
Image Reconstruction of Multibranch Feature Multiplexing Fusion Network with Mixed Multilayer Attention


Abstract
:1. Introduction
- A multibranch feature, reuse fusion attention block, is proposed, which realizes the reuse of features and the fusion of multistage local features through the interaction of information between multiple branches and enriches the hierarchical types of phased features.
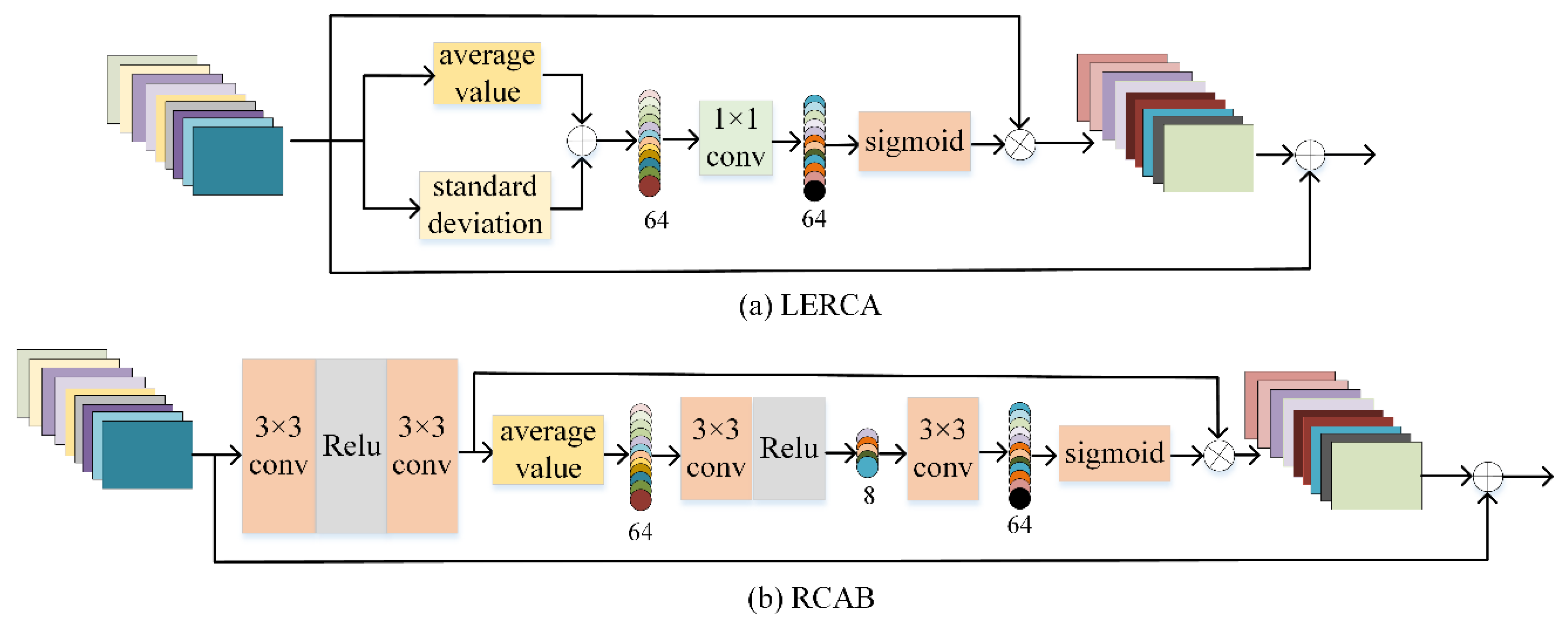
- A lightweight enhanced residual channel attention (LERCA) is proposed, which can pay more attention to the high-frequency information in low resolution space. We use 1 × 1 convolution to establish the interdependence between channels, which avoids the loss of some channel information caused by channel compression, and the module is more lightweight.
- In the reconstruction process, the attention mechanism is introduced, and the U-LERCA is constructed combined with LERCA, which enhances the sensitivity of the network to key information. In particular, few people have studied the attention strategies in the reconstruction process.
- We constructed a multibranch feature multiplexing fusion network with mixed multilayer attention, which achieves a good recovery effect. At the same time, the network achieves a good balance between parameters and performance.
2. Related Work
2.1. Phased Feature Fusion
2.2. Attention Mechanism
3. Paper Method
3.1. Overall Framework
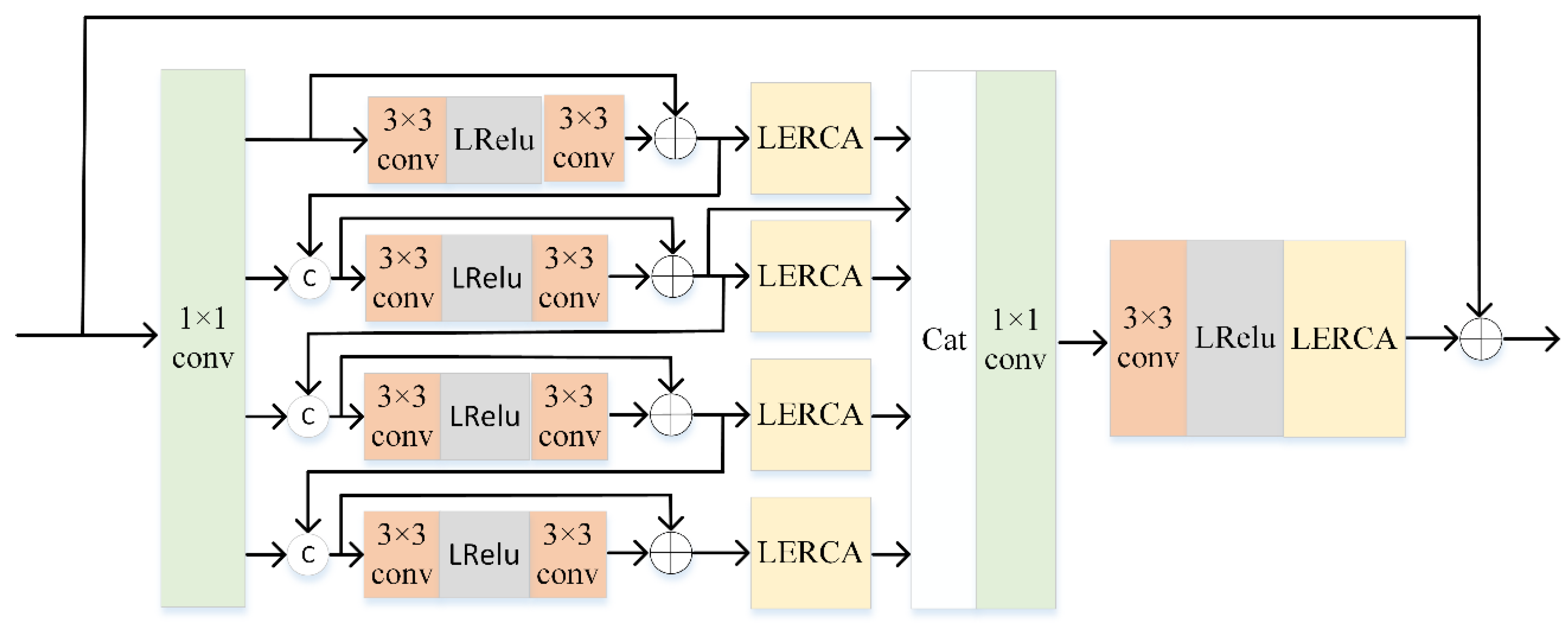
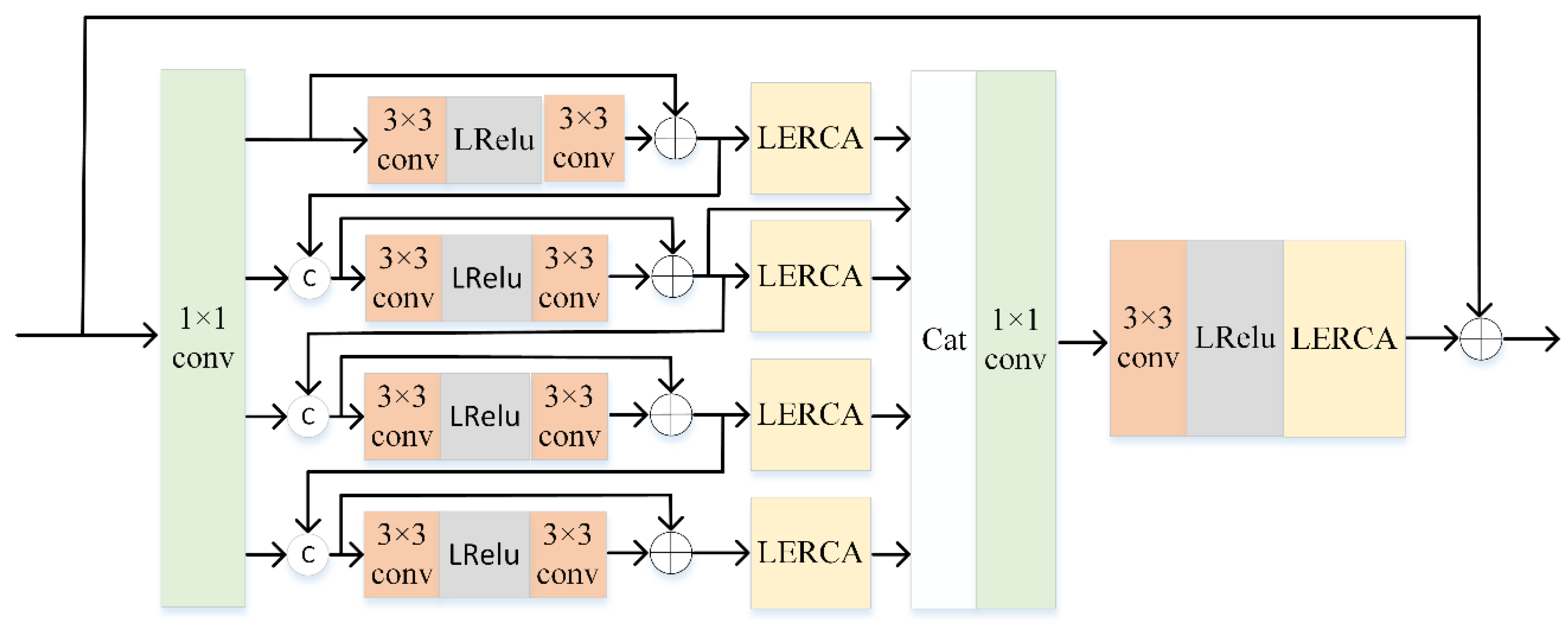
3.2. Multibranch Feature Multiplexing Fusion Attention Block
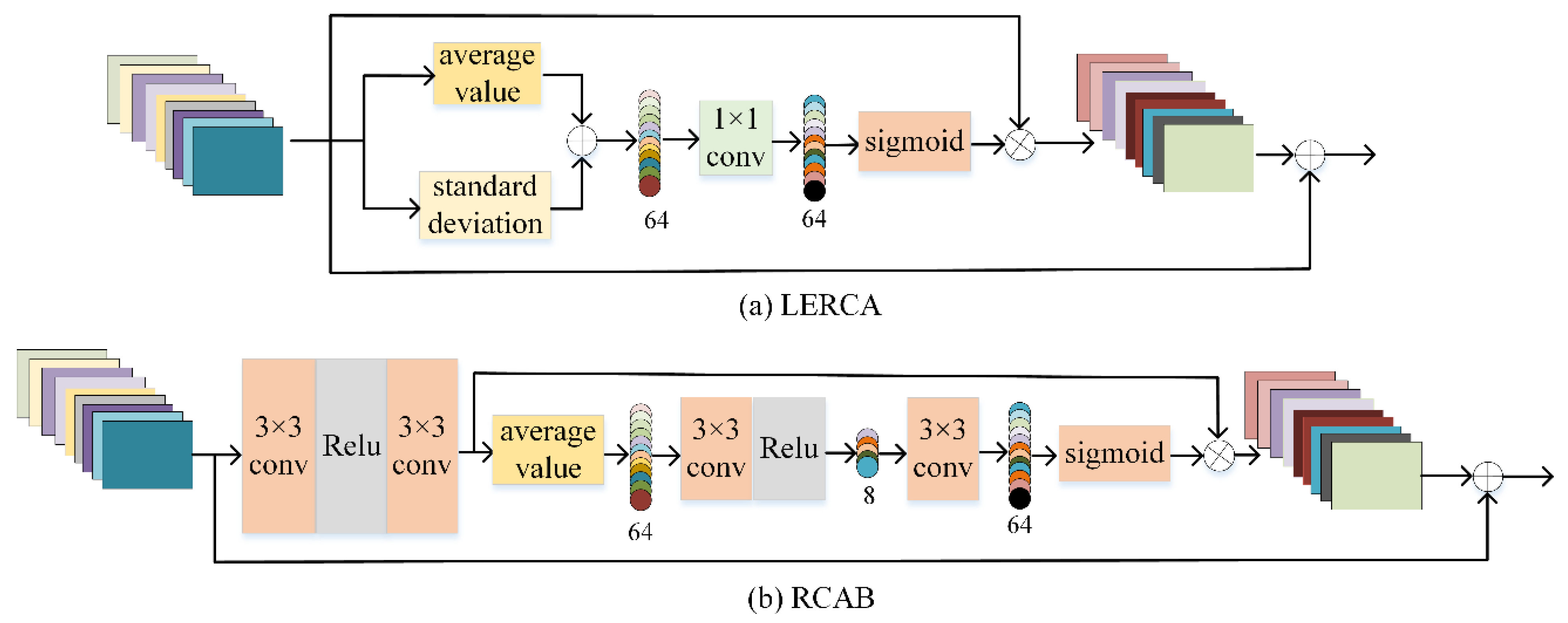
3.3. Lightweight Enhanced Residual Channel Attention
3.4. Reconstruction Block (U-LERCA)
4. Experiment and Analysis
4.1. Experimental Environment and Parameter Setting
4.2. Ablation Experiment
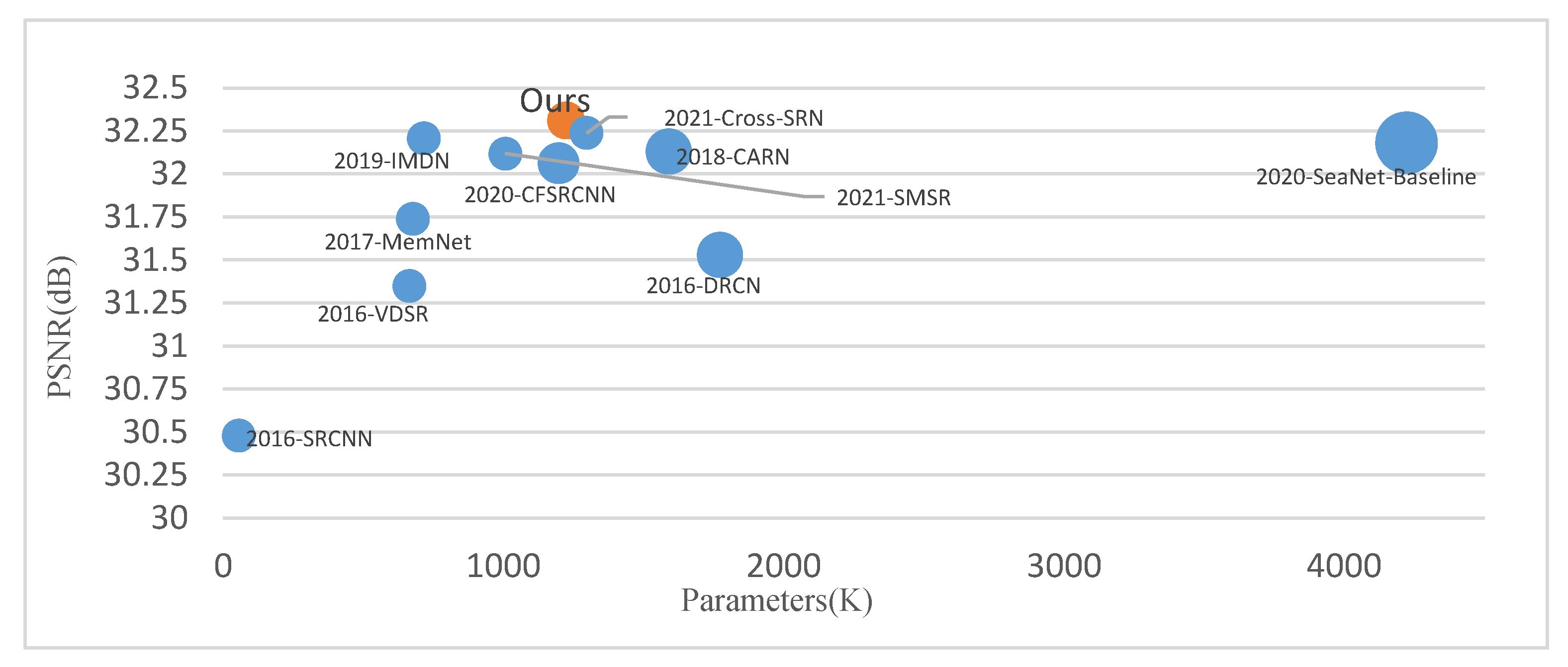
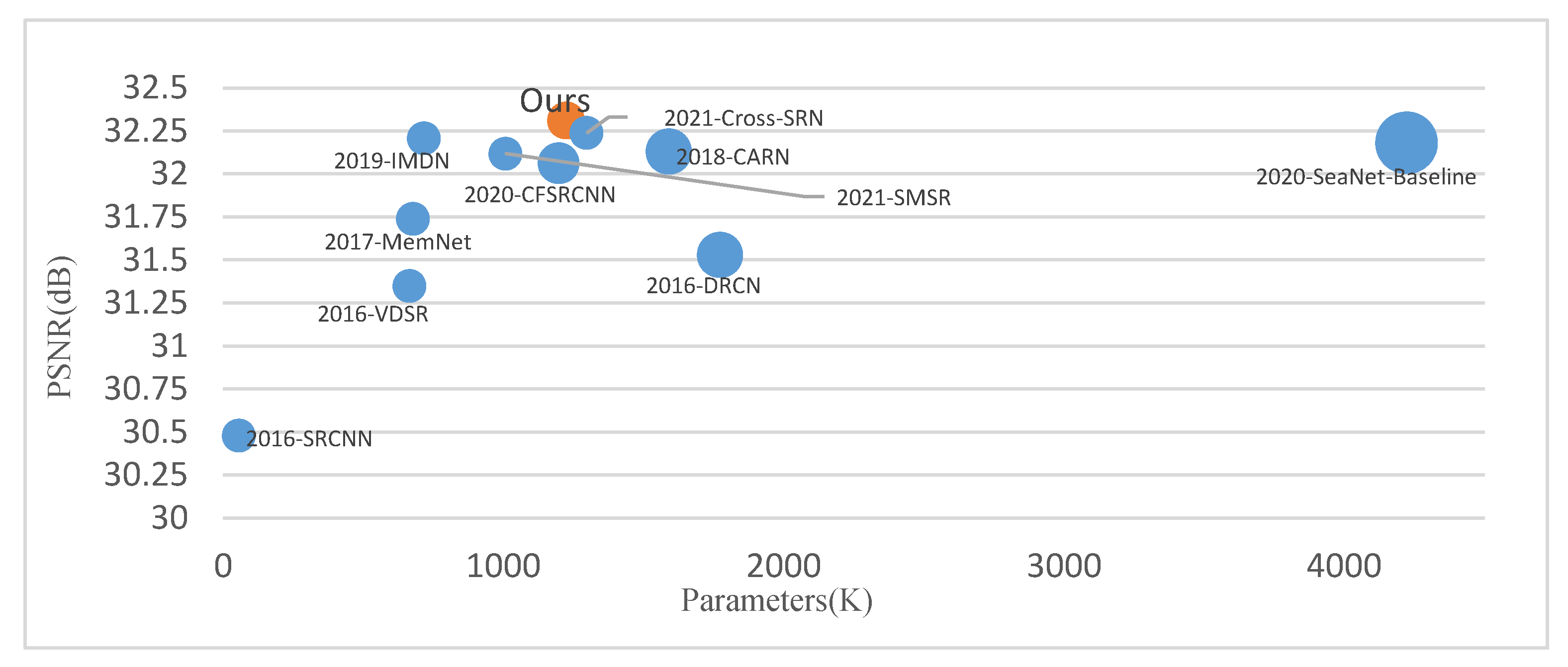
4.3. Comparison with Other Advanced Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Jia, Q.; Fan, X.; Wang, S.; Ma, S.; Gao, W. Cross-SRN: Structure-Preserving Super-Resolution Network with Cross Convolution. IEEE Trans. Circuits Syst. Video Technol. 2021. [Google Scholar] [CrossRef]
- He, Z.; Cao, Y.; Du, L.; Xu, B.; Yang, J.; Cao, Y.; Tang, S.; Zhuang, Y. MRFN: Multi-Receptive-Field Network for Fast and Accurate Single Image Super-Resolution. IEEE Trans. Multimed. 2019, 22, 1042–1054. [Google Scholar] [CrossRef]
- Lan, R.; Sun, L.; Liu, Z.; Lu, H.; Pang, C.; Luo, X. MADNet: A Fast and Lightweight Network for Single-Image Super Resolution. IEEE Trans. Cybern. 2020, 51, 1443–1453. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Liu, J.; Zhang, W.; Tang, J.; Wu, G. Residual feature aggregation network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2359–2368. [Google Scholar]
- Ma, X.; Guo, J.; Tang, S.; Qiao, Z.; Chen, Q.; Yang, Q.; Fu, S. DCANet: Learning connected attentions for convolutional neural networks. arXiv 2020, arXiv:2007.05099. [Google Scholar]
- Wang, L.; Dong, X.; Wang, Y.; Ying, X.; Lin, Z.; An, W.; Guo, Y. Exploring sparsity in image super-resolution for efficient inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4917–4926. [Google Scholar]
- Hui, Z.; Wang, X.; Gao, X. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 723–731. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Liu, J.; Tang, J.; Wu, G. Residual feature distillation network for lightweight image super-resolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 41–55. [Google Scholar]
- Wang, Z.; Gao, G.; Li, J.; Yu, Y.; Lu, H. Lightweight Image Super-Resolution with Multi-scale Feature Interaction Network. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 201; pp. 7132–7141.
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel ‘squeeze & excitation’ in fully convolutional networks. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2018; pp. 421–429. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single Image Super-Resolution via a Holistic Attention Network. In Computer Vision—ECCV 2020; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; pp. 191–207. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, Tennessee, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Qin, J.; Huang, Y.; Wen, W. Multi-scale feature fusion residual network for single image super-resolution. Neurocomputing 2020, 379, 334–342. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Behjati, P.; Rodriguez, P.; Mehri, A.; Hupont, I.; Tena, C.F.; Gonzalez, J. Hierarchical Residual Attention Network for Single Image Super-Resolution. arXiv 2020, arXiv:2012.04578. [Google Scholar]
- Mukherjee, S.; Valenzise, G.; Cheng, I. Potential of deep features for opinion-unaware, distortion-unaware, no-reference image quality assessment. In International Conference on Smart Multimedia; Springer: Cham, Switzerland, 2019; pp. 87–95. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A Persistent Memory Network for Image Restoration. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Xie, C.; Zeng, W.; Lu, X. Fast single-image super-resolution via deep network with component learning. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3473–3486. [Google Scholar] [CrossRef]
- Li, F.; Bai, H.; Zhao, Y. FilterNet: Adaptive Information Filtering Network for Accurate and Fast Image Super-Resolution. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1511–1523. [Google Scholar] [CrossRef]
- Tian, C.; Xu, Y.; Zuo, W.; Zhang, B.; Fei, L.; Lin, C.-W. Coarse-to-fine CNN for image super-resolution. IEEE Trans. Multimed. 2020, 23, 1489–1502. [Google Scholar] [CrossRef]
- Fang, F.; Li, J.; Zeng, T. Soft-edge assisted network for single image super-resolution. IEEE Trans. Image Processing 2020, 29, 4656–4668. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Branch Input Type | BRW | ARW | AAW | PSNR(Set5) | SSIM(Set5) |
|---|---|---|---|---|---|
| Basic Branch | |||||
| No | √ | × | × | 32.209 | 0.8940 |
| × | √ | × | 32.231 | 0.8945 | |
| × | × | √ | 32.216 | 0.8939 | |
| Yes | √ | × | × | 32.223 | 0.8943 |
| × | √ | × | 32.247 | 0.8945 | |
| × | × | √ | 32.243 | 0.8942 |
| Attention Type | MBMFB-No | MBMFB-SE | MBMFB-CA | MBMFB-RCA | MBMFB-CCA | MBMFB-LERCA |
|---|---|---|---|---|---|---|
| PSNR(Set5) | 32.164 | 32.214 | 32.233 | 32.206 | 32.208 | 32.247 |
| SSIM(Set5) | 0.8937 | 0.8943 | 0.8942 | 0.8944 | 0.8941 | 0.8954 |
| Up-Sampling Pattern | U-Nearest- ×4 | U-Nearest-LERCA-×4 | U-Nearest- ×2-×2Weight sharing | U-Nearest-LERCA- ×2-×2Weight sharing | U-Nearest-LERCA- ×2-×2No Weight sharing | U-Subpixel |
|---|---|---|---|---|---|---|
| PSNR(Set5) | 32.207 | 32.221 | 32.219 | 32.247 | 32.246 | 32.216 |
| SSIM(Set5) | 0.8941 | 0.8941 | 0.8942 | 0.8945 | 0.8945 | 0.8943 |
| Parameter | 1220 K | 1224 K | 1220 K | 1224 K | 1291 K | 1250 K |
| Scale | Method | Year | Set5 | Set14 | B100 | Urban100 | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |||
| ×2 | SRCNN | 2016 | 36.66 | 0.9542 | 32.42 | 0.9063 | 31.36 | 0.8879 | 29.50 | 0.8946 |
| VDSR | 2016 | 37.53 | 0.9587 | 33.03 | 0.9124 | 31.90 | 0.8960 | 30.76 | 0.9140 | |
| DRCN | 2016 | 37.63 | 0.9588 | 33.04 | 0.9118 | 31.85 | 0.8942 | 30.75 | 0.9133 | |
| MemNet | 2017 | 37.78 | 0.9597 | 33.28 | 0.9142 | 32.08 | 0.8978 | 31.31 | 0.9195 | |
| CARN | 2018 | 37.76 | 0.9590 | 33.52 | 0.9166 | 32.09 | 0.8978 | 31.92 | 0.9256 | |
| IMDN | 2019 | 38.00 | 0.9605 | 33.63 | 0.9177 | 32.19 | 0.8996 | 32.17 | 0.9283 | |
| DNCL | 2019 | 37.65 | 0.9599 | 33.18 | 0.9141 | 31.97 | 0.8971 | 30.89 | 0.9158 | |
| MRFN | 2019 | 37.98 | 0.9611 | 33.41 | 0.9159 | 32.14 | 0.8997 | 31.45 | 0.9221 | |
| FilterNeL | 2020 | 37.86 | 0.9610 | 33.34 | 0.9150 | 32.09 | 0.8990 | 31.24 | 0.9200 | |
| MADNet-LF | 2020 | 37.85 | 0.9600 | 33.39 | 0.9161 | 32.05 | 0.8981 | 31.59 | 0.9234 | |
| RFDN | 2020 | 38.05 | 0.9606 | 33.68 | 0.9184 | 32.16 | 0.8994 | 32.12 | 0.9278 | |
| CFSRCNN | 2020 | 37.79 | 0.9591 | 33.51 | 0.9165 | 32.11 | 0.8988 | 32.07 | 0.9273 | |
| SeaNet-baseline | 2020 | 37.99 | 0.9607 | 33.60 | 0.9174 | 32.18 | 0.8995 | 32.08 | 0.9276 | |
| SMSR | 2021 | 38.00 | 0.9601 | 33.64 | 0.9179 | 32.17 | 0.8990 | 32.19 | 0.9284 | |
| Cross-SRN | 2021 | 38.03 | 0.9606 | 33.62 | 0.9180 | 32.19 | 0.8997 | 32.28 | 0.9290 | |
| MBMFN | 38.05 | 0.9599 | 33.78 | 0.9193 | 32.21 | 0.8996 | 32.44 | 0.9303 | ||
| ×3 | SRCNN | 2016 | 32.75 | 0.9090 | 29.28 | 0.8209 | 28.41 | 0.7863 | 26.24 | 0.7989 |
| VDSR | 2016 | 33.66 | 0.9213 | 29.77 | 0.8314 | 28.82 | 0.7976 | 27.14 | 0.8279 | |
| DRCN | 2016 | 33.82 | 0.9226 | 29.76 | 0.8311 | 28.80 | 0.7963 | 27.15 | 0.8276 | |
| MemNet | 2017 | 34.09 | 0.9248 | 30.00 | 0.8350 | 28.96 | 0.8001 | 27.56 | 0.8376 | |
| CARN | 2018 | 34.29 | 0.9255 | 30.29 | 0.8407 | 29.06 | 0.8034 | 28.06 | 0.8493 | |
| IMDN | 2019 | 34.36 | 0.9270 | 30.32 | 0.8417 | 29.09 | 0.8046 | 28.17 | 0.8519 | |
| DNCL | 2019 | 33.95 | 0.9232 | 29.93 | 0.8340 | 28.91 | 0.7995 | 27.27 | 0.8326 | |
| MRFN | 2019 | 34.21 | 0.9267 | 30.03 | 0.8363 | 28.99 | 0.8029 | 27.53 | 0.8389 | |
| FilterNeL | 2020 | 34.08 | 0.9250 | 30.03 | 0.8370 | 28.95 | 0.8030 | 27.55 | 0.8380 | |
| MADNet-LF | 2020 | 34.14 | 0.9251 | 30.20 | 0.8395 | 28.98 | 0.8023 | 27.78 | 0.8439 | |
| RFDN | 2020 | 34.41 | 0.9273 | 30.34 | 0.8420 | 29.09 | 0.8050 | 28.21 | 0.8525 | |
| CFSRCNN | 2020 | 34.24 | 0.9256 | 30.27 | 0.8410 | 29.03 | 0.8035 | 28.04 | 0.8496 | |
| SeaNet-baseline | 2020 | 34.36 | 0.9280 | 30.34 | 0.8428 | 29.09 | 0.8053 | 28.17 | 0.8527 | |
| SMSR | 2021 | 34.40 | 0.9270 | 30.33 | 0.8412 | 29.10 | 0.8050 | 28.25 | 0.8536 | |
| Cross-SRN | 2021 | 34.43 | 0.9275 | 30.33 | 0.8417 | 29.09 | 0.8050 | 28.23 | 0.8535 | |
| MBMFN | 34.52 | 0.9273 | 30.41 | 0.8426 | 29.12 | 0.8052 | 28.36 | 0.8553 | ||
| ×4 | SRCNN | 2016 | 30.48 | 0.8628 | 27.49 | 0.7503 | 26.90 | 0.7101 | 24.52 | 0.7221 |
| VDSR | 2016 | 31.35 | 0.8838 | 28.01 | 0.7674 | 27.29 | 0.7251 | 25.18 | 0.7524 | |
| DRCN | 2016 | 31.53 | 0.8854 | 28.02 | 0.7670 | 27.23 | 0.7233 | 25.14 | 0.7510 | |
| MemNet | 2017 | 31.74 | 0.8893 | 28.26 | 0.7723 | 27.40 | 0.7281 | 25.50 | 0.7630 | |
| CARN | 2018 | 32.13 | 0.8937 | 28.60 | 0.7806 | 27.58 | 0.7349 | 26.07 | 0.7837 | |
| IMDN | 2019 | 32.21 | 0.8948 | 28.58 | 0.7811 | 27.56 | 0.7353 | 26.04 | 0.7838 | |
| DNCL | 2019 | 31.66 | 0.8871 | 28.23 | 0.7717 | 27.39 | 0.7282 | 25.36 | 0.7606 | |
| MRFN | 2019 | 31.90 | 0.8916 | 28.31 | 0.7746 | 27.43 | 0.7309 | 25.46 | 0.7654 | |
| FilterNeL | 2020 | 31.74 | 0.8900 | 28.27 | 0.7730 | 27.39 | 0.7290 | 25.53 | 0.7680 | |
| MADNet-LF | 2020 | 32.01 | 0.8925 | 28.45 | 0.7781 | 27.47 | 0.7327 | 25.77 | 0.7751 | |
| RFDN | 2020 | 32.24 | 0.8952 | 28.61 | 0.7819 | 27.57 | 0.7360 | 26.11 | 0.7858 | |
| CFSRCNN | 2020 | 32.06 | 0.8920 | 28.57 | 0.7800 | 27.53 | 0.7333 | 26.03 | 0.7824 | |
| SeaNet-baseline | 2020 | 32.18 | 0.8948 | 28.61 | 0.7822 | 27.57 | 0.7359 | 26.05 | 0.7896 | |
| SMSR | 2021 | 32.12 | 0.8932 | 28.55 | 0.7808 | 27.55 | 0.7351 | 26.11 | 0.7868 | |
| MSFIN | 2021 | 32.28 | 0.8957 | 28.57 | 0.7813 | 27.56 | 0.7358 | 26.13 | 0.7865 | |
| Cross-SRN | 2021 | 32.24 | 0.8954 | 28.59 | 0.7817 | 27.58 | 0.7364 | 26.16 | 0.7881 | |
| MBMFN | 32.31 | 0.8952 | 28.68 | 0.7829 | 27.60 | 0.7363 | 26.26 | 0.7899 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, Y.; Gao, G.; Jia, Z.; Lai, H. Image Reconstruction of Multibranch Feature Multiplexing Fusion Network with Mixed Multilayer Attention. Remote Sens. 2022, 14, 2029. https://doi.org/10.3390/rs14092029
Cai Y, Gao G, Jia Z, Lai H. Image Reconstruction of Multibranch Feature Multiplexing Fusion Network with Mixed Multilayer Attention. Remote Sensing. 2022; 14(9):2029. https://doi.org/10.3390/rs14092029
Chicago/Turabian StyleCai, Yuxi, Guxue Gao, Zhenhong Jia, and Huicheng Lai. 2022. "Image Reconstruction of Multibranch Feature Multiplexing Fusion Network with Mixed Multilayer Attention" Remote Sensing 14, no. 9: 2029. https://doi.org/10.3390/rs14092029
APA StyleCai, Y., Gao, G., Jia, Z., & Lai, H. (2022). Image Reconstruction of Multibranch Feature Multiplexing Fusion Network with Mixed Multilayer Attention. Remote Sensing, 14(9), 2029. https://doi.org/10.3390/rs14092029