
Spatial Negative Co-Location Pattern Directional Mining Algorithm with Join-Based Prevalence



Abstract
:1. Introduction
- Related Work
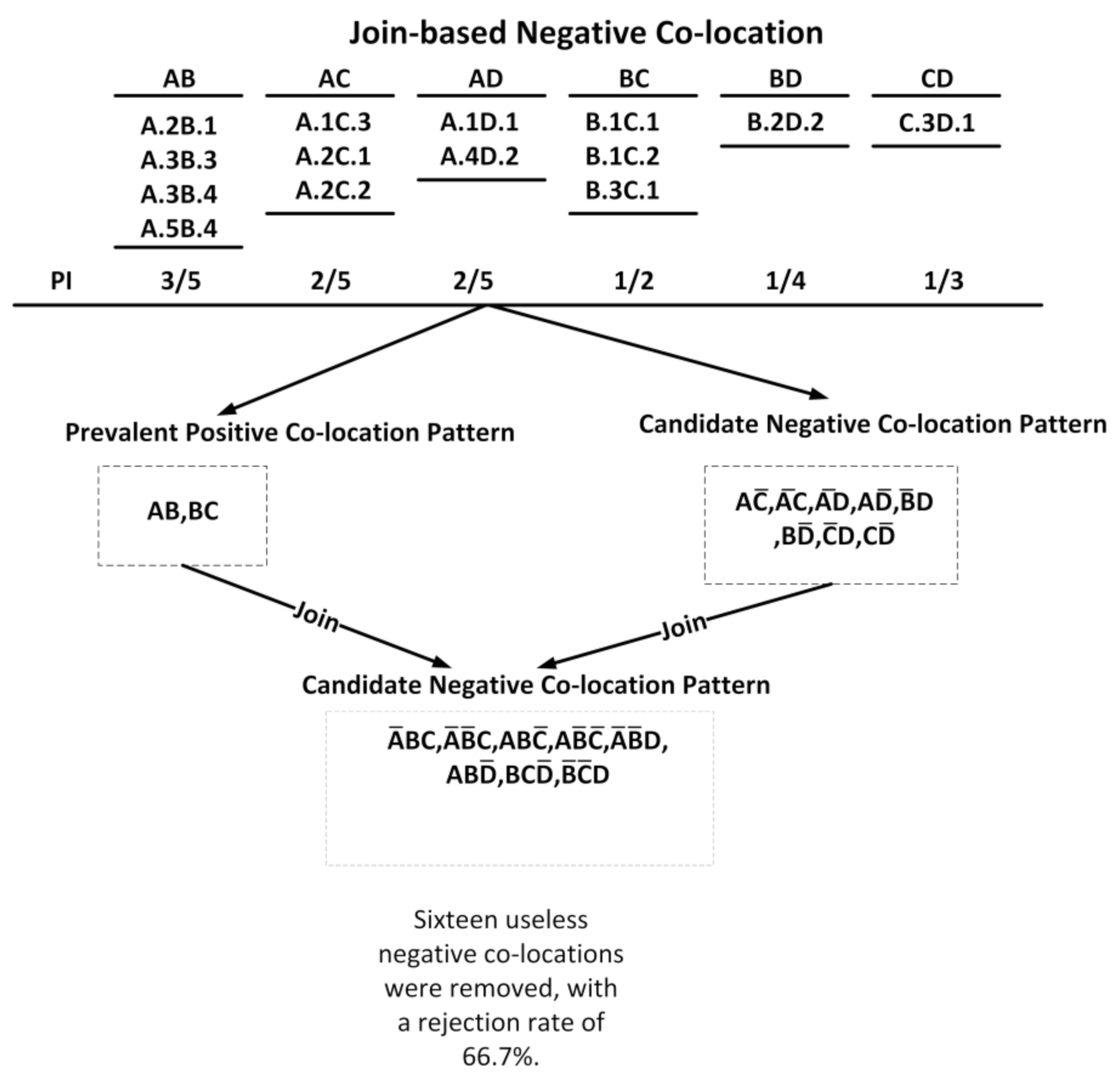
- A candidate negative co-location pattern is proposed based on the definition [49] of prevalent negative co-location patterns. Additionally, we prove that any prevalent negative co-location pattern of size n can be generated by connecting the prevalent co-location of size 2 with an n − 1 size candidate negative co-location pattern or an n − 1 size prevalent positive co-location pattern.
- For the specified spatial feature set , the negative co-location pattern of the specified size can be calculated directly through the join-based algorithm.
- According to the definition of a negative co-location pattern, the monotonous non-decrement of the PI value of a negative co-location pattern is strictly proven, and a quick pruning method is proposed by using this monotonous non-decrement of the PI value.
- By combining the negative co-location patterns from small to large size, two patterns in extreme cases and their meanings are proposed: a “single positive of negative co-location pattern” and a “single negative of negative co-location pattern”. Additionally, an algorithm for solving the pattern is given.
2. Negative Co-Location Definition and Lemma
2.1. Preliminary Definitions
2.2. Basic Definition of Negative Co-Location
2.3. Lemma and Definition of Join-Based Algorithm
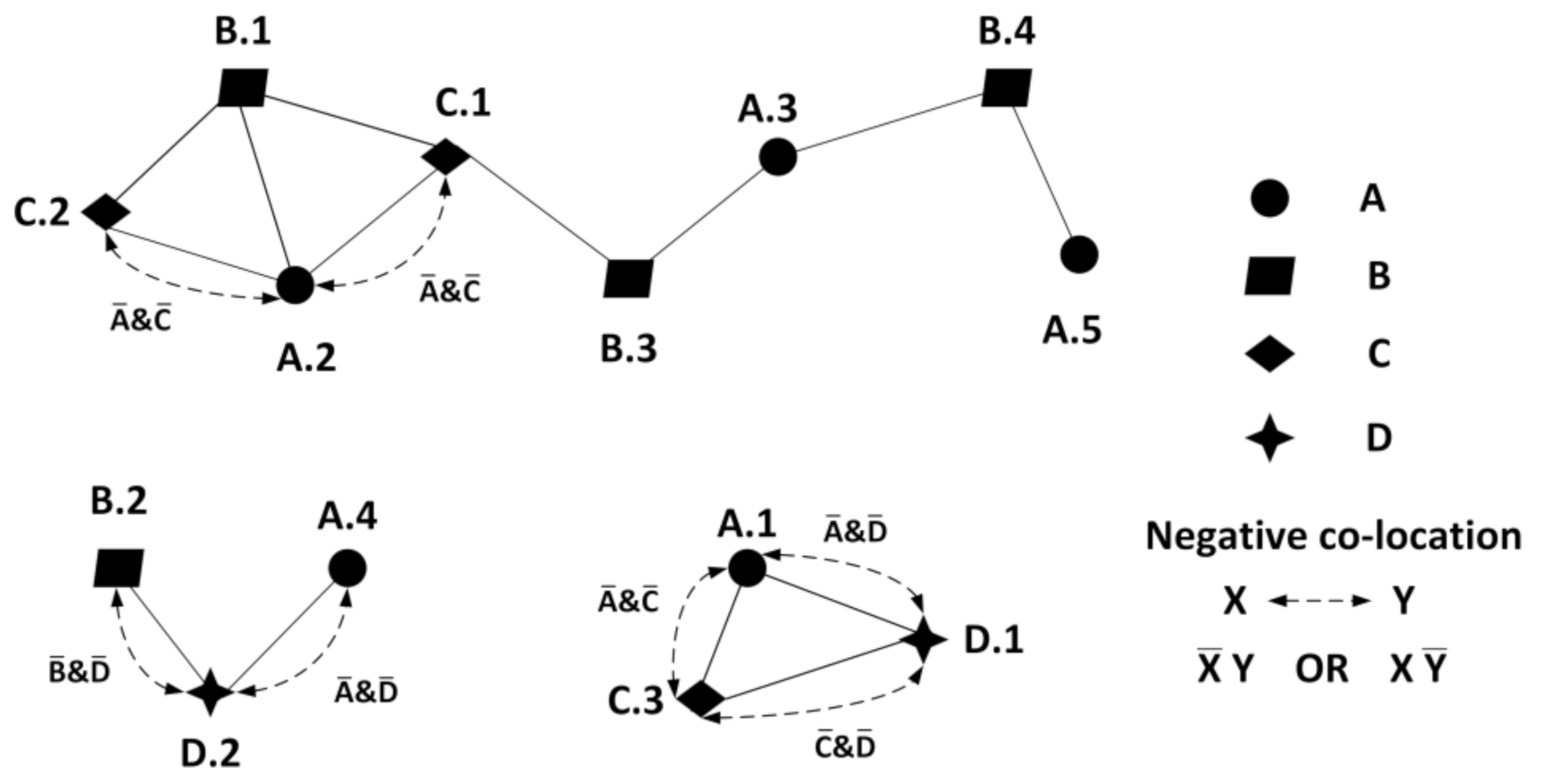
- (1) For any spatial feature in , if one of them is removed, will still be true. The C-LP composed of any two spatial features in must be the SZ 2 prevalent C-LP. In addition, if , . If , then it is prevalent C-LP. If , it is a candidate negative C-LP. . If , it is prevalent C-LP. If , it is a candidate negative C-LP.
- (2) This is the same as It is thus proved that any SZ n candidate negative C-LP must be composed of an SZ n − 1 candidate negative C-LP or prevalent C-LP connected to an SZ 2 prevalent C-LP. □
2.4. An Illustrative Example of Join-Based Co-Location
3. Join-Based Negative Co-Location Algorithm
3.1. Join-Based Prevalent Negative Co-Location Pattern Algorithm
3.2. Join-Based Prevalence Negative Co-Location Pattern Directional Mining Algorithm
4. Experiment and Analysis
| Algorithm 1: Join-based prevalent negative co-location pattern algorithm. |
| 1. Input |
| 2. F: Collection of spatial |
| 3. S: Set of spatial instances |
| 4. R: C-L relationship |
| 5. min_prev: Minimum PI threshold |
| 6. Output: |
| 7. nPPC: SZ n prevalent positive C-L collection |
| 8. 2CNC: SZ 2 candidate negative C-L collection |
| 9. 2PNC: SZ 2 prevalent negative C-L collection |
| 10. nCNC: SZ n candidate negative C-L collection |
| 11. nPNC: SZ n prevalent negative C-L collection |
| 12. Variable: |
| 13. NT: Instance C-L relation |
| 14. Method: |
| 15. Calculate all NT |
| 16. Mine the set |
| 17. for each PT in & |
| 18. PT & 2PPC → 3CNC |
| 19. if 3CNC is not repetitive |
| 20. put 3CNC in Set3CNC} |
| 21. for each PT in 3 & |
| 22. PT & 2PPC → 4CNC |
| 23. if 4CNC is not repetitive |
| 24. put 4CNC in Set4CNC} |
| 25. so on |
| 26. for each PT in & |
| 27. PT & 2PPC → nCNC |
| 30. if nCNC is not repetitive |
| 31. put nCNC in SetnCNC} |
| 32. for each PT in nCNC{ |
| 33. if PT ⊇ lowPNC |
| 34. PT is a nPNC} |
| 35. for other PT in nCNC{ |
| 36. if PI > |
| 37. PT is a nPNC} |
| Algorithm 2: Join-based prevalent negative co-location pattern directional algorithm. |
| 1. Input: |
| 2. F: Collection of spatial features |
| 3. S: Set of spatial instances |
| 4. R: C-L relationship |
| 5. min_prev: Minimum PI threshold |
| 6. C: The SZ of the final directional mining |
| 7. K: The SZ of |
| 8. Output: |
| 9. nPPC: SZ n prevalent positive C-L collection |
| 10. nCNC: SZ n candidate negative C-L collection |
| 11. nPNC: SZ n prevalent negative C-L collection |
| 12. Variable: |
| 13. NT: Instance C-L relation |
| 14. Method: |
| 15. Calculate all NT |
| 16. Mine the set Nppc = |
| 17. for each PT in (c-k)PPC{ |
| 18. for each |
| 19. & → cCNC |
| 20. if cCNC is not repetitive |
| 21. put in SetcCNC |
| 22. } |
| 23.} |
| 24. for each PT in cCNC{ |
| 25. if PI min_prev |
| 26. PT is cPNC |
| 27. else delete} |
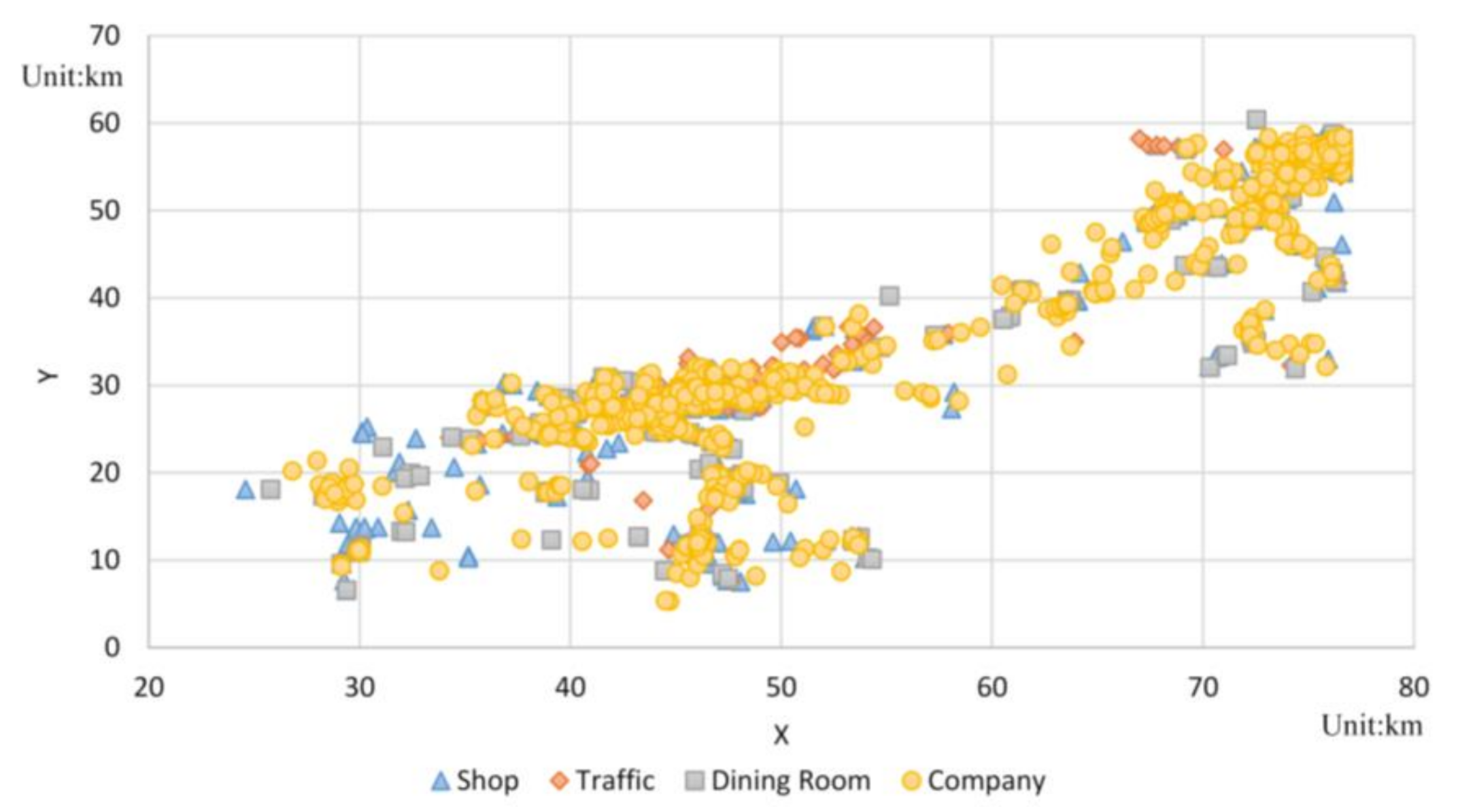
4.1. Experiment and Analysis of Real Data Sets
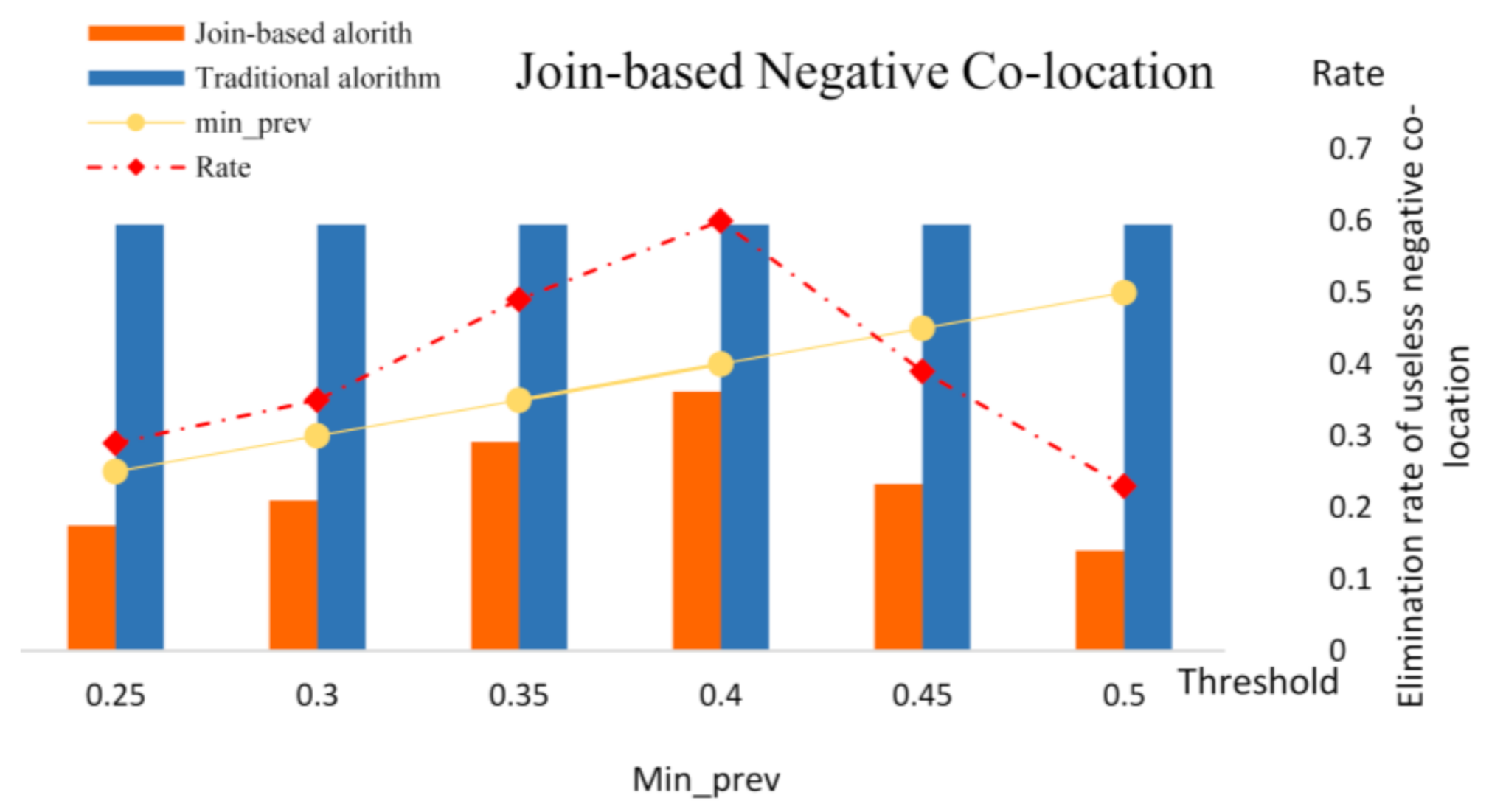
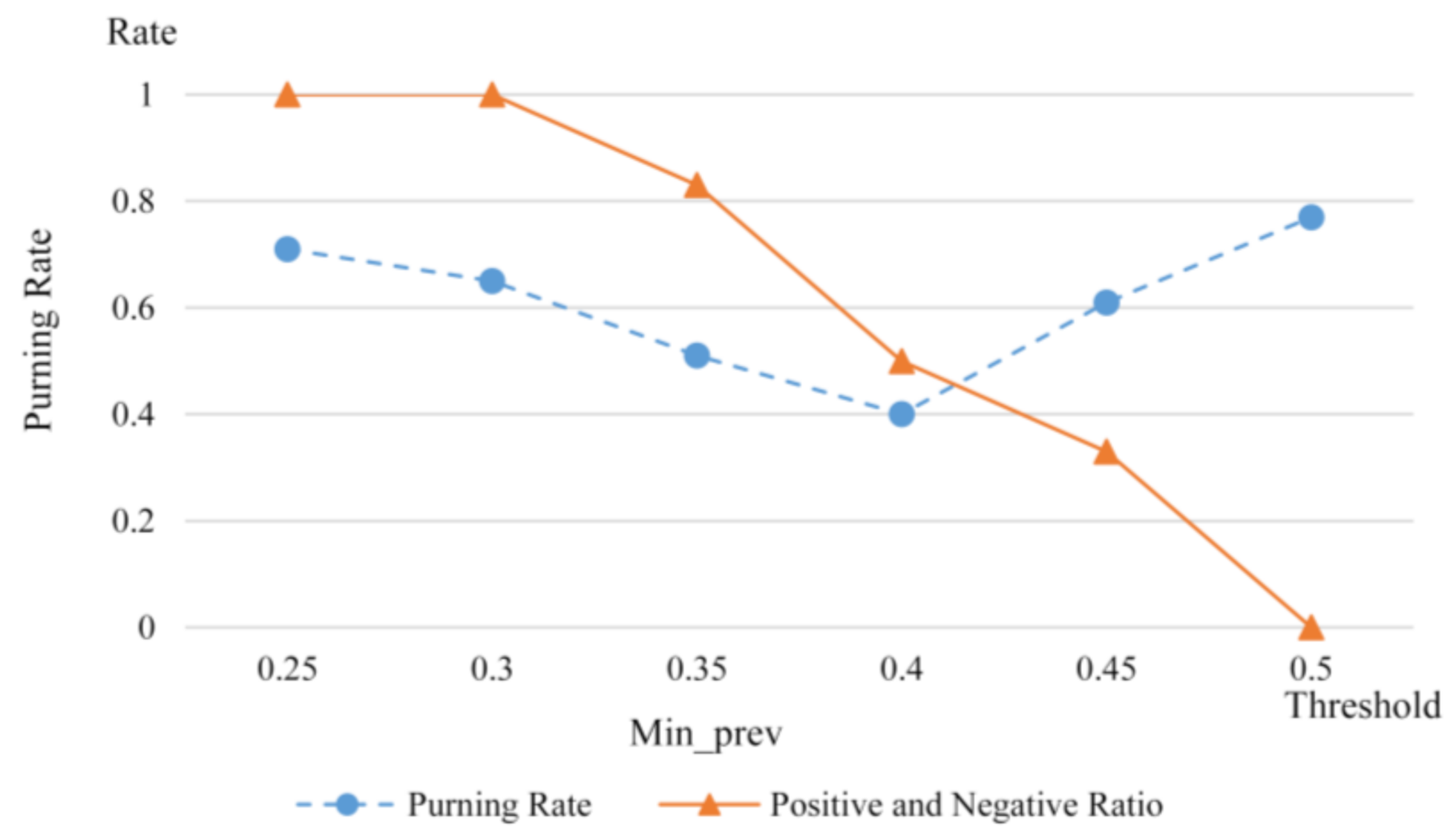
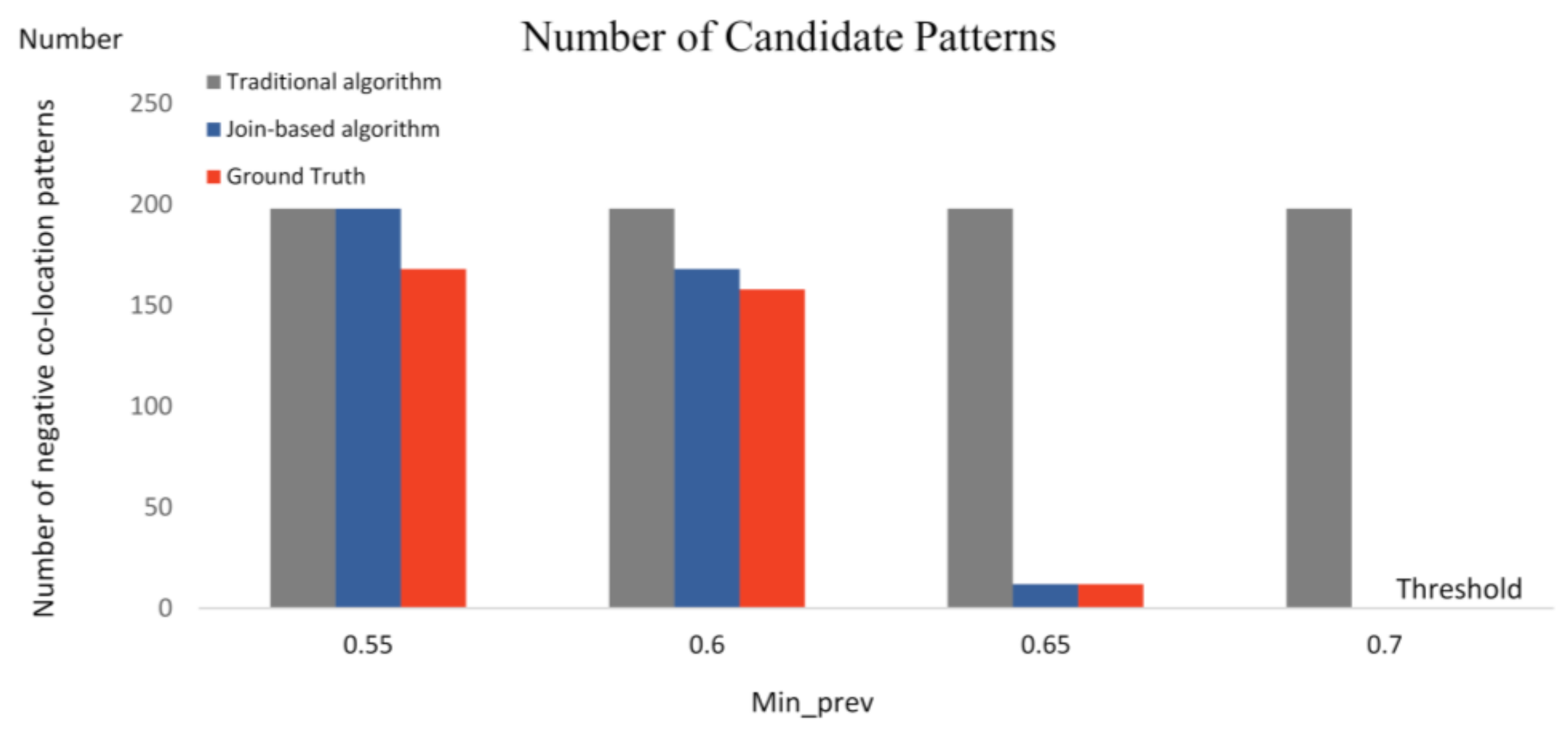
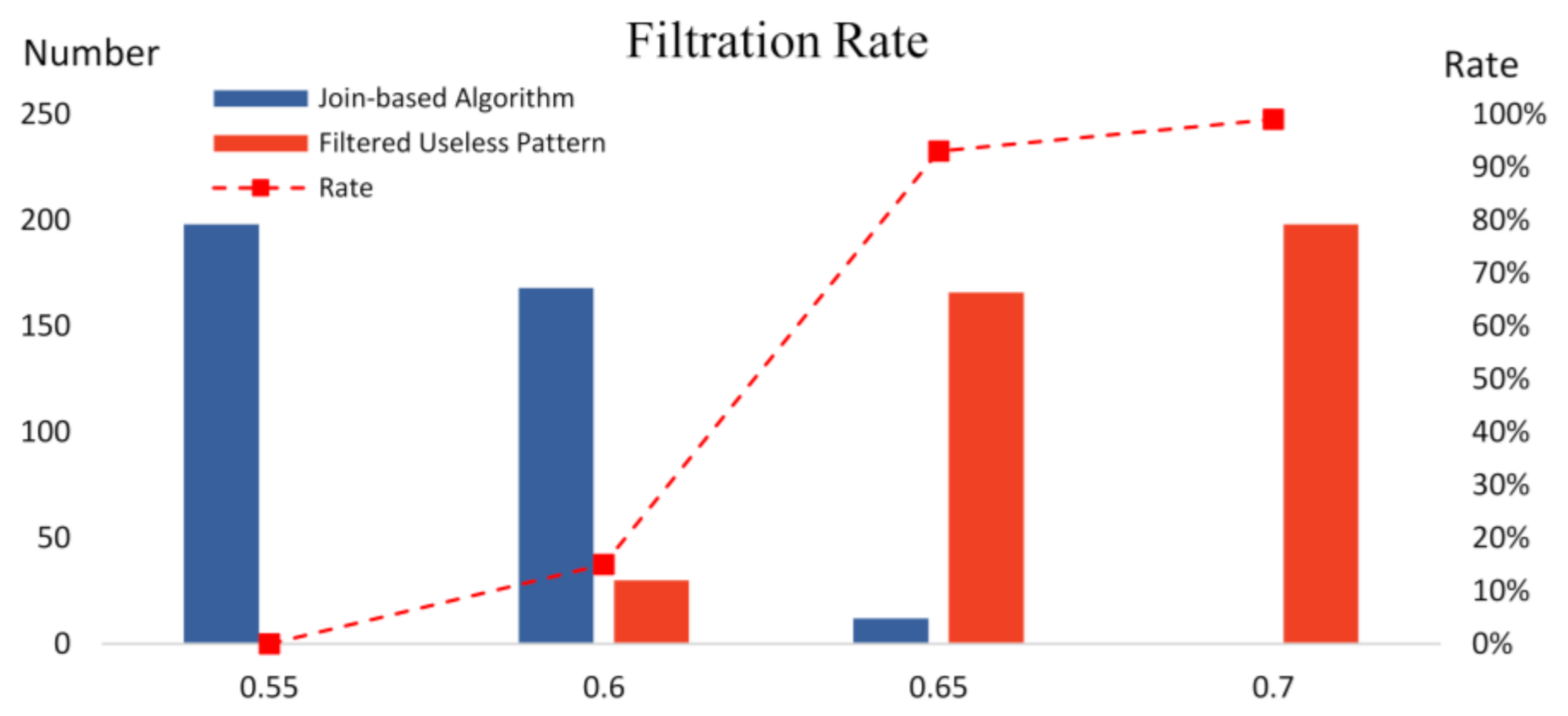
4.2. Experiment-1 with Join-Based Prevalent Negative Co-Location Pattern Algorithm
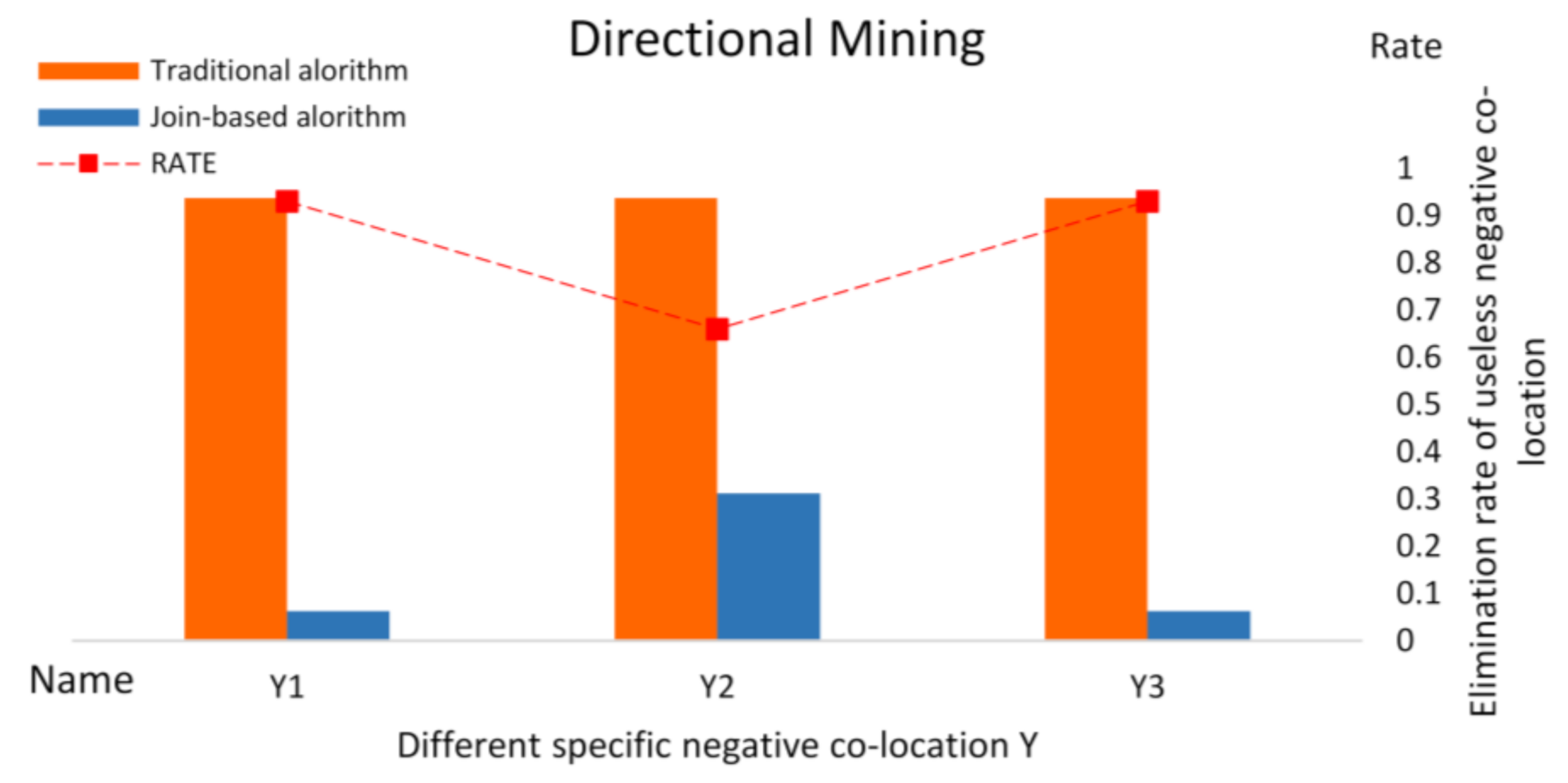
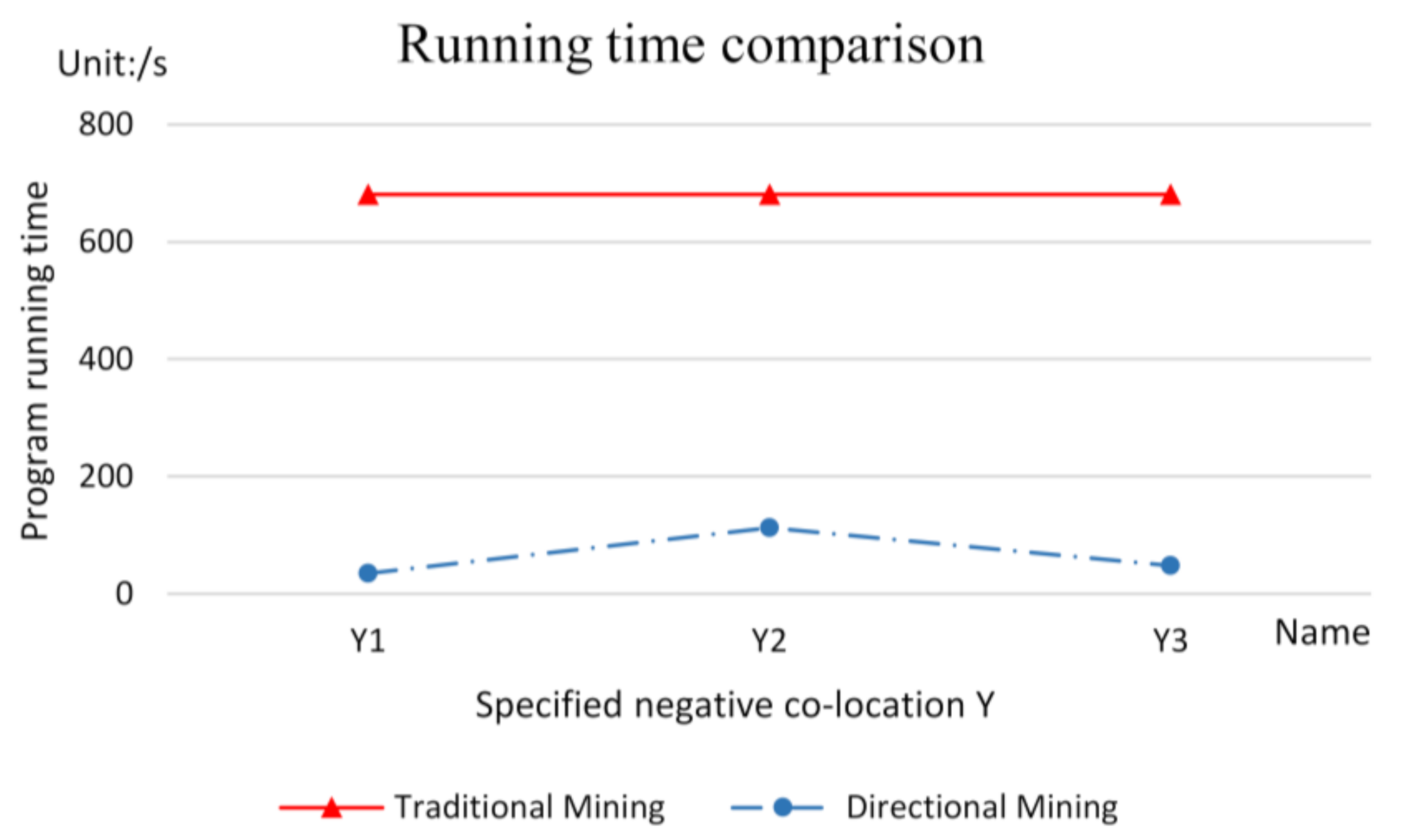
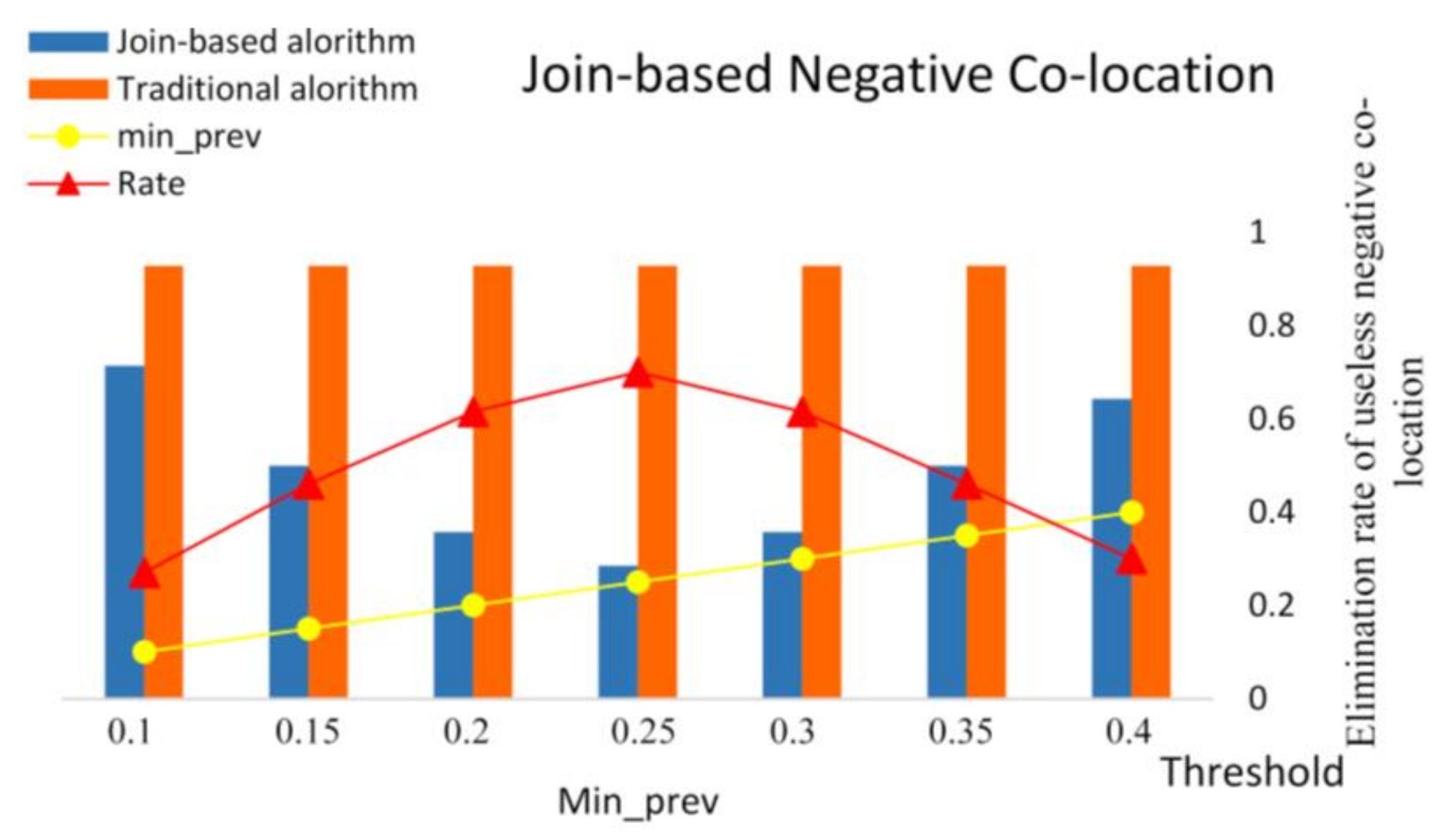
4.3. Experiment-1 with Join-Based Prevalent Negative Co-Location Pattern Directional Mining Algorithm
4.4. Experiments with Real Data-2
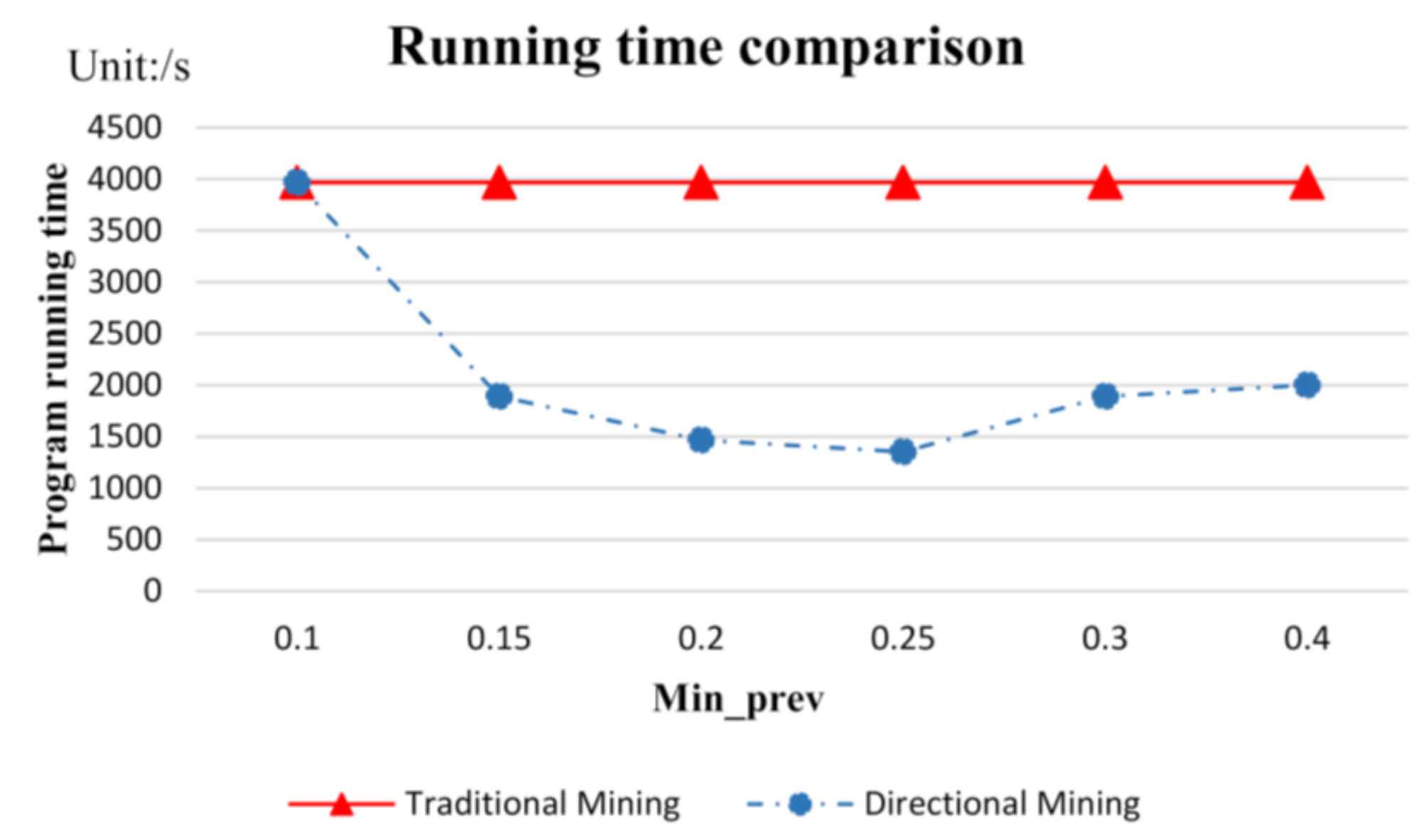
- Algorithm performance analysis
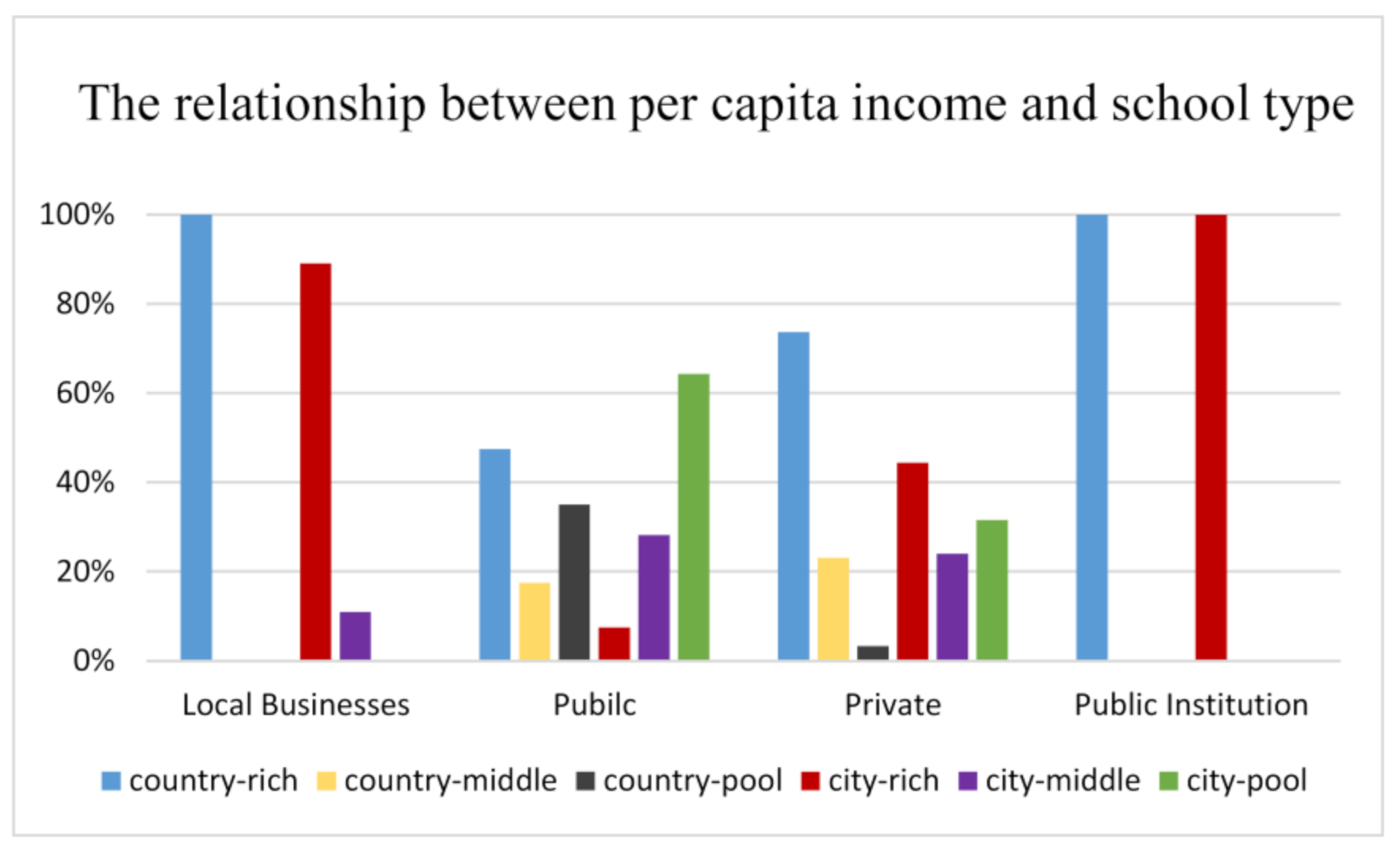
- Spatial co-location analysis
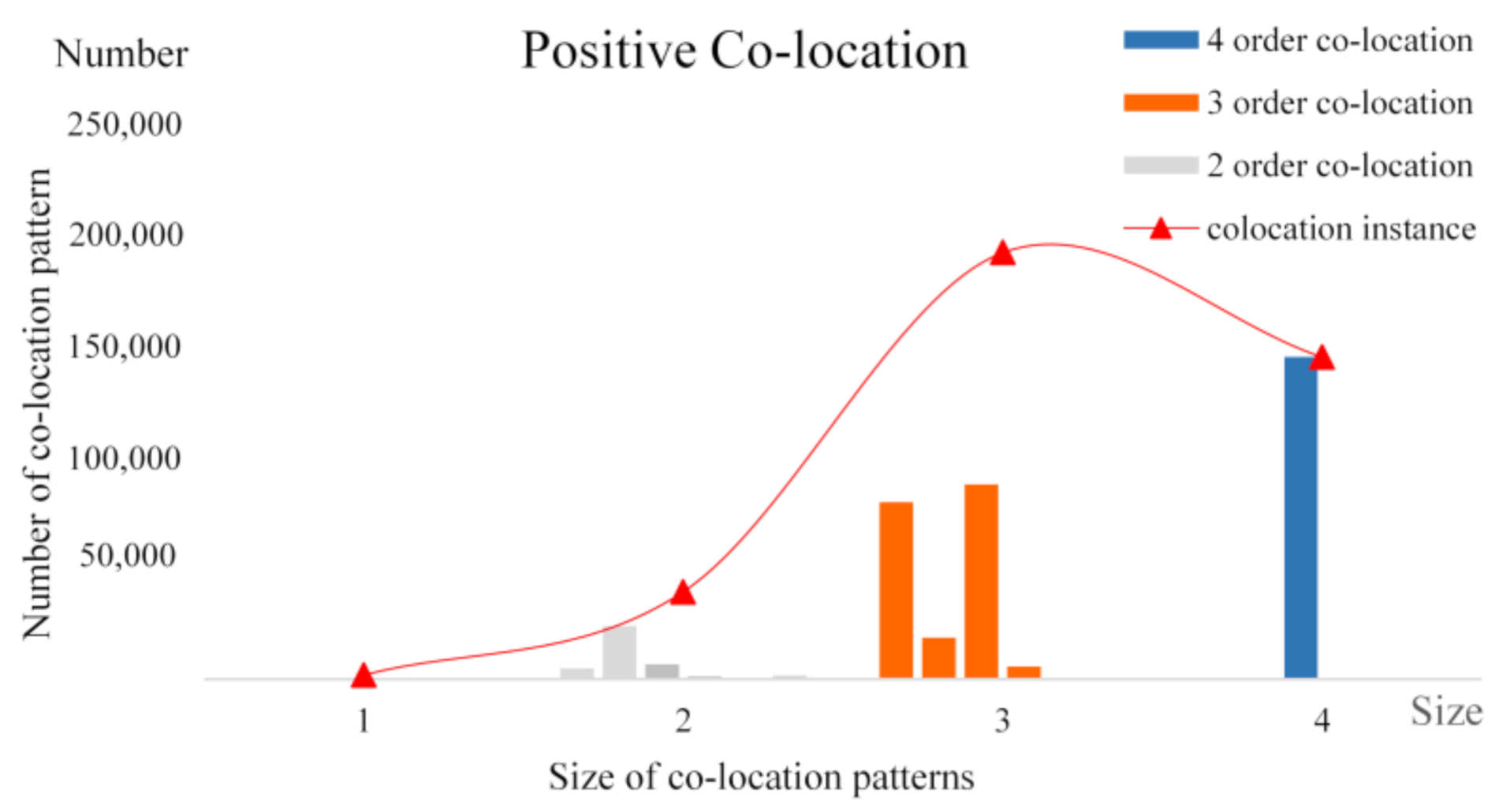
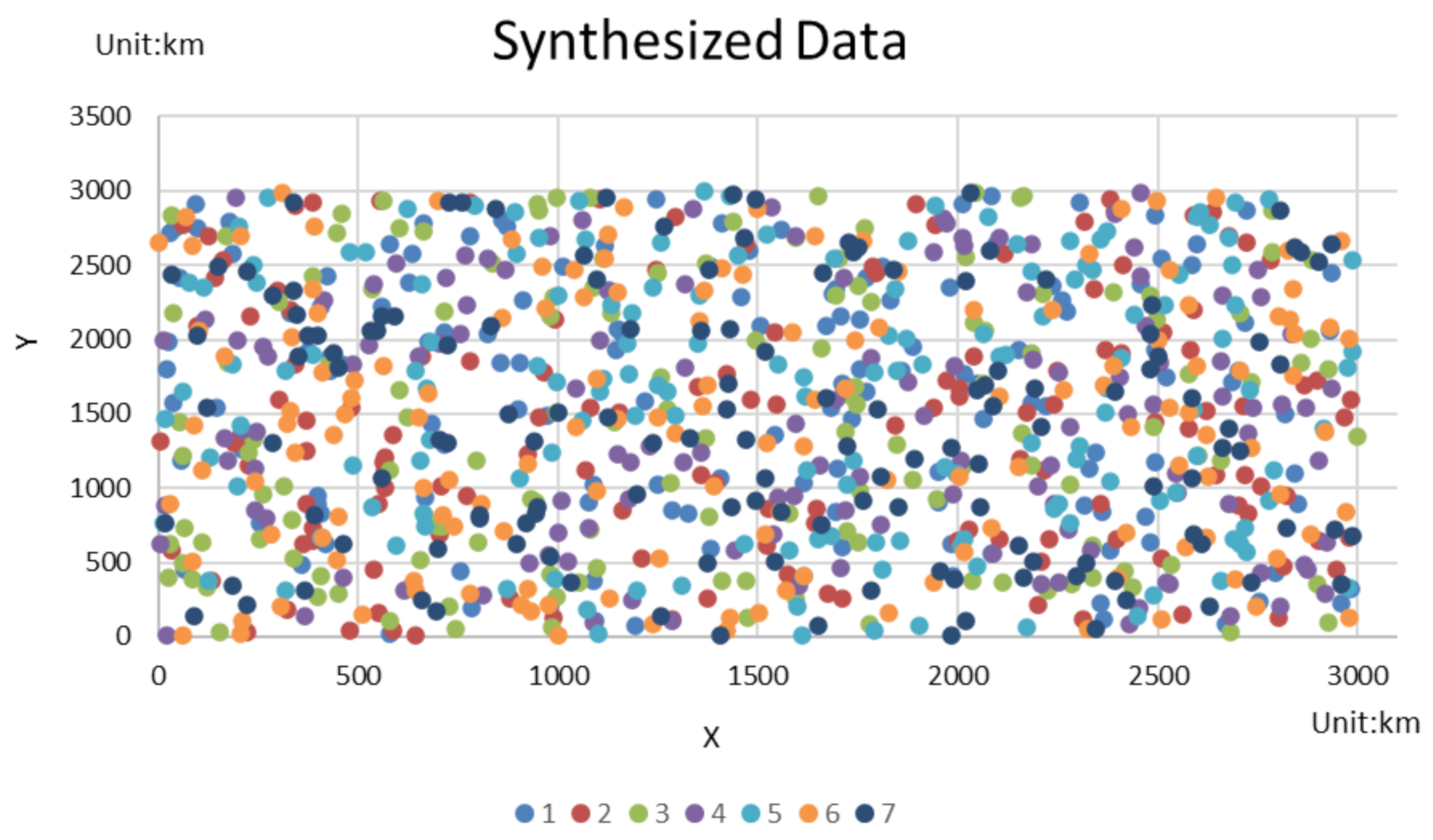
4.5. Experiments and Analysis with Synthetic Data Sets
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Morimoto, Y. Mining Frequent Neighboring Class Sets in Spatial Databases. In Proceedings of the seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26 August 2001; pp. 353–358. [Google Scholar]
- Shekhar, S.; Huang, Y. Co-location Rules Mining: A Summary of Results. In Proceedings of the International Symposium on Spatio and Temporal Database (SSTD’01), Redondo Beach, CA, USA, 12–15 July 2001; Springer: Berlin/Heidelberg, Germany; pp. 236–240. [Google Scholar]
- Huang, Y.; Shekhar, S.; Xiong, H. Discovering colocation patterns from spatial data sets: A general approach. IEEE Trans. Knowl. Data Eng. 2004, 16, 1472–1485. [Google Scholar] [CrossRef] [Green Version]
- Yoo, J.S.; Shekhar, S.; Smith, J.; Kumquat, J.P. A partial join approach for mining co-location patterns. In Proceedings of the 12th Annual ACM International Workshop on Geographic Information Systems (GIS), Washington, DC, USA, 12–13 November 2004; ACM Press: New York, NY, USA, 2004; pp. 241–249. [Google Scholar]
- Yoo, J.S.; Shekhar, S.; Celik, M. A join-less approach for co-location pattern mining: A summary of results. In Proceedings of the IEEE International Conference on Data Mining, Houston, TX, USA, 27–30 November 2005; IEEE Press: Piscataway, NJ, USA, 2005; pp. 813–816. [Google Scholar]
- Wang, L.; Bao, Y.; Lu, J.; Yip, J. A New Join-less Approach for Co-location Pattern Mining. In Proceedings of the IEEE 8th International Conference on Computer and Information Technology (CIT2008), Sydney, NSW, Australia, 8–11 July 2008; pp. 197–202. [Google Scholar]
- Wang, L.; Bao, Y.; Lu, Z. Efficient discovery of spatial co- location patterns using the iCPI-tree. Open Inf. Syst. J. 2009, 3, 69–80. [Google Scholar] [CrossRef] [Green Version]
- Djenouri, Y.; Lin, C.W.; Nrvg, K.; Ramampiaro, H. Highly Efficient Pattern Mining Based on Transaction Decomposition. In Proceedings of the IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019. [Google Scholar]
- Xun, Y.; Zhang, J.; Qin, X.; Zhao, X. FiDoop-DP: Data partitioning in frequent itemset mining on Hadoop clusters. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 101–114. [Google Scholar] [CrossRef]
- Djenouri, Y.; Comuzzi, M. Combining apriori heuristic and bioinspired algorithms for solving the frequent itemsets mining problem. Inf. Sci. 2017, 420, 1–15. [Google Scholar] [CrossRef]
- Deng, Z.-H.; Lv, S.-L. PrePost+: An efficient n-lists-based algorithm for mining frequent itemsets via children—Parent equivalence pruning. Expert Syst. Appl. 2015, 42, 5424–5432. [Google Scholar] [CrossRef]
- Djenouri, Y.; Djenouri, D.; Lin, J.C.-W.; Belhadi, A. Frequent itemset mining in big data with effective single scan algorithms. IEEE Access 2018, 6, 68013–68026. [Google Scholar] [CrossRef]
- Zhang, B.; Lin, J.C.-W.; Shao, Y.; Fournier-Viger, P.; Djenouri, Y. Maintenance of Discovered High Average-Utility Itemsets in Dynamic Databases. Appl. Sci. 2018, 8, 769. [Google Scholar] [CrossRef] [Green Version]
- Deng, Z.H.; Lv, S.L. Fast mining frequent itemsets using nodesets. Expert Syst. Appl. 2014, 41, 4505–4512. [Google Scholar] [CrossRef]
- Yao, H.; Hamilton, H.J.; Butz, C.J. A foundational approach to mining itemset utilities from databases. In Proceedings of the SIAM International Conference on Data Mining, Lake Buena Vista, FL, USA, 22–24 April 2004; pp. 215–221. [Google Scholar]
- Lan, G.C.; Hong, T.P.; Huang, J.P.; Tseng, V.S. On-shelf utility mining with negative item values. Expert Syst. Appl. 2014, 41, 3450–3459. [Google Scholar] [CrossRef]
- Liu, J.; Wang, K.; Fung, B.C.M. Direct discovery of high utility itemsets without candidate generation. In Proceedings of the IEEE International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 984–989. [Google Scholar]
- Bao, X.; Wang, L. A clique-based approach for co-location pattern mining. Inf. Sci. 2019, 490, 244–264. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, L.; Lu, J.; Yip, Y.J. An order-clique-based approach for mining maximal co-locations. Inf. Sci. 2009, 179, 3370–3382. [Google Scholar] [CrossRef]
- Celik, M.; Kang, J.M.; Shekhar, S. Zonal Co-location Pattern Discovery with Dynamic Parameters. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM 2007), Omaha, NE, USA, 28–31 October 2007. [Google Scholar]
- Yu, C. A Review of Spatial Co-location Pattern Mining Algorithms. Comput. Digit. Eng. 2014, 42, 6. [Google Scholar]
- Wang, L.; Bao, X.; Chen, H.; Cao, L. Effective lossless condensed representation and discovery of spatial co-location patterns. Inf. Sci. 2018, 436–437, 197–213. [Google Scholar] [CrossRef]
- Wang, L.; Bao, X.; Zhou, L. Redundancy reduction for prevalent co-location patterns. IEEE Trans. Knowl. Data Eng. 2018, 30, 142–155. [Google Scholar] [CrossRef]
- Hu, X.; Wang, L.; Zhou, L.; Wen, F. Mining Spatial Maximal Co-Location Patterns. J. Front. Comput. Sci. Technol. 2014, 8, 150–160. [Google Scholar]
- Ouyang, Z.; Wang, L.; Chen, H. Research on Mining Spatial Co-location Pattern of Fuzzy Objects. Chin. J. Comput. 2011, 34, 1947–1955. [Google Scholar] [CrossRef]
- He, F.; Jia, Z.; Zhang, D. Mining spatial co-location pattern based on parallel computing. J. Yunnan Norm. Univ. (Nat. Sci. Ed.) 2015, 35, 56–62. [Google Scholar]
- Zhou, G.; Wang, L. Co-location decision tree for enhancing decision-making of pavement maintenance and rehabilitation. Transp. Res. Part C 2011, 21, 287–305. [Google Scholar] [CrossRef] [Green Version]
- Zhou, G.; Zhang, R.; Zhang, D. Manifold Learning Co-Location Decision Tree for Remotely Sensed Imagery Classification. Remote Sens. 2016, 8, 855. [Google Scholar] [CrossRef] [Green Version]
- Zhou, G.; Li, Q.; Deng, G. Maximal Instance Algorithm for Fast Mining of Spatial Co-Location Patterns. Patterns. Remote Sens. 2021, 13, 960. [Google Scholar] [CrossRef]
- Zhou, G. Data Mining for Co-location Pattern: Theory and Application; Taylor & Francis: Oxfordshire, UK; CRC Press: Boca Raton, FL, USA, 2021; 212p, ISBN 978-03-67-654269. [Google Scholar]
- Zhou, G.; Huang, S.; Wang, H.; Zhang, R.; Wang, Q.; Sha, H.; Liu, X.; Pan, Q. A buffer analysis based on co-location algorithm. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-3, 2487–2490. [Google Scholar] [CrossRef] [Green Version]
- Zhou, G.; Li, Q.; Deng, G.; Yue, T.; Zhou, X. Mining co-location patterns with clustering items from spatial data sets. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-3, 2505–2509. [Google Scholar] [CrossRef] [Green Version]
- Zhou, G.; Zhou, X.; Yang, J.; Tao, Y.; Nong, X.; Baysal, O. Flash Lidar Sensor using Fiber Coupled APDs. IEEE Sens. J. 2015, 15, 4758–4768. [Google Scholar] [CrossRef]
- Zhou, G.; Yue, T.; Huang, Y.; Song, B.; Chen, K.; He, G.; Ni, G.; Zhang, L. Study of an SCSG-OSM for the Creation of an Urban Three-Dimensional Building. IEEE Access 2020, 8, 126266–126283. [Google Scholar] [CrossRef]
- Zhang, R.; Zhou, G.; Huang, J.; Zhou, X. Maximum Variance Unfolding Based Co-Location Decision Tree for Remote Sensing Image Classification. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Zhou, G. Urban High-Resolution Remote Sensing: Algorithms and Modelling; Taylor & Francis: Oxfordshire, UK; CRC Press: Boca Raton, FL, USA, 2020; 465p, ISBN 978-03-67-857509. [Google Scholar]
- Wu, X.; Zhang, C.; Zhang, S. Efficient mining of both positive and negative association rules. ACM Trans. Inf. Syst. 2004, 22, 381–405. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhao, Y.; Zuo, Z.; Cao, L. Negative-GSP: An efficient method for mining negative sequential patterns. In Proceedings of the Eighth Australasian Data Mining Conference, Melbourne, Australia, 1 December 2009; ACM Press: New York, NY, USA, 2009; pp. 63–67. [Google Scholar]
- Cao, L.; Dong, X.; Zheng, Z. e-NSP: Efficient negative sequential pattern mining. Artif. Intell. 2016, 235, 156–182. [Google Scholar] [CrossRef] [Green Version]
- Cao, L. In-depth behavior understanding and use: The behavior informatics approach. Inf. Sci. 2010, 180, 3067–3085. [Google Scholar] [CrossRef]
- Cao, L.; Zhao, Y.; Zhang, C. Mining impact-targeted activity patterns in imbalanced data. IEEE Trans. Knowl. Data Eng. 2008, 20, 1053–1066. [Google Scholar] [CrossRef]
- Dong, X.; Zhao, L.; Han, X.; Jiang, H. Comparisons of several definitions about negative containment. In Proceedings of the ICCNT’ 11, Harbin, China, 24–26 December 2011; pp. 553–556. [Google Scholar]
- Zheng, Z.; Zhao, Y.; Zuo, Z.; Cao, L. An efficient ga-based algorithm for mining negative sequential patterns. In Advances in Knowledge Discovery and Data Mining; PAKDD 2010; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6118, pp. 262–273. [Google Scholar]
- Dong, X.; Gong, Y.; Cao, L. F-NSP+: A fast negative sequential patterns mining method with self-adaptive data storage. Pattern Recognit. 2018, 84, 13–27. [Google Scholar] [CrossRef]
- Rastogi, V.; Khare, V.K. Apriori Based: Mining Positive and Negative Frequent Sequential Patterns. Int. J. Latest Trends Eng. Technol. (IJLTET) 2012, 1, 24–33. [Google Scholar]
- Khare, V.K.; Rastogi, V. Mining Positive and Negative Sequential Pattern in Incremental Transaction Databases. Int. J. Comput. Appl. 2013, 71, 18–22. [Google Scholar]
- Mesbah, S.; Taghiyareh, F. A new sequential classification to assist Ad auction agent in making decisions. In Proceedings of the 2010 5th International Symposium on Telecommunications (IST), Kish Island, Iran, 4–6 December 2010; pp. 1006–1012. [Google Scholar]
- Schwartz, G.W.; Shokoufandeh, A.; Ontan, S.; Hershberg, U. Using a novel clumpiness measure to unite data with metadata: Finding common sequence patterns in immune receptor germline V genes. Pattern Recognit. Lett. 2016, 74, 24–29. [Google Scholar] [CrossRef]
- Jiang, Y.; Wang, L.; Lu, Y.; Chen, H. Discovering both positive and negative co-location rules from spatial data sets. In Proceedings of the 2nd International Conference on Software Engineering and Data Mining, Chengdu, China, 23–25 June 2010; IEEE Press: Piscataway, NJ, USA, 2010; pp. 398–403. [Google Scholar]
- Wang, G.; Wang, L.; Yang, P.; Chen, H. Minimal negative Co-location model and Effective Mining Algorithm. Comput. Sci. Explor. 2021, 15, 366. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Terms | Abbreviation | Definition |
|---|---|---|
| Co-location | C-L | Co-location is two spatial feature instances that satisfy R (e.g., Euclidean distance metric). [2] |
| Co-location pattern | C-LP | The co-location pattern is the co-location combination of spatial instance satisfying R in a given spatial feature . [2] |
| The PI value of the C-LP | C-LPI | In this paper, the C-LPI is the value of the participation index for the co-location pattern. |
| Pattern | PT | In this paper, the pattern represents a specific spatial instance co-location relationship. |
| Participation Index | PI | The participation index (PI) of a co-location [49] |
| The value of the participation index | TVPI | The value of the participation index is the minimum in all PR (c, ) of co-location C. [49] |
| Size | SZ | In this paper, size is the number of spatial feature sets . |
| Co-location of Size | C-LSZ | Co-location of size is the number of spatial feature sets . [2] |
| Type | Abbreviation | Number |
|---|---|---|
| Shopping | S | 7284 |
| Traffic | T | 582 |
| Dining Room | D | 1963 |
| Companies | C | 1360 |
| Type | Abbreviation | Number |
|---|---|---|
| School | S | 1466 |
| Automobile Service | A | 1193 |
| Restaurant | R | 4202 |
| Shop | SP | 473 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, G.; Wang, Z.; Li, Q. Spatial Negative Co-Location Pattern Directional Mining Algorithm with Join-Based Prevalence. Remote Sens. 2022, 14, 2103. https://doi.org/10.3390/rs14092103
Zhou G, Wang Z, Li Q. Spatial Negative Co-Location Pattern Directional Mining Algorithm with Join-Based Prevalence. Remote Sensing. 2022; 14(9):2103. https://doi.org/10.3390/rs14092103
Chicago/Turabian StyleZhou, Guoqing, Zhenyu Wang, and Qi Li. 2022. "Spatial Negative Co-Location Pattern Directional Mining Algorithm with Join-Based Prevalence" Remote Sensing 14, no. 9: 2103. https://doi.org/10.3390/rs14092103
APA StyleZhou, G., Wang, Z., & Li, Q. (2022). Spatial Negative Co-Location Pattern Directional Mining Algorithm with Join-Based Prevalence. Remote Sensing, 14(9), 2103. https://doi.org/10.3390/rs14092103