1. Introduction
Pan-sharpening (PS) is an approach to combine spatial details of a high-resolution panchromatic (PAN) image and low-resolution multi-spectral (MS) information of the same region, aiming to produce a high-resolution MS image through the sharpening of the MS bands [
1]. PS methods improve the ability of human viewers to interpret satellite imagery. The basic idea of sharpening is to simultaneously preserve the spectral characteristics and the spatial resolution of the image in the obtained object. The acquired image quality differs depending on the used algorithms, as they provide different image sharpening qualities [
2]. They can be divided into several categories based on the usage of component substitution (CS) [
3,
4], multiresolution analysis (MRA) [
5], variational optimization (VO) [
6], or deep-learning (DL) [
7]. Among the PS approaches, the Hue Saturation Value (HSV) leads to the transformation of the R, G, and B bands of an MS image into HSV components. This process replaces a value of the component with a panchromatic image and performs an inverse transformation to gain an MS image with high spatial resolution [
8]. One of the most common fusion techniques used for sharpening is the Intensity-Hue-Saturation (IHS) technique [
4] that converts a color image to the IHS color space, replaces intensity information with PAN image, and returns to the RGB color space. In another algorithm, Ehlers Fusion (EF), image fusion is based on filtering in the Fourier domain [
9]. The method aims to preserve the spectral characteristics of the lower resolution of MS images. In that work, PAN images are fused with Landsat TM and IKONOS multi-spectral data. The algorithm is based on the IHS transform and can be applied to sharpen hyperspectral images without changing their spectral behavior. The High Pass Filter (HPF) resolution [
5] creates a PS image with great attention to detail and an accurate depiction of the spectral content of the original MS image. Here, the PAN image is convoluted using a high-pass filter. In further steps, it is combined with lower-resolution MS imagery. This technique is mostly applied for a large discrepancy in the pixel ratio between the PAN and MS images. In the PS method of Jing et al. [
10], an image is synthesized of an image with minimum spectral distortion, considering haze. The method modifies several PAN modulation fusion approaches and generates high-quality synthetic outputs. The main goal of the study of Laben et al. [
11] was to create a method that processes any number of bands at the same time. Additionally, it preserves spectral characteristics of the lower spatial resolution MS data in the higher spatial resolution by the Gram-Schmidt transformation on the simulated lower spatial resolution PAN image. The simulated lower spatial resolution image is employed as the first band in the Gram-Schmidt transformation. Another image fusion method that allows the use of any number of bands is the Principal Component Analysis (PCA) [
3]. Its standard version is often used for dynamic analysis of multi-source or multi-temporal remote sensing data. Alparone et al. [
12] introduced Quality with No Reference (QNR) in which complementary spatial and spectral distortion indices are fused. In its recent version, Hybrid Quality with No Reference (HQNR) method [
13], the overall image quality is determined using the DS component of the QNR and spectral distortion metric [
14]. A Universal Image Quality Index (Qq) is created by modeling an image distortion as a combination of loss of correlation, distortion of luminance, and contrast [
15]. The Spectral Angle Mapper (SAM) technique is used in MS image analysis [
16]. It operates on a spectral component and is used to compute the average variation of its angles. This technique has become a common tool for image color analysis or improvement of spatial resolution. In the method, spectral information is reflected by the hue and saturation and is slightly disturbed by a change of intensity. The method proposed by Alcaras et al. [
17] considers automatic the PS process of VHR satellite images and the selection of the best of them. The approach of Zhang et al. [
18], Object-based Area-To-Point Regression Kriging (OATPRK), fuses the MS and PAN images at the object-based scale. It is composed of image segmentation, object-based regression, and residual downscaling stages. An IQA method to support the visual qualitative analysis of pan-sharpened images by using the Natural Scene Statistics (NSS) is presented by Agudelo-Medina et al. [
1]. In the approach, six PS methods are analyzed in the presence of blur and white noise. Since the method requires training a quality model, its development was preceded by the creation of a large PS image database with subjective scores assigned in tests with human observers.
Considering FR PS quality evaluation, the Root Mean Square Error (RMSE) is widely used for this purpose. It measures similarity between bands of original and combined images [
19]. Erreur Relative Globale Adimensionalle de Synthèse (ERGAS) [
20], in turn, takes into account the number of spectral bands, spatial resolutions of PAN and MS images, and RMSE between fused and original bands. The Edge-based image Fusion Metric (EFM) assesses the edge behavior of PS images and compares the obtained results with the input versions of PAN and MS images [
21].
The quality assessment of PS images is a subject of open debate among researchers [
7,
22]. However, the IQA of natural or medical images is represented by a large diversity of approaches which, as shown in this study, can be adapted to the PS image domain. An NR or Blind Image Quality Assessment (BIQA) approach does not require access to the pristine reference image, which is beneficial since, in most applications, reference images are not available. Among IQA methods devoted to natural images, the BPRI uses as a reference a pseudo-reference image (PRI) and a PRI-based BIQA framework [
23], estimating blockiness, sharpness, and noise. A CurveletQA, in turn, operates under a two-stage distortion classification, followed by an evaluation of the quality with a support vector machine (SVM) technique. GWH-GLBP is the NR-IQA method focused on predicting the quality of multiply distorted images, with the help of the weighted local binary pattern (LBP) histogram, calculated based on the gradient map [
24]. In the deep learning-based MEON method, the learning process is divided into two stages, i.e., pre-training of the distortion identification subnetwork and quality prediction sub-network training, where the activation function is selected by generalized divisive normalization (GDN) [
25]. Popular Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE) extracts statistics of the local luminance signals and measures the naturalness of the image based on the distortion information [
26]. A method inspired by the human visual system (HVS), NFERM, extracts image features and uses support vector regression (SVR) to predict image quality [
27]. Among deep learning approaches, Blinder [
28] extracts features from network architecture and uses the minimum and maximum values of feature maps as a feature vector for quality prediction with the SVR, while the approach of Stępień et al. [
29] to IQA of magnetic resonance scans employs jointly trained several networks. In an approach to the IQA of remote sensing images presented by Ieremeiev et al. [
30], a set of FR measures designed for natural images are combined using a neural network.
In this paper, a novel NR PS IQA method, Multi-Level Pan-Sharpening Images Evaluator (MLPSIE) technique, is introduced. The method, contrary to other approaches to the PS image evaluation uses deep learning to obtain quality scores correlated with human judgment. To the best knowledge of the authors, it is the first technique that uses deep learning architectures for assessing PS images. Also, contrary to other deep learning methods devoted to the assessment of images from other domains, it takes two complementary deep learning architectures and separately extracts high-dimensional features from their layers, performs layer-wise dimensionality reduction, and creates quality-aware multi-level image representations used to build the quality model.
Contributions of this study are as follows: (1) Application of deep learning to IQA of PS images, (2) Separate extraction and reduction of high-dimensional data from each layer of the networks to provide features for training a quality model, (3) Successful adaptation of IQA methods from different domains to perform the quality evaluation of PS images, (4) Conducting extensive experiments on a large PS image database.
The remainder of this paper is organized as follows. In
Section 2, the method is introduced. Then, in
Section 3, it is experimentally compared against related IQA methods, and the obtained results are reported and discussed. Finally, in
Section 4, conclusions and possible directions of future work are presented.
2. Proposed Method
The proposed MLPSIE uses the two deep learning networks, ResNet18 [
31] and VGG19 [
32]. However, as it is shown in
Section 3.5 (Ablation Tests) the proposed processing of multi-level data allows for obtaining features sensitive to distortions which can be applied to other network pairs or even single architectures, leading to acceptable results. It is worth noticing that the networks are not trained due to the size of the image database and the obtained promising performance of the approach. However, if needed, it is assumed that the released source code of the MLPSIE can be adapted to perform a fine-tuning of the networks to capture image characteristics of a specific problem. The source code is available at
http://marosz.kia.prz.edu.pl/MLPSIE.html, accessed on 13 January 2022. As presented in
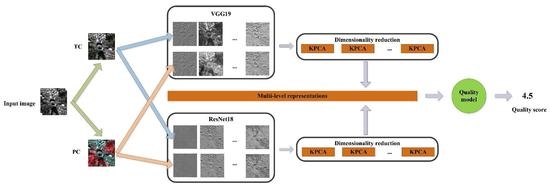
Figure 1 with the block diagram, the PS image composed of the RGB and near-infrared (NIR) bands is used to create the true color (TC) RGB and pseudocolor (PC) NIR + RG inputs to the network pair. Then, high-dimensional network responses at each level are extracted (blue rectangles in the figure) and reduced using the Kernel PCA (KPCA) approach (brown rectangles) [
33]. The reduction takes place for concatenated TC and PC information, represented by dashed lines. Finally, the reduced features are concatenated (longer brown block) and used by the quality model obtained with the SVR to predict the quality of the PS image (green circle).
2.1. Network Architectures
In this paper, ResNet18 and Vgg19 architectures are used for the PS IQA. The Visual Geometry Group Network (VGGNet) is a deep learning algorithm with a multi-layered operation [
34]. It consists of 16 convolution layers and three fully-connected layers, where 3 × 3 convolutional layers are placed on the top to increase with depth level. In the first two convolutional layers, 64 kernels (3 × 3 filter size) and the same padding are included. In this network architecture, the input is of a fixed size of 224 × 224. The pre-processing is done by the subtraction of the mean value from each pixel and is calculated for the entire training set. Moreover, max-pooling is performed over a 2 × 2 pixel window. In the set of fully connected layers, the first two are of size 4096 and the third layer consists of 1000 channels, while the final layer is a SoftMax function. In ResNet18, to avoid two or three layers containing ReLU and batch normalization, the architecture uses shortcut connections. Additionally, it solves the problem of vanishing gradients which increase the training error with a growing number of layers. The shortcut connections that allow skipping the layers allow for the training of deeper networks. At an early stage, the architecture performs the convolution (7 × 7) and max pooling (3 × 3). As the last layers, the average pooling and fully-connected layer are used [
31,
35].
2.2. Multi-Level Features
Since networks are designed to work with three-band RGB images and the proposed approach should be able to produce a quality score based on two three-band images, the feature vector extracted from the l-th layer of the n-th network can be written as , where , and is the number of convolutional layers in the network. Hence, multi-level data extracted from the network can be written as , and taking into account PC and TC images and both networks used in this study ( for ResNet18 and for VGG19), the resulted representation of PS image is . Note that for example, the first layers of ResNet18 and VGG19 contain 802816 and 3211264 values, respectively. Therefore, to create quality models without discarding important information that is stored at various levels of the networks, in this study, each layer is processed independently by the KPCA to produce a compact and distinctive quality-aware vector. Since two networks of each deep learning backbone are used to extract features from the TC and PC images, they are concatenated together. Finally, the vector
.
The KPCA implements classical PCA but it can be also used for non-linear problems or problems in which the number of components should be determined automatically [
33,
36]. It is employed in this work as it provides satisfactory output with ease of implementation.
Once feature vectors characterizing training images are obtained with the proposed method, a quality model can be trained. Here, the SVR is used due to its popularity and dominant position among similar solutions in the IQA literature [
28]. The used
-SVR maps feature vector for an image (
) into its subjective score (
S). Given the training data
, where
denotes feature vectors of
M training images (
) and
S contains their subjective scores, i.e., Differential Mean Opinion Scores (DMOS), (
), a function
,
〉 +
b is determined in which
,
, and
b, are the inner product, weight vector, and a bias parameter, respectively. Once the slack variables
and
are introduced, the
and
b are the solution of the following optimization problem:
where
C balances
,
, and
. The
, where
is a combination coefficient. The
is mapped into
,
For the RBF kernel,
where, the
is the precision parameter.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}