


Vehicle Localization in a Completed City-Scale 3D Scene Using Aerial Images and an On-Board Stereo Camera


Abstract
1. Introduction
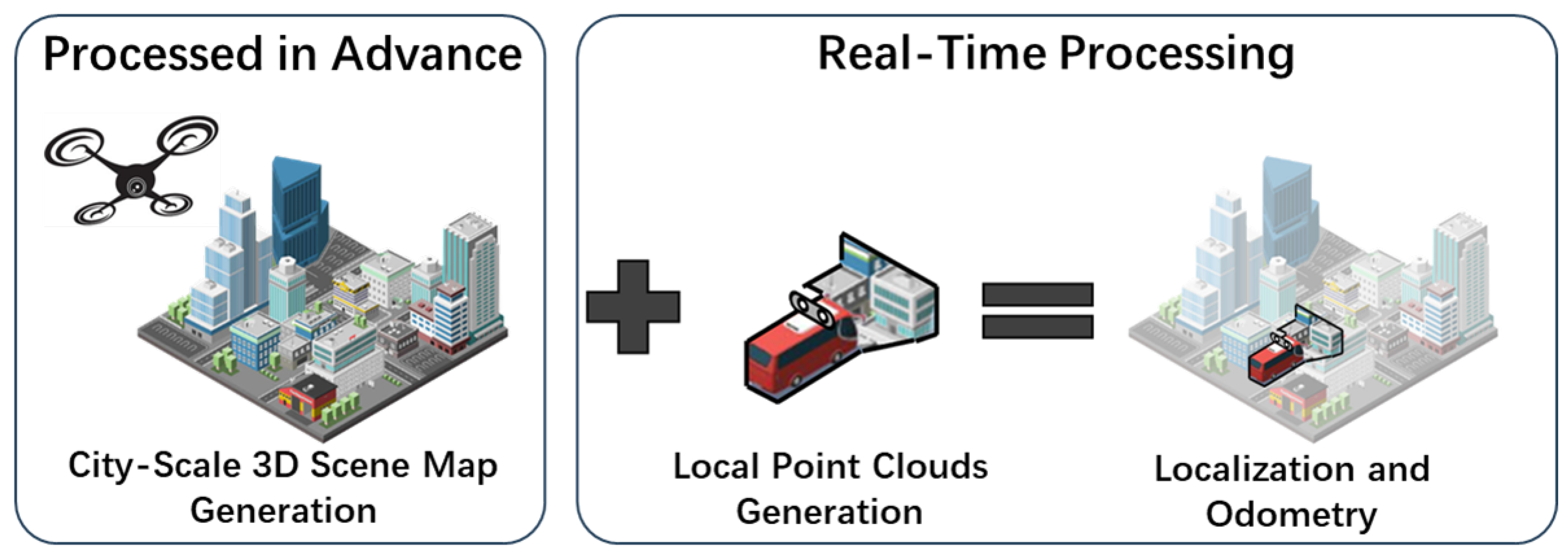
- A novel vehicle localization system is proposed by integrating aerial and ground views. The system enables vehicle localization and odometry while reconstructing the 3D large scene model.
- A building completion algorithm based on a geometric structure that significantly enhances the accuracy of UAV large-scene reconstruction is proposed. The algorithm also helps establish a 3D geometric relationship from the aerial view to the ground view, integrating 3D information from both perspectives.
- Experiments were performed using a dataset generated from the CG simulator to simulate the real scene. The results demonstrate the effectiveness of the proposed vehicle localization system in fusing aerial and ground views.
2. Related Work
2.1. Three-Dimensional Reconstruction with UAVs
2.2. Priori Map-Based SLAM
2.3. Aerial-to-Ground SLAM
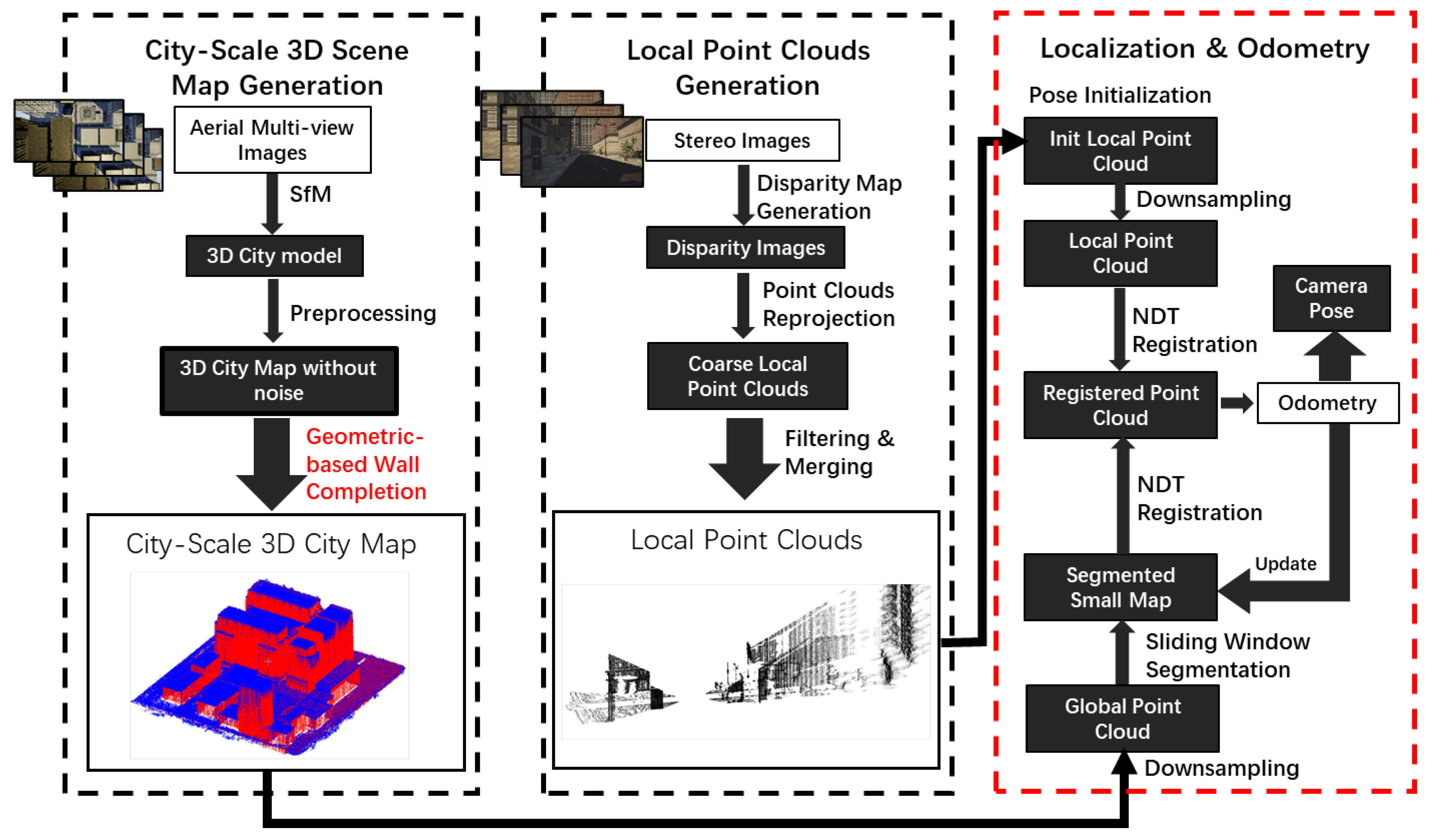
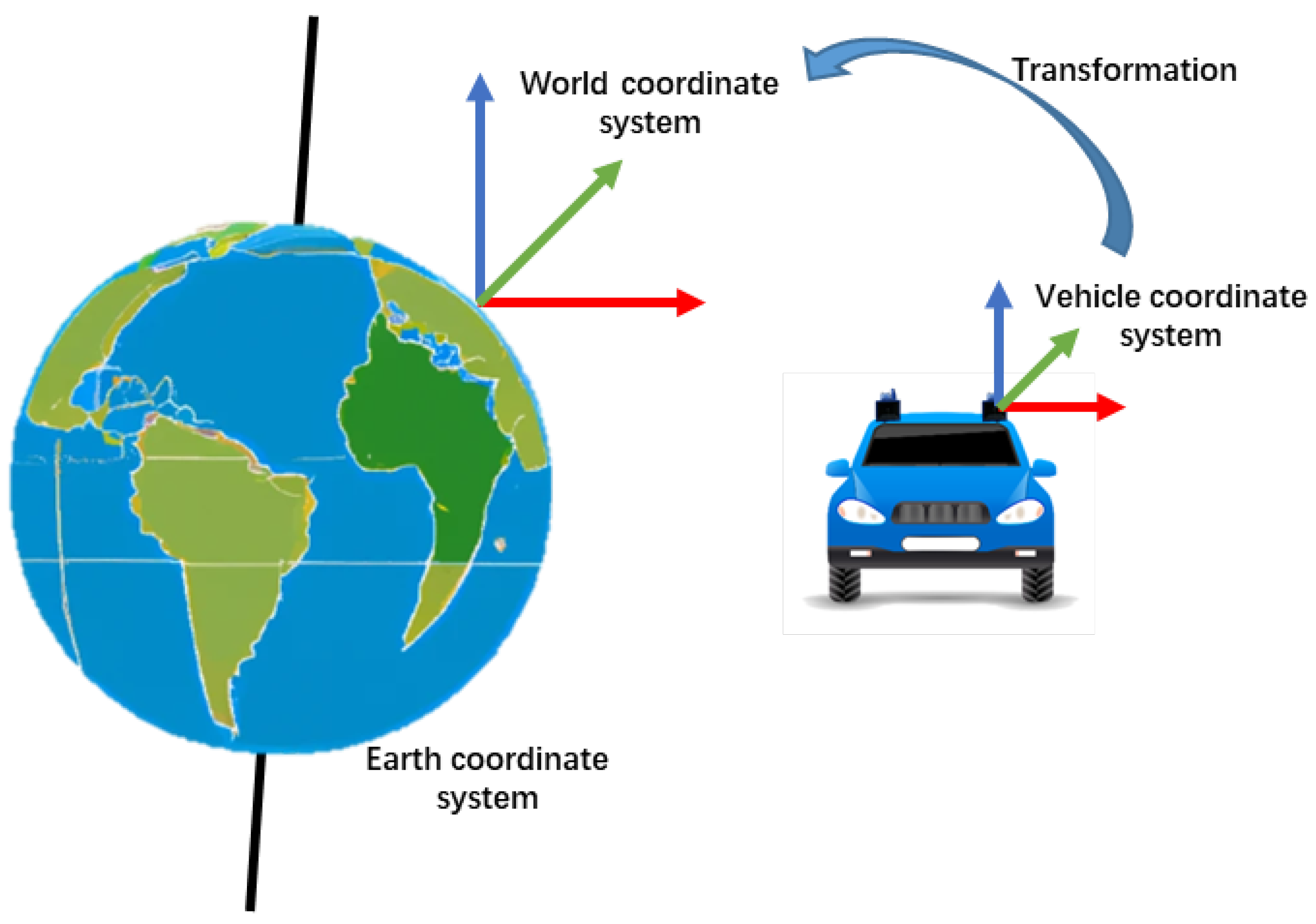
3. System Overview
4. City-Scale 3D Scene Map Generation
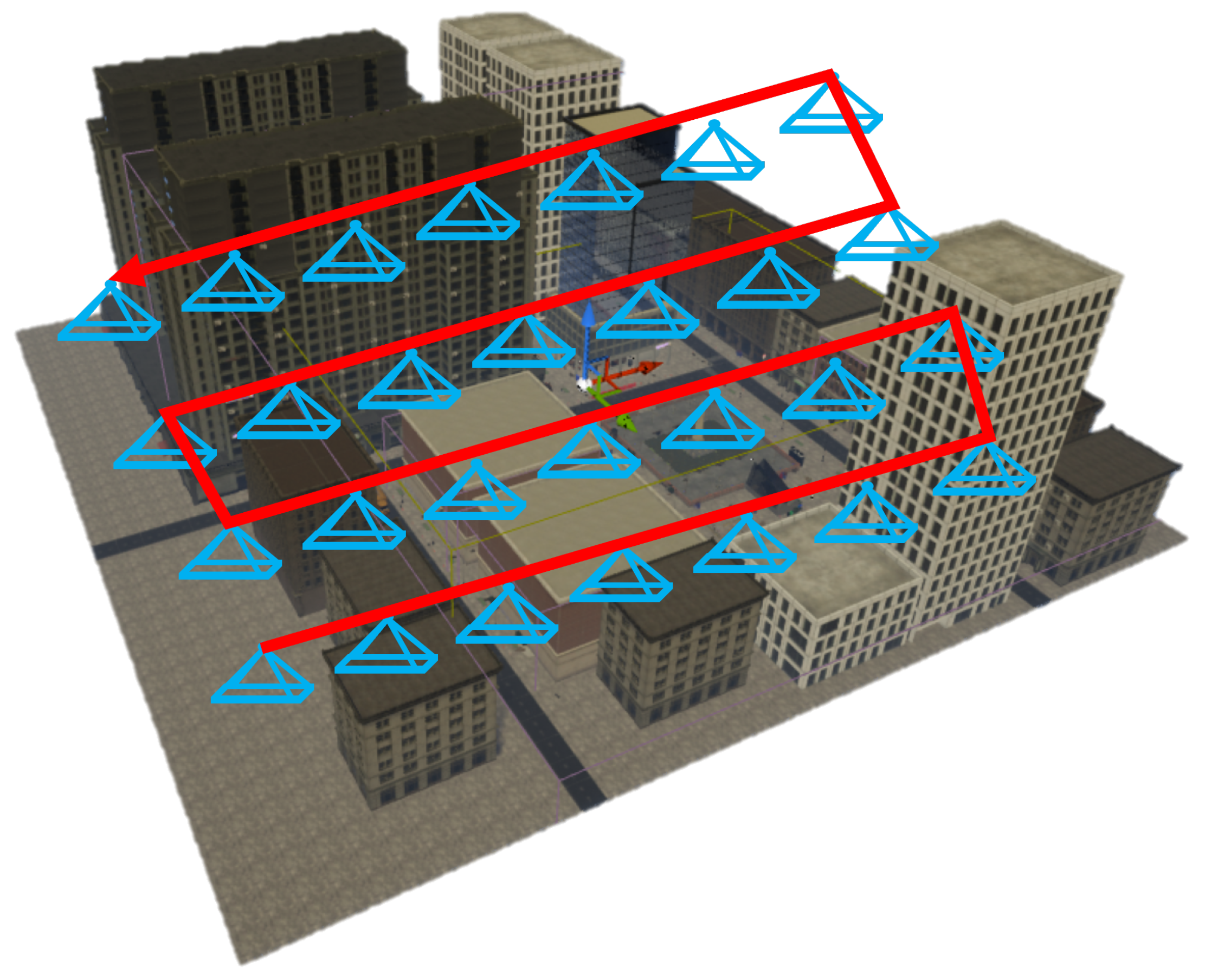
4.1. Structure from Motion
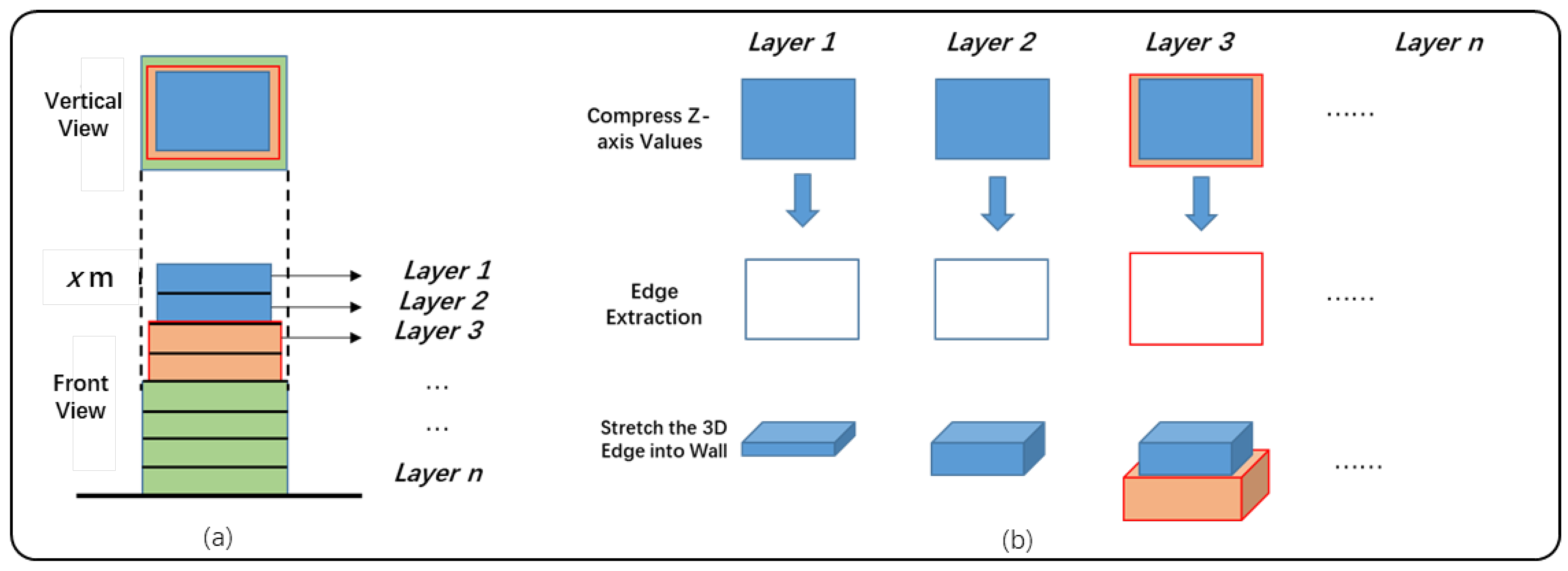
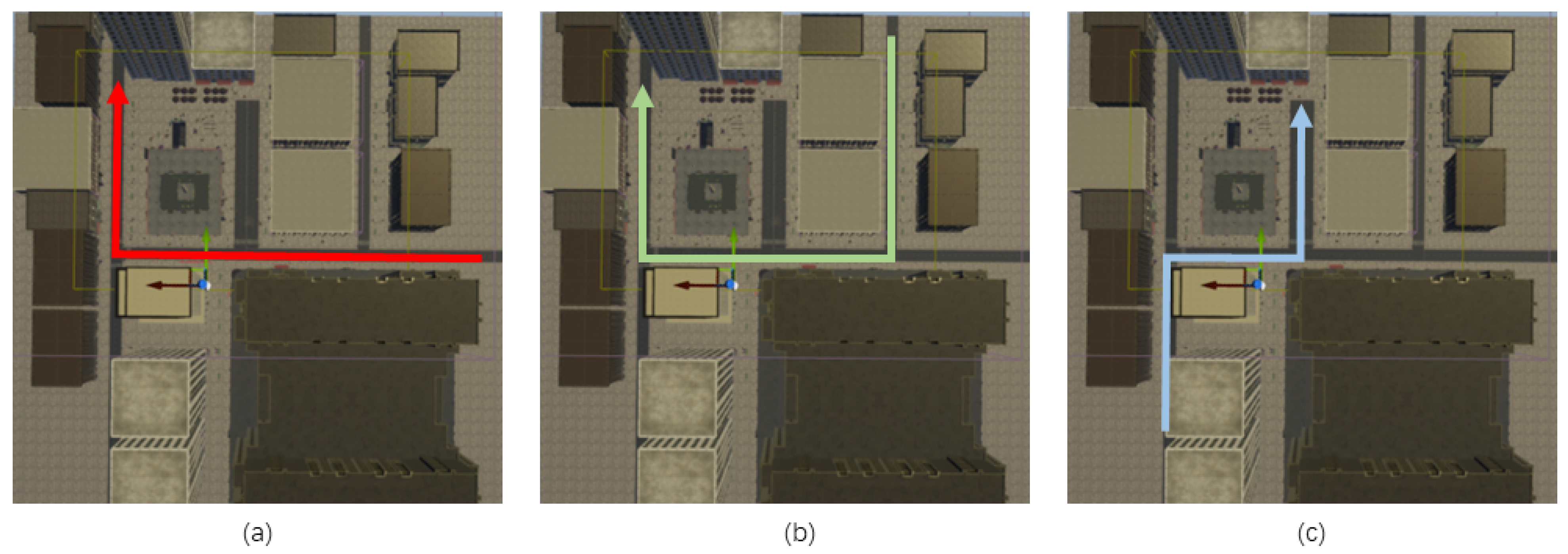
4.2. Geometry-Based Wall Completion
4.2.1. Layer-Based Segmentation
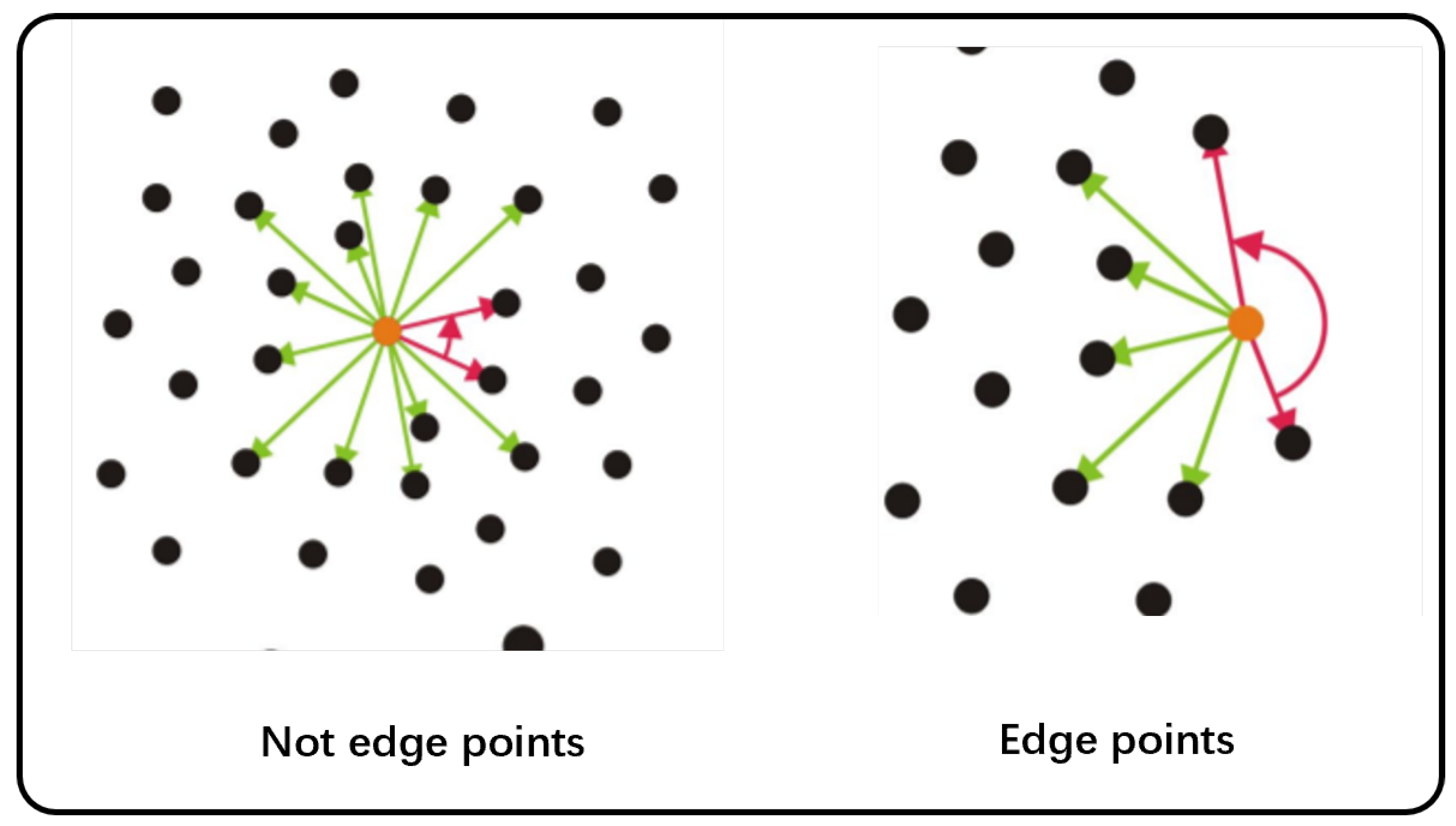
4.2.2. Wall Completion Algorithm
5. Local Point Cloud Generation
5.1. Disparity Map Generation
5.2. Point Cloud Reprojection
5.3. Filtering and Merging
6. Localization and Odometry
6.1. Downsampling
6.2. Sliding Window Segmentation
6.3. Pose Initialization
6.4. NDT Registration
7. Experiment and Results
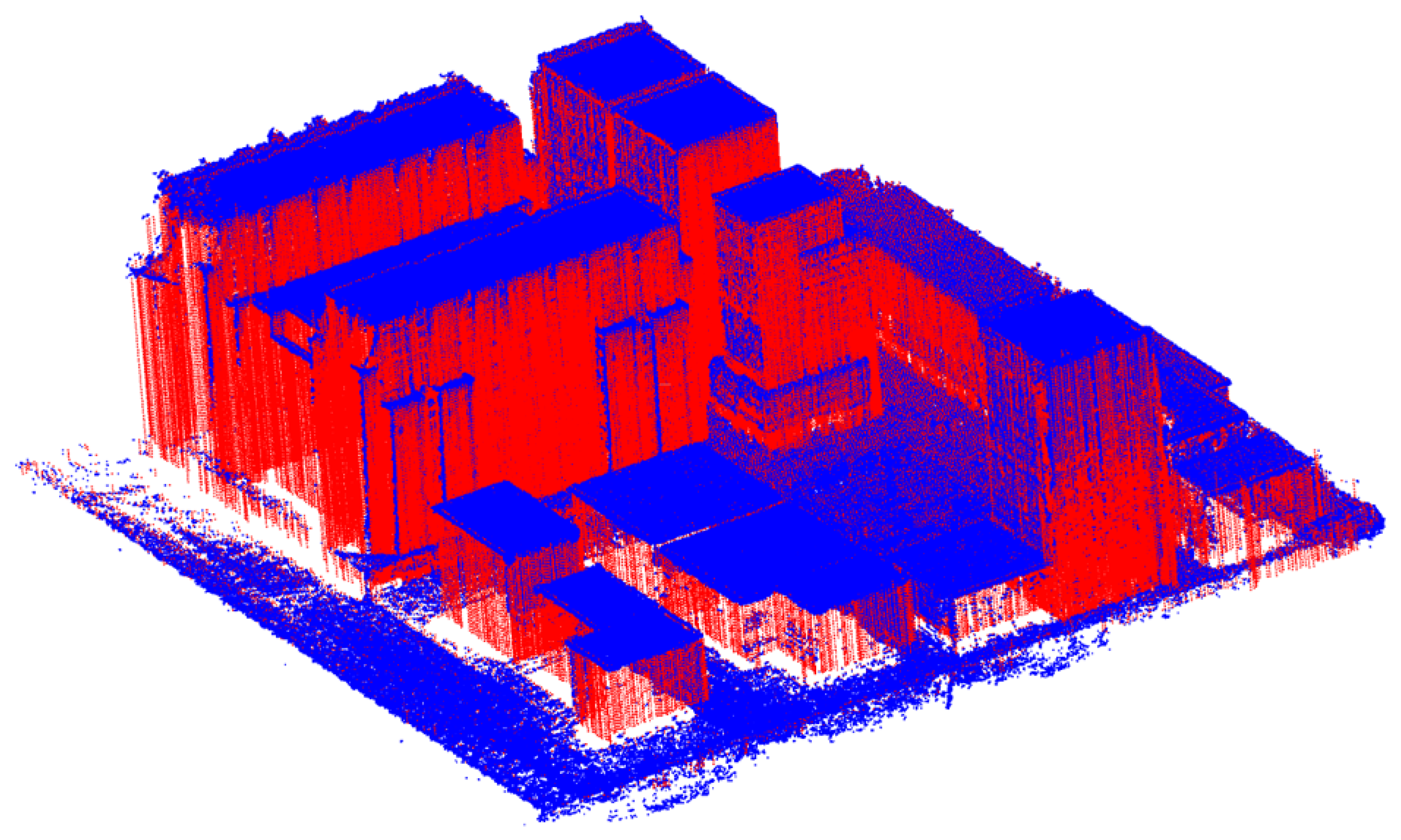
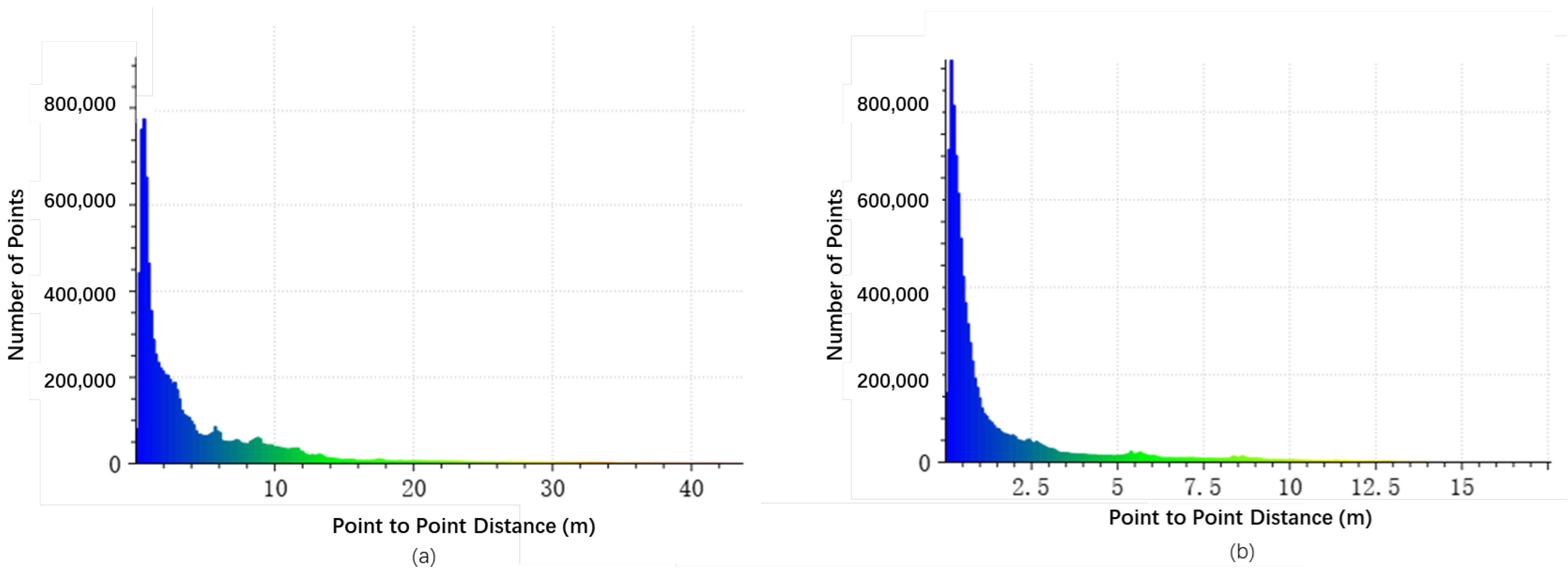
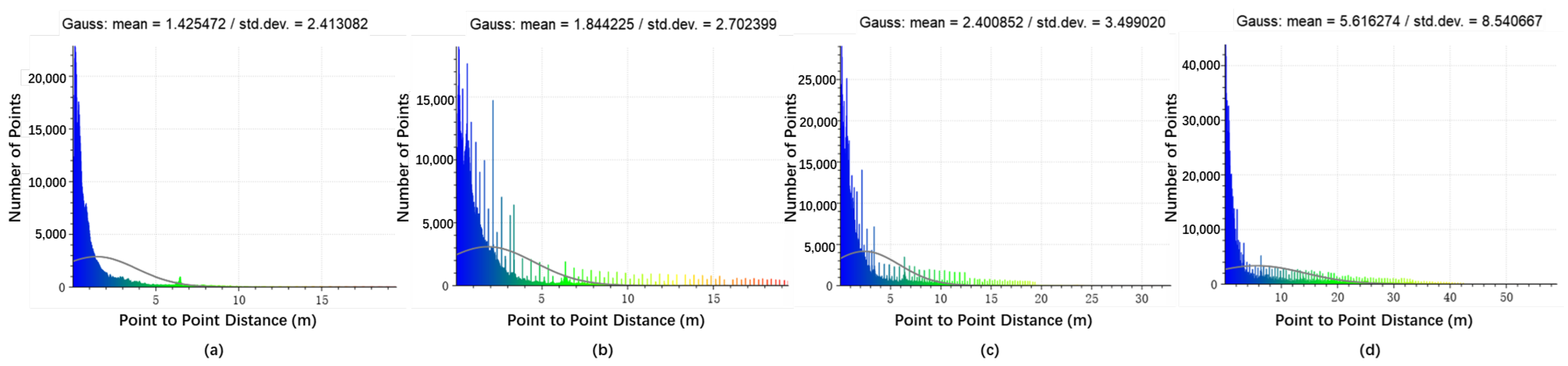
7.1. Point Cloud Completion
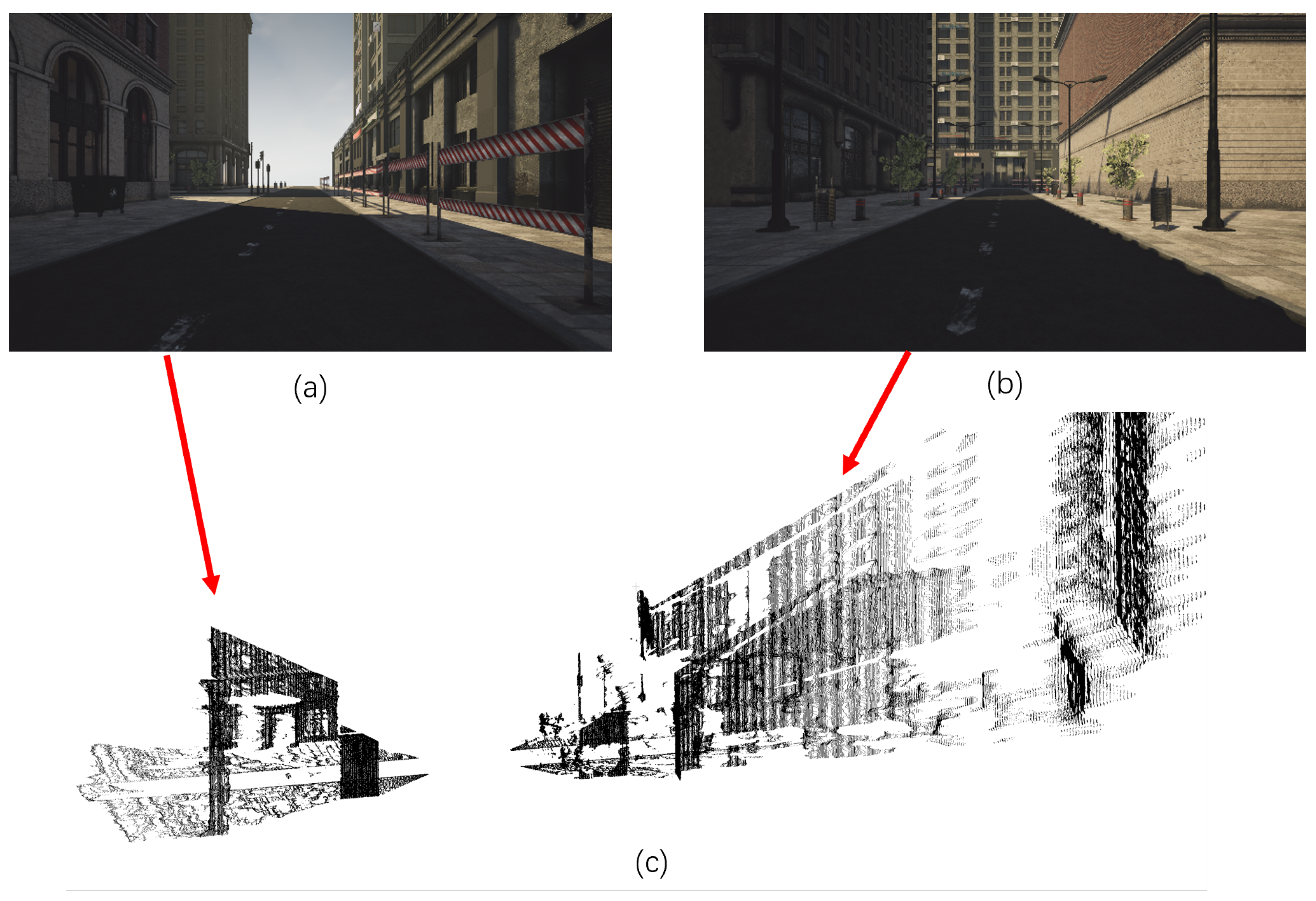
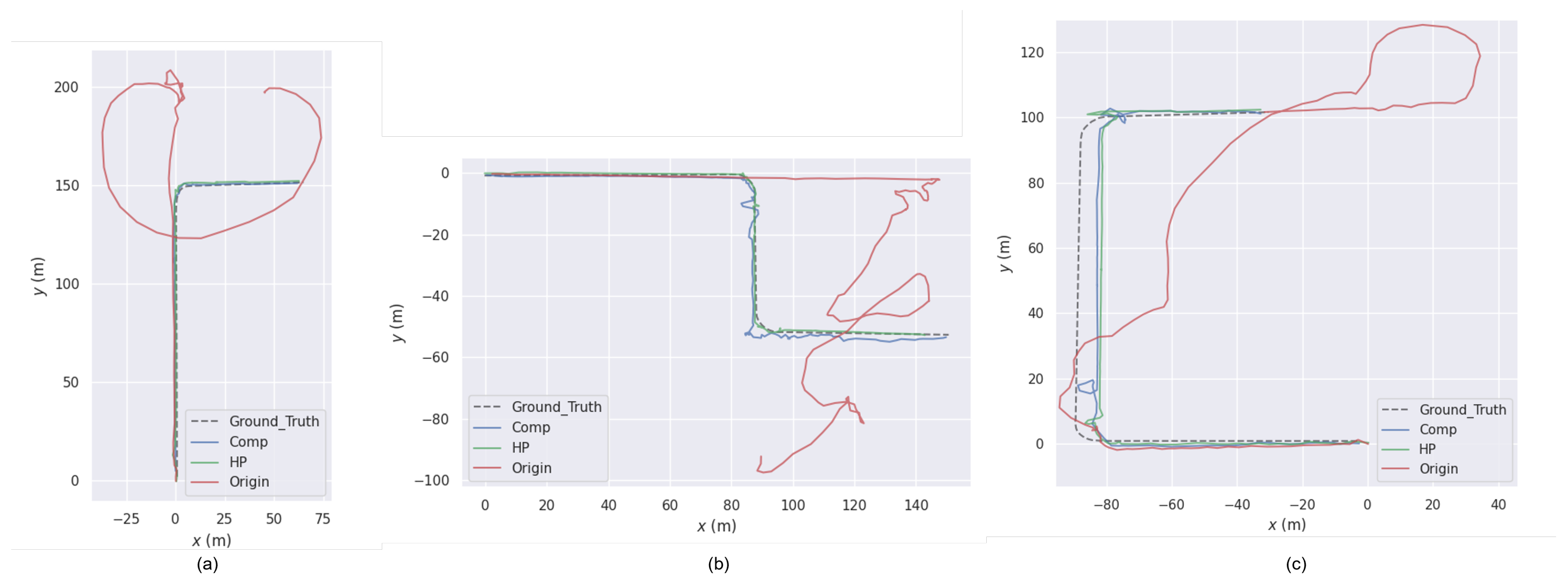
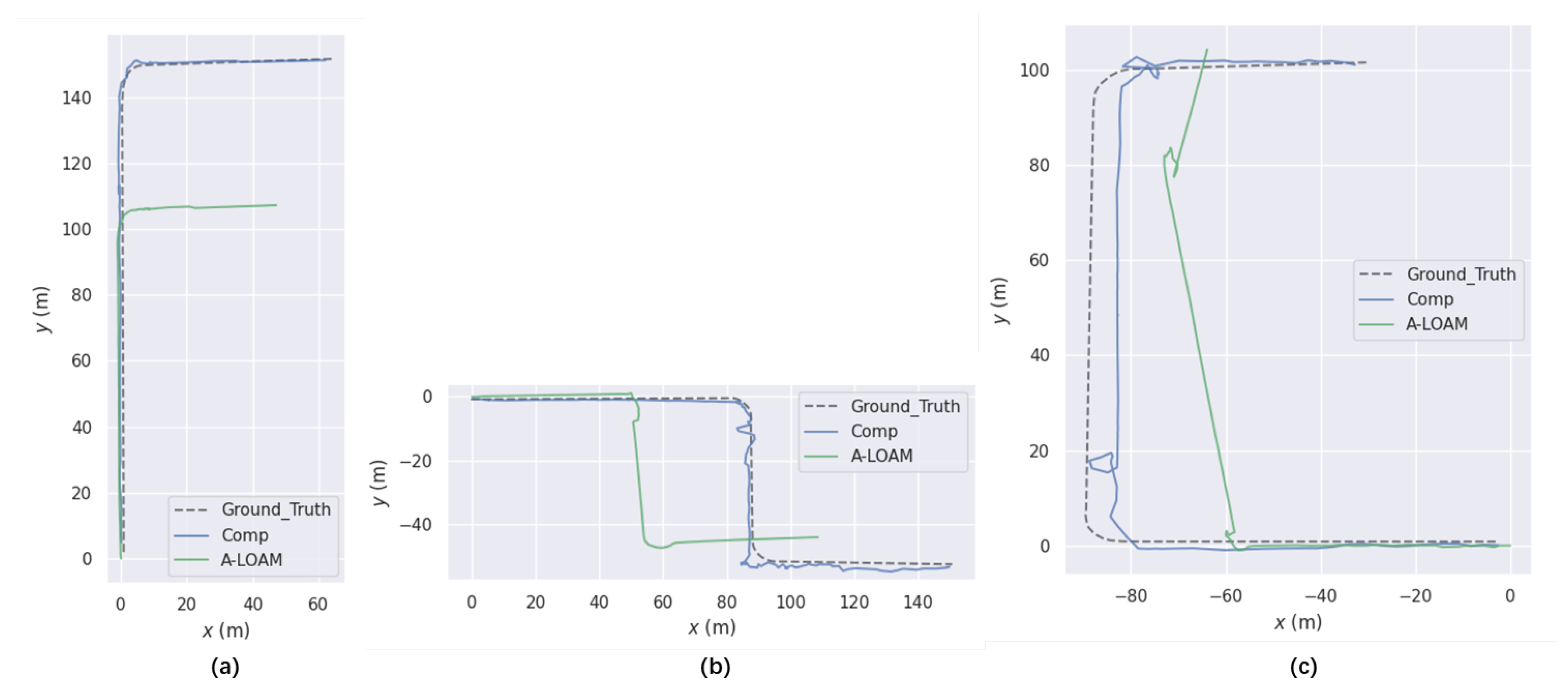
7.2. Localization and Odometry
8. Conclusions
9. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ibragimov, I.Z.; Afanasyev, I.M. Comparison of ROS-based visual SLAM methods in homogeneous indoor environment. In Proceedings of the 2017 14th Workshop on Positioning, Navigation and Communications (WPNC), Bremen, Germany, 25–26 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Blochliger, F.; Fehr, M.; Dymczyk, M.; Schneider, T.; Siegwart, R. Topomap: Topological Mapping and Navigation Based on Visual SLAM Maps. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3818–3825. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B. Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: Pisctaway, NJ, USA, 2018; pp. 4758–4765. [Google Scholar]
- Zhao, S.; Zhang, H.; Wang, P.; Nogueira, L.; Scherer, S. Super odometry: IMU-centric LiDAR-visual-inertial estimator for challenging environments. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: Pisctaway, NJ, USA, 2021; pp. 8729–8736. [Google Scholar]
- Cui, L.; Wen, F. A monocular ORB-SLAM in dynamic environments. J. Phys. Conf. Ser. 2019, 1168, 052037. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, J.; Liu, Y.; Zhang, X. High-Precision and Fast LiDAR Odometry and Mapping Algorithm. J. Adv. Comput. Intell. Intell. Inform. 2022, 26, 206–216. [Google Scholar] [CrossRef]
- Liu, R.; Wang, J.; Zhang, B. High definition map for automated driving: Overview and analysis. J. Navig. 2020, 73, 324–341. [Google Scholar] [CrossRef]
- Fruh, C.; Zakhor, A. Constructing 3D city models by merging aerial and ground views. IEEE Comput. Graph. Appl. 2003, 23, 52–61. [Google Scholar] [CrossRef]
- Alsadik, B.; Khalaf, Y.H. Potential Use of Drone Ultra-High-Definition Videos for Detailed 3D City Modeling. ISPRS Int. J. Geo-Inf. 2022, 11, 34. [Google Scholar] [CrossRef]
- Chen, F.; Lu, Y.; Cai, B.; Xie, X. Multi-Drone Collaborative Trajectory Optimization for Large-Scale Aerial 3D Scanning. In Proceedings of the 2021 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Bari, Italy, 4–8 October 2021; pp. 121–126. [Google Scholar] [CrossRef]
- Esrafilian, O.; Gesbert, D. 3D city map reconstruction from UAV-based radio measurements. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; IEEE: Piscatway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Huang, J.; Stoter, J.; Peters, R.; Nan, L. City3D: Large-scale building reconstruction from airborne LiDAR point clouds. Remote Sens. 2022, 14, 2254. [Google Scholar] [CrossRef]
- Sasiadek, J.Z.; Ahmed, A. Multi-Sensor Fusion for Navigation of Ground Vehicles. In Proceedings of the 2022 26th International Conference on Methods and Models in Automation and Robotics (MMAR), Międzyzdroje, Poland, 22–25 August 2022; pp. 128–133. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, D.; Li, J.; Gu, Y.; Pi, J.; Zhang, X. Stereo Visual-Inertial SLAM with Points and Lines. IEEE Access 2018, 6, 69381–69392. [Google Scholar] [CrossRef]
- Liu, J.; Xiao, J.; Cao, H.; Deng, J. The Status and Challenges of High Precision Map for Automated Driving. In Proceedings of the China Satellite Navigation Conference (CSNC), Beijing, China, 22–25 May 2019; Sun, J., Yang, C., Yang, Y., Eds.; Springer: Singapore, 2019; pp. 266–276. [Google Scholar]
- Guizilini, V.; Ambrus, R.; Pillai, S.; Raventos, A.; Gaidon, A. 3D packing for self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2485–2494. [Google Scholar]
- Lin, L.; Liu, Y.; Hu, Y.; Yan, X.; Xie, K.; Huang, H. Capturing, Reconstructing, and Simulating: The UrbanScene3D Dataset. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Cham, Switzerland, 2022; pp. 93–109. [Google Scholar]
- Kümmerle, R.; Steder, B.; Dornhege, C.; Kleiner, A.; Grisetti, G.; Burgard, W. Large scale graph-based SLAM using aerial images as prior information. Auton. Robot. 2009, 30, 25–39. [Google Scholar] [CrossRef]
- Shi, Y.; Li, H. Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17010–17020. [Google Scholar]
- Ullman, S. The Interpretation of Structure from Motion. Proc. R. Soc. Lond. Ser. B Biol. Sci. 1979, 203, 405–426. [Google Scholar]
- Hong, H.; Lee, B.H. Probabilistic normal distributions transform representation for accurate 3D point cloud registration. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3333–3338. [Google Scholar] [CrossRef]
- Hirschmuller, H. Stereo Processing by Semiglobal Matching and Mutual Information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- An, X.; Pellacini, F. AppProp: All-Pairs appearance-space edit propagation. ACM Trans. Graph. 2008, 27, 40. [Google Scholar] [CrossRef]
- Balta, H.; Velagic, J.; Bosschaerts, W.; De Cubber, G.; Siciliano, B. Fast statistical outlier removal based method for large 3D point clouds of outdoor environments. IFAC-PapersOnLine 2018, 51, 348–353. [Google Scholar] [CrossRef]
- Oh, J. Novel Approach to Epipolar Resampling of HRSI and Satellite Stereo Imagery-Based Georeferencing of Aerial Images. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 22 July 2011. [Google Scholar]
- Li, K.; Li, M.; Hanebeck, U.D. Towards High-Performance Solid-State-LiDAR-Inertial Odometry and Mapping. arXiv 2020, arXiv:2010.13150. [Google Scholar] [CrossRef]
- Deuflhard, P. Newton Methods for Nonlinear Problems: Affine Invariance and Adaptive Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2005; Volume 35. [Google Scholar]
- Zhang, Z. Iterative point matching for registration of free-form curves and surfaces. Int. J. Comput. Vis. 1994, 13, 119–152. [Google Scholar] [CrossRef]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Proceedings of the Field and Service Robotics, Zurich, Switzerland, 12–15 September 2017. [Google Scholar]
- Zhang, Z. Iterative Closest Point (ICP). In Computer Vision: A Reference Guide; Ikeuchi, K., Ed.; Springer: Boston, MA, USA, 2014; pp. 433–434. [Google Scholar] [CrossRef]
- Kerl, C.; Sturm, J.; Cremers, D. Robust odometry estimation for RGB-D cameras. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 3748–3754. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, M.; Meng, M.Q.H. Motion removal for reliable RGB-D SLAM in dynamic environments. Robot. Auton. Syst. 2018, 108, 115–128. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. LOAM: Lidar odometry and mapping in real-time. In Proceedings of the Robotics: Science and Systems, Berkeley, CA, USA, 12–16 June 2014; Volume 2, pp. 1–9. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Origin | Completed | High-Precision | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | |
| L_route | 40.571 | 34.692 | 35.285 | 20.930 | 11.672 | 9.331 | 6.956 | 7.012 | 5.377 | 4.457 | 3.351 | 3.010 |
| Z_route | 28.978 | 24.253 | 19.337 | 15.860 | 3.909 | 3.538 | 3.353 | 1.663 | 3.268 | 2.629 | 1.937 | 1.441 |
| U_route | 28.864 | 26.373 | 25.384 | 11.843 | 5.634 | 4.980 | 4.828 | 2.635 | 4.929 | 4.383 | 4.124 | 2.257 |
| Origin | Completed | High-Precision | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | |
| L_route | 6.339 | 4.964 | 3.864 | 3.943 | 1.689 | 1.108 | 0.895 | 1.275 | 1.272 | 0.939 | 0.760 | 0.858 |
| Z_route | 2.764 | 2.258 | 2.087 | 1.594 | 1.413 | 1.087 | 0.790 | 0.903 | 0.826 | 0.593 | 0.292 | 0.576 |
| U_route | 4.671 | 3.874 | 3.747 | 2.609 | 1.763 | 1.263 | 1.008 | 1.230 | 1.561 | 1.231 | 0.969 | 0.960 |
| A-LOAM | Completed | |||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | |
| L_route | 12.441 | 10.402 | 9.647 | 7.823 | 11.672 | 9.331 | 6.956 | 7.012 |
| Z_route | 9.226 | 7.510 | 6.042 | 5.359 | 3.909 | 3.538 | 3.353 | 1.663 |
| U_route | 13.325 | 12.075 | 10.407 | 5.636 | 5.634 | 4.980 | 4.828 | 2.635 |
| A-LOAM | Completed | |||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | |
| L_route | 3.943 | 2.741 | 2.552 | 1.590 | 1.689 | 1.108 | 0.895 | 1.275 |
| Z_route | 2.841 | 2.350 | 2.213 | 1.394 | 1.413 | 1.087 | 0.790 | 0.903 |
| U_route | 4.263 | 4.011 | 4.817 | 1.824 | 1.763 | 1.263 | 1.008 | 1.230 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Xie, C.; Toriya, H.; Shishido, H.; Kitahara, I. Vehicle Localization in a Completed City-Scale 3D Scene Using Aerial Images and an On-Board Stereo Camera. Remote Sens. 2023, 15, 3871. https://doi.org/10.3390/rs15153871
Zhang H, Xie C, Toriya H, Shishido H, Kitahara I. Vehicle Localization in a Completed City-Scale 3D Scene Using Aerial Images and an On-Board Stereo Camera. Remote Sensing. 2023; 15(15):3871. https://doi.org/10.3390/rs15153871
Chicago/Turabian StyleZhang, Haihan, Chun Xie, Hisatoshi Toriya, Hidehiko Shishido, and Itaru Kitahara. 2023. "Vehicle Localization in a Completed City-Scale 3D Scene Using Aerial Images and an On-Board Stereo Camera" Remote Sensing 15, no. 15: 3871. https://doi.org/10.3390/rs15153871
APA StyleZhang, H., Xie, C., Toriya, H., Shishido, H., & Kitahara, I. (2023). Vehicle Localization in a Completed City-Scale 3D Scene Using Aerial Images and an On-Board Stereo Camera. Remote Sensing, 15(15), 3871. https://doi.org/10.3390/rs15153871