1. Introduction
Hyperspectral images (HSIs) are a kind of large volume and three-dimensional data cube, and they contain hundreds of bands, which range from visible to infrared wavelengths [
1,
2]. HSIs contain rich spectral information, which can reflect the unique spectral characteristics of ground objects [
3]. HSIs are widely applied in many fields, including geological exploration [
4], environmental research [
5], agricultural applications [
6], and city layout planning [
7]. However, because of the limited number of photons in each band, the spatial resolution of HSIs is usually low, which limits their practical application. Thus, it is important to obtain HSIs with high spatial resolution.
Super-resolution (SR) [
8] is an approach of obtaining high-resolution (HR) images from low-resolution (LR) images. Because it is very difficult to improve hardware to acquire HR HSIs, many researchers have focused on software algorithms and proposed many HSI super-resolution methods. These methods are mainly divided into two categories: fusion-based hyperspectral image super-resolution (FHISR) and single hyperspectral image super-resolution (SHISR). The FHISR technique aims to obtain HSIs with high spatial resolution by merging the low-resolution HSIs and high-resolution RGB images [
9,
10], multispectral images [
11], or panchromatic images [
12,
13,
14]. The fusion-based methods make significant progress, but they need well-registered images with high resolution in the same scene, which limits the practical application of the FHISR technique.
Compared with FHISR methods, the SHISR technique, which aims to reconstruct an HR image without the use of any auxiliary images, is more applicable; it mainly includes interpolation, sparse representation [
15], low-rank tensor [
16], and deep learning methods [
17]. Interpolation methods such as bicubic interpolation can conveniently predict unknown pixels, but they often produce blurry images. Because there are many similar structures in land cover maps, Huang et al. [
15] exploited this to capture the spatial dependency via the use of a multi-dictionary based on sparse representation. Different from the assumption on spatial similarity in natural images [
18], He et al. [
16] proposed a tensor model to sufficiently mine both spatial and spectral structure information. The sparse representation and low-rank tensor methods depend on sparsity and low-rank assumption, which may not hold in practical applications. Compared with the above three types of methods, methods based on deep learning have achieved better performance over the past few years. Dong et al. [
19] made the first attempt to introduce deep learning into the natural image super-resolution process. Many natural image super-resolution methods have improved SR performance, e.g., the very deep super-resolution network (VDSR) [
20], enhanced deep super-resolution network (EDSR) [
21], residual dense network [
22], and image restoration using the Swin transformer [
23]. These methods can be used for SHISR methods by super-resolving the HSIs in a band-by-band manner. However, compared with natural image super-resolution, SHISR should improve the spatial resolution while preserving spectral correlation [
24]. These methods [
20,
21,
22,
23,
24,
25] ignore the spectral correlation among bands and result in spectral distortion.
To alleviate spectral distortion, Hu et al. [
26] proposed a super-resolution network to learn the spectral difference between adjacent bands. Li et al. [
27] utilized 2D group convolutions to construct recursive blocks and exploited the spectral angle mapper (SAM) loss function to train the 2D convolutional neural network (CNN) network. The models based on 2D CNN insufficiently extract the spectral features with difficulty. Because 3D convolutions can explore the spatial dependency among adjacent pixels and the spectral similarity among adjacent bands simultaneously, some methods based on 3D CNN have been proposed, e.g., 3D full convolutional neural network (3DFCNN) [
28], mixed 2D/3D convolutional network [
29], multiscale feature fusion and aggregation network with 3D convolution [
30], and multiscale mixed attention network [
31]. Three-dimensional convolutions will produce a number of parameters and will much greater computation consumption. To explore the interdependency among bands, some methods have attempted to aggregate the spectral dependency in a recurrent manner, e.g., spectrum and feature context super-resolution networks [
32], bidirectional 3D quasi-recurrent neural networks [
33], networks with recurrent feedback embedding and spatial-spectral consistency regularization [
34], and progressive split-merge super-resolution with group attention and gradient guidance [
35]. These recurrent networks are time-consuming due to the many bands present in HSIs. Different from the methods that use a recurrent manner, Yuan et al. [
36] employed group convolutions to capture the spectral correlation among bands in the same group and integrated the spectral correlation among groups with a second-order attention mechanism. Even though the CNN-based methods make good progress for SHISR, the CNN-based methods struggle to extract long-range features because of the intrinsic locality of convolution operation.
The nonlocal attention mechanism has shown a powerful ability to capture long-range dependency [
37]. Dosovitskiy et al. [
38] made the first attempt to introduce self-attention into computer vision and proposed a vision transformer to capture the long-range dependency among a sequence of patches, which achieved remarkable results. Nonlocal attention has sparked great interest in the computer vision community, and many methods have been proposed [
39]. Some researchers have also attempted to introduce nonlocal attention into SHISR methods. Because the nonlocal attention mechanism neglects the importance of local details, the applications for SHISR [
40,
41,
42] have focused on combining the convolution with the nonlocal attention. Yang et al. [
40] designed a simplified nonlocal attention mechanism and proposed a novel hybrid local and nonlocal 3D attentive convolution neural network (HLNnet) for SHISR processing; however, they only utilized one model layer to extract the long-range features, while the other model layers were still used for local features extraction. As the computation complexity of vanilla self-attention is quadratic to the image size, it is unaffordable for HSI super-resolution. In order to reduce the computation cost, Hu et al. [
41] decoupled the vanilla self-attention along the height and width dimensions and proposed an interactive transformer and CNN network (Interactformer), which has a linear computation complexity. A multilevel progressive network with a nonlocal channel attention network was presented [
42], which combines the 3D ghost block with a self-attention guided by a spatial-spectral gradient. The nonlocal-attention-based methods can capture the long-range dependency; however, they still insufficiently extract the spectral features, as they still focus on local spectral features. There is still significant room for performance improvement.
Recently, the works that have been based on the multilayer perceptron (MLP) framework have also achieved remarkable results. They are mainly classified into two types: spatial MLP and channel MLP (CMLP). The methods based on spatial MLP [
43,
44,
45] transform the 2D image into a 1D vector and apply the MLP to capture the global dependency from all elements of an image. Their architectures [
43,
44,
45] can achieve competitive performance without the use of the self-attention mechanism or convolution. However, the computational complexity of spatial MLP is quadratic to the image size, and the spatial MLP requires a fixed-size input during both training and inference, which is problematic for SHISR methods. In contrast to spatial MLP, channel MLP (CMLP) is flexible with respect to image sizes; it extracts features along the channel dimension, and the weight parameters of CMLP are only configured by the number of channels. Because the weight parameters of CMLP are not related to the image size, it is more appropriate for dense prediction tasks [
46,
47,
48]. The spatial receptive field of CMLP is limited, so the works based on CMLP have pursued enlarging the spatial receptive field using some novel approaches. Guo et al. [
46] rearranged the spatial region to obtain the local and global spatial receptive field. Lian et al. [
47] shifted the pixels along the height and width to capture local spatial information, obtaining better performance with less computation complexity when compared with transformers. Different from changing pixel positions, Chen et al. [
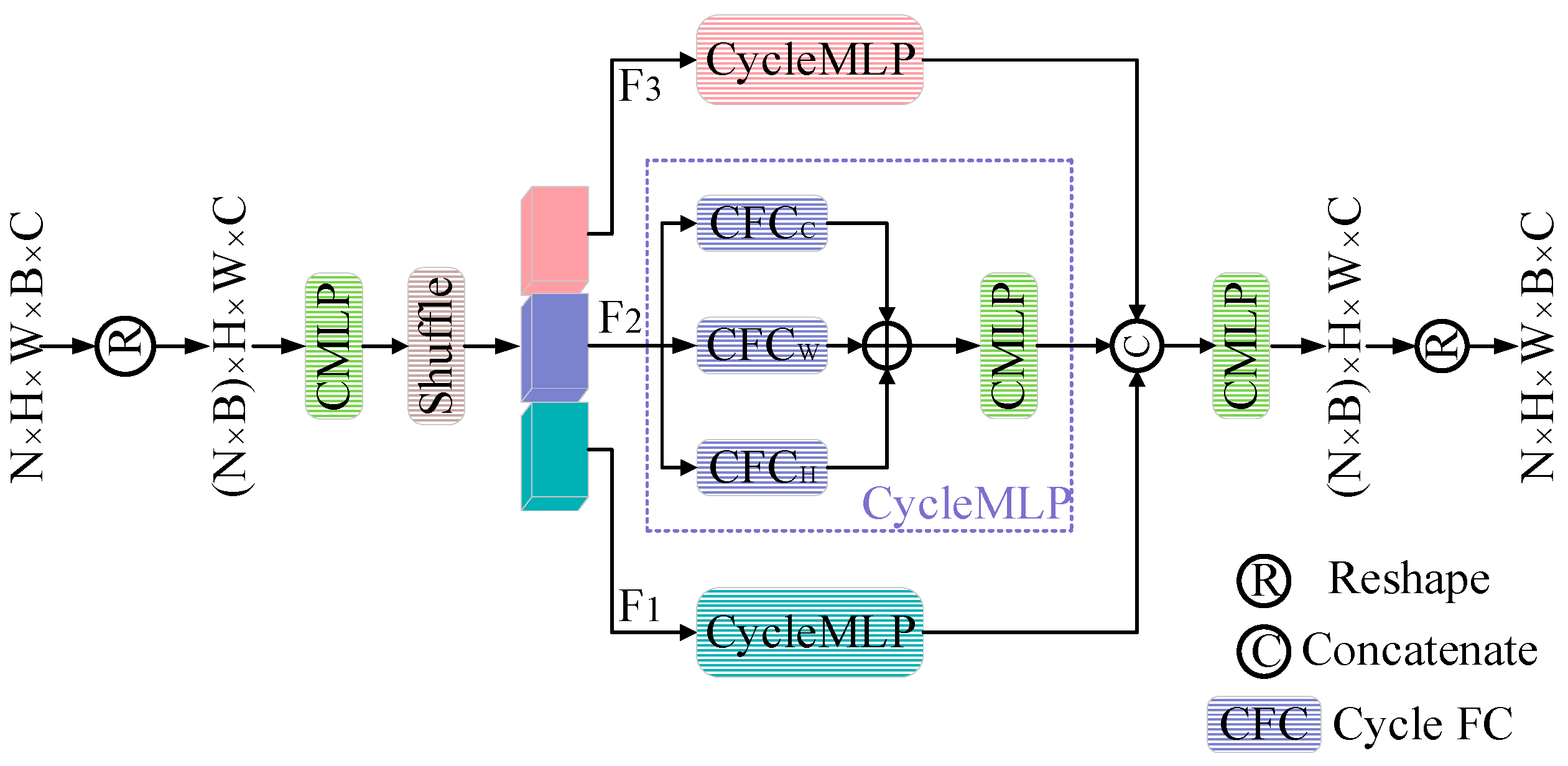
48] designed a novel variant of channel MLP named CycleMLP. The Cycle FC (fully-connected layer) in CycleMLP extracts features from different channels. Though the Cycle FC is a variant of CMLP, it has a larger spatial receptive field, even a global spatial receptive field. In low-level tasks, Tu et al. [
49] solved the fixed-size problem by designing a novel spatial-gated MLP, but the model is large. Some works [
46,
48] have demonstrated that the CMLP framework can effectively extract global and local features and has a tradeoff between accuracy and computation cost. However, they are designed for natural images and ignore the intrinsic spectral correlation of HSIs. For the SHISR technique, SHISR can exploit the CMLP to enhance the spatial resolution while preserving the spectral information. To the best of our knowledge, there is no research on MLP in SHISR applications.
Though many CNN-based and nonlocal attention-based works have achieved good results for SHISR, there are still some problems: (1) Most works focus on local spectral features and neglect long-range spectral features. They do not sufficiently preserve the spectral information to obtain better SR performance. To alleviate spectral distortion, it is more appropriate to sufficiently extract the local and long-range spectral features. (2) Most SHISR works utilize 3D convolutions and the self-attention mechanism to extract spectral-spatial features. Because HSIs have many bands, they usually require high computation to extract the features. The SHISR methods need to better reconstruct the hyperspectral images with low computation complexity.
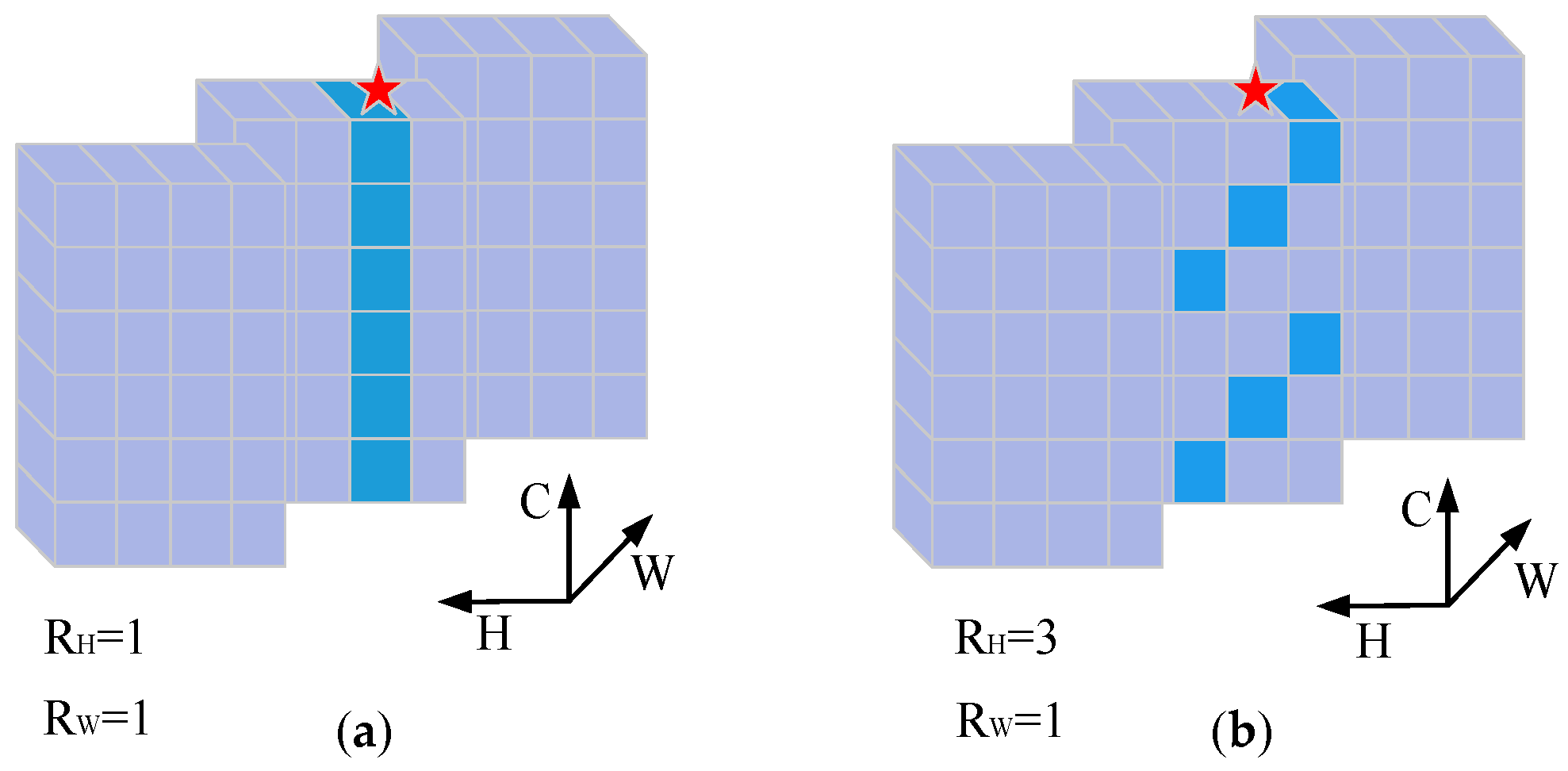
To address the above drawbacks, a spectral-spatial MLP network (SSMN) is proposed for SHISR. Considering that previous works usually reconstruct HSIs using high computation cost, our network aims to apply CMLP to obtain better reconstruction performance while reducing computation cost. Specifically, to sufficiently capture the spectral correlation, a local-global spectral integration block (LGSIB) is proposed. The LGSIB consists of CMLP and band group, band shift, and band shuffle operations, and it aims to capture the local and global spectral correlation and reduce computation complexity. Because the spatial receptive field of CMLP is limited, a spatial feature group extraction block (SFGEB) is designed. SFGEB consists of CycleMLP and a group mechanism, which aims to extract spatial features well while reducing computation complexity and the number of parameters. On the one hand, compared with CMLP, the SFGEB has a larger spatial receptive field, so it can extract more spatial features. On the other hand, compared with the convolution and self-attention mechanism, the computation complexity and number of parameters of SFGEB remain unchanged while the spatial receptive field expands.
In summary, the main contributions of this work are provided as follows:
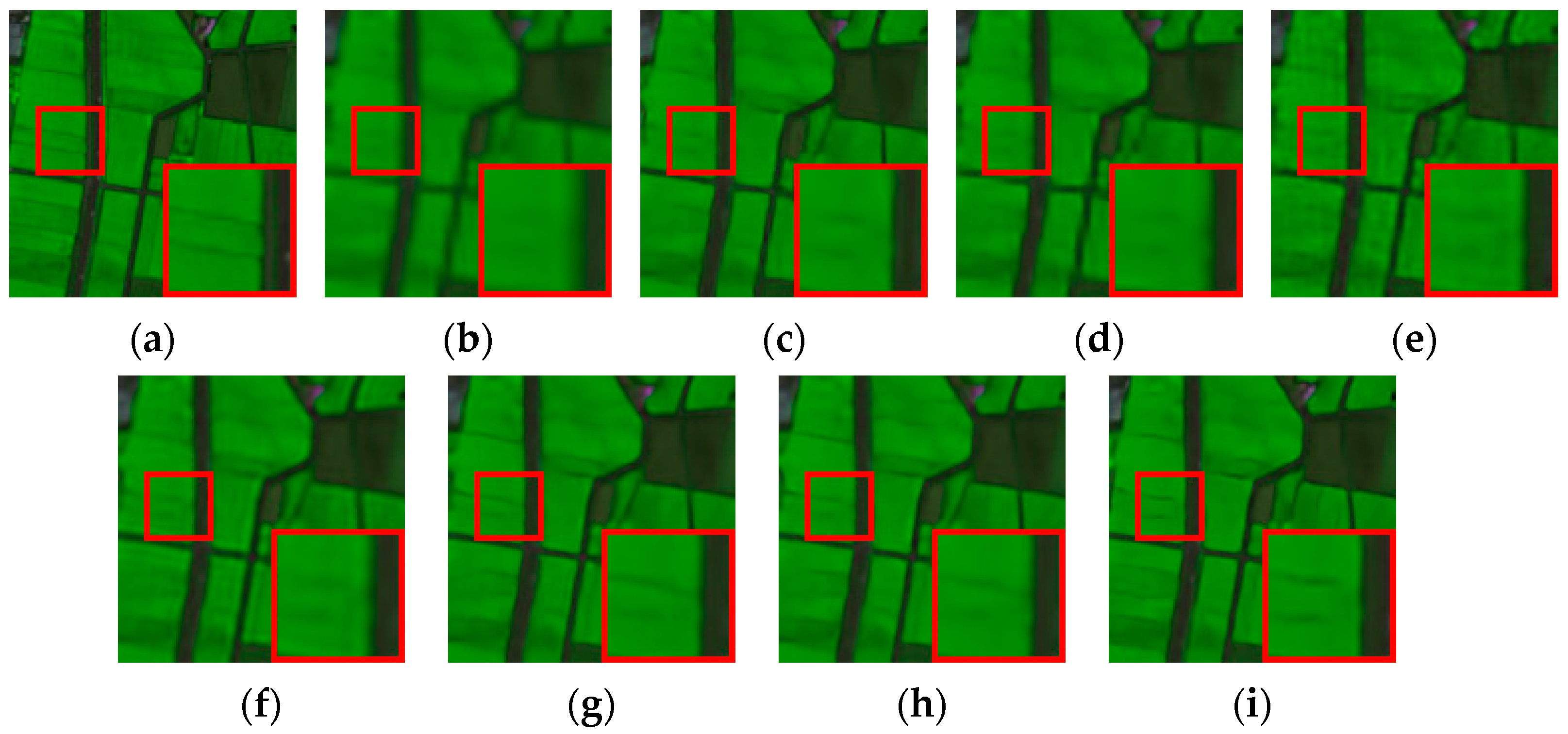
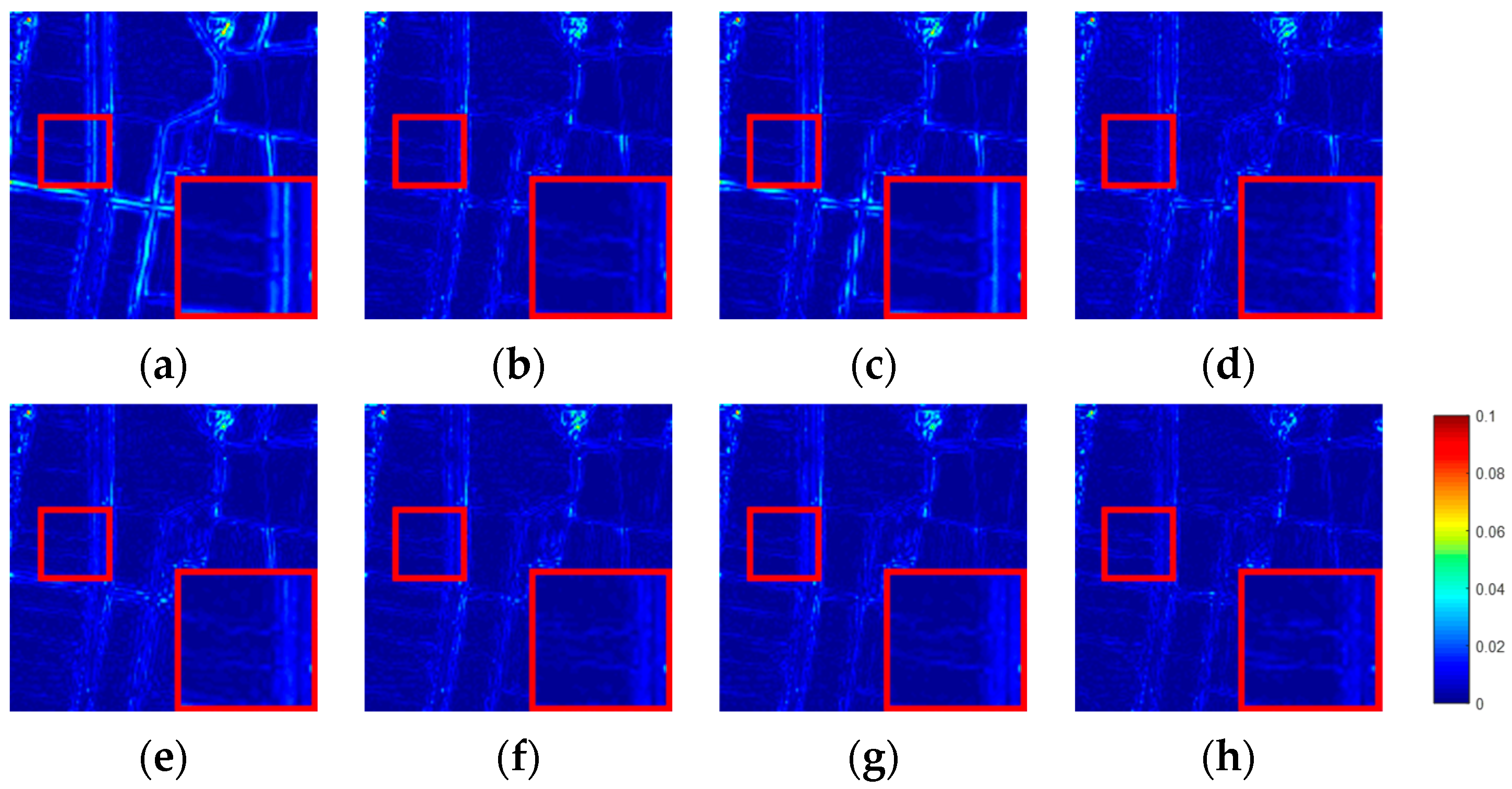
A novel network named SSMN that is based on CMLP is proposed for SHISR. The proposed MLP-based network can handle HSIs of different sizes. The experimental results demonstrate that our network achieves better reconstruction performance compared with other methods based on convolution and nonlocal attention.
An LGSIB is proposed to extract rich spectral features while reducing the computation complexity; it aims to use the CMLP to extract the local spectral features using group and shift manners, and it extracts the long-range spectral features using group and shuffle manners.
In order to extract spatial features well while maintaining computation efficiency, an SFGEB is designed, which consists of CycleMLP and a group manner; its number of parameters and computation complexity do not increase as the spatial receptive field expands.
The rest of this paper is divided into three sections. In
Section 2, the proposed SSMN is introduced. In
Section 3, the experiments and the results are shown. The conclusion is provided in
Section 4.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}