1. Introduction
The regional image products obtained through satellite remote sensing are essential spatial data in the digital development of the region [
1,
2,
3]. However, although remote sensing image processing has been widely researched for region mapping [
4,
5,
6], limited studies have focused on satellite image acquisition technology. Therefore, the acquisition times of regional images have remained long, and periodic production remains difficult because precious satellite resources cannot be efficiently utilized. Imaging satellite mission planning is a crucial technology for improving the efficiency of satellite image acquisition [
7]. Imaging benefits are maximized by appropriately adjusting satellite observation targets at suitable times according to user requirements, satellite attribute information, and relevant constraints, such as energy, mobility, and storage constraints. However, numerous contradictions exist between user requirements and imaging satellite performance. Therefore, trade-offs exist in imaging satellite mission planning, which is a complex multi-objective optimization problem [
8].
Numerous multi-objective evolutionary algorithms [
9] have been proposed to achieve valuable results, such as many-objective optimization [
10], large-scale multi-objective optimization [
11], and parameter configuration [
12]. With the development of evolutionary algorithms, parameter configuration has become critical in evolutionary computing because the performance of EAs depends considerably on their parameters [
13]. However, it was often ignored because the sub-optimal parameter configuration can be compensated by prolonging the evolutionary generation and improving the evolutionary strategy. The parameter configuration methods are categorized into parameter tuning and parameter control. Parameter tuning refers to determining fixed parameter values for EAs before it runs. Manual adjustment is the most common method for parameter tuning [
14,
15]. Parameter tuning is mature and widely used in industry and academia. However, regardless of optimizing the parameter tuning method, a common shortcoming is as follows: the static parameter setting contradicts EAs, which is a dynamic process. Thus, the optimization performance of the EAs is limited.
Parameter control is a parameter configuration method in which the parameters change with the evolution process to improve algorithm performance. According to various parameter control methods, parameter control can be categorized into deterministic and adaptive parameter control.
Deterministic methods [
16] are uninformed, i.e., population feedback information is not considered during the parameter selection. A time-varying function controls parameter selection in a deterministic method, such as the sigmoid [
17] and piecewise functions [
18]. Aiming at the parameter sensitivity problem of MOEA, Dai [
19] proposed a deterministic MOEA framework based on collaborative granular sieving. The proposed method automatically selected evolutionary parameters guided by mathematical principles to guarantee convergence to the global optimal solution.
In adaptive parameter control [
20,
21], the magnitude and direction of evolution parameters are determined based on the partial feedback information. For example, in [
22], instead of reference vectors, the optical solutions and normal-boundary directions were used to guide the population to adapt to the shape of the Pareto front automatically. In [
23], an MOEA was proposed based on a self-adaptive crossover operator and interval initialization. Instead of the adaptive crossover rate, the proposed MOEA-ISa can dynamically determine the number of non-zero genes in offspring based on the similarity degree of parents. In [
24], selection pressure was adapted by encoding the size of the tournament in the genome.
In recent years, some scholars used reinforcement learning (RL) [
25] for parameter control. In this method, evolutionary parameters were selected through the feedback information of the population state, which is not affected by evolutionary strategies. Therefore, this method is a general parameter control method. In [
26], the time difference algorithm was used to map the fitness value to evolutionary parameters (population size, competitive selection ratio, crossover rate, and mutation rate) by a Q table. However, because of the limitations of RL, only discrete small-scale optimization problems can be solved, and this method cannot be adapted to the continuous changes in evolutionary parameters. Therefore, the parameter control based on RL is not feasible. Deep reinforcement learning (DRL) [
27] has been developed as a novel approach to overcome this problem. For example, Schuchardt uses DRL to solve the problem of single-parameter configuration for single objective functions [
28]. Kaiwen transformed the multi-objective discrete problem into multiple single-objective discrete problems and then optimized these single-objective functions by DRL [
29]. To solve the problem of sensitive parameter configuration of EAs, Song [
30] proposed a genetic algorithm based on RL (RL-GA). In RL-GA, Q-learning was used for selecting crossover and mutation operations. Similarly, Tian [
31] proposed a multi-objective optimization algorithm MOEA-DQN based on a deep Q network to solve the adaptive operator selection problem. In MOEA-DQN, four different mutation operators were used as candidate operators for different population states. Reijnen [
32] proposed a differential evolutionary (DE) algorithm based on DRL and parameter adaptive control, called DRL-APC-DE. The mutation parameters of the DE are adaptively controlled through DRL. To solve the scheduling problem of continuous annealing operations in the steel industry, Li [
33] proposed an adaptive multi-objective differential evolutionary algorithm based on DRL, called AMODE-DRL. The AMODE-DRL can adaptively select mutation operators and parameters according to different search domains.
Although adaptive parameter configuration has been studied extensively, the following problems persist: first, the existing parameter control is based on a single parameter or a combination of multiple single parameters, which lacks the consideration of multiple parameters simultaneously. Furthermore, complex interactions exist among various parameters, and these influences are difficult to describe with mathematical expressions [
13]. Second, evolutionary parameter configuration typically obeys the artificially set change rules or uses part of the population information. It results in the population information not accurately guiding the setting of evolutionary parameters, i.e., the parameter setting is sub-optimal. Third, the generality and robustness of the algorithm are unsatisfactory. The parameters of the same algorithm should be reconfigured for various application problems. Limited studies have focused on evolutionary parameter configuration methods based on DRL, configuring multiple evolutionary parameters simultaneously, adapting to continuous and discrete problems simultaneously, and general applicability to most MOEAs.
This study proposed a novel multi-objective learning evolutionary algorithm (MOLEA) based on DRL for satellite imaging task planning for regional mapping. The MOLEA maximizes the evolutionary benefits through DRL, thereby maximizing the optimization efficiency of the proposed algorithm. Specifically, the contribution of this study is summarized as follows:
- (1)
The scene data for fast training were constructed. For imaging satellite mission planning, the calculation is complex, and its efficiency is low, which results in a slow training speed for directly using the mission planning model as the training scene data. The easy-to-calculate public test functions were constructed as the same structure as the task planning model and then used as training scene data to improve the efficiency of algorithm training.
- (2)
Hypervolume (HV) was first proposed as a multi-objective evolutionary reward to guide the evolution of MOEA. As a scalar, HV makes it possible to apply DRL to MOEAs and enables the convergence and distribution of MOEAs to guide evolution simultaneously.
- (3)
The MOLEA was proposed. The MOLEA obtains all the population state information of each generation of the population through population state coding, which is used to guide the setting of evolutionary parameters. A simple neural network was used to map the relationship between population state information and multiple evolutionary parameters without determining its influence relationship. Through training, the parameter setting of each generation exhibits the maximum evolutionary benefit for improving the optimization performance of the algorithm.
- (4)
The effectiveness of the proposed MOLEA in imaging satellite mission planning was verified by comparing the MOLEA with four classical MOEAs. Experimental results revealed that the MOLEA considerably improves optimization efficiency and affects imaging satellite mission planning.
The rest of this paper is organized as follows.
Section 2 briefly introduces the multi-satellite imaging task planning model for region mapping.
Section 3 details the procedure of the proposed MOLEA.
Section 4 presents the experimental results and analysis of the MOLEA and comparison algorithms. Finally, the discussion and conclusion are presented in
Section 5 and
Section 6, respectively.
3. Proposed MOLEA
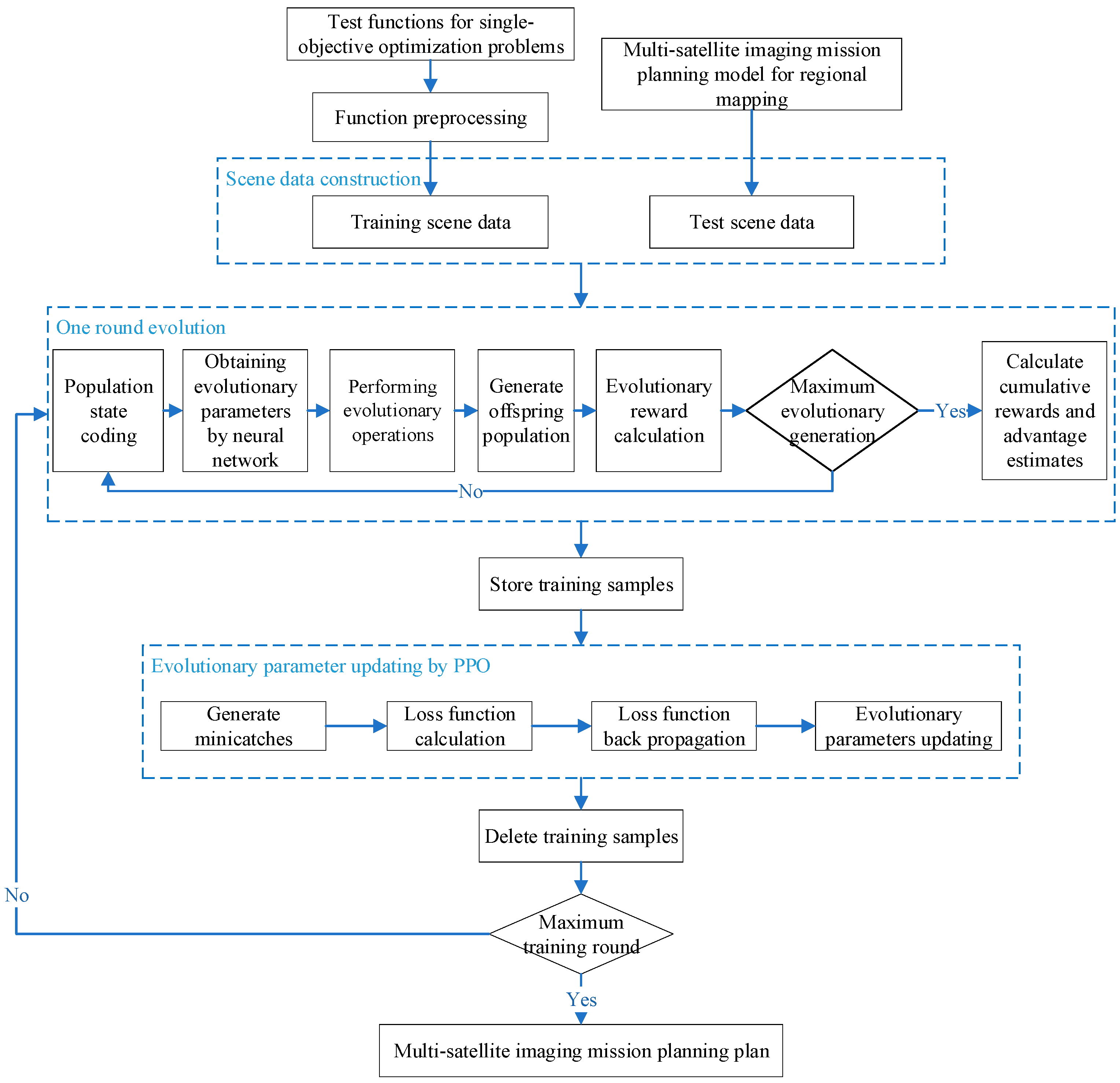
3.1. MOLEA Framework
The MOLEA framework is displayed in
Figure 1. The framework includes three core parts. First, scene data are constructed for fast training based on the public single-objective test function. Second,
N-generation evolution is performed. This step is similar to the conventional evolution process. The difference is that evolutionary parameters are obtained by population state coding and neural network, and the evolutionary parameters need to be evaluated by calculating evolutionary reward, cumulative reward, and advantage estimation. Third, the evolutionary parameters are updated by proximal policy optimization (PPO) [
35] based on the obtained training samples until the evolutionary parameter configuration with the greatest benefit is obtained.
3.2. Scene Data Construction for Fast Training
As we all know, the agent and the environment need to interact many times for DRL to generate sufficient training samples. Therefore, the mission planning model needs to be calculated numerous times. However, the mission planning model calculation involves region information, satellite orbit information, and complex imaging geometric operations. It is complex and inefficient. Therefore, there is a slow training speed by directly using the task planning model as the training scene data.
A novel method is proposed to construct scene data based on the task planning model in
Section 2 to improve the training speed. In this method, seven single-objective test functions with multi-dimensional decision variables are selected. Then, these functions are reconstructed through normalization and multi-objective transformation to have the same structure as the task planning model. The redeveloped functions are used as training scene data. The seven single-objective test functions are as follows: Griewank, rotated hyper-ellipsoid, quartic, Rastrigin, Rosenbrock, sphere, and Styblinski–Tang functions [
36,
37]. The multi-dimensional decision variables correspond to multiple imaging strips in the mission planning model. Normalization makes the value of
changes within [0, 1], which corresponds to the first objective function of the task planning model. The multi-objective transformation adds a function
to
, which corresponds to the second objective function of the task planning model.
determines the decision variables involved in calculating
. The scene data constructed are as follows:
The constructed scene data exhibit the same structure as the task planning model and the same value range of decision variables and objective functions. Compared to the task planning model, the proposed constructed scene data calculation is simple and efficient. It effectively improves the training efficiency when the objective function requires many calculations.
3.3. Evolutionary Operations Based on DRL
The primary purpose of this section is to generate training samples for updating evolutionary parameters by performing evolutionary operations repeatedly. The training samples include the population state of the -th generation, evolutionary parameters of the -th generation, new population state reached, evolutionary reward , cumulative reward , and advantage estimate . In our research, the number of obtained training samples is the number of training scenes (7) × the number of optimizations for each training scene (4) × the evolutionary generation for each optimization (100) × the total number of training iterations (500). The samples are obtained through the following steps.
3.3.1. Population State Coding
In order for the population information to fully influence the evolutionary parameters, the population state is encoded before the evolution. The selection of population states should consider all factors affecting evolutionary parameters and distinguish the differences between various populations. In this study, the following four features were used to code the population state:
Feature 1: the real number solution of each individual in each generation of the population;
Feature 2: the binary solution of each individual in each generation of the population;
Feature 3: evolutionary reward for each generation of the population;
Feature 4: the percentage of remaining generations , where is the total evolutionary generation, and is the current generation.
Among them, Features 1 and 2 jointly describe each solution vector in the population. Feature 3 describes the reward value after the evolution is performed according to the current evolution parameters. Feature 4 describes the position of the current population in the evolution process and distinguishes various populations.
The data structure of the encoded population state information is displayed in
Figure 2. In
Figure 2, different colors represent different numerical values. To facilitate subsequent calculations, we extended Features 3 and 4 for consistency with the data dimensions of Features 1 and 2.
3.3.2. Evolutionary Parameters Acquisition
The neural network in [
28] was used to describe the relationship between the population state and multiple evolutionary parameters. However, in the neural network of this paper, multiple evolutionary parameters can be output simultaneously, whereas the neural network only output one evolutionary parameter in [
28]. The neural network used in this study is displayed in
Figure 3. The population state is the input, and the probability distribution parameters of evolution parameters are the output. The evolutionary parameters can then be obtained by sampling the probability distribution. The evolutionary parameters in this study include parent selection, real crossover, binary crossover, real mutation, and binary mutation parameters.
For the parent selection parameter, the Bernoulli distribution is used:
where
is the output parameter of the neural network,
, and the sampling value of the Bernoulli distribution is 0 or 1 for determining whether the individual in the population is selected as the parent.
For other parameters, beta distribution is adopted:
For each evolutionary parameter, α and β are the outputs of the neural network, and the value range of beta distribution is [0, 1].
The output of the neural network includes nine elements:
As shown in
Figure 3, another output of the neural network, critic, is used to evaluate how good an actor is in DRL. Critic and actor operate in the same environment and exhibit similar features. Therefore, the actor and critic share low-level features and then output actor and critic, respectively.
3.3.3. Evolutionary Reward, Cumulative Reward, and Advantage Estimation
The evolutionary reward can be calculated after performing one-generation evolution according to the obtained evolutionary parameters. For a single-objective function, the difference between the maximum fitness values in the two generations of populations can be used as the evolutionary reward. However, it is difficult to calculate the fitness and the evolutionary reward for the two-dimensional multi-objective function because multiple Pareto solutions do not dominate each other. This paper innovatively uses the difference between the HV of the two generations of populations as the evolutionary reward.
HV represents the volume of the space surrounded by Pareto individuals and the reference point. The schematic of the HV calculation is shown in
Figure 4. Because the HV calculation does not require a true Pareto solution, it is suitable for evaluating practical application problems, e.g., imaging satellite mission planning.
The calculation formula of evolutionary reward based on HV is as follows:
where
and
represent the HV value of generations
and
, respectively, and
represents the evolutionary reward of the
-th generation.
The larger the HV, the better the convergence and distribution of the solution, i.e., the better the quality of the solution.
The evolutionary reward is used to evaluate the evolutionary gain of one-generation evolution. In this study, we should not only make the evolutionary parameters output by the neural network produce the maximum benefit in contemporary evolution but also in future generations. The cumulative reward is the sum of the benefits generated by the current evolutionary parameters in future generations. This value indicates that the evolutionary parameters have foresight.
where
is the discount factor. It represents the loss of the current evolutionary parameters to generate a reward in the future, and
.
To evaluate the rationality of selecting evolutionary parameter
in the state
, we used the advantage estimate [
38]. It is calculated as follows:
where
represents the reward of taking the actor
under the state
.
represents the average reward of all actions under state
.
is the critic obtained by the neural network. The parameter
controls the trade-off between variance and bias of the advantage estimate;
represents the difference between the calculated value by (18) and the estimated value of the cumulative reward of the
-th generation by the neural network.
Furthermore, denotes that the current action is superior to the average action. The higher the probability of action is, the better; otherwise, , the smaller the probability of action is, the better. By increasing the probability of good actions, the evolutionary algorithm can improve evolutionary gains.
3.4. Evolutionary Parameters Updates Using PPO
In the MOLEA, the PPO is used to update the evolutionary parameters for two reasons: first, the PPO introduces importance sampling, so that the sampled data obtained by the interaction can be used for policy updates many times. Thus, data sampling efficiency is improved. Second, in PPO, first-order optimization is used to constrain the changed extent of the difference between the policy interacting with the environment and the policy to be updated. It makes the difference change within a specific range to ensure the stability of the DRL. PPO achieved an excellent balance between data sampling efficiency, algorithm performance, and debugging complexity.
The loss function of the PPO is expressed as follows:
In (21),
is the first-order optimization clipping loss function and calculated as follows:
In (22),
represents the expected value of the sample.
represents the ratio between the strategy interacting with the environment
and the strategy to be updated
. The numerical meanings of
and
are the probability of taking action
in the state
under the probability distribution described by strategies
and
, respectively.
The clipping function renders change within to ensure that the policies and do not differ considerably.
In (21),
represents the mean squared error (MSE) between the neural network estimate
and the value function
:
In (21), represents the exploration based on maximum information entropy, which is used to prevent the algorithm from falling into the local optimum.
After multiple rounds of repeated training, the evolutionary parameters are continuously updated in the direction with more excellent benefits until the parameters’ configuration policy for the maximum benefit is obtained, i.e., the algorithm optimization efficiency reaches the highest point.
5. Discussion
Imaging satellite mission planning scientifically arranges satellites for imaging based on user needs, maximizing the comprehensive imaging benefits. With the improvement of satellite quantity and quality, imaging satellite task planning technology can efficiently utilize satellite resources and accelerate the acquisition of regional remote sensing images for the production of regional surveying products. Mathematical modeling and optimization algorithm solving are key technologies for imaging satellite mission planning. Our previous work investigated the modeling problem of multi-satellite regional mapping. This article studies the optimization algorithm for solving multi-satellite regional mapping problems from the perspective of parameter configuration. Parameter configuration is an important factor affecting the performance of optimization algorithms, which has been emphasized in many studies [
13,
16,
43]. To solve the problem of artificial and sub-optimal parameter configuration of existing optimization algorithms, we use DRL to solve it because DRL has good perception and decision-making ability. This paper uses deep learning to perceive the ever-changing population state and reinforcement learning to make the best evolutionary decisions among various populations. By this way, the optimization performance of optimization algorithms has been fully developed to achieve the highest area coverage in task planning problems with the least satellite resources. Satellite resources are efficiently utilized. In terms of runtime, the evolutionary efficiency of optimization algorithms with optimal parameters is significantly higher than that of optimization algorithms with sub-optimal parameters. Therefore, optimization algorithms with optimal parameters obtain the optimal solution with fewer evolutionary generations, saving computational costs and runtime costs.
There are many optimization problems in the real world. The proposed MOLEA is not only applicable to imaging satellite task planning for regional mapping, but also to imaging satellite task planning problems for other imaging needs, such as fastest imaging time [
44], stereo imaging [
45,
46], multi-region imaging [
47], agile satellite imaging [
48], etc. It can also be used for optimization problems in other fields, such as deep learning network optimization [
49,
50], traffic optimization [
51], ship lock scheduling [
52] and path planning [
53], etc. An optimization algorithm with optimal parameter configuration can greatly save computational costs and economic costs of practical application problems.
In future work, we will mainly focus on two points: In terms of algorithms, we will study large-scale multi-objective optimization algorithms to solve large-area mapping problems, because the search space of solutions increases exponential growth with the increase in decision variables. In terms of application, the regional mapping in this paper refers to the regional orthophoto images, and the regional stereo images and multi-region imaging will be the focus of future research.
6. Conclusions
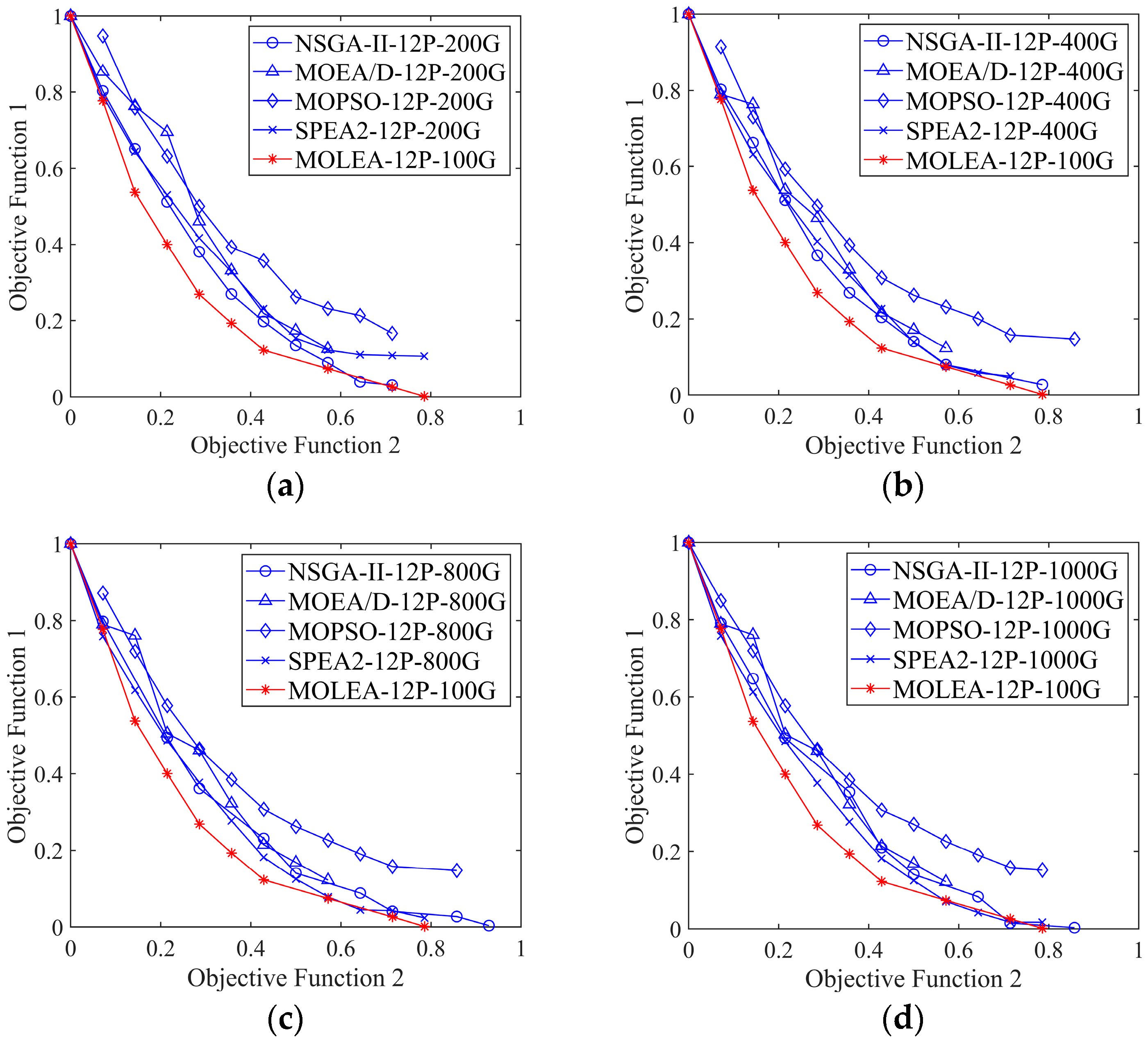
This paper has proposed a multi-objective learning evolutionary algorithm MOLEA based on DRL to solve the regional mission planning problem of imaging satellites. In the MOLEA, the DRL was used to simultaneously configure multiple evolutionary parameters according to the population state to maximize the cumulative benefit, considerably improving the convergence efficiency of the MOLEA. The proposed MOLEA effectively improves the training speed by replacing the practical application problem with the improved multi-objective functions as the training function. To the best of our knowledge, the MOLEA first proposed considering HV as the evolutionary reward of the multi-objective optimization problem. It achieves the ingenious combination of MOEA and DRL. Experimental results revealed that the proposed autonomous parameter configuration method could effectively improve the convergence speed of the algorithm in solving application problems. For the mission planning in Hubei, the planning solution obtained by MOLEA evolution for 100 generations was better than that obtained by the comparison algorithms evolution for 1000 generations. In terms of running time, the MOLEA improved by more than five times.
The proposed MOLEA is particularly suitable for application problems with high requirements for optimal solutions. The parameter configuration method studied in this paper is not limited to a multi-objective evolutionary algorithm, which can provide a reference for MOEA based on genetic algorithm, differential evolutionary, and particle swarm optimization. However, the parameter configuration of MOEAs is still an important issue that is easily overlooked, and the MOEAs based on DRL are still in the nascent stage of development. In the proposed MOLEA, the parameters’ autonomous decision configuration based on DRL is only limited to small-scale problems, and the performance of training data is degraded when testing problems have different scales. In the future, we will study more stable MOEAs based on DRL to solve larger-scale application problems. Moreover, the proposed MOLEA can be used as a theoretical basis for future multi-objective optimization algorithms and satellite imaging mission planning research.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}