4.3. Ablation Study
Wavelet decomposition level: To determine the effect of wavelet decomposition levels on translation performance, we set different wavelet decomposition levels and explore their impact on translation performance. Experiments are conducted on the SEN1-2 dataset, and the results are shown in
Table 2.
With the increase of wavelet decomposition levels, the performance of the network for SAR-to-optical image translation is not improved. The values of RMSE and LPIPS between the generated pseudo-optical images and the real optical images increase, while PSNR and SSIM decrease in value as the number of decomposition levels increases. Additionally, because the number of decomposition levels increases, the training time of the network increases accordingly. Therefore, we choose the 2-level wavelet in our CFRWD-GAN model.
Number of discriminator branches: To determine the impact of different numbers of discriminator branches on translation performance, we set 2, 3, 4, and 5 discriminator branches in the CFRWD-GAN model, respectively. Experiments are performed on the SEN1-2 dataset, and the results are shown in
Table 3.
As the number of discriminator branches increases, the performance of CFRWD-GAN for SAR-to-optical image translation does not improve. When the number of discriminator branches is set to 2, the RMSE and LPIPS between pseudo-optical and real-optical images are the lowest among different numbers of discriminator branches. As the number of discriminator branches increases, the values of PSNR and SSIM decrease, which means that the translation performance becomes worsens. Therefore, we set the number of discriminator branches to 2 in the CFRWD-GAN model.
To confirm the validity of the CFRWD-GAN, experimentations are conducted with different conditions set on the S5, S45, S52, S84, and S100 datasets under the SEN1-2 spring folder.
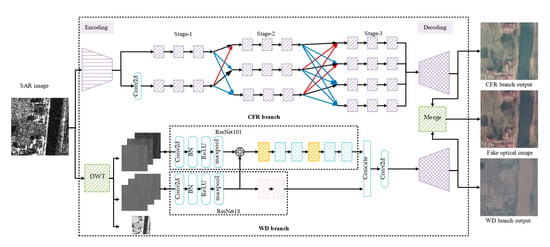
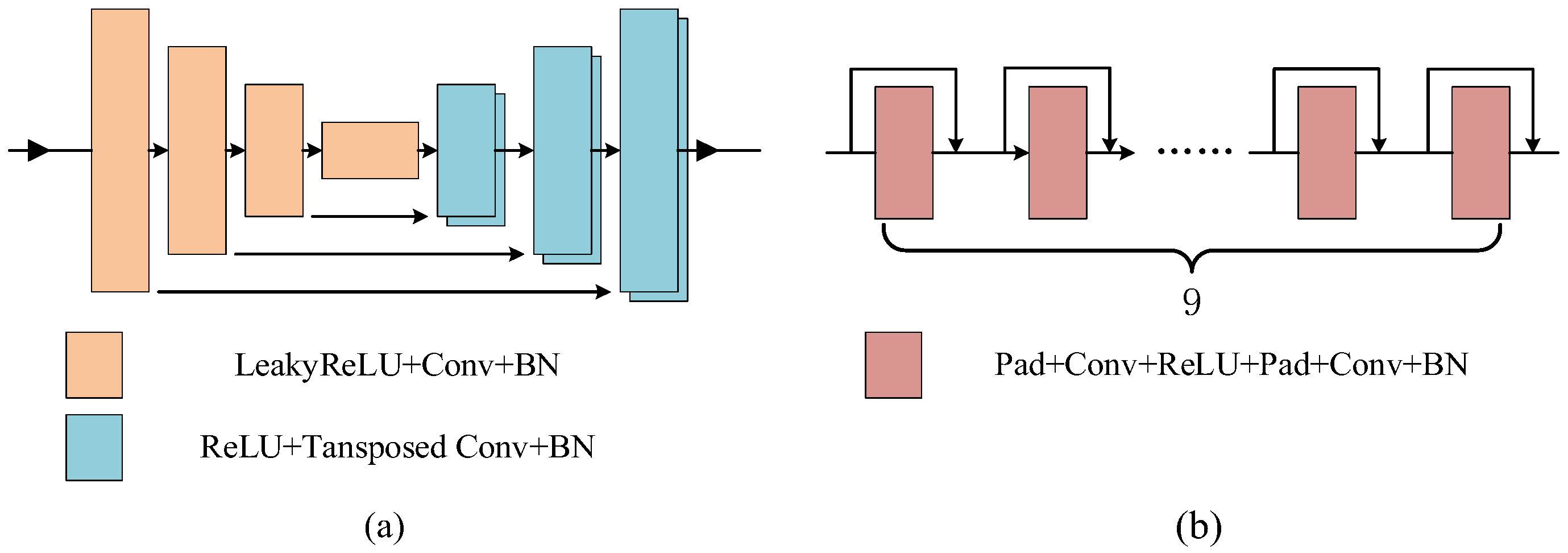
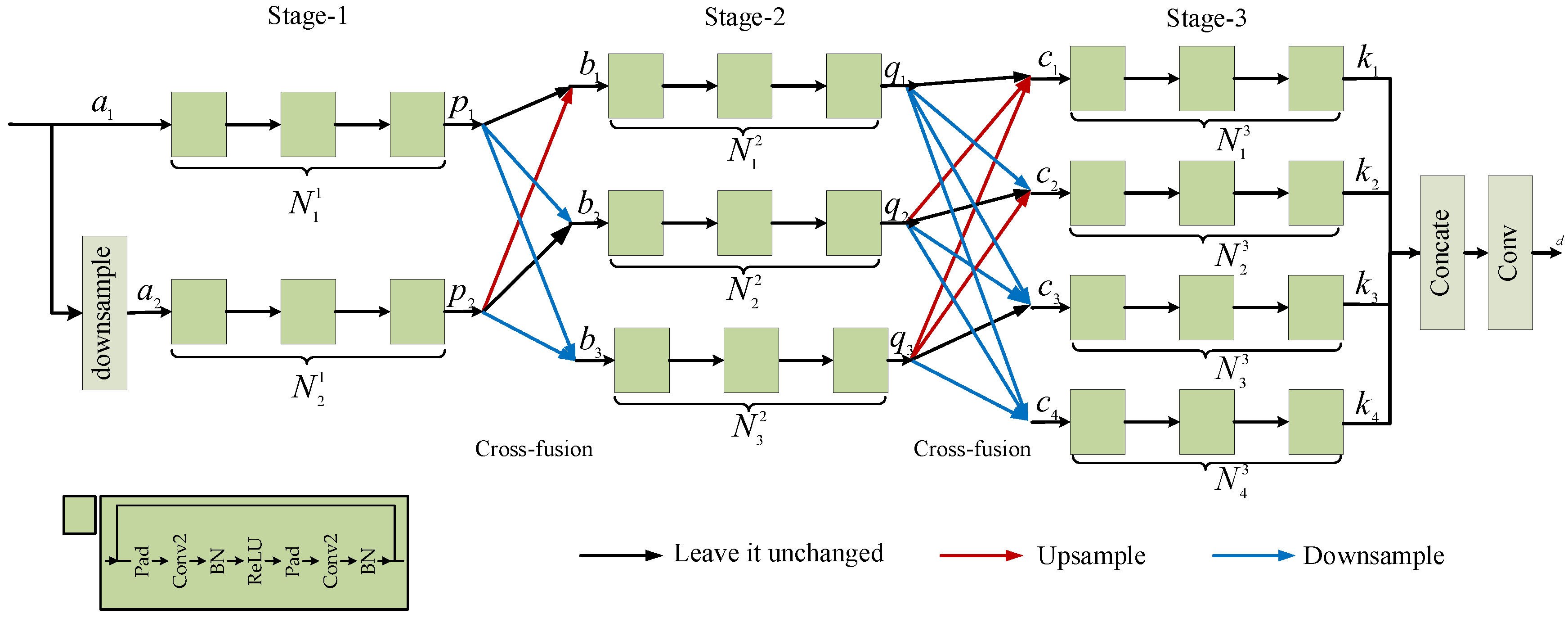
Cross-fusion reasoning structure: In order to translate different scales of SAR features to optical features, the CFR structure is presented to improve the output of the reasoning structure. The assessments are displayed in
Table 4. Compared with the U-Net reasoning structure and CN-ResBlocks reasoning structure, CFR provides PSNR of 4.7059, 4.1901, and 1.1917, 0.9898 improvements and achieves RMSE of 35.8079 and 45.5217, PSNR of 17.7668 and 15.2796, SSIM of 0.4083 and 0.2182, the LPIPS of 0.4739 and 0.5679, respectively, on dataset S5 and S45. The presentation of generated images on SEN1-2 is exhibited in
Figure 7. The particulars are marked with red boxes and magnified for presentation. In
Figure 7, column (a) are SAR images, from column (b) to column (d) are the images generated by the network with U-Net reasoning structure, the CN-ResBlocks reasoning structure, and the CFR structure, respectively. Column (e) are real optical images. As depicted in
Figure 7, images generated with the CFR structure have distinct outlines, clearer edges, and more exact details than images generated by other reasoning structures. In the first row, the residential area in column (d) is well translated compared with those in column (b) and column (c) and more similar to the optical image. In the second row, the edge of the lake in column (d) is clearer than those in column (b) and column (c). Moreover, in the third row, compared with column (b) and column (c), the road is translated perfectly in column (d). In the fourth row, from column (b) to column (d), the green part in the red box is gradually similar to the real one. In order to confirm that the CFR structure retains more feature information during the feature reasoning stage, we visualize the feature maps output from the CFR structure and the features inferred in the U-Net reasoning structure and CN-ResBlock reasoning structure. The visualization is displayed in
Figure 8.
Figure 8a–e is the feature maps output from the U-Net structure, the CN-ResBlock structure, and the CFR structure. According to
Figure 8, we can see that more feature information is clearly preserved in the CFR structure than in the other reasoning structures. In
Figure 8b, the reasoned features suffer many interferences from the encoding stage because of the direct connection between features in the coding stage and the features in the decoding stage. Compared with the reasoned features in
Figure 8d, the reasoned features in
Figure 8c lost other scale information because the feature reasoning was carried out at one scale. The reasoned features obtained by the CFR structure do not interfere with the encoding stage features. Additionally, in the reasoning time, different scale features are fused with each other avoiding incomplete feature reasoning. From these details, it is noticeable that the CFR structure can effectively retain more information than the other two reasoning structures and achieve better translation performance.
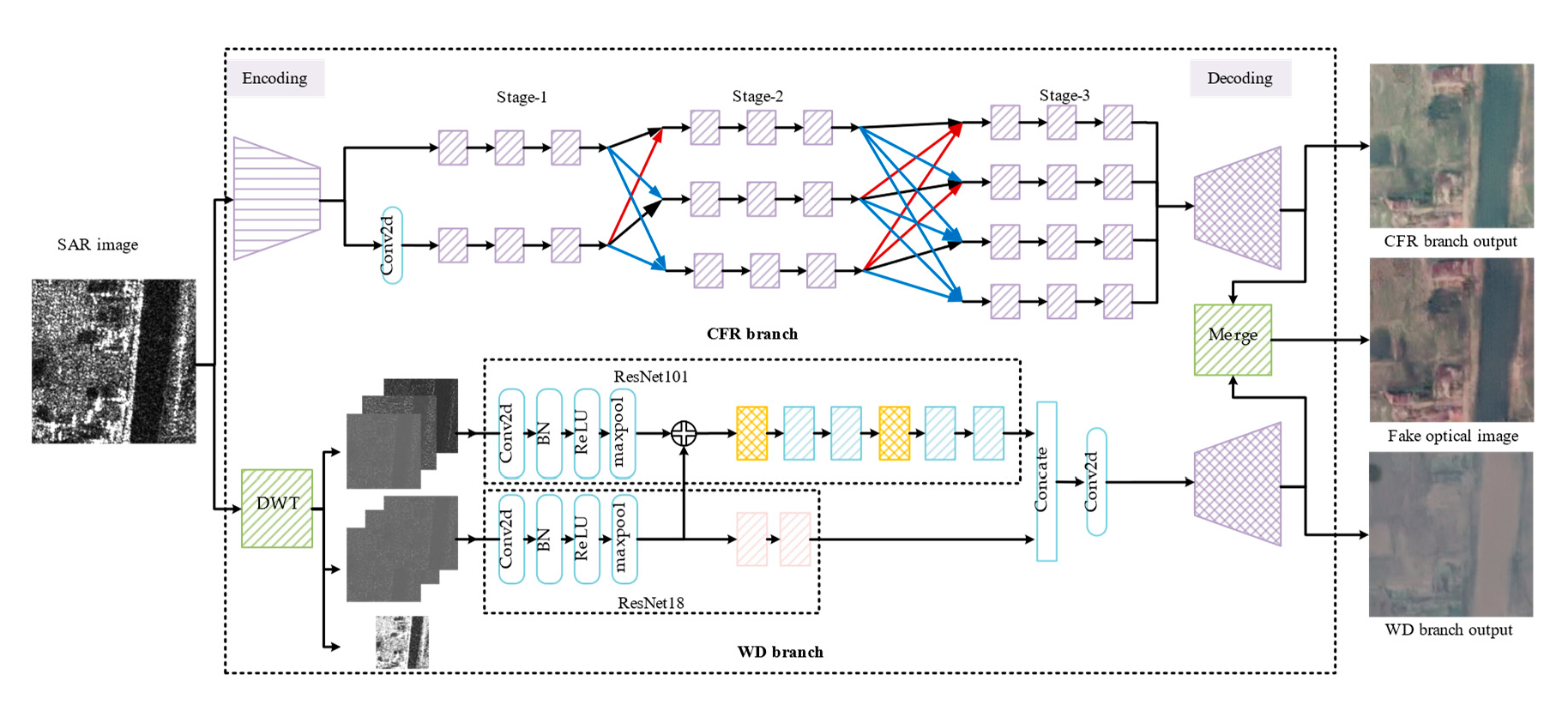
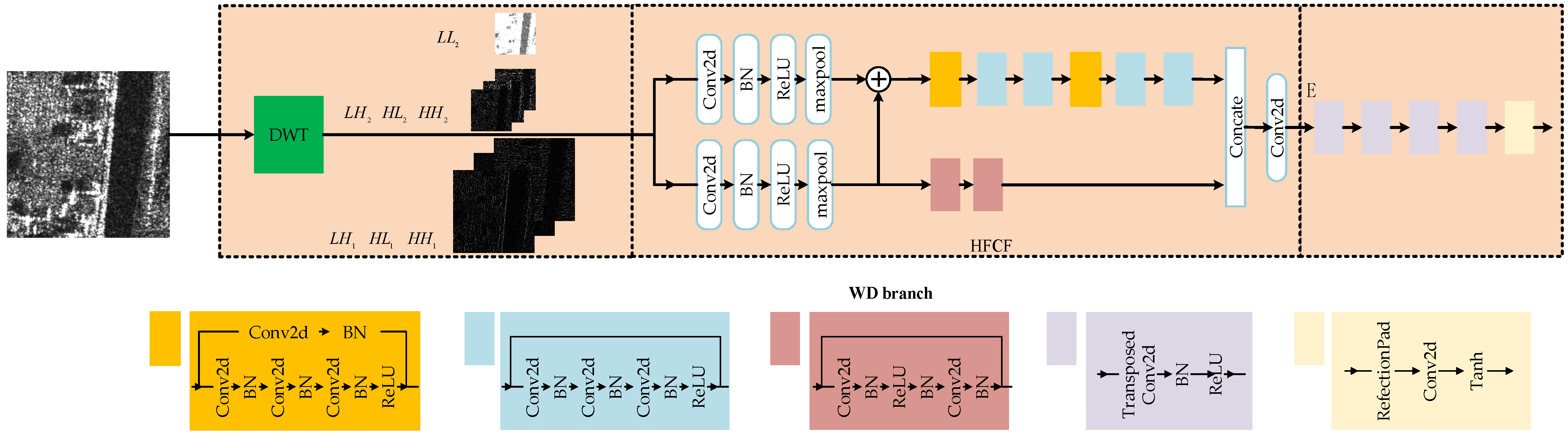
Wavelet Decomposition branch: In order to efficiently separate the frequency information and filter the noise contained in the high-frequency components, the wavelet decomposition branch is presented to enhance the details of the pseudo-optical image. The result of the quantitative evaluation is shown in
Table 5. Compared with the network without WD, the WD branch provides RMSE of 2.2659, PSNR of 0.3113, SSIM of 0.0591 and LPIPS of 0.0101 improvements and achieves RMSE of 33.5420, PSNR of 18.0781, SSIM of 0.4674, and LPIPS of 0.4638 on dataset S5. On dataset S84, the WD branch provides RMSE of 0.9183, PSNR of 0.2520, SSIM of 0.0473, and LPIPS of 0.0025 improvements and achieves RMSE of 33.1132, PSNR of 18.2131, SSIM of 0.4115, and LPIPS of 0.5105. It is obvious that the WD branch can effectively separate SAR images into muti-frequency components and filter the noise contained in high-frequency components of SAR images, and achieves better translation performance. The presentation of generated images on SEN1-2 is exhibited in
Figure 9. In
Figure 9, column (a) are SAR images, column (b) are images generated with the CFR structure, column (c) are images generated with the CFR structure and the WD branch, and column (f) are real optical images. As shown in
Figure 9, with the addition of the WD branch, the faint details in the SAR image translate well to the details in the pseudo-optical image. For example, in the first row of
Figure 9, the white road in the SAR image is covered with speckle noise and cannot be discerned by human eyes, while the white road is well translated in column (c). As shown in
Figure 9, the WD branch can separate the speckle noise and help recover the blurred part of SAR images to clear pseudo-optical images.
The output from the WD branch is exhibited in
Figure 10.
Figure 10a–e are SAR images, the outputs of the WD branch, the outputs of the branch based on CFR structure, the fusion results of the WD branch, and the branch based on CFR structure.
Figure 10e is the real optical image. As shown in
Figure 10, the high-frequency features in the SAR images are preserved and translated into optical features by the WD branch. In
Figure 10a, the high-frequency details are disturbed by speckle noise and unclearly present in SAR images, resulting in vague object edges in
Figure 10b. However, the WD branch is able to separate high-frequency features from SAR images containing speckle noise. As shown in
Figure 10c, the WD branch outputs distinct object edges. Combining the results of CFR and WD branches, the pseudo-optical images with clear edges are generated, as shown in
Figure 10d, which are close to real optical images.
Two sub-branches discriminator: In order to distinguish the images from different scales, two sub-branches are constructed in the discriminator. The result of the quantitative metric is shown in
Table 5. Compared with single scale discriminator, two sub-branches discriminator provides RMSE of 0.7298, PSNR of 0.3964, SSIM of 0.0739, and LPIPS of 0.0178 improvements and achieves RMSE of 32.3843, PSNR of 18.6095, SSIM of 0.4854, and LPIPS of 0.4927 on dataset S84. The assessment of five datasets shows that two sub-branches discriminator improves the quality of the pseudo-optical images. In
Figure 9c, the WD branch recovers detailed edge information; however, the width of edges is still thick, which might be caused by the discriminator that only authenticates the image on one scale. After adding the two sub-branch discriminators, the edges become thinner and close to the edges in real optical images.
loss function: In order to guide the generating of images on different scales and stable the training of the network,
loss function is used in CFRWD-GAN to enhance the output of the network. The result of the quantitative evaluation is displayed in
Table 5. In
Table 5, the pseudo-optical images generated with
loss have increased SSIM value and reduced LPIPS value compared without
loss. Specifically, compared without
used in training,
provides RMSE of 1.2182, PSNR of 0.6336, SSIM of 0.1049, and LPIPS of 0.0802 improvements and achieves RMSE of 31.1652, PSNR of 19.2431, SSIM of 0.5903, and LPIPS of 0.4125 on dataset S84. Qualitative representation is displayed in
Figure 9. Part particulars are annotated with red boxes and magnified for a clear presentation. The results in
Figure 9e show that
loss works well on the texture restoration of pseudo-optical images. In
Figure 9e, the texture and details in pseudo-optical images are clearer than those in
Figure 9d.
loss helps the CFRWD-GAN model generate pseudo-optical images from different levels of features, and finally, pseudo-optical images are gained with true texture information and clear edge information.
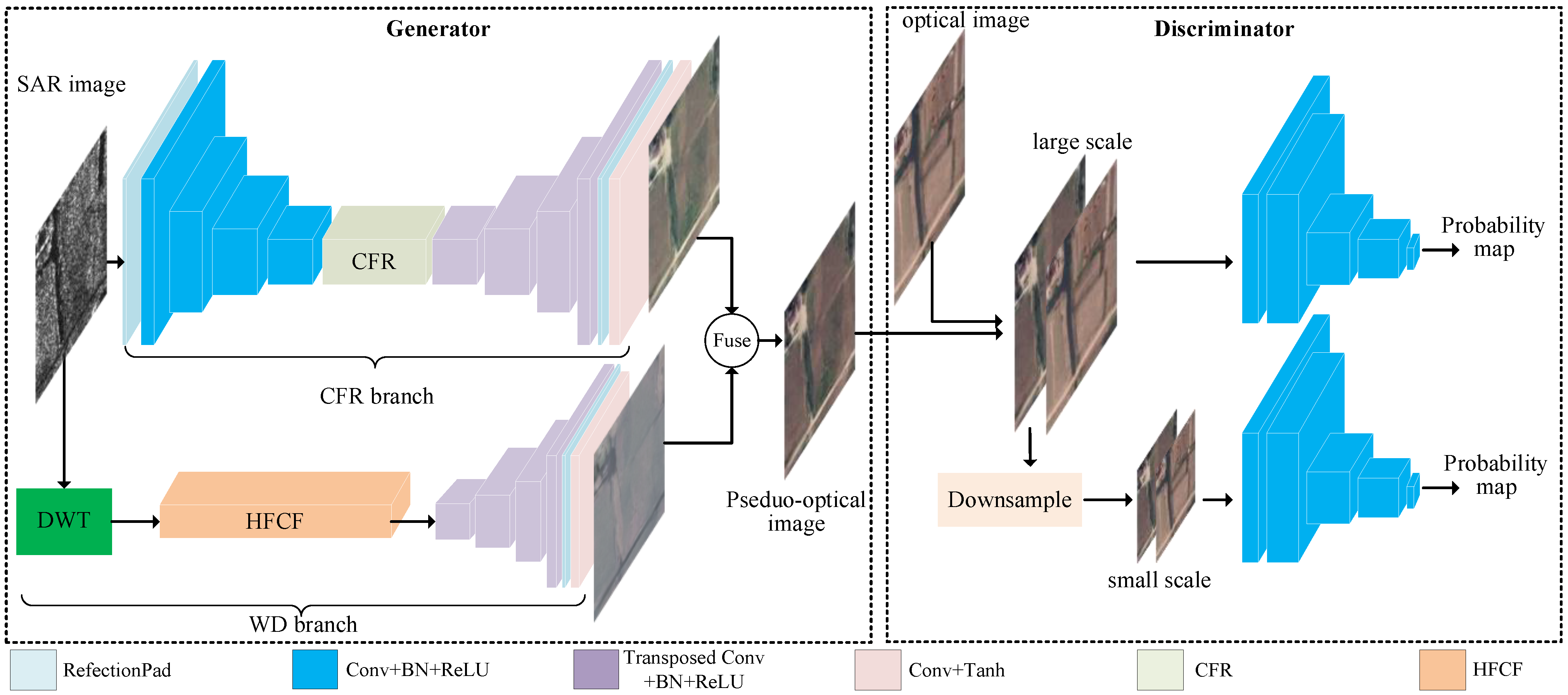
4.4. Comparison Experiments
To validate the effectiveness of the CFRWD-GAN, comparative experiments with pix2pix [
11], cycleGAN [
12], S-cycleGAN [
21], NICEGAN [
15], and GANILILA [
42] are represented on the QXS-SAROPT and SEN1-2. The quantitative comparison results are displayed in
Table 6 and
Table 7, and the best results are marked in boldface. In QXS-SAROPT, the CFRWD-GAN attains the highest values of the PSNR and SSIM among the six models. Regarding LPIPS, the value is the lowest among the six methods, indicating that the pseudo-optical images generated by CFRWD-GAN are better and similar to the ground truth. Regarding SSIM, Our CFR-GAN improved by 30.01%, 27.39%, 17.13%, 34.76%, and 193.60% compared with pix2pix, cycleGAN, S-cycleGAN, NICEGAN, and GANILLA, respectively.
In the SEN1-2 dataset, it is undeniable that not all metrics of CFRWD-GAN are optimal among the six methods; however, in terms of SSIM and LPIPS, CFRWD-GAN has achieved the best results, indicating promising translation performance. Our model achieves SSIM of 0.5619, 0.4884, 0.5414, 0.7168, and 0.4854 on S5, S45, S52, S84, and S100, respectively.
Qualitative experimental results on QXS-SAROPT are shown in
Figure 11. From column (b) to column (h), the image quality is gradually improving. To compare details of the pseudo-optical images, particulars are marked with red boxes in
Figure 11. In the first row of
Figure 11, the images generated by CFRWD-GAN have a clearer white road than other methods. Moreover, the image generated by CFRWD-GAN in the second row is almost as clear as the ground truth, and the red house is more distinct than other methods. By observing images of the third row in
Figure 11, we find that the proposed CFR-GAN retains color information better and consistently than other methods. Furthermore, in the fourth row of
Figure 11, the texture in the image gained by CFRWD-GAN is clearer than the other five methods.
More examples of pseudo-optical images generated in the SEN1-2 dataset are shown in
Figure 12. Some details are marked with red boxes. As shown in
Figure 12, our CFRWD-GAN model can generate higher-quality pseudo-optical images than the alternative methods.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}