1. Introduction
Transmission line serve as the primary means of transportation within the national power system, thereby, playing a crucial role in ensuring the system’s stable operation. In light of rapid advancements in drone inspection technology and artificial intelligence [
1], the inspection of transmission lines in China has only achieved a level of intelligence [
2] whereby preset flight paths enable automatic aerial photography [
3,
4]. Nevertheless, the processing of these aerial images still relies on manual screening, which results in slow detection speeds and substantial consumption of human and material resources. Consequently, intelligent detection and recognition of defects capabilities within vast quantities of transmission line images hold immense significance.
Extensive research has been conducted both domestically and internationally on the detection of defects in transmission lines, yielding phased achievements [
5,
6,
7]. Notably, algorithms based on convolutional neural networks have demonstrated remarkable performance in target detection [
8] and project defect detection [
9]. In one study [
10], the authors proposed a method that employed regional divisions of high-capacity convolutional neural networks, known as R-CNN, to locate and segment detection objects. Subsequently, faster models were developed, such as Fast R-CNN [
11] and Faster R-CNN [
12]. Another study [
13] optimized the R-CNN approach by enhancing regional divisions and employing neural network architecture search technology, resulting in promising outcomes in fabric defect detection. Additionally, a modified Faster R-CNN algorithm was proposed in a separate study [
14], which utilized a cluster algorithm for the initial test box and improved the loss function to address the imbalance of positive and negative samples. Furthermore, the authors of another publication [
15] employed a combination of an empty-hole convolution network and a deep Q network for feature extraction, while incorporating an attention mechanism module to model the defects. The proposed approach exhibited commendable robustness. In a separate study [
16], a TensorFlow platform was introduced, along with a Faster R-CNN model based on this platform. The Concept-Resnet-v2 network was employed as the fundamental feature extraction network, enabling network structure adjustments and parameter optimizations. Considering the current development trend, the R-CNN algorithm is evolving towards lightweight implementations. However, the inherent limitations of this two-stage algorithm, such as its relatively complex model and slower reasoning speed, make it unsuitable for projects requiring large picture batches and limited hardware resources, particularly for real-time monitoring.
The current target recognition algorithms, in addition to the two-stage algorithm led by R-CNN, is the single-stage algorithm dominated by YOLO [
17]. This single-stage algorithm model is relatively concise, with faster inference, which means that the practical application of memory occupation is relatively low; it has better generalization for real-time detection of engineering scenarios and has been applied to power transmission lines [
18]. In another publication [
19], a combination of YOLOv3 and Faster CNN was applied to inspect transmission lines, effectively detecting and determining the types and locations of defects. Despite the notable accuracy breakthrough, the complexity of the model renders it unsuitable for practical project applications. Moreover, it consumes a significant amount of memory and hampers reasoning speed. In a different study [
20], the author enhanced the YOLO network structure by integrating a residual network with a convolutional network. This modification led to substantial improvements in both accuracy and reasoning speed. However, it is worth noting that there is still a risk of insulation being overlooked during the convolution process, resulting in a relatively low degree of adaptation.
In the domain of lightweight networks, such as the Ghost-Net [
21] series, Mobilenetv1 [
22] series, and shufflenet [
23] series, significant advancements have been made. However, it has been observed in the literature [
24] that deep separable convolution employs a substantial number of low FLOPs and entails high data read/write operations. This characteristic renders it more compatible with CPU and ARM mobile devices, while proving less efficient for hardware with high parallelism, such as GPUs. Given that the transmission branch of aerial image screening relies on GPU hardware, RepVGG [
25], a VGG-like convolutional architecture, is better suited to harness the computational power of GPUs. By employing distinct network structures for inference and training, RepVGG achieves a harmonious balance between accuracy and speed, making it an ideal foundational network for this study. Nevertheless, when applied to machine inspection images, the detection of small target insulators still exhibits a high rate of leakage and false positives, necessitating further improvement. Furthermore, the current algorithm overlooks the influence of image quality on detection in practical applications. Therefore, it remains crucial to prioritize the construction of an image preprocessing network while enhancing the algorithm network.
Within the realm of YOLO series algorithms, YOLOv5 stands out as the most prominent and widely adopted approach. Extensive research [
26] has been conducted to enhance the detection of small target defects in integrated circuits, primarily by augmenting the YOLOv5 detection component and incorporating the SE layer. Another study [
27] introduced the BottleneckCSP module into the primary network for header detection, while leveraging Ghost convolution to reduce model complexity and strike a favorable balance between accuracy and speed. This research has yielded valuable insights into the design of lightweight models. In the context of industrial testing, a separate investigation [
28] focused on constructing a lightweight backbone network and substituting SPP with experience-driven wild modules. This approach not only improves accuracy while maintaining model efficiency, but also offers practical guidance for engineering deployment. However, it is important to note that the actual deployment scenario was not fully considered in this study. The detection of insulation poses a significant challenge due to the substantial imbalance between positive and negative samples, leaving ample room for improvement. Recent efforts have focused on addressing common issues encountered in the YOLO algorithm through the utilization of artificially curated datasets. However, it is important to note that the quality of images obtained through direct transmission from drones may not always be guaranteed, and the power grid dataset remains confidential. Furthermore, the performances of most algorithms have not been thoroughly validated using actual machine patrol images. Consequently, there is still considerable potential for enhancing the YOLO algorithm’s ability to detect target defects in real-world scenarios.
Line inspection defect reports of power companies reveal that the majority of defective images are associated with insulators. This finding underscores the practical relevance of employing YOLOv5 for insulator defect detection in engineering applications.
- (1)
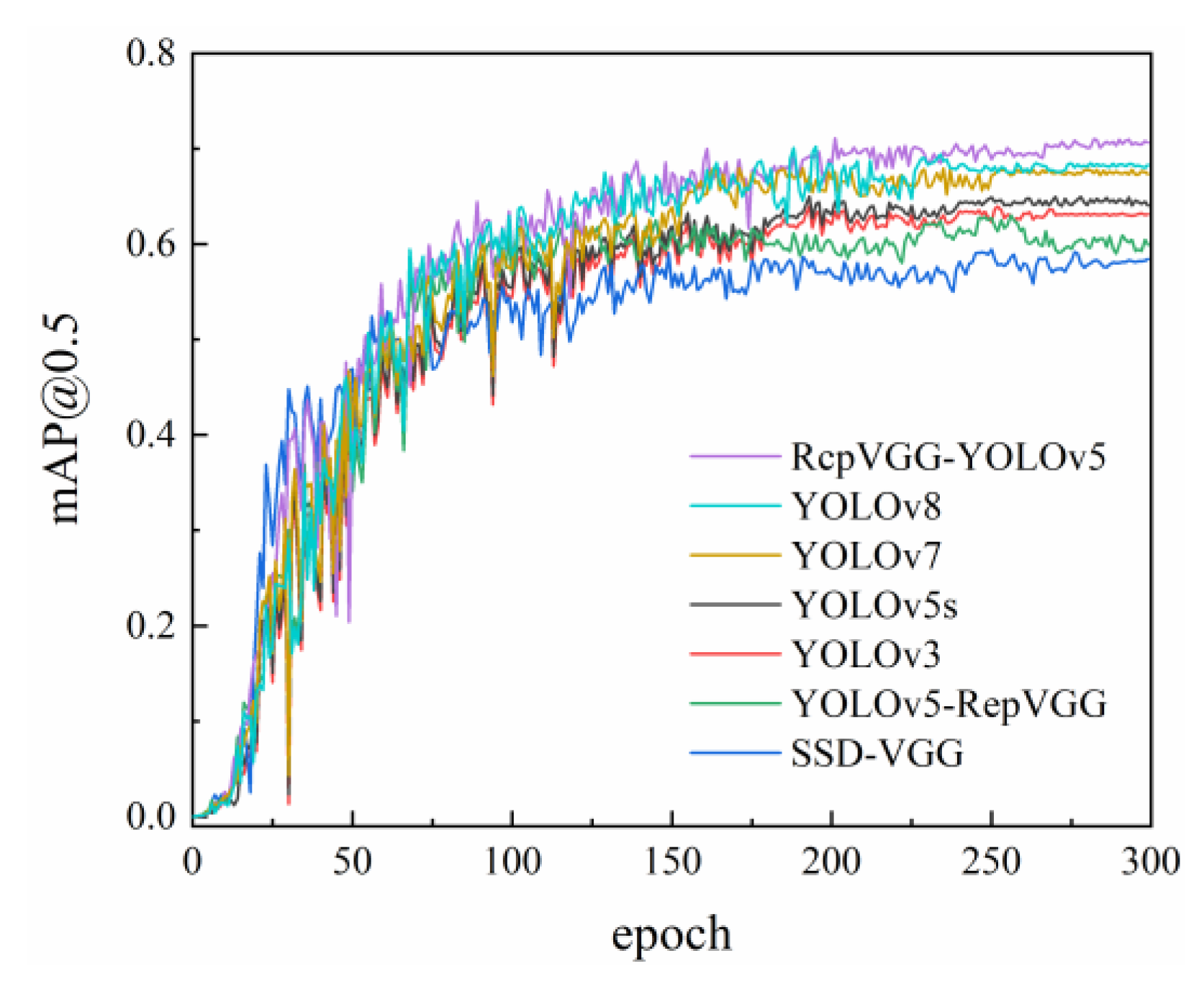
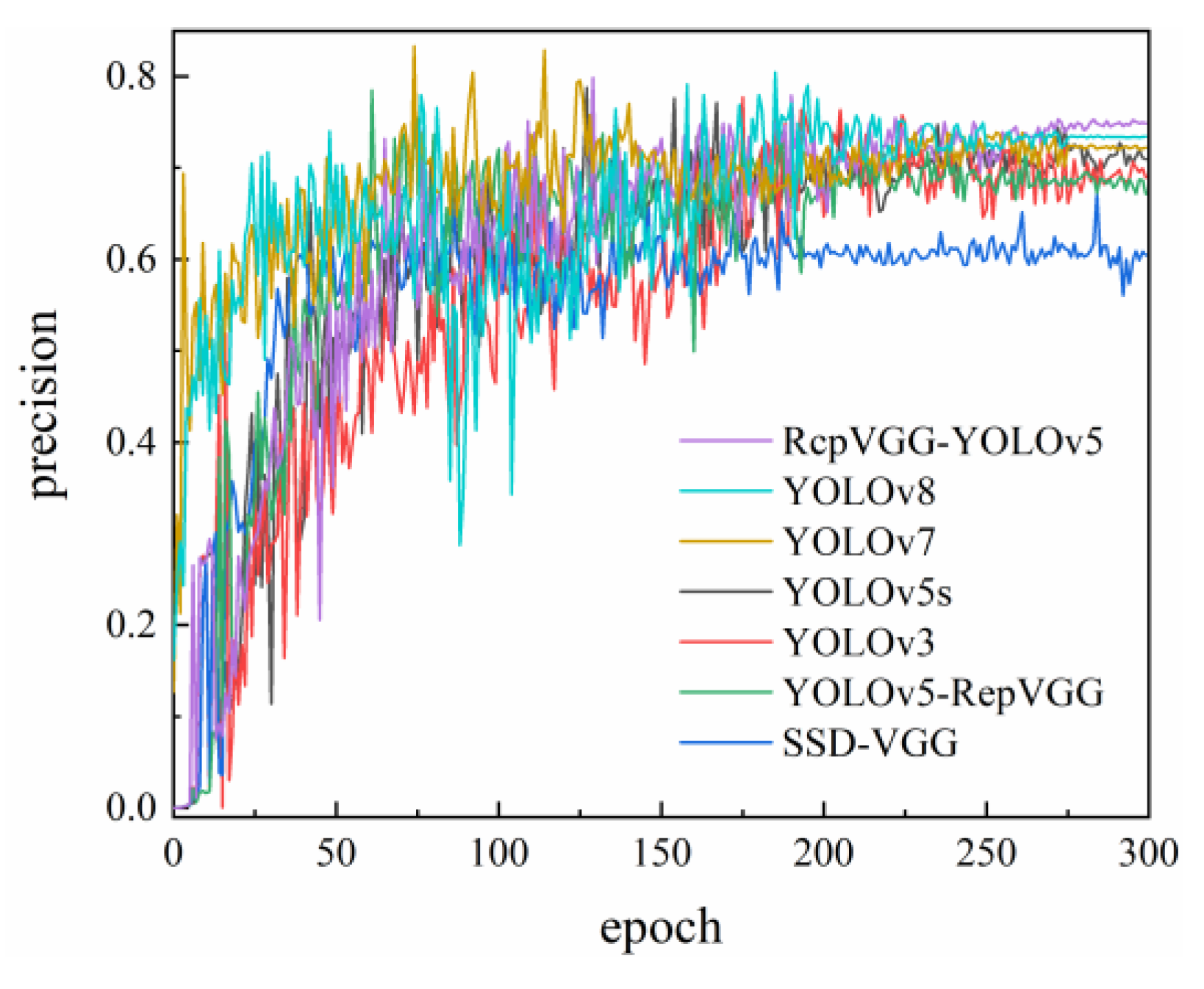
In the current landscape of computer models, the majority of existing models tend to be complex and pose challenges regarding their practical implementation in typical configurations. In this paper, we address this problem by reconfiguring the RepVGG network structure and propose a novel primary network structure called RcpVGG (reconstitution VGG) as the backbone of YOLOv5. The aim of this reconstruction is to streamline the reasoning architecture, enabling faster inference, improving the accuracy of small target detection, and enhancing the overall applicability of the algorithm in various projects.
- (2)
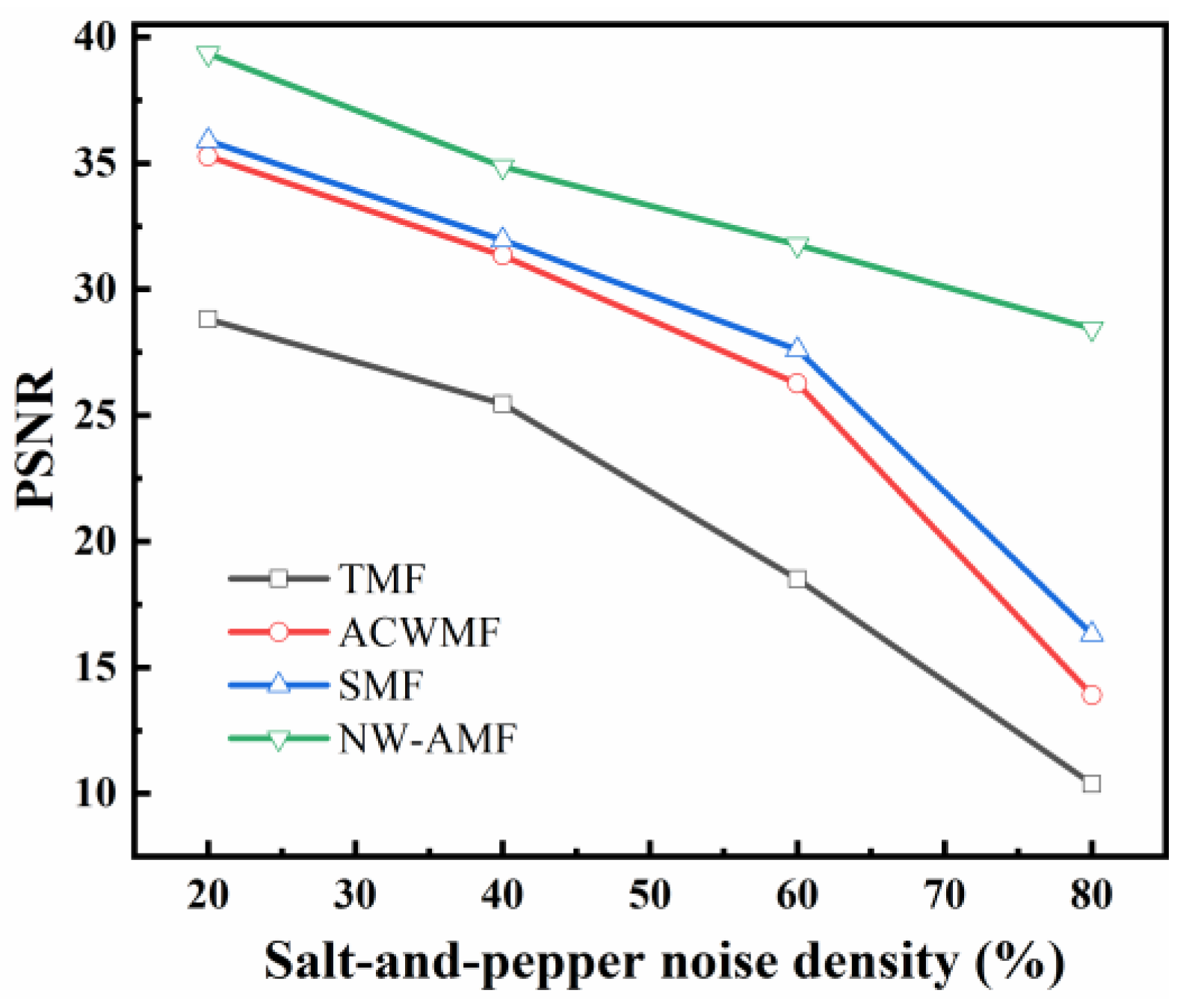
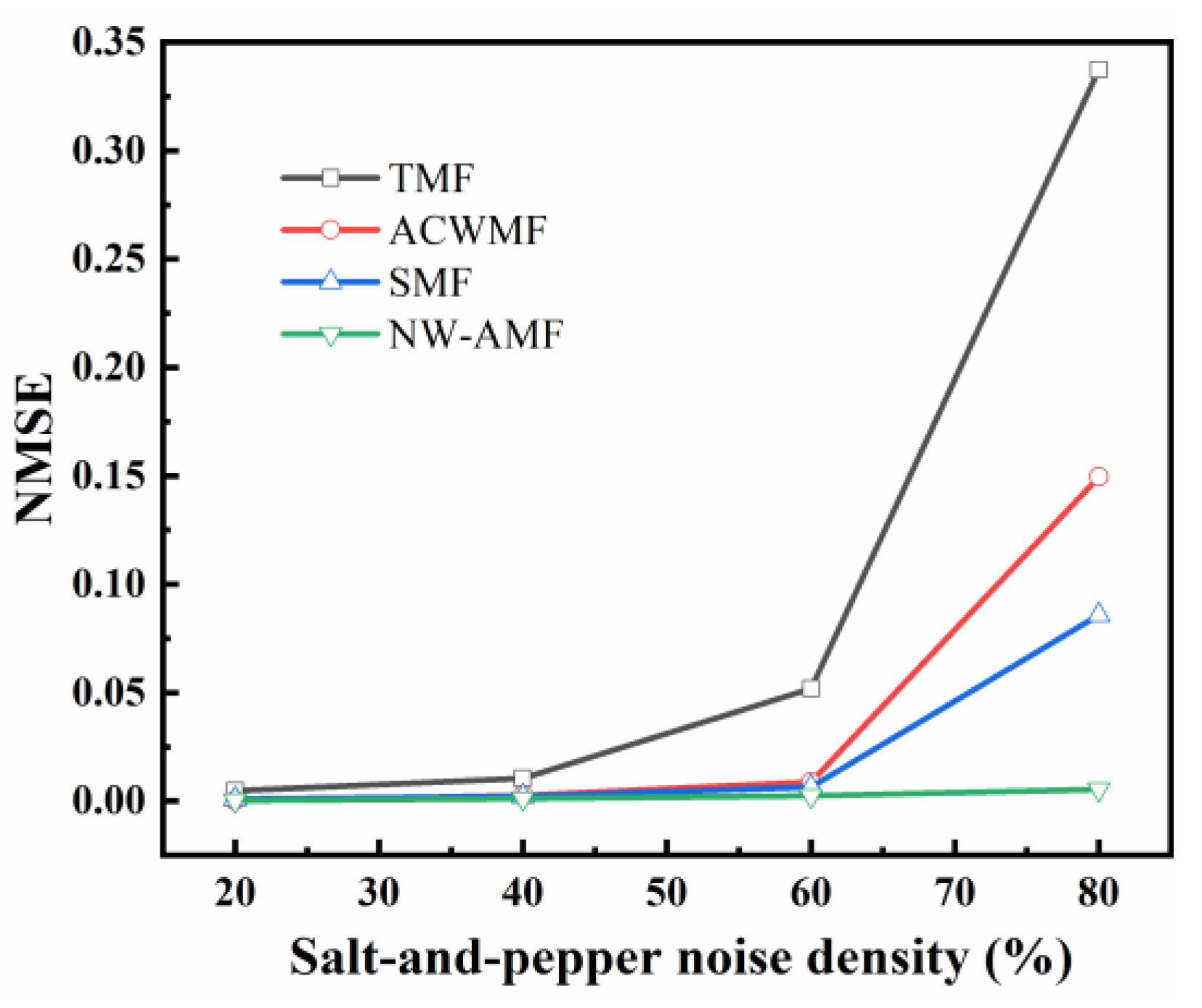
Improving the direct acquisition of drone imagery is the focus of this study, given the complexity of the mechanical vibration background and the presence of attached images. In this paper, the filtering method of the adaptive median filtering algorithm is improved, and a new filtering algorithm is proposed, i.e., NW-AMF, with the aim to mitigate the impact of image quality problems on the accuracy of image defect detection, so as to improve the noise reduction effect and detection accuracy.
- (3)
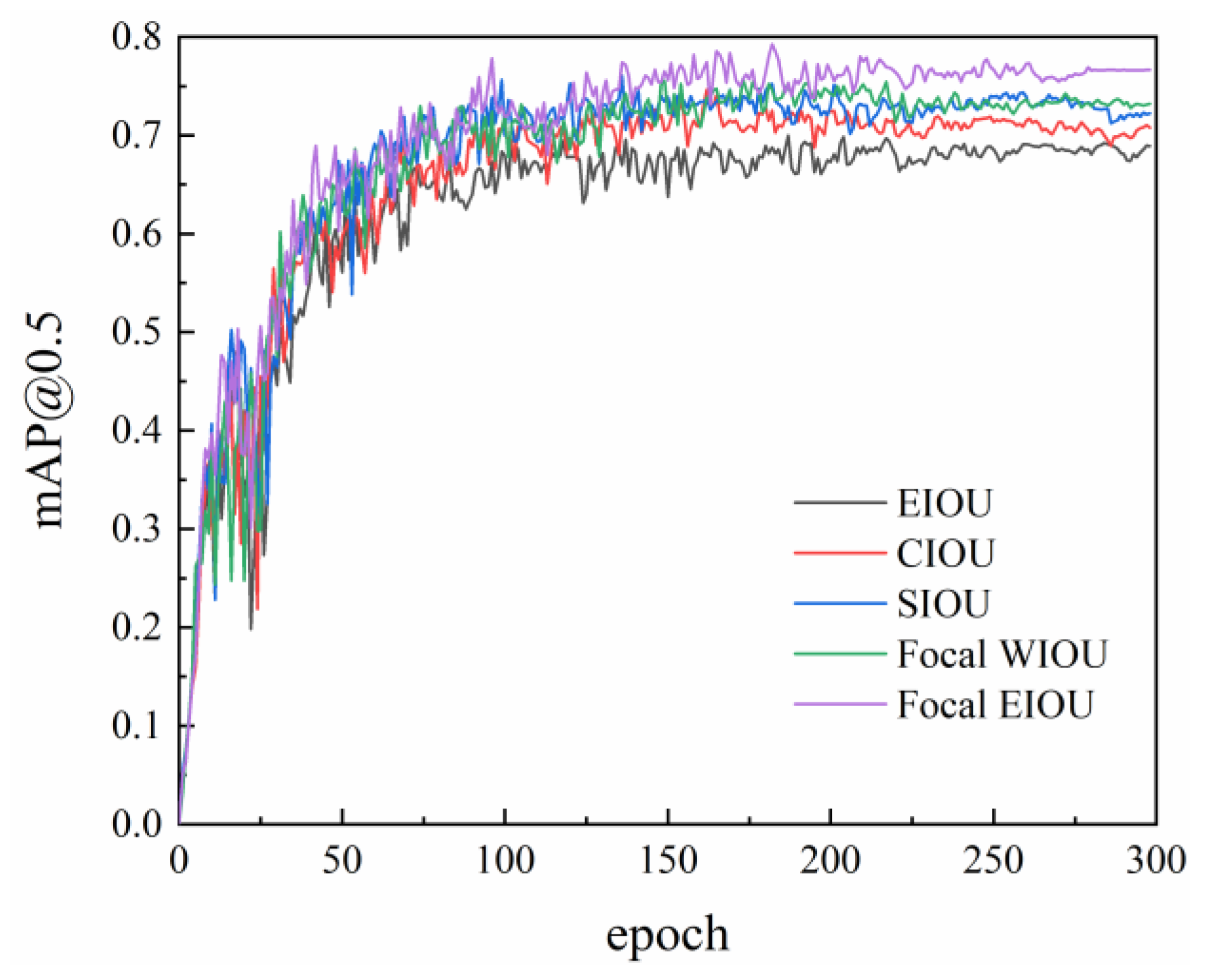
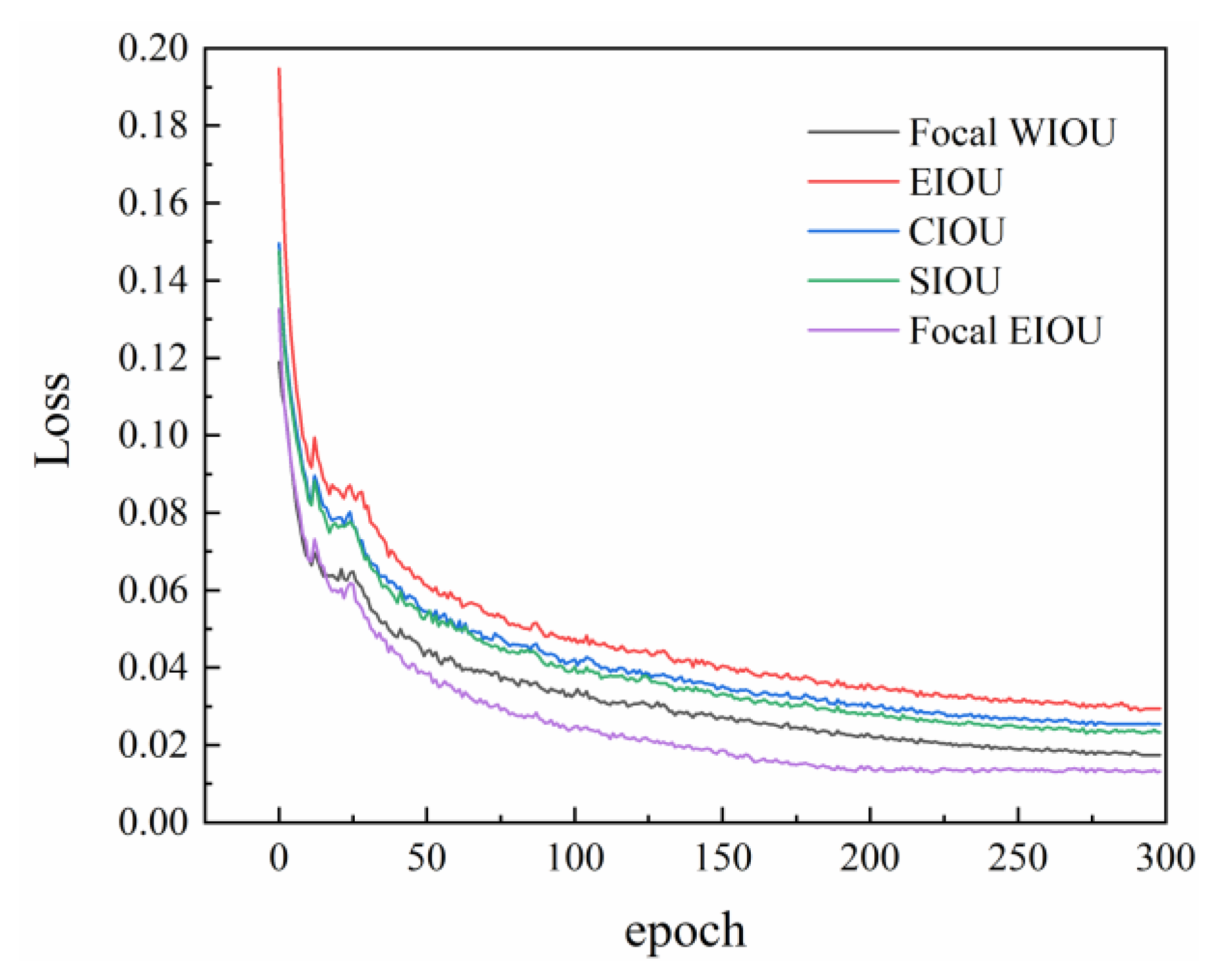
In order to cope with the challenges of small targets and unbalanced positive samples on target detection, we propose a new loss function, i.e., Focal EIOU. Firstly, the original CIOU loss function is replaced by the EIOU loss function with better convergence effect, and is combined with the Focal loss function to suppress positive samples effectively. Together, these improvements contribute by improving the accuracy and acceleration of convergence speed.
- (4)
To verify the efficacy of the proposed algorithm, we use a completely new dataset. This study employs a dataset comprised of non-public machine patrol images obtained from the drone system of a power supply bureau company. This dataset is utilized for both training and validation purposes, serving as a means to assess the practical applicability of the algorithm.
3. RcpVGG-YOLOv5 Algorithm
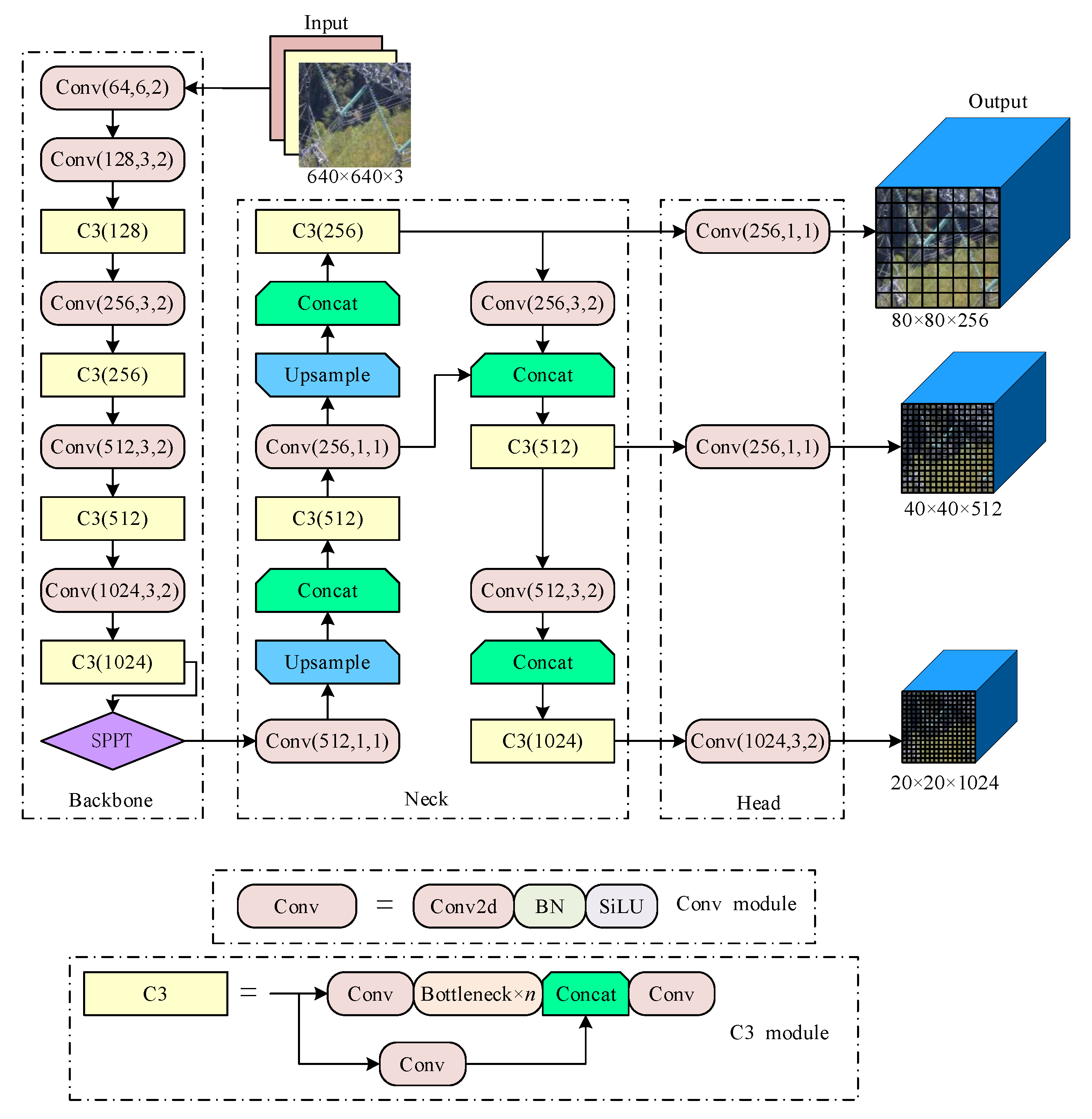
In the context of insulator defect detection, utilization of the YOLOv5 has revealed a notable drawback in terms of its sluggish inference speed. Additionally, it suffers from a high rate of misunderstanding, resulting in subpar accuracy. To address these issues, the present study proposes a novel approach that leverages RepVGG as the primary network prototype to reconfigure the existing framework of YOLOv5. The resultant algorithm, denoted as RcpVGG-YOLOv5, integrates noise and lightweight target detection techniques, as visually depicted in
Figure 3.
3.1. Improved Adaptive Median Filter Algorithm NW-AMF Filtering
When drone footage is captured in a natural environment along a predetermined flight path, the resulting images may be impacted by various types of noise, which include noise from the complex background environment, as well as mechanical jitter and current within the drone itself. Such noise can negatively affect subsequent target testing and other analytical processes. As a result, preprocessing of noise reduction in the input image is necessary [
29]. Adaptive median filtering is the main method of traditional noise reduction filtering [
30]. The principle is: Set two processes, i.e., A and B. The pixels corresponding to the
pixels at the coordinate are
, and the maximum size corresponding to the corresponding window is
. Set
,
,
, which are the maximum, minimum value, and
median value of the corresponding window gray, respectively. The two processes A and B meet the formulas:
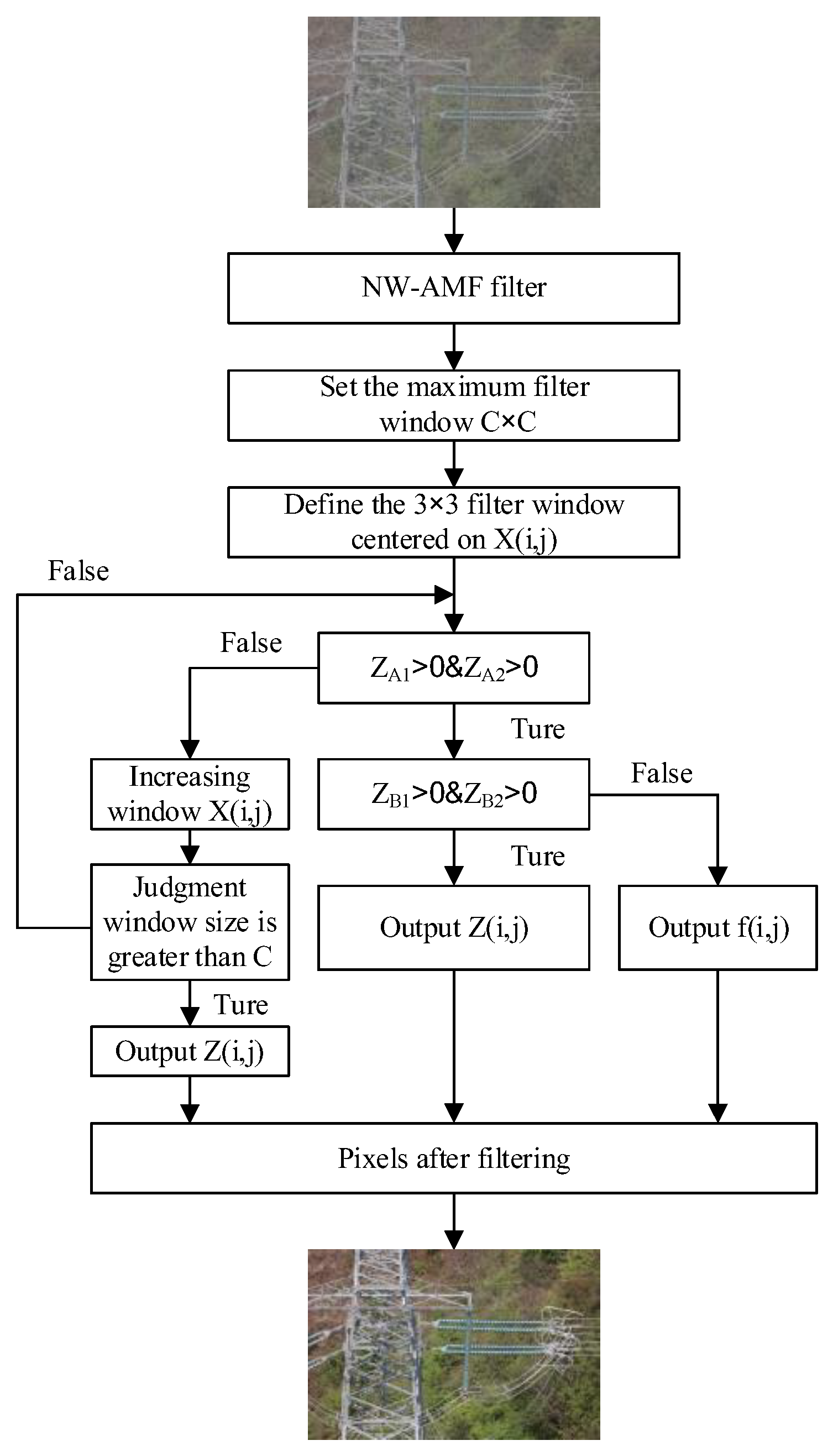
Upon transmitting the noisy image to the filter network, the first step involves conducting grayscale extraction to ascertain whether it falls within the median range. This process is governed by Equations (5) and (6). Subsequently, the conditions are evaluated to determine if they are satisfied, i.e., and . Following this, an assessment is made to verify if the grayscale value of the set window meets the criteria, i.e., and . If these conditions are met, it can be concluded that the pixels are non-noisy, and the actual grayscale value, denoted as , is outputted. Conversely, if the conditions are not met, the output will be the median grayscale value, represented as .
However, in the context of comprehensive high-definition image analysis, the impact on the window is significant once the image details reach a relatively complete state. Optimal information performance of the image details is achieved when the window value is set to a smaller magnitude; however, this comes at the expense of compromised noise reduction capabilities. Conversely, a larger window value enhances filtering performance, albeit at the risk of inducing excessive blurring in the image. To address this issue, the present study introduces an enhanced noise reduction method, namely the adaptive neighborhood-weighted median filtering (NW-AMF) method. The neighboring domain of
is expressed as shown in
Figure 4.
Let the set of corresponding neighborhood pixel values be denoted as
, and let the set of neighborhood pixel values in the up, down, left, and right directions be denoted as
. If the
value satisfies the conditions of being either 0 or 255, it is considered to be noise and subsequently eliminated. The remaining set of neighborhood pixel values is then used to calculate the median value, denoted as
. Weighting coefficients are assigned to each pixel according to Equations (9) and (10). Finally, the remaining pixels and their corresponding weighting coefficients are multiplied and summed to obtain the final filtering output, as illustrated in Equation (11):
Among these variables,
N represents the total number of pixels in
. Once the neighboring pixel collection undergoes the filtering process, the size of the weighted coefficient for each pixel point
is obtained. The resulting filter output is represented by
. The overall structure of this process can be summarized as in
Figure 5:
3.2. Reconstruction of the RepVGG Main Network: RcpVGG
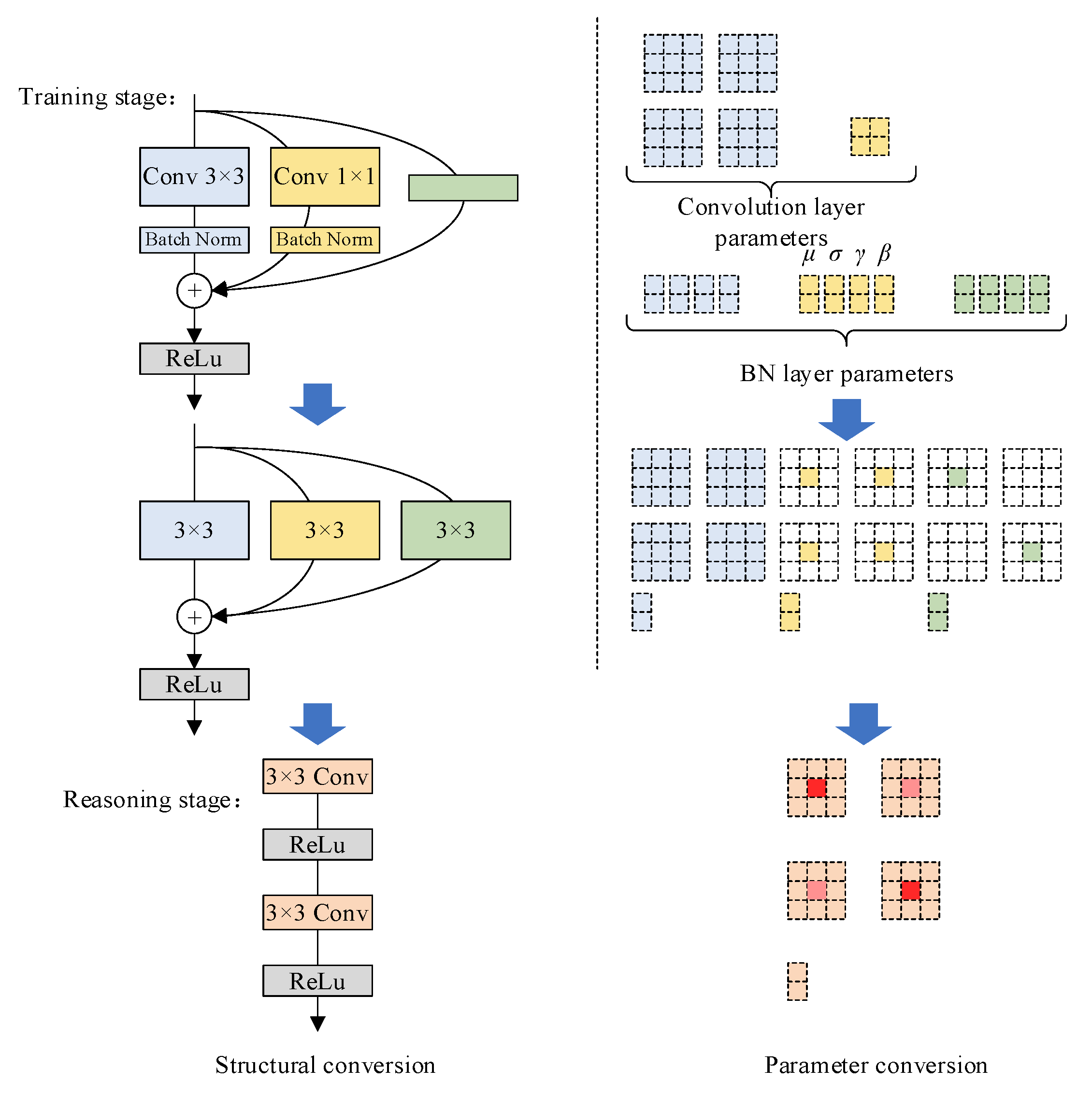
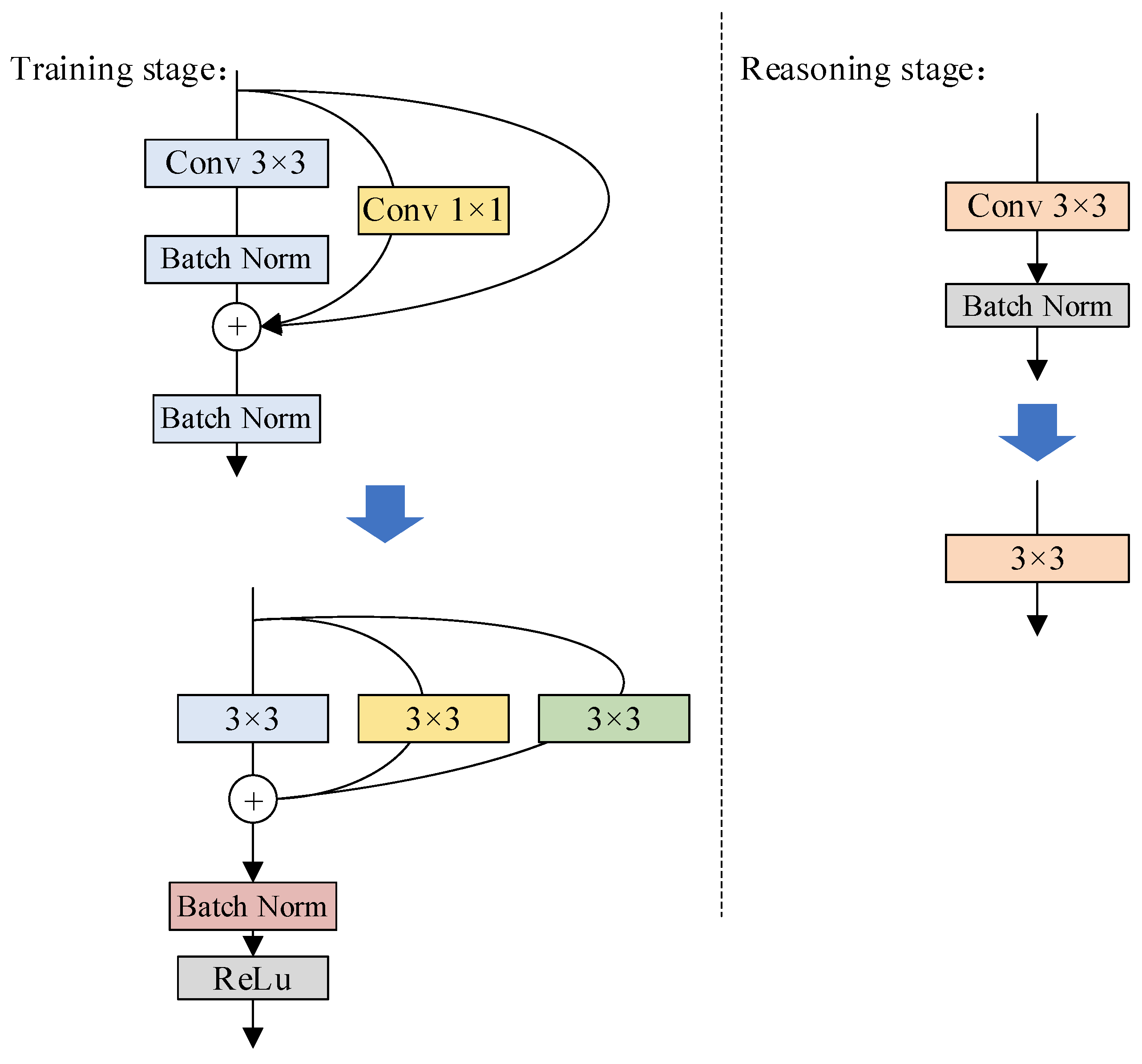
The RepVGG network exhibits a notable enhancement in terms of inference speed, while simultaneously striking a balance between performance and accuracy, thereby fulfilling the fundamental requirements for target detection. However, it has been observed that the accuracy of RepVGG experiences a substantial decline. Furthermore, the rate of misinterpretation escalates, rendering the network’s performance unsuitable for direct deployment. In light of these circumstances, here, we introduce a novel approach, namely RcpVGG (reconstitution VGG), with the aim of augmenting its detection capabilities while preserving its commendable reasoning prowess.
Upon deploying RepVGG in conjunction with YOLO, a notable deterioration in performance and a collapse in quantization emerge as pressing concerns. Notably, the distribution of input channel weights in the model, as well as the tensor distribution values of the output channel, exhibit favorable characteristics that aid in mitigating quantization errors. In an effort to investigate the quantization error, the study referenced as [
31] conducted ablation experiments on the RepVGG architecture, thereby quantifying the error associated with each branch. Intriguingly, it was discovered that the input error experienced a significant increase subsequent to traversing the 1 × 1 branches and identity branches of the BN layer. Building upon this revelation, this study adopts a similar approach by eliminating the 1 × 1 and identity branches. To address the issue of variance drift, the three branches are subsequently aggregated, and to ensure stability during the training process, a BN layer is introduced after the summation of the three branches. For further details regarding the parameters, please refer to
Section 3.1. Consequently, the reconstructed model is represented by Equation (12):
Reshape() corresponds to the convolutional dimension with the underlying structure.
and
represent the inputs and outputs, respectively. The cumulative mean, standard deviation, scale factor, and deviation of the three branches, after their amalgamation with the BN layer during training, are represented by
,
,
, and
, respectively. Following the concatenation of the three branches, the Batch Norm layer is applied to facilitate the reasoning function. The architectural depiction of this structure can be observed in
Figure 6.
3.3. Improvement of Loss Function
In YOLOv5, the estimation of dissimilarity between the predicted values of the network model and the actual values is commonly accomplished through the utilization of the loss function. This loss function serves as a crucial metric for evaluating the algorithm network’s efficacy. Among the fundamental metrics employed, the metric intersection over union (IOU) stands out. Its formula is as follows:
where
A and
B represent the area of the prediction box and the real frame; however, the IOU loss defects are relatively evident. It solely focuses on measuring overlap and fails to account for factors such as overlapping methods, shapes, and colors. To address this issue, the GIOU loss function was introduced. It seeks to rectify the drawback by assigning greater importance to the boundary frame. However, the GIOU loss function suffers from algorithm degeneration and slow convergence due to its computationally intensive nature [
32]. In an attempt to enhance detection accuracy, the DIOU loss function incorporates the consideration of the distance between the target box and the prediction box, as well as the overlapping rate and scale. Nevertheless, it overlooks the vertical ratio of the return of the target box [
33].
The CIOU loss function is employed in YOLOv5, and its calculation formula is as follows:
In Formula (14), the center points of the target and prediction frames are denoted as
and
, respectively. The widths of the target and prediction frames are represented by
and
, while the heights are denoted as and
and
, respectively. The European-style distance between the center point of the prediction box and the real box is represented by
. Additionally,
represents the diagonal distance that encompasses the minimum enclosing area, including both the prediction box and the real frame. The parameter
quantifies the consistency of the length and width ratio, while
denotes a weighting parameter. The types (15) and (16) are derived from Xa, and they are used in the final calculation of the loss function, as shown in Formula (17). The CIOU [
34] introduces the vertical and horizontal ratios of the target box to the prediction box by increasing the influencing factor. However, due to the discrepancy between the reference value and the relative value, the difference in the number of positive and negative samples for small targets is significant.
Accordingly, in this article, we suggest adoption of the EIOU loss function, which offers several advantages. Instead of relying on the coordinate ratio, it utilizes the discrepancy in horizontal and vertical coordinates, resulting in enhanced convergence speed. Moreover, this approach provides a more precise depiction of the box. The expression for the loss function is given by Formula (18):
The EIOU loss function [
35] encompasses three distinct components to calculate functional losses. These components include the overlap loss functions for the predictive and real boxes, the central distance loss functions, and the horizontal and vertical loss functions. These components are denoted as
,
, and
, respectively. In this context,
represents the central point shared by the two boxes, while
signifies the European-style distance between the two center points. In addition,
represents the diagonal distance of the intersecting region between the two frames, while
and
correspond to the minimum width and height of the two frames, respectively.
Simultaneously, the Focal loss function [
36] is introduced as a means to address the issue of the significant disparity in quality between positive and negative samples in practical engineering scenarios. This is expressed by Equation (19) as follows:
where
represents the weighted coefficient of positive and negative samples, which can change the degree of contribution of the positive sample to the loss function by regulating the parameter and
denotes the difficulty of controlling the sample classification. The
value is used to adjust the weighted coefficient of the parameter
.
According to the literature [
37], occurrence of the gradient anomaly can adversely affect the experimental process when the target frame is significantly smaller than the image scale. In order to mitigate this issue, the present study incorporates the concept of the Focal loss function to enhance the EIOU loss function in terms of gradient direction. This modification aims to minimize the influence of low-quality samples on the gradient, as demonstrated by Formula (20):
The loss value increases proportionally with the , resulting in a larger loss for high-quality regression targets. This adjustment aids in enhancing accuracy, and denotes the gradient’s contribution. By adjusting , the algorithm assigns a greater gradient contribution to high-quality samples, thereby facilitating improved convergence of the function.
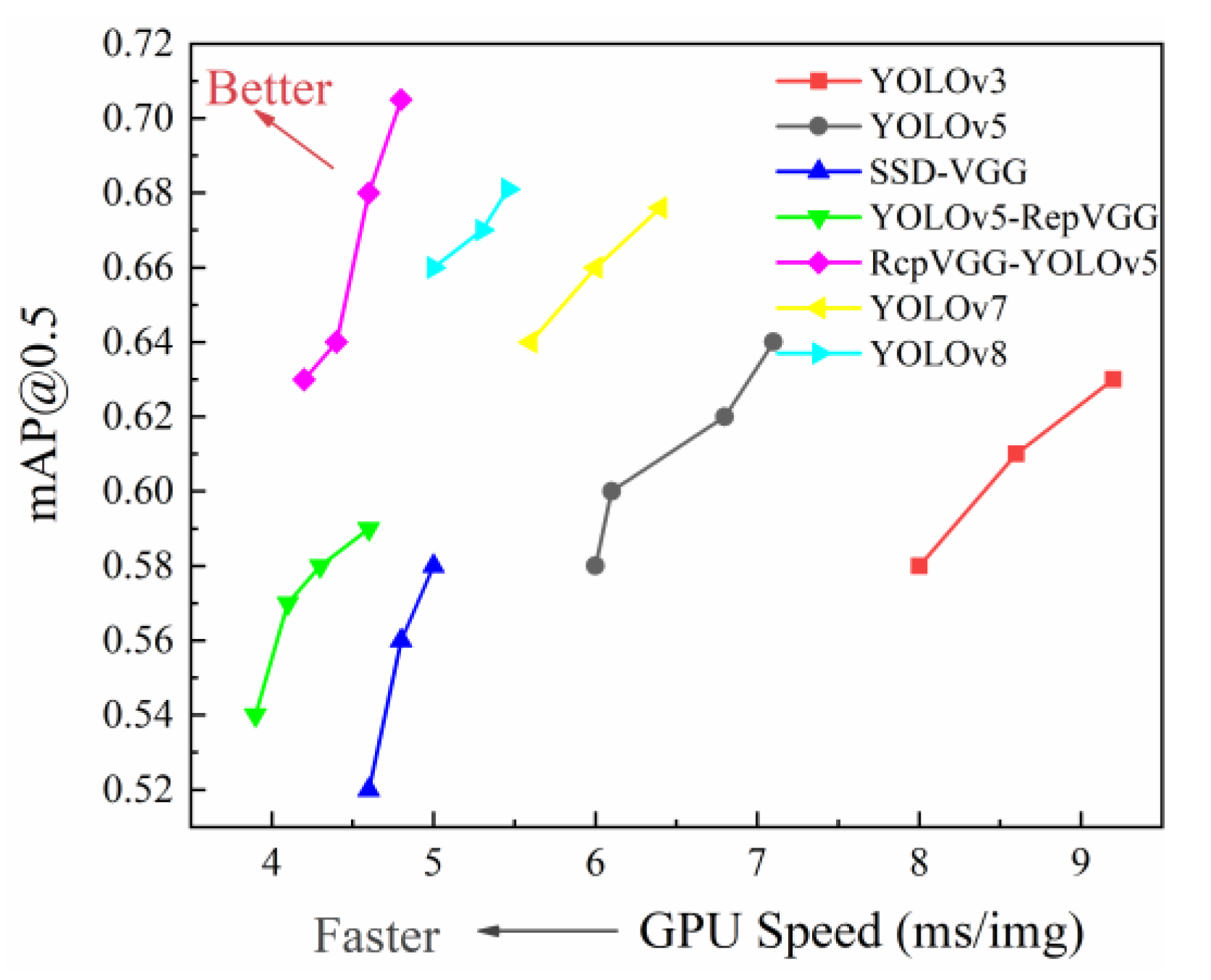
6. Conclusions
In this paper, we introduce an algorithm, namely RcpVGG-YOLOv5, which combines noise reduction and target detection techniques. The experimental findings demonstrate that the enhanced algorithm remains effective and exhibits robustness when dealing with aerial images amidst complex background conditions. In practical scenarios, this algorithm facilitates prompt response by maintenance personnel to defects, thereby offering technical assistance for line detection in power supply companies. It is important to acknowledge that our model does encounter certain limitations. Firstly, the algorithm network lacks a detection strategy for insulators, such as small targets, apart from the loss function component. This aspect presents ample room for improvement. Secondly, the overall dataset size is relatively small and necessitates supplementation. Consequently, the accuracy rate does not surpass 80%. Nevertheless, the model proposed in this study retains high practicality and supports the development of applications in conjunction with the front-end, thereby enabling easy generalization.
Henceforth, future work will focus on two primary areas. Initially, the restricted availability of the transmission line defect dataset due to confidentiality concerns has limited the sample collection process. Consequently, efforts will be made to continue gathering insulator defect samples with varying scales and backgrounds, thereby expanding the experimental dataset and enhancing the detection model’s generalization capabilities. Furthermore, the network structure will undergo further optimization, incorporating targeted strategies for small target detection. This optimization will result in an improved detection performance, enabling real-time and efficient identification of transmission line defects.


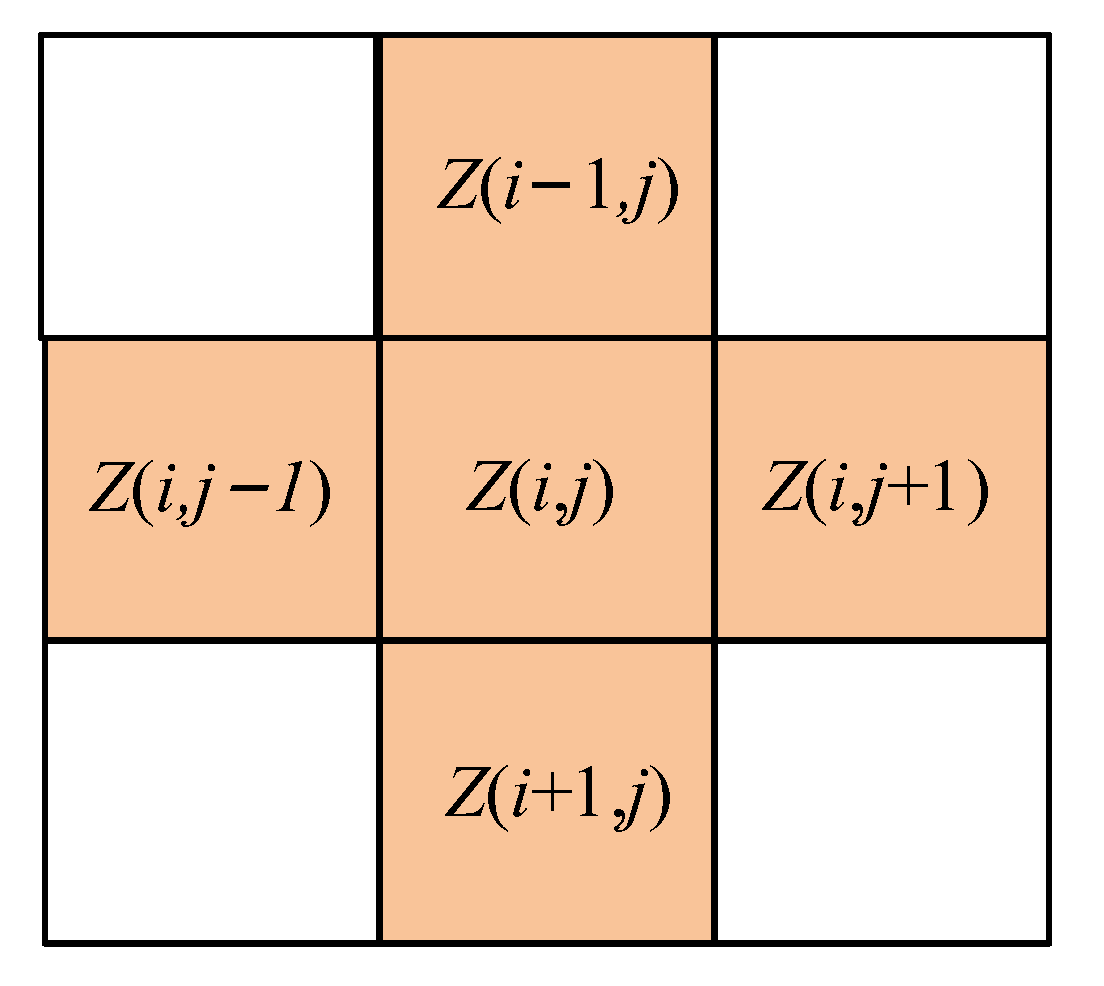








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}