
RemainNet: Explore Road Extraction from Remote Sensing Image Using Mask Image Modeling

Abstract
:1. Introduction
- We introduce MIM to enforce interactions of occluded areas with other areas, thus improving the network inference ability on occluded areas. To the best of our knowledge, it is the first RS image road extraction work based on MIM.
- The proposed RemainNet adopts IPM and SPM for reconstruction. IPM reconstructs original images at the RGB level from low-level features. SPM reconstructs semantic labels at the semantic level from low-level and high-level features.
- We verify the effectiveness of the proposed RemainNet on a Massachusetts Roads dataset and DeepGlobe Road Extraction dataset, and the results indicate that RemainNet outperforms other state-of-the-art methods.
2. Related Works
2.1. Semantic Segmentation
2.2. Road Extraction
2.3. Masked Image Modeling
3. Proposed Methods
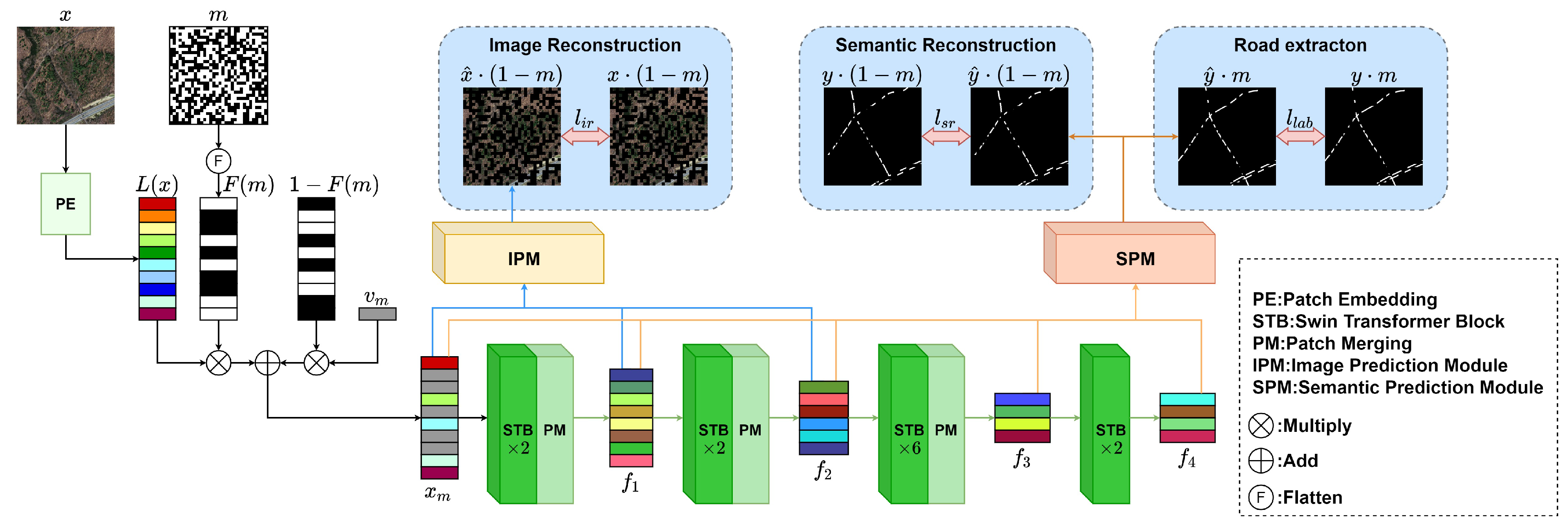
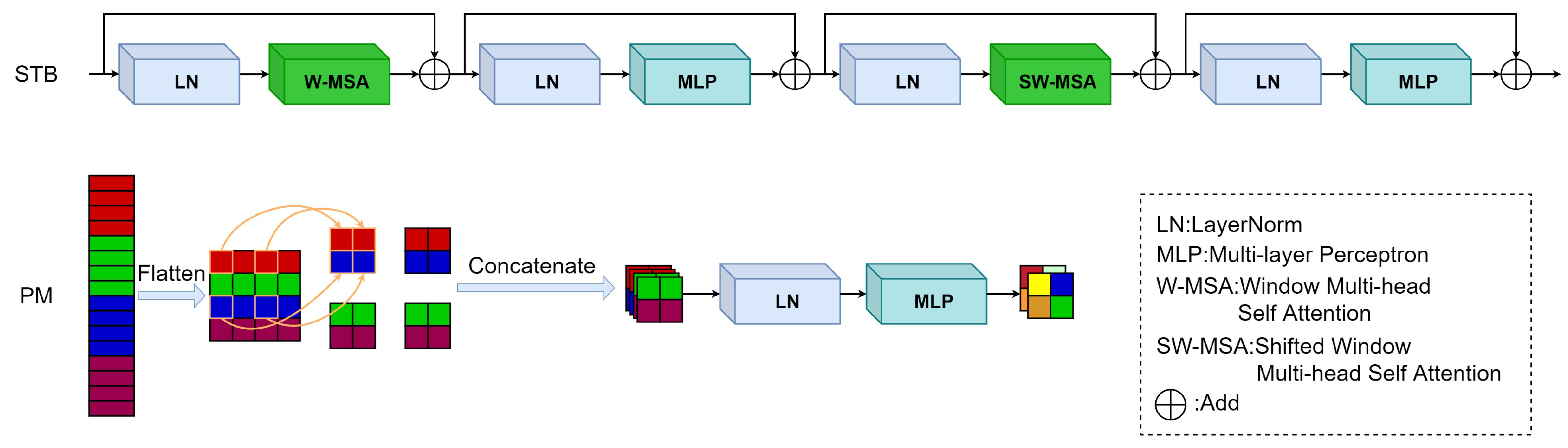
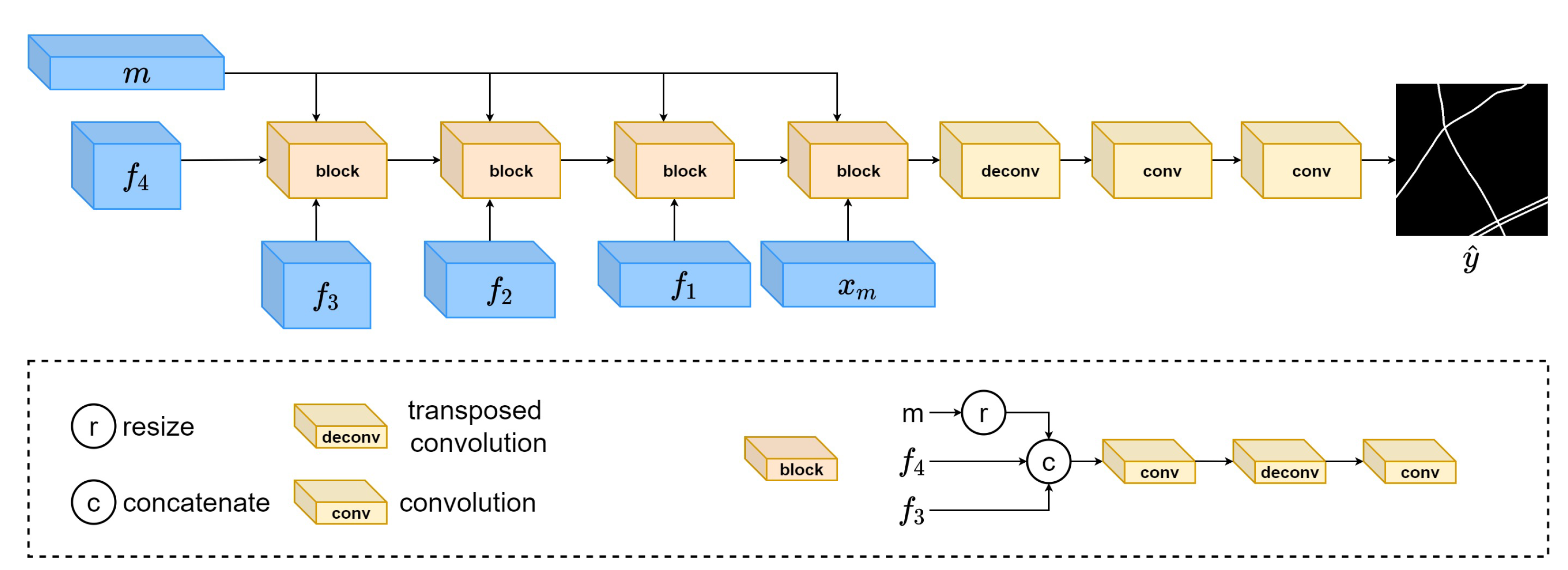
3.1. Framework
3.2. Road Extraction
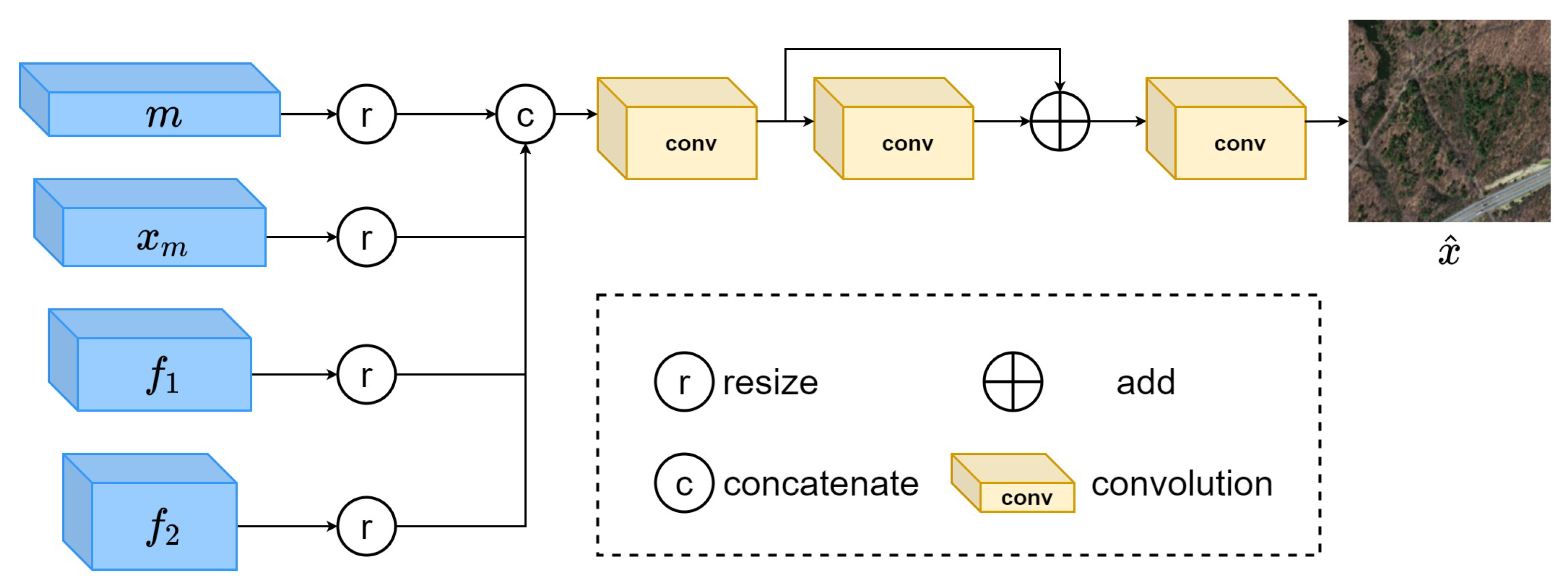
3.3. Image Reconstruction
3.4. Semantic Reconstruction
4. Experiments
4.1. Dataset
- (1)
- The Massachusetts Roads dataset contains 1171 RS images with labels, including 1108 training images, 14 validation images, and 49 test images. The dataset covers around 2600 sq. km area with a resolution of 120 cm/pixel. The original size of each image is 1500 × 1500. We resize them, then crop them into the size of 512 × 512 without overlapping; thus, the training, validation, and test image numbers are 9972, 126, and 441, respectively.
- (2)
- The DeepGlobe Road Extraction dataset consists of 8570 RS images, including 6226 satellite images with labels and 2344 RS images without labels. The dataset covers around 2220 sq. km area with a resolution of 50 cm/pixel. The size of each image is 1024 × 1024. In the experiment, we resize 6226 RS images with labels into 512 × 512, then randomly divide them into subsets with a rate of 0.8 (training set), 0.1 (validation set), and 0.1 (test set).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Training | Validation | Test | Total |
|---|---|---|---|---|
| Massachusetts Roads | 9972 | 126 | 441 | 10,539 |
| DeepGlobe Road Extraction | 4982 | 622 | 622 | 6226 |
4.2. Baselines and Metrics
- (1)
- DeepLab v3+ [27]. DeepLab v3+ is a classical semantic segmentation model, which employs an encoder–decoder structure with atrous convolution. The encoder encodes multiscale contextual information, and the decoder is simple yet effective.
- (2)
- D-LinkNet [49]. D-LinkNet is a classical road extraction model, which is built on a LinkNet architecture. It contains dilated convolution layers to expand a receptive field. The network had the best IoU scores in the CVPR DeepGlobe 2018 Road Extraction Challenge.
- (3)
- NL-LinkNet [10]. NL-LinkNet is the first RS image road extraction model to use nonlocal operations. The nonlocal block ensures the model to capture long-range dependencies and distant information.
- (4)
- MACU-Net [38]. MACU-Net is based on U-Net. MACU-Net employs a multiscale skip connection and asymmetric convolution block for a higher feature extract ability.
- (5)
- RoadExNet [13]. RoadExNet is the generator of SemiRoadExNet. RoadExNet employs a vertical attention module and horizontal attention module to concentrate on road areas.
4.3. Implementation Details
4.4. Experimental Result
4.4.1. Results in Massachusetts Roads Dataset
4.4.2. Results in DeepGlobe Road Extraction Dataset
4.4.3. Comparison of Parameters and Computational Complexity
4.5. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep learning approaches applied to remote sensing datasets for road extraction: A state-of-the-art review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Zi, W.; Xiong, W.; Chen, H.; Li, J.; Jing, N. SGA-Net: Self-constructing graph attention neural network for semantic segmentation of remote sensing images. Remote Sens. 2021, 13, 4201. [Google Scholar] [CrossRef]
- Song, J.; Chen, H.; Du, C.; Li, J. Semi-MapGen: Translation of Remote Sensing Image into Map via Semi-supervised Adversarial Learning. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 4701219. [Google Scholar] [CrossRef]
- Zi, W.; Xiong, W.; Chen, H.; Chen, L. TAGCN: Station-level demand prediction for bike-sharing system via a temporal attention graph convolution network. Inf. Sci. 2021, 561, 274–285. [Google Scholar] [CrossRef]
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road extraction methods in high-resolution remote sensing images: A comprehensive review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Feng, S.; Ji, K.; Wang, F.; Zhang, L.; Ma, X.; Kuang, G. PAN: Part Attention Network Integrating Electromagnetic Characteristics for Interpretable SAR Vehicle Target Recognition. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5204617. [Google Scholar] [CrossRef]
- Wu, S.; Du, C.; Chen, H.; Xu, Y.; Guo, N.; Jing, N. Road extraction from very high resolution images using weakly labeled OpenStreetMap centerline. ISPRS Int. J. Geo-Inf. 2019, 8, 478. [Google Scholar] [CrossRef]
- Chen, H.; Peng, S.; Du, C.; Li, J.; Wu, S. SW-GAN: Road Extraction from Remote Sensing Imagery Using Semi-Weakly Supervised Adversarial Learning. Remote Sens. 2022, 14, 4145. [Google Scholar] [CrossRef]
- Mei, J.; Li, R.J.; Gao, W.; Cheng, M.M. CoANet: Connectivity attention network for road extraction from satellite imagery. IEEE Trans. Image Process. 2021, 30, 8540–8552. [Google Scholar] [CrossRef]
- Wang, Y.; Seo, J.; Jeon, T. NL-LinkNet: Toward lighter but more accurate road extraction with nonlocal operations. IEEE Geosci. Remote Sens. Lett. 2021, 19, 3000105. [Google Scholar] [CrossRef]
- Chen, S.B.; Ji, Y.X.; Tang, J.; Luo, B.; Wang, W.Q.; Lv, K. DBRANet: Road extraction by dual-branch encoder and regional attention decoder. IEEE Geosci. Remote Sens. Lett. 2021, 19, 3002905. [Google Scholar] [CrossRef]
- Li, R.; Gao, B.; Xu, Q. Gated auxiliary edge detection task for road extraction with weight-balanced loss. IEEE Geosci. Remote Sens. Lett. 2020, 18, 786–790. [Google Scholar] [CrossRef]
- Chen, H.; Li, Z.; Wu, J.; Xiong, W.; Du, C. SemiRoadExNet: A semi-supervised network for road extraction from remote sensing imagery via adversarial learning. ISPRS J. Photogramm. Remote Sens. 2023, 198, 169–183. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, K.; Ji, S. Simultaneous road surface and centerline extraction from large-scale remote sensing images using CNN-based segmentation and tracing. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8919–8931. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, H.; Du, C.; Li, J. MSACon: Mining spatial attention-based contextual information for road extraction. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5604317. [Google Scholar] [CrossRef]
- Ding, L.; Bruzzone, L. DiResNet: Direction-aware residual network for road extraction in VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10243–10254. [Google Scholar] [CrossRef]
- Yang, Z.; Zhou, D.; Yang, Y.; Zhang, J.; Chen, Z. Road Extraction From Satellite Imagery by Road Context and Full-Stage Feature. IEEE Geosci. Remote. Sens. Lett. 2022, 20, 8000405. [Google Scholar] [CrossRef]
- Li, S.; Wu, D.; Wu, F.; Zang, Z.; Sun, B.; Li, H.; Xie, X.; Li, S. Architecture-Agnostic Masked Image Modeling–From ViT back to CNN. arXiv 2022, arXiv:2205.13943. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Khan, S.H.; Bennamoun, M.; Sohel, F.; Togneri, R. Geometry driven semantic labeling of indoor scenes. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 679–694. [Google Scholar]
- Jaiswal, S.; Pandey, M. A Review on Image Segmentation. Rising Threat. Expert Appl. Solut. 2021, 2020, 233–240. [Google Scholar]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ulku, I.; Akagündüz, E. A survey on deep learning-based architectures for semantic segmentation on 2d images. Appl. Artif. Intell. 2022, 36, 2032924. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.A. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Lv, P.; Wu, W.; Zhong, Y.; Zhang, L. Review of Vision Transformer Models for Remote Sensing Image Scene Classification. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 2231–2234. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; Volume 139, pp. 10347–10357. [Google Scholar]
- Chu, X.; Tian, Z.; Zhang, B.; Wang, X.; Wei, X.; Xia, H.; Shen, C. Conditional Positional Encodings for Vision Transformers. arXiv 2021, arXiv:2102.10882. [Google Scholar]
- Li, Y.; Zhang, K.; Cao, J.; Timofte, R.; Gool, L.V. LocalViT: Bringing Locality to Vision Transformers. arXiv 2021, arXiv:2104.05707. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2021; pp. 7262–7272. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Advances in Neural Information Processing Systems; Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; IEEE: Piscataway Township, NJ, USA, 2021. [Google Scholar]
- Jin, Y.; Han, D.; Ko, H. TrSeg: Transformer for semantic segmentation. Pattern Recognit. Lett. 2021, 148, 29–35. [Google Scholar] [CrossRef]
- Li, R.; Duan, C.; Zheng, S.; Zhang, C.; Atkinson, P.M. MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. IEEE Geosci. Remote. Sens. Lett. 2021, 19, 8007205. [Google Scholar] [CrossRef]
- Wan, Q.; Huang, Z.; Lu, J.; Yu, G.; Zhang, L. SeaFormer: Squeeze-enhanced Axial Transformer for Mobile Semantic Segmentation. arXiv 2023, arXiv:2301.13156. [Google Scholar]
- Yuan, F.; Zhang, Z.; Fang, Z. An effective CNN and Transformer complementary network for medical image segmentation. Pattern Recognit. 2023, 136, 109228. [Google Scholar] [CrossRef]
- Chen, Z.; Deng, L.; Luo, Y.; Li, D.; Marcato Junior, J.; Nunes Gonçalves, W.; Awal Md Nurunnabi, A.; Li, J.; Wang, C.; Li, D. Road extraction in remote sensing data: A survey. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102833. [Google Scholar] [CrossRef]
- Sghaier, M.O.; Lepage, R. Road extraction from very high resolution remote sensing optical images based on texture analysis and beamlet transform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 9, 1946–1958. [Google Scholar] [CrossRef]
- Wang, J.; Qin, Q.; Yang, X.; Wang, J.; Ye, X.; Qin, X. Automated road extraction from multi-resolution images using spectral information and texture. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; IEEE: Piscataway Township, NJ, USA, 2014; pp. 533–536. [Google Scholar]
- He, C.; Liao, Z.x.; Yang, F.; Deng, X.p.; Liao, M.s. Road extraction from SAR imagery based on multiscale geometric analysis of detector responses. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1373–1382. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N. Extraction of road features from UAV images using a novel level set segmentation approach. Int. J. Urban Sci. 2019, 23, 391–405. [Google Scholar] [CrossRef]
- Xin, J.; Zhang, X.; Zhang, Z.; Fang, W. Road extraction of high-resolution remote sensing images derived from DenseUNet. Remote Sens. 2019, 11, 2499. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Sharma, G.; Maulud, K.N.A.; Alamri, A. Improving road semantic segmentation using generative adversarial network. IEEE Access 2021, 9, 64381–64392. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 8–23 June 2018; pp. 182–186. [Google Scholar]
- Abdollahi, A.; Bakhtiari, H.R.R.; Nejad, M.P. Investigation of SVM and level set interactive methods for road extraction from google earth images. J. Indian Soc. Remote Sens. 2018, 46, 423–430. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Li, Y.; Wang, H.; Li, H. Spatial information inference net: Road extraction using road-specific contextual information. ISPRS J. Photogramm. Remote Sens. 2019, 158, 155–166. [Google Scholar] [CrossRef]
- Zhou, Q.; Yu, C.; Luo, H.; Wang, Z.; Li, H. MimCo: Masked Image Modeling Pre-training with Contrastive Teacher. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 4487–4495. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; 2018; p. 12. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 20 June 2023).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative pretraining from pixels. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 1691–1703. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. BEiT: BERT Pre-Training of Image Transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9650–9660. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 16000–16009. [Google Scholar]
- Zhang, C.; Zhang, C.; Song, J.; Yi, J.S.K.; Zhang, K.; Kweon, I.S. A Survey on Masked Autoencoder for Self-supervised Learning in Vision and Beyond. arXiv 2022, arXiv:2208.00173. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9653–9663. [Google Scholar]
- Li, G.; Zheng, H.; Liu, D.; Su, B.; Zheng, C. SemMAE: Semantic-Guided Masking for Learning Masked Autoencoders. arXiv 2022, arXiv:2206.10207. [Google Scholar]
- Xue, H.; Gao, P.; Li, H.; Qiao, Y.; Sun, H.; Li, H.; Luo, J. Stare at What You See: Masked Image Modeling Without Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 22732–22741. [Google Scholar]
- Qi, G.J.; Shah, M. Adversarial Pretraining of Self-Supervised Deep Networks: Past, Present and Future. arXiv 2022, arXiv:2210.13463. [Google Scholar]
- Chen, X.; Ding, M.; Wang, X.; Xin, Y.; Mo, S.; Wang, Y.; Han, S.; Luo, P.; Zeng, G.; Wang, J. Context Autoencoder for Self-Supervised Representation Learning. arXiv 2022, arXiv:2202.03026. [Google Scholar]
- Wei, C.; Fan, H.; Xie, S.; Wu, C.Y.; Yuille, A.; Feichtenhofer, C. Masked Feature Prediction for Self-Supervised Visual Pre-Training. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14648–14658. [Google Scholar] [CrossRef]
- Chen, X.; Liu, W.; Liu, X.; Zhang, Y.; Han, J.; Mei, T. MAPLE: Masked Pseudo-Labeling AutoEncoder for Semi-Supervised Point Cloud Action Recognition. In Proceedings of the 30th ACM International Conference on Multimedia, New York, NY, USA, 10–14 October 2022; pp. 708–718. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling; University of Toronto: Toronto, ON, Canada, 2013. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth Through Satellite Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Vancouver, BC, Canada, 17–24 June 2018. [Google Scholar]
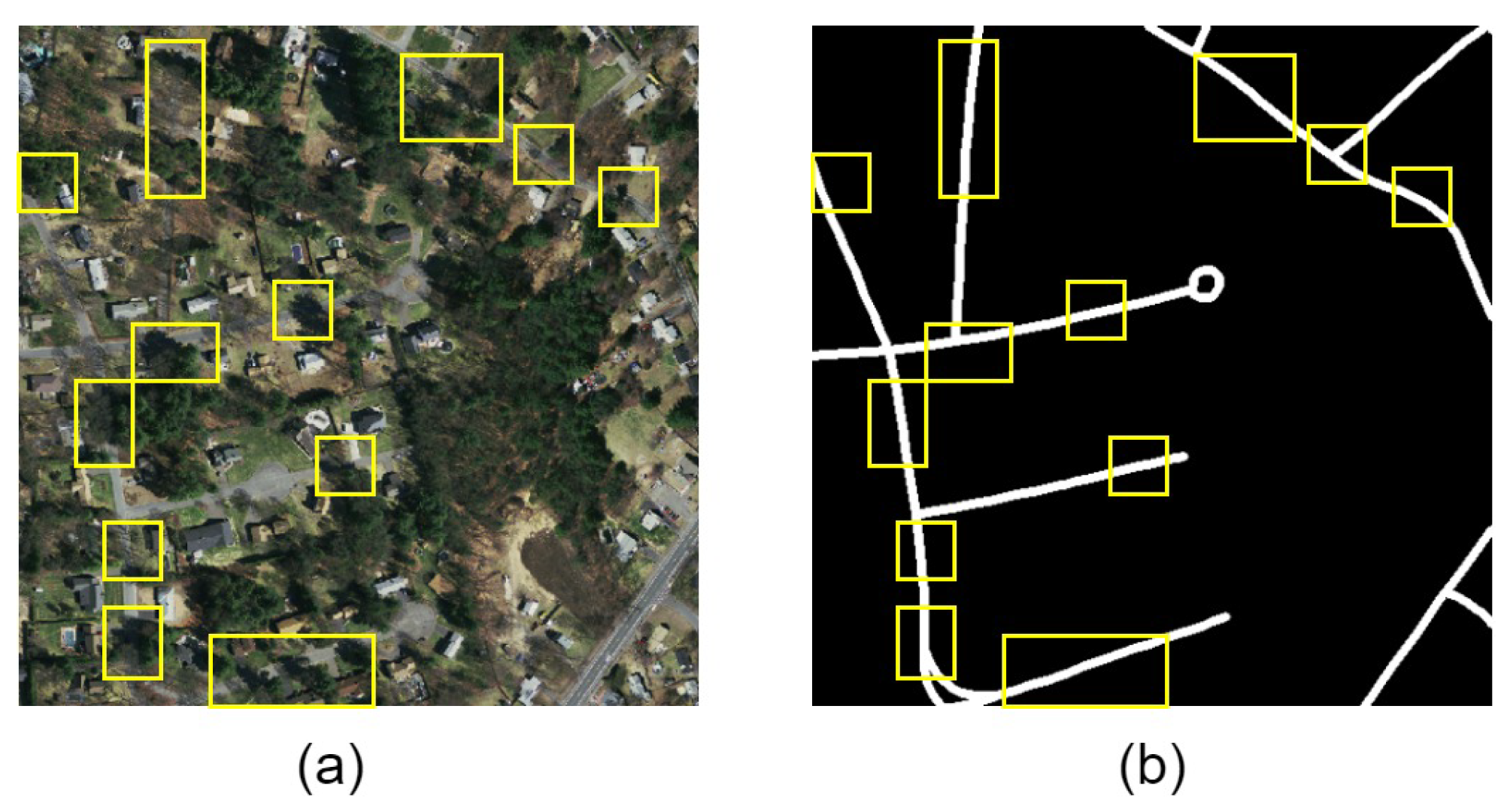


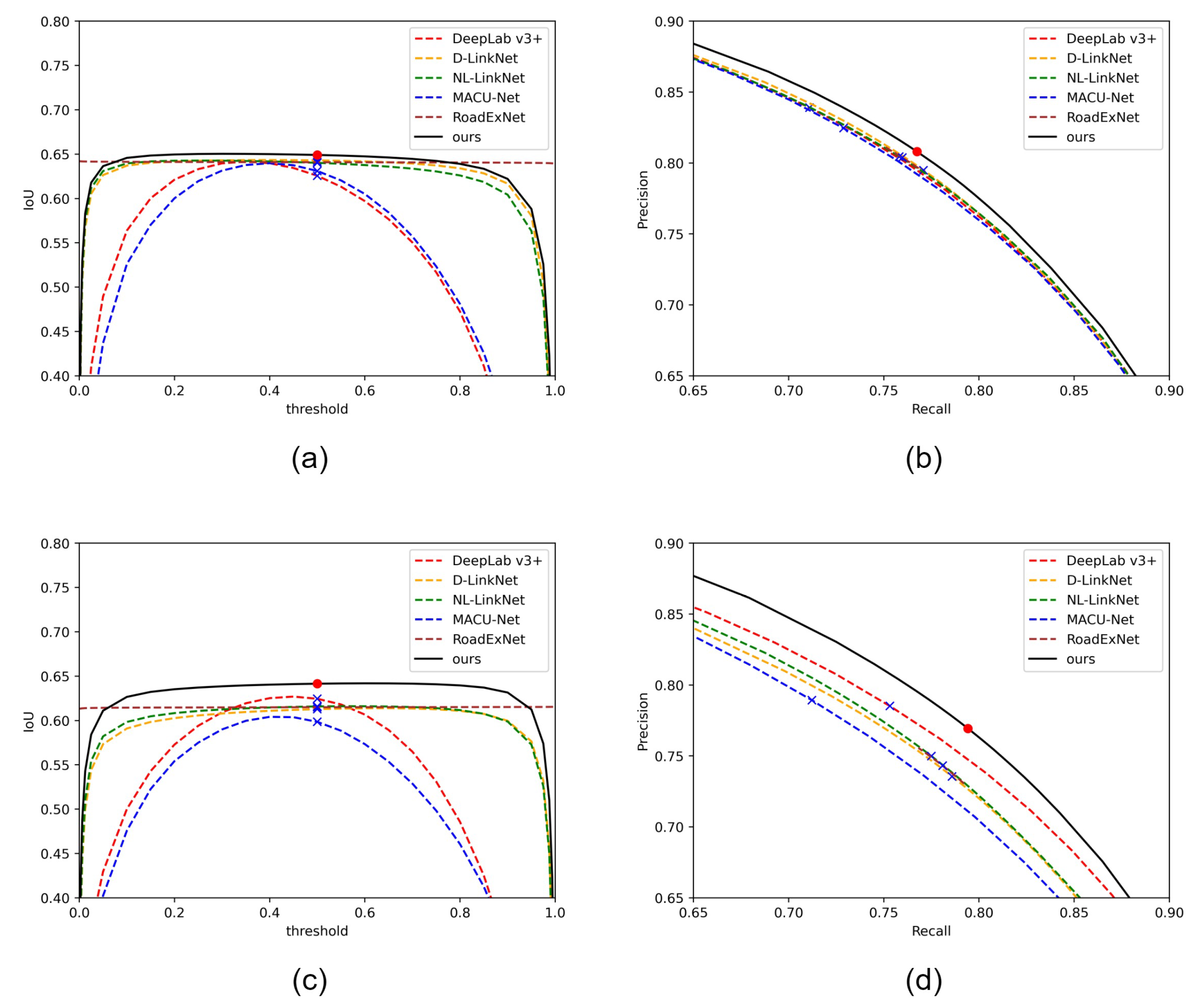

| Method | P | R | F1 | IoU |
|---|---|---|---|---|
| DeepLab v3+ [27] | 0.8391 | 0.7110 | 0.7697 | 0.6257 |
| D-LinkNet [49] | 0.7914 | 0.7681 | 0.7796 | 0.6387 |
| NL-LinkNet [10] | 0.8045 | 0.7581 | 0.7806 | 0.6402 |
| MACU-Net [38] | 0.8246 | 0.7289 | 0.7738 | 0.6310 |
| RoadExNet [13] | 0.8038 | 0.7598 | 0.7812 | 0.6409 |
| RemainNet | 0.8080 | 0.7675 | 0.7872 | 0.6491 |
| Method | P | R | F1 | IoU |
|---|---|---|---|---|
| DeepLab v3+ [27] | 0.7852 | 0.7532 | 0.7689 | 0.6245 |
| D-LinkNet [49] | 0.7356 | 0.7858 | 0.7599 | 0.6128 |
| NL-LinkNet [10] | 0.7499 | 0.7750 | 0.7623 | 0.6159 |
| MACU-Net [38] | 0.7893 | 0.7123 | 0.7488 | 0.5985 |
| RoadExNet [13] | 0.7431 | 0.7809 | 0.7616 | 0.6149 |
| RemainNet | 0.7694 | 0.7942 | 0.7816 | 0.6415 |
| Method | FLOPs/G | Parameters/M |
|---|---|---|
| DeepLab v3+ [27] | 88.54 | 59.23 |
| D-LinkNet [49] | 33.59 | 31.10 |
| NL-LinkNet [10] | 31.44 | 21.82 |
| MACU-Net [38] | 33.59 | 5.15 |
| RoadExNet [13] | 33.87 | 31.13 |
| RemainNet | 60.90 | 33.59 |
| Method | Massachusetts Roads | DeepGlobe Road Extraction | ||||||
|---|---|---|---|---|---|---|---|---|
| P | R | F1 | IoU | P | R | F1 | IoU | |
| RemainNet without IR and SR | 0.8126 | 0.7541 | 0.7822 | 0.6423 | 0.7538 | 0.7873 | 0.7702 | 0.6263 |
| RemainNet without SR | 0.8064 | 0.7618 | 0.7834 | 0.6440 | 0.7553 | 0.7931 | 0.7738 | 0.6310 |
| RemainNet without IR | 0.8058 | 0.7655 | 0.7851 | 0.6462 | 0.7569 | 0.7918 | 0.7740 | 0.6313 |
| RemainNet | 0.8080 | 0.7675 | 0.7872 | 0.6491 | 0.7694 | 0.7942 | 0.7816 | 0.6415 |
| Mask Rate Strategy | Massachusetts Roads | DeepGlobe Road Extraction | ||||||
|---|---|---|---|---|---|---|---|---|
| P | R | F1 | IoU | P | R | F1 | IoU | |
| keep unchanging(0.75) | 0.8056 | 0.7632 | 0.7838 | 0.6445 | 0.7626 | 0.7910 | 0.7765 | 0.6347 |
| keep unchanging(0.375) | 0.8015 | 0.7677 | 0.7842 | 0.6450 | 0.7531 | 0.7997 | 0.7757 | 0.6336 |
| linearly reduce | 0.8080 | 0.7675 | 0.7872 | 0.6491 | 0.7694 | 0.7942 | 0.7816 | 0.6415 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Chen, H.; Jing, N.; Li, J. RemainNet: Explore Road Extraction from Remote Sensing Image Using Mask Image Modeling. Remote Sens. 2023, 15, 4215. https://doi.org/10.3390/rs15174215
Li Z, Chen H, Jing N, Li J. RemainNet: Explore Road Extraction from Remote Sensing Image Using Mask Image Modeling. Remote Sensing. 2023; 15(17):4215. https://doi.org/10.3390/rs15174215
Chicago/Turabian StyleLi, Zhenghong, Hao Chen, Ning Jing, and Jun Li. 2023. "RemainNet: Explore Road Extraction from Remote Sensing Image Using Mask Image Modeling" Remote Sensing 15, no. 17: 4215. https://doi.org/10.3390/rs15174215
APA StyleLi, Z., Chen, H., Jing, N., & Li, J. (2023). RemainNet: Explore Road Extraction from Remote Sensing Image Using Mask Image Modeling. Remote Sensing, 15(17), 4215. https://doi.org/10.3390/rs15174215