
Three-Dimensional Reconstruction and Geometric Morphology Analysis of Lunar Small Craters within the Patrol Range of the Yutu-2 Rover

Abstract
:1. Introduction
- (1)
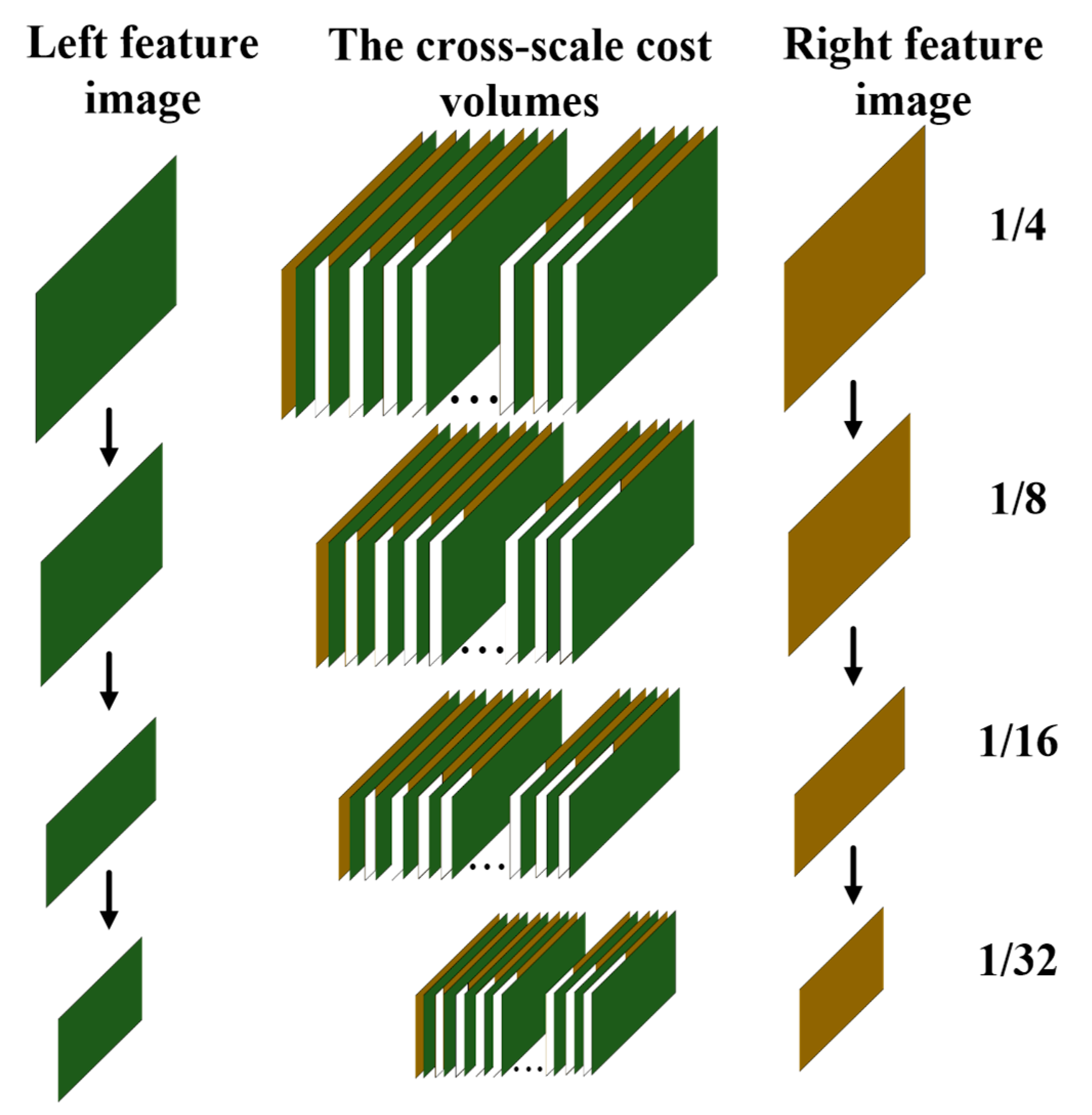
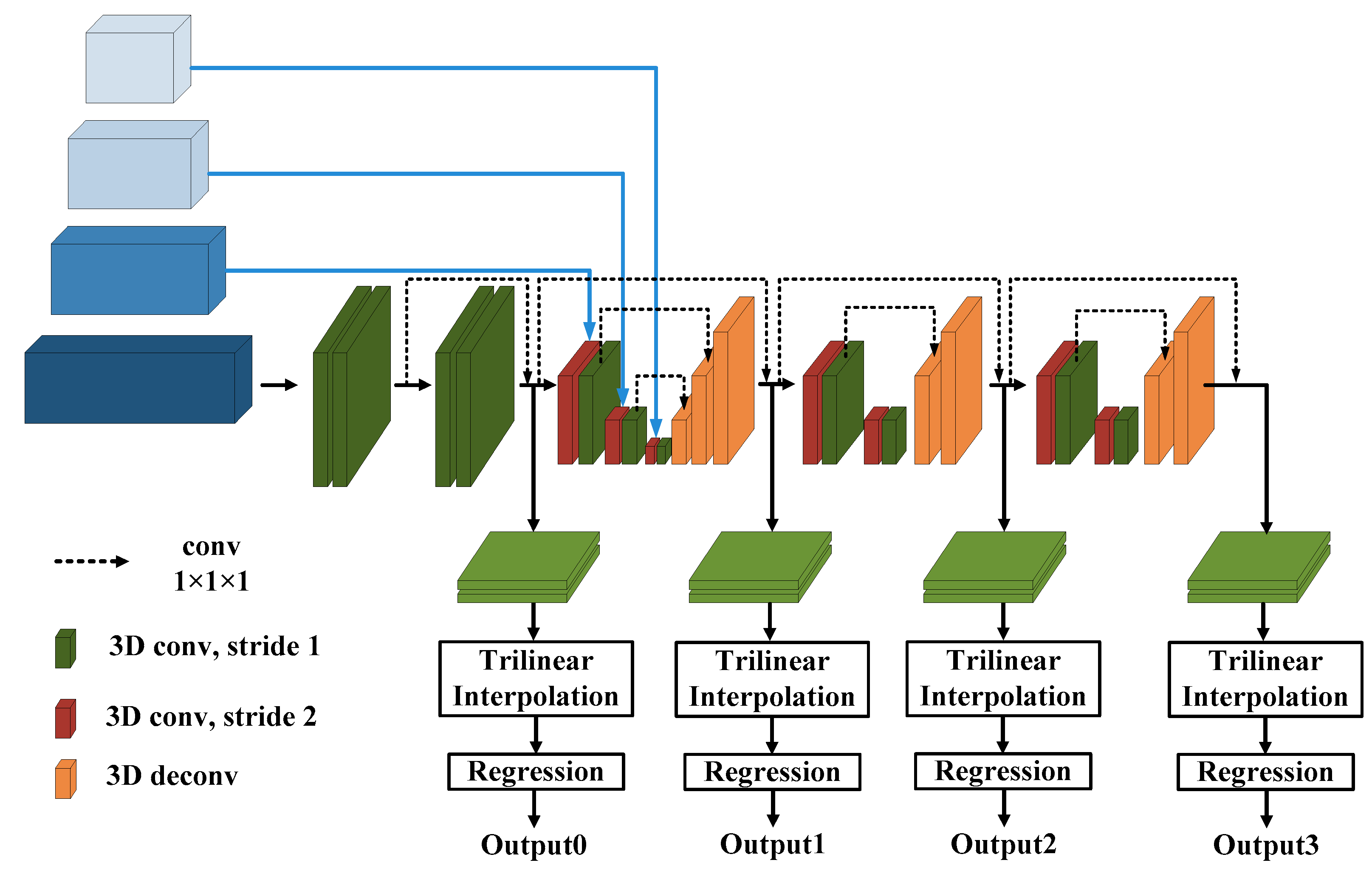
- Considering the single sparse texture feature of the lunar surface, the cross-scale cost aggregation for a stereo matching network (CscaNet) is proposed.
- (2)
- For the first time, the proposed CscaNet and forward intersection [40] (triangulation) method is used to reconstruct the fine lunar terrain based on the image data obtained by the navigation camera. The small craters within the range are extracted, and a geometric morphological law analysis is carried out, which fills the gap in the morphological analysis of craters in the dorsal region of the Moon at the miniature scale.
- (3)
- For the first time, the geometric pattern of small craters is discovered, and the relationship between the depth and diameter of craters within the scope of the Yutu-2 patrol mission is analyzed.
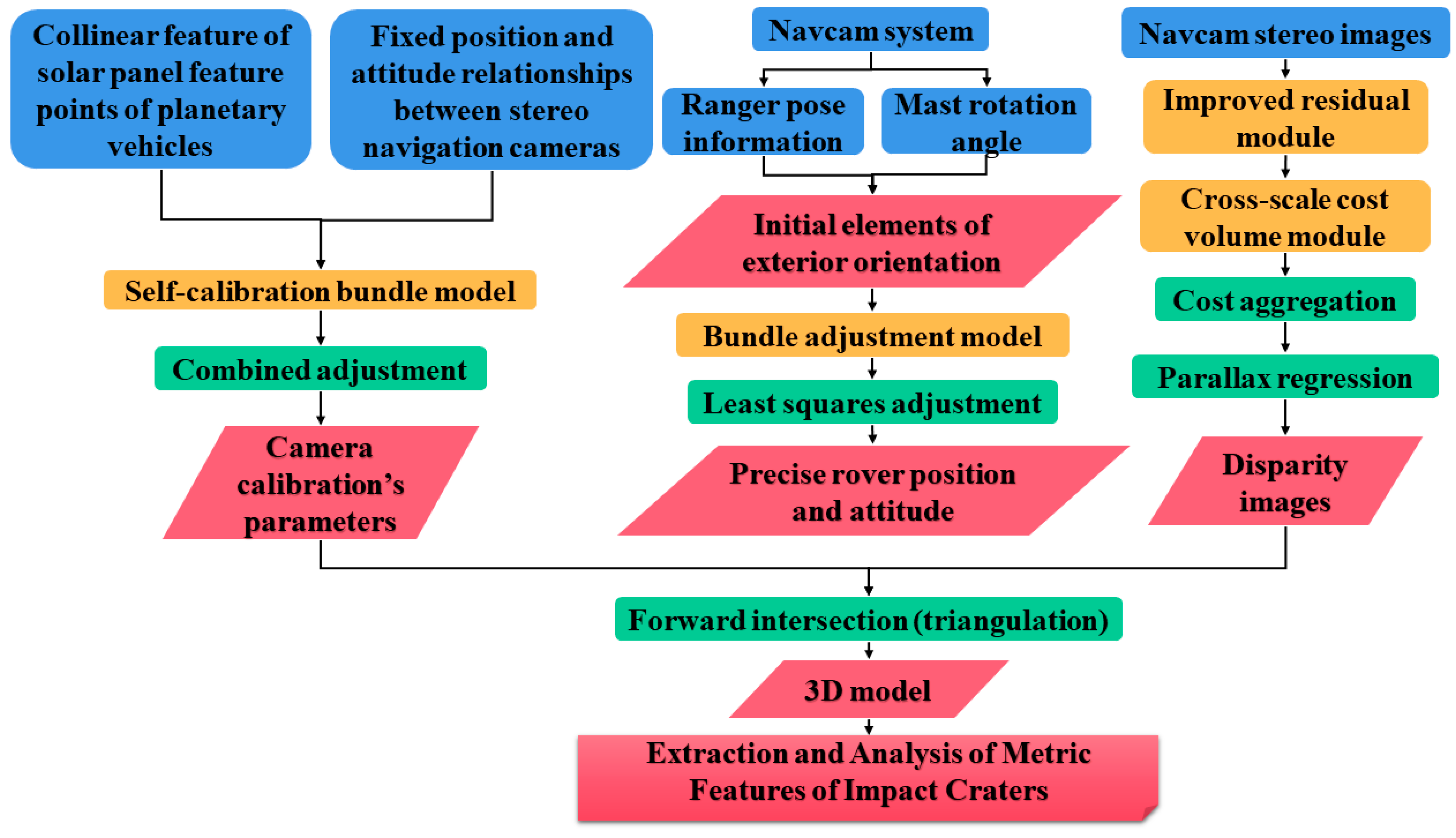
2. Methodology
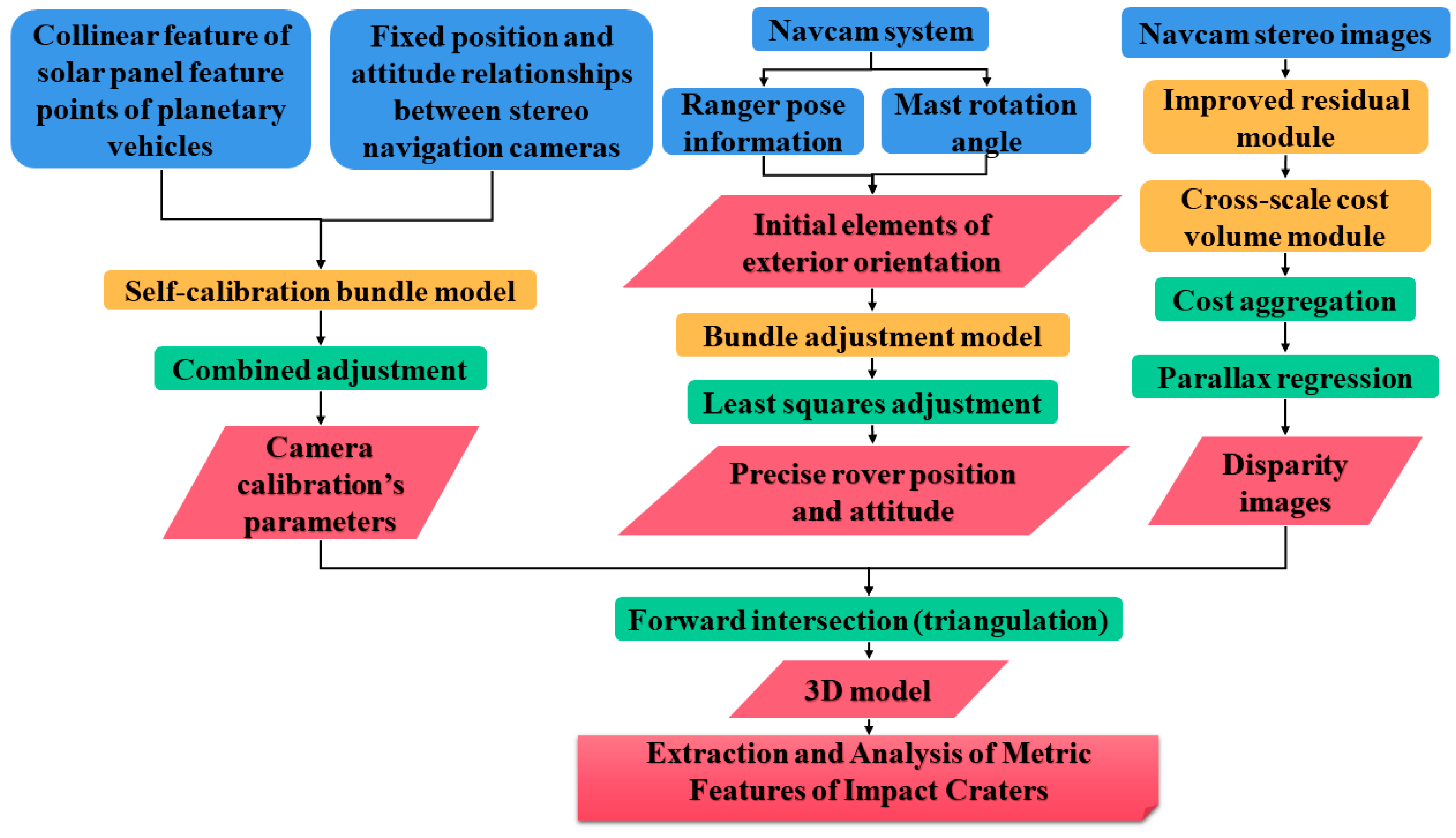
2.1. Yutu-2 Navigation Camera Calibration
2.2. Visual Positioning of the Lunar Rover
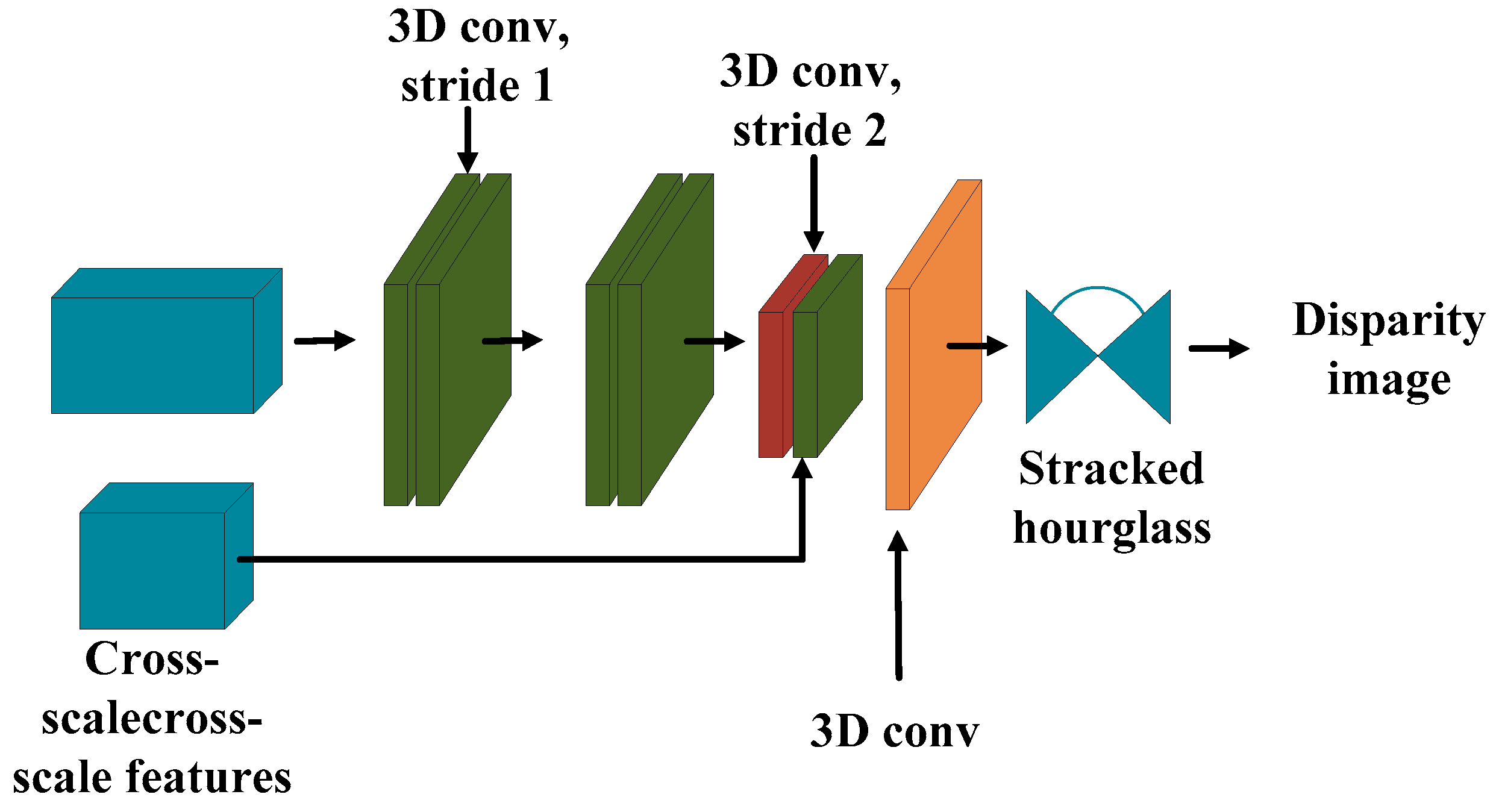
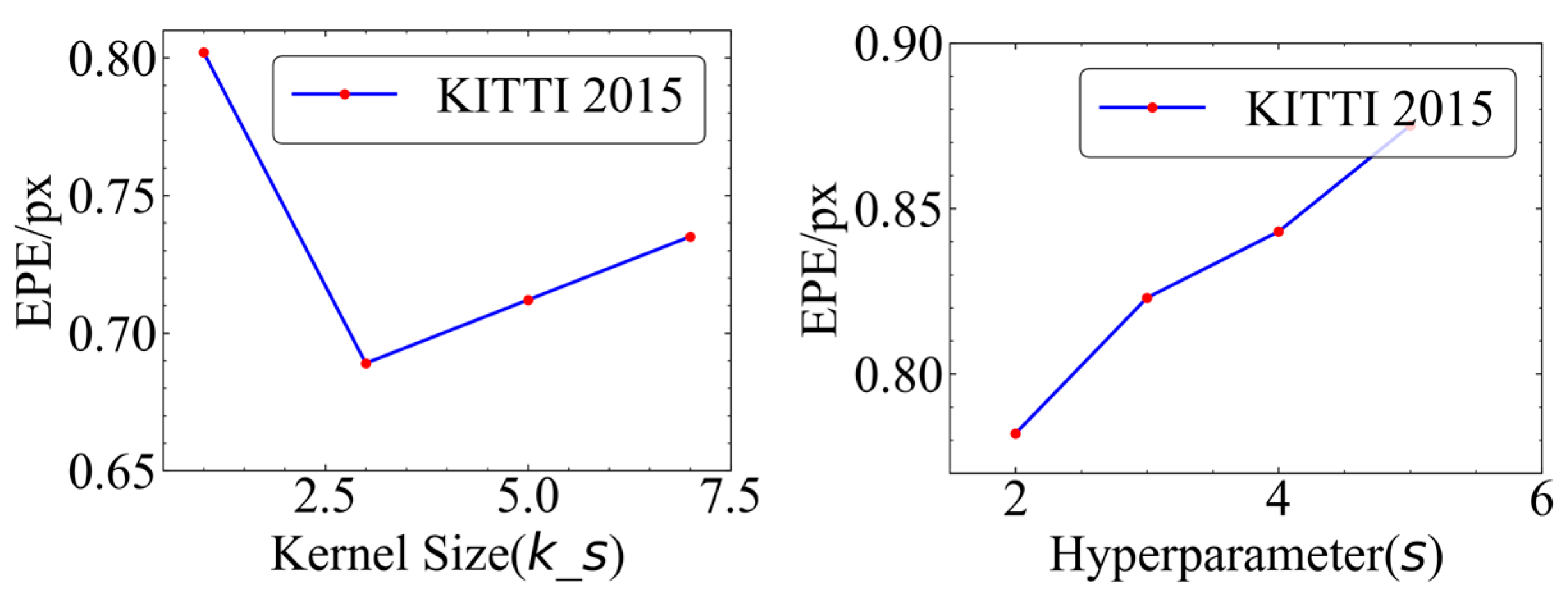
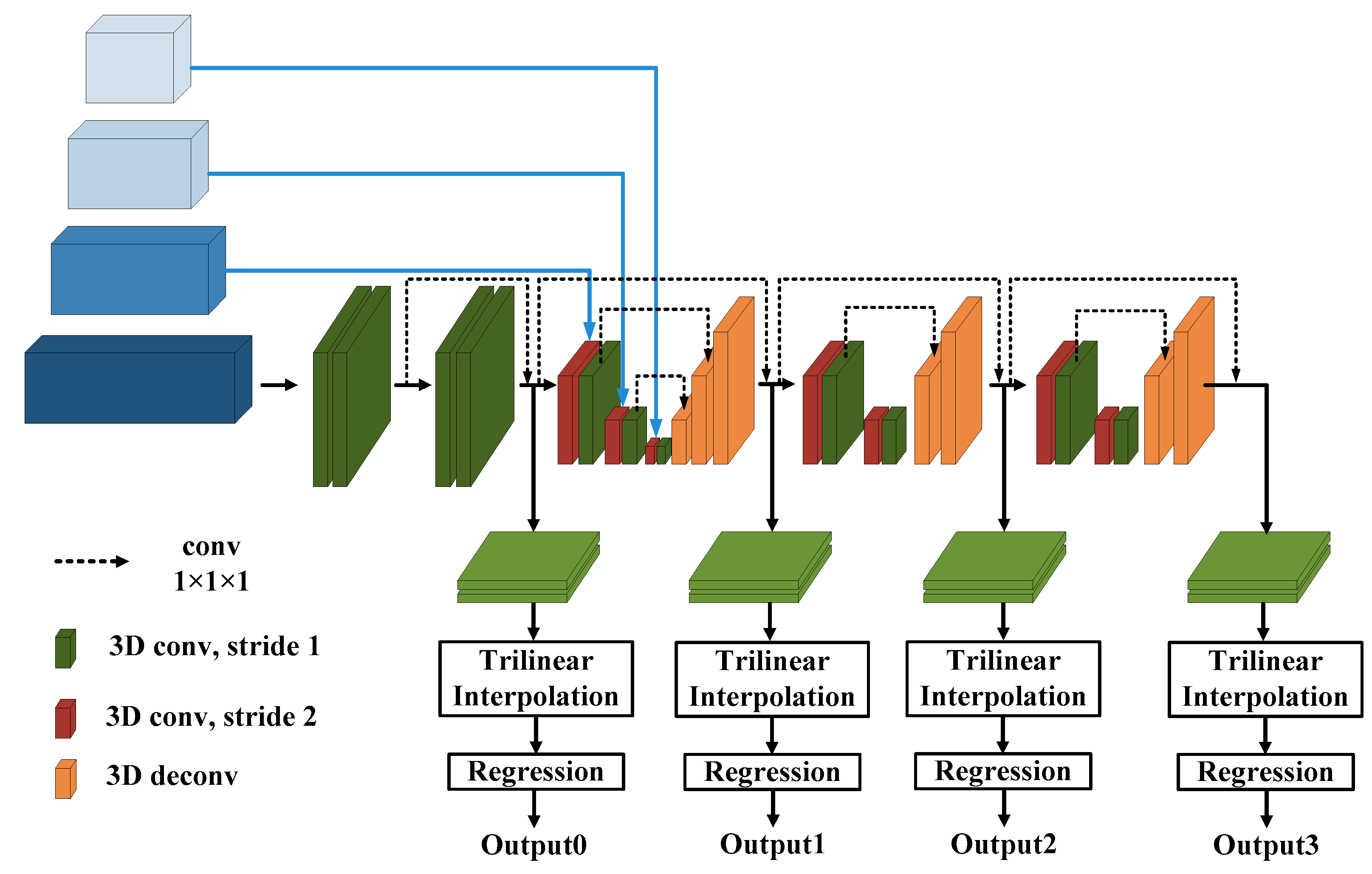
2.3. Stereo Matching of Navigation Images from the Lunar Rover
2.4. Three-Dimensional Crater Modeling
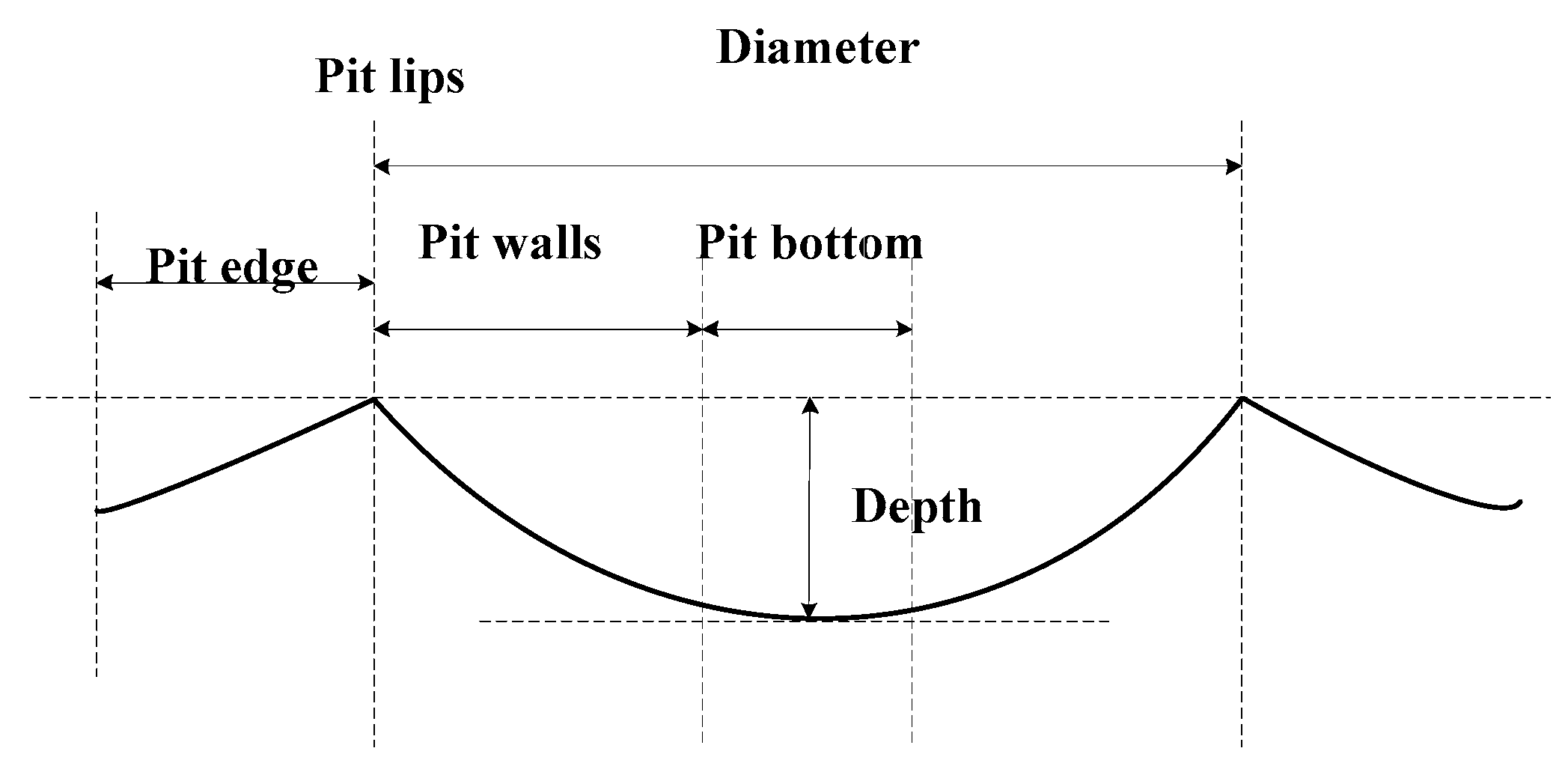
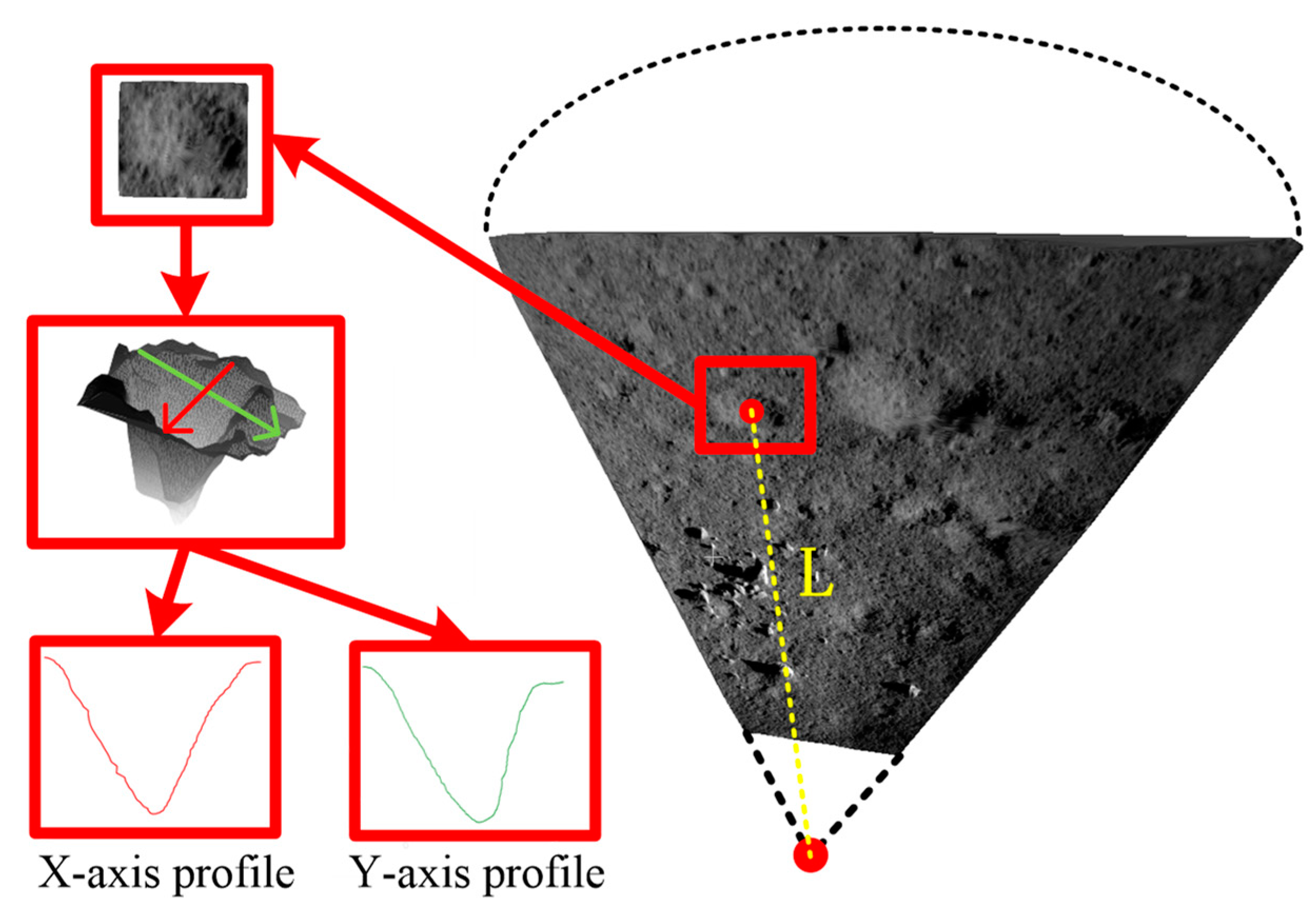
2.5. Construction of Characteristic Metrics of Craters
- (1)
- Manually select the crater area in the reconstructed 3D terrain using cloudcompare software.
- (2)
- Rotate the point cloud of the selected crater area to ensure that the area outside the crater edge is in the same horizontal plane.
- (3)
- Automatically search for the lowest point within the region.
- (4)
- Take the x-axis and y-axis profiles that pass through the lowest point, and project them in the x-axis and y-axis directions to obtain the corresponding contour lines (x-axis and y-axis profiles).
- (5)
- Calculate the diameter of the crater based on the distance between two farthest points on the crater edge.
- (6)
- Calculate the vertical distance from the lowest point to the line (the line connecting the two points at the crater edge) to obtain the depth of the crater.
3. Experiment and Analysis
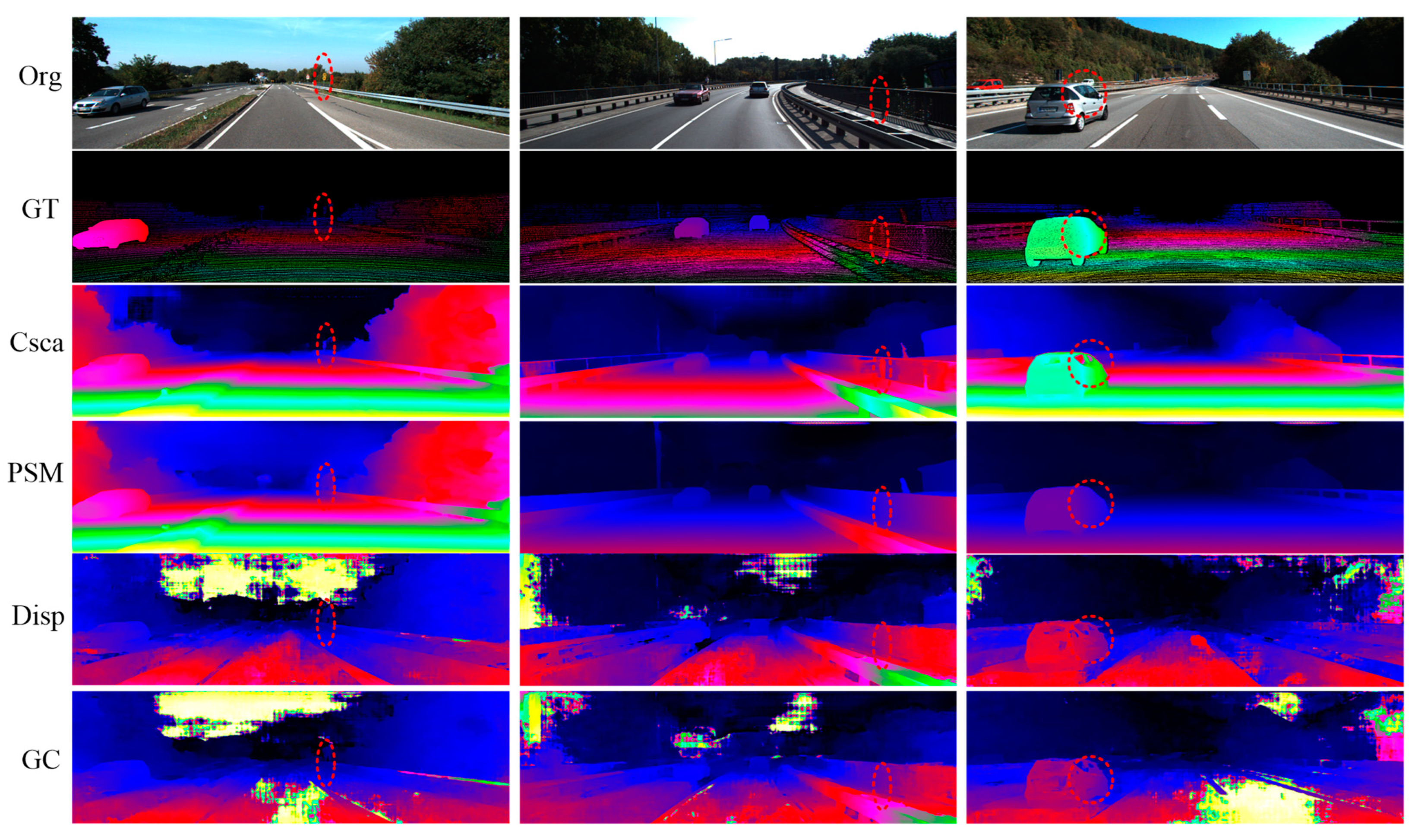
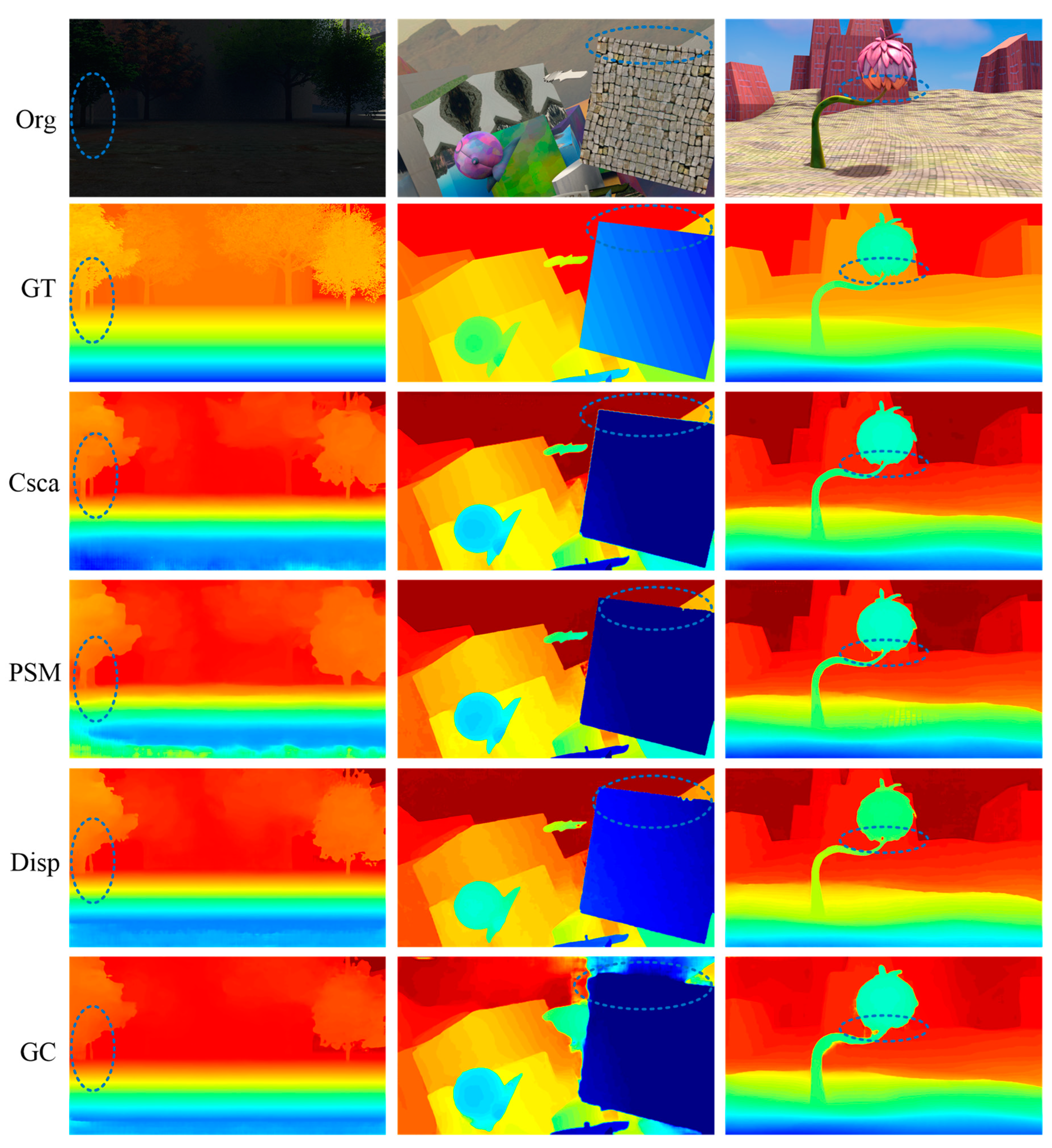
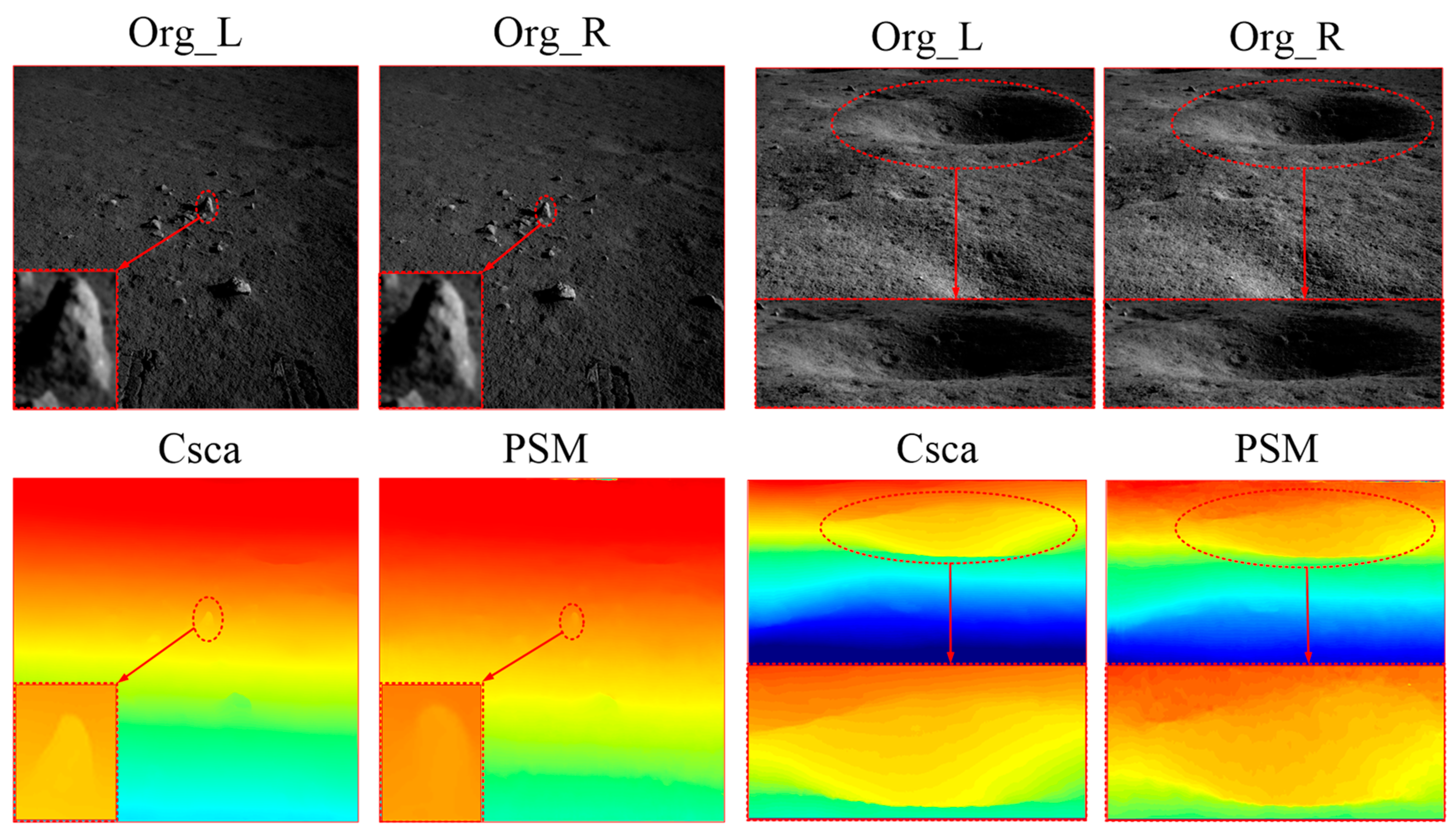
3.1. Experimental Analysis of Stereo Image Matching
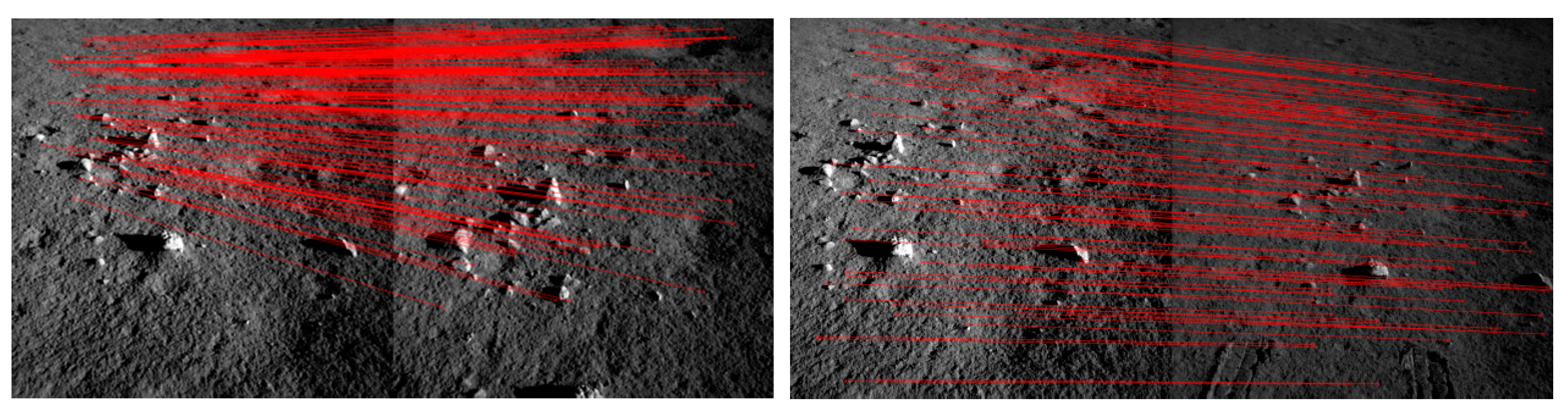
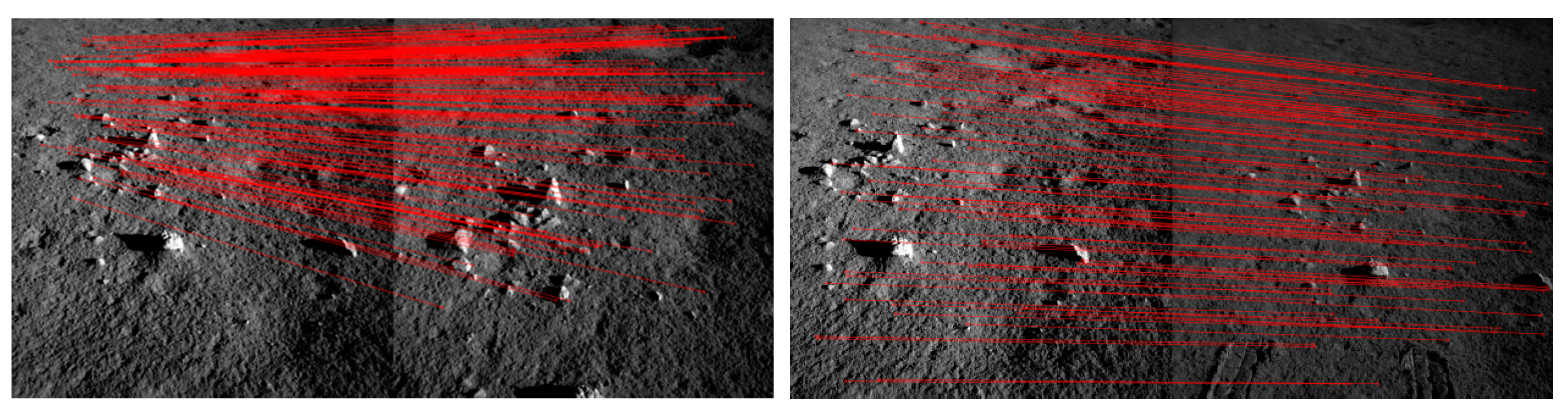
3.1.1. Parallax Estimation
- (1)
- Parallax estimations on public datasets
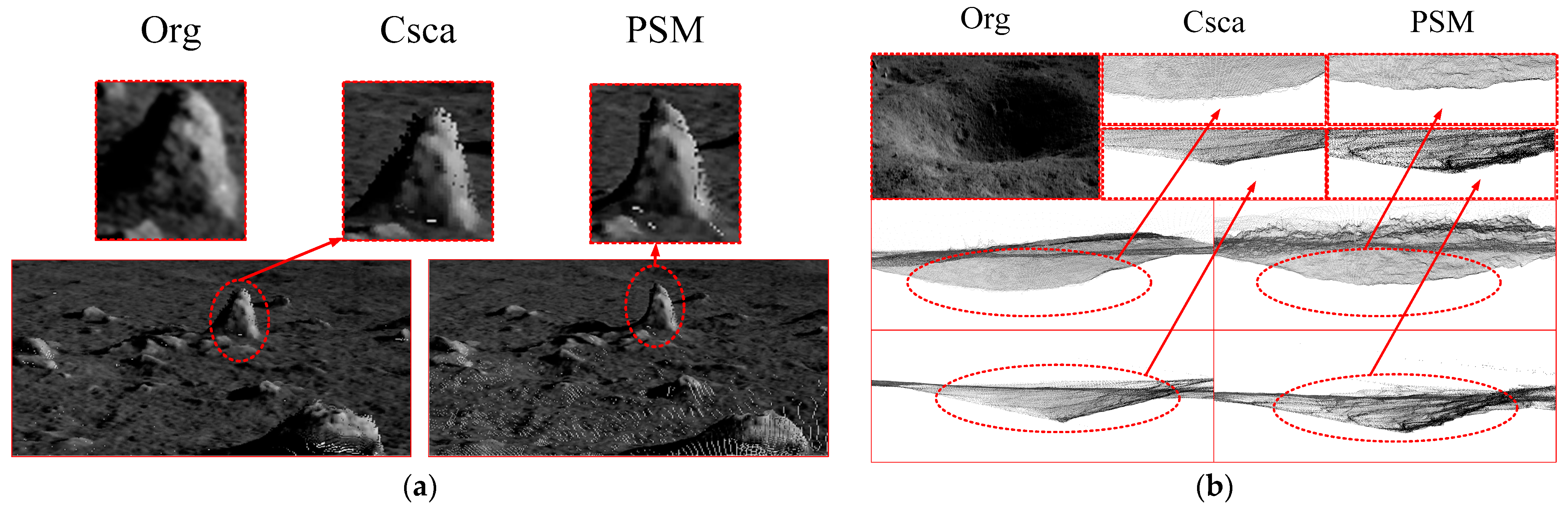
- (2)
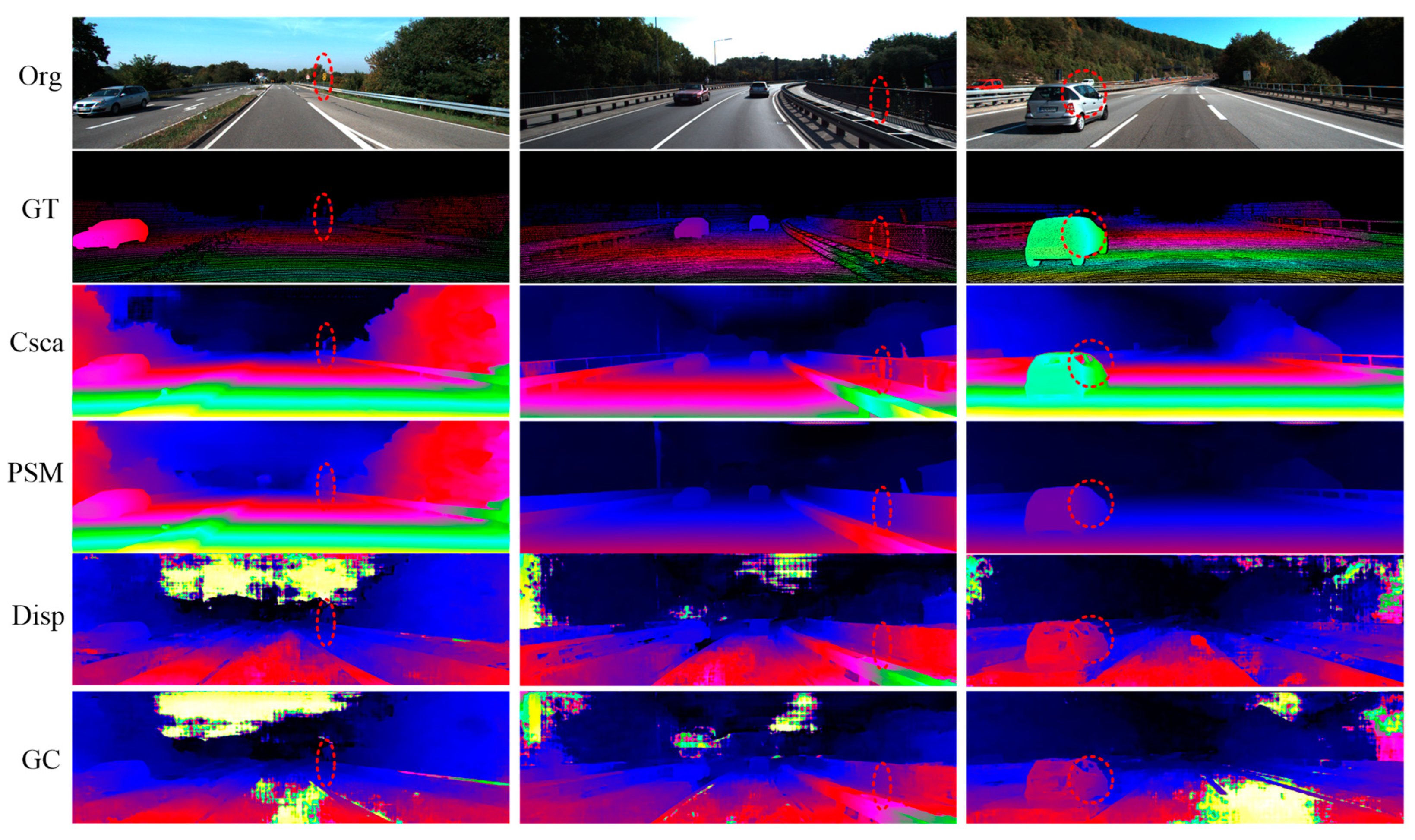
- Three-dimensional reconstruction results of stereo navigation images
3.1.2. Performance of CscaNet
- (1)
- Under the condition that the residual modules are consistent, the effect of the cross-scale 3D aggregation module is better than those of the series cost volume and joint cost volume. With respect to the residual module for PSMNet, the series cost volume, the joint cost volume, and the cross-scale 3D aggregation module are compared with one another; their D1-all are 2.32%, 2.03%, and 1.93%, respectively.
- (2)
- Under the condition that the cost aggregation modules are consistent, the module with improved convolution is superior to the residual module for PSMNet. In the case of the series cost volume, their D1-alls are 2.32% and 1.87%, respectively. In the case of the joint cost volume, the D1-alls are 2.03% and 1.81%. In the case of the cross-scale 3D aggregation module, the D1-alls are 1.93% and 1.73%, respectively.
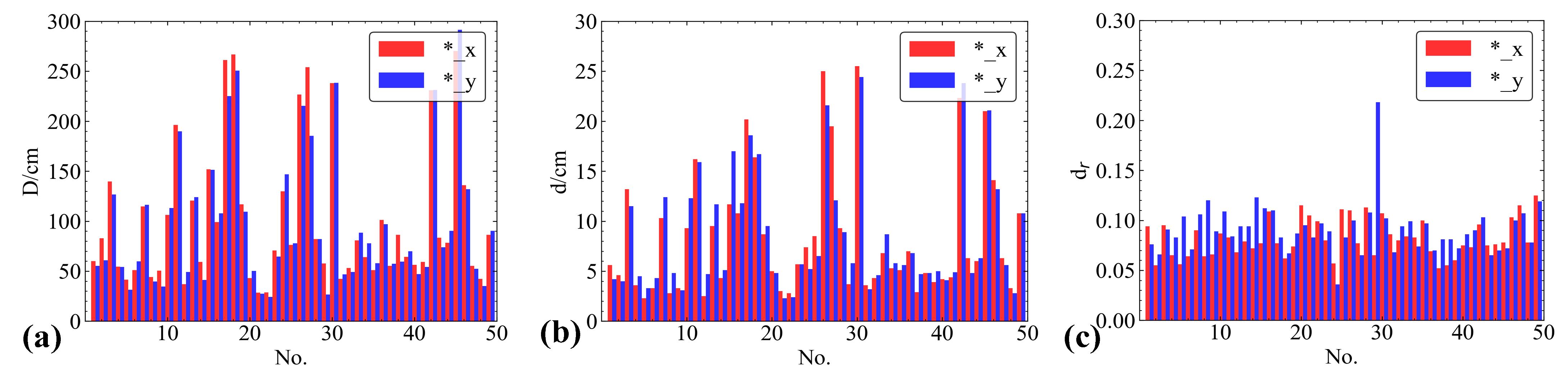
3.2. Extraction and Analysis of the Metric Features of Craters
3.2.1. Crater Profile Shape Indicator Statistics
3.2.2. Analysis of the Correlation and Distribution Relationships of Crater Indicators
3.3. Geometrical Morphology Analysis of Craters
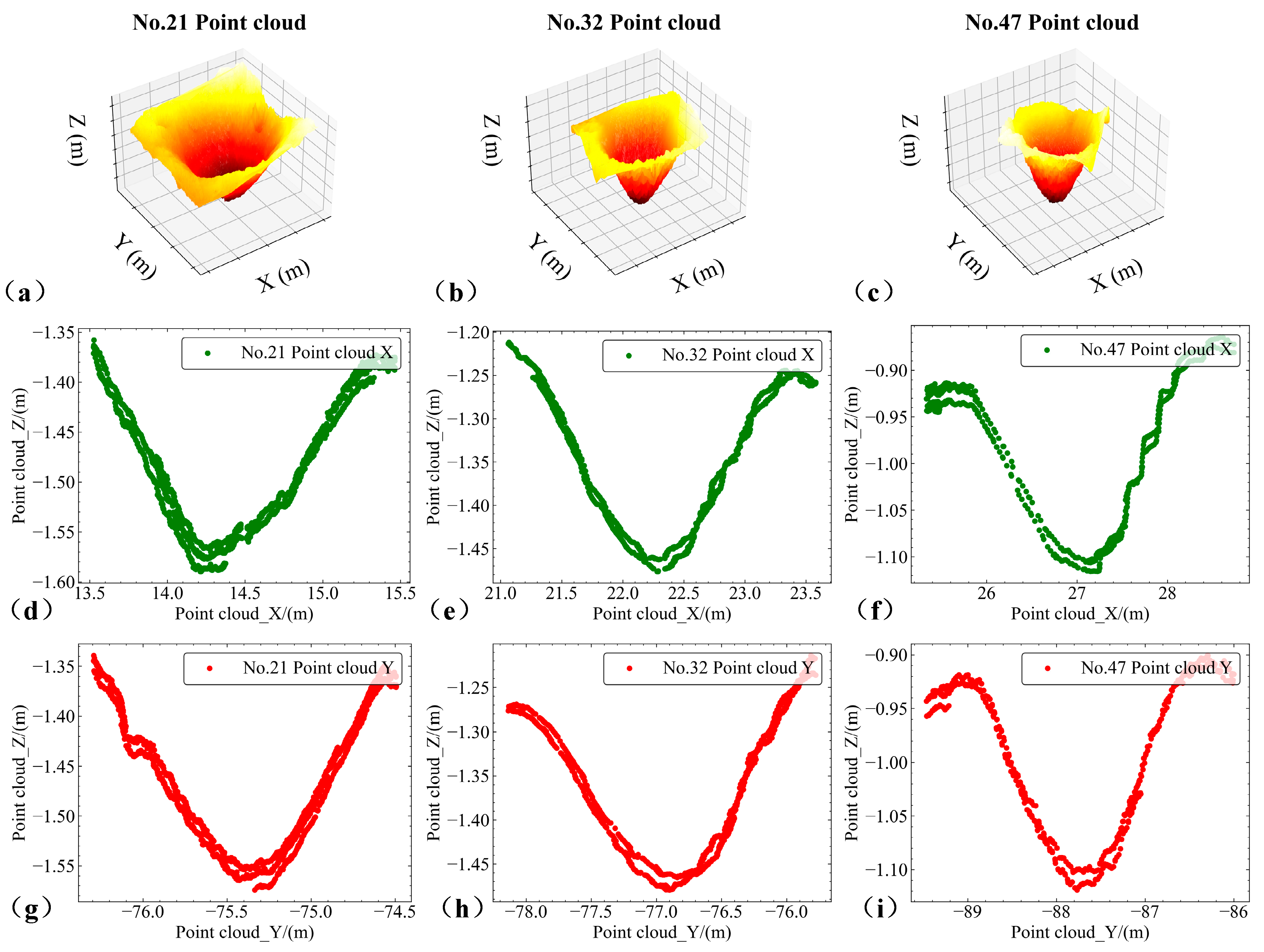
3.3.1. Morphological Fitting along the X-Axis and Y-Axis Profiles
3.3.2. Morphological Fitting along Different Profile Directions and Segments
3.3.3. Segmented Fitting by Segmentation
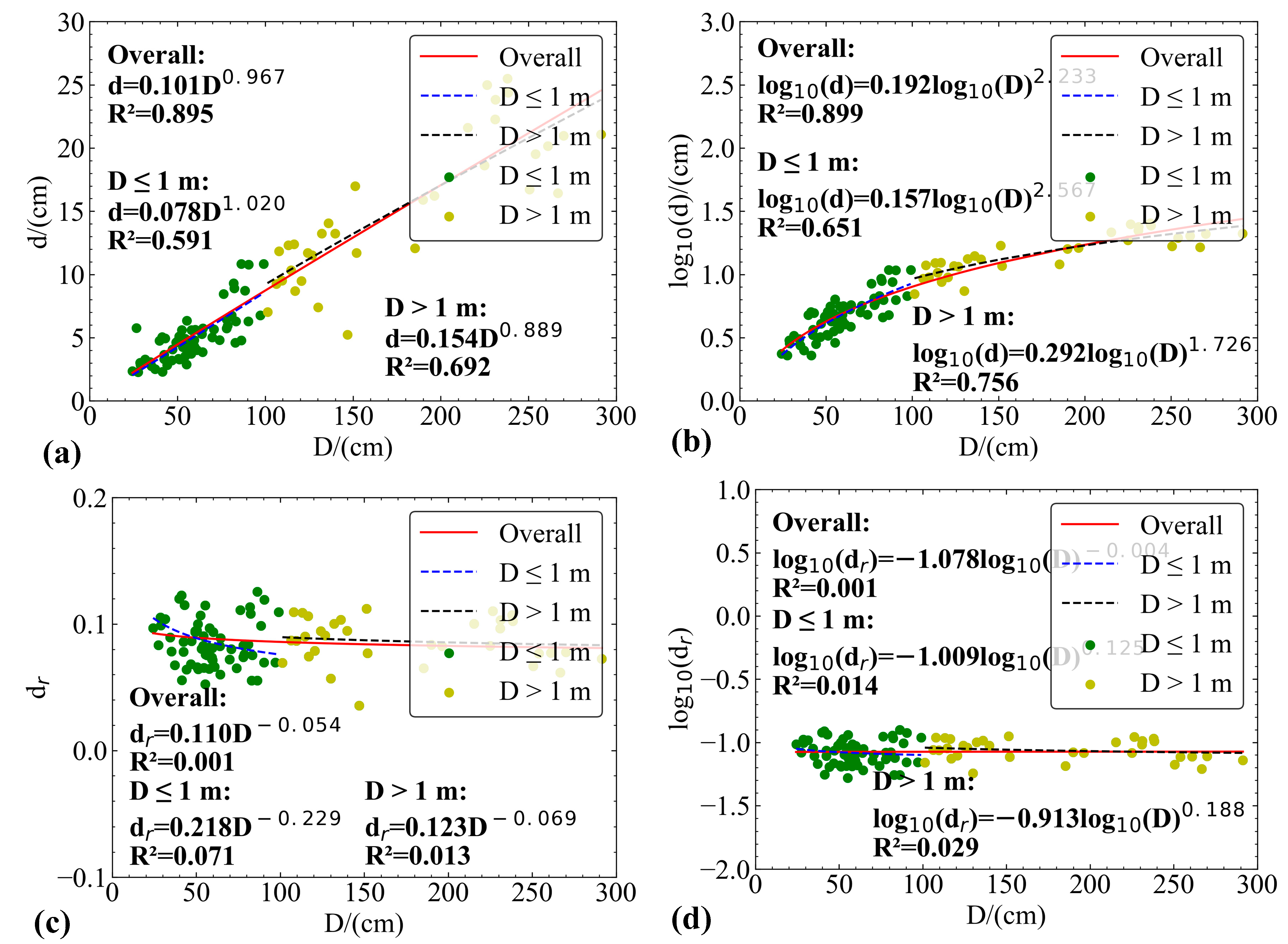
- (1)
- The PCC of the depth–diameter relationship in craters is high, indicating a strong correlation between the two factors.
- (2)
- The PCC of the depth–diameter ratio and diameter relationship in craters is low, indicating a weak correlation and an underfitting function expression.
- (3)
- Compared to exponential fitting, logarithmic fitting shows a higher PCC and a smoother curve.
4. Discussion
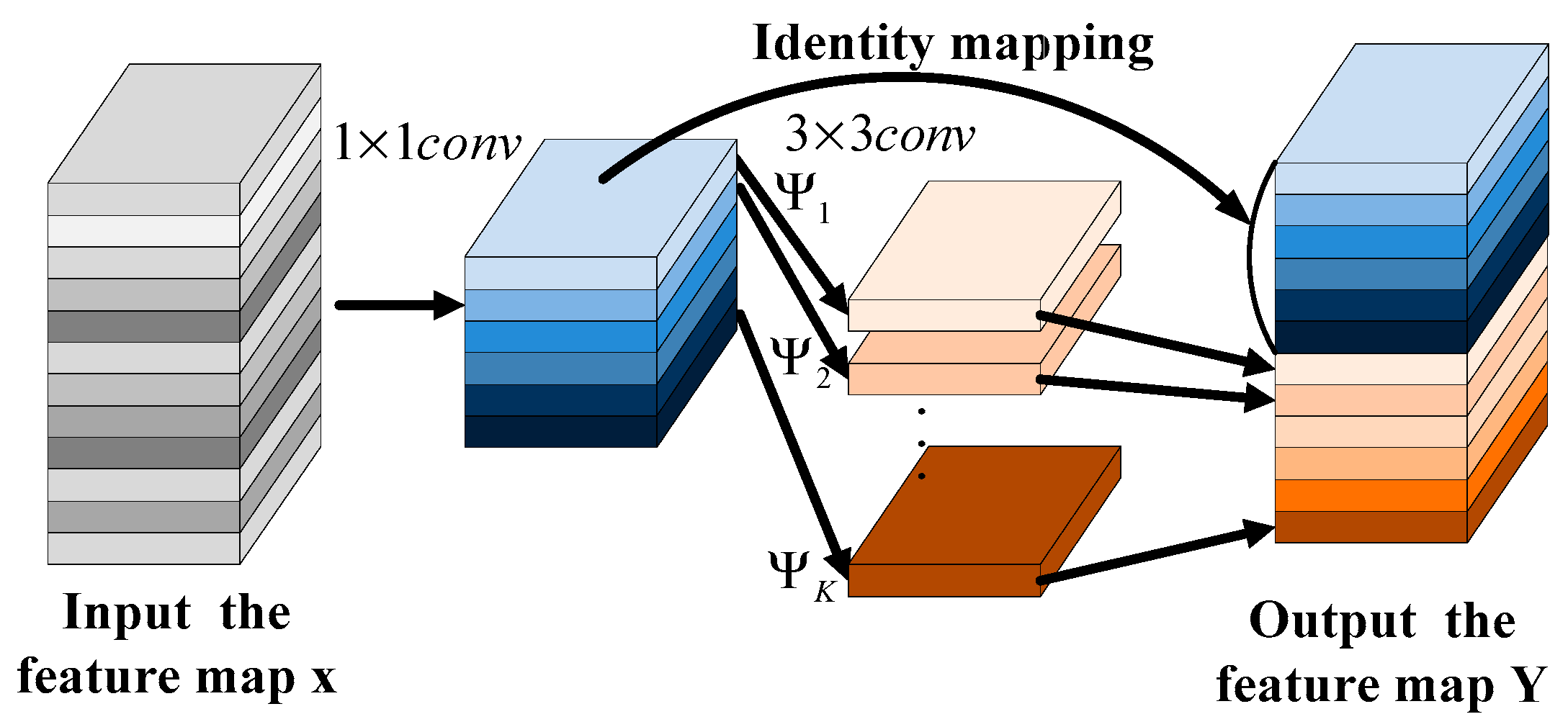
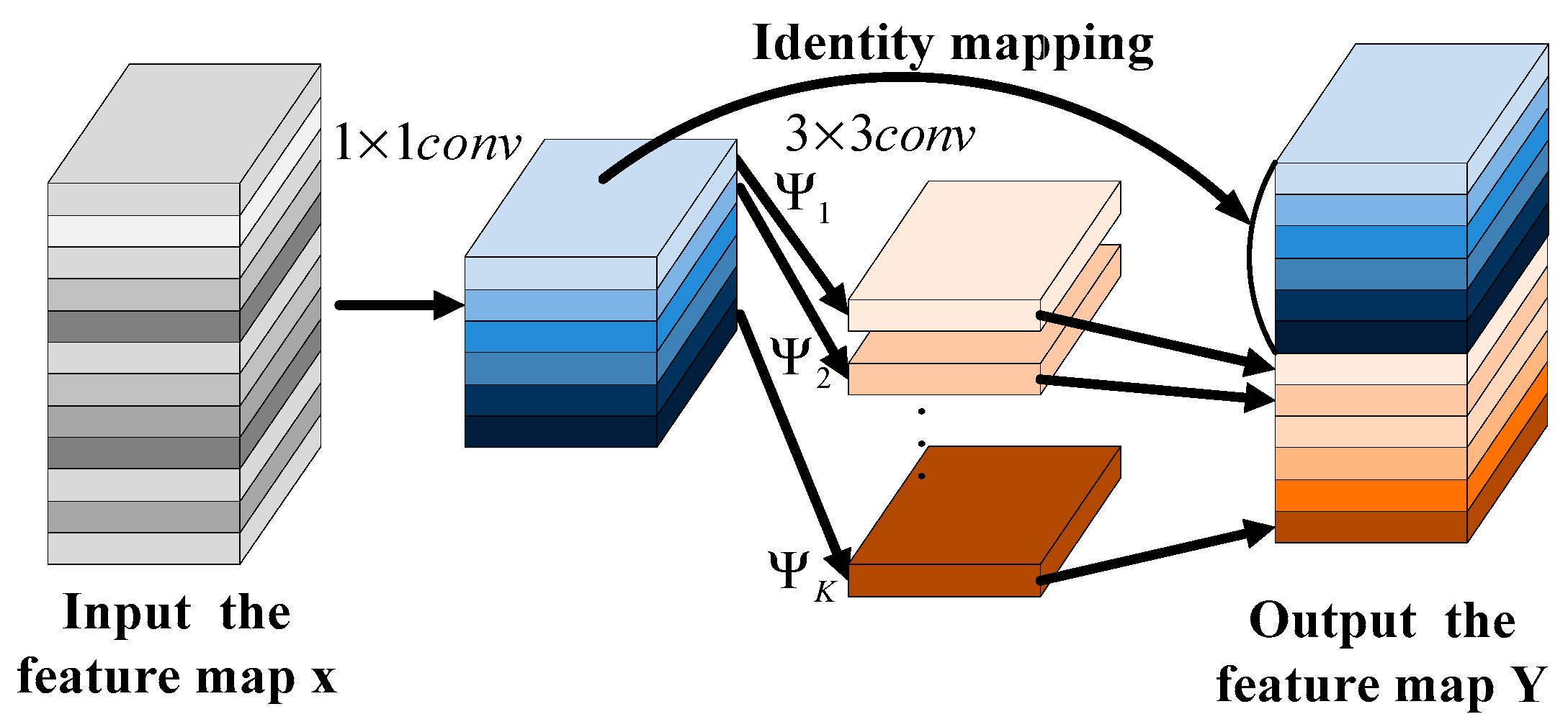
- The features extracted through traditional neural networks are relatively few, especially in the case of special texture features in lunar navigation images. We used deep convolution to complete the training task, which can obtain more redundant features in the feature map, ensuring that the image feature information is expanded and more internal features are extracted and providing more sufficient starting data for subsequent matching.
- Adopting an improved residual module network structure, cascading operations were carried out between different low-level internal features and using the upper level as prior information to further improve the performance of feature extraction. The fusion of low-level internal features and high-level semantic information made the image features more complete and better preserved the detailed information of the extracted image feature maps. It is more helpful for extracting detailed features of navigation images in lunar scenes.
- The proposed method constructs a multi-scale cost volume, taking into account multi-scale spatial relationships, and uses four scale feature maps for multi-scale feature information extraction. The feature information of different scales is extracted at different levels of the spatial feature map, and the above level is used as prior knowledge. After up-sampling to the same scale, the previous scale information is used as prior knowledge for cascading operations, which can provide a more accurate, more complete similarity measurement and global context information. Due to the different matching costs at different scales, the final cost obtained by using small scales as prior knowledge is more accurate in matching the results.
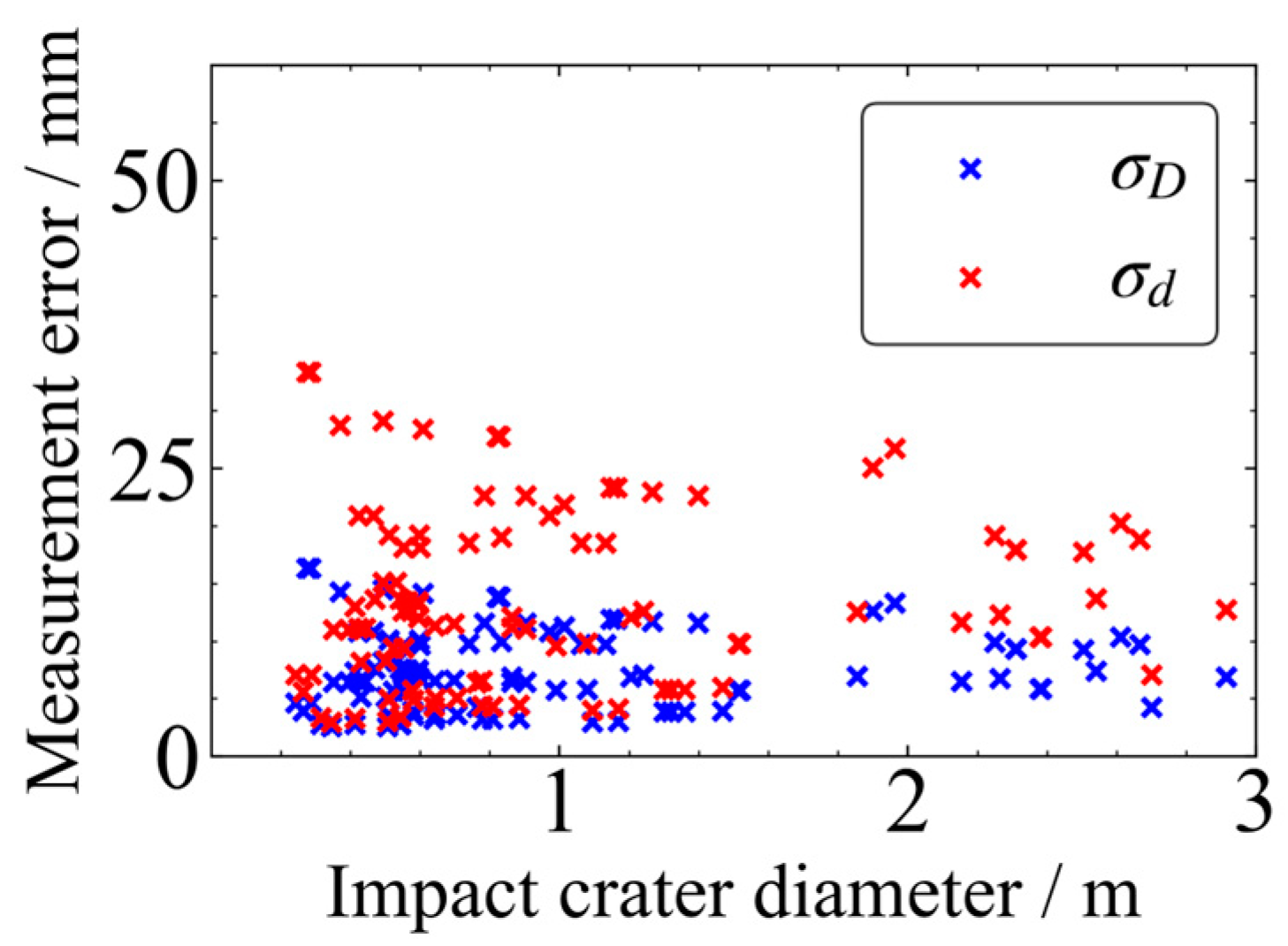
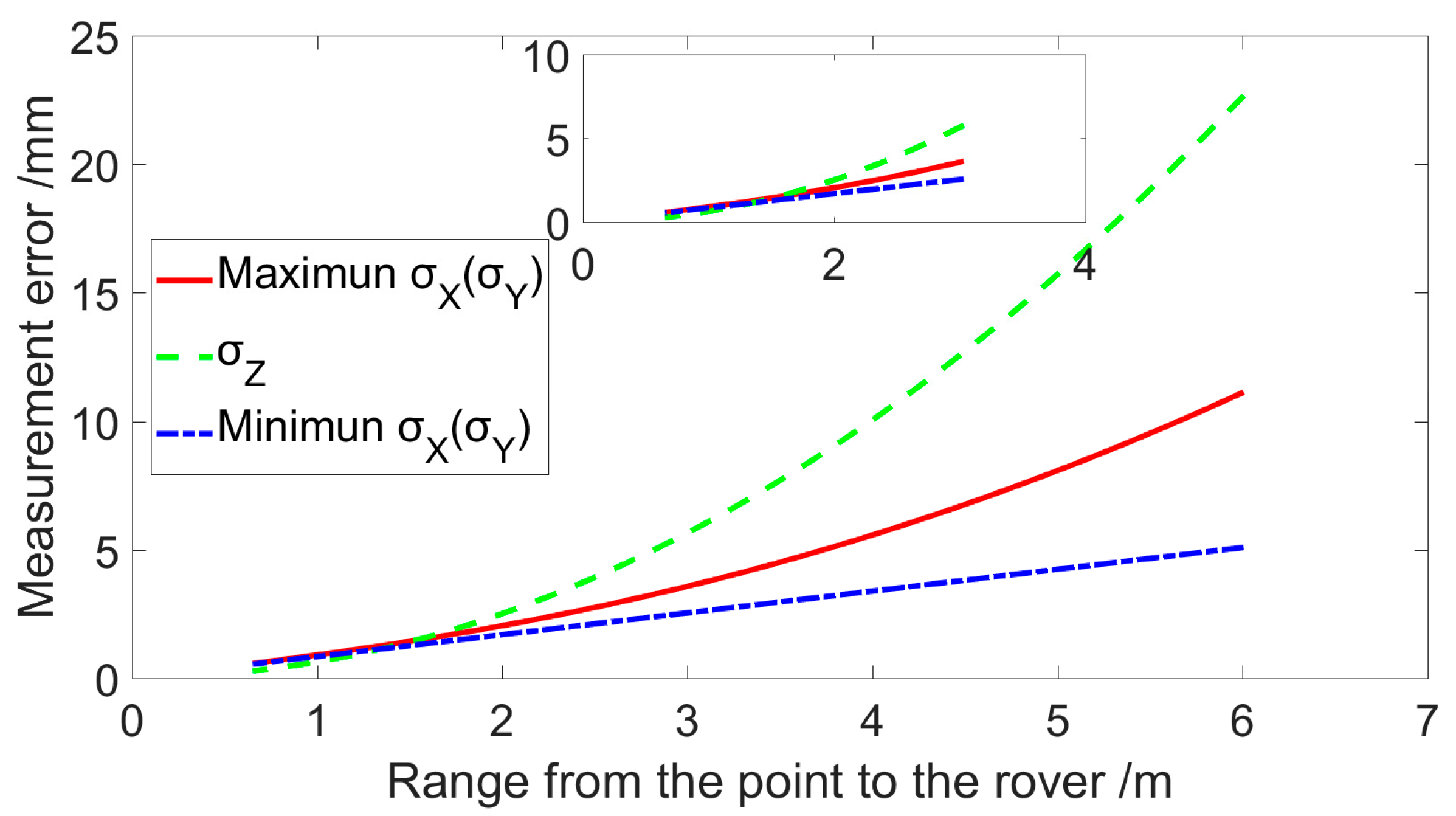
- The average error in diameter caused by the 3D reconstruction results is 7 mm and the average error in depth is 13 mm, which fully demonstrates that the extraction of crater diameter and depth indicators in this paper is reliable.
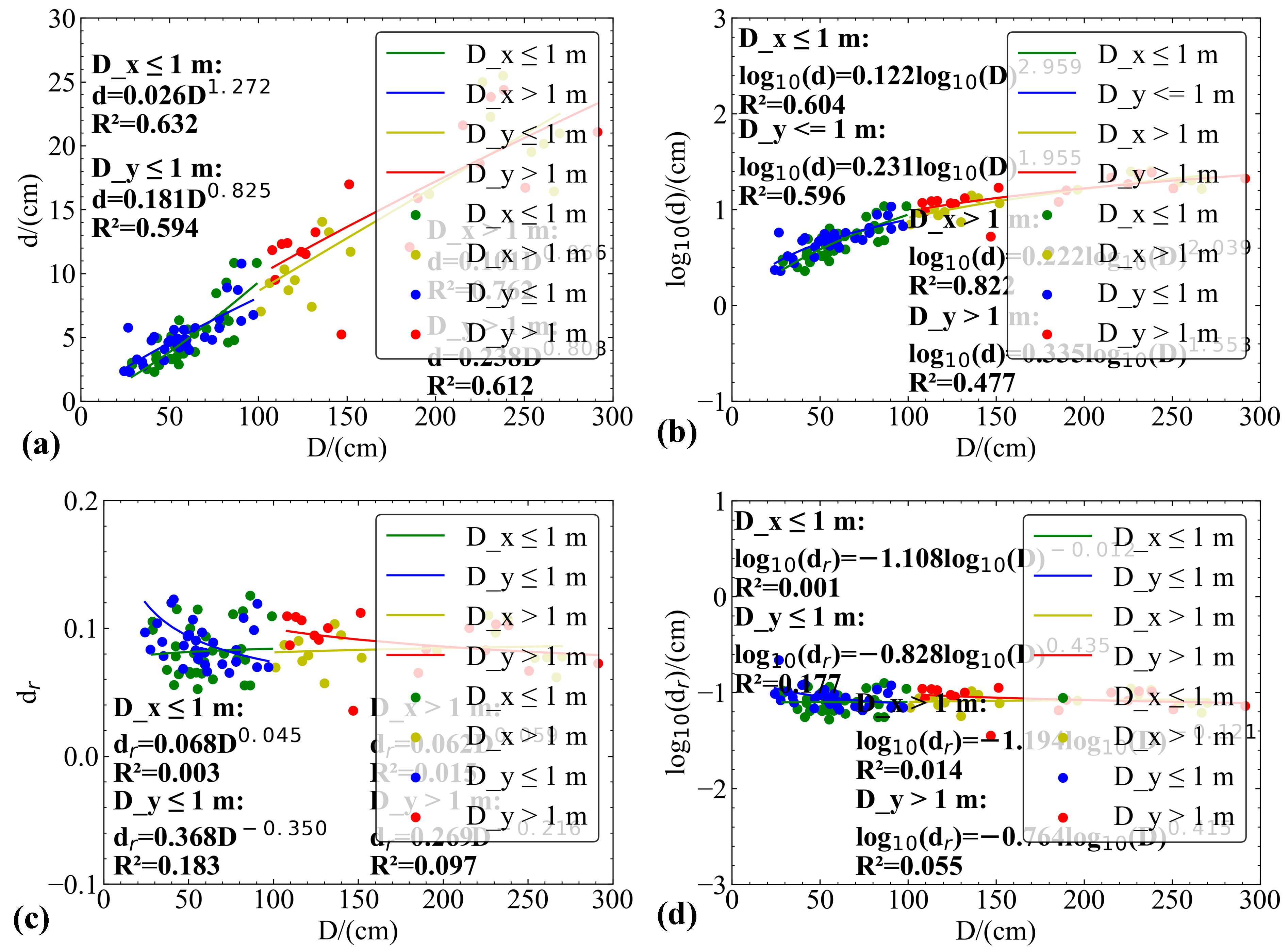
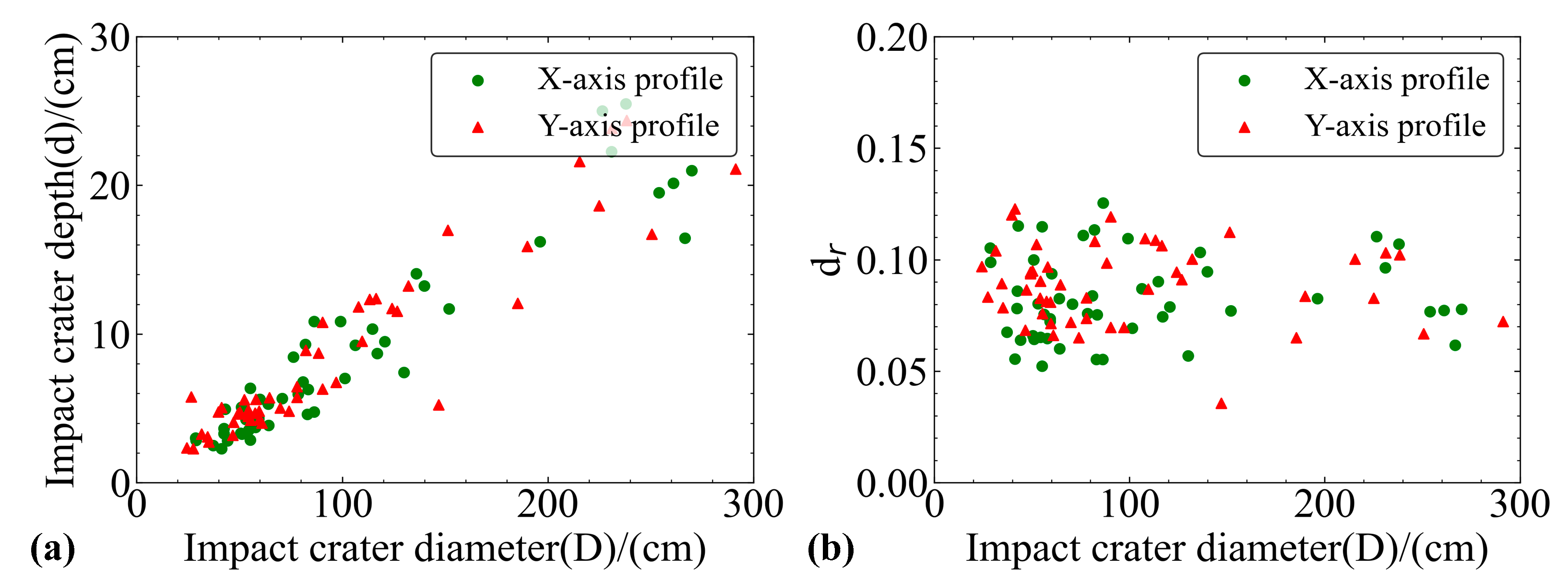
- The law between the D and dr of small craters (diameter < 3 m) was analyzed, and the degree of steepness of small craters is inversely proportional to their D. As the D increases, dr decreases. The mathematical expression of the two has a correlation coefficient of only , indicating a small correlation between the two. The mathematical expression indicates that the surface between the two appears to conform to a certain trend but cannot be better fitted.
- As the D increases, d also increases, and there is a positive correlation between the two. The mathematical expression obtained by fitting D and d has a higher correlation coefficient and a better correlation.
- The obtained expression is different from the results of other scholars. The 3D reconstruction of high-precision small craters can have higher accuracy, and the fitting results are reliable, indicating that there may be significant differences in the formation and evolution process of small craters compared to large craters (with a diameter greater than 3 m). In addition, it can provide better data support for other scholars in studying lunar soil composition, lunar evolution, and other processes.
5. Conclusions
- (1)
- The reconstruction accuracy of the proposed CscaNet is superior to GC-Net, DispNet, and PSMnet. The reconstruction accuracy is better than 0.98 cm within the range of 0.8–6.1 m between the crater and the lunar rover.
- (2)
- When the diameter is less than 1 m, the depth and diameter indicators of the crater are relatively concentrated. When the diameter is less than 3 m, there is a significant difference in the shape of the crater, and the distribution of the depth and diameter indicators is relatively discrete.
- (3)
- Quantitative fitting was conducted, and the relationship between d and D was obtained: or . However, the correlation between dr and d is low and it is not suitable for expressing the morphology of small craters.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Breccia, L. A breccia is a rock that is composed of other rock fragments. On the lunar surface, the main process for fragmentation is meteorite impacts. J. Am. Assoc. Adv. Sci. 2023, 8, 26. [Google Scholar]
- Ping, J.; Huang, Q.; Yan, J.; Meng, Z.; Wang, M. A Hidden Lunar Mascon Under the South Part of Von Kármán Crater. J. Deep. Space Explor. 2018, 5, 34–40. [Google Scholar]
- Head, J.W. Origin of central peaks and peak rings: Evidence from peak-ring basins on Moon, Mars, and Mercury. In Proceedings of the 9th Lunar and Planetary Science Conference, Houston, TX, USA, 13–17 March 1978; pp. 485–487. [Google Scholar]
- Head, J.W., III; Fassett, C.I.; Kadish, S.J.; Smith, D.E.; Zuber, M.T.; Neumann, G.A.; Mazarico, E. Global distribution of large lunar craters: Implications for resurfacing and impactor populations. Science 2010, 329, 1504–1507. [Google Scholar] [CrossRef]
- Kadish, S.J.; Fassett, C.I.; Head, J.W.; Smith, D.E.; Zuber, M.T.; Neumann, G.A.; Mazarico, E. A global catalog of large lunar craters (≥20 km) from the Lunar Orbiter Laser Altimeter. In Proceedings of the 42nd Annual Lunar and Planetary Science Conference, The Woodlands, TX, USA, 7–11 March 2011; p. 1006. [Google Scholar]
- McDowell, J. A Merge of a Digital Version of the List of Lunar Craters from Andersson and Whitaker with the List from the USGS Site. Available online: http://www.planet4589.org/astro/lunar/CratersS (accessed on 24 June 2023).
- Salamunićcar, G.; Lončarić, S.; Mazarico, E. LU60645GT and MA132843GT catalogues of Lunar and Martian craters developed using a Crater Shape-based interpolation crater detection algorithm for topography data. Planet. Space Sci. 2012, 60, 236–247. [Google Scholar] [CrossRef]
- Robbins, S.J. A New Global Database of Lunar Craters >1–2 km: 1. Crater Locations and Sizes, Comparisons With Published Databases, and Global Analysis. J. Geophys. Res. Planets 2018, 124, 871–892. [Google Scholar] [CrossRef]
- Robbins, S.J.; Antonenko, I.; Kirchoff, M.R.; Chapman, C.R.; Fassett, C.I.; Herrick, R.R.; Singer, K.; Zanetti, M.; Lehan, C.; Huang, D.; et al. The variability of crater identification among expert and community crater analysts. Icarus 2014, 234, 109–131. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, C.; Cheng, W. The Spatial Pattern of Lunar Craters on a Global Scale. Geomat. Inf. Sci. Wuhan Univ. 2017, 42, 512–519. [Google Scholar]
- Hou, L. Spatial Distribution and Morphology Characteristics Quantitative Description of the Lunar Craters. Master’s Thesis, Northeast Normal University, Changchun, China, 2013. [Google Scholar]
- Li, K. Study on Small-Scale Lunar Craters’ Morphology and Degradation. Ph.D. Thesis, Wuhan University, Wuhan, China, 2013. [Google Scholar]
- Zhao, D. Intelligent Identification and Spatial Distribution Analysis of Small Craters in Lunar Landing Area. Master’s Thesis, Jilin University, Jilin, China, 2022. [Google Scholar]
- Zuo, W.; Li, C.; Yu, L.; Zhang, Z.; Wang, R.; Zeng, X.; Liu, Y.; Xiong, Y. Shadow–highlight feature matching automatic small crater recognition using high-resolution digital orthophoto map from Chang’E Missions. Acta Geochim. 2019, 38, 541–554. [Google Scholar] [CrossRef]
- Hu, Y.; Xiao, J.; Liu, L.; Zhang, L.; Wang, Y. Detection of Small Craters via Semantic Segmenting Lunar Point Clouds Using Deep Learning Network. Remote Sens. 2021, 13, 1826. [Google Scholar] [CrossRef]
- Kang, Z.; Wang, X.; Hu, T.; Yang, J. Coarse-to-fine extraction of small-scale lunar craters from the CCD images of the Chang’E lunar orbiters. IEEE Trans. Geosci. Remote Sens. 2018, 57, 181–193. [Google Scholar] [CrossRef]
- Yang, H.; Xu, X.; Ma, Y.; Xu, Y.; Liu, S. CraterDANet: A Convolutional Neural Network for Small-Scale Crater Detection via Synthetic-to-Real Domain Adaptation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4600712. [Google Scholar] [CrossRef]
- Heiken, G.; Vaniman, D.; French, B.M. Lunar Sourcebook—A User’s Guide to the Moon; Cambridge University Press: Cambridge, UK, 1991; 753 p. [Google Scholar]
- Bouška, J. Crater Diameter–Depth Relationship from Ranger Lunar Photographs. Nature 1967, 213, 166. [Google Scholar] [CrossRef]
- Pike, R.J.; Spudis, P.D. Basin-ring spacing on the Moon, Mercury, and Mars. Earth Moon Planets 1987, 39, 129–194. [Google Scholar] [CrossRef]
- Pike, R.J. Craters on Earth, Moon, and Mars: Multivariate classification and mode of origin. Earth Planet. Sci. Lett. 1974, 22, 245–255. [Google Scholar] [CrossRef]
- Cintala, M.J.; Head, J.W.; Mutch, T.A. Martian crater depth/diameter relationships-Comparison with the moon and Mercury. In Proceedings of the 7th Lunar and Planetary Science Conference Proceedings, Houston, TX, USA, 15–19 March 1976; pp. 3575–3587. [Google Scholar]
- Hale, W.S.; Grieve, R.A.F. Volumetric analysis of complex lunar craters: Implications for basin ring formation. J. Geophys. Res. Solid Earth 1982, 87, A65–A76. [Google Scholar] [CrossRef]
- Croft, S.K. Lunar crater volumes-Interpretation by models of cratering and upper crustal structure. In Proceedings of the 9th Lunar and Planetary Science Conference Proceedings, Houston, TX, USA, 13–17 March 1978; pp. 3711–3733. [Google Scholar]
- Hu, H.; Yang, R.; Huang, D.; Yu, B. Analysis of depth-diameter relationship of craters around oceanus procellarum area. J. Earth Sci. 2010, 21, 284–289. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, S.; Ma, Y.; Qi, C.; Ma, H.; Yang, H. Self calibration of the stereo vision system of the Chang’e-3 lunar rover based on the bundle block adjustment. ISPRS J. Photogramm. Remote Sens. 2017, 128, 287–297. [Google Scholar] [CrossRef]
- Xu, X.; Liu, M.; Peng, S.; Ma, Y.; Zhao, H.; Xu, A. An In-Orbit Stereo Navigation Camera Self-Calibration Method for Planetary Rovers with Multiple Constraints. Remote Sens. 2022, 14, 402. [Google Scholar] [CrossRef]
- Yan, Y.; Peng, S.; Ma, Y.; Zhang, S.; Qi, C.; Wen, B.; Li, H.; Jia, Y.; Liu, S. A calibration method for navigation cameras’ parameters of planetary detector after landing. Acta Geod. Cartogr. Sin. 2022, 51, 437–445. [Google Scholar]
- Wang, B.; Zhou, J.; Tang, G.; Di, K.; Wan, W.; Liu, C.; Wang, Z. Research on visual localization method of lunar rover. Sci. China Inf. Sci. 2014, 44, 452–460. [Google Scholar]
- Liu, C.; Tang, G.; Wang, B.; Wang, J. Integrated INS and Vision-Based Orientation Determination and Positioning of CE-3 Lunar Rover. J. Spacecr. TT C Technol. 2014, 33, 250–257. [Google Scholar]
- Ma, Y.; Peng, S.; Zhang, J.; Wen, B.; Jin, S.; Jia, Y.; Xu, X.; Zhang, S.; Yan, Y.; Wu, Y.; et al. Precise visual localization and terrain reconstruction for China’s Zhurong Mars rover on orbit. Chin. Sci. Bull. 2022, 67, 2790–2801. [Google Scholar] [CrossRef]
- Li, M.; Liu, S.; Peng, S.; Ma, Y. Improved Dynamic Programming in the Lunar Terrain Reconstruction. Opto-Electron. Eng. 2013, 40, 6–11. [Google Scholar]
- Cao, F.; Wang, R. Stereo matching algorithm for lunar rover vision system. J. Jilin Univ. (Eng. Technol. Ed.) 2011, 41, 24–28. [Google Scholar]
- Qi, N.; Hou, J.; Zhang, H. Stereo Matching Algorithm for Lunar Rover. J. Nanjing Univ. Sci. Technol. 2008, 159, 176–180. [Google Scholar]
- Peng, M.; Di, K.; Liu, Z. Adaptive Markov random field model for dense matchingof deep space stereo images. J. Remote Sens. 2014, 18, 77–89. [Google Scholar]
- Zbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 2287–2318. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 66–75. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5410–5418. [Google Scholar]
- Ma, Y.; Liu, S.; Bing, S.; Wen, B.; Peng, S. A precise visual localisation method for the chinese chang’e-4 Yutu-2 rover. Photogramm. Rec. 2020, 35, 10–39. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar]
- Xu, B.; Xu, Y.; Yang, X.; Jia, W.; Guo, Y. Bilateral grid learning for stereo matching networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12497–12506. [Google Scholar]
- Garvin, J.B.; Frawley, J.J. Geometric properties of Martian craters: Preliminary results from the Mars Orbiter Laser Altimeter. Geophys. Res. Lett. 1998, 25, 4405–4408. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Pre-Calibration Results | Calibration Results of the on-Orbit Calibration | ||
|---|---|---|---|---|
| Left Camera | Right Camera | Left Camera | Right Camera | |
| f | 1179.587843 | 1183.532439 | 1181.342823 | 1178.34611 |
| 6.790105 | 6.585086 | 7.852315 | 5.325352 | |
| 6.566679 | 6.559867 | 4.636378 | 8.286354 | |
| −1.786 × 10−8 | 2.840 × 10−9 | −2.464 × 10−8 | 2.353 × 10−9 | |
| 1.870 × 10−14 | 7.106 × 10−15 | 2.354 × 10−14 | 7.542 × 10−15 | |
| −1.053 × 10−6 | 3.021 × 10−7 | −0.214 × 10−6 | 2.761 × 10−7 | |
| 2.105 × 10−7 | 2.917 × 10−7 | 1.426 × 10−7 | 1.874 × 10−7 | |
| Position Vector (mm) | Rotation Matrix | ||
|---|---|---|---|
| 262.5 | 0.999991903 | 0.001396510 | 0.0037572 |
| 0.48 | −0.001396475 | 0.999978577 | 0.006419021 |
| 0.91 | −0.003757001 | −0.006422024 | 0.999973014 |
| Level Name | Parameter Settings | Output Dimensions |
|---|---|---|
| Il/Ir | Convolution kernel size, number of channels, and step size | H × W × 3 |
| conv0_1 | 3 × 3, 32, 2 | H/2 × W/2 × 32 |
| conv0_2 | 3 × 3, 32 | H/2 × W/2 × 32 |
| conv0_3 | 3 × 3, 32 | H/2 × W/2 × 32 |
| conv1_x | H/2 × W/2 × 32 | |
| conv2_x | H/4 × W/4 × 64 | |
| conv3_x | H/4 × W/4 × 128 | |
| conv4_x | H/4 × W/4 × 128 | |
| Cascade: Conv2_x, Conv3_x, and Conv4_x | H/4 × W/4 × 320 |
| Network Settings | KITTI 2015 | ||||
|---|---|---|---|---|---|
| Residual Module | Cost Aggregation | D1-bg | D1-fg | D1-all | Number of Parameters |
| × | Series cost volume | 1.86 | 4.62 | 2.32 | 20.513 M |
| × | Joint cost volume | 1.81 | 3.83 | 2.03 | 22.545 M |
| × | Cross-scale 3D aggregation module | 1.44 | 3.65 | 1.93 | 21.742 M |
| √ | Series cost volume | 1.36 | 4.06 | 1.87 | 11.645 M |
| √ | Joint cost volume | 1.42 | 3.72 | 1.81 | 12.657 M |
| √ | Cross-scale 3D aggregation module | 1.25 | 3.31 | 1.73 | 10.528 M |
| Algorithm | Noc (%) | All (%) | ||||
|---|---|---|---|---|---|---|
| D1-bg | D1-fg | D1-all | D1-bg | D1-fg | D1-all | |
| DispNet | 4.11 | 3.72 | 4.05 | 4.32 | 4.41 | 4.34 |
| GC-Net | 2.02 | 5.58 | 2.61 | 2.21 | 6.16 | 2.87 |
| PSMNet | 1.71 | 4.31 | 2.14 | 1.86 | 4.62 | 2.32 |
| CscaNet | 1.59 | 3.51 | 1.59 | 1.25 | 3.31 | 1.73 |
| Algorithm | GC-Net | DispNet | PSMNet | CscaNet |
|---|---|---|---|---|
| EPE | 2.51 | 1.68 | 1.09 | 0.74 |
| Crater Diameter D (cm) | Crater Depth d (cm) | ||
|---|---|---|---|
| Minimum | 24.3 | 2.3 | 0.036 |
| Maximum | 291.4 | 25.5 | 0.218 |
| Mean | 99.7 | 8.5 | 0.087 |
| Median | 78.5 | 6.0 | 0.078 |
| Standard deviation | 68.5 | 6.1 | 0.023 |
| Kurtosis | 0.6 | 0.9 | −0.730 |
| Skewness | 1.3 | 1.3 | 1.935 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Fu, X.; Zhao, H.; Liu, M.; Xu, A.; Ma, Y. Three-Dimensional Reconstruction and Geometric Morphology Analysis of Lunar Small Craters within the Patrol Range of the Yutu-2 Rover. Remote Sens. 2023, 15, 4251. https://doi.org/10.3390/rs15174251
Xu X, Fu X, Zhao H, Liu M, Xu A, Ma Y. Three-Dimensional Reconstruction and Geometric Morphology Analysis of Lunar Small Craters within the Patrol Range of the Yutu-2 Rover. Remote Sensing. 2023; 15(17):4251. https://doi.org/10.3390/rs15174251
Chicago/Turabian StyleXu, Xinchao, Xiaotian Fu, Hanguang Zhao, Mingyue Liu, Aigong Xu, and Youqing Ma. 2023. "Three-Dimensional Reconstruction and Geometric Morphology Analysis of Lunar Small Craters within the Patrol Range of the Yutu-2 Rover" Remote Sensing 15, no. 17: 4251. https://doi.org/10.3390/rs15174251
APA StyleXu, X., Fu, X., Zhao, H., Liu, M., Xu, A., & Ma, Y. (2023). Three-Dimensional Reconstruction and Geometric Morphology Analysis of Lunar Small Craters within the Patrol Range of the Yutu-2 Rover. Remote Sensing, 15(17), 4251. https://doi.org/10.3390/rs15174251