1. Introduction
A hyperspectral image is a combination of imaging and spectroscopy to obtain high-dimensional spatial and spectral information simultaneously. Since ground features have different characteristics in different dimensions, their dense spectral dimensions provide good conditions for the accurate classification of ground features. Therefore, hyperspectral images have a wide range of applications in agricultural production, environmental and climate detection, urban development, and military security [
1,
2,
3,
4,
5,
6,
7,
8]. In the early days, conventional machine learning classification methods were used to classify hyperspectral images [
9,
10,
11,
12,
13,
14,
15,
16], such as the K-nearest neighbor algorithm (KNN) [
9], support vector machine (SVM) [
10,
11], and random forest (RF) [
12], which are unable to automatically learn deep features and rely on prior expert knowledge, making effective feature extraction difficult for datasets with high-order nonlinear distributions.
In recent years, HSI classification methods based on deep learning have become increasingly popular. Because deep learning can extract deep abstract features effectively, it has gradually replaced the previous classification model with manually created features. Deep learning uses an end-to-end learning strategy which greatly improves the performance of HSI classification. Chen et al. [
17] proposed a deep belief network (DBN), that combines spectrum-space finite elements and classification to improve the accuracy of HSI classification. Zhao et al. [
18] constructed a spatial-spectral joint feature set and used a stacked sparse autoencoder (SAE) to extract image features. Deng et al. [
19] proposed a unified deep network using a hierarchical stacked sparse autoencoder (SSAE) network to extract the deep joint spectral features. Since these methods compress the spatial dimension into a vector, they ignore the spatial correlation and local consistency of the HSI, which often results in the loss of spatial information.
Subsequently, two-dimensional convolutional neural networks have been introduced to the HSI task. Cao et al. [
20] integrated spectral and spatial information into a unified Bayesian framework and used convolutional neural networks to learn the posterior distribution. Hao et al. [
21] used a three-layer Super Resolution convolutional neural network to create high-resolution images and then constructed an unsupervised triple convolutional network (TCNN). Pan et al. [
22] proposed an end-to-end segmentation method that can directly label each pixel. Li et al. [
23] used two two-dimensional convolutional neural networks to extract spectral, local spatial, and global spatial features simultaneously. To adaptively learn the fusion weights of spectral spatial features from two parallel streams, a fusion scheme with hierarchic regularization and smooth normalization fusion was proposed. Yang et al. [
24] proposed an HSI classification model using spatial background and spectral correlation. These methods improve the classification performance of HSI to a certain extent; however, since the two-dimensional convolution kernel cannot use the context between the spectral cores, spectral spatial information is easily lost.
To solve this problem, some studies introduced the attention mechanism into the HSI classification task, and chose to extract the spectral and spatial features separately. Sun et al. [
25] proposed a spectral-spatial attention network (SSAN), used to extract the information from the HSI. In this approach, characteristic spectral-spatial features are captured in the attention area of the cube while the influence of interfering pixels is suppressed. Zhu et al. [
26] proposed a dual-attention boost residual frequency-doubling network. In feature extraction, the high -and low-frequency components are convolved separately, and dual self-attention is used to output the feature map. It is improved to obtain a refined feature map. Zhu et al. [
27] proposed an end-to-end residual spectrum and spatial attention network, that directly processed the original three-dimensional data, and used dual attention modules for adaptive feature refinement for spectral spatial feature learning. Li et al. [
28] designed a spatial-spectral attention block (S2A) to simultaneously capture the long-term interdependence of spatial and spectral data through similarity assessment. Qing et al. [
29] proposed a multiscale residual network model with an attention mechanism (MSRN). The model uses an improved residual network and a spatial–spectral attention module to extract hyperspectral image information from different scales multiple times and fully integrate and extract the spatial spectral features of the image. In addition, some studies have used 3-dimensional convolutional nerves, which can better utilize the contextual information of the bands between spectra for HSI classification [
30,
31,
32,
33,
34,
35]. Lu et al. [
30] proposed a new multi-scale spatial spectrum residual network (CSMS-SSRN) based on three-dimensional channels and spatial attention, which continuously learns the spectrum and space from the respective residual blocks through different three-dimensional convolution kernels features. Tang et al. [
32] proposed a three-dimensional convolutional frequency multiplication space-spectral attention network (3DOC-SSAN) that can simultaneously mine spatial information from both high and low frequencies and simultaneously acquire spectral information. Farooque et al. [
33] proposed a residual network (SSCRN) based on end-to-end spectral space three-dimensional ConvLSTM-CNN, that combines three-dimensional ConvLSTM and three-dimensional CNN to process spectral and spatial information, respectively. Lu et al. [
34] proposed a three-dimensional cascaded spectrum-spatial element attention network (3D-CSSEAN), in which two attention modules can focus on the main spectral features and meaningful spatial features. Yin et al. [
35] used a three-dimensional convolutional neural network and bidirectional long short-term memory network (Bi-LSTM) based on band grouping for HSI classification.
Although the convolution operation has the advantages of spatial locality and shared weights, it has also achieved great advantages in the HSI classification task. However, it is difficult to model long-distance dependencies using the convolutional neural network, and is difficult to capture the global feature representation. Since multi-head self-attention can capture long-distance interactions well, the transformer module with multi-head self-attention has been applied to the HSI classification task in many works. He et al. [
36] proposed a HSI-BERT model with a global receptive domain. This model supports dynamic input regions without considering the spatial distance between pixels, and directly captures the global dependencies between pixels. Qing et al. [
37] proposed an end-to-end transformer model called SAT-Net, which uses a spectral attention and self-attention mechanism to extract the spectral and spatial features of HSI and capture the long-distance continuous spectrum relation. He et al. [
38] explored the spatial transformation network (STN), and Zhong et al. [
39] proposed a spectrum-spatial transformer network (SSTN) consisting of a spatial attention module and spectrum correlation module. Gao et al. [
40] combined the transformer and CNN and used the stage model to extract coarse -and fine-grained feature representations at different scales of implication.
Inspired by the above methods, to fully exploit the joint spectral-spatial information essential for the HSI classification, we propose a multiscale feature fusion network that incorporates 3D self-attention for HSI classification tasks. The network first uses convolution kernels of different sizes for multiscale feature extraction and adds the feature results extracted from different branches to perform effective feature fusion. Then, the proposed 3DCOV_attention block is used multiple times to improve the feature extraction of the obtained feature map, while modeling the global dependency relationship, performing comprehensive feature extraction from local to global, and improving the local receptive field while capturing long-distance interactions. At the end, the output feature map is flattened and converted into a one-dimensional vector, successively passed through several fully connected layers, to finally output the classification result.
The main contributions of this work are as follows:
We propose a multiscale feature fusion module to sample the different granularities of the feature map and effectively fuse the spatial and spectral features of the feature map.
We propose an improved 3D multi-head self-attention module that provides local feature details for self-attention branches while fully utilizing the context of the input matrix.
We propose a 3DCOV_attention block which combines convolutional mapping that extracts local features, with self-attention feature mapping that can be globally dependent, and improving the feature extraction capabilities of the entire network.
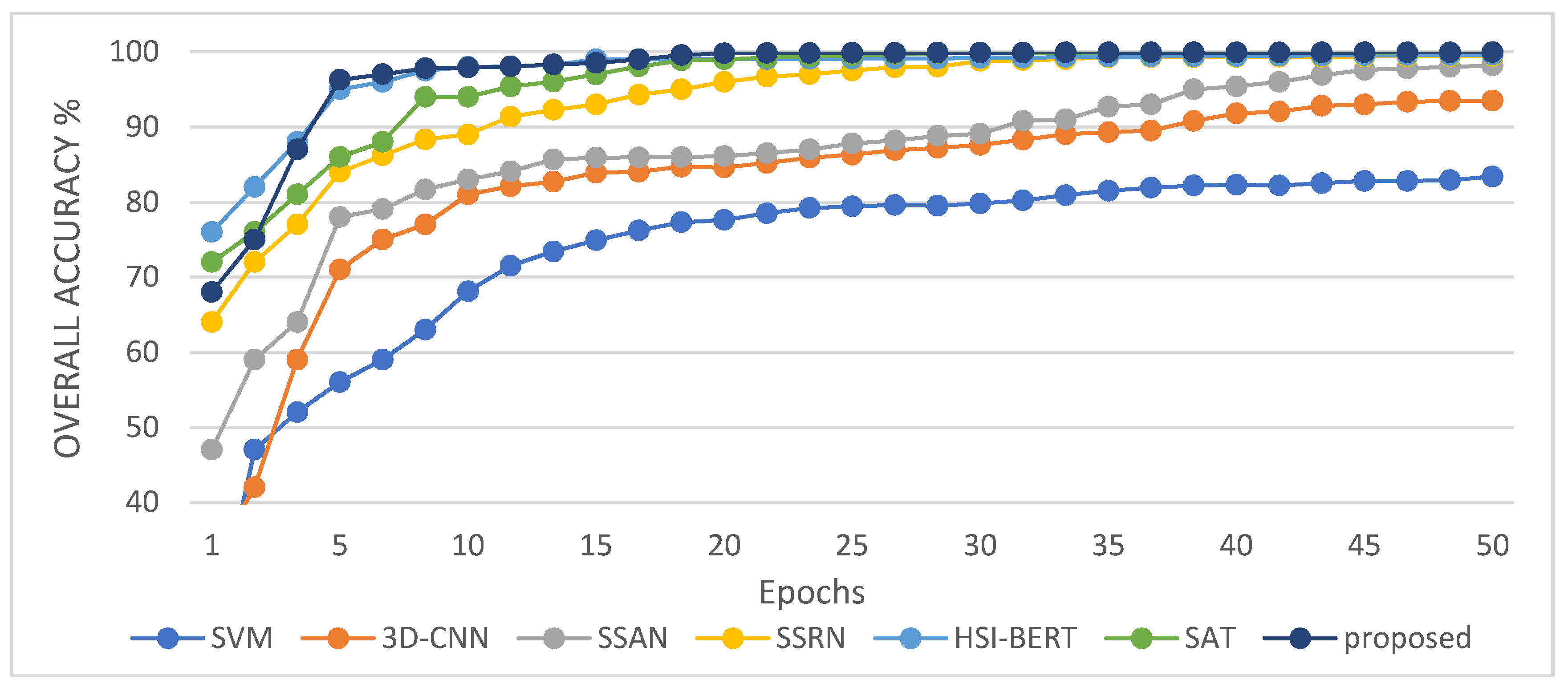
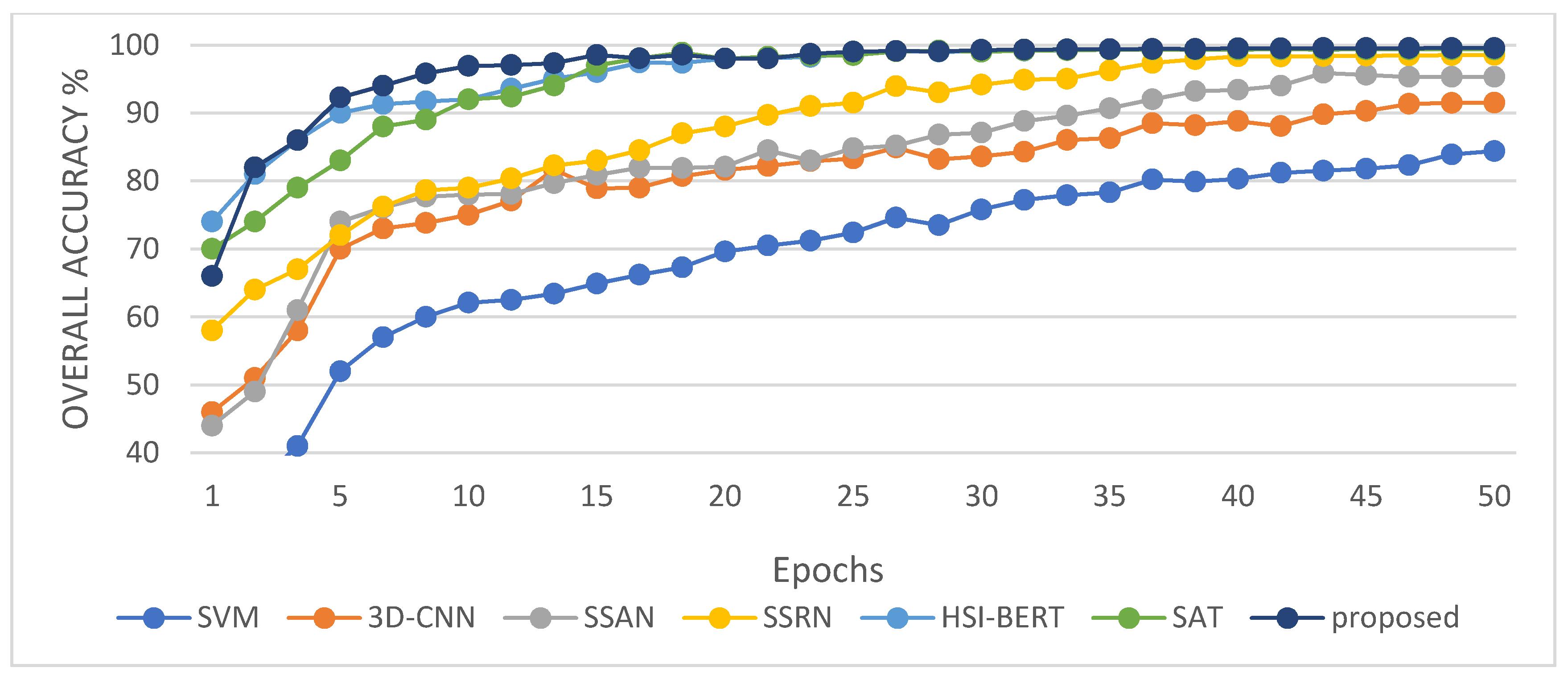
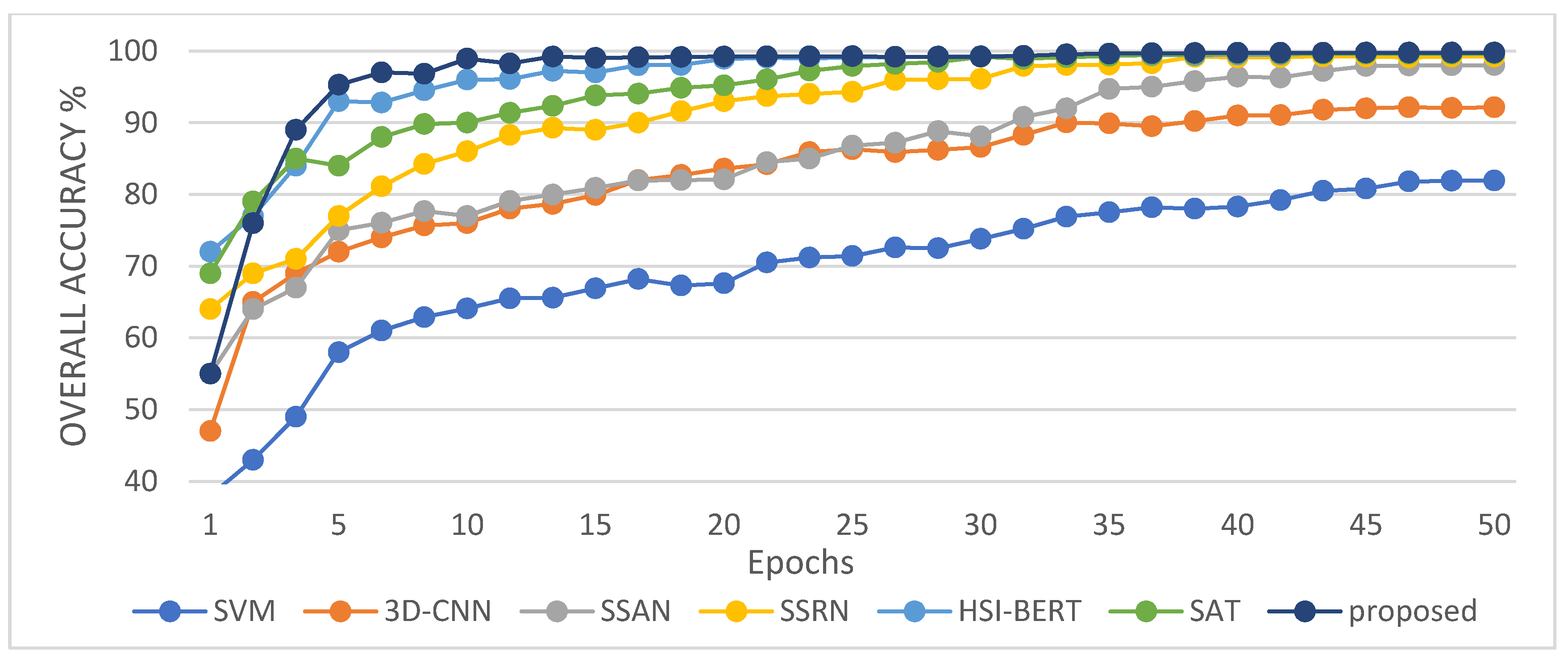
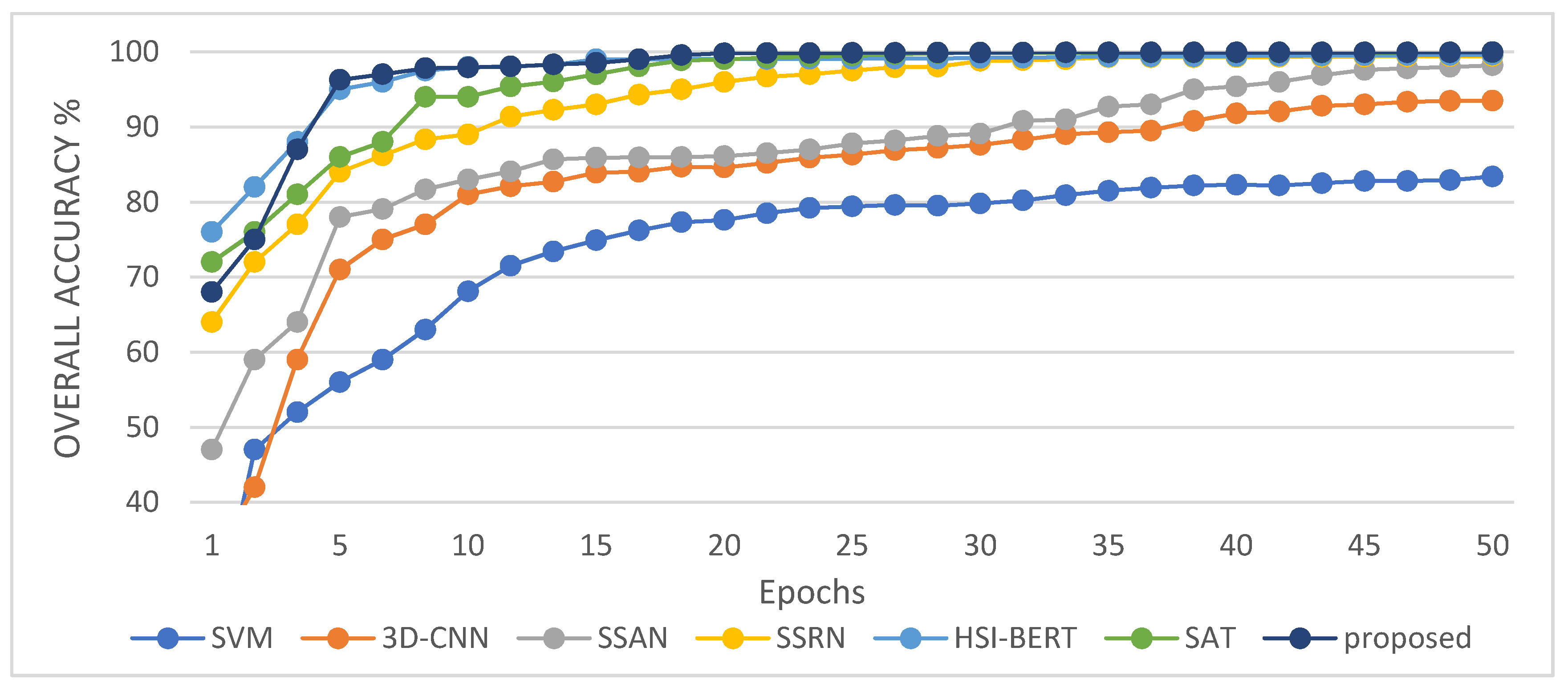
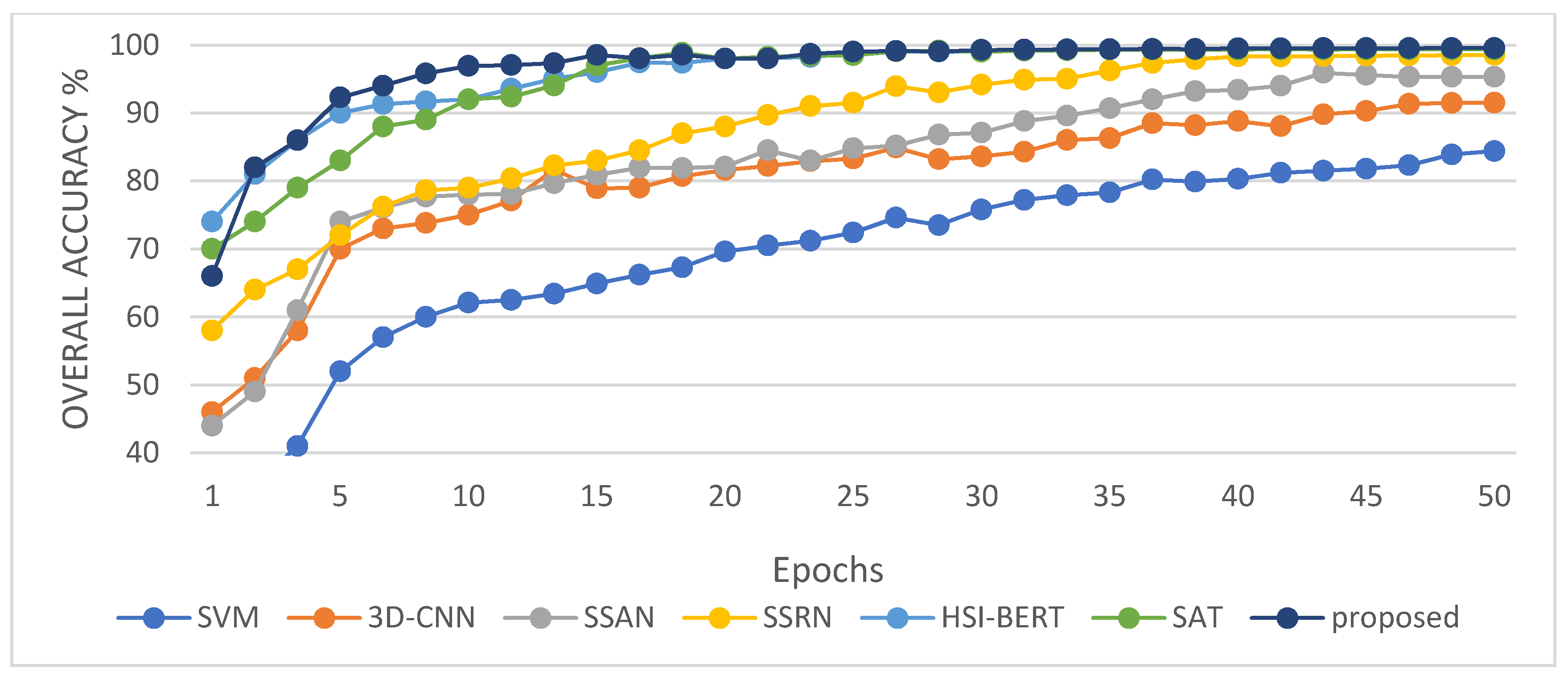
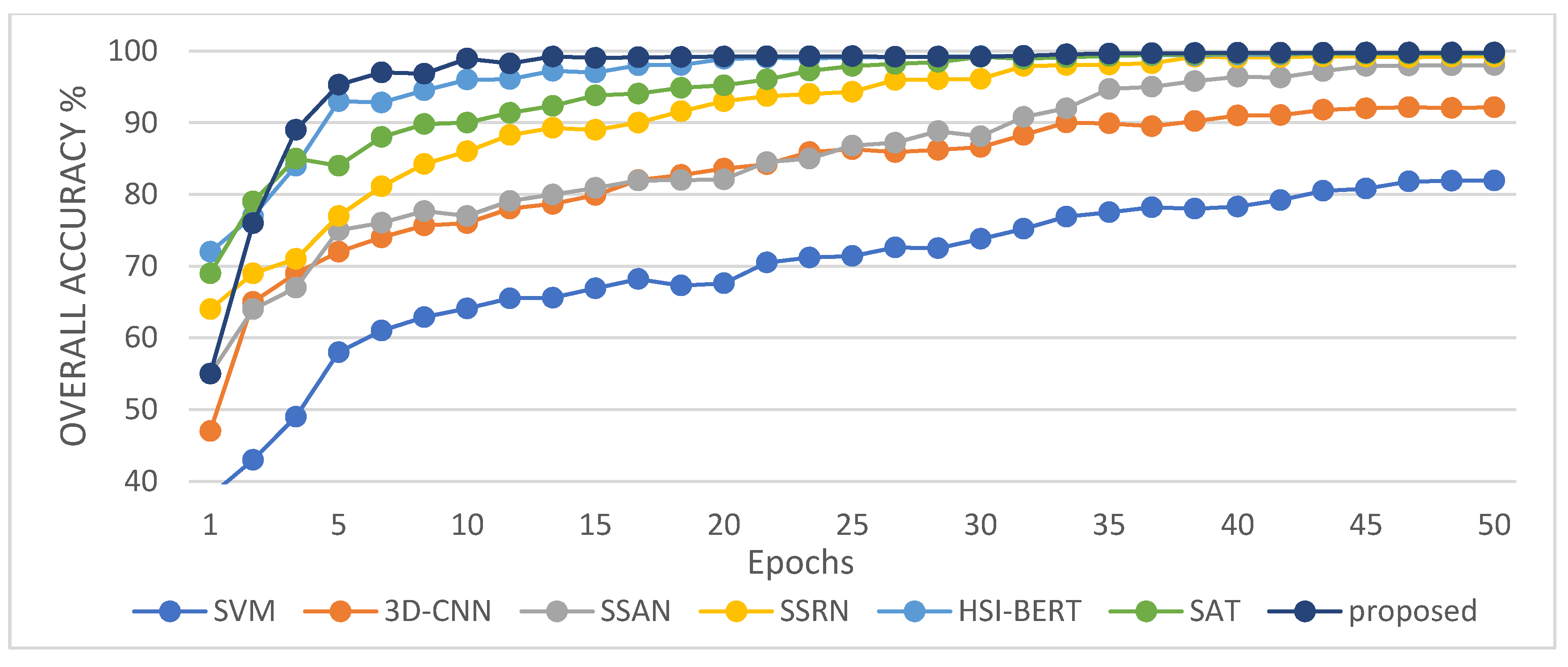
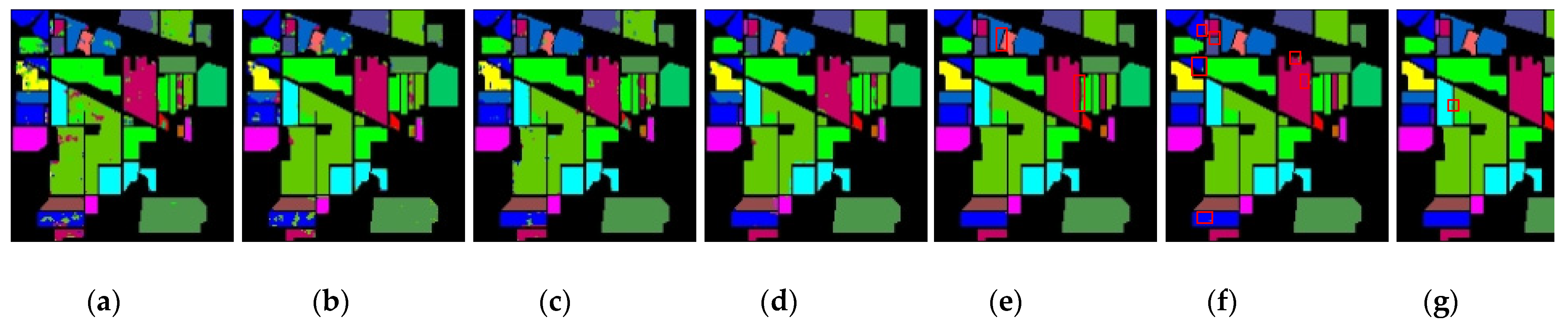
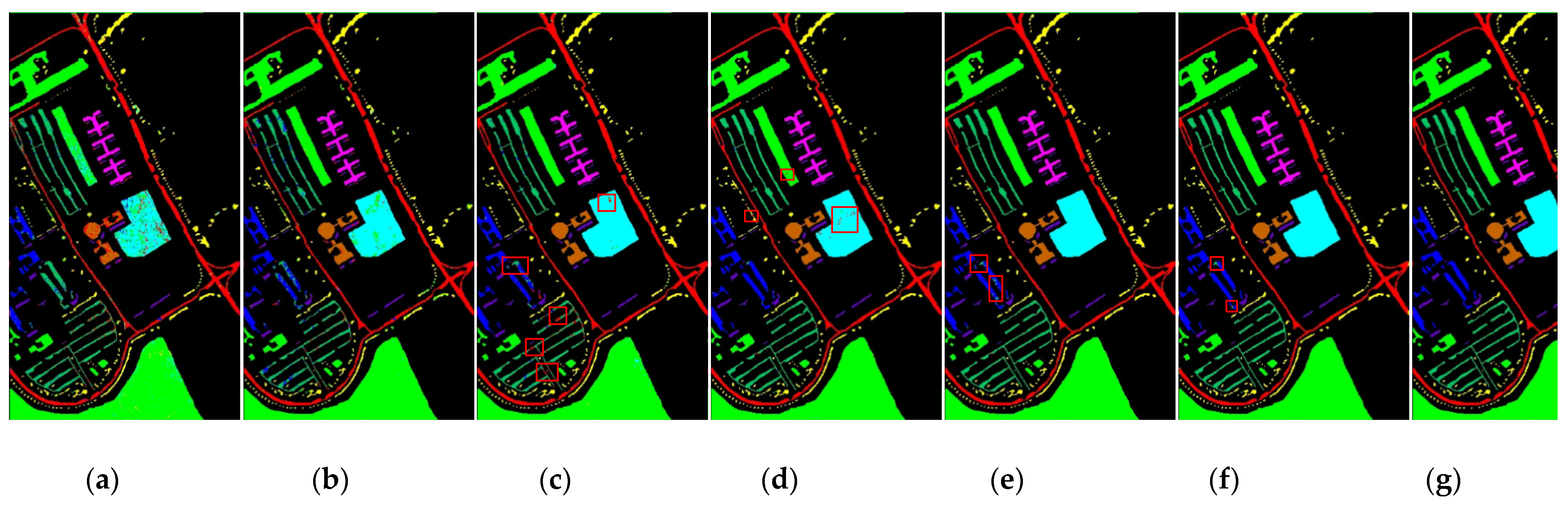
Experimental evaluation of the HSI classification against six current methods highlights the effectiveness of the proposed 3DSA-MFN model.
The remainder of this study is organized as follows. In the second section the proposed 3DSA-MFN, multi-scale feature fusion module, improved 3D self-attention, 3DCOV_attention, and other modules, and the corresponding loss function are presented in detail. The third section presents the ablation and comparative experiments. The fourth section summarizes this article.
2. Materials and Methods
In this section, we first introduce the proposed 3DSA-MFN network, then explain the multiscale feature fusion module and the improved 3D multi-head self-attention module, and then present the 3DCOV_attention module in detail and explain the formula derivation. Finally, the loss function and optimization method of the network framework are presented.
2.1. Overview of the Proposed Model
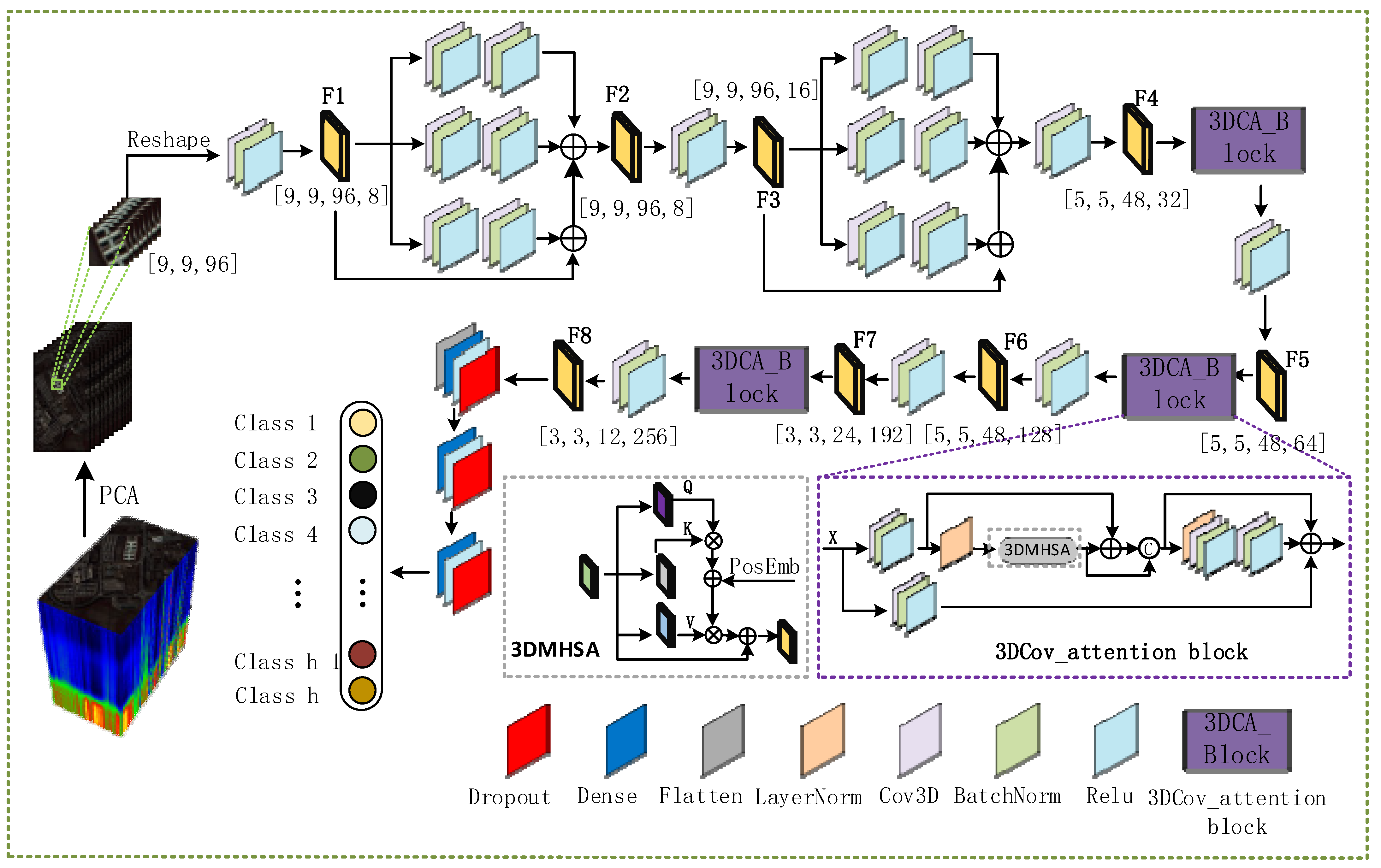
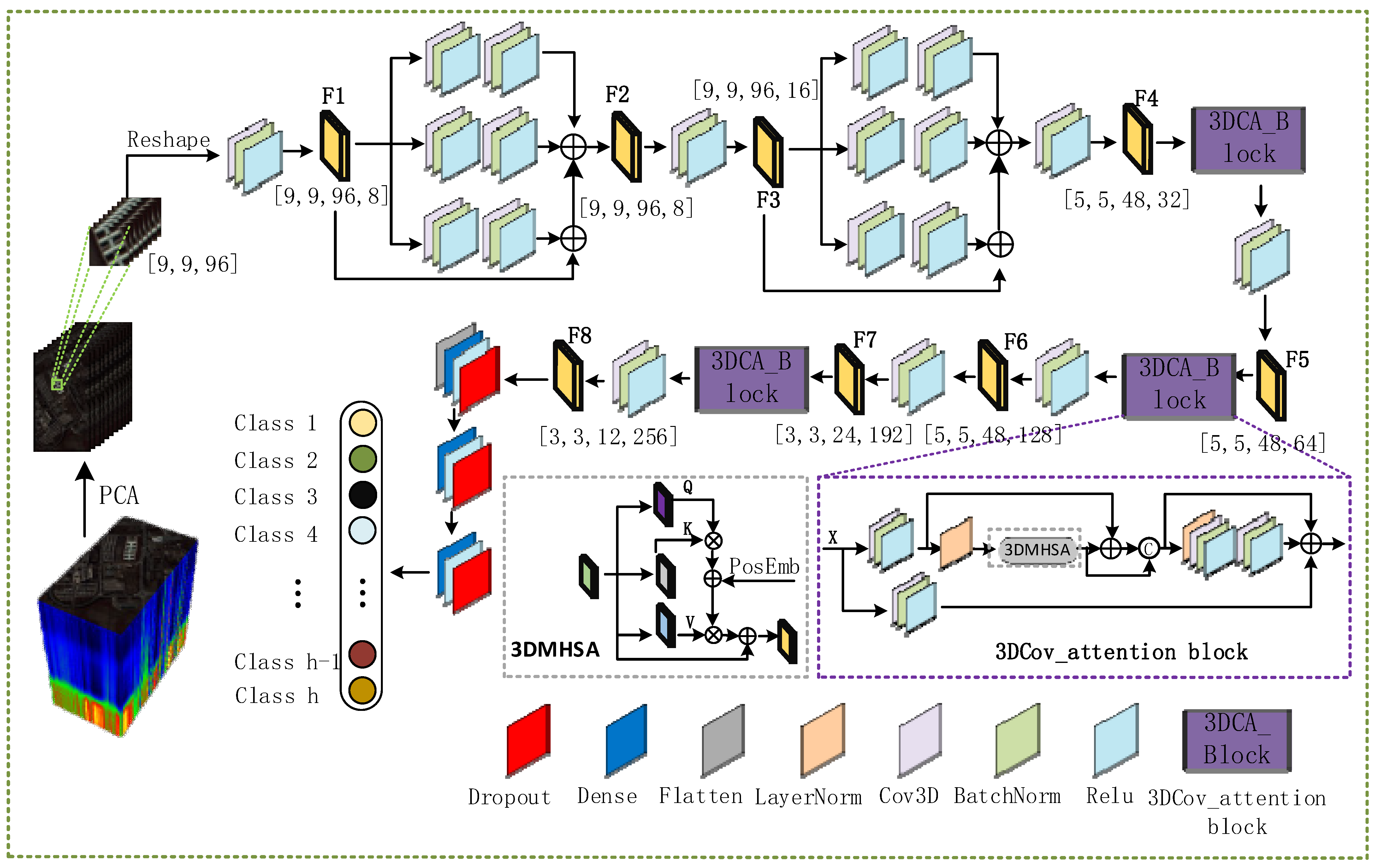
Since hyperspectral data is three-dimensional, and the number of spectra is usually tens or hundreds, extremely high resolution can better determine the characteristics of ground objects. However, the collection of extremely high-resolution images often contains a large amount of noise, and redundant data will affect the results of hyperspectral classification. We first applied the Principal Component Analysis (PCA) algorithm to the original hyperspectral data. Following a linear transformation strategy, the noise and redundant bands were removed while reducing the dimensionality of the data. Then, a 9 × 9 size window was used to process the reduced data. Data of the corresponding size were obtained as a sample, and the sample was randomly divided into a training set, a test set, and a verification set. We first passed the processed data samples through two multiscale feature fusion modules to extract the features of the hyperspectral image while reducing the shape of the feature map and increasing the number of feature maps. Then, we continuously passed the output feature map through three 3DCOV_attention modules to further extract the hyperspectral image features while modeling the global dependencies. At the same time, we used the 3D convolution from step 2 in different 3DCOV_attention modules to change the feature map shape. Finally, the output feature map was passed through multiple fully connected layers to output the final classification result. These parts are presented in detail in later sections. The overall process is shown in
Figure 1.
Specifically, after processing the original data by the PCA algorithm and a 9 × 9 window, multiple data with a size of {9, 9, 96} were obtained. We first expand the dimensions to fit the data format to the 3D volume-product neural network; the size of the expanded feature map is {9, 9, 96, 1}. The expanded feature map is first passed through a CBR block with a convolution kernel of 3 × 3 × 3, a step size of 1 × 1 × 1, and a filter of 8 (CBR block refers to 3D convolutional neural network, BatchNorm, and ReLU activation function modules are executed sequentially), and the feature map F1 of size {9, 9, 96, 8}, then input F1 into a multi-scale feature fusion module, and add the three feature maps and F1 to obtain the feature map F2 of size {9, 9, 96, 8}. Pass F2 through a CBR block with a convolution kernel of 3 × 3 × 3, a step size of 1 × 1 × 1, and a filter of 16 to further increase the number of feature maps and obtain Feature map F3 of size {9, 9, 96, 16}. Similar to the conversion of feature map F1 to feature map F2, feature map F3 obtains a feature map of the same size ({9, 9, 96, 16}) after the multi-scale feature fusion module and passes it through a convolution kernel into 1 × 1 × 1, a step size of 2 × 2 × 2, and a CBR block with a filter of 32 to obtain a feature map F4 with a size of {5, 5, 48, 32}. After F4 passes through a 3DCOV_attention module that does not change the shape of the feature map, it passes through a CBR block with a convolution kernel of 1 × 1 × 1, a step size of 1 × 1 × 1, and a filter of 64 to obtain a size of {5, 5, 48, 64}. The feature map F5 to feature map F6 is the same as the operation of feature map F4 to feature map F5. From F5, we obtain a feature map F6 of size {5, 5, 48, 128}. F6 first passes through a CBR block with a convolution kernel of 1 × 1 × 1, step size of 2 × 2 × 2, and filter of 192 to obtain the feature map F7({5, 5, 48, 64}). F7 goes through after the 3DCOV_attention module, passes a CBR block with a convolution kernel of 1 × 1 × 1, a step size of 1 × 1 × 2, and a filter of 256 to obtain the feature map F8({3, 3, 12, 256}). Finally, after the flattening operation, F8 is converted into a one-dimensional vector, and then passed through the fully connected module of size 256 and 128 (dropout is 0.5). Finally, the classification result is output.
2.2. Multi-Scale Feature Fusion Module
Many studies have shown that the feature information extracted in different scales is different, and the feature extraction in a single scale often misses some feature information. Therefore, many methods use multiscale feature extraction to improve the feature extraction capability of the network. Szegedy et al. [
41] proposed a module called Inception, which contains four parallel branch structures: 1 × 1 convolution, 3 × 3 convolution, 5 × 5 convolution, and 3 × 3 maximum pooling. This module performs feature extraction and pooling at different scales to obtain multiple scales of information. Finally, the features are superimposed and output, and the sparse matrix is clustered into denser submatrices to improve the computational performance. Chen et al. [
42] proposed a network called Deeplab V3, which added a multi-scale feature extraction module ASPP [
42] and parallel sampling of the given input with different sampling rates of the whole convolution at the end of its feature extraction network which is equivalent in the context of multiple scale image acquisition. Zhao et al. [
43] proposed a pyramid pool module and pyramid scene analysis network. The acquired feature layer was divided into grids of different sizes, and each grid was internally averaged. The aggregation of contextual information in different areas is realized, which improves the ability to obtain global information. Chen et al. [
44] created a multibranch network and frequently merged branch features of different scales to obtain multiscale features. Inspired by the above methods, we propose a multiscale feature-fusion module, as shown in
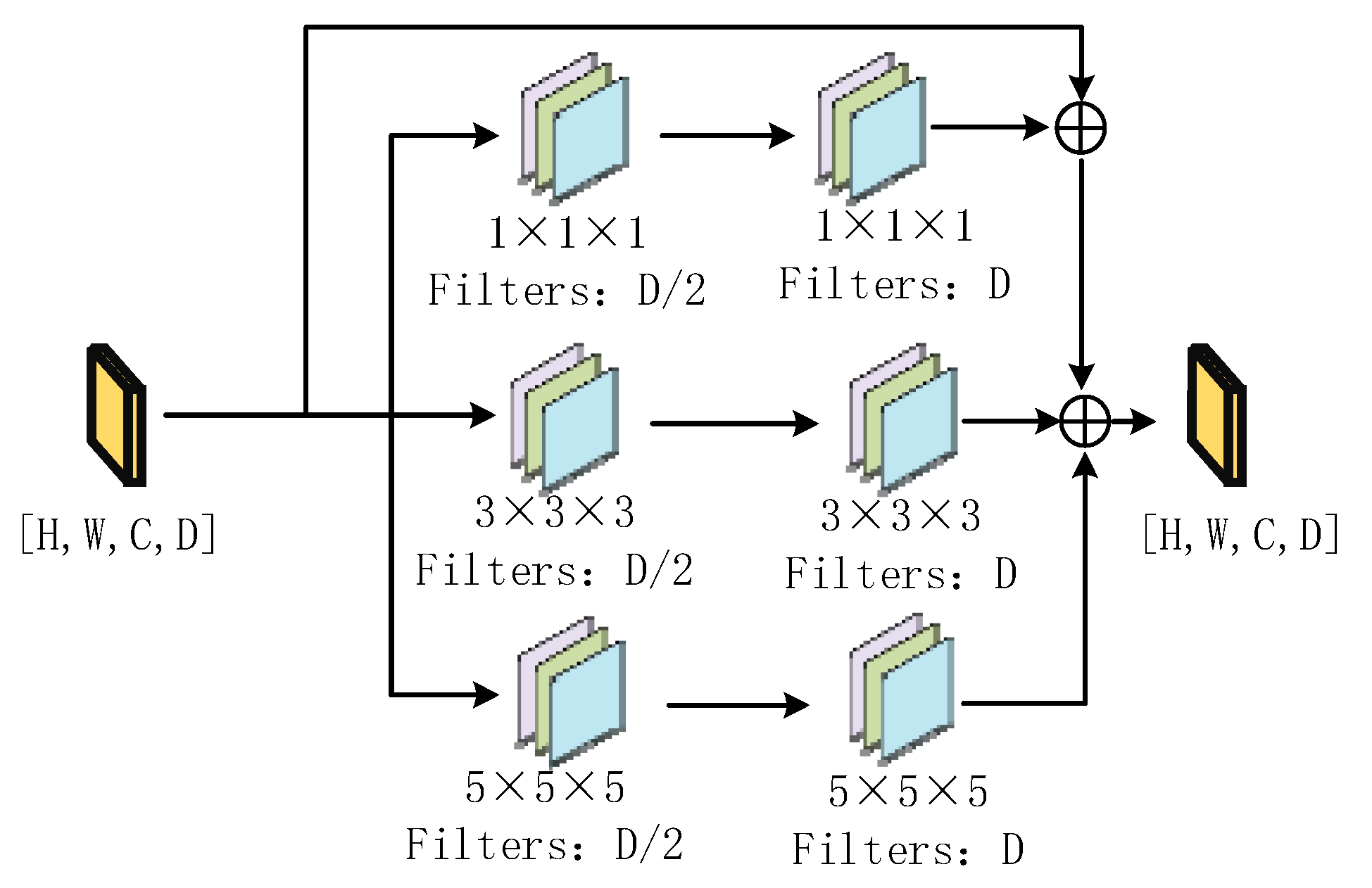
Figure 2. We use convolution kernels of different sizes for multiscale feature extraction on the input feature map, and finally add the feature results extracted from different branches to the output, sample the different granularities of the feature map, and fuse the spatial and spectral features of the feature map effectively.
When we input the feature map of size {H, W, C, D}, the feature map is first sent to the CBR of the convolution kernel size of 1 × 1 × 1, 3 × 3 × 3, and 5 × 5 × 5 in the module (execute 3D convolution, BatchNorm, and Relu activation functions in sequence), the filters are D/2, and the feature map of size {H, W, C, D/2} is obtained. The obtained feature maps were sent to the CBR modules with convolution kernel sizes of 1 × 1 × 1, 3 × 3 × 3, and 5 × 5 × 5, respectively, and the filters were D. At this time, three feature maps of sizes {H, W, C, D} were obtained, and finally, the three results were added to the input to obtain the final output feature map.
2.3. Improved 3D Multi-Headed Self-Attention
The attention mechanism originally refers to the fact that people pay more attention to interesting information while ignoring less important information. Bahdanauet et al. [
45] first applied the attention mechanism to the field of natural language processing, and subsequently self-attention has been used in many studies in the field of machine translation and natural language processing [
46,
47,
48,
49]. Attention has also been applied in the field of computer vision. Dosovitskiy et al. [
50] cut the original image into patches of different sizes and then sent the cut region into a transformer block consisting of multi-headed self-attention and other structures to extract features for image classification. Touvron et al. [
51] added a feedforward network (FFN) on top of a multi-head self-attention layer and introduced a specific teacher-student strategy for image classification tasks. For the target detection task, Zhu et al. [
52] proposed a variable attention module, and Carion et al. [
53] proposed a new design for object detection systems based on transformers and bipartite matching loss for direct set prediction. In the segmentation task, Zheng et al. [
54] and others employed a pure transformer module with multi-headed self-attention as a component and established a global context.
However, these designs on the one hand, project the image patch onto the vector, resulting in a loss of local detail [
55]. In a CNN, the convolution kernel slides on overlapping feature maps, which provides the opportunity to retain detailed local features. Therefore, the CNN branch can continuously provide local feature details to the self-attention branch. On the other hand, the existing self-attention directly obtains the attention matrix of Q and K at each spatial position (see the next paragraph for a detailed definition). Ignoring the contextual relationship between adjacent K matrices [
56], after using the CNN operation, the local spatial context can be further captured and the semantic ambiguity in the attention mechanism can be reduced [
57]. Therefore, in this study, we used a three-dimensional convolutional neural network operation with a convolution kernel of size 1 × 1 × 1 to replace the linear projection operation in the above method. The convolution kernel has overlapping sliding in the input feature map, and retains the detailed local features of the feature map, but on the other hand, makes full use of the context information between the input matrix K.
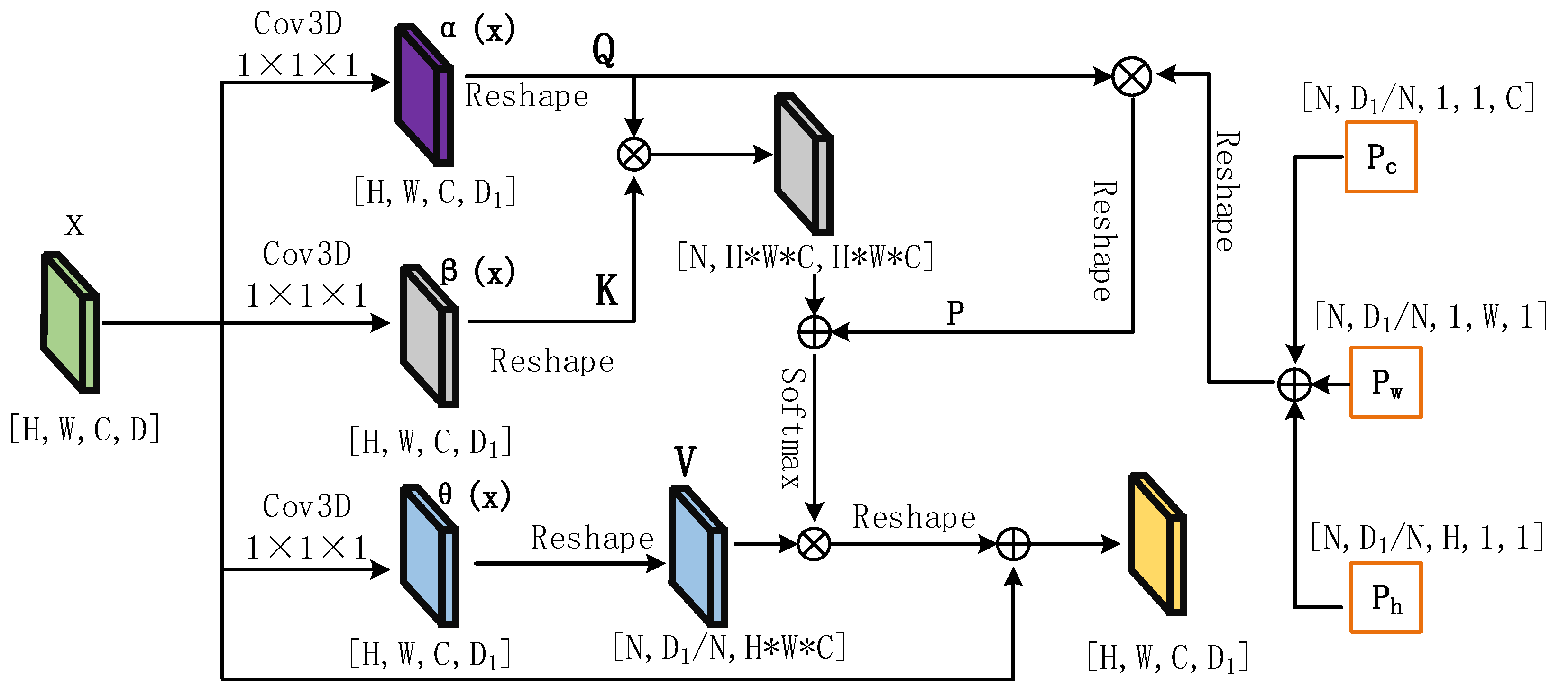
Specifically, we define the input feature map
, where H and W represent the length and width of the feature map, respectively, C represents the number of spectra of the feature map (number of channels), and D represents the feature map quantity. We first map the input feature map to three feature spaces a
,
and
, and then reshape the feature maps in the a(x), β(x) and θ(x) spaces to obtain three matrices Q, K and V, respectively, as shown in Equation (1):
Cov3D represents a three-dimensional convolutional layer with a convolution kernel size of 1 × 1 × 1, and represents a reshaping operation on the shape of the obtained feature map.
Then, we perform the inner product operation on Q and
, match sequence Q with K, obtain the attention map, and obtain the attention score. The attention score of each pixel represents the relationship between each pixel and the target feature. The attention is not sensitive to the order of the input vector. Like [
58,
59], we add a relative position bias P here. Then, the attention map is standardized to the attention weight using the softmax function. Subsequently, we aggregate all the values of V, use the attention weight to calculate the output of the final attention matrix, and perform the Reshape operation to the final output, as shown in Equation (2).
As shown in
Figure 3, P is obtained by adding three random position codes, where the H, W, C, and Q matrices are the same. After performing the reshape operation, the position codes are multiplied by the Q matrix to obtain the position code P.
Given the feature map x of the shape {H, W, C, D}, we first pass through three convolution kernels of size 1 × 1 × 1 and a three-dimensional convolution of step size of 1 × 1 × 1 to obtain three A feature maps with a shape of {H, W, C, D}. After performing the reshape operation on them, we obtain three matrices Q, K, and V with sizes {N, D/N, H*W*C}, where the context information and local feature details are preserved, and N is the number of heads. Then, the matrices Q and K are multiplied to obtain an attention matrix of size {N, H*W*C, H*W*C }. To confirm the position information between images, we introduce position coding information here. Initialize three matrices with sizes {N, D/N, H, 1,1}, {N, D/N, 1, W,1}, {N, D/N, 1, 1,C}. It should be noted that H, W, and C here are the H, W, and C of Q matrix. As shown in
Figure 3, we first add the three position matrices to obtain a matrix of size {N, D/N, H, W, C}, perform the reshaping operation, and multiply it by the Q matrix to obtain the final position coding matrix P. The position coding matrix P is added to the attention matrix, and multiplied by matrix V after the Softmax activation function to output a matrix of shape {N, D/N, H*W*C }. After performing the reshaping operation, the output is a feature map of size {H, W, C, D}.
2.4. DCOV_Attention Block
In convolutional neural networks (CNN), the convolution operation is based on discrete convolution operators. It has the properties of spatial locality and variance, such as translation and shared weights. It is now widely used in computer vision tasks [
60,
61,
62,
63]. However, the convolution operation only works in the local neighborhood and is effective in extracting local features. In turn, the limited receptive domain hinders the modeling of global dependencies, and it is difficult to capture the global representation, resulting in the loss of global features. However, since self-attention can capture interactions over long distances, it is widely used in computer vision. Currently, many methods combine self-attention and convolution operations [
64,
65,
66,
67,
68,
69,
70]. Srinivas et al. [
64] used global self-attention instead of spatial convolution in the last three bottleneck blocks of the ResNet. Graham et al. [
67] proposed a CNN and transformer hybrid neural network. At the front end of the proposed method, a convolutional neural network was used to first extract image features, and then a self-attention module was used to produce global dependencies. Wang et al. [
70] proposed a pyramid vision transformer which could improve the performance of many downstream tasks. Inspired by the above methods, we applied it to a three-dimensional convolutional neural network and used a 3D self-attention mechanism to improve the convolution. We created a 3DCOV_attention block, that combines the convolution map that extracts local features with the self-attention feature map which can establish a global dependency to enhance the local receptive field while capturing interactions over a long distance. As shown in
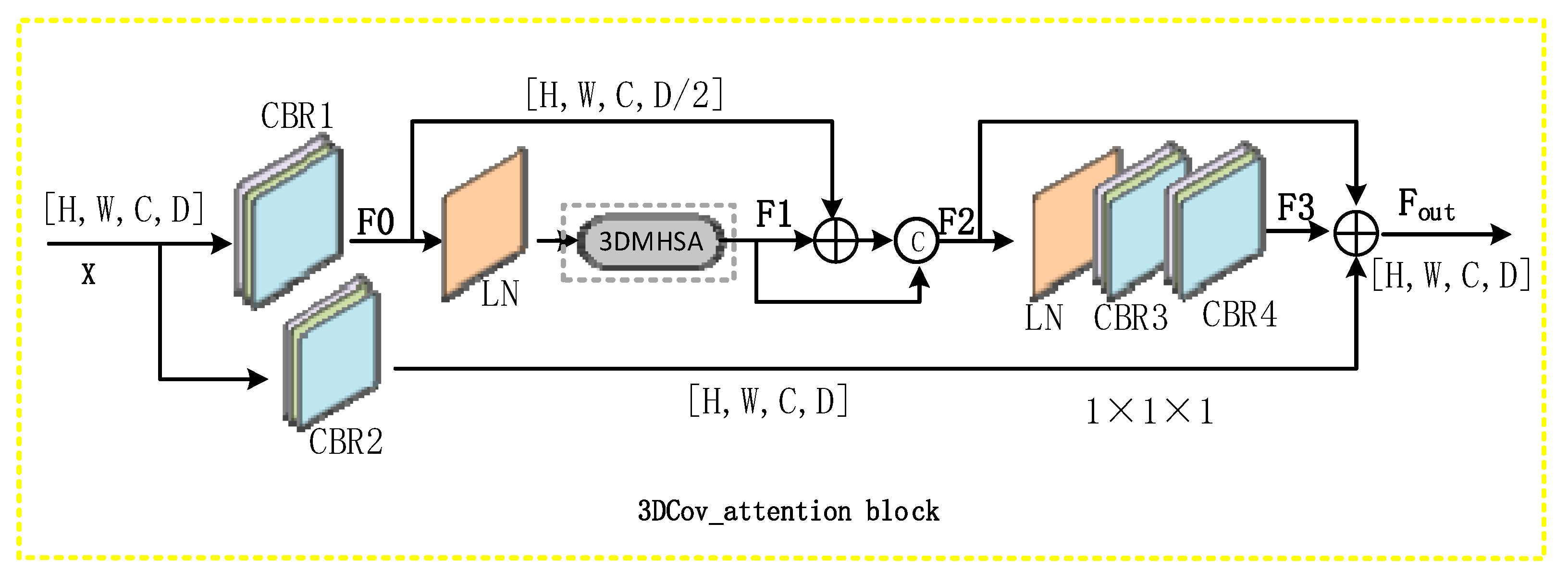
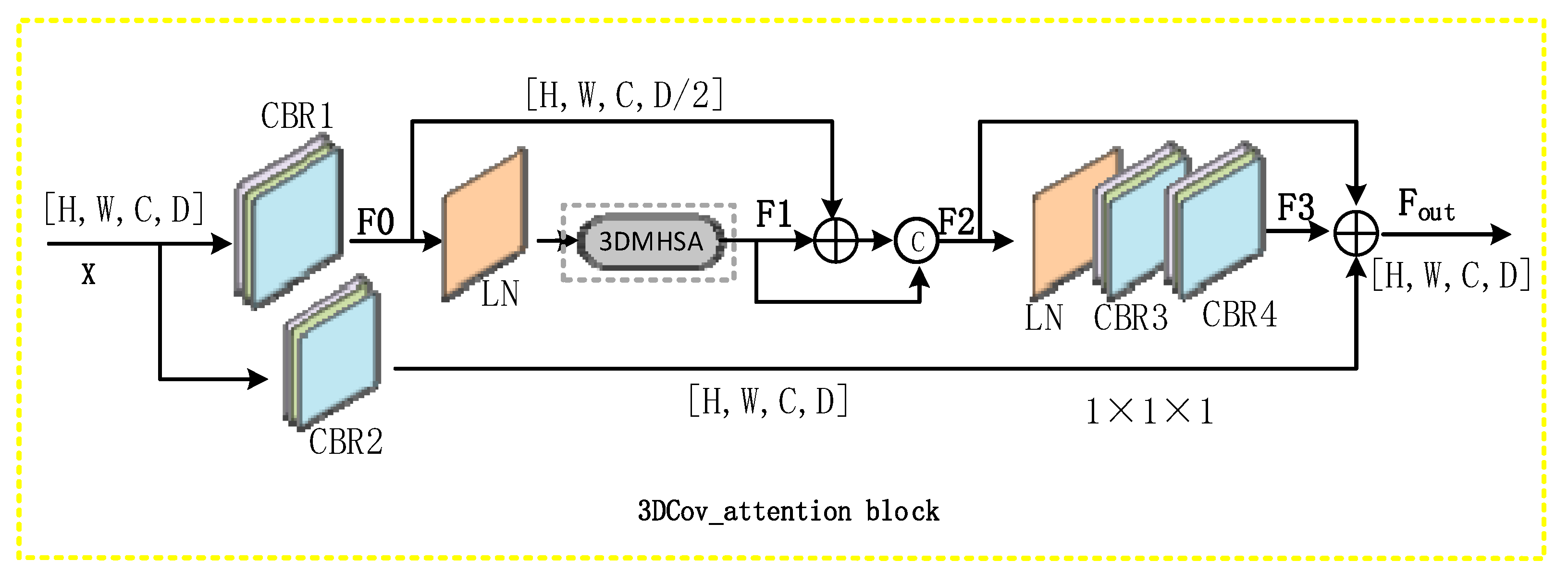
Figure 4, the entire module consists of three-dimensional convolution, BatchNorm, activation function (Relu), LayerNorm, concatenate, 3DMHSA, and other components, as shown in Equation (3).
The CBR module performs three-dimensional convolution, BatchNorm, and activation function (Relu), among others, sequentially. The size of the convolution kernel of three-dimensional convolution in
and
is 3 × 3 × 3, and the step size of is 1 × 1 × 1. the size of the convolution kernel of the three-dimensional convolution in
and
is 1 × 1 × 1, and the step size is 1 × 1 × 1. LN stands for LayerNorm operation,
stands for the concatenation operation, and 3DMHSA stands for 3D multi-head self-attention (
Figure 3).
If the size of the input feature map x is {H, W, C, D}, we first reduce the dimensions of the feature map through the module. Without affecting the classification performance of the module, we reduce the calculation amount of the 3DMHSA module, and obtain the feature map F0 with size {H, W, C, D/2}. Then, we successively pass the feature map F0 through the LN and 3DMHSA modules to obtain a feature map F1 with size {H, W, C, D/2}. Then, we merge F0 and F1, and then perform the splicing operation with F1 to obtain a feature map F2 with size {H, W, C, D}. While we changed the shape of the feature map, we increased the receptive field of the entire module and introduced the residuals. The poor connectivity avoids problems such as gradient dissipation. Then, the feature map F2 is successively passed through the , , and modules to obtain a feature map F3 with a size of {H, W, C, D}, which improves the feature extraction ability of the network, and finally passes through the the feature map of the module is added with the feature map F2 and the feature map F3, and the final output size is the {H, W, C, D} feature map . The feature information of the feature map is aggregated, and a large distance between the images is created. The dependency to note here is that the Cov_attention block does not change the shape of the input feature map (the input and output feature maps are equal in size).
2.5. Loss Function
The cross-entropy loss function is often used in multi-label classification models. To optimize the proposed model (3DSA-MFN), we used cross-entropy as the loss function of the HSI classification task, which is defined as follows:
where M is the number of samples in each batch, C is the number of feature types in the training samples, y is the real feature label, and
is the predicted label.
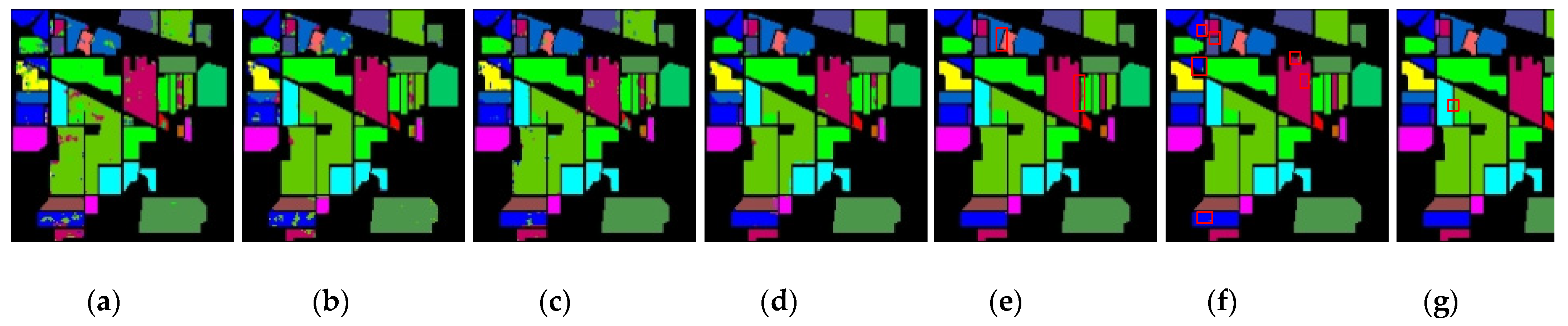
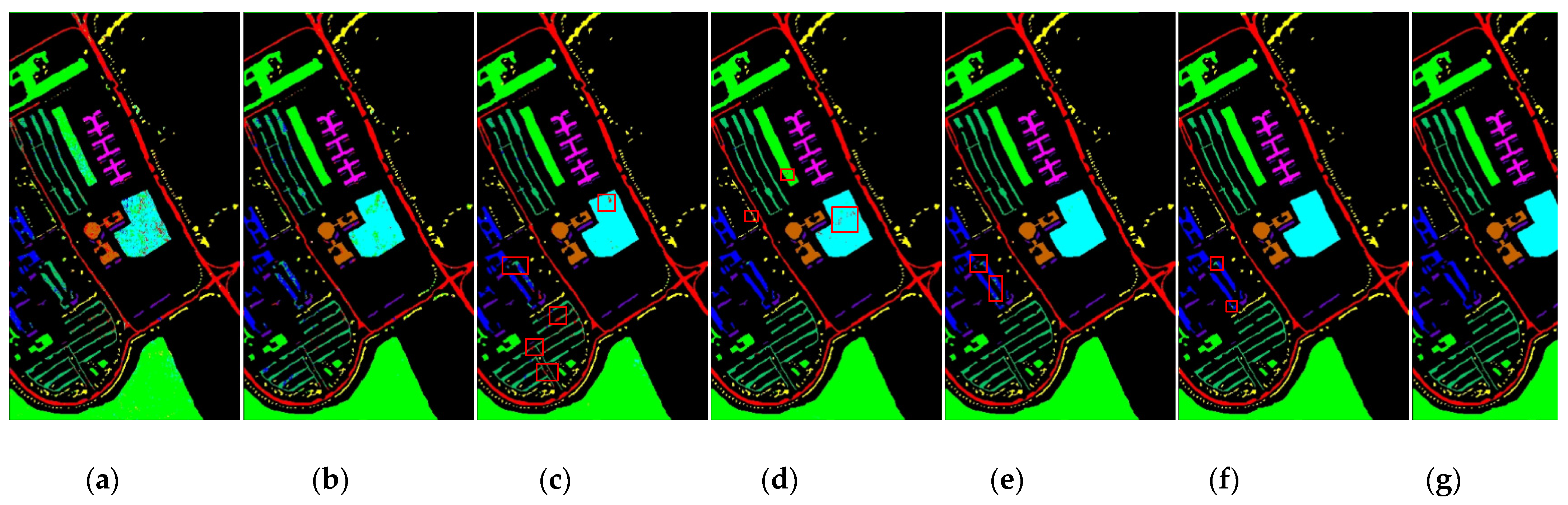
4. Conclusions
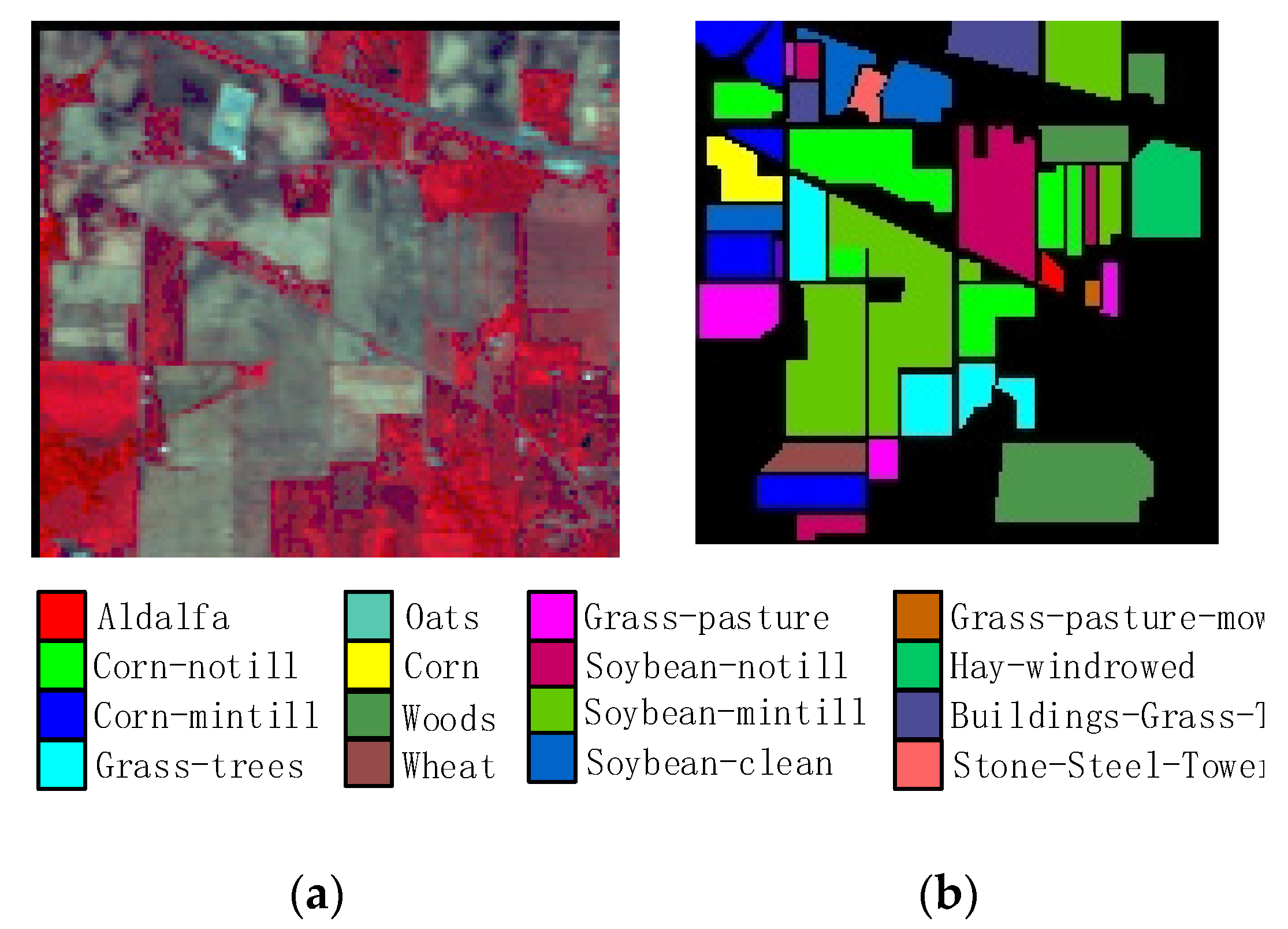
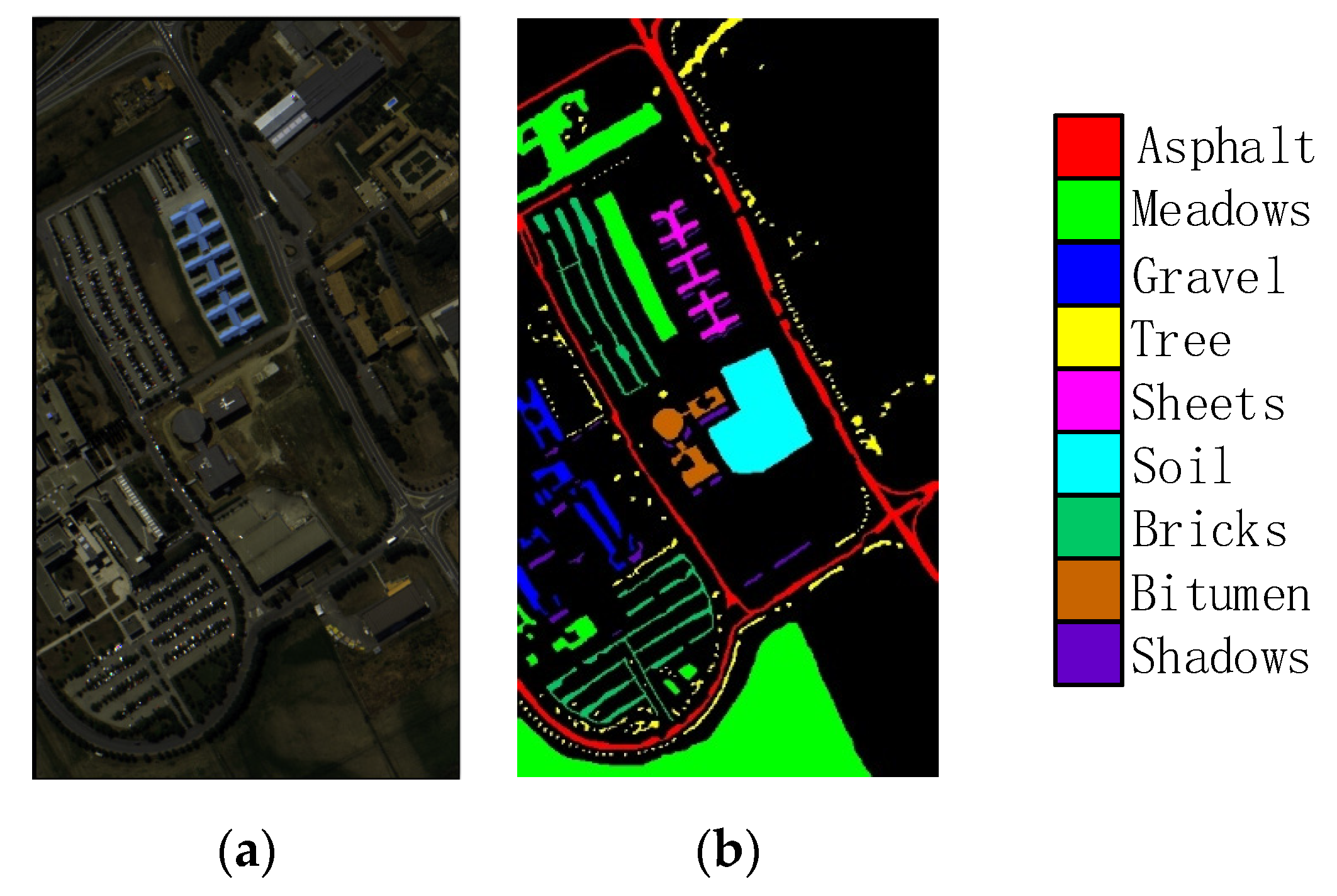
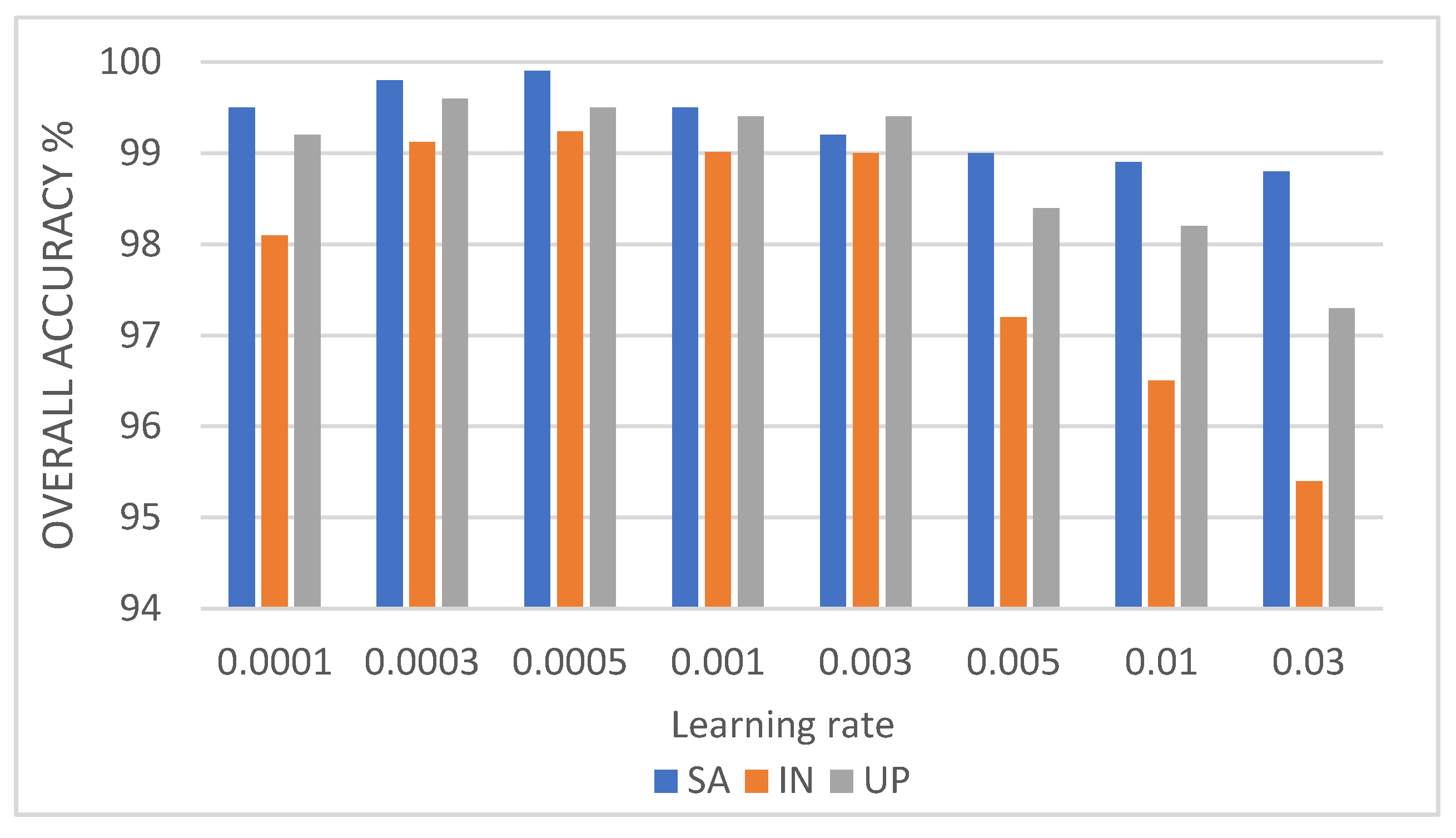
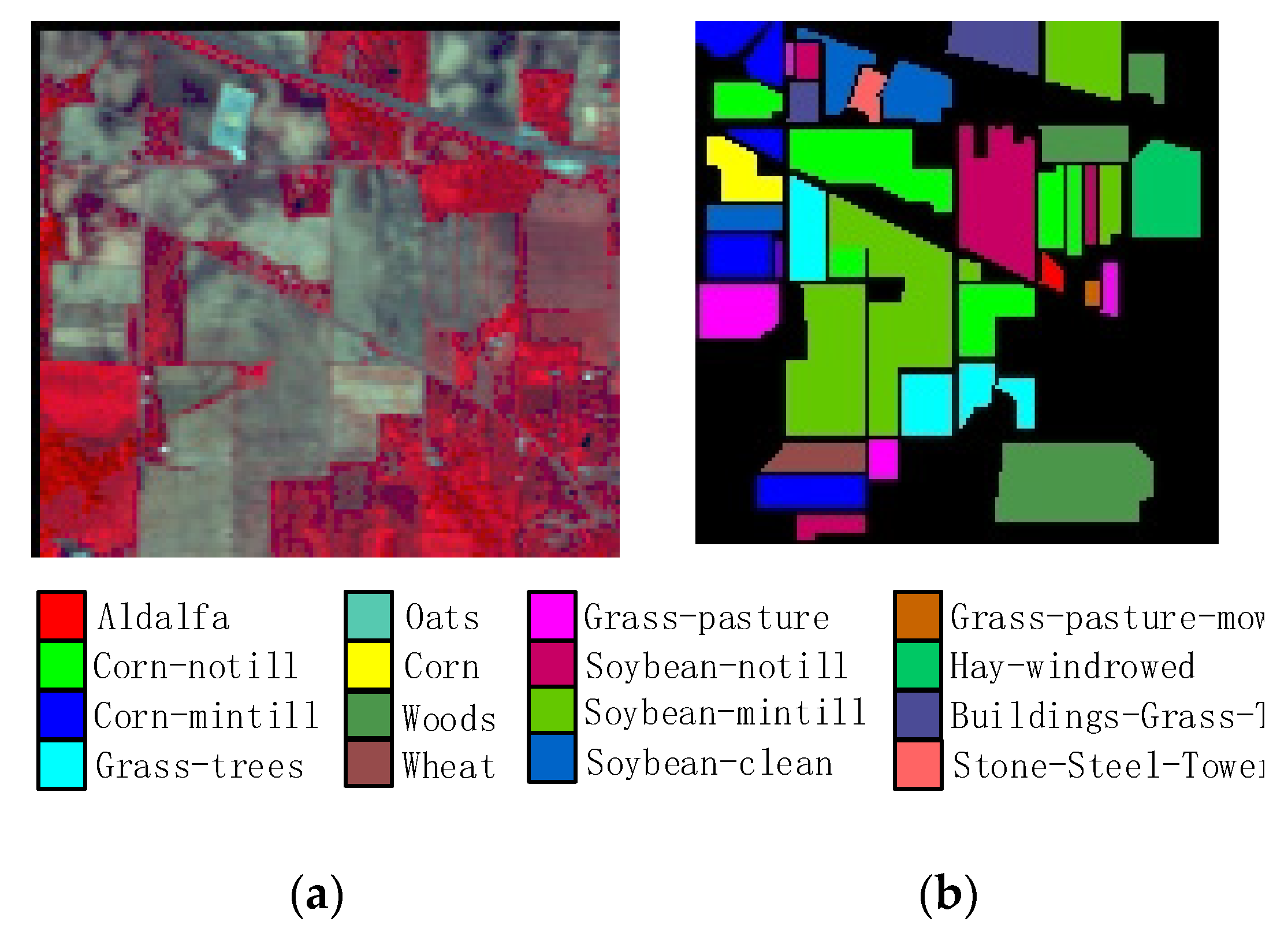
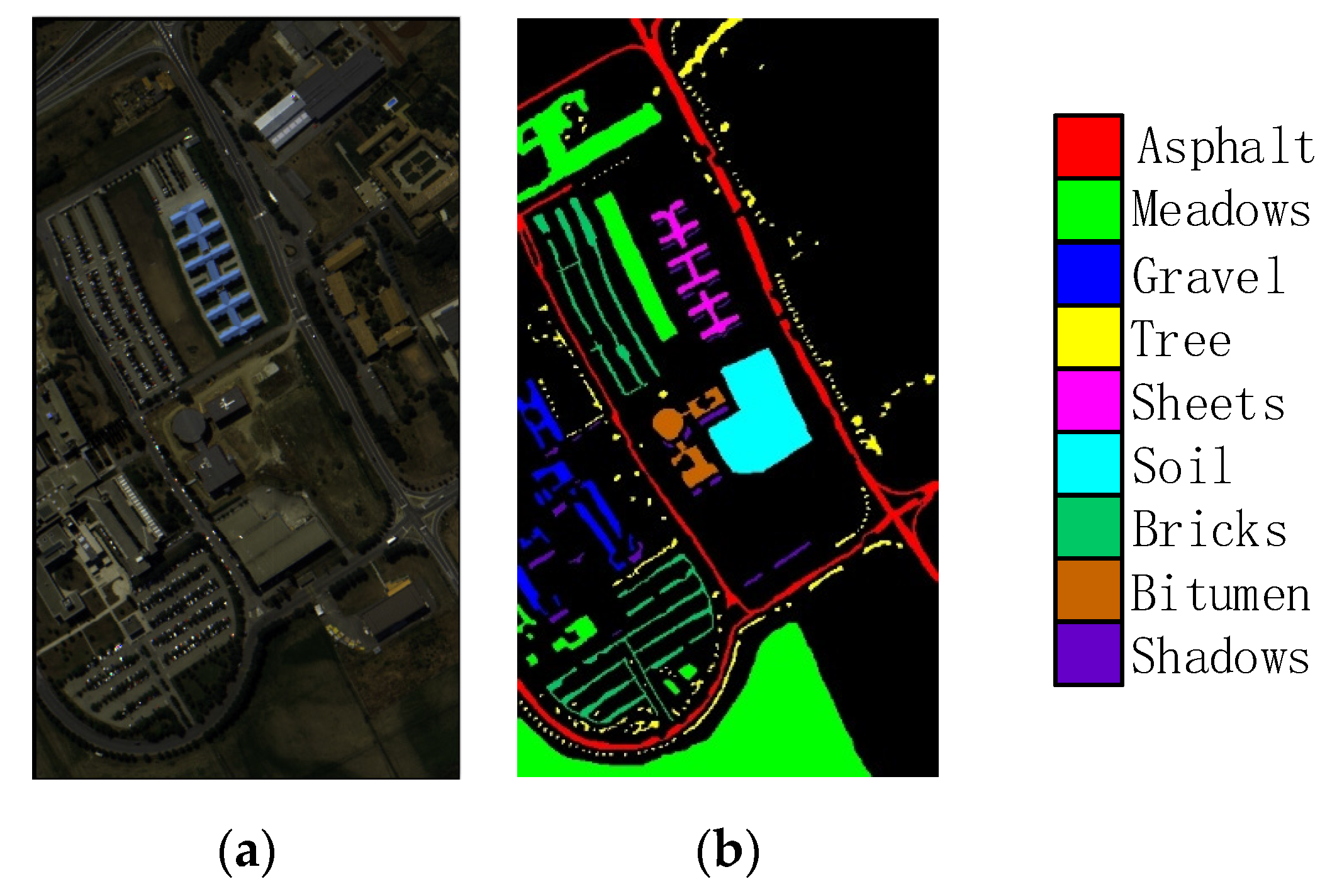
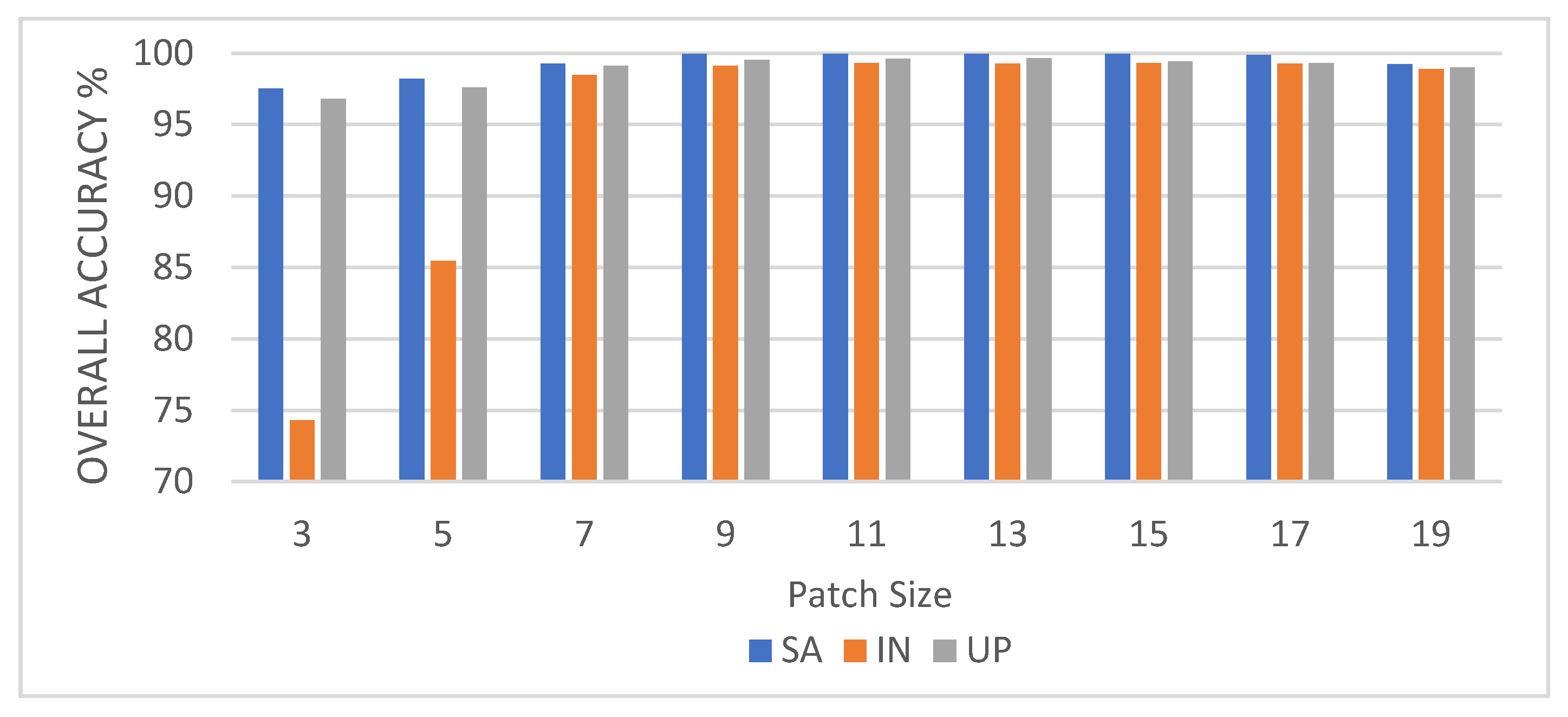
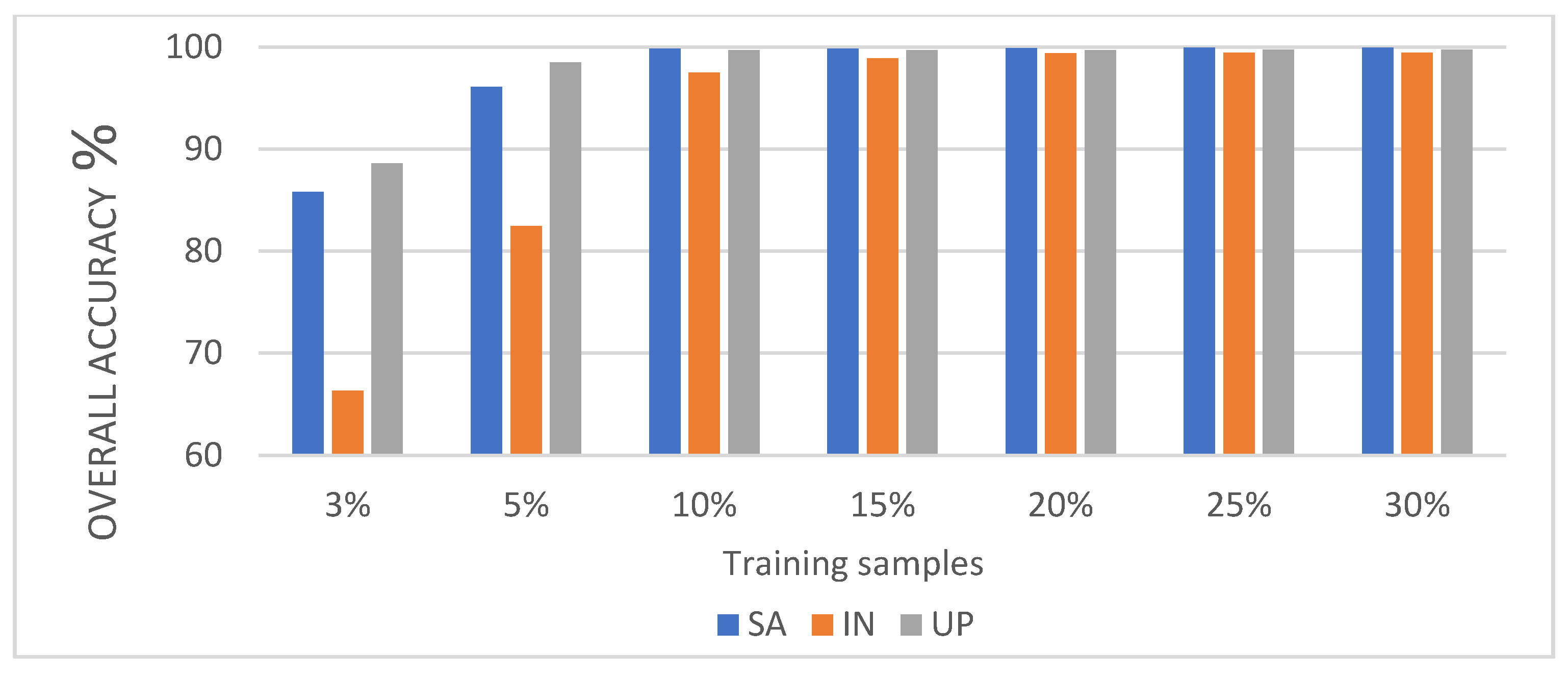
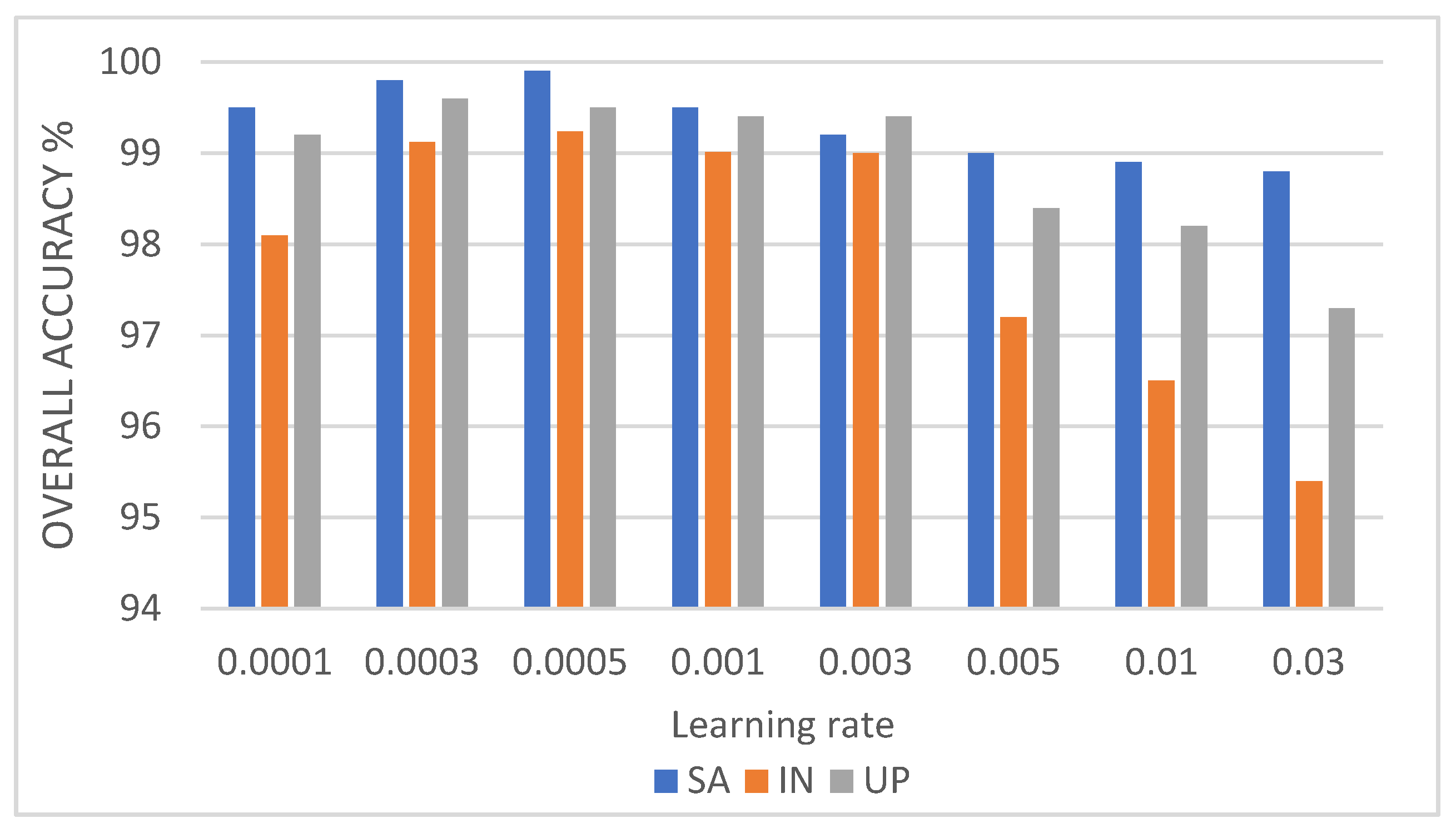
In this study, we propose a network model called 3DSA-MFN for the HSI classification task. The network includes a three-dimensional multi-head attention mechanism, multiscale feature fusion, and other modules. We first use the PCA algorithm to reduce the dimensionality of the spectrum and remove noisy and redundant data. In the feature extraction stage, we first use the multi-scale feature fusion module to first extract the feature information of HSI from different scales. Then, we generalize the multi-head self-attention from two-dimensional to three-dimensional and effectively improve it so that it can fully utilize the input matrix contextual information. Then, we use the improved 3D-MHSA to improve the convolutional neural network and get the 3DCOV_attention module. This module establishes the remote dependency while extracting local features, which can simultaneously improve the local receptive field, capture long-distance interactions, and improve the classification performance of the model. To test the effectiveness of the proposed method, experiments were conducted on three public datasets. Compared to methods such as SVM, 3D-CNN, SSAN, SSRN, HSI-BERT, and SAT, 3DSA-MFN achieved the best classification performance on the SA and UP datasets. For the IN dataset, the classification performance is slightly lower than that of HSI-BERT and achieved a classification performance comparable to that of SAT. Specifically, for the SA, IN, and UP datasets, 3DSA-MFN achieved OA values of 99.92%, 99.52%, and 99.77%, respectively, and AA values of 99.84%, 99.32%, and 99.68%, respectively. In future work, we will focus on optimizing the attention mechanism in HSI classification tasks and classifying small samples of HSIs.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}