




Comparison of Machine Learning Algorithms for Flood Susceptibility Mapping

 , ,
, ,  ,
,  and
and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Areas
2.2. Flood Samples
2.3. Flood Conditioning Factors
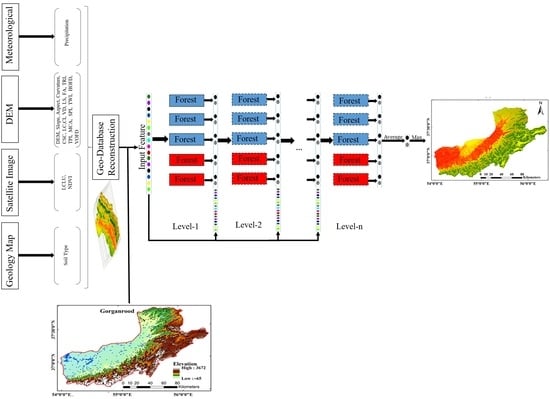
2.4. Cascade Forest Model (CFM)
2.5. Feature Selection
2.6. Accuracy Assessment
3. Results
3.1. Variable Dependency
3.2. FSM of the Karun Basin
3.3. FSM of the Gorganrud Basin
4. Discussion
4.1. Accuracy of the Proposed CFM
4.2. Flood Susceptible Areas
4.3. Feature Selection
4.4. Model Generalization
4.5. Dimension Reduction Impact on FSM
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Seydi, S.T.; Hasanlou, M.; Chanussot, J. Burnt-Net: Wildfire burned area mapping with single post-fire Sentinel-2 data and deep learning morphological neural network. Ecol. Indic. 2022, 140, 108999. [Google Scholar] [CrossRef]
- Shimada, G. The impact of climate-change-related disasters on africa’s economic growth, agriculture, and conflicts: Can humanitarian aid and food assistance offset the damage? Int. J. Environ. Res. Public Health 2022, 19, 467. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Luo, C.; Zhao, Z. Application of probabilistic method in maximum tsunami height prediction considering stochastic seabed topography. Nat. Hazards 2020, 104, 2511–2530. [Google Scholar] [CrossRef]
- Mahdavi, S.; Salehi, B.; Huang, W.; Amani, M.; Brisco, B. A PolSAR change detection index based on neighborhood information for flood mapping. Remote Sens. 2019, 11, 1854. [Google Scholar] [CrossRef]
- Glago, F.J. Flood disaster hazards; causes, impacts and management: A state-of-the-art review. In Natural Hazards-Impacts, Adjustments and Resilience; IntechOpen: London, UK, 2021. [Google Scholar] [CrossRef]
- Seydi, S.T.; Saeidi, V.; Kalantar, B.; Ueda, N.; van Genderen, J.; Maskouni, F.H.; Aria, F.A. Fusion of the Multisource Datasets for Flood Extent Mapping Based on Ensemble Convolutional Neural Network (CNN) Model. J. Sens. 2022, 2022, 2887502. [Google Scholar] [CrossRef]
- Kinouchi, T.; Sayama, T. A comprehensive assessment of water storage dynamics and hydroclimatic extremes in the Chao Phraya River Basin during 2002–2020. J. Hydrol. 2021, 603, 126868. [Google Scholar]
- Sharifipour, M.; Amani, M.; Moghimi, A. Flood Damage Assessment Using Satellite Observations within the Google Earth Engine Cloud Platform. J. Ocean Technol. 2022, 17, 65–75. [Google Scholar]
- Parsian, S.; Amani, M.; Moghimi, A.; Ghorbanian, A.; Mahdavi, S. Flood hazard mapping using fuzzy logic, analytical hierarchy process, and multi-source geospatial datasets. Remote Sens. 2021, 13, 4761. [Google Scholar] [CrossRef]
- Duan, Y.; Xiong, J.; Cheng, W.; Wang, N.; He, W.; He, Y.; Liu, J.; Yang, G.; Wang, J.; Yang, J. Assessment and spatiotemporal analysis of global flood vulnerability in 2005–2020. Int. J. Disaster Risk Reduct. 2022, 80, 103201. [Google Scholar] [CrossRef]
- Pollack, A.B.; Sue Wing, I.; Nolte, C. Aggregation bias and its drivers in large-scale flood loss estimation: A Massachusetts case study. J. Flood Risk Manag. 2022, 15, e12851. [Google Scholar] [CrossRef]
- Abd Rahman, N.; Tarmudi, Z.; Rossdy, M.; Muhiddin, F.A. Flood mitigation measres using intuitionistic fuzzy dematel method. Malays. J. Geosci. 2017, 1, 1–5. [Google Scholar] [CrossRef]
- Gazi, M.Y.; Islam, M.A.; Hossain, S. flood-hazard mapping in a regional scale way forward to the future hazard atlas in Bangladesh. Malays. J. Geosci. 2019, 3, 1–11. [Google Scholar] [CrossRef]
- Khojeh, S.; Ataie-Ashtiani, B.; Hosseini, S.M. Effect of DEM resolution in flood modeling: A case study of Gorganrood River, Northeastern Iran. Nat. Hazards 2022, 112, 2673–2693. [Google Scholar] [CrossRef]
- Parizi, E.; Khojeh, S.; Hosseini, S.M.; Moghadam, Y.J. Application of Unmanned Aerial Vehicle DEM in flood modeling and comparison with global DEMs: Case study of Atrak River Basin, Iran. J. Environ. Manag. 2022, 317, 115492. [Google Scholar] [CrossRef]
- Balogun, A.-L.; Sheng, T.Y.; Sallehuddin, M.H.; Aina, Y.A.; Dano, U.L.; Pradhan, B.; Yekeen, S.; Tella, A. Assessment of data mining, multi-criteria decision making and fuzzy-computing techniques for spatial flood susceptibility mapping: A comparative study. Geocarto Int. 2022, 1–27. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pradhan, B.; Dikshit, A.; Mahdi, A.M. Comparative study of convolutional neural network (CNN) and support vector machine (SVM) for flood susceptibility mapping: A case study at Ras Gharib, Red Sea, Egypt. Geocarto Int. 2022, 1–28. [Google Scholar] [CrossRef]
- Ha, H.; Bui, Q.D.; Nguyen, H.D.; Pham, B.T.; Lai, T.D.; Luu, C. A practical approach to flood hazard, vulnerability, and risk assessing and mapping for Quang Binh province, Vietnam. Environ. Dev. Sustain. 2022, 1–30. [Google Scholar] [CrossRef]
- Mudashiru, R.B.; Sabtu, N.; Abustan, I. Quantitative and semi-quantitative methods in flood hazard/susceptibility mapping: A review. Arab. J. Geosci. 2021, 14, 1–24. [Google Scholar]
- Vojinović, Z.; Golub, D.; Weesakul, S.; Keerakamolchai, W.; Hirunsalee, S.; Meesuk, V.; Sanchez-Torres, A.; Kumara, S. Merging Quantitative and Qualitative Analyses for Flood Risk Assessment at Heritage Sites, The Case of Ayutthaya, Thailand. In Proceedings of the 11th International Conference on Hydroinformatics, New York, NY, USA, 17–21 August 2014. [Google Scholar]
- Kanani-Sadat, Y.; Arabsheibani, R.; Karimipour, F.; Nasseri, M. A new approach to flood susceptibility assessment in data-scarce and ungauged regions based on GIS-based hybrid multi criteria decision-making method. J. Hydrol. 2019, 572, 17–31. [Google Scholar] [CrossRef]
- Pathan, A.I.; Girish Agnihotri, P.; Said, S.; Patel, D. AHP and TOPSIS based flood risk assessment-a case study of the Navsari City, Gujarat, India. Environ. Monit. Assess. 2022, 194, 1–37. [Google Scholar]
- Dano, U.L. An AHP-based assessment of flood triggering factors to enhance resiliency in Dammam, Saudi Arabia. GeoJournal 2022, 87, 1945–1960. [Google Scholar] [CrossRef]
- Chang, L.-C.; Liou, J.-Y.; Chang, F.-J. Spatial-temporal flood inundation nowcasts by fusing machine learning methods and principal component analysis. J. Hydrol. 2022, 612, 128086. [Google Scholar] [CrossRef]
- Ahmad, M.; Al Mehedi, M.A.; Yazdan, M.M.S.; Kumar, R. Development of Machine Learning Flood Model Using Artificial Neural Network (ANN) at Var River. Liquids 2022, 2, 147–160. [Google Scholar] [CrossRef]
- Chen, H.; Yang, D.; Hong, Y.; Gourley, J.J.; Zhang, Y. Hydrological data assimilation with the Ensemble Square-Root-Filter: Use of streamflow observations to update model states for real-time flash flood forecasting. Adv. Water Resour. 2013, 59, 209–220. [Google Scholar] [CrossRef]
- Anjum, M.N.; Ding, Y.; Shangguan, D.; Tahir, A.A.; Iqbal, M.; Adnan, M. Comparison of two successive versions 6 and 7 of TMPA satellite precipitation products with rain gauge data over Swat Watershed, Hindukush Mountains, Pakistan. Atmos. Sci. Lett. 2016, 17, 270–279. [Google Scholar] [CrossRef]
- Batelaan, O.; De Smedt, F. WetSpass: A flexible, GIS based, distributed recharge methodology for regional groundwater. In Impact of Human Activity on Groundwater Dynamics, Proceedings of the International Symposium (Symposium S3) Held During the Sixth Scientific Assembly of the International Association of Hydrological Sciences (IAHS), Maastricht, The Netherlands, 18–27 July 2001; International Association of Hydrological Sciences: Wallingford, UK, 2001; p. 11. [Google Scholar]
- Liu, Z.; Martina, M.L.; Todini, E. Flood forecasting using a fully distributed model: Application of the TOPKAPI model to the Upper Xixian Catchment. Hydrol. Earth Syst. Sci. 2005, 9, 347–364. [Google Scholar] [CrossRef]
- Liu, J.; Xiong, J.; Cheng, W.; Li, Y.; Cao, Y.; He, Y.; Duan, Y.; He, W.; Yang, G. Assessment of flood susceptibility using support vector machine in the belt and road region. Nat. Hazards Earth Syst. Sci. Discuss. 2021, 1–37. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Ataie-Ashtiani, B.; Hosseini, S.M. Comparison of statistical and mcdm approaches for flood susceptibility mapping in northern iran. J. Hydrol. 2022, 612, 128072. [Google Scholar] [CrossRef]
- Tung, Y.-K. River flood routing by nonlinear Muskingum method. J. Hydraul. Eng. 1985, 111, 1447–1460. [Google Scholar] [CrossRef]
- Prasad, P.; Loveson, V.J.; Das, B.; Kotha, M. Novel ensemble machine learning models in flood susceptibility mapping. Geocarto Int. 2022, 37, 4571–4593. [Google Scholar] [CrossRef]
- Avand, M.; Kuriqi, A.; Khazaei, M.; Ghorbanzadeh, O. DEM resolution effects on machine learning performance for flood probability mapping. J. Hydro-Environ. Res. 2022, 40, 1–16. [Google Scholar] [CrossRef]
- Saber, M.; Boulmaiz, T.; Guermoui, M.; Abdrabo, K.I.; Kantoush, S.A.; Sumi, T.; Boutaghane, H.; Nohara, D.; Mabrouk, E. Examining LightGBM and CatBoost models for wadi flash flood susceptibility prediction. Geocarto Int. 2021, 1–26. [Google Scholar] [CrossRef]
- Ma, M.; Zhao, G.; He, B.; Li, Q.; Dong, H.; Wang, S.; Wang, Z. XGBoost-based method for flash flood risk assessment. J. Hydrol. 2021, 598, 126382. [Google Scholar] [CrossRef]
- Ha, M.C.; Vu, P.L.; Nguyen, H.D.; Hoang, T.P.; Dang, D.D.; Dinh, T.B.H.; Şerban, G.; Rus, I.; Brețcan, P. Machine Learning and Remote Sensing Application for Extreme Climate Evaluation: Example of Flood Susceptibility in the Hue Province, Central Vietnam Region. Water 2022, 14, 1617. [Google Scholar] [CrossRef]
- Yaseen, A.; Lu, J.; Chen, X. Flood susceptibility mapping in an arid region of Pakistan through ensemble machine learning model. Stoch. Environ. Res. Risk Assess. 2022, 36, 3041–3061. [Google Scholar] [CrossRef]
- Costache, R.; Țîncu, R.; Elkhrachy, I.; Pham, Q.B.; Popa, M.C.; Diaconu, D.C.; Avand, M.; Costache, I.; Arabameri, A.; Bui, D.T. New neural fuzzy-based machine learning ensemble for enhancing the prediction accuracy of flood susceptibility mapping. Hydrol. Sci. J. 2020, 65, 2816–2837. [Google Scholar] [CrossRef]
- Seydi, S.T.; Hasanlou, M.; Chanussot, J. DSMNN-Net: A Deep Siamese Morphological Neural Network Model for Burned Area Mapping Using Multispectral Sentinel-2 and Hyperspectral PRISMA Images. Remote Sens. 2021, 13, 5138. [Google Scholar] [CrossRef]
- Seydi, S.T.; Shah-Hosseini, R.; Amani, M. A Multi-Dimensional Deep Siamese Network for Land Cover Change Detection in Bi-Temporal Hyperspectral Imagery. Sustainability 2022, 14, 12597. [Google Scholar] [CrossRef]
- Liao, L.; Du, L.; Guo, Y. Semi-supervised SAR target detection based on an improved faster R-CNN. Remote Sens. 2021, 14, 143. [Google Scholar] [CrossRef]
- Seydi, S.T.; Hasanlou, M.; Amani, M.; Huang, W. Oil spill detection based on multiscale multidimensional residual CNN for optical remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10941–10952. [Google Scholar] [CrossRef]
- Seydi, S.T.; Hasanlou, M.; Chanussot, J. A Quadratic Morphological Deep Neural Network Fusing Radar and Optical Data for the Mapping of Burned Areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4194–4216. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, L. A new lightweight network based on MobileNetV3. KSII Trans. Internet Inf. Syst. (TIIS) 2022, 16, 1–15. [Google Scholar]
- Chen, J.; Du, L.; Guo, Y. Label constrained convolutional factor analysis for classification with limited training samples. Inf. Sci. 2021, 544, 372–394. [Google Scholar] [CrossRef]
- Zhou, Z.-H.; Feng, J. Deep forest. Natl. Sci. Rev. 2019, 6, 74–86. [Google Scholar] [CrossRef]
- Zhou, Z.-H.; Feng, J. Deep Forest: Towards An Alternative to Deep Neural Networks. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 3553–3559. [Google Scholar]
- Jamali, A.; Mahdianpari, M.; Brisco, B.; Granger, J.; Mohammadimanesh, F.; Salehi, B. Deep Forest classifier for wetland mapping using the combination of Sentinel-1 and Sentinel-2 data. GIScience Remote Sens. 2021, 58, 1072–1089. [Google Scholar] [CrossRef]
- Yang, F.; Xu, Q.; Li, B.; Ji, Y. Ship detection from thermal remote sensing imagery through region-based deep forest. IEEE Geosci. Remote Sens. Lett. 2018, 15, 449–453. [Google Scholar] [CrossRef]
- Cheng, J.; Chen, M.; Li, C.; Liu, Y.; Song, R.; Liu, A.; Chen, X. Emotion recognition from multi-channel eeg via deep forest. IEEE J. Biomed. Health Inform. 2020, 25, 453–464. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, H.; Rao, Z.; Ji, H. Hyperspectral imaging technology combined with deep forest model to identify frost-damaged rice seeds. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 229, 117973. [Google Scholar] [CrossRef] [PubMed]
- Mahdavi, S.; Salehi, B.; Amani, M.; Granger, J.; Brisco, B.; Huang, W. A dynamic classification scheme for mapping spectrally similar classes: Application to wetland classification. Int. J. Appl. Earth Obs. Geoinf. 2019, 83, 101914. [Google Scholar] [CrossRef]
- Taradeh, M.; Mafarja, M.; Heidari, A.A.; Faris, H.; Aljarah, I.; Mirjalili, S.; Fujita, H. An evolutionary gravitational search-based feature selection. Inf. Sci. 2019, 497, 219–239. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Seydi, S.T.; Akhoondzadeh, M.; Amani, M.; Mahdavi, S. Wildfire damage assessment over Australia using sentinel-2 imagery and MODIS land cover product within the google earth engine cloud platform. Remote Sens. 2021, 13, 220. [Google Scholar] [CrossRef]
- Islam, M.Z.; Wahab, N.I.A.; Veerasamy, V.; Hizam, H.; Mailah, N.F.; Guerrero, J.M.; Mohd Nasir, M.N. A Harris Hawks optimization based single-and multi-objective optimal power flow considering environmental emission. Sustainability 2020, 12, 5248. [Google Scholar] [CrossRef]
- Arabameri, A.; Chandra Pal, S.; Costache, R.; Saha, A.; Rezaie, F.; Seyed Danesh, A.; Pradhan, B.; Lee, S.; Hoang, N.-D. Prediction of gully erosion susceptibility mapping using novel ensemble machine learning algorithms. Geomat. Nat. Hazards Risk 2021, 12, 469–498. [Google Scholar] [CrossRef]
- Kaiser, M.; Günnemann, S.; Disse, M. Regional-scale prediction of pluvial and flash flood susceptible areas using tree-based classifiers. J. Hydrol. 2022, 612, 128088. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Study Area | Number of Samples | Percentage (%) | Non-Flood | Flood |
|---|---|---|---|---|---|
| Training | Karun | 1123 | 27 | 747 | 376 |
| Gorganrud | 383 | 30 | 211 | 172 | |
| Test | Karun | 3037 | 73 | 2029 | 1008 |
| Gorganrud | 895 | 70 | 476 | 419 | |
| Total | Karun | 4160 | 100 | 2776 | 1384 |
| Gorganrud | 1278 | 100 | 687 | 591 |
| Factor | Description | Basin | Resolution | Source | |
|---|---|---|---|---|---|
| Gorganrud | Karun | ||||
| Digital Elevation Model (DEM) | Elevation is one of the most significant criteria in identifying flood susceptible areas. Areas with lower elevation values are more likely to experience flood. | Max: 3672 Min: −65 | Max: 4418 Min: −66 | 30 m | SRTM 1 |
| Slope | Slope is a criterion that controls run off and flow velocity in a way that the possibility of flood events is accelerated in flat areas. | Max: 3927 Min: 0 | Max: 833 Min: 0 | 30 m | DEM |
| Aspect | Aspect examines the direction of slope which affects many features, such as water flow direction, receiving precipitation, land cover scheme and sunshine. | Max: 359 Min: −1 | Max: 359 Min: 0 | 30 m | DEM |
| Curvature | Geomorphological characteristics of the surface is determined by this criterion which has three classes, namely, convex, concave and flat. | Max: 397 Min: −494 | Max: 193 Min: −138 | 30 m | DEM |
| Plan Curvature | This morphometric criterion identifies the type of surface runoff, and whether it is convergent or divergent and controls the water movement. | Max: 0.467 Min: −0.424 | Max: 0.13 Min: −0.07 | 30 m | DEM |
| Profile Curvature | The level of runoff, whether it is high or low, is identified using this morphometric factor. | Max: 0.475 Min: −0.455 | Max: 0.09 Min: −0.09 | 30 m | DEM |
| Convergence Index | This morphometric criterion corresponds to the river valleys and interfluvial areas using negative and higher than zero values, respectively. | Max: 99 Min: −99 | Max: 99 Min: −99 | 30 m | DEM |
| Valley Depth | This measure estimates the vertical distance from interpolated ridge level to a river network base level for each pixel. | Max: 2222 Min: 0 | Max: 1543 Min: 0 | 30 m | DEM |
| LS Factor (LS) | This quantity has two components, slope length and slope steepness, and it defines the impact of topography on soil erosion. | Max: 248 Min: 0 | Max: 2281 Min: 0 | 30 m | DEM |
| Flow Accumulation (FA) | For each pixel, this criterion indicates the number of pixels which flow into it. Therefore, there is a direct relationship between this factor and flood occurrence possibility. | Max: 1.15 × 1010 Min: 900 | Max: 6.19 × 1010 Min: 0 | 30 m | DEM |
| Terrain Ruggedness Index (TRI) | This criterion calculates the elevation difference among a pixel and its adjacent pixels. Flood susceptible areas have a lower TRI value. | Max: 1815 Min: 0 | Max: 390 Min: 0 | 30 m | DEM |
| Topographic Position Index (TPI) | This criterion identifies valleys, ridges, or flat parts of the landscape. Positive and negative values of TPI indicate valleys and ridges, respectively. | Max: 238 Min: −2072 | Max: 461 Min: −332 | 30 m | DEM |
| Modified Catchment Area (MCA) | Catchment area is the area of the upstream watershed. In order to not consider the flow as a thin layer, the modified catchment area can be used to obtain more realistic results. | Max: 1.32 × 1010 Min: 0 | Max: 5.95 × 1010 Min: 909 | 30 m | DEM |
| Stream Power Index (SPI) | This hydrological criterion measures the erosive power of the runoff and discharge degree within the catchment area. A higher value of SPI indicates the higher potential of flood occurrence. | Max: 1.61 × 109 Min: 0 | Max: 1.61 × 109 Min: 0 | 30 m | DEM |
| Topographic Wetness Index (TWI) | This index predicts the regions which have a high potential to witness overland runoff. There is a direct relationship between TWI and flooding. | Max: 16 Min: −2 | Max: 27 Min: 1.6 | 30 m | DEM |
| Horizontal Overland Flow Distance (HOFD) | Instead of Euclidean distance from the river network, the horizontal component of water flow is considered. This criterion computes the actual movement of water flow from each pixel to others. Areas with lower value of HOFD are more prone to flooding. | Max: 15,931 Min: 0 | Max: 3008 Min: 0 | 30 m | DEM and Stream |
| Vertical Overland Flow Distance (VOFD) | VOFD is the vertical height difference between each cell and the river network. Areas with lower value of VOFD are more susceptible to flooding. | Max: 1765 Min: 0 | Max: 2581 Min: 0 | 30 m | DEM and Stream |
| Curve Number | This criterion consists of land use data and soil map, and measures the permeability feature of the surface. The amount of penetration is low in areas with high CN values. | Max: 94 Min: 72 | Max: 94 Min: 68 | 250 m | Soil and LULC |
| Land Use/Land Cover (LULC) | The hydrological processes, such as runoff, permeability and evaporation and sediment transportation, vary based on LULC types. | 8 classes | 8 classes | 10 m | ESA 2 |
| Normalized Difference Vegetation Index (NDVI) | NDVI is used to examine the vegetation coverage of the area. There is a negative correlation between compact vegetation cover and flooding. | Max: 0.56 Min: −0.28 | Max: 0.49 Min: −0.19 | 30 m | Landsat Satellite Images |
| Modified Fournier Index (MFI) | The level of precipitation is determined using this criterion. MFI is calculated using monthly and annual average values of rainfall. | Max: 37 Min: 14 | Max: 119 Min: 12 | 30 m | Precipitation |
| Method | Optimum Value |
|---|---|
| SVM | Radial Basis Function (RBF) kernel function parameter 10−3, and penalty coefficient 102 |
| RF | Number of trees 155, and the number of randomly selected predictor variables 5 |
| DNN | Number of layers = 5, activation function = rectified linear unit (Relu), number of hidden layers = [150,150,150], weight-initializer = He-Normal, optimizer = ADAM, dropout rate = 0.18 |
| LightGBM | Number of estimators = 150, learning rate = 0.1, regularization parameter = 0.9, number of leaves = 150, and maximum depth = 9 |
| CatBoost | Number of estimators = 105, learning rate = 0.1, and subsample ratio = 0.9 |
| XGBoost | Number of estimators = 105, learning rate = 0.1, maximum depth = 20, and subsample ratio = 0.7 |
| CFM | Number of bins = 90, the maximum number of layers = 8, number of estimator = 5, number of trees = 170, maximum depth = 8, and predictor = XGboost. |
| Method | OA (%) | F1-Score (%) | BA (%) | IOU | KC |
|---|---|---|---|---|---|
| SVM | 85.34 | 78.47 | 84.11 | 0.646 | 0.673 |
| RF | 92.98 | 89.29 | 91.75 | 0.806 | 0.840 |
| DNN | 87.72 | 80.10 | 84.39 | 0.668 | 0.713 |
| Decision Tree | 90.25 | 85.17 | 88.76 | 0.741 | 0.779 |
| LightGBM | 93.64 | 90.16 | 92.17 | 82.09 | 0.855 |
| CatBoost | 93.58 | 90.00 | 92.05 | 0.819 | 0.853 |
| XGBoost | 93.58 | 90.14 | 92.29 | 0.820 | 0.854 |
| CFM | 94.04 | 90.92 | 92.99 | 0.833 | 0.865 |
| Method | OA (%) | F1-Score (%) | BA (%) | IOU | KC |
|---|---|---|---|---|---|
| SVM | 90.83 | 89.54 | 90.41 | 0.811 | 0.815 |
| RF | 88.94 | 87.82 | 88.71 | 0.783 | 0.777 |
| DNN | 86.70 | 83.98 | 85.97 | 0.724 | 0.729 |
| Decision Tree | 87.60 | 86.64 | 87.50 | 0.764 | 0.751 |
| LightGBM | 90.39 | 89.64 | 90.29 | 0.812 | 0.807 |
| CatBoost | 91.51 | 90.57 | 91.24 | 0.828 | 0.829 |
| XGBoost | 89.27 | 88.85 | 89.58 | 0.799 | 0.793 |
| CFM | 92.40 | 91.60 | 92.17 | 0.845 | 0.847 |
| Model | OA (%) | F1-Score (%) | BA (%) | IOU | KC |
|---|---|---|---|---|---|
| SVM | 65.62 | 62.85 | 71.40 | 0.458 | 0.355 |
| RF | 50.41 | 56.30 | 62.26 | 0.392 | 0.179 |
| DNN | 70.43 | 65.57 | 74.26 | 0.487 | 0.420 |
| Decision Tree | 49.34 | 55.79 | 61.49 | 0.387 | 0.167 |
| LightGBM | 59.17 | 60.32 | 68.10 | 0.431 | 0.281 |
| CatBoost | 77.47 | 65.44 | 74.24 | 0.486 | 0.487 |
| XGBoost | 73.86 | 68.80 | 77.33 | 0.524 | 0.480 |
| Cascade-Forest | 79.39 | 73.87 | 81.69 | 0.585 | 0.576 |
| Model | OA (%) | F1-Score (%) | BA (%) | IOU | KC |
|---|---|---|---|---|---|
| SVM | 78.65 | 79.95 | 79.39 | 0.666 | 0.578 |
| RF | 82.23 | 79.38 | 81.68 | 0.658 | 0.639 |
| DNN | 80.78 | 74.25 | 79.49 | 0.590 | 0.604 |
| Decision Tree | 49.38 | 41.84 | 48.76 | 0.265 | −0.02 |
| LightGBM | 79.11 | 71.96 | 77.79 | 0.562 | 0.569 |
| CatBoost | 83.35 | 79.44 | 82.47 | 0.659 | 0.660 |
| XGBoost | 65.36 | 62.10 | 65.08 | 0.450 | 0.302 |
| Cascade-Forest | 83.80 | 80.85 | 83.15 | 0.678 | 0.671 |
| Method | OA (%) | F1-Score (%) | BA (%) | IOU | KC |
|---|---|---|---|---|---|
| SVM | 70.23 | 24.91 | 56.30 | 0.142 | 0.158 |
| RF | 92.78 | 89.01 | 91.58 | 0.802 | 0.836 |
| DNN | 86.23 | 79.55 | 84.83 | 0.660 | 0.692 |
| Decision Tree | 90.00 | 84.60 | 88.29 | 0.734 | 0.773 |
| LightGBM | 93.61 | 90.25 | 92.48 | 0.822 | 0.855 |
| CatBoost | 93.57 | 90.00 | 91.97 | 0.818 | 0.852 |
| XGBoost | 93.33 | 89.81 | 92.10 | 0.815 | 0.849 |
| CFM | 93.94 | 90.70 | 92.69 | 0.830 | 0.862 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seydi, S.T.; Kanani-Sadat, Y.; Hasanlou, M.; Sahraei, R.; Chanussot, J.; Amani, M. Comparison of Machine Learning Algorithms for Flood Susceptibility Mapping. Remote Sens. 2023, 15, 192. https://doi.org/10.3390/rs15010192
Seydi ST, Kanani-Sadat Y, Hasanlou M, Sahraei R, Chanussot J, Amani M. Comparison of Machine Learning Algorithms for Flood Susceptibility Mapping. Remote Sensing. 2023; 15(1):192. https://doi.org/10.3390/rs15010192
Chicago/Turabian StyleSeydi, Seyd Teymoor, Yousef Kanani-Sadat, Mahdi Hasanlou, Roya Sahraei, Jocelyn Chanussot, and Meisam Amani. 2023. "Comparison of Machine Learning Algorithms for Flood Susceptibility Mapping" Remote Sensing 15, no. 1: 192. https://doi.org/10.3390/rs15010192
APA StyleSeydi, S. T., Kanani-Sadat, Y., Hasanlou, M., Sahraei, R., Chanussot, J., & Amani, M. (2023). Comparison of Machine Learning Algorithms for Flood Susceptibility Mapping. Remote Sensing, 15(1), 192. https://doi.org/10.3390/rs15010192