
Multi-Attention Multi-Image Super-Resolution Transformer (MAST) for Remote Sensing


 and
and
Abstract
:1. Introduction
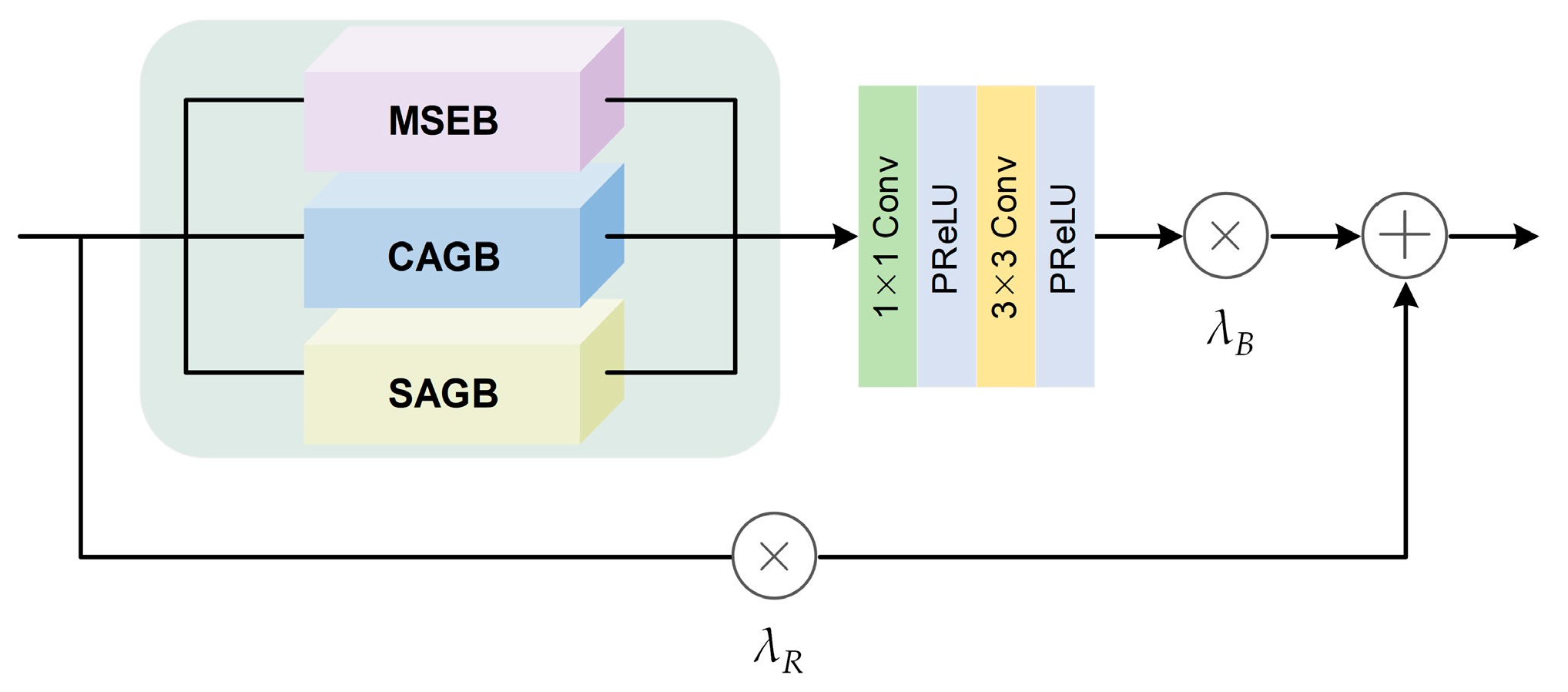
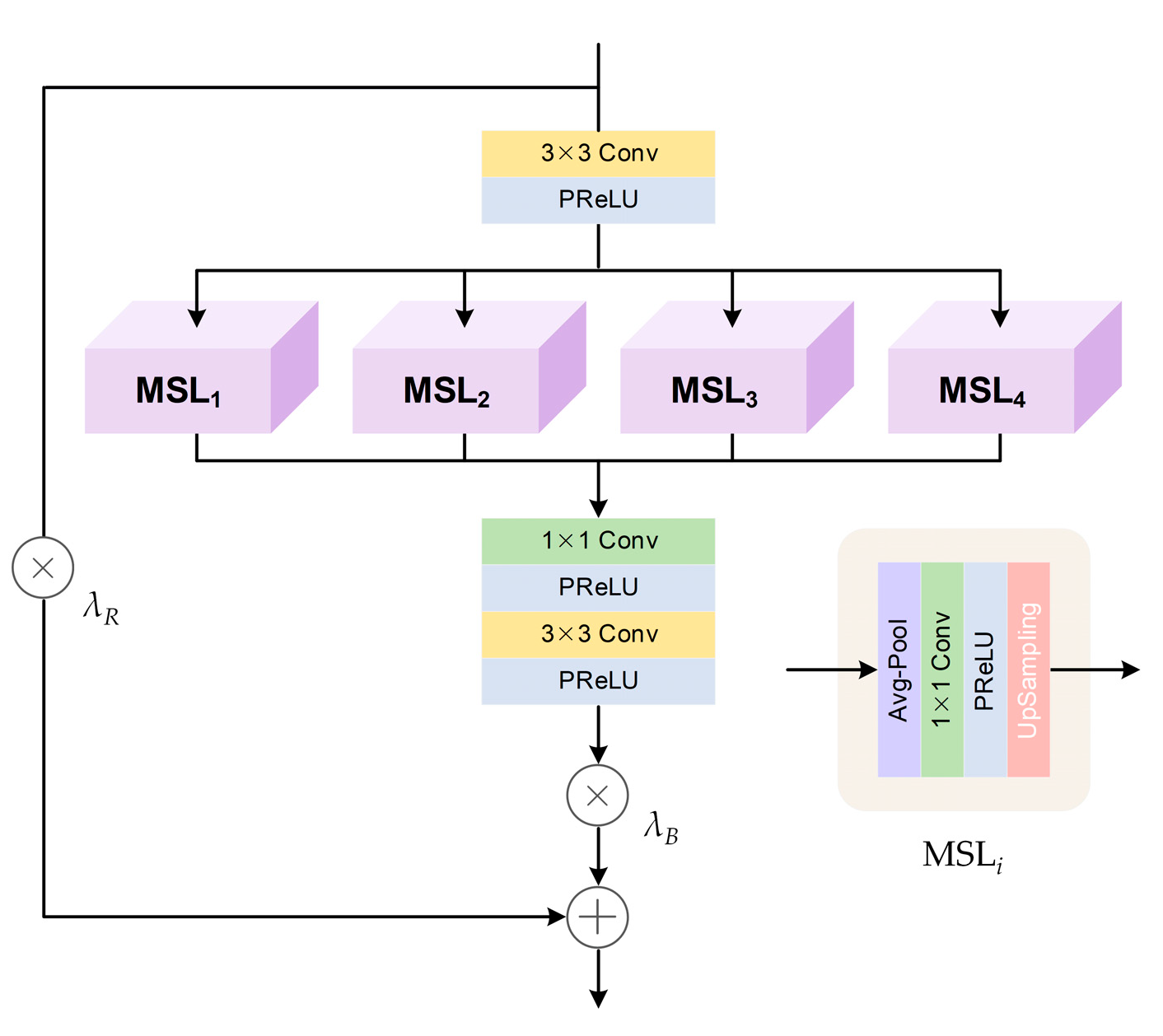
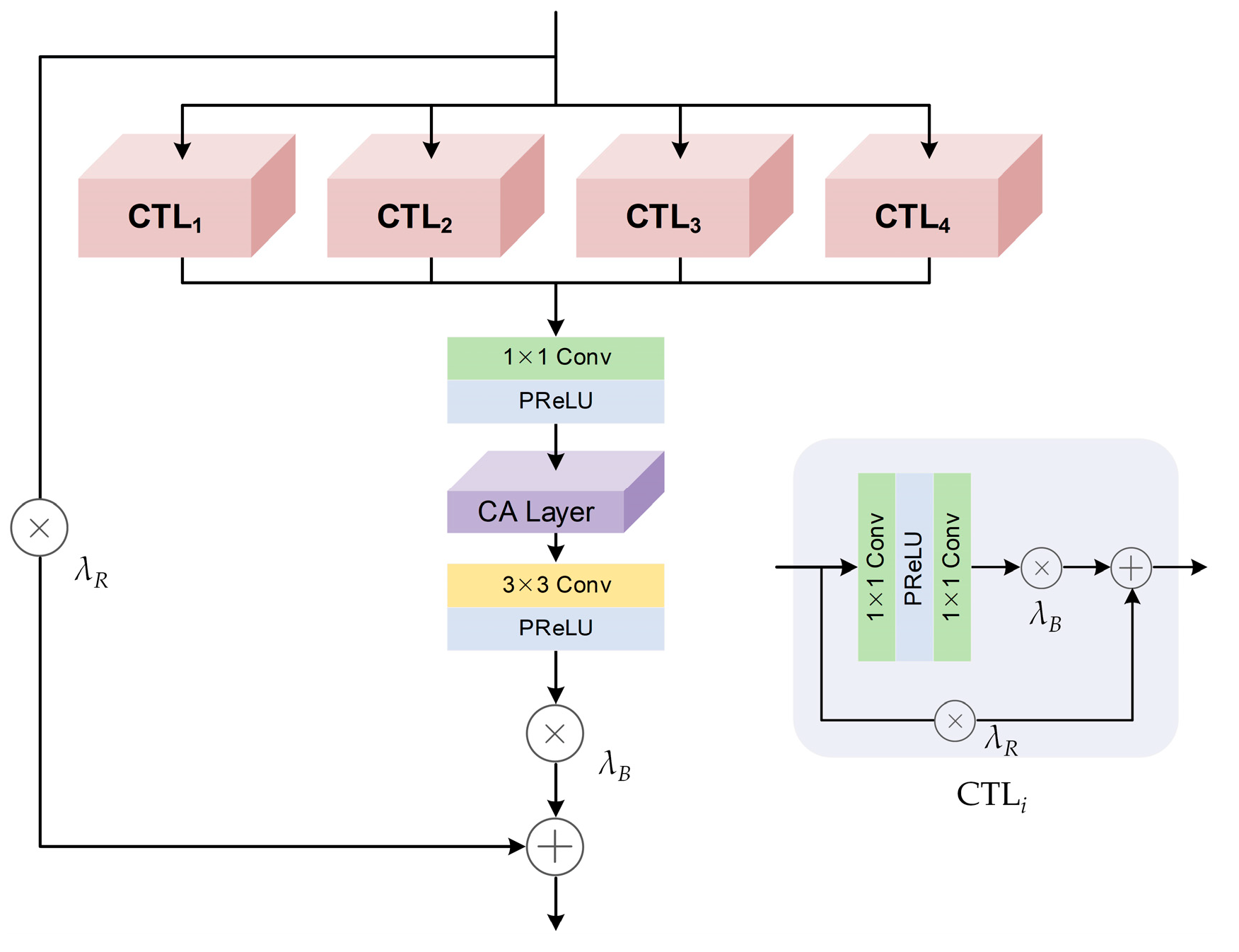
- We innovatively proposed a Multi-Scale and Mixed Attention Block (MMAB) that enabled a model to fully extract complementary information from multiple images. Specifically, we introduced a Multi-Scale Extraction Block (MSEB) to obtain more reference information and effectively suppress registration errors. We also presented a Channel Attention Guided Block (CAGB) and a Spatial Attention Guided Block (SAGB) to enhance the model’s perception of high-frequency features with high contributions to the super-resolution task in each image.
- We also presented a Collaborative Attention Fusion Block (CAFB) based on the Transformer, which constructed a more comprehensive feature fusion mechanism incorporating self-attention, channel attention, and local attention. The embedding of channel attention enhanced the advantage of the Transformer in establishing global correlations between multiple frames. The introduction of the Residual Local Attention Block (RLAB) largely broke through the limitations of the Transformer in capturing local high-frequency information, enabling the model to simultaneously restore the overall structure and local details of the image.
2. Related Work
2.1. Multi-Image Super-Resolution
2.2. Deep Learning for Multi-Image Super-Resolution
2.3. Transformers for Multi-Image Super-Resolution
3. Methodology
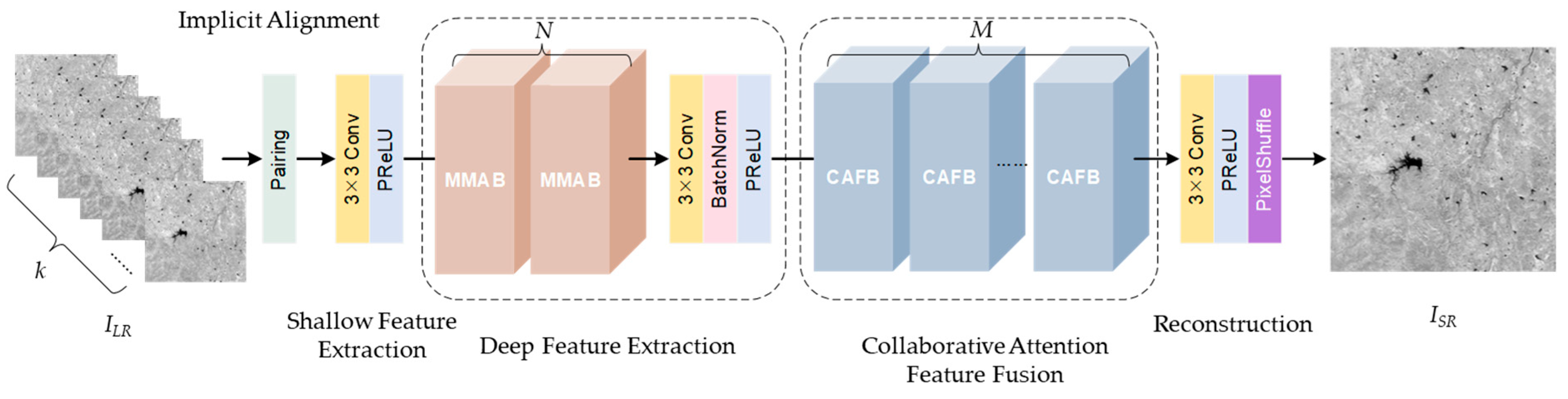
3.1. Network Architecture
3.2. Deep Feature Extraction Module
3.2.1. Multi-Scale Extraction Block (MSEB)
3.2.2. Channel Attention Guided Block (CAGB)
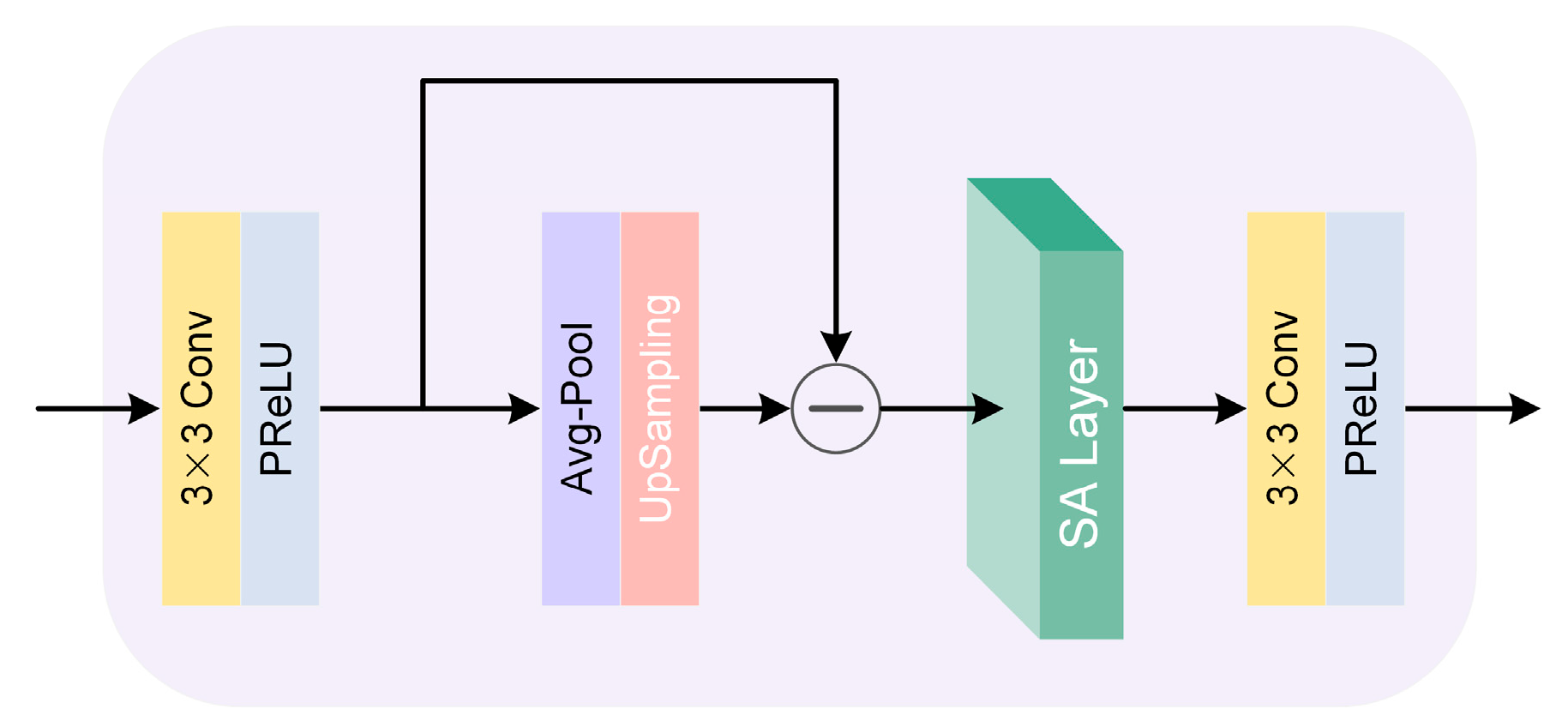
3.2.3. Spatial Attention Guided Block (SAGB)
3.3. Collaborative Attention Feature Fusion Module
4. Experiments
4.1. PROBA-V Kelvin Dataset
4.2. Evaluation Metric
4.3. Experimental Settings
4.3.1. Data Pre-Processing
4.3.2. Parameter Settings
5. Discussion
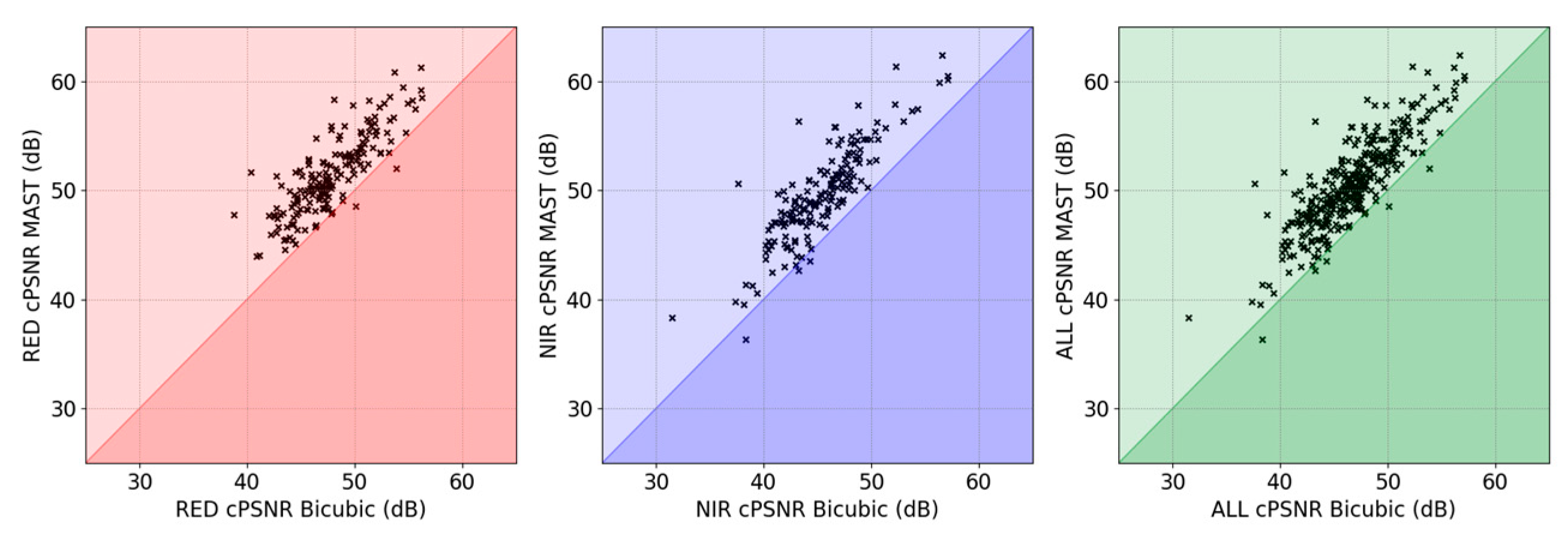
5.1. Comparison with State-of-the-Art Methods
- Classical MISR Methods:
- 2.
- SISR Method:
- 3.
- Video Super-Resolution Method:
- 4.
- Deep Learning Super-Resolution Methods:
5.2. Analysis of Ablation Experiments
5.2.1. Effectiveness of Each Module
- Importance of MMAB
- 2.
- Importance of CAFB
5.2.2. Analysis of the Effect of the Number of Input Images
5.2.3. Impact of the Number of Blocks
5.2.4. Impact of the Size of the Training Images
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hussain, S.; Lu, L.; Mubeen, M.; Nasim, W.; Karuppannan, S.; Fahad, S.; Tariq, A.; Mousa, B.; Mumtaz, F.; Aslam, M. Spatiotemporal variation in land use land cover in the response to local climate change using multispectral remote sensing data. Land 2022, 11, 595. [Google Scholar] [CrossRef]
- Ngo, T.D.; Bui, T.T.; Pham, T.M.; Thai, H.T.; Nguyen, G.L.; Nguyen, T.N. Image deconvolution for optical small satellite with deep learning and real-time GPU acceleration. J. Real-Time Image Process. 2021, 18, 1697–1710. [Google Scholar] [CrossRef]
- Wang, X.; Yi, J.; Guo, J.; Song, Y.; Lyu, J.; Xu, J.; Yan, W.; Zhao, J.; Cai, Q.; Min, H. A review of image super-resolution approaches based on deep learning and applications in remote sensing. Remote Sens. 2022, 14, 5423. [Google Scholar] [CrossRef]
- Jo, Y.; Oh, S.W.; Vajda, P.; Kim, S.J. Tackling the ill-posedness of super-resolution through adaptive target generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16236–16245. [Google Scholar]
- Harris, J. Diffraction and Resolving Power. J. Opt. Soc. Am. 1964, 54, 931. [Google Scholar] [CrossRef]
- Milanfar, P. Super-Resolution Imaging; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, S.C. Deep learning for image super-resolution: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhou, Y. Image super-resolution with non-local sparse attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3517–3526. [Google Scholar]
- Chan, K.C.; Wang, X.; Xu, X.; Gu, J.; Loy, C.C. Glean: Generative latent bank for large-factor image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14245–14254. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Shi, Y.; Han, L.; Han, L.; Chang, S.; Hu, T.; Dancey, D. A latent encoder coupled generative adversarial network (le-gan) for efficient hyperspectral image super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–19. [Google Scholar] [CrossRef]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5791–5800. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 22367–22377. [Google Scholar]
- Zhang, J.; Xu, T.; Li, J.; Jiang, S.; Zhang, Y. Single-Image Super Resolution of Remote Sensing Images with Real-World Degradation Modeling. Remote Sens. 2022, 14, 2895. [Google Scholar] [CrossRef]
- Yue, L.; Shen, H.; Li, J.; Yuan, Q.; Zhang, H.; Zhang, L. Image super-resolution: The techniques, applications, and future. Signal Process. 2016, 128, 389–408. [Google Scholar] [CrossRef]
- Wronski, B.; Garcia-Dorado, I.; Ernst, M.; Kelly, D.; Krainin, M.; Liang, C.-K.; Levoy, M.; Milanfar, P. Handheld multi-frame super-resolution. ACM Trans. Graph. (ToG) 2019, 38, 1–18. [Google Scholar] [CrossRef]
- Tarasiewicz, T.; Nalepa, J.; Kawulok, M. A graph neural network for multiple-image super-resolution. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Virtual, 19–22 September 2021; pp. 1824–1828. [Google Scholar]
- Deudon, M.; Kalaitzis, A.; Goytom, I.; Arefin, M.R.; Lin, Z.; Sankaran, K.; Michalski, V.; Kahou, S.E.; Cornebise, J.; Bengio, Y. Highres-net: Recursive fusion for multi-frame super-resolution of satellite imagery. arXiv 2020, arXiv:2002.06460. [Google Scholar]
- Bhat, G.; Danelljan, M.; Timofte, R.; Cao, Y.; Cao, Y.; Chen, M.; Chen, X.; Cheng, S.; Dudhane, A.; Fan, H. NTIRE 2022 burst super-resolution challenge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 1041–1061. [Google Scholar]
- Huang, B.; He, B.; Wu, L.; Guo, Z. Deep residual dual-attention network for super-resolution reconstruction of remote sensing images. Remote Sens. 2021, 13, 2784. [Google Scholar] [CrossRef]
- Jia, S.; Wang, Z.; Li, Q.; Jia, X.; Xu, M. Multiattention generative adversarial network for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Yang, Z.; Dan, T.; Yang, Y. Multi-temporal remote sensing image registration using deep convolutional features. IEEE Access 2018, 6, 38544–38555. [Google Scholar] [CrossRef]
- Qin, P.; Huang, H.; Tang, H.; Wang, J.; Liu, C. MUSTFN: A spatiotemporal fusion method for multi-scale and multi-sensor remote sensing images based on a convolutional neural network. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103113. [Google Scholar] [CrossRef]
- Ye, Y.; Tang, T.; Zhu, B.; Yang, C.; Li, B.; Hao, S. A multiscale framework with unsupervised learning for remote sensing image registration. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Qiao, B.; Xu, B.; Xie, Y.; Lin, Y.; Liu, Y.; Zuo, X. HMFT: Hyperspectral and Multispectral Image Fusion Super-Resolution Method Based on Efficient Transformer and Spatial-Spectral Attention Mechanism. Comput. Intell. Neurosci. 2023, 2023, 4725986. [Google Scholar] [CrossRef]
- Qiu, Z.; Shen, H.; Yue, L.; Zheng, G. Cross-sensor remote sensing imagery super-resolution via an edge-guided attention-based network. ISPRS J. Photogramm. Remote Sens. 2023, 199, 226–241. [Google Scholar] [CrossRef]
- TSAI, R. Multiframe Image Restoraition and Registration. Adv. Comput. Vis. Image Process. 1984, 1, 317–339. [Google Scholar]
- Guo, M.; Zhang, Z.; Liu, H.; Huang, Y. Ndsrgan: A novel dense generative adversarial network for real aerial imagery super-resolution reconstruction. Remote Sens. 2022, 14, 1574. [Google Scholar] [CrossRef]
- Bhat, G.; Danelljan, M.; Yu, F.; Van Gool, L.; Timofte, R. Deep reparametrization of multi-frame super-resolution and denoising. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 2460–2470. [Google Scholar]
- Luo, Z.; Yu, L.; Mo, X.; Li, Y.; Jia, L.; Fan, H.; Sun, J.; Liu, S. Ebsr: Feature enhanced burst super-resolution with deformable alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 471–478. [Google Scholar]
- Dudhane, A.; Zamir, S.W.; Khan, S.; Khan, F.S.; Yang, M.-H. Burst image restoration and enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 5759–5768. [Google Scholar]
- Luo, Z.; Li, Y.; Cheng, S.; Yu, L.; Wu, Q.; Wen, Z.; Fan, H.; Sun, J.; Liu, S. BSRT: Improving burst super-resolution with swin transformer and flow-guided deformable alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 998–1008. [Google Scholar]
- Dudhane, A.; Zamir, S.W.; Khan, S.; Khan, F.S.; Yang, M.-H. Burstormer: Burst Image Restoration and Enhancement Transformer. arXiv 2023, arXiv:2304.01194. [Google Scholar]
- Molini, A.B.; Valsesia, D.; Fracastoro, G.; Magli, E. Deepsum: Deep neural network for super-resolution of unregistered multitemporal images. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3644–3656. [Google Scholar] [CrossRef]
- Arefin, M.R.; Michalski, V.; St-Charles, P.-L.; Kalaitzis, A.; Kim, S.; Kahou, S.E.; Bengio, Y. Multi-image super-resolution for remote sensing using deep recurrent networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 206–207. [Google Scholar]
- Dorr, F. Satellite image multi-frame super resolution using 3D wide-activation neural networks. Remote Sens. 2020, 12, 3812. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Valente, J.; Van Der Voort, M.; Tekinerdogan, B. Effect of attention mechanism in deep learning-based remote sensing image processing: A systematic literature review. Remote Sens. 2021, 13, 2965. [Google Scholar] [CrossRef]
- Lu, E.; Hu, X. Image super-resolution via channel attention and spatial attention. Appl. Intell. 2022, 52, 2260–2268. [Google Scholar] [CrossRef]
- Xia, B.; Hang, Y.; Tian, Y.; Yang, W.; Liao, Q.; Zhou, J. Efficient non-local contrastive attention for image super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; pp. 2759–2767. [Google Scholar]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient long-range attention network for image super-resolution. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Part XVII. pp. 649–667. [Google Scholar]
- Salvetti, F.; Mazzia, V.; Khaliq, A.; Chiaberge, M. Multi-image super resolution of remotely sensed images using residual attention deep neural networks. Remote Sens. 2020, 12, 2207. [Google Scholar] [CrossRef]
- Valsesia, D.; Magli, E. Permutation invariance and uncertainty in multitemporal image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Bhat, G.; Danelljan, M.; Van Gool, L.; Timofte, R. Deep burst super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9209–9218. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Zhang, D.; Huang, F.; Liu, S.; Wang, X.; Jin, Z. SwinFIR: Revisiting the SWINIR with fast Fourier convolution and improved training for image super-resolution. arXiv 2022, arXiv:2208.11247. [Google Scholar]
- An, T.; Zhang, X.; Huo, C.; Xue, B.; Wang, L.; Pan, C. TR-MISR: Multiimage super-resolution based on feature fusion with transformers. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1373–1388. [Google Scholar] [CrossRef]
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 2021, 34, 30392–30400. [Google Scholar]
- Fang, N.; Zhan, Z. High-resolution optical flow and frame-recurrent network for video super-resolution and deblurring. Neurocomputing 2022, 489, 128–138. [Google Scholar] [CrossRef]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 457–466. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Recanatesi, S.; Farrell, M.; Advani, M.; Moore, T.; Lajoie, G.; Shea-Brown, E. Dimensionality compression and expansion in deep neural networks. arXiv 2019, arXiv:1906.00443. [Google Scholar]
- Zebari, R.; Abdulazeez, A.; Zeebaree, D.; Zebari, D.; Saeed, J. A comprehensive review of dimensionality reduction techniques for feature selection and feature extraction. J. Appl. Sci. Technol. Trends 2020, 1, 56–70. [Google Scholar] [CrossRef]
- d’Ascoli, S.; Touvron, H.; Leavitt, M.L.; Morcos, A.S.; Biroli, G.; Sagun, L. Convit: Improving vision transformers with soft convolutional inductive biases. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 2286–2296. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Patel, K.; Bur, A.M.; Li, F.; Wang, G. Aggregating global features into local vision transformer. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 1141–1147. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Märtens, M.; Izzo, D.; Krzic, A.; Cox, D. Super-resolution of PROBA-V images using convolutional neural networks. Astrodynamics 2019, 3, 387–402. [Google Scholar] [CrossRef]
- Farsiu, S.; Robinson, M.D.; Elad, M.; Milanfar, P. Fast and robust multiframe super resolution. IEEE Trans. Image Process. 2004, 13, 1327–1344. [Google Scholar] [CrossRef]
- Irani, M.; Peleg, S. Improving resolution by image registration. CVGIP Graph. Models Image Process. 1991, 53, 231–239. [Google Scholar] [CrossRef]
- Jo, Y.; Oh, S.W.; Kang, J.; Kim, S.J. Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3224–3232. [Google Scholar]
- Molini, A.B.; Valsesia, D.; Fracastoro, G.; Magli, E. Deepsum++: Non-local deep neural network for super-resolution of unregistered multitemporal images. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 609–612. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band | NIR | RED | ||
|---|---|---|---|---|
| Metric | cPSNR | cSSIM | cPSNR | cSSIM |
| Bicubic | 45.44 | 0.9770 | 47.33 | 0.9840 |
| BTV [63] | 45.93 | 0.9794 | 48.12 | 0.9861 |
| IBP [64] | 45.96 | 0.9796 | 48.21 | 0.9965 |
| RCAN [9] | 45.66 | 0.9798 | 49.22 | 0.9870 |
| VSR-DUF [65] | 47.20 | 0.9850 | 49.59 | 0.9902 |
| HighRes-net [22] | 47.55 | 0.9855 | 49.75 | 0.9904 |
| 3DWDSRNet [40] | 47.58 | 0.9856 | 49.90 | 0.9908 |
| DeepSUM [38] | 47.84 | 0.9858 | 50.00 | 0.9908 |
| MISR-GRU [39] | 47.88 | 0.9861 | 50.11 | 0.9910 |
| DeepSUM++ [66] | 47.93 | 0.9862 | 50.08 | 0.9912 |
| RAMS [45] | 48.23 | 0.9875 | 50.17 | 0.9913 |
| RAMS+20 [45] | 48.51 | 0.9880 | 50.44 | 0.9917 |
| PIUnet [46] | 48.72 | 0.9883 | 50.62 | 0.9921 |
| TR-MISR [50] | 48.54 | 0.9882 | 50.67 | 0.9921 |
| MAST (this study) | 49.63 | 0.9884 | 51.48 | 0.9924 |
| MMAB | NIR | RED | ||||
|---|---|---|---|---|---|---|
| MSEB | SAGB | CAGB | cPSNR | cSSIM | cPSNR | cSSIM |
| √ | × | × | 48.93 | 0.9867 | 50.96 | 0.9916 |
| √ | √ | × | 48.98 | 0.9869 | 50.99 | 0.9919 |
| √ | √ | √ | 50.99 | 0.9879 | 51.22 | 0.9921 |
| CAFB | NIR | RED | ||||
|---|---|---|---|---|---|---|
| Transformer | CA | RLAB | cPSNR | cSSIM | cPSNR | cSSIM |
| √ | √ | × | 48.89 | 0.9874 | 50.84 | 0.9914 |
| √ | √ | √ | 49.23 | 0.9881 | 51.19 | 0.9920 |
| Band | NIR | RED | ||
|---|---|---|---|---|
| k | cPSNR | cSSIM | cPSNR | cSSIM |
| 32 | 49.43 | 0.9883 | 51.36 | 0.9922 |
| 24 | 49.26 | 0.9884 | 51.27 | 0.9922 |
| 16 | 48.87 | 0.9879 | 51.02 | 0.9920 |
| 8 | 48.41 | 0.9865 | 50.64 | 0.9908 |
| Band | NIR | RED | |||
|---|---|---|---|---|---|
| NMMAB | NCAFB | cPSNR | cSSIM | cPSNR | cSSIM |
| 2 | 6 | 49.43 | 0.9883 | 51.36 | 0.9922 |
| 2 | 4 | 49.21 | 0.9873 | 51.15 | 0.9918 |
| 2 | 2 | 48.96 | 0.9868 | 50.82 | 0.9912 |
| 3 | 4 | 49.30 | 0.9877 | 51.25 | 0.9923 |
| 1 | 6 | 48.50 | 0.9862 | 50.35 | 0.9908 |
| Band | NIR | RED | ||
|---|---|---|---|---|
| Size | cPSNR | cSSIM | cPSNR | cSSIM |
| 64 | 49.63 | 0.9884 | 51.48 | 0.9924 |
| 68 | 49.68 | 0.9892 | 51.52 | 0.9925 |
| 72 | 49.77 | 0.9889 | 51.54 | 0.9925 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Lv, Q.; Zhang, W.; Zhu, B.; Zhang, G.; Tan, Z. Multi-Attention Multi-Image Super-Resolution Transformer (MAST) for Remote Sensing. Remote Sens. 2023, 15, 4183. https://doi.org/10.3390/rs15174183
Li J, Lv Q, Zhang W, Zhu B, Zhang G, Tan Z. Multi-Attention Multi-Image Super-Resolution Transformer (MAST) for Remote Sensing. Remote Sensing. 2023; 15(17):4183. https://doi.org/10.3390/rs15174183
Chicago/Turabian StyleLi, Jiaao, Qunbo Lv, Wenjian Zhang, Baoyu Zhu, Guiyu Zhang, and Zheng Tan. 2023. "Multi-Attention Multi-Image Super-Resolution Transformer (MAST) for Remote Sensing" Remote Sensing 15, no. 17: 4183. https://doi.org/10.3390/rs15174183
APA StyleLi, J., Lv, Q., Zhang, W., Zhu, B., Zhang, G., & Tan, Z. (2023). Multi-Attention Multi-Image Super-Resolution Transformer (MAST) for Remote Sensing. Remote Sensing, 15(17), 4183. https://doi.org/10.3390/rs15174183