
Assessment of Six Machine Learning Methods for Predicting Gross Primary Productivity in Grassland




Abstract
1. Introduction
2. Study Area and Data
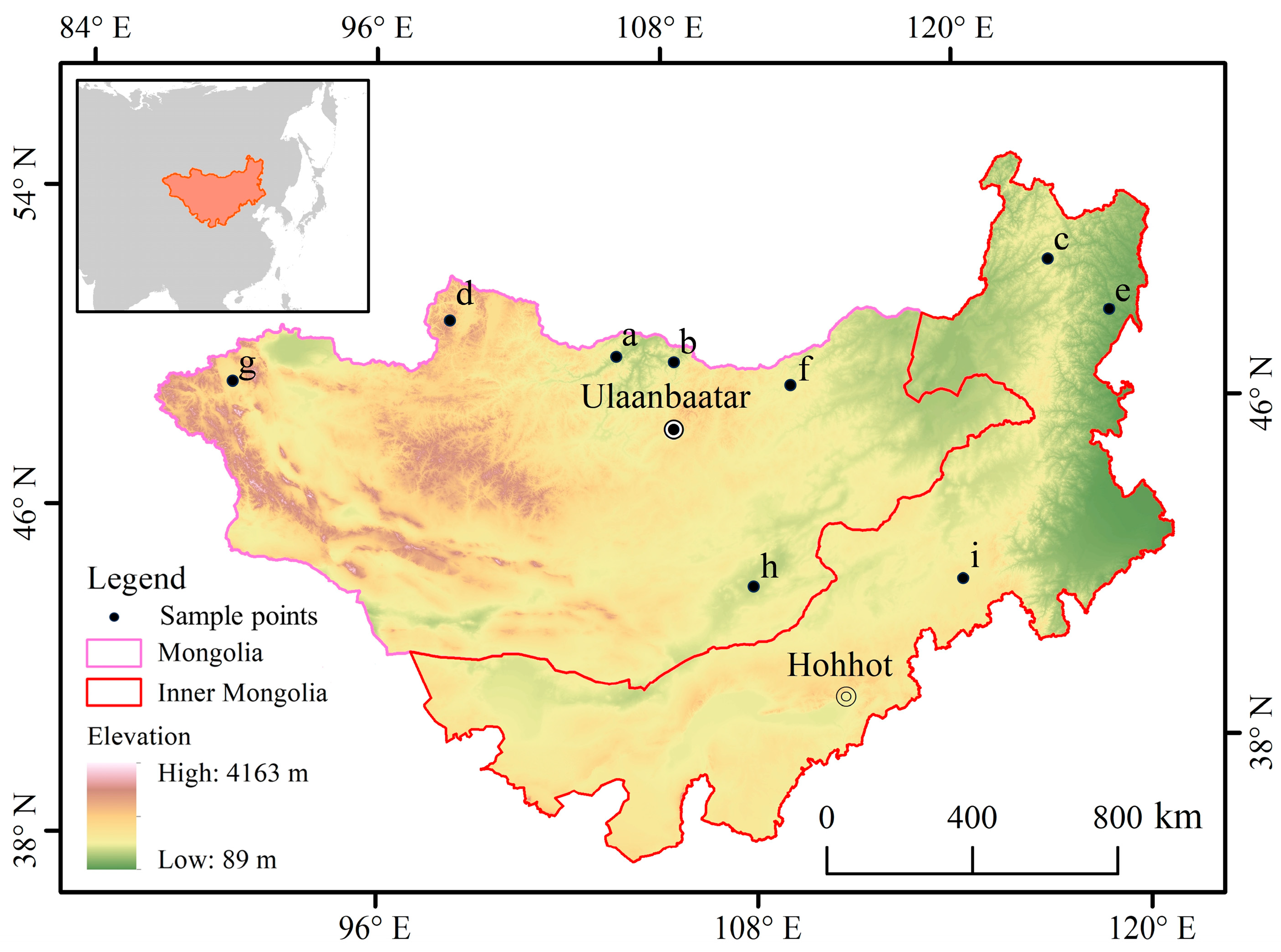
2.1. Study Area
2.2. Impact Factor Data
2.3. GPP Data
3. Methods
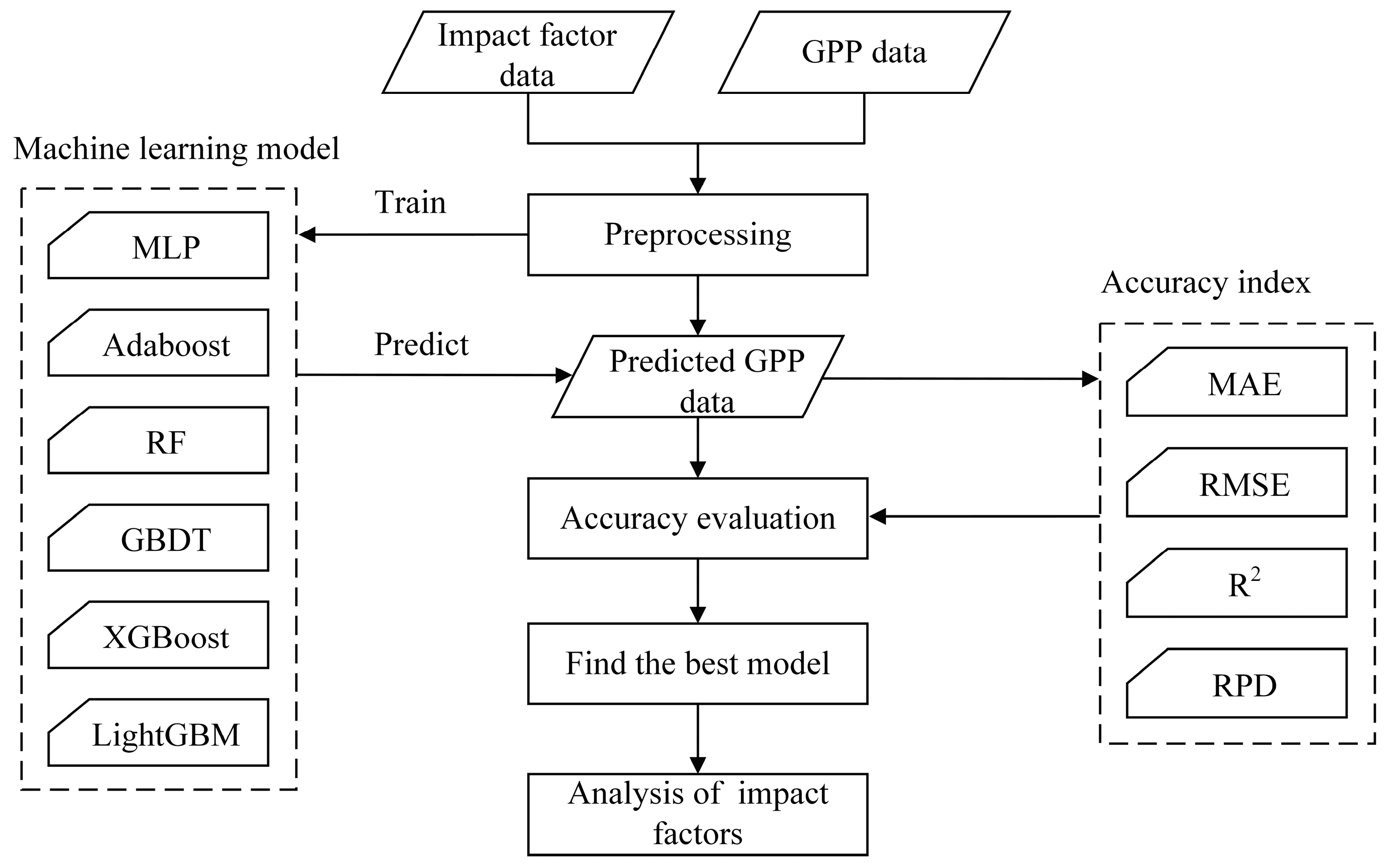
3.1. Research Framework
3.2. Machine Learning Models
3.3. Accuracy Assessment Methods
4. Results
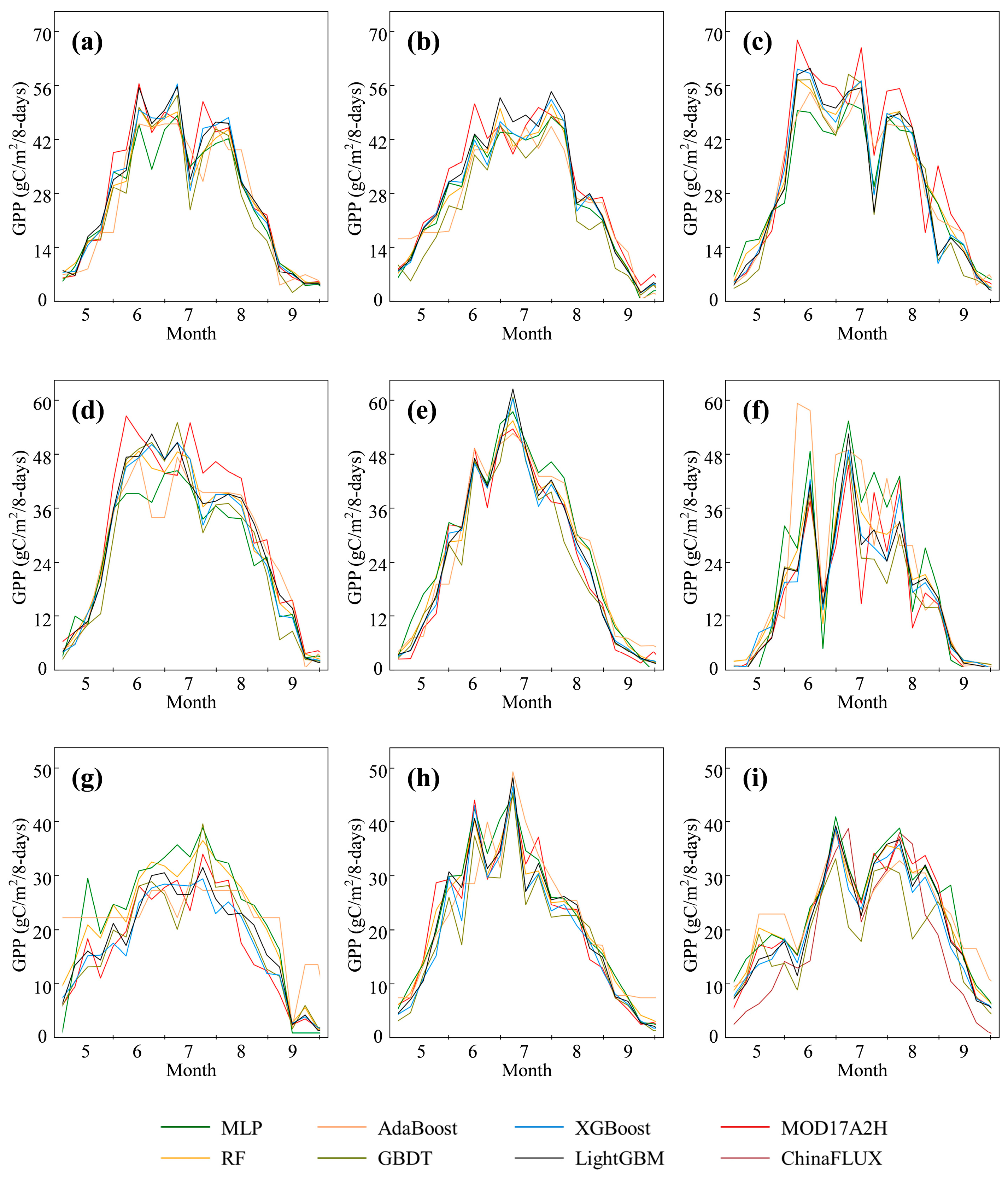
4.1. GPP Prediction Results
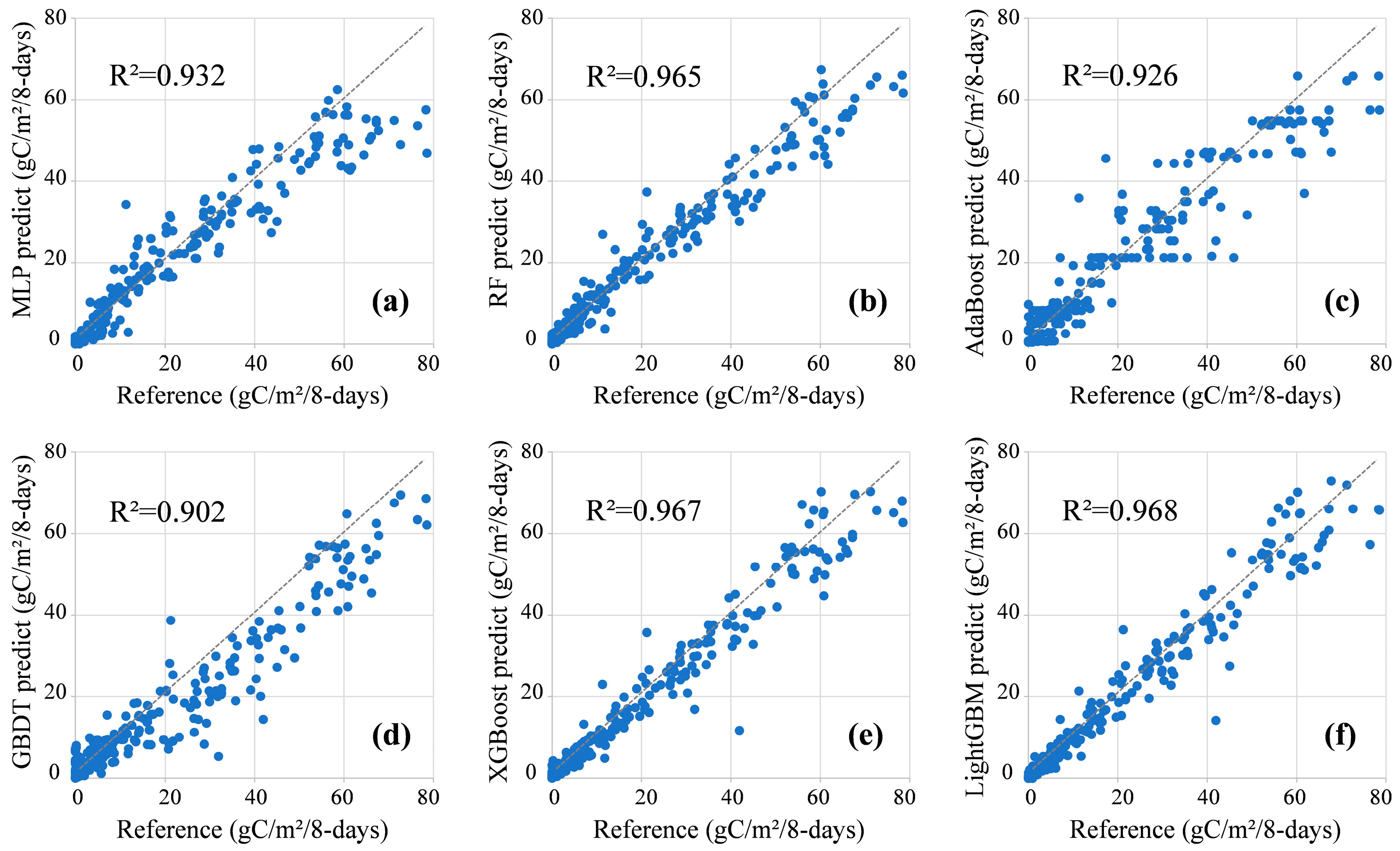
4.2. Accuracy Assessment Results
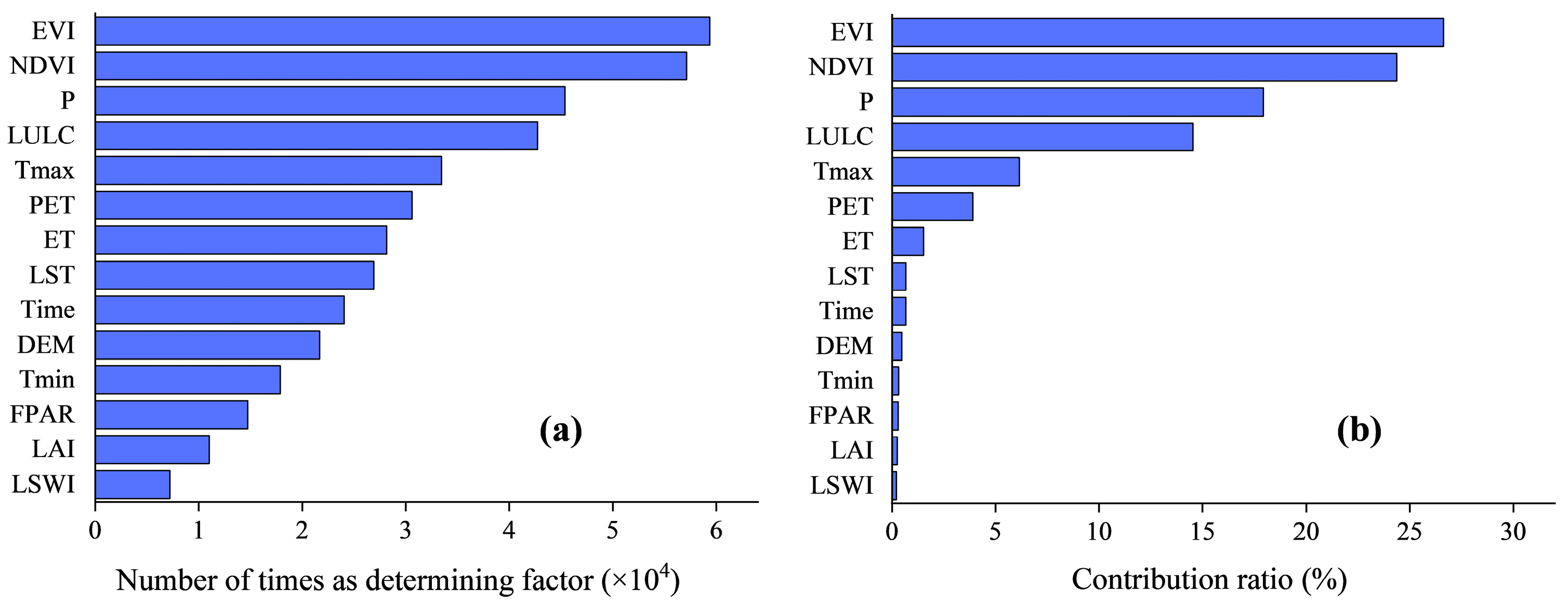
4.3. Key Factors and Contribution Ratio
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nielsen, J.M.; Pelland, N.A.; Bell, S.W.; Lomas, M.W.; Eisner, L.B.; Stabeno, P.; Harpold, C.; Stalin, S.; Mordy, C.W. Seasonal Dynamics of Primary Production in the Southeastern Bering Sea Assessed Using Continuous Temporal and Vertical Dissolved Oxygen and Chlorophyll-a Measurements. J. Geophys. Res. Ocean. 2023, 128, e2022JC019076. [Google Scholar] [CrossRef]
- Martini, D.; Sakowska, K.; Wohlfahrt, G.; Pacheco-Labrador, J.; van der Tol, C.; Porcar-Castell, A.; Magney, T.S.; Carrara, A.; Colombo, R.; El-Madany, T.S.; et al. Heatwave breaks down the linearity between sun-induced fluorescence and gross primary production. New Phytol. 2022, 233, 2415–2428. [Google Scholar] [CrossRef] [PubMed]
- Montibeller, B.; Marshall, M.; Mander, U.; Uuemaa, E. Increased carbon assimilation and efficient water usage may not compensate for carbon loss in European forests. Commun. Earth Environ. 2022, 3, 194. [Google Scholar] [CrossRef]
- Perolo, P.; Escoffier, N.; Chmiel, H.E.; Many, G.; Bouffard, D.; Perga, M.E. Alkalinity contributes at least a third of annual gross primary production in a deep stratified hardwater lake. Limnol. Oceanogr. Lett. 2023, 8, 359–367. [Google Scholar] [CrossRef]
- Yang, Y.; Shi, Y.; Sun, W.; Chang, J.; Zhu, J.; Chen, L.; Wang, X.; Guo, Y.; Zhang, H.; Yu, L.; et al. Terrestrial carbon sinks in China and around the world and their contribution to carbon neutrality. Science China. Life Sci. 2022, 65, 861–895. [Google Scholar] [CrossRef]
- Liu, F.; Xiao, X.M.; Qin, Y.W.; Yan, H.M.; Huang, J.K.; Wu, X.C.; Zhang, Y.; Zou, Z.H.; Doughty, R.B. Large spatial variation and stagnation of cropland gross primary production increases the challenges of sustainable grain production and food security in China. Sci. Total Environ. 2022, 811, 151408. [Google Scholar] [CrossRef] [PubMed]
- Hamdan, M.; Karlsson, J.; Bystrom, P.; Al-Haidarey, M.J.; Ask, J. Carbon dioxide limitation of benthic primary production in a boreal lake. Freshw. Biol. 2022, 67, 1752–1760. [Google Scholar] [CrossRef]
- Wei, X.N.; He, W.; Zhou, Y.L.; Ju, W.M.; Xiao, J.F.; Li, X.; Liu, Y.B.; Xu, S.H.; Bi, W.J.; Zhang, X.Y.; et al. Global assessment of lagged and cumulative effects of drought on grassland gross primary production. Ecol. Indic. 2022, 136, 108646. [Google Scholar] [CrossRef]
- Yang, J.Q.; Diao, H.J.; Li, G.L.; Wang, R.; Jia, H.L.; Wang, C.H. Higher N Addition and Mowing Interactively Improved Net Primary Productivity by Stimulating Gross Nitrification in a Temperate Steppe of Northern China. Plants 2023, 12, 1481. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, Y.; Zhao, X.; Tang, Z.; Wang, S.; Fang, J. Global patterns and climatic drivers of above- and belowground net primary productivity in grasslands. Sci. China Life Sci. 2021, 64, 739–751. [Google Scholar] [CrossRef]
- Wang, D.; Chen, J.; Felton, A.J.; Xia, L.L.; Zhang, Y.F.; Luo, Y.Q.; Cheng, X.L.; Cao, J.J. Post-fire co-stimulation of gross primary production and ecosystem respiration in a meadow grassland on the Tibetan Plateau. Agric. For. Meteorol. 2021, 303, 108388. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, Y.; Zhang, Y.; Shang, J. Review of Remote Sensing Applications in Grassland Monitoring. Remote Sens. 2022, 14, 2903. [Google Scholar] [CrossRef]
- Hoover, D.L.; Knapp, A.K.; Smith, M.D. Resistance and resilience of a grassland ecosystem to climate extremes. Ecology 2014, 95, 2646–2656. [Google Scholar] [CrossRef]
- Domysheva, V.M.; Panchenko, M.V.; Pestunov, D.A.; Sakirko, M.V.; Shamrin, A.M. Estimation of Primary Production in the Water of the Coastal Zone of Lake Baikal Based on Daily Variations in CO2 Concentration in Different Seasons of 2005–2021. Atmos. Ocean. Opt. 2023, 36, 92–100. [Google Scholar] [CrossRef]
- Jung, M.; Reichstein, M.; Bondeau, A. Towards global empirical upscaling of FLUXNET eddy covariance observations: Validation of a model tree ensemble approach using a biosphere model. Biogeosciences 2009, 6, 2001–2013. [Google Scholar] [CrossRef]
- Lee, T.; Hoang, T.; Nguyen, D.; Soo, H.K. Simulating the Gross Primary Production and Ecosystem Respiration of Estuarine Ecosystem in Nakdong Estuary with AQUATOX. J. Korean Geoenviron. Soc. 2021, 22, 15–29. [Google Scholar] [CrossRef]
- Zhang, H.L.; Bai, J.; Sun, R.; Wang, Y.; Pan, Y.H.; McGuire, P.C.; Xiao, Z.Q. Improved Global Gross Primary Productivity Estimation by Considering Canopy Nitrogen Concentrations and Multiple Environmental Factors. Remote Sens. 2023, 15, 698. [Google Scholar] [CrossRef]
- Chen, F.; Cui, N.B.; Huang, Y.W.; Hu, X.T.; Gong, D.Z.; Wang, Y.S.; Lv, M.; Jiang, S.Z. Investigating the Patterns and Controls of Ecosystem Light Use Efficiency with the Data from the Global Farmland Fluxdata Network. Sustainability 2021, 13, 12673. [Google Scholar] [CrossRef]
- Song, C.; Dannenberg, M.P.; Hwang, T. Optical remote sensing of terrestrial ecosystem primary productivity. Prog. Phys. Geogr. Earth Environ. 2013, 37, 834–854. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, J.M.; Chen, J.; Gough, C.M.; Martin, T.A.; Dragoni, D. Evaluating spatial and temporal patterns of MODIS GPP over the conterminous U.S. against flux measurements and a process model. Remote Sens. Environ. 2012, 124, 717–729. [Google Scholar] [CrossRef]
- Yu, P.X.; Zhou, T.; Luo, H.; Liu, X.; Shi, P.J.; Zhao, X.; Xiao, Z.Q.; Zhang, Y.J.; Zhou, P.F. Interannual variation of gross primary production detected from optimal convolutional neural network at multi-timescale water stress. Remote Sens. Ecol. Conserv. 2022, 8, 409–425. [Google Scholar] [CrossRef]
- Yu, Y.; Gao, Y.; Zhu, T.; Li, J. Application Comparison of Two Marine Primary Production Models in the Adjacent Sea Area of the Changjiang River Estuary. Period. Ocean Univ. China 2023, 53, 22–31. [Google Scholar]
- Yuan, W.; Liu, S.; Zhou, G.; Zhou, G.; Tieszen, L.L.; Baldocchi, D.; Bernhofer, C.; Gholz, H.; Goldstein, A.H.; Goulden, M.L.; et al. Deriving a light use efficiency model from eddy covariance flux data for predicting daily gross primary production across biomes. Agric. For. Meteorol. 2007, 143, 189–207. [Google Scholar] [CrossRef]
- Wang, H.B.; Xiao, J.F. Improving the Capability of the SCOPE Model for Simulating Solar-Induced Fluorescence and Gross Primary Production Using Data from OCO-2 and Flux Towers. Remote Sens. 2021, 13, 794. [Google Scholar] [CrossRef]
- El Masri, B.; Schwalm, C.; Huntzinger, D.N.; Mao, J.; Shi, X.; Peng, C.; Fisher, J.B.; Jain, A.K.; Tian, H.; Poulter, B.; et al. Carbon and Water Use Efficiencies: A Comparative Analysis of Ten Terrestrial Ecosystem Models under Changing Climate. Sci. Rep. 2019, 9, 14680. [Google Scholar] [CrossRef]
- Wu, W.; Epstein, H.E.; Guo, H.; Li, X.; Gong, C. A pigment ratio index based on remotely sensed reflectance provides the potential for universal gross primary production estimation. Environ. Res. Lett. 2021, 16, 054065. [Google Scholar] [CrossRef]
- Huang, X.; Xiao, J.; Wang, X.; Ma, M. Improving the global MODIS GPP model by optimizing parameters with FLUXNET data. Agric. For. Meteorol. 2021, 300, 108314. [Google Scholar] [CrossRef]
- Hou, E.Q.; Ma, S.; Huang, Y.Y.; Zhou, Y.; Kim, H.S.; Lopez-Blanco, E.; Jiang, L.F.; Xia, J.Y.; Tao, F.; Williams, C.; et al. Across-model spread and shrinking in predicting peatland carbon dynamics under global change. Glob. Change Biol. 2023, 29, 2759–2775. [Google Scholar] [CrossRef]
- Wei, S.; Yi, C.; Fang, W.; Hendrey, G. A global study of GPP focusing on light-use efficiency in a random forest regression model. Ecosphere 2017, 8, e01724. [Google Scholar] [CrossRef]
- Gang, C.C.; Wang, Z.N.; You, Y.F.; Liu, Y.; Xu, R.T.; Bian, Z.H.; Pan, N.Q.; Gao, X.R.; Chen, M.X.; Zhang, M. Divergent responses of terrestrial carbon use efficiency to climate variation from 2000 to 2018. Glob. Planet. Chang. 2022, 208, 103709. [Google Scholar] [CrossRef]
- Liu, L.Q.; Gao, X.; Cao, B.H.; Ba, Y.J.; Chen, J.L.; Cheng, X.F.; Zhou, Y.; Huang, H.; Zhang, J.S. Comparing Different Light Use Efficiency Models to Estimate the Gross Primary Productivity of a Cork Oak Plantation in Northern China. Remote Sens. 2022, 14, 5905. [Google Scholar] [CrossRef]
- Huang, X.J.; Lin, S.R.; Li, X.Q.; Ma, M.G.; Wu, C.Y.; Yuan, W.P. How Well Can Matching High Spatial Resolution Landsat Data with Flux Tower Footprints Improve Estimates of Vegetation Gross Primary Production. Remote Sens. 2022, 14, 6062. [Google Scholar] [CrossRef]
- Yu, T.; Zhang, Q.; Sun, R. Comparison of Machine Learning Methods to Up-Scale Gross Primary Production. Remote Sens. 2021, 13, 2448. [Google Scholar] [CrossRef]
- Huang, Y.B.; Nicholson, D.; Huang, B.Q.; Cassar, N. Global Estimates of Marine Gross Primary Production Based on Machine Learning Upscaling of Field Observations. Glob. Biogeochem. Cycle 2021, 35, e2020GB006718. [Google Scholar] [CrossRef]
- Yan, H.; Ran, Q.; Hu, R.; Xue, K.; Zhang, B.; Zhou, S.; Zhang, Z.; Tang, L.; Che, R.; Pang, Z.; et al. Machine learning-based prediction for grassland degradation using geographic, meteorological, plant and microbial data. Ecol. Indic. 2022, 137, 108738. [Google Scholar] [CrossRef]
- Guo, R.J.; Chen, T.X.; Chen, X.; Yuan, W.P.; Liu, S.C.; He, B.; Li, L.; Wang, S.Z.; Hu, T.; Yan, Q.Y.; et al. Estimating Global GPP From the Plant Functional Type Perspective Using a Machine Learning Approach. J. Geophys. Res. Biogeosci. 2023, 128, e2022JG007100. [Google Scholar] [CrossRef]
- Shangguan, W.; Xiong, Z.L.; Nourani, V.; Li, Q.L.; Lu, X.J.; Li, L.; Huang, F.N.; Zhang, Y.; Sun, W.Y.; Dai, Y.J. A 1 km Global Carbon Flux Dataset Using In Situ Measurements and Deep Learning. Forests 2023, 14, 913. [Google Scholar] [CrossRef]
- Pei, Y.; Dong, J.; Zhang, Y.; Yang, J.; Zhang, Y.; Jiang, C.; Xiao, X. Performance of four state-of-the-art GPP products (VPM, MOD17, BESS and PML) for grasslands in drought years. Ecol. Inform. 2020, 56, 101052. [Google Scholar] [CrossRef]
- Tian, Z.K.; Yi, C.X.; Fu, Y.Y.; Kutter, E.; Krakauer, N.Y.; Fang, W.; Zhang, Q.; Luo, H. Fusion of Multiple Models for Improving Gross Primary Production Estimation With Eddy Covariance Data Based on Machine Learning. J. Geophys. Res. Biogeosci. 2023, 128, e2022JG007122. [Google Scholar] [CrossRef]
- Lee, B.; Kim, N.; Kim, E.-S.; Jang, K.; Kang, M.; Lim, J.-H.; Cho, J.; Lee, Y. An Artificial Intelligence Approach to Predict Gross Primary Productivity in the Forests of South Korea Using Satellite Remote Sensing Data. Forests 2020, 11, 1000. [Google Scholar] [CrossRef]
- Prakash Sarkar, D.; Uma Shankar, B.; Ranjan Parida, B. Machine learning approach to predict terrestrial gross primary productivity using topographical and remote sensing data. Ecol. Inform. 2022, 70, 101697. [Google Scholar] [CrossRef]
- Yang, Q.M.; Nie, N.M.; Wang, Y.A.; Wu, X.J.; Liu, W.H.; Ren, X.L.; Wang, Z.J.; Wan, M.; Cao, R.Q. Spatial-Temporal Correlation Considering Environmental Factor Fusion for Estimating Gross Primary Productivity in Tibetan Grasslands. Appl. Sci. 2023, 13, 6290. [Google Scholar] [CrossRef]
- Bai, Y.; Liang, S.L.; Yuan, W.P. Estimating Global Gross Primary Production from Sun-Induced Chlorophyll Fluorescence Data and Auxiliary Information Using Machine Learning Methods. Remote Sens. 2021, 13, 963. [Google Scholar] [CrossRef]
- Shen, H.F.; Wang, Y.C.; Guan, X.B.; Huang, W.L.; Chen, J.J.; Lin, D.K.; Gan, W.X. A Spatiotemporal Constrained Machine Learning Method for OCO-2 Solar-Induced Chlorophyll Fluorescence (SIF) Reconstruction. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4413817. [Google Scholar] [CrossRef]
- Bao, G.; Qin, Z.; Bao, Y.; Zhou, Y.; Li, W.; Sanjjav, A. NDVI-Based Long-Term Vegetation Dynamics and Its Response to Climatic Change in the Mongolian Plateau. Remote Sens. 2014, 6, 8337–8358. [Google Scholar] [CrossRef]
- Tong, R.; Yang, Y.; Chen, X. Consistent Analysis and Accuracy Evaluation of Multisource Land Cover Datasets in 30 m Spatial Resolution over the Mongolian Plateau. J. Geo-Inf. Sci. 2022, 24, 2420–2434. [Google Scholar]
- Wulan, T. Characteristics of grassland utilization in Mongolian Plateau and their differences among countries. Acta Geogr. Sin. 2021, 76, 1722–1731. [Google Scholar]
- Bai, Q.; Alatengtuya. Response of grassland cover change to drought in the Mongolian Plateau from 2001 to 2020. Pratacultural Sci. 2022, 39, 443–454. [Google Scholar]
- Wang, X.; Ma, M.; Li, X.; Song, Y.; Tan, J.; Huang, G.; Zhang, Z.; Zhao, T.; Feng, J.; Ma, Z. Validation of MODIS-GPP product at 10 flux sites in northern China. Int. J. Remote Sens. 2013, 34, 587–599. [Google Scholar] [CrossRef]
- Karlik, B.; Olgac, A.V. Performance analysis of various activation functions in generalized MLP architectures of neural networks. Int. J. Artif. Intell. Expert Syst. 2011, 1, 111–122. [Google Scholar]
- Nandy, S.; Singh, R.; Ghosh, S.; Watham, T.; Kushwaha, S.P.S.; Kumar, A.S.; Dadhwal, V.K. Neural network-based modelling for forest biomass assessment. Carbon Manag. 2017, 8, 305–317. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3149–3157. [Google Scholar]
- Zhou, J.; Li, E.; Wang, M.; Chen, X.; Shi, X.; Jiang, L. Feasibility of stochastic gradient boosting approach for evaluating seismic liquefaction potential based on SPT and CPT case histories. J. Perform. Constr. Facil. 2019, 33, 04019024. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, H.; Niu, X.; Shao, W.; Yang, Y. Comparative Analysis and Comprehensive Trade-Off of Four Spatiotemporal Fusion Models for NDVI Generation. Remote Sens. 2022, 14, 5996. [Google Scholar] [CrossRef]
- Wang, H.; Yan, H.; Hu, Y.; Xi, Y.; Yang, Y. Consistency and Accuracy of Four High-Resolution LULC Datasets—Indochina Peninsula Case Study. Land 2022, 11, 758. [Google Scholar] [CrossRef]
- Guan, X.; Chen, J.M.; Shen, H.; Xie, X.; Tan, J. Comparison of big-leaf and two-leaf light use efficiency models for GPP simulation after considering a radiation scalar. Agric. For. Meteorol. 2022, 313, 108761. [Google Scholar] [CrossRef]
- Liang, J.C.; Bu, Y.D.; Tan, K.F.; Pan, J.C.; Yi, Z.P.; Kong, X.M.; Fan, Z. Estimation of Stellar Atmospheric Parameters with Light Gradient Boosting Machine Algorithm and Principal Component Analysis. Astron. J. 2022, 163, 4. [Google Scholar] [CrossRef]
- Lyu, J.; Zheng, P.J.; Qi, Y.; Huang, G.H. LightGBM-LncLoc: A LightGBM-Based Computational Predictor for Recognizing Long Non-Coding RNA Subcellular Localization. Mathematics 2023, 11, 602. [Google Scholar] [CrossRef]
- Cui, Z.J.; Qing, X.X.; Chai, H.X.; Yang, S.X.; Zhu, Y.; Wang, F.F. Real-time rainfall-runoff prediction using light gradient boosting machine coupled with singular spectrum analysis. J. Hydrol. 2021, 603, 127124. [Google Scholar] [CrossRef]
- Qiu, Y.L.; Wang, J.; Li, Z.Y. Personalized HRTF Prediction Based on LightGBM Using Anthropometric Data. China Commun. 2023, 20, 166–177. [Google Scholar] [CrossRef]
- Gong, P.; Wang, D.; Yuan, H.; Chen, G.; Wu, R. Fishing Ground Forecast Model of Albacore Tuna Based on LightGBM in the South Pacific Ocean. Fish. Sci. 2021, 40, 762–767. [Google Scholar]
- Guo, Y.K.; Li, Y.Y.; Xu, Y. Study on the application of LSTM-LightGBM Model in stock rise and fall prediction. In Proceedings of the 2020 2nd International Conference on Computer Science Communication and Network Security (CSCNS2020), Sanya, China, 22–23 December 2020. [Google Scholar]
- Ghosh, D.; Cabrera, J. Enriched Random Forest for High Dimensional Genomic Data. IEEE-ACM Trans. Comput. Biol. Bioinform. 2022, 19, 2817–2828. [Google Scholar] [CrossRef] [PubMed]
- Byeon, H. Comparing the Accuracy and Developed Models for Predicting the Confrontation Naming of the Elderly in South Korea using Weighted Random Forest, Random Forest, and Support Vector Regression. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 326–331. [Google Scholar] [CrossRef]
- Zhong, D.; Yang, C. Spatiotemporal Variation Characteristics of Vegetation EVI and Driving Forces of Climate Factors in Western Sichuan Plateau from 2001 to 2020. Res. Soil Water Conserv. 2022, 29, 223–230. [Google Scholar]
- Gu, Z.N.; Zhang, Z.; Yang, J.H.; Wang, L.L. Quantifying the Influences of Driving Factors on Vegetation EVI Changes Using Structural Equation Model: A Case Study in Anhui Province, China. Remote Sens. 2022, 14, 4203. [Google Scholar] [CrossRef]
- Roy, B. Optimum machine learning algorithm selection for forecasting vegetation indices: MODIS NDVI & EVI. Remote Sens. Appl. Soc. Environ. 2021, 23, 100582. [Google Scholar] [CrossRef]
- Chen, F.; Shi, X.; Ding, H.; Li, Y.; Shi, M. Differences in response of vegetation NDVI /EVI to SPEI in the upper reaches of Luanhe River. J. Water Resour. Water Eng. 2021, 32, 71–77, 86. [Google Scholar]
- Zhu, X.; Zhang, S.; Liu, T.; Liu, Y. Impacts of heat and drought on gross primary productivity in China. Remote Sens. 2021, 13, 378. [Google Scholar] [CrossRef]
- Bao, G.; Chen, J.; Chopping, M.; Bao, Y.; Bayarsaikhan, S.; Dorjsuren, A.; Tuya, A.; Jirigala, B.; Qin, Z. Dynamics of net primary productivity on the Mongolian Plateau: Joint regulations of phenology and drought. Int. J. Appl. Earth Obs. Geoinf. 2019, 81, 85–97. [Google Scholar] [CrossRef]
- Bai, J.; Zhang, H.L.; Sun, R.; Li, X.; Xiao, J.F.; Wang, Y. Estimation of global GPP from GOME-2 and OCO-2 SIF by considering the dynamic variations of GPP-SIF relationship. Agric. For. Meteorol. 2022, 326, 109180. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, D.; Fan, J.; Guo, Q.; Chen, S.; Wang, R.; Li, Y. Contrasting the performance of eight satellite-based GPP models in water-limited and temperature-limited grassland ecosystems. Remote Sens. 2019, 11, 1333. [Google Scholar] [CrossRef]
- Chen, X.; Tao, X.; Yang, Y. Distribution and Attribution of Gross Primary Productivity Increase Over the Mongolian Plateau, 2001–2018. IEEE Access 2022, 10, 25125–25134. [Google Scholar] [CrossRef]
- Cheng, D.N.; Li, S.G.; Zhang, H.P.; Xia, F.; Zhang, Y.Q. Why Dataset Properties Bound the Scalability of Parallel Machine Learning Training Algorithms. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 1702–1712. [Google Scholar] [CrossRef]
- Park, Y.; Shin, Y. A Block-Based Interactive Programming Environment for Large-Scale Machine Learning Education. Appl. Sci. 2022, 12, 13008. [Google Scholar] [CrossRef]
- Zhuravlev, R.; Dara, A.; dos Santos, A.L.D.; Demidov, O.; Burba, G. Globally Scalable Approach to Estimate Net Ecosystem Exchange Based on Remote Sensing, Meteorological Data, and Direct Measurements of Eddy Covariance Sites. Remote Sens. 2022, 14, 5529. [Google Scholar] [CrossRef]
- Zhang, C.; Luo, G.P.; Hellwich, O.; Chen, C.B.; Zhang, W.Q.; Xie, M.J.; He, H.L.; Shi, H.Y.; Wang, Y.G. A framework for estimating actual evapotranspiration at weather stations without flux observations by combining data from MODIS and flux towers through a machine learning approach. J. Hydrol. 2021, 603, 127047. [Google Scholar] [CrossRef]
- Khan, M.S.; Jeon, S.B.; Jeong, M.H. Gap-Filling Eddy Covariance Latent Heat Flux: Inter-Comparison of Four Machine Learning Model Predictions and Uncertainties in Forest Ecosystem. Remote Sens. 2021, 13, 4976. [Google Scholar] [CrossRef]
- Tang, H.; Li, Z.; Ding, L.; Shen, B.; Wang, X.; Xu, L.; Xin, X. Validation of GPP remote sensing products using eddy covariance flux observations in the grassland area of China. Pratacultural Sci. 2018, 35, 2568–2583. [Google Scholar]
- Ranjan, A.K.; Gorai, A.K. Characterization of vegetation dynamics using MODIS satellite products over stone-mining dominated Rajmahal Hills in Jharkhand, India. Remote Sens. Appl. Soc. Environ. 2022, 27, 100802. [Google Scholar] [CrossRef]
- Barkhordarian, A.; Bowman, K.W.; Cressie, N.; Jewell, J.; Liu, J.J. Emergent constraints on tropical atmospheric aridity-carbon feedbacks and the future of carbon sequestration. Environ. Res. Lett. 2021, 16, 114008. [Google Scholar] [CrossRef]
- Shi, H.F.; Miao, K.; Ren, X.C. Short-term load forecasting based on CNN-BiLSTM with Bayesian optimization and attention mechanism. Concurr. Comput. Pract. Exp. 2021, e6676. [Google Scholar] [CrossRef]
- Wang, L.; Tian, T.; Tong, H. Short-term Load Forecasting Based on Visualization Dimension Reduction of Meteorological Data and Multi-model Weighted Combination. Inf. Control 2022, 51, 741–752, 762. [Google Scholar]
- Zampieri, M.; Grizzetti, B.; Toreti, A.; De Palma, P.; Collalti, A. Rise and fall of vegetation annual primary production resilience to climate variability projected by a large ensemble of Earth System Models’ simulations. Environ. Res. Lett. 2021, 16, 105001. [Google Scholar] [CrossRef]
- Moore, D.J.P. A framework for incorporating ecology into Earth System Models is urgently needed COMMENT. Glob. Chang. Biol. 2022, 28, 343–345. [Google Scholar] [CrossRef]
- Braghiere, R.K.; Fisher, J.B.; Miner, K.R.; Miller, C.E.; Worden, J.R.; Schimel, D.S.; Frankenberg, C. Tipping point in North American Arctic-Boreal carbon sink persists in new generation Earth system models despite reduced uncertainty. Environ. Res. Lett. 2023, 18, 025008. [Google Scholar] [CrossRef]
- Zhou, J.X.; Chen, J.; Chen, X.H.; Zhu, X.L.; Qiu, Y.A.; Song, H.H.; Rao, Y.H.; Zhang, C.S.; Cao, X.; Cui, X.H. Sensitivity of six typical spatiotemporal fusion methods to different influential factors: A comparative study for a normalized difference vegetation index time series reconstruction. Remote Sens. Environ. 2021, 252, 112130. [Google Scholar] [CrossRef]
- Zhang, F.Y.; Lu, X.H.; Huang, Q.; Jiang, F. Impact of different ERA reanalysis data on GPP simulation. Ecol. Inform. 2022, 68, 101520. [Google Scholar] [CrossRef]
- Xu, L.; Yu, H.C.; Chen, Z.Q.; Du, W.Y.; Chen, N.C.; Zhang, C. Monthly Ocean Primary Productivity Forecasting by Joint Use of Seasonal Climate Prediction and Temporal Memory. Remote Sens. 2023, 15, 1417. [Google Scholar] [CrossRef]
- Zhao, W.Q.; Zhu, Z.C. Exploring the Best-Matching Plant Traits and Environmental Factors for Vegetation Indices in Estimates of Global Gross Primary Productivity. Remote Sens. 2022, 14, 6316. [Google Scholar] [CrossRef]
- Pagaduan, J.A. Do higher-quality nighttime lights and net primary productivity predict subnational GDP in developing countries? Evidence from the Philippines. Asian Econ. J. 2022, 36, 288–317. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Impact Factor | Spatial Resolution | Temporal Resolution | Data Source |
|---|---|---|---|---|
| Vegetation physiology | Enhanced vegetation index | 500 m | 8 d | Calculated from MODIS images |
| Normalized difference vegetation index | 500 m | 8 d | MOD15A2H | |
| Leaf area index | 500 m | 8 d | Calculated from MODIS images | |
| Land surface feature | Land surface water index | 500 m | 8 d | Calculated from MODIS images |
| Digital elevation model | 90 m | - | SRTM V4 | |
| Land use/land cover | 500 m | 1 a | MCD12Q1 | |
| Land surface temperature | 1 km | 8 d | MOD11A2 | |
| Fraction of photosynthetically active radiation | 500 m | 8 d | MOD15A2H | |
| Climatic environment | Precipitation | 0.25° | 1 d | ERA5 |
| Minimum air temperature | 0.25° | 1 d | ERA5 | |
| Maximum air temperature | 0.25° | 1 d | ERA5 | |
| Evapotranspiration | 500 m | 8 d | MOD16A2 | |
| Potential evapotranspiration | 500 m | 8 d | MOD16A2 |
| Category | Model | Aggregating Strategy | Reference |
|---|---|---|---|
| Neural network | Multilayer Perception | - | [50,51] |
| Aggregating learning | Random Forest | Bagging | [52] |
| Adaboost | Boosting | [53] | |
| Gradient Boosting Decision Tree | Boosting | [54] | |
| XGBoost | Boosting | [55] | |
| LightGBM | Boosting | [56] |
| Model | MAE | RMSE | RPD | R2 | Bias |
|---|---|---|---|---|---|
| MLP | 1.920 | 3.919 | 4.837 | 0.956 | −0.492 |
| RF | 1.344 | 3.309 | 5.633 | 0.968 | −0.416 |
| AdaBoost | 3.067 | 5.307 | 3.499 | 0.918 | −0.047 |
| GBDT | 1.388 | 3.337 | 5.629 | 0.968 | −0.751 |
| XGBoost | 1.252 | 3.148 | 5.922 | 0.971 | −0.239 |
| LightGBM | 1.212 | 3.149 | 5.920 | 0.971 | −0.034 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Shao, W.; Hu, Y.; Cao, W.; Zhang, Y. Assessment of Six Machine Learning Methods for Predicting Gross Primary Productivity in Grassland. Remote Sens. 2023, 15, 3475. https://doi.org/10.3390/rs15143475
Wang H, Shao W, Hu Y, Cao W, Zhang Y. Assessment of Six Machine Learning Methods for Predicting Gross Primary Productivity in Grassland. Remote Sensing. 2023; 15(14):3475. https://doi.org/10.3390/rs15143475
Chicago/Turabian StyleWang, Hao, Wei Shao, Yunfeng Hu, Wei Cao, and Yunzhi Zhang. 2023. "Assessment of Six Machine Learning Methods for Predicting Gross Primary Productivity in Grassland" Remote Sensing 15, no. 14: 3475. https://doi.org/10.3390/rs15143475
APA StyleWang, H., Shao, W., Hu, Y., Cao, W., & Zhang, Y. (2023). Assessment of Six Machine Learning Methods for Predicting Gross Primary Productivity in Grassland. Remote Sensing, 15(14), 3475. https://doi.org/10.3390/rs15143475