
Classification of Marine Sediment in the Northern Slope of the South China Sea Based on Improved U-Net and K-Means Clustering Analysis


Abstract
1. Introduction
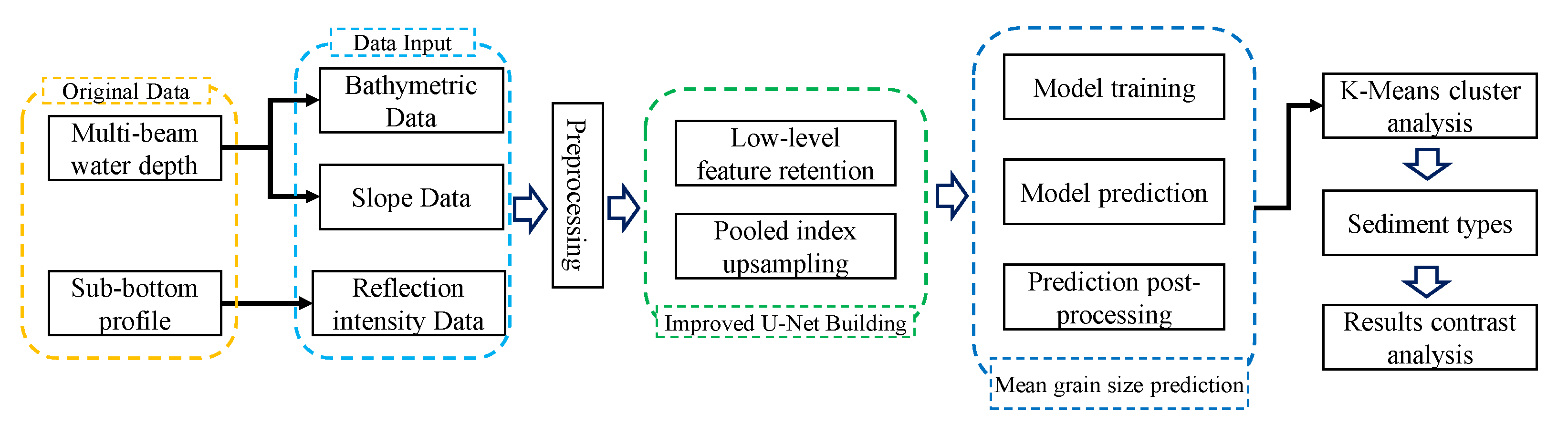
2. Data and Methods
2.1. Data Collection
2.1.1. Multibeam Survey
2.1.2. Sub-Bottom Profiling
2.1.3. Sediment Sampling
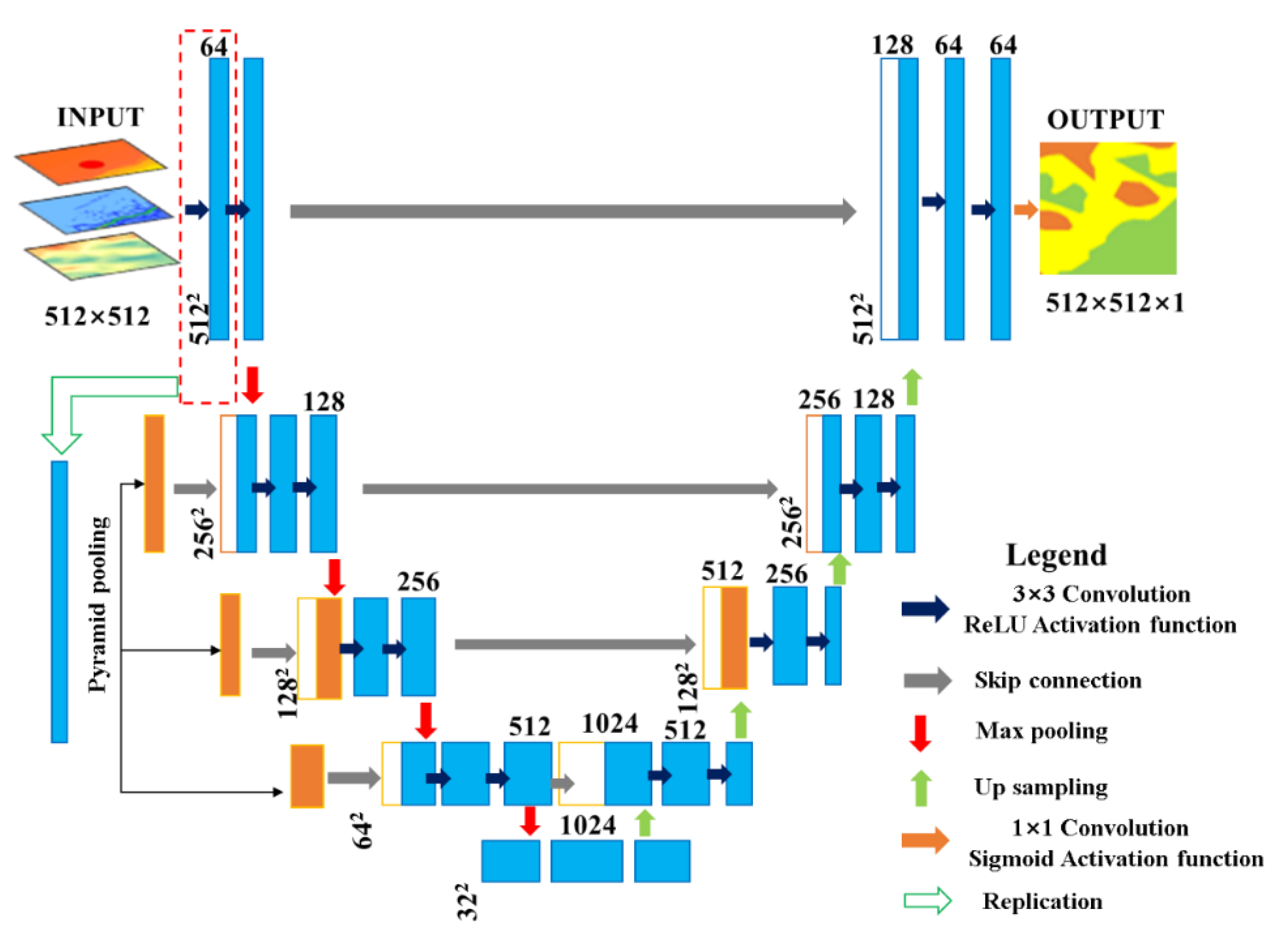
2.2. Improved U-Net
2.3. Optimized K-Means Clustering Algorithm
- Initialization: The algorithm starts by dividing all samples into K initial clusters.
- Classification: Each sample in the dataset is assigned to the cluster with the closest center (mean). The distance between samples is typically calculated using Euclidean distance, either with standardized or non-standardized data. After classification, the centers of the clusters are recalculated based on the samples assigned to each cluster.
- Iteration: Step 2 is repeated until no further sample can be reassigned to a different cluster.
- For each data sample in the dataset, consider it as a potential clustering center and calculate its corresponding sum of squared errors. Select the data vector with the smallest sum of squared errors as the first initial clustering center.
- Based on the existing clustering centers, calculate the average sum of squared errors () for the current dataset.
- To select the next initial clustering center, calculate the sum of squared errors that can be reduced when each data sample is considered as a potential clustering center. For a data sample (xi, yi) as a potential clustering center, the expression is:
3. Results
3.1. Improved U-Net Classification
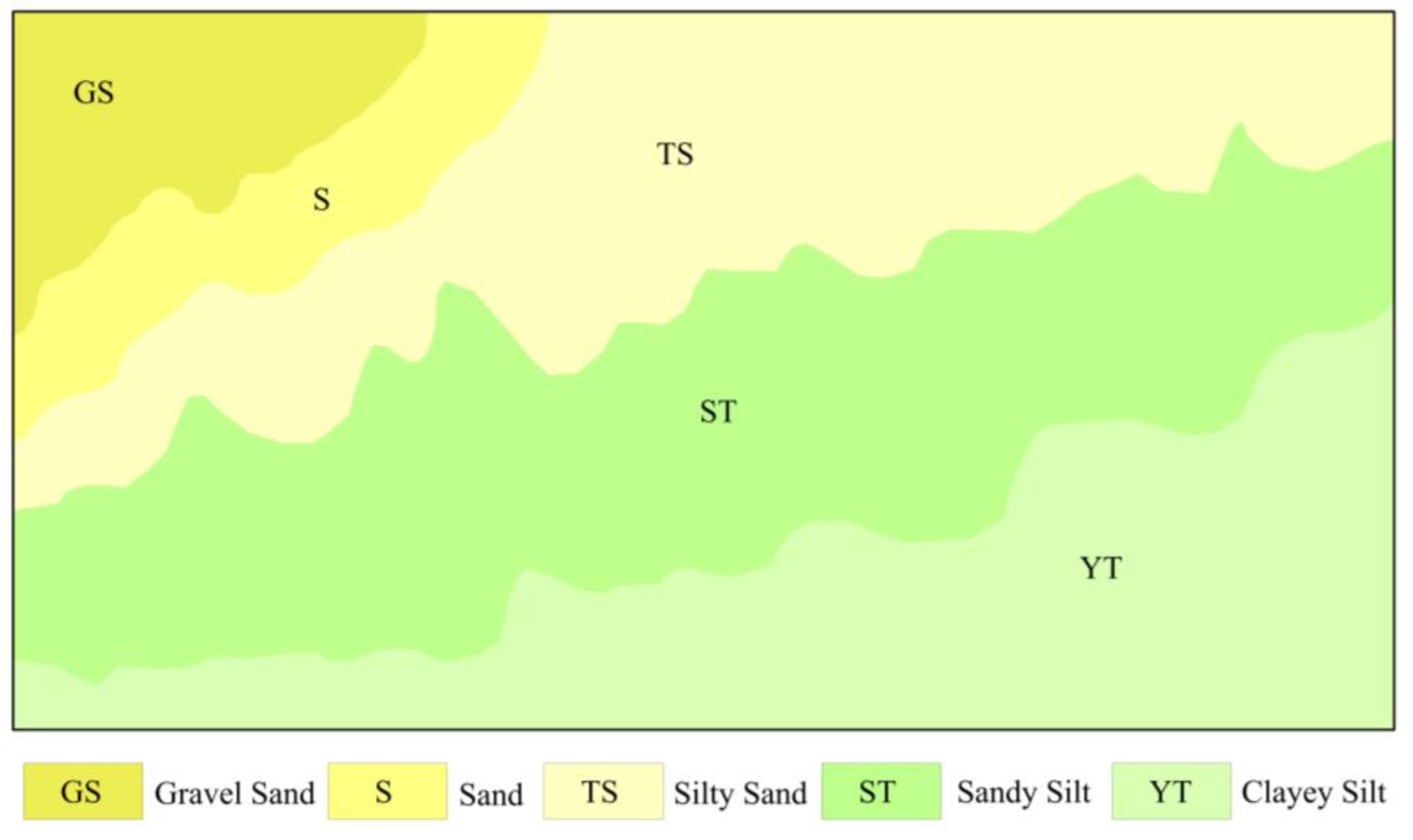
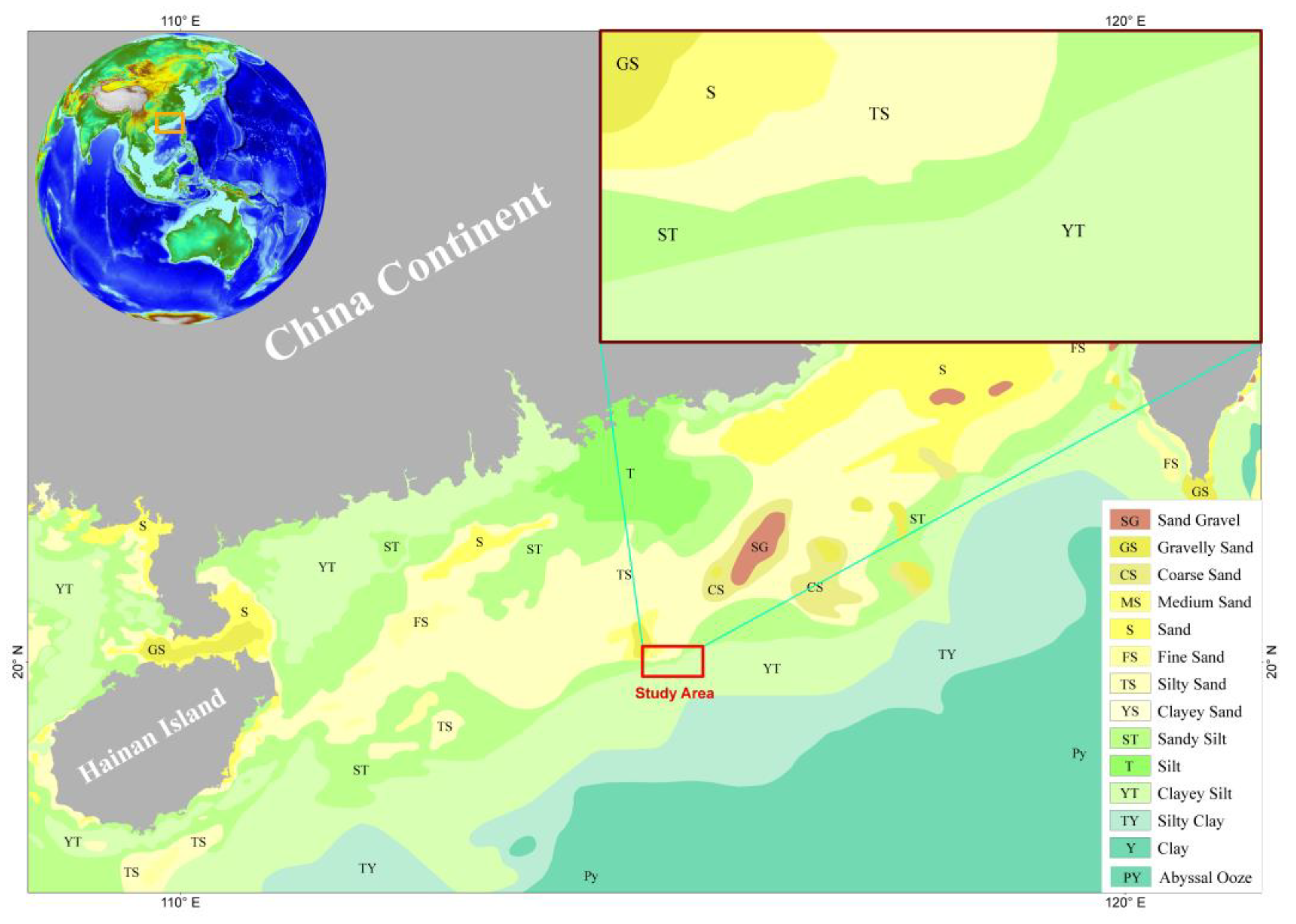
3.2. K-Means Cluster Analysis
- The classification principle of first-class groups in the Φ standard grain size classification table:The Udden–Wentworth isometric grain size classification standard (hereinafter referred to as the “Φ Size Standard”) is currently the most widely used grain size classification standard for sediments [42]. The Φ particle size standard divides the seafloor into five types: rock, gravel, sand, silt, and clay. Based on these five types, the seafloor is further classified into subcategories, such as pebbled muddy sand, silty sand, muddy silt, silty mud, and so on. To determine the value of the classification number K, the number of class groups belonging to the seafloor sampling point type in the Φ standard classification table of particle size is first determined, and its value is set as the K value.
- The principle of regional variation of marine sediment type:
4. Discussion
4.1. Benefits of Improved U-Net Method for Predicting Mean Grain Size
4.2. Comparison of Sediment Classification Results
5. Conclusions
- (1)
- We developed a sediment classification method based on an improved U-Net network and K-means clustering analysis. This method allowed us to classify five sediment types, including gravelly sand, sand, silty sand, sandy silt, and clayey silt, in the study area.
- (2)
- In this study, we compared the results obtained from an improved U-Net model with those of a standard U-Net model for mean grain size prediction. It was found that the improved U-Net model outperformed the standard U-Net model in terms of IoU and F1-Score, with improvements of 4.9% and 2.8%, respectively, in the two metrics for mean grain size prediction. This indicates that the improved U-Net model can improve the accuracy of mean grain size prediction in the study area.
- (3)
- An optimized K-means clustering algorithm was employed to conduct sediment type classification, improving the effectiveness of edge extraction for sediment types and enhancing the accuracy of sediment type classification. A comparison with the sediment type map of the South China Sea demonstrated a high level of consistency, further validating the applicability of this method in sediment classification.
Author Contributions
Funding
Conflicts of Interest
References
- Hamilton, L.; Mulhearn, P.; Poeckert, R. Comparison of RoxAnn and QTC-View acoustic bottom classification system performance for the Cairns area, Great Barrier Reef, Australia. Cont. Shelf Res. 1999, 19, 1577–1597. [Google Scholar] [CrossRef]
- Preston, J.M.; Collins, W.T.; Mosher, D.C.; Poeckert, R.H.; Kuwahara, R.H. The strength of correlations between geotechnical variables and acoustic classifications. In Proceedings of the Oceans ‘99. MTS/IEEE. Riding the Crest into the 21st Century. Conference and Exhibition. Conference Proceedings (IEEE Cat. No.99CH37008), Seattle, WA, USA, 13–16 September 1999; pp. 1123–1128. [Google Scholar]
- Tęgowski, J.; Łubniewski, Z. The use of fractal properties of echo signals for acoustical classification of bottom sediments. Acta Acust. United Acust. 2000, 86, 276–282. [Google Scholar]
- Preston, J.M. Shallow-water bottom classification: High speed echo-sampling captures detail for precise sediment classification. Hydro Int. 2001, 5, 30–33. [Google Scholar]
- Preston, J.M.; Christney, A.C.; Bloomer, S.F.; Beaudet, I.L. Seabed classification of multibeam sonar image. In Proceedings of the MTS/IEEE Oceans 2001. An Ocean Odyssey. Conference Proceedings (IEEE Cat. No.01CH37295), Honolulu, HI, USA, 5–8 November 2001; Volume 4, pp. 2616–2623. [Google Scholar]
- Giovanni, D.F.; Renato, T.; Gabriella, D.M.; Sara, I.; Simone, S.; Iain, M.P. Relationships between multibeam backscatter, sediment grain size and Posidonia oceanica seagrass distribution. Cont. Shelf Res. 2010, 30, 1941–1950. [Google Scholar]
- Wienberg, C.; Wintersteller, P.; Beuck, L.; Hebbeln, D. Coral Patch seamount (NE Atlantic) a sedimentological and megafaunal reconnaissance based on video and hydroacoustic surveys. Biogeosciences 2013, 10, 3421–3443. [Google Scholar] [CrossRef]
- Mcgee, T.M. The use of marine seismic profiling for environmental assessment. Geophys. Prospect. 1990, 38, 861–880. [Google Scholar] [CrossRef]
- Wu, Z.Y.; Zheng, Y.L.; Chu, F.Y.; Tao, C.H.; Gao, J.Y. Research Status and Prospect of Sonar Detecting Techniques Near Submarine. Adv. Earth Sci. 2005, 20, 1210–1217. [Google Scholar]
- Li, X.; Liu, B.; Liu, L.; Zheng, J.; Zhou, S.; Zhou, Q. Prediction for potential landslide zones using seismic amplitude in Liwan gas field, northern South China Sea. J. Ocean. Univ. China 2017, 16, 1035–1042. [Google Scholar] [CrossRef]
- Dong, Y.K.; Wang, D.; Randolph, M. Investigation of impact forces on pipeline by submarine landslide with material point method. Ocean. Eng. 2017, 146, 21–28. [Google Scholar] [CrossRef]
- Tao, C.; Jin, X.; Xu, F.; Gu, C.; He, Y. Current Status and Prospects of Research on Acoustic Seabed Sediment Classification Technologies. East China Sea 2004, 22, 28–33. [Google Scholar]
- Dong, Y.K.; Liao, Z.X.; Liu, Q.B.; Cui, L. Potential failure patterns of a large landslide complex in the Three Gorges Reservoir area. Bull. Eng. Geol. Environ. 2023, 82, 41. [Google Scholar] [CrossRef]
- Kim, G.; Kim, D.C.; Park, S.C.; Lee, G.H. Chirp (2–7 kHz) echo characters and geotechnical properties of surface sediments in the Ulleung Basin, the East Sea. J. Geosci. 1999, 3, 213–224. [Google Scholar] [CrossRef]
- Schock, S.G. A method for estimating the physical and acoustic properties of the sea bed using chirp sonar data. IEEE J. Ocean. Eng. 2004, 29, 1200–1217. [Google Scholar] [CrossRef]
- Schock, S.G. Remote estimates of physical and acoustic sediment properties in the South China Sea using chirp sonar data and the biot model. IEEE J. Ocean. Eng. 2004, 29, 1218–1230. [Google Scholar] [CrossRef]
- Vardy, M.E. Deriving shallow-water sediment properties using post-stack acoustic impedance inversion. Near Surf. Geophys. 2015, 13, 143–154. [Google Scholar] [CrossRef]
- Zhang, Z.M.; Huo, H.; Zhao, F.Y. Survey of object detection algorithm based on deep convolutional neural networks. J. Chin. Mini-Micro Comput. Syst. 2019, 40, 1825–1831. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2016. [Google Scholar]
- Dong, Y.K.; Cui, L.; Zhang, X. Multiple-GPU for three dimensional MPM based on single-root complex. Int. J. Numer. Methods Eng. 2022, 123, 1481–1504. [Google Scholar] [CrossRef]
- Berthold, T.; Leichter, A.; Rosenhahn, B.; Berkhahn, V.; Valerius, J. Seabed sediment classification of side-scan sonar data using convolutional neural networks. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 8 February 2018. [Google Scholar]
- Luo, X.; Qin, X.; Wu, Z.; Yang, F.; Wang, M.; Shang, J. Sediment classification of small-size seabed acoustic images using convolutional neural networks. IEEE Access 2019, 7, 98331–98339. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, Q.; Wei, S.; Xue, X.; Zhou, X.; Zhang, X. Research on Seabed Sediment Classification Based on the MSC-Transformer and Sub-Bottom Profiler. J. Mar. Sci. Eng. 2023, 11, 1074. [Google Scholar] [CrossRef]
- Tegowski, J. Acoustical classification of the bottom sediments in the southern Baltic Sea. Quat. Int. 2005, 130, 153–161. [Google Scholar] [CrossRef]
- Lu, L.; Jin, S.; Bian, G.; Cui, Y.; Xia, W. The application of K-means clustering analysis algorithm in multibeam seafloor classification. Hydrogr. Surv. Charting 2018, 38, 64–68. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer Assisted Intervention; Springer: Munich, Germany, 2015; pp. 234–241. [Google Scholar]
- Maayan, F.A.; Avi, B.C.; Rula, A.; Hayit, G. Improving the Segmentation of Anatomical Structures in Chest Radiographs Using U-Net with an ImageNet Pre-trained Encoder. Image Anal. Mov. Organ Breast Thorac. Images 2018, 11040, 159–168. [Google Scholar]
- Iglovikov, V.; Shvets, A. TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Ward, J.H. Hierarchical Grouping to Optimize an Objective Function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Kaski, S.; Kangas, J.; Kohonen, T. Bibliography of self-organizing map (SOM) papers: 1981–1997. Neural Comput. Surv. 2002, 1, 1–156. [Google Scholar]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef]
- Zhu, L.; Fu, M.; Liu, L.; Li, J.; Gao, S. Canyon morphology and sediments on northern slope of the Baiyun Sag. Mar. Geol. Quat. Geol. 2014, 34, 1–9. [Google Scholar]
- Zhou, Q.; Li, X.; Xu, Y.; Liu, L. A rapid method to recognize submarine landslides based on the principle of water depth gradient: A case of Baiyun deep-water area, north slope of the South China Sea. Acta Oceanol. Sin. 2017, 39, 138–147. [Google Scholar]
- Li, A.; Li, Y.; Le, G. Origin of tellurium anomalies in deep-sea sediments. Acta Geosci. Sin. 2005, 26, 186–189. [Google Scholar]
- Zhu, C.; Zhou, L.; Zhang, H.; Sheng, C. Preliminary study of physical and mechanical properties of surface sediment in Northern South China Sea. J. Eng. Geol. 2017, 25, 1566–1573. [Google Scholar]
- Vijay, B.; Alex, K.; Roberto, C. SegNet: A Deep Convolutional Encoder-decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar]
- Li, Y.; Wang, Q.; Chen, J.; Xu, L. K-means algorithm based on particle swarm optimization for the identification of rock discontinuity sets. Rock Mech. Rock Eng. 2015, 48, 375–385. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Kumar, P.; Nagar, P.; Arora, C.; Gupta, A. U-SegNet: Fully Convolutional Neural Network based automatic Brain tissue segmentation Tool. arXiv 2018, arXiv:1806.04429. [Google Scholar]
- Ketkar, N. Stochastic Gradient Descent. In Deep Learning with Python; Apress: Berkeley, CA, USA, 2017; pp. 113–132. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 3431–3440. [Google Scholar]
- Terry, J.P.; Goff, J. Megaclasts: Proposed Revised Nomenclature at the Coarse End of the Udden-Wentworth Grain-Size Scale for Sedimentary Particles. J. Sediment. Res. 2014, 84, 192–197. [Google Scholar] [CrossRef]
- Folk, R.L.; Andrews, P.B.; Lewis, D.W. Detrital sedimentary rock classification and nomenclature for use in New Zealand. New Zealand J. Geol. Geophys. 1970, 13, 937–968. [Google Scholar] [CrossRef]
- Blair, T.C.; Mcpherson, J.G. Grain-size and textural classification of coarse sedimentary particles. J. Sediment. Res. 1999, 69, 6–19. [Google Scholar] [CrossRef]
- Rahman, M.A.; Wang, Y. Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation. In International Symposium on Visual Computing; Springer International Publishing: Las Vegas, Nevada, 2016; pp. 234–244. [Google Scholar]
- Lever, J.; Krzywinski, M.; Altman, N. Points of singnificance: Classification evaluation. Nat. Methods 2016, 13, 603–604. [Google Scholar] [CrossRef]
- Bao, C. Buride ancient channels and deltas in the Zhujiang River mouth shelf area. Mar. Geol. Quat. Geol. 1995, 15, 25–36. [Google Scholar]
- Yang, T.; Xue, Z.; Yang, J.; Jiang, S. Characteristics of hydrogen and oxygen isotopic composition of pore water in Marine sediments in the northern part of the south China sea. Acta Geosci. Sin. 2003, 24, 511–514. [Google Scholar]
- Qin, Y. A preliminary study on the topography and sedimentary types of continental shelf seas in China. Oceanol. Et Limnol. Sin. 1963, 71–85. [Google Scholar]
- Lu, B. Study on sediments and their physical properties in the waters of Dongsha Islands. Acta Oceanol. Sin. 1996, 18, 82–89. [Google Scholar]
- Shi, X.; Liu, S.; Qiao, S.; Liu, Y.; Wang, K. Sediment Type Map of the South China Sea; Science Press: Beijing, China, 2022. [Google Scholar]
- Liu, J.; Xiang, R.; Chen, Z.; Chen, M.; Yan, W.; Zhang, L.; Chen, H. Sources, transport and deposition of surface sediments from the South China Sea. Deep. Sea Res. Part I Oceanogr. Res. Pap. 2013, 71, 92–102. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sediment Types | Water Depth (m) | Slope (°) | SBP Reflection Intensity (db) | Mean Grain Size (Φ) | Dataset | Label |
|---|---|---|---|---|---|---|
| Gravelly sand | 255 | 1.28 | 0.62 | 5.45 | TrD | 0 |
| 207 | 0.48 | 1.61 | 5.05 | TtD | ||
| Sand | 259 | 0.75 | 0.54 | 5.58 | TrD | 1 |
| 508 | 0.92 | 0.33 | 5.96 | |||
| 213 | 0.52 | 0.49 | 5.56 | TtD | ||
| 533 | 2.62 | 0.34 | 5.64 | |||
| Silty sand | 580 | 0.98 | 0.36 | 6.17 | TrD | 2 |
| 628 | 0.91 | 0.25 | 6.11 | |||
| 543 | 1.70 | 0.33 | 6.38 | TtD | ||
| 680 | 1.17 | 0.27 | 6.20 | |||
| Sandy silt | 864 | 3.24 | 0.18 | 6.47 | TrD | 3 |
| 803 | 6.75 | 0.23 | 6.64 | |||
| 1009 | 5.72 | 0.12 | 6.64 | |||
| 912 | 3.12 | 0.21 | 6.88 | |||
| 711 | 2.29 | 0.23 | 5.88 | |||
| 849 | 1.68 | 0.21 | 6.64 | TtD | ||
| 830 | 4.21 | 0.18 | 6.80 | |||
| 689 | 1.78 | 0.24 | 6.06 | |||
| Clayey silt | 1227 | 1.06 | 0.08 | 7.06 | TrD | 4 |
| 1413 | 1.30 | 0.09 | 7.38 | |||
| 1405 | 4.17 | 0.09 | 7.01 | |||
| 1431 | 3.47 | 0.11 | 6.98 | |||
| 1455 | 1.83 | 0.11 | 6.72 | |||
| 1383 | 3.67 | 0.07 | 6.97 | |||
| 1408 | 2.55 | 0.07 | 6.88 | |||
| 1323 | 3.39 | 0.10 | 6.97 | |||
| 1300 | 3.67 | 0.07 | 6.64 | |||
| 1192 | 5.28 | 0.09 | 6.64 | |||
| 1183 | 6.15 | 0.10 | 6.80 | |||
| 1088 | 1.65 | 0.11 | 6.74 | |||
| 1066 | 3.23 | 0.13 | 7.08 | |||
| 1084 | 1.61 | 0.12 | 6.72 | |||
| 1060 | 7.23 | 0.14 | 7.38 | |||
| 1023 | 6.74 | 0.15 | 7.64 | |||
| 953 | 1.33 | 0.17 | 6.16 | |||
| 1199 | 2.98 | 0.05 | 6.81 | TtD | ||
| 1337 | 2.98 | 0.09 | 6.97 | |||
| 1302 | 2.04 | 0.07 | 6.80 | |||
| 1204 | 0.75 | 0.09 | 6.72 | |||
| 965 | 5.57 | 0.18 | 6.64 | |||
| 1276 | 1.56 | 0.09 | 6.84 |
| IoU (%) | F1-Score (%) | ||
|---|---|---|---|
| U-Net | Improved U-Net | U-Net | Improved U-Net |
| 83.2 | 88.1 | 91.7 | 94.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Q.; Li, X.; Liu, L.; Wang, J.; Zhang, L.; Liu, B. Classification of Marine Sediment in the Northern Slope of the South China Sea Based on Improved U-Net and K-Means Clustering Analysis. Remote Sens. 2023, 15, 3576. https://doi.org/10.3390/rs15143576
Zhou Q, Li X, Liu L, Wang J, Zhang L, Liu B. Classification of Marine Sediment in the Northern Slope of the South China Sea Based on Improved U-Net and K-Means Clustering Analysis. Remote Sensing. 2023; 15(14):3576. https://doi.org/10.3390/rs15143576
Chicago/Turabian StyleZhou, Qingjie, Xishuang Li, Lejun Liu, Jingqiang Wang, Linqing Zhang, and Baohua Liu. 2023. "Classification of Marine Sediment in the Northern Slope of the South China Sea Based on Improved U-Net and K-Means Clustering Analysis" Remote Sensing 15, no. 14: 3576. https://doi.org/10.3390/rs15143576
APA StyleZhou, Q., Li, X., Liu, L., Wang, J., Zhang, L., & Liu, B. (2023). Classification of Marine Sediment in the Northern Slope of the South China Sea Based on Improved U-Net and K-Means Clustering Analysis. Remote Sensing, 15(14), 3576. https://doi.org/10.3390/rs15143576