
Testing Textural Information Base on LiDAR and Hyperspectral Data for Mapping Wetland Vegetation: A Case Study of Warta River Mouth National Park (Poland)

 ,
,  ,
,  ,
,  and
and
Abstract

1. Introduction
2. Study Area and Object of Research
3. Materials and Methods
3.1. Aerial Data
3.2. Image Preprocessing
3.3. Reference Data
3.4. Data Analysis
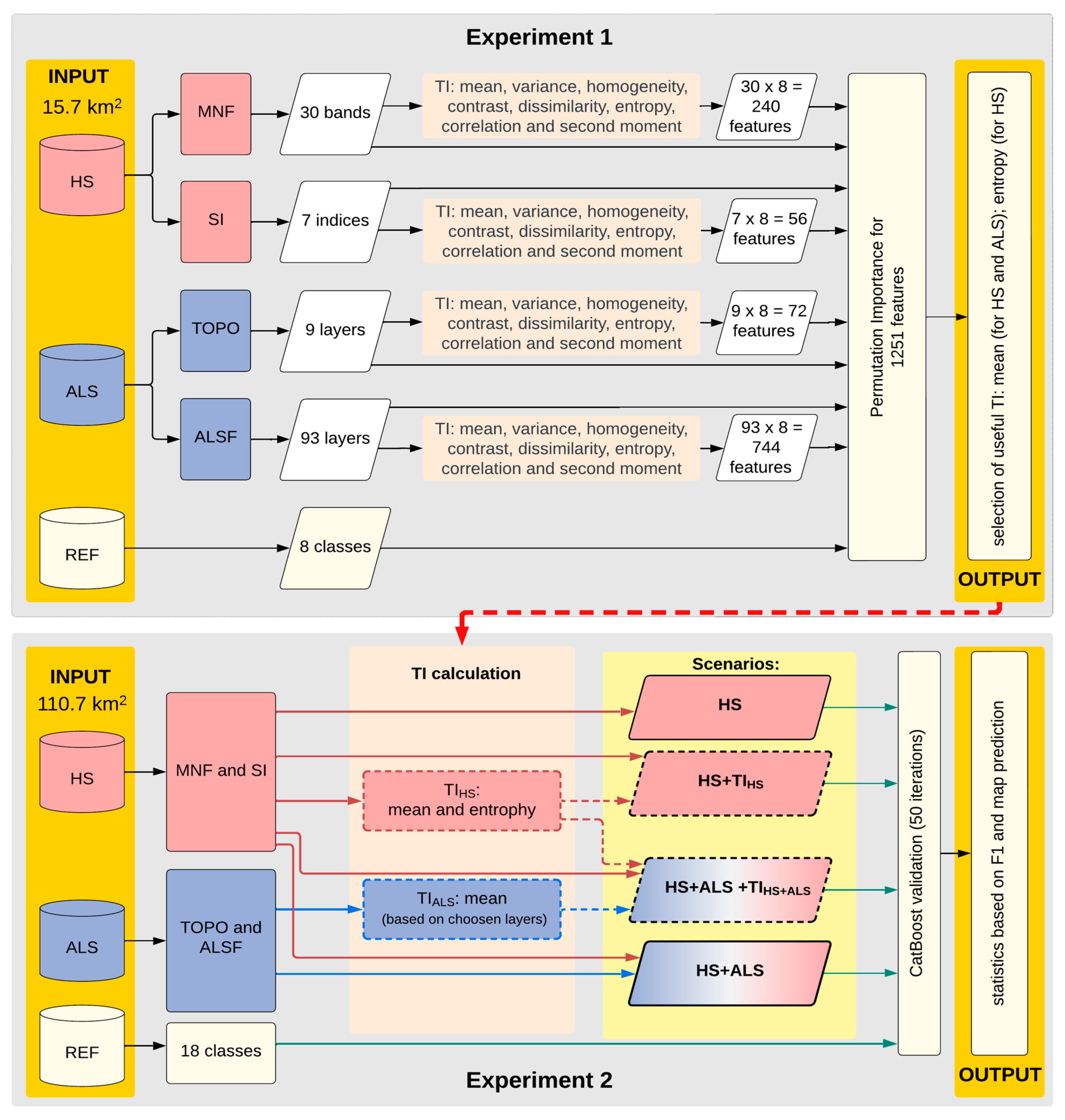
3.4.1. The Determination of Influential TI (Experiment 1)
3.4.2. Mapping of Wetland Communities with the Use of TI (Experiment 2)
4. Results
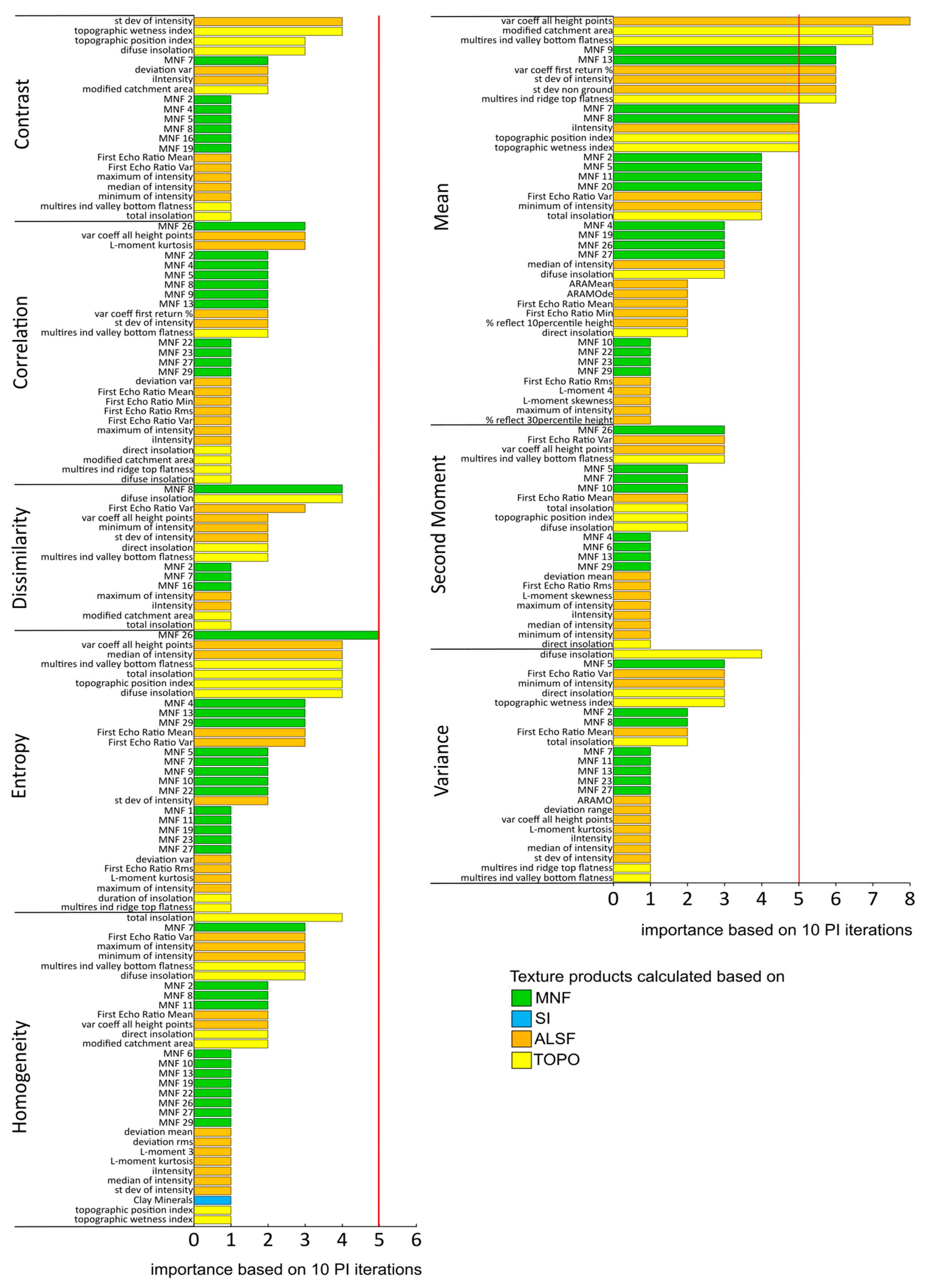
4.1. A Selection of TI Features Influential for Communities Identification (Experiment 1)
4.2. The Accuracy of Wetland Communities Mapping Depending on the Use of TI (Experiment 2)
4.2.1. The Influence of TI on Classification Accuracy Using HS Data
4.2.2. The Influence of TI on Classification Accuracy Using HS and ALS Data
4.2.3. Influence of TI on the Effectiveness of Patches Delineation Based on Acquired Communities Maps
5. Discussion
5.1. The Utility of TI in Wetland Communities Mapping
5.2. Applicability of the Results
6. Conclusions
- The textural information with the highest information potential for identifying wetland communities are mean for HS and ALS data and entropy for HS data;
- The addition of textural information in the dataset leads to an increase in mean F1 accuracy of 0.005 when using HS data and 0.011 when using a fusion of HS and ALS data;
- The resulting maps from the scenarios using TI allow for better delineation of the patch boundaries of individual community units and eliminate the “salt and pepper” effect and the visibility of mosaic lines. In order to analyse this change in quality in the maps, it is necessary to have verification polygons located as close as possible to the real patch boundary. Since there was a small proportion of polygons close to the patch boundary in the reference dataset, the changes in accuracy measures were also smaller than the visual differences;
- A comparison of the classification with TI and without TI shows the greatest increase in accuracy after the application of TI for scrub and forest communities (by 0.019 for the scenarios with HS and 0.022 for the scenarios with HS + ALS).
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Formula | Source |
|---|---|---|
| Anthocyanin Reflectance Index 2 | ARI2 = R800(1/R550 − 1/R700) | [56] |
| Carotenoid Reflectance Index 1 | CRI1 = 1/R510 − 1/R550 | [57] |
| Clay Minerals | CM = R1650/R2215 | [58] |
| Iron Oxide | IO =R660/R485 | [59] |
| Normalized Difference Nitrogen Index | NDNI = (log(1/R1510) − log(1/R1680))/(log(1/R1510) + log(1/R1680)) | [60] |
| Red Green Ratio Index | RGRI = (∑(i = 600)^699 Ri)/(∑(j = 500)^599 Rj) | [61] |
| WorldView Water Index | WWI = (R427 − R950)/(R427 + R950) | [62] |
| ALSF | Description | Source |
|---|---|---|
| ARAMean | All returns above mean divided by (total first returns) × 100 | [63] |
| ARAMOde | All returns above mode divided by (total first returns) × 100 | [63] |
| 1st decile of height | 10th percentile of height values | [41] |
| 2nd decile of height | 20th percentile of height values | [41] |
| 3nd decile of height | 30th percentile of height values | [41] |
| 4nd decile of height | 40th percentile of height values | [41] |
| 5nd decile of height | 50th percentile of height values | [41] |
| 6nd decile of height | 60th percentile of height values | [41] |
| 7nd decile of height | 70th percentile of height values | [41] |
| 8nd decile of height | 80th percentile of height values | [41] |
| 9nd decile of height | 90th percentile of height values | [41] |
| Deviation max | Maximum value of deviation from pulse shape in the grid cell | [41] |
| Deviation mean | Mean value of deviation from pulse shape in the grid cell | [41] |
| Deviation median | Median value of deviation from pulse shape in the grid cell | [41] |
| Deviation min | Minimum value of deviation from pulse shape in the grid cell | [41] |
| Deviation range | Range of deviation values from pulse shape in the grid cell | [41] |
| Deviation rms | Squared mean value of deviation from pulse shape in the grid cell | [41] |
| Deviation var | Variance of deviation from pulse shape in the grid cell | [41] |
| 25th percentile of dev | 25th percentile of deviation from pulse shape in the grid cell | [41] |
| 75th percentile of dev | 75th percentile of deviation from pulse shape in the grid cell | [41] |
| Largest eigen of the cov matrix | Largest eigenvalue of the covariance matrix of the points 3D position in the grid cell | [41] |
| Medium eigen of the cov matrix | Largest eigenvalue of the covariance matrix of the points 3D position in the grid cell | [41] |
| Smallest eigen of the cov matrix | Largest eigenvalue of the covariance matrix of the points 3D position in the grid cell | [41] |
| Fraction of first return | Fraction of first return pulses intercepted by tree | [64] |
| First_Echo_Ratio_Mean | Mean value of number of points defined in 3D fixed neighborhood divided by number of points defined in fixed 2D neighborhood in the grid cell | [65] |
| First_Echo_Ratio_Min | Min value of number of points defined in 3D fixed neighborhood divided by number of points defined in fixed 2D neighborhood in the grid cell | [65] |
| First_Echo_Ratio_Range | Range of values of number of points defined in 3D fixed neighborhood divided by number of points defined in fixed 2D neighborhood in the grid cell | [65] |
| First_Echo_Ratio_Rms | Root mean square of values of number of points defined in 3D fixed neighborhood divided by number of points defined in fixed 2D neighborhood in the grid cell | [65] |
| First_Echo_Ratio_Var | Variance of values of number of points defined in 3D fixed neighborhood divided by number of points defined in fixed 2D neighborhood in the grid cell | [65] |
| Fraction of all returns | Fraction of all returns classified as tree | [64] |
| Max height above gr first returns | Maximum height above ground of all first returns | [66] |
| 90th–25th perc | 90th percentile–25th percentile of height values | [67] |
| 90th–50th perc | 90th percentile–50th percentile of height values | [67] |
| 99th–25th perc | 99th percentile–25th percentile of height values | [67] |
| 99th–50th perc | 99th percentile–50th percentile of height values | [67] |
| Var coeff all height points | The coefficient of variation of all height points within each pixel | [68] |
| Var coeff first return % | Coefficient of variation percentage of heights of all first returns relative to all returns | [66] |
| L-moment 1 | 1st L-moment of height values | [63] |
| L-moment 2 | 2st L-moment of height values | [63] |
| L-moment 3 | 3st L-moment of height values | [63] |
| L-moment 4 | 4st L-moment of height values | [63] |
| L-moment kurtosis | L-moment kurtosis of height values | [63] |
| L-moment skewness | L-moment skewness of height values | [63] |
| MADev from Median Height | The Median Absolute Deviation from Median Height value (HMAD) of all height points within each pixel, where HMAD = 1.4826 × median (|height − median height|) | [68] |
| MADev from overall mode | Median of the absolute deviations from the overall mode | [63] |
| Horizontality | Measure of horizontality of points based on eigenvalues of the covariance matrix of the points 3D position in the grid cell | [41] |
| 25th Percentile intensity | 25th Percentile of intensity | [67] |
| 50th Percentile intensity | 50th Percentile of intensity | [67] |
| 75th Percentile intensity | 75th Percentile of intensity | [67] |
| 99th Percentile intensity | 99th Percentile of intensity | [67] |
| Kurtosis of intensity | Kurtosis of Intensity | [69] |
| Kurtosis of reflectance | Kurtosis of Reflectance | [69] |
| Maximum of intensity | Maximum of Intensity | [69] |
| Maximum of reflectance | Maximum of Reflectance | [69] |
| Mean of intensity | Mean of Intensity | [69] |
| Mean of reflectance | Mean of Reflectance | [69] |
| Median of intensity | Median of Intensity | [69] |
| Median of reflectance | Median of Reflectance | [69] |
| Minimum of intensity | Minimum of Intensity | [69] |
| Minimum of reflectance | Minimum of Reflectance | [69] |
| % intens 10percentile height | Percentage of intensity values for heights below the 10th percentile of heights | [41] |
| % reflect 10percentile height | Percentage of reflectance values for heights below the 10th percentile of heights | [41] |
| % intens 30percentile height | Percentage of intensity values for heights below the 30th percentile of heights | [41] |
| % reflect 30percentile height | Percentage of reflectance values for heights below the 30th percentile of heights | [41] |
| % intens 50percentile height | Percentage of intensity values for heights below the 50th percentile of heights | [41] |
| % reflect 50percentile height | Percentage of reflectance values for heights below the 50th percentile of heights | [41] |
| % intens 70percentile height | Percentage of intensity values for heights below the 70th percentile of heights | [41] |
| % reflect 70percentile height | Percentage of reflectance values for heights below the 70th percentile of heights | [41] |
| % intens 90percentile height | Percentage of intensity values for heights below the 90th percentile of heights | [41] |
| % reflect 90percentile height | Percentage of reflectance values for heights below the 90th percentile of heights | [41] |
| Interquartile range of dev | Interquartile range (P75–P25) of deviation from pulse shape in the grid cell | [41] |
| Interquartile range of dev | Interquartile range (P75–P25) of deviation from pulse shape in the grid cell | [41] |
| Range of reflectance | Range of reflectance | [67] |
| Values | values | [67] |
| St dev of intensity | Standard deviation of intensity | [69] |
| St dev of reflectance | Standard deviation of reflectance | [69] |
| Skewn of intensity | Skewness of intensity | [69] |
| Skewn of reflectance | Skewness of reflectance | [69] |
| Linearity | Measure of linearity of points based on eigenvalues of the covariance matrix of the points 3D position in the grid cell | [41] |
| Median abs dev | Median absolute deviation = median (|height − median height|) of tree returns Meters MAD | [64] |
| Nb of points below GT | The total number of all the points within each pixel that are below the specified Ground Threshold value (GT) | [68] |
| Nb of modes | Number of Modes | [70] |
| St dev non ground | Standard deviation of heights for points between 0 and 1 m | [41] |
| Nb of points above CT | The total number of all the points within each pixel that are above the specified Crown Threshold value (CT) | [68] |
| % returns above mean | Percentage all returns above mean/total all returns | [63] |
| Feature | Index Full Name |
|---|---|
| direct insolation | Direct Insolation |
| duration of insolation | Duration of Insolation |
| modified catchment area | Modified Catchment Area |
| multi-resolution ridge top flatness | Multi-resolution index of the Ridge Top Flatness |
| multi-resolution valley bottom flatness | Multi-resolution Index of Valley Bottom Flatness |
| total insolation | Total Insolation |
| topographic position index | Topographic Position Index |
| topographic wetness index | Topographic Wetness Index |
| diffuse insolation | Diffuse Insolation |
| Feature | Formula |
|---|---|
| Mean | |
| Variance | |
| Homogeneity | |
| Contrast | |
| Dissimilarity | |
| Entropy | |
| Second Moment | |
| Correlation |
| Nb | Scenario | Products |
|---|---|---|
| 1 | HS | HS data: 30 MNF, 7 SI |
| 2 | HS + TIHS | HS data: 30 MNF, 7 SI, texture features (mean and entropy) calculated based on HS bands |
| 3 | HS + ALS | HS and ALS data: 30 MNF, 7 SI, 93 ALSF and 9 TOPO |
| 4 | HS + ALS + TIHS+ALS | HS and ALS data: 30 MNF, 7 SI, mean and entropy calculated based on HS data; 93 ALSF, 9 TOPO, 24 mean texture features calculated based on chosen ALSF(ARAMean, ARAMOde, deviation mean, deviation range, deviation rms, deviation var, duration of insolation, First_Echo_Ratio_Mean, First_Echo_Ratio_Min, First_Echo_Ratio_Rms, First_Echo_Ratio_Var, var coeff all height points, var coeff first return %, L-moment 3, L-moment 4, L-moment kurtosis, L-moment skewness, maximum of intensity, mean of intensity, median of intensity, % reflect 10percentile height, % reflect 30percentile height, st dev of intensity, st dev non ground) and 9 mean texture features calculated using TOPO products |
References
- Amesbury, M.J.; Gallego-Sala, A.; Loisel, J. Peatlands as Prolific Carbon Sinks. Nat. Geosci. 2019, 12, 880–881. [Google Scholar] [CrossRef]
- Kimmel, K.; Mander, Ü. Ecosystem Services of Peatlands: Implications for Restoration. Prog. Phys. Geogr. Earth Environ. 2010, 34, 491–514. [Google Scholar] [CrossRef]
- Nichols, J.E.; Peteet, D.M. Rapid Expansion of Northern Peatlands and Doubled Estimate of Carbon Storage. Nat. Geosci. 2019, 12, 917–921. [Google Scholar] [CrossRef]
- Guo, M.; Li, J.; Sheng, C.; Xu, J.; Wu, L. A Review of Wetland Remote Sensing. Sensors 2017, 17, 777. [Google Scholar] [CrossRef] [PubMed]
- Food and Agricultire Organization of the United Nations. Peatlands Mapping and Monitoring. Food & Agriculture ORG: S.l., 2020. Available online: https://www.fao.org/documents/card/en/c/ca8200en/ (accessed on 10 April 2023).
- Kopeć, D.; Michalska-Hejduk, D.; Sławik, Ł.; Berezowski, T.; Borowski, M.; Rosadziński, S.; Chormański, J. Application of Multisensoral Remote Sensing Data in the Mapping of Alkaline Fens Natura 2000 Habitat. Ecol. Indic. 2016, 70, 196–208. [Google Scholar] [CrossRef]
- Huang, H.; Wu, D.; Fang, L.; Zheng, X. Comparison of Multiple Machine Learning Models for Estimating the Forest Growing Stock in Large-Scale Forests Using Multi-Source Data. Forests 2022, 13, 1471. [Google Scholar] [CrossRef]
- Ozturk, M.Y.; Colkesen, I. Evaluation of Effectiveness of Patch Based Image Classification Technique Using High Resolution Worldview-2 Image. In The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences; Copernicus GmbH: Safranbolu, Turkey, 2021; Volume XLVI-4-W5-2021, pp. 417–423. [Google Scholar] [CrossRef]
- Samat, A.; Li, E.; Du, P.; Liu, S.; Miao, Z.; Zhang, W. CatBoost for RS Image Classification With Pseudo Label Support From Neighbor Patches-Based Clustering. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8004105. [Google Scholar] [CrossRef]
- Zhang, C. Combining Hyperspectral and Lidar Data for Vegetation Mapping in the Florida Everglades. Photogramm. Eng. Remote Sens. 2014, 80, 733–743. [Google Scholar] [CrossRef]
- Rapinel, S.; Hubert-Moy, L.; Clément, B. Combined Use of LiDAR Data and Multispectral Earth Observation Imagery for Wetland Habitat Mapping. Int. J. Appl. Earth Obs. Geoinf. 2015, 37, 56–64. [Google Scholar] [CrossRef]
- Jarocińska, A.; Kopeć, D.; Niedzielko, J.; Wylazłowska, J.; Halladin-Dąbrowska, A.; Charyton, J.; Piernik, A.; Kamiński, D. The Utility of Airborne Hyperspectral and Satellite Multispectral Images in Identifying Natura 2000 Non-Forest Habitats for Conservation Purposes. Sci. Rep. 2023, 13, 4549. [Google Scholar] [CrossRef]
- Jollineau, M.Y.; Howarth, P.J. Mapping an Inland Wetland Complex Using Hyperspectral Imagery. Int. J. Remote Sens. 2008, 29, 3609–3631. [Google Scholar] [CrossRef]
- Rosso, P.H.; Ustin, S.L.; Hastings, A. Mapping Marshland Vegetation of San Francisco Bay, California, Using Hyperspectral Data. Int. J. Remote Sens. 2005, 26, 5169–5191. [Google Scholar] [CrossRef]
- Szporak-Wasilewska, S.; Piórkowski, H.; Ciężkowski, W.; Jarzombkowski, F.; Sławik, Ł.; Kopeć, D. Mapping Alkaline Fens, Transition Mires and Quaking Bogs Using Airborne Hyperspectral and Laser Scanning Data. Remote Sens. 2021, 13, 1504. [Google Scholar] [CrossRef]
- Marcinkowska-Ochtyra, A.; Gryguc, K.; Ochtyra, A.; Kopeć, D.; Jarocińska, A.; Sławik, Ł. Multitemporal Hyperspectral Data Fusion with Topographic Indices—Improving Classification of Natura 2000 Grassland Habitats. Remote Sens. 2019, 11, 2264. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, H.; Lin, H.; Fang, C. Textural–Spectral Feature-Based Species Classification of Mangroves in Mai Po Nature Reserve from Worldview-3 Imagery. Remote Sens. 2016, 8, 24. [Google Scholar] [CrossRef]
- Mohammadpour, P.; Viegas, D.X.; Viegas, C. Vegetation Mapping with Random Forest Using Sentinel 2 and GLCM Texture Feature—A Case Study for Lousã Region, Portugal. Remote Sens. 2022, 14, 4585. [Google Scholar] [CrossRef]
- Bunting, P.; He, W.; Zwiggelaar, R.; Lucas, R. Combining Texture and Hyperspectral Information for the Classification of Tree Species in Australian Savanna Woodlands. In Innovations in Remote Sensing and Photogrammetry; Lecture Notes in Geoinformation and, Cartography; Jones, S., Reinke, K., Eds.; Springer: Berlin, Heidelberg, 2009; pp. 19–26. [Google Scholar] [CrossRef]
- Yalçın, H. Phenology Monitoring Of Agricultural Plants Using Texture Analysis. In Proceedings of the 2015 Fourth International Conference on Agro-Geoinformatics (Agro-geoinformatics), Istanbul, Turkey, 20–24 July 2015. [Google Scholar] [CrossRef]
- Abeysinghe, T.; Simic Milas, A.; Arend, K.; Hohman, B.; Reil, P.; Gregory, A.; Vázquez-Ortega, A. Mapping Invasive Phragmites Australis in the Old Woman Creek Estuary Using UAV Remote Sensing and Machine Learning Classifiers. Remote Sens. 2019, 11, 1380. [Google Scholar] [CrossRef]
- Shendryk, Y.; Rossiter-Rachor, N.A.; Setterfield, S.A.; Levick, S.R. Leveraging High-Resolution Satellite Imagery and Gradient Boosting for Invasive Weed Mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4443–4450. [Google Scholar] [CrossRef]
- Murray, H.; Lucieer, A.; Williams, R. Texture-Based Classification of Sub-Antarctic Vegetation Communities on Heard Island. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 138–149. [Google Scholar] [CrossRef]
- Xu, Z.; Chen, J.; Xia, J.; Du, P.; Zheng, H.; Gan, L. Multisource Earth Observation Data for Land-Cover Classification Using Random Forest. IEEE Geosci. Remote Sens. Lett. 2018, 15, 789–793. [Google Scholar] [CrossRef]
- Demarchi, L.; Kania, A.; Ciężkowski, W.; Piórkowski, H.; Oświecimska-Piasko, Z.; Chormański, J. Recursive Feature Elimination and Random Forest Classification of Natura 2000 Grasslands in Lowland River Valleys of Poland Based on Airborne Hyperspectral and LiDAR Data Fusion. Remote Sens. 2020, 12, 1842. [Google Scholar] [CrossRef]
- Solon, J.; Borzyszkowski, J.; Bidłasik, M.; Richling, A.; Badora, K.; Balon, J.; Brzezińska-Wójcik, T.; Chabudziński, Ł.; Dobrowolski, R.; Grzegorczyk, I.; et al. Physico-Geographical Mesoregions of Poland: Verification and Adjustment of Boundaries on the Basis of Contemporary Spatial Data. Geogr. Pol. 2018, 91, 143–170. [Google Scholar] [CrossRef]
- Warta River Mouth National Park. Available online: https://zpppn.pl/warta-river-mouth-national-park-en/park (accessed on 17 April 2023).
- Jaworski, M. Mapa Hydrogeologiczna Polski; PIG: Słubice, Poland, 1986. [Google Scholar]
- Skompski, S. Mapa Geologiczna Polski, Mapa Utworów Powierzchniowych; Wyd. Geologiczne: Słubice, Poland, 1976. [Google Scholar]
- Choiński, A.; Ławniczak, A.E.; Ptak, M. Park Narodowy “Ujście Warty”. In Wody w Parkach Narodowych Polski; Bogdanowicz, R., Jokiel, P., Pociask-Karteczka, J., Eds.; IGiGP Uniwersytet Jagielloński: Kraków, Poland, 2012. [Google Scholar]
- Climate of Poland in 2021. Available online: https://www.imgw.pl/sites/default/files/2022-06/imgw-pib-klimat-polski-2021-eng-final.pdf (accessed on 18 April 2023).
- Sławik, Ł.; Niedzielko, J.; Kania, A.; Piórkowski, H.; Kopeć, D. Multiple Flights or Single Flight Instrument Fusion of Hyperspectral and ALS Data? A Comparison of Their Performance for Vegetation Mapping. Remote Sens. 2019, 11, 970. [Google Scholar] [CrossRef]
- HySpex. Available online: https://www.hyspex.com/ (accessed on 7 July 2021).
- RiProcess Data Sheet for RIEGL Scan Data. Available online: http://www.riegl.com/uploads/tx_pxpriegldownloads/RiProcess_Datasheet_2020-08-20_01.pdf (accessed on 17 April 2023).
- PARGE Airborne Image Rectification. Available online: http://www.rese-apps.com/software/parge/index.html (accessed on 7 July 2021).
- ATCOR for Airborne Remote Sensing. Available online: https://www.rese-apps.com/software/atcor-4-airborne/index.html (accessed on 17 April 2023).
- RiAnalyze Data Sheet for Automated Resolution of Range Ambiguities. Available online: https://www.rieglusa.com/pdf/als/rianalyze-datasheet.pdf (accessed on 17 April 2023).
- TerraSolid Terrascan User Guide. Available online: http://www.terrasolid.com/guides/tscan/index.html (accessed on 17 April 2023).
- Harris Geospatial Solutions, Broomfield, CO, USA. Available online: https://www.l3harrisgeospatial.com/Software-Technology/ENVI (accessed on 17 April 2023).
- Terrascan, Terrasolid’s Software for LiDAR Data Processing and 3D Vector Data Creation. Available online: https://terrasolid.com/products/terrascan/ (accessed on 17 April 2023).
- Roussel, J.-R.; Auty, D.; Coops, N.C.; Tompalski, P.; Goodbody, T.R.H.; Meador, A.S.; Bourdon, J.-F.; de Boissieu, F.; Achim, A. LidR: An R Package for Analysis of Airborne Laser Scanning (ALS) Data. Remote Sens. Environ. 2020, 251, 112061. [Google Scholar] [CrossRef]
- Conrad, O.; Bechtel, B.; Bock, M.; Dietrich, H.; Fischer, E.; Gerlitz, L.; Wehberg, J.; Wichmann, V.; Böhner, J. System for Automated Geoscientific Analyses (SAGA) v. 2.1.4. Geosci. Model Dev. 2015, 8, 1991–2007. [Google Scholar] [CrossRef]
- Trimble Catalyst | Catalyst GNSS Systems|Trimble Geospatial. Available online: https://geospatial.trimble.com/products-and-solutions/trimble-catalyst (accessed on 18 April 2023).
- Mapit GIS LTD—Aplikacje na Androida w Google Play. Available online: https://play.google.com/store/apps/dev?id=9214118068832022925&hl=pl&gl=US (accessed on 18 April 2023).
- Kącki, Z.; Czarniecka, M.; Swacha, G. Statistical Determination of Diagnostic, Constant and Dominant Species of the Higher Vegetation Units of Poland. Monogr. Bot. 2014, 103, 1–267. [Google Scholar] [CrossRef]
- Matuszkiewicz, W. Przewodnik Do Oznaczania Zbiorowisk Roślinnych Polski; Wydawnictwo Naukowe PWN: Warszawa, Poland, 2008. [Google Scholar]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- CatBoost. Available online: https://catboost.ai/en/docs/ (accessed on 18 April 2023).
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient Boosting with Categorical Features Support. arxiv 2018. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. arxiv 2019. [CrossRef]
- Zhou, G.; Ni, Z.; Zhao, Y.; Luan, J. Identification of Bamboo Species Based on Extreme Gradient Boosting (XGBoost) Using Zhuhai-1 Orbita Hyperspectral Remote Sensing Imagery. Sensors 2022, 22, 5434. [Google Scholar] [CrossRef]
- Tang, J.; Liang, J.; Yang, Y.; Zhang, S.; Hou, H.; Zhu, X. Revealing the Structure and Composition of the Restored Vegetation Cover in Semi-Arid Mine Dumps Based on LiDAR and Hyperspectral Images. Remote Sens. 2022, 14, 978. [Google Scholar] [CrossRef]
- Feng, S.; Cao, Y.; Xu, T.; Yu, F.; Zhao, D.; Zhang, G. Rice Leaf Blast Classification Method Based on Fused Features and One-Dimensional Deep Convolutional Neural Network. Remote Sens. 2021, 13, 3207. [Google Scholar] [CrossRef]
- Franklin, S.E.; Hall, R.J.; Moskal, L.M.; Maudie, A.J.; Lavigne, M.B. Incorporating Texture into Classification of Forest Species Composition from Airborne Multispectral Images. Int. J. Remote Sens. 2000, 21, 61–79. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Merzlyak, M.N.; Chivkunova, O.B. Optical Properties and Nondestructive Estimation of Anthocyanin Content in Plant Leaves. Photochem. Photobiol. 2001, 74, 38–45. [Google Scholar] [CrossRef]
- Gitelson, A.; Zur, Y.; Chivkunova, O.; Merzlyak, M. Assessing Carotenoid Content in Plant Leaves with Reflectance Spectroscopy. Photochem. Photobiol. 2002, 75, 272–281. [Google Scholar] [CrossRef]
- Drury, S.A. Image Interpretation in Geology. Geocarto Int. 1987, 2, 48. [Google Scholar] [CrossRef]
- Segal, D. Theoretical Basis for Differentiation of Ferric-Iron Bearing Minerals, Using Landsat MSS Data. In Proceedings of the International Symposium on Remote Sensing of Environment, 2nd Thematic Conference, Remote Sensing for Exploration Geology, Fort Worth, TX, USA, 6–10 December 1982; pp. 949–951. [Google Scholar]
- Fourty, T.; Baret, F.; Jacquemoud, S.; Schmuck, G.; Verdebout, J. Leaf Optical Properties with Explicit Description of Its Biochemical Composition: Direct and Inverse Problems. Remote Sens. Environ. 1996, 56, 104–117. [Google Scholar] [CrossRef]
- Gamon, J.A.; Surfus, J.S. Assessing Leaf Pigment Content and Activity with a Reflectometer. New Phytol. 1999, 143, 105–117. [Google Scholar] [CrossRef]
- Wolf, A.F. Using WorldView-2 Vis-NIR Multispectral Imagery to Support Land Mapping and Feature Extraction Using Normalized Difference Index Ratios. In Proceedings of the SPIE 8390, Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery, Baltimore, MD, USA, 14 May 2012; p. 83900. [Google Scholar] [CrossRef]
- Botequim, B.; Fernandes, P.M.; Borges, J.G.; González-Ferreiro, E.; Guerra-Hernández, J. Improving Silvicultural Practices for Mediterranean Forests through Fire Behaviour Modelling Using LiDAR-Derived Canopy Fuel Characteristics. Int. J. Wildland Fire 2019, 28, 823. [Google Scholar] [CrossRef]
- Marrs, J.; Ni-Meister, W. Machine Learning Techniques for Tree Species Classification Using Co-Registered LiDAR and Hyperspectral Data. Remote Sens. 2019, 11, 819. [Google Scholar] [CrossRef]
- Pfeifer, N.; Mandlburger, G.; Otepka, J.; Karel, W. OPALS—A Framework for Airborne Laser Scanning Data Analysis. Comput. Environ. Urban Syst. 2014, 45, 125–136. [Google Scholar] [CrossRef]
- Shen, X.; Cao, L. Tree-Species Classification in Subtropical Forests Using Airborne Hyperspectral and LiDAR Data. Remote Sens. 2017, 9, 1180. [Google Scholar] [CrossRef]
- García, M.; Saatchi, S.; Casas, A.; Koltunov, A.; Ustin, S.L.; Ramirez, C.; Balzter, H. Extrapolating Forest Canopy Fuel Properties in the California Rim Fire by Combining Airborne LiDAR and Landsat OLI Data. Remote Sens. 2017, 9, 394. [Google Scholar] [CrossRef]
- Li, A.; Dhakal, S.; Glenn, N.F.; Spaete, L.P.; Shinneman, D.J.; Pilliod, D.S.; Arkle, R.S.; McIlroy, S.K. Lidar Aboveground Vegetation Biomass Estimates in Shrublands: Prediction, Uncertainties and Application to Coarser Scales. Remote Sens. 2017, 9, 903. [Google Scholar] [CrossRef]
- Ørka, H.O.; Næsset, E.; Bollandsås, O.M. Classifying Species of Individual Trees by Intensity and Structure Features Derived from Airborne Laser Scanner Data. Remote Sens. Environ. 2009, 113, 1163–1174. [Google Scholar] [CrossRef]
- Falkowski, M.J.; Evans, J.S.; Martinuzzi, S.; Gessler, P.E.; Hudak, A.T. Characterizing Forest Succession with Lidar Data: An Evaluation for the Inland Northwest, USA. Remote Sens. Environ. 2009, 113, 946–956. [Google Scholar] [CrossRef]









| Sensor | Producer | Spatial Resolution | FOV | Side Overlap |
|---|---|---|---|---|
| HySpex VNIR-1800 | NEO | 1 m GSD | 34 | 30 |
| HySpex SWIR-384 x2 | NEO | 1 m GSD | 2 × 16 (~1 overlap) | ~30 |
| VQ-780II | Riegl | 7.6 point/m2 (>15 with overlap) | 60 | 50 |
| Experiment 1 | Experiment 2 | ||||
|---|---|---|---|---|---|
| Class Name | Ref. Polygons 1 | Class Name— Syntaxonomic Units | Class Description | Vertical Structure (Plant Dominants) | Ref. Polygons 1 |
| Aquatic vegetation | 10/232 | Lemnetea and Potametea | Aquatic macrophyte vegetation from Cl. Lemnetea minoris and Cl. Potametea | Underwater plants and plants on the water surface | 90/1971 |
| Rushes | 73/2084 | Phalaridetum arundinaceae | Marsh vegetation dominated by Phalaris arundinaceae | high perennials | 144/3885 |
| Magnocaricion | Marsh vegetation from All. Magnocaricion | high perennials | 96/2840 | ||
| Phragmition | Marsh vegetation from All. Phragmition | high perennials | 170/4603 | ||
| Annuals | 16/277 | Isoëto-Nanojuncetea | Amphibious short annual pioneer vegetation from Cl. Isoeto-Nanojuncetea | low annuals | 42/613 |
| Bidentetea | Annual pioneer nitrophilous vegetation from Cl. Bidentetea tripartiti | low annuals | 78/1867 | ||
| Meadows, grasslands and pastures | 33/1073 | Trifolio-Agrostietalia and Plantaginetalia | Pastures vegetation, periodically covered with flood water and vegetation of trodden surfaces from O. Trifolio fragiferae-Agrostietalia stoloniferae and O. Plantaginetalia majoris | low perennials | 110/3520 |
| Molinietalia | Wet meadows and nitrophilous perennials from O. Molinietalia caeruleae | low perennials | 190/6398 | ||
| Arrhenatheretalia | Lowland hay meadows from O. Arrhenatheretalia | low perennials | 54/1647 | ||
| Koelerio-Corynephoretea and Festuco-Brometea | Xeric sand semi-dry calcareous grasslands from Cl. Koelerio glaucae-Corynephoretea canescentis and Cl. Festuco-Brometea | low perennials | 107/3430 | ||
| Nitrophilous perennials | 23/392 | Artemisietea and Epilobietea | Nitrophilous perennials and shrubs from the Cl. Artemisietea vulgaris and Cl. Epilobietea angustifolii | high perennials | 190/4725 |
| Forests and shrubs | 29/1880 | Salicetea purpureae | Swamp forests and shrubs from Cl. Salicetea purpureae | shrubs and trees | 53/4208 |
| Ribeso nigri-Alnetum and Alno-Ulmion | Swamp forests from Ass. Ribeso nigri-Alnetum and All. Alno-Ulmion | trees | 56/4472 | ||
| Salicetum pentandro-cinereae | Shrub communities from Ass. Salicetum pentandro-cinereae | shrubs | 18/1055 | ||
| Vaccinio-Piceetea | Pine forests from Cl. Vaccinio-Piceetea and others communities with pine | trees | 20/880 | ||
| Others wooded communities | Wooded communities without syntaxonomic assignment | shrubs and trees | 82/2683 | ||
| Areas without vegetation | 10/171 | Areas without vegetation | Land areas without vegetation | no plants | 57/1591 |
| Surface water | 10/825 | Surface water | Surface water without aquatic macrophyte vegetation | no plants | 51/3553 |
| Nb | Scenario | Products | Layers |
|---|---|---|---|
| 1 | HS | HS data: MNF, SI | 37 |
| 2 | HS + TIHS | HS data: MNF, SI, TI (mean and entropy) calculated based on HS data | 111 |
| 3 | HS + ALS | HS and ALS data: MNF, SI, ALSF and TOPO | 139 |
| 4 | HS + ALS + TIHS+ALS | HS and ALS data: MNF, SI, TI (mean and entropy) calculated based on HS data; ALSF and TOPO, and mean TI calculated based on ALS data | 246 |
| F1 Value (Mean) | HS | HS + TIHS | HS + ALS | HS + ALS + TIHS+ALS |
|---|---|---|---|---|
| average F1 | 0.730 * | 0.735 * | 0.764 * | 0.775 * |
| Lemnetea and Potametea | 0.800 | 0.799 | 0.834 | 0.837 |
| Phalaridetum arundinaceae | 0.681 | 0.684 | 0.707 * | 0.735 * |
| Magnocaricion | 0.793 | 0.796 | 0.784 | 0.791 |
| Phragmition | 0.681 | 0.688 | 0.724 * | 0.740 * |
| Isoëto-Nanojuncetea | 0.346 | 0.353 | 0.381 | 0.393 |
| Bidentetea | 0.650 | 0.643 | 0.643 | 0.643 |
| Trifolio-Agrostietalia and Plantaginetalia | 0.665 | 0.671 | 0.777 | 0.780 |
| Molinietalia | 0.674 | 0.676 | 0.705 | 0.710 |
| Arrhenatheretalia | 0.462 | 0.436 | 0.459 | 0.446 |
| Koelerio-Corynephoretea and Festuco-Brometea | 0.787 | 0.786 | 0.803 | 0.812 |
| Artemisietea and Epilobietea | 0.510 * | 0.523 * | 0.618 | 0.632 |
| Salicetea purpureae | 0.867 * | 0.904 * | 0.894 * | 0.925 * |
| Ribeso nigri-Alnetum and Alno-Ulmion | 0.928 | 0.928 | 0.943 * | 0.960 * |
| Salicetum pentandro-cinereae | 0.843 * | 0.913 * | 0.885 * | 0.925 * |
| Vaccinio-Piceetea | 0.885 | 0.875 | 0.854 | 0.860 |
| Others wooded communities | 0.684 | 0.684 | 0.820 * | 0.836 * |
| Areas without vegetation | 0.936 * | 0.921 * | 0.963 | 0.966 |
| Surface water | 0.944 | 0.944 | 0.960 | 0.959 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jarocińska, A.; Niedzielko, J.; Kopeć, D.; Wylazłowska, J.; Omelianska, B.; Charyton, J. Testing Textural Information Base on LiDAR and Hyperspectral Data for Mapping Wetland Vegetation: A Case Study of Warta River Mouth National Park (Poland). Remote Sens. 2023, 15, 3055. https://doi.org/10.3390/rs15123055
Jarocińska A, Niedzielko J, Kopeć D, Wylazłowska J, Omelianska B, Charyton J. Testing Textural Information Base on LiDAR and Hyperspectral Data for Mapping Wetland Vegetation: A Case Study of Warta River Mouth National Park (Poland). Remote Sensing. 2023; 15(12):3055. https://doi.org/10.3390/rs15123055
Chicago/Turabian StyleJarocińska, Anna, Jan Niedzielko, Dominik Kopeć, Justyna Wylazłowska, Bozhena Omelianska, and Jakub Charyton. 2023. "Testing Textural Information Base on LiDAR and Hyperspectral Data for Mapping Wetland Vegetation: A Case Study of Warta River Mouth National Park (Poland)" Remote Sensing 15, no. 12: 3055. https://doi.org/10.3390/rs15123055
APA StyleJarocińska, A., Niedzielko, J., Kopeć, D., Wylazłowska, J., Omelianska, B., & Charyton, J. (2023). Testing Textural Information Base on LiDAR and Hyperspectral Data for Mapping Wetland Vegetation: A Case Study of Warta River Mouth National Park (Poland). Remote Sensing, 15(12), 3055. https://doi.org/10.3390/rs15123055