
Impact of Deep Convolutional Neural Network Structure on Photovoltaic Array Extraction from High Spatial Resolution Remote Sensing Images



Abstract
:1. Introduction
2. Dataset
3. Methodology
- (1)
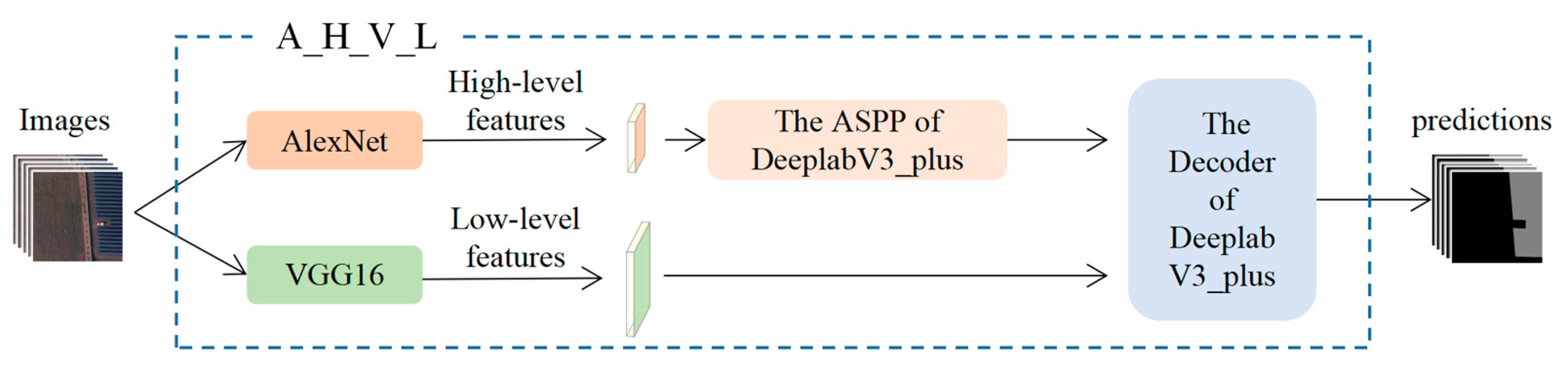
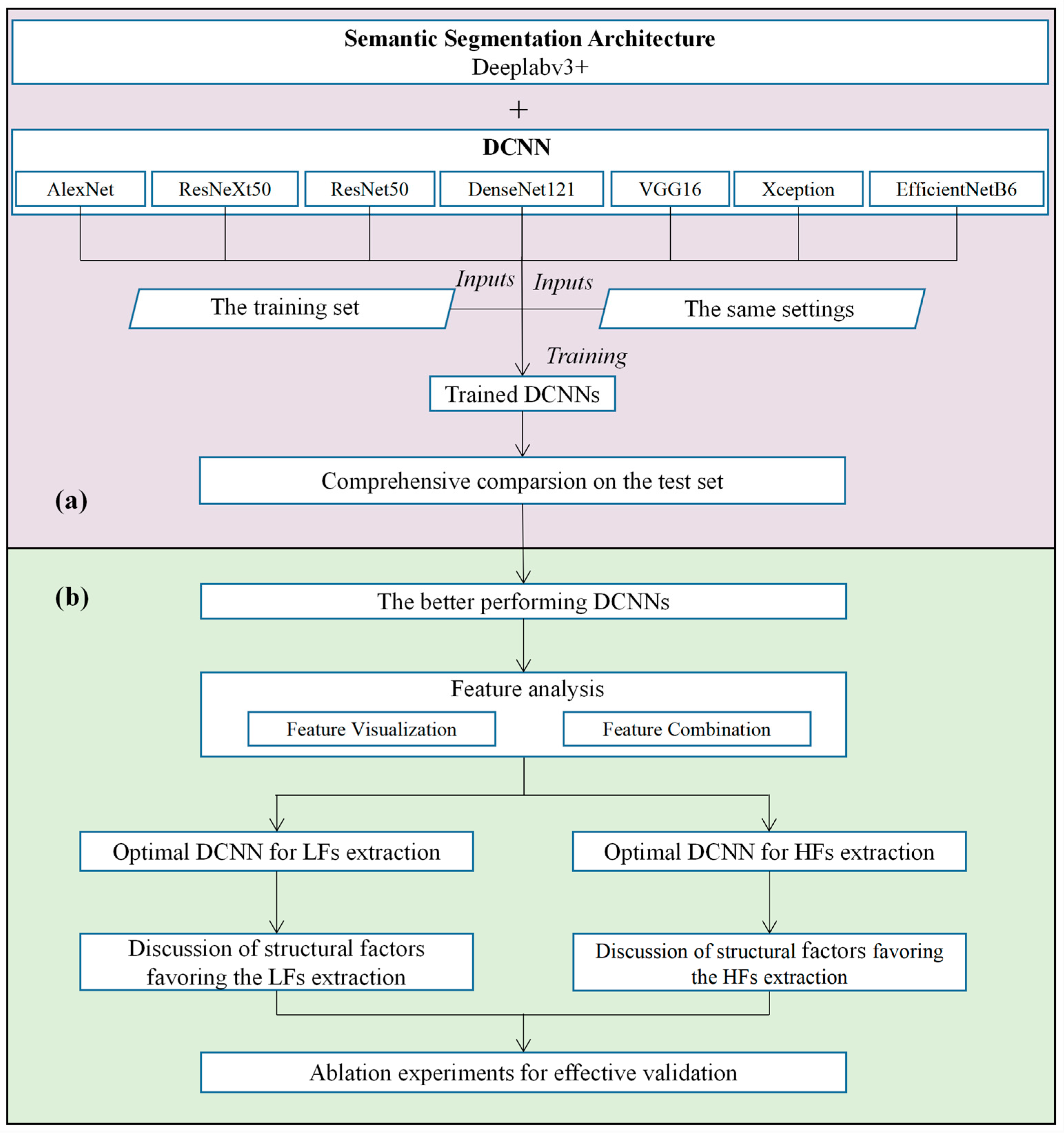
- A comprehensive comparison of seven DCNNs for extracting PV arrays from HSRRS images (Figure 2a). These DCNNs are used as the backbone of the DeeplabV3_plus architecture to build seven semantic segmentation models. Then, these models are trained in the same way and compared on a unified dataset to gain insight into the differences between DCNNs.
- (2)
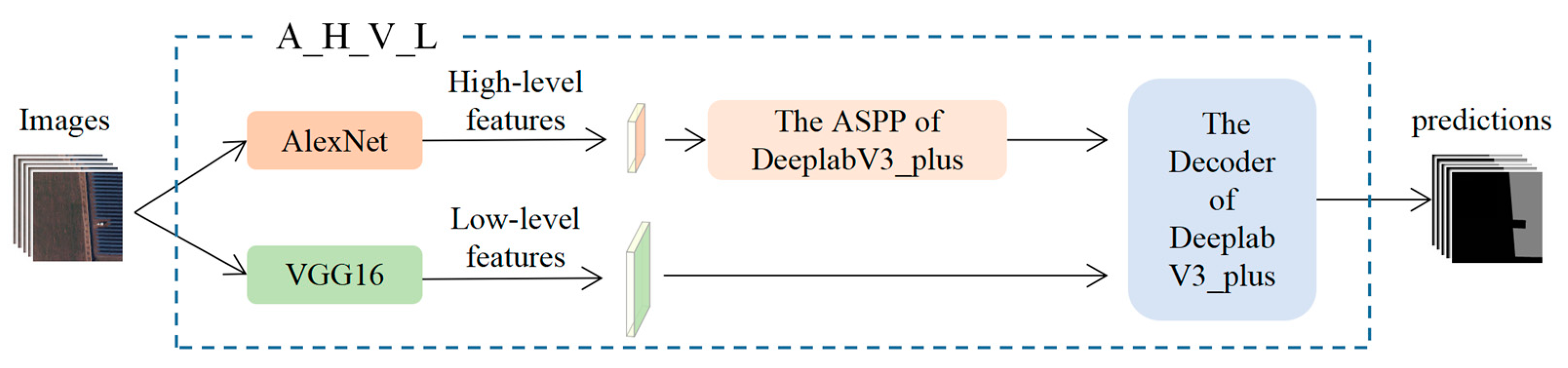
- An investigation of structural factors that favor the extraction of PV array features (Figure 2b). Both LFs and HFs are important for the extraction of PV arrays [36]. In this phase, we first analyze the differences between the better performing DCNNs in terms of LFs and HFs through feature visualization and combination. Then, through the structural analysis of the DCNNs with the best extraction of LFs and HFs, we identify the structural factors that favor the extraction of LFs and HFs and confirm their validity through ablation experiments.
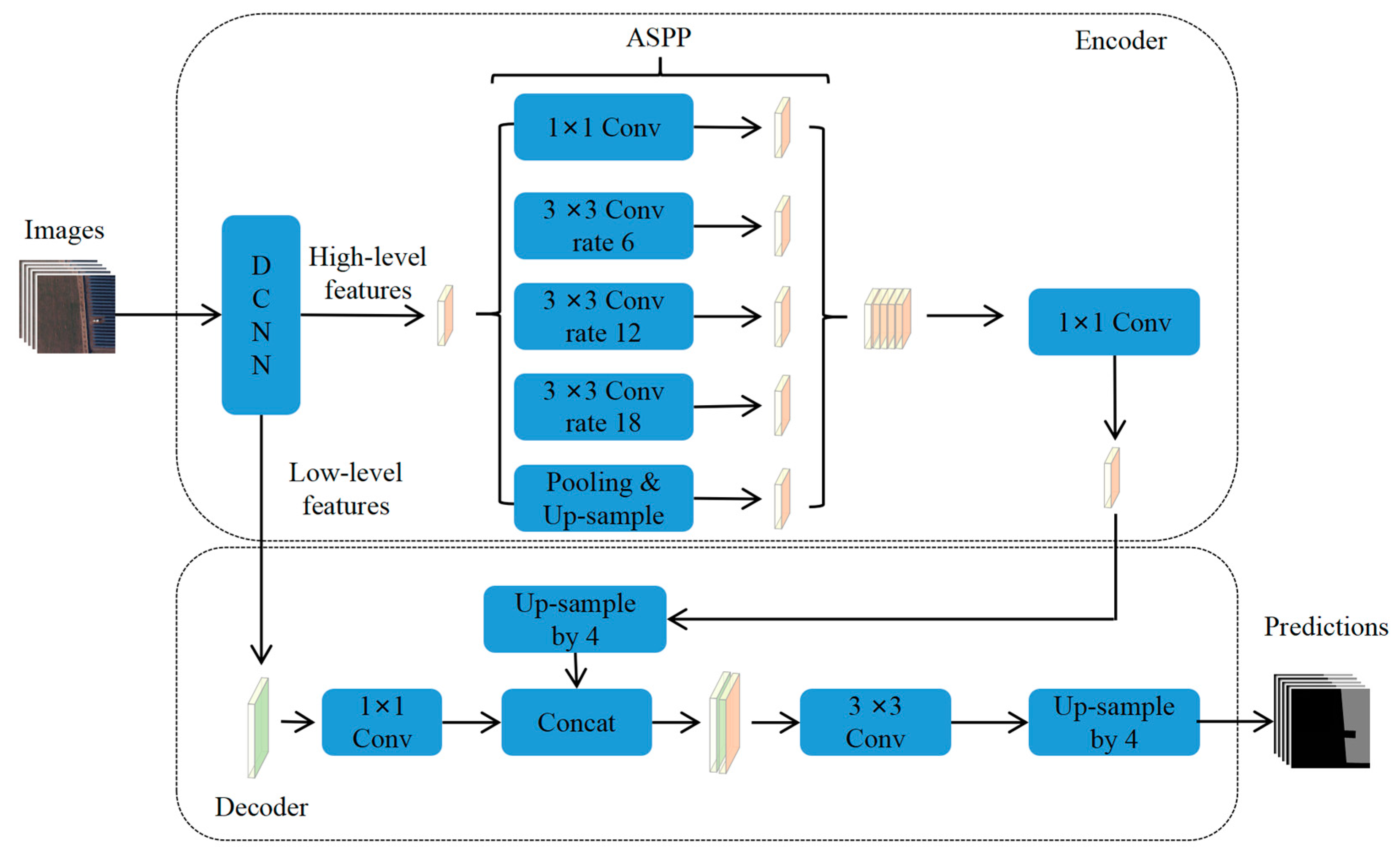
3.1. Combination of the DCNNs and the DeeplabV3_Plus Architecture
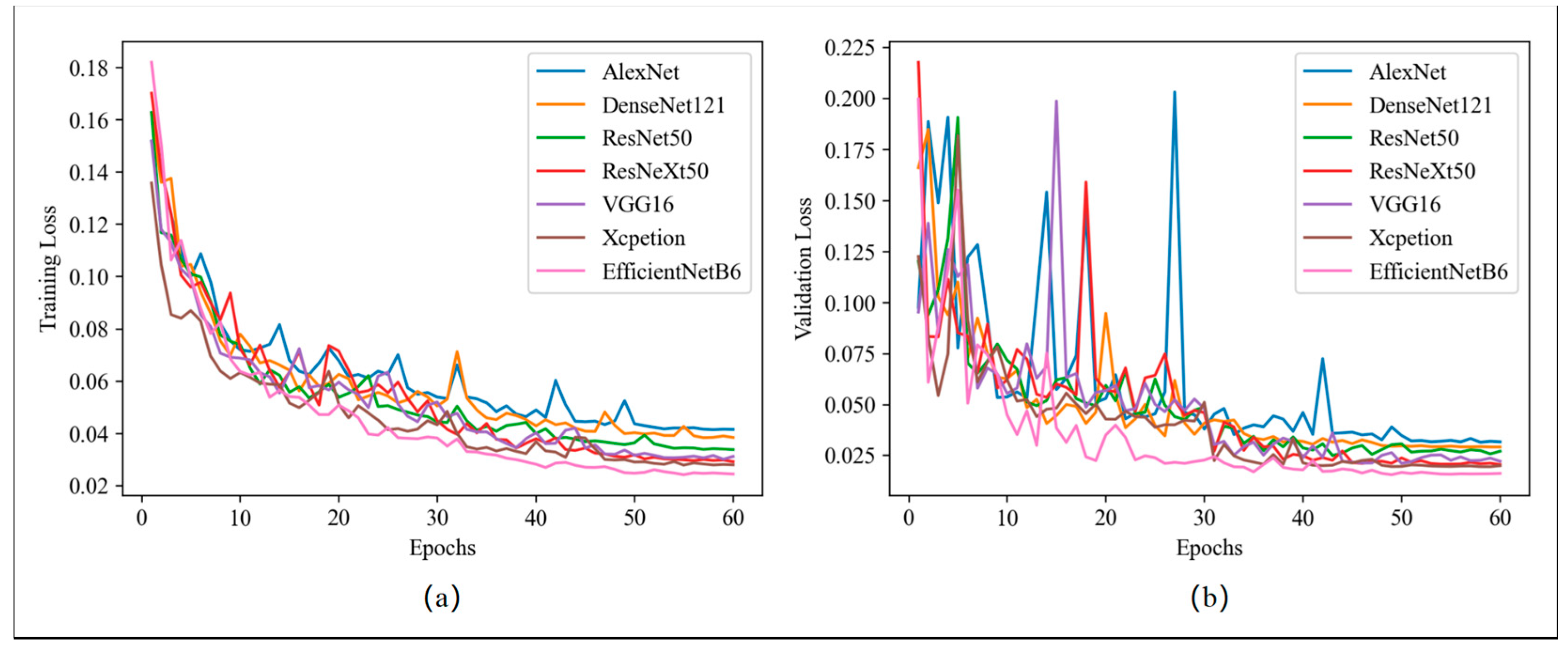
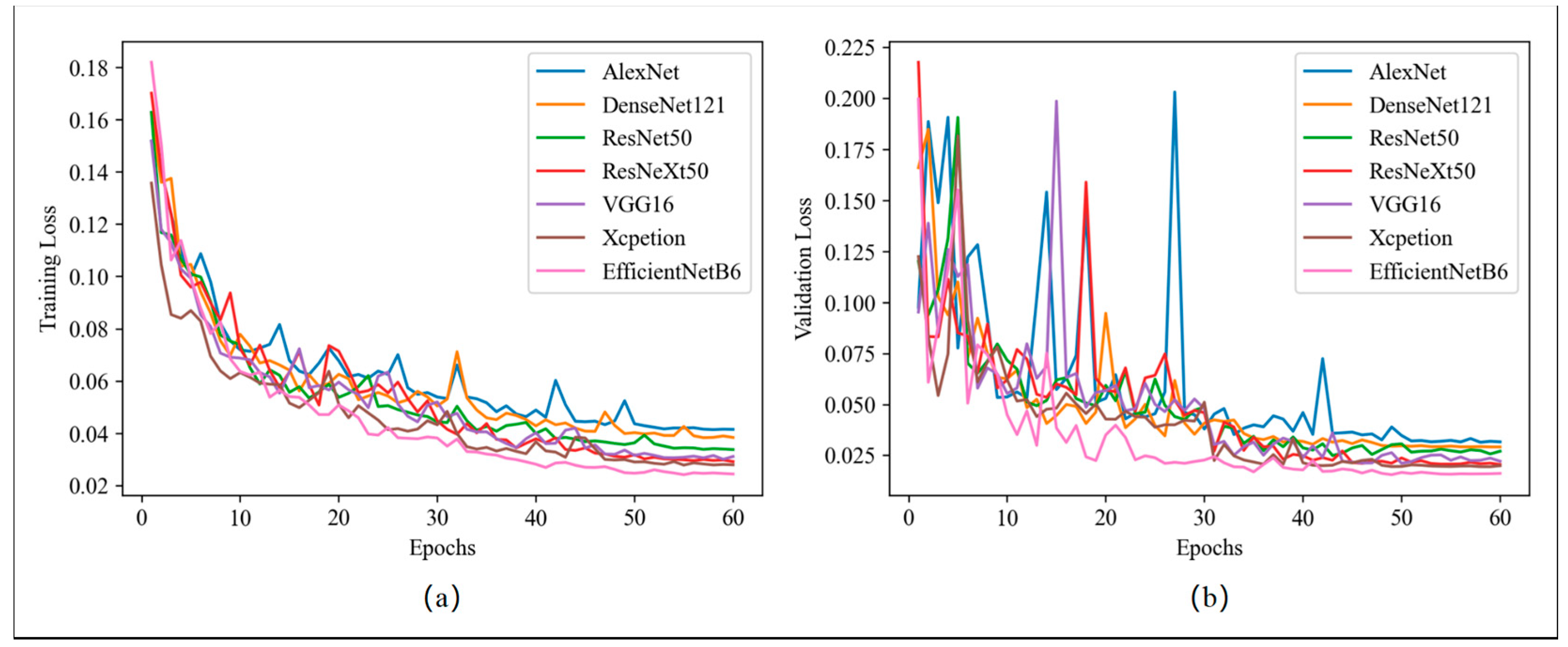
3.2. Training and Evaluation of DCNNs
3.3. Feature Visualization
3.4. Feature Combination
4. Comparison of Different DCNNs
5. Structural Factors Favoring the PV Array Feature Extraction
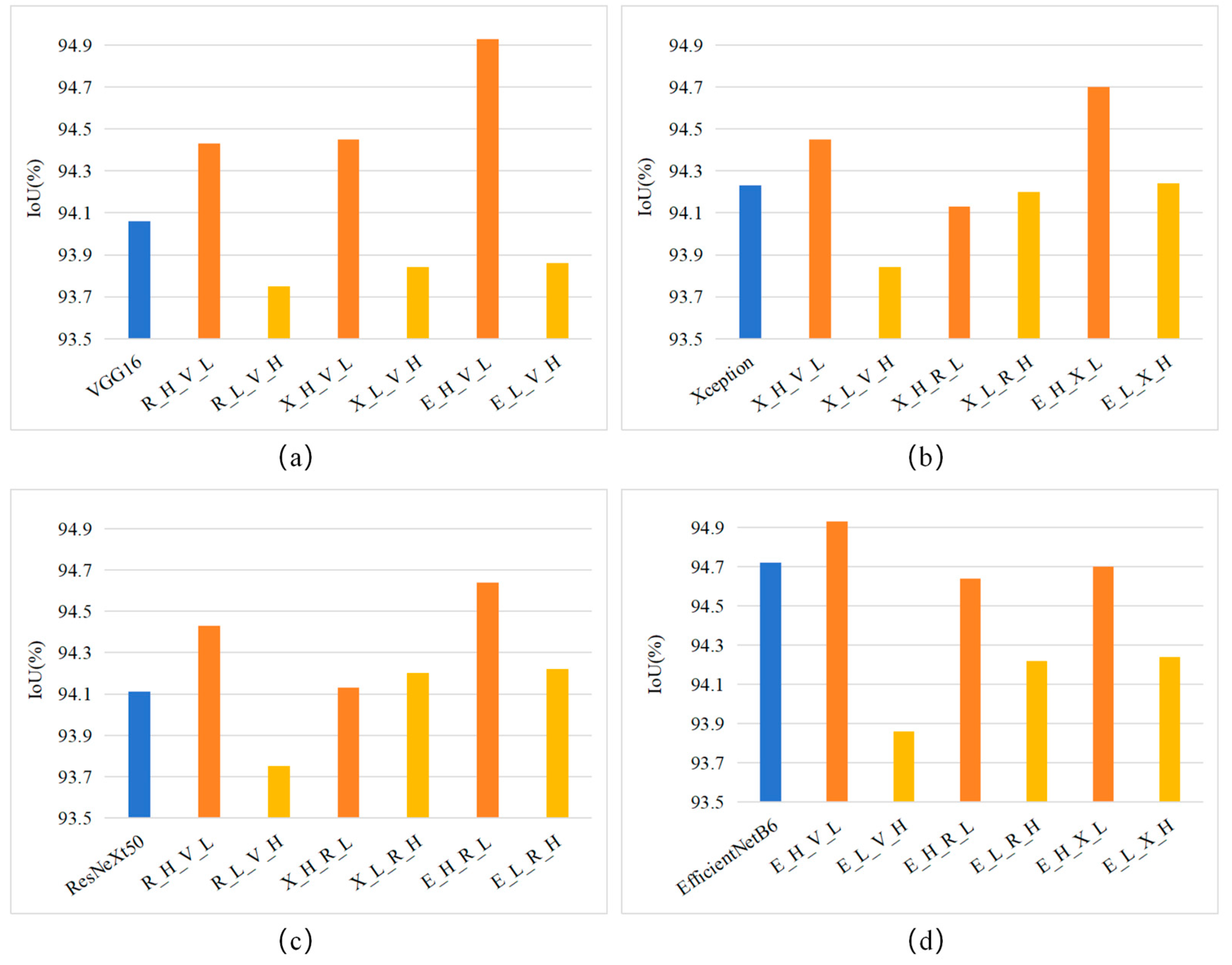
- (1)
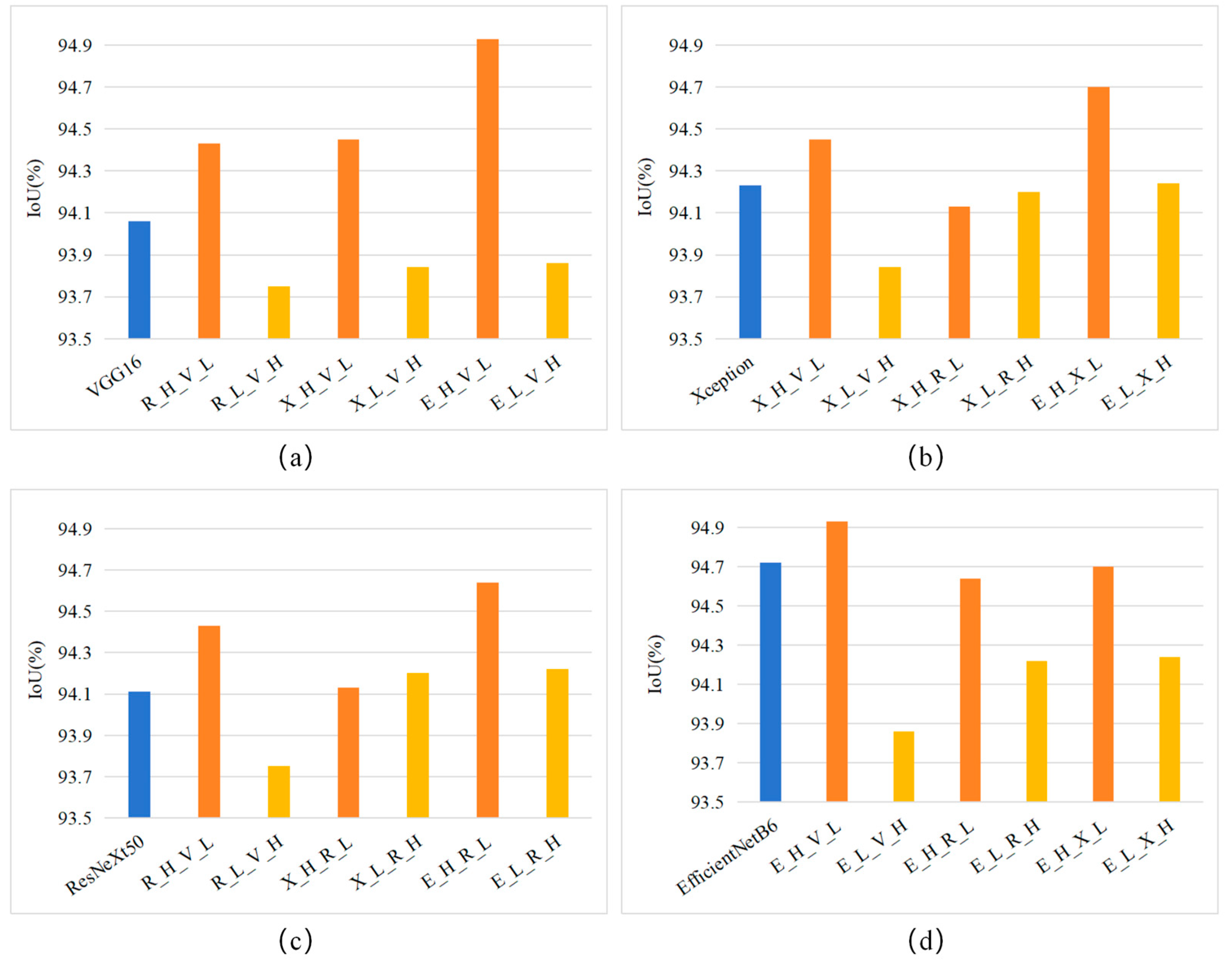
- VGG16 performs best in extracting the LFs of the PV array, as the IoU value of VGG16 is higher than those of R_L_V_H, X_L_V_H_ and E_L_V_H (Figure 7a).
- (2)
- (3)
- EfficientNetB6 shows the best ability in extracting the HFs of PV arrays, as it outperforms the new models using the HFs extracted by the other DCNNs (Figure 7d).
- (1)
- Construction of three DCNNs: VGG16 with downsampling in the first feature extraction block (VD), EfficientNetB6 without separable convolution (EW/OS), EfficientNetB6 without attention mechanism (EW/OA). Note that VD is constructed by setting the stride of the first convolutional layer of VGG16 to 2, while eliminating the first Maxpooling layer of VGG16
- (2)
- Integrate these three DCNNs into the DeeplabV3_plus architecture, and training them using the training set and settings described in Section 3.2.
- (3)
- Construction of V_H_VD_L by combining the HFs extracted by the trained VGG16 and the LFs extracted by the trained VD; EW/OS_H_E_L by combining the HFs extracted by the trained EW/OS and the LFs extracted by the trained EfficientNetB6. EW/OA_H_E_L by combining the HFs extracted by the trained EW/OA and the LFs extracted by the trained EfficientNetB6.
- (4)
- Performance comparison between V_H_VD_L, VGG16, EW/OS_H_E_L, EW/OA_H_E_L, and EfficientNetB6.
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Olson, C.; Lenzmann, F. The social and economic consequences of the fossil fuel supply chain. MRS Energy Sustain. 2016, 3, E6. [Google Scholar] [CrossRef]
- Aman, M.M.; Solangi, K.H.; Hossain, M.S.; Badarudin, A.; Jasmon, G.B.; Mokhlis, H.; Bakar, A.H.A.; Kazi, S.N. A review of Safety, Health and Environmental (SHE) issues of solar energy system. Renew. Sustain. Energy Rev. 2015, 41, 1190–1204. [Google Scholar] [CrossRef]
- Yan, J.Y.; Yang, Y.; Campana, P.E.; He, J.J. City-level analysis of subsidy-free solar photovoltaic electricity price, profits and grid parity in China. Nat. Energy 2019, 4, 709–717. [Google Scholar] [CrossRef]
- International Renewable Energy Agency. Renewable Capacity Statistics. 2022. Available online: https://www.irena.org/Publications/2023/Jul/Renewable-energy-statistics-2023 (accessed on 31 August 2023).
- Lv, T.; Yang, Q.; Deng, X.; Xu, J.; Gao, J. Generation Expansion Planning Considering the Output and Flexibility Requirement of Renewable Energy: The Case of Jiangsu Province. Front. Energy Res. 2020, 8, 39. [Google Scholar] [CrossRef]
- Nassar, Y.F.; Hafez, A.A.; Alsadi, S.Y. Multi-Factorial Comparison for 24 Distinct Transposition Models for Inclined Surface Solar Irradiance Computation in the State of Palestine: A Case Study. Front. Energy Res. 2020, 7, 163. [Google Scholar] [CrossRef]
- Manfren, M.; Nastasi, B.; Groppi, D.; Garcia, D.A. Open data and energy analytics—An analysis of essential information for energy system planning, design and operation. Energy 2020, 213, 118803. [Google Scholar] [CrossRef]
- Feng, D.; Chen, H.; Xie, Y.; Liu, Z.; Liao, Z.; Zhu, J.; Zhang, H. GCCINet: Global feature capture and cross-layer information interaction network for building extraction from remote sensing imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 114, 103046. [Google Scholar] [CrossRef]
- Zefri, Y.; Sebari, I.; Hajji, H.; Aniba, G. Developing a deep learning-based layer-3 solution for thermal infrared large-scale photovoltaic module inspection from orthorectified big UAV imagery data. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102652. [Google Scholar] [CrossRef]
- Li, P.; Zhang, H.; Guo, Z.; Lyu, S.; Chen, J.; Li, W.; Song, X.; Shibasaki, R.; Yan, J. Understanding rooftop PV panel semantic segmentation of satellite and aerial images for better using machine learning. Adv. Appl. Energy 2021, 4, 100057. [Google Scholar] [CrossRef]
- Zheng, J.; Yuan, S.; Wu, W.; Li, W.; Yu, L.; Fu, H.; Coomes, D. Surveying coconut trees using high-resolution satellite imagery in remote atolls of the Pacific Ocean. Remote Sens. Environ. 2023, 287, 113485. [Google Scholar] [CrossRef]
- Carletti, V.; Greco, A.; Saggese, A.; Vento, M. An intelligent flying system for automatic detection of faults in photovoltaic plants. J. Ambient Intell. Humaniz. Comput. 2020, 11, 2027–2040. [Google Scholar] [CrossRef]
- Grimaccia, F.; Leva, S.; Niccolai, A. PV plant digital mapping for modules’ defects detection by unmanned aerial vehicles. Iet Renew. Power Gener. 2017, 11, 1221–1228. [Google Scholar] [CrossRef]
- Jiang, W.; Tian, B.; Duan, Y.; Chen, C.; Hu, Y. Rapid mapping and spatial analysis on the distribution of photovoltaic power stations with Sentinel-1&2 images in Chinese coastal provinces. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 10328. [Google Scholar] [CrossRef]
- Xia, Z.; Li, Y.; Guo, X.; Chen, R. High-resolution mapping of water photovoltaic development in China through satellite imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 10270. [Google Scholar] [CrossRef]
- Wu, A.N.; Biljecki, F. Roofpedia: Automatic mapping of green and solar roofs for an open roofscape registry and evaluation of urban sustainability. Landsc. Urban Plan. 2021, 214, 104167. [Google Scholar] [CrossRef]
- Ge, F.; Wang, G.; He, G.; Zhou, D.; Yin, R.; Tong, L. A Hierarchical Information Extraction Method for Large-Scale Centralized Photovoltaic Power Plants Based on Multi-Source Remote Sensing Images. Remote Sens. 2022, 14, 4211. [Google Scholar] [CrossRef]
- Sizkouhi, A.M.M.; Aghaei, M.; Esmailifar, S.M.; Mohammadi, M.R.; Grimaccia, F. Automatic Boundary Extraction of Large-Scale Photovoltaic Plants Using a Fully Convolutional Network on Aerial Imagery. IEEE J. Photovolt. 2020, 10, 1061–1067. [Google Scholar] [CrossRef]
- Zhang, H.; Tian, P.; Zhong, J.; Liu, Y.; Li, J. Mapping Photovoltaic Panels in Coastal China Using Sentinel-1 and Sentinel-2 Images and Google Earth Engine. Remote Sens. 2023, 15, 3712. [Google Scholar] [CrossRef]
- Chen, Z.; Kang, Y.; Sun, Z.; Wu, F.; Zhang, Q. Extraction of Photovoltaic Plants Using Machine Learning Methods: A Case Study of the Pilot Energy City of Golmud, China. Remote Sens. 2022, 14, 2697. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Jie, Y.S.; Ji, X.H.; Yue, A.Z.; Chen, J.B.; Deng, Y.P.; Chen, J.; Zhang, Y. Combined Multi-Layer Feature Fusion and Edge Detection Method for Distributed Photovoltaic Power Station Identification. Energies 2020, 13, 6742. [Google Scholar] [CrossRef]
- Chen, L.C.E.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- He, K.M.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Tan, H.; Guo, Z.; Zhang, H.; Chen, Q.; Lin, Z.; Chen, Y.; Yan, J. Enhancing PV panel segmentation in remote sensing images with constraint refinement modules. Appl. Energy 2023, 350, 121757. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Atik, S.O.; Atik, M.E.; Ipbuker, C. Comparative research on different backbone architectures of DeeplabV3_plus for building segmentation. J. Appl. Remote Sens. 2022, 16, 024510. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar] [CrossRef]
- Jiang, H.; Yao, L.; Lu, N.; Qin, J.; Liu, T.; Liu, Y.; Zhou, C. Multi-resolution dataset for photovoltaic panel segmentation from satellite and aerial imagery. Earth Syst. Sci. Data 2021, 13, 5389–5401. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. Proc. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Wu, G.; Guo, Z.; Shi, X.; Chen, Q.; Xu, Y.; Shibasaki, R.; Shao, X. A Boundary Regulated Network for Accurate Roof Segmentation and Outline Extraction. Remote Sens. 2018, 10, 1195. [Google Scholar] [CrossRef]
- Jiang, P.T.; Zhang, C.B.; Hou, Q.; Cheng, M.M.; Wei, Y. LayerCAM: Exploring Hierarchical Class Activation Maps for Localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef]
- Liu, T.; Yao, L.; Qin, J.; Lu, N.; Jiang, H.; Zhang, F.; Zhou, C. Multi-scale attention integrated hierarchical networks for high-resolution building footprint extraction. Int. J. Appl. Earth Obs. Geoinf. 2022, 109, 102768. [Google Scholar] [CrossRef]
- Lu, R.; Wang, N.; Zhang, Y.B.; Lin, Y.E.; Wu, W.Q.; Shi, Z. Extraction of Agricultural Fields via DASFNet with Dual Attention Mechanism and Multi-scale Feature Fusion in South Xinjiang, China. Remote Sens. 2022, 14, 2253–2275. [Google Scholar] [CrossRef]
- da Costa, M.V.C.V.; de Carvalho, O.L.F.; Orlandi, A.G.; Hirata, I.; de Albuquerque, A.O.; e Silva, F.V.; Guimarães, R.F.; Gomes, R.A.T.; Júnior, O.A.d.C. Remote Sensing for Monitoring Photovoltaic Solar Plants in Brazil Using Deep Semantic Segmentation. Energies 2021, 14, 2960. [Google Scholar] [CrossRef]
- Kruitwagen, L.; Story, K.T.; Friedrich, J.; Byers, L.; Skillman, S.; Hepburn, C. A global inventory of photovoltaic solar energy generating units. Nature 2021, 598, 604–610. [Google Scholar] [CrossRef]
- Zhu, R.; Guo, D.; Wong, M.S.; Qian, Z.; Chen, M.; Yang, B.; Chen, B.; Zhang, H.; You, L.; Heo, J.; et al. Deep solar PV refiner: A detail-oriented deep learning network for refined segmentation of photovoltaic areas from satellite imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 116, 103134. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3141–3149. [Google Scholar] [CrossRef]
- Zheng, J.; Zhao, Y.; Wu, W.; Chen, M.; Li, W.; Fu, H. Partial Domain Adaptation for Scene Classification From Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DCNN | Precision (%) | Recall (%) | F1 score (%) | IoU (%) |
|---|---|---|---|---|
| AlexNet | 95.69 | 96.45 | 96.07 | 92.44 |
| DenseNet121 | 95.85 | 96.76 | 96.30 | 92.86 |
| ResNet50 | 96.01 | 97.03 | 96.52 | 93.28 |
| ResNeXt50 | 96.21 | 97.74 | 96.97 | 94.11 |
| VGG16 | 96.59 | 97.30 | 96.94 | 94.06 |
| Xception | 96.28 | 97.79 | 97.03 | 94.23 |
| EfficientNetB6 | 96.47 | 98.12 | 97.29 | 94.72 |
| DCNN | Number of Parameters (Millions) | Depth | Inference Time (ms) | Memory Usage (GB) |
|---|---|---|---|---|
| AlexNet | 7.2 | 10 | 2.43 | 0.19 |
| DenseNet121 | 16.2 | 125 | 9.60 | 0.71 |
| ResNet50 | 40.4 | 54 | 8.08 | 0.65 |
| ResNeXt50 | 38.9 | 54 | 9.52 | 0.99 |
| VGG16 | 20.2 | 18 | 3.41 | 0.97 |
| Xception | 37.7 | 41 | 5.97 | 0.75 |
| EfficientNetB6 | 59.5 | 141 | 19.95 | 2.47 |
| DCNN | Precision (%) | Recall (%) | F1 Score (%) | IoU (%) |
|---|---|---|---|---|
| AlexNet | 95.87 | 96.13 | 95.99 | 92.27 |
| DenseNet121 | 96.09 | 96.41 | 96.25 | 92.77 |
| ResNet50 | 96.19 | 96.68 | 96.43 | 93.09 |
| ResNeXt50 | 96.40 | 97.42 | 96.91 | 94.01 |
| VGG16 | 96.75 | 96.98 | 96.86 | 93.91 |
| Xception | 96.49 | 97.41 | 96.95 | 94.07 |
| EfficicentNetB6 | 96.59 | 97.84 | 97.22 | 94.59 |
| DCNN | Precision (%) | Recall (%) | F1 Score (%) | IoU (%) |
|---|---|---|---|---|
| V_H_VD_L | 96.44 | 96.25 | 96.82 | 93.83 |
| VGG16 | 96.59 | 97.30 | 96.94 | 94.06 |
| EW/OS_H_E_L | 96.30 | 97.54 | 96.92 | 94.02 |
| EW/OA_H_E_L | 96.32 | 97.86 | 97.08 | 94.33 |
| EfficientNetB6 | 96.47 | 98.12 | 97.29 | 94.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Lu, N.; Jiang, H.; Qin, J. Impact of Deep Convolutional Neural Network Structure on Photovoltaic Array Extraction from High Spatial Resolution Remote Sensing Images. Remote Sens. 2023, 15, 4554. https://doi.org/10.3390/rs15184554
Li L, Lu N, Jiang H, Qin J. Impact of Deep Convolutional Neural Network Structure on Photovoltaic Array Extraction from High Spatial Resolution Remote Sensing Images. Remote Sensing. 2023; 15(18):4554. https://doi.org/10.3390/rs15184554
Chicago/Turabian StyleLi, Liang, Ning Lu, Hou Jiang, and Jun Qin. 2023. "Impact of Deep Convolutional Neural Network Structure on Photovoltaic Array Extraction from High Spatial Resolution Remote Sensing Images" Remote Sensing 15, no. 18: 4554. https://doi.org/10.3390/rs15184554
APA StyleLi, L., Lu, N., Jiang, H., & Qin, J. (2023). Impact of Deep Convolutional Neural Network Structure on Photovoltaic Array Extraction from High Spatial Resolution Remote Sensing Images. Remote Sensing, 15(18), 4554. https://doi.org/10.3390/rs15184554