1. Introduction
In recent years, aerospace remote sensing imaging technology has been applied to many fields, such as land and mineral resource management and monitoring, traffic and road network safety monitoring, geological disaster early warning, and national defense system construction [
1,
2,
3]. Meanwhile, deep learning technology has also greatly promoted the research of remote sensing images in detection and classification [
4]. A sufficient amount of data is the cornerstone for achieving high-performance deep learning algorithms, and large high-quality datasets can greatly improve the algorithm performance [
5]. However, there are two constraints in the construction of existing remote sensing image datasets: on the one hand, compared with natural image datasets captured by ground-based equipment [
6,
7], the capture of remote sensing images requires high-cost imaging platforms such as aircraft or satellites, and the acquisition process is limited by aircraft routes and satellite orbits; on the other hand, the influence of factors such as light, rain, fog, and clouds [
8] makes it difficult to collect effective high-quality images due to the high proportion of invalid data in each acquisition [
9]. The above factors mean that existing datasets cannot meet the demand of artificial intelligence algorithm training in the field of remote sensing [
10], which is mainly reflected in two aspects:
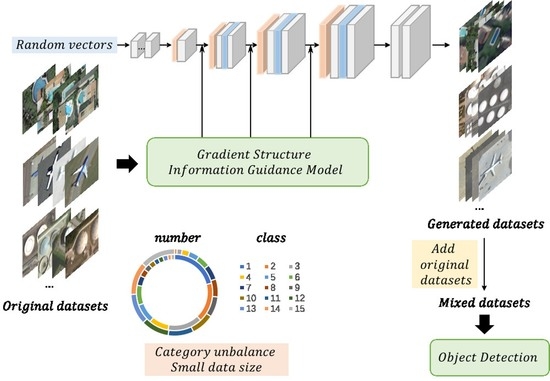
Issue 1: Insufficient data size. Take the commonly used DOTA dataset as an example. It includes 15 object classes with nearly 190,000 objects, while the non-remote sensing natural image dataset COCO contains 80 classes with more than 1.5 million objects in total, a size 8 times that of DOTA. The lack of data scale leads to a high risk of overfitting the model.
Issue 2: Large differences in the samples within and between classes. There are more than 20,000 ships in the DOTA dataset but only 6000 planes, and the specific classes and sizes of planes are not uniform. The lack of image diversity and unbalanced numbers between classes in the existing dataset [
11] can bias the model toward majority class prediction [
12], limiting further improvement in the performance of network models in target detection and classification, for example [
13].
In recent years, some mitigation approaches have been proposed at the algorithm level for issue 2 [
14,
15]. Zhou et al. [
16] proposed a dynamic balancing weighting method based on the number of effective samples for remote sensing image segmentation tasks with data imbalance. CBCL [
11] dynamically constructs a class-balanced memory queue during the training of object detection models by memorizing training samples to alleviate class imbalance. However, these approaches are unable to mitigate issue 1.
Data enhancement is an effective approach that can alleviate both of these problems at the same time [
17], can obtain large amounts of data from a limited dataset, and can effectively alleviate the problems of insufficient data size and class imbalance, especially in aerospace remote sensing applications, which are widely used by researchers [
18,
19]. However, many traditional data enhancement methods, such as flipping, scaling, cropping, rotating, or adding noise, only increase the number of remotely sensed images and cannot improve the quality of semantic information as well as the diversity of remotely sensed images in applications. In interpretation tasks such as object detection of remote sensing images, geometric transformation or randomly varying pixel values can no longer meet the increasing accuracy requirements. Therefore, it has become an urgent and indispensable task to use artificial neural network methods for data enhancement to generate sample data of remote sensing images.
Generative adversarial networks (GANs) [
20] have led to technological breakthroughs in many areas of deep learning and have been rapidly applied in many directions in the field of aerospace remote sensing [
21,
22]. Remote sensing images usually contain feature information with a large amount of texture and structure information, which is complex [
23], and existing natural image generation models rarely consider the structure information in the generation process. Therefore, if they are used in remote sensing image generation, they will lead to geometric structure distortion in the generated sample images, and the generated pseudo-sample images are often poorly realistic and insufficiently diverse to be reliably used as the basis for various analyses and applications in remote sensing [
24]. Additionally, almost all existing related studies in the direction of remote sensing are focused on tasks such as image classification and segmentation, and there are few studies on object detection tasks.
To address the above problems, based on StyleGANv2 [
25], this paper innovatively proposes a gradient structure information-guided attention generative adversarial network improvement method for remote sensing image generation to alleviate the model performance degradation problem due to insufficient remote sensing data. This paper uses a multidimensional self-attentive feature selection module (MAFM) to guide the generator to make better use of global information, which can help the generator to better control the generation process and generate higher-quality remote sensing images. Meanwhile, the gradient structure information branching network is used to guide the generator body network, so that the generated images have more realistic structure information, thus alleviating the structural distortion phenomenon existing in remote sensing image generation. The mode seeking [
26] regularization term is introduced to increase the ratio of the distance between the generated images to the distance between the corresponding latent codes to solve the problem of insufficient diversity.
The main contributions of this paper are as follows:
A multidimensional self-attentive module applicable to remote sensing image generation is proposed to enhance the convolution and improve the generator model performance. Contextual information is captured by tandemly connecting two cross-attentive modules and modeling the importance of feature maps and interdependencies in three dimensions of the spatial and channel domains. The attention model is embedded into the generative adversarial network to guide the generator to utilize global information while adaptively focusing on important regions.
- 2.
Gradient structure information guidance model
Adding a branching network to the remote sensing image generation network and using the gradient structure information guidance method to improve the generation quality of remote sensing images can better preserve the structural information of the samples, allowing the generation network to output remote sensing images with high perceptual quality and less geometric distortion.
3. Method
In this paper, we propose a gradient structure information-guided attention generative adversarial network (SGA-GAN). The structure sketch is shown in
Figure 1, including the generator and discriminator. The generator network generates fake images from some random numbers extracted from a uniform distribution, and the discriminator network, as the adversary of the generator, tries to distinguish real images from fake images; both are trained iteratively. Finally, the generator network can perfectly generate realistic fake images, and the discriminator network can effectively determine whether the images are real or fake [
20].
In order to improve the performance of the model in remote sensing images, this paper introduces the multidimensional self-attentive feature selection module (MAFM in
Figure 1) into the generator network. Additionally, this paper uses the gradient structure information to guide the model to generate more realistic sample images.
3.1. Multidimensional Self-Attentive Module
The generator is the core part of the whole generative adversarial network, and the performance of this part determines the final quality of the generated images. The convolutional layer can only operate on the local proximity context of each spatial location in the feature map, which does not make good use of the contextual information.
CCNet [
52] proposes the Criss-Cross Network to obtain contextual information in a more effective and efficient way, based on which this paper proposes a multidimensional self-attentive feature selection module (MAFM) for remote sensing image generation, which can improve the generator model performance by modeling the attentional feature map and connecting the localized convolutional feature map to a farther range. The data flow is shown in
Figure 2a,b, which are two parts in series.
As shown in
Figure 2a, the cross-attention module captures contextual information by obtaining the relationship of each point on the feature map with each of its points horizontally and vertically. This vertical and horizontal attention module is more lightweight and uses two cross-attention modules in series for the self-attention calculation on each feature map in the channel domain. The
and
weights are shared, and the relationship between each point and all points on that feature map can be obtained via cross-attention twice, which can capture dense global contextual information.
However, it is difficult to capture the relationship between feature maps; therefore, in order to learn the long-distance dependencies within the channel dimension of the feature maps,
is passed sequentially through the spatial attention module and the channel attention module. The feature attention selection module shown in
Figure 2b is added after
Figure 2a to model the importance and interdependence of the feature maps in three dimensions: two in the spatial domain and one in the channel domain.
and
are the spatial attention maps and
is the channel attention map, which are obtained in the same way, the only difference being that the dimensions are different.
As shown in
Figure 3, taking channel attention as an example, F is first reduced to a one-dimensional vector along the channel dimension, using the maximum pooling operation. Then, the importance of each channel feature map is obtained by a 1 × 1 convolutional layer, ReLU activation function, 1 × 1 convolutional layer, and sigmoid activation function in turn. Subsequent to multiplying the features after the spatial attention module, they are summed with
after the 1 × 1 convolutional layer and ReLU activation function in turn to obtain the final output feature
.
contains not only the long-range dependencies of all spatial locations within the whole spatial dimension but also the correlations between channel dimensions and the importance of each feature map under that dimension, which enables the generator to better use the global information to generate high-quality remote sensing images.
3.2. Gradient Structure Information Guidance Model
Since the gradient map reveals clear details of each local region in the sample image [
53], the gradient structure information can be used to guide the generation process of the image generation network. However, the sample gradient map extracted by the conventional operator can only reflect one aspect of the sample structure (i.e., the value difference of neighboring pixels), and it is difficult to obtain richer and more general information (e.g., more complex structural textures) in the sample structure.
In this paper, we propose a learnable gradient structure information branching network, GSNet, to generate high-quality remote sensing images with clear structures by extracting the gradient structure information of samples in real remote sensing images and guiding the generator to pay attention to the sample structure information during the generation process.
A structural diagram of the gradient structure information branching network used in this paper is shown in
Figure 4. Since most of the area of the gradient map is close to zero and the convolutional neural network can focus more on the spatial relationships of the contours, the network model may capture structural dependencies more easily. To ensure that GSNet can learn the geometric structural information of the samples rather than the deep semantic information of the samples, GSNet does not use too many convolutional layers, and the conv block is a residual block consisting of three layers of convolution. GSNet is divided into three stages to extract the sample image structure tensor, and the spatial size of the structure information feature map is downsampled by a factor of 2 each time and incorporated into the corresponding position of the main structure of the generative network.
The gradient block is used to obtain the gradient map of the original image of the sample without considering the gradient direction information but using a convolutional layer with a fixed kernel, as shown in Equation (1). The gradient calculation formula used is shown in Equation (2).
After obtaining the gradient map, it is first fed into the first convolutional block to extract simple structural features, which consists of a 3 × 3 convolutional layer with a step size of 1 and an instance normalization layer. It is then fed into three modules consisting of a convolution block and a multidimensional feature selection module (FSM) in turn to further extract structural features. The convolutional block consists of three dense residual blocks, each consisting of five 3 × 3 convolutional layers using dense connections and the Leaky-ReLU activation function. The specific structure of the multidimensional feature selection module (FSM) is shown in
Figure 5, which uses transposition operations to select features from three dimensions, namely the spatial dimension W, spatial dimension H, and channel dimension C, respectively. Each feature selection module consists of a maximum pooling layer, a 1 × 1 convolutional layer, a ReLU activation function, a 1 × 1 convolutional layer, and a sigmoid activation function.
The structural features at different scales are obtained in the branching network of the gradient structural information, and they are input into the generator as a priori structural information to guide the generation process. Using a learnable attention graph, we assign each part of the input different weights to extract more critical and important information so that the branching network can output structural information with more details. The branching network can effectively extract the structural information of the preserved sample images, allowing the generative network to obtain results with high perceptual quality and less geometric distortion. In addition, the obtained gradient information can highlight the sharpness and structural regions that need more attention, thus implicitly leading to the high-quality generation of remote sensing images.
3.3. Loss Function
In order to train the algorithm in this paper, it is necessary to compare the image in the training phase, the reconstructed image, and the original image under certain metrics. We designed a loss function L consisting of three components. It is denoted by the following equation:
where
is the adversarial loss,
is the perceptual length regularization term,
is the mode seeking regularization term, and
,
, and
are the weight coefficients.
The work in this paper is mainly based on StyleGANv2 for improvement, and thus the loss function in StyleGANv2 is retained, while the mode seeking regularization term is added to improve the diversity of the generated images.
3.3.1. Adversarial Loss
This paper uses the adversarial loss to make the image distribution of the generated image match the image distribution of the real image with the following equation:
where
tries to generate images that look similar to the real image, and
tries to distinguish the generated images from the real image. The goal of
is to minimize the adversarial loss, while the goal of
is to maximize the adversarial loss.
3.3.2. Path Length Regularization
The perceptual path length (PPL), proposed in StyleGANv2 [
25], which measures the degree of feature coupling between different random input vectors, representing the perceptual distance length, is also found to be correlated with the quality of the generated images, and thus the quality of the generated images can be improved using the PPL regularization term.
where
, W is the intermediate potential space [
35],
,
obeys a normal distribution,
denotes the Jacobian matrix,
denotes the exponential moving average, which aims to preserve the expected length of the vector regardless of the vector direction, and
is a random image whose pixel (numerical) intensities obey a normal distribution.
3.3.3. Mode Seeking Regularization
GANs can easily fall into mode collapse, which leads to a loss of diversity in the generated images. Therefore, additional regularization terms need to be introduced to alleviate mode collapse and thus ensure the diversity of the generated images.
When mode collapse occurs, two different random input vectors,
and
, are mapped to images
and
with similar patterns, which means that the GAN learns only a few patterns and loses the diversity of the generated images. Therefore, we introduce the mode seeking regularization term to maximize the ratio of the distance between
and
relative to the distance between
and
with the following equation:
where
and
are two different random vectors,
and
denote the corresponding generated images of
and
, respectively, and
and
are distance metrics.
4. Experiments
In order to verify the effectiveness and generalizability of the model proposed in this paper, the model proposed in this paper and other advanced models were tested on two remote sensing datasets and compared. To quantitatively evaluate the performance of the different network models, the IS (Inception Score), FID (Frechet Inception Distance), and KID (Kernel Inception Distance) were used to evaluate the quality of the images generated by the different models. These are widely used metrics for image generation quality evaluation.
In addition, in this paper, the generated remote sensing sample images were tested in practical applications using current commonly used object detection models, including single-object class experiments as well as multi-object class experiments. The object detection models included YOLOv5 [
54], YOLOX [
55], and Efficientdet [
56]. The results of object detection using the DOTA and UCAS-AOD datasets were used to verify the effectiveness of the generated images.
In this paper, we conducted an ablation study, which is presented in
Section 4.5, to verify the effectiveness of the gradient structure information guidance model proposed in this paper and explore the effect of adding a multidimensional self-attentive module on the algorithm.
4.1. Evaluation Metrics
The larger the value of the Inception Score (
) [
57], the better the image quality and diversity. Specifically, the generated image
is fed into the Inception [
58] classification network, which outputs a 1000-dimensional vector
. It is desired that the entropy
of the generated image over the conditional distribution is small, and that the edge distribution
of the generated image over all class probabilities is large.
is the average KL divergence of these two distributions, and is expressed as follows:
The
[
59] determines the quality of the generated image by calculating the distance between the feature vectors of the real image and the generated image, which is extracted and calculated using an image classification model (e.g., Inception v3). A lower
score means that the two sets of images, or the statistics of the two, are more similar. The calculation formula is as follows:
where
and
represent the mean values of the real image and the generated image on a certain layer of features of Inception v3, respectively;
and
represent the variance of the real image and the generated image on a certain layer of features, respectively.
The
[
60] is used to evaluate the realism of the generated image, and the lower the
, the higher the visual similarity between the real image and the generated image. It calculates the square of the maximum mean discrepancy (MMD) of the higher perceptual features of the image (the last layer of the Inception model). The two data distributions of the real and generated images are
and
, respectively. The
between the two distributions can be expressed as follows:
where
and
denote the high-level perceptual features of the real image and the generated image, respectively, and
denotes the kernel function used for feature transformation:
4.2. Datasets
1. DOTA dataset [
61,
62]: This is a large image dataset for aerial image object detection. The image sources include different sensors and platforms, including Google Earth, the JL-1 satellite, and the GF-2 satellite of the China Resource Satellite Data and Application Center. The dataset consists of a total of 2806 aerial images, each with pixel sizes ranging from 800 × 800 to 4000 × 4000, containing objects of different scales, orientations, and shapes, and the images are annotated by experts using 15 common target categories. In this paper, the images were cropped to a 640 × 640 pixel size for testing.
2. UCAS-AOD dataset [
63]: Remote sensing images were collected from Google Earth and used for plane detection. The plane dataset consists of 600 images of 3210 planes, and all the images are carefully selected so that the target directions in the dataset are evenly distributed. In this paper, the images were cropped to a 640 × 640 pixel size for testing.
4.3. Image Generation Comparison Results
In order to evaluate the performance of the algorithm in this paper, the method in this paper was compared with other SOTA image generation methods on two datasets. All comparison procedures and test results of the compared models were obtained from their authors’ official websites.
DOTA dataset: The results of the algorithm proposed in this paper and the other algorithms were quantitatively analyzed on the DOTA dataset. The FID, KID, and IS metrics of different image generation algorithms are shown in
Table 1. Compared with the other five image generation models, the SGA-GAN algorithm proposed in this paper returned the optimal results for the three metrics, i.e., FID, KID, and IS. Compared with the baseline model StyleGANv2, the SGA-GAN algorithm proposed in this paper reduced the FID value from 85.967 to 72.924, the KID value from 0.059 to 0.047, and the IS value from 4.581 to 4.815. Compared with StyleGAN-XL, the FID and KID of SGA-GAN decreased by 23.927 and 0.003, respectively, and the IS improved by 2.351 on the DOTA dataset. The quantitative comparison in terms of the FID, KID, and IS indicates that the SGA-GAN algorithm proposed in this paper can generate higher-quality remote sensing images.
The qualitative evaluation of the results of the different algorithms on the DOTA dataset is shown in
Figure 6. The remote sensing sample images generated by ProGAN and StyleGANv1 were more seriously distorted, and the partial structures of the wings of some planes in the images were severely distorted. The StyleGANv2, FastGAN, and StyleGAN-XL methods generated a few clearer sample images, but there was also distortion in the partial structures of the wings and tails. In contrast, the method proposed in this paper generated sample images with realistic visual effects, and the image structure was more realistic and reliable.
UCAS-AOD dataset: The results of the algorithm proposed in this paper and the other algorithms were quantitatively analyzed on the UCAS-AOD dataset. The FID, KID, and IS metrics of the different image generation algorithms are shown in
Table 2. Compared with the other five image generation models, SGA-GAN again returned the optimal results for the three metrics, i.e., FID, KID, and IS. Compared with StyleGANv2, the SGA-GAN algorithm proposed in this paper decreased the FID value from 58.405 to 54.096, the KID value from 0.047 to 0.042, and the IS value from 3.493 to 3.728. Compared to StyleGAN-XL, the FID and KID of SGA-GAN on the UCAS-AOD dataset decreased by 41.464 and 0.009, respectively, and the IS improved by 1.646. The quantitative comparison of the three metrics, i.e., FID, KID, and IS, shows that the SGA-GAN algorithm proposed in this paper can generate higher-quality remote sensing images.
The qualitative evaluation of the results of the different algorithms on the UCAS-AOD dataset is shown in
Figure 7. The target types in the UCAS-AOD dataset are more concentrated with less inter-class variation. ProGAN, StyleGANv1, and StyleGAN-XL generated a small number of sample target images with a clear structure, but most of the images were severely distorted. The StyleGANv2 and FastGAN methods generated clearer sample images, but there was structural distortion. The method proposed in this paper generated more realistic sample images with clearer and more reliable structures.
Comparing the results of all algorithms on the DOTA and UCAS-AOD datasets, it can be seen that the algorithms in this paper have good performance metrics and visual effects on both datasets.
4.4. Object Detection Test Results
To evaluate the performance of the algorithm in this paper, target samples generated using the method in this paper were added to the training set of two publicly available aerial remote sensing object detection datasets, while the test set was left unchanged. Comparative experiments were conducted on three different types of generic object detection models, namely YOLOv5 [
51], YOLOX [
52], and Efficientdet [
53], to verify the ability of this paper’s method to solve the problems of insufficient image diversity and unbalanced numbers between classes in existing datasets.
4.4.1. Multi-Class Object Data
Adding single-class targets to multi-class target data: The DOTA airborne remote sensing dataset contains 15 common object classes. The number of plane targets is significantly lower than that of ships and vehicles, and the plane targets are of different sizes. We added 1000 samples of plane targets of different sizes generated by the method in this paper to the training set of the original dataset, as shown in
Figure 8; the left subfigure (a) shows the image slices of the original dataset, and the right subfigure (b) shows the added generated data to compare the experimental results of object detection.
To verify the effectiveness of SGA-GAN in improving the performance of remote sensing object detection, the YOLOv5 and YOLOX detection networks were used to verify the effectiveness on the DOTA dataset. The test results are shown in
Table 3.
ORI
1000 represents 1000 plane target images in the original DOTA data with conventional data enhancement (random cropping, scaling, rotation, etc.). GEN
1000 represents 1000 plane target samples generated using this paper’s method, SGA-GAN, stitched into a 640 × 640-size image and added to the training set. From
Table 3, it can be seen that, for YOLOv5, the mAP and AP of plane objects were improved by 1.0% and 1.7%, respectively, after adding the plane target images generated by SGA-GAN. For YOLOX, the mAP and AP of plane objects were improved by 0.9% and 1.3%, respectively, after adding the plane target sample images generated by SGA-GAN. It can also be seen from the table that, compared with the traditional data enhancement methods, the SGA-GAN-generated images had a greater enhancement effect on remote sensing object detection, which can effectively alleviate the inter-class and intra-class imbalance problems existing in the dataset.
Adding multi-class targets to the multi-class target data: A total of 1000 images each of swimming pools, storage tanks, and planes were added to the training dataset of the original dataset, as shown in
Figure 9; the left subfigure (a) shows the image slices of the original dataset, and the right subfigure (b) shows the added generated data. The experimental results of multi-class object detection were compared and observed using the YOLOv5 and YOLOX detection networks.
The test results are shown in
Table 4, where ORIm
1000 represents the multi-class target images in the original DOTA data with conventional data enhancement, and GENm
1000 represents the multi-class target samples generated using the SGA-GAN method proposed in this paper. As can be seen from the table, for YOLOv5, the mAP and AP of the three classes of objects were improved by 2.1%, 1.9%, 0.9%, and 2.4% after adding the target images generated by SGA-GAN. For YOLOX, the mAP and AP of the three classes of objects were improved by 1.7%, 0.9%, 1.7%, and 3.1% after adding the target images generated by SGA-GAN.
4.4.2. Single-Class Data
Using the UCAS-AOD dataset, which contains only a single plane target, 1000 generated plane targets of different sizes were added to the original dataset, as shown in
Figure 10, with the original dataset on the left (a) and the added generated data on the right (b), to compare the experimental results of the observed object detection.
The test results are shown in
Table 5. ORI
1000 represents 1000 plane target images in the original UCAS-AOD data, and GEN
1000 represents 1000 plane target samples generated by the method proposed in this paper. The AP of plane objects was significantly improved by 1.6% for YOLOv5, 0.3% for YOLOX, and 1.8% for Efficientdet, after adding the plane objects generated by the method proposed in this paper, which proves that this paper’s method can effectively alleviate the problem of the model performance being limited by the size of the dataset.
4.5. Ablation Experiments
4.5.1. The Effectiveness of Mode Seeking Regularization ()
During the model training, mode seeking regularization () was removed, and the network was retrained on the DOTA dataset using the same training scheme to verify its effect on the model.
As can be seen from
Table 6, the addition of
reduced the FID from 74.421 to 72.924, the KID from 0.049 to 0.047, and the IS from 4.710 to 4.815. Thus, the effectiveness of mode seeking regularization in the image generation process is verified, showing that it can increase the diversity of the generated images.
4.5.2. The Effectiveness of Path Length Regularization ()
During the model training, path length regularization () was removed, and the network was retrained on the DOTA dataset using the same training scheme to verify its effect on the model.
As can be seen from
Table 7, the addition of
reduced the FID from 103.777 to 72.924, the KID from 0.076 to 0.047, and the IS from 4.560 to 4.815. Thus, the effectiveness of path length regularization in the image generation process is verified.
4.5.3. The Effectiveness of the Attention Module (MAFM)
The attention module (MAFM) was removed from the generator structure, and the network was retrained on the DOTA dataset using the same training scheme to verify the effectiveness of the MAFM.
As can be seen from
Table 8, the addition of the MAFM reduced the FID from 85.967 to 80.156, the KID from 0.059 to 0.054, and the IS from 4.581 to 4.643, thus verifying the effectiveness of the MAFM in the image generation process.
4.5.4. Impact of the Gradient Structure Information-Guided Model on the Algorithm (GSNet)
GSNet was removed, and the network was retrained on the DOTA dataset using the same training scheme to verify its effectiveness.
As can be seen from
Table 9, the FID was decreased from 80.156 to 72.924, the KID was decreased from 0.054 to 0.047, and the IS was decreased from 4.643 to 4.815 after adding the branching network, which verifies the effectiveness of the gradient structure information guidance in the image generation process.
5. Conclusions
The distortion phenomenon exists in remote sensing images generated by existing image generation methods. To address this problem, this paper proposed an attention generative adversarial network based on gradient structure information guidance (SGA-GAN) for remote sensing image generation. The gradient structure information extraction branching network can effectively alleviate the structure distortion phenomenon existing in remote sensing image generation and improve the quality of the generated remote sensing images. Comparison experiments were conducted on two remote sensing datasets, namely UCAS-AOD and DOTA. Compared with five other advanced image generation models, the SGA-GAN algorithm proposed in this paper returned the optimal results for the three studied metrics, i.e., FID, KID, and IS, and generated reliable structures and realistic visual sample images. At the same time, experiments were conducted on two datasets using three different object detection models, namely YOLOv5, YOLOX, and EfficientDet. After adding aircraft target images generated by SGA-GAN to the DOTA dataset, the APs of YOLOv5 and YOLOX for aircraft objects were improved by 1.7% and 1.3%, respectively. The comparison experiments show that the algorithm in this paper can effectively alleviate the problems of the insufficient scale of existing remote sensing datasets and the imbalance within and between categories, meaning it can be useful in practical applications.
In the next step, we will jointly train the remote sensing image generation and object detection networks to improve the performance of the model in practical applications and provide data and experimental support for the interpretation of satellite remote sensing images.



 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}