4.1. Training Results
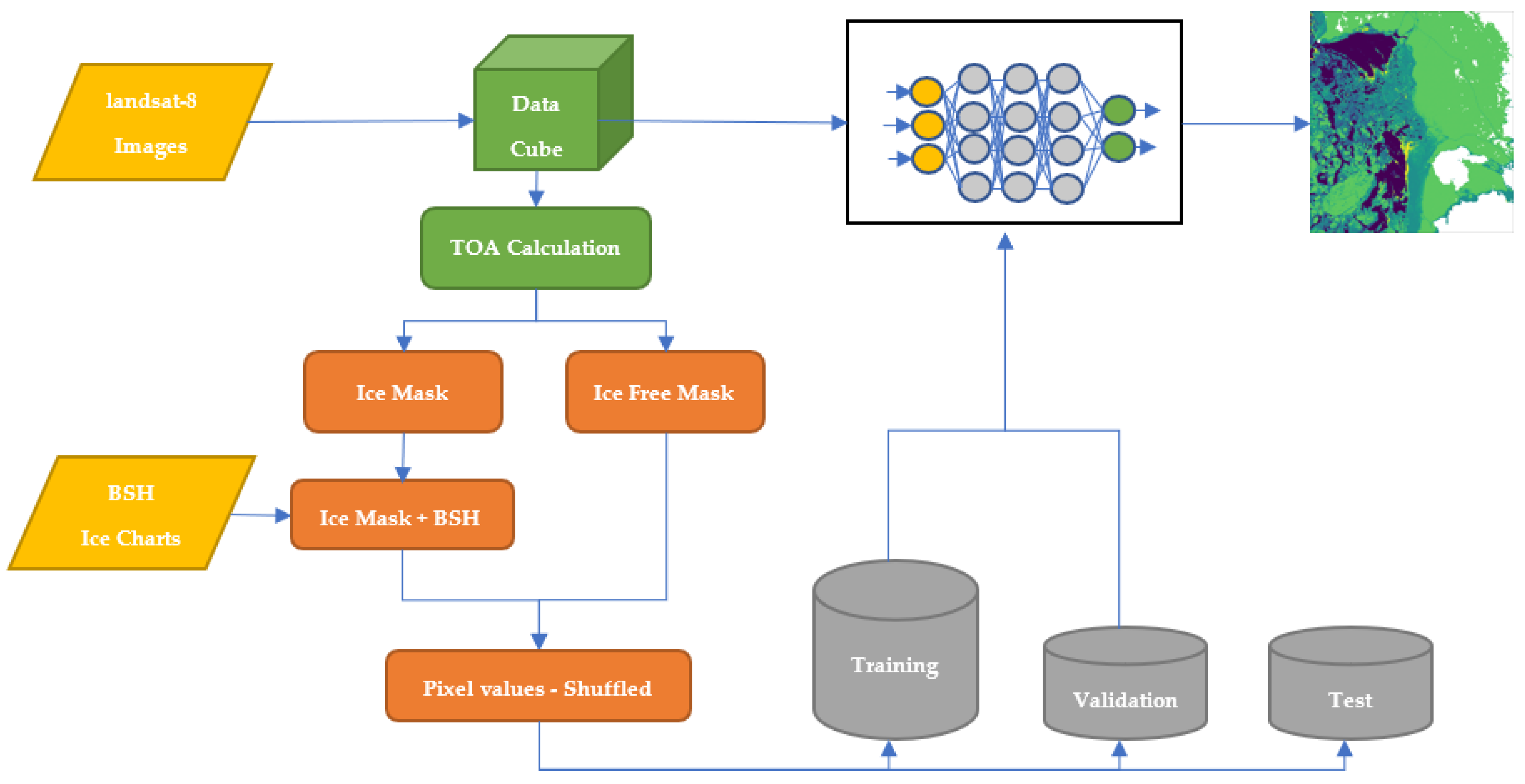
The model was trained in a virtual machine with the characteristics presented in
Table 7. A batch size of 100,000 was selected to divide the training data set in chunks. An early stopping callback was applied; this stops the iteration process after each epoch in case the validation accuracy decreases two times in a row. Multiprocessing with 12 processors was deployed. The training time was 4 min and it was finished after 21 epochs.
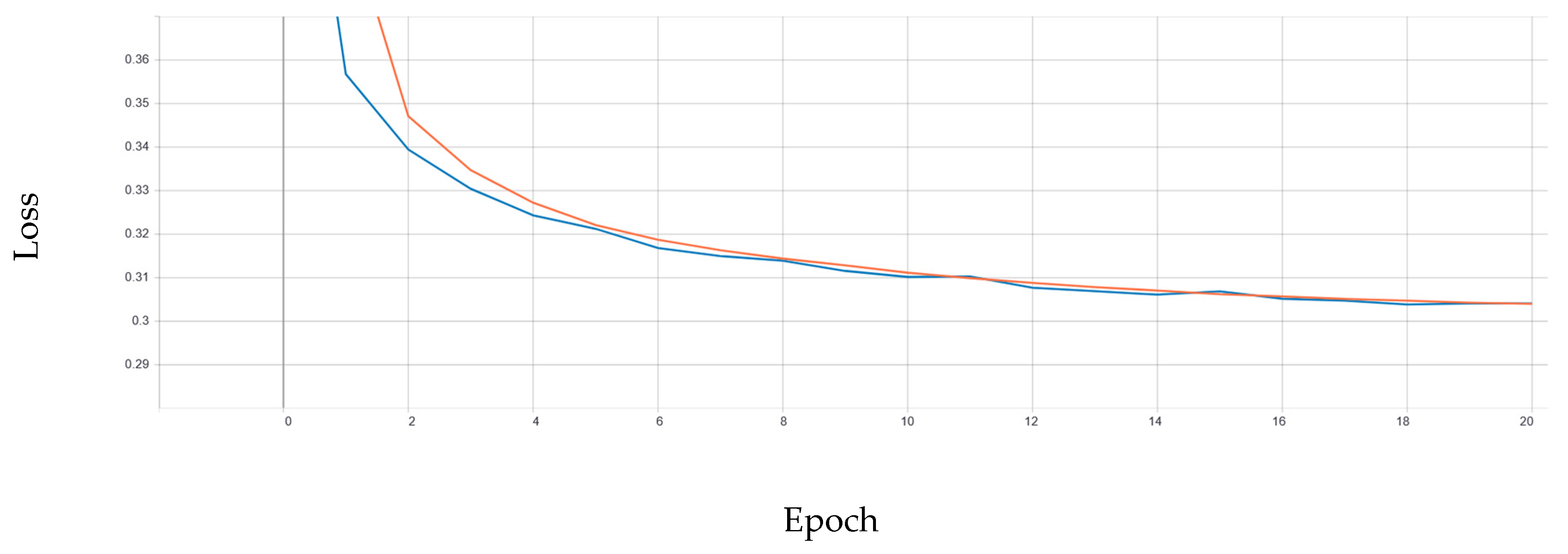
The training of the model has shown a purposeful behavior that can be seen in terms of the loss and accuracy. The decrease in the loss is presented in
Figure 7. The increase in the accuracy is presented in
Figure 8.
After the training was finished, the results of the model were validated using the dedicated test data set. This data set was not previously involved in the training process. The final loss and accuracy are 0.3043 and 0.8748, respectively, showing an overall successful training process.
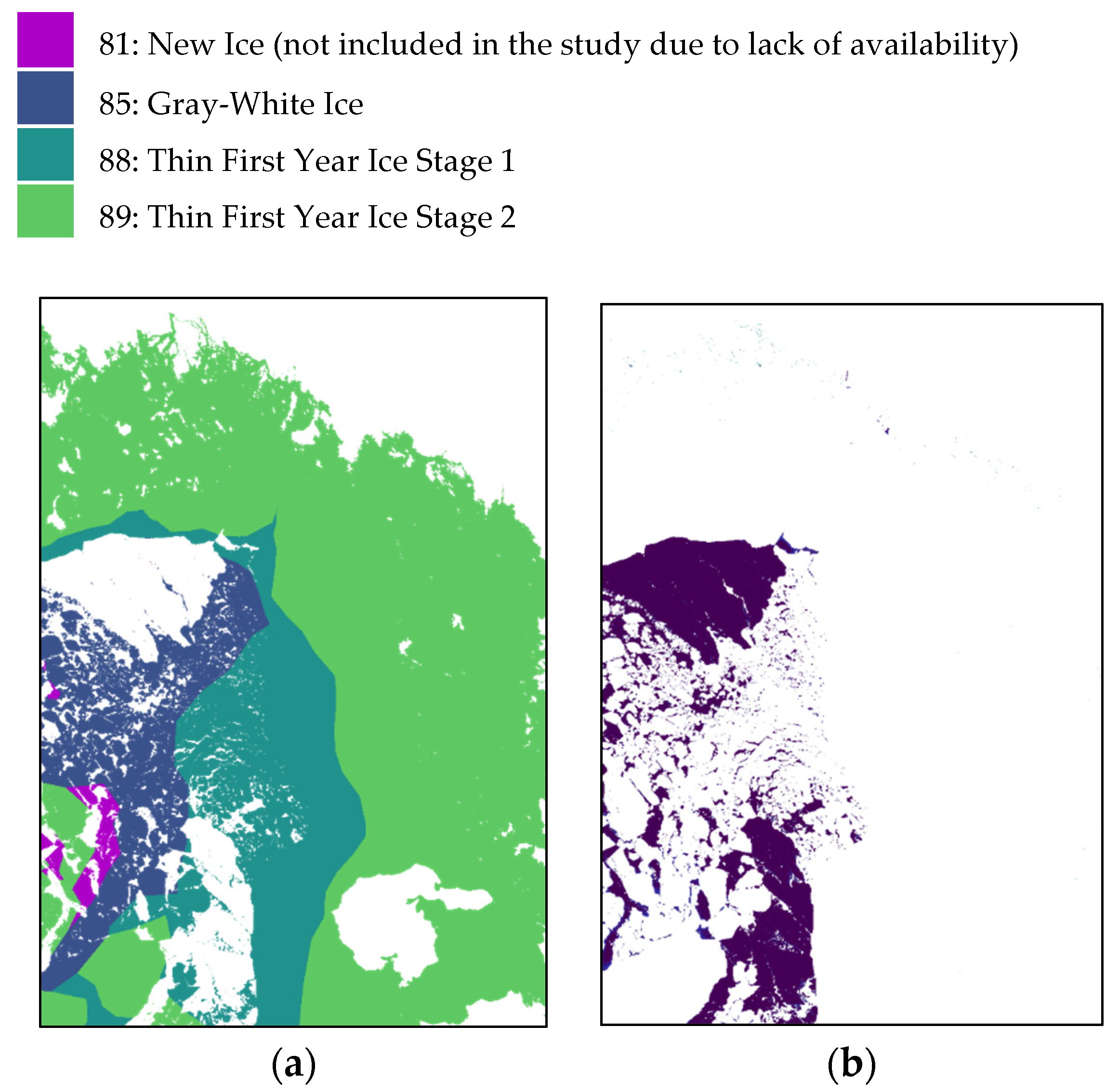
It is important to note that the training data set is imbalanced.
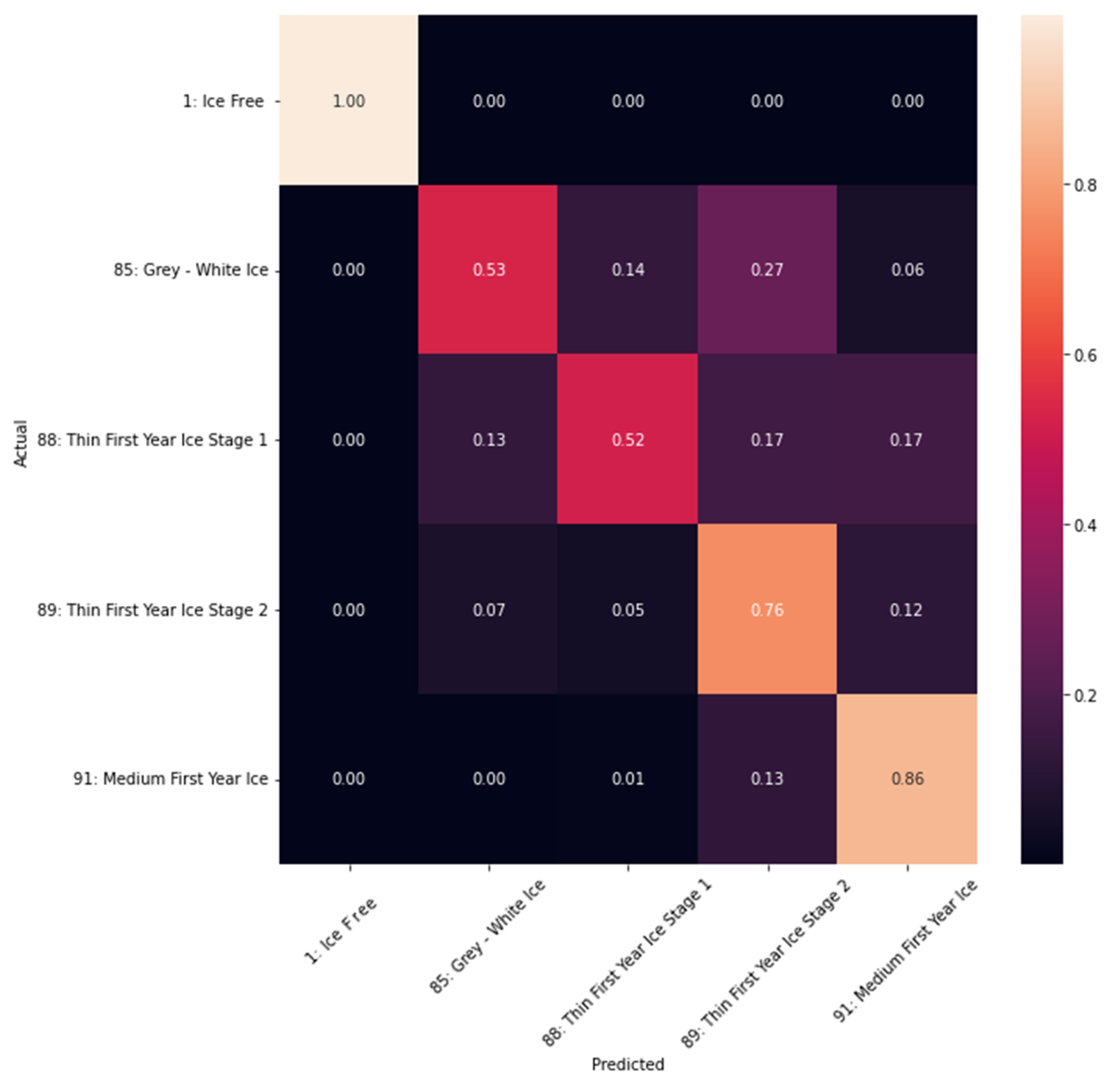
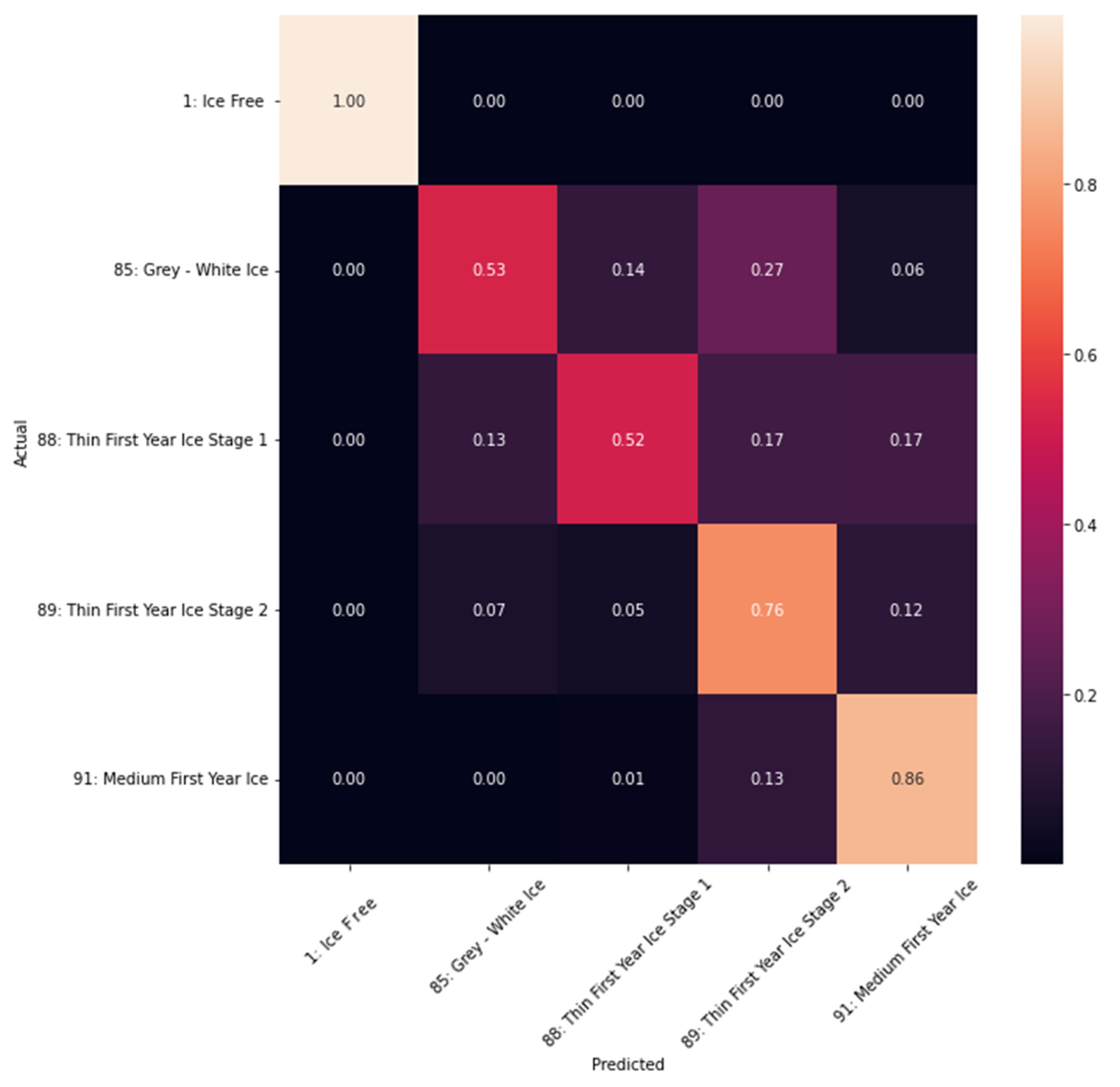
Table 4 shows the sample size of different classes showing more data available for the classes of 1 (Ice Free), 89 (Thin First Year Ice Stage 2) and 91 (Medium First Year Ice) with little data for 85 (Gray-White Ice), and 88 (Thin First Year Ice Stage 1). The reason for this huge imbalance is caused by the nature of the ice represented in the ice charts used for the training. The accuracy of the different classes can be seen in the confusion matrix. The confusion matrix is a cross table that represents the accuracy between classes considered as ground truth (rows) and their predictions (columns) [
25].
Figure 9 shows the confusion matrix used for the test data set. It can be seen that the accuracy is lower for the classes with less available training data, while the other classes with more data, show higher accuracy, especially Ice Free with a 100% of accuracy followed by 91 with 86% and 89 with 76%. Apparently, these classes have higher accuracy because their features are more presented in the data set. Balancing the dataset, that means, making all the classes to have the same proportion of the dataset while removing additional data, will produce a loss on the quality and quantity on the training, thus affecting the results. In this scenario, additional extraction of training data on 85 and 88 is suggested.
4.3. Discussion
The DNN classification show very good results with the Landsat-8 imagery regarding the distinction between ice and no ice. The agreement with the BSH ice charts depends on the accuracy of each class related to the availability of training data as shown in the confusion matrix, see
Figure 9. However, there is a clear improvement when moving from polygons to pixels while maintaining the original BSH classes. The first evaluation of the model results in an accuracy of 87.5%. This result is based on the test data set, which is not part of the training or validation data set.
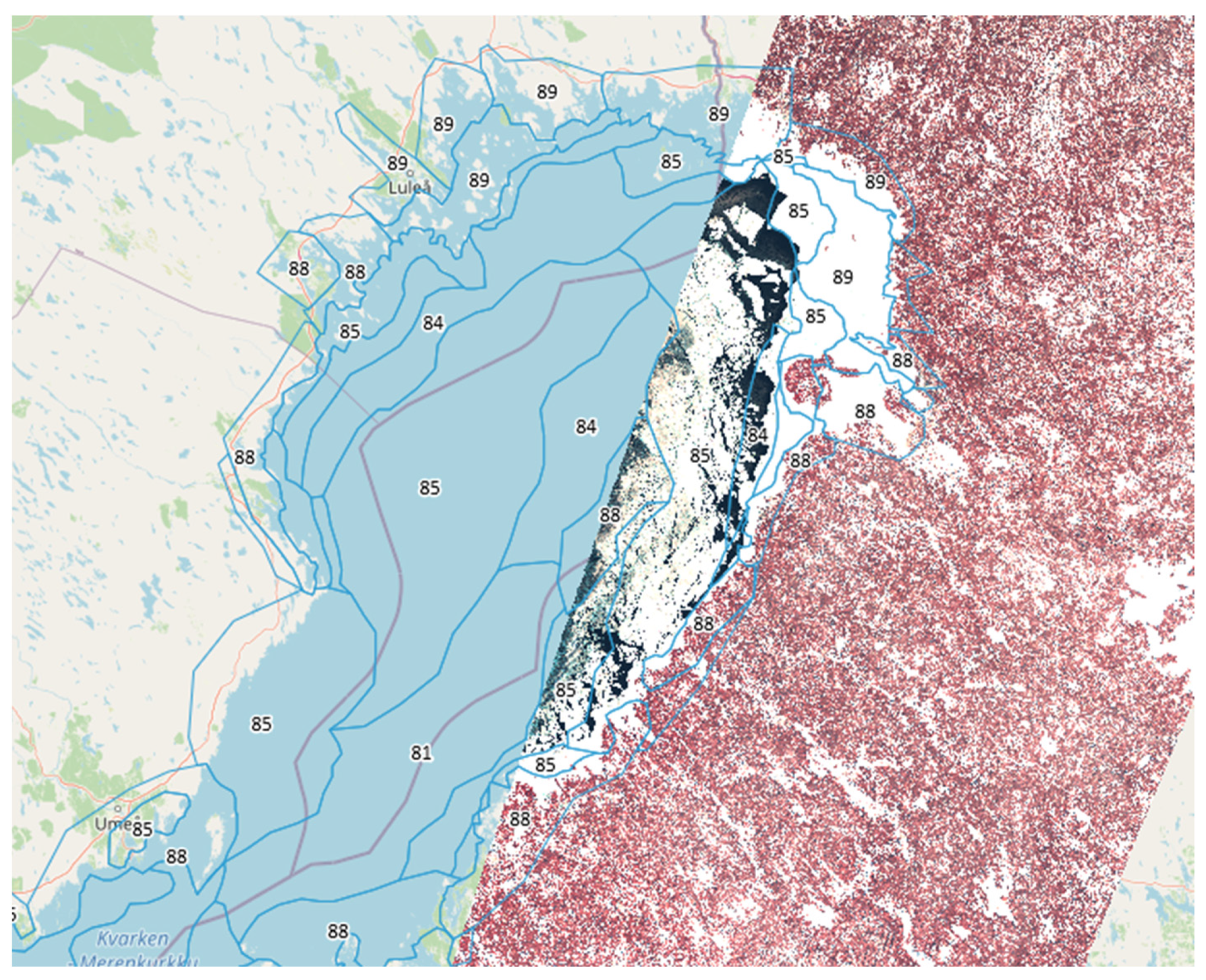
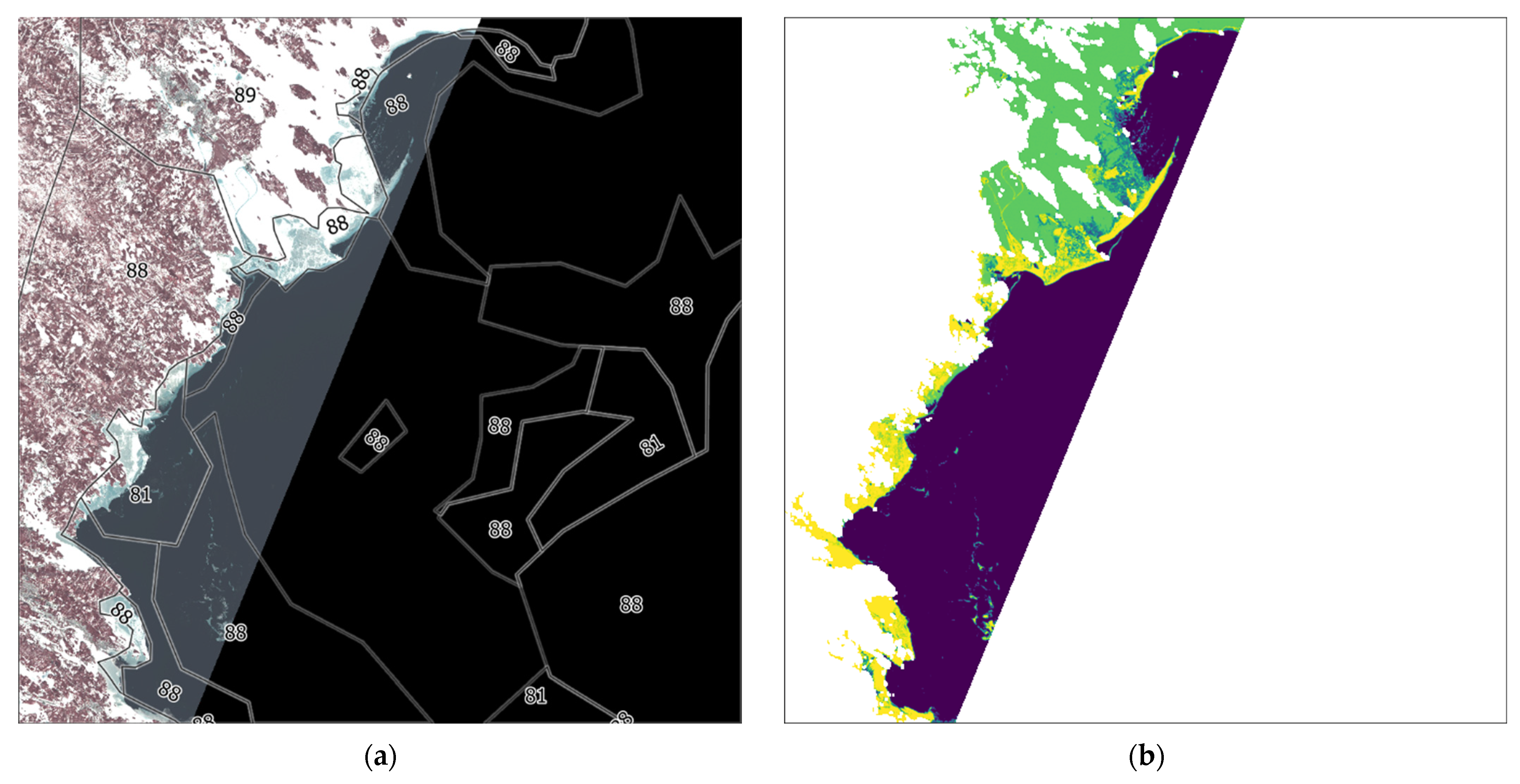
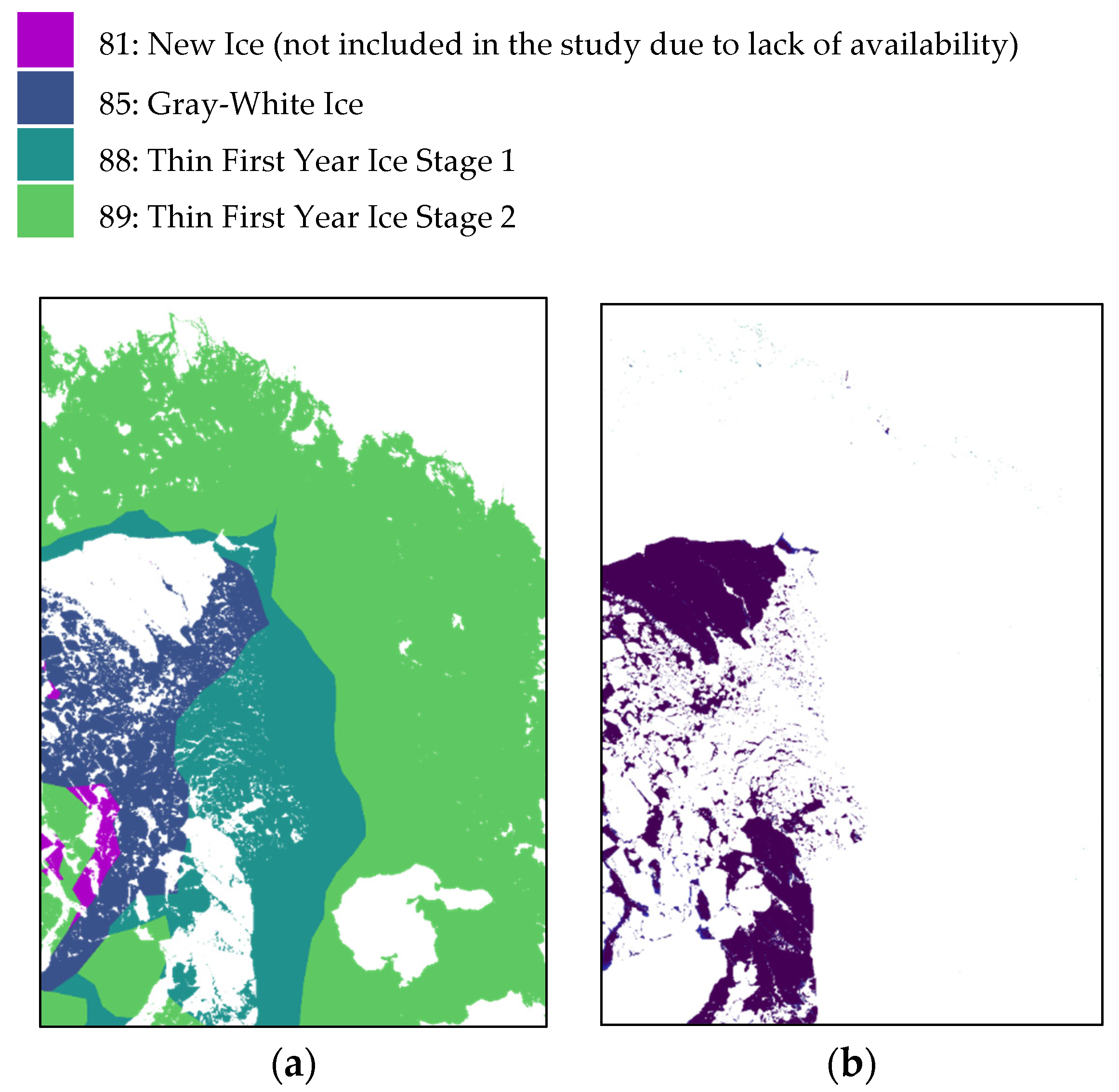
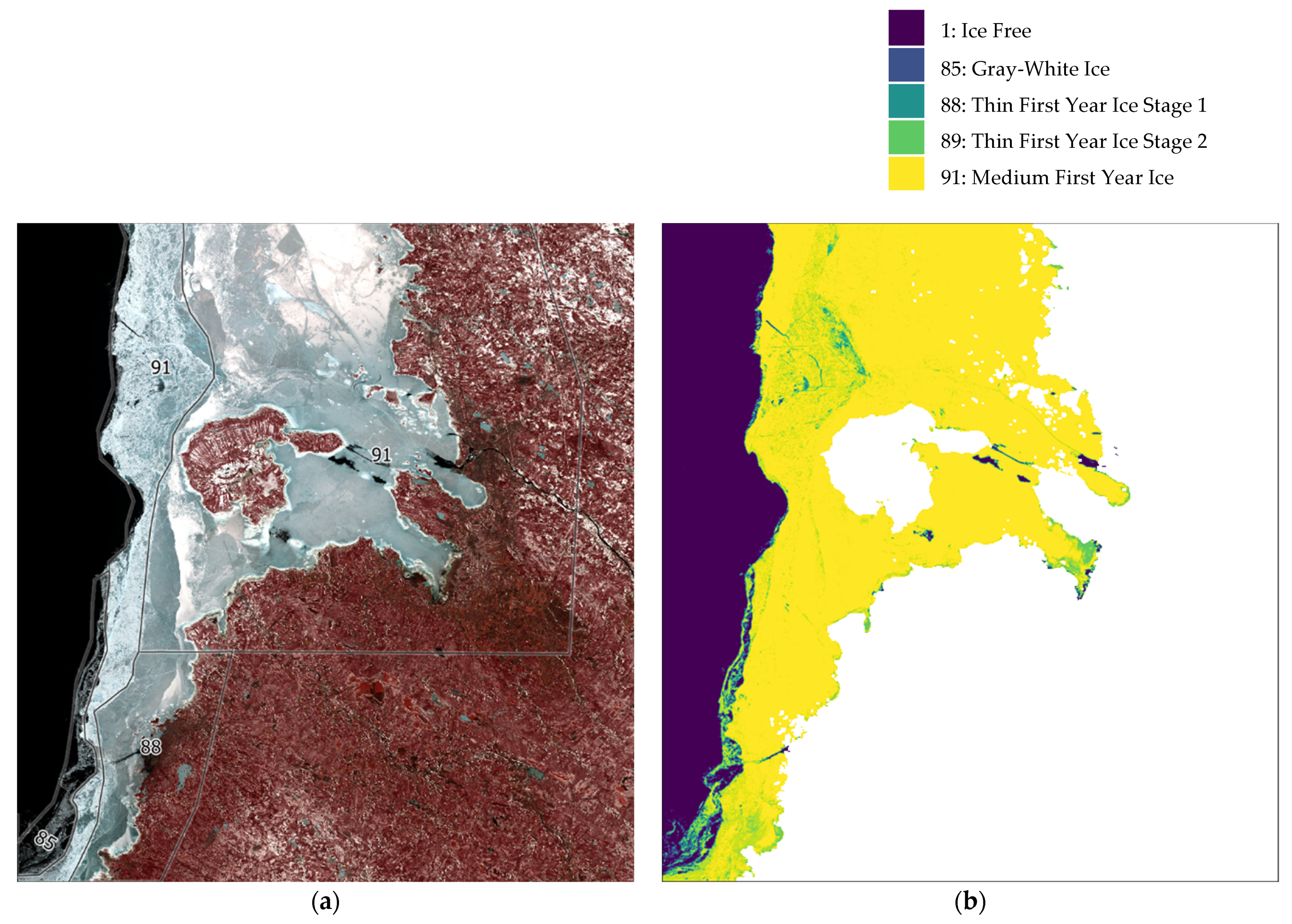
Figure 10 output shows a predominance of class 88 (Thin First Year Ice Stage 1) which corresponds to some polygons of the training data. In addition, the algorithm detects class 85 (Gray-White ice) which does not appear in the training data for this region.
Figure 11 shows a good representation; there is a clear distinction between classes 88 (Thin First Year Ice Stage 1) and 89 (Thin First Year Ice Stage 2) and a smooth transition between 88 and 85. Class 91 is shown in some boundaries. Ice Free is clearly marked and some icebreaker vessel routes are also visible.
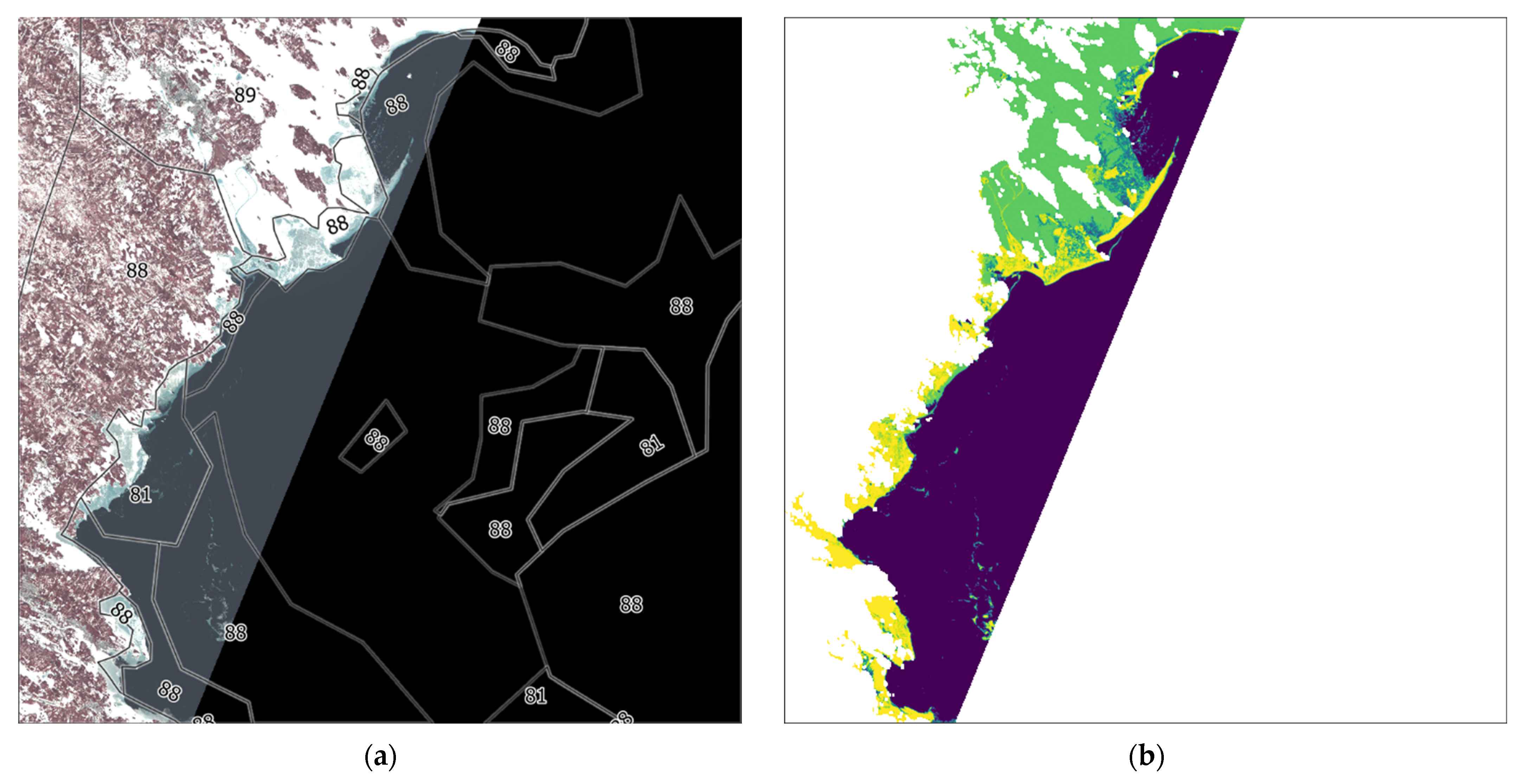
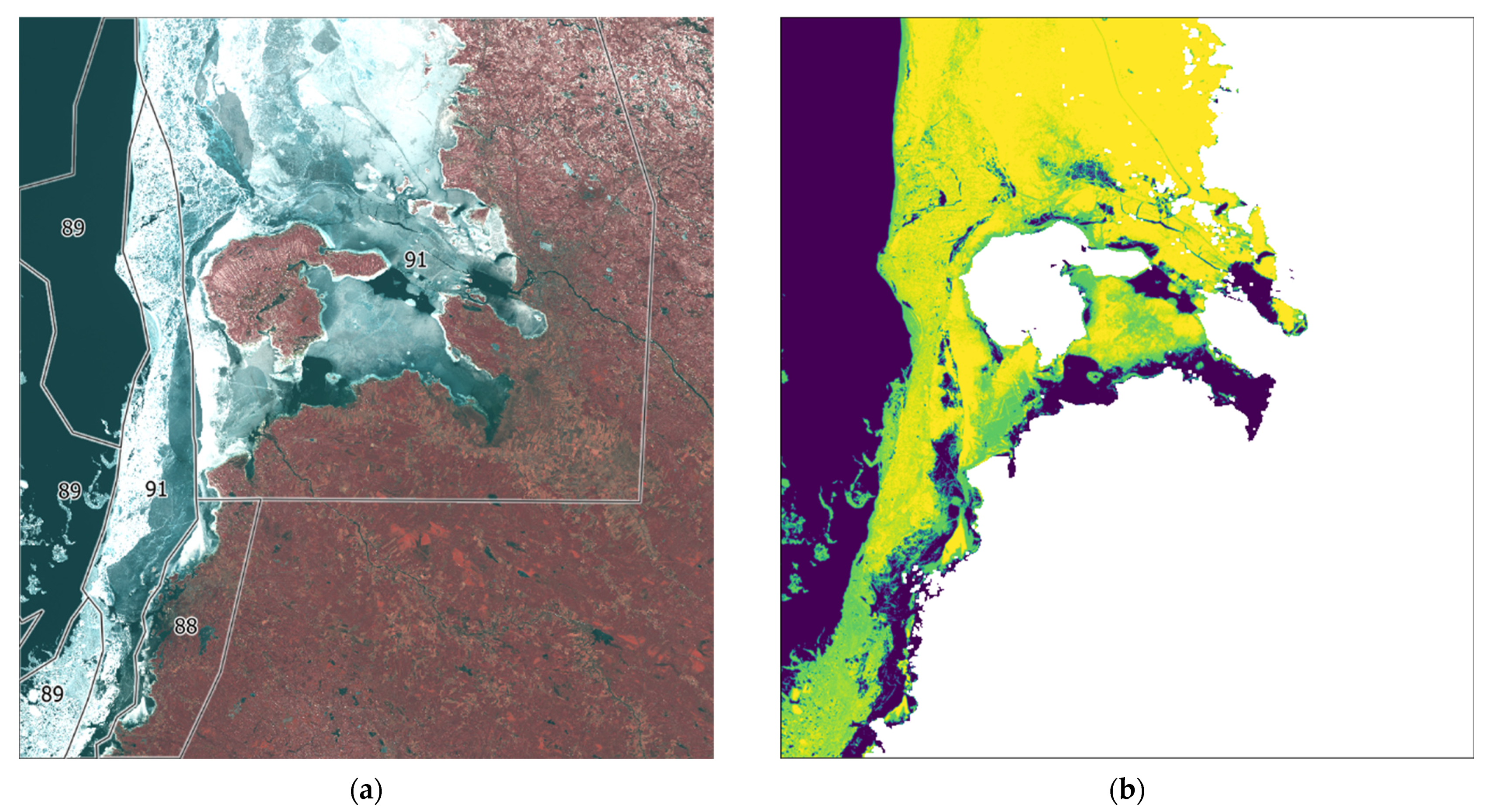
Figure 12 shows that the training polygons are shifted relative to the ice locations in the false color image. This difference occurs because the Landsat-8 image and the BSH ice chart differ by one day. Nevertheless, the algorithm distinguishes well between water and ice and the two classes most represented in the false color image (88 and 89) are therefore classified.
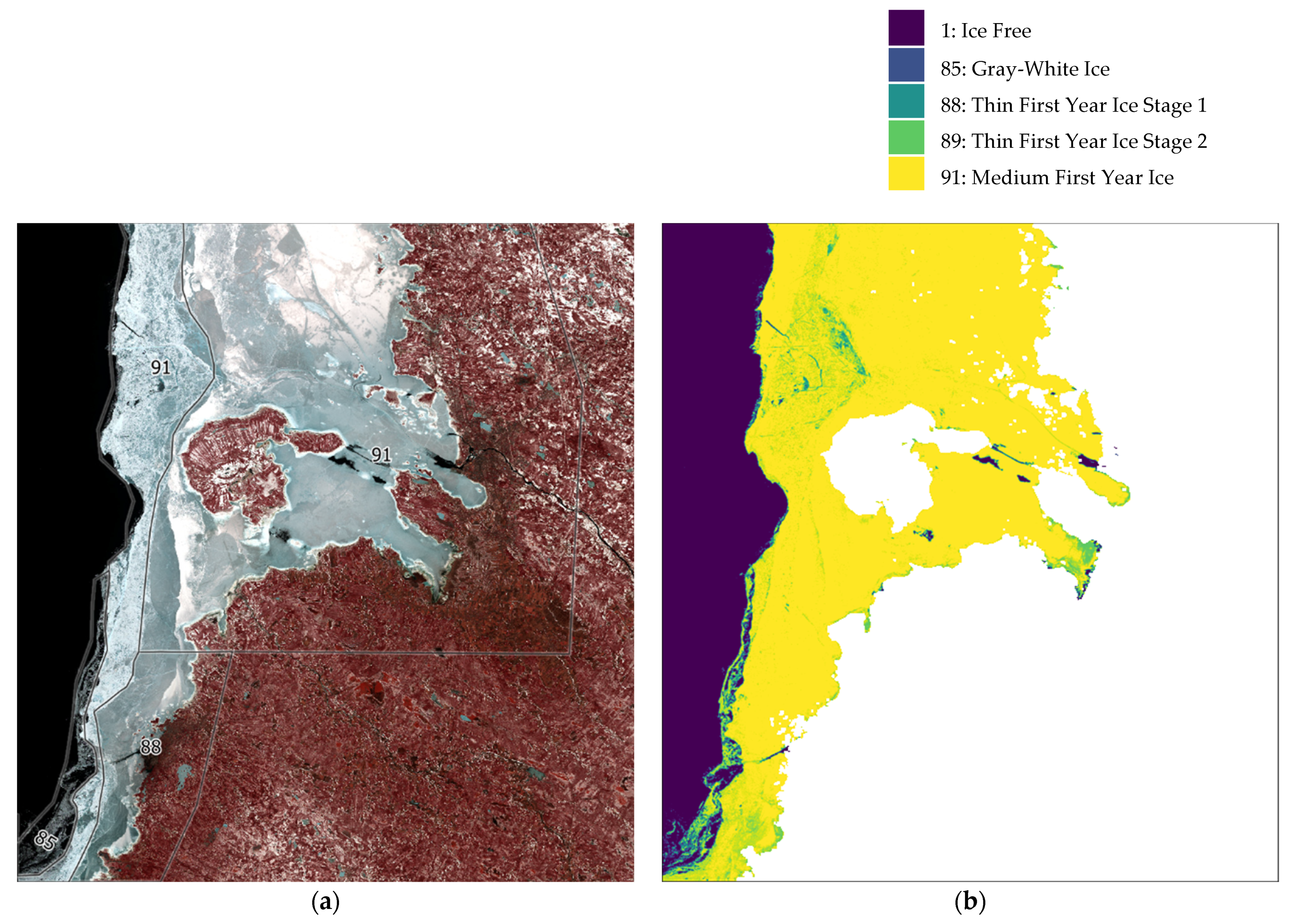
Figure 13 shows a good representation of class 89 from the training polygons. However, class 91, which is not presented in the ice chart, is shown in the classification.
Figure 14 shows a dominance of class 91 which is very similar to the training data.
Figure 15 shows a classification of Ice Free in the center of the image as well as in the lower part where it looks like there is ice. Since melting usually already starts in April, this is most likely water on top of the ice; this issue needs to be investigated in future studies.
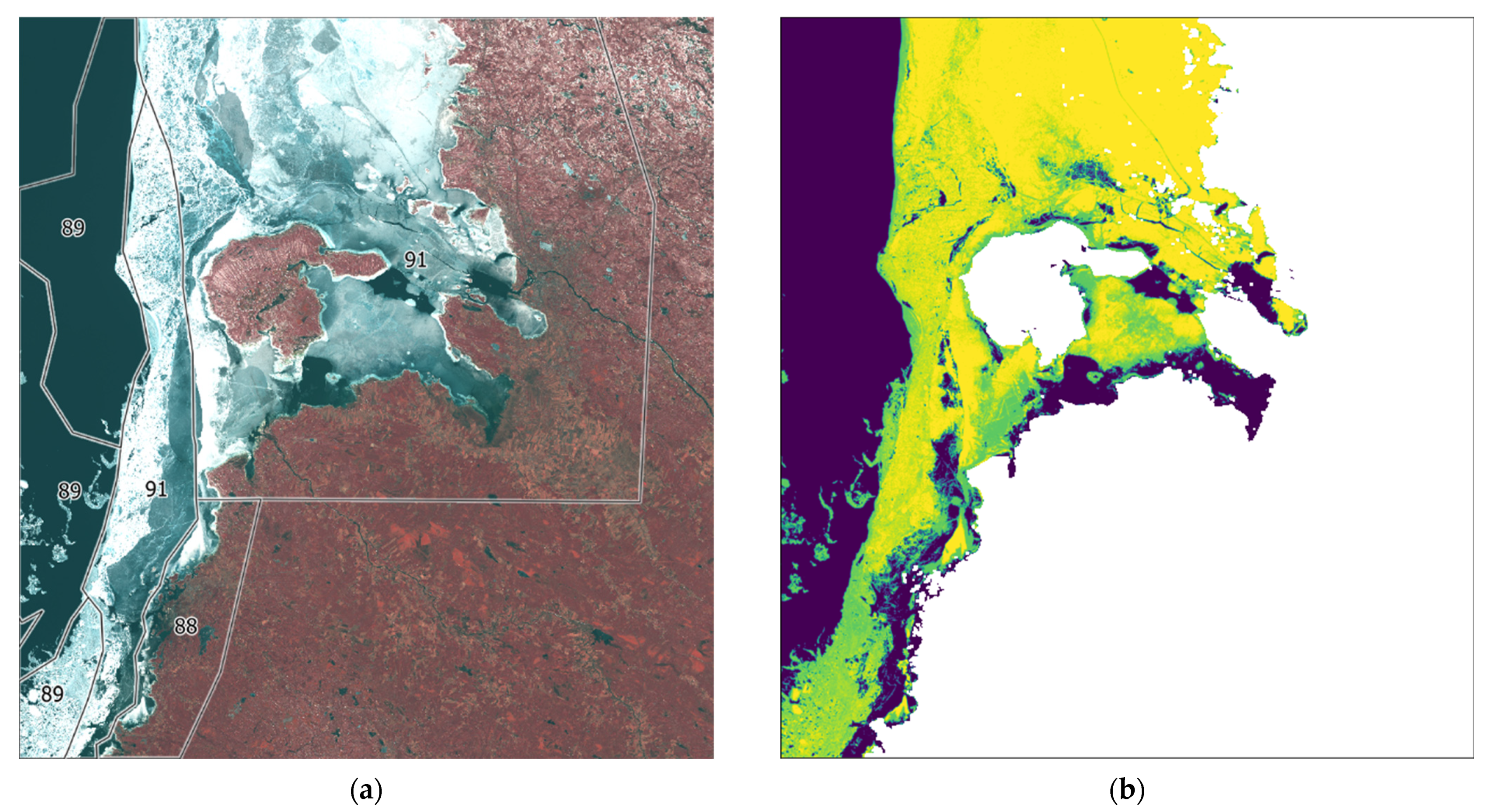
Figure 16 shows equivalence in classes 85 and 89.
Figure 17 shows dominance of class 85, which is very similar to the training data. There is a clear visual discrepancy between near coastal ice (clear white) and the ice further out (darker and partly thinner), but from the classification model, no difference is reported at this time. According to the confusion matrix, the classes 85 and 88 have an accuracy of 50% each. To improve this issue, we recommend including more training data representing these two classes.
It should be noted that the use of the BSH ice charts were of limited use due to the time difference between the acquisition time of the satellite image and the ice chart used for the overlay. The boundaries of the polygons were not accurate enough in respect to the satellite image, which means that the training data did not perfectly match all image areas. The reason for the incoherence of the ice charts provided is that they were not created on the basis of Landsat-8 images itself. Despite these limitations, we used these ice charts because they were a source of training data in digital format for this region. In this study, it can be seen that the model has learned to interpret the classes and make a reliable distinction between ice and water as well as a classification that matches the training data.
When we started our study, we tried to use the whole content image data set of the data cube, thinking that the more data available, the more reliable the results would be. However, this is not necessary if the classification training is done with high quality images, such as the cloud-free images we used. Adding the Ice Free class to the ice classes has greatly improved the results.
Currently, the results do not include all classes that might be represented. By extending the training data, it will be possible to subdivide the results into additional, more sophisticated classes in the future.
The major limitation in using optical imagery is cloud cover. An attempt was made during the study to classify overcast imagery, nevertheless, the embedded cloud mask of the Landsat-8 quality filter is not precise enough to allow a clear distinction. Since the results were not satisfactory, it was decided to perform the study only with cloud-free images. Creating a more realistic cloud mask is an issue for future analysis. In the meantime, the cloud mask provided by Landsat-8 can be used for a usability assessment for value, adding ice classification in an upstream pre-processing step.
The suggested approach is intended to be used in NRT maritime operations. Therefore, the proposed model was designed to provide better performance compared to CNN models, since there was an avoidance of convolutional computation [
26].













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}