
Estimating Next Day’s Forest Fire Risk via a Complete Machine Learning Methodology

 and
and
Abstract
:1. Introduction
- The proposed methods, including the extended feature set, the alternative cross-validation processes, and the task-specific evaluation measures, considerably improve sensitivity (recall of fire class) and specificity (recall of no-fire class) compared to our previous work [13]. To the best of our knowledge, the achieved effectiveness comprises the current state of the art in the problem of next day fire prediction, for the considered real-world setting, with respect to data scale and imbalance.
- The proposed methodology produces a range of models, allowing the selection of the most suitable model, with respect to the desirable trade-off between sensitivity and specificity.
- An extended analysis and discussion on the specificities of the task is performed, tying the proposed methods and schemes with specific gaps, shortcomings and errors of existing methodologies that handle the task. Further, insights, intuitions, and directions for further improving the proposed methods are discussed.
2. Materials
2.1. Problem Definition and Specificities
- Extreme data imbalance. Due to the fact that each instance of the dataset corresponds to a daily snapshot of an area (grid cell), it is evident that we end up with extreme imbalance in favor of the no-fire class. Consider for example a fire that spanned for two days of month August 2018 and through an area of 16 grid cells. This fire generates 32 fire instances and more than 3300 no-fire instances for year 2018, if we consider the whole seven-months period, for the specific grid cells. The imbalance becomes even larger given that fire occurrences naturally correspond to a small percentage of a whole territory (country) and that it is rather unusual to have a fire occurrence in the same area during consecutive (or even close) years. Indicatively, considering the whole Greek territory, one of the most prone countries to wildfires, for the 11-year period of 2010–2020, the ratio of fire to non-fire areas (grid cells) is in the order of :100,000. Note that the difference in data distribution to the much more widely uptaken task of fire susceptibility is vast, where even a single day’s fire occurrence in a grid cell generates one fire instance (but no no-fire instances) for the whole prediction interval, which might be e.g., monthly or yearly. As a consequence, most approaches in the literature handling fire susceptibility end up with balanced or slightly imbalanced (at most 1:10) datasets [2,3,4,5,6,8,9,10].
- Massive scale of data. In order to be exploitable by the fire service, a next day fire prediction system needs to produce individual daily predictions for areas that are adequately granular. Consider for example a system that produces predictions per prefecture; it is quite possible that during the summer period, several prefectures are predicted as having a fire, for the same day. Then, it is essentially impossible for a fire service to organize their resources in order to cover the whole range of them. Instead, if the predictions regard small enough areas, it is then feasible to distribute their forces to the areas with the highest risk, even if these individual areas are distributed through various prefectures. To satisfy the above requirement, in our work we consider grid cells 500 m wide, ending up with a total of 360 K grid cells (distinct areas 500 m wide) to cover the whole Greek territory. Considering that, each of these cells “generate” daily instances, for a 7-month fire period and for an 11-year interval, this amounts to a dataset of more than 830 M instances. Such scale makes the task of properly selecting and learning expressive ML models rather difficult, requiring high performance computing (HPC) infrastructure, which is hardly the case for fire services. Essentially, a significant amount of undersampling needs to be carefully performed to produce a realistically exploitable training set, upon which proper cross-validation/model selection processes can be executed.
- Heterogeneity and concept drifts (dataset shift). It is observed from our analysis that different months of each year can demonstrate significant differences with respect to the suitability and effectiveness of different ML models on the task, while different ML models are able to produce quite different prediction distributions, with respect to the sensitivity/specificity trade-off.
- Absence of fire. Finally, it is empirically known that fire occurrence can be caused by rather unpredictable factors (i.e., a person’s decision to start a fire, a cigarette thrown by a driver, a lightning), which are impossible to be captured and utilized as training features within the prediction algorithms; as a result any algorithm deployed to discriminate between fire and no-fire instances (areas) is bound to decide lacking such crucial information and is inevitably expected to classify instances based on their proneness on fire occurrence. Thus, several instances with “absence” of fire are areas that could as well have displayed a fire occurrence based on their characteristics, however, due to almost random factors did not. Such instances lead to significant restrictions of potentially any algorithm’s achieved specificity.
2.2. Study Area and Evaluation Dataset
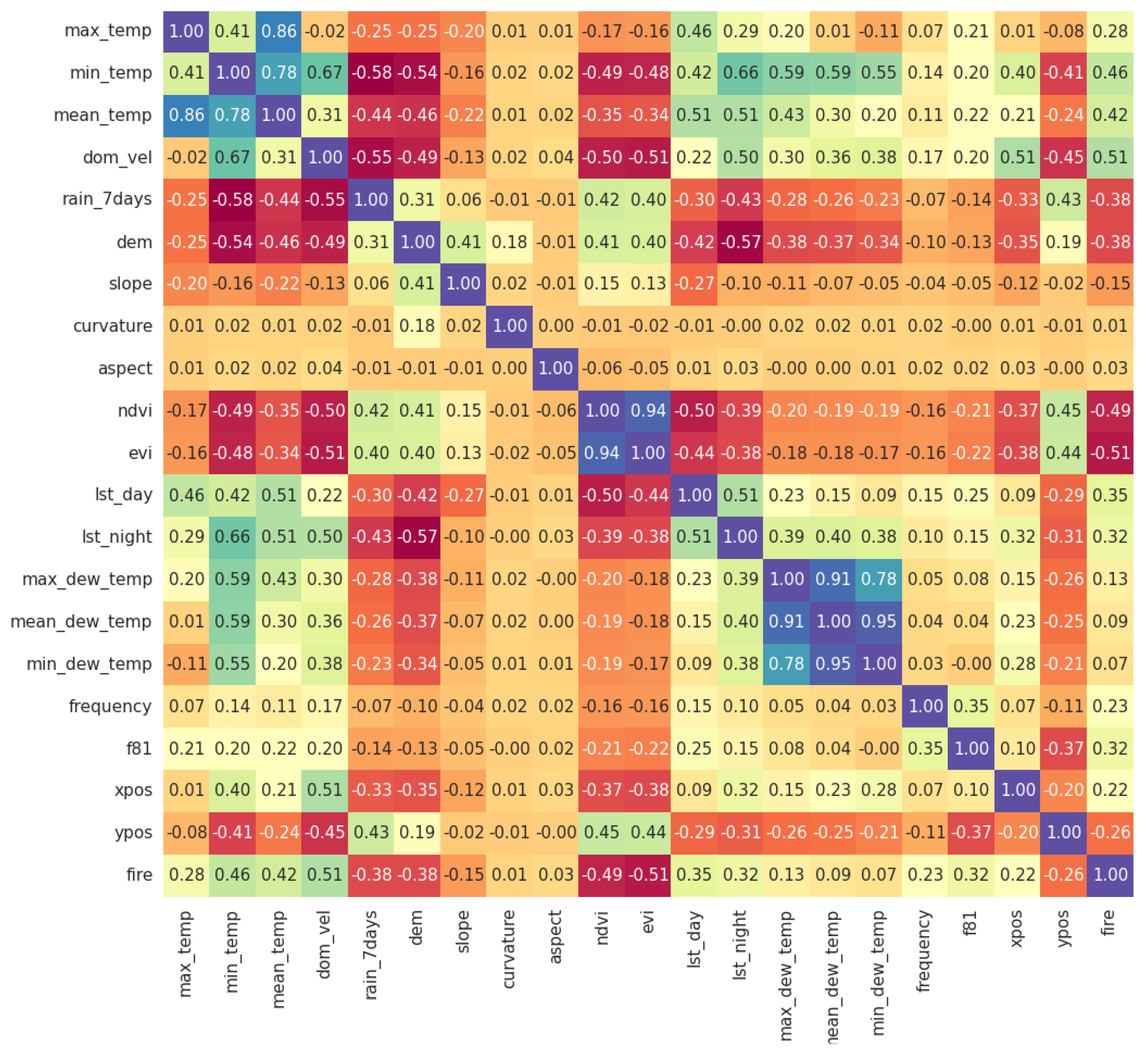
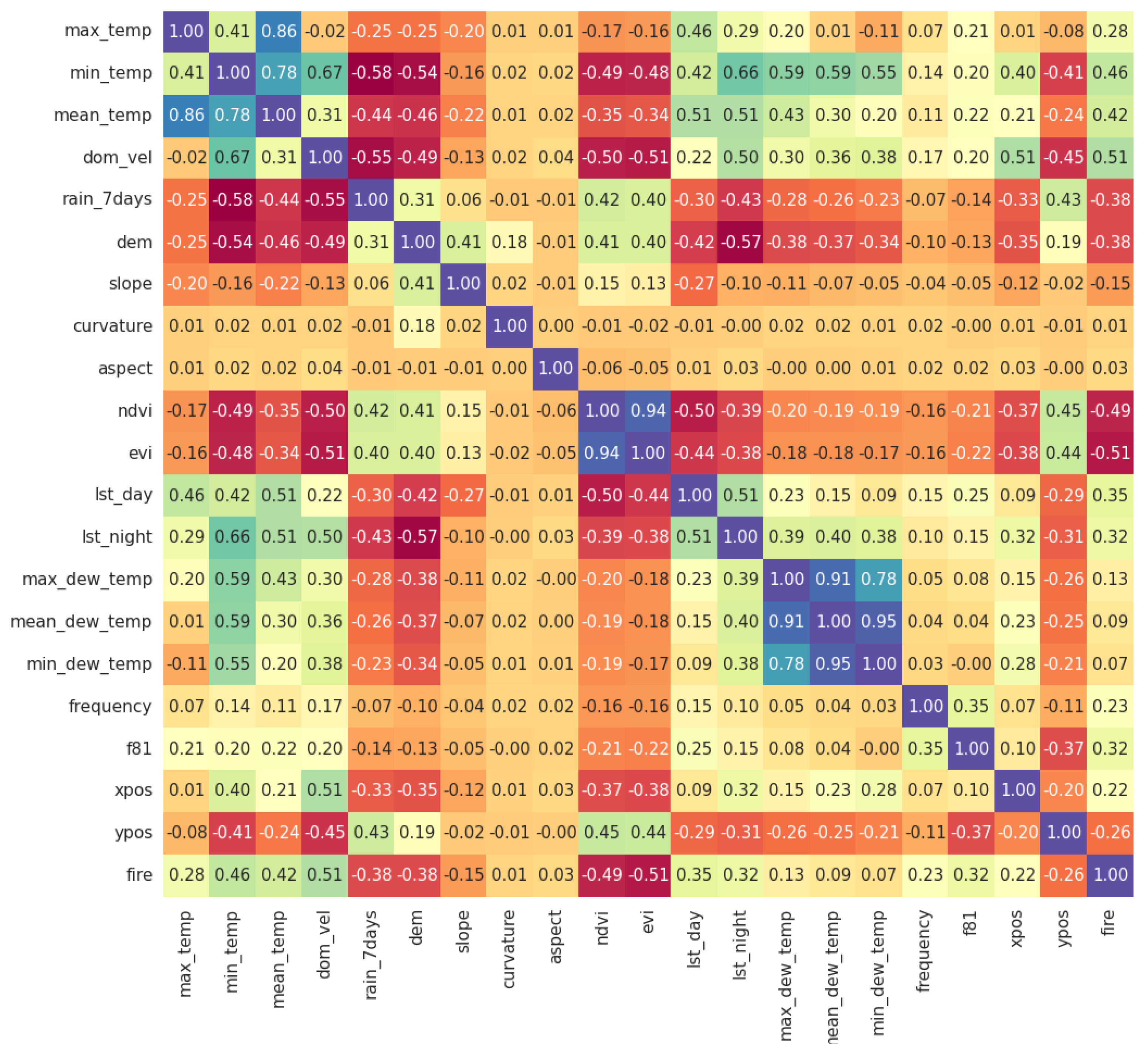
2.3. Training Features

{kind=link}
{kind=link}
| Category | Feature | Code Name | Source Spatial Resolution | Source Temporal Resolution | Source |
|---|---|---|---|---|---|
| DEM | Elevation | dem | 25 m | - | Copernicus DEM |
| Slope | slope | ||||
| Curvature | curvature | ||||
| Aspect | aspect | ||||
| Land cover | Corine Land Cover | corine | 100 m | 3 years | Copernicus Corine Land Cover |
| Temperature | Maximum daily temperature | max_temp | 9 km | hourly | ERA5 land |
| Minimum daily temperature | min_temp | ||||
| Mean daily temperature | mean_temp | ||||
| Dewpoint | Maximum dewpoint temperature | max_dew | 9 km | hourly | ERA5 land |
| Minimum dewpoint temperature | min_dew | ||||
| Mean dewpoint temperature | mean_dew | ||||
| Wind speed | Maximum wind speed | dom_vel | 9 km | hourly | ERA5 land |
| Wind direction | Wind direction of the maximum wind speed | dir_max | 9 km | hourly | ERA5 land |
| Wind direction of the dominant wind speed | dom_dir | ||||
| Precipitation | 7 day accumulated precipitation | rain_7days | 9 km | hourly | ERA5 land |
| Vegetation indices | NDVI | ndvi | 500 m | 8 days | NASA MODIS |
| EVI | evi | ||||
| LST | LST-day | lst_day | 1 km | 8 days | NASA MODIS |
| LST-night | lst_night | ||||
| Fire history | Fire history | frequency | 500 m | daily | FireHub BSM |
| Spatially smoothed fire history | f81 | ||||
| Cell coordinates | x position | xpos | 500 m | daily | FireHub cell grid |
| y position | ypos | ||||
| Calendar cycles | Month of the year | month | 500 m | daily | Fire Inventory date field |
| Week day | wkd |
3. Method
3.1. ML Algorithms
3.2. Cross-Validation Schemes and Measures
3.2.1. The Generic Methodology
3.2.2. The Proposed Schemes
4. Results
4.1. Evaluation Setting
- ROC-AUC. Area under the receiver operating characteristic curve [42] is a widely utilized evaluation measure, since it is a measure that summarizes the performance of a classification model over a range of different classification thresholds, that produce different sensitivity/specificity thresholds. Due to its definition, ROC-AUC is imbalance insensitive [39], which is a desirable property for out setting. However, a significant disadvantage of the measure is that it does not allow adjusting the relative importance of sensitivity and specificity values.
- F-score. This is also a widely used evaluation measure [40], that can also tackle data imbalance, since it produces a joint score by weighting precision and recall. Its downside in our setting is that weighting these two factors cannot be easily performed in an intuitive way, since, due to extreme imbalance in combination with the importance that is given on fire class recall (sensitivity), precision values are expected to be orders of magnitude lower than recall.
- rh-2, rh-5. Ratio-based hybrid, with setting weight k to values 2 and 5, are two instantiations our proposed measure (first introduced in [14]), that directly produces a joint score on sensitivity and specificity and allows boosting the importance of the former via parameter k.
- sh-2, sh-5, sh-10. Sum-based hybrid, with setting weight k to values 2, 5, and 10, are three instantiations our second proposed measure that target exactly the same goal as rh-k, but performs the weighting (boosting of sensitivity) in a more direct way, as presented in Section 3.2.
- Algorithms. The notation for the three tree ensembles, Random Forest, Extra Trees, and XGBoost are RF, XT, and XGB respectively. For Neural Networks, we consider two variations, without and with dropout, denoted NN and NNd, respectively.
- Cross-validation measure. In order to denote that a model has been selected based on a specific evaluation measure on the validation sets, we append the measure’s abbreviation (AUC, fscore, rh2, rh5, sh2, sh5, sh10) at the end of the model. For example, if a RF is selected via shybrid-5 is selected, then it is denoted as RF-sh5.
- Cross-validation scheme. In order to discriminate which of the two presented cross-validation schemes, we append the terms defCV or altCV respectively at the end of the model’s name. Thus, to further denote that the above model has been trained on the alternative cross-validation scheme, then we write it as RF-sh5-altCV.
4.2. Evaluation Results
4.2.1. Overall Effectiveness
4.2.2. Gains from New Training Features
4.2.3. Gains from Hybrid Measures and Alternative Cross Validation Scheme
4.2.4. Model Generalization
5. Discussion
5.1. Data Scale and Imbalance
5.2. Concept Drifts and Model Robustness
5.3. Deep Learning
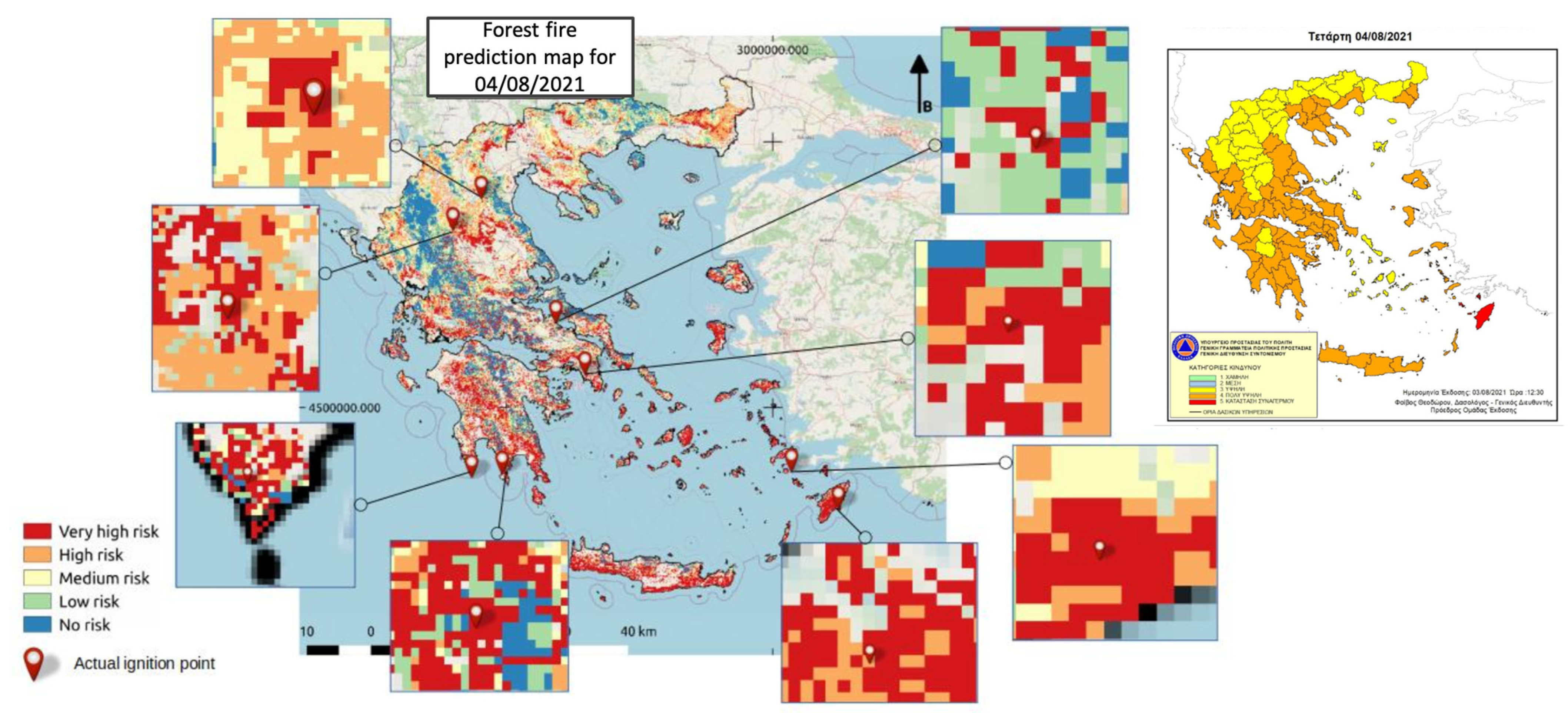
5.4. Operational Mode
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Hyperparameter Spaces
Appendix A.1. FCNN Parameter Space
Appendix A.2. Ensemble Trees Algorithms Parameter Spaces
References
- Jain, P.; Coogan, S.C.; Subramanian, S.G.; Crowley, M.; Taylor, S.; Flannigan, M.D. A review of machine learning applications in wildfire science and management. Environ. Rev. 2020, 28, 478–505. [Google Scholar] [CrossRef]
- Tonini, M.; D’Andrea, M.; Biondi, G.; Degli Esposti, S.; Trucchia, A.; Fiorucci, P. A Machine Learning-Based Approach for Wildfire Susceptibility Mapping. The Case Study of the Liguria Region in Italy. Geosciences 2020, 10, 105. [Google Scholar] [CrossRef] [Green Version]
- Gigović, L.; Pourghasemi, H.R.; Drobnjak, S.; Bai, S. Testing a New Ensemble Model Based on SVM and Random Forest in Forest Fire Susceptibility Assessment and Its Mapping in Serbia’s Tara National Park. Forests 2019, 10, 408. [Google Scholar] [CrossRef] [Green Version]
- Rodrigues, M.; de la Riva, J. An insight into machine-learning algorithms to model human-caused wildfire occurrence. Environ. Model. Softw. 2014, 57, 192–201. [Google Scholar] [CrossRef]
- Tehrany, M.; Jones, S.; Shabani, F.; Martínez-Álvarez, F.; Bui, D. A Novel Ensemble Modelling Approach for the Spatial Prediction of Tropical Forest Fire Susceptibility Using Logitboost Machine Learning Classifier and Multi-source Geospatial Data. Theor. Appl. Climatol. 2019, 137, 637–653. [Google Scholar] [CrossRef]
- Zhang, G.; Wang, M.; Liu, K. Forest Fire Susceptibility Modeling Using a Convolutional Neural Network for Yunnan Province of China. Int. J. Disaster Risk Sci. 2019, 10, 386–403. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Li, M.; Wang, B.; Quan, Y.; Liu, J. Using Artificial Intelligence to Estimate the Probability of Forest Fires in Heilongjiang, Northeast China. Remote Sens. 2021, 13, 1813. [Google Scholar] [CrossRef]
- Alonso-Betanzos, A.; Fontenla-Romero, O.; Guijarro-Berdiñas, B.; Hernández-Pereira, E.; Inmaculada Paz Andrade, M.; Jiménez, E.; Luis Legido Soto, J.; Carballas, T. An intelligent system for forest fire risk prediction and fire fighting management in Galicia. Expert Syst. Appl. 2003, 25, 545–554. [Google Scholar] [CrossRef]
- Vasilakos, C.; Kalabokidis, K.; Hatzopoulos, J.; Kallos, G.; Matsinos, Y. Integrating new methods and tools in fire danger rating. Int. J. Wildland Fire 2007, 16, 306–316. [Google Scholar] [CrossRef]
- Stojanova, D.; Kobler, A.; Ogrinc, P.; Ženko, B.; Džeroski, S. Estimating the risk of fire outbreaks in the natural environment. Data Min. Knowl. Discov. 2012, 24, 411–442. [Google Scholar] [CrossRef]
- Bisquert, M.; Caselles, E.; Sánchez, J.M.; Caselles, V. Application of artificial neural networks and logistic regression to the prediction of forest fire danger in Galicia using MODIS data. Int. J. Wildland Fire 2012, 21, 1025–1029. [Google Scholar] [CrossRef]
- Massada, A.B.; Syphard, A.; Stewart, S.I.; Radeloff, V. Wildfire ignition-distribution modelling: A comparative study in the Huron-Manistee National Forest, Michigan, USA. Int. J. Wildland Fire 2013, 22, 174–183. [Google Scholar] [CrossRef]
- Apostolakis, A.; Girtsou, S.; Kontoes, C.; Papoutsis, I.; Tsoutsos, M. Implementation of a Random Forest Classifier to Examine Wildfire Predictive Modelling in Greece Using Diachronically Collected Fire Occurrence and Fire Mapping Data. In Proceedings of the MultiMedia Modeling—27th International Conference, MMM 2021, Prague, Czech Republic, 22–24 June2021; Lokoc, J., Skopal, T., Schoeffmann, K., Mezaris, V., Li, X., Vrochidis, S., Patras, I., Eds.; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12573, pp. 318–329. [Google Scholar] [CrossRef]
- Girtsou, S.; Apostolakis, A.; Giannopoulos, G.; Kontoes, C. A Machine Learning methodology for next day wildfire prediction. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021. [Google Scholar]
- Yerushalmy, J. Statistical Problems in Assessing Methods of Medical Diagnosis, with Special Reference to X-ray Techniques. Public Health Rep. (1896–1970) 1947, 62, 1432–1449. [Google Scholar] [CrossRef]
- Kontoes, C.; Keramitsoglou, I.; Papoutsis, I.; Sifakis, N.; Xofis, P. National Scale Operational Mapping of Burnt Areas as a Tool for the Better Understanding of Contemporary Wildfire Patterns and Regimes. Sensors 2013, 13, 11146–11166. [Google Scholar] [CrossRef] [Green Version]
- Hellenic National Meteorological Service.Climate Atlas of Greece. Available online: http://climatlas.hnms.gr/sdi/?lang=EN (accessed on 22 February 2022).
- © European Union. Copernicus Land Monitoring Service 2018; European Environment Agency (EEA). Available online: https://land.copernicus.eu/pan-european/corine-land-cover/clc2018 (accessed on 22 February 2022).
- Pausas, J. Changes in fire and climate in the Eastern Iberian Peninsula (Mediterranean Basin). Clim. Chang. 2004, 63, 337–350. [Google Scholar] [CrossRef]
- Pausas, J.; Fernández-Muñoz, S. Fire regime changes in the Western Mediterranean Basin: From fuel-limited to drought-driven fire regime. Clim. Chang. 2012, 110, 215–226. [Google Scholar] [CrossRef] [Green Version]
- Lancaster, D. A Review of Some Image Pixel Interpolation Algorithms. 2012. Available online: https://www.tinaja.com/glib/pixintpl.pdf (accessed on 22 February 2022).
- Hancock, J.T.; Khoshgoftaar, T.M.; Hancock, K.J. Survey on categorical data for neural networks. Big Data 2020, 7, 28. [Google Scholar] [CrossRef] [Green Version]
- Zumbrunnen, T.; Pezzatti, G.B.; Menéndez, P.; Bugmann, H.; Bürgi, M.; Conedera, M. Weather and human impacts on forest fires: 100 years of fire history in two climatic regions of Switzerland. For. Ecol. Manag. 2011, 261, 2188–2199. [Google Scholar] [CrossRef]
- Ganteaume, A.; Camia, A.; Jappiot, M.; San-Miguel-Ayanz, J.; Long-Fournel, M.; Lampin, C. A review of the main driving factors of forest fire ignition over Europe. Environ. Manag. 2013, 51, 651–662. [Google Scholar] [CrossRef] [Green Version]
- Maselli, F.; Romanelli, S.; Bottai, L.; Zipoli, G. Use of NOAA-AVHRR NDVI images for the estimation of dynamic fire risk in Mediterranean areas. Remote Sens. Environ. 2003, 86, 187–197. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.; Gao, X.; Ferreira, L. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Matsushita, B.; Yang, W.; Chen, J.; Yuyichi, O.; Guoyu, Q. Sensitivity of the Enhanced Vegetation Index (EVI) and Normalized Difference Vegetation Index (NDVI) to Topographic Effects: A Case Study in High-Density Cypress Forest. Sensors 2007, 7, 2636. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maffei, C.; Alfieri, S.; Menenti, M. Time Series of Land Surface Temperature from Daily MODIS Measurements for the Prediction of Fire Hazard; 2014; pp. 1024–1029. Available online: https://www.researchgate.net/profile/Carmine-Maffei/publication/271646072_Time_series_of_land_surface_temperature_from_daily_MODIS_measurements_for_the_prediction_of_fire_hazard/links/54cea28a0cf298d65661e2a9/Time-series-of-land-surface-temperature-from-daily-MODIS-measurements-for-the-prediction-of-fire-hazard.pdf (accessed on 22 February 2022).
- Pulfer, E.M. Different Approaches to Blurring Digital Images and Their Effect on Facial Detection. Bachelor Thesis, University of Arkansas, Fayetteville, AR, USA, 2019. [Google Scholar]
- Forsyth, D.A.; Ponce, J. Computer Vision—A Modern Approach, 2nd ed.; Prentice Hall: Hoboken, NJ, USA, 2012; pp. 1–791. [Google Scholar]
- Vasilakos, C.; Kostas, A.E.; Ae, K.; Hatzopoulos, J.; Vasilakos, C.; Hatzopoulos, J.; Matsinos, Á.I.; Kalabokidis, K. Identifying Wildland Fire Ignition Factors through Sensitivity Analysis of a Neural Network. Nat. Hazards 2009, 50, 125–143. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef] [Green Version]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 22 February 2022).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- He, H.; Ma, Y. Imbalanced Learning: Foundations, Algorithms, and Applications, 1st ed.; Wiley-IEEE Press: Hoboken, NJ, USA, 2013. [Google Scholar]
- Rijsbergen, C.J.V. Information Retrieval, 2nd ed.; Butterworth-Heinemann: Oxford, UK, 1979. [Google Scholar]
- Youden, W.J. Index for rating diagnostic tests. Cancer 1950, 3, 32–35. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Padilla, M.; Vega-Garcia, C. On the comparative importance of fire danger rating indices and their integration with spatial and temporal variables for predicting daily human-caused fire occurrence in Span. Int. J. Wildland Fire 2011, 20, 46–58. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Chen, W.; Yang, Y.; Wang, Z. In Defense of the Triplet Loss Again: Learning Robust Person Re-Identification with Fast Approximated Triplet Loss and Label Distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1454–1463. [Google Scholar] [CrossRef]
- Mitsakis, E.; Stamos, I.; Papanikolaou, A.; Ayfantopoulou, G.; Charalabos, K. Assessment of extreme weather events on transport networks: Case study of the 2007 wildfires in Peloponnesus. Nat. Hazards 2014, 72, 87–107. [Google Scholar] [CrossRef]
- Parselia, E.; Charalabos, K.; Tsouni, A.; Hadjichristodoulou, C.; Kioutsioukis, I.; Magiorkinis, G.; Stilianakis, N. Satellite Earth Observation Data in Epidemiological Modeling of Malaria, Dengue and West Nile Virus: A Scoping Review. Remote Sens. 2019, 11, 1862. [Google Scholar] [CrossRef] [Green Version]
- Quionero-Candela, J.; Sugiyama, M.; Schwaighofer, A.; Lawrence, N. Dataset Shift in Machine Learning; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 972–981. [Google Scholar]
- Gorishniy, Y.; Rubachev, I.; Khrulkov, V.; Babenko, A. Revisiting Deep Learning Models for Tabular Data. arXiv 2021, arXiv:2106.11959. [Google Scholar]
- Vijay Kumar, B.; Carneiro, G.; Reid, I. Learning Local Image Descriptors with Deep Siamese and Triplet Convolutional Networks by Minimizing Global Loss Functions. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5385–5394. [Google Scholar] [CrossRef]
- Yu, L.; Twardowski, B.; Liu, X.; Herranz, L.; Wang, K.; Cheng, Y.; Jui, S.; van de Weijer, J. Semantic Drift Compensation for Class-Incremental Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Drozdov, I.; Szubert, B.; Cole, J.; Monaco, C. Structure-preserving visualisation of high dimensional single-cell datasets. Sci. Rep. 2019, 9, 8914. [Google Scholar]
- Bengio, Y.; Lecun, Y. Convolutional Networks for Images, Speech, and Time-Series. Handb. Brain Theory Neural Netw. 1997, 3361, 1995. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Gal, Y.; Ghahramani, Z. Bayesian Convolutional Neural Networks with Bernoulli Approximate Variational Inference. arXiv 2016, arXiv:1506.02158. [Google Scholar]
- Skamarock, C.; Klemp, B.; Dudhia, J.; Gill, O.; Liu, Z.; Berner, J.; Wang, W.; Powers, G.; Duda, G.; Barker, D.; et al. A Description of the Advanced Research WRF Model Version 4; National Center for Atmospheric Research: Boulder, CO, USA, 2019. [Google Scholar]
| Year | August | Sum June–September | ||
|---|---|---|---|---|
| No Fire | Fire | No Fire | Fire | |
| 2010 | 11,687,055 | 347 | 45,995,051 | 607 |
| 2011 | 11,685,953 | 1468 | 45,993,489 | 2202 |
| 2012 | 11,685,532 | 1816 | 45,992,810 | 2806 |
| 2013 | 11,686,833 | 599 | 45,994,470 | 1233 |
| 2014 | 11,687,130 | 304 | 45,994,809 | 899 |
| 2015 | 11,687,290 | 144 | 45,994,915 | 793 |
| 2016 | 11,687,188 | 246 | 45,993,758 | 1950 |
| 2017 | 11,686,508 | 926 | 45,994,210 | 1498 |
| 2018 | 11,687,345 | 87 | 45,995,092 | 598 |
| 2019 | 11,562,808 | 386 | 45,100,739 | 631 |
| 2020 | 11,560,400 | 221 | 44,926,467 | 749 |
| # | Algorithm/Model | August 2019 | June–September 2019 | ||
|---|---|---|---|---|---|
| Sens. | Spec. | Sens. | Spec. | ||
| 1 | NN-AUC-defCV (igarss21) | 0.87 | 0.42 | - | - |
| 2 | RF-AUC-defCV (igarss21) | 0.92 | 0.36 | - | - |
| 3 | XG-rh5-defCV (igarss21) | 0.91 | 0.39 | - | - |
| 4 | NN-rh5-defCV (current) | 0.90 | 0.51 | 0.90 | 0.66 |
| 5 | NNd-sh5-altCV (current) | 0.94 | 0.47 | 0.90 | 0.62 |
| 6 | RF-sh5-defCV (current) | 0.89 | 0.42 | 0.90 | 0.55 |
| 7 | XG-sh5-defCV (current) | 0.91 | 0.46 | 0.91 | 0.56 |
| 8 | ET-sh5-defCV (current) | 0.92 | 0.38 | 0.94 | 0.54 |
| 9 | ET-rh5-altCV (current) | 0.91 | 0.47 | 0.92 | 0.59 |
| Rank | NNd (nh2-defCV) | RF (nh5-defCV) | XGB (nh5-defCV) | |||
|---|---|---|---|---|---|---|
| Feature | Imp. (%) | Feature | Imp. (%) | Feature | Imp. (%) | |
| 1 | dom_vel | 6.07 | dom_vel | 12.94 | dom_vel | 7.47 |
| 2 | evi | 2.38 | evi | 2.37 | evi | 2.24 |
| 3 | f81 | 1.99 | f81 | 2.18 | dem | 1.68 |
| 4 | xpos | 1.47 | ndvi_new | 2.13 | max_temp | 1.63 |
| 5 | xpos | 1.18 | mean_temp | 1.72 | xpos | 1.58 |
| 6 | dem | 1.17 | max_temp | 1.71 | xpos | 1.48 |
| 7 | rain_7days | 0.57 | lst_day | 1.48 | f81 | 1.36 |
| 8 | max_temp | 0.44 | xpos | 1.20 | rain_7days | 0.80 |
| 9 | frequency | 0.26 | xpos | 1.12 | mean_dew_temp | 0.67 |
| 10 | slope | 0.19 | mean_dew_temp | 1.11 | mean_temp | 0.47 |
| Algo | AUC | f-Score | rh2 | rh5 | sh2 | sh5 | sh10 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sens. | Spec. | Sens. | Spec. | Sens. | Spec. | Sens. | Spec. | Sens. | Spec. | Sens. | Spec. | Sens. | Spec. | |
| Default (k-fold) Cross-Validation | ||||||||||||||
| RF | 0.87 | 0.66 | 0.86 | 0.67 | 0.78 | 0.71 | 0.88 | 0.59 | 0.87 | 0.61 | 0.90 | 0.55 | 0.94 | 0.47 |
| ET | 0.57 | 0.83 | 0.79 | 0.69 | 0.75 | 0.73 | 0.81 | 0.68 | 0.79 | 0.69 | 0.94 | 0.54 | 0.79 | 0.68 |
| XGB | 0.54 | 0.80 | 0.57 | 0.75 | 0.67 | 0.74 | 0.74 | 0.69 | 0.68 | 0.71 | 0.91 | 0.56 | 0.93 | 0.51 |
| NN | 0.71 | 0.77 | 0.67 | 0.80 | 0.72 | 0.78 | 0.90 | 0.66 | 0.83 | 0.68 | 0.92 | 0.58 | 0.96 | 0.47 |
| NNd | 0.66 | 0.84 | 0.77 | 0.78 | 0.79 | 0.76 | 0.91 | 0.65 | 0.90 | 0.67 | 0.93 | 0.59 | 0.97 | 0.47 |
| Alternative Cross-Validation | ||||||||||||||
| RF | 0.74 | 0.80 | 0.13 | 0.99 | 0.82 | 0.71 | 0.87 | 0.64 | 0.91 | 0.47 | 0.91 | 0.47 | 0.91 | 0.47 |
| ET | 0.32 | 0.96 | 0.27 | 0.97 | 0.85 | 0.69 | 0.92 | 0.59 | 0.94 | 0.52 | 0.93 | 0.52 | 0.95 | 0.45 |
| XGB | 0.70 | 0.77 | 0.34 | 0.94 | 0.74 | 0.69 | 0.82 | 0.62 | 0.91 | 0.59 | 0.95 | 0.46 | 0.95 | 0.46 |
| NN | 0.90 | 0.61 | 0.48 | 0.88 | 0.84 | 0.67 | 0.90 | 0.61 | 0.84 | 0.64 | 0.91 | 0.61 | 0.93 | 0.62 |
| NNd | 0.81 | 0.71 | 0.51 | 0.87 | 0.85 | 0.68 | 0.89 | 0.64 | 0.88 | 0.66 | 0.91 | 0.59 | 0.91 | 0.61 |
| Model | 2019 | 2020 | ||
|---|---|---|---|---|
| Sens. | Spec. | Sens. | Spec. | |
| RF-sh5-defCV | 0.90 | 0.55 | 0.97 | 0.56 |
| ET-sh5-defCV | 0.94 | 0.54 | 0.97 | 0.54 |
| XGB-sh5-defCV | 0.91 | 0.56 | 0.97 | 0.58 |
| XGB-sh10-defCV | 0.93 | 0.51 | 0.98 | 0.52 |
| ET-rh5-altCV | 0.92 | 0.59 | 0.96 | 0.59 |
| ET-sh2-altCV | 0.94 | 0.52 | 0.98 | 0.52 |
| ET-sh5-altCV | 0.93 | 0.52 | 0.98 | 0.52 |
| XGB-sh2-altCV | 0.91 | 0.59 | 0.96 | 0.58 |
| NN-rh5-defCV | 0.90 | 0.66 | 0.95 | 0.67 |
| NNd-rh5-defCV | 0.91 | 0.65 | 0.95 | 0.66 |
| NNd-sh2-defCV | 0.90 | 0.67 | 0.95 | 0.67 |
| NN-sh5-defCV | 0.92 | 0.58 | 0.95 | 0.59 |
| NNd-sh5-defCV | 0.93 | 0.59 | 0.96 | 0.62 |
| NN-auc-altCV | 0.90 | 0.61 | 0.97 | 0.59 |
| NN-rh5-altCV | 0.90 | 0.61 | 0.97 | 0.58 |
| NN-sh5-altCV | 0.91 | 0.61 | 0.96 | 0.58 |
| NNd-sh5-altCV | 0.91 | 0.59 | 0.98 | 0.55 |
| NN-sh10-altCV | 0.93 | 0.62 | 0.97 | 0.58 |
| NNd-sh10-altCV | 0.91 | 0.61 | 0.97 | 0.60 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Apostolakis, A.; Girtsou, S.; Giannopoulos, G.; Bartsotas, N.S.; Kontoes, C. Estimating Next Day’s Forest Fire Risk via a Complete Machine Learning Methodology. Remote Sens. 2022, 14, 1222. https://doi.org/10.3390/rs14051222
Apostolakis A, Girtsou S, Giannopoulos G, Bartsotas NS, Kontoes C. Estimating Next Day’s Forest Fire Risk via a Complete Machine Learning Methodology. Remote Sensing. 2022; 14(5):1222. https://doi.org/10.3390/rs14051222
Chicago/Turabian StyleApostolakis, Alexis, Stella Girtsou, Giorgos Giannopoulos, Nikolaos S. Bartsotas, and Charalampos Kontoes. 2022. "Estimating Next Day’s Forest Fire Risk via a Complete Machine Learning Methodology" Remote Sensing 14, no. 5: 1222. https://doi.org/10.3390/rs14051222
APA StyleApostolakis, A., Girtsou, S., Giannopoulos, G., Bartsotas, N. S., & Kontoes, C. (2022). Estimating Next Day’s Forest Fire Risk via a Complete Machine Learning Methodology. Remote Sensing, 14(5), 1222. https://doi.org/10.3390/rs14051222