1. Introduction
Benefiting from the capability of all-weather and all-time Earth observation, the synthetic aperture radar (SAR) sensor has been used in numerous applications increasingly, including but not limited to urban planning, disaster monitoring, and land-cover/land-use (LCLU) analysis [
1,
2,
3,
4,
5,
6,
7]. In reality, change detection (CD) in SAR images is crucial in these applications, which seeks to precisely identify the changed and unchanged parts by analyzing two or more SAR images acquired over the same geographic region at different times [
2,
3,
7,
8,
9]. However, SAR images exhibit diversified inherent characteristics, such as ubiquitous multiplicative speckle noise and geometrical distortions, that inevitably impose some challenges in SAR image CD [
8,
9,
10].
The challenges of SAR image CD mainly come from three aspects: (1) the speckle noise and pseudochange [
3,
9,
10,
11,
12], (2) the scarcity of accessible labeled samples, and (3) class imbalance [
13].
- 1.
Speckle Noise and Pseudochange: Due to the particular imaging mechanism that creates SAR images by processing the radar backscatter responses coherently [
10,
11], speckle noise inevitably appears all over the images, which dramatically affects the intensity of the SAR images; consequently, changed pixels share a wide range of intensity values with unchanged pixels, namely intensity fluctuations. This is because speckle causes dramatic intensity fluctuations and further results in the overlapped nature between the changed and unchanged classes [
9,
10], which brings difficulty for accurate change feature extraction. In addition, pseudochanges can also be caused by the slight variation of the acquisition parameters, such as the imaging configuration, incidence angles, and radiometric variations, making it difficult to detect changes of interest precisely [
14,
15].
- 2.
Scarcity of Labeled Samples: It is acknowledged that collecting a large quantity of high-quality pixel-wise annotations in a short time is infeasible, raising the problem of training data scarcity. On the one hand, the problem poses challenges for the existing supervised CD approaches [
13] that rely heavily on either ground truth or a significant amount of labeled training samples. On the other hand, the absence of label information makes it difficult for the unsupervised methods [
9,
11,
12,
14,
15,
16,
17,
18,
19] that rely on handcrafted features to model the change information accurately.
- 3.
Class Imbalance: Considering that the prior probability of occurrence of changed objects is much lower than unchanged ones, SAR CD is a typical class imbalance classification issue in practical scenarios. That is to say, the number of changed pixels is much smaller than unchanged ones in the context of bitemporal SAR scenes. Such an imbalance problem will severely undermine the performance of data-driven approaches [
13]. However, almost all existing methods overlook this problem.
In summary, all these problems together form the major obstacles for SAR CD and impede the detection performance from improving, which motivates us to explore a more effective model further. By reviewing the existing literature, the above issues are usually addressed from the perspectives of difference image (DI) generation (i.e., shallow feature extraction), classifier design, and sample selection strategy.
Firstly, to capture discriminant change features and counteract the speckle effect, researchers have developed a series of DI generation methods, including but not limited to mathematical difference descriptors [
20,
21,
22,
23] and statistical modeling [
24,
25,
26,
27], such as the log-ratio operator [
21], wavelet-based DI fusion methods [
23,
28,
29], likelihood-ratio method [
27], and multiresolution analysis-based method [
28], etc. Recently, saliency detection has been employed to robustly locate the conspicuous changed regions and to remove the easily confusable regions in the background, such that better quality can be gained in the produced DI [
30,
31,
32]. However, these saliency-guided methods focus on long-range contextual information at the expense of details due to the inevitable blurring effect.
Secondly, most previous SAR image CD works [
8,
9,
11,
12,
14,
15,
16,
17,
18,
19] focus on how to design an unsupervised model to achieve good performance, wherein clustering-based classifiers [
9,
15,
17,
18,
28] are considered most representative and popular. Although their effectiveness and efficiency have been demonstrated, traditional clustering algorithms still suffer from some significant drawbacks, the major one of which is the poor ability in data fitting. Recently, deep learning models, such as the autoencoder [
30], convolutional neural network (CNN) [
33], and capsule network [
34], have been adopted to accurately process the complex and nonlinear SAR data, where pseudolabels inferred by clustering algorithms are used as supervised signals. These methods are regarded as a novel CD framework named the preclassification scheme. Even if this scheme alleviates the scarcity of labeled samples to a certain extent, the label information is still derived from the clustering, whose accuracy cannot be ensured. Consequently, this may lead to image CD systems that cannot learn exact change semantics. More recently, some studies [
11,
35] have resorted to transfer learning, thus providing an alternative solution to the problem of labeled data scarcity. Transfer learning can make use of prior knowledge in the source domain (e.g., optical data with/without ground truth) to train a deep network for application in the target domain (i.e., SAR data). However, the distribution discrepancy between the target and source domains cannot be easily bridged, restricting the performance of transfer learning-based methods.
As for the class imbalance in SAR data, very few methods have tried to explicitly provide a practical and feasible solution, such as [
13], where the ground truth map is utilized to guide the training data set construction in a supervised manner. We argue that the strategy in [
13] is inapplicable in practical SAR scenarios where accurate labels are costly and expensive to collect. Among the existing unsupervised methods [
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40], this problem has always been neglected, where training instances of changed and unchanged classes are usually sampled from the imbalanced class distributions, further leading to the imbalance in the training set. Considering that this problem will inevitably hinder the model training, a specialized strategy is necessary to rebalance the class distributions in the training data set to learn class knowledge better.
Apart from the aforementioned problems, changed regions in bitemporal SAR scenes tend to occur at various sizes in arbitrary orientations and also exhibit highly varied shapes and textures, typically summarized as “hybrid variabilities”. Specifically, changed regions usually occupy connected areas ranging from a dozen of pixels to thousands of pixels, the so-called scale variation. Furthermore, the changes that occur between bitemporal images may correspond to various natural or manmade objects, which are naturally exhibited as irregular shapes and somewhat different textures in images. All these hybrid variabilities together increase the difficulty of accurately recognizing real changed parts. Although a large number of SAR image CD methods have been proposed, none of them has put enough emphasis on this unique characteristic inherently existing in changed regions.
In this article, we propose a label-free SAR CD system to comprehensively tackle all these problems, which formulates the local structure information learning and the multiscale–multiresolution (MS-MR) information encoding into a unified framework to strengthen the feature distinguishability and fulfill the classification in a completely unsupervised way. It includes three parts: shallow feature extraction, the class rebalance strategy, and the training of the Hybrid Variability Aware Network (HVANet). At first, considering the importance of the context information in describing images, we generalize the conventional single-scale spatial patch (SP) feature to focus on the MS-MR information for the representation at each image pixel, referred to as extended SP (ESP). The key novelty of the feature extraction is MS-MR patch feature construction, which can greatly help to characterize both image details and semantic content from multiple levels and perspectives. Second, a class rebalance strategy is proposed to realize a manageable balance in the training data set. Third, for the purpose of the label-free detection of changes, a self-supervised network named HVANet is specially tailored for completely unsupervised feature learning and change identification. Specifically, we establish two streams in HVANet to concurrently learn local structure information and encode MS-MR information, referred to as the local spatial stream and the scale-resolution stream. Intrinsically, HVANet projects the input ESP features into a new learned feature space in a self-supervised manner, where pixels of different categories with diverse appearances can be better differentiated. Finally, training and inference can be performed end-to-end. The main contributions of this paper can be summarized as follows:
- 1.
We define a completely unsupervised SAR image CD framework, under which a novel label-free method is accomplished. Specifically, the idea of self-supervised learning is introduced to enable end-to-end high-level feature learning and classifier training without any labeled samples.
- 2.
We propose to represent each pixel in the images using both the conventional single-scale patch (i.e., SP feature) and the MS-MR patches simultaneously, which is capable of comprehensively describing pixel information through the complementary local spatial information and long-range context information. These features are gathered together as the shallow feature for each pixel, from which the network can extract multiple types of high-level features for better feature representation and feature classification.
- 3.
We devise a novel two-stream network architecture called HVANet, which decomposes the feature learning into the local spatial and the scale-resolution streams. The local spatial stream employs the Siamese network (SiamNet) to extract the intrinsic structural information around each pixel, while the scale-resolution stream encodes the corresponding MS-MR information to compensate for the spatial context for intensifying representation power.
The rest of this paper is organized as follows.
Section 2 reviews the existing unsupervised SAR image CD works.
Section 3 presents in detail the proposed label-free CD framework for SAR images. Experimental results are presented in
Section 4. Finally, the discussions and conclusions are provided in
Section 5 and
Section 6, respectively.
2. Related Work
SAR image CD is one of the challenging scene understanding tasks in the SAR community. In the literature, the process of CD typically consists of change feature extraction and feature classification. Accordingly, we review the existing CD methods from these two perspectives: change feature extraction and feature classification.
(1) Change Feature Extraction: Feature extraction in CD, known for its capability to generate DI or features focusing on change information, is a key step. At the very beginning, some mathematical operators, such as the subtraction, ratio, and log-ratio operators [
20,
21,
22,
23], are adopted to measure change information pixel-by-pixel, thus deriving a DI. Most of the operators are often susceptible to speckle and pseudochanges. Then, considering the better representation ability inherent in the spatial context, a variety of methods have been exploited to improve the accuracy and robustness of change information measurement by leveraging the wavelet-related algorithms [
23,
28,
29,
31,
33,
36] due to their ability to extract multiscale (or multiresolution) context information. However, it has been observed that wavelet transform cannot fully characterize the real changes in complex scenes. Recently, some strategies [
30,
31,
32] have been dedicated to making use of the saliency information obtained by considering long-range dependencies in images and have thus been able to effectively reduce distraction in the complex background. Typically, Geng et al. [
30] use a segmented saliency map as the binary spatial weight for the log-ratio DI to filter the distraction in the background. Unfortunately, these saliency-guided methods [
30,
31,
32] suffer from a major drawback: they can enhance context but inevitably induce a blurring effect to edge and image details due to their emphasis on global information; thus, the changed regions may be shrunken or dilated, causing a great deal of misclassified pixels near the borders and finally detail loss.
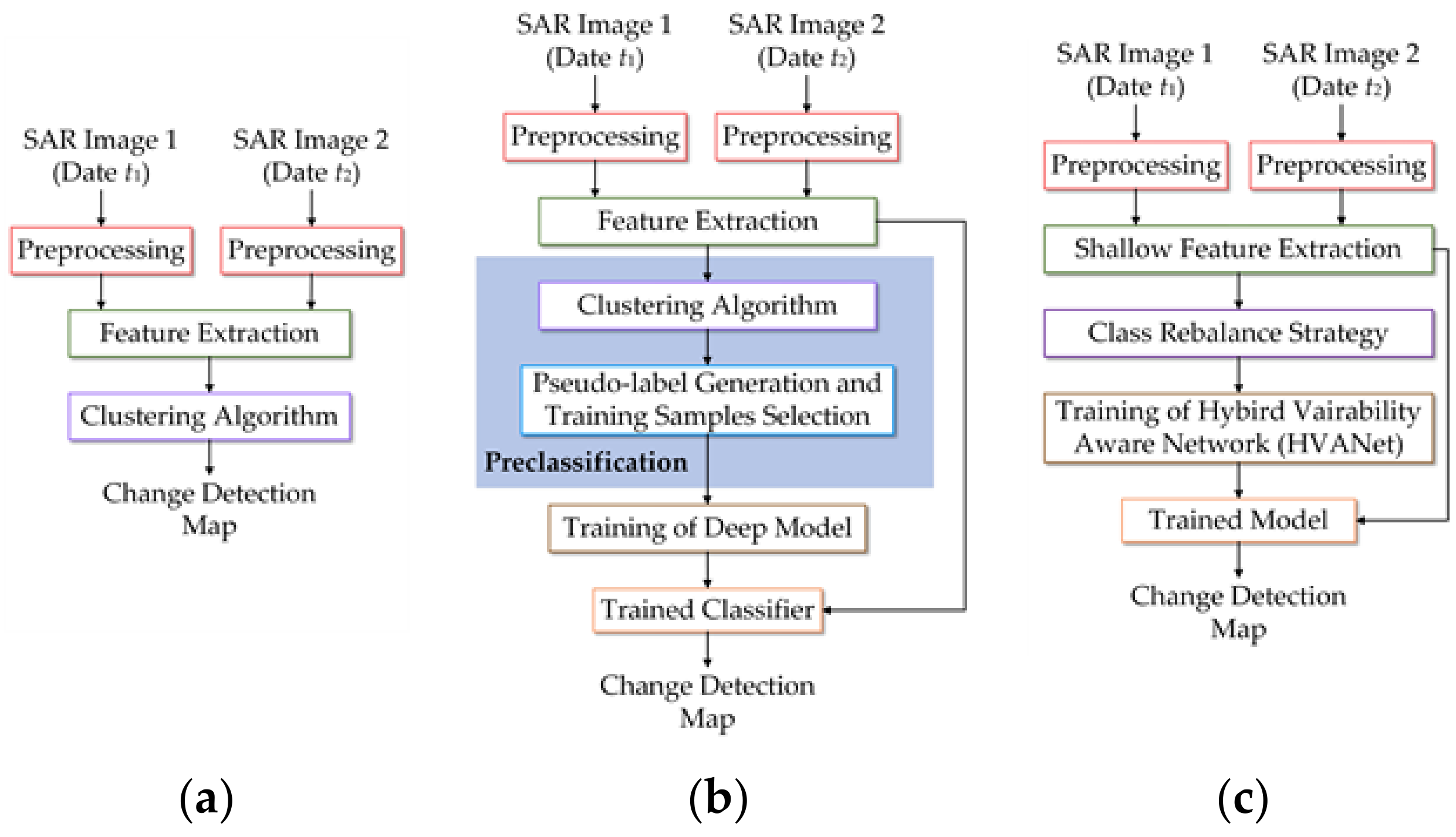
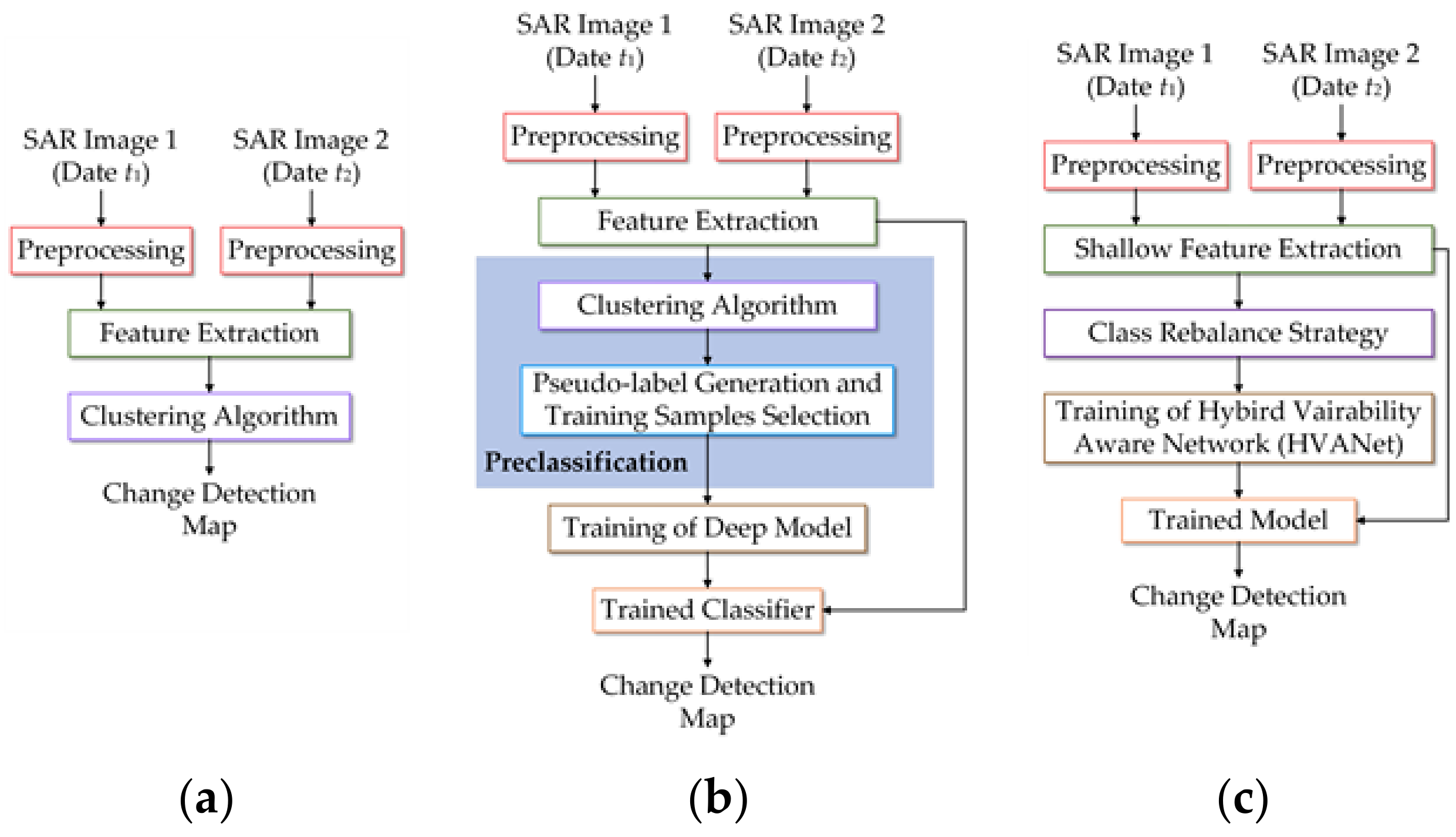
(2) Feature Classification: This process aims to assign a label (changed or unchanged semantic label) for each pixel, following which the class labels are mosaiced to a change map. The process can be roughly categorized into two classes, i.e., supervised and unsupervised, based on whether labels are necessary or not. Considering the labeled data scarcity, unsupervised classifiers are preferable in feature classification where no ground-truth labels are required, thus relieving the reliance on real labels. The representative methods of this kind typically use the feature extraction techniques described above to acquire low-level handcrafted features and directly use clustering models to obtain a change map, as shown in
Figure 1a. In this direction, Aiazzi et al. [
15], Celik [
17], Gong, Zhou, and Ma [
27] have made many remarkable advances in unsupervised SAR CD. Although they have been shown to be effective, the conventional clustering models are susceptible to speckle and pseudochanges and fail to make a precise decision because of their weak fitting capability under complex SAR data distribution.
Stepping into the era of artificial intelligence, recent years have witnessed an increasing interest in deep learning methods to address a number of problems in remote sensing (RS) image analysis and interpretation. In this context, a deep learning-based preclassification scheme has been recently developed, as shown in
Figure 1b, which casts the unsupervised problem into a supervised deep learning problem. Under the scheme, a shallow unsupervised classifier is first applied to assign pseudolabels to unlabeled samples, following which deep models can be effectively trained in a supervised way. Here, clustering models mainly serve as the shallow classifier [
30,
32,
33,
34,
37,
38,
39,
40], which means that methods under this scheme remain clustering-guided. In [
36], Gong et al. firstly proposed a pioneering deep neural network (DNN)-based SAR image CD approach. Afterward, a variety of works [
30,
32,
33,
34,
38,
39,
40] have followed this scheme to take advantage of the superiority of deep learning techniques in automatic feature learning and classification. Despite the good achievements achieved, the weak data fitting ability of the critical clustering-based shallow classifier causes two main limitations: i) the pattern diversity of the pseudolabeled training samples is overly simple, and ii) noisy labels are inevitable. As a consequence, both the diversity and credibility of the pseudolabeled samples cannot be ensured, hindering the training and finally limiting the generalization performance of deep models.
With the development of deep learning technology, there is a new trend of SAR image CD that exploits the newly proposed transfer learning paradigm to circumvent the limitations thanks to a domain knowledge transfer trait [
11,
35,
41]. The rationale is to exploit a large amount of accessible heterogeneous images with/without ground truth to pretrain a deep model and then transfer it into the target data domain in the fine-tuning stage. In this regard, it helps to efficiently reduce the reliance of deep models on labeled samples in the target domain where pixel-wise annotations are very difficult and costly to gather. Gao et al. [
35] use 10 multitemporal SAR images with ground truth to train a CD network, which is transferred to the considered SAR scene for CD through a fine-tuning operation. Tan et al. [
41] introduce the idea of transfer learning into the dictionary learning for PolSAR CD. Saha et al. [
11] build an SAR-optical transcoding network to implement SAR image CD in the feature space of the optical domain. Nevertheless, the data shift between two different data domains caused by the vast difference in imaging mechanisms is a gap that is not easy to bridge, thus limiting the domain knowledge transfer performance.
Recently, thanks to its ability to effectively mine category knowledge for model learning through the nature of unlabeled data, self-supervised learning, served as a special branch of unsupervised learning, has been prevailing in the context of RS image interpretation [
42,
43,
44]. Specific for self-supervised learning, the learning signal can be constructed by uncovering and exploiting the latent structure and nature in unlabeled data, while the entire training procedure is completely label-free [
45]. Notably, self-supervised learning figures out an effective fashion to fully exploit the unlabeled samples to excavate underlying category knowledge and learn useful features for some downstream tasks, such that the scarcity of labeled samples can be tackled to a certain extent. However, existing self-supervised learning-based CD works [
46,
47,
48] almost focus on multispectral/hyperspectral images [
46] or cross-sensor images [
47,
48]. In [
47], Chen and Bruzzone explored building a self-supervised pseudo-Siamese network for multispectral-SAR images CD based on contrastive learning. It constructs positive samples using the bitemporal images from the same scene and constructs the negative samples using paired images from different scenes, such that the network is trained end-to-end in an unsupervised way. Finally, the cross-sensor bitemporal images can be compared by the deep features extracted by the pseudo-Siamese network. In [
48], Saha et al. proposed a CD framework for optical-SAR image CD using a self-supervised model. To the best of our knowledge, few studies have investigated the self-supervised CD methods purely for bitemporal SAR images so far. As a consequence, the intrinsic challenges in SAR data still remain. It is necessary to explore a self-supervised framework to overcome the challenges in SAR image CD.
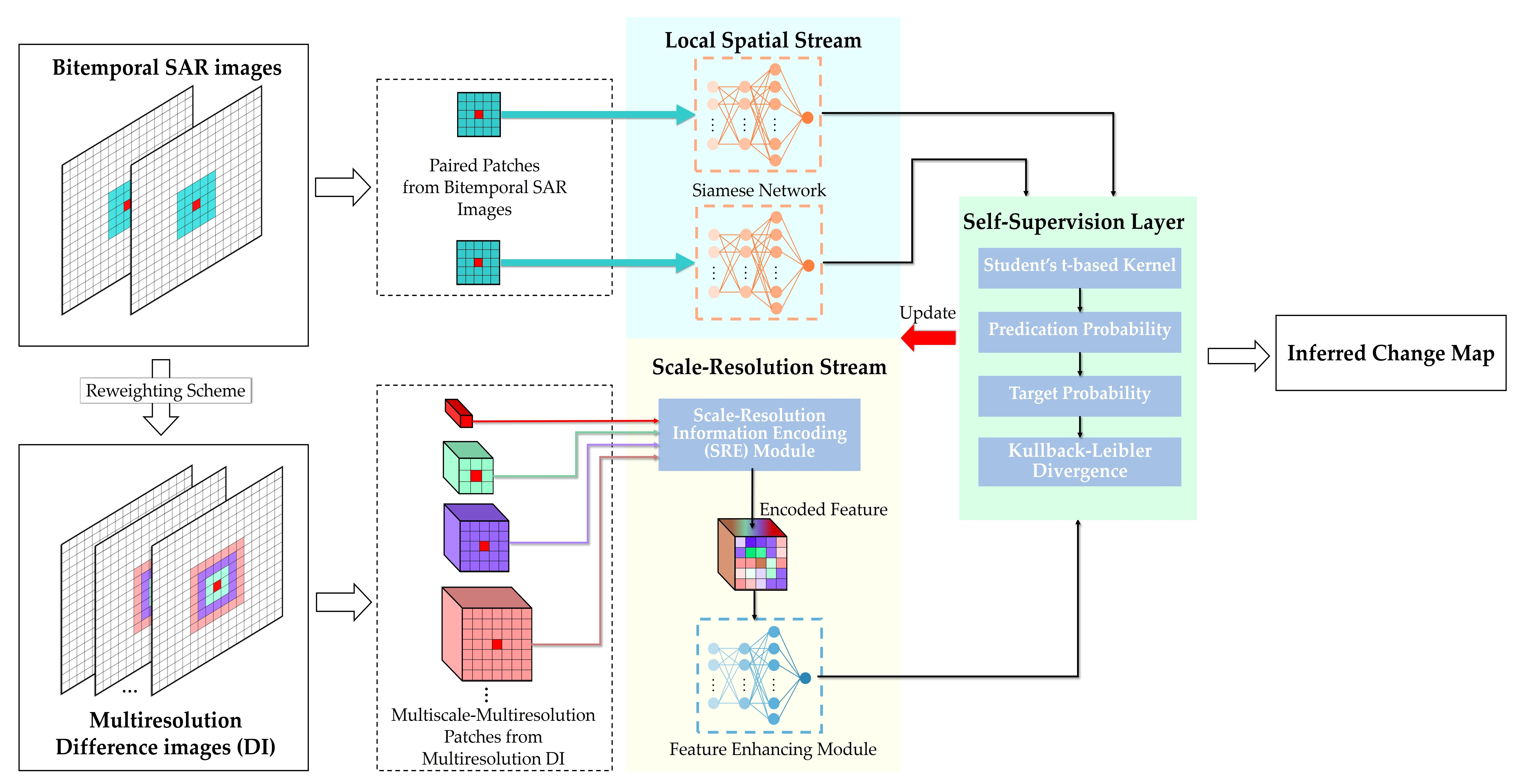
In this work, we exploit self-supervised learning to realize an end-to-end and label-free learning of the task-specific high-level features from original bitemporal SAR images. To this end, a self-supervised learning paradigm is used to enable label-free feature learning and change identification. As shown in
Figure 1c, thanks to the label-free property of self-supervised learning, real labels are unnecessary in the training process, such that the preclassification scheme and its defects can be avoided and a completely unsupervised deep learning-based CD framework can be established.
3. The Proposed Method
Denote the bitemporal single-channel SAR images acquired over the same geographic region at two different times and as and of the same size , where H and W refer to height and width, respectively. In bitemporal SAR images, the geometry and appearances of different changed regions may be significantly different, typically manifested by the high variabilities in size, shape, and texture, which are not trivial to model. In addition, the other challenges, including the scarcity of labeled data, the speckle effect, and the class imbalance problem, also severely restrict the performance and generalization of the detection model.
Our goal is to overcome these challenges, that is, precisely locating the real changes between
and
while keeping the number of false and missed changes low. To this end, we propose a self-supervised framework to make full use of latent category knowledge in unlabeled samples for the purpose of label-free SAR image CD. The overall flowchart of the framework is depicted in
Figure 1c, which mainly consists of the shallow feature extraction stage, class rebalance strategy, and self-supervised HVANet training stage. Finally, the detection results on real data are inferred by the well-trained HVANet. Specific details about the proposed framework are described in the following subsections.
3.1. Shallow Feature Extraction
As discussed earlier, the changed regions always tend to present high variability in size, shape, and texture, making it intractable to capture robust features to model the change information. For this reason, SAR scenes are usually hard to interpret if the shallow feature cannot fully reflect or characterize the variation of sizes, shapes, and textures. Thus, enriching the input features is necessary for overcoming the defects of the widely used single-scale spatial patch (SP) [
30,
32,
33,
34,
35,
37,
38,
39,
40] and reducing the learning difficulty. This motivates us to propose a novel shallow feature by taking inspiration from the human visual perception mechanism that processes local and global information in different functional areas of the brain [
49,
50].
Our intuition is that these internal hybrid variabilities should be described by different types of shallow features in order to improve the expression ability and generalization of the later feature learning and classification. We argue that shallow input features should be characterized as (i) long-range spatial context that is beneficial to exhibit global spatial semantic and suppress the speckle and pseudochanges, (ii) multiresolution and multiscale information that helps to identify the various sizes and textures of changed regions, and (iii) local structure information that helps to describe fine shape and texture further.
With the insight acquired from the above analysis, we generalize the SP feature to focus on the multiscale and multiresolution information for better change information characterization, referred to as extended SP (ESP). Specifically, the shallow feature extraction consists mainly of three steps: long-range context modeling, multiresolution DI generation, and ESP generation. Next, we elaborate on this process in detail.
3.1.1. Long-Range Context Modelling
In bitemporal SAR images, the speckle and pseudochanges caused by the nature of the SAR imaging process make it difficult to extract shallow information precisely. This is mainly because extensively used change feature descriptors such as log-ratio operators generally compute dissimilar value pixel-by-pixel without considering the long-range context information. To reduce the negative effect brought by the speckle and pseudochanges, we use context-aware saliency detection (CASD) [
51] to model the long-range context. To be specific, CASD is inspired by the following psychological principles:
- 1.
Considering the low-level local spatial information, namely appearance characteristics, such as contrast and magnitude;
- 2.
Global spatial information is necessary to highlight the salient pixels and suppress the background pixels;
- 3.
According to the selective visual attention mechanism, salient pixels should cluster around one or more attention centers, rather than distribute all over the image;
- 4.
High-level factors, such as the location prior regarding the salient areas.
Following the above principles, the CASD algorithm was proposed. First, it computes the single-scale local-global saliency; second, it integrates the saliency maps computed at multiple scales; third, attention information and other priors are taken into account to strengthen spatial description. Accordingly, we directly apply the CASD algorithm to the log-ratio DI, i.e.,
, and then, a saliency map
that carries rich spatial context is obtained. Please refer to [
51] for more details about CASD.
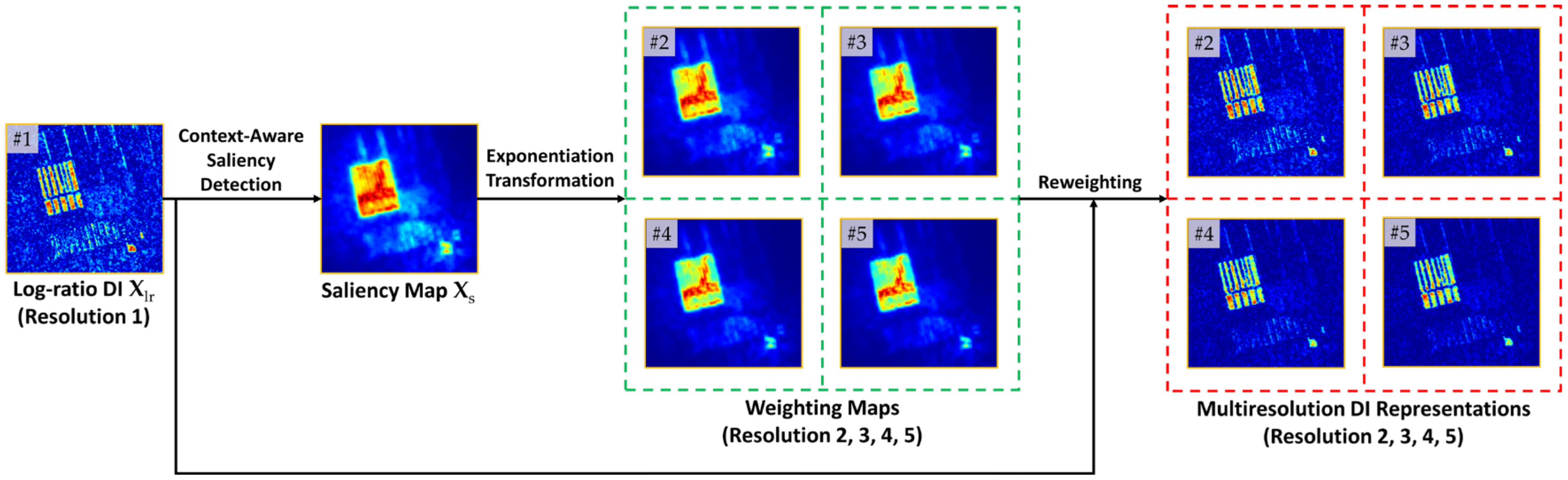
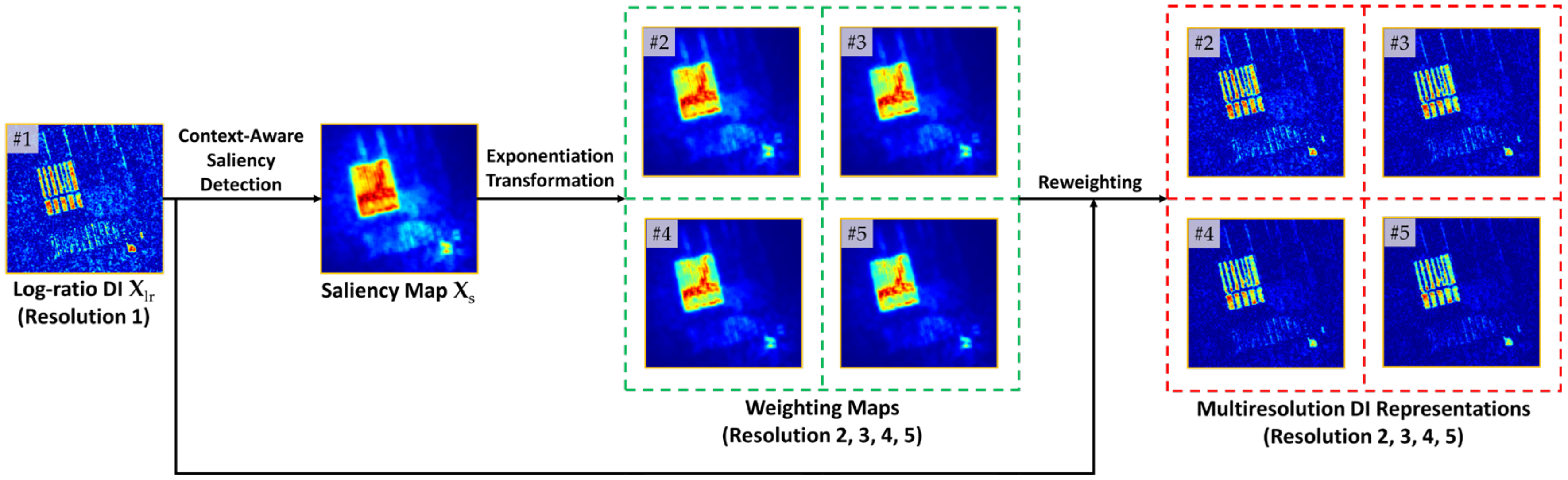
3.1.2. Multiresolution DI Generation
After acquiring the long-range context information, namely, the saliency prior
, we follow the general idea of multiresolution analysis (MRA) [
52,
53] for DI generation, thus allowing the change information to be represented at multiple levels. Unlike the typical MRA strategy that decomposes an input into different frequency sub-images, such as wavelet decomposition [
52] and Laplacian pyramid [
53], we empirically build on our previous work [
54]. In [
54], we constructed a spatially enhanced (SE) DI by fusing the saliency map with the log-ratio DI under a reweighting scheme. The main shortcoming of the SE DI generation was its dependence on the manual selection of the optimal fused DI, limiting the flexibility and expression capability.
In order to generalize this method to deal with the hybrid variabilities of SAR images, in this article, multiresolution DI is reconstructed level by level, which is automatic and selection-free. Here, MRA is a postprocessing fashion to convert the input image into different levels, and the concept of “resolution” here refers to the image level at which the fine image details can be expressed. At different resolutions, the details of an image describing different spatial structures can be reflected to different degrees.
To be specific, we reconstruct DIs from high resolution to low resolution under the reweighting scheme [
54]. The modeled spatial context
is injected into
to generate multiresolution representations of
by allocating varying degrees of attention to the salient changed parts. The reconstruction process at the resolution
l can be formulated as
where
denotes the reconstructed change magnitude at pixel position
at resolution level
l,
is the respective attention weight, and
is the normalized saliency map. In particular,
indicates the resolution level. As a consequence, the multiresolution representations
are established, where resolution 1 corresponds to the input itself, i.e.,
. As illustrated in
Figure 2, reconstructed images at high-resolution levels focus on describing small-scale regions or local details, while images at low-resolution levels emphasize large-scale regions or semantic content. To adequately represent change information at each pixel position, DIs
are hierarchically stacked in a high-resolution-to-low-resolution manner, denoted as
.
3.1.3. ESP Generation
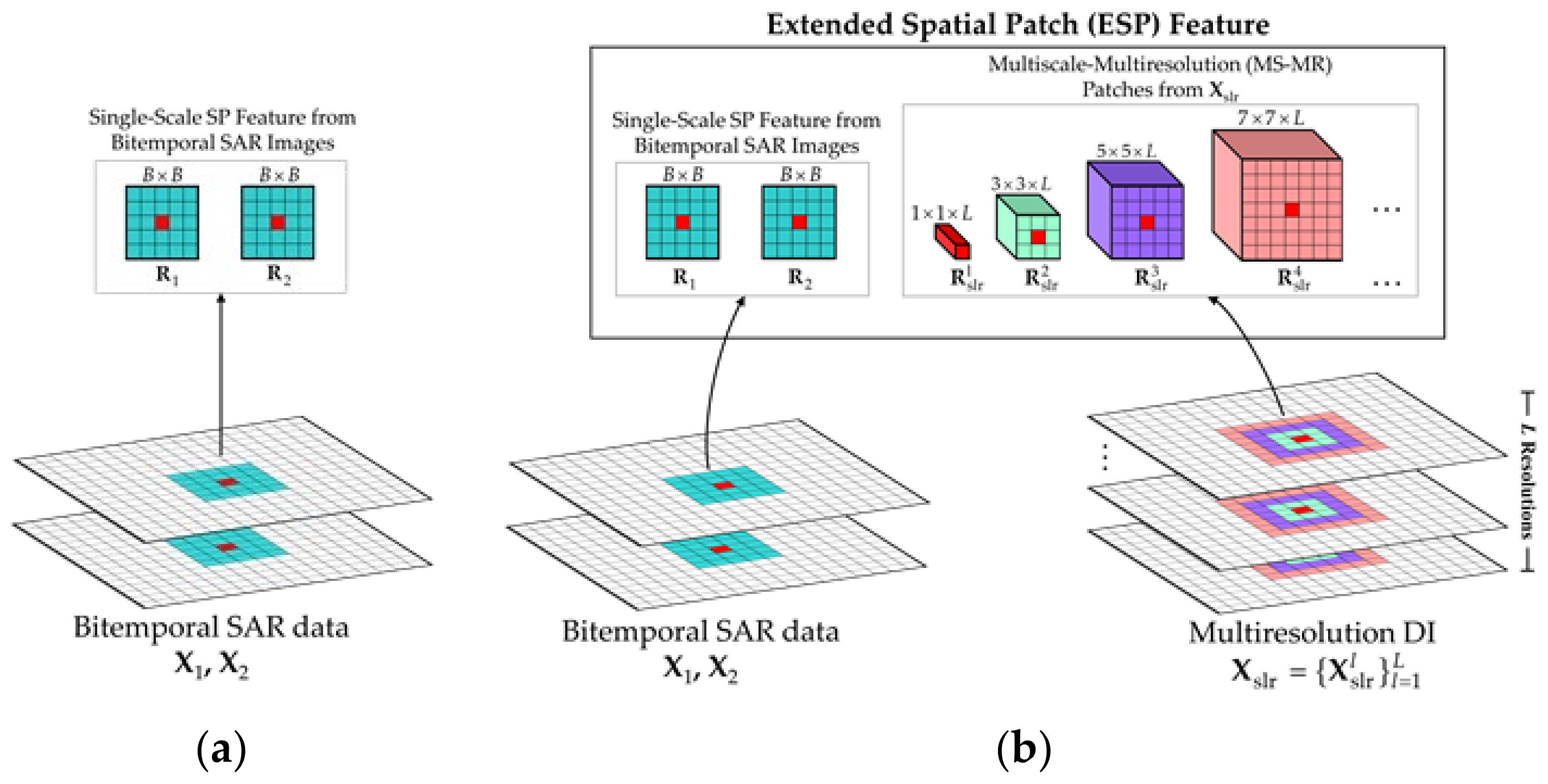
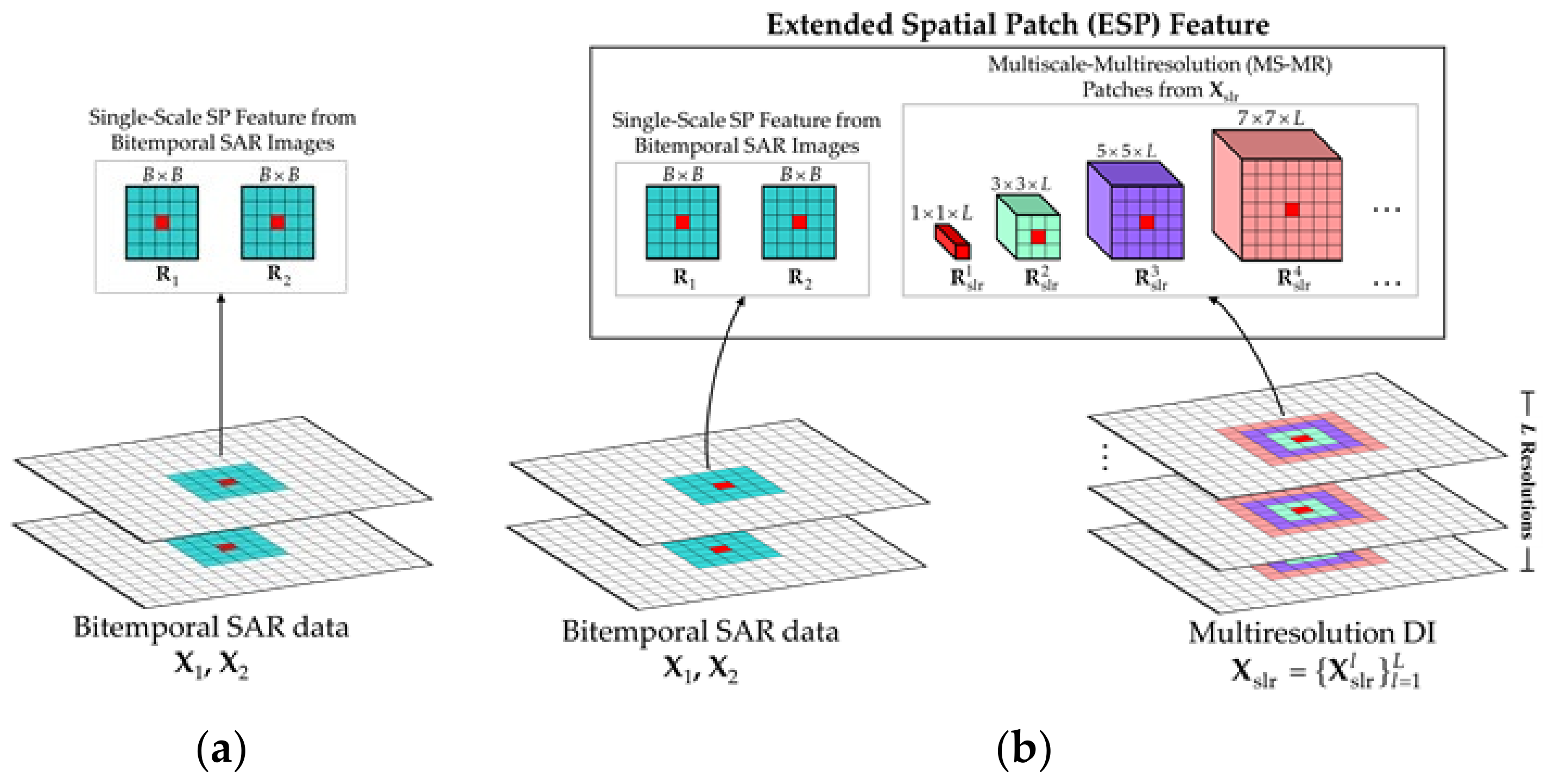
Due to the existence of diversified characteristics in real changed regions, the single-scale image patch feature, as shown in
Figure 3a, which is commonly utilized as the basic processing unit in deep learning-based CD approaches, fails to precisely and flexibly describe diverse characteristics of changed regions and differentiate pseudochanges. Motivated by seeking a new processing unit that can overcome the disadvantages of the single-scale patch, the ESP feature is constructed to better correlate with the human perception mechanism [
49,
50]. As shown in
Figure 3b, the generation of the ESP feature is accomplished by carrying out the following steps.
- 1.
MS-MR PatchAcquisition: Multiple overlapped adjacent regions at different scales but centered at the same pixel are extracted from
, constituting the MS-MR patch features
. Here, the
K scales of
correspond to the
K spatial dimensions
that allow the representational pixel to be located at the same central position, as shown in
Figure 3b. Particularly, for the
kth scale, the corresponding feature
is a localized cube of size
cropped from
. The MS-MR patch feature extraction is quite suitable for characterizing the change information at each pixel since it intuitively allows the central pixel to be represented at multiple levels.
- 2.
SP Feature Acquisition: To avoid information loss in the generation of DI, the original SP features are still cropped from SAR images and , respectively. These two patches separately carry respective local spatial information and content, which are of critical importance to delineate the shape and texture characteristics, especially for strip areas and edge areas surrounded by many easily confused pixels.
In this way, the bitemporal SAR images can be transformed into the ESP feature set where the subscript i denotes the image pixel index. In the proposed label-free CD framework, the ESP feature would be regarded as a basic element to perform the CD. Particularly, the ESP feature can be considered as a diverse information description for each pixel, making it feasible for deep models to capture different features. Note that the spatial dimension of , namely , is defined as the basic scale by default.
3.2. Class Rebalance Strategy
Theoretically, self-supervised learning can make use of all the pixels in images as training samples, similar to traditional clustering. Nevertheless, the significantly unequal contribution from the changed and unchanged class caused by the imbalance problem in SAR data [
13] will lead to training failure.
To tackle this problem, a class rebalance strategy based on hierarchical
k-means clustering is specially tailored to maintain the balance in the constructed training set, which is inspired by the clustering algorithm in [
38] but has a different purpose. That is to say, the label information estimated by the strategy is merely utilized to maintain a manageable class balance in the training set, rather than utilized as pseudolabels as in [
38]. Specifically, in this strategy, the reconstructed DI at the lowest resolution, namely
, is utilized as an input since it contains salient changed regions with less speckle and pseudochanges. Algorithm 1 details the rebalance strategy.
| Algorithm 1: Class Rebalance Strategy |
| Input: Image |
| Initialization: Iteration number ; counting parameter ; training set . |
1: Partitions into two clusters: changed cluster and unchanged cluster
by using k-means clustering.
(Here, the number of pixels in is denoted by .) |
| 2: Determines a threshold . |
| 3: Partitions into five subgroups: by using k-means clustering and their corresponding number of pixels is denoted as . |
| 4: Sort the subgroups by the average magnitude value in descending order. |
|
5: repeat |
| 6: , and . |
| 7: If , assign pixels in to changed set . |
| 8: If , assign pixels in to unchanged set . |
| 9: until |
10: Integrate all the pixels in changed set to . Sample the same number of
pixels from unchanged set into . |
| Output: Training set . |
In Algorithm 1, the parameter is empirically set to 1.5. Using this strategy, the balance between changed and unchanged classes in the obtained training set can be roughly reached, such that the inherent imbalance problem in SAR data can be greatly relieved. Meanwhile, the estimated labels resulting from this strategy are merely utilized as an important prior for rectifying the class distribution in the training set but not involved in subsequent network training.
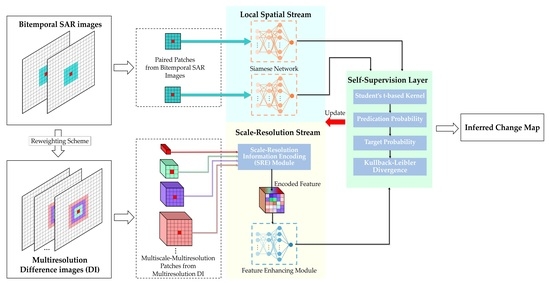
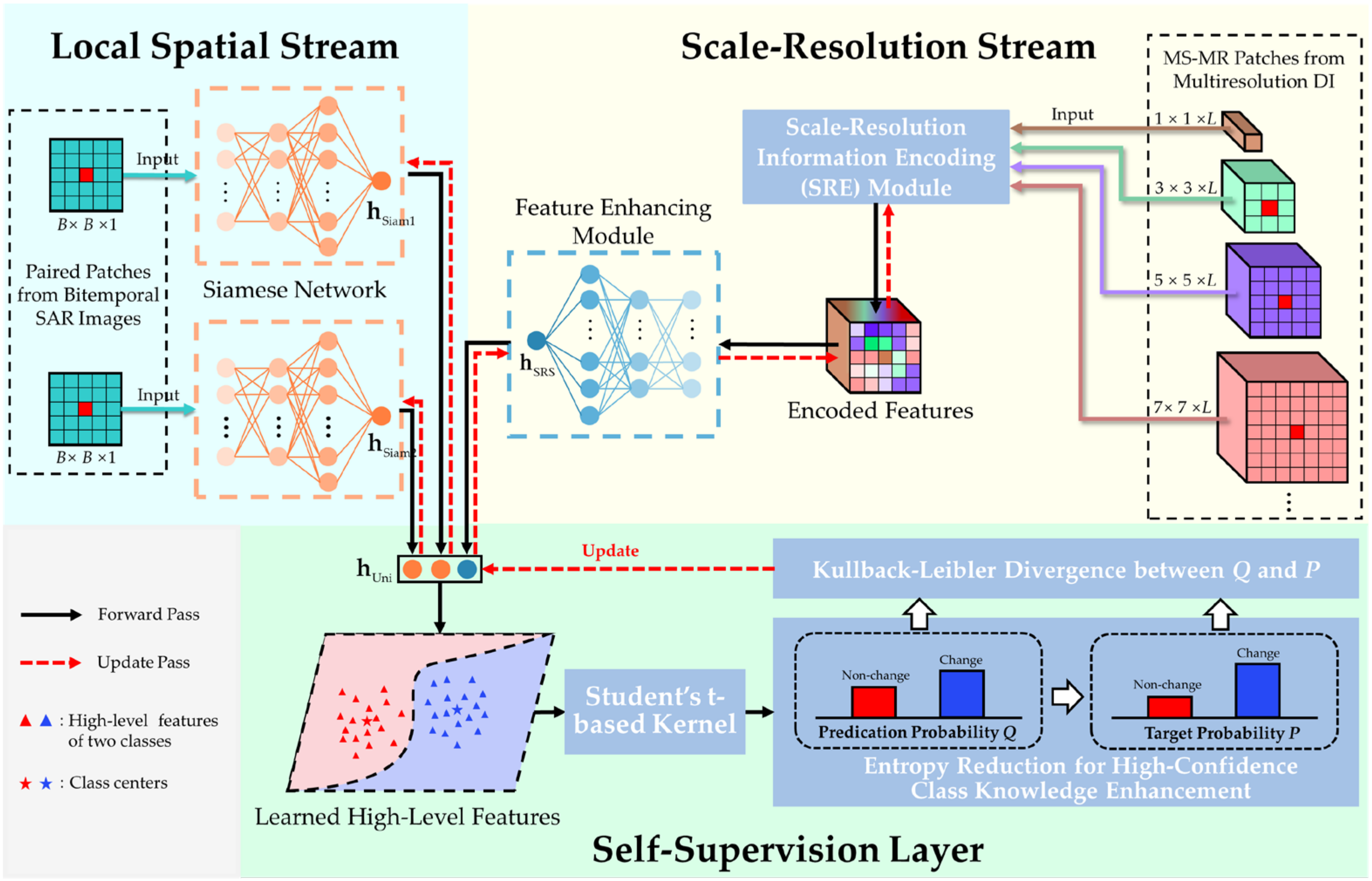
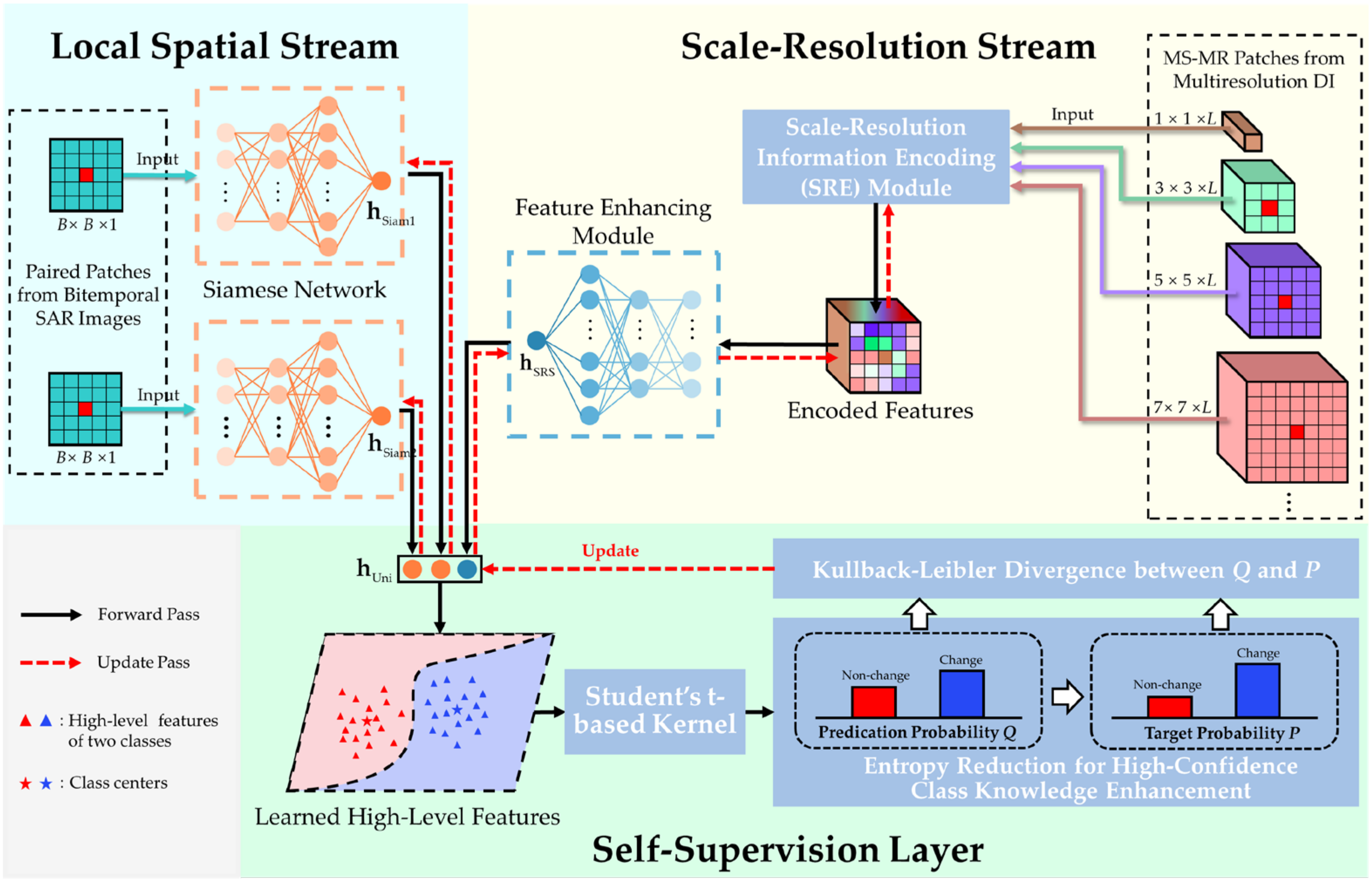
3.3. Hybrid Variability Aware Network
The pipeline of the proposed hybrid variability aware network (HVANet) is graphically illustrated in
Figure 4. The whole HVANet consists of two streams (i.e., the local spatial stream and the scale-resolution stream) and a self-supervision layer. The local spatial stream is a Siamese network (SiamNet) that handles the SP part in the ESP feature, while the scale-resolution stream is composed of two modules that are in charge of processing the MS-MR part in the ESP feature. In this way, local structural features and encoded MS-MR features that contribute to the changed region identification are further extracted, following which the self-supervision layer combines the two types of features together into a high-level feature and classifies it. Intrinsically, the HVANet projects the ESP features into a learned high-level feature space, where the features are semantically discriminative and feature classification is easier.
3.3.1. Local Spatial Stream
As shown in
Figure 4, the local spatial stream consists of a pair of twin subnetworks with symmetric structure and shared weights, referred to as the Siamese network (SiamNet) [
47,
48,
55]. Unlike the traditional DNN-based methods [
30,
37], which concatenates the paired patches, i.e., SP, and processes it using a deep network, the two-branch architecture enables the SiamNet to learn respective local structural features from the paired inputs in the same way. Hence, the changed patch pair will have paired features away from each other. Meanwhile, the unchanged patch pair will have pretty similar activations on the corresponding features. Considering that the CD task seeks to measure the dissimilarity between the paired pixels, such a SiamNet architecture is naturally appropriate for further improving the accuracy of change information extraction. Specifically, the SiamNet is composed of
fully connected layers, where layer-wise feature extraction can be formulated as
where
and
denote the bilateral inputs and outputs corresponding to the
lth fully connected layer,
represent the weights and bias at this layer, and
is a nonlinear function. The final outcomes
at the
fully connected layer are the learned features in the local spatial stream, denoted as
for clarity.
Benefiting from the bilateral feature extraction nature of the SiamNet architecture, the fine structure information in and is separately and independently preserved in and , thus promoting better spatial information description.
3.3.2. Scale-Resolution Stream
In the local spatial stream, the patch-wise content primarily influences the local structure feature extraction. However, as SAR images often contain too many changed regions with arbitrary sizes, shapes, and textures, it is still arduous to accurately identify changes of interest using merely the original SP features. To further facilitate the distinguishability of learned high-level features, the scale-resolution stream is appended to compensate for the missing contextual information to cope with the hybrid variabilities.
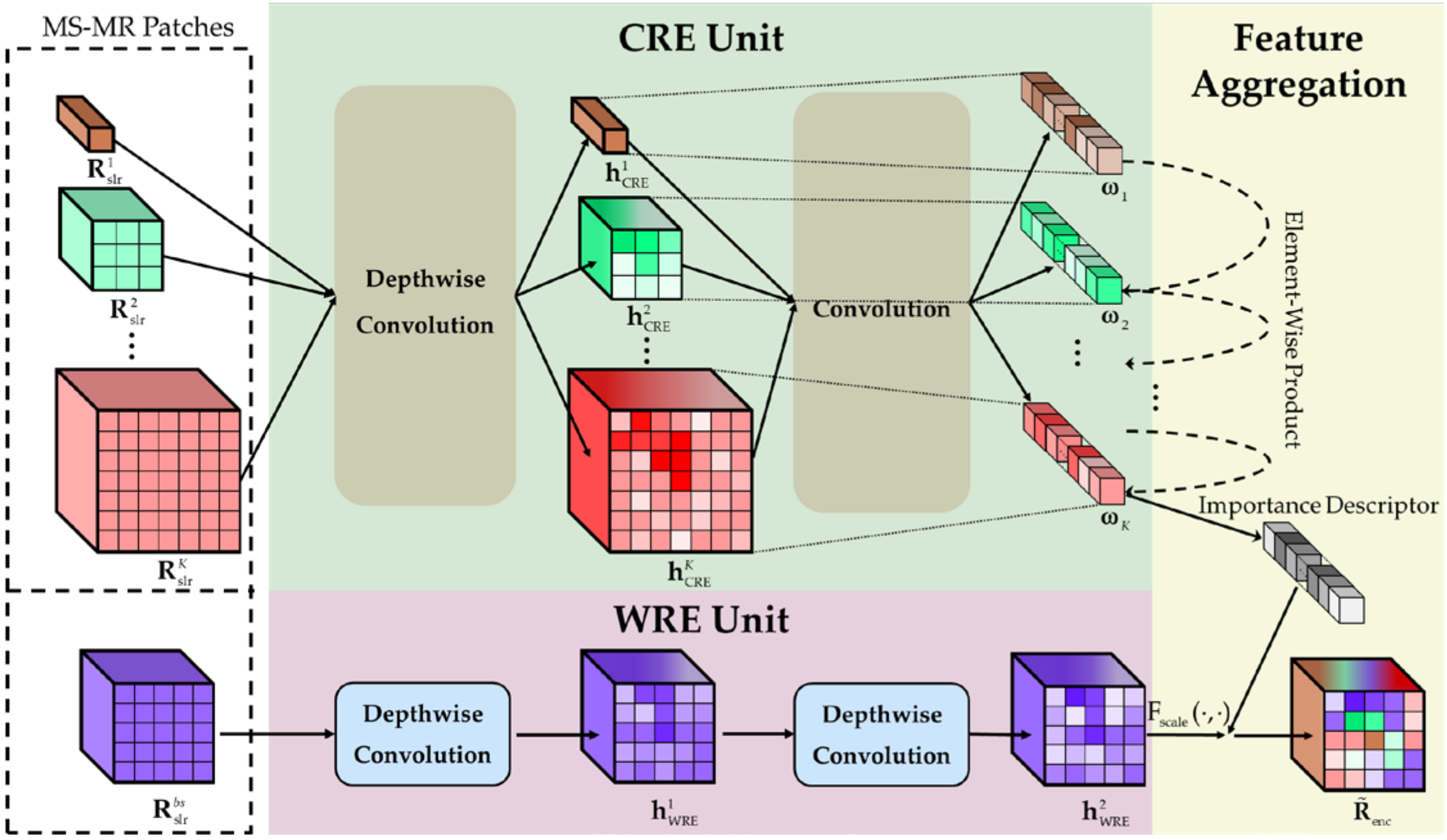
To fully make use of the MS-MR information to obtain a spatially and semantically powerful feature representation complementary to the structure feature in the local spatial stream, a scale-resolution information encoding module (SRE) is first devised to encode the information in the MS-MR patches. In reality, not all scales or resolutions are equally important for contributing to the CD task. Therefore, channel attention [
56] is introduced into SRE to learn what features to highlight; that is, more informative scales and resolutions should be emphasized while secondary ones should be suppressed, thus acquiring an encoded feature. Immediately after the SRE module, an ordinary DNN is attached to extract high-level representation further.
(1)Scale-ResolutionInformationEncoding Module: To concentrate on the task-related features and suppress secondary information automatically, the SRE is proposed. The MS-MR patches in the ESP feature, i.e.,
, are used as inputs of this module. Specifically, the cross-resolution information encoding unit (CRE) and within-resolution information encoding unit (WRE) are placed in parallel to process the MS-MR input
. The CRE is responsible for capturing the informative scale and resolution clues and compressing the secondary information, while WRE is in charge of compensating the necessary spatial content. Later, the features extracted by the two units are aggregated as in channel attention [
56] to embrace the key scale and resolution clues and redistribute the change feature representation, finally strengthening the representation ability. The SRE module is illustrated graphically in
Figure 5.
The CRE unit contains
K-1 convolution branches, each of which is composed of two convolution operations: a depthwise convolution (DWC) [
57] and an ordinary convolution. The CRE unit aims to explore the cross-resolution correspondence for each patch feature in
to capture the informative scale and resolution clues. Particularly, the patch at the basic scale, i.e.,
, is utilized as the input of WRE and not involved in this unit. Without loss of generality, we describe the encoding process for the
kth feature
to illustrate the CRE unit. Specifically, a DWC operation with kernel size 1 × 1 is firstly applied to
as
where weight and bias
correspond to
,
denotes a nonlinear activation function, and the symbol
represents the DWC operation. Here, the 1 × 1 DWC convolves the input patch channel-by-channel, thus capturing the nonlinear spatial features at each resolution without changing the spatial dimension. Following this, the cross-resolution correspondence is realized through a normal convolution (Conv) with the kernel size
, thus learning an importance descriptor of the different resolutions adaptively, as
where
denote the weights and biases of the current Conv layer,
represent the sigmoid function, and the symbol
denotes convolution. Since the regular Conv kernel will fuse the entities across channels, the compressed feature vector
is captured by summarizing both the within-resolution and cross-resolution information. Moreover, the importance descriptor of different resolutions can be learned at each scale, which carries both resolution and scale clues.
After extracting importance descriptors at
K-1 scales in the CRE unit, most secondary information in
is compressed. To compensate for the compressed information, we propose a simple yet effective WRE unit. Specifically, the WRE unit is in charge of processing the unique feature
at the basic scale
bs (
), of which the height and width are the same as the SP feature
. This unit encodes the internal change information at each resolution in
without any cross-resolution correspondence by sequentially using two learnable 1 × 1 DWC layers, as
where
and
denote the weights and biases of the two 1 × 1 DWC layers, respectively, and
,
are the corresponding outputs. Relying on the depthwise operation nature that employs a single convolutional filter per input channel, dimension-invariant nonlinear transformation is realized using the 1 × 1 DWC kernels, and internal spatial information at different resolutions can be separately preserved.
To embrace the different scale clues and focus on the informative resolutions simultaneously, it is a natural belief that the learned importance descriptors at different scales in CRE should be fully combined and then weight the extracted features in WRE; thus, the scale, resolution, and spatial information can be harmoniously integrated together. To this end, the features
and
are aggregated as in the channel attention mechanism [
56]. Formally,
where the symbol
denotes the element-wise product and
is the integrated importance descriptor. Particularly,
refers to the channel-wise product between
and
, and its output
is the final encoded features, where the whole MS-MR information is selectively and automatically summarized. As described earlier, the SRE module intrinsically performs the channel-wise attention, which jointly emphasizes the features from informative resolutions and scales according to the learned importance descriptors and promotes the feature learning to be aware of the variable size and texture characteristics.
(2) FeatureEnhancing Module: Immediately after the SRE module, a regular DNN is utilized as a feature extractor to learn high-level features to enhance the representation power, called the feature enhancing module (FE), which has the same architecture as the two branches of SiamNet. This module learns an adaptive mapping function that takes the encoded feature as the input and generates the high-level feature , namely the final outcome of the scale-resolution stream.
3.3.3. Greedy Layer-Wise Unsupervised Pretraining
The direct application of self-supervised learning is very challenging given the high dimensionality of the ESP features. To better initialize the network weights and capture some useful features, we propose to adopt greedy layer-wise unsupervised pretraining [
58,
59,
60]. Specifically, the SiamNet in the local spatial stream and the FE module in the scale-resolution stream are individually pretrained.
Considering the specific architecture of the SiamNet, we design a symmetric layer-wise pretraining strategy to promote the target-specific feature learning. Specifically, the initial weight matrix and bias vector of the
lth layer in SiamNet is learned through a specially designed Siamese autoencoder (SiamAE) with a single hidden layer. For the
lth layer in SiamNet, the corresponding SiamAE can be formulated as
where
,
, and
denote the input, hidden representation, and output of the SiamAE.
and
represent the weight matrix and bias vector of the encoder and decoder in the SiamAE, respectively. The input
of the first layer is the SP feature; i.e.,
. Finally, initialization is achieved by minimizing the L2 norm of the difference between
and
:
After being pretrained by this strategy, the weights and biases of the lth layer will be kept unchanged in the pretraining stage. With the symmetric layer-wise pretraining strategy that enforces the SiamAE to reconstruct the SP feature, the SiamNet in the local spatial stream is encouraged to extract some useful features to provide a better parameter initialization.
Similar to the symmetric layer-wise pretraining described above, the pretraining strategy for the
lth layer of the FE module in the scale-resolution stream can be summarized as follows:
Here, the input of the first layer is
in the ESP feature. As such, the FE module is pretrained layer-by-layer. By means of the pretraining strategy, most network weights in HVANet can be well initialized. Since the multi-branch architecture of the SRE module in the scale-resolution stream cannot be pretrained in such a layer-wise way, weights in the SRE are initialized using the technique described in [
61].
3.3.4. Self-Supervised Fine-Tuning
(1) Self-supervision Layer: Due to the lack of ground truth labels in SAR data, training targets are not available for unsupervised learning. As a result, it is necessary to explore how to eliminate the requirement of labeled data by creating learning signals for model training. To this end, a specialized self-supervision layer is constructed to allow performing feature classification and providing learning signals for fine-tuning simultaneously, which is inspired by the deep embedded clustering method [
62].
Specifically, given the training set , the two streams in HVANet can extract three features for each input. The self-supervision layer combines them together to form a united feature, as , under which the two streams are also united into one framework. Later, we compute the initial class centers by performing k-means on , where subscript “0” represents the unchanged class and “1” represents the changed class. These initial class centers will provide an approximate optimization direction and enable the later learning process, namely the self-supervision.
We calculate the probability that the
ith input sample is assigned to the
jth class by measuring the similarity between
and
based on a Student’s
t-distribution-based kernel [
62], as
where
is the united high-level feature corresponding to the
ith input
. The rationale behind the probability calculation is to use the Student’s
t-distribution as a kernel to transform the similarity of a feature to a certain class center into the class probability. In this regard, the heavy-tailed property of the Student’s
t-distribution is powerful for robustly fitting and describing the feature distribution in the high-level feature space. In addition, beyond the initial class centers
that are calculated by directly performing
k-means on
H, the class centers can be updated automatically in training, as further described in the following subsections.
It is intuitive that the inputs with high confidence could provide more reliable class knowledge and be utilized as learning signals to guide the network fine-tuning in a self-supervised manner. In this direction, the supervision signal is constructed by raising
to the second power to emphasize the reliable class knowledge, as
where
is the soft frequency of the
jth class and
is the newly created supervision signal for the
ith input feature. The soft frequency
helps to normalize the contribution of each training sample, such that class imbalance can be further alleviated.
The supervision signal is completely generated from the probability but with reduced entropy since it is calculated by raising to the second power. Consequently, the training target is constructed by paying attention to the credible unlabeled samples with high predicated class probability, the so-called self-supervision.
(2) Self-supervision Loss: To progressively force the model to learn with useful class knowledge from unlabeled features themselves, the training target
is constructed and can provide a meaningful optimization objective for the fine-tuning of HVANet. Using such a self-supervision strategy, the HVANet is encouraged to output low-entropy (i.e., highly confident) predictions and progressively achieve entropy minimization. Following this idea, a Kullback–Leibler (KL) divergence-based loss function is adopted to quantify the similarity between the predicted distribution
Q and the target distribution
P, as
Herein, KL divergence between distributions Q and P is adopted as an objective for network optimization. Minimizing the objective function encourages the similar features to cluster together while separating the dissimilar features in the learned high-level space, such that the classification in the feature space becomes easier.
(3) Optimization: To effectively fine-tune the HVANet in a completely unsupervised manner, both the network weights
and class centers
should be updated with back propagation based on the self-supervised loss
. The optimization can be formulated as
where
denotes the learning rate. The update of class centers provides the optimization direction for the next training epoch. More importantly, the repeated update of network weights encourages HVANet to learn useful class knowledge from unlabeled samples and promote the model performance progressively.
3.3.5. Computational Complexity Analysis
Here, we provide a rough evaluation on the computational complexity of the HVANet. To be specific, the computational cost of each training epoch comes mainly from calculating features in the local spatial stream and calculating feature in the scale-resolution stream. Hence, in this section, we analyze the computational complexity of the HVANet, given n input ESP features .
In the training of the local spatial stream, the
n pairs of patches
are fed into the first layer with
neutrons. For each output neuron at the first fully connected layer, when one flattened image patch is fed, there are
multiplications between weights and inputs and
additions to sum the multiplication results and bias. As the nonlinear activation function is applied to the outputs of the fully connected layers, the computational complexity of the utilized nonlinear function should be considered, which is denoted as
floating point operations (flops) for the sake of clarity. Therefore, there are
flops for a pair of input patches
. Similarly, the next fully connected layer has
flops. In this way, for the SiamNet in the local spatial stream which has
fully connected layers, the total number of flops (abbreviated as
) can be formulated as
Hence, the computational complexity of the local spatial stream at each training epoch can be represented as flops.
As for the scale-resolution stream, both the computational complexities of the SRE module and the FE module should be considered, respectively. As the elaboration in
Section 3.3.2, when
n MS-MR patch features
are fed into the SRE module, the CRE unit processes the features
while the WRE unit processes the feature
. On the one hand, the CRE unit contains
branches, each of which successively performs the DWC and an ordinary convolution operation. For the
kth branch in the CRE unit, the corresponding input feature
is processed using a DWC operation with kernel size
, which involves
multiplications for the combination between the kernel and input, and
additions between the combination and bias. Since each pixel in the feature map of DWC should be processed by the nonlinear function, the resulting computational complexity is
flops. Later, when the activated output
is fed into an ordinary Conv layer with kernel size
, there are
multiplications and
additions. Besides, there is an additional computational complexity
caused by the nonlinear function. Thus, the total computational complexity of the
branches in the CRE unit can be summarized as
flops. On the other hand, the WRE unit processes the
using two successive DWC operations with kernel size
, which involves
multiplications,
additions. Two nonlinear functions also cause
flops. For the feature aggregation in CRE, the integration of the learned importance descriptors
involves
multiplications and channel-wise attention requires
multiplications. Finally, the encoded feature
is fed into the FE module, which has an identical network architecture to the SiamNet, but the dimension number of the input layer is
. In summary, the total number of flops of the scale-resolution stream (abbreviated as
) can be summarized as
Consequently, given n input ESP features , the computational complexity of the entire HVANet at each training epoch can be represented as flops.
According to the above analysis, the main computational cost comes from the SiamNet in the local spatial stream and the FE module in the scale-resolution stream, where the fully connected layers account for most parameters in HVANet. By contrast, we introduce the channel-wise attention and the DWC operation for the MS-MR information encoding in the SRE module, enabling effective feature extraction with negligible computation cost. Moreover, the small sizes of the patches in the ESP feature determine that the scale of the utilized fully connected layers and the corresponding computational complexity is relatively limited, which means the HVANet is lightweight and efficient in the training phase and inference phase. To further illustrate the computational complexity of the HVANet, we compare the training time and inference time of the HVANet with other unsupervised CD methods in
Section 4.
5. Discussion
The experimental results are provided in
Section 4 and illustrate that the proposed label-free method achieves better and more robust CD performance for SAR images than the competing methods. The reason why the proposed method surpasses the compared state-of-the-art methods resides in three aspects. One is that, inspired by the human perception mechanism that processes local and global information independently, we construct the shallow feature by combining the local patches and context-rich MS-MR patches, displacing the traditional single-scale processing unit. The context information and diverse scale and resolution information contained in the constructed ESP features are conducive to improving the description for change information and making it more differentiated from the speckle and pseudochanges. The second reason lies in the two-stream feature extraction in HVANet, which combines the local spatial feature extraction and MS-MR information encoding into one framework, improving the representation power of the learned high-level features. Particularly, the channel attention mechanism is adopted in the scale-resolution stream to effectively aggregate the key multiscale clues and multiresolution clues for better feature representation. Third, the self-supervision layer enables the feature learning and classification to be automatic, end-to-end, and label-free. Despite real labels and the corresponding class knowledge being unavailable, the performance of our HVANet matches or exceeds that of the compared state-of-the-art methods.
From the ablation experiments in
Section 4.3, we illustrate the contribution of each component in HVANet and the class rebalance strategy. In
Table 2, the results show that the Siamese structure is naturally more suitable for CD tasks due to the separate processing of the SAR image patch pair. As in
Table 3, the results show that the scale-resolution stream really extracts semantically distinguishable features that can greatly enhance the description of change information, thus improving the detection accuracy. For the hybrid variations of sizes, shapes, and textures in changed regions, the scale-resolution can better model them and intensify the robustness of the CD system. The main reason is that not only can the deep architecture process the complex SAR data in a nonlinear way, but also local features and contextual semantic features can be extracted in the two streams of HVANet to contribute to the CD tasks. Meanwhile, the class imbalance in SAR data also poses challenges for CD tasks. For this, we propose the class rebalance strategy to redistribute the training samples to achieve a balanced class distribution in the training set. The results in
Table 4 demonstrate that the proposed hierarchal clustering-based strategy can provide better results than ordinary
k-means clustering. Moreover, the deep learning-based competing methods, including PCANet, DDNet, CWNN, INLPG-CWNN, and SGDNNs, neglect this problem, where the distribution of the constructed training set is severely imbalanced. According to the results in
Table 8,
Table 9,
Table 10 and
Table 11 and
Figure 10,
Figure 11 and
Figure 12, the detection performance of these methods is unstable, which more or less reflects the negative impact of the class imbalance on the model performance.
According to the experimental results in
Section 4.6, we can conclude that the proposed method matches or even exceeds the competing methods from the perspectives of performance, generalization, and robustness. It can be seen from
Figure 10,
Figure 11 and
Figure 12 that the results of the proposed methods are closer to the ground truth map, with fewer false positive and false negative pixels. The same conclusion can also be made from the evaluation criteria provided in
Table 8,
Table 9,
Table 10 and
Table 11. Accordingly, all these results confirm that both local structure information and the context-rich MS-MR information help to jointly retrieve more details and suppress speckle and pseudochanges, meaning that the shallow feature extraction and the corresponding two-stream network architecture are obviously suitable for the CD tasks in SAR imagery.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}