1. Introduction
Continuous, robust, and accurate localization is crucial for autonomous robots and aircraft in complex environments. With the maturity of drone and electric vertical take-off and landing (eVTOL) technologies, the concept of urban air mobility (UAM) is gradually becoming a trend. This concept involves the development of low-altitude airspace in densely populated urban areas through emerging vehicles to establish a safe and efficient aerial transportation system. Drones and eVTOL share similarities with helicopters, as they can vertically land and take off. However, they possess additional advantages, such as being fully electric, compact, producing low noise, and having lower operational costs. These attributes enable them to penetrate urban centers and facilitate point-to-point transportation. However, a crucial safety concern is the need for drones and eVTOL to autonomously navigate and fly under extreme conditions, especially when facing GNSS signal loss or malicious interference. They must be able to accurately self-locate within a range of several kilometers and promptly proceed to alternative landing points or their intended destinations. Therefore, instead of relying solely on a single GNSS positioning system for drones, eVTOL is required in practical applications.Leveraging the complementary attributes among multiple sensors to achieve accurate and robust state estimation becomes crucial. Currently, most research in this area is focused on ground-based autonomous navigation and positioning, which needs more extensive experimentation in the challenging field of aerial visual navigation and positioning, especially concerning long-range navigation issues spanning tens of kilometers. Establishing aerial flight experimental platforms is more challenging than ground-based vehicle platforms. Ordinary drones have limited endurance and computational resources, making conducting extensive, long-range aerial drone navigation tests difficult. Additionally, there needs to be large-scale, long-distance aerial drone navigation datasets available for research purposes.
The mainstream solution for achieving fully autonomous driving involves integrating GNSS/RTK, LiDAR (light detection and ranging), previously acquired LiDAR maps, and IMU (inertial measurement unit)-based localization [
1,
2,
3]. However, the widespread adoption of LiDAR sensors in autonomous driving applications is limited due to their high cost. Compared to drones, the use of LiDAR is further constrained in high-altitude flights due to issues such as limited detection range and high power consumption, as well as concerns related to the size and weight of the LiDAR equipment. In comparison, visual odometry (VO) and SLAM systems have garnered significant attention due to their low cost, compact size, and straightforward hardware layout [
4,
5,
6,
7]. Cameras possess the advantages of being cost effective and occupying minimal physical space while providing abundant visual information. Superior systems have been developed using cameras alone or in conjunction with inertial sensors. Many localization solutions rely on visual-inertial odometry (VIO) [
8,
9] because it offers precise short-range tracking capabilities.
However, these systems also face numerous challenges. Firstly, the positions and orientations generated by cameras and IMUs are in a local coordinate system and cannot be directly used for global localization and navigation. Secondly, odometry drift is inevitable for any visual-inertial navigation system without the constraint of global positioning information. Although loop closure detection and relocalization algorithms have been implemented to reduce the accumulation of relative errors [
6,
10], these methods have significant drawbacks in long-distance autonomous driving scenarios, including increased computational complexity and memory requirements. Our experiments indicate that existing SLAM techniques are unsuitable for long-distance visual navigation beyond several tens of kilometers, as they exhibit average root mean square errors as large as several tens of meters. Finally, the majority of visual-inertial navigation systems (VINS) are vision-centric or vision-dominant, and they do not fully consider the precision of the inertial navigation system (INS). Low-cost inertial navigation systems (INS) based on MEMS (microelectromechanical systems) technology cannot provide high-precision positioning for extended periods beyond 1 min. As sensors for local navigation, their long-term accuracy is insufficient, leading to significant issues with accumulated errors. Each time an inertial navigation system starts operating, it requires time calibration. If this calibration step introduces significant errors, it can lead to substantial issues with the integration process. Furthermore, in these systems, the information from low-cost inertial navigation systems has minimal contribution to the visual process, which can potentially reduce the robustness and accuracy of the system in optically degraded environments. In large-scale applications requiring precise global localization, VIO faces limitations when used without expensive pre-built maps or assistance from global localization information. This constraint limits the VINS (visual-inertial navigation system) to operate only within small-scale scenarios.
Considering that GNSS can provide drift-free measurements in a global coordinate system, some research has focused on combining visual SLAM techniques with inertial and GNSS technologies, resulting in approaches such as VINS-Fusion [
11], GVINS [
12], IC-GVINS [
13] and G-VIDO [
14]. Although various integration algorithms have been discussed, further research is needed to explore their performance in specific critical scenarios, such as GNSS spoofing or complete loss. The primary focus of these studies is to use the robot as a real-time state estimator for its motion rather than concerning itself with the construction of an environmental map. Most visual odometry (VO) systems primarily match map elements obtained in the past few seconds, and once they lose sight of these environmental elements, they tend to forget them. This behavior can lead to continuous estimation drift, even if the system moves in the same area. The lack of multi-map construction in visual systems can reduce robustness and accuracy due to the influence of various degradation scenarios in complex environments. Even worse, once the GNSS signal is completely lost, these systems degrade to a single localization mode without any other information sources to continue providing global positioning information for the robot. The key issue lies in utilizing the map to continue providing global positioning information under the condition of GNSS signal loss. In 2022, Mohammad ALDIBAJA et al. comprehensively analyzed the challenges faced in precise mapping using the GNSS/INS-RTK system in their work [
15]. They emphasized integrating SLAM (simultaneous localization and mapping) technology into the mapping module to enhance map accuracy.
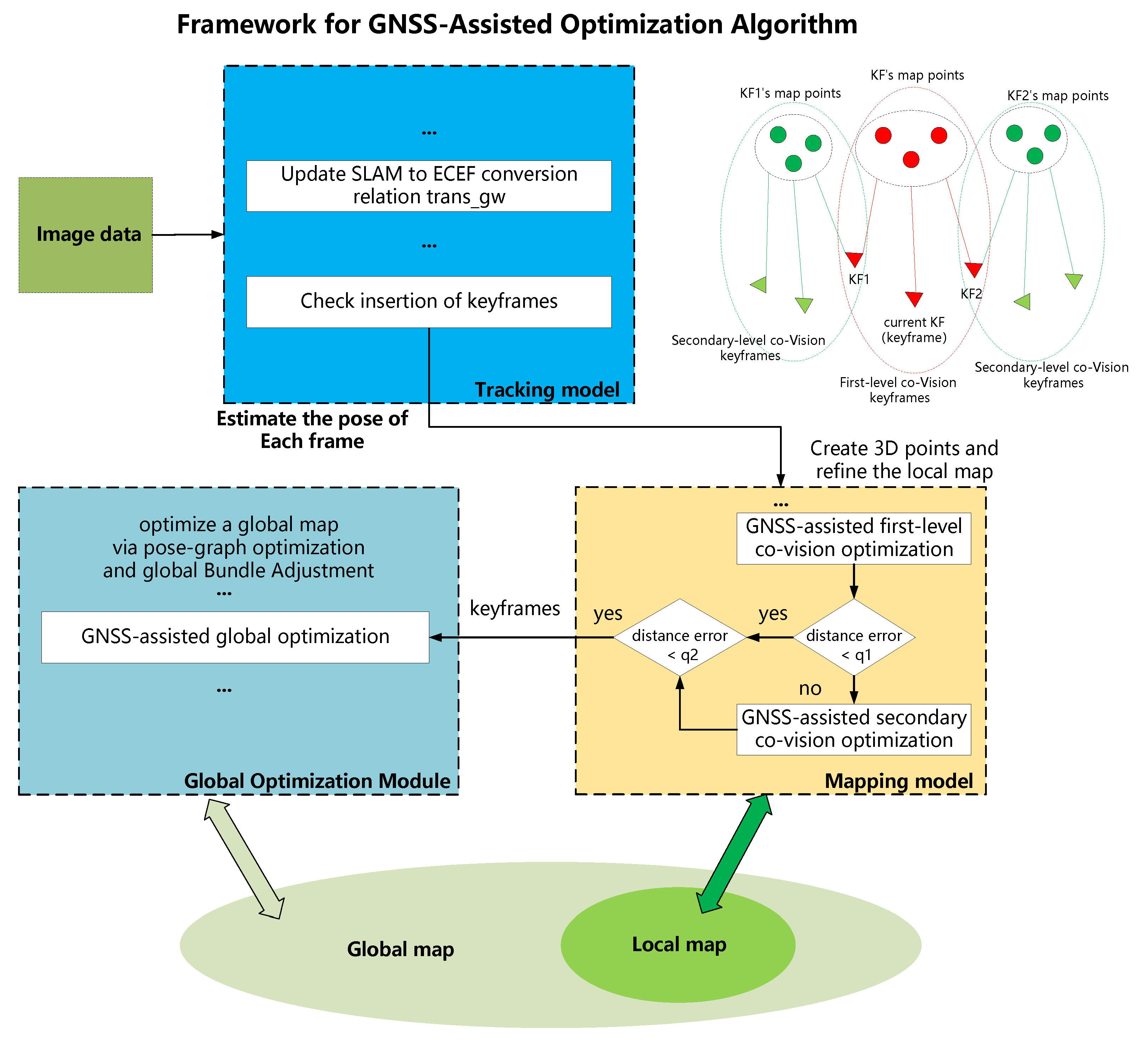
Among the various methods available, our primary focus is on integrating the complementary features of the global positioning sensor GNSS, the camera as a local positioning sensor, and high-precision multi-maps to achieve real-time and accurate state estimation in unknown environments. Combining small and low-cost sensors, such as cameras and GNSS receivers, into an integrated system makes it possible to create a robust localization system with lower construction costs, reduced complexity, and easier integration. Based on the objectives above, we developed a robust and accurate multi-map system with GNSS assistance for long-distance visual navigation. This system is designed to achieve continuous, robust, and precise localization in large-scale and complex environments. Firstly, the system utilizes low-cost visual odometry to independently provide accurate and high-frequency pose estimation in the short term, unaffected by external environmental disturbances or signal losses. The system employs place recognition techniques to match the observations with elements in previously visited areas, allowing for drift reset and utilizing pose graph optimization or bundle adjustment (BA) for map correction with higher accuracy. Secondly, the system reduces the accumulated errors of pure visual odometry by formulating a GNSS-visual multi-sensor fusion optimization algorithm on the factor graph. This approach enables accurate initialization and absolute localization in large-scale environments. The system can easily integrate measurements from other sensors as new factors into the framework. Then, with GNSS assistance, the system automatically creates multiple high-precision maps based on the scenes encountered. These maps encompass diverse geographical locations and periods. Constructing multiple maps at different times and seasons allows the system to cope with complex environmental changes, thereby maximizing the robustness of visual matching. Finally, during the online localization phase, if the GNSS signal is lost for an extended period, the system seamlessly switches to using the high-precision multi-maps as a substitute for GNSS to continue providing global positioning information for the aircraft. This approach prevents degradation to the pure visual odometry mode, which could lead to accumulated errors and localization failures. The main contributions of this paper are as follows:
We propose a graph optimization model that combines GNSS data and visual information using multi-sensor fusion navigation and positioning technology. This model establishes optimization constraints to enhance overall positioning and mapping accuracy.
To enhance the accuracy and robustness of large-scale map construction, we propose a method for partitioning visual maps based on the health condition of the maps. By considering factors such as feature quality, pose accuracy, and coordinate system transformation errors, the method effectively divides extensive scenes into appropriate segments to create multiple maps.
To address the issue of excessive discrete maps leading to resource wastage and reduced map-switching efficiency, we propose a multi-map-matching and fusion algorithm based on geographical location and visual information. Unlike the standard bag-of-words model, we employ GNSS assistance to detect overlapping areas, accelerating detection speed and reducing false matches from similar scenes. By performing map fusion, the integrity of the SLAM operation area is maximized, and the system’s robustness in long-distance visual navigation is enhanced.
This paper proposes a multi-map-based visual SLAM online localization algorithm that robustly manages and coordinates multiple geographical maps in different temporal and spatial domains. The working area of UAVs and eVTOL is divided into a grid-like structure, and the map coverage of each grid cell is recorded and stored. When the visual navigation system fails to locate a grid cell or the localization accuracy is insufficient, the system selects a new map from neighboring cells based on multi-map grid information.
Based on the aerial drone experimental platform we established, we created a test dataset for aerial drone navigation and positioning, covering long distances (on the order of tens of kilometers). The proposed system was extensively evaluated in both simulated and real-world environments. Based on our experimental results concerning the potential degradation or unavailability of GNSS positioning for UAVs and eVTOL in complex environments, we achieved an average positioning accuracy of 1.5 m over a flight distance of up to 30 km using only a monocular camera and multiple maps. The system offers advantages in construction cost, complexity reduction, and ease of integration, enabling continuous, robust, and precise localization in large-scale and complex environments. Compared to the solutions commonly used in the industry, our system offers lower costs, reduced complexity, and easier integration while ensuring the precision of localization for UAVs and eVTOL.
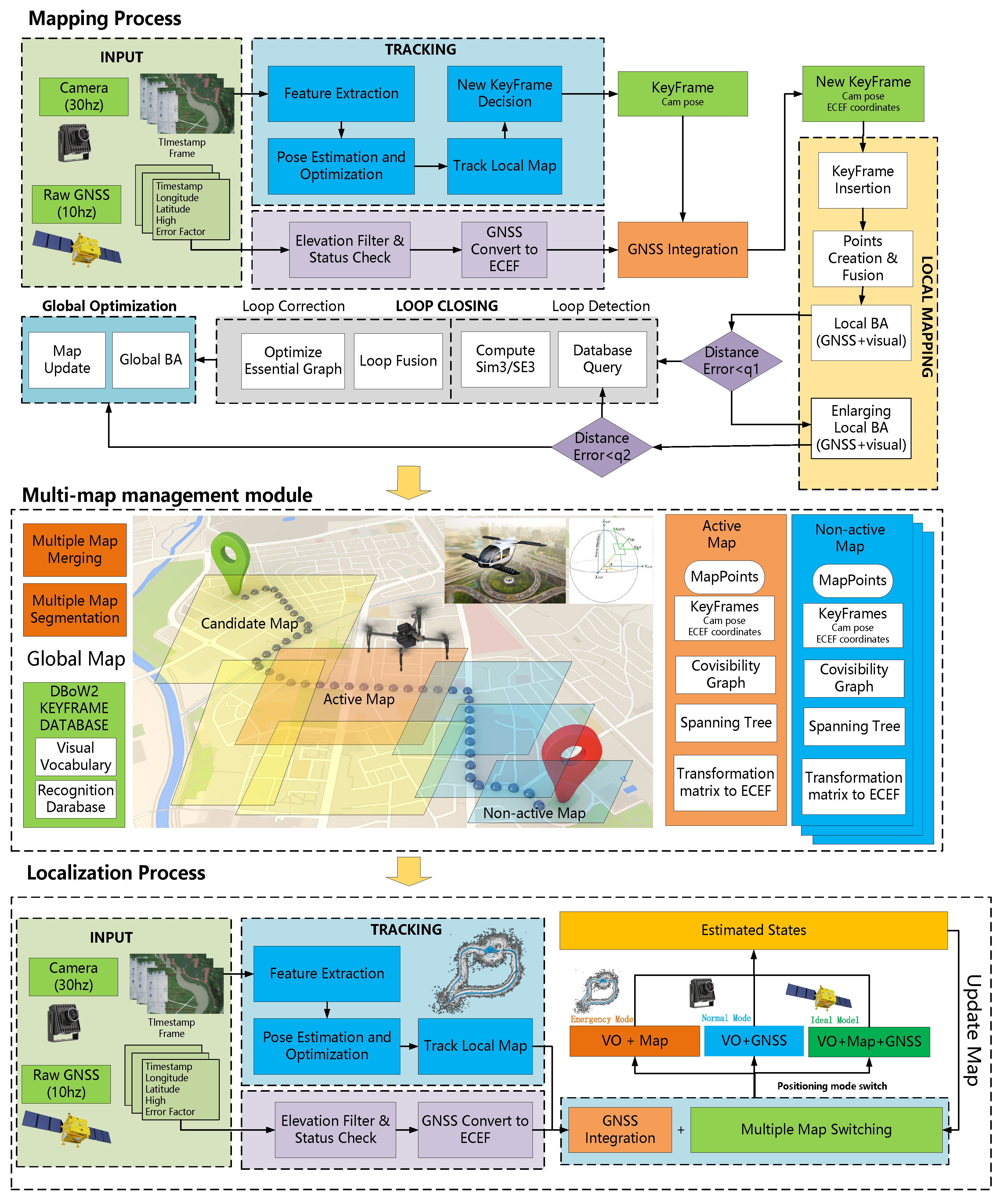
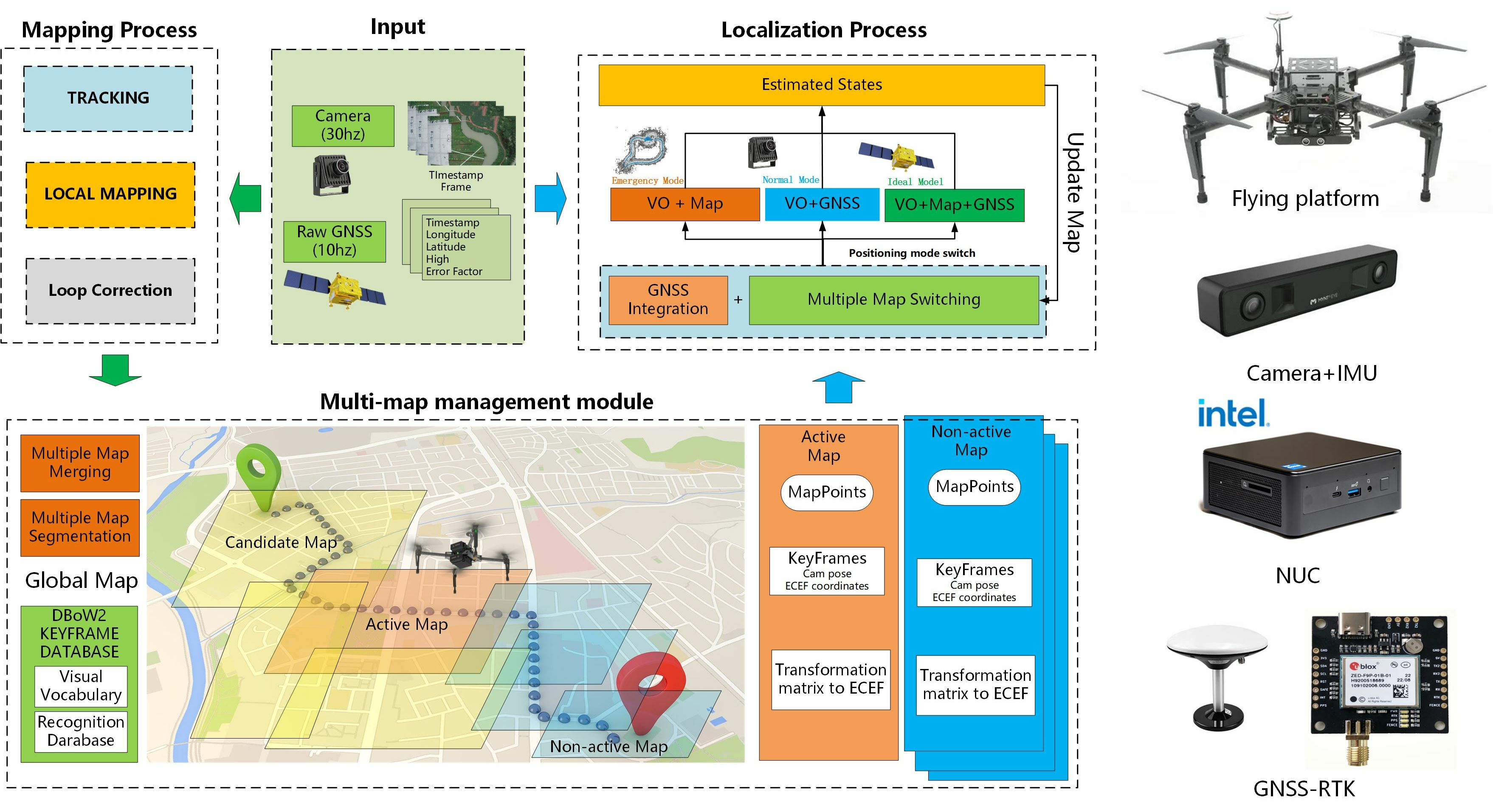
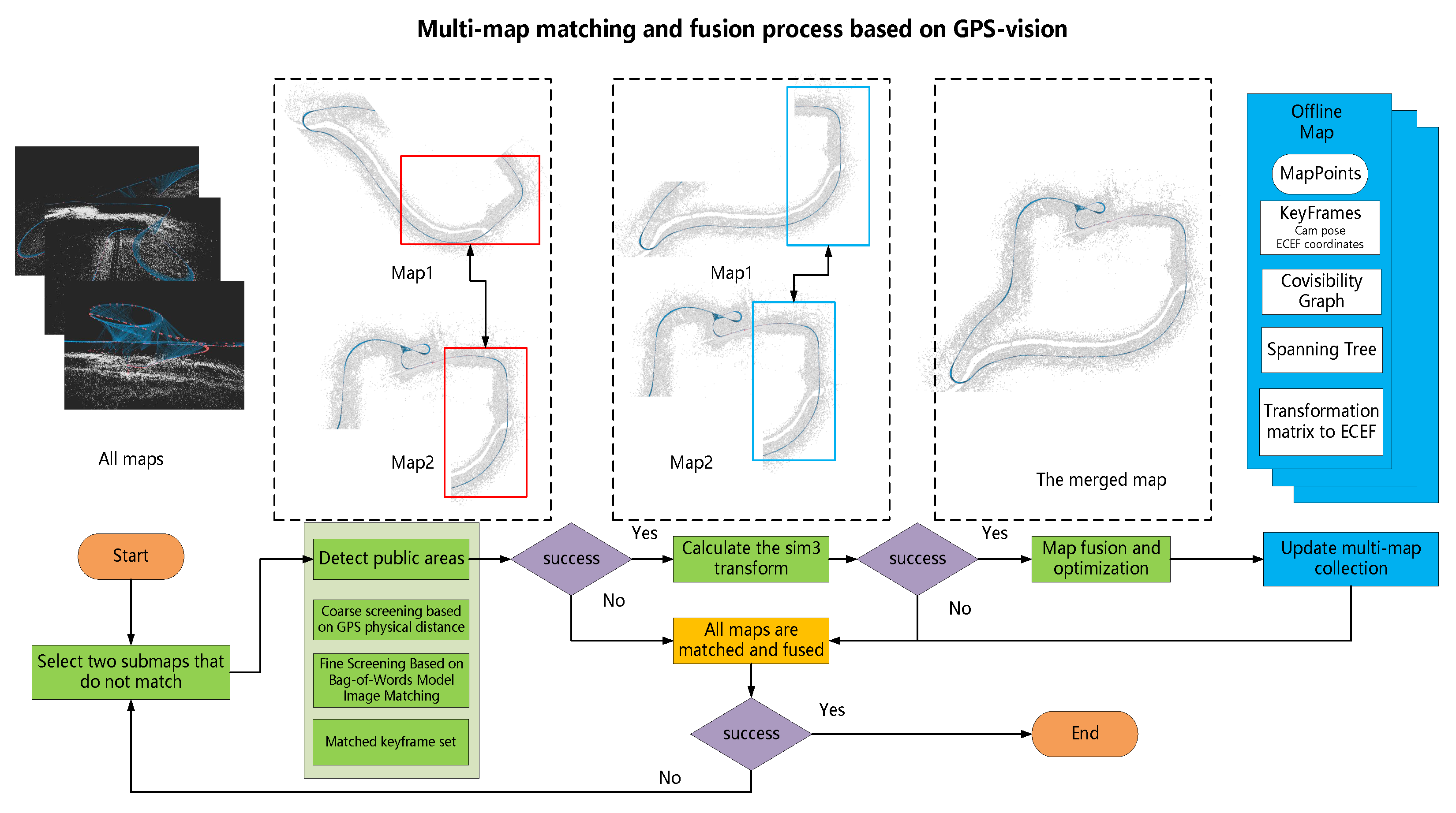
5. Multi-Map Management System
During visual navigation in large-scale environments, there are challenges posed by data redundancy resulting from long distances and dynamic variations within complex scenes. These challenges make it difficult to rely solely on a single map to fulfill the navigation tasks and requirements during the SLAM mapping and localization process. During the mapping stage, it is essential to effectively partition the large-scale environment into multiple maps based on feature quality and pose accuracy. Furthermore, in cases with overlapping areas between multiple maps, precise map fusion can be achieved automatically by integrating geographical location and visual information. The SLAM system can dynamically switch between multiple maps built offline, enabling robust and effective visual localization.
5.1. Multi-Map Auto-Segmentation
Drones and eVTOL need to divide the map for drawing when mapping large scenes. On the one hand, scale drift may occur during the map construction process in large-scale scenes due to complex terrain and image-matching errors. On the other hand, multiple maps are advantageous for loading and usage due to limited onboard resources of the equipment and issues related to map maintenance and updates. In order to improve the accuracy and robustness of large-scale map construction, this paper proposes a method of dividing SLAM maps based on their health. The health of a map reflects the quality of the current mapping process. During the tracking of each frame, the health of the current frame is calculated, and if the health value is 0, it is considered a lost frame. If more than three consecutive frames are lost during the mapping process, the currently active map is saved, and a new map construction is initiated. Health primarily comprises three aspects: the number of tracked map points, the number of inliers in the pose estimation, and the GNSS distance error.
(1) The number of tracked map points: During the tracking process of the current frame, the initial step involves constructing a frame object and extracting the feature points from it. Usually, feature points in the sky region are typically excluded to prevent significant errors caused by these points. Subsequently, different tracking modes are employed to perform image matching between the current frame and the reference frame. This process enables the establishment of a correspondence between the two-dimensional feature points in the image and the three-dimensional points in the current map. Based on these matching results, the pose estimation is carried out. Therefore, if a limited number of matching relationships is obtained, the pose estimation of the current frame becomes infeasible, and its health is considered to be 0. In practical scenarios, this reflects the significant changes that may occur between the scene captured by the current frame and the previously constructed map. These changes can include variations in texture, lighting conditions, dynamic elements, and more. In general, for UAVs and eVTOL performing repetitive tasks in the same area, these regions can be avoided through post-flight route evaluation and planning.
(2) Number of inliers in pose estimation: After obtaining the aforementioned 2D-3D matching relationships, the system performs robust camera pose estimation using PnP (perspective-n-point) and RANSAC (random sample consensus). Subsequently, nonlinear bundle adjustment (BA) optimization is conducted to refine and obtain more accurate results. If the observed points have poor geometric conditions, then the estimated pose is highly inaccurate, introducing significant errors to the subsequent mapping process. Therefore, based on the chi-square test, a threshold is calculated to determine the optimization error. This threshold is used to filter the number of inliers and outliers in the pose estimation. The reprojection error, denoted as
e, is defined as the difference between the 2D position obtained by projecting using the pose and the actual detected 2D coordinates of the feature. The reprojection error follows a Gaussian distribution as shown in Equation (
4):
whereas the covariance matrix
is typically determined based on the number of pyramid levels used for feature point extraction.
If the scaling factor between pyramid layers is
q and the standard deviation at the lowest layer is
m pixels, the covariance calculation for the reprojection error of the detected 2D features in the current kth layer can be expressed as Equation (
5):
Since the error
e is a 2D vector, it is not straightforward to set a threshold directly. Therefore, the error is weighted by the covariance, and the inner product
r of the error is computed based on Equation (
6):
However, Equation (
7) can be transformed into Equation (
8), where the content within the parentheses represents a multidimensional normal distribution as shown in Equation (
8):
Therefore, a chi-square test threshold is designed around r. Since the projection error has 2 degrees of freedom at a significance level of 0.05, the threshold value for the chi-square statistic is 5.99. Based on this threshold, the 3D-2D relationships involved in the optimization can be filtered to identify which ones are outliers and which ones are inliers. When the number of inliers does not meet the specified threshold, the health of the current frame is considered to be 0.
(3) The GNSS distance error: This study addresses the issue of scale drift in the map construction process by introducing GNSS assistance to calculate real-time errors in the map. The current map is saved, and map construction restarts when the error exceeds the threshold range. In order to calculate the errors in the map creation process, a keyframe is included in the process to create a local map. This process uses the keyframe and its corresponding GNSS information to convert the coordinates of the model being constructed to the ECEF coordinate system, which is then used to calculate the errors. The ECEF coordinates corresponding to the current model coordinates are then determined, and the errors between these coordinates and the true values are calculated. These errors serve as the basis for map segmentation.
Assume that the model coordinates corresponding to the keyframe set are marked as
. Using the iterative closest point (ICP) algorithm, the model coordinate is transformed into the ECEF coordinate system, represented by the transformation matrix in
. The conversion relationship between the two coordinate systems is shown in Equation (
9).
where
represents the rotation matrix,
T represents the translation vector, and
s represents the scale factor. If the threshold is set to
M, the error is expressed as Equation (
10):
where
denotes the ECEF coordinate corresponding to the real GNSS. If the error
exceeds
, the current mapping process is terminated, and the map is saved to start building a new map.
Compared to traditional methods for visual map construction, our approach incorporates GNSS information to enhance the optimization of visual map creation and partitioning. The map segmentation strategy enables large scene maps to be segmented using scene texture and map accuracy criteria, and multiple small maps that meet the positioning accuracy and robustness requirements can be constructed, thereby significantly reducing the scale drift phenomenon.
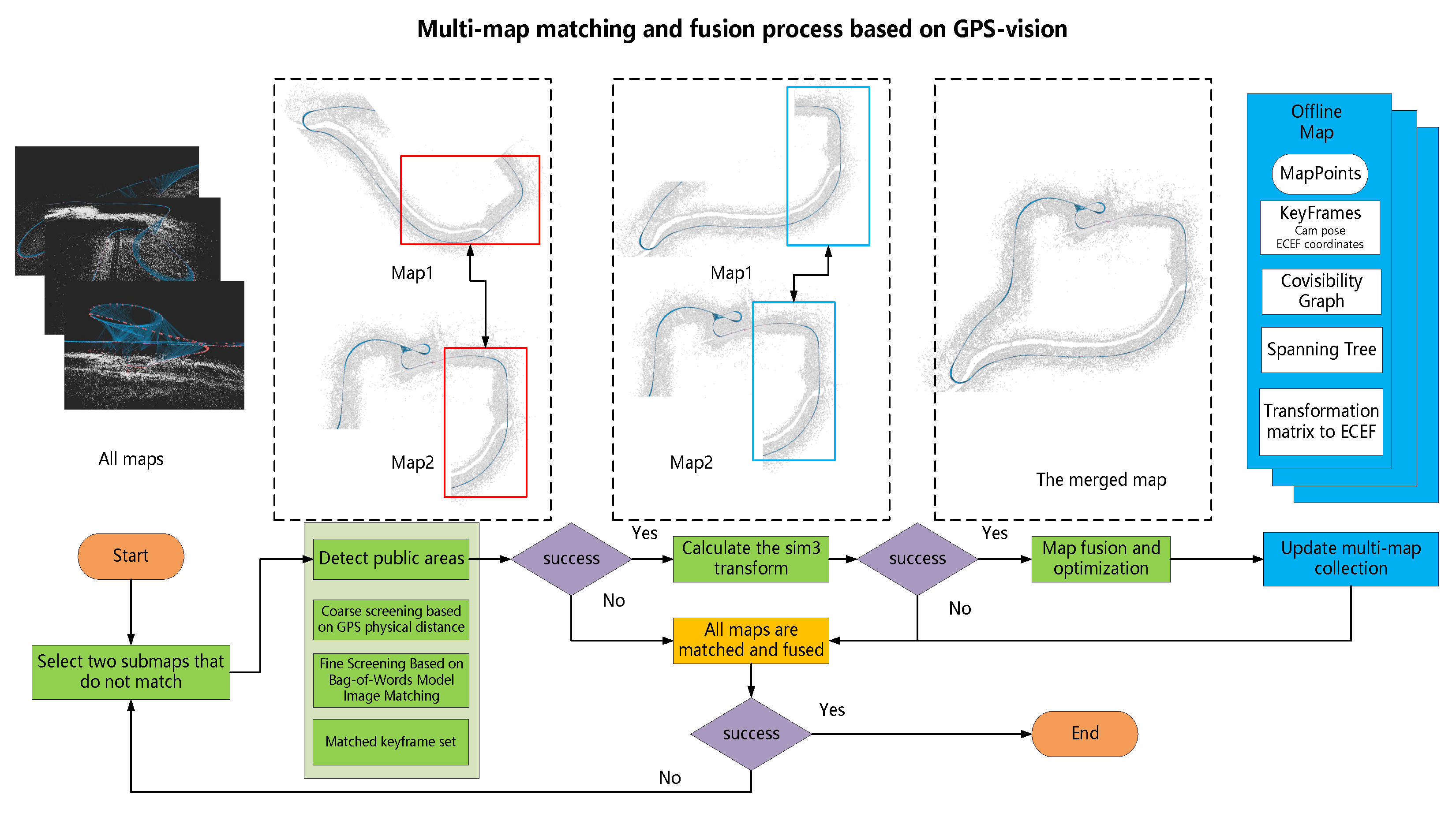
5.2. Multi-Map Merging
Since the data sequence may have an overlapping area at different times, and too many discrete maps cause resource loss and affect location switching, the map management module creates a multi-map fusion strategy to merge the discrete maps with an overlapping area. The specific map merging operation to fuse the current map with the candidate map is shown in
Figure 3.
(1) Detection of overlapping areas: The classical visual SLAM often utilizes the bag-of-words model, such as DBOW2, to compute image similarity for detecting overlapping areas. However, this detection method is not robust. Relying solely on visual cues may lead to the failure to detect overlapping areas or even produce erroneous results.
Compared to the commonly used DBOW2 detection in traditional visual SLAM, this paper introduces a GNSS-assisted method for detecting overlapping areas, which greatly enhances the speed and reliability of the detection. This method significantly speeds up the detection process while also reducing the chances of erroneous matches caused by similar scenes. The distance between the current keyframe
and all keyframes in the candidate map set
is calculated for the current map, and the nearest candidate map
m is obtained as Equation (
11), where
is the GNSS coordinate of the keyframe. The set
of the first n nearest candidate fusion keyframes is also preserved in the
m map:
(2) Calculate the sim3 transformation: Traverse all keyframe matching pairs and apply the bag-of-words DBOW2-based image-matching method to obtain the matching relationships between 2D feature points, thus obtaining the matching relationships between 2D points and their corresponding 3D points in the map. Using the ICP algorithm, point cloud registration is performed based on the 3D matching relationships, computing the similarity transformation matrix between the current map and the candidate map as . During this process, record the candidate keyframe with the highest number of points.
Due to the presence of multiple matching keyframe pairs in set C, it is possible to calculate multiple similarity transformation matrices. Among these calculation results, it is necessary to select the best set to participate in the subsequent computations. First, using
, the 3D points in keyframe K1 are projected onto the image of keyframe K2. Then, the 3D points in keyframe K2 are projected onto the image of keyframe K1. Subsequently, according to Equation (
6), the vector inner product
r of the reprojection errors is computed. Further, the inliers and outliers are selected using a threshold based on the chi-square test. Finally, select the keyframe matching pair KF1 and KF2 with the highest number of inliers as representatives of the overlapping area between the two maps, and record the similarity transformation matrix Q calculated based on them.
(3) Map fusion: After computing the overlapping areas between the two maps and the coordinate transformation matrix between the maps, the actual map fusion operation can be performed. Record the current key frame
and its co-view keyframe as the active co-view window
, and record the fusion key frame and its co-view keyframe as the fusion co-view window
. Through the similar transformation relationship
calculated between the two maps, the keyframes and map points of the current common view window
are transformed into the candidate map
m coordinate system and added to the candidate map. The above process is shown in Equation (
12):
where
T represents the position and pose of the keyframe, and
P represents the coordinates of the map point.
Using these two co-visual windows, the old map’s spanning tree is merged and updated, and the connections between map points and keyframes are updated to eliminate duplicate map points.
In this paper, the fusion of map points differs from some traditional SLAM methods, as it does not directly use either of the two. Instead of performing a simple replacement, the fusion is weighted based on the weights of each map point, which leads to a more rigorous and effective approach. Specifically, assuming that the map point
l is observed in
keyframes and the corresponding point
is observed in
keyframes, the fusion result of
l and
denoted as
is given by Equation (
13):
Finally, all other keyframes and map points in the current map are transformed and added to the candidate map m to complete the basic map fusion.
(4) Map optimization: In the stitching area, non-linear bundle adjustment (BA) is performed on keyframes and map points in the current frame co-view window , while the frames in the fusion co-view window are fixed. Subsequently, a global pose graph optimization is performed to refine the keyframes and map points throughout the entire map.
After the fusion process is complete, the multi-map collection is updated by removing the previous outdated maps and adding the newly merged map. Repeat the above process until the number of maps is reduced to 1, or all maps have been attempted for matching and fusion.
5.3. Multiple Map Switching
When navigating in large-scale environments, even with the assistance of map fusion, relying solely on a single map for visual localization in a planned scene remains highly challenging. For instance, when multiple geographic maps exist involving different temporal and spatial domains, a localization and navigation system needs to possess robust online management and coordination capabilities. Therefore, this paper proposes a multi-map-based visual SLAM online localization system that can effectively localize the scene based on the results of multi-map construction presented earlier. Even in the online motion of unmanned aerial vehicles or ground vehicles, in the event of GNSS data loss, the proposed system can accurately estimate its own position and achieve system relocalization. The experiments demonstrate that the proposed algorithm exhibits higher robustness and accuracy compared to existing SLAM systems.
(1) Map-switching conditions: The switching between multiple maps is based on specific criteria. If the current frame’s localization result is unsatisfactory, the tracking module selects an appropriate map. During the online localization process, the success of the current frame’s pose estimation is determined by the number of tracked map points and the number of inliers in the pose estimation. Additionally, map switching is triggered based on three specific conditions.
Condition 1: During the online relocalization process, if the pose estimation fails for three consecutive frames, it cannot reestablish the localization.
Condition 2: There is no co-vision between the current image and all keyframes on the active map.
Condition 3: The current image is relocalized if its localization accuracy or healthiness does not meet the threshold.
We primarily rely on Condition 1 and Condition 2 for determination. In our assumed working scenario, UAVs and eVTOL experience long periods of GNSS signal interference and loss while performing transportation tasks within mapped areas. Therefore, real-time localization heavily relies on purely visual methods. In any of the situations above, a multi-map switching operation is triggered, leading to the abandonment of the current map and the selection of a new map to facilitate subsequent localization tasks. Condition 3 is only utilized in ideal scenarios with good GNSS signal conditions. The best localization results can be achieved by combining reliable GNSS signals and visual maps. The visual relocalization accuracy is evaluated based on the current real-time GNSS information. This condition can be used to assess the reusability of existing maps and further determine whether to update historical maps or add new map sets.
(2) Map-switching algorithm: During the offline automatic construction of multiple maps, all keyframes, 3D points, transformation matrices to the world coordinate system, and other relevant information in the maps are recorded. This paper provides grid-based map information for the offline map workspace based on these conditions. This information records the distribution of all maps within the entire map scene. First, the unmanned aerial or ground vehicle’s working area is defined as a large rectangle. The GNSS with the strongest satellite positioning system signal among all keyframes is chosen as the origin of the grid coordinate system. The longitude is assigned to the y-axis, and the latitude is to the x-axis. We set the size of each small square as 700 × 700 m (precisely adjusted based on the size of the mission area and onboard equipment resources). By utilizing the conversion relationship between meters and latitude/longitude, we can determine the actual latitude and longitude values for each grid in the map. Next, based on the GNSS with the strongest signal among the keyframes, the number of squares in the longitude and latitude directions can be calculated and numbered starting from 0. Finally, we can determine their corresponding coordinates on the grid map using the GNSS positions of each keyframe on the map. This allows us to obtain a list of maps for each grid.
During the initialization process, the online relocalization system will load all the offline constructed multi-map grid information. When the UAV or ground vehicle triggers the map-switching conditions described earlier during its motion, the system will automatically initiate the map-switching algorithm. When selecting the candidate map for switching, the system will prioritize the principle of minimum distance. If the current frame fails to localize, the system will use the pose result from the previous frame as the current localization position. Then, it will search for the candidate map with the closest physical distance to the current situation in the candidate map collection and switch to using that map. Specifically, the estimated pose
of the previous frame is converted into the ECEF coordinate system through the transformation matrix of the current map, and the calculation formula is as follows:
where
s,
R and
t represent the scaling factor from the model coordinate system to the ECEF coordinate system, 3 × 3 rotation matrix and 3 × 1 translation vector, then the position coordinates
of the current UAV or vehicle in the grid coordinate system are
where
is
, which corresponds to the position under the GNSS coordinate system, while
is the GNSS coordinates of the grid coordinate system origin.
and
represent the scale of a grid in the x and y directions, respectively.
Then, according to the current coordinates, all maps in the four fields above, below, left and right of the grid are obtained to generate an Atlas. The current GNSS and the GNSS of all keyframes in each map are used to calculate the Euclidean distance, and the Atlas is sorted from near to far. A new map is selected from the sequence when a map is switched.
Additionally, we designed a criterion to determine the success of map switching. After the switch, continuous successful localization across multiple frames is required within the switched map to confirm a successful switch. Lastly, the system outputs the current UAV or ground vehicle’s valid position and attitude information to the control terminal.
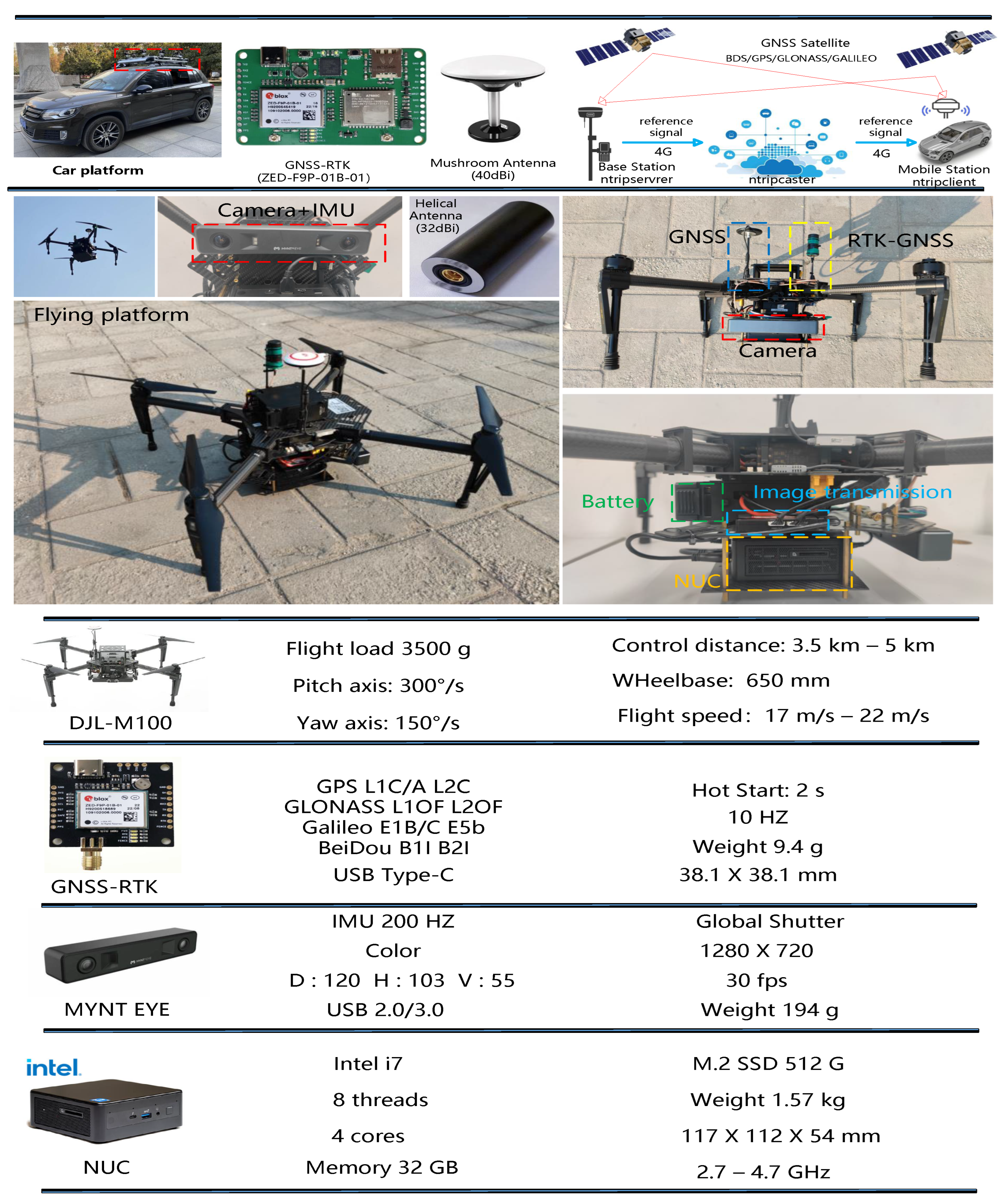
6. Experimental Results
We evaluate the proposed system utilizing both real-world trials and aerial simulation datasets. Then we construct a real LD-SLAM system that includes a fisheye camera, GNSS, and an Intel NUC tiny PC. The specific information on the experimental equipment is shown in
Figure 4. Comprising UE4 and Airsim, we first generate an aerial dataset with sceneries of towns, villages, roads, rivers, etc. The dataset used is shown in
Figure 5. In our experiment, we deploy the system on drones and ground vehicles to assess its performance in a distant outdoor space. Finally, we investigate and discuss the system’s overall processing speed as well as the duration of each component’s calculations. The precision, robustness and efficiency of our technology are clearly shown by the quantity and quality analyses.
The selected multi-frequency GNSS receiver model used in the experiment is the ZED-F9P module, which is a 4-constellation GNSS system capable of simultaneously receiving GPS, GLONASS, Galileo, and BeiDou navigation signals. When combined with an RTK base station, it achieves centimeter-level accuracy within seconds. The RTK system provides various types of positioning, including “NARROW-INT” (a multi-frequency RTK solution that resolves narrow lane integer carrier phase ambiguities), “PSRDIFF” (a solution calculated with differential pseudo-range corrections using DGPS or DGNSS), and “SINGLE” (a solution computed solely using data provided by GNSS satellites). The compact and energy-efficient nature of this module makes it suitable for deployment on UAVs. It exhibits short convergence time and reliable performance, providing a fast update rate for high dynamic application scenarios. All sensors are synchronized with the GNSS time through hardware triggering. The specific parameters are shown in the
Figure 4. Before integrating GNSS information into sensor fusion systems, it is necessary to perform a preliminary detection of outlier states. Failure to do so may result in reduced accuracy due to erroneous GNSS information. GNSS measurements include information such as receiver status, number of satellites, position dilution of precision (PDOP), and the covariance matrix of the positioning results. The provided information can be used for the initial filtering of GNSS measurements to eliminate abnormal frames. On the one hand, adding a constraint to the starting point position ensures better quality of the GNSS data collected. On the other hand, accumulating a sufficient amount of high-quality GNSS points and performing batch optimization is essential to achieve the alignment of GPS and SLAM trajectories in one step. By utilizing a high-precision visual map established with the assistance of GNSS, the proposed system can provide accurate, robust, and seamless localization estimates along the entire trajectory, even in long-term GNSS-obstructed conditions.
The reliability of GNSS is compromised within urban canyons or tunnels. We only consider the reference pose when GNSS is available and the standard deviation of the observed position is small. An outlier processing algorithm is applied to the data from visual and GNSS observations to enhance the system’s robustness, particularly in complex environments. GNSS anomaly detection enables the identification of faults in GNSS signals, ensuring that anomalous GNSS positioning outcomes do not impact the entirety of the trajectory. For the GNSS raw data, we exclude satellites with low elevation angles and those in an unhealthy state, as these satellites are prone to introducing errors. To reject unstable satellite signals, only those satellites that maintain a continuous lock for a certain number of epochs are permitted to enter the system.
For future convenience in understanding, we established several symbols and terms.
VO Map: The map was built using only visual information without GNSS optimization.
VO + GNSS Map: The map was constructed by fusing data from multiple sensors, including visual and GNSS information.
VO Localization: The pose estimation was conducted solely using visual odometry without GNSS optimization.
VO + GNSS Localization: The pose estimation was optimized using the joint information of visual odometry and GNSS.
To validate our algorithm’s performance, we conducted relocalization experiments in three distinct environments: virtual simulations, real-world unmanned aerial vehicle flights, and real-world ground vehicle operations. These will be presented in the following three subsections: A, B, and C. We conducted three separate sets of controlled experiments in each experimental setting to validate the performance of our algorithm in multiple modes fully. The three experimental conditions are shown below:
The first mode (VO Map—VO Localization) utilizes pure vision to perform relocalization on a map built purely of visual information. In scenarios of long-range navigation (e.g., flying for tens of kilometers), this mode serves as a fundamental benchmark for localization comparison due to the accumulation of errors caused by the lack of global optimization assistance.
In the second mode (VO + GNSS Map − VO + GNSS Localization), GNSS signals are utilized for optimization in both map generation and online localization stages. This model is the most optimal working solution since GNSS signals are of good quality during the online localization phase, allowing continuous participation in localization optimization. Moreover, the employed high-precision map fuses global positioning information for improved accuracy. Unfortunately, the electromagnetic environment is complex and variable, and GNSS signals may be lost for a long time. Malicious interference with GNSS signals may occur for some important safety applications, leading to the unavailability of global positioning information.
In the third mode (VO + GNSS Map − VO Localization), pure visual relocalization is performed using a high-precision map optimized with GNSS data. This mode closely matches real-world application scenarios. In some fixed use cases, such as unmanned aerial vehicle logistics, a high-precision map can be constructed in advance under the premise of good GNSS signals. During online use, pure visual localization is primarily used, and global positioning information can be obtained using an offline map regardless of the quality of GNSS signals.
We utilize GNSS-RTK data as a reference for the ground truth trajectory. In long-range navigation tasks, the traditional visual localization method, which solely relies on loop closure detection and global BA, cannot effectively reduce cumulative error, as evidenced by the experimental comparison of Patterns 1 and 3. However, incorporating GNSS global information into a multi-sensor data fusion-based localization method can effectively address this issue. Through the experimental comparison of Patterns 2 and 3, we find that the accuracy of high-precision map-based localization optimized with GNSS assistance is comparable to that of GNSS localization. The experimental results for this section are presented in
Table 1.
- A.
Simulation Environment: Chicago Scene Data
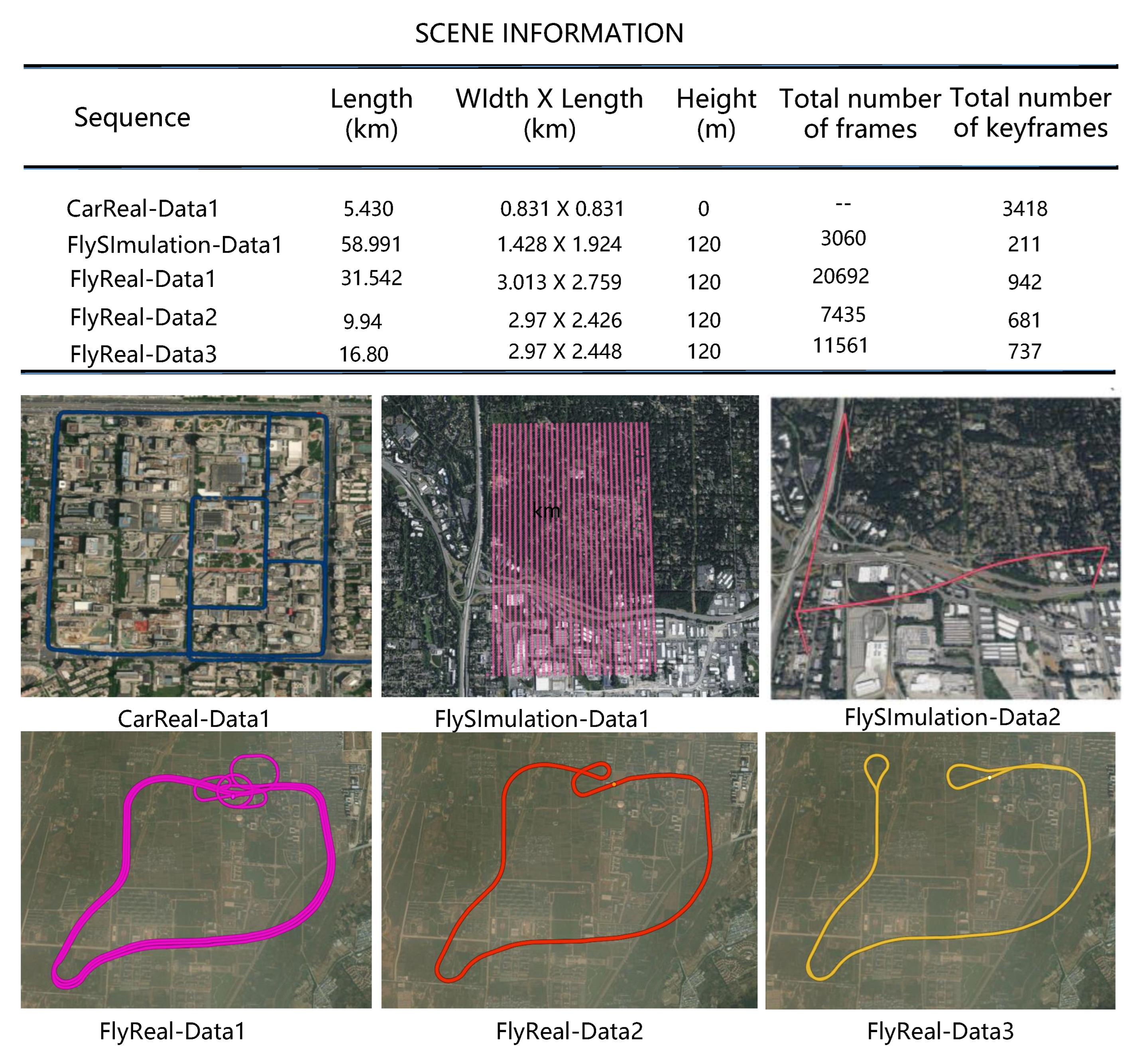
Mapping data: We use Unreal Engine 4 to create a Chicago city simulation scene in a virtual environment and use Airsim to simulate the drone collecting images and GNSS data in strips over the city, which includes three takeoff and landing sites. The drone has a flight altitude of 200 m, a bandwidth of 1.420 km, a band length of 1.924 km, a total mileage of 58.991 km, and a frame rate of 10 frames per second. For each image in this dataset, there is ground truth for the drone’s position, attitude, and GNSS, and the total number of aerial images is over 20,000.
Localization data: In the area of the mapping data, the drone flies in a curve. The flight altitude is 200 m, and the total flight distance is 31.43 km.
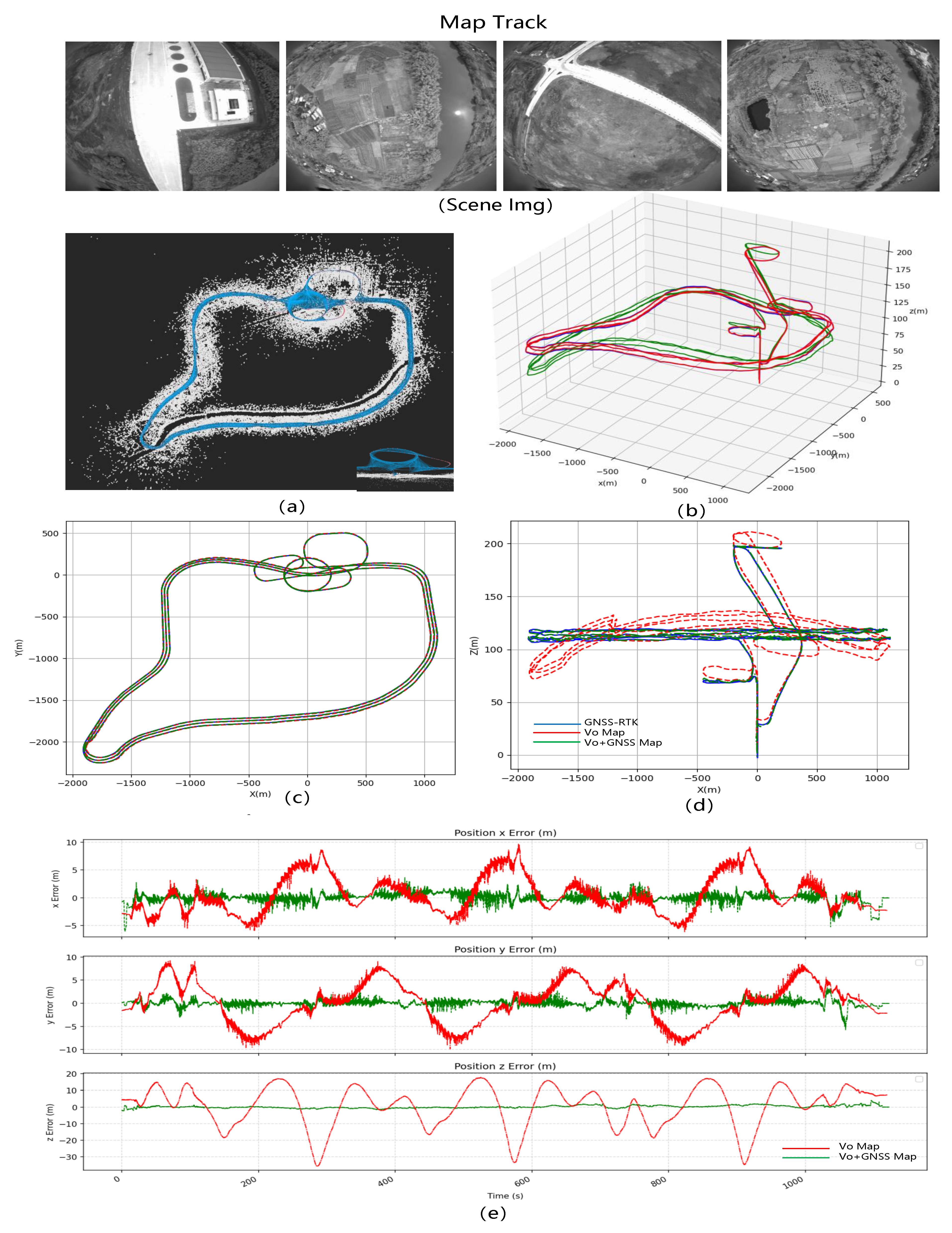
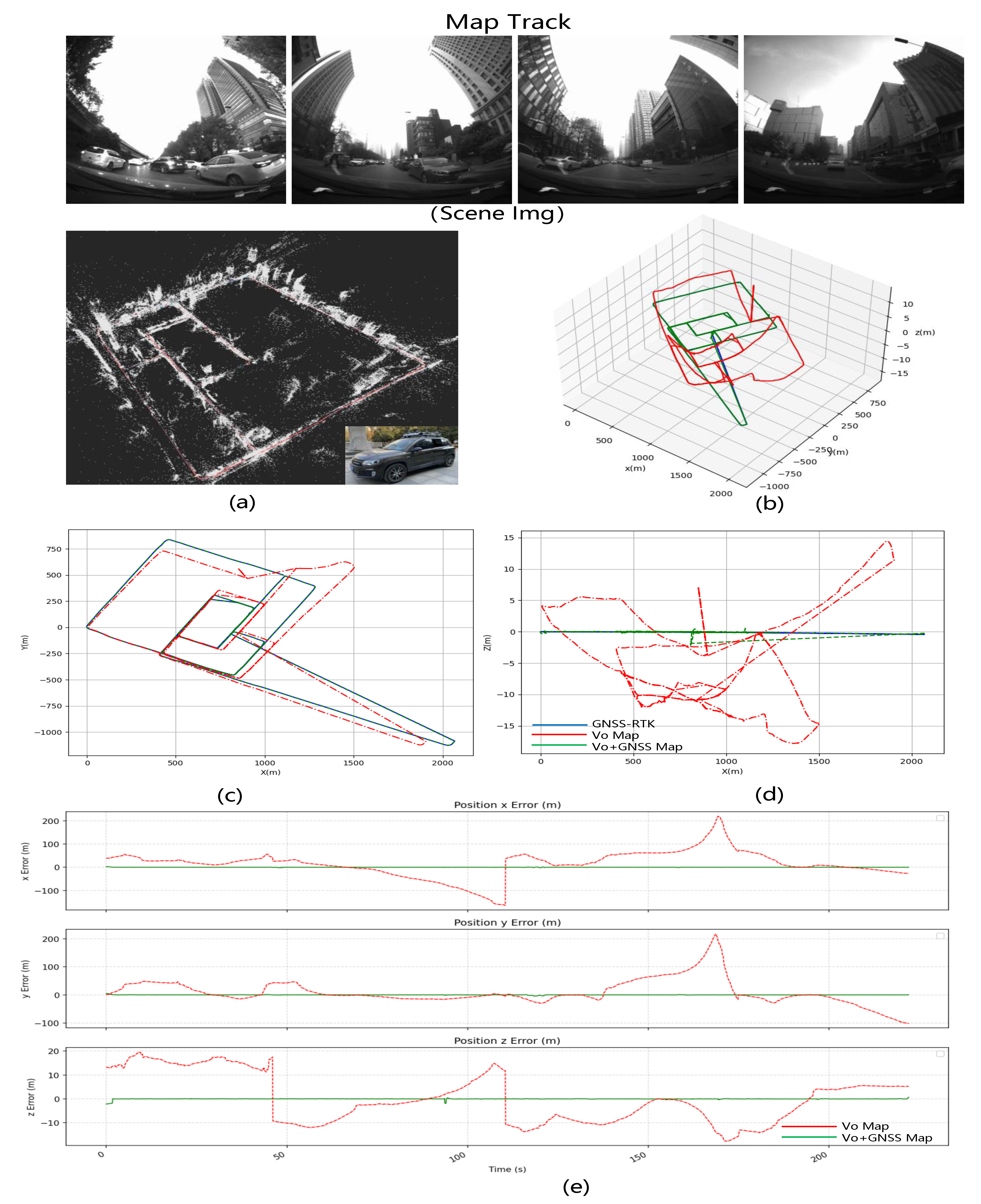
LD-SLAM Result: We use the mapping data to build the map in two modes: pure vision SLAM and vision + GNSS optimization, draw the trajectory and compare the error by converting the calculated value and real GNSS to ECEF coordinate system.
Figure 6 shows the mapping data with
Figure 6a the point cloud map,
Figure 6b the trajectory of the mapping results and
Figure 6c–e the error comparison between the visual SLAM mapping results and the visual+GNSS optimized mapping results. The trajectory figure shows that the z-direction of flight varies significantly under purely visual SLAM. After adding the GNSS optimization, the jitter decreases, and the trajectory approaches the true value. The total error of the three XYZ directions is 0.2 to 0.3 m smaller.
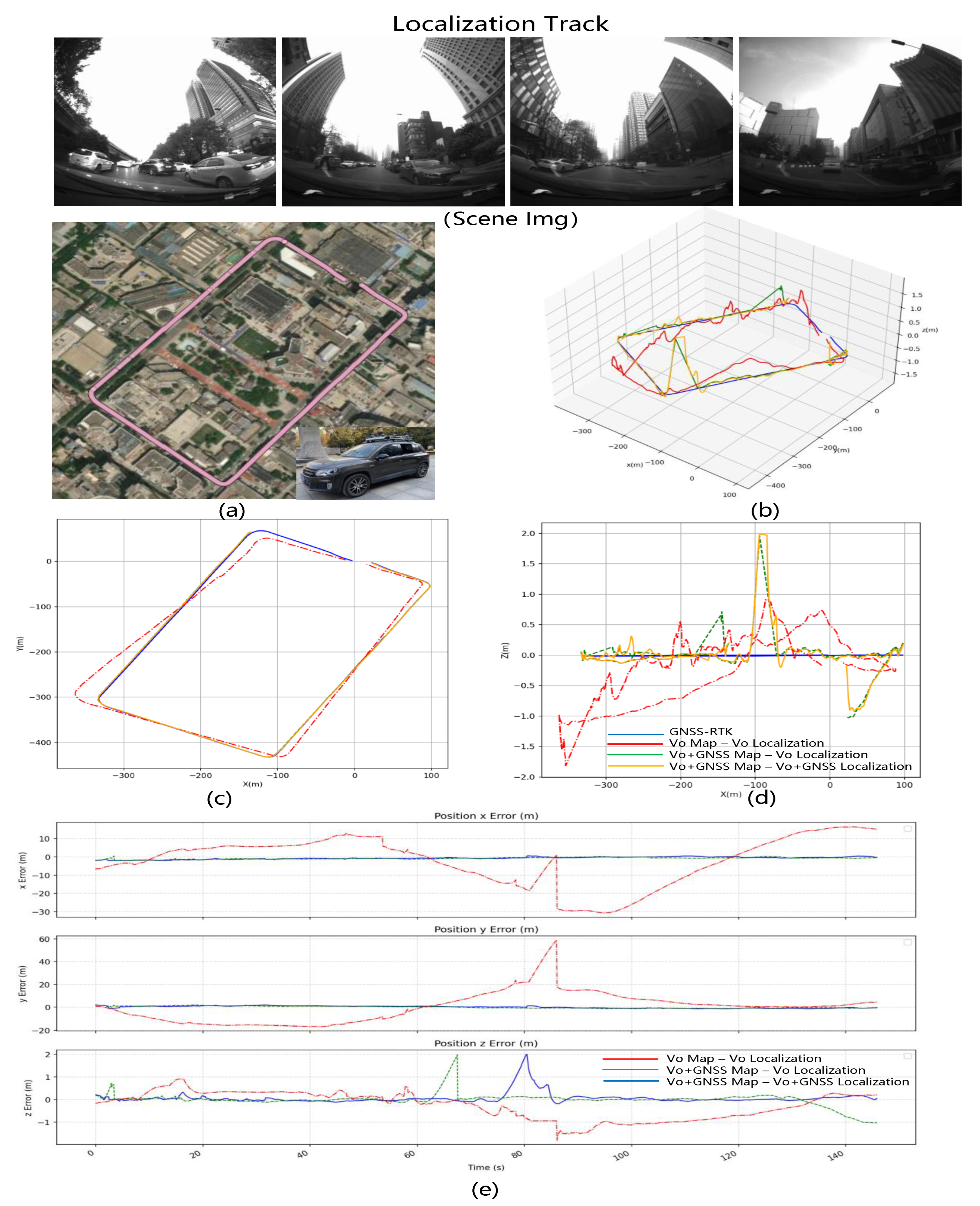
Using the aforementioned mapping data, we created two maps—the VO map and the VO + GNSS map—which will be used in subsequent relocation experiments. In the simulation test environment, we observed an overall root mean square error (RMSE) of 4.69 m in Pattern 1 (VO Map − VO Localization), with no greater deviation due to the dense strip-shaped flight trajectory that is conducive to visual mapping and localization. In Pattern 2 (VO + GNSS Map − VO Localization), the relocation accuracy improved to 2.232 m, thanks to the use of GNSS assistance that improved the accuracy of the visual map. In Pattern 3 (VO + GNSS Map − VO + GNSS Localization), the relocation accuracy further improved to 0.919 m, undoubtedly due to the excellent GNSS global information assistance for both the mapping and online visual localization optimization. Although Pattern 3 is the optimal pattern, we must consider the possibility of long-term GNSS loss in practical situations. Therefore, in practice, Pattern 2 will be used in most cases.
Figure 7 shows the results. The error curve shows that the position accuracy of the optimized map with GNSS is superior to the purely visual map in terms of longitude and latitude errors.
Figure 7 shows that after adding the GNSS optimization, the error in the xy direction break is 1 to 2 m less than just what is seen.
- B.
Real Scene UAV Aerial Photography Data
Mapping data FlyReal-Data1: We use a drone to capture multiple sets of data in the normal environment. The trajectory of the drone is shown in
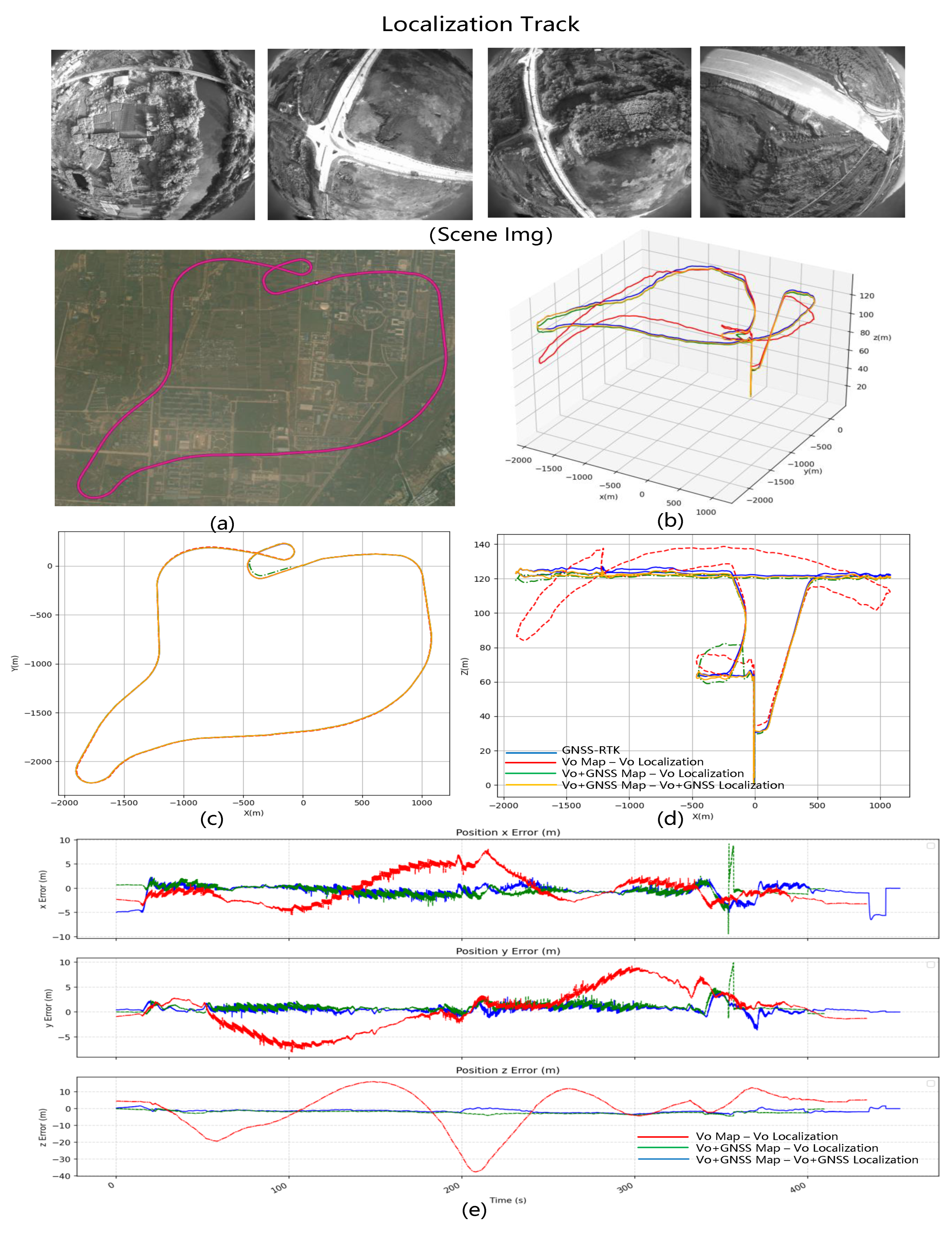
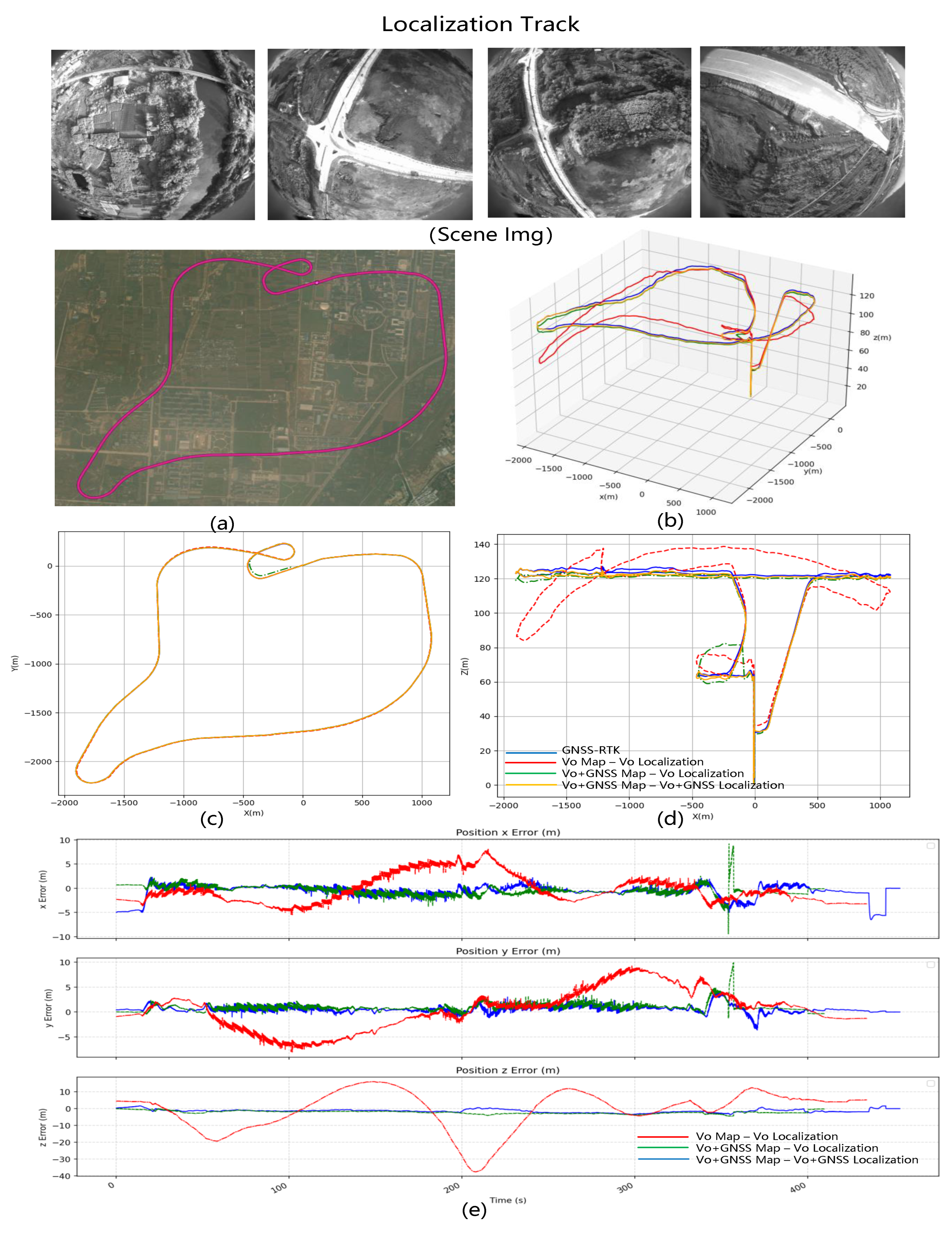
Figure 8. The flight altitude is 120 m, the total mileage is 31.54 km, the frame rate of image acquisition is 15 frames, and the frame rate of GNSS acquisition is 10 frames.
Localization data FlyReal-Data2: Within the same scene, the drone flies back and forth according to the mapping data track. The specific trace is shown in
Figure 9. The flight altitude is 120 m, the total mileage is 16.808 km, the frame rate of image acquisition is 15 frames, and the frame rate of GNSS acquisition is 10 frames.
Localization data FlyReal-Data3: We fly a circle in the mapping scene x according to the mapping track.
Figure 10 shows the specific lane. The flight altitude is 120 m, the total mileage is 9.945 km, the frame rate of image acquisition is 15 frames per second, and the frame rate of GNSS acquisition is 10 frames per second.
LD-SLAM Result: Similar to the Chicago experiment, we created maps for both the Vision + GNSS Optimization and Pure Vision Slam modes using this dataset, as shown in
Figure 8. Since an actual drone captured this dataset, the results are more convincing than those obtained with simulated data. In the simulation scenario, the flight path was changed from an ideal strip to a multi-layer circular long-distance path with varying elevations. The purely visual elevation gain error fluctuation was clearly visible in the real long-distance data, with the error reaching up to 30 m. After GNSS optimization, the error in all three directions was reduced to within 1 m.
We conducted three experimental groups utilizing the FlyReal-Data2 test dataset, similar to the Chicago experiment. Test results are shown in
Figure 9. The location results obtained with maps after GNSS optimization are significantly better than those obtained using the pure Vision Slam. In vision-only mode, errors in the XYZ direction can reach up to 30 m, whereas GNSS optimization can often reduce errors in all three directions to within 2 m. The pure vision error map has a sudden increase in error due to the UAV flying out of the map during testing. Due to the tendency for errors to accumulate during SLAM turning without GNSS optimization, errors can rapidly grow and exceed 30 m in a short amount of time. The system will start repositioning and create sharp increases in errors when significant errors occur. With GNSS optimization, the UAV error after leaving the mapped region is always within 2 m, and it can maintain a high level of accuracy without requiring loopback data.
Figure 10 shows similarities between the FlyReal-Data3 test results and the previously discussed results. Applying GNSS optimization leads to improved positioning accuracy, particularly at higher altitudes. In pure visual mode, errors in the xy direction can reach up to 5 m; in the z-direction, errors can be as high as 30 m. However, after applying GNSS optimization, errors in all three directions are often reduced to within 2 m. The drone flew beyond the map’s limits in some parts of the middle and rear sections. Our method can accurately track and relocate the drone, even under challenging circumstances such as flying out of the map’s limits.
These experiments further validate the reliability of our system in real-world scenarios. During the 16 km long-distance flight relocalization test, the precision error difference between mode 2 (VO + GNSS Map − VO + GNSS Localization) and mode 3 (VO + GNSS Map − VO + GNSS Localization) was only around 0.5 m. This fully demonstrates the effectiveness of the maps optimized with GNSS assistance. For multi-rotor aircraft performing tasks, such as the delivery and transport of people, it is possible to construct high-precision offline maps in advance within the flight mission area when the GNSS signal is strong. When the GNSS signal is lost due to malicious interference, high-precision offline maps can provide global positioning information to replace GNSS.
- C.
Real Scene Ground Vehicle Data
Our ground dataset was collected by a modified SUV in intricate urban settings, with the vehicle reaching a maximum speed of approximately 15 m per second during the data acquisition process, as shown in
Figure 4. The road where the collection took place is flanked by tall buildings spanning several tens of meters, with the heights of these high-rise mainstream structures ranging from 150 to 250 m. Near the central garden square in the city center, there is a circular road surrounded by towering skyscrapers, highly convenient transportation, and some dynamic objects present. Additionally, data are collected by driving on elevated bridge roads within the urban area. These structures serve as prominent landmarks, facilitating the extraction of visual features. During collection, the vehicle will pass through several traffic light intersections, typically maintaining a certain distance from the preceding vehicles. Rapid passage beneath elevated bridges may occasionally temporarily degrade GNSS signals for a few seconds. Therefore, outlier processing algorithms are applied to the data from visual and GNSS observations to enhance the system’s robustness, particularly in complex environments.
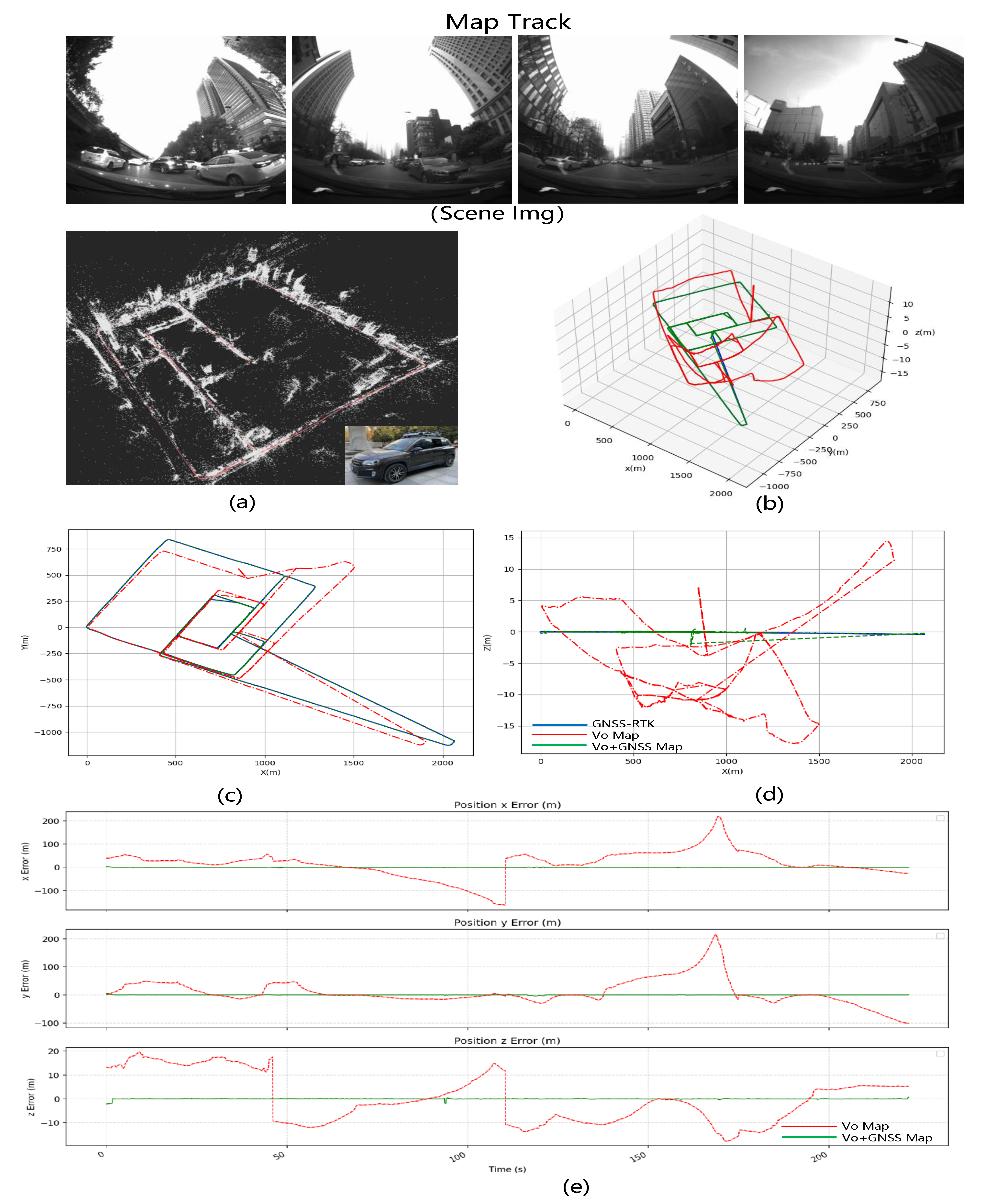
Mapping data: Install our SLAM system on the ground vehicle and collect data on the road with the front fisheye camera.
Figure 11 shows the vehicle run distance with a total mileage of 5.430 km, a frame rate of 15 and a GNSS frame rate of 10.
Localization data: The vehicle moves through the city blocks in the test data.
Figure 12 shows the vehicle route. The vehicle’s total mileage is 2.318 km, the frame rate is 15, and the GNSS frame rate is 10.
LD-SLAM Result: Two mapping modes are utilized for ground data: pure vision SLAM and vision + GNSS optimization as shown in
Figure 11. Ground imagery poses more complex analysis conditions than aerial imagery due to factors such as lower texture, poor illumination, and accumulation errors. In pure vision, the turning scale is significant. Pure vision typically employs loopback to correct scale drift and cumulative errors. However, the loopback’s global BA optimization is time-consuming and produces an unstable optimized result for long-distance driving and fewer feature points extracted from the image. For instance, in the pure visual mode of
Table 1, the original square trace becomes irregular due to the loopback optimization, drastically decreasing the overall accuracy.
Three experimental groups were conducted similarly to Chicago using test data.
Figure 12 shows the test results. The GNSS-optimized map positioning results are significantly better than pure vision SLAM. Due to the complex and changeable environment, in the pure visual mode, the error in the two directions of xy can be as high as 30 m, the overall trajectory is offset, and the error remains within 1 m after adding GNSS optimization, which shows that our system still has good robustness in the complex environment of high exposure and multiple moving objects.
An additional advantage of these visual maps is their dynamic updating capability while maintaining accuracy. During each unmanned aerial vehicle’s operation within the same region, updated visual positioning information is integrated into the previous map to improve the accuracy of subsequent UAV relocalization. Multiple visual maps can be constructed at different times in the same area to improve relocalization accuracy. Thus, it becomes favorable in addressing complex illumination changes, particularly seasonal variation that results in significant texture changes.
The final root mean square error (RMSE) of each approach is shown in
Table 1.
- D.
Multi-algorithm Comparison Experiment
In order to further compare the excellent performance of the algorithm, we selected ORB-SLAM3, Openvslam, and Vins-Fusion, three advanced algorithms, for comparison. Among them, Openvslam and ORB-SLAM3 are pure monocular vision SLAM systems, and Vins-Fusion is a SLAM system that uses GNSS to participate in optimization. VINS-Fusion is a multi-sensor state estimator that operates based on optimization principles. VINS-Fusion supports four types of visual-inertial sensors: monocular camera + IMU, binocular camera + IMU, binocular camera only, and binocular camera + GNSS. In our study, we specifically focus on the joint-optimized positioning of visual odometry (VO) and GNSS. Therefore, we selected the binocular camera + GNSS working mode of VINS-Fusion for comparison.
In order to ensure the integrity of the experiment, we selected three typical long-distance aerial photography datasets in the air. We compared the root mean square errors of the four algorithms in each scenario and visualized the 3D trajectory and the error trend of the trajectory in each direction. By comparing with Openvslam and ORB-SLAM3 monocular pure vision SLAM systems, it highlights the advantages of SLAM systems optimized with GNSS in long-distance visual navigation, which can greatly reduce the cumulative error of vision and improve the accuracy of positioning. By comparing with the Vins-Fusion algorithm, the experiment shows that our algorithm works stably and has higher accuracy in the same GNSS-optimized SLAM system, especially in the face of long-distance cumulative errors, large-scale rotation of viewing angles, high-level jumps, and other complex positioning problems.
Table 2 shows the average root error of the four algorithms under three sets of data.
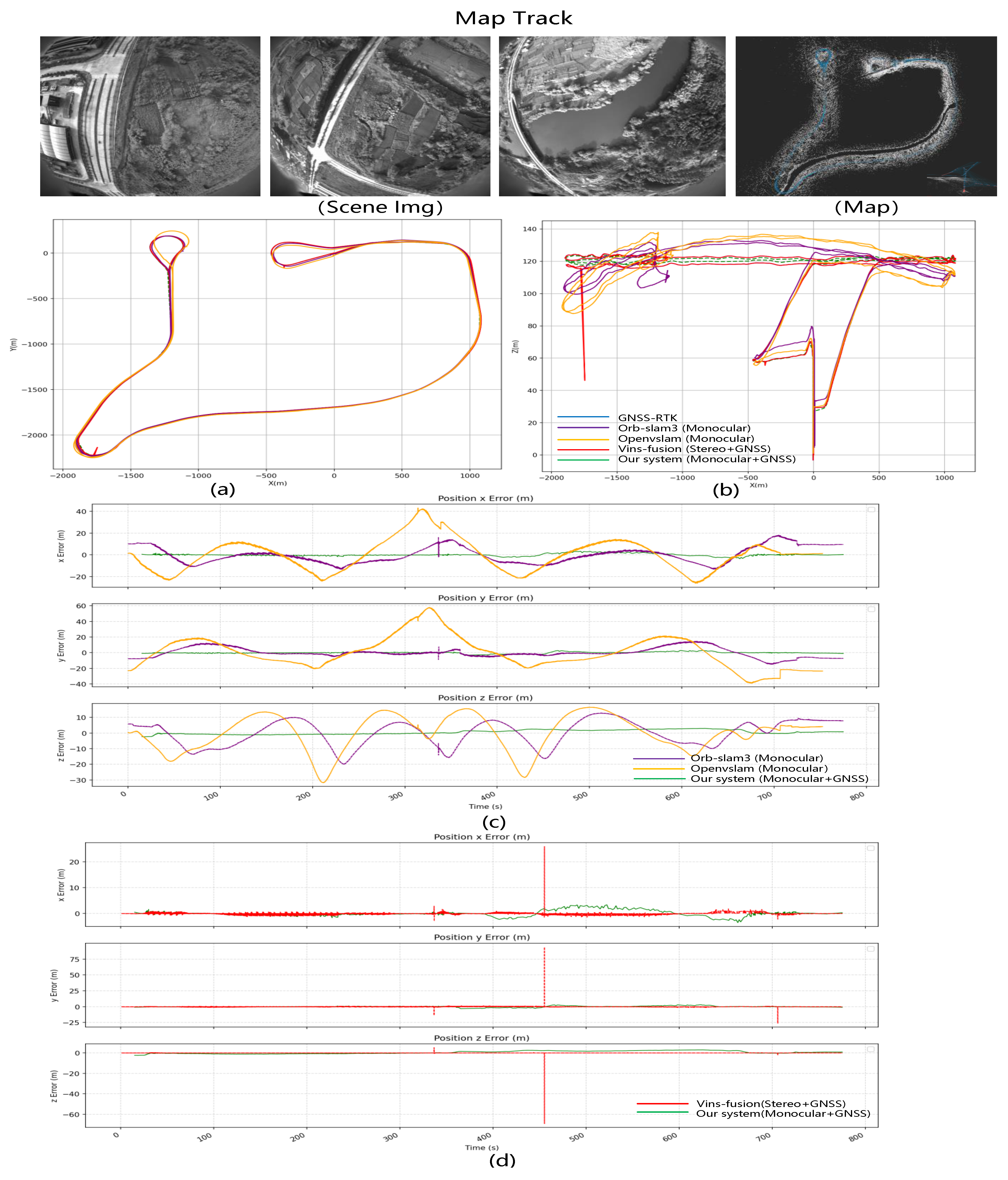
(1) Real-scene data FlyReal-Data1 Comparative Experiment
Mapping data FlyReal-Data1: We use a drone to capture multiple sets of data in the normal environment. The trajectory of the drone is shown in
Figure 13. The flight altitude is 110 m, the total mileage is 31.54 km, the frame rate of image acquisition is 15 frames, and the frame rate of GNSS acquisition is 10 frames.
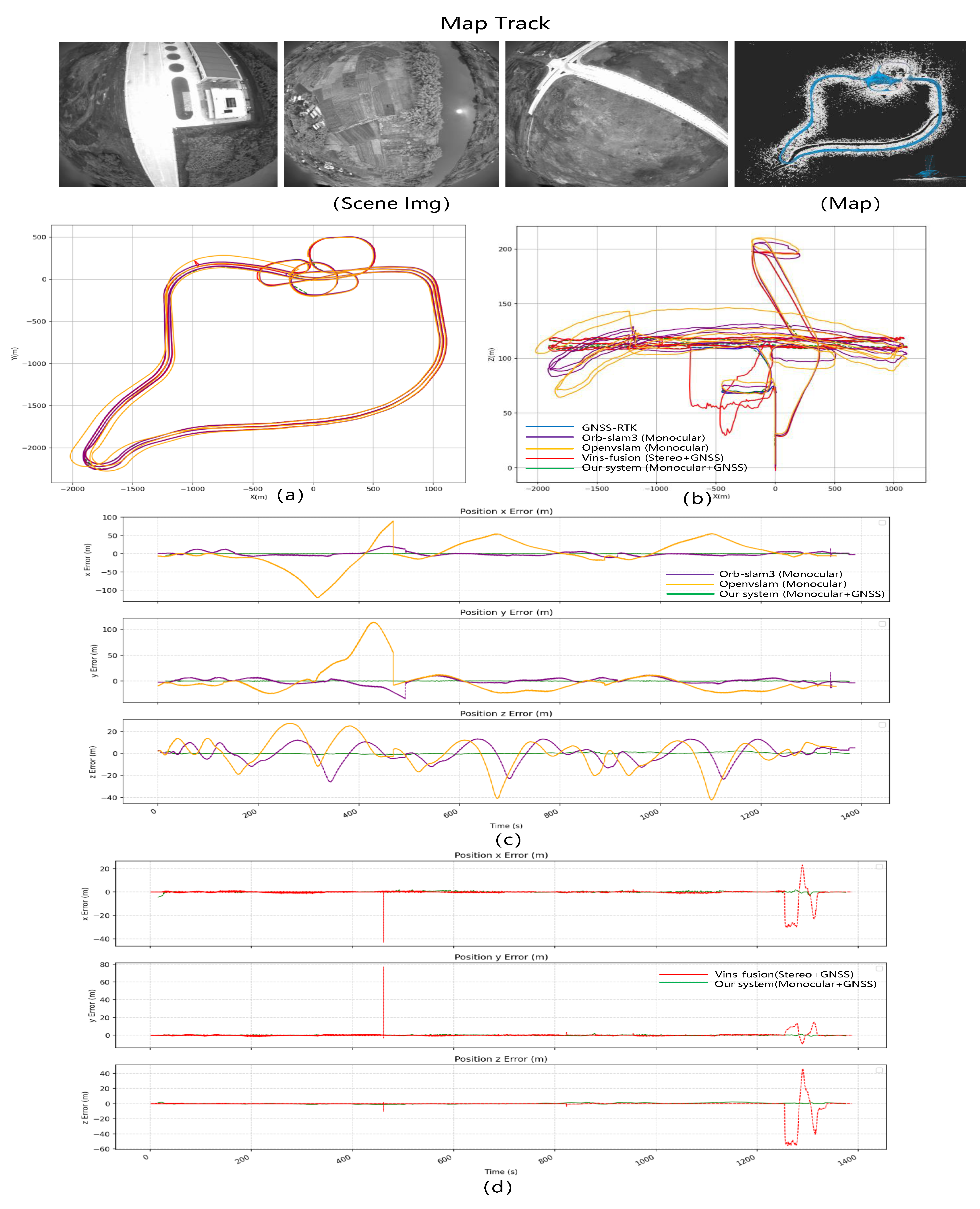
Compare Results: Among the three test scenarios, this set of data is for the longest flight distance. For the monocular pure vision SLAM system, the cumulative error is the largest. In the turning part of the flight path, the camera shooting angle changes too much following the rotation of the drone, resulting in serious deviations in pure visual positioning. From the trajectory diagram in the lower left corner of
Figure 13a, it can be seen that the monocular vision Openvslam pose prediction seriously deviates from the actual track. From the trajectory diagram in the middle part of
Figure 13b, it can be seen that Openvslam and ORB-SLAM3 have serious fluctuations in the pose estimation of height, especially in the turning stage. The limitation of the monocular vision SLAM system causes the pose estimation to seriously deviate from the actual position when turning and height changes and is accompanied by long-term cumulative errors. Finally, the RMSE of Openvslam and ORB-SLAM3 is 46.041 m and 19.827 m. In the case of long-distance visual navigation, after using GNSS data fusion, our algorithm and VINS-fusion successfully reduce the cumulative error and achieve good results in altitude prediction. However, due to the severe estimation error of the pose of VINS-fusion during the UAV return rotation and descent stage, its RMSE is 5.829 m. The serious deviation of the red track can be seen from the height of 50 m in
Figure 13b. However, the same position and pose estimation of our algorithm is normal, and the RMSE is finally 0.838 m. It fully reflects the stability of our algorithm in the face of rotation and height changes.
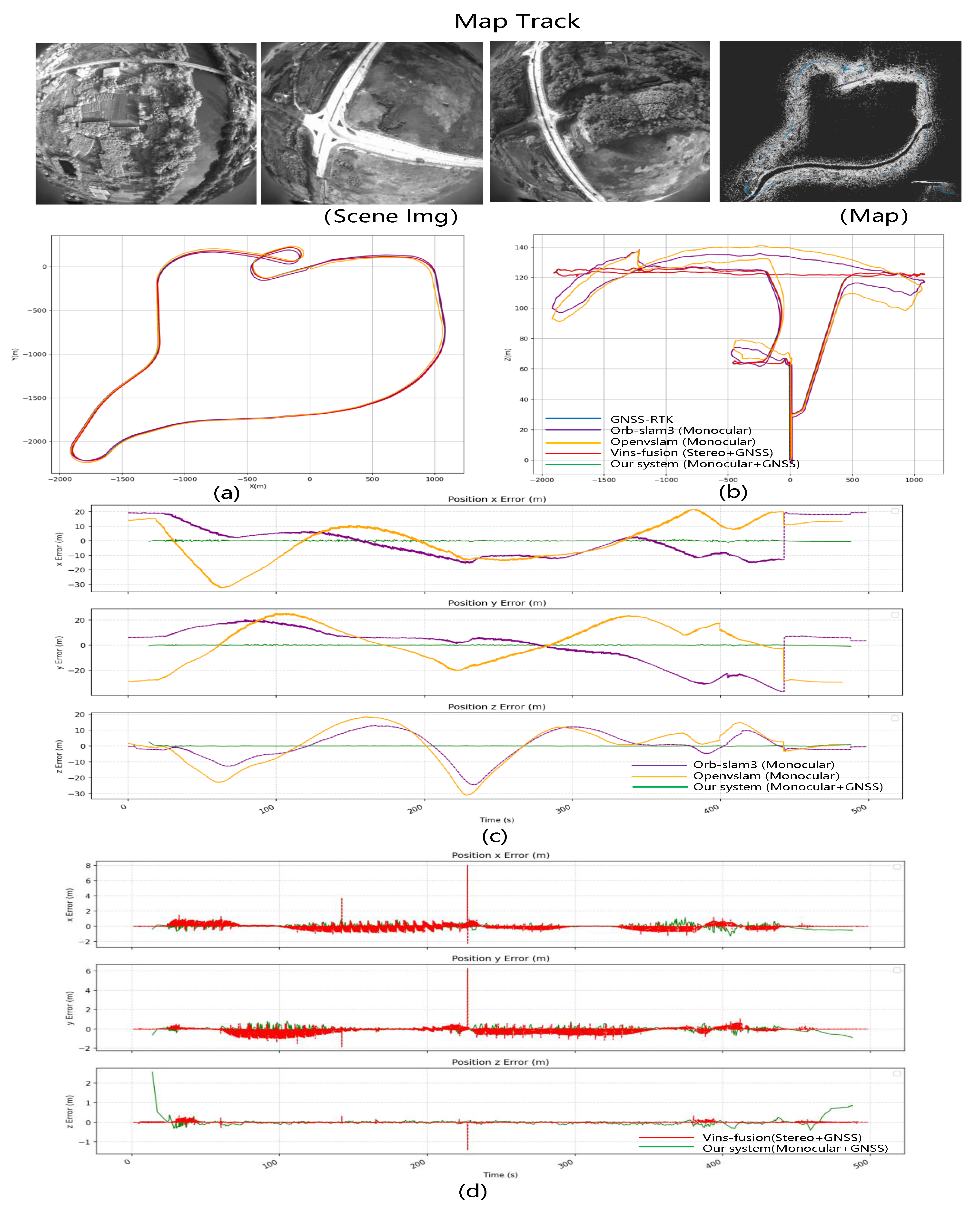
(2) Real-scene Data FlyReal-Data2 Comparative Experiment
Mapping data FlyReal-Data2: We use a drone to capture multiple sets of data in the normal environment. The trajectory of the drone is shown in
Figure 14. The flight altitude is 120 m, the total mileage is 16.808 km, the frame rate of image acquisition is 15 frames, and the frame rate of GNSS acquisition is ten frames.
Compare Results: Compared with the other two sets of data, this set of data is not a trajectory of a large circular closed loop. This mode is more likely to cause cumulative errors and pose estimation errors, which is more challenging for pure visual SLAM systems and also highlights the importance of optimization with GNSS data. It can be seen from
Figure 14c that Openvslam and ORB-SLAM3 monocular vision SLAM errors fluctuate more. The RSME of Openvslam and ORB-SLAM3 are 26.863 m and 12.416 m, respectively. Compared with the first set of test data, since the length of the whole track is 20 km shorter, their accumulated errors are also smaller. But compared with Vins-Fusion and our system, the error is still large. In this data group, the take-off and landing stages of the aircraft are relatively stable, so Vins-Fusion has no special prediction errors, and its RMSE is only 1.601 m. Our system performs well, and the RMSE is only 1.601 m, which is still the smallest among the four algorithms.
(3) Real-scene Data FlyReal-Data3 Comparative Experiment
Mapping data FlyReal-Data3: We use a drone to capture multiple datasets in the normal environment. The trajectory of the drone is shown in
Figure 15. The flight altitude is 120 m, the total mileage is 9.945 km, the image acquisition frame rate is 15 frames per second, and the frame rate of GNSS acquisition is 10 frames per second.
Compare Results: The length of the third set of data is 16.8 km, which is only half of the first set of data, and the shape is a closed great circle trajectory, which is beneficial further to reduce the cumulative error of the four algorithms. It can be seen from
Figure 15b that the pose prediction error of Openvslam and ORB-SLAM at an altitude of 120 m is still huge. At the flight altitude of 60 m, the altitude prediction of the aircraft in the orbiting stage has an error of about 20 m. The RSMEs of Openvslam and ORB-SLAM3 are 24.196 m and 11.919 m, respectively. The flight trajectory of the aircraft is relatively smooth during the ascent and descent stages, so VINS-fusion also achieves good positioning results, and its RMSE is 0.501 m. The RMSE of our algorithm is 0.44 m, which is more accurate than Vins-Fusion and is the most accurate among the four algorithms.
The RSME of the data comparison of the four algorithms is shown in
Table 2. Based on the comparison of several sets of data experiments, the pure visual monocular SLAM system represented by ORB-SLAM3 and Openvslam has a large error ratio in the case of long-distance aerial photography data, multiple altitude changes, and sudden rotation. Although these algorithms adopt loop closure detection and global optimization, the localization error is significant without the assistance of GNSS global absolute positioning information. In the experimental comparison of FlySImulation-Data1 and FlySImulation-Data3, our algorithm is more stable than Vins-Fusion, which also uses GNSS global optimization.
To enable experimental comparison, the experiment was conducted in an environment with reliable GNSS signals, resulting in VINS-Fusion achieving satisfactory positioning performance. However, real-world environments are highly complex and prone to sudden changes, with GNSS signals susceptible to malicious interference and disruption. Under the circumstance of extended GNSS unavailability, VINS-Fusion falls short of providing dependable positioning information for long-distance flight navigation missions due to the lack of global positioning support. Such a deficiency could entail significant hazards for small- to medium-sized logistics drones and large multirotor aircraft carrying passengers. Our proposed system overcomes GNSS constraints by utilizing high-precision pre-established visual maps to support global positioning. VINS-Fusion leverages corner point detection and optical flow tracking for its front-end implementation. When dealing with small-scale motion, the optical flow tracking method proves to be more advantageous than the feature point matching method. Our system utilizes ORB feature point matching for tracking the long-distance movement of UAVs in large scenes. This method is particularly advantageous regarding rotational invariance and contributes to the flexible flight tracking and positioning of UAVs in the air.
Despite ORB-SLAM3 and Openvslam’s ability to build offline maps for relocalization, their maps lack GNSS signal integration, resulting in considerable inaccuracies for long-distance navigation tasks.
- E.
Computing Time
Table 3 highlights the runtimes of the main operations performed in the tracking and mapping threads, demonstrating that our system can operate in real time at 20–30 frames per second. Since the tracking and mapping threads consistently operate on the active map, adding multi-mapping does not introduce significant overhead.
Table 4 summarizes the time consumed for loop closure. Running posture map optimization can keep the merging and cycle closing time below 0.5 s. Depending on the size of the associated keyframes on the map, performing a full beam adjustment during loop closure could potentially increase the timing by several seconds. In terms of map switching, the new map detection method only needs ten milliseconds to switch maps. In any case, since each operation is executed in a separate thread, the overall real-time performance of the system will not be affected.
All in all, our system can fully meet the needs of real-time navigation, and our processing speed is comparable to the latest ORB-SLAM3 system. While this is interesting, we do not further compare runtimes of other systems, as this would require a significant effort beyond the scope of this work.
Furthermore, we utilize the widely adopted SFM algorithm, Colmap, to construct offline three-dimensional sparse maps of these test datasets on a ground-based workstation. The time consumed for this process is presented in
Table 5.
It is evident that for datasets with a smaller number of images, such as Scene1, Colmap can produce a satisfactory sparse map in approximately 14 min. In contrast, our system only requires a total of 0.274 min. For datasets containing thousands of images, particularly video data, the process takes more than 10 h, and the results are also inconsistent in terms of quality. In contrast, our system only requires 2.491 min. In conclusion, when the dataset is small, and there is no strict requirement for processing time, SFM algorithms can be employed for denser three-dimensional map construction, leading to enhanced geographic localization accuracy. However, in cases of large datasets or emergency applications, the proposed algorithm simultaneously addresses both speed and accuracy concerns, enabling real-time geolocation.
In the context of our application scenarios, despite the higher speeds at which aerial robots operate, the associated optimization factors do not exhibit a substantial increase. In comparison to ground-based scenarios, the optimization elements involved are even fewer.
Firstly, our system employs a keyframe mechanism, meaning we do not store and optimize the pose of every image. Keyframes are generated, and their poses are recorded only when certain conditions are met. For example, a keyframe is triggered when the motion distance between adjacent frames surpasses a specific threshold. While aerial vehicles exhibit higher flight speeds, their elevated flying altitudes and downward-facing cameras provide a broader field of view. Compared to ground scenarios, aerial vehicles’ adjacent frames can observe larger overlapping scenes, requiring them to cover longer distances to trigger keyframe generation. Overall, this is manifested by a significantly lower number of keyframes generated from aerial viewpoints for the same area than ground viewpoints. Consequently, this greatly reduces the quantity of camera poses to be optimized as illustrated in
Figure 16.
Compare the real-ground collected data, CarReal-Data1, with the real-flight collected data, FlyReal-Data1. The total trajectory length for ground operation in CarReal-Data1 is 4.986 km, with 3418 keyframes. The total aerial flight trajectory length for FlyReal-Data1 is 31.542 km, with 942 keyframes. By comparing these two sets of data, it becomes evident that the aerial flight perspective generates significantly fewer keyframes than the ground perspective.
Compare the simulated flight data, FlySimulation-Data1, with the real-flight collected data, FlyReal-Data1. The total aerial flight trajectory length for FlySimulation-Data1 is 58.9911 km, with 211 keyframes. FlySimulation-Data1 employs dense strip flight patterns in the air, resulting in longer distances but a more miniature overall scene. In contrast, FlyReal-Data1 consists of only three flight strips, yet it captures a larger scene area. The configuration of flight trajectories also affects the number of keyframes.
Compare the real-flight collected data, FlyReal-Data2, with the real-flight collected data, FlyReal-Data1. The total aerial flight trajectory length for FlyReal-Data2 is 9.94 km, with 681 keyframes. For the same scene, FlyReal-Data2 covered only one flight strip, whereas FlyReal-Data1 covered three. Despite this difference, the increase in keyframes is only around 160 frames, accounting for an approximate 23% increase.
Furthermore, for local optimization during backend bundle adjustment (BA) computations, controlling the scale of the graph optimization becomes necessary. Hence, the adoption of a sliding window strategy is employed. This strategy involves consistently fixing a set of N frames. The result is that BA optimization is constrained within a temporal window. Once new image frames are introduced, old image frames are discarded. This approach significantly reduces the computational scale compared to traditional bundle adjustment.
Lastly, for global optimization, the nonlinear optimization library G2O is employed. The optimization process is carried out in a dedicated thread to enhance runtime efficiency. We utilize NUC microcomputers equipped with an Intel i7 processor featuring four cores and eight threads in its processing configuration. Our system can achieve real-time online optimization based on the current scene scale. In addition to online real-time mapping and optimization, we can also establish maps during the offline stage. During the localization phase, the map can be loaded for positioning, further alleviating the computational burden on the onboard processing unit.
In summary, aerial robots offer an enhanced vertical and expansive field of view. As the flight altitude increases for the same area, the generated number of keyframes is fewer compared to ground viewpoints. As a result, a reduced number of keyframe poses require optimization, leading to improved speed in graph optimization. When integrated with the optimization strategies employed across the entire system, this approach effectively fulfills the speed requisites of aerial drones.


 and
and 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}