
A Fast Inference Vision Transformer for Automatic Pavement Image Classification and Its Visual Interpretation Method



Abstract
:1. Introduction
2. Methodology and Materials
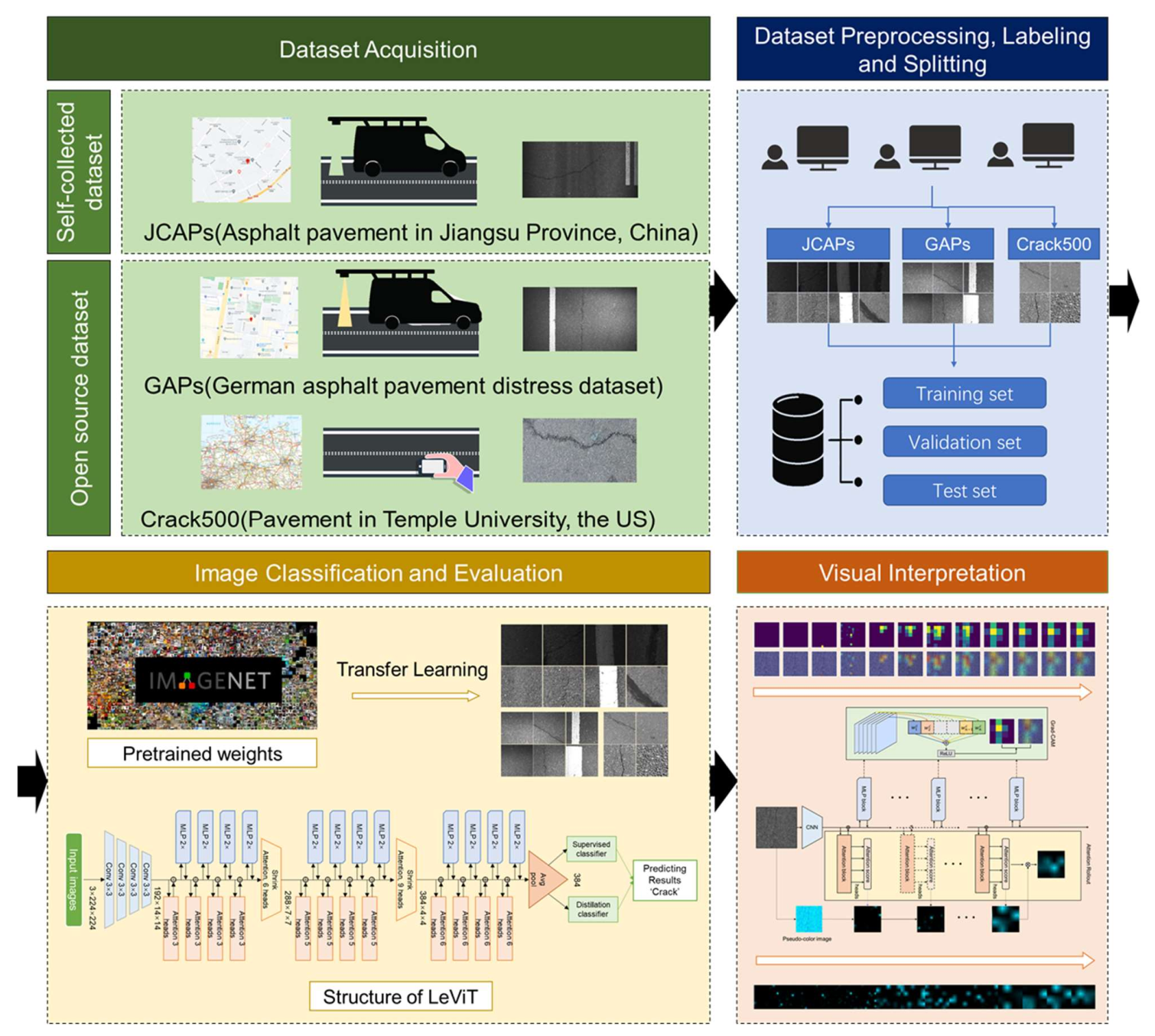
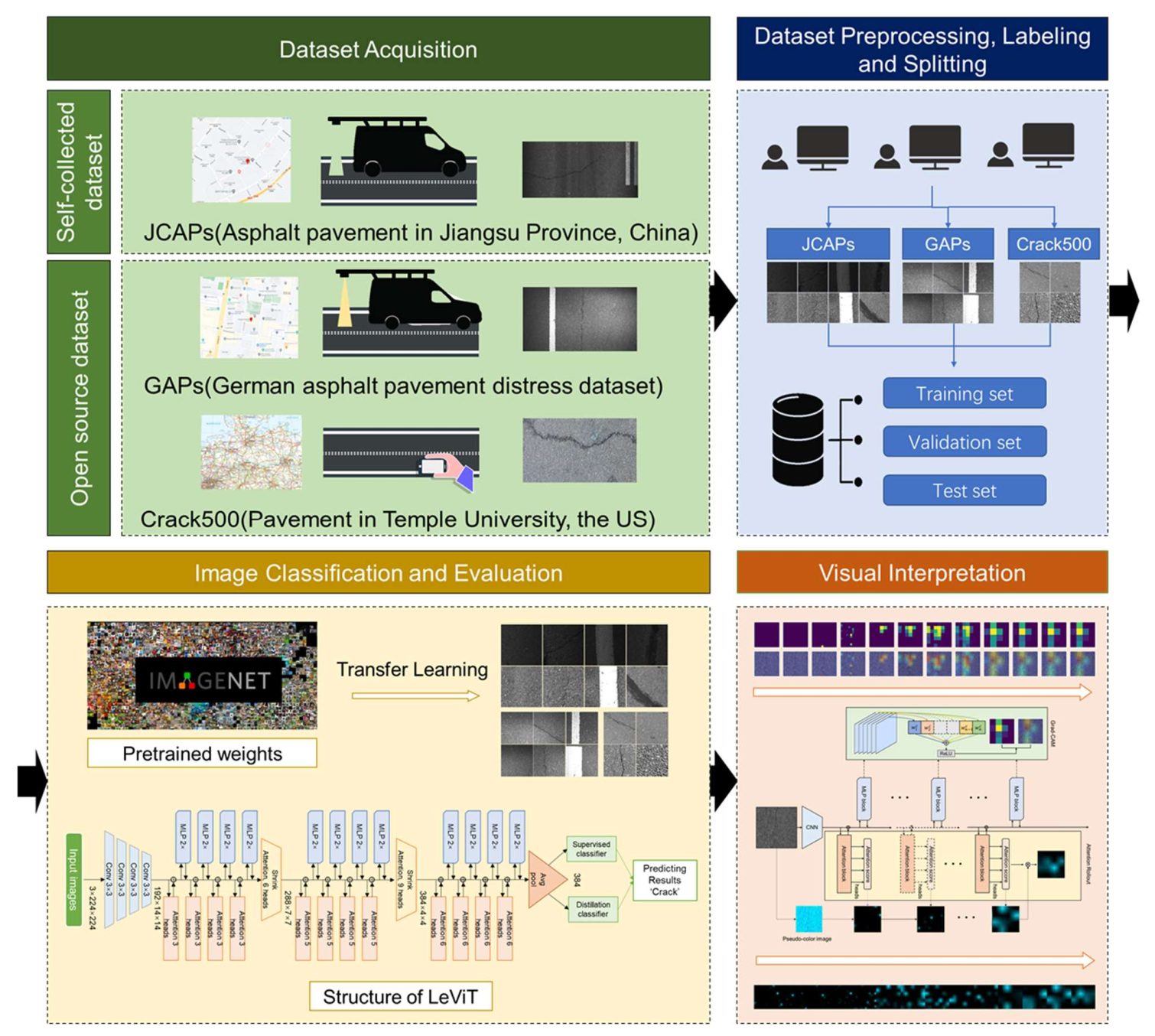
2.1. Overall Procedure
2.2. Data Acquisition
- (1)
- JCAPs: The first dataset was collected from the multi-functional intelligent road detection vehicle on asphalt pavement on Lanhua Road, Nanjing, Jiangsu Province, China, in April 2018. This multi-functional pavement detection vehicle was equipped with onboard computers and embedded integrated multi-sensor synchronous control units to automatically capture pavement pictures. It took about half an hour for the vehicle to collect the original images. The original data collected were RGB images of 4096 × 2000 pixels. To satisfy the training requirements, the original images were processed to a proper size. First, the original images were horizontally resized to 4000 × 2000 pixels via bilinear interpolation. Then, the resized images were continuously clipped to 400 × 400 pixels. Subsequently, the sub-images were resized to 224 × 224 pixels. To balance the number of images of various samples in the dataset, 1600 images were selected, including 400 pavement background images, pavement marking images, crack images, and sealed crack images. In terms of the crack images, transverse and longitudinal crack images are included in the dataset. This dataset is named as JCAPs. Example images of different classifications in JCAPs are shown in Figure 2. As the images were affected by the equipment and lighting conditions, the original dataset contained road images with good lighting exposure and poor lighting exposure. In addition, the cracks in this image dataset have a relatively smaller width, and the image feature is inconspicuous, which may increase the difficulty of classification for deep learning models.
- (2)
- GAPs: The German Asphalt Pavement Distress (GAPs) dataset is an open-source dataset with various classes of distress using a mobile mapping system. Four-year cycle images are contained in the original GAPs dataset. The resolution of the original images is 1920 × 1080 pixels. More details of the dataset are presented in [35]. We randomly selected several of the original images and cropped the original GAPs images into tiny images with 400 × 400 pixels using the sliding-window method and resized them into 224 × 224 pixels to prevent the problem of running out of memory while computing. A total of 1200 images with the size of 224 × 224 were manually labeled, including 400 pavement background images, pavement marking images, and crack images. Longitudinal and transverse cracking are included in the crack images. Figure 3 shows the example images from the GAPs dataset.
- (3)
- Crack500: This dataset is also an open-source dataset collected from the main campus of Temple University, Philadelphia, Pennsylvania, U.S. The resolution of the original images in the Crack500 dataset is 2000 × 1500 pixels. More details of the dataset are presented in [36,37]. We also randomly selected several of the original images and cropped the original images into 500 × 500 pixels using the sliding-window method. The tiny images were also resized to 224 × 224 pixels before inputting into the training networks. A total of 2000 images with the size of 224 × 224 were manually categorized, including 1000 pavement background images and 1000 crack images. The crack images include longitudinal and transverse cracks. Figure 4 shows the example preprocessed images in the Crack500 dataset.
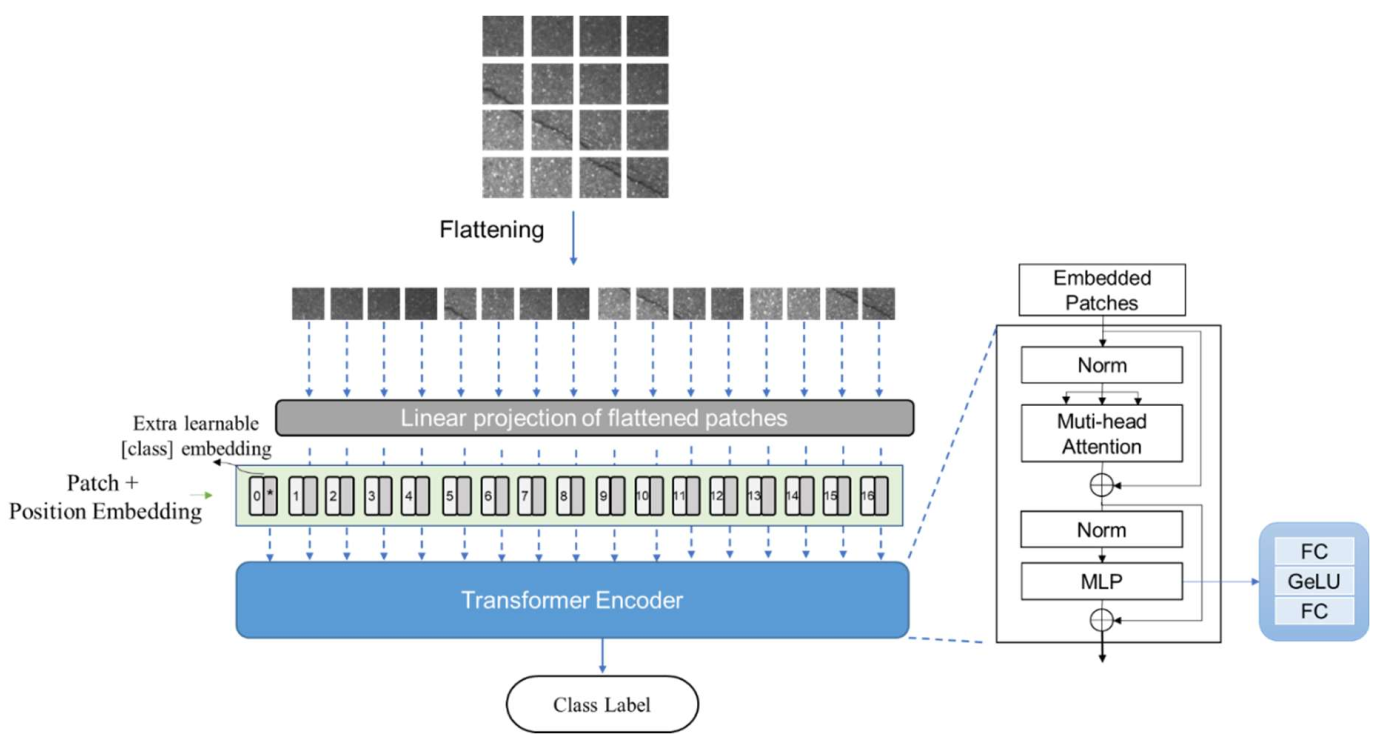
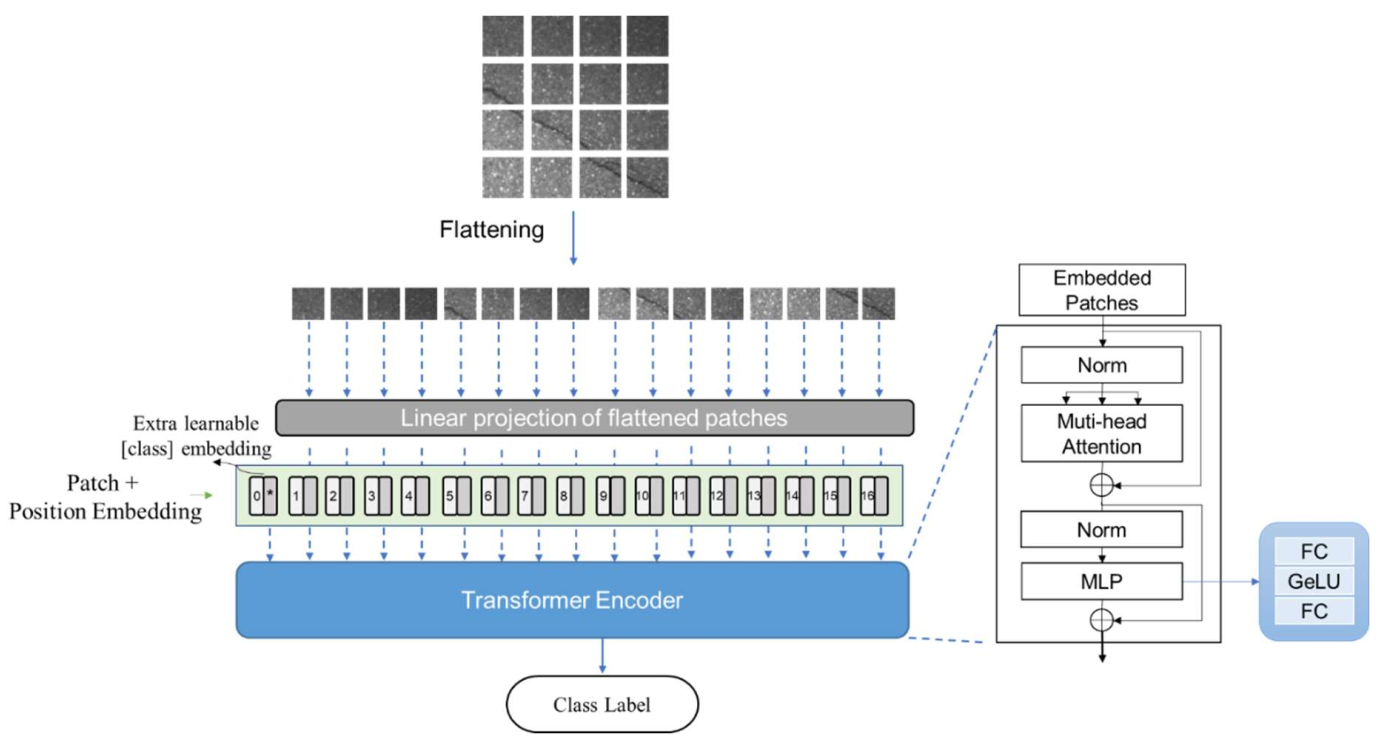
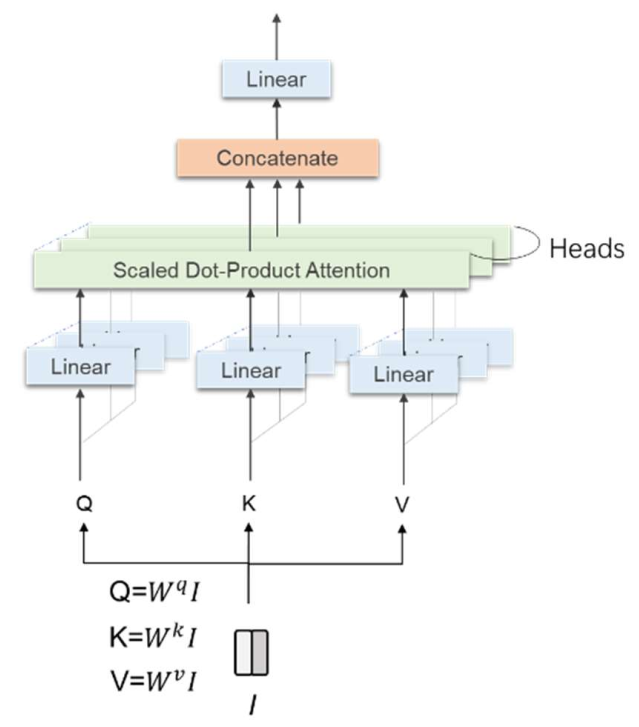
2.3. Vision Transformer
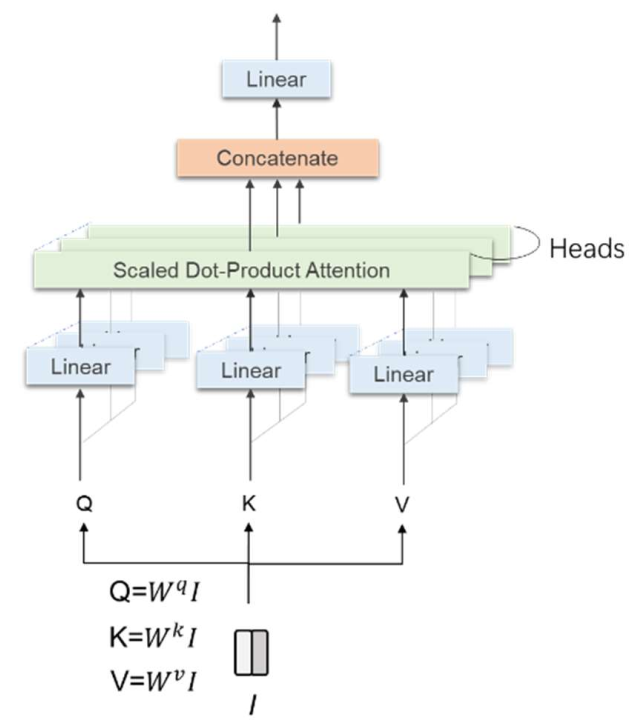
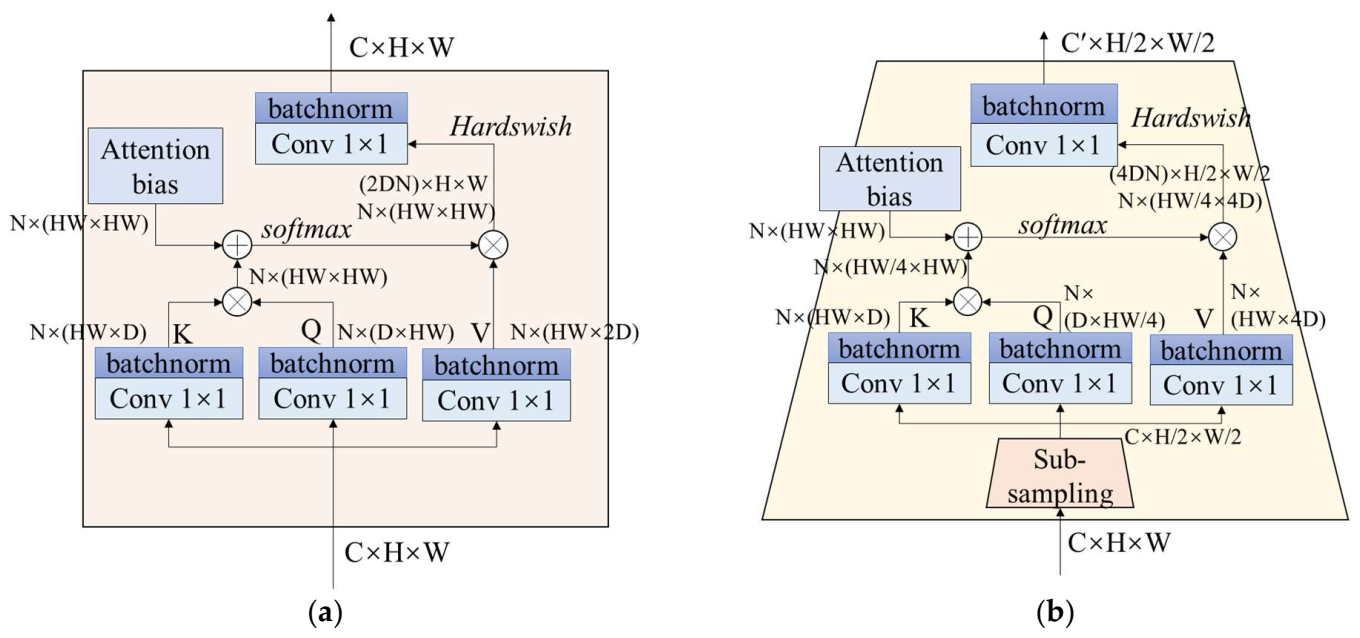
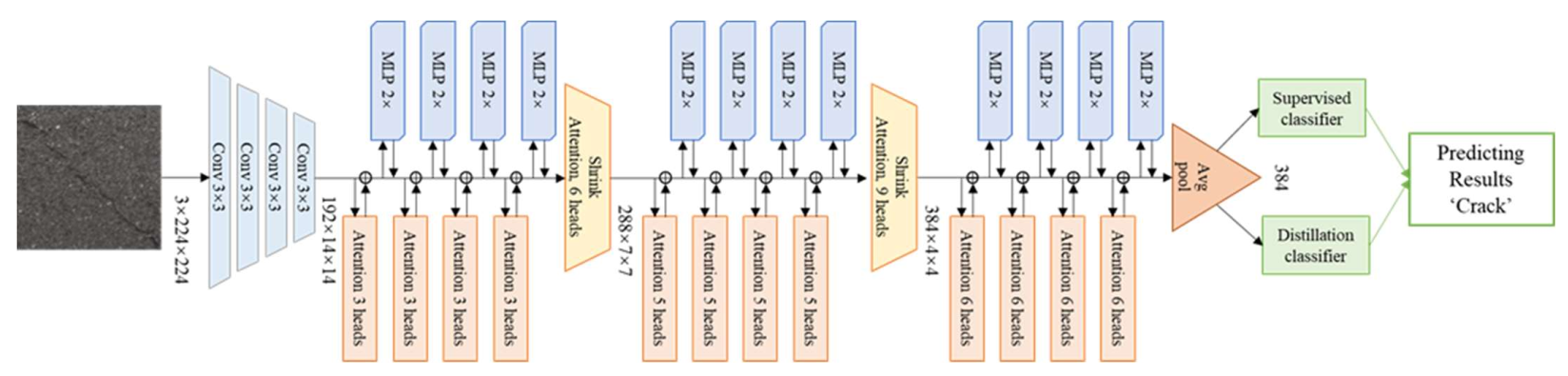
2.4. Levit Structure
- (1)
- Convolutional layers
- (2)
- Transformer stages
- (3)
- Classification layers
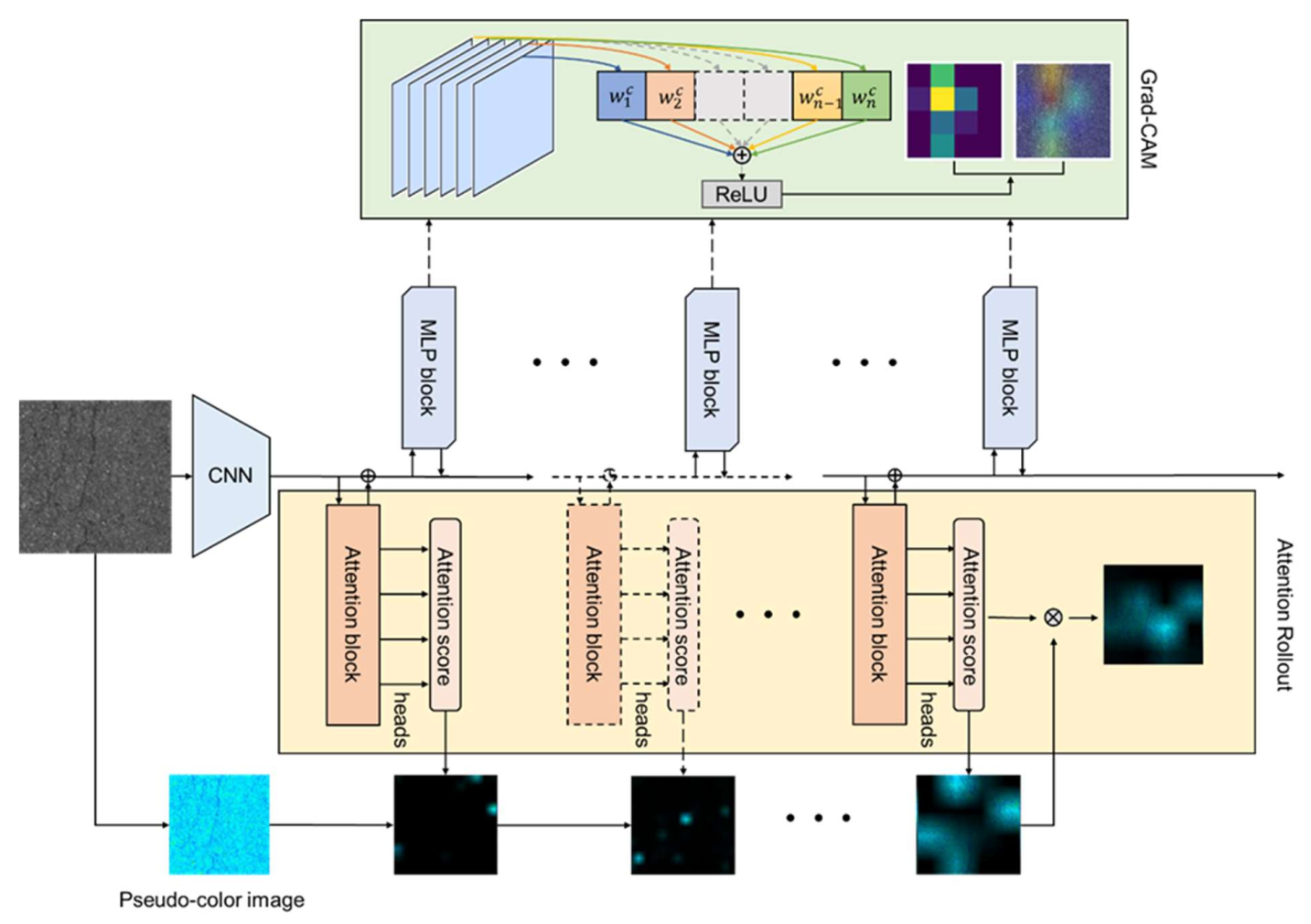
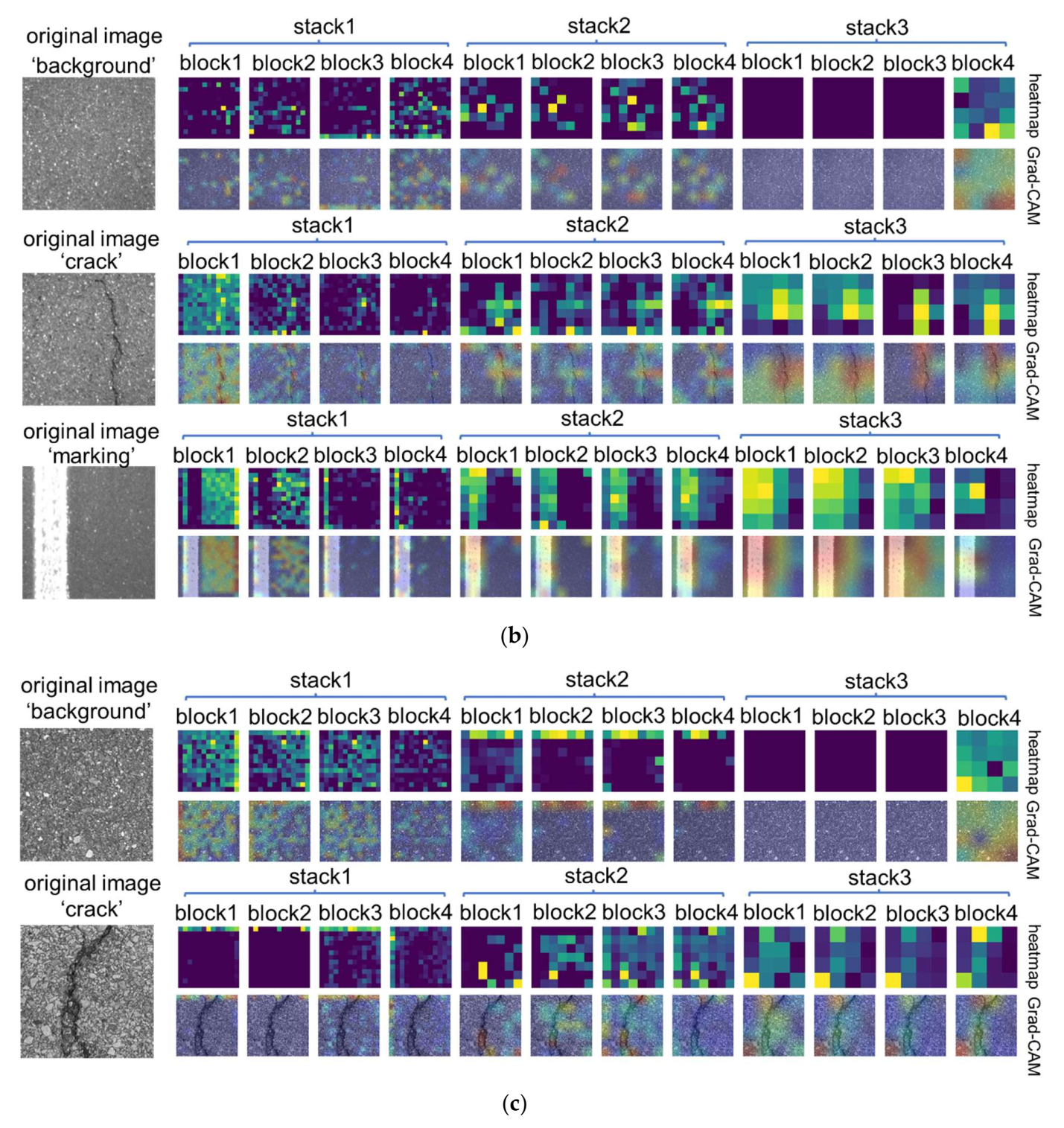
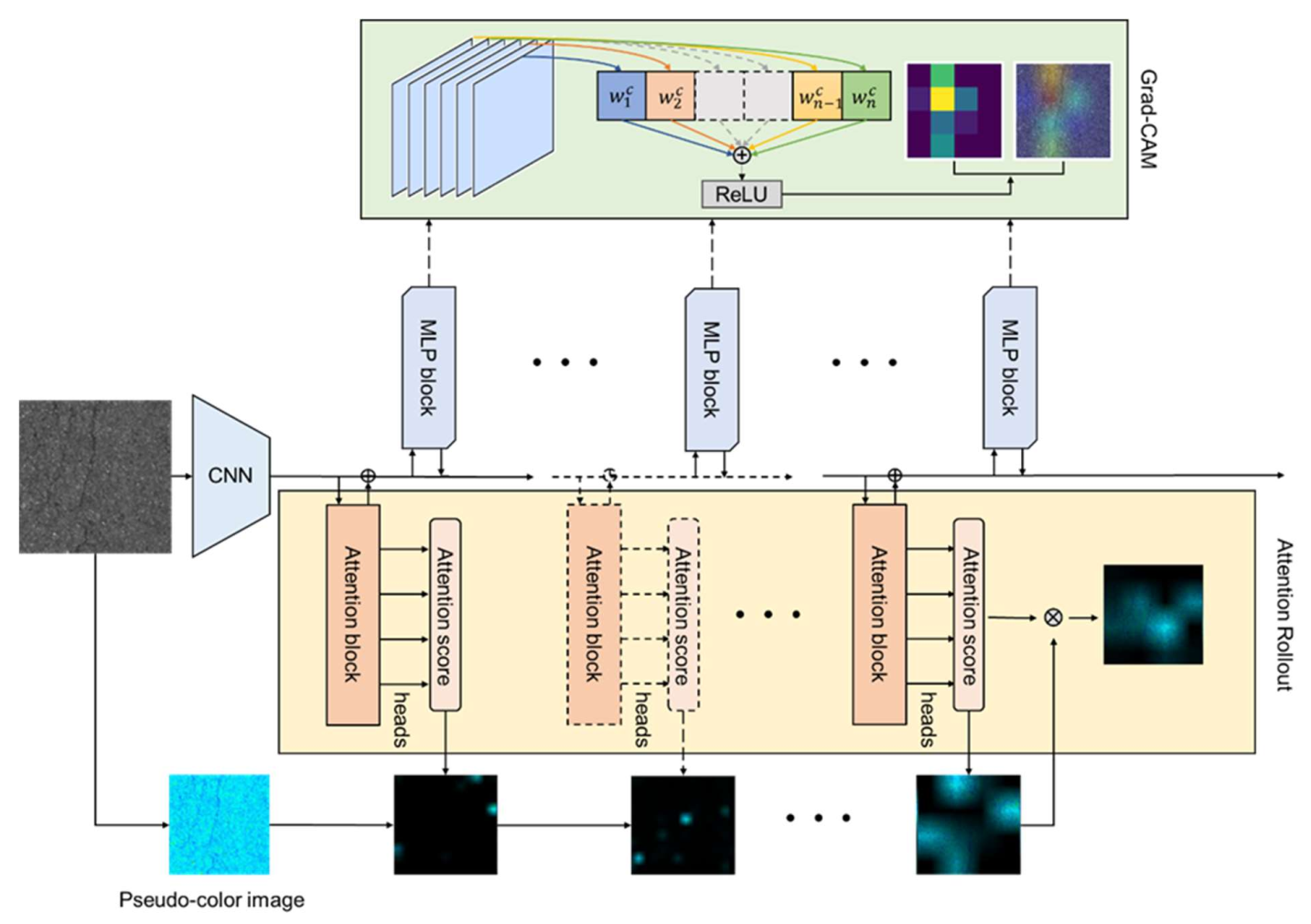
2.5. Visual Interpretation Methods
2.6. Evaluation Indexes
3. Experimental Results and Analysis
3.1. Experimental Environment and Hyperparameters
- (1)
- The learning rate was 1 × 10−4. The learning rate can control the weight update ratio and a lower learning rate allows the model to achieve better convergence.
- (2)
- β1 was 0.9 and β2 was 0.999. β1 and β2 can control the decay rates of the first and second moment means, respectively.
- (3)
- ε was 1 × 10−8, which prevented a relatively fixed value division by zero in the implementation.
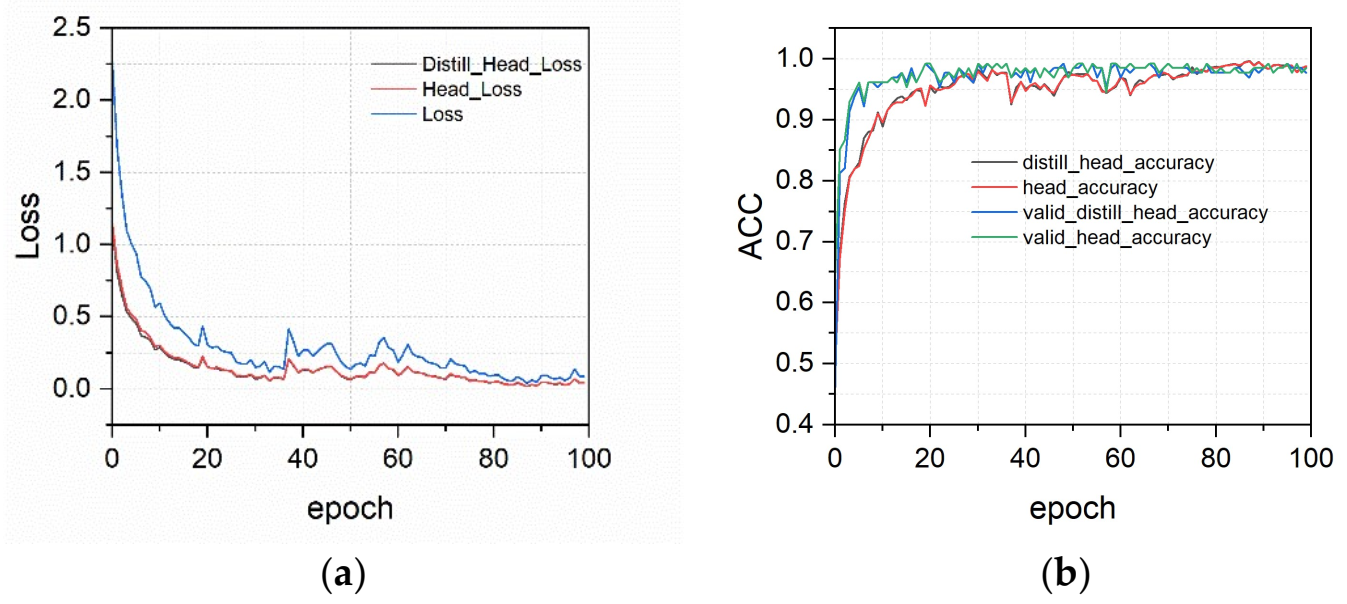
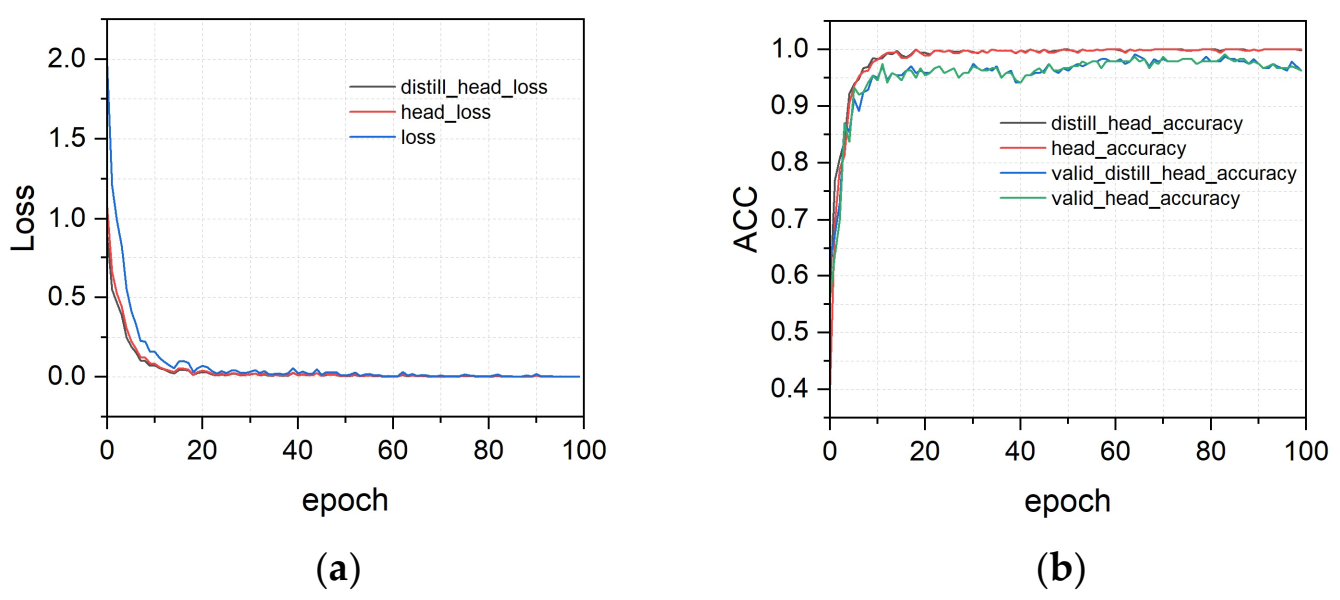
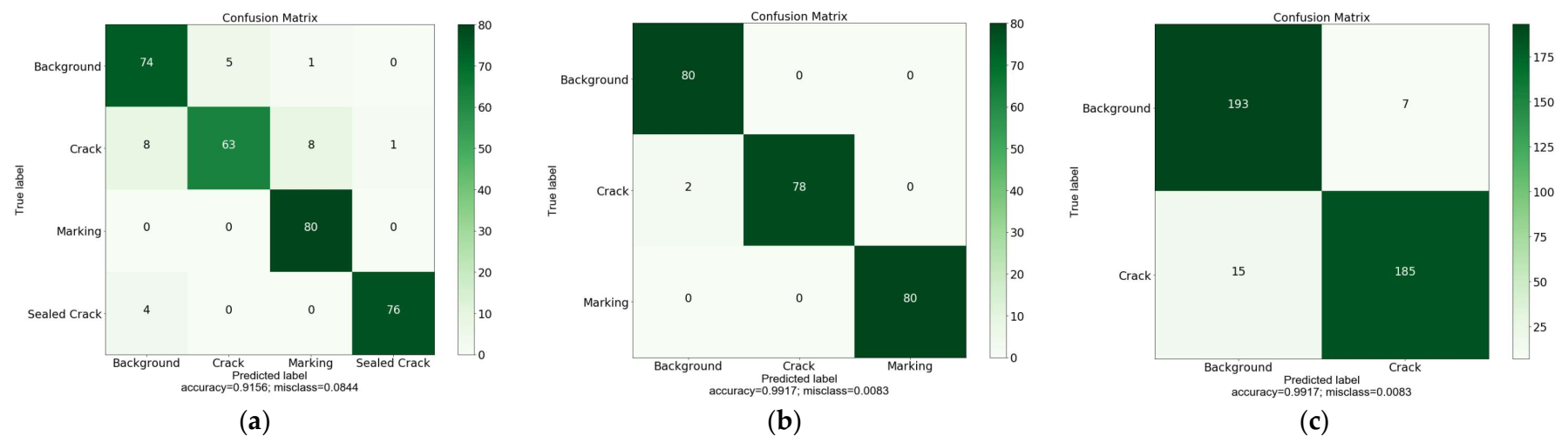
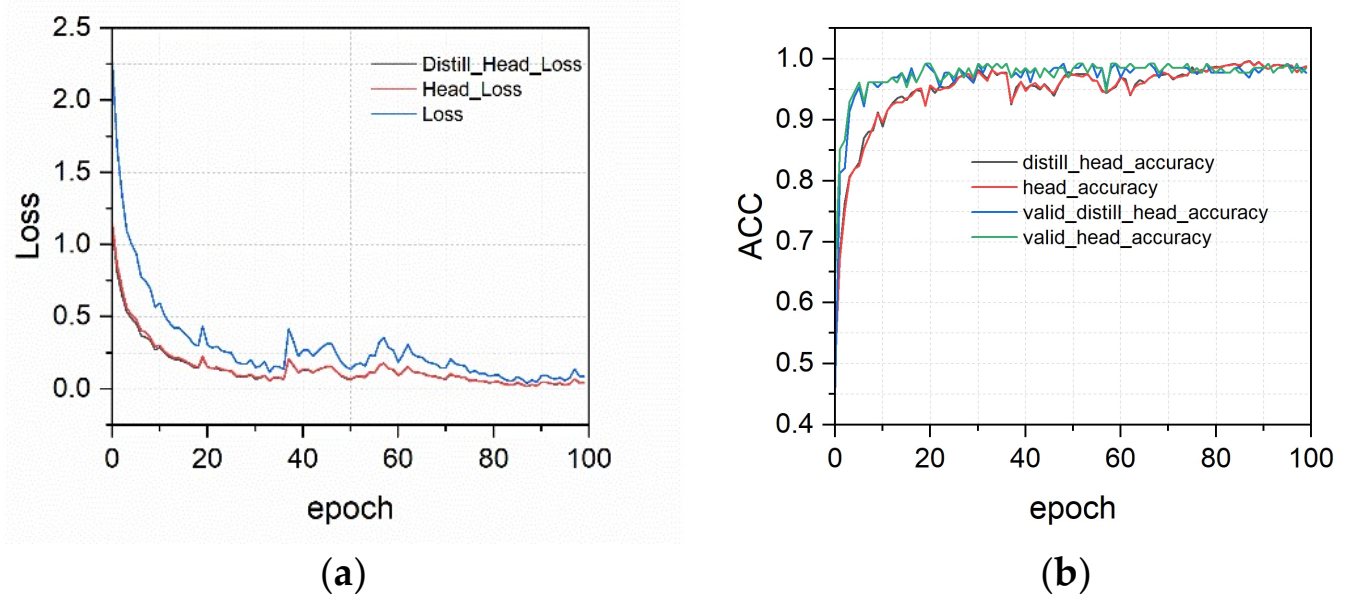
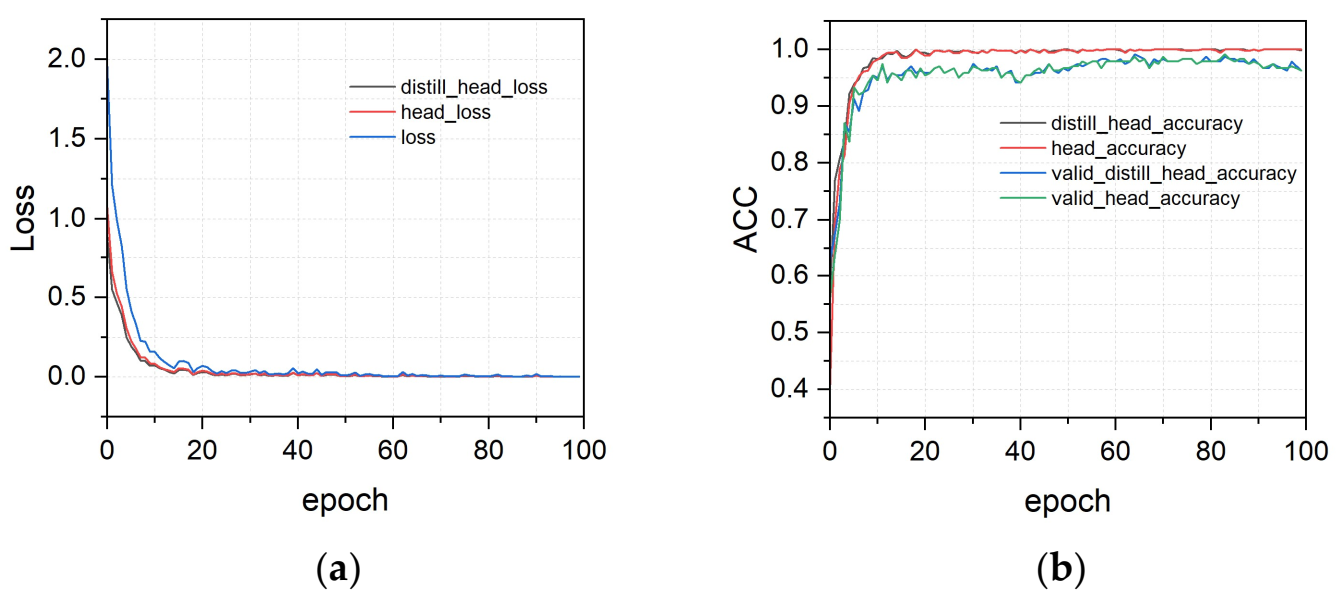
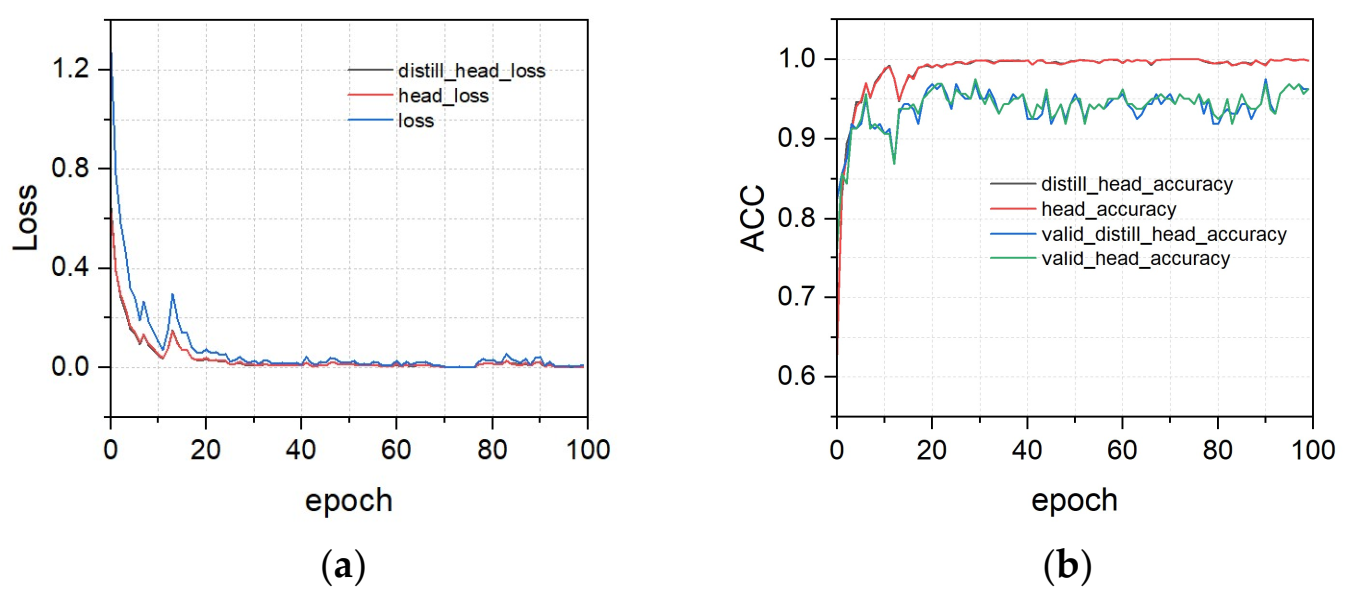
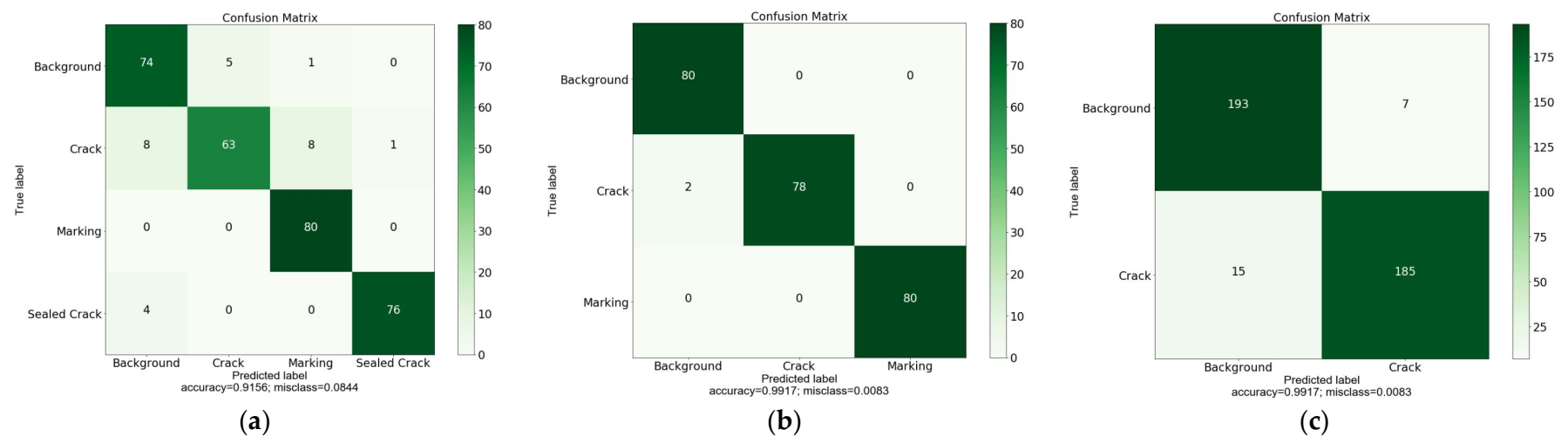
3.2. Training Results of LeViT
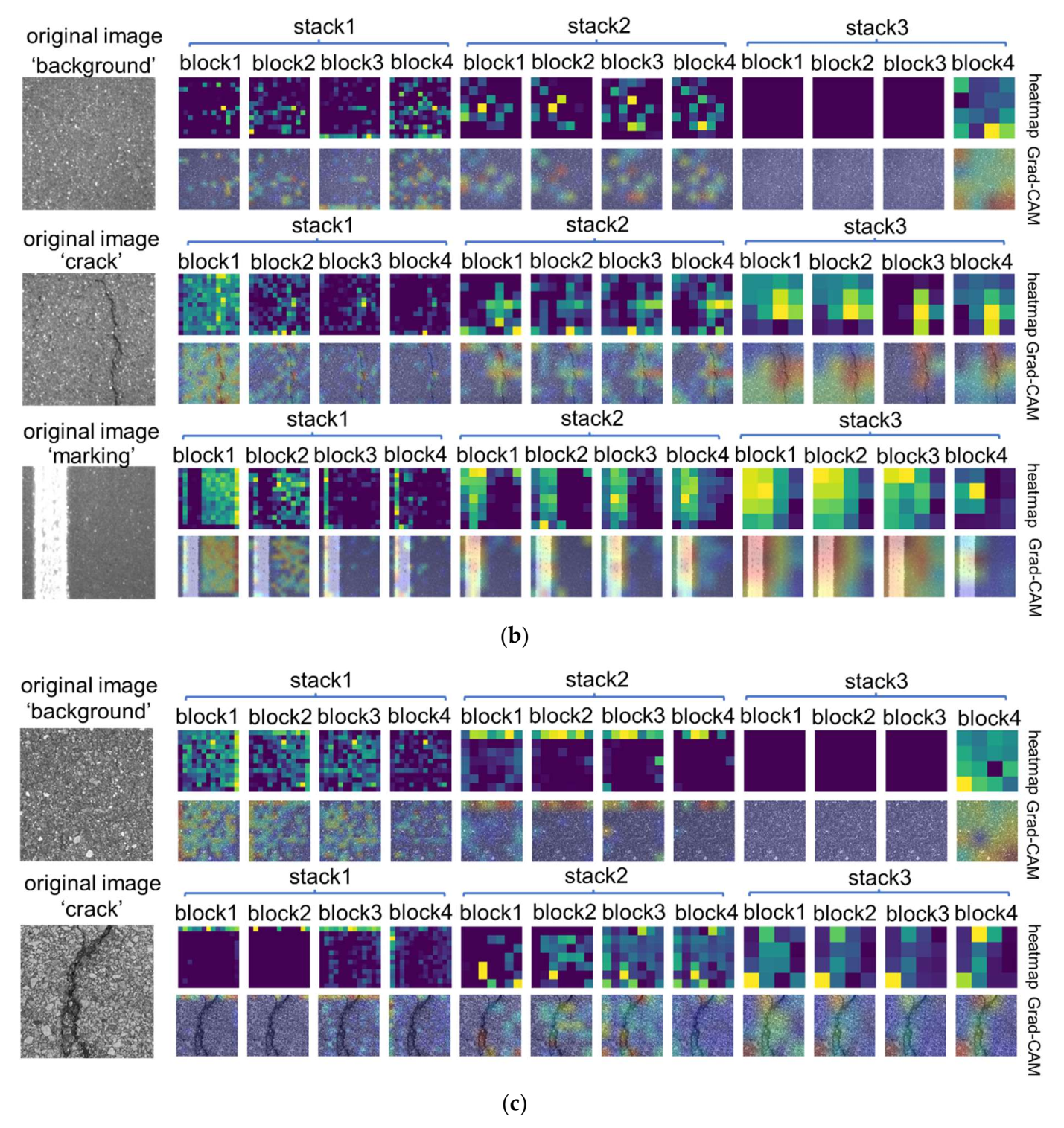
3.3. Visual Interpretation
4. Discussion and Comparison
- VGG-16 [7]: This adopts a convolution kernel with a smaller size (3 × 3) and uses deeper layers to achieve good performance. VGG-16 means the number of its weight layer is 16.
- ResNet-50 [9]: The core idea of this network is its shortcut or skip connections. In residual blocks, the input information can detour to the output, which is helpful to decrease learning difficulties. ResNet-50 represents that the number of its weight layer is 50.
- InceptionNet-V3 [46]: Its main idea is to find out how to approximate the optimal locally sparse junction with dense components.
- Densenet-121 [10]: The core of the network is a dense block. The input to each layer of the network in the structure comes from the outputs of all the previous layers.
- MobileNet-V1 [47]: It is a lightweight network. A structure of depth-wise separable convolutions was introduced in this network.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, C.; Chandra, S.; Han, Y.; Seo, H. Deep Learning-Based Thermal Image Analysis for Pavement Defect Detection and Classification Considering Complex Pavement Conditions. Remote Sens. 2021, 14, 106. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, W.; Gu, X.; Li, S.; Wang, L.; Zhang, T. Application of combining YOLO models and 3D GPR images in road detection and maintenance. Remote Sens. 2021, 13, 1081. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Hou, Y.; Li, Q.; Zhang, C.; Lu, G.; Ye, Z.; Chen, Y.; Wang, L.; Cao, D. The state-of-the-art review on applications of intrusive sensing, image processing techniques, and machine learning methods in pavement monitoring and analysis. Engineering 2021, 7, 845–856. [Google Scholar] [CrossRef]
- Liu, Z.; Gu, X.; Dong, Q.; Tu, S.; Li, S. 3D visualization of airport pavement quality based on BIM and WebGL integration. J. Transp. Eng. Part B Pavements 2021, 147, 04021024. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, A.; Wang, K.C.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated pixel-level pavement crack detection on 3D asphalt surfaces using a deep-learning network. Comput.-Aided Civil Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.; Fei, Y.; Liu, Y.; Tao, S.; Chen, C.; Li, J.Q.; Li, B. Deep learning–based fully automated pavement crack detection on 3D asphalt surfaces with an improved CrackNet. J. Comput. Civil. Eng. 2018, 32, 04018041. [Google Scholar] [CrossRef] [Green Version]
- Fei, Y.; Wang, K.C.; Zhang, A.; Chen, C.; Li, J.Q.; Liu, Y.; Yang, G.; Li, B. Pixel-level cracking detection on 3D asphalt pavement images through deep-learning-based CrackNet-V. IEEE Trans. Intell. Transp. Syst. 2019, 21, 273–284. [Google Scholar] [CrossRef]
- Hou, Y.; Li, Q.; Han, Q.; Peng, B.; Wang, L.; Gu, X.; Wang, D. MobileCrack: Object classification in asphalt pavements using an adaptive lightweight deep learning. J. Transp. Eng. Part B Pavements 2021, 147, 04020092. [Google Scholar] [CrossRef]
- Ali, L.; Alnajjar, F.; Jassmi, H.A.; Gochoo, M.; Khan, W.; Serhani, M.A. Performance Evaluation of Deep CNN-Based Crack Detection and Localization Techniques for Concrete Structures. Sensors 2021, 21, 1688. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.; Yuvaraj, N.; Preethaa, K.S.; Pandian, R.A. Surface crack detection using deep learning with shallow CNN architecture for enhanced computation. Neural Comput. Appl. 2021, 33, 9289–9305. [Google Scholar] [CrossRef]
- Wu, Y.; Qi, S.; Sun, Y.; Xia, S.; Yao, Y.; Qian, W. A vision transformer for emphysema classification using CT images. Phys. Med. Biol. 2021, 66, 245016. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, Y.; Gu, X.; Yeoh, J.K.; Zhang, Q. Visibility classification and influencing-factors analysis of airport: A deep learning approach. Atmos. Environ. 2022, 278, 119085. [Google Scholar] [CrossRef]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Zhang, A.; Wang, K.C.; Fei, Y.; Liu, Y.; Chen, C.; Yang, G.; Li, J.Q.; Yang, E.; Qiu, S. Automated pixel-level pavement crack detection on 3D asphalt surfaces with a recurrent neural network. Comput.-Aided Civil Infrastruct. Eng. 2019, 34, 213–229. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, online, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Chen, C.-F.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. arXiv 2021, arXiv:2103.14899. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Liu, H.; Miao, X.; Mertz, C.; Xu, C.; Kong, H. CrackFormer: Transformer Network for Fine-Grained Crack Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3783–3792. [Google Scholar]
- Guo, J.-M.; Markoni, H. Transformer based Refinement Network for Accurate Crack Detection. In Proceedings of the 2021 International Conference on System Science and Engineering (ICSSE), Ho Chi Minh City, Vietnam, 26–28 August 2021; pp. 442–446. [Google Scholar]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. LeViT: A Vision Transformer in ConvNet’s Clothing for Faster Inference. arXiv 2021, arXiv:2104.01136. [Google Scholar]
- Castelvecchi, D. Can we open the black box of AI? Nat. News 2016, 538, 20–23. [Google Scholar] [CrossRef] [Green Version]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Serrano, S.; Smith, N.A. Is attention interpretable? arXiv 2019, arXiv:1906.03731. [Google Scholar]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H.-M. How to get pavement distress detection ready for deep learning? A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2039–2047. [Google Scholar]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature pyramid and hierarchical boosting network for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1525–1535. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lile, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seol, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Abnar, S.; Zuidema, W. Quantifying attention flow in transformers. arXiv 2020, arXiv:2005.00928. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704. 04861. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Number of Images | Background | Crack | Pavement Marking | Sealed Crack | |
|---|---|---|---|---|---|---|
| JCAPs | Training set | 960 | 240 | 240 | 240 | 240 |
| Validation set | 320 | 80 | 80 | 80 | 80 | |
| Test set | 320 | 80 | 80 | 80 | 80 | |
| All | 1600 | 400 | 400 | 400 | 400 | |
| GAPs | Training set | 720 | 240 | 240 | 240 | - |
| Validation set | 240 | 80 | 80 | 80 | ||
| Test set | 240 | 80 | 80 | 80 | - | |
| All | 1200 | 400 | 400 | 400 | - | |
| Crack500 | Training set | 1200 | 600 | 600 | - | - |
| Validation set | 400 | 200 | 200 | - | ||
| Test set | 400 | 200 | 200 | - | - | |
| All | 2000 | 1000 | 1000 | - | - | |
| Layers | Operation | Output Size | |
|---|---|---|---|
| Convolutional layers | 4 × [Conv 3 × 3, stride = 2] | 14 × 14 × 192 | |
| Transformer stages | Stage 1 | 14 × 14 × 192 | |
| Subsample | , N = 6] | 7 × 7 × 288 | |
| Stage 2 | 7 × 7 × 288 | ||
| Subsample | . ] | 4 × 4 × 384 | |
| Stage 3 | 4 × 4 × 384 | ||
| Classification layers | Average Pooling | 384 | |
| Classifiers | [n, n] | ||
| Dataset | Method | All Classifications | Background | Crack | Pavement Marking | Sealed Crack | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC (%) | P (%) | R (%) | F1 (%) | ACC (%) | F1 (%) | ACC (%) | F1 (%) | ACC (%) | F1 (%) | ACC (%) | F1 (%) | ||
| JCAPs | ViT | 88.13 | 89.33 | 88.13 | 88.21 | 83.75 | 88.16 | 77.50 | 82.67 | 93.75 | 96.77 | 97.50 | 85.25 |
| ResNet | 88.75 | 89.12 | 88.75 | 88.80 | 88.75 | 87.65 | 85.00 | 85.54 | 87.50 | 92.71 | 93.75 | 89.29 | |
| DenseNet | 88.75 | 89.55 | 88.75 | 88.61 | 97.50 | 96.30 | 70.00 | 79.43 | 97.50 | 96.89 | 90.00 | 81.81 | |
| VGG | 89.38 | 90.16 | 89.38 | 89.45 | 92.50 | 82.50 | 87.50 | 87.50 | 91.25 | 94.81 | 96.25 | 87.50 | |
| InceptionNet | 89.69 | 90.12 | 89.69 | 89.64 | 91.25 | 87.95 | 78.75 | 85.71 | 93.75 | 94.94 | 95.50 | 89.94 | |
| MobileNet | 90.31 | 91.03 | 90.31 | 90.35 | 96.25 | 91.12 | 82.50 | 82.50 | 88.75 | 94.04 | 93.75 | 88.24 | |
| Levit(ours) | 91.56 | 91.72 | 91.56 | 91.45 | 92.50 | 89.16 | 78.75 | 85.14 | 100.00 | 99.38 | 95.00 | 92.12 | |
| GAPs | InceptionNet | 97.08 | 97.15 | 97.08 | 97.10 | 96.25 | 96.86 | 97.50 | 95.71 | 97.50 | 98.73 | - | - |
| DenseNet | 98.33 | 98.38 | 98.33 | 98.32 | 100.00 | 98.16 | 95.00 | 97.44 | 100.00 | 99.38 | - | - | |
| ViT | 98.33 | 98.38 | 98.33 | 98.32 | 100.00 | 98.16 | 95.00 | 97.44 | 100.00 | 99.38 | - | - | |
| ResNet | 98.75 | 98.80 | 98.75 | 98.75 | 100.00 | 98.16 | 97.50 | 98.73 | 98.75 | 99.37 | - | - | |
| MobileNet | 98.75 | 98.80 | 98.75 | 98.75 | 100.00 | 98.16 | 96.25 | 98.09 | 100.00 | 100.00 | - | - | |
| VGG | 98.75 | 99.17 | 99.17 | 99.17 | 100.00 | 99.38 | 98.75 | 98.75 | 98.75 | 99.37 | - | - | |
| Levit(ours) | 99.17 | 99.19 | 99.17 | 99.17 | 100.00 | 100.00 | 97.50 | 98.73 | 100.00 | 100.00 | - | - | |
| Crack500 | InceptionNet | 92.00 | 92.60 | 92.00 | 91.97 | 98.00 | 92.45 | 86.00 | 91.49 | - | - | - | - |
| MobileNet | 93.75 | 93.88 | 93.75 | 93.75 | 96.50 | 93.92 | 91.00 | 93.57 | - | - | - | - | |
| VGG | 94.00 | 94.02 | 94.00 | 94.00 | 95.00 | 94.06 | 93.00 | 93.94 | - | - | - | - | |
| ViT | 94.00 | 94.07 | 94.00 | 94.00 | 96.00 | 94.12 | 92.00 | 93.88 | - | - | - | - | |
| LeViT(ours) | 94.50 | 94.57 | 94.50 | 94.50 | 96.50 | 94.61 | 92.50 | 94.39 | - | - | - | - | |
| ResNet | 94.75 | 95.08 | 94.75 | 94.74 | 99.00 | 94.96 | 90.50 | 94.52 | - | - | - | - | |
| DenseNet | 95.00 | 95.11 | 95.00 | 95.00 | 97.50 | 95.12 | 92.50 | 94.87 | - | - | - | - | |
| Method | Number of Parameters | Inference Time/Step | Average Training Time/Epoch |
|---|---|---|---|
| MobileNetV1 | 3.2 M | 3 s | 210.83 s |
| ViT-b16 | 85.8 M | 333 ms | 24.08 s |
| DenseNet-121 | 7.0 M | 103 ms | 7.45 s |
| VGG-16 | 14.7 M | 107 ms | 7.74 s |
| ResNet-50 | 23.6 M | 108 ms | 7.94 s |
| InceptionNetV3 | 21.8 M | 95 ms | 6.90 s |
| LeViT(ours) | 10.2 M | 86 ms | 6.21 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Gu, X.; Liu, Z.; Liang, J. A Fast Inference Vision Transformer for Automatic Pavement Image Classification and Its Visual Interpretation Method. Remote Sens. 2022, 14, 1877. https://doi.org/10.3390/rs14081877
Chen Y, Gu X, Liu Z, Liang J. A Fast Inference Vision Transformer for Automatic Pavement Image Classification and Its Visual Interpretation Method. Remote Sensing. 2022; 14(8):1877. https://doi.org/10.3390/rs14081877
Chicago/Turabian StyleChen, Yihan, Xingyu Gu, Zhen Liu, and Jia Liang. 2022. "A Fast Inference Vision Transformer for Automatic Pavement Image Classification and Its Visual Interpretation Method" Remote Sensing 14, no. 8: 1877. https://doi.org/10.3390/rs14081877
APA StyleChen, Y., Gu, X., Liu, Z., & Liang, J. (2022). A Fast Inference Vision Transformer for Automatic Pavement Image Classification and Its Visual Interpretation Method. Remote Sensing, 14(8), 1877. https://doi.org/10.3390/rs14081877