


ADD-UNet: An Adjacent Dual-Decoder UNet for SAR-to-Optical Translation



Abstract
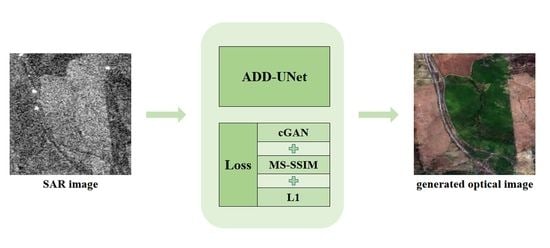
1. Introduction
2. Materials and Methods
2.1. Adjacent Dual-Decoder UNet
2.2. Improved Loss Function
2.3. Datasets
2.4. Evaluation Metrics
2.5. Implementation Details
3. Results
3.1. Selection of the Additional Decoder Branch
3.2. Comparison of Different Generators
3.3. Comparison of Different Loss Functions
3.4. Comparison with the State of the Art
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Singh, P.; Komodakis, N. Cloud-Gan: Cloud Removal for Sentinel-2 Imagery Using a Cyclic Consistent Generative Adversarial Networks. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1772–1775. [Google Scholar]
- Darbaghshahi, F.N.; Mohammadi, M.R.; Soryani, M. Cloud Removal in Remote Sensing Images Using Generative Adversarial Networks and SAR-to-Optical Image Translation. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–9. [Google Scholar] [CrossRef]
- Nie, H.; Fu, Z.; Tang, B.-H.; Li, Z.; Chen, S.; Wang, L. A Dual-Generator Translation Network Fusing Texture and Structure Features for SAR and Optical Image Matching. Remote Sens. 2022, 14, 2946. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, C.; Li, S. A Perceptive Uniform Pseudo-Color Coding Method of SAR Images. In Proceedings of the 2006 CIE International Conference on Radar, Shanghai, China, 16–19 October 2006; pp. 1–4. [Google Scholar]
- Li, Z.; Liu, J.; Huang, J. Dynamic Range Compression and Pseudo-Color Presentation Based on Retinex for SAR Images. In Proceedings of the 2008 International Conference on Computer Science and Software Engineering, Wuhan, China, 12–14 December 2008; Volume 6, pp. 257–260. [Google Scholar]
- Deng, Q.; Chen, Y.; Zhang, W.; Yang, J. Colorization for Polarimetric SAR Image Based on Scattering Mechanisms. In Proceedings of the 2008 Congress on Image and Signal Processing, Sanya, China, 27–30 May 2008; pp. 697–701. [Google Scholar]
- Wang, P.; Wang, L.; Leung, H.; Zhang, G. Super-Resolution Mapping Based on Spatial–Spectral Correlation for Spectral Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2256–2268. [Google Scholar] [CrossRef]
- Shang, X.; Song, M.; Wang, Y.; Yu, C.; Yu, H.; Li, F.; Chang, C.-I. Target-Constrained Interference-Minimized Band Selection for Hyperspectral Target Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6044–6064. [Google Scholar] [CrossRef]
- Cuomo, S.; Di Cola, V.S.; Giampaolo, F.; Rozza, G.; Raissi, M.; Piccialli, F. Scientific Machine Learning Through Physics–Informed Neural Networks: Where We Are and What’s Next. J. Sci. Comput. 2022, 92, 88. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, Y.; Sun, H. Physics-Informed Learning of Governing Equations from Scarce Data. Nat. Commun. 2021, 12, 6136. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets 2014. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Kim, J.; Kim, M.; Kang, H.; Lee, K.H. U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30April 2020. [Google Scholar]
- Niu, X.; Yang, D.; Yang, K.; Pan, H.; Dou, Y. Image Translation Between High-Resolution Remote Sensing Optical and SAR Data Using Conditional GAN. In Proceedings of the Advances in Multimedia Information Processing—PCM 2018: 19th Pacific-Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; Springer: Berlin/Heidelberg, Germany; pp. 245–255. [Google Scholar]
- Merkle, N.; Auer, S.; Muller, R.; Reinartz, P. Exploring the Potential of Conditional Adversarial Networks for Optical and SAR Image Matching. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1811–1820. [Google Scholar] [CrossRef]
- Fu, S.; Xu, F.; Jin, Y.-Q. Translating SAR to Optical Images for Assisted Interpretation 2019. arXiv 2019, arXiv:1901.03749. [Google Scholar]
- Fuentes Reyes, M.; Auer, S.; Merkle, N.; Henry, C.; Schmitt, M. SAR-to-Optical Image Translation Based on Conditional Generative Adversarial Networks—Optimization, Opportunities and Limits. Remote Sens. 2019, 11, 2067. [Google Scholar] [CrossRef]
- Wang, L.; Xu, X.; Yu, Y.; Yang, R.; Gui, R.; Xu, Z.; Pu, F. SAR-to-Optical Image Translation Using Supervised Cycle-Consistent Adversarial Networks. IEEE Access 2019, 7, 129136–129149. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, J.; Lu, X. Feature-Guided SAR-to-Optical Image Translation. IEEE Access 2020, 8, 70925–70937. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, X.; Liu, M.; Zou, X.; Zhu, L.; Ruan, X. Comparative Analysis of Edge Information and Polarization on SAR-to-Optical Translation Based on Conditional Generative Adversarial Networks. Remote Sens. 2021, 13, 128. [Google Scholar] [CrossRef]
- Li, H.; Gu, C.; Wu, D.; Cheng, G.; Guo, L.; Liu, H. Multiscale Generative Adversarial Network Based on Wavelet Feature Learning for SAR-to-Optical Image Translation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, Y.; Zhang, Y. Hybrid CGAN: Coupling Global and Local Features for SAR-to-Optical Image Translation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Guo, J.; He, C.; Zhang, M.; Li, Y.; Gao, X.; Song, B. Edge-Preserving Convolutional Generative Adversarial Networks for SAR-to-Optical Image Translation. Remote Sens. 2021, 13, 3575. [Google Scholar] [CrossRef]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Wang, X.; Gupta, A. Generative Image Modeling Using Style and Structure Adversarial Networks. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 318–335. [Google Scholar]
- Zhou, Y.; Berg, T.L. Learning Temporal Transformations from Time-Lapse Videos. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Amsterdam, The Netherlands, 2017; pp. 262–277. [Google Scholar]
- Yoo, D.; Kim, N.; Park, S.; Paek, A.S.; Kweon, I.S. Pixel-Level Domain Transfer. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 517–532. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A Neural Algorithm of Artistic Style 2015. arXiv 2015, arXiv:1508.06576. [Google Scholar]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation With Conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef]
- Qian, Z.; Huang, K.; Wang, Q.-F.; Xiao, J.; Zhang, R. Generative Adversarial Classifier for Handwriting Characters Super-Resolution. Pattern Recognit. 2020, 107, 107453. [Google Scholar] [CrossRef]
- Fang, Y.; Deng, W.; Du, J.; Hu, J. Identity-Aware CycleGAN for Face Photo-Sketch Synthesis and Recognition. Pattern Recognit. 2020, 102, 107249. [Google Scholar] [CrossRef]
- Li, D.; Du, C.; He, H. Semi-Supervised Cross-Modal Image Generation with Generative Adversarial Networks. Pattern Recognit. 2020, 100, 107085. [Google Scholar] [CrossRef]
- Xu, W.; Shawn, K.; Wang, G. Toward Learning a Unified Many-to-Many Mapping for Diverse Image Translation. Pattern Recognit. 2019, 93, 570–580. [Google Scholar] [CrossRef]
- Zhao, S.; Li, J.; Wang, J. Disentangled Representation Learning and Residual GAN for Age-Invariant Face Verification. Pattern Recognit. 2020, 100, 107097. [Google Scholar] [CrossRef]
- Yao, R.; Gao, C.; Xia, S.; Zhao, J.; Zhou, Y.; Hu, F. GAN-Based Person Search via Deep Complementary Classifier with Center-Constrained Triplet Loss. Pattern Recognit. 2020, 104, 107350. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 649–666. [Google Scholar]
- Yang, X.; Zhao, J.; Wei, Z.; Wang, N.; Gao, X. SAR-to-Optical Image Translation Based on Improved CGAN. Pattern Recognit. 2022, 121, 108208. [Google Scholar] [CrossRef]
- Li, Y.; Fu, R.; Meng, X.; Jin, W.; Shao, F. A SAR-to-Optical Image Translation Method Based on Conditional Generation Adversarial Network (CGAN). IEEE Access 2020, 8, 60338–60343. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Image Restoration With Neural Networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale Structural Similarity for Image Quality Assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; pp. 1398–1402. [Google Scholar]
- Schmitt, M.; Hughes, L.H.; Zhu, X.X. The SEN1-2 Dataset for Deep Learning in SAR-Optical Data Fusion 2018. arXiv 2018, arXiv:1807.01569. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Paul Smolley, S. Least Squares Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IQA | Dataset | UNet7 | UNet27 | UNet37 | UNet47 | UNet57 | UNet67 |
|---|---|---|---|---|---|---|---|
| SSIM | Test1 | 0.399 | 0.350 | 0.392 | 0.412 | 0.426 | 0.478 |
| Test2 | 0.534 | 0.598 | 0.599 | 0.572 | 0.550 | 0.671 | |
| PSNR | Test1 | 19.249 | 18.983 | 19.586 | 19.751 | 19.690 | 20.462 |
| Test2 | 21.242 | 22.127 | 22.133 | 21.823 | 21.273 | 23.146 |
| IQA | Dataset | UNet | Johnson’s | UNet++ | ADD-UNet |
|---|---|---|---|---|---|
| SSIM | Test1 | 0.399 | 0.309 | 0.460 | 0.478 |
| Test2 | 0.534 | 0.619 | 0.626 | 0.671 | |
| PSNR | Test1 | 19.249 | 18.149 | 20.531 | 20.462 |
| Test2 | 21.242 | 22.155 | 22.481 | 23.146 |
| Generator | Params. | Inference Time (s) |
|---|---|---|
| UNet | 41.83 M | 0.016 |
| Johnson’s | 48.01 M | 0.022 |
| UNet++ | 102.29 M | 0.071 |
| ADD-UNet | 74.03 M | 0.031 |
| IQA | Dataset | cGAN + L1 | cGAN + MS-SSIM + L1 |
|---|---|---|---|
| SSIM | Test1 | 0.478 | 0.529 |
| Test2 | 0.671 | 0.724 | |
| PSNR | Test1 | 20.462 | 20.763 |
| Test2 | 23.146 | 23.395 |
| IQA | Dataset | Pix2pix | CycleGAN | U-GAT-IT | Ours |
|---|---|---|---|---|---|
| SSIM | Test1 | 0.399 | 0.160 | 0.154 | 0.529 |
| Test2 | 0.534 | 0.125 | 0.148 | 0.724 | |
| PSNR | Test1 | 19.249 | 13.301 | 12.371 | 20.763 |
| Test2 | 21.242 | 12.446 | 12.560 | 23.395 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Q.; Li, H.; Chen, Z.; Li, J. ADD-UNet: An Adjacent Dual-Decoder UNet for SAR-to-Optical Translation. Remote Sens. 2023, 15, 3125. https://doi.org/10.3390/rs15123125
Luo Q, Li H, Chen Z, Li J. ADD-UNet: An Adjacent Dual-Decoder UNet for SAR-to-Optical Translation. Remote Sensing. 2023; 15(12):3125. https://doi.org/10.3390/rs15123125
Chicago/Turabian StyleLuo, Qingli, Hong Li, Zhiyuan Chen, and Jian Li. 2023. "ADD-UNet: An Adjacent Dual-Decoder UNet for SAR-to-Optical Translation" Remote Sensing 15, no. 12: 3125. https://doi.org/10.3390/rs15123125
APA StyleLuo, Q., Li, H., Chen, Z., & Li, J. (2023). ADD-UNet: An Adjacent Dual-Decoder UNet for SAR-to-Optical Translation. Remote Sensing, 15(12), 3125. https://doi.org/10.3390/rs15123125