
Hyperspectral Anomaly Detection via Dual Dictionaries Construction Guided by Two-Stage Complementary Decision





Abstract
:
1. Introduction
- (1)
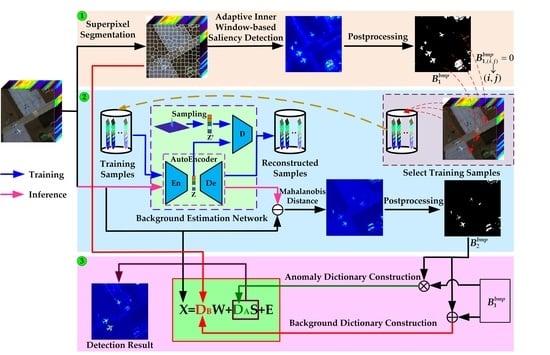
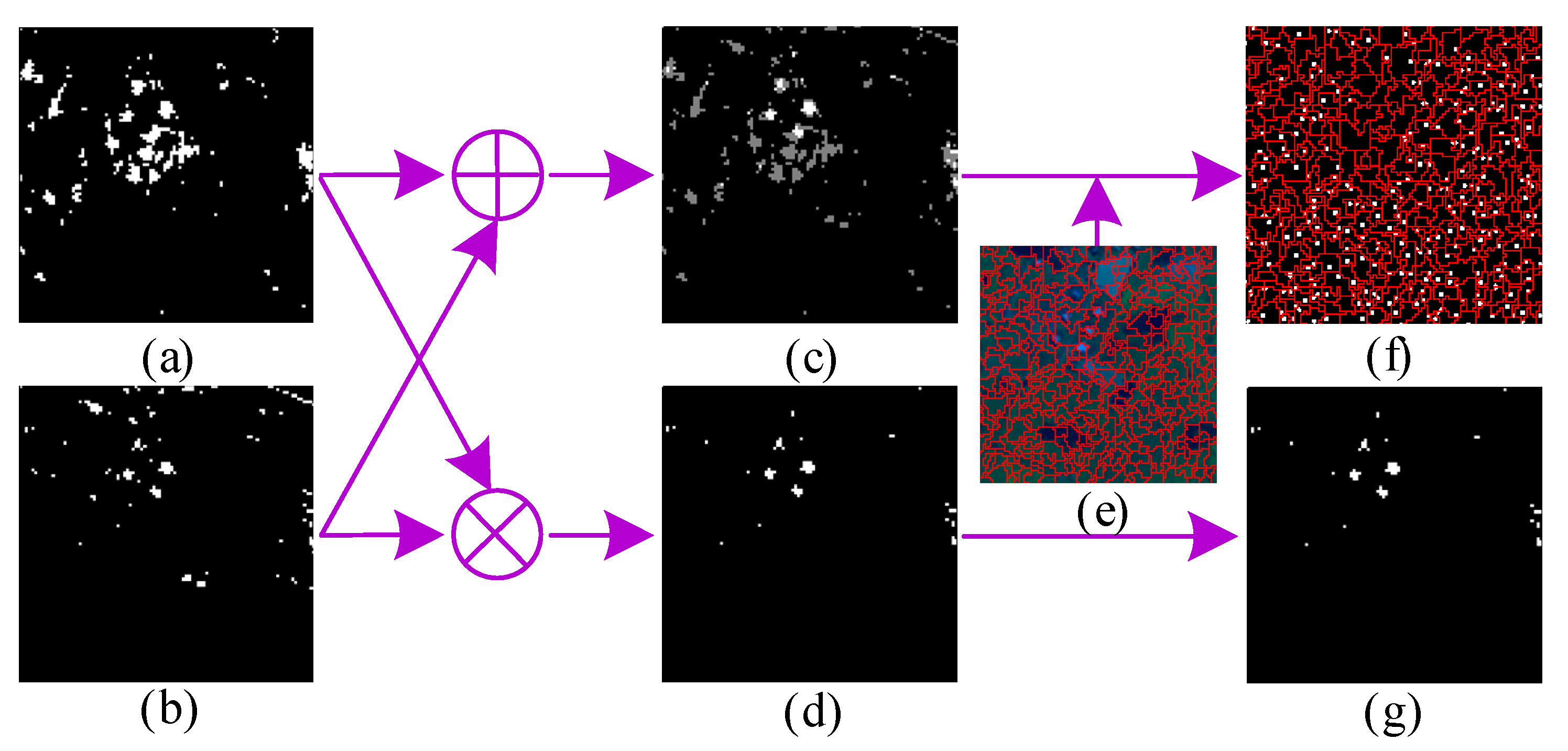
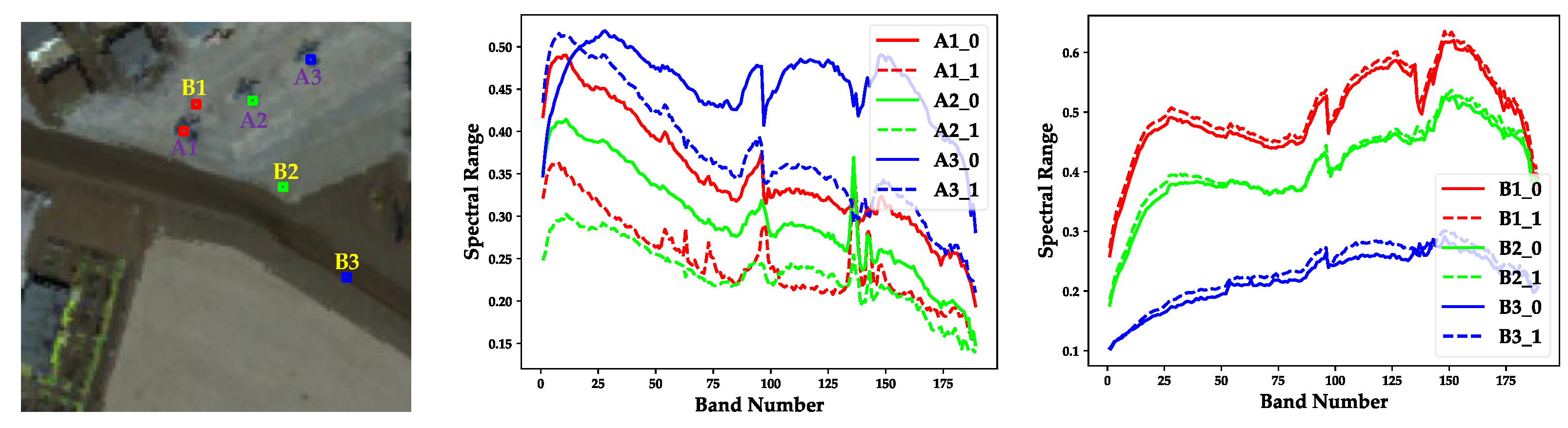
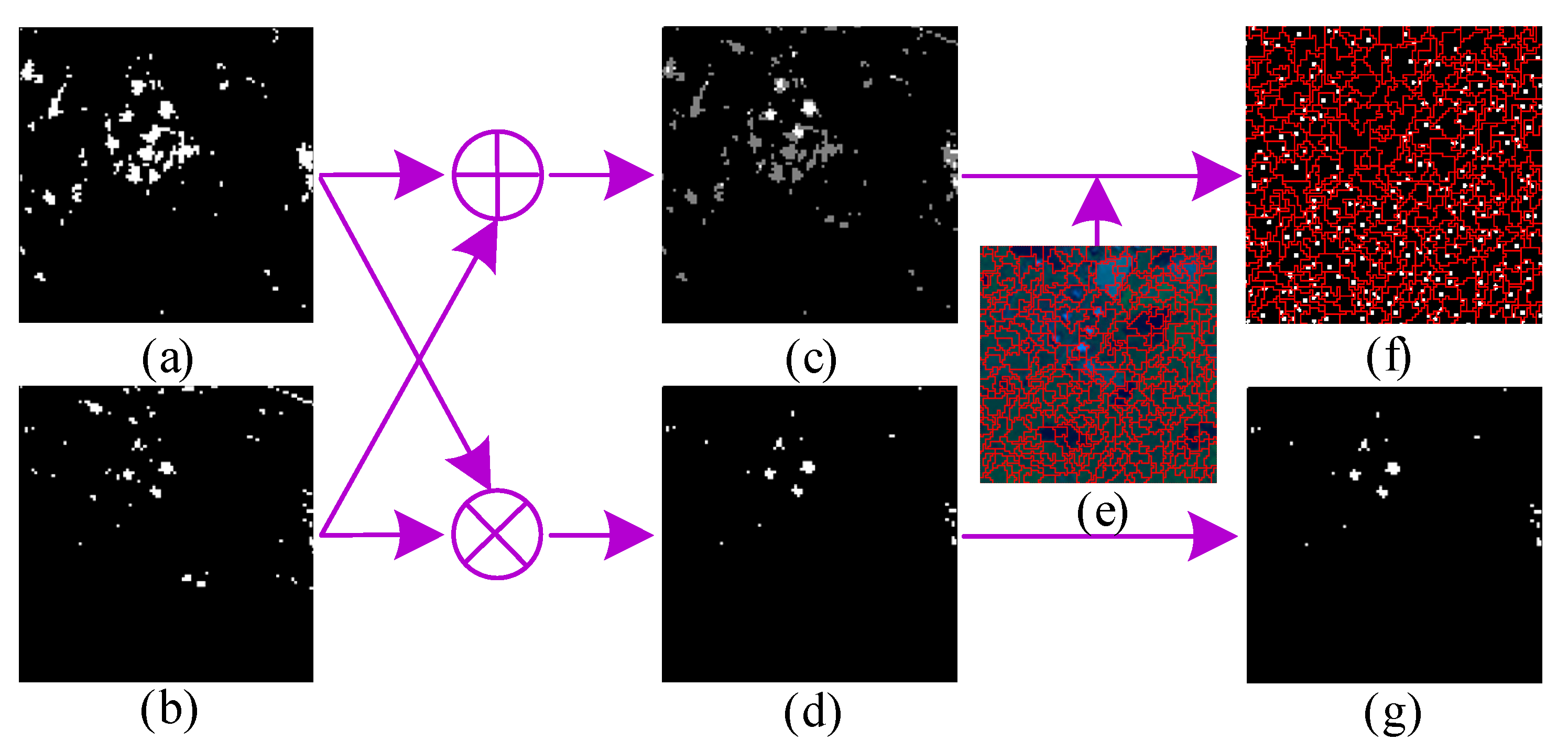
- A novel dual dictionaries construction method via two-stage complementary decision, to the best of our knowledge, is first proposed to construct pure background and potential anomaly dictionaries in this paper. To be specific, the product of both coarse and fine binary maps acts as the indicator to sift anomalous pixels, and the sum of them is employed to assist in selecting background pixels.
- (2)
- A coarse background–anomaly separation strategy, which detects anomalies by performing the adaptive inner window–based saliency detection, is proposed to generate a coarse binary map. For the saliency detection, the key is that the superpixels act as the inner windows, which can effectively alleviate the situation that the testing pixel is affected by the pixels with similar characteristics distributed in the area between the inner and outer windows.
- (3)
- To obtain a fine binary map, a background estimation network, which consists of AE and GAN, is designed to acquire a strong background reconstruction ability and poor anomaly reconstruction effect.
- (4)
- To reduce the number of atoms in the background dictionary, the superpixels are employed to act as the auxiliary indicator to select the atoms in the construction of the background dictionary.
2. Related Work
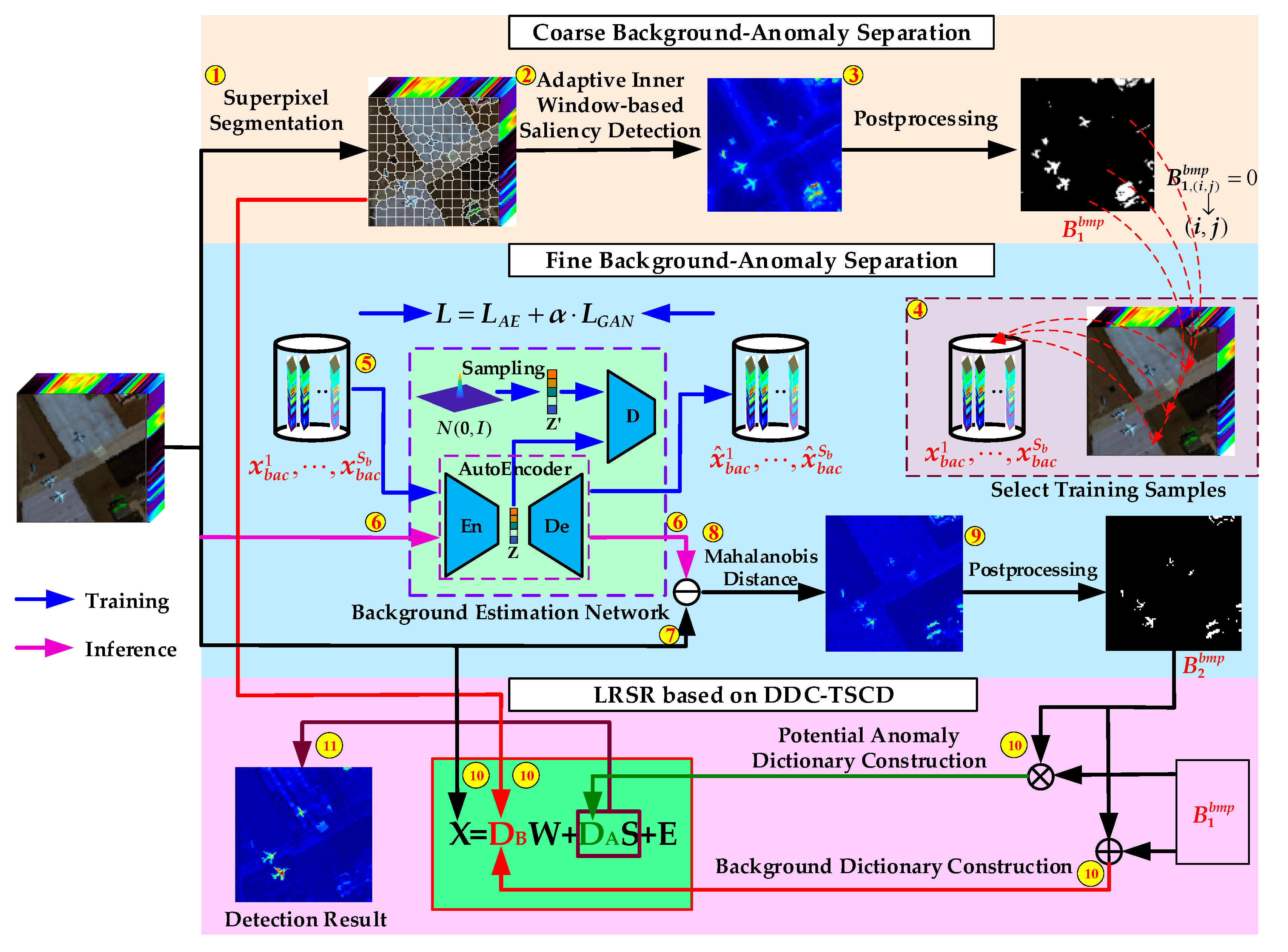
3. Methodology
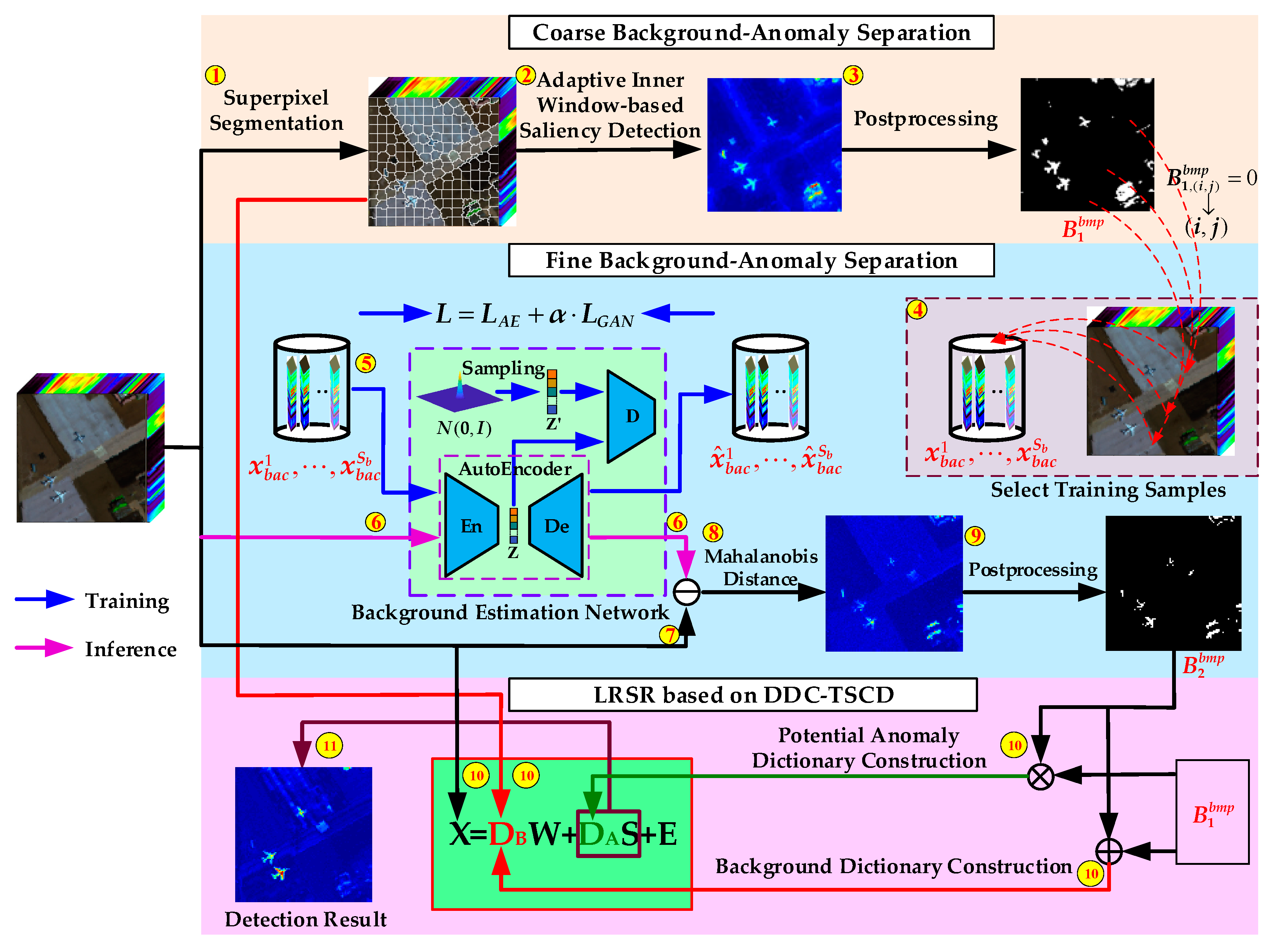
3.1. Coarse Background–Anomaly Separation
3.1.1. Superpixel Segmentation
3.1.2. Adaptive Inner Window–Based Saliency Detection
3.1.3. Post-Processing
3.2. Fine Background–Anomaly Separation
3.2.1. Network Architecture
3.2.2. Training Process
3.2.3. Anomaly Detection on Residual HSI
3.3. Dual-Dictionaries-Based Low Rank and Sparse Representation
3.3.1. Dual Dictionaries Construction
3.3.2. Low Rank and Sparse Representation
- (1)
- Update J while fixing L, E, W and S. The objective function can be derived as follows:
- (2)
- Update L while fixing J, E, W and S. The objective function can be derived as follows:
- (3)
- Update E while fixing J, L, W and S. The objective function can be derived as follows:
- (4)
- Update W while fixing J, L, E and S. The objective function can be derived as follows:
- (5)
- Update S while fixing J, L, E and W. The objective function can be derived as follows:
| Algorithm 1. Solve (25) by ADMM. |
| Input:, balance parameter λ and β. Initialize: W = J = S = L = 0, E = 0, Y1 = Y2 = Y3 = 0, μ = 10−6, μmax = 1010, ρ = 1.2, ε = 10−6. 1: While do 2: Update J while fixing other variables by (26): 3: Update L while fixing other variables by (27): 4: Update E while fixing other variables by (28): 5: Update W while fixing other variables by (29): 6: Update S while fixing other variables by (30): 7: Update the three Lagrange multipliers: 8: Update the balance parameter : 9: End While |
| Output: W, S, E |
4. Experiments and Results
4.1. Datasets and Evaluation Metrics
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.2. Experimental Setup
4.2.1. Implementation Details
4.2.2. Compared Methods
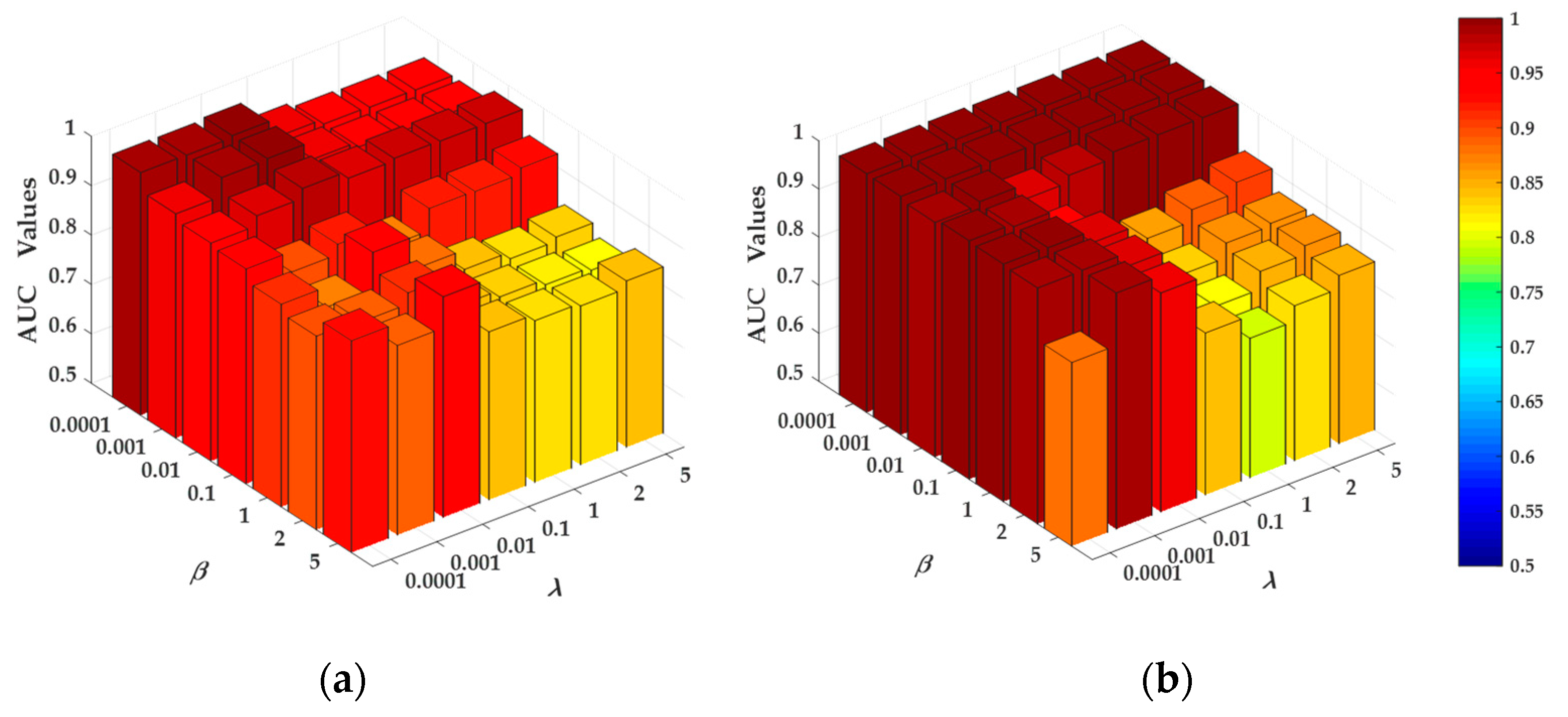
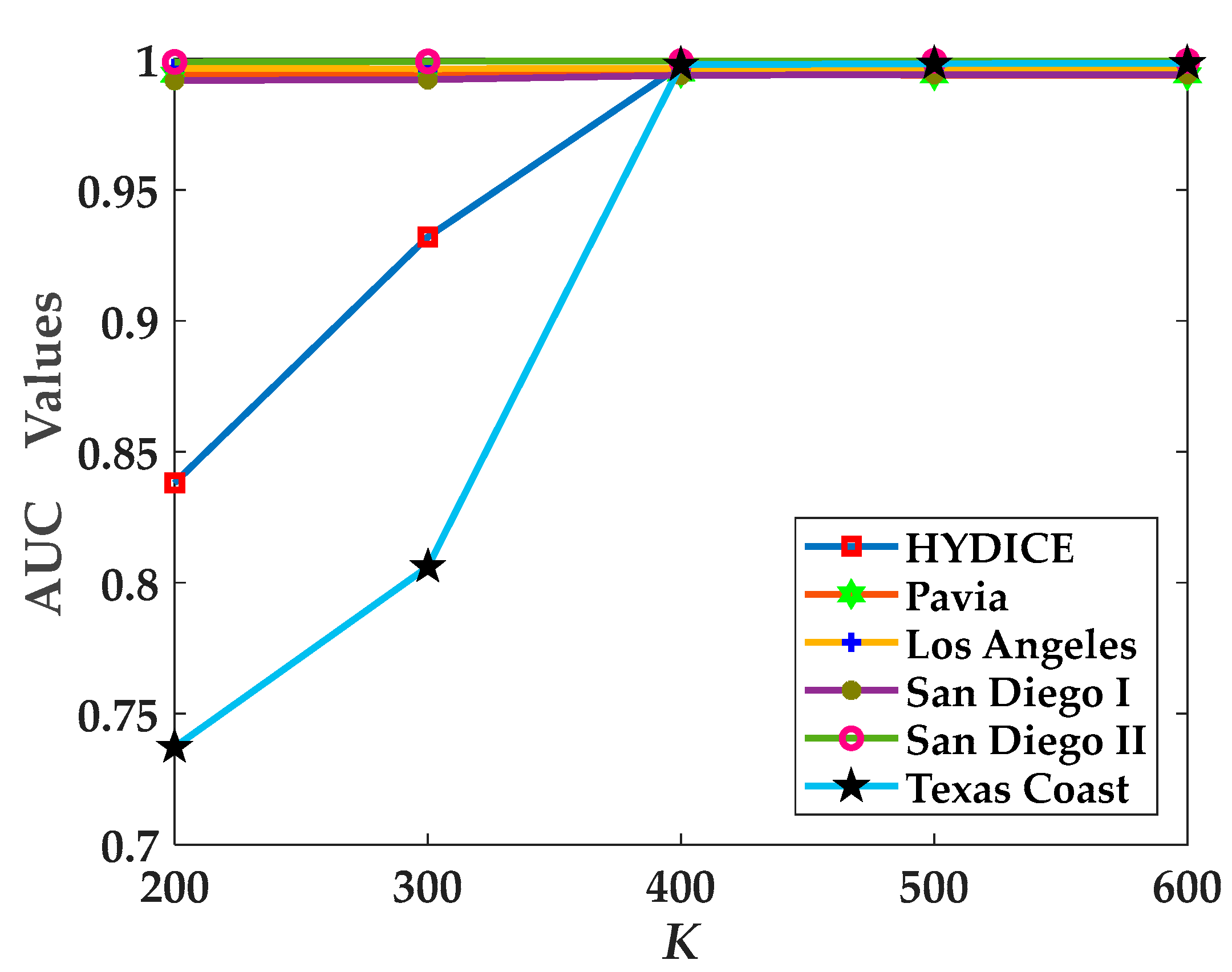
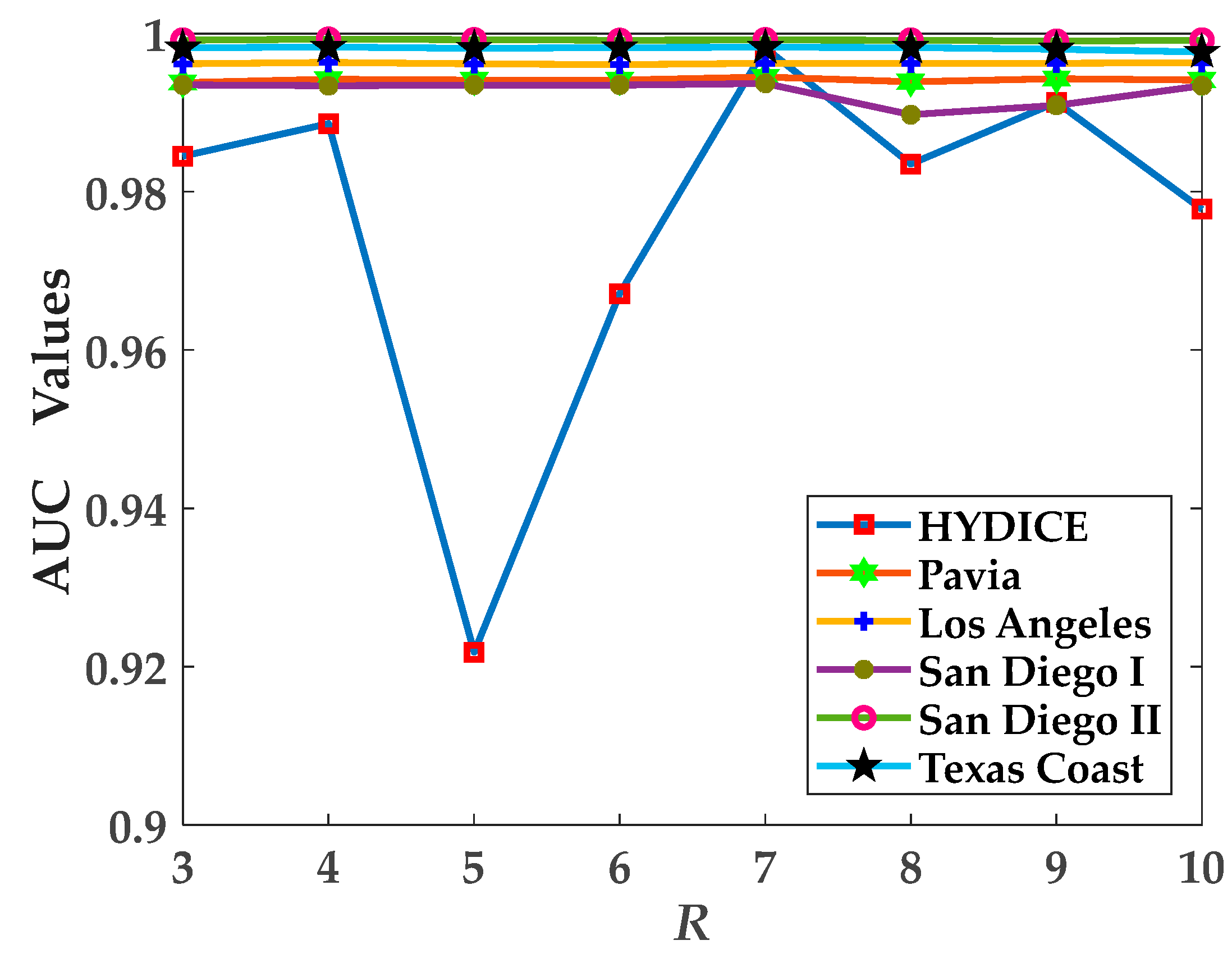
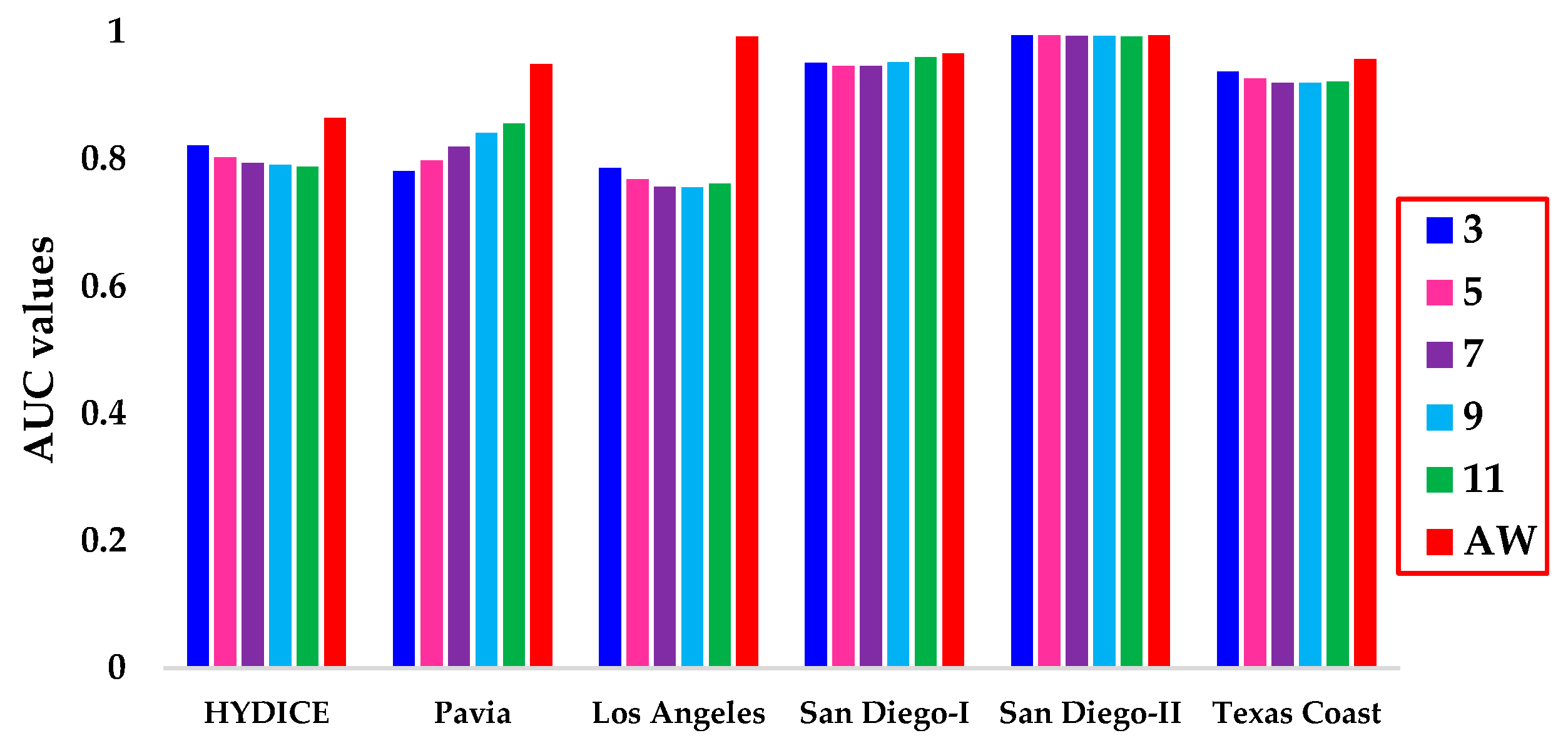
4.3. Parameter Analysis
4.4. Component Analysis
4.4.1. Effectiveness Evaluation of Adaptive Inner Window–Based Saliency Detection
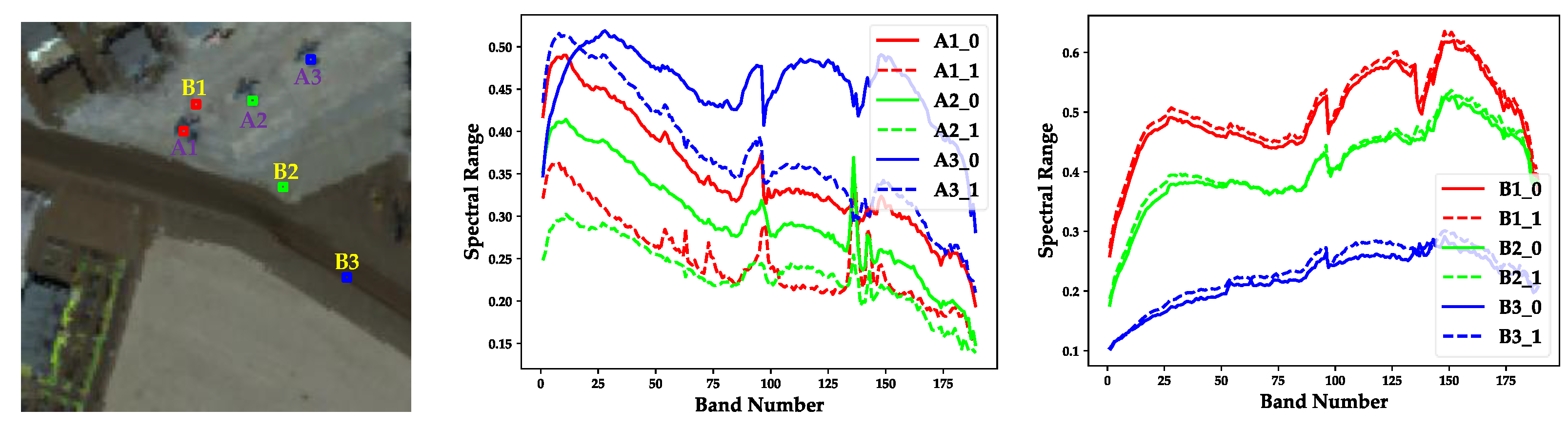
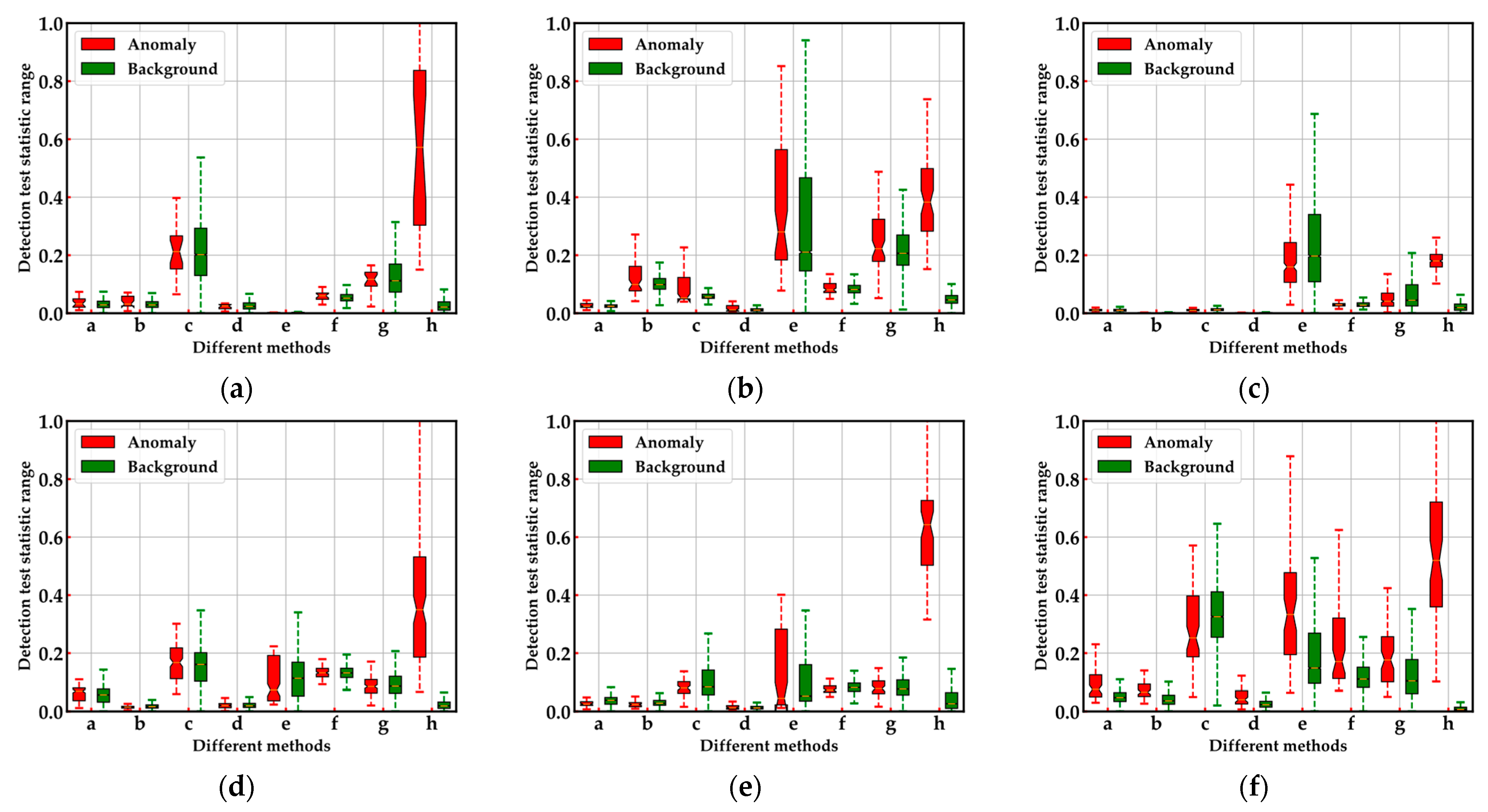
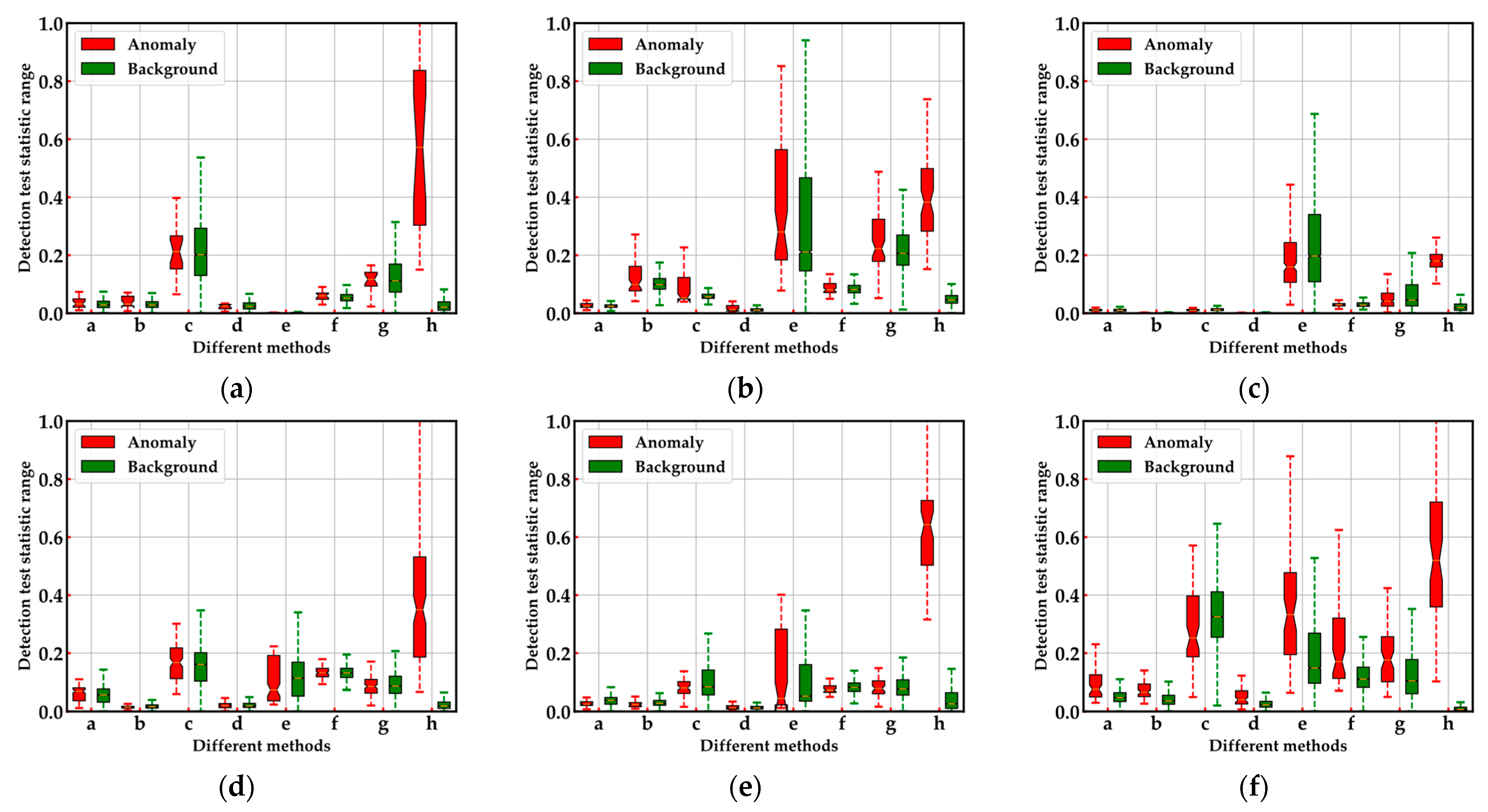
4.4.2. Effectiveness Evaluation of Two-Stage Complementary Decision
4.5. Detection Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent Advances of Hyperspectral Imaging Technology and Applications in Agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Zou, L.; Zhang, Z.; Du, H.; Lei, M.; Xue, Y.; Wang, Z.J. Da-Imrn: Dual-Attention-Guided Interactive Multi-Scale Residual Network for Hyperspectral Image Classification. Remote Sens. 2022, 14, 530. [Google Scholar] [CrossRef]
- Shah, C.; Du, Q.; Xu, Y. Enhanced Tabnet: Attentive Interpretable Tabular Learning for Hyperspectral Image Classification. Remote Sens. 2022, 14, 716. [Google Scholar] [CrossRef]
- Su, Y.; Li, J.; Plaza, A.; Marinoni, A.; Gamba, P.; Chakravortty, S. Daen: Deep Autoencoder Networks for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4309–4321. [Google Scholar] [CrossRef]
- Dong, L.; Yuan, Y. Sparse Constrained Low Tensor Rank Representation Framework for Hyperspectral Unmixing. Remote Sens. 2021, 13, 1473. [Google Scholar] [CrossRef]
- Liu, Y.; Li, X.; Hua, Z.; Zhao, L. Ebarec-Bs: Effective Band Attention Reconstruction Network for Hyperspectral Imagery Band Selection. Remote Sens. 2021, 13, 3602. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, F.; Li, X. Optimal Clustering Framework for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5910–5922. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Li, X.; Chen, S.; Zhao, L. Exploring the Intrinsic Probability Distribution for Hyperspectral Anomaly Detection. Remote Sens. 2022, 14, 441. [Google Scholar] [CrossRef]
- Zhang, L.; Ma, J.; Cheng, B.; Lin, F. Fractional Fourier Transform-Based Tensor Rx for Hyperspectral Anomaly Detection. Remote Sens. 2022, 14, 797. [Google Scholar] [CrossRef]
- Macfarlane, F.; Murray, P.; Marshall, S.; White, H. Investigating the Effects of a Combined Spatial and Spectral Dimensionality Reduction Approach for Aerial Hyperspectral Target Detection Applications. Remote Sens. 2021, 13, 1647. [Google Scholar] [CrossRef]
- Zhu, D.; Du, B.; Zhang, L. Target Dictionary Construction-Based Sparse Representation Hyperspectral Target Detection Methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1254–1264. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, J.; Song, S.; Zhang, C.; Liu, D. Low-Rank and Sparse Matrix Decomposition with Orthogonal Subspace Projection-Based Background Suppression for Hyperspectral Anomaly Detection. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1378–1382. [Google Scholar] [CrossRef]
- Bai, Z.; Liu, Z.; Li, G.; Ye, L.; Wang, Y. Circular Complement Network for Rgb-D Salient Object Detection. Neurocomputing 2021, 451, 95–106. [Google Scholar] [CrossRef]
- Qian, X.; Cheng, X.; Cheng, G.; Yao, X.; Jiang, L. Two-Stream Encoder Gan with Progressive Training for Co-Saliency Detection. IEEE Signal Process. Lett. 2021, 28, 180–184. [Google Scholar] [CrossRef]
- Liu, W.; Feng, X.; Wang, S.; Hu, B.; Gan, Y.; Zhang, X.; Lei, T. Random Selection-Based Adaptive Saliency-Weighted Rxd Anomaly Detection for Hyperspectral Imagery. Int. J. Remote Sens. 2018, 39, 2139–2158. [Google Scholar] [CrossRef]
- Hou, Z.; Li, W.; Tao, R.; Ma, P.; Shi, W. Collaborative Representation with Background Purification and Saliency Weight for Hyperspectral Anomaly Detection. Sci. China Inf. Sci. 2022, 65, 112305. [Google Scholar] [CrossRef]
- Goferman, S.; Zelnik-Manor, L.; Tal, A. Context-Aware Saliency Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1915–1926. [Google Scholar] [CrossRef] [Green Version]
- Yu, J.; Rui, Y.; Tang, Y.Y.; Tao, D. High-Order Distance-Based Multiview Stochastic Learning in Image Classification. IEEE Trans. Cybern. 2014, 44, 2431–2442. [Google Scholar] [CrossRef] [PubMed]
- Huyan, N.; Zhang, X.; Zhou, H.; Jiao, L. Hyperspectral Anomaly Detection via Background and Potential Anomaly Dictionaries Construction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2263–2276. [Google Scholar] [CrossRef] [Green Version]
- Reed, I.S.; Yu, X. Adaptive Multiple-Band Cfar Detection of an Optical Pattern with Unknown Spectral Distribution. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 1760–1770. [Google Scholar] [CrossRef]
- Molero, J.M.; Garzon, E.M.; Garcia, I.; Plaza, A. Analysis and Optimizations of Global and Local Versions of the Rx Algorithm for Anomaly Detection in Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 801–814. [Google Scholar] [CrossRef]
- Guo, Q.; Zhang, B.; Ran, Q.; Gao, L.; Li, J.; Plaza, A. Weighted-Rxd and Linear Filter-Based Rxd: Improving Background Statistics Estimation for Anomaly Detection in Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2351–2366. [Google Scholar] [CrossRef]
- Heesung, K.; Nasrabadi, N.M. Kernel Rx-Algorithm: A Nonlinear Anomaly Detector for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2005, 43, 388–397. [Google Scholar] [CrossRef]
- Tao, R.; Zhao, X.; Li, W.; Li, H.-C.; Du, Q. Hyperspectral Anomaly Detection by Fractional Fourier Entropy. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4920–4929. [Google Scholar] [CrossRef]
- Li, W.; Du, Q. Collaborative Representation for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1463–1474. [Google Scholar] [CrossRef]
- Li, J.; Zhang, H.; Zhang, L.; Ma, L. Hyperspectral Anomaly Detection by the Use of Background Joint Sparse Representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2523–2533. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, B.; Zhang, L.; Wang, S. A Low-Rank and Sparse Matrix Decomposition-Based Mahalanobis Distance Method for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1376–1389. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Li, J.; Plaza, A.; Wei, Z. Anomaly Detection in Hyperspectral Images Based on Low-Rank and Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1990–2000. [Google Scholar] [CrossRef]
- Li, L.; Li, W.; Du, Q.; Tao, R. Low-Rank and Sparse Decomposition with Mixture of Gaussian for Hyperspectral Anomaly Detection. IEEE Trans. Cybern. 2020, 51, 4363–4372. [Google Scholar] [CrossRef] [PubMed]
- Cheng, T.; Wang, B. Graph and Total Variation Regularized Low-Rank Representation for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2019, 58, 391–406. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Qian, X.; Lin, S.; Cheng, G.; Yao, X.; Ren, H.; Wang, W. Object Detection in Remote Sensing Images Based on Improved Bounding Box Regression and Multi-Level Features Fusion. Remote Sens. 2020, 12, 143. [Google Scholar] [CrossRef] [Green Version]
- Zhou, K.; Zhang, M.; Wang, H.; Tan, J. Ship Detection in Sar Images Based on Multi-Scale Feature Extraction and Adaptive Feature Fusion. Remote Sens. 2022, 14, 755. [Google Scholar] [CrossRef]
- Li, W.; Wu, G.; Du, Q. Transferred Deep Learning for Anomaly Detection in Hyperspectral Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 597–601. [Google Scholar] [CrossRef]
- Zhang, L.; Cheng, B. Transferred Cnn Based on Tensor for Hyperspectral Anomaly Detection. IEEE Geosci. Remote Sens. Lett. 2020, 17, 2115–2119. [Google Scholar] [CrossRef]
- Wang, S.; Wang, X.; Zhang, L.; Zhong, Y. Auto-Ad: Autonomous Hyperspectral Anomaly Detection Network Based on Fully Convolutional Autoencoder. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5503314. [Google Scholar] [CrossRef]
- Zhao, C.; Zhang, L. Spectral-Spatial Stacked Autoencoders Based on Low-Rank and Sparse Matrix Decomposition for Hyperspectral Anomaly Detection. Infrared Phys. Technol. 2018, 92, 166–176. [Google Scholar] [CrossRef]
- Xie, W.; Liu, B.; Li, Y.; Lei, J.; Du, Q. Autoencoder and Adversarial-Learning-Based Semisupervised Background Estimation for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5416–5427. [Google Scholar] [CrossRef]
- Arisoy, S.; Nasrabadi, N.M.; Kayabol, K. Unsupervised Pixel-Wise Hyperspectral Anomaly Detection via Autoencoding Adversarial Networks. IEEE Geosci. Remote Sens. Lett. 2021, 19, 5502905. [Google Scholar] [CrossRef]
- Jiang, T.; Li, Y.; Xie, W.; Du, Q. Discriminative Reconstruction Constrained Generative Adversarial Network for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4666–4679. [Google Scholar] [CrossRef]
- Jiang, K.; Xie, W.; Li, Y.; Lei, J.; He, G.; Du, Q. Semisupervised Spectral Learning with Generative Adversarial Network for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5224–5236. [Google Scholar] [CrossRef]
- Xie, W.; Zhang, X.; Li, Y.; Lei, J.; Li, J.; Du, Q. Weakly Supervised Low-Rank Representation for Hyperspectral Anomaly Detection. IEEE Trans. Cybern. 2021, 51, 3889–3900. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Zhang, J.; Liu, D.; Wu, X. Low-Rank and Sparse Matrix Decomposition with Background Position Estimation for Hyperspectral Anomaly Detection. Infrared Phys. Technol. 2019, 96, 213–227. [Google Scholar] [CrossRef]
- Ren, X.; Malik, J. Learning a Classification Model for Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 13–16. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. Slic Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Zhao, C.; Li, C.; Feng, S.; Su, N.; Li, W. A Spectral–Spatial Anomaly Target Detection Method Based on Fractional Fourier Transform and Saliency Weighted Collaborative Representation for Hyperspectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5982–5997. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. Syst. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Eckstein, J.; Bertsekas, D.P. On the Douglas—Rachford Splitting Method and the Proximal Point Algorithm for Maximal Monotone Operators. Math. Program. 1992, 55, 293–318. [Google Scholar] [CrossRef] [Green Version]
- Cai, J.-F.; Candès, E.J.; Shen, Z. A Singular Value Thresholding Algorithm for Matrix Completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Lin, Z.; Chen, M.; Ma, Y. The Augmented Lagrange Multiplier Method for Exact Recovery of Corrupted Low-Rank Matrices. arXiv 2010, arXiv:1009.5055. [Google Scholar]
- Li, S.; Zhang, K.; Duan, P.; Kang, X. Hyperspectral Anomaly Detection with Kernel Isolation Forest. IEEE Trans. Geosci. Remote Sens. 2019, 58, 319–329. [Google Scholar] [CrossRef]
- Kang, X.; Zhang, X.; Li, S.; Li, K.; Li, J.; Benediktsson, J.A. Hyperspectral Anomaly Detection with Attribute and Edge-Preserving Filters. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5600–5611. [Google Scholar] [CrossRef]
- Bradley, A.P. The Use of the Area under the Roc Curve in the Evaluation of Machine Learning Algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Ling, C.X. Using Auc and Accuracy in Evaluating Learning Algorithms. IEEE Trans. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar] [CrossRef] [Green Version]
- Manolakis, D.; Shaw, G. Detection Algorithms for Hyperspectral Imaging Applications. IEEE Signal Process. Mag. 2002, 19, 29–43. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jin, Q.; Ma, Y.; Mei, X.; Ma, J. Tanet: An Unsupervised Two-Stream Autoencoder Network for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5506215. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | HYDICE | Pavia | Los Angeles | San Diego-I | San Diego-I | Texas Coast |
|---|---|---|---|---|---|---|
| K | 400 | 400 | 400 | 400 | 400 | 400 |
| R | 7 | 7 | 7 | 7 | 7 | 7 |
| Λ | 1 | 0.01 | 0.01 | 1 | 1 | 1 |
| Β | 0.01 | 0.001 | 0.001 | 0.01 | 0.1 | 0.1 |
| HYDICE | Pavia | Los Angeles | San Diego-I | San Diego-II | Texas Coast | |
|---|---|---|---|---|---|---|
| Coarse | 0.9700 | 0.9622 | 0.9865 | 0.9890 | 0.9940 | 0.9955 |
| Fine | 0.9862 | 0.9728 | 0.9923 | 0.9916 | 0.9973 | 0.9951 |
| Complementary | 0.9991 | 0.9951 | 0.9968 | 0.9923 | 0.9986 | 0.9969 |
| Dataset | RX | CRD | LRASR | LSMAD | PAB-DC | LSDM–MoG | KIFD | DDC–TSCD |
|---|---|---|---|---|---|---|---|---|
| HYDICE | 0.9857 | 0.9951 | 0.8402 | 0.9861 | 0.9955 | 0.9792 | 0.9966 | 0.9991 |
| Pavia | 0.9887 | 0.9650 | 0.9889 | 0.9842 | 0.8858 | 0.9482 | 0.8589 | 0.9951 |
| Los Angeles | 0.9887 | 0.9794 | 0.8748 | 0.9814 | 0.8757 | 0.9745 | 0.9766 | 0.9968 |
| San Diego-I | 0.9403 | 0.9412 | 0.8950 | 0.9701 | 0.9780 | 0.9339 | 0.9914 | 0.9923 |
| San Diego-II | 0.9111 | 0.9791 | 0.9853 | 0.9732 | 0.9941 | 0.9320 | 0.9922 | 0.9986 |
| Texas Coast | 0.9907 | 0.9796 | 0.7656 | 0.9928 | 0.9747 | 0.9913 | 0.9354 | 0.9969 |
| Average | 0.9675 | 0.9732 | 0.8916 | 0.9813 | 0.9506 | 0.9599 | 0.9585 | 0.9965 |
| Dataset | RX | CRD | LRASR | LSMAD | PAB-DC | LSDM–MoG | KIFD | DDC–TSCD |
|---|---|---|---|---|---|---|---|---|
| HYDICE | 0.23 | 2.62 | 29.84 | 8.25 | 257.15 | 6.61 | 46.42 | 265.32 |
| Pavia | 0.29 | 9.48 | 39.16 | 13.93 | 352.12 | 8.57 | 56.37 | 364.18 |
| Los Angeles | 0.38 | 5.90 | 42.12 | 12.47 | 358.52 | 10.64 | 54.09 | 376.80 |
| San Diego-I | 0.33 | 10.15 | 41.60 | 11.61 | 362.68 | 9.21 | 66.59 | 380.19 |
| San Diego-II | 0.52 | 15.06 | 53.89 | 17.67 | 410.23 | 16.09 | 68.31 | 430.22 |
| Texas Coast | 0.36 | 7.24 | 44.25 | 12.76 | 354.43 | 11.84 | 63.61 | 370.51 |
| Average | 0.35 | 8.41 | 41.81 | 12.78 | 349.19 | 10.49 | 59.23 | 364.54 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, S.; Zhang, M.; Cheng, X.; Wang, L.; Xu, M.; Wang, H. Hyperspectral Anomaly Detection via Dual Dictionaries Construction Guided by Two-Stage Complementary Decision. Remote Sens. 2022, 14, 1784. https://doi.org/10.3390/rs14081784
Lin S, Zhang M, Cheng X, Wang L, Xu M, Wang H. Hyperspectral Anomaly Detection via Dual Dictionaries Construction Guided by Two-Stage Complementary Decision. Remote Sensing. 2022; 14(8):1784. https://doi.org/10.3390/rs14081784
Chicago/Turabian StyleLin, Sheng, Min Zhang, Xi Cheng, Liang Wang, Maiping Xu, and Hai Wang. 2022. "Hyperspectral Anomaly Detection via Dual Dictionaries Construction Guided by Two-Stage Complementary Decision" Remote Sensing 14, no. 8: 1784. https://doi.org/10.3390/rs14081784
APA StyleLin, S., Zhang, M., Cheng, X., Wang, L., Xu, M., & Wang, H. (2022). Hyperspectral Anomaly Detection via Dual Dictionaries Construction Guided by Two-Stage Complementary Decision. Remote Sensing, 14(8), 1784. https://doi.org/10.3390/rs14081784