


A Deep Learning Network for Individual Tree Segmentation in UAV Images with a Coupled CSPNet and Attention Mechanism



Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Datasets and Processing
2.3. Introduction to Object Detection Algorithms
2.3.1. YOLOv5
2.3.2. Faster R-CNN
2.3.3. Mask R-CNN
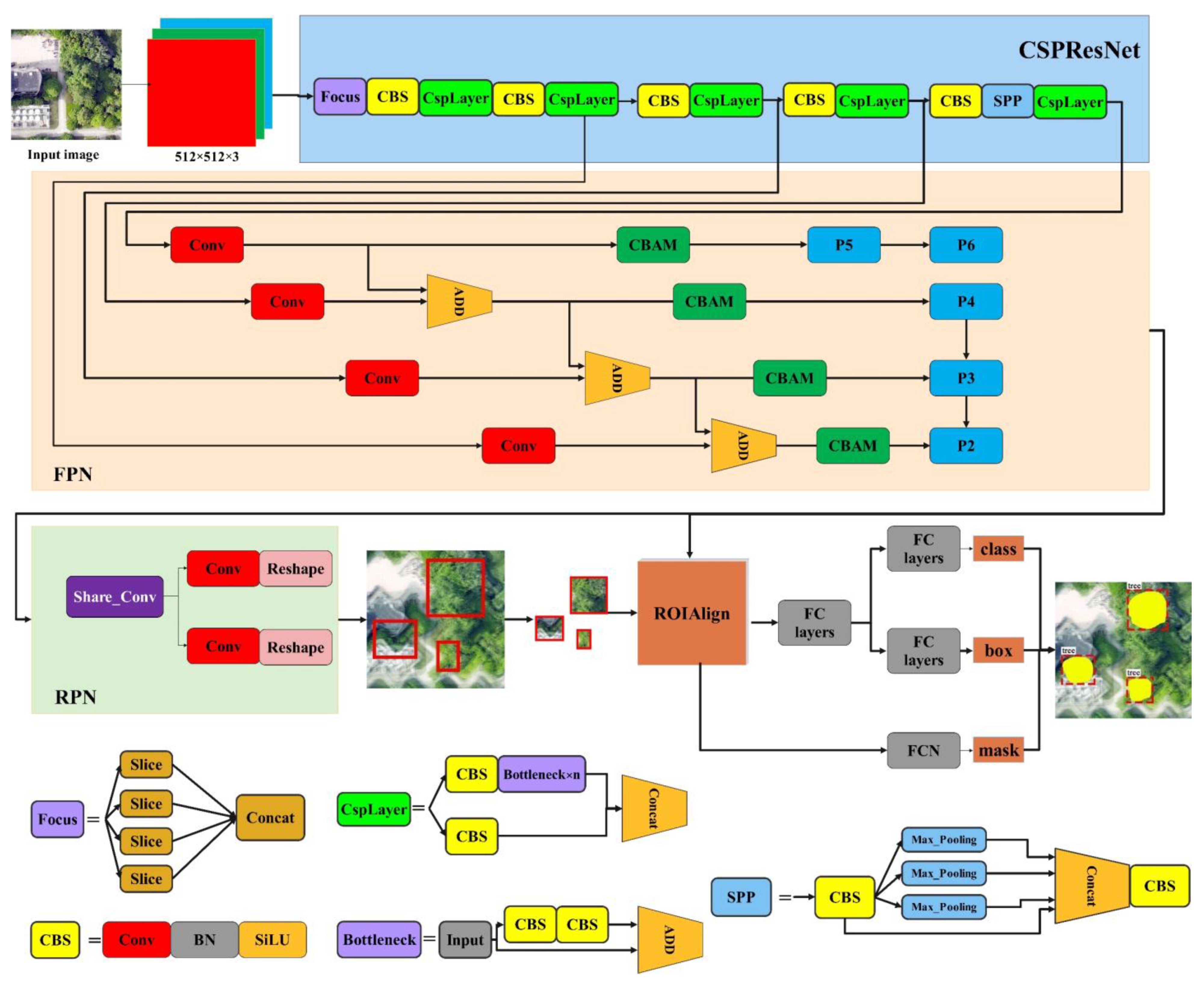
2.4. MCAN
2.4.1. The Overall Framework of MCAN
2.4.2. CSPResNet
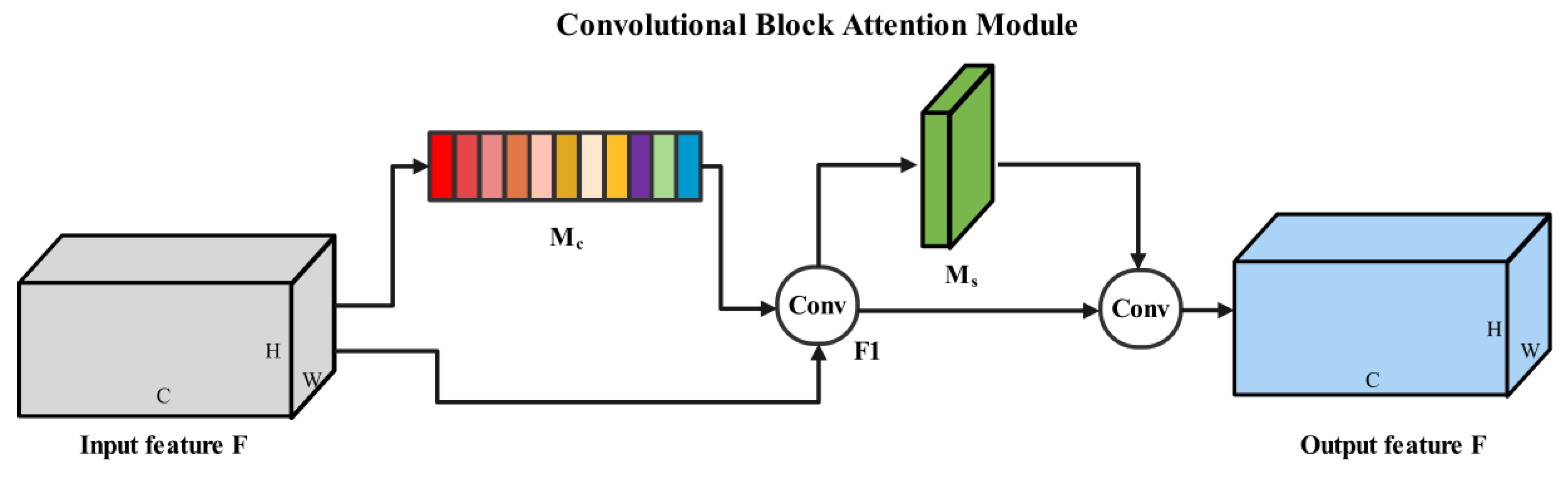
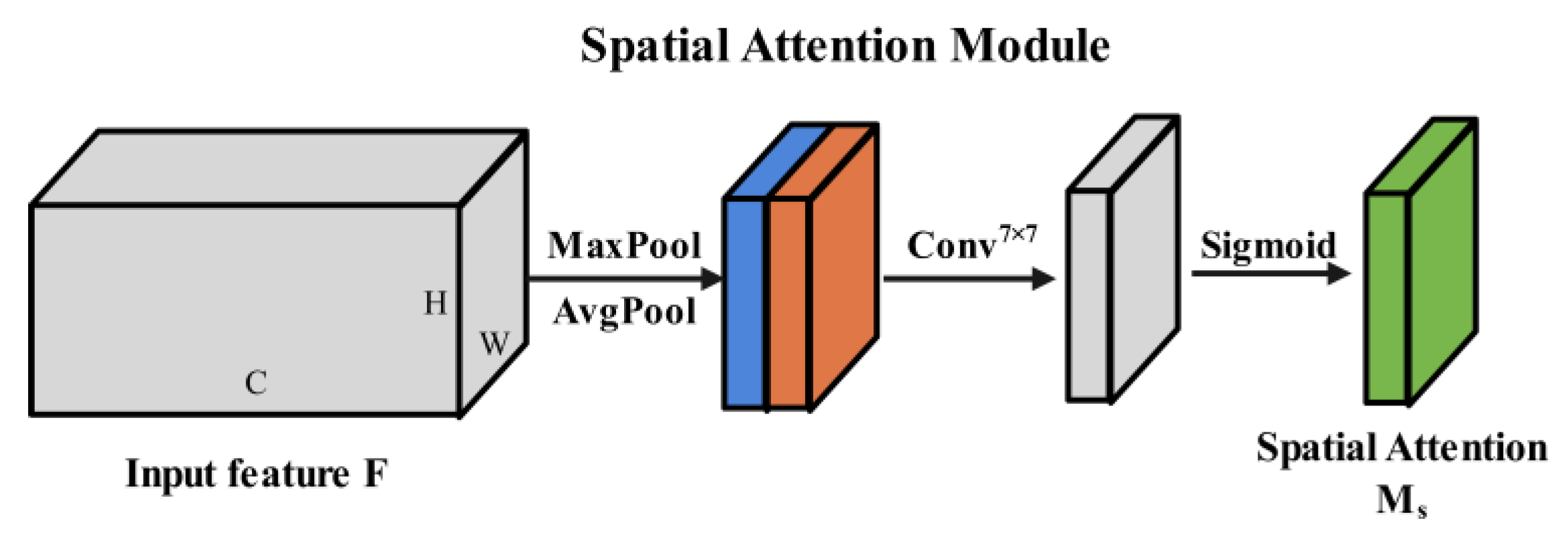
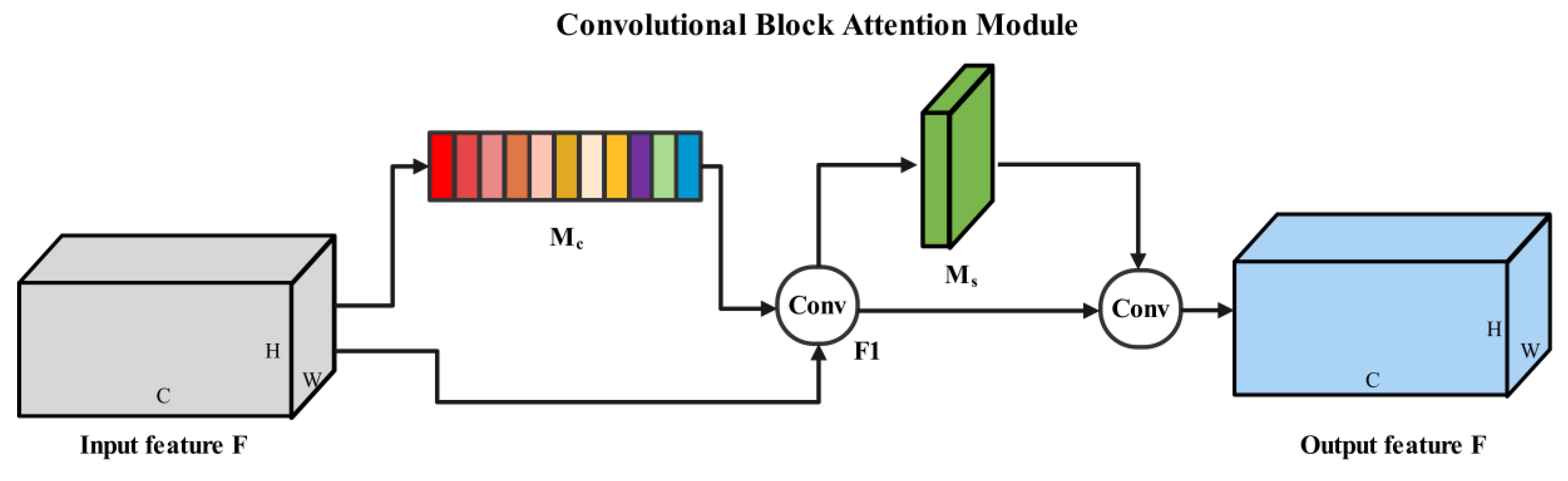
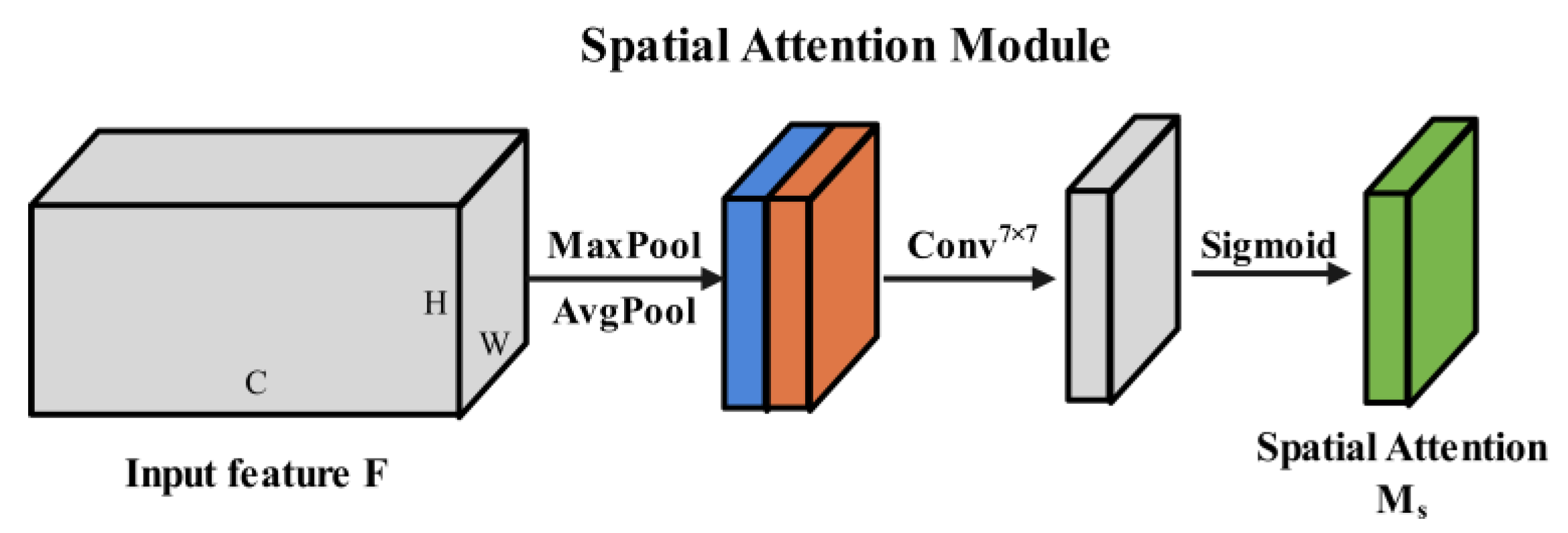
2.4.3. Channel–Spatial Attention Module
2.5. Dataset Production
2.6. Loss Function and Training Experiment
2.7. Accuracy Assessment
3. Results
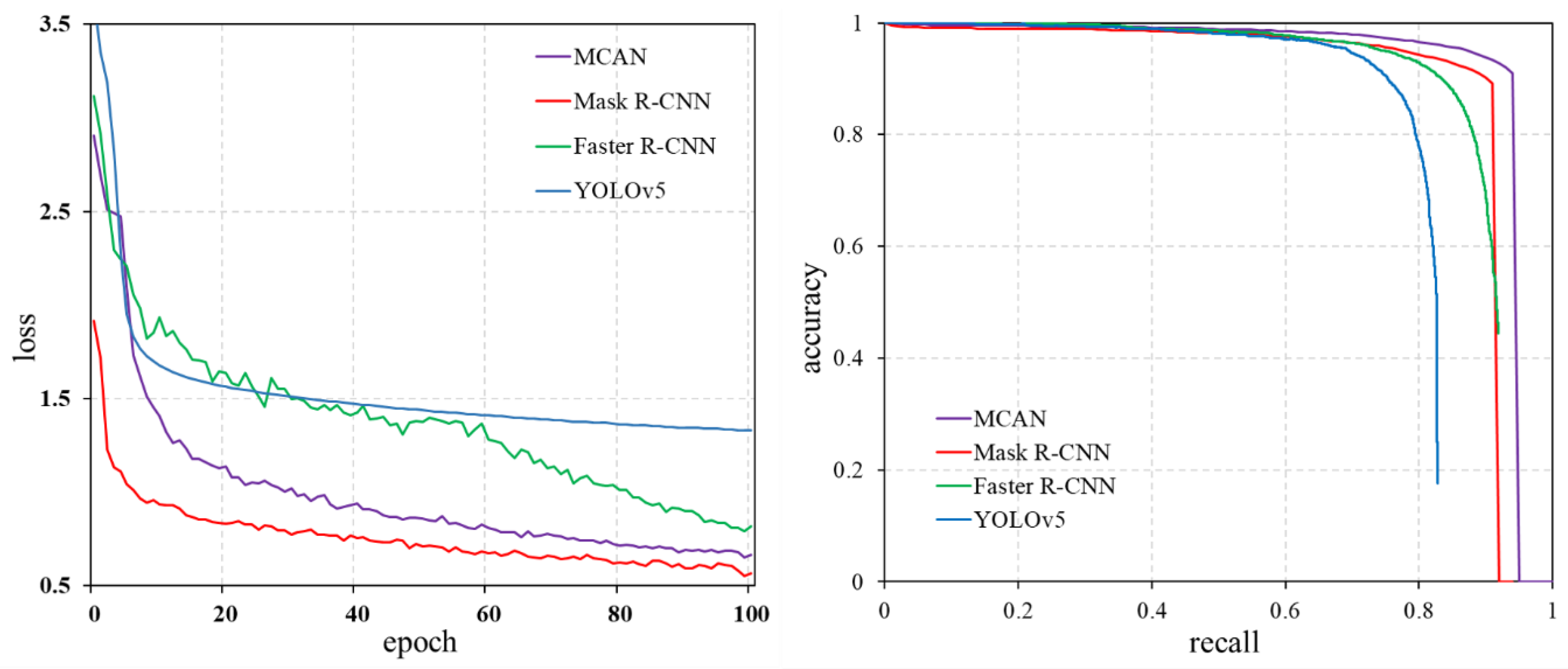
3.1. Model Training Results and Accuracy Evaluation
3.2. Comparison of Individual Tree Segmentation Results
3.3. MCAN in Multi-Scene Urban Forest Canopy Segmentation Application
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nowak, D.J.; Greenfield, E.J.; Hoehn, R.E.; Lapoint, E. Carbon storage and sequestration by trees in urban and community areas of the United States. Environ. Pollut. 2013, 178, 229–236. [Google Scholar] [CrossRef]
- Wagner, F.H.; Ferreira, M.P.; Sanchez, A.; Hirye, M.C.M.; Zortea, M.; Gloor, E.; Phillips, O.L.; de Souza Filho, C.R.; Shimabukuro, Y.E.; Aragão, L.E.O.C. Individual Tree Crown Delineation in a Highly Diverse Tropical Forest Using Very High Resolution Satellite Images. ISPRS J. Photogramm. Remote Sens. 2018, 145, 362–377. [Google Scholar] [CrossRef]
- Harding, D.J.; Lefsky, M.A.; Parker, G.G.; Blair, J.B. Laser Altimeter Canopy Height Profiles: Methods and Validation for Closed-Canopy, Broadleaf Forests. Remote Sens. Environ. 2001, 76, 283–297. [Google Scholar] [CrossRef]
- Bai, Y.; Walsworth, N.; Roddan, B.; Hill, D.A.; Broersma, K.; Thompson, D. Quantifying Tree Cover in the Forest–Grassland Ecotone of British Columbia Using Crown Delineation and Pattern Detection. For. Ecol. Manag. 2005, 212, 92–100. [Google Scholar] [CrossRef]
- Zhang, W.; Ying, H.; Ke, Y.; Lindi, J.; QuackenbushL, J.; Quackenbush; Lian, J.; Zhang, L. Using error-in-variable regression to predict tree diameter and crown width from remotely sensed imagery. Can. J. For. Research 2010, 40, 1095–1108. [Google Scholar] [CrossRef]
- Popescu, S.C. Estimating Biomass of Individual Pine Trees Using Airborne Lidar. Biomass Bioenergy 2007, 31, 646–655. [Google Scholar] [CrossRef]
- Crowther, T.W.; Glick, H.B.; Covey, K.R.; Bettigole, C.; Maynard, D.S.; Thomas, S.M.; Smith, J.R.; Hintler, G.; Duguid, M.C.; Amatulli, G.; et al. Mapping Tree Density at a Global Scale. Nature 2015, 525, 201–205. [Google Scholar] [CrossRef]
- Sun, Y.; Li, Z.; He, H.; Guo, L.; Zhang, X.; Xin, Q. Counting Trees in a Subtropical Mega City Using the Instance Segmentation Method. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102662. [Google Scholar] [CrossRef]
- He, S.; Du, H.; Zhou, G.; Li, X.; Mao, F.; Zhu, D.; Xu, Y.; Zhang, M.; Huang, Z.; Liu, H.; et al. Intelligent Mapping of Urban Forests from High-Resolution Remotely Sensed Imagery Using Object-Based U-Net-DenseNet-Coupled Network. Remote Sens. 2020, 12, 3928. [Google Scholar] [CrossRef]
- Ampatzidis, Y.; Partel, V. UAV-Based High Throughput Phenotyping in Citrus Utilizing Multispectral Imaging and Artificial Intelligence. Remote Sens. 2019, 11, 410. [Google Scholar] [CrossRef]
- Dash, J.P.; Watt, M.S.; Paul, T.S.H.; Morgenroth, J.; Pearse, G.D. Early Detection of Invasive Exotic Trees Using UAV and Manned Aircraft Multispectral and LiDAR Data. Remote Sens. 2019, 11, 1812. [Google Scholar] [CrossRef]
- Pearse, G.D.; Tan, A.Y.S.; Watt, M.S.; Franz, M.O.; Dash, J.P. Detecting and Mapping Tree Seedlings in UAV Imagery Using Convolutional Neural Networks and Field-Verified Data. ISPRS J. Photogramm. Remote Sens. 2020, 168, 156–169. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, Q.; Jiang, P.; Zheng, Y.; Yuan, L.; Yuan, P. LDS-YOLO: A Lightweight Small Object Detection Method for Dead Trees from Shelter Forest. Comput. Electron. Agric. 2022, 198, 107035. [Google Scholar] [CrossRef]
- Mohan, M.; Silva, C.A.; Klauberg, C.; Jat, P.; Catts, G.; Cardil, A.; Hudak, A.T.; Dia, M. Individual Tree Detection from Unmanned Aerial Vehicle (UAV) Derived Canopy Height Model in an Open Canopy Mixed Conifer Forest. Forests 2017, 8, 340. [Google Scholar] [CrossRef]
- Jing, L.; Hu, B.; Noland, T.; Li, J. An Individual Tree Crown Delineation Method Based on Multi-Scale Segmentation of Imagery. ISPRS J. Photogramm. Remote Sens. 2012, 70, 88–98. [Google Scholar] [CrossRef]
- Liu, T.; Im, J.; Quackenbush, L.J. A Novel Transferable Individual Tree Crown Delineation Model Based on Fishing Net Dragging and Boundary Classification. ISPRS J. Photogramm. Remote Sens. 2015, 110, 34–47. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, J.; Sohn, G.; Brédif, M. A Hybrid Framework for Single Tree Detection from Airborne Laser Scanning Data: A Case Study in Temperate Mature Coniferous Forests in Ontario, Canada. ISPRS J. Photogramm. Remote Sens. 2014, 98, 44–57. [Google Scholar] [CrossRef]
- Hao, Z.; Lin, L.; Post, C.J.; Mikhailova, E.A.; Li, M.; Chen, Y.; Yu, K.; Liu, J. Automated Tree-Crown and Height Detection in a Young Forest Plantation Using Mask Region-Based Convolutional Neural Network (Mask R-CNN). ISPRS J. Photogramm. Remote Sens. 2021, 178, 112–123. [Google Scholar] [CrossRef]
- Yu, K.; Hao, Z.; Post, C.J.; Mikhailova, E.A.; Lin, L.; Zhao, G.; Tian, S.; Liu, J. Comparison of Classical Methods and Mask R-CNN for Automatic Tree Detection and Mapping Using UAV Imagery. Remote Sens. 2022, 14, 295. [Google Scholar] [CrossRef]
- Zheng, Y.; Wu, G. Single Shot MultiBox Detector for Urban Plantation Single Tree Detection and Location With High-Resolution Remote Sensing Imagery. Front. Environ. Sci. 2021, 9, 755587. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in Vegetation Remote Sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Weimer, D.; Scholz-Reiter, B.; Shpitalni, M. Design of Deep Convolutional Neural Network Architectures for Automated Feature Extraction in Industrial Inspection. CIRP Ann. 2016, 65, 417–420. [Google Scholar] [CrossRef]
- Yun, L.; Zhang, X.; Zheng, Y.; Wang, D.; Hua, L. Enhance the Accuracy of Landslide Detection in UAV Images Using an Improved Mask R-CNN Model: A Case Study of Sanming, China. Sensors 2023, 23, 4287. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep Learning in Environmental Remote Sensing: Achievements and Challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Mahmud, M.S.; Zahid, A.; Das, A.K.; Muzammil, M.; Khan, M.U. A Systematic Literature Review on Deep Learning Applications for Precision Cattle Farming. Comput. Electron. Agric. 2021, 187, 106313. [Google Scholar] [CrossRef]
- Zhu, L.; Geng, X.; Li, Z.; Liu, C. Improving YOLOv5 with Attention Mechanism for Detecting Boulders from Planetary Images. Remote Sens. 2021, 13, 3776. [Google Scholar] [CrossRef]
- Yang, L.; Xu, Y.; Wang, S.; Yuan, C.; Zhang, Z.; Li, B.; Hu, W. PDNet: Toward Better One-Stage Object Detection with Prediction Decoupling. IEEE Trans. Image Process. 2022, 31, 5121–5133. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June 2016; pp. 779–788. [Google Scholar]
- Huang, H.; Liang, Q.; Luo, D.; Lee, D. Attention-Enhanced One-Stage Algorithm for Traffic Sign Detection and Recognition. J. Sens. 2022, 2022, 3705256. [Google Scholar] [CrossRef]
- Jintasuttisak, T.; Edirisinghe, E.; Elbattay, A. Deep Neural Network Based Date Palm Tree Detection in Drone Imagery. Comput. Electron. Agric. 2022, 192, 106560. [Google Scholar] [CrossRef]
- He, H.; Xu, H.; Zhang, Y.; Gao, K.; Li, H.; Ma, L.; Li, J. Mask R-CNN Based Automated Identification and Extraction of Oil Well Sites. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102875. [Google Scholar] [CrossRef]
- Zhang, S.; Wen, L.; Lei, Z.; Li, S. RefineDet plus plus: Single-Shot Refinement Neural Network for Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 674–687. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the International Conference on Neural Information Processing Systems 28, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Mubin; Nurulain, A.; Nadarajoo, E.; Shafri, H.Z. Young and mature oil palm tree detection and counting using convolutional neural network deep learning method. Int. J. Remote Sens. 2019, 40, 7500–7515. [Google Scholar] [CrossRef]
- Xi, X.; Xia, K.; Yang, Y.; Du, X.; Feng, H. Urban individual tree crown detection research using multispectral image dimensionality reduction with deep learning. Natl. Remote Sens. Bulletin. 2022, 26, 711–721. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wang, D.; He, D. Fusion of Mask RCNN and Attention Mechanism for Instance Segmentation of Apples under Complex Background. Comput. Electron. Agric. 2022, 196, 106864. [Google Scholar] [CrossRef]
- Iqbal, M. Coconut trees detection and segmentation in aerial imagery using mask region-based convolution neural network. arXiv 2021, arXiv:2105.04356. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, J.; Wang, H.; Tan, T.; Cui, M.; Huang, Z.; Wang, P.; Zhang, L. Multi-Species Individual Tree Segmentation and Identification Based on Improved Mask R-CNN and UAV Imagery in Mixed Forests. Remote Sens. 2022, 14, 874. [Google Scholar] [CrossRef]
- Lumnitz, S.; Devisscher, T.; Mayaud, J.R.; Radic, V.; Coops, N.C.; Griess, V.C. Mapping Trees along Urban Street Networks with Deep Learning and Street-Level Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 144–157. [Google Scholar] [CrossRef]
- Ocer, N.E.; Kaplan, G.; Erdem, F.; Kucuk Matci, D.; Avdan, U. Tree Extraction from Multi-Scale UAV Images Using Mask R-CNN with FPN. Remote Sens. Lett. 2020, 11, 847–856. [Google Scholar] [CrossRef]
- Zimmermann, R.S.; Siems, J.N. Faster Training of Mask R-CNN by Focusing on Instance Boundaries. Comput. Vis. Image Underst. 2019, 188, 102795. [Google Scholar] [CrossRef]
- Yang, M.; Mou, Y.; Liu, S.; Meng, Y.; Liu, Z.; Li, P.; Xiang, W.; Zhou, X.; Peng, C. Detecting and Mapping Tree Crowns Based on Convolutional Neural Network and Google Earth Images. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102764. [Google Scholar] [CrossRef]
- Wang, C.; Liao, H.; Yeh, I.; Wu, Y.; Chen, P.; Hsieh, J. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. arXiv 2019, arXiv:1911.11929. [Google Scholar]
- Xue, J.; Zheng, Y.; Dong, C.; Wang, P.; Yasir, M. Improved YOLOv5 Network Method for Remote Sensing Image-Based Ground Objects Recognition. Soft Comput. 2022, 26, 10879–10889. [Google Scholar] [CrossRef]
- Yang, G.; Feng, W.; Jin, J.; Lei, Q.; Li, X.; Gui, G.; Wang, W. Face Mask Recognition System with YOLOV5 Based on Image Recognition. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11 December 2020; pp. 1398–1404. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21 July 2017; pp. 936–944. [Google Scholar]
- Neubeck, A.; Gool, L.V. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Wang, S.; Qu, Z. Multiscale Anchor Box and Optimized Classification with Faster R-CNN for Object Detection. IET Image Process. 2023, 17, 1322–1333. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Chen, Y.P.; Li, Y.; Wang, G. An Enhanced Region Proposal Network for Object Detection Using Deep Learning Method. PLoS ONE 2018, 13, e0203897. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.; Wu, Y.; Dong, F.; Zhang, J.; Sun, S. Developing an Image Manipulation Detection Algorithm Based on Edge Detection and Faster R-CNN. Symmetry 2019, 11, 1223. [Google Scholar] [CrossRef]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Hassanin, M.; Anwar, S.; Radwan, I. Visual Attention Methods in Deep Learning: An In-Depth Survey. arXiv 2022, arXiv:2204.07756. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Simard, P.Y.; Steinkraus, D.; Platt, J.C. Best practices for convolutional neural networks applied to visual document analysis. In Proceedings of the 7th International Conference on Document Analysis and Recognition (ICDAR 2003), Edinburgh, UK, 3–6 August 2003; Volume 3. [Google Scholar]
- Wang, W.; Shi, Y.; Zhang, J.; Hu, L.; Li, S.; He, D.; Liu, F. Traditional Village Building Extraction Based on Improved Mask R-CNN: A Case Study of Beijing, China. Remote Sens. 2023, 15, 2616. [Google Scholar] [CrossRef]
- Li, Z.; Li, Y.; Yang, Y.; Guo, R.; Yang, J.; Yue, J.; Wang, Y. A High-Precision Detection Method of Hydroponic Lettuce Seedlings Status Based on Improved Faster RCNN. Comput. Electron. Agric. 2021, 182, 106054. [Google Scholar] [CrossRef]
- Xia, K.; Wang, H.; Yang, Y.; Du, X.; Feng, H. Automatic Detection and Parameter Estimation of Ginkgo Biloba in Urban Environment Based on RGB Images. J. Sens. 2021, 2021, 6668934. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar] [CrossRef]
- Jouhari, H.; Lei, D.; Al-qaness, M.A.A.; Elaziz, M.A.; Ewees, A.A.; Farouk, O. Sine-Cosine Algorithm to Enhance Simulated Annealing for Unrelated Parallel Machine Scheduling with Setup Times. Mathematics 2019, 7, 1120. [Google Scholar] [CrossRef]
- Kim, Y.; Ohn, I.; Kim, D. Fast Convergence Rates of Deep Neural Networks for Classification. Neural Netw. 2021, 138, 179–197. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, H.; Zhang, L.; Wang, F.; He, R. Object detection algorithm based on attention mechanism and context information. J. Comput. Appl. 2023, 43, 1557–1564. [Google Scholar]
- Li, W.; Zhan, W.; Zhou, W.; Han, T.; Wang, P.; Liu, H.; Xiong, M.; Sun, Y. Research and Application of Lightweight Yolov7-TSA Network in Tea Disease Detection and Identification. J. Henan Agric. Sci. 2023, 52, 162–169. [Google Scholar]
- Wang, X.; Liang, Z.; Liu, T. Feature attention pyramid-based remote sensing image object detection method. Natl. Remote Sens. Bulletin. 2023, 27, 92–501. [Google Scholar] [CrossRef]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H.; et al. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Individual Trees |
|---|---|
| Training | 32,840 |
| validation | 12,110 |
| Test | 11,070 |
| Total | 56,020 |
| Parameters | Network | |||
|---|---|---|---|---|
| MCAN | Mask R-CNN | Faster R-CNN | YOLOv5 | |
| Optimizer | Adam | Adam | Adam | Adam |
| Initial learning rate | 0.001 | 0.001 | 0.001 | 0.001 |
| Momentum | 0.937 | 0.937 | 0.937 | 0.937 |
| Learning rate decay mode | Cosine annealing | Cosine annealing | Cosine annealing | Cosine annealing |
| Weight decay | 0.0005 | 0.0005 | 0.0005 | 0.0005 |
| epoch | 100 | 100 | 100 | 100 |
| batch size | 16 | 16 | 16 | 16 |
| Backbone network | CSPResNet | Resnet101 | Resnet50 | CSPDarkNet |
| Activation function | SiLU | SiLU | SiLU | SiLU |
| Model | Recall | Accuracy | F1 Score | AP (@.5:.95) |
|---|---|---|---|---|
| YOLOv5 | 69.26% | 95.22% | 80.19% | 79.87% |
| Faster RCNN | 71.80% | 89.01% | 79.48% | 88.56% |
| Mask R-CNN | 72.40% | 96.14% | 82.60% | 88.70% |
| MCAN | 75.74% | 97.84% | 87.48% | 92.40% |
| Model | Recall | Accuracy | F1 Score | AP |
|---|---|---|---|---|
| Mask R-CNN | 62.60% | 87.22% | 72.89% | 88.80% |
| MCAN | 73.50% | 88.04% | 80.12% | 97.70% |
| Scenario | Number of Tested Plants | Number of Real Plants | Number of Missed Plants | Number of Wrong Plants | Accuracy | Recall |
|---|---|---|---|---|---|---|
| Dense forest distribution a | 696 | 704 | 39 | 31 | 95.55% | 94.46% |
| Building forest intersection b | 421 | 409 | 22 | 34 | 91.92% | 94.62% |
| Active plaza vegetation c | 355 | 364 | 34 | 25 | 92.96% | 90.66% |
| Street trees d | 378 | 386 | 37 | 29 | 92.33% | 90.41% |
| Total | 1850 | 1863 | 132 | 119 | 93.57% | 92.91% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, L.; Li, X.; Mao, F.; Zhou, L.; Xuan, J.; Zhao, Y.; Yu, J.; Song, M.; Huang, L.; Du, H. A Deep Learning Network for Individual Tree Segmentation in UAV Images with a Coupled CSPNet and Attention Mechanism. Remote Sens. 2023, 15, 4420. https://doi.org/10.3390/rs15184420
Lv L, Li X, Mao F, Zhou L, Xuan J, Zhao Y, Yu J, Song M, Huang L, Du H. A Deep Learning Network for Individual Tree Segmentation in UAV Images with a Coupled CSPNet and Attention Mechanism. Remote Sensing. 2023; 15(18):4420. https://doi.org/10.3390/rs15184420
Chicago/Turabian StyleLv, Lujin, Xuejian Li, Fangjie Mao, Lv Zhou, Jie Xuan, Yinyin Zhao, Jiacong Yu, Meixuan Song, Lei Huang, and Huaqiang Du. 2023. "A Deep Learning Network for Individual Tree Segmentation in UAV Images with a Coupled CSPNet and Attention Mechanism" Remote Sensing 15, no. 18: 4420. https://doi.org/10.3390/rs15184420
APA StyleLv, L., Li, X., Mao, F., Zhou, L., Xuan, J., Zhao, Y., Yu, J., Song, M., Huang, L., & Du, H. (2023). A Deep Learning Network for Individual Tree Segmentation in UAV Images with a Coupled CSPNet and Attention Mechanism. Remote Sensing, 15(18), 4420. https://doi.org/10.3390/rs15184420