1. Introduction
Geographic Information Systems (GISs) are more prevalent today than ever before. The rapid adoption of GIS has been fueled by the increase in the number of satellites orbiting the Earth, which are estimated to be over 4500 [
1]. These satellites are important for many purposes, such as communications, navigation, planetary observations, military, radio, and remote sensing. In this work, we focus on remote sensing, the scanning of the Earth by satellite or high-flying aircraft to obtain information, due to being increasingly relied upon in various industries. Remote sensing has many applications such as monitoring ocean temperature, forest fires, weather patterns, growth of urban areas, and vegetation conditions [
2]. Due to climate change, monitoring vegetation conditions has become extremely important to ensure the health of forests, wetlands, grasslands, and agricultural sites. Leveraging the data obtained by remote sensing equipment allows us to identify trends and intervene to maximize the health of these ecosystems.
The agriculture industry is a vital aspect of economies and societies around the world. For example, agriculture had a total gross domestic product contribution to the Canadian economy of over 30 billion CAD in 2020 [
3]. Smart agriculture employs remote sensing technologies for optimal setting of growing environments to maximize yield (i.e., precision farming). It is unsurprising that remote sensing satellites have become a widely used tool for farming by “increase[ing] production, reducing costs, and providing an effective means of managing land resources” [
4] through the means of automated analysis of aggregated farmland satellite data. With this, farmers and farming companies can generate various metrics to estimate crop yield and guide interventions to increase crop production. However, satellite imagery are often fully or partially obscured by clouds and their respective shadows, limiting the effectiveness of such analysis. Directly using data from these obscured regions can produce invalid results. One way to mitigate this issue is to reject images with non-negligible cloud cover. However, if we are able to identify clouds and their shadows within the image data, then partial data could be salvaged and incorporated into analysis. Moreover, the identified shadow regions could be digitally corrected for further use after identification [
5,
6].
Occlusion by clouds and their shadows impedes any analysis of the underlying regions of interest, and thus, methods identifying clouds and their shadows can improve remote sensing analysis for many other applications (e.g., dark mining locations [
7]). Recently, this has led to satellites that provide data that greatly simplify the process of cloud identification. For instance, the Sentinel-2 satellite launched in 2015 takes images of the Earth at a high temporal and spatial resolution (at most 5 day intervals, with a 10 m
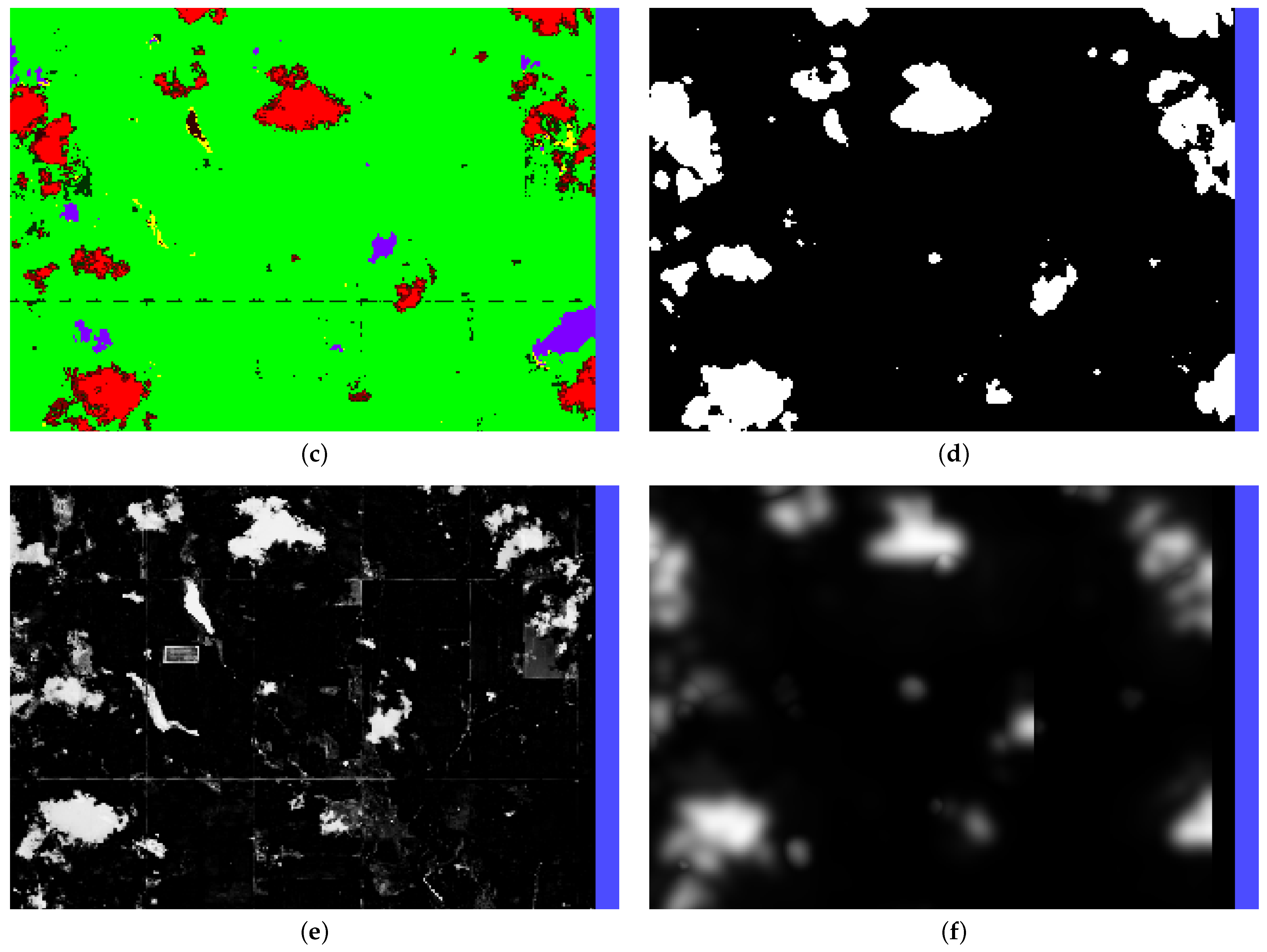
pixel size for most regions). It also produces several bands that identify cloud-obscured pixels, allowing for their straightforward removal, while bands that can similarly facilitate cloud shadow removal have been investigated, they produce inaccurate results due to the exclusion of cloud shadows from the shadow mask (false negatives) and the inclusion of other structures in the images such as bodies of water or dirt (false positives). See
Appendix B,
Figure A2c for several example clouds (red) missing cloud shadows (purple) in the scene classification layer (SCL) provided by the Sentinel-2.
There exist many image-based techniques for identifying and removing cloud shadows from satellite images [
8,
9,
10]. However, object-based methods (i.e., constructing a 3D space consisting of the Sun, satellite, clouds, and Earth) are a promising alternative [
7,
11,
12,
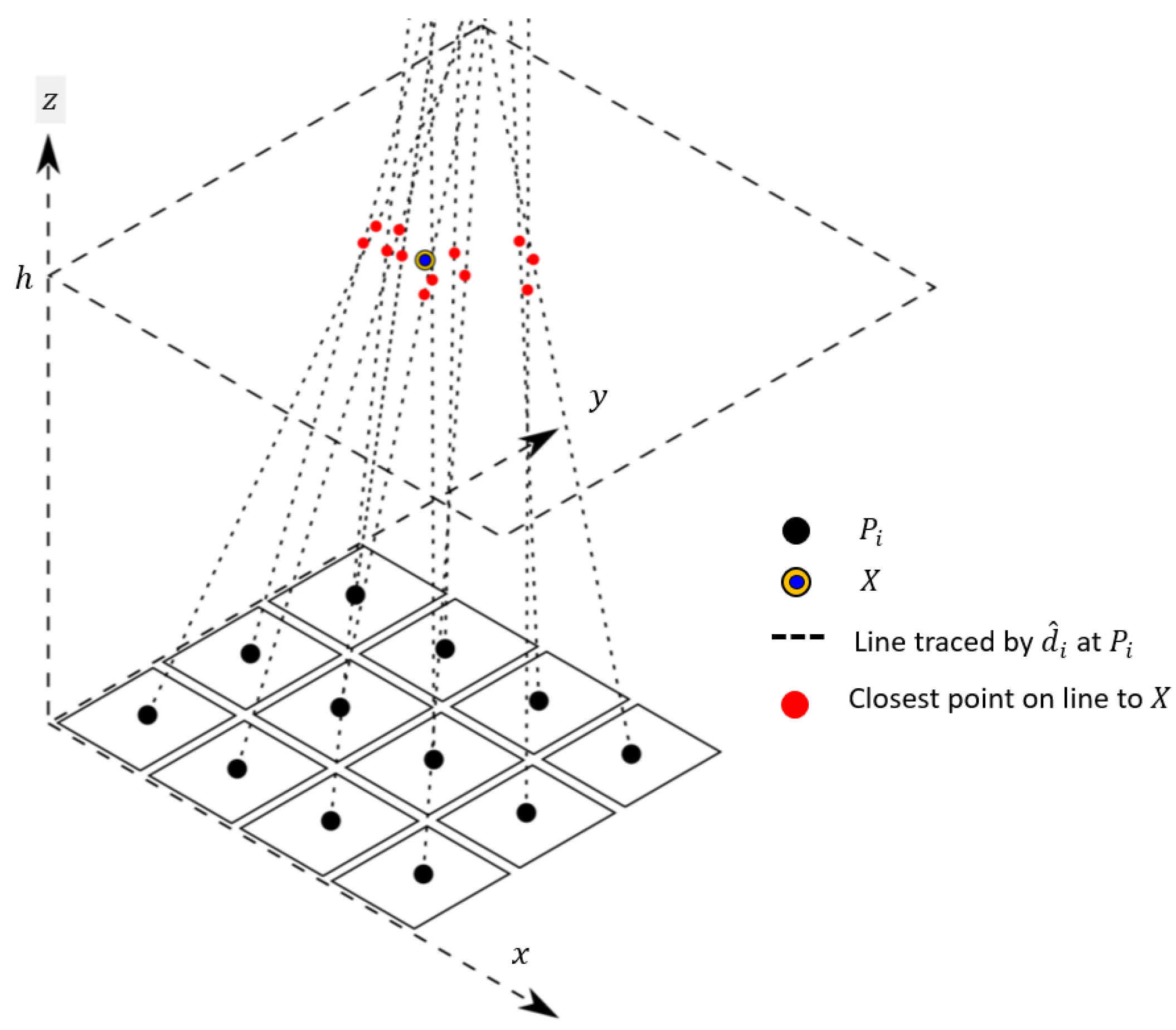
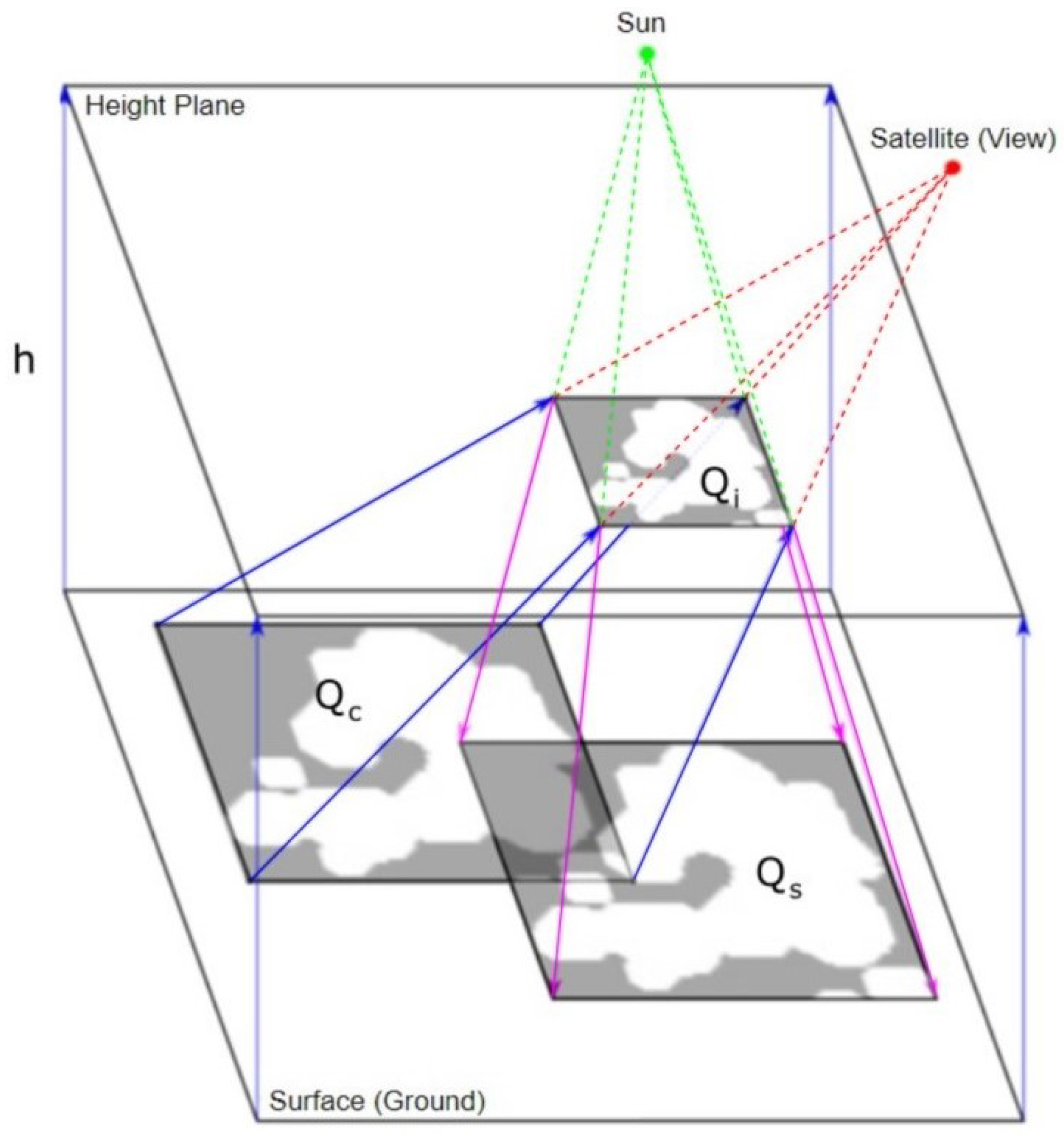
13]. Object-based methods can infer the position of cloud shadows based on the positions of the clouds in the image. More specifically, if the position of the Sun and the height/geometry of the cloud are known, we can trace the light rays from the Sun through the cloud to determine where the cloud’s shadows are located. This ray-tracing process has been extensively developed for lighting and shading in the rendering of 3D graphics [
14]. The results from this technique are impressive, and the base principle for ray casting and ray tracing is utilized in all popular rendering tools, such as Blender and Autodesk 3ds Max, by both amateur and professional rendering production.
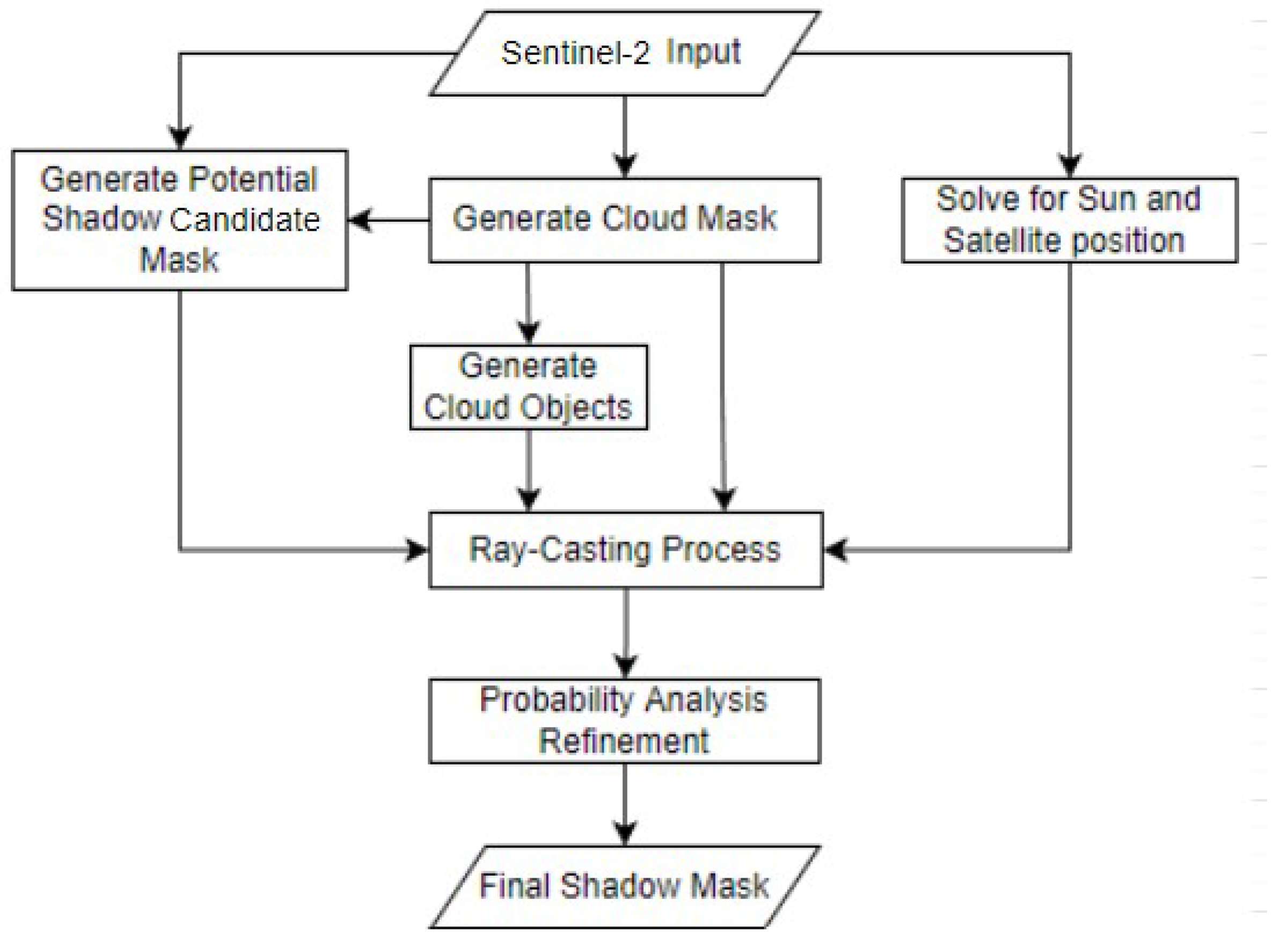
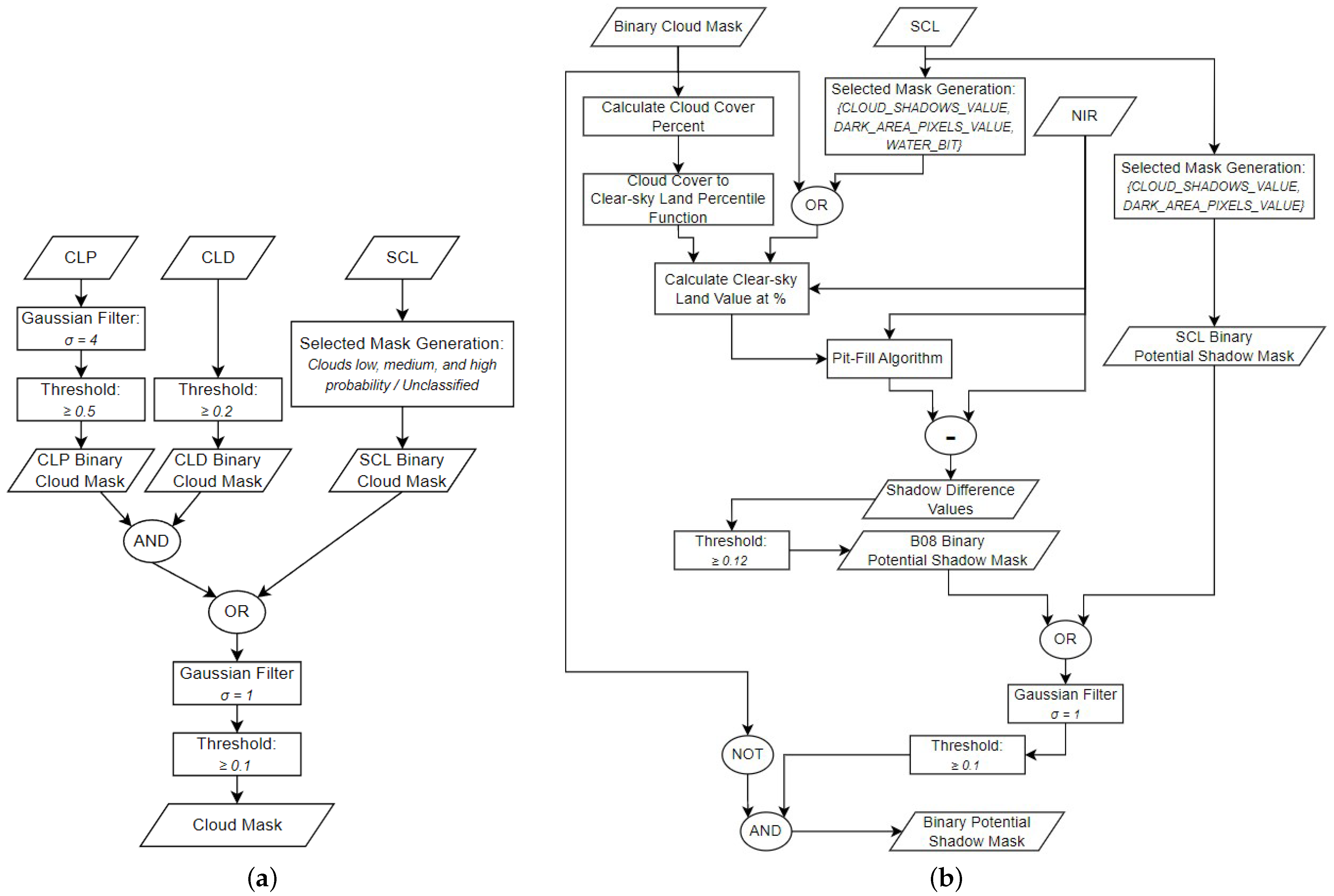
Our method uses ray-casting and probabilistic techniques to improve upon the methods introduced by Zhu and Woodcock [
11] and depends on Sentinel-2 GIS imaging. Since Sentinel-2 provides several cloud identification processes, Sen2Cor [
15] and s2cloudless [
16], we leverage these to generate the cloud mask. The generation of potential cloud shadows builds on the image-based approach described by Zhu and Woodcock [
11]. We then use a least squares approach to solve for the optimal global position of the Sun and satellite, relative to the image, utilizing the Sentinel-2 satellite and Sun angle bands. Our approach uses a modified version of the object-based method outlined by Zhu and Woodcock [
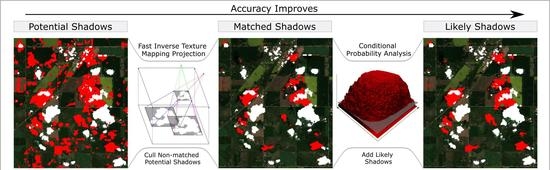
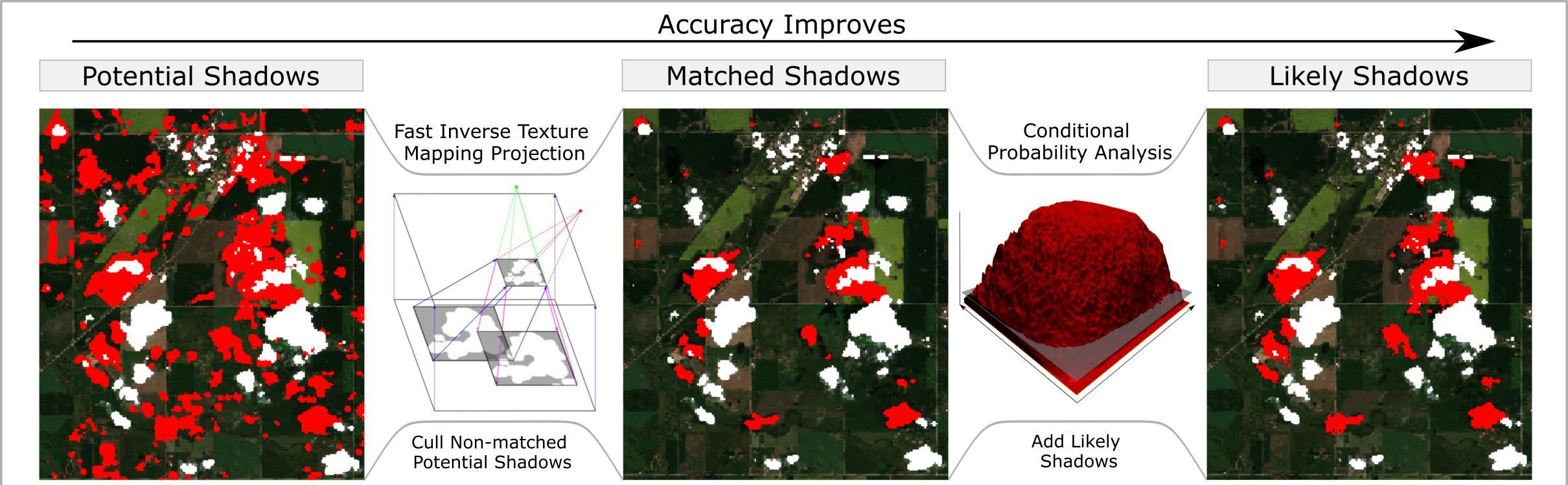
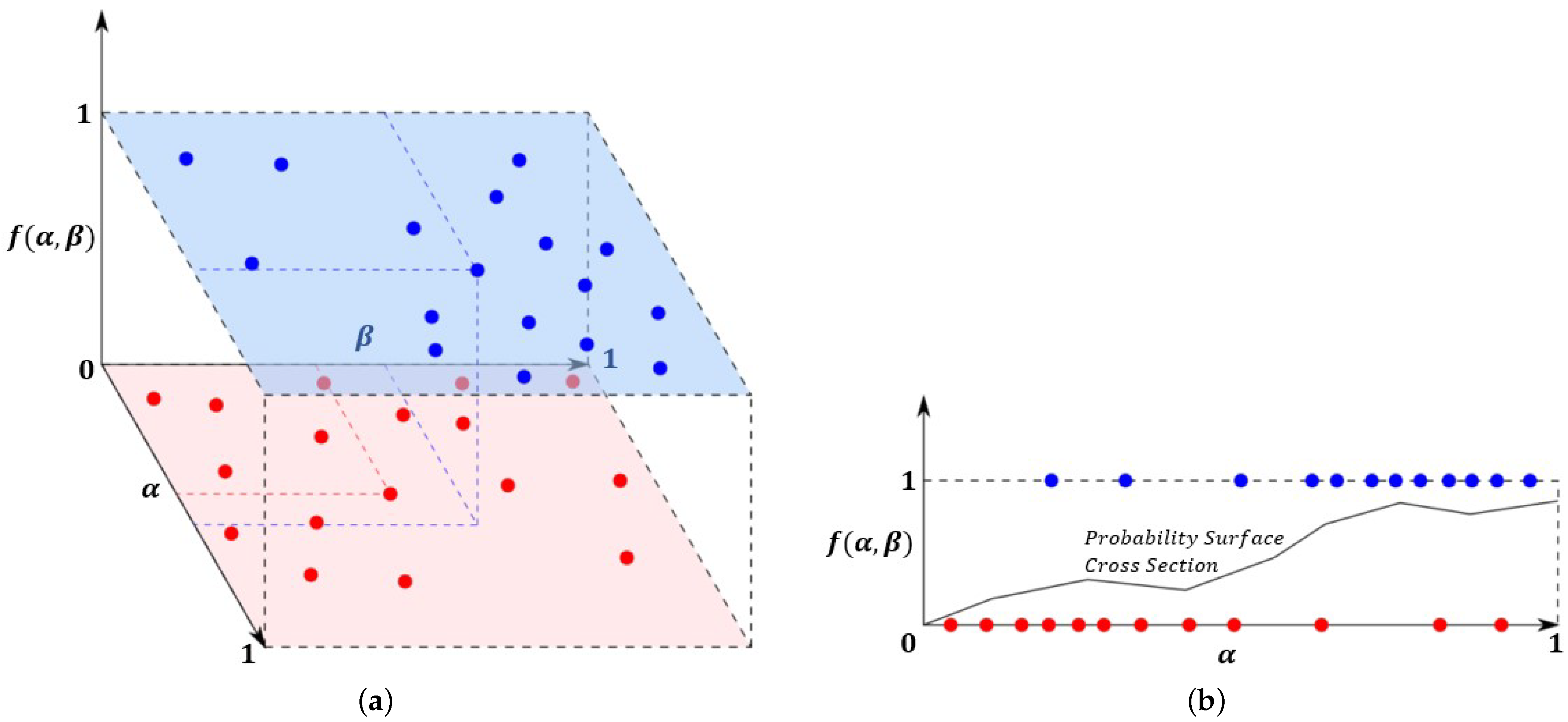
11] for producing a shadow mask by considering various candidate cloud heights for each cloud. Then, using the cloud height and shape and the view/Sun positions, we can produce a shadow mask via efficient ray-casting methods and then shape match these projected shadows against the image-based shadow masks produced in previous steps to find the best match. Finally, we use a novel probabilistic approach to determine the likelihood that each candidate shadow pixel was generated from a cloud shadow and form a final cloud mask by thresholding the probability surface.
To evaluate our method, we selected six datasets from a chosen study area consisting of diverse features (agriculture, villages, bodies of water, barren land, etc.). For each dataset, we manually generated ground-truth shadow masks and compared these masks to those created by successive stages of our method. To compare, we measured the false positive, false negative, and total pixel error percentage normalized to both the number of pixels and the number of shadow pixels in the image. Our analysis showed a clear improvement in the total error percentage for shadow pixels identified in each successive step of the algorithm. The error metrics clearly showed an improvement when adding the novel statistical approach when compared to the ray-casting process output alone. In addition, we used the cloud shadow metrics employed in Zhu and Woodcock’s 2012 paper, the producer and user accuracy [
11]. Our method has an average producer accuracy of 82.82% and user accuracy of 75.55%, which is an improvement over the results reported by Zhu and Woodcock [
11] (greater than 70% and approximately 50%, respectively). Since our algorithm uses ideas and concepts from computer graphics, an implementation of our algorithm is able to utilize well-established parallelization methods for a computational speedup using commonly available commercial hardware.
Related Work
Due to their importance to problems arising in remote sensing, methods for cloud shadow identification have been extensively studied [
17]. We can categorize these techniques into four main types: image processing, temporal analysis, machine learning classification, and geometric relation analysis. It should be noted that many of the processes implemented for cloud shadow detection use more than one of the types listed. Image processing techniques utilize various electromagnetic field (EMF) wavelengths to deduce which pixels are cloud shadows. For example, the US Naval Research Laboratory conducted a study utilizing only the red, green, and blue (RGB) channels of satellites to detect clouds and cloud shadows over ocean water [
8]. Next, temporal analysis techniques are closely linked to image processing techniques, but a set of images taken over time are used to compare changes between successive images to determine which pixels are likely cloud or cloud shadows. For example, Jin et al. proposed a method for identifying cloud and cloud shadows by utilizing two-date analysis in Landsat imagery [
9]. A limitation of temporal analysis approaches is they require a sufficiently dense temporal sampling data and, thus, if data is sparse, the quality of the result degrades. The next approach is machine learning classification. Leveraging the power of neural networks, algorithms have been produced to identify cloud and cloud shadow data by training a network on previous remote sensing imagery [
10]. A recent paper details a method to detect cloud and cloud shadows over mining areas to minimize the misidentification of cloud shadows as mining locations, or vice versa [
7]. This approach utilizes a “supervised support-vector-machine classification to identify clouds, cloud shadows, and clear pixels” in the initial identification step [
7]. Using the classification results, the last technique of geometric relation analysis, is used to refine the identification data [
7]. More specifically, the algorithm projects the centroid of clouds to identify which cloud shadows identified previously are true or false positives. Machine learning can result in very accurate results; however, the system must be trained with a large dataset, requiring substantial temporal data, and is often difficult to fine-tune due to the weak interpretability of machine learning systems [
18]. In addition to this, training requires ground-truth data, which is currently being generated manually for our evaluation of our method and is a time-intensive task. This limitation makes it difficult to identify potential improvements, as opposed to geometric analysis methods, where improving the representation of clouds and the rendering of their shadows offer a clear path for improvement.
Zhu and Woodcock propose a series of methods that utilizes image processing and geometric relation analysis [
11,
12,
13]. Their initial method identified candidate clouds and candidate cloud shadows via image processing techniques, then employed a cloud shadow projection technique to eliminate false positive shadows [
11].
Our method is similar but distinct from their method. We use a different process to identify clouds, as they use various visual data metrics, such as normalized difference vegetation index, normalized difference snow index, whiteness tests, water tests, and temperature metrics, while our method leverages various cloud data/probability bands provided by Sentinel-2, which is not available in the Landsat satellites, bypassing the issue of Sentinel-2 not having temperature bands. Likewise, the geometric relation analysis of the clouds to their shadows are different. Their algorithm “treats each cloud as a 3D object with a base height retrieved by matching clouds and cloud shadows, and a top height estimated by a constant lapse rate and its corresponding base height” [
11] while our method treats each cloud as a 2D object and leverages inverse texture mapping for matching cloud and cloud shadows. This allows our algorithm to project cloud shadows in an effective and efficient manner by only projecting the four corners of a quadrilateral containing the cloud. Our algorithm introduces an additional innovation by adding the probability analysis of the geometric relation analysis output to improve the shadow mask result. Their algorithm has a cloud shadow accuracy of >70% and 50% for producer’s accuracy, related to false negatives, and user accuracy, related to false positives, respectively, (see
Section 3 for the definitions of these metrics). Various refinements in their initial method were outlined in subsequent papers, including adding a multi-temporal solution for land cover, a prototype algorithm for the Sentinel-2 satellite [
13]. However, the prototype algorithm for the Sentinel-2 satellite was not used directly for our algorithm, though similarities exist since their method is also based on their original method proposed for Landsats 4–7. Both methods treat the cloud as a flat planar object and both utilize cloud probability metrics to generate the cloud mask. Our algorithm surpasses the prototype algorithm by implementing the novel probabilistic method to further refine the results after the ray-casting method.
3. Results
For evaluating our method, we chose a study area with diverse features (
Figure 1), ensuring we have variation in the underlying surface in a controlled manner for comparisons between datasets. Using the test datasets described in
Table 1, we evaluated the shadow masks generated by our method to determine their suitability. Our method produces three different shadow masks, and in order to understand how well each phase of the method was affected our results, we evaluated the shadow masks produced at each stage, including the candidate shadow mask, object-based shadow mask, and final shadow mask. For each mask, we compared it to a baseline ground-truth image manually generated by the authors.
Figure 13b shows one of these manually generated images. When creating the baseline, there is inherent ambiguity regarding the state of each pixel (shadow or not shadow), leading to some human error. This ambiguity was particularly notable around areas where cloud edges intersected underlying shadows, resulting in increased uncertainty. In this situation, pixels that could not be definitively classified as either shadow or cloud were assigned as shadow pixels. We did this without effecting the error metric calculations because either the pixel is truly a shadow pixel or is a cloud pixel and removed from the metric calculations.
Using this ground-truth shadow baseline, we evaluated the predictive accuracy error of the three shadow masks, for each of the six datasets, based on the six metrics in
Table 3. Each metric was normalized to yield a pixel percentage, with
indicating that no errors were found and the shadow mask perfectly reproduces the ground-truth shadow baseline. Finally, to facilitate a direct comparison between our results and those reported by Zhu and Woodcock [
11], we also report the cloud shadow producer accuracy and cloud shadow user accuracy (Equations (
4) and (
5)). These metrics represent the predictive accuracy of our masks with regard to missed shadow pixels (false negatives) and the inclusion of non-shadow pixels (false positives). For both, a percentage of
means no false negatives exist or no false positives to exist. Lastly, since some cloud shadows in the data are a result of clouds outside the image bounds, we added a restriction to the evaluation region. An example of this can be see as a purple line in
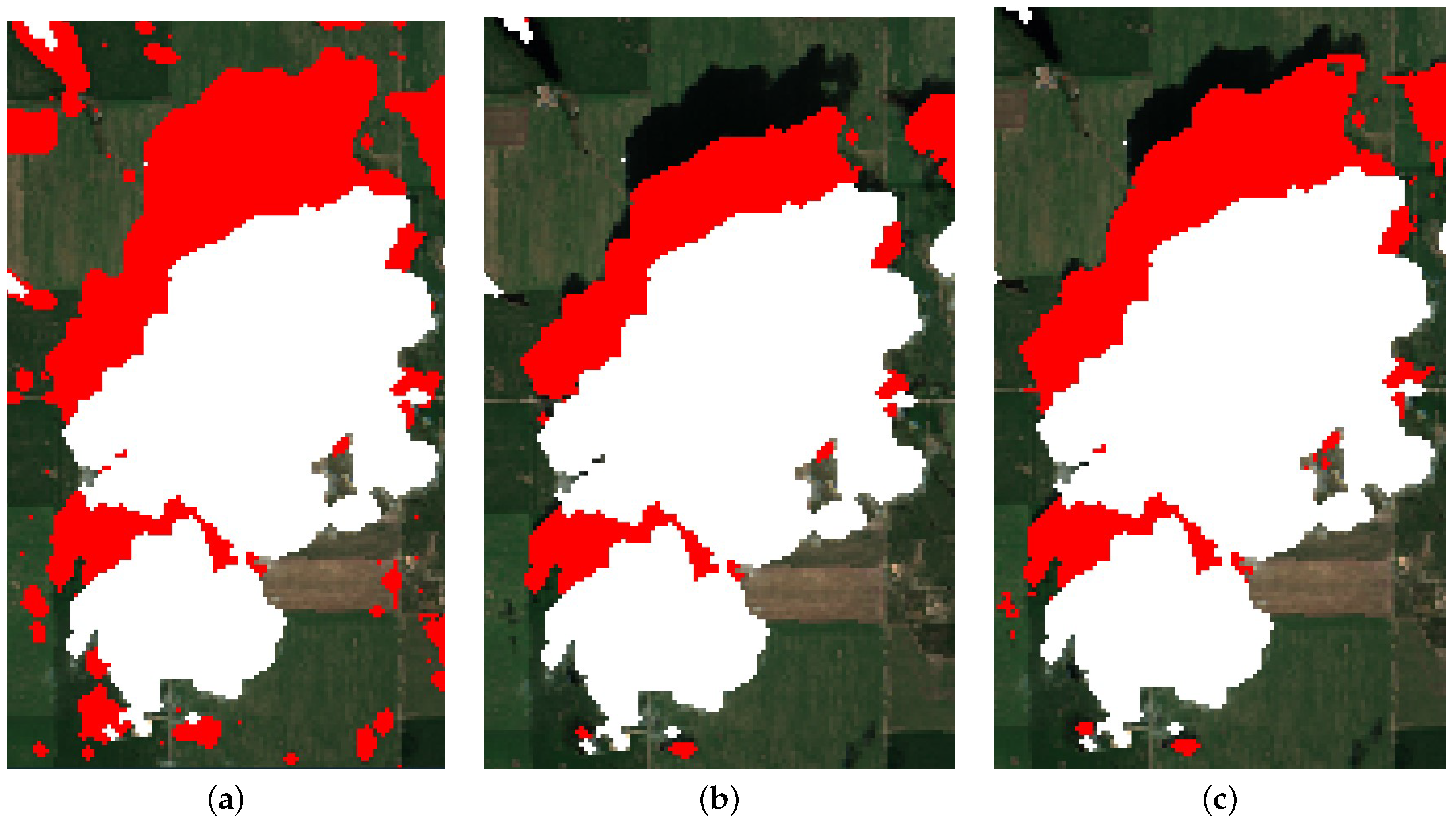
Figure 9b, which indicates that the bottom and right edges of the image were not included. Without this restriction, the false negative number would increase, reducing the quality of our quantitative error metrics. This can be observed in
Appendix B,
Figure A3c–f, where the cloud clipping the lower right side is projected properly but with a harsh edge bisecting it due to the harsh edge in the corresponding projected shadow probability (
) values (
Figure A2f). The restricted region is determined by averaging the middle 80% of cloud heights in the scene determined in
Section 2.2.4 and performing the ray-casting process on the image boundaries. Any pixel outside this transformed image boundary will be ignored.
The results for our metrics are detailed in
Table 4,
Table 5 and
Table 6. To assist in comparison and discussion,
Table 7 details the mean of each metric per shadow mask stage and the percentage changes in these mean values between stages. As discussed before, while ideally all metrics should be low, false negatives are more problematic in the case of shadow pixel identification, and their respective metrics should be slightly prioritized for minimization.
4. Discussion
As shown by the results reported in
Table 7, the overall accuracy of the masks improves through the three stages. The percentage change relative to the total number of pixels and to the shadow pixels in the baseline both decrease. On average, the object-based shadow mask offers an 80% improvement over the candidate mask. The final shadow mask provides a further improvement of 17% compared to the object-based shadow mask. Overall, from the candidate mask to the final mask, there was an improvement of 84%. The total error improvement when metrics were normalized by the number of shadow pixels was similar, being 44%, 18%, and 54%. According to either metric, the total error of the overall image decreases, and thus, the resulting shadow mask quality is increased at every stage.
Comparing the candidate and the object-based results in
Table 7, the false positives are significantly lower with a percent change of false positives of 94% and 80% for the total number of pixels and shadow pixels, respectively. These numbers align with expectations, as the candidate mask is deliberately designed to significantly overestimate the number of shadow pixels. During the ray-casting process, we remove shadow pixels from the candidate mask, leading to the elimination of many false positives. However, this action inadvertently results in the removal of some true positives as well. Consequently, there is a modest increase in the absolute number of false negatives (~2%). However, their relative values increase drastically by 679% and 2018% for the total and shadow normalized metrics, respectively. This is primarily due to the over-representation of false positives in the candidate mask. These errors can come from several sources including errors in the cloud mask, incorrectly matching cloud shadows, or a byproduct of our assumptions in the ray casting process, mainly clouds being restricted to a 2D object.
When comparing the object-based and the final results in
Table 7, the false negatives in the final results are much lower than in the object-based shadow mask with a drop of 27.54% to only 13.85% on average, a 50% decrease, which is expected. Even though our preference is to minimize the false negatives, this should be obtained without unduly increasing the number of false positives, striking a balance between the two. The total false positives in the final shadow mask are much lower than the original candidate mask with a drop of 74.72% to 21.35% on average, a 71% decrease, as expected. This is slightly worse than the object-based result of 15.14%, an 80% decrease, but given the false negative error of 27.54% at this stage, the result did not fit our criteria of prioritizing false negatives over false positives, and thus, the post-probability mask offers the best result out of the three masks analyzed.
We compared our results to those reported by Zhu and Woodcock in their 2012 paper, where the producer and user accuracy metrics were used [
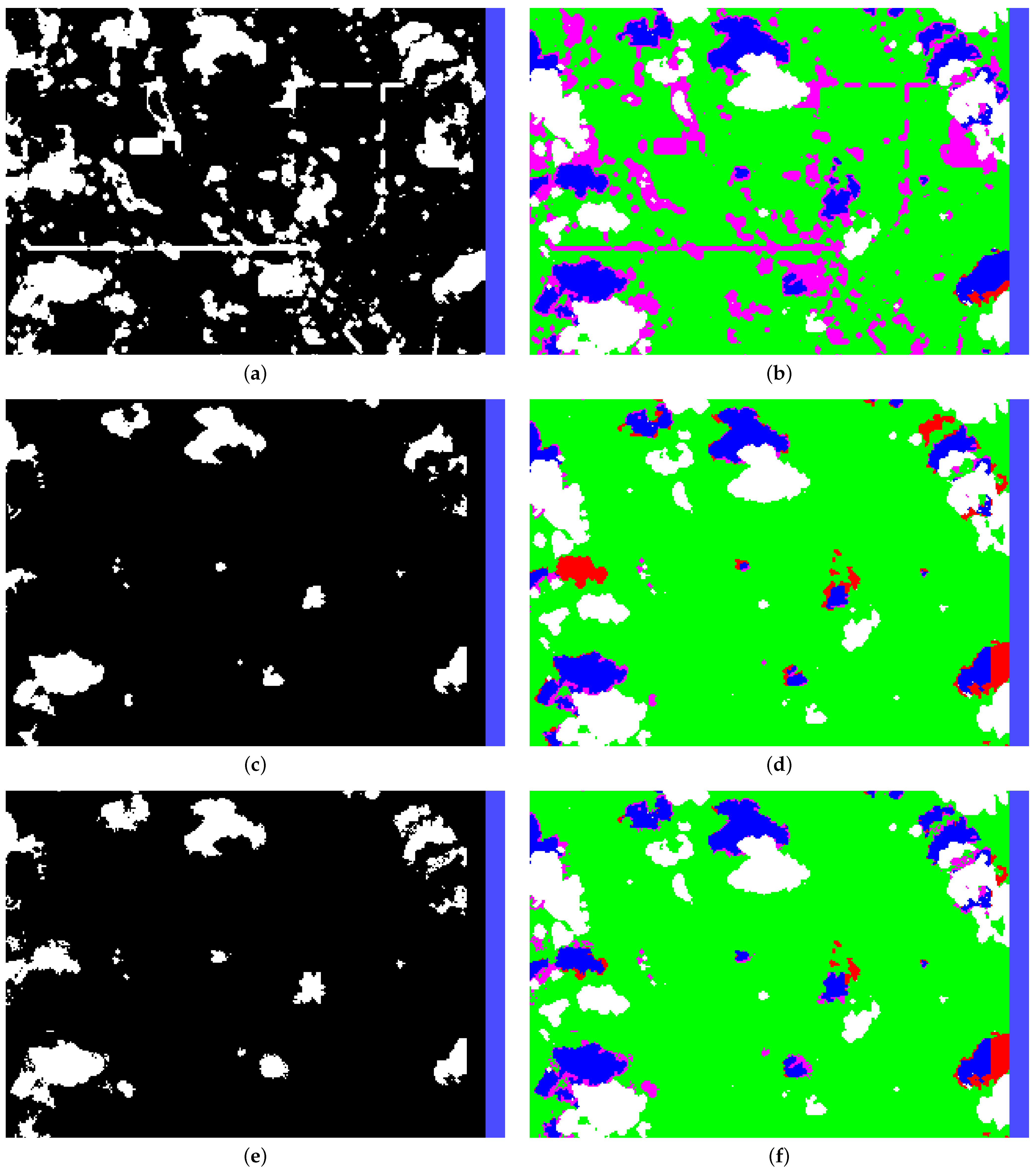
11]. Their method achieved an average producer accuracy of over 70% and an average user accuracy of approximately 50%. Their algorithm is designed for a much larger set of potential scenes with snow and water detection integrated in the algorithm; however, our post-probability shadow mask significantly improves upon their method. This is demonstrated by our algorithm having an average producer and user accuracy of 82.82% and 75.55% respectively. To evaluate the improvement due to the probability analysis, we evaluated the progression of pixels that were added to the final shadow mask and shadow pixels that were not added to the final shadow mask (
Figure 14). We found that the probability analysis correctly added 1.13% of the image’s pixels to the final shadow mask, whereas 0.53% of the image’s pixels were incorrectly added, resulting in a net increase in shadow mask accuracy. However, 1.71% of the image’s pixels were shadow pixel and were not added to the final shadow mask (~60% of possible shadow pixels to add). Looking at the these pixels in
Figure 14, 0.34% of the image pixels were incorrectly skipped by the probability analysis were also not present in the potential shadow mask. Since the potential shadow mask overestimates the shadow pixels, these 0.34% pixels are likely to contain pixels that were incorrectly labeled as shadows in the baseline due to human error. Additionally, if we compare our object-based shadow mask to Zhu and Woodcock’s results, we notice that our producer accuracy is similar, being only 67.92%. However, our object-based shadow mask user accuracy is much better at 79.50% already and only reduces about 5% in the final shadow mask. The disparity between the user accuracy may be a result of their algorithm buffering their Fmask, which includes their resulting shadow mask, “by 3 pixels in 8 interconnected directions for each of the matched cloud shadow pixels to fill those small holes” [
11]. This results in a low user accuracy due to all the extra pixels added to the edges of detected cloud shadows. Due to the improvement in both the producer and user accuracy of our final result, we conclude that replacing Zhu and Woodcock’s shadow pixel buffer with our proposed statistical model improves the accuracy of the shadow mask output.
Examining the output of our algorithm, it is evident that thin stratus or “wispy” clouds are a conspicuous source of error, as they often produce faint shadows that are difficult to detect for our algorithm. An example of missing cloud shadows for these types of clouds can be seen in
Figure 15. The metrics for this scene contains the lowest producer accuracy in
Table 5 and
Table 6 compared to the other test scenes. Zhu and Woodcock encountered similar issues with their method and noted that their algorithm “may fail to identify a cloud if it is both thin and warm” [
11]. Fortunately, often the shadows of these clouds tend to have a smaller impact on the data when missed when compared to thicker and less “wispy” clouds.
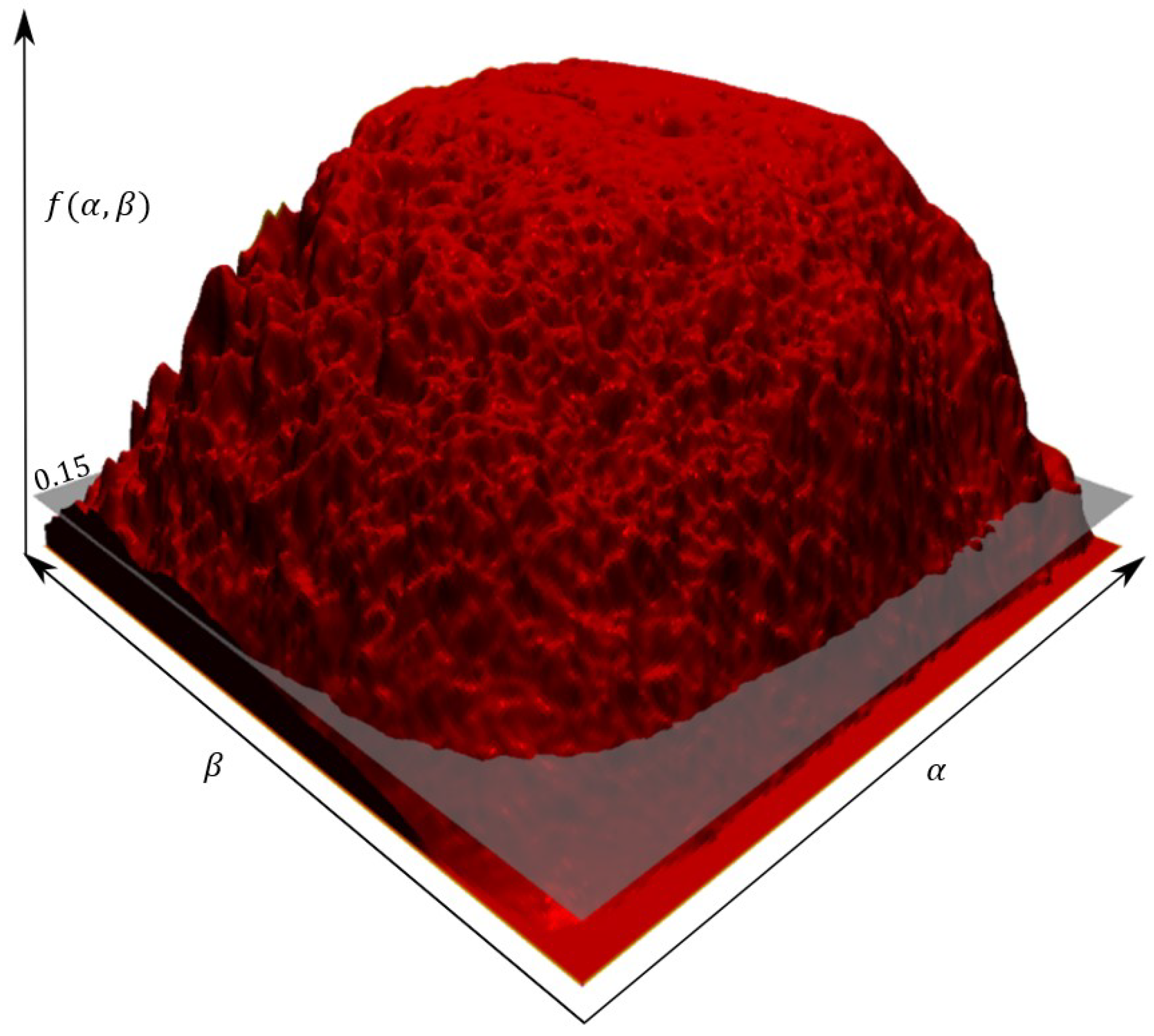
Since we use a wide range of heights to test each cloud, clouds will sometimes incorrectly identify the optimal shadow projection and attribute them to other cloud shadows, particularly when the incorrect shadow is larger than the correct shadow. However, as a consequence of the influence distance, the probability analysis often corrects such issues since nearby clouds being correctly projected will inadvertently project the incorrect cloud’s projected shadow probability (
) values. An example of this is included in
Appendix B,
Figure A3d, on the left side, where a cloud was missed (seen in red), and
Figure A3f, where the cloud was recognized (seen in mostly blue).
Our method works well in the time periods critical for farmland analysis, the focus of our research; however, evaluating our method outside these times helps to determine the viability or our method for year round analysis, particularly when snow is present, and highlight possible directions for future work. As such, several alternate sets outside the growth season were chosen to qualitatively assess the method’s effectiveness in other seasons. It was found that in the spring/fall season with no snow and dominated by brown vegetation, the result sometimes yields satisfactory results. Specifically, the sets that effectively generated a cloud and shadow mask were 16 April 2020 (
Figure 16b) and 1 May 2020 (
Figure 16c). However, the proposed method is less successful for datasets 11 April 2020 (
Figure 16a) and 15 October 2020 (
Figure 16d). In these two examples, the generated cloud mask is poor with excessive false positive cloud pixels, and thus, further processing generates poor shadow masks. In analyzing the snow dataset (11 April 2020), we found that errors in the cloud mask are likely due to poor cloud probability values (too high) generated by Sentinel-2 in CLP
2 (
Figure 17b) in the bottom half of the image. However, CLP
1 (
Figure 17a) seems correct. The same issue persisted in the 15 October 2020 dataset, though to a lower degree. There may also be a slight problem with CLP
1 (
Figure 17c) by inspection. As such, errors in out-of-season data processing are mainly attributed to cloud mask generation.
One assumption made in the methodology similar to Zhu and Woodcock’s method [
13] was that clouds are considered as 2D objects. However, for larger cumulus and cumulonimbus clouds, this representation could be less accurate due to the vertical profile of the clouds. Therefore, when the 2D representation is projected, it is missing the elongated portion of the shadow corresponding to the vertical profile. This is evident in
Figure 18 from the 27 June 2020 dataset. Through visual inspection, it becomes evident that the subject cloud exhibits a non-negligible vertical component, as observed from the fact that the shadow profile extends beyond the cloud profile. In the potential shadow mask, this extended portion is appropriately identified, which is consistent with expectations. However, in the object-based shadow mask, this extended section is absent due to the lack of overlapping pixels within the projected shadow from the 2D representation, which is absent of a vertical contribution. Although the final shadow mask partially addresses this concern, it remains insufficient in fully rectifying the issue. The other simplifications of zero Earth curvature (flat surface), single view/Sun position, and fixed height of the view/Sun position had no noticeable effects at the given scale.
Limitations and Future Work
The results reported in the previous section illustrate the potential of our method for cloud shadow detection. Nonetheless, manually generating baselines is time-consuming, limiting the number of tests performed. A further study using larger sample size would increase the confidence of the result and possibly allow for further algorithmic optimizations, in particular, the choice of method parameters. We also note that manually generating baselines is a potential source of error.
As discussed previously, this method was developed for a subset of the total possible images Sentinel-2 produces and excludes scenes containing large amounts of water, snow, ice, and dense urban areas. Since water has a low NIR reflectivity, water is included in the potential shadow mask during the pit-filling process, thereby introducing false positives into the candidate mask. As a result, the ray-casting process may select the wrong region as a cloud’s shadow, introducing false negatives by missing the correct shadow. As for snow, ice, and dense urban areas, further testing is required to identify the efficacy of the algorithm for these conditions. Directly incorporating the snow/ice band provided by Sentinel-2 would provide a means to account for images containing snow and ice in our method. For more persistent features, such as bodies of water and urban areas, modifying the method to utilize prior knowledge has the potential to improve the results for data containing such features. Our qualitative analysis suggests that one problem is generating an accurate cloud mask from the cloud probability bands in out-of-season contexts. It appears that improving the cloud mask generation process may substantially reduce the current errors in these contexts. Such extensions are appealing, as they would allow this method to be applied in other contexts aside from farmland analysis.
An extension of the probability analysis could be to use the final shadow mask as input to the ray-casting process for further improvement. This would facilitate an iterative approach, where repeating the ray casting could be used to further improve the results. Similarly, a more complex design of the shadow probability distance factor function, such as utilizing eigenanalysis of the cloud contour (shape), could improve the quality of the generated shadow probability. A further study on the sampling process for the conditional probability function to generate a more accurate statistical model may also be beneficial.
One simplification made by our method was the assumption that clouds can be represented as a planar object to integrate the inverse texture mapping technique for speeding up the ray-casting process. However, clouds with larger vertical components produce a shadow that extend past the shape of the cloud captured from the satellite’s perspective and are often missed. Improving the accuracy of the geometric representation of the cloud, by introducing a 3D representation of the cloud, would increase the accuracy of the results from the improved projected shadows in the ray-casting process. Representing clouds as 3D objects using voxel data has the added benefit of allowing the ray-casting process to consider the density of the cloud to determine its optical transparency. Such a representation would better capture the projected shadow of clouds, especially those that are thin and produce faint shadows. One method to generate 3D clouds by utilizing a “deep learning-based method [that] was developed to address the problem of modelling 3D cumulus clouds from a single image” [
24]. Alternative methods have been developed for generating 3D cloud shapes by generating opacity and intensity image to generate volumetric density data for a voxel representation [
25]. Other methods using sketch-based techniques for generating volumetric clouds could be automated to generate our cloud objects [
26].
Finally, our algorithm depends heavily on the processes developed by Sentinel Hub to produce the CLP1, CLP2, and SCL bands. As such, alternative methods for identifying clouds and the cloud probability map are required to apply the proposed method to data originating from other satellites without equivalent data bands. One possible method is to use Sentinel-2’s data to train a neural network to automatically estimate the CLP1, CLP2, and SCL bands given data from a different source.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}