1. Introduction
Infrared (IR) and visible sensors provide different modalities of visual information, and their fusion is one of the significant research topics in the remote sensing field. IR images highlight thermal radiation objects through pixel brightness, but they have low resolutions and lack structural texture details. Although visible images display rich structural details through gradients and edges, it is difficult for them to provide useful information about thermal radiation objects under weak light conditions. A single IR image or visible image cannot provide complete information about the target scene. Two or more images with different modalities in the same scene help us to better understand the target scene. Complementary features from different modalities should be integrated into a single image to provide a more accurate scene description than any single image. The fusion system can extract and combine information from these complementary images to generate a fused image, helping people and computers better understand the information in the images. IR and visible image fusion is widely applied in remote sensing [
1], object tracking [
2,
3,
4], and wildlife protection [
5].
Image fusion approaches mainly include the following: multi-scale transformation (MST) approaches, sparse representation (SR) approaches, saliency-based approaches, optimization-based approaches, and deep learning approaches.
(1) The MST approach first decomposes the images into multiple scales (mainly including low frequencies and high frequencies), then fuses the images on different scales through specific fusion strategies, and at last acquires the fused image via the corresponding inverse transformation. The classic MST methods include ratio of low-pass pyramid (RP) [
6], discrete wavelet transform (DWT) [
7], curvelet transform (CVT) [
8], dual-tree complex wavelet transform (DTCWT) [
9], etc. The authors in [
10] proposed a multi-resolution singular value decomposition (MSVD) technique, and applied Daubechies 2 to decompose images. In [
11], the authors decomposed the source images into global structures and local structures by the latent low-rank representation (LatLRR) method, where the global structures applied a weighted-average strategy and the local structures used a sum strategy. Tan et al. [
12] proposed a fusion method based on multi-level Gaussian curvature filtering (MLGCF), and applied max-value, integrated, and energy-based fusion strategies. Although the MST method represents the source images through multiple different scales of information, the method and number of layers of decomposition are not easily determined, and the fusion rules are generally pretty complicated.
(2) The SR approach first learns an over-complete dictionary from high-quality images. Secondly, the sliding window approach decomposes the images into multiple patches, and these patches form a matrix. Thirdly, the matrix is fed into the SR model to figure out the SR coefficients, and then the fusion coefficients are obtained via a specific rule. At last, the fusion coefficients are rebuilt through the over-complete dictionary to obtain the fused image. Zhang et al. [
13] developed a joint sparse representation (JSR) technique, and proposed a new dictionary learning scheme. Furthermore, Gao et al. [
14] proposed a fusion method of a joint sparse model (JSM) and expressed the source image as two different components through an over-complete dictionary. The SR-based method is generally robust to noise, but the learning process of over-complete dictionary and image reconstruction are extremely time-consuming.
(3) The thermal radiation areas in IR images are more attractive to human visual perception than other areas. The saliency method tends to extract the salient IR targets in the image and generally improves the pixel intensity and visual quality of significant regions. In [
15], the authors proposed a weight map construction method for saliency, called two-scale saliency detection (TSSD). Ma et al. [
16] presented a weighted least square (WLS) optimization and saliency scheme to highlight IR features and make background details more natural. Moreover, Xu et al. [
17] proposed a pixel classification saliency (CSF) model, and this method generated a classification saliency map based on the contribution of pixels. The saliency methods well highlight the features of salient regions in the image, but these methods are usually very complex.
(4) The idea of the optimization-based approach is to transform the fusion issue into a total variation minimization issue, and the representative fusion methods are gradient transfer fusion (GTF) [
18] and different resolution total variation (DRTV) [
19].
(5) The deep learning method extracts the features of different modalities through the encoder of the deep network, then fuses them via a specific fusion strategy, and at last reconstructs the fused image via the decoder. Compared with other traditional fusion methods, the deep learning method can capture the deep features of input samples and excavate the internal relationship between samples.
Currently, although the deep learning fusion techniques have achieved great fusion results in most conditions, there is still a disadvantage. To be specific, these fusion methods did not consider the saliency targets in the infrared image and the background detail regions in the visible image when constructing the loss function, resulting in the introduction of a large amount of redundant or even invalid information in the fusion result, which may lead to the loss of useful information in the fused image.
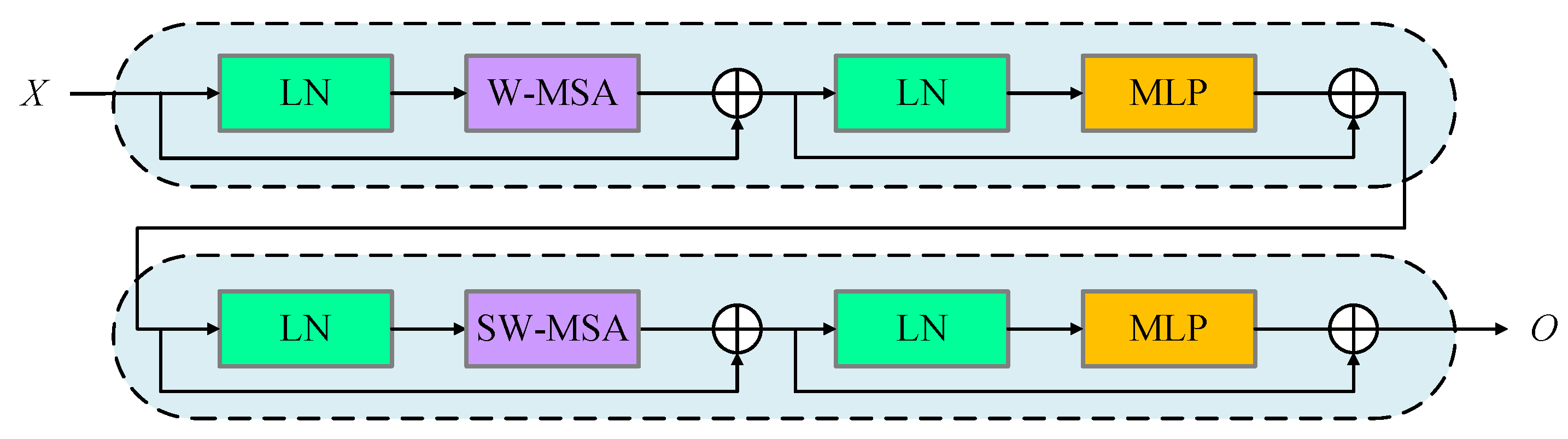
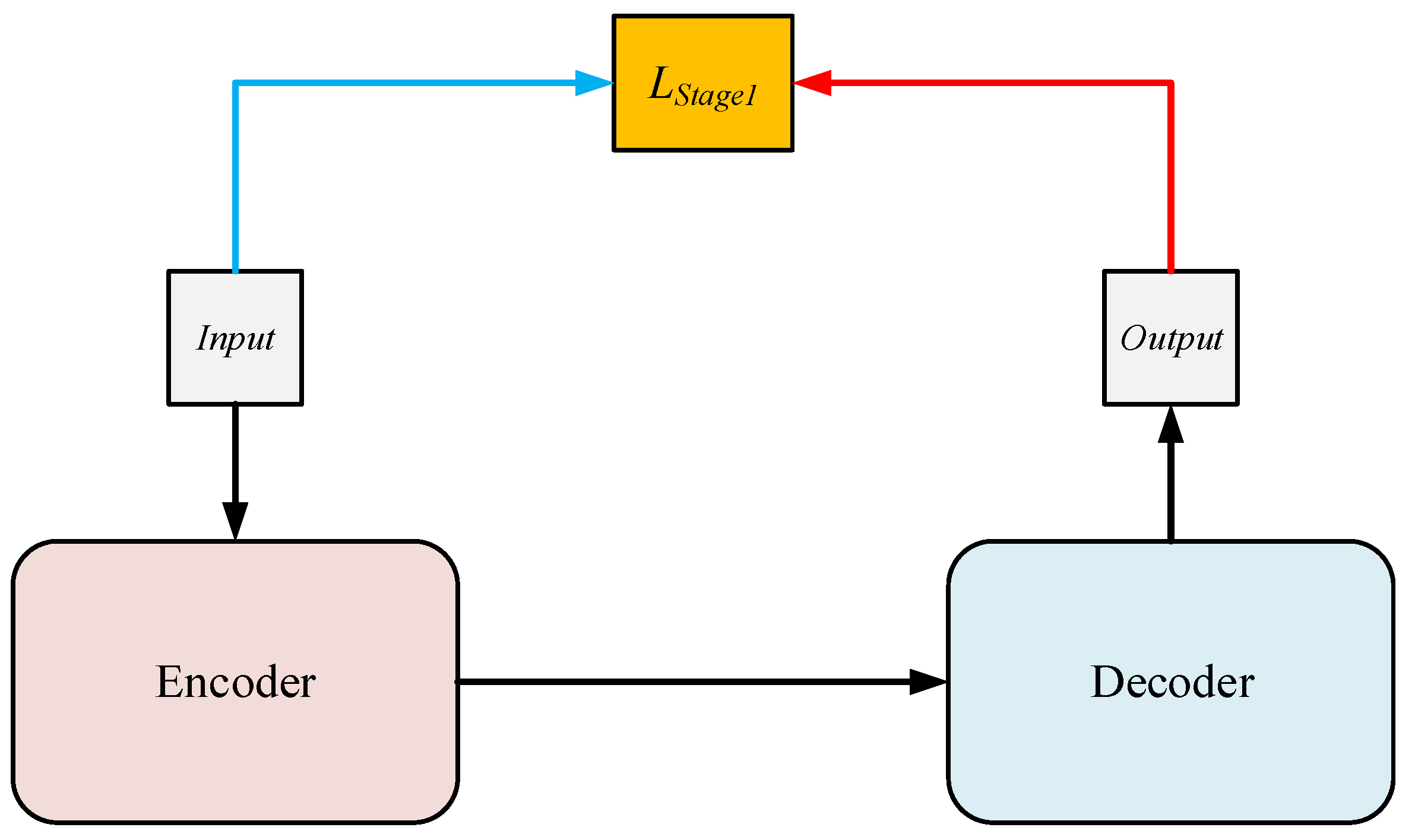
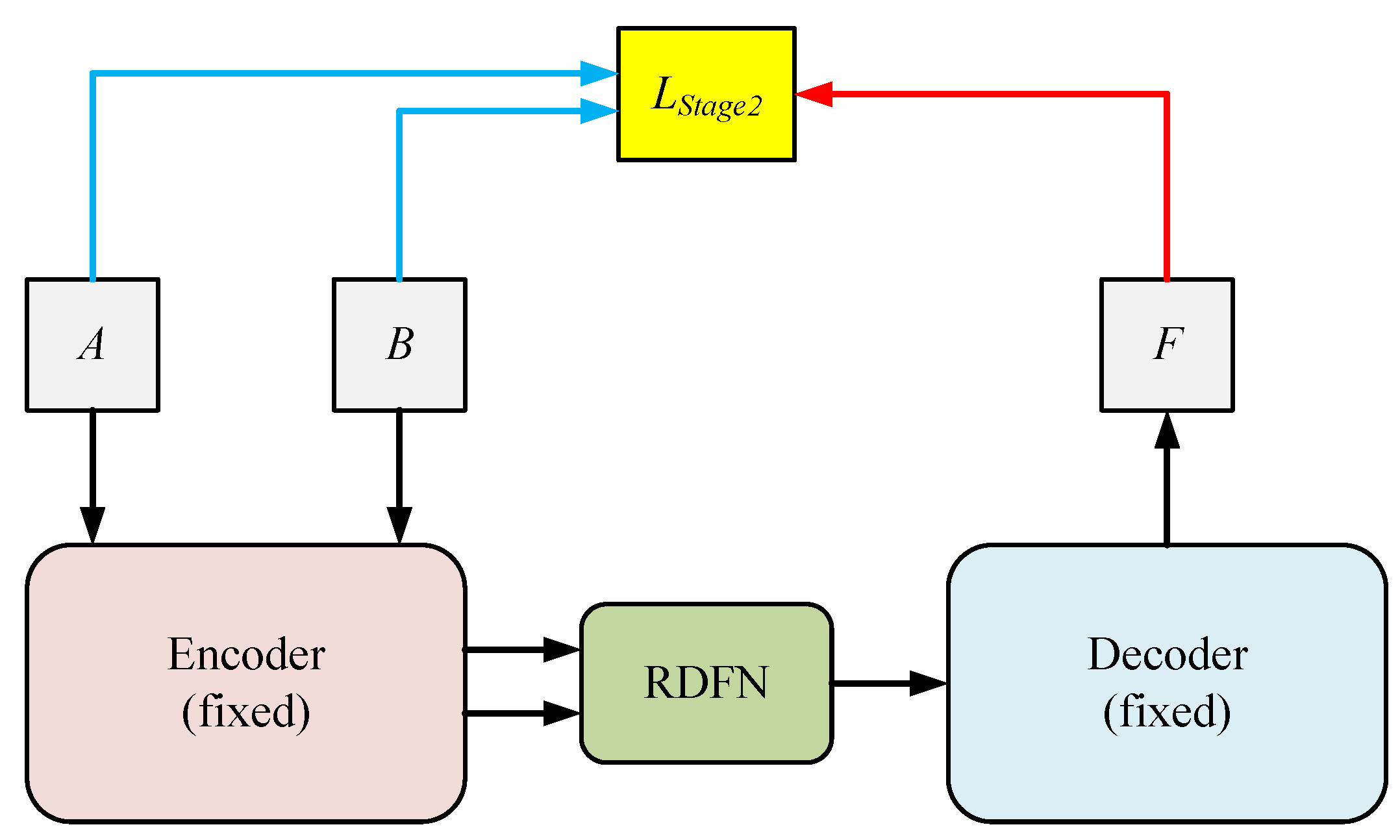
To address the issue, we develop an end-to-end residual Swin Transformer fusion network based on saliency detection for IR and visible images, termed SDRSwin, which aims to preserve salient targets in IR images and texture details in visible images. The proposed framework consists of three components: an encoder network, a residual dense network (RDFN), and a decoder network. Both the encoder network and decoder network are constructed based on the residual Swin Transformer [
20,
21]. The encoder is designed to extract the global and long-range semantic information of source images with different modalities, and the decoder aims to reconstruct the desired results. The SDRSwin method is trained with a two-stage training method. In the first stage, we train the encoder and decoder networks with the aim of obtaining an encoder–decoder architecture with powerful feature extraction and reconstruction capabilities. In the second stage, we develop a novel salient loss function to guide RDFN to detect and fuse salient thermal radiation targets in IR images. The SDRSwin is able to capture salient features effectively.
To visually demonstrate the performance of our method, we provide a Hainan gibbon example for comparison with the excellent RFN-Nest [
22] and FusionGAN [
23] methods. In
Figure 1, although the RFN-Nest method has rich tropical rainforest details, the Hainan gibbon lacks brightness. The FusionGAN method has high-brightness thermal radiation objects but loses a large number of tropical rainforest details. Our method has both rich tropical rainforest details and high-luminance Hainan gibbon information. Therefore, our method can highlight important targets and key information.
The contributions of the proposed approach are listed as follows:
We develop a novel salient loss function to guide the network to fuse salient thermal radiation targets in IR images and background texture details in visible images, aiming to preserve as many significant features as possible in the source images and reduce the influence of redundant information;
The extensive results and 21 comparison methods demonstrate that the proposed method achieves state-of-the-art fusion performance and strong robustness.
The remaining sections are arranged as follows:
Section 2 is about the work on deep learning, the Swin Transformer, and test datasets.
Section 3 is a specific description of the proposed method.
Section 4 includes experimental setups and experiments.
Section 5 is the discussion.
Section 6 is the conclusion of the paper.
4. Experimental Results
The first part describes the experimental settings. The second part introduces subjective and objective evaluation metrics. The third part shows several ablation studies. The last part is three comparative experiments on the TNO, RoadScene, and Hainan gibbon datasets.
4.1. Experimental Settings
MS-COCO [
47] is a dataset based on natural images, and KAIST [
48] is a dataset based on infrared and visible images. The first stage of training aims to train a powerful encoder–decoder network to reconstruct the input image. The purpose of the second stage of training is to train a RDFN to fuse salient features.
In the first-stage training, we trained the encoder–decoder network by using 80,000 images from the MS-COCO dataset, and each image was converted to a grayscale image. We set the patch size and sliding window size to and , respectively. Furthermore, we selected Adam as the optimizer and set the following parameters: for learning rate, 4 for batch size, and 3 for epoch. The head numbers of the three RSTLs in the encoder were set to 1, 2, and 4, respectively. The head numbers of the three RSTLs in the decoder were also set to 1, 2, and 4, respectively. In addition, was specifically analyzed in the ablation study.
In the second-stage training, we used 50,000 pairs of images from the KAIST dataset to train the RDFN, and each image was converted to a grayscale image. In addition, we selected Adam as the optimizer and set the learning rate, batch size, and epoch to , 4, and 3, respectively.
In the fusion stage, we converted the grayscale range of test images to −1 and 1 and applied the sliding window to partition them into several patches, where the value of the invalid region is filled with 0. After the combination of each patch pair, we conducted the reverse operation according to the previous partition order to obtain the fusion image. The experimental environments of our method were Intel Core i7 13700KF, NVIDIA GeForce RTX 4090 24 GB and PyTorch.
4.2. Evaluation Metrics
The validity of the proposed approach is assessed in terms of both subjective visual evaluation and objective evaluation metrics.
Subjective evaluation is the evaluation of the visual effect of the fused image by human eyes, including color, brightness, definition, contrast, noise, fidelity, etc. The subjective evaluation is essentially to judge whether the fused image gives a satisfactory feeling.
Objective evaluation is a comprehensive assessment of the fusion performance of algorithms through various objective evaluation metrics. We selected eight important and common evaluation metrics:
Entropy (
) [
49]:
is an information theory-based evaluation metric that calculates the degree of information contained in the fused image;
Standard deviation (
) [
50]:
reflects the contrast and distribution of the fused image;
Normalized mutual information metric
[
51]:
measures normalized mutual information between the fused image and the source images;
Nonlinear correlation information entropy metric
[
52]:
calculates the nonlinear correlation information entropy of the fused image;
Phase-congruency-based metric
[
53]:
measures the extent to which salient features in the source images are transferred to the fused image, and it is based on the absolute measure of image features;
Chen–Varshney metric
[
54]:
provides a fusion metric of a human vision system that can fit the results of human visual inspection well;
Visual information fidelity (
) [
55]:
measures the fidelity of the fused image;
Mutual information (
) [
56]:
computes the amount of information transferred from the source images to the fused image.
In all the above metrics, except , the higher the value of the metrics, the better the fusion performance. The smaller the value of , the better the fusion performance. In objective evaluation, the more optimal the values of a method, the stronger the fusion performance of the method.
4.3. Ablation Study
In this part, we carried out several ablation studies to verify the validity of the proposed method. We used the above-mentioned 21 pairs of images from the TNO dataset as test images, and the average of eight objective evaluation metrics as reference standards.
4.3.1. Parameter Ablation Study in Loss Function in the First Stage
In the first stage of training, due to the different orders of magnitude of
and
, we set the trade-off parameter
as 1, 10, 100, 1000, and 10,000, respectively.
Table 2 shows the average values of different
objective evaluation metrics, where the best values are indicated in red font. The model obtains the most optimal values when
. Therefore, we chose
as the trade-off parameter in the following experiments.
4.3.2. Residual Connections Ablation Study
We verified the impact of residual connections on the fusion model. The without residual connections method means that residual connections are removed from all RSTLs, and all other parameters are set the same.
Table 3 presents the average values of objective evaluation metrics without and with residual connections, and we notice that the model with residual connections is obviously better than the model without residual connections, because residual connections preserve more critical information from the previous layer.
4.3.3. Salient Loss Function Ablation Study
In this part, we analyzed the impact of the salient loss function in the second stage of training on the fusion performance. We performed an ablation study to test the validity of the salient loss function. We trained a network without salient loss in the second stage, and the loss function is defined as follows:
Table 4 presents the average values of objective evaluation metrics for the networks without and with salient losses. We observe that the fusion performance of the network with salient loss is significantly better than that of the network without salient loss, demonstrating that the proposed salient loss function can guide the network to better fuse the salient features.
4.4. The Three Comparative Experiments
In this section, we used 21 pairs of images from the TNO dataset, 44 pairs of images from the RoadScene dataset, and 21 pairs of images from the Hainan gibbon dataset as test images. We selected 21 classical and state-of-the-art competitive algorithms for comparison. The 21 comparison methods mainly contain five types, i.e., MST methods (RP [
6], DWT [
7], CVT [
8], DTCWT [
9], MSVD [
10], LatLRR [
11], MLGCF [
12]), SR methods (JSM [
14]), saliency methods (TSSD [
15], CSF [
17]), optimization-based methods (GTF [
18], DRTV [
19]), and deep learning methods (VggML [
24], ResNet-ZCA [
26], DenseFuse [
28], FusionGAN [
23], GANMcC [
30], U2Fusion [
31], RFN-Nest [
22], DRF [
29], SwinFuse [
21]). All parameters of the comparison approaches are the default values provided by the corresponding authors.
4.4.1. The Experiment on the TNO Dataset
Figure 11,
Figure 12 and
Figure 13 exhibit several representative fusion examples. Some parts of the images are enlarged by rectangular boxes for a better visual effect.
Figure 11 shows the scene on the road at night. The IR image shows information about thermal radiation objects at night-time, such as pedestrians, cars, and street lights. Due to the night scene, the visible image can only capture the details of the panels of the store with high brightness. The desired fusion effect in this case is to maintain the high luminance of the thermal radiation object information and simultaneously keep the clarity of the store panels’ details. The RP, DWT, and CVT methods introduce some artifacts around pedestrians (see the red boxes in
Figure 11c–e). The pedestrians in the DTCWT method suffer from low brightness and contrast (as shown in the man in
Figure 11f). The MSVD result brings in obvious noise in the store panels (see
Figure 11g). The pedestrians in the LatLRR technique have low luminance (as shown in the man in
Figure 11h), and this result produces some artifacts during the fusion process (see the road in
Figure 11h). The MLGCF approach obtains a great fusion result. The fused image of the JSM algorithm is significantly blurred (as shown in
Figure 11j). In the saliency-based fusion approaches, the IR targets in the TSSD and CSF methods have low luminance (see the red boxes in
Figure 11k,l). The panels in the GTF and DRTV methods introduce an excessive infrared spectrum, resulting in a lack of details in the panels (see green boxes in
Figure 11m,n). In this example, most of the visible information around the panels is desired. In deep-learning-based methods, the pedestrians in the red boxes in VggML, ResNet-ZCA, DenseFuse, FusionGAN, GANMcC, U2Fusion, and RFN-Nest approaches suffer from low luminance and contrast (as shown in the man in
Figure 11o–u). The DRF-based method appears overexposed, and the panels are fuzzy (see
Figure 11v). The SwinFuse is a non-end-to-end fusion approach that employs a fusion strategy based on an artificially designed
-norm. The SwinFuse method appears excessively dark because the
-norm fusion rule does not integrate infrared and visible features well (see
Figure 11w). Compared with other methods, our method obtains a higher brightness and contrast of the IR saliency targets (as shown in the man in
Figure 11x), and clearer panel details (as shown in the store panels in
Figure 11x).
Figure 12 and
Figure 13 show more fusion results.
Table 5 exhibits the average values of different objective evaluation metrics on the TNO dataset, where the best values are indicated in red font.
Table 5 displays that our approach achieves optimal results in all objective evaluation metrics except
, demonstrating that our approach has a stronger fusion performance than the other 21 comparison approaches.
4.4.2. The Experiment on the Roadscene Dataset
In this section, we verified the effectiveness of the proposed algorithm by employing the RoadScene dataset. We used 44 pairs of images from the RoadScene dataset as test images.
Figure 14,
Figure 15 and
Figure 16 show several representative examples.
Figure 14 depicts a person waiting on the roadside. The pedestrian and vehicle have high brightness in the IR image, and the visible image provides clearer background details. The fonts on the walls in the RP and MSVD methods are obviously blurred (see the green boxes in
Figure 14c,g). The DWT-based approach introduces some noticeable noise around the vehicle (see the vehicle in
Figure 14d). The results of CVT, DTCWT, and MLGCF are alike, and the IR targets in their results lack brightness (see the red boxes in
Figure 14e,f,i). The pedestrians in the LatLRR method suffer from weak luminance and contrast (as shown by the man in
Figure 14h). The JSM approach obtains a low fusion performance because its fusion result is fuzzy (see
Figure 14j). In the saliency-based methods, the fonts in the wall of the TSSD approach are unclear (see the wall in
Figure 14k). The fonts on the wall in the CSF approach bring in an excessive IR spectrum, leading to unnatural visual perception (see green boxes in
Figure 14l). In this case, most of the visible details on the walls are desired. The GTF and DRTV methods achieve poor fusion results because of the introduction of obvious artifacts (see green boxes in
Figure 14m,n). The fonts on the walls in the VggML, ResNet-ZCA, and DenseFuse approaches are significantly blurred (see the green boxes in
Figure 14o–q). The pedestrian, vehicle, and trees in the FusionGAN method are fuzzy (as shown on the wall in
Figure 14r). The GANMcC, U2Fusion, and RFN-Nest methods obtain a good fusion performance, but their IR targets lack some brightness (as shown in the man in
Figure 14s–u). The DRF-based method achieves high luminance for the pedestrian and vehicle, but the background details are blurred, leading to an unnatural visual effect (as shown on the wall in
Figure 14v). The upper-left tree in the SwinFuse method introduces a number of undesired little black dots, leading to an unnatural visual experience. In addition, the contrast in the fusion result of SwinFuse is low, which makes it difficult to highlight the targets well (see
Figure 14w). Our approach highlights the brightness of the pedestrian and vehicle (as shown in the man in
Figure 14x) and simultaneously maintains the details of the fonts on the walls well (see the green box in
Figure 14x). As a result, our approach achieves a more natural visual experience and higher fusion performance.
In addition,
Figure 15 and
Figure 16 show more examples.
Table 6 exhibits the average values of different objective evaluation metrics on the RoadScene dataset, where the best values are indicated in red font. The proposed method achieved five best values (
,
,
,
,
) and three second-best values (
,
,
). The fusion performance of the proposed approach is significantly superior to the other 21 comparative approaches.
4.4.3. The Experiment on the Hainan Gibbon Dataset
In this section, we used 21 pairs of images from the Hainan gibbon dataset as test images.
Figure 17,
Figure 18 and
Figure 19 present several representative Hainan gibbon image fusion examples.
Figure 17 depicts the scene of a gibbon preparing to jump in the tropical rainforest. The IR image accurately locates the position of the gibbon, but the tropical rainforest in the background is blurred. The visible image can hardly locate the position of the gibbon, but there are clear details of the tropical rainforest. The fusion of IR and visible images can be used to observe the movements and habitat of gibbons, providing an important reference for the protection of endangered animals. In RP, DWT, CVT, and DTCWT approaches, the gibbons are dim, and their results make it difficult to locate the position of the gibbons (see the gibbons in
Figure 17c–f). In the MSVD, LatLRR, and JSM techniques, the tropical rainforests are fuzzy (see tropical rainforests in
Figure 17g,h,j). Although the MLGCF approach achieves a relatively good fusion effect, the brightness of the gibbon in the fusion result is relatively low (see the thermal radiation target in
Figure 17i). In the saliency-based scheme, the brightness of the gibbon in the TSSD and CSF schemes is similar to the background brightness, which makes it difficult to find the position of the gibbon (see the gibbons in
Figure 17k,l). In addition, the GTF and DRTV approaches extract too much of the infrared spectrum, resulting in the loss of a large amount of tropical rainforest details (as shown in the background areas in
Figure 17m,n). Among the deep-learning-based approaches, the gibbons in VggML, ResNet-ZCA, DenseFuse, U2Fusion, and RFN-Nest approaches have low brightness and contrast, making it difficult to discover the location of the gibbon (as shown in the red boxes in
Figure 17o,p,q,t,u). Although the gibbons in FusionGAN, GANMCC, and DRF approaches have relatively high brightness and contrast, the backgrounds have lost a lot of details (see
Figure 17r,s,v). The Hainan gibbon in the SwinFuse method is almost invisible, and the rainforest in the method loses a great number of details (see
Figure 17w). The proposed method has a bright gibbon and a clear tropical rainforest background (see the red and green boxes in
Figure 17x). Our method can easily locate the position of gibbons and observe their habitat.
Figure 18 and
Figure 19 show more examples.
Table 7 exhibits the average values of different objective evaluation metrics on the Hainan gibbon dataset, where the best values are indicated in red font. The proposed method achieved six best values (
,
,
,
,
,
) and a second-best values (
).






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}