
FusionPillars: A 3D Object Detection Network with Cross-Fusion and Self-Fusion




Abstract
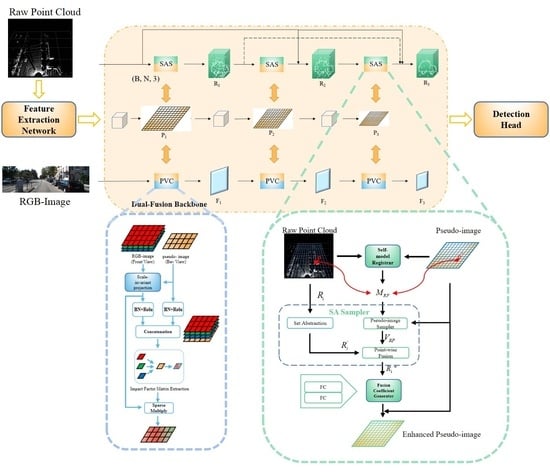
1. Introduction

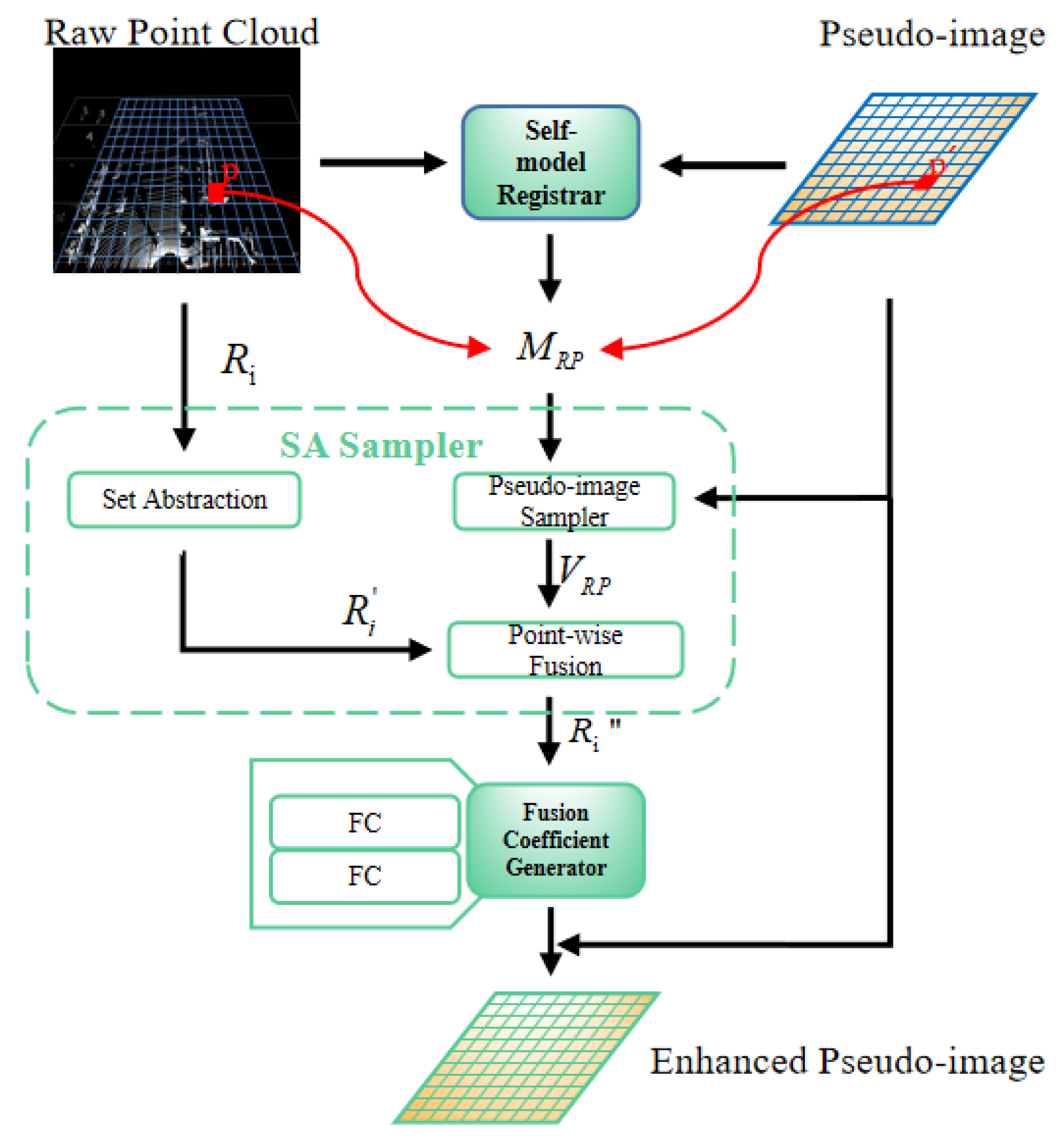
- The SAS fusion module performs self-fusion by using the point-based method and voxel-based method to strengthen the spatial expression of the pseudo-image.
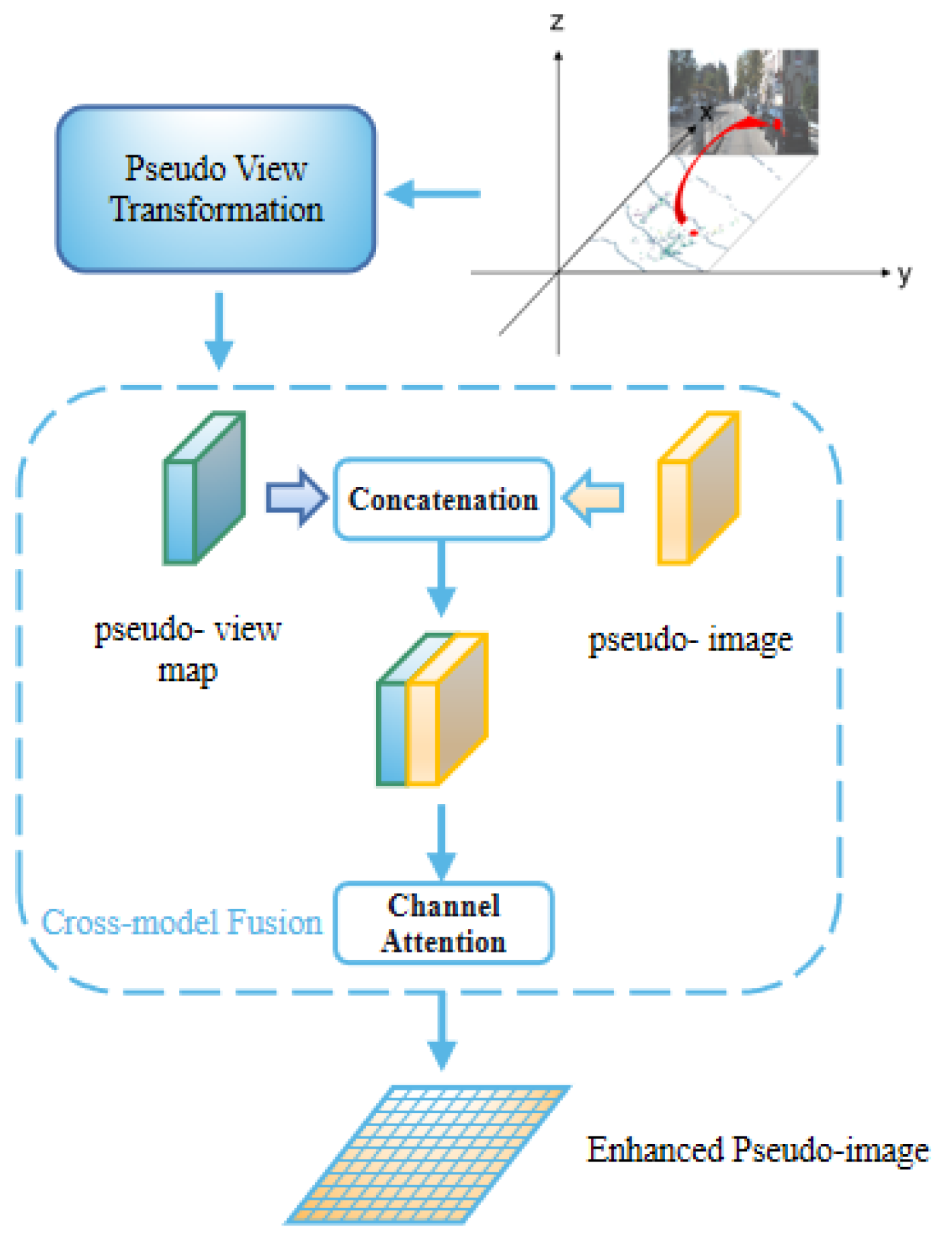
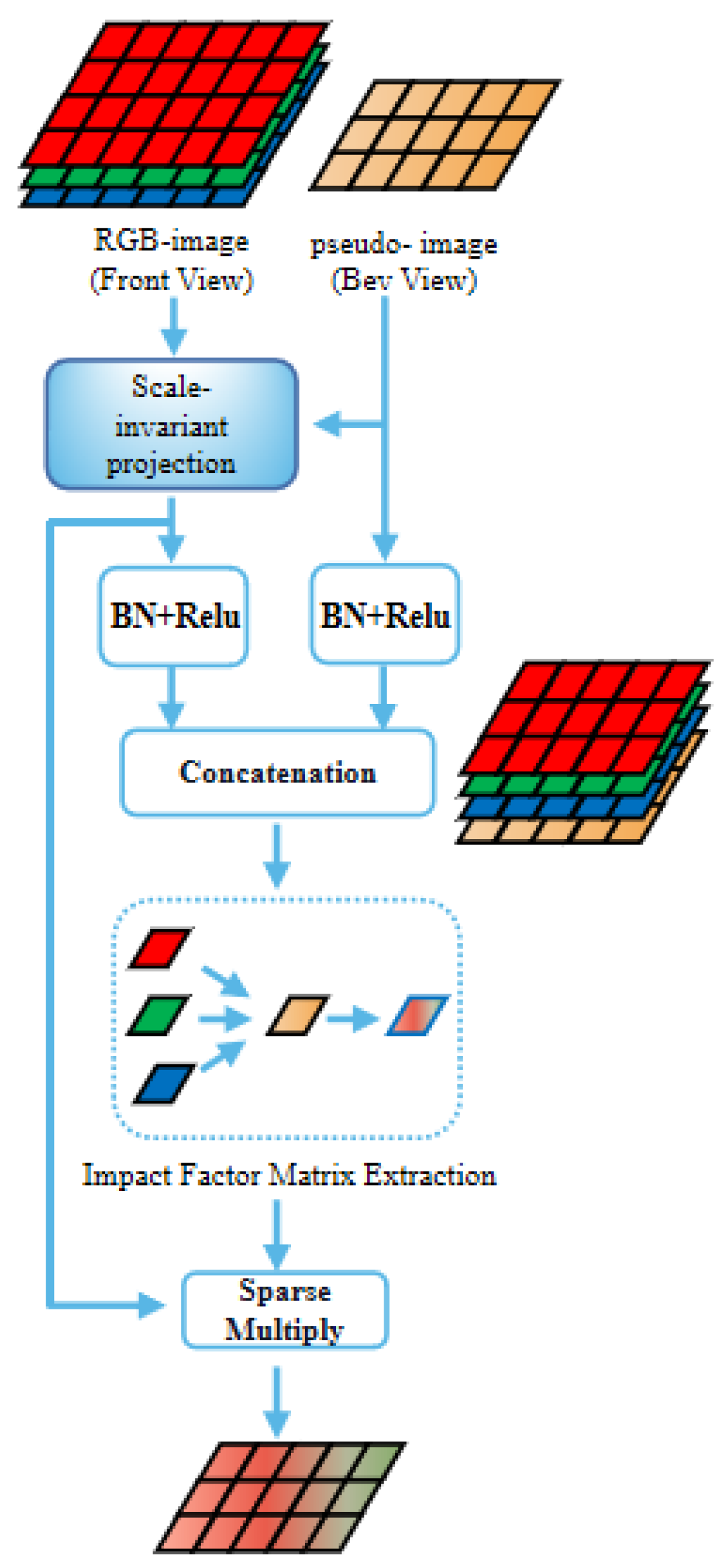
- The PVC fusion module cross-fuses the pseudo-image and the RGB image through the pseudo-conversion of the view angle to strengthen the color expression of the pseudo-image.
- We aggregate the SAS and PVC modules in the proposed network called FusionPillars, a one-stage end-to-end trainable modal that performs well on the KITTI dataset, with a particularly pronounced improvement in detection precision for small objects.
2. Materials
2.1. Point-Based Methods
2.2. Voxel-Based Methods
2.3. Lidar-Camera Fusion Methods
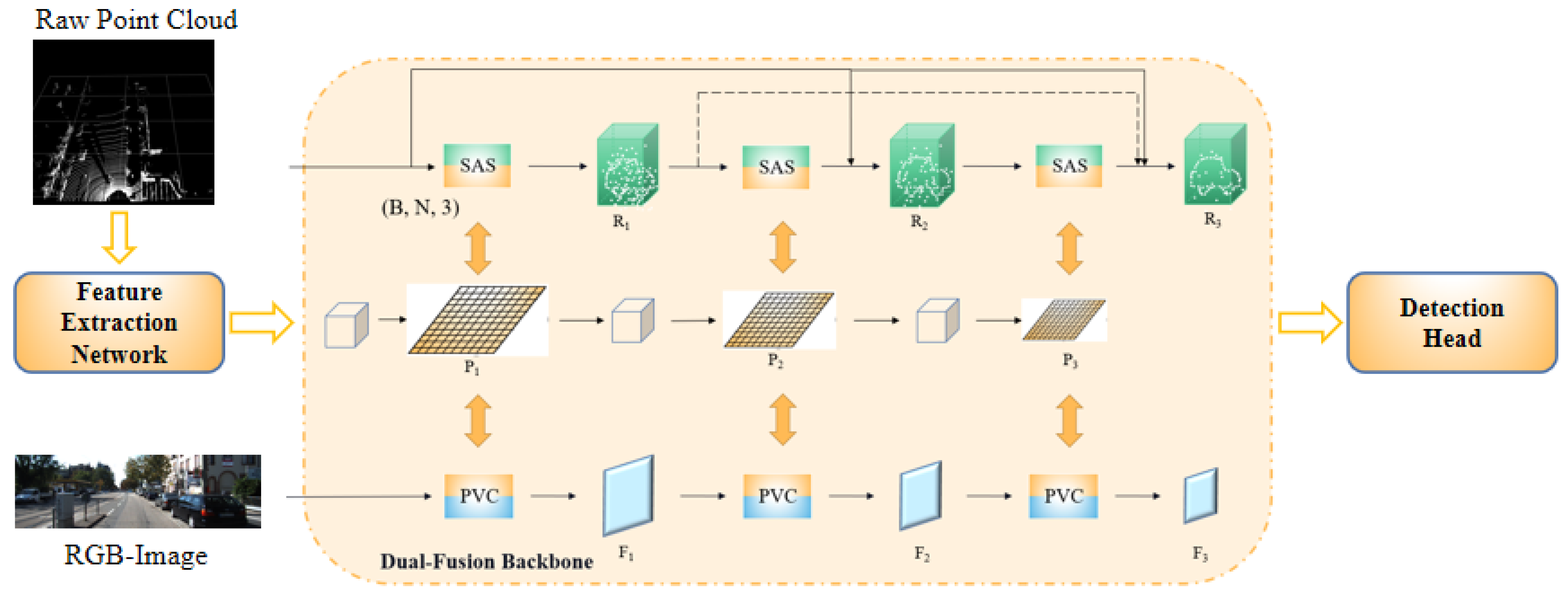
3. Methods
- Feature Extraction Network: it is the preprocessing network for point cloud voxelization.
- Dual-fusion Backbone: it fuses feature information from secondary branches into features of primary branches.
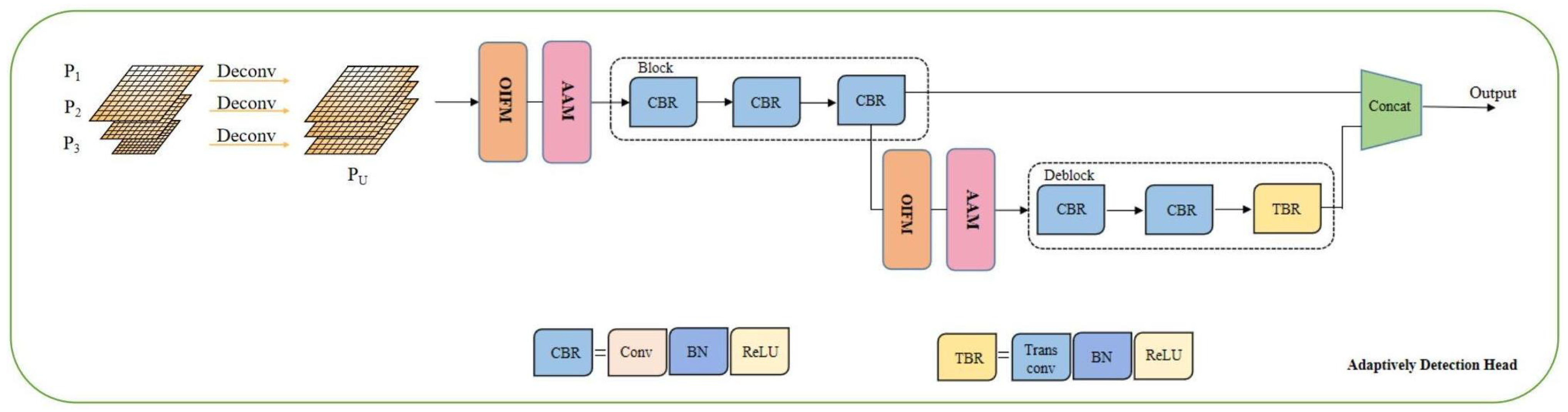
- Detection Head: it performs the concatenation operation for feature maps to generate the final feature map and outputs the label and bounding box of the object.

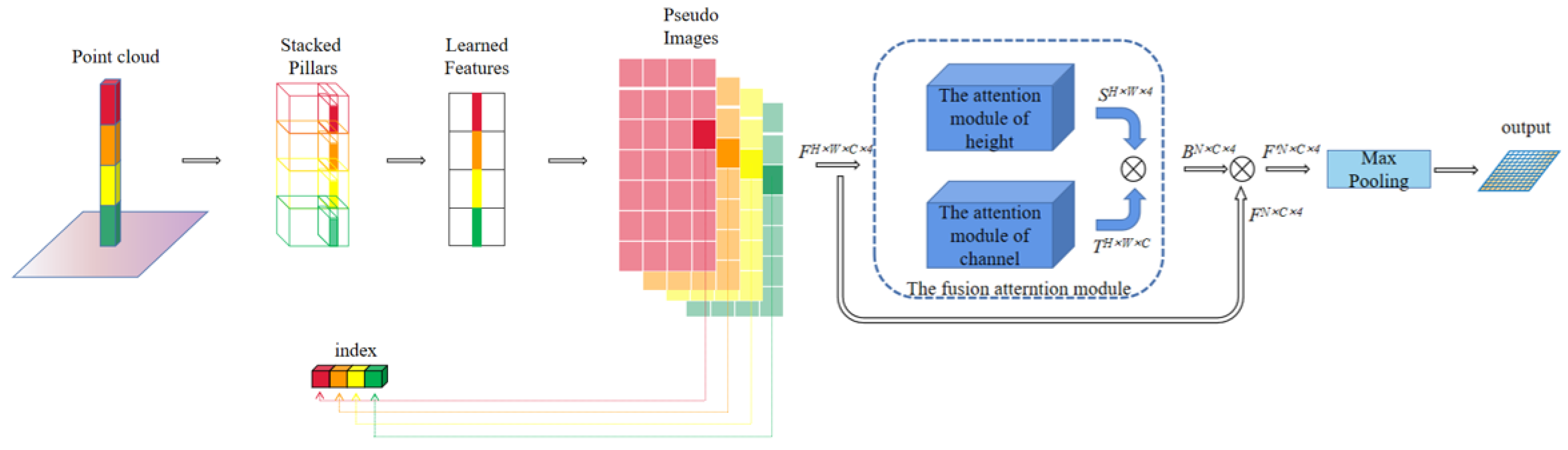
3.1. Feature Extraction Network
- The point cloud is separated using a uniform grid network with a size of 0.16 m2 in the x-y direction. With the grid network as the bottom and the point cloud height (4 ∗ 1 m) as the height, the point cloud space is divided into P pillars.
- The arithmetic mean and the offset from the central point in the x-y direction are calculated, and then the coordinate data ( dimensional) is augmented. Now, the augmented coordinate data are dimensional .
- The sparsity of the point cloud results in an uneven distribution of the point cloud, which results in a large number of empty pillars. Thus, a threshold is set to randomly sample the pillars with an excessive amount of points, whereas the pillars with too few points are operated zero-padding. In this manner, dense tensors are created, where N represents the number of points in each pillar.
- The features are encoded and scattered back to the locations of the original pillars to create B pseudo-images of size , where H and W indicate the height and width of the pseudo-image.
- B pseudo-images are fed into two attention sub-modules to calculate the height-attention weight S and the channel-attention weight T. The final pseudo-image is then obtained by performing operations such as multiplication and maximum pooling.indicates fully connected layer, F indicates 4 pseudo-images.

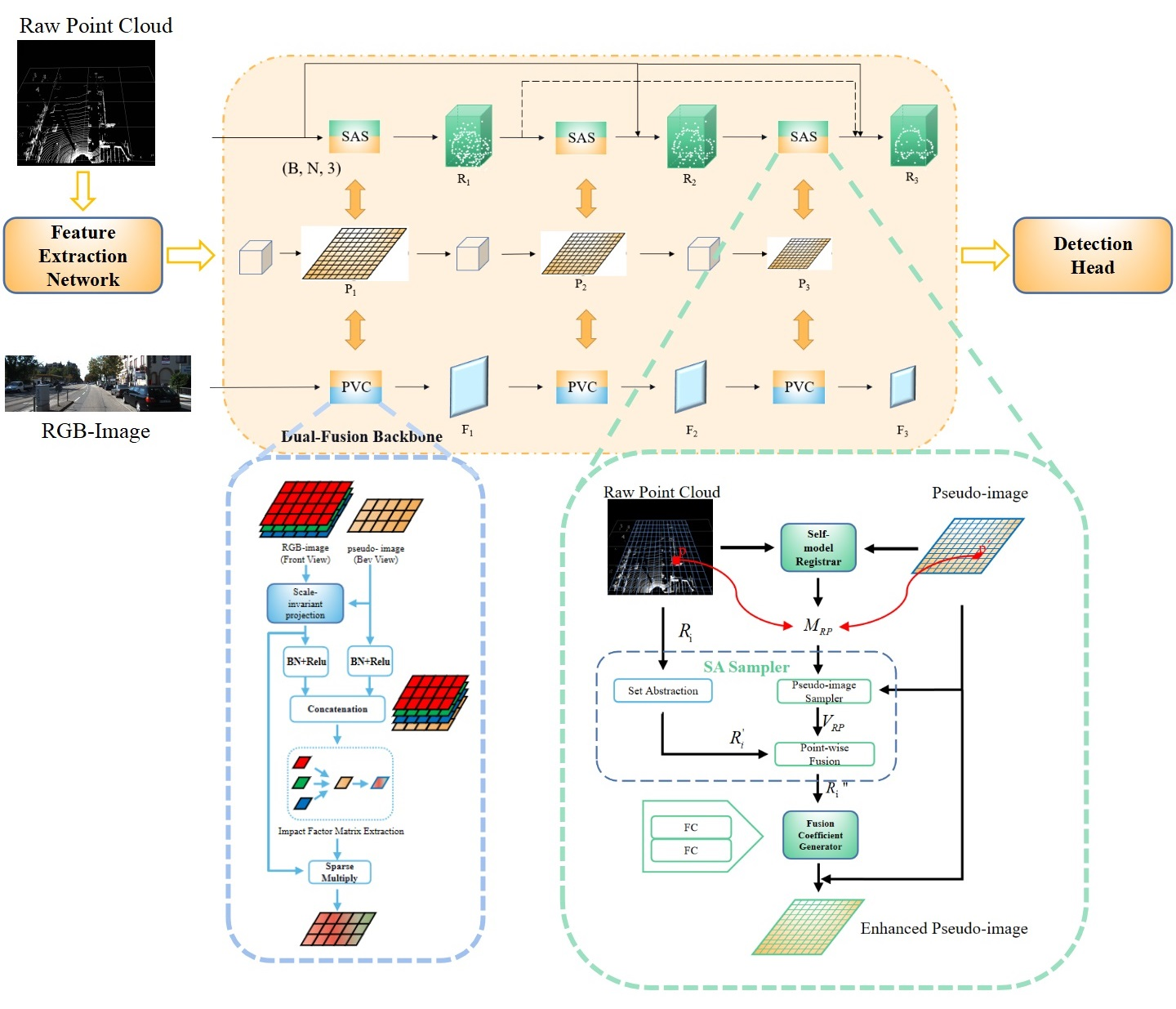
3.2. Dual-Fusion Backbone
3.2.1. Voxel-Based Branch
3.2.2. Point-Based Branch
3.2.3. Image-Based Branch
3.2.4. Set Abstraction Self (SAS) Fusion Module
3.2.5. Pseudo View Cross (PVC) Fusion Module
3.3. Detection Head
3.4. Loss Function
4. Experiment
4.1. Experiment Environment
- CUDA: 10.2
- Pytorch: 1.10.2
- Python: 3.6
- GPU: GeForce RTX 2080Ti
4.2. Experiment Dataset
4.3. Experimental Settings
4.4. Experimental Results
4.5. Evaluation Indicators
4.5.1. Results with Single-Modal Networks
4.5.2. Results with Multi-Modal Networks
4.6. Ablation Studies
4.7. Effectiveness Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. Acm Trans. Graph. (Tog) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Wang, Y.; Chao, W.L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8445–8453. [Google Scholar]
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1355–1361. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Yang, B.; Luo, W.; Urtasun, R. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7652–7660. [Google Scholar]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-task multi-sensor fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7345–7353. [Google Scholar]
- Liang, Z.; Zhang, M.; Zhang, Z.; Zhao, X.; Pu, S. Rangercnn: Towards fast and accurate 3d object detection with range image representation. arXiv 2020, arXiv:2009.00206. [Google Scholar]
- Deng, J.; Zhou, W.; Zhang, Y.; Li, H. From multi-view to hollow-3D: Hallucinated hollow-3D R-CNN for 3D object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4722–4734. [Google Scholar] [CrossRef]
- Sugimura, D.; Yamazaki, T.; Hamamoto, T. Three-dimensional point cloud object detection using scene appearance consistency among multi-view projection directions. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3345–3357. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 244–253. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4604–4612. [Google Scholar]
- Xie, L.; Xiang, C.; Yu, Z.; Xu, G.; Yang, Z.; Cai, D.; He, X. PI-RCNN: An efficient multi-sensor 3D object detector with point-based attentive cont-conv fusion module. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton, NY, USA, 7–12 February 2020; Volume 34, pp. 12460–12467. [Google Scholar]
- Wang, J.; Li, J.; Shi, Y.; Lai, J.; Tan, X. AM³Net: Adaptive Mutual-Learning-Based Multimodal Data Fusion Network. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5411–5426. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, K.; Bao, H.; Zheng, Y.; Yang, Y. PMPF: Point-Cloud Multiple-Pixel Fusion-Based 3D Object Detection for Autonomous Driving. Remote Sens. 2023, 15, 1580. [Google Scholar] [CrossRef]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3d object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Swizerland, 2020; pp. 35–52. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Swizerland, 2020; pp. 720–736. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V.; et al. Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17182–17191. [Google Scholar]
- Xu, X.; Dong, S.; Xu, T.; Ding, L.; Wang, J.; Jiang, P.; Song, L.; Li, J. FusionRCNN: LiDAR-Camera Fusion for Two-Stage 3D Object Detection. Remote Sens. 2023, 15, 1839. [Google Scholar] [CrossRef]
- Kim, T.; Ghosh, J. Robust detection of non-motorized road users using deep learning on optical and LIDAR data. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 271–276. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral deep neural networks for pedestrian detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 10386–10393. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11040–11048. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually. 2–9 February 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Zhang, J.; Xu, D.; Wang, J.; Li, Y. An Improved Detection Algorithm For Pre-processing Problem Based On PointPillars. In Proceedings of the 2021 14th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 23–25 October 2021; pp. 1–6. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Zhang, J.; Wang, J.; Xu, D.; Li, Y. HCNET: A Point Cloud Object Detection Network Based on Height and Channel Attention. Remote Sens. 2021, 13, 5071. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Liu, Z.; Zhao, X.; Huang, T.; Hu, R.; Zhou, Y.; Bai, X. Tanet: Robust 3d object detection from point clouds with triple attention. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton, NY, USA, 7–12 February 2020; Volume 34, pp. 11677–11684. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-gnn: Graph neural network for 3d object detection in a point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1711–1719. [Google Scholar]
- Wang, M.; Chen, Q.; Fu, Z. Lsnet: Learned sampling network for 3d object detection from point clouds. Remote Sens. 2022, 14, 1539. [Google Scholar] [CrossRef]
- Yang, B.; Liang, M.; Urtasun, R. Hdnet: Exploiting hd maps for 3d object detection. In Proceedings of the Conference on Robot Learning, PMLR, Zürich, Switzerland, 29–31 October 2018; pp. 146–155. [Google Scholar]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep continuous fusion for multi-sensor 3d object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 641–656. [Google Scholar]
- Sindagi, V.A.; Zhou, Y.; Tuzel, O. Mvx-net: Multimodal voxelnet for 3d object detection. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7276–7282. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Ipod: Intensive point-based object detector for point cloud. arXiv 2018, arXiv:1812.05276. [Google Scholar]
- Wang, Z.; Jia, K. Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3d object detection. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1742–1749. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Benchmark | Network | Cars | Pedestrains | Cyclists | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | ||
| BEV | MV3D | 66.77 | 52.73 | 51.31 | N/A | N/A | N/A | N/A | N/A | N/A |
| VoxelNet | 89.35 | 79.26 | 77.39 | 46.13 | 40.74 | 38.11 | 66.70 | 54.76 | 50.55 | |
| SECOND | 88.07 | 79.37 | 77.95 | 55.10 | 46.27 | 44.76 | 73.67 | 56.04 | 48.78 | |
| PointPillars | 89.46 | 86.65 | 83.44 | 57.89 | 53.05 | 49.73 | 82.36 | 63.63 | 60.31 | |
| PointRCNN | 85.94 | 75.76 | 68.32 | 49.43 | 41.78 | 38.63 | 73.93 | 59.60 | 53.59 | |
| H23D RCNN | 92.85 | 88.87 | 86.07 | 58.14 | 50.43 | 46.72 | 82.76 | 67.90 | 60.49 | |
| Point-GNN | 93.11 | 89.17 | 83.90 | 55.36 | 47.07 | 44.61 | 81.17 | 67.28 | 59.67 | |
| LSNet | 92.12 | 85.89 | 80.80 | N/A | N/A | N/A | N/A | N/A | N/A | |
| FusionPillars | 92.15 | 88.00 | 85.53 | 62.33 | 55.46 | 50.13 | 87.63 | 66.56 | 62.67 | |
| 3D | MV3D | 71.09 | 62.35 | 55.12 | N/A | N/A | N/A | N/A | N/A | N/A |
| VoxelNet | 77.47 | 65.11 | 57.73 | 39.48 | 33.69 | 31.51 | 61.22 | 48.36 | 44.37 | |
| SECOND | 83.13 | 73.66 | 66.20 | 51.07 | 42.56 | 37.29 | 70.51 | 53.85 | 46.90 | |
| PointPillars | 83.68 | 74.56 | 71.82 | 53.32 | 47.76 | 44.80 | 71.82 | 56.62 | 52.98 | |
| PointRCNN | 85.94 | 75.76 | 68.32 | 49.43 | 41.78 | 38.63 | 73.93 | 59.60 | 53.59 | |
| TANet | 83.81 | 75.38 | 67.66 | 54.92 | 46.67 | 42.42 | 73.84 | 59.86 | 53.46 | |
| H23D RCNN | 90.43 | 81.55 | 77.22 | 52.75 | 45.26 | 41.56 | 78.67 | 62.74 | 55.78 | |
| Point-GNN | 88.33 | 79.47 | 72.29 | 51.92 | 43.77 | 40.14 | 78.60 | 63.48 | 57.08 | |
| LSNet | 86.13 | 73.55 | 68.58 | N/A | N/A | N/A | N/A | N/A | N/A | |
| FusionPillars | 86.96 | 75.74 | 73.03 | 55.87 | 48.42 | 45.42 | 80.62 | 59.43 | 55.76 | |
| Benchmark | Network | Pedestrians | Cyclists | ||||
|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | ||
| BBOX | PointPillars | 59.54 | 56.14 | 54.29 | 86.23 | 70.24 | 66.87 |
| FusionPillars | 63.58 | 58.21 | 54.55 | 90.88 | 73.18 | 69.99 | |
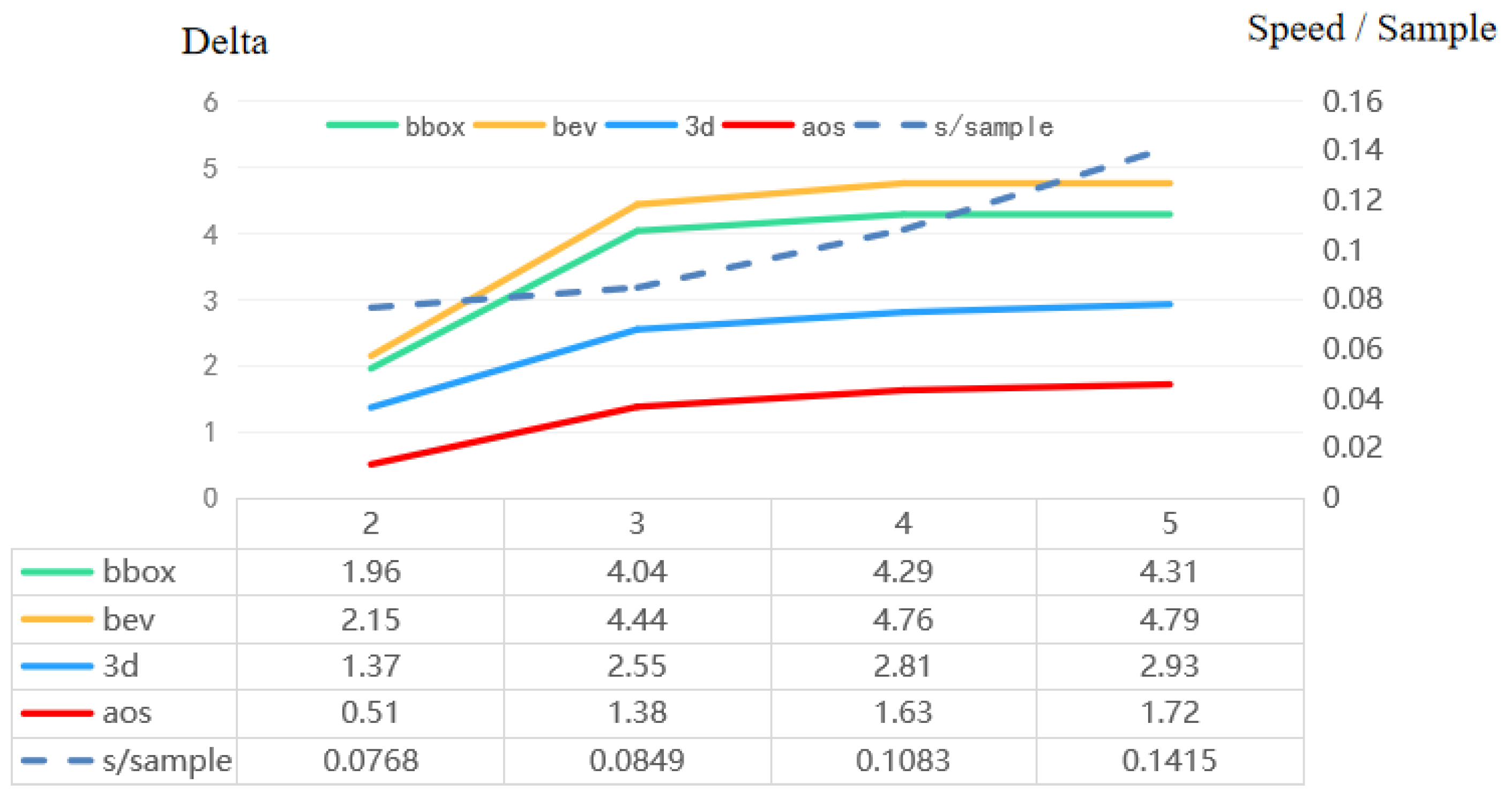
| Delta | 4.04 | 2.07 | 0.26 | 4.65 | 2.94 | 3.11 | |
| BEV | PointPillars | 57.89 | 53.05 | 49.73 | 82.36 | 63.63 | 60.31 |
| FusionPillars | 62.33 | 55.46 | 50.13 | 87.63 | 66.56 | 62.67 | |
| Delta | 4.44 | 2.41 | 0.40 | 5.27 | 2.93 | 2.36 | |
| 3D | PointPillars | 53.32 | 47.76 | 44.80 | 71.82 | 56.62 | 52.98 |
| FusionPillars | 55.87 | 48.42 | 45.42 | 80.62 | 59.43 | 55.76 | |
| Delta | 2.55 | 0.66 | 0.62 | 8.80 | 2.81 | 2.78 | |
| AOS | PointPillars | 45.06 | 42.51 | 41.08 | 85.67 | 67.98 | 64.59 |
| FusionPillars | 46.44 | 41.98 | 39.06 | 90.43 | 70.49 | 67.38 | |
| Delta | 1.38 | 4.76 | 2.51 | 2.79 | |||
| Benchmark | Network | Easy | Mod. | Hard |
|---|---|---|---|---|
| BEV | F-PointNet | 88.7 | 84 | 75.3 |
| HDNet | 89.1 | 86.6 | 78.3 | |
| Cont-Fuse | 88.8 | 85.8 | 77.3 | |
| MVX-Net | 89.2 | 85.9 | 78.1 | |
| FusionRCNN | 89.9 | 86.45 | 79.32 | |
| FusionPillars | 92.2 | 88.0 | 85.5 | |
| 3D | F-PointNet | 81.2 | 70.4 | 62.2 |
| HDNet | N/A | N/A | N/A | |
| Cont-Fuse | 82.5 | 66.2 | 64.0 | |
| MVX-Net | 83.2 | 72.7 | 65.2 | |
| FusionPillars | 87.0 | 75.7 | 73.0 |
| Network | Cars | Pedestrains | Cyclists | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | |
| MV3D | 86.62 | 78.93 | 69.8 | N/A | N/A | N/A | N/A | N/A | N/A |
| AVOD-FPN | 90.99 | 84.82 | 79.62 | 58.49 | 50.32 | 46.98 | 69.39 | 57.12 | 51.09 |
| IPOD | 89.64 | 84.62 | 79.96 | 60.88 | 49.79 | 45.43 | 78.19 | 59.4 | 51.38 |
| F-ConvNet | 89.69 | 83.08 | 74.56 | 58.9 | 50.48 | 46.72 | 82.59 | 68.62 | 60.62 |
| PointPainting | 92.45 | 88.11 | 83.36 | 58.7 | 49.93 | 46.29 | 83.91 | 71.54 | 62.97 |
| H23D RCNN | 92.85 | 88.87 | 86.07 | 58.14 | 50.43 | 46.72 | 82.76 | 67.90 | 60.49 |
| FusionPillars | 92.15 | 88.00 | 85.53 | 62.33 | 55.46 | 50.13 | 87.63 | 66.56 | 62.67 |
| SAS | Dense | PVC | Cars | Pedestrains | Cyclists |
|---|---|---|---|---|---|
| ✘ | ✘ | ✘ | 76.68 | 48.62 | 60.47 |
| ✔ | ✘ | ✘ | 76.71 | 48.89 | 60.92 |
| ✔ | ✔ | ✘ | 76.75 | 48.96 | 61.52 |
| ✘ | ✘ | ✔ | 76.69 | 49.01 | 62.56 |
| ✔ | ✔ | ✔ | 77.86 | 49.37 | 63.95 |
| Fea. Ext. Net. | Dua. Bac. | Det. Hea. | Car. | Ped. | Cyc. |
|---|---|---|---|---|---|
| ✘ | ✔ | ✘ | 77.86 | 49.37 | 63.95 |
| ✔ | ✔ | ✘ | 77.88 | 49.52 | 64.47 |
| ✘ | ✔ | ✔ | 77.93 | 49.47 | 64.81 |
| ✔ | ✔ | ✔ | 78.58 | 49.91 | 65.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Xu, D.; Li, Y.; Zhao, L.; Su, R. FusionPillars: A 3D Object Detection Network with Cross-Fusion and Self-Fusion. Remote Sens. 2023, 15, 2692. https://doi.org/10.3390/rs15102692
Zhang J, Xu D, Li Y, Zhao L, Su R. FusionPillars: A 3D Object Detection Network with Cross-Fusion and Self-Fusion. Remote Sensing. 2023; 15(10):2692. https://doi.org/10.3390/rs15102692
Chicago/Turabian StyleZhang, Jing, Da Xu, Yunsong Li, Liping Zhao, and Rui Su. 2023. "FusionPillars: A 3D Object Detection Network with Cross-Fusion and Self-Fusion" Remote Sensing 15, no. 10: 2692. https://doi.org/10.3390/rs15102692
APA StyleZhang, J., Xu, D., Li, Y., Zhao, L., & Su, R. (2023). FusionPillars: A 3D Object Detection Network with Cross-Fusion and Self-Fusion. Remote Sensing, 15(10), 2692. https://doi.org/10.3390/rs15102692