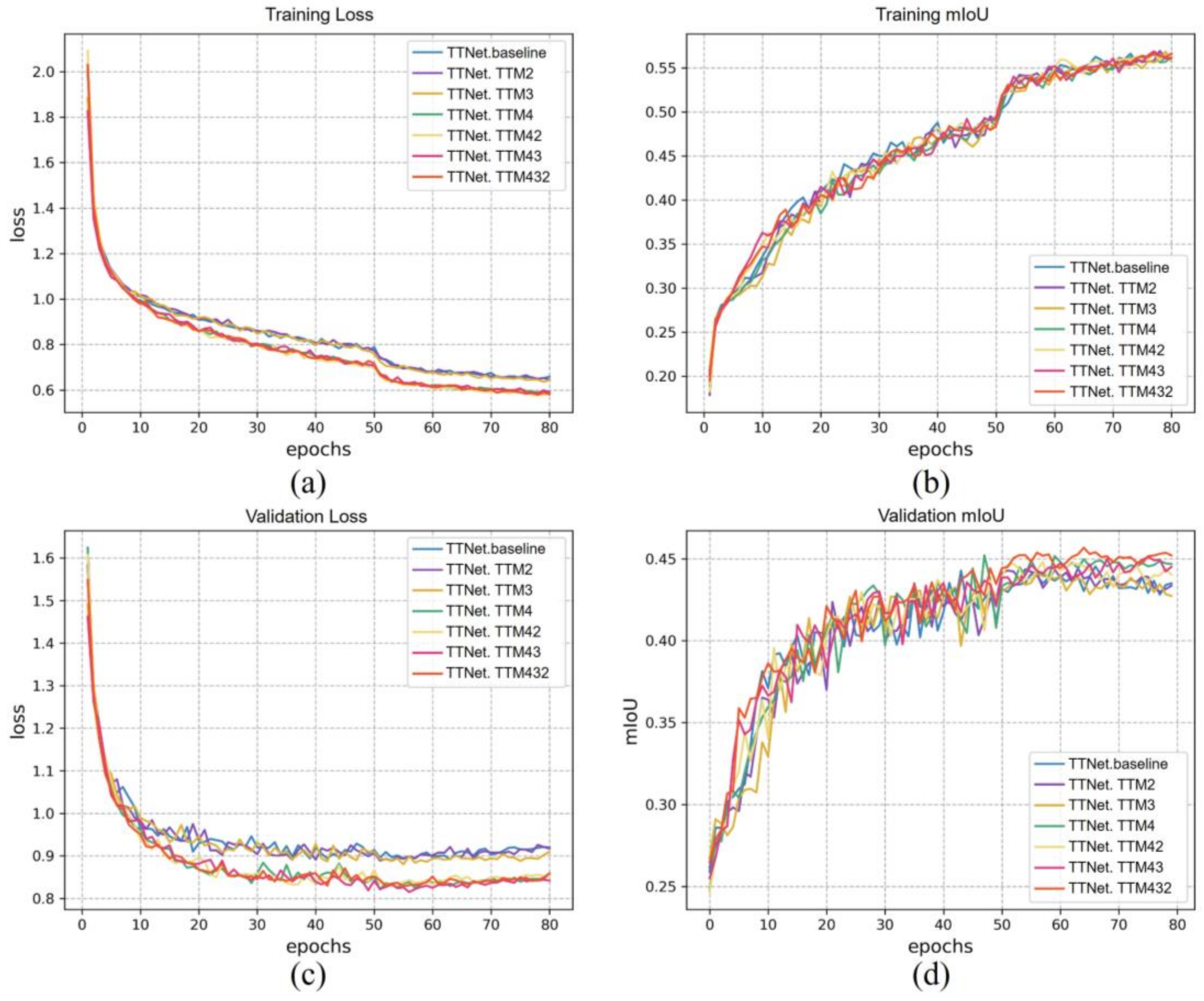
In
Figure 11, we have illustrated the semantic metric curves derived from the seven ablation experiments during the training and validation phases. Observing
Figure 11a,c, it becomes apparent that when compared to TTNet.baseline, both the training and validation semantic losses of TTNet.TTM432, TTNet.TTM43, and TTNet.TTM42 exhibit steeper descents with lower values as these models converge. In line with this trend, the validation semantic mIoU of these three models is higher. Furthermore, TTNet.TTM2 and TTNet.TTM3 exhibit performance comparable to TTNet in terms of both mIoU and loss. The insights drawn from the semantic metric curves align with our experimental findings and the preceding analysis.
4.5.2. Evaluation of TTM Design
We conducted a more in-depth exploration of the TTM architecture design, as presented in
Table 6. An intuitive approach to capturing the change relationship is through Concatenation (CAT), wherein feature maps from the two bi-temporal images are concatenated and processed through a 1 × 1 convolutional layer to reduce channel dimensions. The results depicted in the last three rows of
Table 6 reveal that both the CAT and TTM designs significantly enhance the baseline’s performance when semantic change maps are derived from the actual labels of binary change maps. Notably, the integration of TTM boosts the baseline’s mIoU by 3.08%. This emphasizes the significance of capturing change relationships through the fusion of bi-temporal image features, ultimately improving the accuracy of land cover classification for individual temporal images.
When actual labels of binary change areas are not employed to generate semantic change detection results, the performance of the CAT structure closely aligns with the baseline. This might be due to the fact that the CAT structure concatenates dual-temporal features, which does capture change relationships between the two temporal phases. However, this approach might inadvertently reduce the distinctiveness between these features, thereby diminishing the binary change detection branch’s performance. On the other hand, the TTM structure captures change relationships by calculating the similarity between dual-temporal features. This approach enables raw features to complement change information while better retaining feature differences.
4.5.3. TTM Weight Sharing Analysis
Given that TTM must be inserted into two separate semantic segmentation branches to capture the enhancements associated with the bidirectional change relationship, we examine whether TTM should share its weight across both branches. We present the findings of our ablation experiments in
Table 7. The results from
Table 7 clearly demonstrate that TTM with shared weights outperforms its counterpart with non-shared weights in both overall semantic change detection performance and semantic segmentation performance. This suggests that TTM with shared weights across both semantic segmentation branches can acquire more robust and representative features, benefiting from the simultaneous consideration of the bidirectional change relationship.
5. Conclusions
This paper argues that the change relationship among distinct temporal remote sensing images holds a pivotal role in the context of semantic change detection. It can significantly improve the distinguishability of raw features and effectively mitigate the mis-detection and un-detection challenges encountered in conventional post-classification techniques. To address this, we introduced the Temporal-Transformation Module designed to capture the change relationship through similarity calculations between features extracted from bi-temporal images. Concurrently, we devised a novel end-to-end fully convolutional network named TTNet, integrating multiple TTMs with shared weights into two semantic segmentation branches to effectively model bi-directional change relationships. The experimentation conducted on the SECOND dataset has demonstrated the superior performance of TTNet over several benchmark methods in semantic change detection tasks, underscoring the efficacy of incorporating change relationships in SCD methodologies.
The proposed approach, with its focus on capturing bi-directional change relationships in remote sensing imagery, holds promising implications for various applications. By refining the TTM design, optimizing TTNet architecture, and exploring multi-source data integration, this approach could be tailored to diverse environmental monitoring scenarios, from tracking urban development to detecting changes in agricultural landscapes. The implications also extend beyond the realm of remote sensing. For instance, the ability to capture intricate change relationships between images has potential applications in fields such as medical imaging, security surveillance, and autonomous systems.
However, it is important to acknowledge that while our approach shows promise, it is not a one-size-fits-all solution. The effectiveness of TTNet may vary across different datasets, geographical regions, spectrum bands, or types of land cover changes. Different datasets may yield varying results, as TTNet’s effectiveness is tied to the types of land cover changes within the dataset. For instance, it may excel in detecting certain change patterns, such as urban development, but its performance might be less optimal when confronted with other types of changes. A broader exploration of diverse change patterns is needed to comprehensively evaluate its capabilities. Additionally, the study’s robustness to noisy input data should be further examined to assess its applicability in less controlled environments. TTNet’s performance may be influenced by factors such as image quality, cloud cover, and seasonal variations, all of which can impact the effectiveness of SCD algorithms.
Our work opens several promising avenues for future investigations. First, refining the TTM design and further optimizing TTNet architecture can potentially enhance its performance in various remote sensing applications. Second, incorporating advanced machine learning techniques, such as deep reinforcement learning or domain adaptation, could lead to even more robust SCD models. Third, exploring the integration of multi-source data, including SAR and optical imagery, could expand the applicability of our approach to diverse environmental monitoring scenarios.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}