
The Suitability of Machine-Learning Algorithms for the Automatic Acoustic Seafloor Classification of Hard Substrate Habitats in the German Bight


Abstract
:1. Introduction
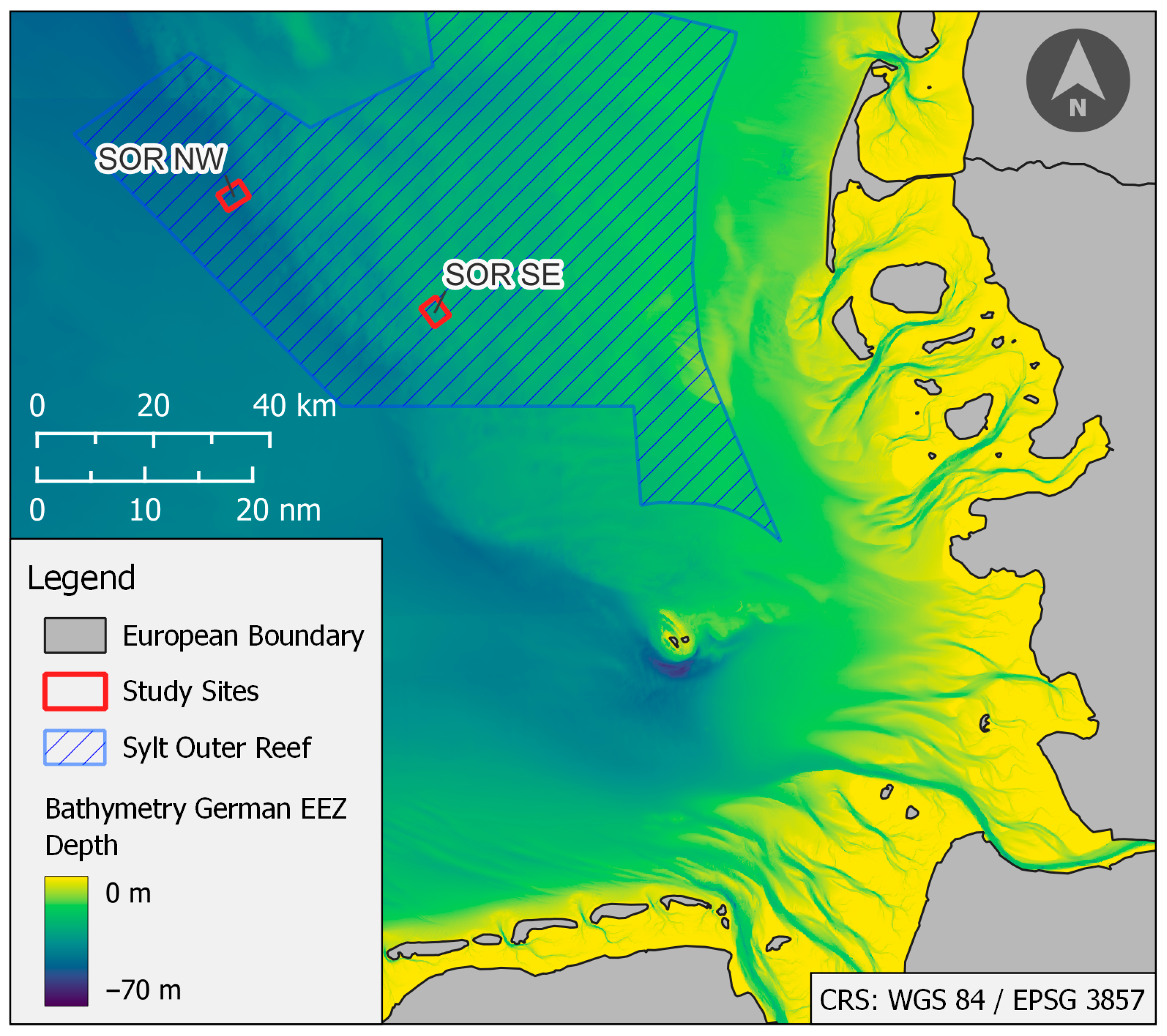
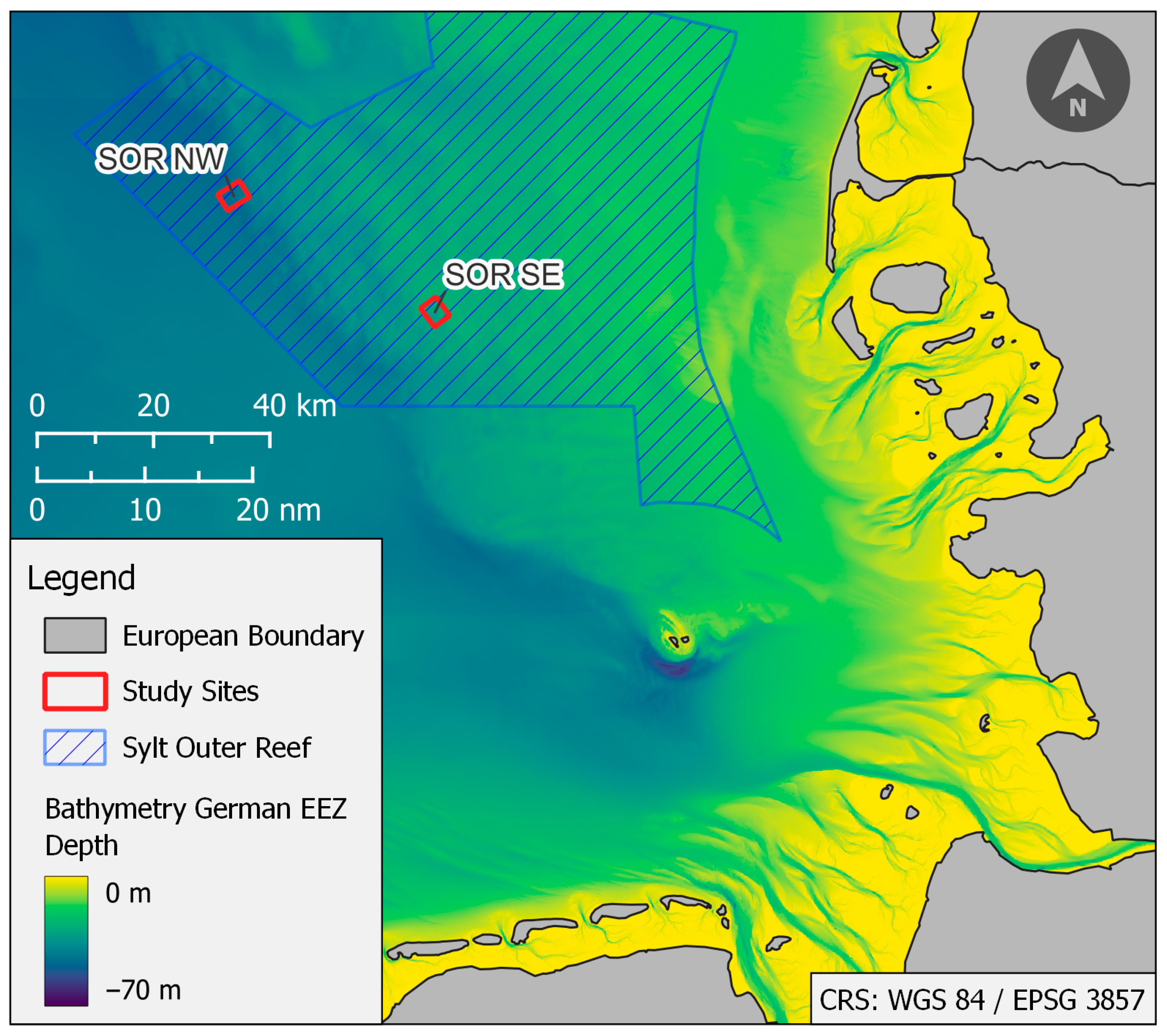
2. Geographical Setting and Study Sites
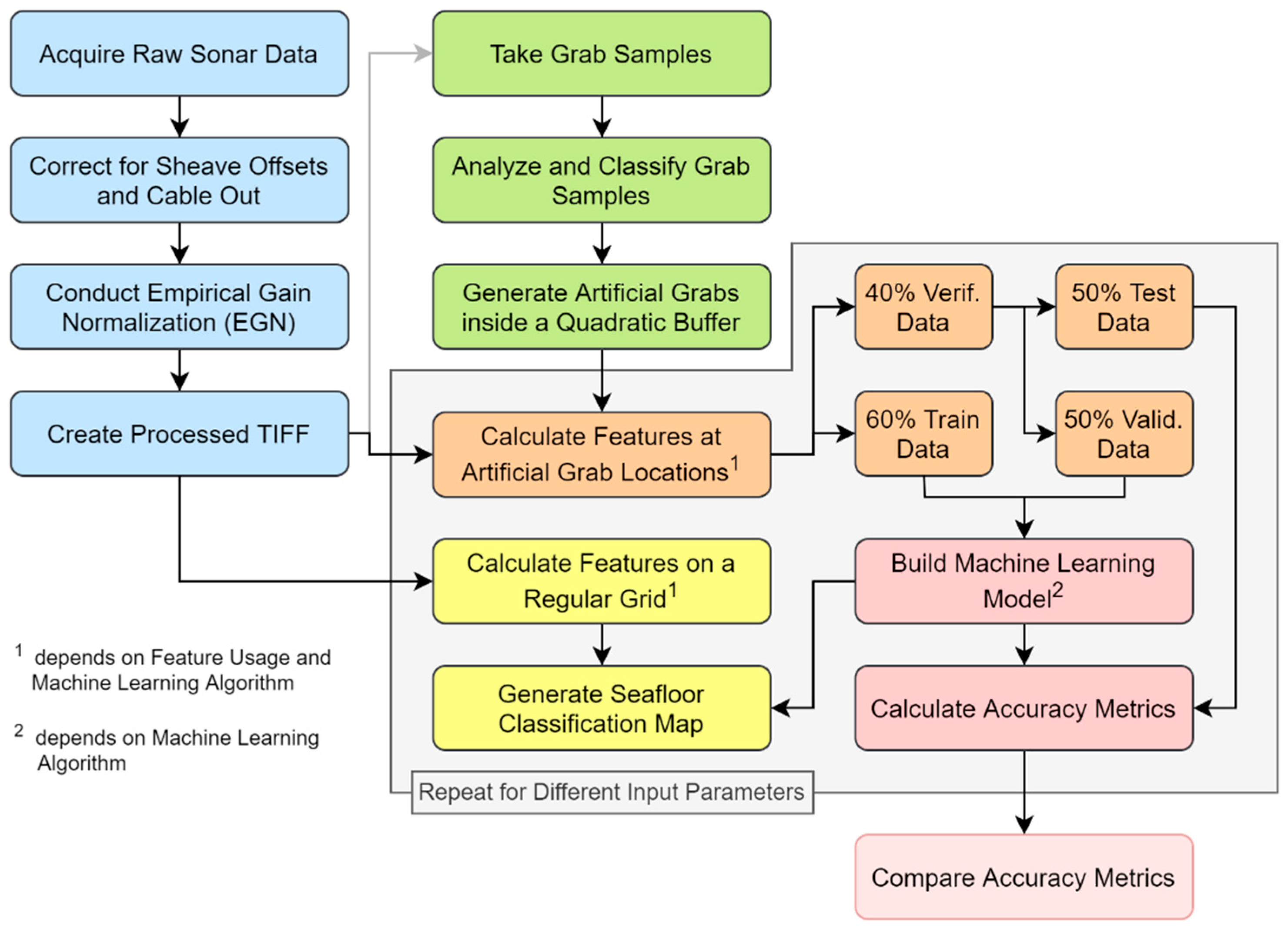
3. Material and Methods
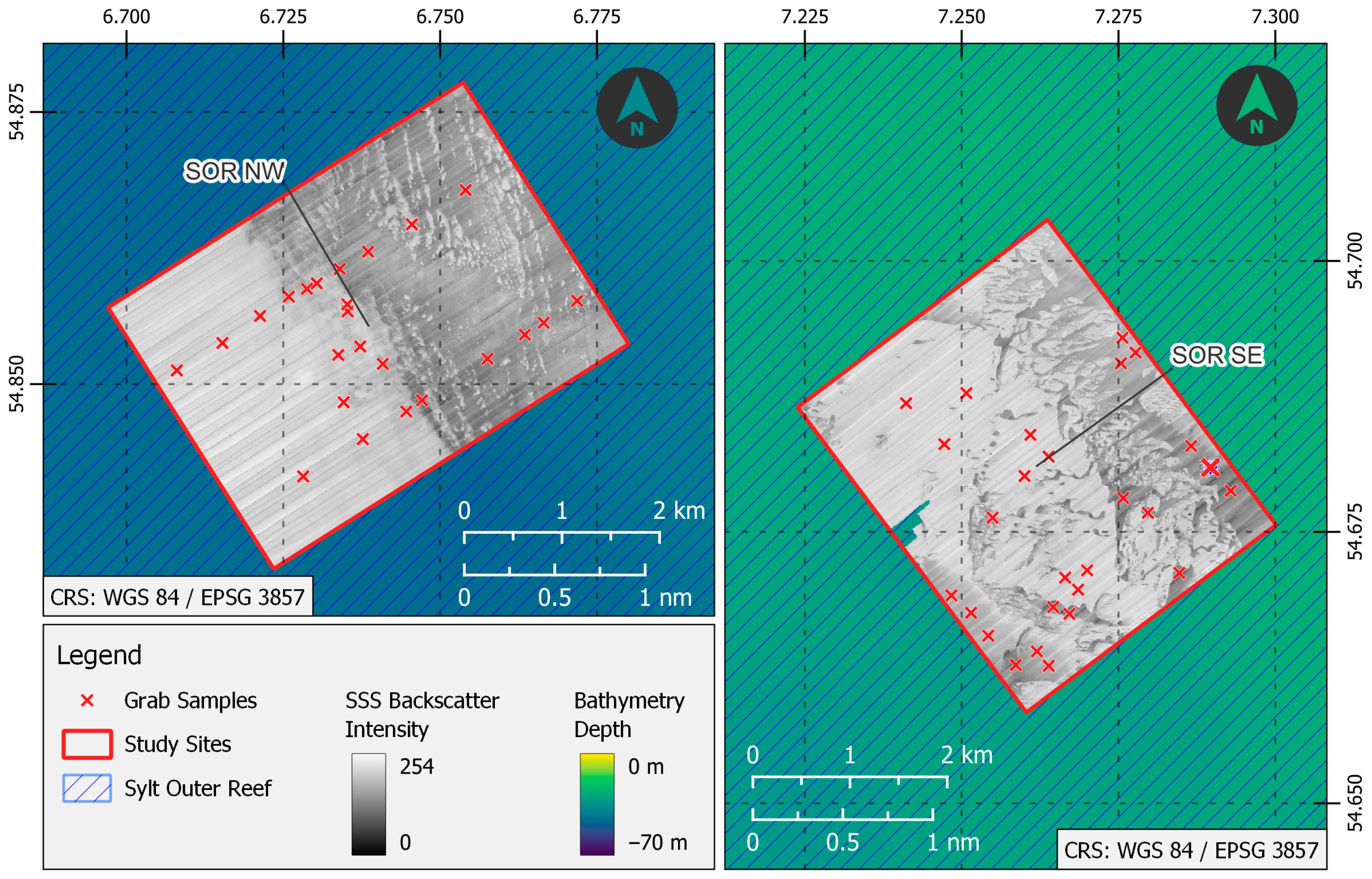
3.1. Spatial Mapping with a SSS System

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Frequencies | Horizontal Beam Width | Vertical Beam Width | Across-Track Resolution | File Formats |
|---|---|---|---|---|---|
| EdgeTech 4200 MP | 300 kHz | 0.54° | 50° | 3 cm | .jsf, .xtf |
| 600 kHz | 0.34° | 1.5 cm |
3.2. Ground-Truth Data from Grab Samples
3.3. Quantization Level and Size of the Image Patches for the Classification
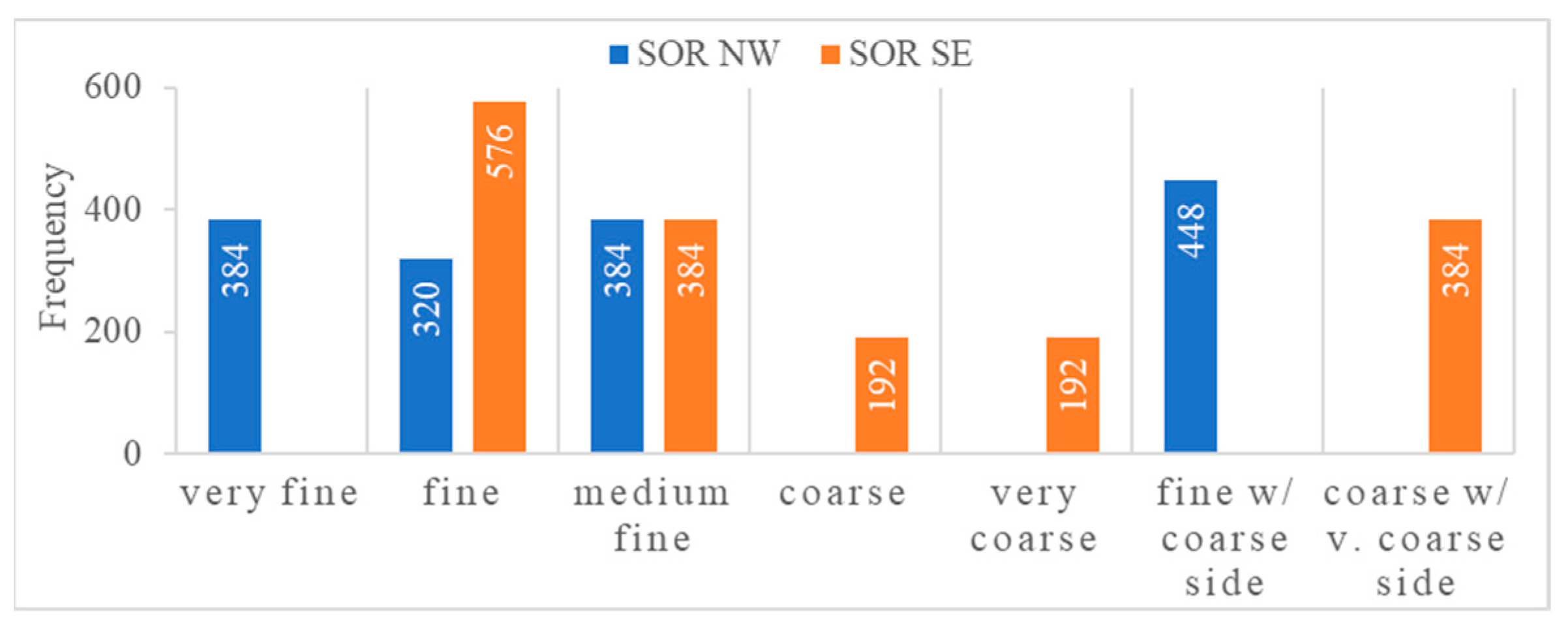
3.4. Generating Training, Test and Validation Data from Sample Locations
3.5. Machine-Learning Algorithms
3.6. Input Data and Input Data Processing
4. Experimental Results
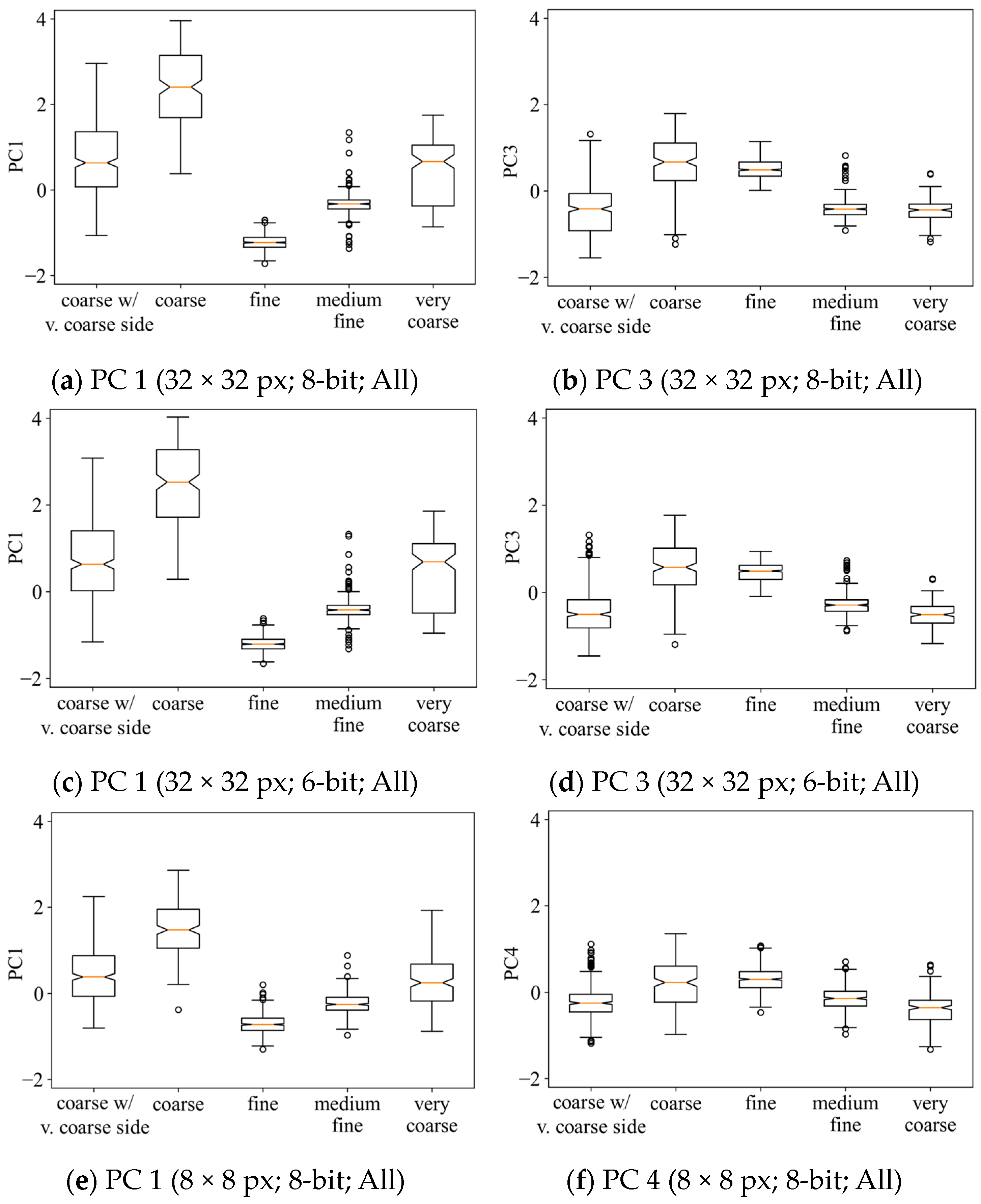
4.1. Impact of the Quantization Level and Image Patch Size
4.2. Impact of the Machine-Learning Algorithm and Input Data
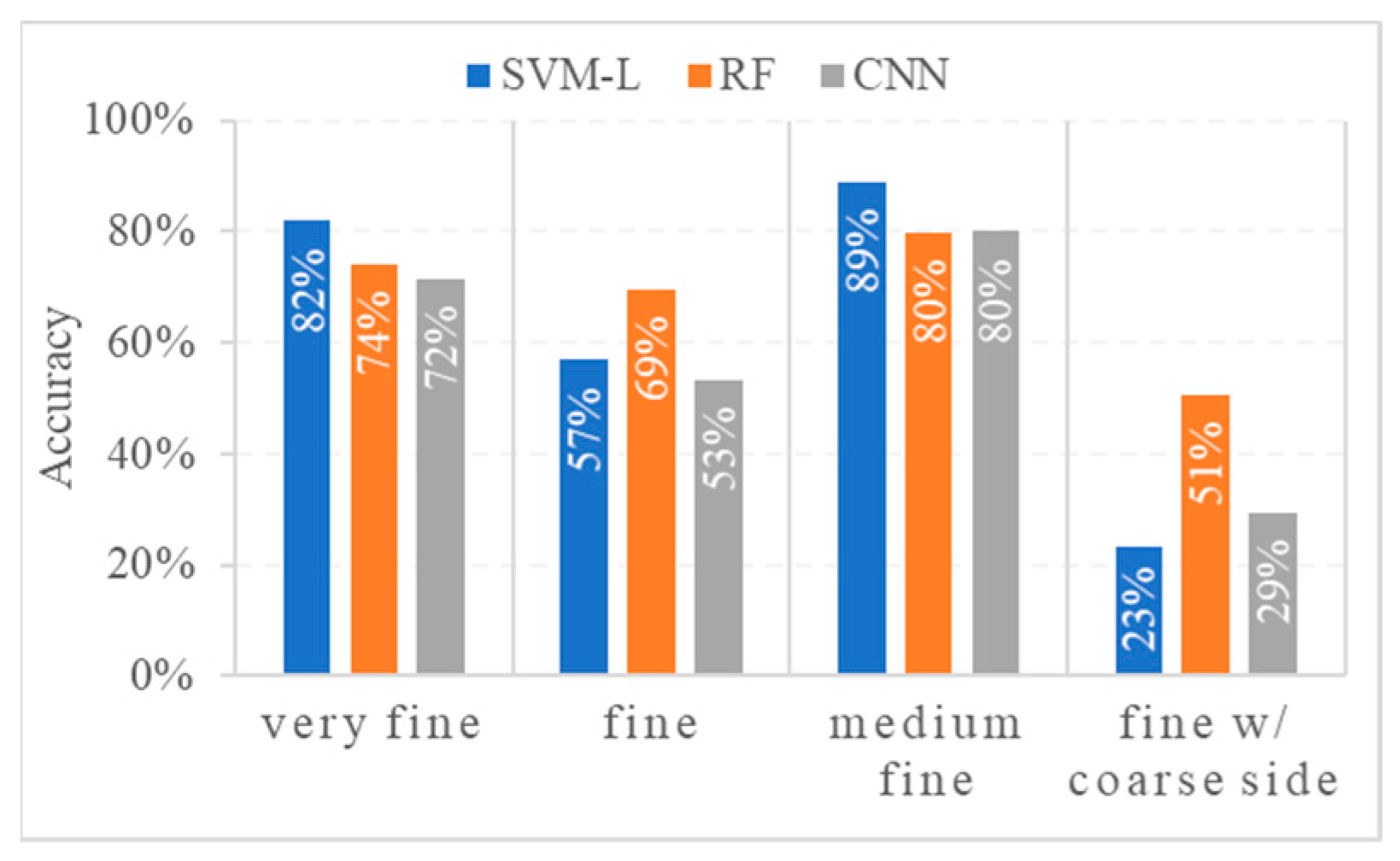
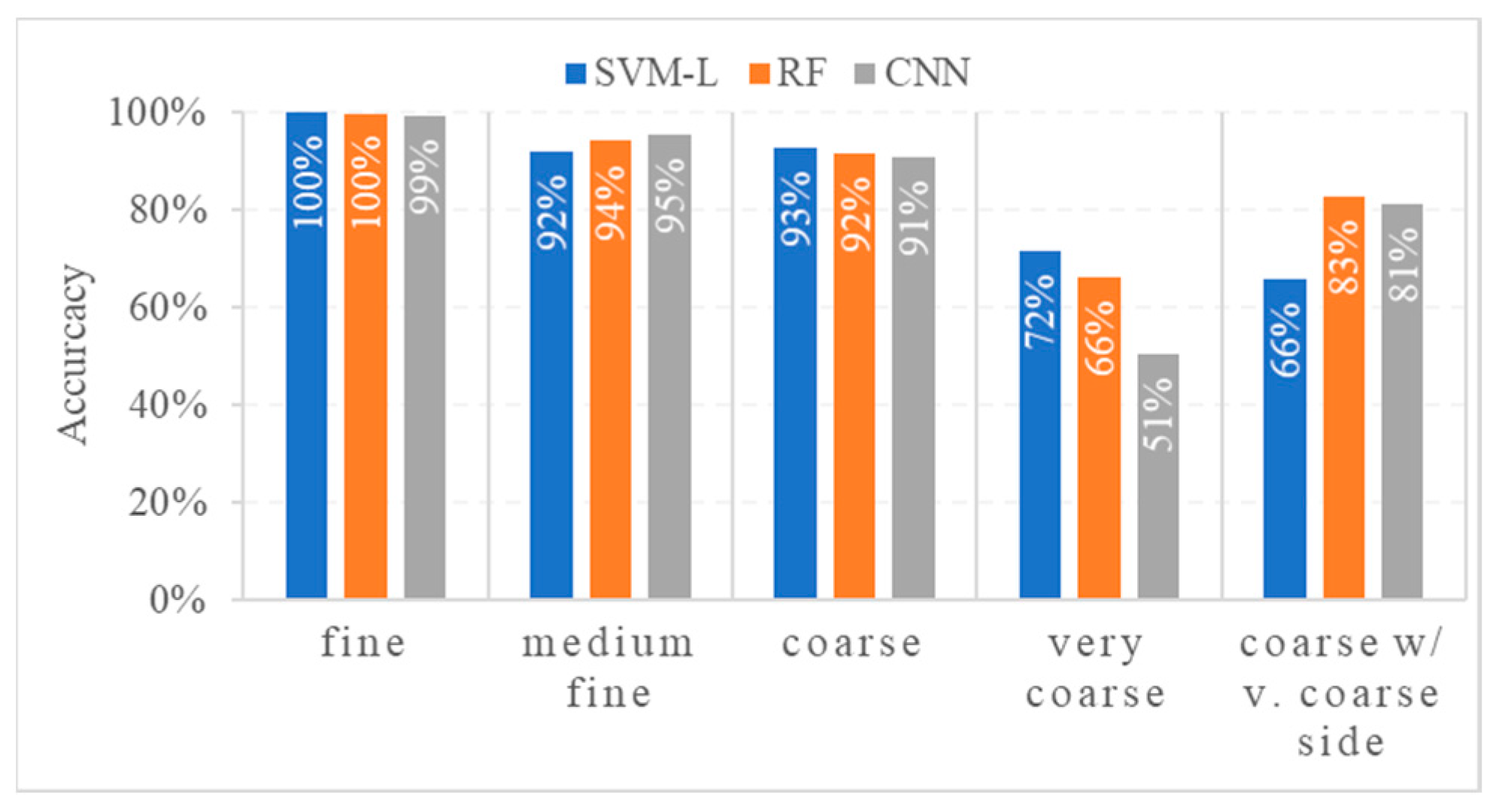
4.3. Model Performances on Different Seafloor Sediment Classes
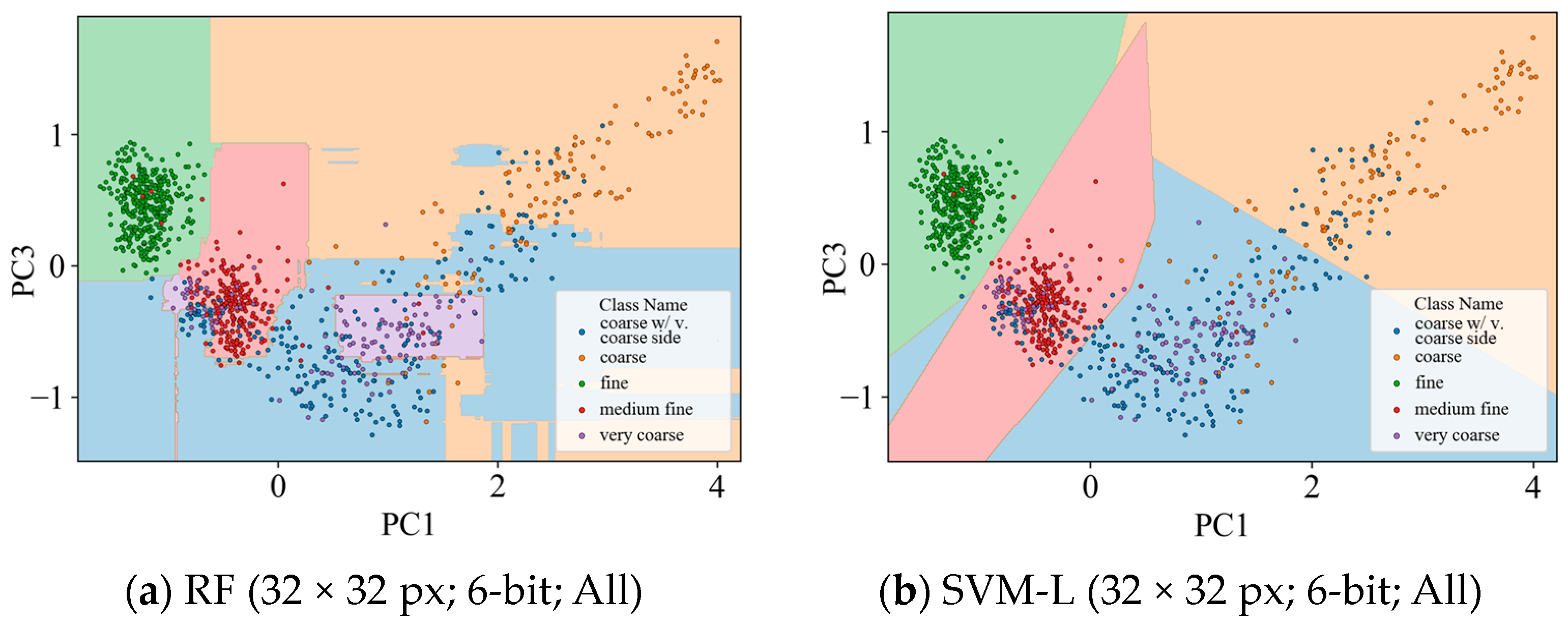
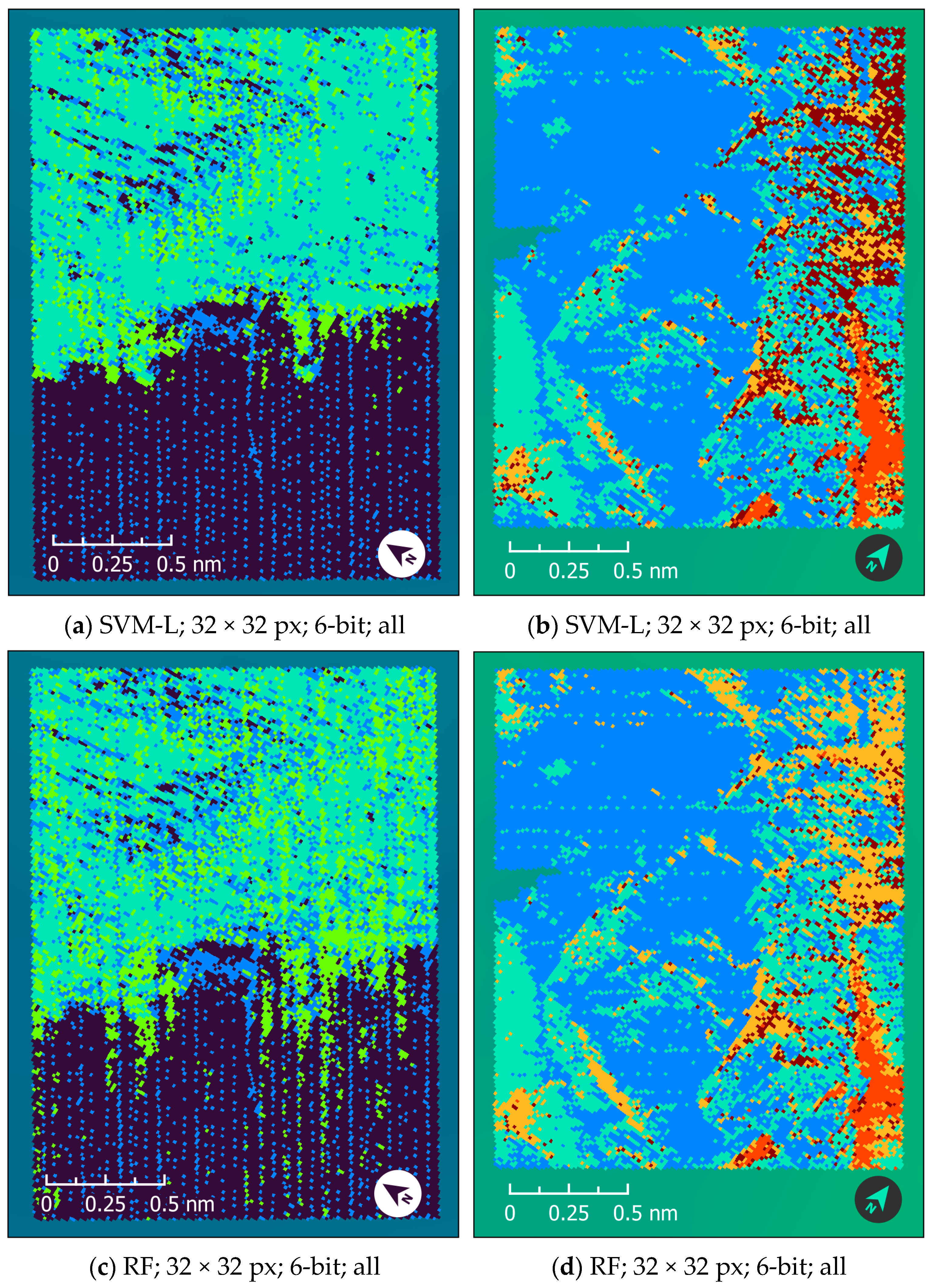
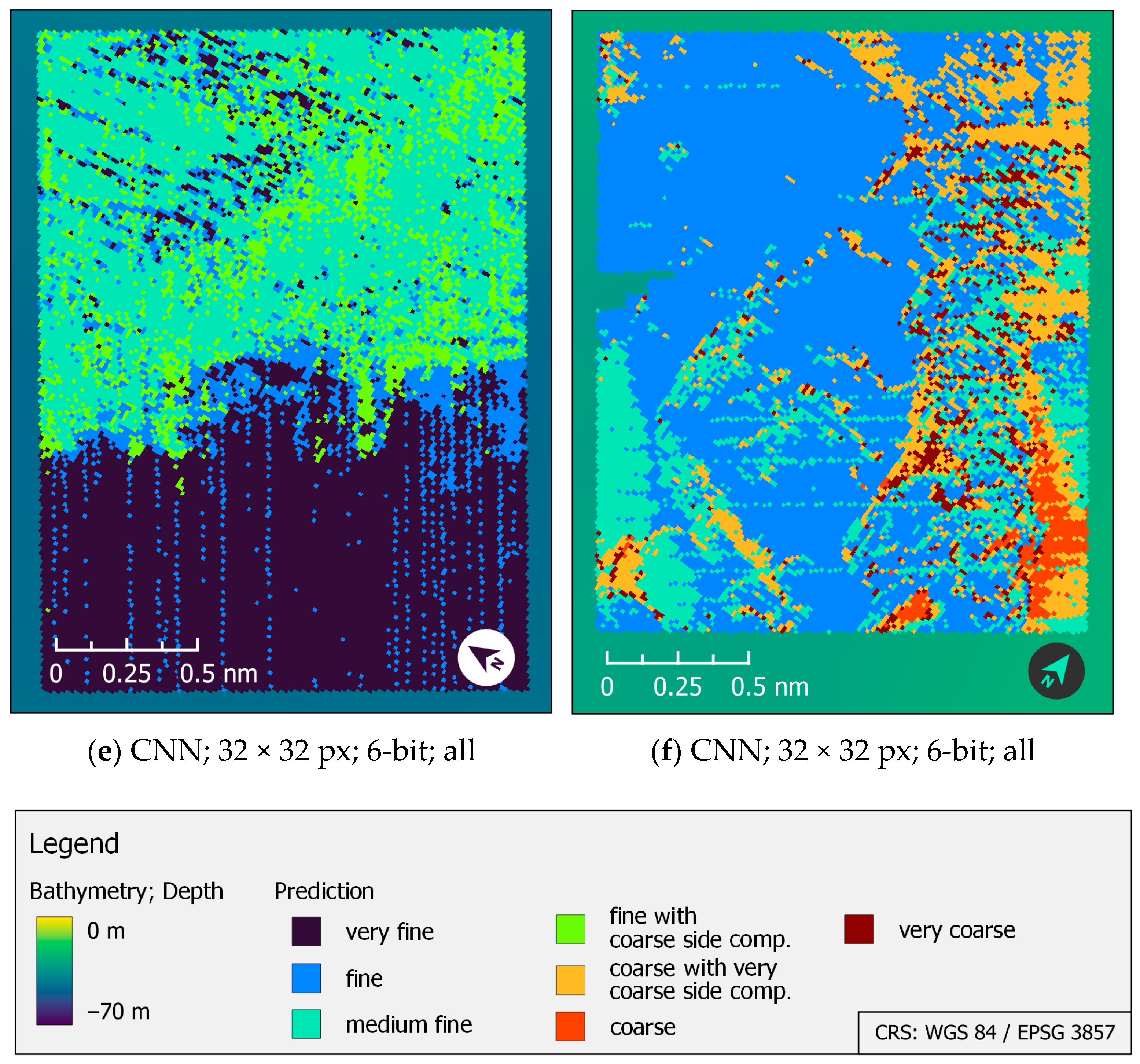
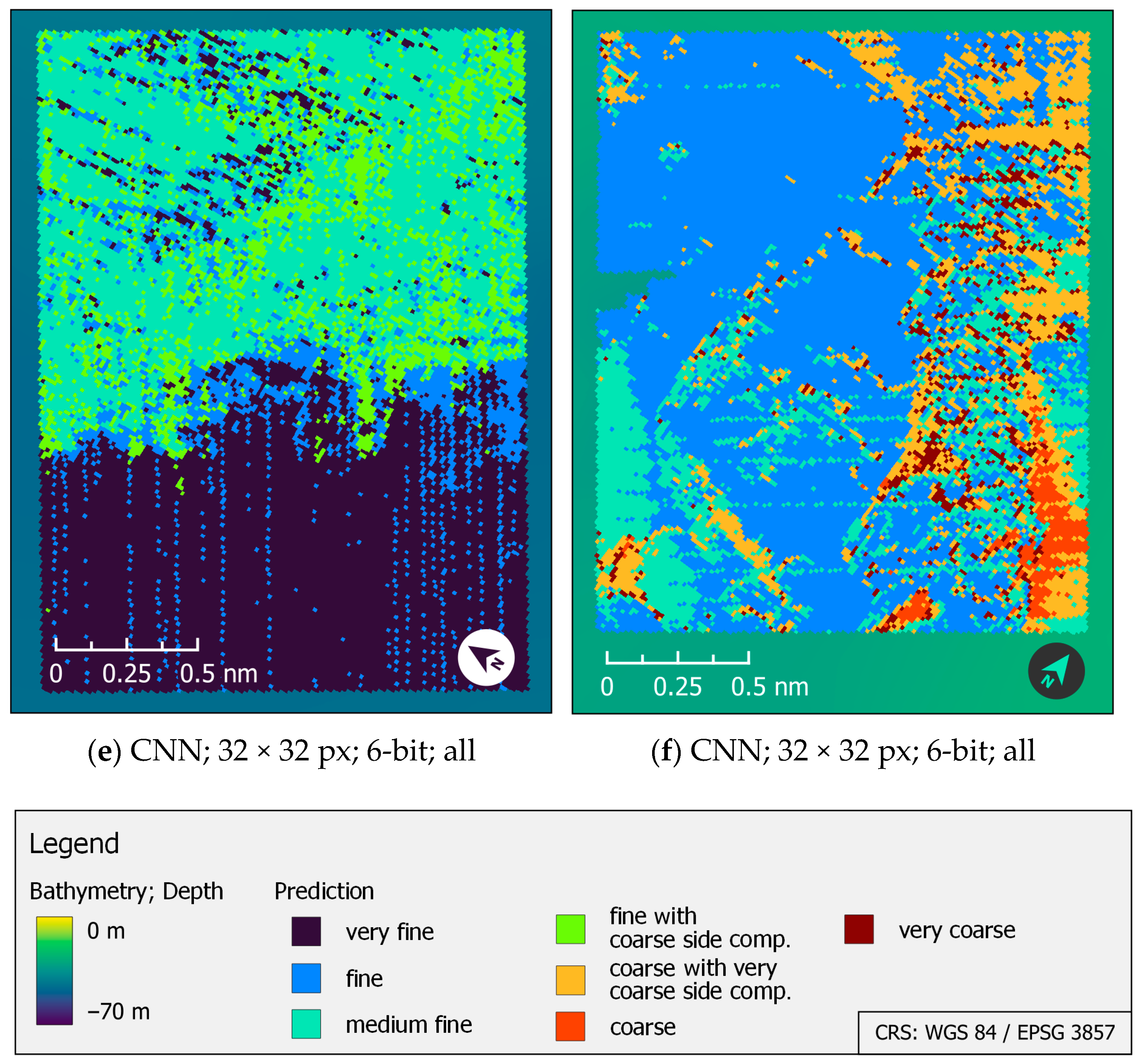
4.4. Visual Assessment of the Classification Maps
5. Discussion
6. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Galvez, D.; Papenmeier, S.; Sander, L.; Hass, H.; Fofonova, V.; Bartholomä, A.; Wiltshire, K. Ensemble Mapping and Change Analysis of the Seafloor Sediment Distribution in the Sylt Outer Reef, German North Sea from 2016 to 2018. Water 2021, 13, 2254. [Google Scholar] [CrossRef]
- Zhao, T.; Montereale Gavazzi, G.; Lazendić, S.; Zhao, Y.; Pižurica, A. Acoustic Seafloor Classification Using the Weyl Transform of Multibeam Echosounder Backscatter Mosaic. Remote Sens. 2021, 13, 1760. [Google Scholar] [CrossRef]
- Diesing, M.; Green, S.L.; Stephens, D.; Lark, R.M.; Stewart, H.A.; Dove, D. Mapping seabed sediments: Comparison of manual, geostatistical, object-based image analysis and machine learning approaches. Cont. Shelf Res. 2014, 84, 107–119. [Google Scholar] [CrossRef]
- Ierodiaconou, D.; Schimel, A.C.G.; Kennedy, D.; Monk, J.; Gaylard, G.; Young, M.; Diesing, M.; Rattray, A. Combining pixel and object based image analysis of ultra-high resolution multibeam bathymetry and backscatter for habitat mapping in shallow marine waters. Mar. Geophys. Res. 2018, 39, 271–288. [Google Scholar] [CrossRef]
- Misiuk, B.; Diesing, M.; Aitken, A.; Brown, C.J.; Edinger, E.N.; Bell, T. A Spatially Explicit Comparison of Quantitative and Categorical Modelling Approaches for Mapping Seabed Sediments Using Random Forest. Geosciences 2019, 9, 254. [Google Scholar] [CrossRef]
- Menandro, P.S.; Bastos, A.C.; Boni, G.; Ferreira, L.C.; Vieira, F.V.; Lavagnino, A.C.; Moura, R.L.; Diesing, M. Reef Mapping Using Different Seabed Automatic Classification Tools. Geosciences 2020, 10, 72. [Google Scholar] [CrossRef]
- Lark, R.M.; Marchant, B.P.; Dove, D.; Green, S.L.; Stewart, H.; Diesing, M. Combining observations with acoustic swath bathymetry and backscatter to map seabed sediment texture classes: The empirical best linear unbiased predictor. Sediment. Geol. 2015, 328, 17–32. [Google Scholar] [CrossRef]
- Diesing, M.; Stephens, D. A multi-model ensemble approach to seabed mapping. J. Sea Res. 2015, 100, 62–69. [Google Scholar] [CrossRef]
- Zelada Leon, A.; Huvenne, V.A.I.; Benoist, N.M.A.; Ferguson, M.; Bett, B.J.; Wynn, R.B. Assessing the Repeatability of Automated Seafloor Classification Algorithms, with Application in Marine Protected Area Monitoring. Remote Sens. 2020, 12, 1572. [Google Scholar] [CrossRef]
- Turner, J.A.; Babcock, R.C.; Hovey, R.; Kendrick, G.A. Can single classifiers be as useful as model ensembles to produce benthic seabed substratum maps? Estuar. Coast. Shelf Sci. 2018, 204, 149–163. [Google Scholar] [CrossRef]
- Callies, U.; Gaslikova, L.; Kapitza, H.; Scharfe, M. German Bight residual current variability on a daily basis: Principal components of multi-decadal barotropic simulations. Geo-Mar. Lett. 2016, 37, 151–162. [Google Scholar] [CrossRef]
- Port, A.; Gurgel, K.-W.; Staneva, J.; Schulz-Stellenfleth, J.; Stanev, E.V. Tidal and wind-driven surface currents in the German Bight: HFR observations versus model simulations. Ocean Dyn. 2011, 61, 1567–1585. [Google Scholar] [CrossRef]
- Papenmeier, S.; Hass, H. Detection of Stones in Marine Habitats Combining Simultaneous Hydroacoustic Surveys. Geosciences 2018, 8, 279. [Google Scholar] [CrossRef]
- Papenmeier, S.; Hass, H.C. Revisiting the Paleo Elbe Valley: Reconstruction of the Holocene, Sedimentary Development on Basis of High-Resolution Grain Size Data and Shallow Seismics. Geosciences 2020, 10, 505. [Google Scholar] [CrossRef]
- EuroGeographics for the Administrative Boundaries. Countries—GISCO: Geographical Information and Maps—Eurostat. Available online: https://ec.europa.eu/eurostat/en/web/gisco/geodata/reference-data/administrative-units-statistical-units/countries#countries20 (accessed on 6 February 2023).
- Verordnung über die Festsetzung des Naturschutzgebietes „Sylter Außenriff–Östliche Deutsche Bucht” vom 22. September 2017 (BGBl. I S. 3423); Bundesanzeiger Verlag GmbH: Köln, Germany, 2017.
- Sievers, J.; Rubel, M.; Milbradt, P. EasyGSH-DB: Bathymetrie (1996–2016) Bathymetrie 2016. Available online: https://datenrepository.baw.de/trefferanzeige?docuuid=8a917a5c-aa8c-4a74-a10e-12cfa0c41f8b (accessed on 6 February 2023).
- Rohde, S.; Neumann, A.; Meunier, C.; Sander, L.; Zandt, E.; Schönke, M.; Breyer, G.; Bartholomä, A. Fisheries Exclusion in Natura 2000 Sites: Effects on Benthopelagic Habitats on Sylter Outer Reef and Borkum Reefground, Cruise No. HE602, 23.06.2023–06.07.2022; Bremerhaven: Bonn, Germany, 2022. [Google Scholar]
- EdgeTech. Discover 4200 User Software Manual. Available online: https://www.edgetech.com/wp-content/uploads/2019/07/0004841_Rev_C.pdf (accessed on 31 July 2023).
- Chesapeake Technology Inc. SonarWiz Sidescan | Mosaics, Contacts, Reports. Available online: https://chesapeaketech.com/products/sonarwiz-sidescan/ (accessed on 6 February 2023).
- Bruns, I.; Holler, P.; Capperucci, R.M.; Papenmeier, S.; Bartholomä, A. Identifying Trawl Marks in North Sea Sediments. Geosciences 2020, 10, 422. [Google Scholar] [CrossRef]
- Propp, C.; Papenmeier, S.; Bartholomä, A.; Richter, P.; Hass, C.; Schwarzer, K.; Holler, P.; Tauber, F.; Lambers-Huesmann, M.; Zeiler, M. Guideline for Seafloor Mapping in German Marine Waters Using High-Resolution Sonars. BSH 2016, 7201, 147. [Google Scholar]
- EdgeTech. 4200 Side Scan Sonar System. Available online: https://www.edgetech.com/wp-content/uploads/2019/07/0004842_Rev_P.pdf (accessed on 6 February 2023).
- Blott, S.J.; Pye, K. Gradistat: A grain size distribution and statistics package for the analysis of unconsolidated sediments. Earth Surf. Process. Landf. 2001, 26, 1237–1248. [Google Scholar] [CrossRef]
- Capperucci, R.M.; Kubicki, A.; Holler, P.; Bartholomä, A. Sidescan sonar meets airborne and satellite remote sensing: Challenges of a multi-device seafloor classification in extreme shallow water intertidal environments. Geo-Mar. Lett. 2020, 40, 117–133. [Google Scholar] [CrossRef]
- Xu, Y.; Goodacre, R. On Splitting Training and Validation Set: A Comparative Study of Cross-Validation, Bootstrap and Systematic Sampling for Estimating the Generalization Performance of Supervised Learning. J. Anal. Test. 2018, 2, 249–262. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009; Volume 2. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Steiniger, Y.; Kraus, D.; Meisen, T. Generating Synthetic Sidescan Sonar Snippets Using Transfer-Learning in Generative Adversarial Networks. J. Mar. Sci. Eng. 2021, 9, 239. [Google Scholar] [CrossRef]
- Valavi, R.; Elith, J.; Lahoz-Monfort, J.J.; Guillera-Arroita, G.; Warton, D. blockCV: An r package for generating spatially or environmentally separated folds for k-fold cross-validation of species distribution models. Methods Ecol. Evol. 2018, 10, 225–232. [Google Scholar] [CrossRef]
- Efron, B. Bootstrap Methods: Another Look at the Jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Shao, J. Linear Model Selection by Cross-validation. J. Am. Stat. Assoc. 1993, 88, 486–494. [Google Scholar] [CrossRef]
- Cui, X.; Liu, H.; Fan, M.; Ai, B.; Ma, D.; Yang, F. Seafloor habitat mapping using multibeam bathymetric and backscatter intensity multi-features SVM classification framework. Appl. Acoust. 2021, 174, 107728. [Google Scholar] [CrossRef]
- Wang, M.; Wu, Z.; Yang, F.; Ma, Y.; Wang, X.H.; Zhao, D. Multifeature Extraction and Seafloor Classification Combining LiDAR and MBES Data around Yuanzhi Island in the South China Sea. Sensors 2018, 18, 3828. [Google Scholar] [CrossRef]
- Dartnell, P.; Gardner, J.V. Predicting Seafloor Facies from Multibeam Bathymetry and Backscatter Data. Photogramm. Eng. Remote Sens. 2004, 70, 1081–1091. [Google Scholar] [CrossRef]
- Pillay, T.; Cawthra, H.C.; Lombard, A.T. Characterisation of seafloor substrate using advanced processing of multibeam bathymetry, backscatter, and sidescan sonar in Table Bay, South Africa. Mar. Geol. 2020, 429, 106332. [Google Scholar] [CrossRef]
- Porskamp, P.; Rattray, A.; Young, M.; Ierodiaconou, D. Multiscale and Hierarchical Classification for Benthic Habitat Mapping. Geosciences 2018, 8, 119. [Google Scholar] [CrossRef]
- Berthold, T.; Leichter, A.; Rosenhahn, B.; Berkhahn, V.; Valerius, J. Seabed sediment classification of side-scan sonar data using convolutional neural networks. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–8. [Google Scholar]
- Luo, X.; Qin, X.; Wu, Z.; Yang, F.; Wang, M.; Shang, J. Sediment Classification of Small-Size Seabed Acoustic Images Using Convolutional Neural Networks. IEEE Access 2019, 7, 98331–98339. [Google Scholar] [CrossRef]
- Qin, X.; Luo, X.; Wu, Z.; Shang, J. Optimizing the Sediment Classification of Small Side-Scan Sonar Images Based on Deep Learning. IEEE Access 2021, 9, 29416–29428. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Sun, B.-Y.; Lee, M.-C. Support Vector Machine for Multiple Feature Classifcation. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 501–504. [Google Scholar]
- Muller, K.R.; Mika, S.; Ratsch, G.; Tsuda, K.; Scholkopf, B. An introduction to kernel-based learning algorithms. IEEE Trans. Neural Netw. 2001, 12, 181–201. [Google Scholar] [CrossRef] [PubMed]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Probst, P.; Boulesteix, A.-L. To tune or not to tune the number of trees in random forest. J. Mach. Learn. Res. 2017, 18, 6673–6690. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaria, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef]
- Steiniger, Y.; Kraus, D.; Meisen, T. Survey on deep learning based computer vision for sonar imagery. Eng. Appl. Artif. Intell. 2022, 114, 105157. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Kai, L.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Li, X.; Chen, S.; Hu, X.; Yang, J. Understanding the Disharmony Between Dropout and Batch Normalization by Variance Shift. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2677–2685. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Chollet, F.; others. Keras. 2015. Available online: https://keras.io (accessed on 6 February 2023).
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Blondel, P. Segmentation of the Mid-Atlantic Ridge south of the Azores, based on acoustic classification of TOBI data. Geol. Soc. Lond. Spec. Publ. 1996, 118, 17–28. [Google Scholar] [CrossRef]
- Gao, D.; Hurst, S.D.; Karson, J.A.; Delaney, J.R.; Spiess, F.N. Computer-aided interpretation of side-looking sonar images from the eastern intersection of the Mid-Atlantic Ridge with the Kane Transform. J. Geophys. Res. Solid Earth 1998, 103, 20997–21014. [Google Scholar] [CrossRef]
- Heinrich, C.; Feldens, P.; Schwarzer, K. Highly dynamic biological seabed alterations revealed by side scan sonar tracking of Lanice conchilega beds offshore the island of Sylt (German Bight). Geo-Mar. Lett. 2016, 37, 289–303. [Google Scholar] [CrossRef]
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective, 4th ed.; Pearson: Upper Saddle River, NJ, USA, 2015. [Google Scholar]
- Qiu, Q.; Thompson, A.; Calderbank, R.; Sapiro, G. Data Representation Using the Weyl Transform. IEEE Trans. Signal Process. 2016, 64, 1844–1853. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Ahn, H.K.; Qiu, Q.; Bosch, E.; Thompson, A.; Robles, F.E.; Sapiro, G.; Warren, W.S.; Calderbank, R. Classifying pump-probe images of melanocytic lesions using the WEYL transform. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Matthews, B.W. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Biophys. Acta 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Delgado, R.; Tibau, X.A. Why Cohen’s Kappa should be avoided as performance measure in classification. PLoS ONE 2019, 14, e0222916. [Google Scholar] [CrossRef] [PubMed]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Huvenne, V.A.I.; Blondel, P.; Henriet, J.P. Textural analyses of sidescan sonar imagery from two mound provinces in the Porcupine Seabight. Mar. Geol. 2002, 189, 323–341. [Google Scholar] [CrossRef]
- Wilken, D.; Feldens, P.; Wunderlich, T.; Heinrich, C. Application of 2D Fourier filtering for elimination of stripe noise in side-scan sonar mosaics. Geo-Mar. Lett. 2012, 32, 337–347. [Google Scholar] [CrossRef]
- Divyabarathi, G.; Shailesh, S.; Judy, M.V. Object Classification in Underwater SONAR Images using Transfer Learning Based Ensemble Model. In Proceedings of the 2021 International Conference on Advances in Computing and Communications (ICACC), Kochi, India, 21–23 October 2021; pp. 1–4. [Google Scholar]
- Williams, D.P. On the Use of Tiny Convolutional Neural Networks for Human-Expert-Level Classification Performance in Sonar Imagery. IEEE J. Ocean. Eng. 2021, 46, 236–260. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]









| Used Features | 32 px | 16 px | 8 px | ||||
|---|---|---|---|---|---|---|---|
| 8-bit | 6-bit | 8-bit | 6-bit | 8-bit | 6-bit | ||
| SVM-L and RF | All | 8 | 12 | 15 | 45 | 20 | 114 |
| AGG | 1389 | 1316 | 1493 | 1453 | 1429 | 1431 | |
| GLCM | 17 | 303 | 22 | 327 | 21 | 322 | |
| WT | 13 | 12 | 50 | 52 | 168 | 172 | |
| CNN | All | 13 | 12 | 309 | 304 | 1190 | 1272 |
| Gray * | - | - | - | - | - | - | |
| PWT | 13 | 12 | 309 | 304 | 1190 | 1272 | |
| Used Features | 32 px | 16 px | 8 px | ||||
|---|---|---|---|---|---|---|---|
| 8-bit | 6-bit | 8-bit | 6-bit | 8-bit | 6-bit | ||
| SVM-L | All | 0.49 | 0.50 | 0.44 | 0.45 | 0.36 | 0.36 |
| AGG | 0.38 | 0.37 | 0.37 | 0.38 | 0.37 | 0.38 | |
| GLCM | 0.52 | 0.52 | 0.46 | 0.47 | 0.39 | 0.37 | |
| WT | 0.22 | 0.21 | 0.12 | 0.13 | 0.05 | 0.05 | |
| RF | All | 0.57 * | 0.55 | 0.42 | 0.47 | 0.39 | 0.38 |
| AGG | 0.43 | 0.43 | 0.39 | 0.42 | 0.39 | 0.39 | |
| GLCM | 0.57 * | 0.57 * | 0.49 | 0.48 | 0.37 | 0.38 | |
| WT | 0.27 | 0.26 | 0.12 | 0.10 | 0.05 | 0.03 | |
| CNN | All | 0.41 | 0.42 | 0.38 | 0.37 | 0.33 | 0.31 |
| Gray | 0.43 | 0.44 | 0.39 | 0.40 | 0.37 | 0.37 | |
| PWT | 0.18 | 0.24 | 0.06 | 0.09 | 0.06 | 0.03 | |
| Used Features | 32 px | 16 px | 8 px | ||||
|---|---|---|---|---|---|---|---|
| 8-bit | 6-bit | 8-bit | 6-bit | 8-bit | 6-bit | ||
| SVM-L | All | 0.82 | 0.82 | 0.75 | 0.75 | 0.66 | 0.67 |
| AGG | 0.70 | 0.70 | 0.69 | 0.69 | 0.62 | 0.62 | |
| GLCM | 0.62 | 0.65 | 0.62 | 0.65 | 0.62 | 0.61 | |
| WT | 0.55 | 0.55 | 0.41 | 0.41 | 0.27 | 0.27 | |
| RF | All | 0.85 | 0.87 * | 0.80 | 0.79 | 0.62 | 0.65 |
| AGG | 0.73 | 0.73 | 0.71 | 0.70 | 0.67 | 0.67 | |
| GLCM | 0.75 | 0.76 | 0.67 | 0.70 | 0.65 | 0.64 | |
| WT | 0.65 | 0.61 | 0.48 | 0.45 | 0.29 | 0.31 | |
| CNN | All | 0.73 | 0.73 | 0.65 | 0.66 | 0.60 | 0.59 |
| Gray | 0.85 | 0.85 | 0.79 | 0.79 | 0.71 | 0.70 | |
| PWT | 0.42 | 0.52 | 0.26 | 0.38 | 0.17 | 0.24 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Breyer, G.; Bartholomä, A.; Pesch, R. The Suitability of Machine-Learning Algorithms for the Automatic Acoustic Seafloor Classification of Hard Substrate Habitats in the German Bight. Remote Sens. 2023, 15, 4113. https://doi.org/10.3390/rs15164113
Breyer G, Bartholomä A, Pesch R. The Suitability of Machine-Learning Algorithms for the Automatic Acoustic Seafloor Classification of Hard Substrate Habitats in the German Bight. Remote Sensing. 2023; 15(16):4113. https://doi.org/10.3390/rs15164113
Chicago/Turabian StyleBreyer, Gavin, Alexander Bartholomä, and Roland Pesch. 2023. "The Suitability of Machine-Learning Algorithms for the Automatic Acoustic Seafloor Classification of Hard Substrate Habitats in the German Bight" Remote Sensing 15, no. 16: 4113. https://doi.org/10.3390/rs15164113
APA StyleBreyer, G., Bartholomä, A., & Pesch, R. (2023). The Suitability of Machine-Learning Algorithms for the Automatic Acoustic Seafloor Classification of Hard Substrate Habitats in the German Bight. Remote Sensing, 15(16), 4113. https://doi.org/10.3390/rs15164113