
Mapping Land Cover Types for Highland Andean Ecosystems in Peru Using Google Earth Engine

 ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
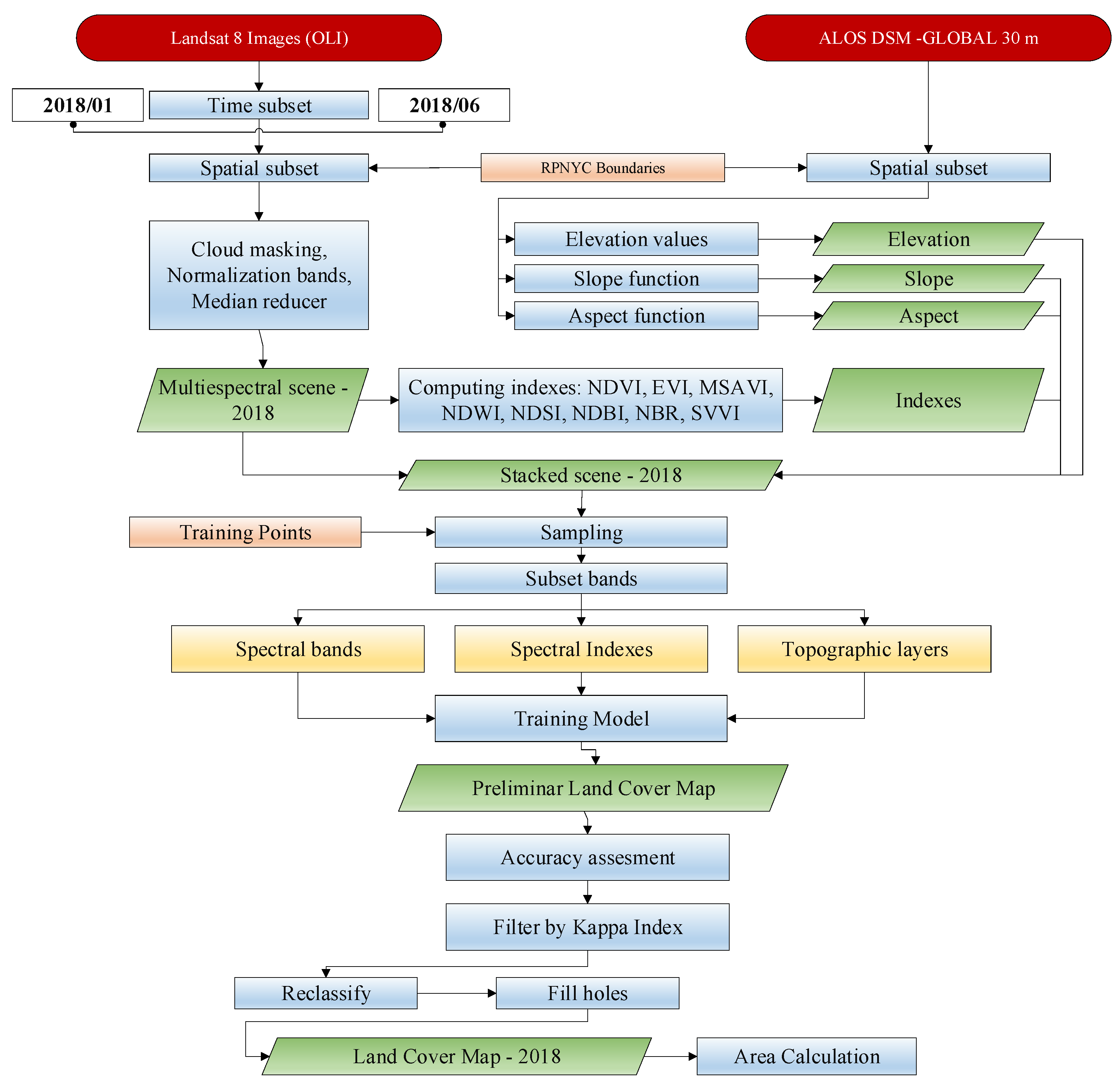
2.2. Methodological Framework
2.3. Landsat Image Preprocessing
2.4. Training and Validation Sample Collection
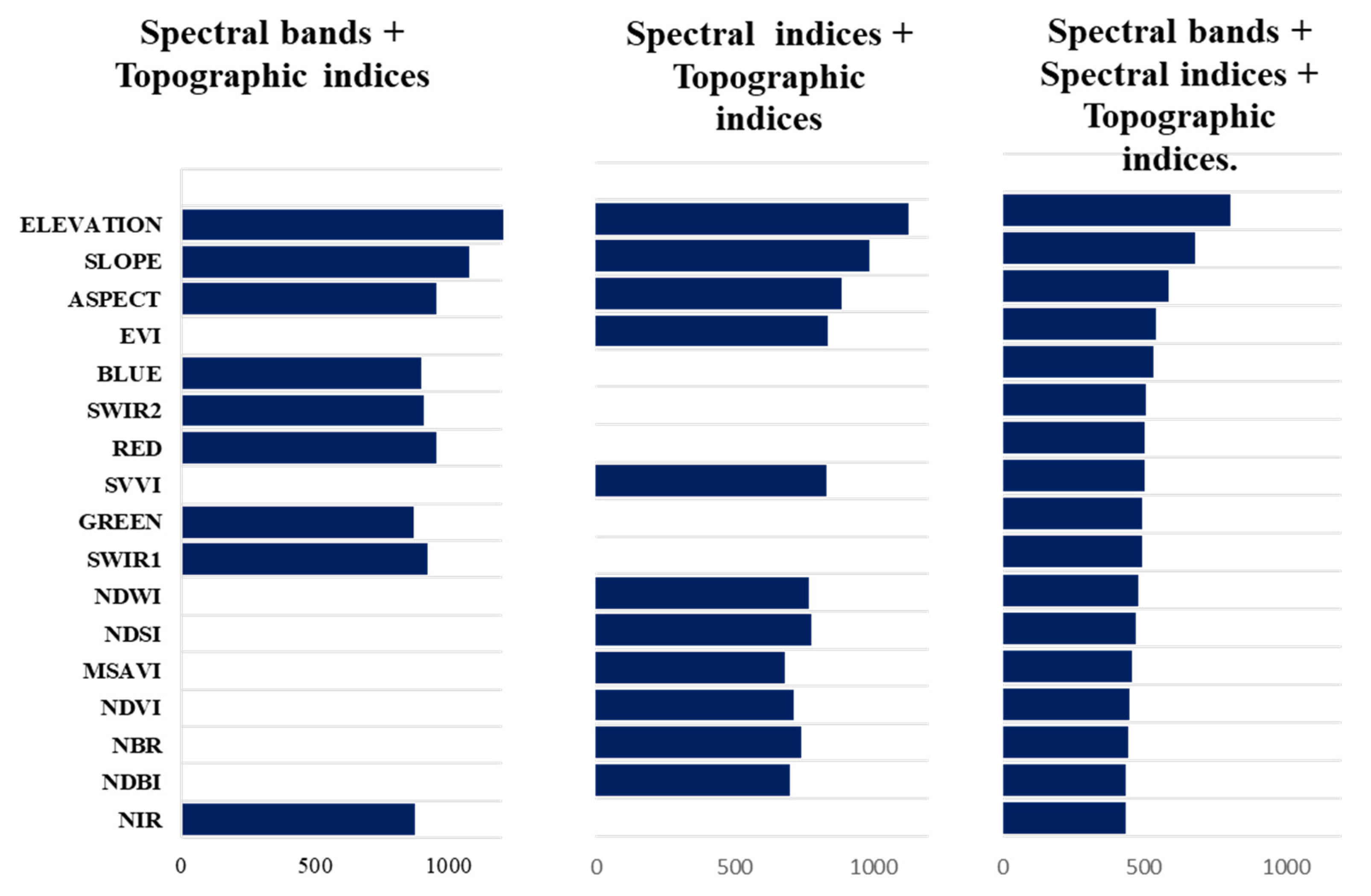
2.5. Classification Feature Input
2.6. Separability Analysis
2.7. Classifiers
2.8. Accuracy Assessment
2.9. Calculation of Land Cover Areas/Extents
3. Results
3.1. Separability Analysis
3.2. Accuracy Assessment Results
3.3. Classification Result
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- De Jong, L.; De Bruin, S.; Knoop, J.; van Vliet, J. Understanding Land-Use Change Conflict: A Systematic Review of Case Studies. J. Land Use Sci. 2021, 16, 223–239. [Google Scholar] [CrossRef]
- Yan, Y.; Zhuang, Q.; Zan, C.; Ren, J.; Yang, L.; Wen, Y.; Zeng, S.; Zhang, Q.; Kong, L. Using the Google Earth Engine to Rapidly Monitor Impacts of Geohazards on Ecological Quality in Highly Susceptible Areas. Ecol. Indic. 2021, 132, 108258. [Google Scholar] [CrossRef]
- UNCCD. SDG 15: Life on Land- Facts and Figures, Targets, Why It Matters. Available online: https://knowledge.unccd.int/publications/sdg-15-life-land-facts-and-figures-targets-why-it-matters (accessed on 29 January 2022).
- Lambin, E.F.; Geist, H.J.; Lepers, E. Dynamics of Land-Use and Land-Cover Change in Tropical Regions. Annu. Rev. Environ. Resour. 2003, 28, 205–241. [Google Scholar] [CrossRef] [Green Version]
- Bian, J.; Li, A.; Lei, G.; Zhang, Z.; Nan, X. Global High-Resolution Mountain Green Cover Index Mapping Based on Landsat Images and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2020, 162, 63–76. [Google Scholar] [CrossRef]
- Flores, E.R. Climate Change: High Andean Rangelands and Food Security. Rev. Glaciares Y Ecosistemas Montaña 2016, 1, 73–80. [Google Scholar]
- Herrick, J.E.; Beh, A.; Barrios, E.; Bouvier, I.; Coetzee, M.; Dent, D.; Elias, E.; Hengl, T.; Karl, J.W.; Liniger, H.; et al. The Land-potential Knowledge System (Landpks): Mobile Apps and Collaboration for Optimizing Climate Change Investments. Ecosyst. Health Sustain. 2016, 2, e01209. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global Land Cover Mapping at 30 m Resolution: A POK-Based Operational Approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef] [Green Version]
- Joshi, N.; Baumann, M.; Ehammer, A.; Fensholt, R.; Grogan, K.; Hostert, P.; Jepsen, M.R.; Kuemmerle, T.; Meyfroidt, P.; Mitchard, E.T.A.; et al. A Review of the Application of Optical and Radar Remote Sensing Data Fusion to Land Use Mapping and Monitoring. Remote Sens. 2016, 8, 70. [Google Scholar] [CrossRef] [Green Version]
- Townshend, J.R.G.; Huang, C.; Kalluri, S.N.V.; Defries, R.S.; Liang, S.; Yang, K. Beware of Per-Pixel Characterization of Land Cover. Int. J. Remote Sens. 2000, 21, 839–843. [Google Scholar] [CrossRef] [Green Version]
- Roberts, D.A.; Gardner, M.; Church, R.; Ustin, S.; Scheer, G.; Green, R.O. Mapping Chaparral in the Santa Monica Mountains Using Multiple Endmember Spectral Mixture Models. Remote Sens. Environ. 1998, 65, 267–279. [Google Scholar] [CrossRef]
- Pimple, U.; Sitthi, A.; Simonetti, D.; Pungkul, S.; Leadprathom, K.; Chidthaisong, A. Topographic Correction of Landsat TM-5 and Landsat OLI-8 Imagery to Improve the Performance of Forest Classification in the Mountainous Terrain of Northeast Thailand. Sustainability 2017, 9, 258. [Google Scholar] [CrossRef] [Green Version]
- Srinet, R.; Nandy, S.; Padalia, H.; Ghosh, S.; Watham, T.; Patel, N.R.; Chauhan, P. Mapping Plant Functional Types in Northwest Himalayan Foothills of India Using Random Forest Algorithm in Google Earth Engine. Int. J. Remote Sens. 2020, 41, 7296–7309. [Google Scholar] [CrossRef]
- Sluiter, R.; Pebesma, E.J. Comparing Techniques for Vegetation Classification Using Multi- and Hyperspectral Images and Ancillary Environmental Data. Int. J. Remote Sens. 2010, 31, 6143–6161. [Google Scholar] [CrossRef]
- Alpaydın, E. Introduction to Machine Learning, 3rd ed.; MIT Press: London, UK, 2014; ISBN 978-0-262-02818-9. [Google Scholar]
- Mananze, S.; Pôças, I.; Cunha, M. Mapping and Assessing the Dynamics of Shifting Agricultural Landscapes Using Google Earth Engine Cloud Computing, a Case Study in Mozambique. Remote Sens. 2020, 12, 1279. [Google Scholar] [CrossRef] [Green Version]
- Bauddh, K.; Kumar, S.; Singh, R.P.; Korstad, J. Ecological and Practical Applications for Sustainable Agriculture; Springer: Singapore, 2020; ISBN 9789811533723. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Kumar, L.; Mutanga, O. Google Earth Engine Applications; Remote Sensing. Remote. Sens. 2019, 11, 591. [Google Scholar]
- Zhou, B.; Okin, G.S.; Zhang, J. Leveraging Google Earth Engine (GEE) and Machine Learning Algorithms to Incorporate in Situ Measurement from Different Times for Rangelands Monitoring. Remote Sens. Environ. 2020, 236, 111521. [Google Scholar] [CrossRef]
- Tsai, Y.H.; Stow, D.; Chen, H.L.; Lewison, R.; An, L.; Shi, L. Mapping Vegetation and Land Use Types in Fanjingshan National Nature Reserve Using Google Earth Engine. Remote Sens. 2018, 10, 927. [Google Scholar] [CrossRef] [Green Version]
- Schroeder, T.A.; Cohen, W.B.; Song, C.; Canty, M.J.; Yang, Z. Radiometric Correction of Multi-Temporal Landsat Data for Characterization of Early Successional Forest Patterns in Western Oregon. Remote Sens. Environ. 2006, 103, 16–26. [Google Scholar] [CrossRef]
- Xie, Y.; Sha, Z.; Yu, M. Remote Sensing Imagery in Vegetation Mapping: A Review. J. Plant Ecol. 2008, 1, 9–23. [Google Scholar] [CrossRef]
- MINAM. Inventario y Evaluación Del Patrimonio Natural En La Reserva Paisajística Nor Yauyos Cochas; MINAM: Lima, Peru, 2011; p. 264. [Google Scholar]
- INRENA. Reserva Paisajística Nor Yauyos Cochas—Plan Maestro 2006—2011; INRENA: Lima, Peru, 2006; p. 263.
- Dourojeanni, P.; Fernandez-Baca, E.; Giada, S.; Leslie, J.; Podvin, K.; Zapata, F. Vulnerability assessments for ecosystem-based adaptation: Lessons from the Nor Yauyos Cochas Landscape Reserve in Peru. In Climate Change Adaptation Strategies–An Upstream-downstream Perspective; Springer: Cham, Switzerland, 2016; pp. 141–160. [Google Scholar] [CrossRef] [Green Version]
- FDA. Estudio de La Vulnerabilidad e Impacto Del Cambio Climático Sobre La Reserva Paisajística Nor Yauyos Cochas. In Escenarios Climáticos Futuros y Distribución Futura de Especies; EbA Montaña: Lima, Peru, 2013. [Google Scholar]
- SERNANP. Reserva Paisajística Nor Yauyos-Cocha—Plan Maestro 2016–2020; MINAM: Lima, Peru, 2016; p. 107.
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Joseph Hughes, M.; Laue, B. Cloud Detection Algorithm Comparison and Validation for Operational Landsat Data Products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef] [Green Version]
- Ministerio del Ambiente (MINAM). Mapa Nacional de Cobertura Vegetal—Memoria Descriptiva. Available online: https://www.gob.pe/institucion/minam/informes-publicaciones/2674-mapa-nacional-de-cobertura-vegetal-memoria-descriptiva (accessed on 15 January 2022).
- Chen, W.; Li, X.; He, H.; Wang, L. Assessing Different Feature Sets’ Effects on Land Cover Classification in Complex Surface-Mined Landscapes by ZiYuan-3 Satellite Imagery. Remote Sens. 2018, 10, 23. [Google Scholar] [CrossRef] [Green Version]
- Wu, C. Normalized Spectral Mixture Analysis for Monitoring Urban Composition Using ETM + Imagery. Remote Sens. Environ. 2004, 93, 480–492. [Google Scholar] [CrossRef]
- Rouse, J.; Haas, R.; Schell, J.; Deering, D. Monitoring Vegetation Systems in the Great Plains with ERTS. In Proceedings of the Third Earth Resources Technology Satellite Symposium, Remote Sensingcenter, Texas A&M hivemity, Colfegp Station, Texas, Washington, DC, USA, 10–14 December 1974; Volume 351, p. 309. [Google Scholar]
- Huete, A.R.; Didan, K.; Miura, T.; Rodriguez, E.; Gao, X.; Ferreira, L. Overview of the Radiometric and Biophysical Performance of the MODIS Vegetation Indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Qi, J.; Chehbouni, A.; Huete, A.R.; Kerr, Y.H.; Sorooshian, S. A Modified Soil Adjusted Vegetation Index. Remote Sens. Environ. 1994, 48, 119–126. [Google Scholar] [CrossRef]
- McFeeters, S.K. The Use of the Normalized Difference Water Index (NDWI) in the Delineation of Open Water Features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Hall, D.K.; Riggs, G.A. Mapping Global Snow Cover Using Moderate Resolution Imaging Spectroradiometer (MODIS) Data. Glaciol. Data 1995, 33, 13–17. [Google Scholar]
- Key, C.H.; Benson, N. Measuring and Remote Sensing of Burn Severity: The CBI and NBR; U.S. Geological survey Open-File Report; U.S. Geological Survey Wildland Fire Workshop: Los Alamos, NM, USA, 2000; pp. 2–11. [Google Scholar]
- Zha, Y.; Gao, J.; Ni, S. Use of Normalized Difference Built-up Index in Automatically Mapping Urban Areas from TM Imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- Coulter, L.L.; Stow, D.A.; Tsai, Y.H.; Ibanez, N.; Shih, H.C.; Kerr, A.; Benza, M.; Weeks, J.R.; Mensah, F. Classification and Assessment of Land Cover and Land Use Change in Southern Ghana Using Dense Stacks of Landsat 7 ETM + Imagery. Remote Sens. Environ. 2016, 184, 396–409. [Google Scholar] [CrossRef]
- Rosenqvist, A.; Shimada, M.; Ito, N.; Watanabe, M. ALOS PALSAR: A Pathfinder Mission for Global-Scale Monitoring of the Environment. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3307–3316. [Google Scholar] [CrossRef]
- Jiliang, X.; Xiaohui, Z.; Zhengwang, Z.; Guangmei, Z.; Xiangfeng, R. Multi- Scale Analysis on Wintering Habitat Selection of Reeves’ s Pheasant (Syrmaticus Reevesii) in Dongzhai National Nature Reserve, Henan Province, China. Acta Ecol. Sin. 2006, 26, 2061–2067. [Google Scholar]
- Richards, J.A. Supervised Classification Techniques, 5th ed.; Springer: Berlin/Heidelberg, Germany, 2013; ISBN 9783642300615. [Google Scholar]
- Noi, P.T.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2018, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Vega Isuhuaylas, L.A.; Hirata, Y.; Santos, L.C.V.; Torobeo, N.S. Natural Forest Mapping in the Andes (Peru): A Comparison of the Performance of Machine-Learning Algorithms. Remote Sens. 2018, 10, 782. [Google Scholar] [CrossRef] [Green Version]
- Petropoulos, G.P.; Kalaitzidis, C.; Prasad Vadrevu, K. Support Vector Machines and Object-Based Classification for Obtaining Land-Use/Cover Cartography from Hyperion Hyperspectral Imagery. Comput. Geosci. 2012, 41, 99–107. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Kotsiantis, S. Supervised Machine Learning: A Review of Classification Techniques. Informatica 2007, 31, 249–268. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning, 1st ed.; Springer: Singapore, 2006; ISBN 9780387310732. [Google Scholar]
- Mayr, A.; Binder, H.; Gefeller, O.; Schmid, M. The Evolution of Boosting Algorithms: From Machine Learning to Statistical Modelling. Methods Inf. Med. 2014, 53, 419–427. [Google Scholar] [CrossRef] [Green Version]
- Wacker, A.G.; Landgrebe, D.A. Minimum Distance Classification in Remote Sensing; LARS Technical Reports; Purdue University: Lafayette, Indiana, 1972; p. 25. [Google Scholar]
- Caruana, R.; Niculescu-Mizil, A. An Empirical Comparison of Supervised Learning Algorithms. In Proceedings of the 23rd International Conference on Machine Learning—ICML’06, Carnegie Mellon University, Pittsburgh, Pennsylvania, 25–29 June 2006; pp. 161–168. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning, 2nd ed.; Springer: New York, NY, USA, 1999; ISBN 0387987800. [Google Scholar]
- Max, K.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Ziem, A.; Scrucca, L.; et al. Caret: Classification and Regression Training; R Package Version 6.0-86; Astrophysics Source Code Library: Cambridge, MA, USA, 2020. [Google Scholar]
- Pontius, R.; Ali, S. DiffeR: Metrics of Difference for Comparing Pairs of Maps or Pairs of Variables. 2019, p. 19. Available online: https://cran.r-project.org/web/packages/diffeR/diffeR.pdf (accessed on 28 January 2022).
- Pontius, R.; Millones, M. Death to Kappa: Birth of Quantity Disagreement and Allocation Disagreement for Accuracy Assessment. Int. J. Remote Sens. 2011, 37–41. [Google Scholar] [CrossRef]
- Congalton, R.G. A Review of Assessing the Accuracy of Classifications of Remotely Sensed Data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Hijmans, R.J.; Van Etten, J.; Sumner, M.; Cheng, J.; Baston, D.; Bevan, A.; Bivand, R.; Busetto, L.; Canty, M.; Fasoli, B.; et al. Raster: Geographic Data Analysis and Modeling. 2020, p. 249. Available online: https://cran.r-project.org/web/packages/raster/raster.pdf (accessed on 28 January 2022).
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [Green Version]
- Räsänen, A.; Virtanen, T. Data and Resolution Requirements in Mapping Vegetation in Spatially Heterogeneous Landscapes. Remote Sens. Environ. 2019, 230, 111207. [Google Scholar] [CrossRef]
- Azzari, G.; Lobell, D.B. Landsat-Based Classification in the Cloud: An Opportunity for a Paradigm Shift in Land Cover Monitoring. Remote Sens. Environ. 2017, 202, 64–74. [Google Scholar] [CrossRef]
- Campos-Taberner, M.; Moreno-Martínez, Á.; García-Haro, F.J.; Camps-Valls, G.; Robinson, N.P.; Kattge, J.; Running, S.W. Global Estimation of Biophysical Variables from Google Earth Engine Platform. Remote Sens. 2018, 10, 1167. [Google Scholar] [CrossRef] [Green Version]
- Yaranga, R.; Custodio, M.; Chanamé, F.; Pantoja, R. Floristic Diversity in Grasslands According to Plant Formation in the Shullcas River Sub-Basin, Junin, Peru. Sci. Agropecu. 2018, 9, 511–517. [Google Scholar] [CrossRef] [Green Version]
- Weng, C.; Bush, M.B.; Curtis, J.H.; Kolata, A.L.; Dillehay, T.D.; Binford, M.W. Deglaciation and Holocene Climate Change in the Western Peruvian Andes. Quat. Res. 2006, 66, 87–96. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Land Cover | Description |
|---|---|
| Wetlands | Areas with excess of water from high rates of orographic precipitation, dominated by cushion plants, distributed in low-slope areas and above 3800 m.a.s.l. |
| Tall grass | Areas composed chiefly of perennial grasses such as Festuca, Poa, Stipa and Calamagrostis species, distributed along the slopes and tops of hilly and mountains landscapes, between an altitude range of 3900 to 4900 m.a.s.l. |
| Short grass | Areas dominated by dwarf herbaceous forbs and cushion plants growing in areas of moderate water content. Erect shrubs, mosses and lichens are of minor importance. Spatial distribution similar to tall grass land cover. |
| Shrublands | Communities conformed by species of Baccharis and Parastrephia, distributed between an altitude range of 2750 to 3800 m.a.s.l. |
| Andean forest | Areas generally relegated to rocky slopes or ravines dominated by shrubs of the genus Polylepis associated with the genera: Buddleja, Clethra, Gynoxys, Podocarpus or Prumnopitys, distributed between a wide altitude range of 600 to 4100 m.a.s.l. |
| Bands | Wavelength (µm) |
|---|---|
| Normalized Difference Vegetation Index (NDVI) | |
| Enhanced Vegetation Index (EVI) | |
| Modified Soil Adjusted Vegetation Index (MSAVI) | |
| Normalized Difference Water Index (NDWI) | |
| Normalized Difference Snow Index (NDSI) | |
| Normalized Burn Ratio (NBR) | |
| Normalized Difference Built-Up Index (NDBI) | |
| Spectral Variability Vegetation Index (SVVI) |
| Group | Algorithm |
|---|---|
| Logic-based algorithms | CART (Classification and Regression Tree) [49] Random Forest [47] Gradient Tree Boosting [50] |
| Statistical learning algorithms | Minimum Distance [51] Naive Bayes classifiers [52] |
| Support vector machines | Voting SVM (Support Vector Machines) [53] |
| Combination | Metric | Supervised Classification Algorithm | |||||
|---|---|---|---|---|---|---|---|
| CART | Random Forest | Support Vector Machine | Minimum Distance | Gradient Tree Boosting | Naïve Bayes | ||
| Spectral bands | K | 0.57 | 0.66 | 0.58 | 0.38 | 0.65 | 0.43 |
| Q (%) | 6.31 | 5.99 | 9.79 | 17.46 | 5.93 | 14.56 | |
| A (%) | 32.80 | 24.36 | 27.84 | 38.92 | 25.13 | 36.92 | |
| Spectral indices | K | 0.55 | 0.64 | 0.51 | 0.19 | 0.63 | 0.07 |
| Q (%) | 5.80 | 6.19 | 21.71 | 33.18 | 5.93 | 84.34 | |
| A (%) | 34.60 | 26.03 | 21.97 | 42.14 | 27.38 | 3.25 | |
| Spectral bands + Spectral indices | K | 0.57 | 0.66 | 0.59 | 0.38 | 0.65 | 0.37 |
| Q (%) | 6.38 | 6.19 | 9.79 | 17.91 | 5.86 | 22.23 | |
| A (%) | 32.60 | 24.16 | 27.32 | 38.47 | 25.64 | 35.70 | |
| Spectral bands + Topographic indices | K | 0.74 | 0.81 | 0.66 | 0.40 | 0.80 | 0.50 |
| Q (%) | 4.64 | 4.06 | 7.41 | 25.71 | 3.67 | 20.43 | |
| A (%) | 18.69 | 12.89 | 23.52 | 29.25 | 13.92 | 25.52 | |
| Spectral indices + Topographic indices | K | 0.73 | 0.79 | 0.60 | 0.30 | 0.81 | 0.21 |
| Q (%) | 4.90 | 4.90 | 11.28 | 27.71 | 4.19 | 48.20 | |
| A (%) | 19.07 | 13.79 | 24.87 | 36.79 | 12.89 | 26.22 | |
| Spectral bands + Spectral indices + Topographic indices | K | 0.72 | 0.78 | 0.65 | 0.40 | 0.81 | 0.48 |
| Q (%) | 3.87 | 5.41 | 8.18 | 25.39 | 3.80 | 19.14 | |
| A (%) | 21.52 | 14.24 | 23.45 | 29.51 | 13.60 | 27.90 | |
| Class | WT | TG | SG | SR | AF | BS | MR | RC | WB | GL | SH | CR | FA | BU | Total | UA | PA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WT | 140 | 3 | 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 149 | 93.96 | 86.96 |
| TG | 8 | 191 | 31 | 0 | 8 | 2 | 0 | 1 | 0 | 0 | 3 | 0 | 0 | 0 | 244 | 78.28 | 81.28 |
| SG | 13 | 28 | 200 | 4 | 1 | 4 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 254 | 78.74 | 78.74 |
| SR | 0 | 1 | 0 | 51 | 2 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 56 | 91.07 | 85.00 |
| AF | 0 | 6 | 7 | 1 | 108 | 0 | 0 | 0 | 0 | 0 | 0 | 19 | 6 | 0 | 147 | 73.47 | 75.52 |
| BS | 0 | 2 | 1 | 1 | 1 | 108 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 118 | 91.53 | 93.91 |
| MR | 0 | 0 | 0 | 0 | 0 | 0 | 64 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 68 | 94.12 | 64.00 |
| RC | 0 | 2 | 11 | 2 | 0 | 1 | 4 | 101 | 0 | 0 | 0 | 0 | 0 | 0 | 121 | 83.47 | 85.59 |
| WB | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 58 | 0 | 0 | 0 | 0 | 0 | 58 | 100.00 | 100.00 |
| GL | 0 | 0 | 0 | 0 | 0 | 0 | 31 | 2 | 0 | 114 | 6 | 0 | 0 | 0 | 153 | 74.51 | 100.00 |
| SH | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 30 | 0 | 0 | 0 | 32 | 93.75 | 75.00 |
| CR | 0 | 2 | 0 | 0 | 19 | 0 | 0 | 0 | 0 | 0 | 0 | 81 | 2 | 0 | 104 | 77.88 | 81.00 |
| FA | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 13 | 76.92 | 50.00 |
| BU | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 33 | 35 | 94.29 | 97.06 |
| Total | 161 | 235 | 254 | 60 | 143 | 115 | 100 | 118 | 58 | 114 | 40 | 100 | 20 | 34 | OA: 83.05% | ||
| K: 0.81 | Q: 4.06 | A: 12.89 | |||||||||||||||
| Land Cover Class | RF. (Spectral Bands + TOPOGRAPHIC Indices) | MINAM—2015 | ||
|---|---|---|---|---|
| Zone | Core (%) | Buffer (%) | Core (%) | Buffer (%) |
| Wetlands | 3.95 | 6.04 | 0.65 | 2.30 |
| Tall grass | 24.26 | 20.96 | 66.60 | 72.57 |
| Short grass | 28.35 | 31.47 | ||
| Shrublands | 2.84 | 1.48 | 5.76 | 2.51 |
| Andean forest | 6.32 | 2.99 | 0.79 | 0.39 |
| Bare soil | 9.11 | 12.15 | 21.07 | 17.15 |
| Moraine | 4.76 | 4.81 | ||
| Rocky | 13.81 | 14.35 | ||
| Water bodies | 1.79 | 0.94 | 1.90 | 1.25 |
| Glacier | 3.26 | 3.87 | 1.90 | 2.75 |
| Agriculture | 0.94 | 0.40 | 1.32 | 1.07 |
| Forested Areas | 0.08 | 0.04 | ||
| Built-up | 0.53 | 0.51 | 0.01 | |
| Total | 100.00 | 100.00 | 100.00 | 100.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pizarro, S.E.; Pricope, N.G.; Vargas-Machuca, D.; Huanca, O.; Ñaupari, J. Mapping Land Cover Types for Highland Andean Ecosystems in Peru Using Google Earth Engine. Remote Sens. 2022, 14, 1562. https://doi.org/10.3390/rs14071562
Pizarro SE, Pricope NG, Vargas-Machuca D, Huanca O, Ñaupari J. Mapping Land Cover Types for Highland Andean Ecosystems in Peru Using Google Earth Engine. Remote Sensing. 2022; 14(7):1562. https://doi.org/10.3390/rs14071562
Chicago/Turabian StylePizarro, Samuel Edwin, Narcisa Gabriela Pricope, Daniella Vargas-Machuca, Olwer Huanca, and Javier Ñaupari. 2022. "Mapping Land Cover Types for Highland Andean Ecosystems in Peru Using Google Earth Engine" Remote Sensing 14, no. 7: 1562. https://doi.org/10.3390/rs14071562
APA StylePizarro, S. E., Pricope, N. G., Vargas-Machuca, D., Huanca, O., & Ñaupari, J. (2022). Mapping Land Cover Types for Highland Andean Ecosystems in Peru Using Google Earth Engine. Remote Sensing, 14(7), 1562. https://doi.org/10.3390/rs14071562