
Improved U-Net Remote Sensing Classification Algorithm Based on Multi-Feature Fusion Perception

Abstract
:1. Introduction
Related Work
2. Materials and Methods
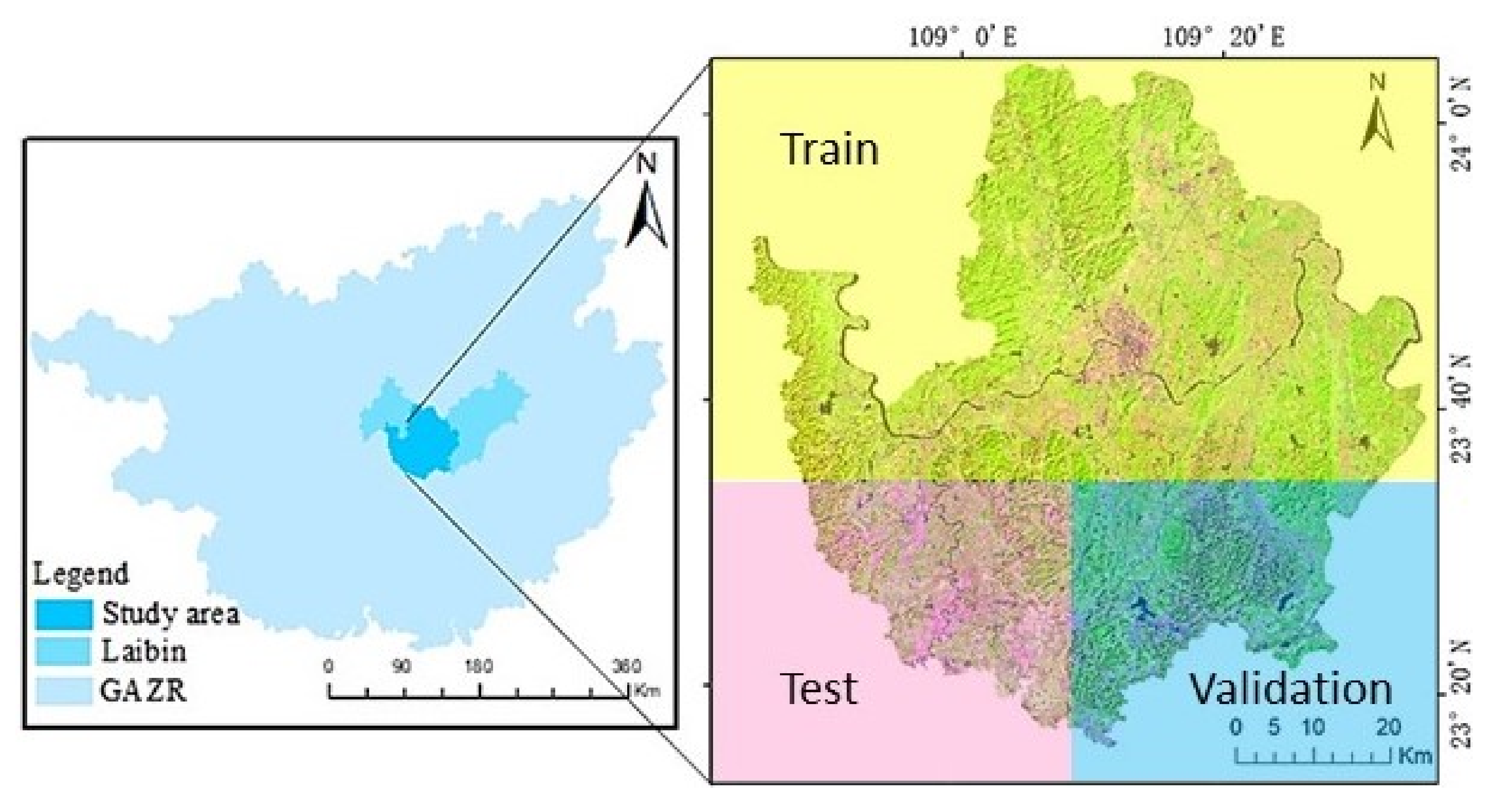
2.1. Study Area Overview
2.2. Field Sampling and Remote Sensing Image Preprocessing
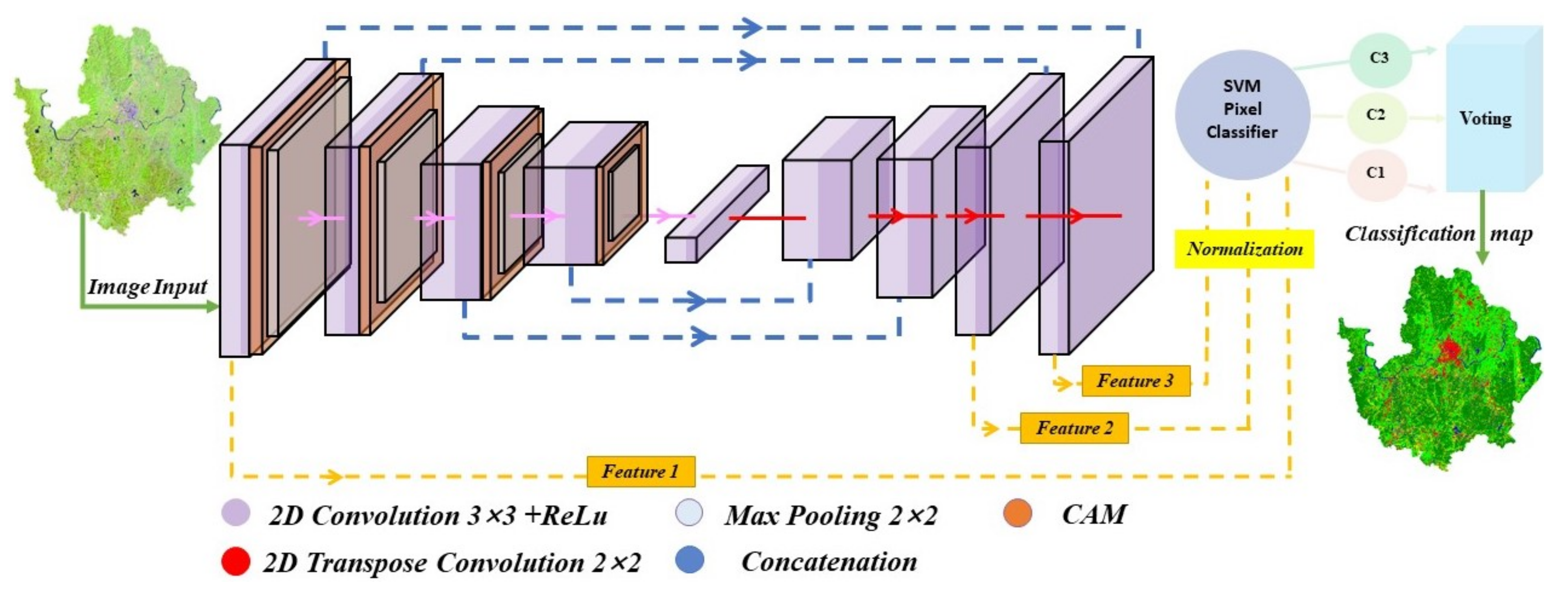
2.3. Improvements to U-Net
2.3.1. U-Net Model
2.3.2. Classifier
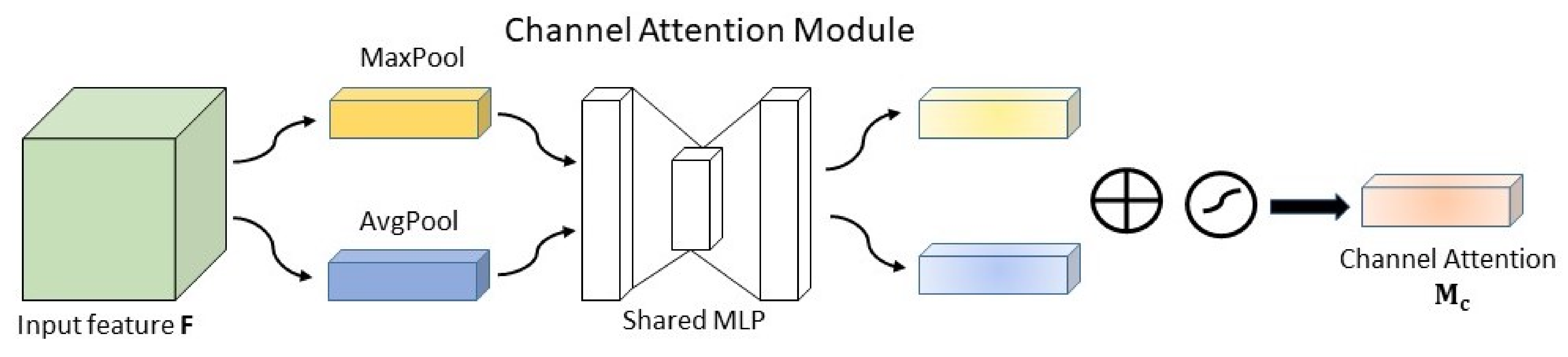
2.3.3. Channel Attention Module
2.3.4. Feature Extraction and Fusion
2.4. Experimental Environment
3. Results
3.1. Model Building
3.1.1. Parameter Optimization and Network Optimization
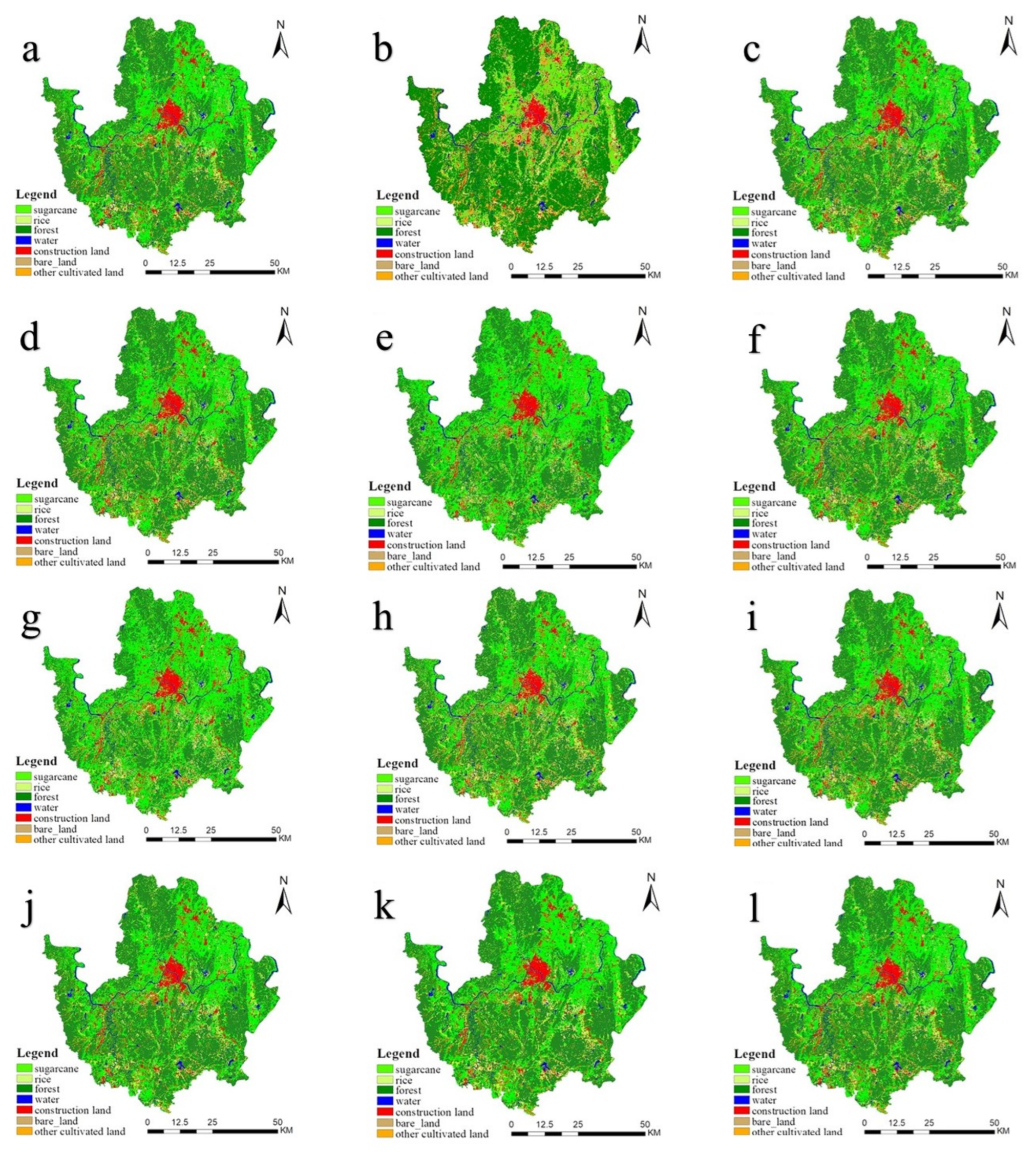
3.1.2. Comparison of Multiple Methods
3.2. Land Use Change in Laibin
3.3. Changes in Forest Dynamics
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Full name |
| BP | Back propagation |
| SVM | Support vector machine |
| CNN | Deep convolutional neural network |
| ELM | Extreme learning machine |
| FCN | Fully convolution network |
| CRF | Conditional Random Fields |
| ASPP | Atrous spatial pyramid pooling |
| SE | Squeeze and Excitation |
| CAM | Channel attention moudle |
| GZAR | Guangxi Zhuang Autonomous Region |
References
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent Advances of Hyperspectral Imaging Technology and Applications in Agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Cheng, T.; Yang, Z.; Inoue, Y.; Zhu, Y.; Cao, W. Preface: Recent Advances in Remote Sensing for Crop Growth Monitoring. Remote Sens. 2016, 8, 116. [Google Scholar] [CrossRef] [Green Version]
- Sishodia, R.P.; Ray, R.L.; Singh, S.K. Applications of Remote Sensing in Precision Agriculture: A Review. Remote Sens. 2020, 12, 3136. [Google Scholar] [CrossRef]
- Zhao, P.; Wang, D.; He, S.; Lan, H.; Chen, W.; Qi, Y. Driving forces of NPP change in debris flow prone area: A case study of a typical region in SW China. Ecol. Indic. 2020, 119, 106811. [Google Scholar] [CrossRef]
- Lv, Z.; Liu, T.; Shi, C.; Benediktsson, J.A.; Du, H. Novel Land Cover Change Detection Method Based on k-Means Clustering and Adaptive Majority Voting Using Bitemporal Remote Sensing Images. IEEE Access 2019, 7, 34425–34437. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, L.; Wang, Y.; Qi, Q. An Improved Hybrid Segmentation Method for Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2019, 8, 543. [Google Scholar] [CrossRef] [Green Version]
- Menon, R.V.; Kalipatnapu, S.; Chakrabarti, I. High speed VLSI architecture for improved region based active contour segmentation technique. Integration 2021, 77, 25–37. [Google Scholar] [CrossRef]
- Tianyang, D.; Jian, Z.; Sibin, G.; Ying, S.; Jing, F. Single-Tree Detection in High-Resolution Remote-Sensing Images Based on a Cascade Neural Network. ISPRS Int. J. Geo-Inf. 2018, 7, 367. [Google Scholar] [CrossRef] [Green Version]
- Sun, G.; Rong, X.; Zhang, A.; Huang, H.; Rong, J.; Zhang, X. Multi-scale mahalanobis kernel-based support vector machine for classification of high-resolution remote sensing images. Cogn. Comput. 2021, 13, 787–794. [Google Scholar] [CrossRef]
- Li, L.; Jing, W.; Wang, H. Extracting the Forest Type From Remote Sensing Images by Random Forest. IEEE Sens. J. 2021, 21, 17447–17454. [Google Scholar]
- Li, W.; Wang, Z.; Wang, Y.; Wu, J.; Wang, J.; Jia, Y.; Gui, G. Classification of High-Spatial-Resolution Remote Sensing Scenes Method Using Transfer Learning and Deep Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1986–1995. [Google Scholar] [CrossRef]
- Zhang, C.; Gao, S.; Yang, X.; Li, F.; Yue, M.; Han, Y.; Zhao, H.; Zhang, Y.; Fan, K. Convolutional Neural Network-Based Remote Sensing Images Segmentation Method for Extracting Winter Wheat Spatial Distribution. Appl. Sci. 2018, 8, 1981. [Google Scholar] [CrossRef] [Green Version]
- Boualleg, Y.; Farah, M.; Farah, I.R. Remote Sensing Scene Classification Using Convolutional Features and Deep Forest Classifier. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1944–1948. [Google Scholar] [CrossRef]
- Guo, Y.; Cao, H.; Bai, J.; Bai, Y. High Efficient Deep Feature Extraction and Classification of Spectral-Spatial Hyperspectral Image Using Cross Domain Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 345–356. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep Learning Earth Observation Classification Using ImageNet Pretrained Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 105–109. [Google Scholar] [CrossRef] [Green Version]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Csillik, O.; Cherbini, J.; Johnson, R.; Lyons, A.; Kelly, M. Identification of citrus trees from unmanned aerial vehicle imagery using convolutional neural networks. Drones 2018, 2, 39. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Zhang, X.; Hao, Y. A method combining CNN and ELM for feature extraction and classification of SAR image. J. Sens. 2019, 2019, 6134610. [Google Scholar] [CrossRef]
- Cao, X.; Gao, S.; Chen, L.; Wang, Y. Ship recognition method combined with image segmentation and deep learning feature extraction in video surveillance. Multimed. Tools Appl. 2020, 79, 9177–9192. [Google Scholar] [CrossRef]
- Meng, X.; Zhang, S.; Zang, S. Lake wetland classification based on an SVM-CNN composite classifier and high-resolution images using wudalianchi as an example. J. Coast. Res. 2019, 93, 153–162. [Google Scholar] [CrossRef]
- Sun, X.; Liu, L.; Li, C.; Yin, J.; Zhao, J.; Si, W. Classification for remote sensing data with improved CNN-SVM method. IEEE Access 2019, 7, 164507–164516. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Li, H.; Wang, C.; Cui, Y.; Hodgson, M. Mapping salt marsh along coastal South Carolina using U-Net. ISPRS J. Photogramm. Remote Sens. 2021, 179, 121–132. [Google Scholar] [CrossRef]
- Xu, Q.; Yuan, X.; Ouyang, C.; Zeng, Y. Attention-Based Pyramid Network for Segmentation and Classification of High-Resolution and Hyperspectral Remote Sensing Images. Remote Sens. 2020, 12, 3501. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, M.; Wang, Y.; Shang, J.; Liu, X.; Li, B.; Song, A.; Li, Q. Automated delineation of agricultural field boundaries from Sentinel-2 images using recurrent residual U-Net. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102557. [Google Scholar] [CrossRef]
- Zeyada, H.H.; Mostafa, M.S.; Ezz, M.M.; Nasr, A.H.; Harb, H.M. Resolving phase unwrapping in interferometric synthetic aperture radar using deep recurrent residual U-Net. Egypt. J. Remote Sens. Space Sci. 2022, 25, 1–10. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ge, Z.; Cao, G.; Shi, H.; Zhang, Y.; Li, X.; Fu, P. Compound Multiscale Weak Dense Network with Hybrid Attention for Hyperspectral Image Classification. Remote Sens. 2021, 13, 3305. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Pham, V.T.; Tran, T.T.; Wang, P.C.; Chen, P.Y.; Lo, M.T. EAR-UNet: A deep learning-based approach for segmentation of tympanic membranes from otoscopic images. Artif. Intell. Med. 2021, 115, 102065. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Lv, P.; Wang, H.; Shi, C. SAR-U-Net: Squeeze-and-excitation block and atrous spatial pyramid pooling based residual U-Net for automatic liver CT segmentation. arXiv 2021, arXiv:2103.06419. [Google Scholar] [CrossRef] [PubMed]
- Cao, K.; Zhang, X. An improved res-unet model for tree species classification using airborne high-resolution images. Remote Sens. 2020, 12, 1128. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- John, D.; Zhang, C. An attention-based U-Net for detecting deforestation within satellite sensor imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102685. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Sugarcane | Rice | Water | Construction Land | Forest | Bare Land | Other Land | Total |
|---|---|---|---|---|---|---|---|---|
| Samples | 826 | 342 | 116 | 665 | 680 | 114 | 133 | 2876 |
| No. | Class | Train | Val | Test |
|---|---|---|---|---|
| 1 | Sugarcane | 1,090,123 | 150,147 | 223,668 |
| 2 | Rice | 130,736 | 63,053 | 62,050 |
| 3 | Water | 74,437 | 12,503 | 14,818 |
| 4 | Construction land | 228,496 | 33,128 | 48,244 |
| 5 | Forest | 1,219,936 | 510,557 | 443,841 |
| 6 | Bare land | 142,496 | 46,798 | 83,573 |
| 7 | Other land | 172,069 | 73,276 | 70,835 |
| Total | 3,058,293 | 889,462 | 947,029 |
| MinibatchSize = 8 | MinibatchSize = 16 | |||
|---|---|---|---|---|
| Class | Test | Validation | Test | Validation |
| Sugarcane | 90.24 | 89.28 | 92.68 | 90.04 |
| Rice | 68.57 | 62.54 | 62.67 | 56.48 |
| Water | 86.60 | 88.62 | 91.84 | 91.59 |
| Construction land | 92.28 | 92.56 | 88.93 | 90.50 |
| Forest | 94.79 | 95.03 | 95.66 | 95.26 |
| Bare land | 84.56 | 83.60 | 88.62 | 87.65 |
| Other land | 72.21 | 73.89 | 78.61 | 79.33 |
| OA (%) | 92.40 | 92.46 | 90.71 | 87.80 |
| AA (%) | 88.76 | 88.28 | 86.06 | 83.96 |
| kappa | 0.8412 | 0.8270 | 0.8643 | 0.8343 |
| CAM-UNet | Res-CAM-UNet | |||
|---|---|---|---|---|
| Class | Test | Validation | Test | Validation |
| Sugarcane | 91.74 | 87.35 | 98.27 | 98.09 |
| Rice | 77.91 | 79.17 | 47.43 | 37.99 |
| Water | 92.33 | 92.47 | 94.36 | 91.59 |
| Construction land | 89.72 | 89.72 | 91.90 | 95.58 |
| Forest | 97.14 | 97.41 | 93.41 | 90.70 |
| Bare land | 88.28 | 87.78 | 90.38 | 89.71 |
| Other land | 84.19 | 84.06 | 86.64 | 84.09 |
| OA (%) | 92.40 | 92.46 | 90.71 | 87.80 |
| AA (%) | 88.76 | 88.28 | 86.06 | 83.96 |
| kappa | 0.8916 | 0.8785 | 0.8675 | 0.8083 |
| Class | CAM-UNet +SVM | U-Net | SegNet | Attention -UNet | SAR -UNet | U-Net +SVM | Res-UNet +SVM | Deeplabv3 +Resnet50 | Deeplabv3 +Xception | Deeplabv3 +MobileNet |
|---|---|---|---|---|---|---|---|---|---|---|
| Sugarcane | 92.9 | 92.69 | 93.52 | 93.55 | 98.76 | 90.49 | 88.06 | 81.05 | 80.51 | 82.12 |
| Rice | 76.9 | 62.7 | 13.63 | 69.95 | 29.44 | 75.08 | 70.51 | 39.5 | 60.62 | 41.6 |
| Water | 93.23 | 91.85 | 67.33 | 89.74 | 90.36 | 92.56 | 94.39 | 72.47 | 74.26 | 72.17 |
| Construction land | 90.69 | 88.94 | 80.6 | 89.92 | 98.74 | 87.89 | 87.34 | 73.86 | 76.71 | 74.63 |
| Forest | 97.16 | 95.66 | 79.82 | 94.56 | 75.36 | 97.2 | 97.88 | 91.57 | 92.66 | 92.95 |
| Bare land | 89.84 | 88.62 | 62.7 | 89.55 | 85.74 | 88.61 | 89.62 | 59.76 | 62.6 | 60.96 |
| Other land | 84.24 | 78.61 | 55.8 | 77.07 | 79.16 | 81.07 | 81.45 | 42.72 | 48.86 | 44.2 |
| OA (%) | 92.82 | 90.5 | 75.26 | 90.6 | 80.5 | 91.66 | 91.22 | 78.01 | 80.66 | 79.3 |
| AA (%) | 89.28 | 85.58 | 64.77 | 86.33 | 79.65 | 87.56 | 87.04 | 65.85 | 70.89 | 66.95 |
| Kappa | 0.8976 | 0.8643 | 0.6515 | 0.8666 | 0.7307 | 0.8807 | 0.8737 | 0.6791 | 0.7203 | 0.6973 |
| Class | CAM-UNet +SVM | U-Net | SegNet | Attention -UNet | SAR -UNet | U-Net +SVM | Res-UNet +SVM | Deeplabv3 +Resnet50 | Deeplabv3 +Xception | Deeplabv3 +MobileNet |
|---|---|---|---|---|---|---|---|---|---|---|
| Sugarcane | 89.43 | 90.04 | 91.94 | 92.07 | 98.35 | 86.69 | 85.9 | 76.06 | 74.04 | 76.4 |
| Rice | 77.26 | 53.5 | 12.61 | 67.7 | 25.77 | 69.11 | 56.85 | 35.9 | 58.39 | 45.63 |
| Water | 92.83 | 91.59 | 73.81 | 91.74 | 88.72 | 92.35 | 90.79 | 72.97 | 73.93 | 71.46 |
| Construction land | 91.24 | 90.49 | 82.21 | 92.1 | 99.68 | 90.06 | 92.45 | 75.46 | 76.29 | 74.09 |
| Forest | 97.47 | 95.26 | 80.07 | 94.15 | 73.26 | 96.7 | 95.57 | 90.38 | 93.14 | 92.61 |
| Bare land | 89.37 | 87.65 | 64.26 | 89.11 | 86.7 | 87.13 | 88.33 | 60.28 | 62.15 | 62.08 |
| Other land | 84.59 | 79.33 | 56.06 | 79.39 | 78.54 | 81.02 | 82.12 | 43.87 | 49.44 | 45.95 |
| OA (%) | 92.89 | 89.69 | 74.48 | 90.33 | 76.47 | 90.95 | 89.52 | 77.88 | 81.33 | 80.1 |
| AA (%) | 88.88 | 83.98 | 65.85 | 86.61 | 78.72 | 86.15 | 84.57 | 64.99 | 69.63 | 66.89 |
| Kappa | 0.8856 | 0.8343 | 0.611 | 0.847 | 0.6552 | 0.8539 | 0.8309 | 0.639 | 0.694 | 0.6726 |
| Class | Sugarcane | Rice | Water | Construction Land | Forest | Bare Land | Other Land | Total |
|---|---|---|---|---|---|---|---|---|
| Sugarcane | 207,796 | 1362 | 9 | 1619 | 6195 | 2354 | 2614 | 221,949 |
| Rice | 2278 | 47,717 | 411 | 0 | 3172 | 23 | 889 | 54,490 |
| Water | 8 | 216 | 13,815 | 218 | 113 | 4 | 136 | 14,510 |
| Construction land | 608 | 7 | 231 | 43,753 | 4 | 2918 | 1065 | 48,586 |
| Forest | 6989 | 11,321 | 179 | 10 | 431,241 | 355 | 1092 | 451,187 |
| Bare land | 2014 | 6 | 1 | 1892 | 40 | 75,080 | 5371 | 84,404 |
| Other land | 3975 | 1421 | 172 | 752 | 3076 | 2839 | 59,668 | 71,903 |
| Total | 223,668 | 62,050 | 14,818 | 48,244 | 443,841 | 83,573 | 70,835 | 947,029 |
| User’s Accurcy (%) | 93.62 | 87.57 | 95.21 | 90.05 | 95.58 | 88.95 | 82.98 | - |
| Producer’s Accuray (%) | 92.9 | 76.9 | 93.23 | 90.69 | 97.16 | 89.84 | 84.24 | - |
| OA (%) | 92.82 | |||||||
| Kappa | 0.8976 | |||||||
| Class | Sugarcane | Rice | Water | Construction Land | Forest | Bare Land | Other Land | Total |
|---|---|---|---|---|---|---|---|---|
| Sugarcane | 134,272 | 2453 | 7 | 725 | 5539 | 1449 | 3021 | 147,466 |
| Rice | 2112 | 48,717 | 277 | 3 | 4474 | 8 | 1771 | 57,362 |
| Water | 4 | 172 | 11,606 | 158 | 114 | 7 | 185 | 12,246 |
| Construction land | 562 | 3 | 95 | 3,0225 | 5 | 1020 | 718 | 32,628 |
| Forest | 8574 | 10,534 | 386 | 4 | 497,624 | 204 | 2060 | 519,386 |
| Bare land | 1000 | 6 | 1 | 880 | 44 | 41,825 | 3538 | 47,294 |
| Other land | 3623 | 1168 | 131 | 1133 | 2757 | 2285 | 61,983 | 73,080 |
| Total | 150,147 | 63,053 | 12,503 | 33,128 | 510,557 | 46,798 | 73,276 | 889,462 |
| User’s Accurcy (%) | 91.05 | 84.93 | 94.77 | 92.64 | 95.81 | 88.44 | 84.82 | - |
| Producer’s Accuray (%) | 89.43 | 77.26 | 92.83 | 91.24 | 97.47 | 89.37 | 84.59 | - |
| OA (%) | 92.89 | |||||||
| Kappa | 0.8856 | |||||||
| Class | Sugarcane | Rice | Water | Construction Land | Forest | Bare Land | Other Land | Total |
|---|---|---|---|---|---|---|---|---|
| Sugarcane | 1,738,978 | 16,978 | 8 | 24,857 | 30,125 | 25,444 | 5504 | 1,841,894 |
| Rice | 7186 | 81,929 | 749 | 6575 | 287 | 1280 | 3326 | 101,332 |
| Water | 12 | 1065 | 112,631 | 3183 | 2434 | 1152 | 187 | 120,664 |
| Construction land | 16,566 | 10,557 | 5001 | 391,476 | 455 | 15,696 | 705 | 440,456 |
| Forest | 24,364 | 530 | 2937 | 684 | 1,712,164 | 11,897 | 3636 | 1,756,212 |
| Bare land | 19,272 | 1818 | 2504 | 15,845 | 10,212 | 495,667 | 5 | 545,323 |
| Other land | 5397 | 3737 | 560 | 3029 | 4336 | 2499 | 69,367 | 88,925 |
| Total | 1,811,775 | 116,614 | 124,390 | 445,649 | 1,760,013 | 553,635 | 82,730 | 4,894,806 |
| User’s Accurcy (%) | 94.41 | 80.85 | 93.34 | 88.88 | 97.49 | 90.89 | 78.01 | - |
| Producer’s Accuray (%) | 95.98 | 70.26 | 90.55 | 87.84 | 97.28 | 89.53 | 83.85 | - |
| OA (%) | 94.02 | |||||||
| Kappa | 0.9157 | |||||||
| Class | Sugarcane | Rice | Water | Construction Land | Forest | Bare Land | Other Land | Total |
|---|---|---|---|---|---|---|---|---|
| Sugarcane | 1,115,511 | 28,890 | 2 | 14,170 | 58,446 | 65,754 | 4858 | 1,287,631 |
| Rice | 7946 | 83,477 | 0 | 1291 | 565 | 5292 | 3526 | 102,097 |
| Water | 8 | 1 | 64,381 | 3997 | 712 | 5 | 0 | 69,104 |
| Construction land | 10,709 | 2095 | 2483 | 412,243 | 2877 | 23,160 | 10 | 453,577 |
| Forest | 45,100 | 2243 | 279 | 3184 | 2,260,528 | 48,003 | 3955 | 2,363,292 |
| Bare land | 45,503 | 8705 | 1 | 29,322 | 23,637 | 473,550 | 6529 | 587,247 |
| Other land | 3477 | 2328 | 21 | 775 | 3889 | 5982 | 17,401 | 33,873 |
| Total | 1,228,254 | 127,739 | 67,167 | 464,982 | 2,350,654 | 621,746 | 36279 | 4,896,821 |
| User’s Accurcy (%) | 86.63 | 81.76 | 93.17 | 90.89 | 95.65 | 80.64 | 51.37 | - |
| Producer’s Accuray (%) | 90.82 | 65.35 | 95.85 | 88.66 | 96.17 | 76.16 | 47.96 | - |
| OA (%) | 90.41 | |||||||
| Kappa | 0.85842497 | |||||||
| Class | Sugarcane | Rice | Water | Construction Land | Forest | Bare Land | Other Land | Total |
|---|---|---|---|---|---|---|---|---|
| Sugarcane | 1,388,389 | 10,652 | 25 | 8298 | 36,382 | 9134 | 17,896 | 1,470,776 |
| Rice | 9091 | 186,789 | 1321 | 9 | 16,838 | 54 | 4930 | 219,032 |
| Water | 52 | 1117 | 97,608 | 1176 | 541 | 20 | 653 | 101,167 |
| Construction land | 5289 | 28 | 1071 | 286,889 | 18 | 9490 | 4960 | 307,745 |
| Forest | 37,617 | 51,684 | 929 | 21 | 2,111,327 | 903 | 5781 | 2,208,262 |
| Bare land | 6394 | 22 | 11 | 7805 | 139 | 243,454 | 13,905 | 271,730 |
| Other land | 17106 | 5493 | 793 | 5670 | 9089 | 9812 | 268,055 | 316,018 |
| Total | 1,463,938 | 255,785 | 101,758 | 309,868 | 2,174,334 | 272,867 | 316,180 | 4,894,730 |
| User’s Accurcy (%) | 94.40 | 85.28 | 96.48 | 93.22 | 95.61 | 89.59 | 84.82 | - |
| Producer’s Accuray (%) | 94.84 | 73.03 | 95.92 | 92.58 | 97.10 | 89.22 | 84.78 | - |
| OA (%) | 93.62 | |||||||
| Kappa | 0.908313744 | |||||||
| Class | 2010 (km) | 2015 (km) | 2019 (km) | 2010–2015 Area Change Rate | 2015–2019 Area Change Rate | 2010–2019 Area Change Rate |
|---|---|---|---|---|---|---|
| Forest | 1580.59 | 2126.96 | 1987.43 | 0.3456 | −0.0656 | 0.2574 |
| Sugarcane | 1657.7 | 1158.86 | 1323.69 | −0.3009 | 0.1422 | −0.2015 |
| Construction land | 396.41 | 408.21 | 276.97 | 0.0297 | −0.3215 | −0.3013 |
| Rice | 91.19 | 91.88 | 197.12 | 0.0075 | 1.1453 | 1.1615 |
| Water | 108.59 | 62.19 | 91.05 | −0.4273 | 0.4639 | −0.1616 |
| Bare land | 490.79 | 528.52 | 244.56 | 0.0768 | −0.5373 | −0.5017 |
| Other land | 80.03 | 30.48 | 284.41 | −0.6191 | 8.3295 | 2.5537 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, C.; Fan, X.; Fan, J.; Wang, N. Improved U-Net Remote Sensing Classification Algorithm Based on Multi-Feature Fusion Perception. Remote Sens. 2022, 14, 1118. https://doi.org/10.3390/rs14051118
Yan C, Fan X, Fan J, Wang N. Improved U-Net Remote Sensing Classification Algorithm Based on Multi-Feature Fusion Perception. Remote Sensing. 2022; 14(5):1118. https://doi.org/10.3390/rs14051118
Chicago/Turabian StyleYan, Chuan, Xiangsuo Fan, Jinlong Fan, and Nayi Wang. 2022. "Improved U-Net Remote Sensing Classification Algorithm Based on Multi-Feature Fusion Perception" Remote Sensing 14, no. 5: 1118. https://doi.org/10.3390/rs14051118
APA StyleYan, C., Fan, X., Fan, J., & Wang, N. (2022). Improved U-Net Remote Sensing Classification Algorithm Based on Multi-Feature Fusion Perception. Remote Sensing, 14(5), 1118. https://doi.org/10.3390/rs14051118