
Data Gap Filling Using Cloud-Based Distributed Markov Chain Cellular Automata Framework for Land Use and Land Cover Change Analysis: Inner Mongolia as a Case Study




Abstract
:1. Introduction
1.1. Missing Data in LULC Change Research
1.2. Gap Filling Modeling Approaches
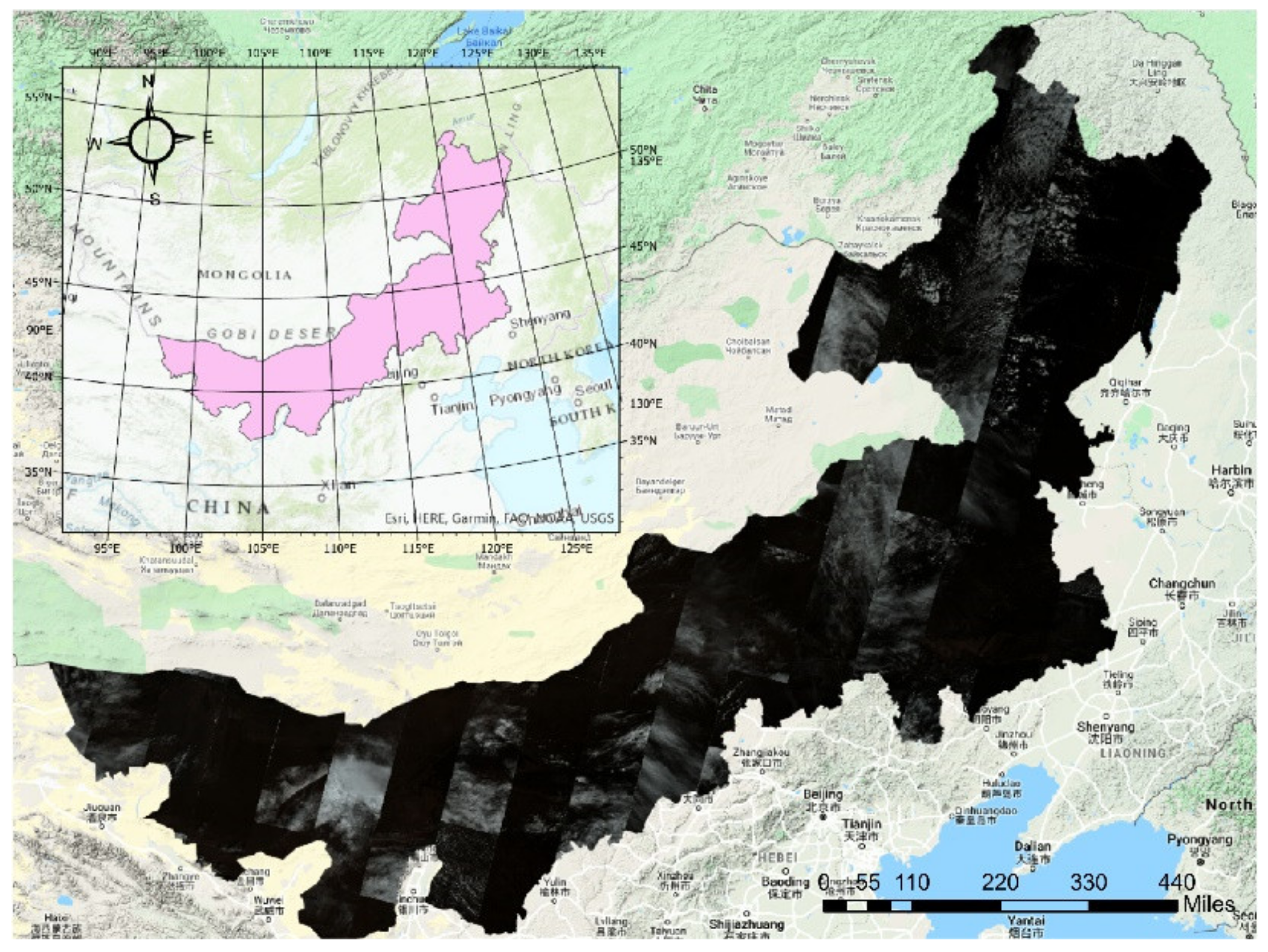
2. Study Area and Dataset
2.1. Study Area
2.2. Data Availability
3. Methodology
3.1. Workflow
3.2. LULC Data Preparation
3.3. Sub-Space Simulation by Adopting Data Mining Techniques
3.4. Implementing Cloud-Based Distributed Markov–CA Model
3.4.1. Multi-Temporal Markov Processing for Filling Missing Data
| Algorithm 1 Distributed calculating probability matrix using Apache Spark |
| 1: def Mapper (Key, Value) |
| 2: Foreach cell in LULC dataset: |
| 3: Emit (Cij, 1); |
| 4: |
| 5: def Reducer (Key, int[] Values) |
| 6: int SUM = 0; |
| 7: Foreach count in values: |
| 8: SUM += count; |
| 9: Emit (Cij, SUMij); |
| 10: Pij = SUMij/SUMTotal |
| 11: Emit (SUMij, Pij) |
3.4.2. Localized Model Training to Fine-Tune Transition Rules
3.4.3. Fine-Tuned CA Simulation on the Cloud
| Algorithm 2 Distributed processing CA model with Apache Giraph |
| 1: class GiraphCA |
| 2: MaxSuperStep ← user defined value |
| 3: function compute (vertex, messages): |
| 4: if getSuperstep() == 0 then |
| 5: sendMessage to all neighbors, assign weight, |
| 6: compute (Eij = neighbor weight × suitability value) |
| 7: if getSuperstep() <= MaxSuperStep then |
| 8: Foreach cell in study area: |
| 9: While (true): |
| 10: if max(Eij) > area limit then |
| 11: max(Eij) = 0 |
| 12: else |
| 13: convert i to j; |
| 14: break; |
| 15: end if |
| 16: else |
| 17: voteToHalt() |
| 18: end if |
| 19: end if |
3.5. Experiment Environment
4. Results
4.1. Simulation Results and Accuracy Assessment
4.2. The Performance of Cloud-Based LULC Data Gap Filling Framework
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Townshend, J.; Justice, C.; Li, W.; Gurney, C.; McManus, J. Global land cover classification by remote sensing: Present capabilities and future possibilities. Remote Sens. Environ. 1991, 35, 243–255. [Google Scholar] [CrossRef]
- Dewan, A.M.; Yamaguchi, Y. Land use and land cover change in Greater Dhaka, Bangladesh: Using remote sensing to promote sustainable urbanization. Appl. Geogr. 2009, 29, 390–401. [Google Scholar] [CrossRef]
- Liu, J.; Kuang, W.; Zhang, Z.; Xu, X.; Qin, Y.; Ning, J.; Zhou, W.; Zhang, S.; Li, R.; Yan, C. Spatiotemporal characteristics, patterns, and causes of land-use changes in China since the late 1980s. J. Geogr. Sci. 2014, 24, 195–210. [Google Scholar] [CrossRef]
- Li, X.; Shen, H.; Li, H.; Zhang, L. Patch matching-based multitemporal group sparse representation for the missing information reconstruction of remote-sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3629–3641. [Google Scholar] [CrossRef]
- Xing, J.; Sieber, R.; Caelli, T. A scale-invariant change detection method for land use/cover change research. ISPRS J. Photogramm. Remote Sens. 2018, 141, 252–264. [Google Scholar] [CrossRef]
- Zeng, C.; Shen, H.; Zhang, L. Recovering missing pixels for Landsat ETM+ SLC-off imagery using multi-temporal regression analysis and a regularization method. Remote Sens. Environ. 2013, 131, 182–194. [Google Scholar] [CrossRef]
- Gafurov, A.; Bárdossy, A. Cloud removal methodology from MODIS snow cover product. Hydrol. Earth Syst. Sci. 2009, 13, 1361–1373. [Google Scholar] [CrossRef] [Green Version]
- Tseng, D.-C.; Tseng, H.-T.; Chien, C.-L. Automatic cloud removal from multi-temporal SPOT images. Appl. Math. Comput. 2008, 205, 584–600. [Google Scholar] [CrossRef]
- Shen, H.; Li, X.; Cheng, Q.; Zeng, C.; Yang, G.; Li, H.; Zhang, L. Missing information reconstruction of remote sensing data: A technical review. IEEE Geosci. Remote Sens. Mag. 2015, 3, 61–85. [Google Scholar] [CrossRef]
- Ballester, C.; Bertalmio, M.; Caselles, V.; Sapiro, G.; Verdera, J. Filling-in by joint interpolation of vector fields and gray levels. IEEE Trans. Image Process. 2000, 10, 1200–1211. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Li, W.; Travis, D. Gaps-fill of SLC-off Landsat ETM+ satellite image using a geostatistical approach. Int. J. Remote Sens. 2007, 28, 5103–5122. [Google Scholar] [CrossRef]
- Shen, H.; Zeng, C.; Zhang, L. Recovering reflectance of AQUA MODIS band 6 based on within-class local fitting. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 185–192. [Google Scholar] [CrossRef]
- Gladkova, I.; Grossberg, M.D.; Shahriar, F.; Bonev, G.; Romanov, P. Quantitative restoration for MODIS band 6 on Aqua. IEEE Trans. Geosci. Remote Sens. 2012, 50, 2409–2416. [Google Scholar] [CrossRef]
- Melgani, F. Contextual reconstruction of cloud-contaminated multitemporal multispectral images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 442–455. [Google Scholar] [CrossRef]
- Zhang, J.; Clayton, M.K.; Townsend, P.A. Functional concurrent linear regression model for spatial images. J. Agric. Biol. Environ. Stat. 2011, 16, 105–130. [Google Scholar] [CrossRef]
- Cheng, Q.; Shen, H.; Zhang, L.; Yuan, Q.; Zeng, C. Cloud removal for remotely sensed images by similar pixel replacement guided with a spatio-temporal MRF model. ISPRS J. Photogramm. Remote Sens. 2014, 92, 54–68. [Google Scholar] [CrossRef]
- Halmy, M.W.A.; Gessler, P.E.; Hicke, J.A.; Salem, B.B. Land use/land cover change detection and prediction in the north-western coastal desert of Egypt using Markov-CA. Appl. Geogr. 2015, 63, 101–112. [Google Scholar] [CrossRef]
- Baker, W.L. A review of models of landscape change. Landsc. Ecol. 1989, 2, 111–133. [Google Scholar] [CrossRef]
- Fan, F.; Wang, Y.; Wang, Z. Temporal and spatial change detecting (1998–2003) and predicting of land use and land cover in Core corridor of Pearl River Delta (China) by using TM and ETM+ images. Environ. Monit. Assess. 2008, 137, 127. [Google Scholar] [CrossRef]
- Weng, Q. Land use change analysis in the Zhujiang Delta of China using satellite remote sensing, GIS and stochastic modelling. J. Environ. Manag. 2002, 64, 273–284. [Google Scholar] [CrossRef] [Green Version]
- Overmars, K.D.; de Koning, G.; Veldkamp, A. Spatial autocorrelation in multi-scale land use models. Ecol. Model. 2003, 164, 257–270. [Google Scholar] [CrossRef]
- Pontius, R.G., Jr.; Chen, H. GEOMOD Modeling; Clark University: Worcester, MA, USA, 2006; Volume 44, pp. 1–45. [Google Scholar]
- Ye, B.; Bai, Z. Simulating land use/cover changes of Nenjiang County based on CA-Markov model. In Proceedings of the International Conference on Computer and Computing Technologies in Agriculture, Wuyishan, China, 18–20 August 2007; pp. 321–329. [Google Scholar]
- Mendes, R.L.; Santos, A.A.; Martins, M.; Vilela, M. Cluster size distribution of cell aggregates in culture. Phys. A Stat. Mech. Appl. 2001, 298, 471–487. [Google Scholar] [CrossRef]
- Zhao, Y.; Billings, S.A.; Coca, D.; Ristic, R.; DeMatos, L. Identification of the transition rule in a modified cellular automata model: The case of dendritic NH4Br crystal growth. Int. J. Bifurc. Chaos 2009, 19, 2295–2305. [Google Scholar] [CrossRef] [Green Version]
- Qiu, G.; Kandhai, D.; Sloot, P. Understanding the complex dynamics of stock markets through cellular automata. Phys. Rev. E 2007, 75, 046116. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, Y. A generalized model for cellular urban dynamics. Geogr. Anal. 1996, 28, 350–373. [Google Scholar] [CrossRef]
- He, C.; Okada, N.; Zhang, Q.; Shi, P.; Li, J. Modelling dynamic urban expansion processes incorporating a potential model with cellular automata. Landsc. Urban Plan. 2008, 86, 79–91. [Google Scholar] [CrossRef]
- Di Gregorio, S.; Kongo, R.; Siciliano, C.; Sorriso-Valvo, M.; Spataro, W. Mount Ontake landslide simulation by the cellular automata model SCIDDICA-3. Phys. Chem. Earth Part A Solid Earth Geod. 1999, 24, 131–137. [Google Scholar] [CrossRef]
- Batty, M.; Xie, Y.; Sun, Z. Modeling urban dynamics through GIS-based cellular automata. Comput. Environ. Urban Syst. 1999, 23, 205–233. [Google Scholar] [CrossRef] [Green Version]
- Fonstad, M.A. Cellular automata as analysis and synthesis engines at the geomorphology–Ecology interface. Geomorphology 2006, 77, 217–234. [Google Scholar] [CrossRef]
- Guan, D.; Li, H.; Inohae, T.; Su, W.; Nagaie, T.; Hokao, K. Modeling urban land use change by the integration of cellular automaton and Markov model. Ecol. Model. 2011, 222, 3761–3772. [Google Scholar] [CrossRef]
- Xie, Y.; Fan, S. Multi-city sustainable regional urban growth simulation—MSRUGS: A case study along the mid-section of Silk Road of China. Stoch. Environ. Res. Risk Assess. 2014, 28, 829–841. [Google Scholar] [CrossRef]
- Hou, X. 1:1 Million Vegetation Map of China; National Tibetan Plateau Data Center: Beijing, China, 2019. [Google Scholar]
- Lan, H.; Xie, Y. A semi-ellipsoid-model based fuzzy classifier to map grassland in Inner Mongolia, China. ISPRS J. Photogramm. Remote Sens. 2013, 85, 21–31. [Google Scholar] [CrossRef]
- Tong, C.; Wu, J.; Yong, S.-p.; Yang, J.; Yong, W. A landscape-scale assessment of steppe degradation in the Xilin River Basin, Inner Mongolia, China. J. Arid Environ. 2004, 59, 133–149. [Google Scholar] [CrossRef]
- Bai, Y.; Han, X.; Wu, J.; Chen, Z.; Li, L. Ecosystem stability and compensatory effects in the Inner Mongolia grassland. Nature 2004, 431, 181–184. [Google Scholar] [CrossRef]
- Xie, Y.; Zhang, Y.; Lan, H.; Mao, L.; Zeng, S.; Chen, Y. Investigating long-term trends of climate change and their spatial variations caused by regional and local environments through data mining. J. Geogr. Sci. 2018, 28, 802–818. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Zhong, J.; Lan, H.; Wang, Z.; Sha, Z. Association analysis between spatiotemporal variation of net primary productivity and its driving factors in inner Mongolia, China during 1994–2013. Ecol. Indic. 2019, 105, 355–364. [Google Scholar] [CrossRef]
- IMIRSD. GIS Maps of Inner Mongolia Land Uses and Land Covers in 2000, 2010, and 2016; IMIRSD: Minnetonka, MN, USA, 2020. [Google Scholar]
- OpenStreetMap. Available online: https://www.openstreetmap.org/ (accessed on 3 February 2020).
- CMDC. Available online: http://data.cma.cn/data/ (accessed on 3 February 2020).
- Hutchinson, M.F.; Xu, T. Anusplin Version 4.2 User Guide; Centre for Resource and Environmental Studies, The Australian National University: Canberra, Australia, 2004; Volume 54. [Google Scholar]
- U.S. Department of the Interior. U.S. Geological Survey. Landsat 8. Available online: https://www.usgs.gov/landsat-missions/landsat-8 (accessed on 4 February 2020).
- Lan, H.; Zheng, X.; Torrens, P.M. Spark Sensing: A Cloud Computing Framework to Unfold Processing Efficiencies for Large and Multiscale Remotely Sensed Data, with Examples on Landsat 8 and MODIS Data. J. Sens. 2018, 2018, 2075057. [Google Scholar] [CrossRef]
- Teluguntla, P.; Thenkabail, P.S.; Oliphant, A.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K.; Huete, A. A 30-m landsat-derived cropland extent product of Australia and China using random forest machine learning algorithm on Google Earth Engine cloud computing platform. ISPRS J. Photogramm. Remote Sens. 2018, 144, 325–340. [Google Scholar] [CrossRef]
- Wang, N.; Chen, F.; Yu, B.; Qin, Y. Segmentation of large-scale remotely sensed images on a Spark platform: A strategy for handling massive image tiles with the MapReduce model. ISPRS J. Photogramm. Remote Sens. 2020, 162, 137–147. [Google Scholar] [CrossRef]
- Ippoliti, C.; Candeloro, L.; Gilbert, M.; Goffredo, M.; Mancini, G.; Curci, G.; Falasca, S.; Tora, S.; di Lorenzo, A.; Quaglia, M. Defining ecological regions in Italy based on a multivariate clustering approach: A first step towards a targeted vector borne disease surveillance. PLoS ONE 2019, 14, e0219072. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat.-Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- McLachlan, G.J. Discriminant Analysis and Statistical Pattern Recognition; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 544. [Google Scholar]
- Radenski, A. Using MapReduce streaming for distributed life simulation on the cloud. In Proceedings of the Artificial Life Conference, Taormina, Italy, 2–6 September 2013; pp. 284–291. [Google Scholar]
- Marques, R.; Feijo, B.; Breitman, K.; Gomes, T.; Ferracioli, L.; Lopes, H. A cloud computing based framework for general 2D and 3D cellular automata simulation. Adv. Eng. Softw. 2013, 65, 78–89. [Google Scholar] [CrossRef]
- Amazon. Amazon Web Services. 2015. Available online: http://aws.amazon.com/es/ec2/ (accessed on 1 November 2020).
- Wilder, B. Cloud Architecture Patterns: Using Microsoft Azure; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Sanderson, D. Programming Google App Engine: Build and Run Scalable Web Apps on Google’s Infrastructure; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Fan, X.; Lang, B.; Zhou, Y.; Zang, T. Adding network bandwidth resource management to Hadoop YARN. In Proceedings of the Seventh International Conference on Information Science and Technology (ICIST), Da Nang, Vietnam, 16–19 April 2017; pp. 444–449. [Google Scholar]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2002. [Google Scholar]
- Eastman, J.R. TerrSet Manual; Accessed in TerrSet Version; Clark Labs: Worcester, MA, USA, 2015; Volume 18, pp. 1–390. [Google Scholar]
- Viera, A.J.; Garrett, J.M. Understanding interobserver agreement: The kappa statistic. Fam. Med. 2005, 37, 360–363. [Google Scholar] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class ID | Classes | Subclass ID | Subclasses |
|---|---|---|---|
| 1 | Temperate meadow-steppe (TMS) | 30011 | Plain and hilly area of meadow steppe subclass |
| 30012 | Mountain land of meadow steppe subclass | ||
| 30013 | Sand land of meadow steppe subclass | ||
| 2 | Temperate steppe (TS) | 30021 | Plain and hilly area of steppe subclass |
| 30022 | Mountain land of steppe subclass | ||
| 30023 | Sand land of steppe subclass | ||
| 3 | Temperate desert-steppe (TDS) | 30031 | Plain and hilly area of desert-steppe subclass |
| 30032 | Mountain land of desert-steppe subclass | ||
| 30033 | Sand land of desert-steppe subclass | ||
| 4 | Temperate steppe-desert (TSD) | 30070 | Temperate Steppe-desert subclass |
| 5 | Temperate desert (TD) | 30081 | Gravel soil of desert subclass |
| 30082 | Sand soil of desert subclass | ||
| 30083 | Salt soil of desert subclass | ||
| 6 | Lowland meadow (LM) | 30151 | Lowland meadow subclass |
| 30152 | Salinized lowland meadow subclass | ||
| 30154 | Marshy lowland meadow subclass | ||
| 7 | Montane meadow (MM) | 30161 | Low-middle hills of mountains meadow subclass |
| 30162 | Subalpine of mountains meadow subclass | ||
| 8 | Marsh (MA) | 30180 | Marsh |
| 9 | Water area (WA) | w | N/A |
| 10 | Non-grassland (NG) | f | Forest |
| s | Sand | ||
| r | Road | ||
| 1 | Human land use and all others non-grassland |
| Factors | Definition | Function Shape | Control Point (s)/SB | |
|---|---|---|---|---|
| DEM | Elevation of whole IMAR (m) | MDJ | SSS 1 | 690, 1143 |
| SSS 2 | 387, 973 | |||
| SSS 3 | 1024, 1672 | |||
| SSS 4 | 1414, 1969 | |||
| SSS 5 | 1316, 1852 | |||
| SLOPE | Slope calculated by DEM (degree) | MDJ | SSS 1 | 6.1, 20.5 |
| SSS 2 | 3.9, 17.3 | |||
| SSS 3 | 4.1, 14.9 | |||
| SSS 4 | 11.1, 27.7 | |||
| SSS 5 | 4.5, 15.8 | |||
| DisRoad | Distance to roads | Linear | N/A | |
| DisRail | Distance to railways | Linear | N/A | |
| PPT | Yearly average precipitation (mm) | SS | SSS 1 | 389.35 |
| SSS 2 | 419.88 | |||
| SSS 3 | 276.29 | |||
| SSS 4 | 361.9 | |||
| SSS 5 | 152.4 | |||
| TEMP | Yearly average temperature (centigrade) | SS | SSS 1 | −1.58 |
| SSS 2 | 5.97 | |||
| SSS 3 | 3.28 | |||
| SSS 4 | 6.5 | |||
| SSS 5 | 8.38 | |||
| POP | Population density per each county (people per km2) | MDJ | SSS 1 | 5.1, 37 |
| SSS 2 | 37.8, 338.1 | |||
| SSS 3 | 8.1, 194.5 | |||
| SSS 4 | 52.0, 379.4 | |||
| SSS 5 | 1.8, 57.5 | |||
| LS | Livestock density per each county (livestock per km2) | MDJ | SSS 1 | 11.1, 74.9 |
| SSS 2 | 115.9, 474.6 | |||
| SSS 3 | 36.9, 240.6 | |||
| SSS 4 | 116.4, 521.2 | |||
| SSS 5 | 14.2, 138.9 | |||
| CP | Compensation policy | Linear | 0, 1, 2 | |
| WA | Water area | Boolean | N/A | |
| LU | Human land use | Boolean | N/A | |
| Hardware | Software | ||||
|---|---|---|---|---|---|
| Role | Count | CPU | RAM | Name | Version |
| Master Node | 2 | 2× Intel Xeon E5-2680v4 2.4 GHz | 256 G | Apache Spark | 2.2.0 |
| Apache Giraph | 1.2.0 | ||||
| Computing Node | 18 | 2× Intel Xeon E5-2690v4 2.6 GHz | 256 G | Centos | 6.9 |
| Java Server VM | 1.8.0_152 64Bit | ||||
| Network | 10 Gbps | Cloudera | 5.12.0 | ||
| Desktop (ArcGIS for Data Processing. IDRIS [58] for Markov-CA Simulation) | Cloud-Based Framework | |
|---|---|---|
| Data acquisition | ~600 Landsat 8 images covered the whole study area for three years. Assuming those images can be downloaded with 1 min each, it takes ~10 h in total | Can access directly from cloud storage such as S3. No time required |
| Data pre-processing | Assuming using ArcGIS to merge those images into three time periods and perform classification. The merge operation takes about 20 h with ~7 h each. The classification process is fully depended on the classifier. Using SVM as an example, it takes over 24 h for a single year image be processed | No need to merge data, can read data into memory from distributed file system directly include HDFS or S3. Can leverage cloud-based classification framework, which will take ~1 h. |
| Markov Chain | This is text-based processing. With Python script, it takes ~3 min. However, reading raster values takes extra time | Using Spark-based Markov chain, it takes ~20 s. No data reading time needed because it has been loaded into memory during data classification step. |
| Suitability analysis | Using IDRIS to process suitability maps, it takes over 24 h for the whole area | This process takes ~1.5 h to process with setup user-defined parameters into code. |
| CA process | Skip suitability process and apply CA process directly in IDRIS for performance test purpose only, it takes over 24 h for the whole area | This process takes ~2 h to finish gap filling and results filtering |
| Results’ visualization | Put text-based results into ArcGIS, it takes ~3 mins to show the results. | No time cost needed because results are designed as a PPM output, which is a text-based human readable figure. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, H.; Stewart, K.; Sha, Z.; Xie, Y.; Chang, S. Data Gap Filling Using Cloud-Based Distributed Markov Chain Cellular Automata Framework for Land Use and Land Cover Change Analysis: Inner Mongolia as a Case Study. Remote Sens. 2022, 14, 445. https://doi.org/10.3390/rs14030445
Lan H, Stewart K, Sha Z, Xie Y, Chang S. Data Gap Filling Using Cloud-Based Distributed Markov Chain Cellular Automata Framework for Land Use and Land Cover Change Analysis: Inner Mongolia as a Case Study. Remote Sensing. 2022; 14(3):445. https://doi.org/10.3390/rs14030445
Chicago/Turabian StyleLan, Hai, Kathleen Stewart, Zongyao Sha, Yichun Xie, and Shujuan Chang. 2022. "Data Gap Filling Using Cloud-Based Distributed Markov Chain Cellular Automata Framework for Land Use and Land Cover Change Analysis: Inner Mongolia as a Case Study" Remote Sensing 14, no. 3: 445. https://doi.org/10.3390/rs14030445
APA StyleLan, H., Stewart, K., Sha, Z., Xie, Y., & Chang, S. (2022). Data Gap Filling Using Cloud-Based Distributed Markov Chain Cellular Automata Framework for Land Use and Land Cover Change Analysis: Inner Mongolia as a Case Study. Remote Sensing, 14(3), 445. https://doi.org/10.3390/rs14030445