
Select Informative Samples for Night-Time Vehicle Detection Benchmark in Urban Scenes


Abstract
:1. Introduction
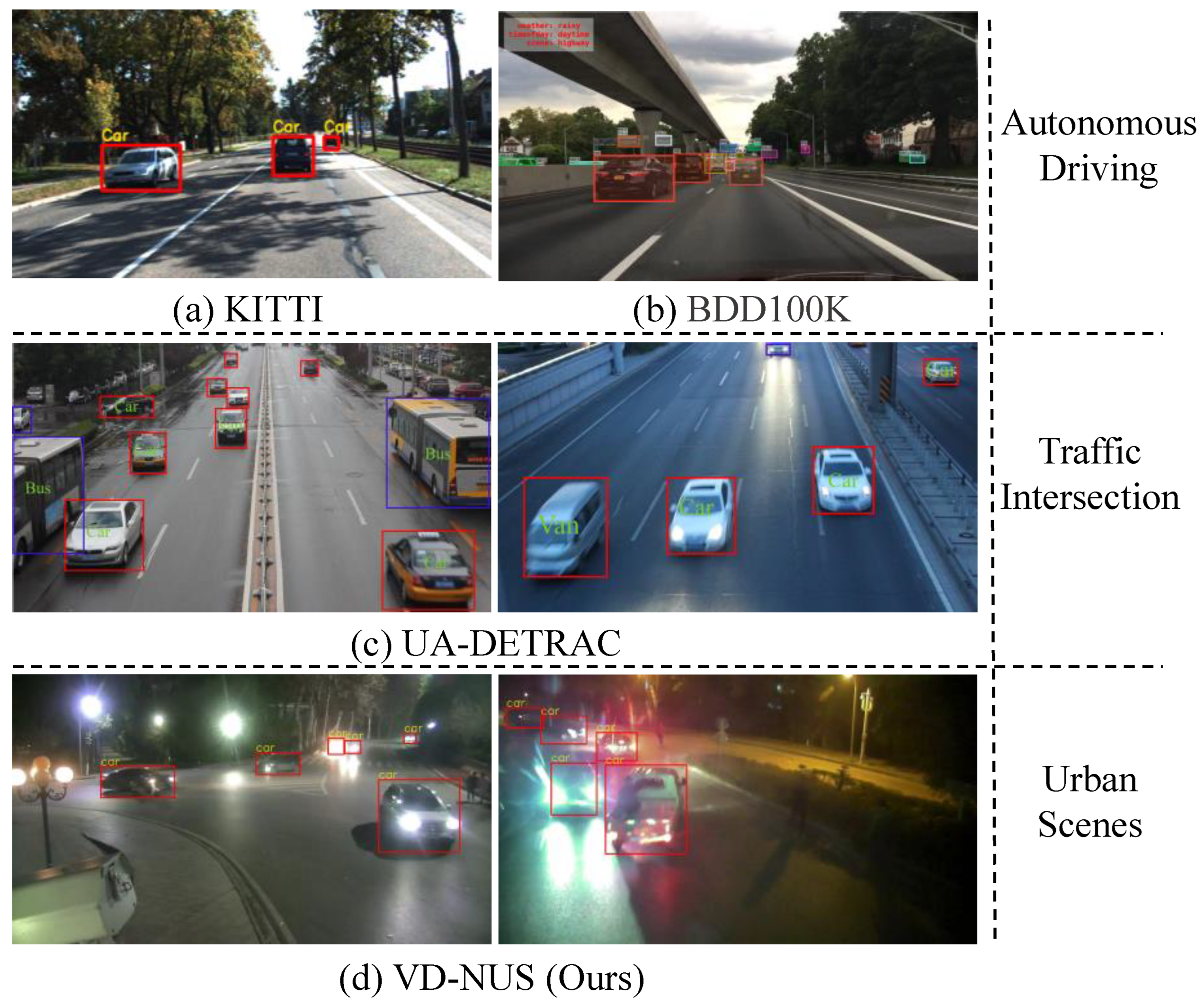
- Viewpoint. For autonomous driving, vehicles are photographed by cameras at parallel angles. For urban scenes, vehicles are photographed by cameras at downward angles, as illustrated in Figure 1. Difficult cases (small scale, occlusion, and rain) in such a situation are more challenging.
- Position. For traffic intersection, cameras are placed in the centre of the road to obtain more visible vehicle information, such as license plates. For urban scenes, the cameras are placed anywhere on the road to obtain any angle of the vehicles.
- Illumination. There are also significant differences in the distribution of the light at night. In autonomous driving, the light distribution is more concentrated in the bottom and middle of a picture, with a light source mainly coming from the car itself. At traffic intersections, the camera often captures an image with the aid of the flash, so the images obtained are very clear. However, the illumination in urban scenes is relatively imbalanced at night-time, involving street lights and vehicle lights.
- Under the background of a high incidence of abnormal events at night, this paper presents the first night-time vehicle detection dataset VD-NUS in urban surveillance scenarios. The dataset differs significantly from existing vehicle detection datasets in terms of viewpoint, position, and illumination.
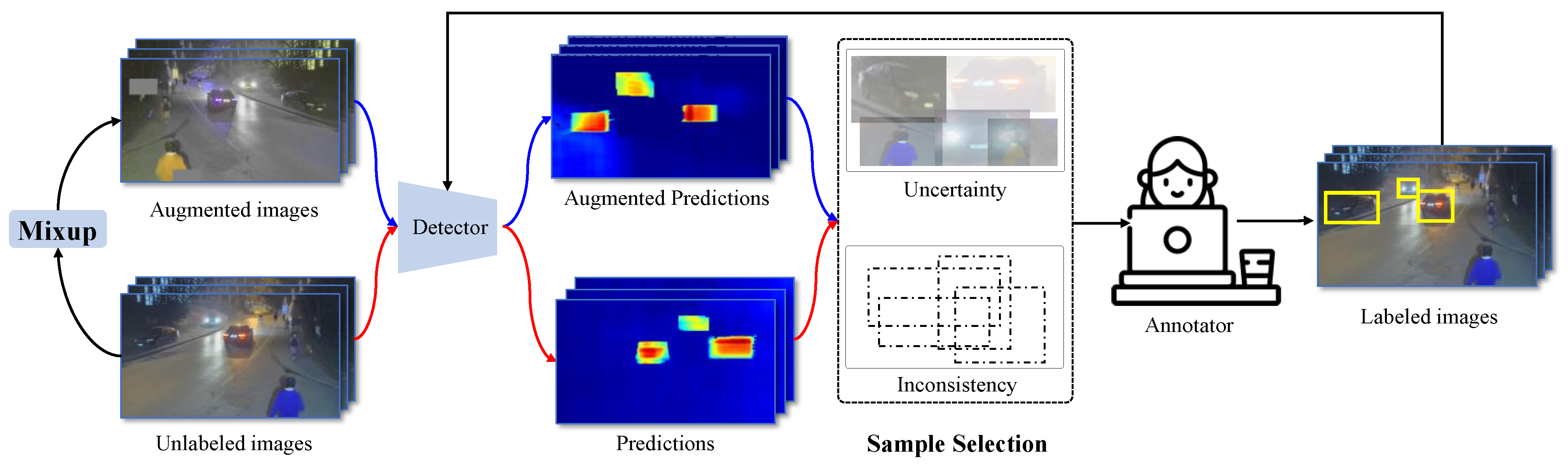
- Considering the problem exists that the amount of data to be annotated is exceedingly large in urban security applications, this paper presents an effective auxiliary labelling system. The system reduces the annotation workload through an active learning sampling strategy (AAM) and a computer-assisted identity recommendation module.
- The effectiveness of the approach is demonstrated on the proposed VD-NUS dataset. AAM outperforms the baseline method (random sampling) by up to 0.91 AP and 3.0 MR−2 on the VD-NUS dataset. The AAM framework reduces manual labeling and selects informative samples. It is suitable for a wide range of other detection labeling tasks.
2. Related Work
2.1. Vehicle Detection Datasets
2.2. Vehicle Detection Methods
3. VD-NUS Benchmark
3.1. Description
- Keyframe extraction. For each video, the authors utilized FFmpeg to extract sixteen keyframes per second, resulting in a total of 500 k keyframes.
- Manual correction. To ensure the accuracy of the intercepted bounding boxes, the authors added a manually assisted verification phase using the colabeler (http://www.colabeler.com/, accessed on 1 July 2020) tool. Eight volunteers were invited to check and correct the bounding boxes for vehicles. Since fewer vehicles are active at night, there are a large number of frames with no vehicles at night-time than in the daytime. To reduce these invalid frames, most of the invalid frames without vehicles were removed.
3.2. Diversity
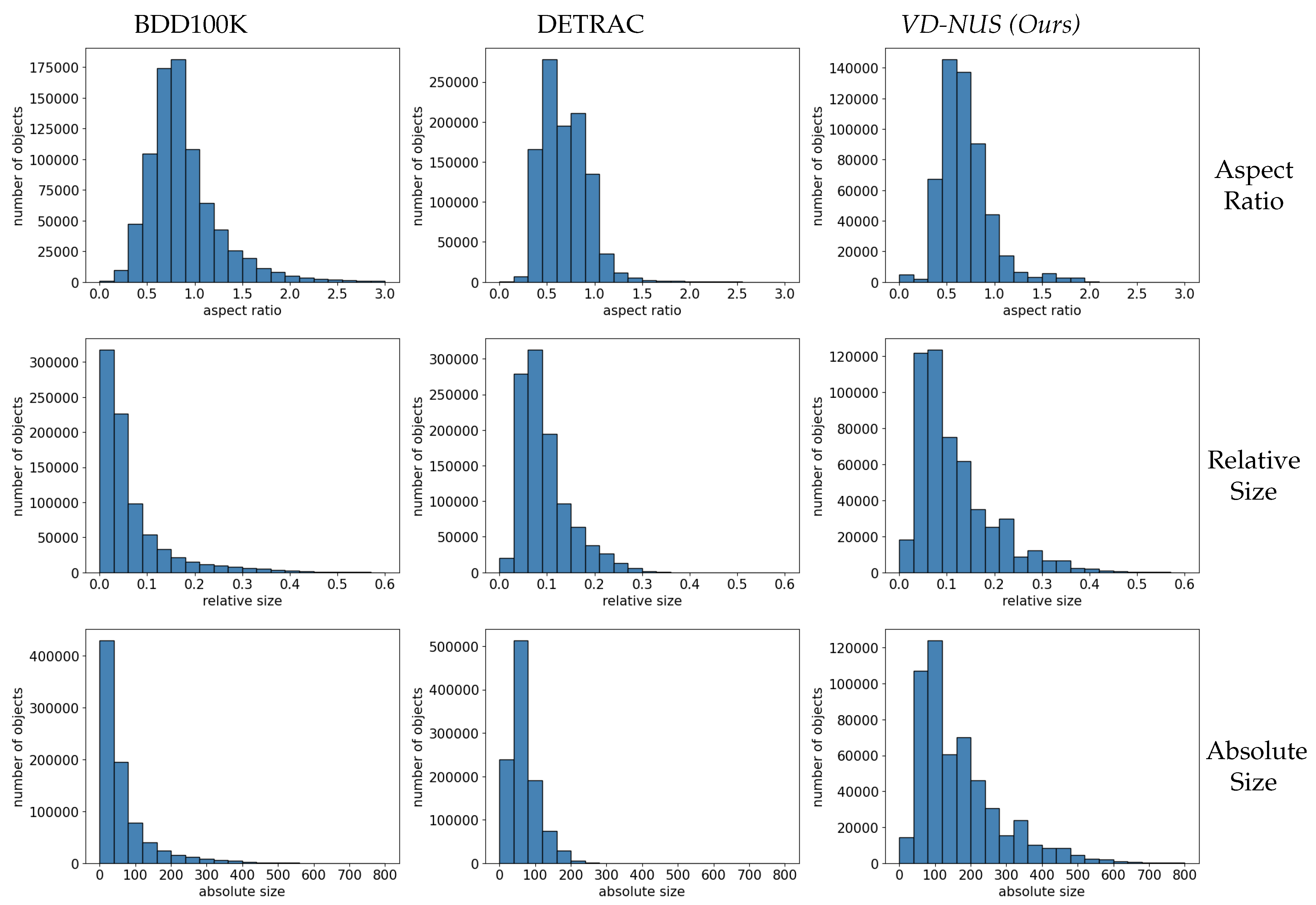
- Scale. The camera has a long shooting distance in urban surveillance. Its scale is large when the vehicle is closer to the camera, while the scale is small when the vehicle is far from the camera. The diversity of different scales increases the difficulty of vehicle detection. The authors observed differences in several different scales of vehicles in BDD100K, DETRAC, and our VD-NUS datasets. In the case of aspect ratio and relative size, the distribution is relatively similar. However, the absolute size and the data distribution in our VD-NUS dataset are relatively diverse and rich.
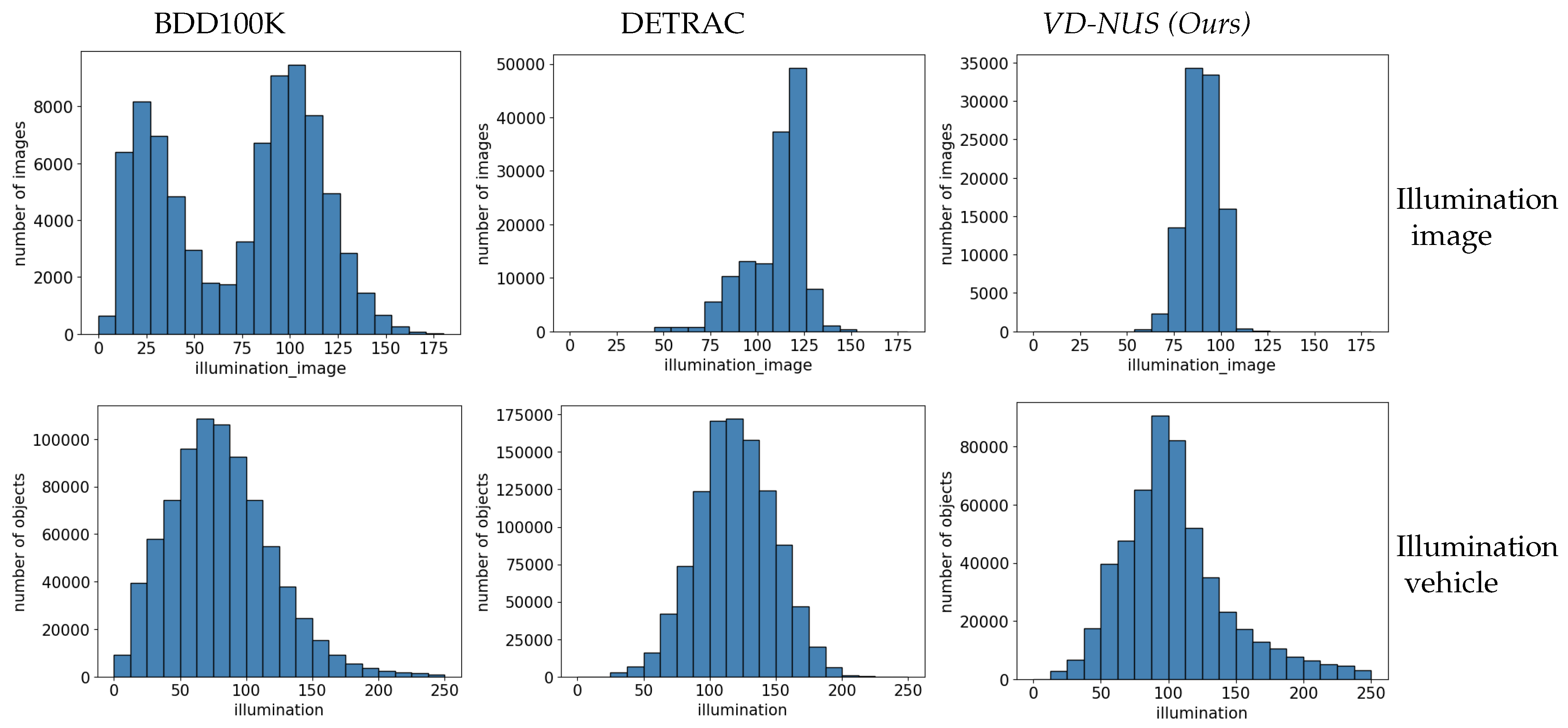
- Illumination. This paper examines the distribution of light in images and vehicles in several existing night-time datasets. Compared with the existing datasets, the VD-NUS dataset has a more concentrated distribution of light in the entire image and a more divergent distribution of light in the vehicles.
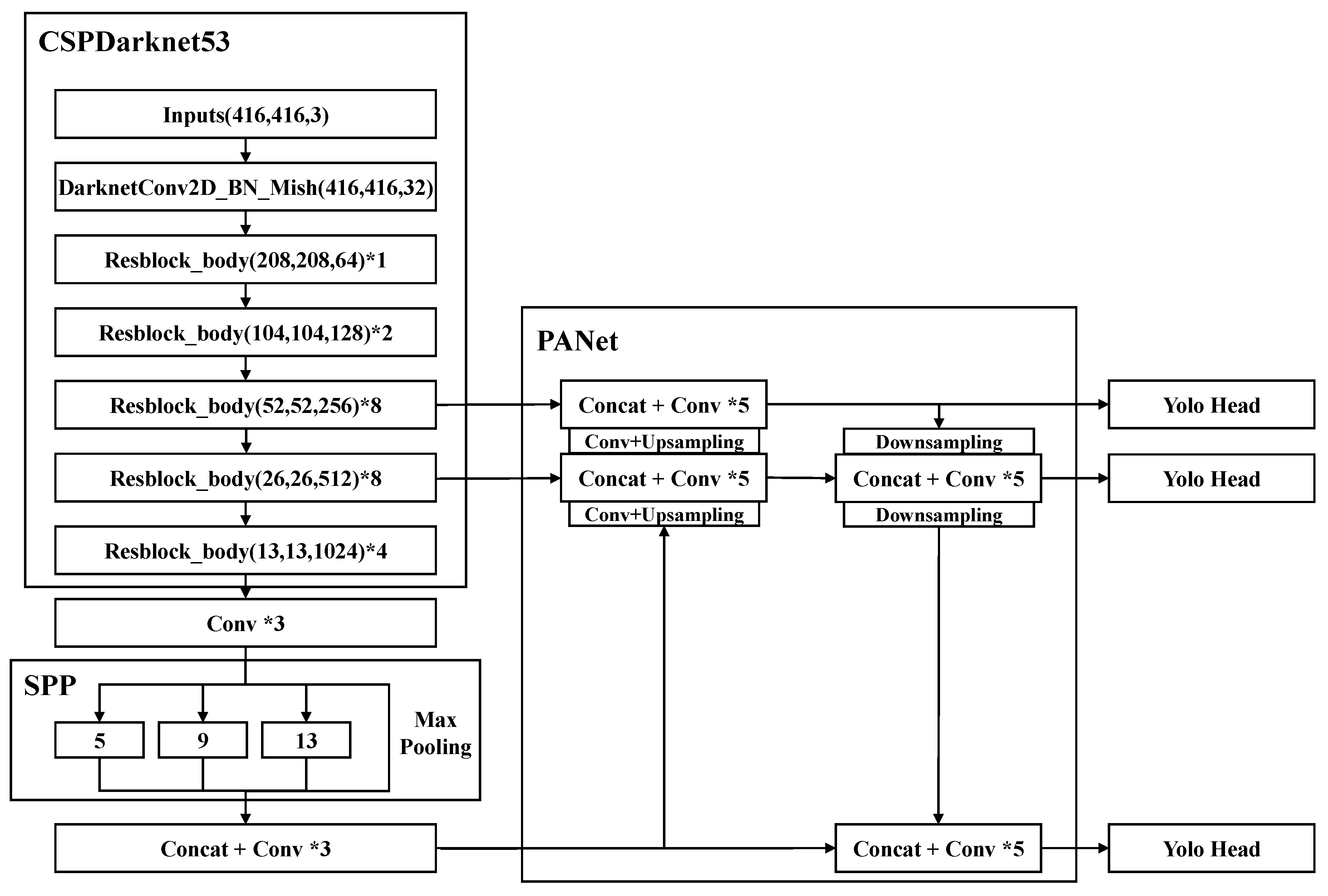
4. Active Auxiliary Mechanism for Vehicle Detection
4.1. Overview
4.2. Mixup
4.3. Sample Selection
5. Experiment
5.1. Datasets
5.2. Evaluation Metrics
5.3. Implementation Details
5.4. Comparison with the State-of-the-Art Detection Models
5.5. Discussion and Analysis
6. Conclusions
6.1. Limitations
6.2. Prospects
- Light. The biggest difference between a night scene and a day scene is the absence of natural light. Night-time light sources mainly come from streetlights and vehicle headlights on the roadside. There is often low light when the vehicle is stopped. Exposure often exists when the vehicle is in motion. Enhancement of low light and suppression of exposure are important topics that favor vehicle detection at night.
- Scale. Vehicles often traverse the entire frame when moving. They are easy to find when they are closer to the camera; however, they can be missed when they are farther away from the camera. Vehicles farther away from the camera are small in scale. The optimization of super-resolution or detection methods for small-scale vehicles at night is intuitively important for night-time vehicle detection research.
- Occlusion. On peak congested roads, vehicles are closer to each other. It is difficult to see the full outline of the vehicle from the camera’s point of view, resulting in severe occlusion. This situation can bring about serious performance degradation. Completing the occluded area with information about the visible area of the vehicle can solve this problem to some extent.
- Blur. The surveillance camera’s recording is uninterrupted, including at day and night. Due to long-term recording, equipment easily ages, and as a result this affects the camera imaging quality. The large temperature difference between day and night leads to increased fog, leading to seriously blurred images. On the other hand, the quality of images also reduces when images are sampled from the second night of surveillance due to the lower light. The current methods cannot be directly applied to practice, and the corresponding optimization techniques are needed to overcome the above problems.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Deng, Z.; Weng, D.; Liu, S.; Tian, Y.; Xu, M.; Wu, Y. A survey of urban visual analytics: Advances and future directions. Comput. Vis. Media 2023, 9, 3–39. [Google Scholar] [CrossRef] [PubMed]
- Xiao, J.; Wang, X.; Liao, L.; Satoh, S.; Lin, C.W. 1ST International Workshop on Visual Tasks and Challenges under Low-quality Multimedia Data. In Proceedings of the MMAsia ’21: ACM Multimedia Asia, Gold Coast, Australia, 1–3 December 2021; p. 1. [Google Scholar]
- Neumann, L.; Karg, M.; Zhang, S.; Scharfenberger, C. NightOwls: A Pedestrians at Night Dataset. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 691–705. [Google Scholar]
- Liu, P.; Fu, H.; Ma, H. An end-to-end convolutional network for joint detecting and denoising adversarial perturbations in vehicle classification. Comput. Vis. Media 2021, 7, 217–227. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2633–2642. [Google Scholar]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.; Qi, H.; Lim, J.; Yang, M.; Lyu, S. UA-DETRAC: A new benchmark and protocol for multi-object detection and tracking. Comput. Vis. Image Underst. 2020, 193, 1–27. [Google Scholar] [CrossRef]
- Wu, Z.; Xu, J.; Wang, Y.; Sun, F.; Tan, M.; Weise, T. Hierarchical fusion and divergent activation based weakly supervised learning for object detection from remote sensing images. Inf. Fusion 2022, 80, 23–43. [Google Scholar] [CrossRef]
- ElTantawy, A.; Shehata, M.S. Local null space pursuit for real-time moving object detection in aerial surveillance. Signal Image Video Process 2020, 14, 87–95. [Google Scholar] [CrossRef]
- Mou, Q.; Wei, L.; Wang, C.; Luo, D.; He, S.; Zhang, J.; Xu, H.; Luo, C.; Gao, C. Unsupervised domain-adaptive scene-specific pedestrian detection for static video surveillance. Pattern Recognit. 2021, 118, 108038. [Google Scholar] [CrossRef]
- Toprak, T.; Belenlioglu, B.; Aydin, B.; Güzelis, C.; Selver, M.A. Conditional Weighted Ensemble of Transferred Models for Camera Based Onboard Pedestrian Detection in Railway Driver Support Systems. IEEE Trans. Veh. Technol. 2020, 69, 5041–5054. [Google Scholar] [CrossRef]
- Chen, L.; Lin, S.; Lu, X.; Cao, D.; Wu, H.; Guo, C.; Liu, C.; Wang, F. Deep Neural Network Based Vehicle and Pedestrian Detection for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3234–3246. [Google Scholar] [CrossRef]
- Yuan, T.; Wan, F.; Fu, M.; Liu, J.; Xu, S.; Ji, X.; Ye, Q. Multiple Instance Active Learning for Object Detection. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5330–5339. [Google Scholar]
- Xu, X.; Liu, L.; Zhang, X.; Guan, W.; Hu, R. Rethinking data collection for person re-identification: Active redundancy reduction. Pattern Recognit. 2021, 113, 107827. [Google Scholar] [CrossRef]
- Shahraki, A.; Abbasi, M.; Taherkordi, A.; Jurcut, A.D. Active Learning for Network Traffic Classification: A Technical Study. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 422–439. [Google Scholar] [CrossRef]
- Zou, D.N.; Zhang, S.H.; Mu, T.J.; Zhang, M. A new dataset of dog breed images and a benchmark for fine-grained classification. Comput. Vis. Media 2020, 6, 477–487. [Google Scholar] [CrossRef]
- Zhang, W.; Guo, Z.; Zhi, R.; Wang, B. Deep Active Learning For Human Pose Estimation Via Consistency Weighted Core-Set Approach. In Proceedings of the International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; pp. 909–913. [Google Scholar]
- Deng, J.; Xie, X. 3D Interactive Segmentation With Semi-Implicit Representation and Active Learning. IEEE Trans. Image Process. 2021, 30, 9402–9417. [Google Scholar] [CrossRef]
- Leitloff, J.; Hinz, S.; Stilla, U. Vehicle Detection in Very High Resolution Satellite Images of City Areas. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2795–2806. [Google Scholar] [CrossRef]
- Cao, L.; Ji, R.; Wang, C.; Li, J. Towards Domain Adaptive Vehicle Detection in Satellite Image by Supervised Super-Resolution Transfer. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1138–1144. [Google Scholar]
- Lyu, S.; Chang, M.C.; Du, D.; Wen, L.; Qi, H.; Li, Y.; Wei, Y.; Ke, L.; Hu, T.; Del Coco, M.; et al. UA-DETRAC 2017: Report of AVSS2017 & IWT4S Challenge on Advanced Traffic Monitoring. In Proceedings of the International Conference on Advanced Video and Signal Based Surveillance, Lecce, Italy, 29 August–1 September 2017; pp. 1–7. [Google Scholar]
- Lyu, S.; Chang, M.C.; Du, D.; Wen, L.; Qi, H.; Li, Y.; Wei, Y.; Ke, L.; Hu, T.; Del Coco, M.; et al. UA-DETRAC 2018: Report of AVSS2018 & IWT4S Challenge on Advanced Traffic Monitoring. In Proceedings of the International Conference on Advanced Video and Signal Based Surveillance, Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P.A. SINet: A scale-insensitive convolutional neural network for fast vehicle detection. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1010–1019. [Google Scholar] [CrossRef]
- Wang, H.; Yu, Y.; Cai, Y.; Chen, X.; Chen, L.; Liu, Q. A comparative study of state-of-the-art deep learning algorithms for vehicle detection. IEEE Intell. Transp. Syst. Mag. 2019, 11, 82–95. [Google Scholar] [CrossRef]
- Li, X.; Zhu, L.; Xue, Q.; Wang, D.; Zhang, Y.J. Fluid-inspired field representation for risk assessment in road scenes. Comput. Vis. Media 2020, 6, 401–415. [Google Scholar] [CrossRef]
- Shao, X.; Wei, C.; Shen, Y.; Wang, Z. Feature enhancement based on CycleGAN for nighttime vehicle detection. IEEE Access 2020, 9, 849–859. [Google Scholar] [CrossRef]
- Mu, Q.; Wang, X.; Wei, Y.; Li, Z. Low and non-uniform illumination color image enhancement using weighted guided image filtering. Comput. Vis. Media 2021, 7, 529–546. [Google Scholar] [CrossRef]
- Huang, S.; Hoang, Q.; Jaw, D. Self-Adaptive Feature Transformation Networks for Object Detection in low luminance Images. ACM Trans. Intell. Syst. Technol. 2022, 13, 13. [Google Scholar] [CrossRef]
- Liu, R.; Yuan, Z.; Liu, T. Learning TBox With a Cascaded Anchor-Free Network for Vehicle Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 321–332. [Google Scholar] [CrossRef]
- Sivaraman, S.; Trivedi, M.M. Looking at Vehicles on the Road: A Survey of Vision-Based Vehicle Detection, Tracking, and Behavior Analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1795. [Google Scholar] [CrossRef]
- Yin, G.; Yu, M.; Wang, M.; Hu, Y.; Zhang, Y. Research on highway vehicle detection based on faster R-CNN and domain adaptation. Appl. Intell. 2022, 52, 3483–3498. [Google Scholar] [CrossRef]
- Lyu, W.; Lin, Q.; Guo, L.; Wang, C.; Yang, Z.; Xu, W. Vehicle Detection Based on an Imporved Faster R-CNN Method. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2021, 104-A, 587–590. [Google Scholar] [CrossRef]
- Vaquero, V.; del Pino, I.; Moreno-Noguer, F.; Solà, J.; Sanfeliu, A.; Andrade-Cetto, J. Dual-Branch CNNs for Vehicle Detection and Tracking on LiDAR Data. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6942–6953. [Google Scholar] [CrossRef]
- Chadwick, S.; Newman, P. Radar as a Teacher: Weakly Supervised Vehicle Detection using Radar Labels. In Proceedings of the International Conference on Robotics and Automation, Paris, France, 31 May–31 August 2020; pp. 222–228. [Google Scholar]
- Waltner, G.; Opitz, M.; Krispel, G.; Possegger, H.; Bischof, H. Semi-supervised Detector Training with Prototypes for Vehicle Detection. In Proceedings of the Intelligent Transportation Systems Conference, Auckland, New Zealand, 27–30 October 2019; pp. 4261–4266. [Google Scholar]
- Feng, R.; Lin, D.; Chen, K.; Lin, Y.; Liu, C. Improving Deep Learning by Incorporating Semi-automatic Moving Object Annotation and Filtering for Vision-based Vehicle Detection. In Proceedings of the International Conference on Systems, Man and Cybernetics, Bari, Italy, 6–9 October 2019; pp. 2484–2489. [Google Scholar]
- Li, Y.; Wu, J.; Bai, X.; Yang, X.; Tan, X.; Li, G.; Wen, S.; Zhang, H.; Ding, E. Multi-Granularity Tracking with Modularlized Components for Unsupervised Vehicles Anomaly Detection. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2501–2510. [Google Scholar]
- Khorramshahi, P.; Peri, N.; Kumar, A.; Shah, A.; Chellappa, R. Attention Driven Vehicle Re-identification and Unsupervised Anomaly Detection for Traffic Understanding. In Proceedings of the Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 239–246. [Google Scholar]
- Brust, C.A.; Käding, C.; Denzler, J. Active learning for deep object detection. arXiv 2018, arXiv:1809.09875. [Google Scholar]
- Elezi, I.; Yu, Z.; Anandkumar, A.; Leal-Taixe, L.; Alvarez, J.M. Not all labels are equal: Rationalizing the labeling costs for training object detection. In Proceedings of the Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14492–14501. [Google Scholar]
- Sener, O.; Savarese, S. Active learning for convolutional neural networks: A core-set approach. arXiv 2017, arXiv:1708.00489. [Google Scholar]
- Yoo, D.; Kweon, I.S. Learning loss for active learning. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 93–102. [Google Scholar]
- Choi, J.; Elezi, I.; Lee, H.J.; Farabet, C.; Alvarez, J.M. Active learning for deep object detection via probabilistic modeling. In Proceedings of the International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10264–10273. [Google Scholar]
- Kao, C.C.; Lee, T.Y.; Sen, P.; Liu, M.Y. Localization-aware active learning for object detection. In Proceedings of the Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part VI 14, 2019. pp. 506–522. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Chun, S.; Kim, W.; Park, S.; Chang, M.; Oh, S.J. Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–27 October 2022; Volume 13668, pp. 1–19. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 743–761. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Yu, W.; Zhu, S.; Yang, T.; Chen, C. Consistency-based active learning for object detection. In Proceedings of the Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3951–3960. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1497. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Val | Test | Imagesize | Scene | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Images | Boxes (Car) | Night-Time Images | Images | Boxes (Car) | Night-Time Images | Images | Boxes (Car) | |||
| KITTI | 7481 | 28,742 | - | - | - | - | 7518 | - | 1242 × 375 | Autonomous Driving |
| BDD100K | 70,000 | 714,121 | 28,028 (40.04%) | 10,000 | 102,540 | 3929 (39.29%) | 20,000 | 205,214 | 1280 × 720 | |
| UA-DETRAC | 83,791 | 503,853 | 22,819 (27.23%) | - | - | - | 56,340 | 548,555 | 960 × 540 | Traffic Intersection |
| VD-NUS | 60,137 | 305,223 | 60,137 (100%) | 10,023 | 51,290 | 10,023 (100%) | 30,058 | 153,163 | 1920 × 1080 | Urban Scenes |
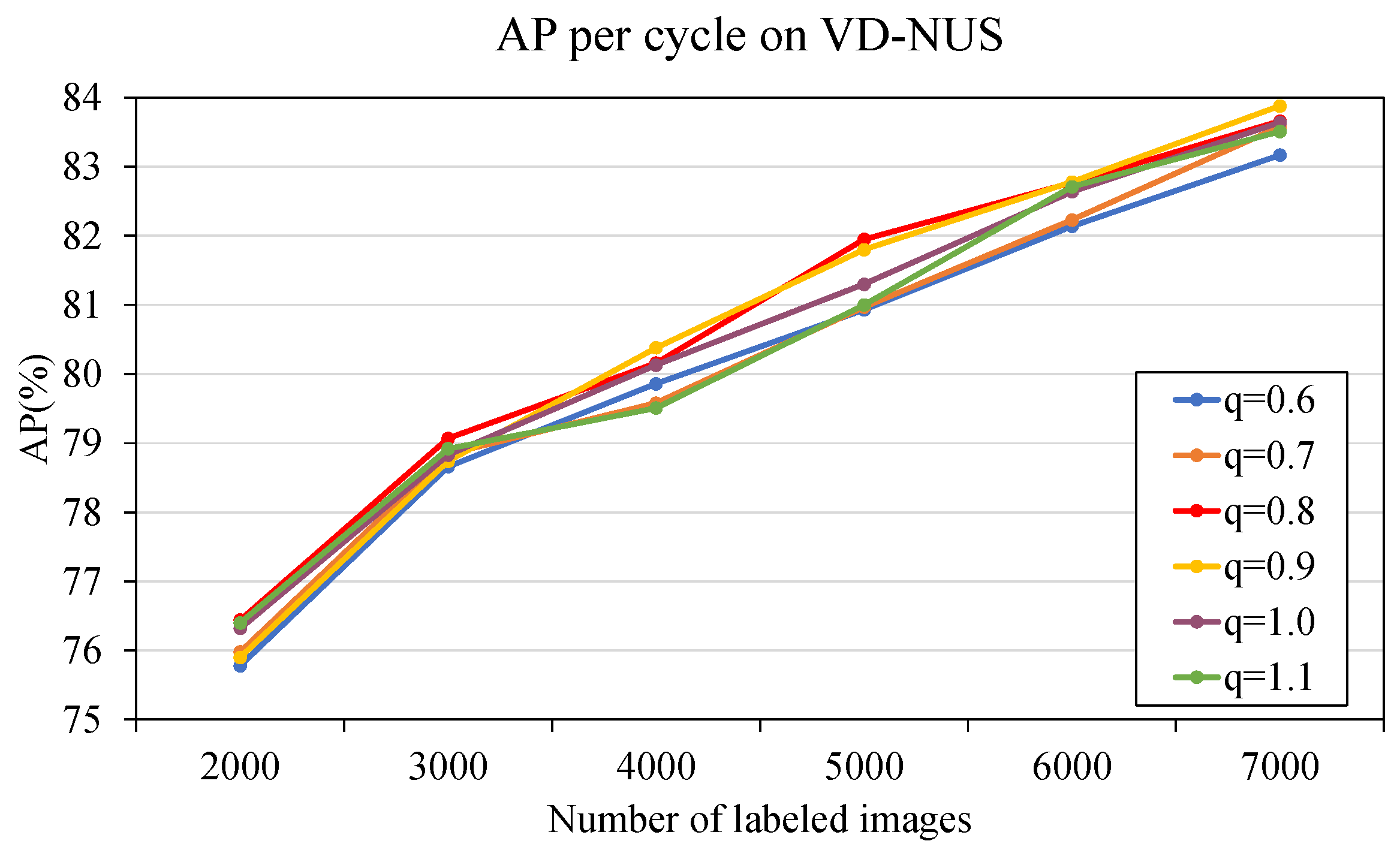
| Method | Inconsistency-Based Scoring | q | Min | Average | Number of Labeled Images | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2000 | 3000 | 4000 | 5000 | 6000 | 7000 | |||||
| Random | 75.53 | 78.58 | 80.12 | 81.42 | 82.46 | 83.46 | ||||
| Ours | ✓ | ✓ | 75.95 | 78.34 | 80.21 | 81.92 | 82.75 | 83.95 | ||
| ✓ | ✓ | ✓ | 76.44 | 79.07 | 80.16 | 81.95 | 82.77 | 83.66 | ||
| ✓ | ✓ | ✓ | 72.89 | 75.75 | 77.31 | 78.25 | 79.19 | 80.92 | ||
| Model | Method | Number of Labeled Images | Metric | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Random | AAM | 1000 | 2000 | 3000 | 4000 | 5000 | 6000 | 7000 | ||
| YOLOv4 | ✓ | 68.22 | 75.53 | 78.58 | 80.12 | 81.42 | 82.46 | 83.46 | ||
| ✓ | 68.22 | 76.44 | 79.07 | 80.16 | 81.95 | 82.77 | 83.66 | |||
| ✓ | 0.65 | 0.55 | 0.49 | 0.46 | 0.43 | 0.41 | 0.39 | |||
| ✓ | 0.65 | 0.52 | 0.46 | 0.44 | 0.41 | 0.40 | 0.37 | |||
| Faster R-CNN | ✓ | 82.18 | 83.97 | 84.76 | 84.96 | 85.39 | 85.51 | 85.89 | ||
| ✓ | 82.18 | 84.17 | 85.29 | 85.92 | 85.81 | 86.38 | 86.06 | |||
| ✓ | 0.4 | 0.37 | 0.36 | 0.36 | 0.35 | 0.35 | 0.33 | |||
| ✓ | 0.4 | 0.38 | 0.35 | 0.33 | 0.33 | 0.32 | 0.32 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Tu, X.; Al-Hassani, B.; Lin, C.-W.; Xu, X. Select Informative Samples for Night-Time Vehicle Detection Benchmark in Urban Scenes. Remote Sens. 2023, 15, 4310. https://doi.org/10.3390/rs15174310
Wang X, Tu X, Al-Hassani B, Lin C-W, Xu X. Select Informative Samples for Night-Time Vehicle Detection Benchmark in Urban Scenes. Remote Sensing. 2023; 15(17):4310. https://doi.org/10.3390/rs15174310
Chicago/Turabian StyleWang, Xiao, Xingyue Tu, Baraa Al-Hassani, Chia-Wen Lin, and Xin Xu. 2023. "Select Informative Samples for Night-Time Vehicle Detection Benchmark in Urban Scenes" Remote Sensing 15, no. 17: 4310. https://doi.org/10.3390/rs15174310
APA StyleWang, X., Tu, X., Al-Hassani, B., Lin, C.-W., & Xu, X. (2023). Select Informative Samples for Night-Time Vehicle Detection Benchmark in Urban Scenes. Remote Sensing, 15(17), 4310. https://doi.org/10.3390/rs15174310