
Evaluating the Quality of Semantic Segmented 3D Point Clouds



Abstract
:
1. Introduction
2. State of the Art
2.1. Classification, Object Detection and Segmentation
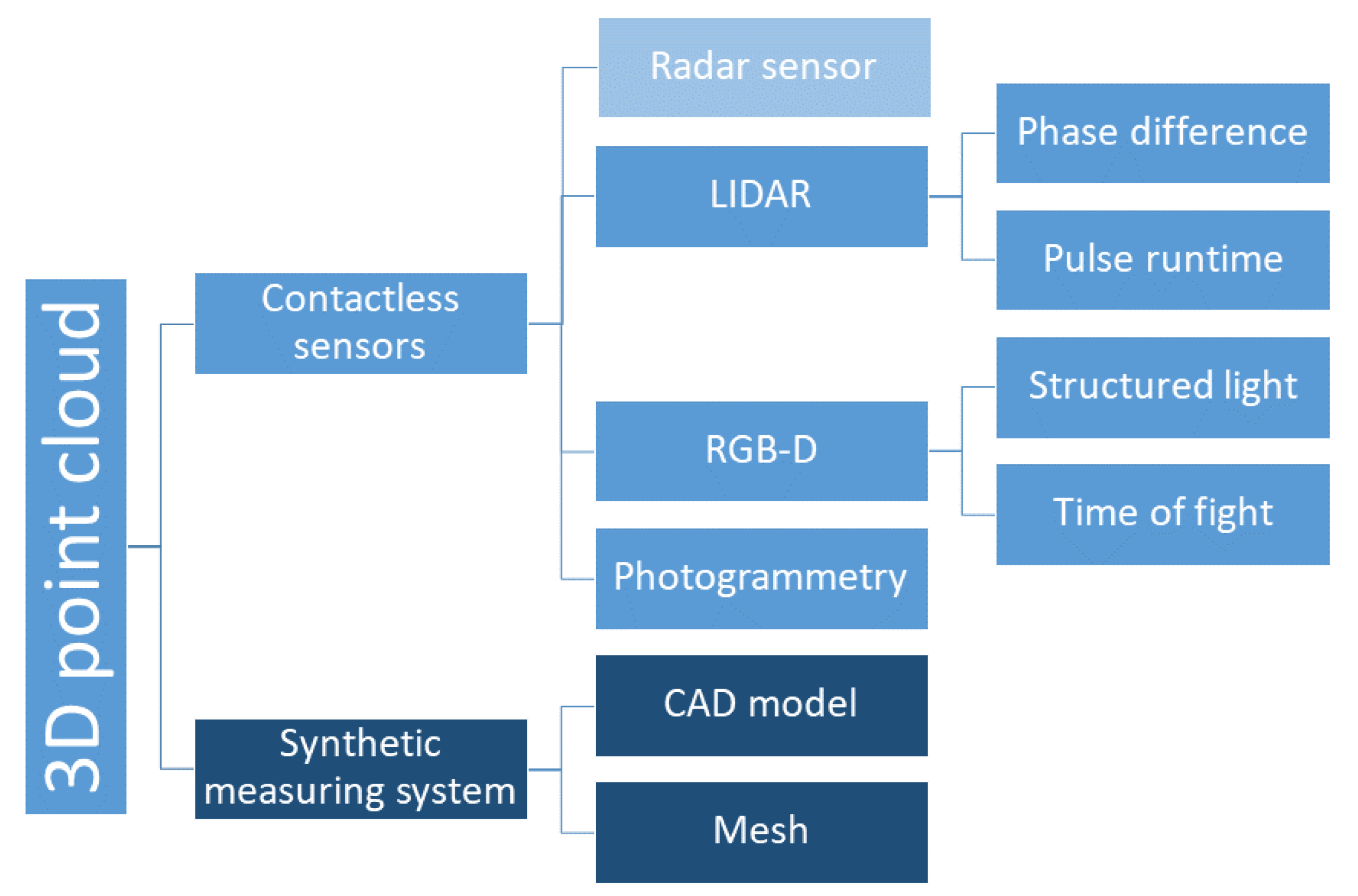
2.2. Captured and Synthetic Point Clouds
2.3. 3D Point Cloud Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | Sensor | Sensor Method | Separation Method | No. of Points | No. of Classes | Environment |
|---|---|---|---|---|---|---|---|
| Paris Lille 3D [64] | 2018 | Velod. HDL-32E | MMS car | SSeg | 1431 M | 50 | Outdoor |
| Semantic3D [15] | 2017 | Unknown TLS | TLS | SSeg | 4 B | 8 | Outdoor |
| SemanticKITTI [13] | 2019 | Velod. HDL-64E | MMS car | SSeg | 4.5 B | 28 | Outdoor |
| MSL1 TUM CC [14] | 2020 | Velod. HDL-64E | MMS car | SSeg, ISeg | 1.7 M | 8 | Outdoor |
| Toronto3D [65] | 2020 | Teled. Opt. Mev. | MMS car | SSeg | 78.3 M | 8 | Outdoor |
| CSPC-Dataset [66] | 2020 | Velod. VLP-16 | MMS backp. | SSeg | 68.3 M | 6 | Outdoor |
| BIPC-Dataset [63] | 2021 | Velod. VLP-16 | MMS backp. | SSeg | - | 30 | Indoor |
2.4. Point Cloud Annotation Tools
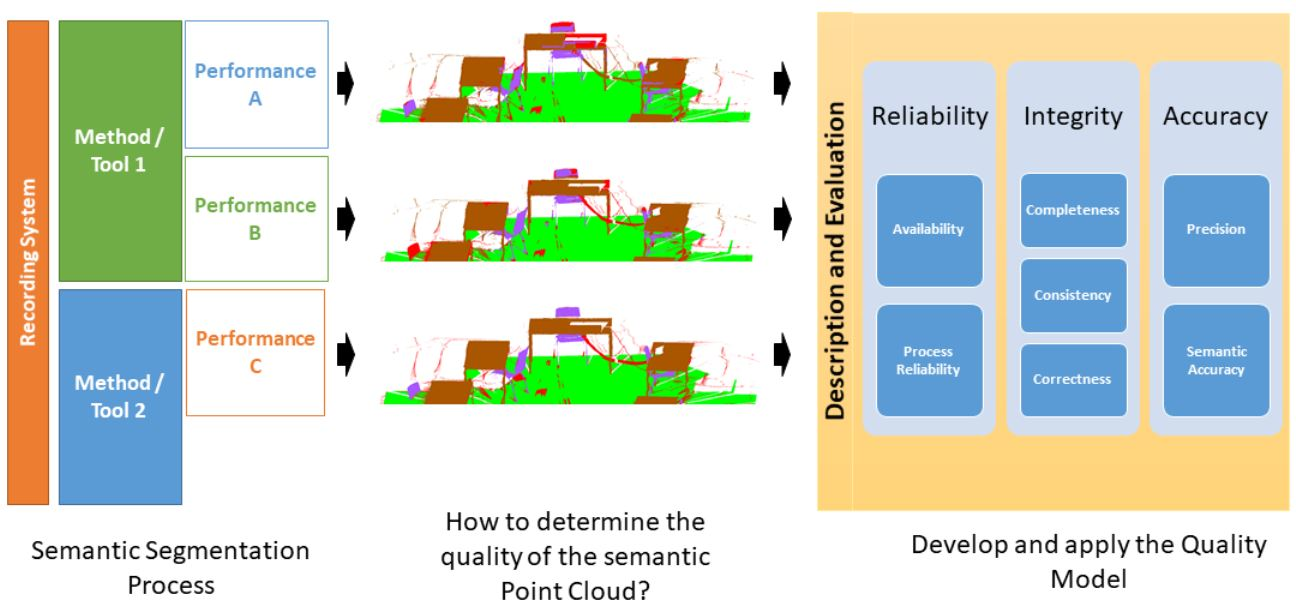
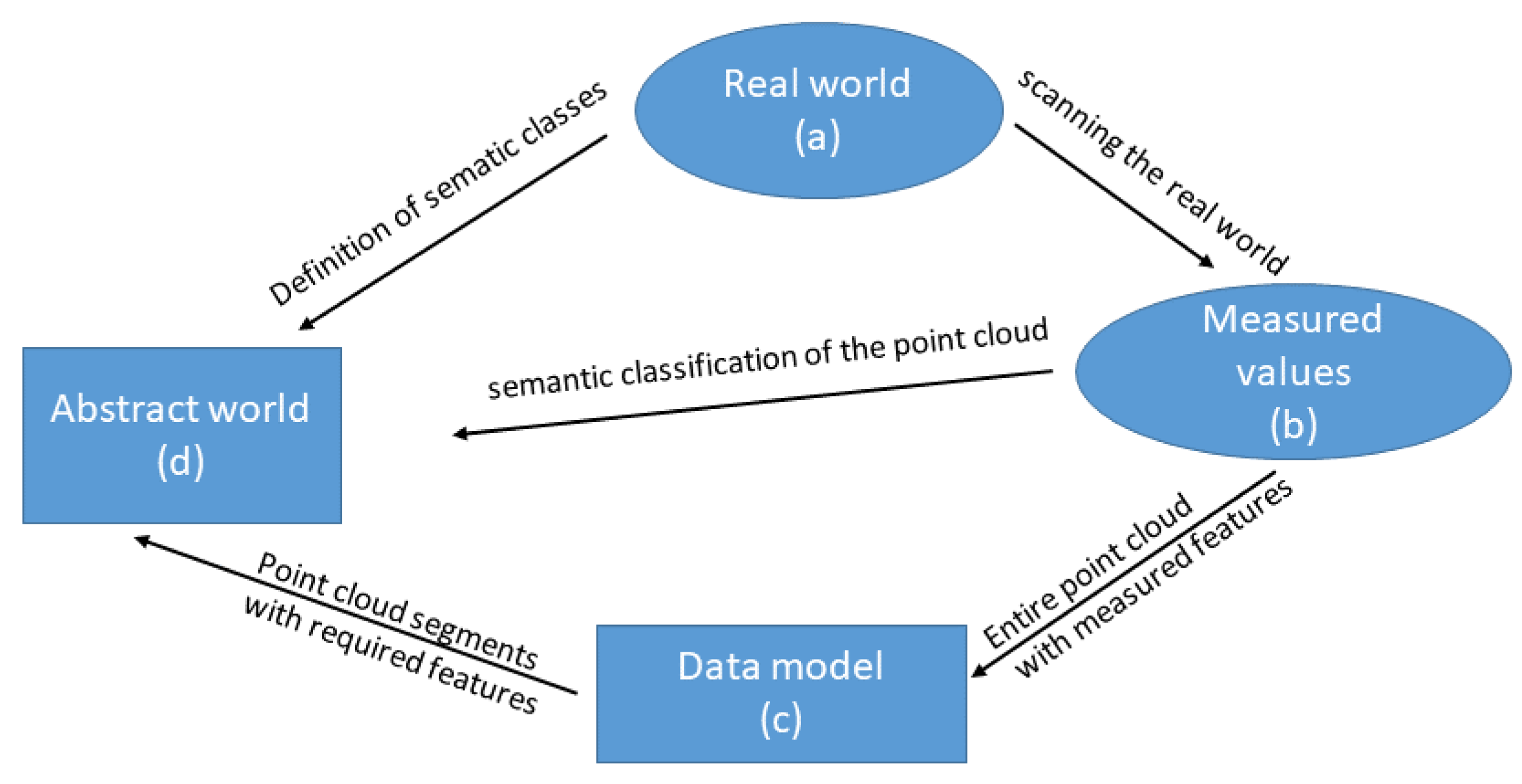
3. Quality Model for Semantic Point Clouds
- An application must be defined;
- A semantic segmentation process must be described;
- An abstract model of the semantic must be created;
- A data model must be created;
- Measured or synthetic point clouds must be available;
- Characteristics and parameters must be defined;
- Target values for the quality parameters must be defined.
3.1. Classification Process
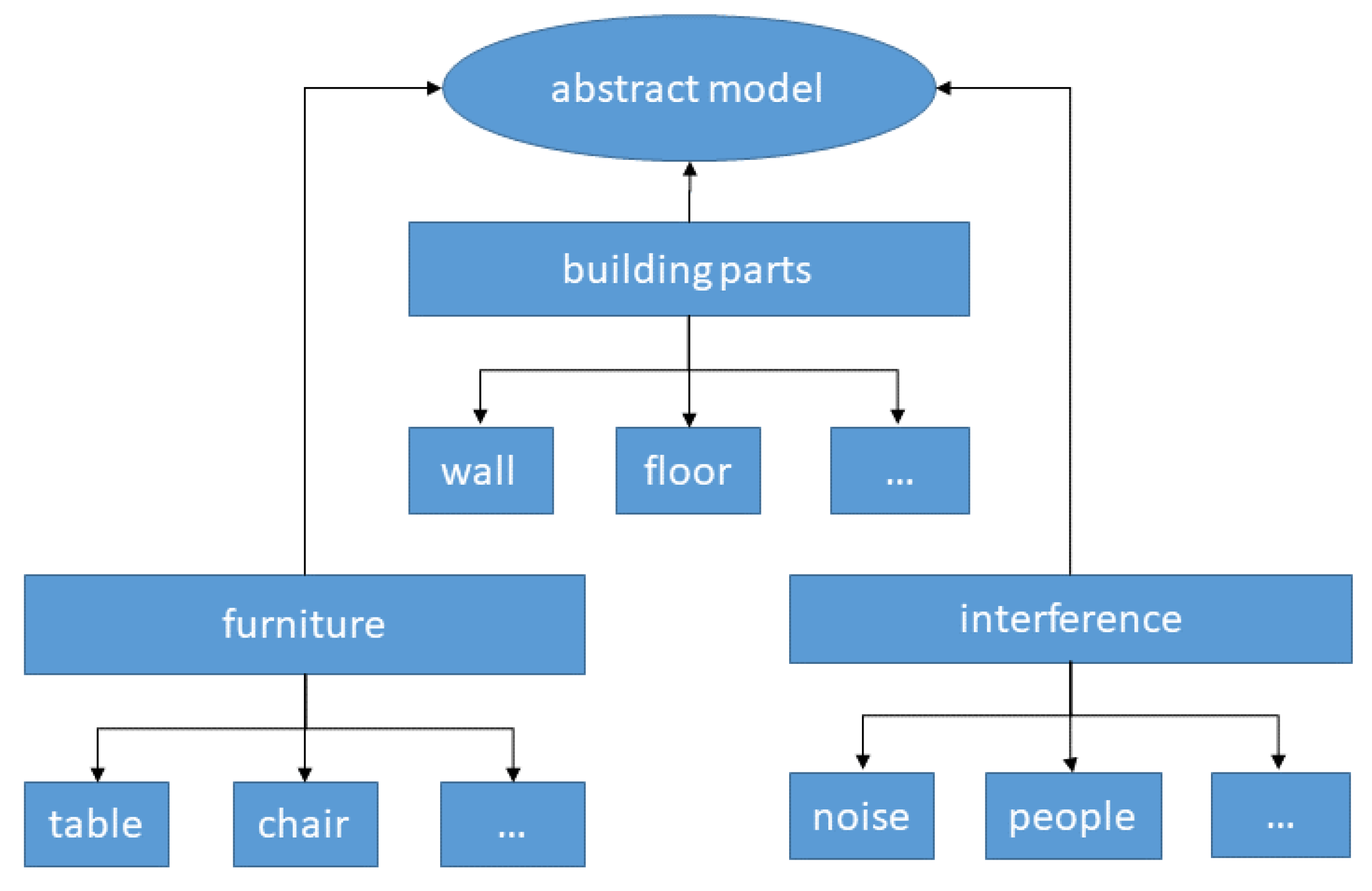
3.2. Abstract Model
- A general semantic model should provide the structure for the abstract model;
- The classes of the abstract model should be structured hierarchically, so that, in one definition level, only a number of around five classes exists. The next lower-definition level should contain only points of one higher-level class;
- For each level, all points are classified;
- The classification is an iterative process;
- The level of detail is mainly based on the application and the existing technical functions of the tool.
- The semantic definition must be written in the language of the annotator in order to avoid linguistic misunderstandings, such as translation errors.
- Objects must be described unambiguously by describing their shape, size or color. It is to be considered that objects of the same semantic class are represented differently in the point clouds. If objects appear in different designs, then this is to be described adequately. A definition of objects can be created, as described in [84].
- Special and unknown objects are to be illustrated by examples, so that the idea of the annotator is identical with what is being represented.
- A definition consists of a written and a figurative description.
- Topological relations should be represented to facilitate the decision in case of difficult-to-recognize object appearances. For example, furniture could be defined as standing on the floor or walls running perpendicular to the floor.
- Geometric boundaries should be clearly defined, as this is the only way to achieve the required geometric accuracy. Using the class door as an example, the following definition is possible: A door ends at the frame, at the seal or at the wall. Erroneous points should be separated completely from the objects.
3.3. Data Model
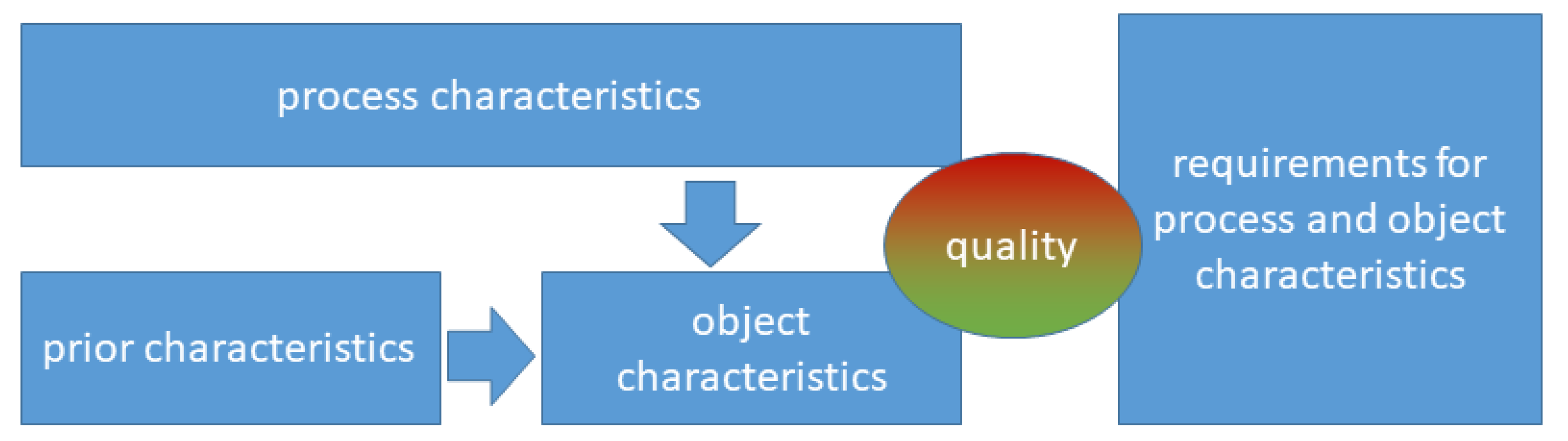
3.4. Quality Model
3.4.1. Quality Characteristics
3.4.2. Quality Parameters
3.4.3. Descriptive and Evaluative Function
4. Applying the Quality Model
- Semantic point cloud as a model;
- Semantic point cloud as a modeling basis;
- Semantic point cloud as training data.
4.1. Quality Model to Describe Semantic Point Clouds
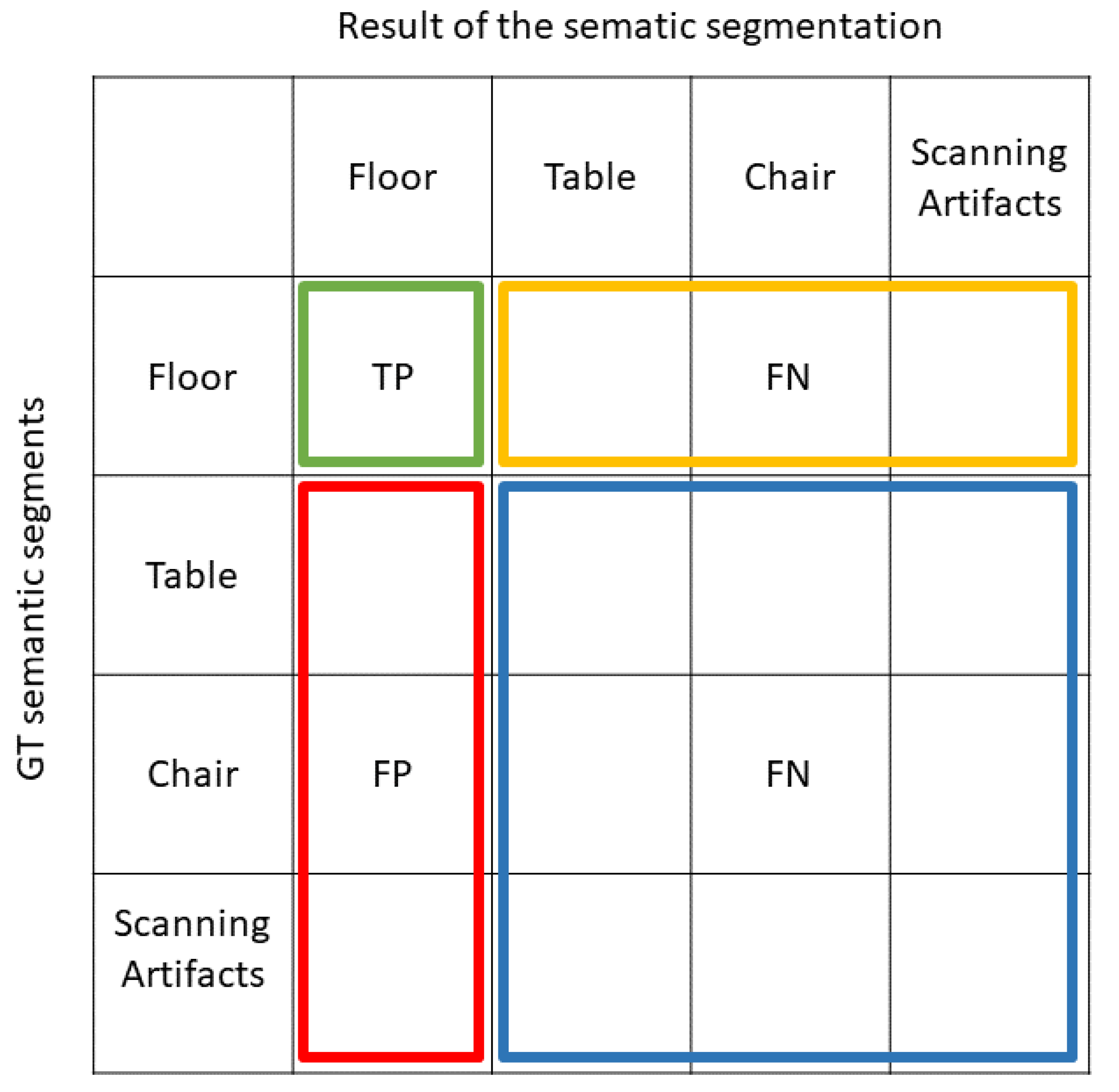
4.1.1. Reliability Characteristics
4.1.2. Integrity Characteristics
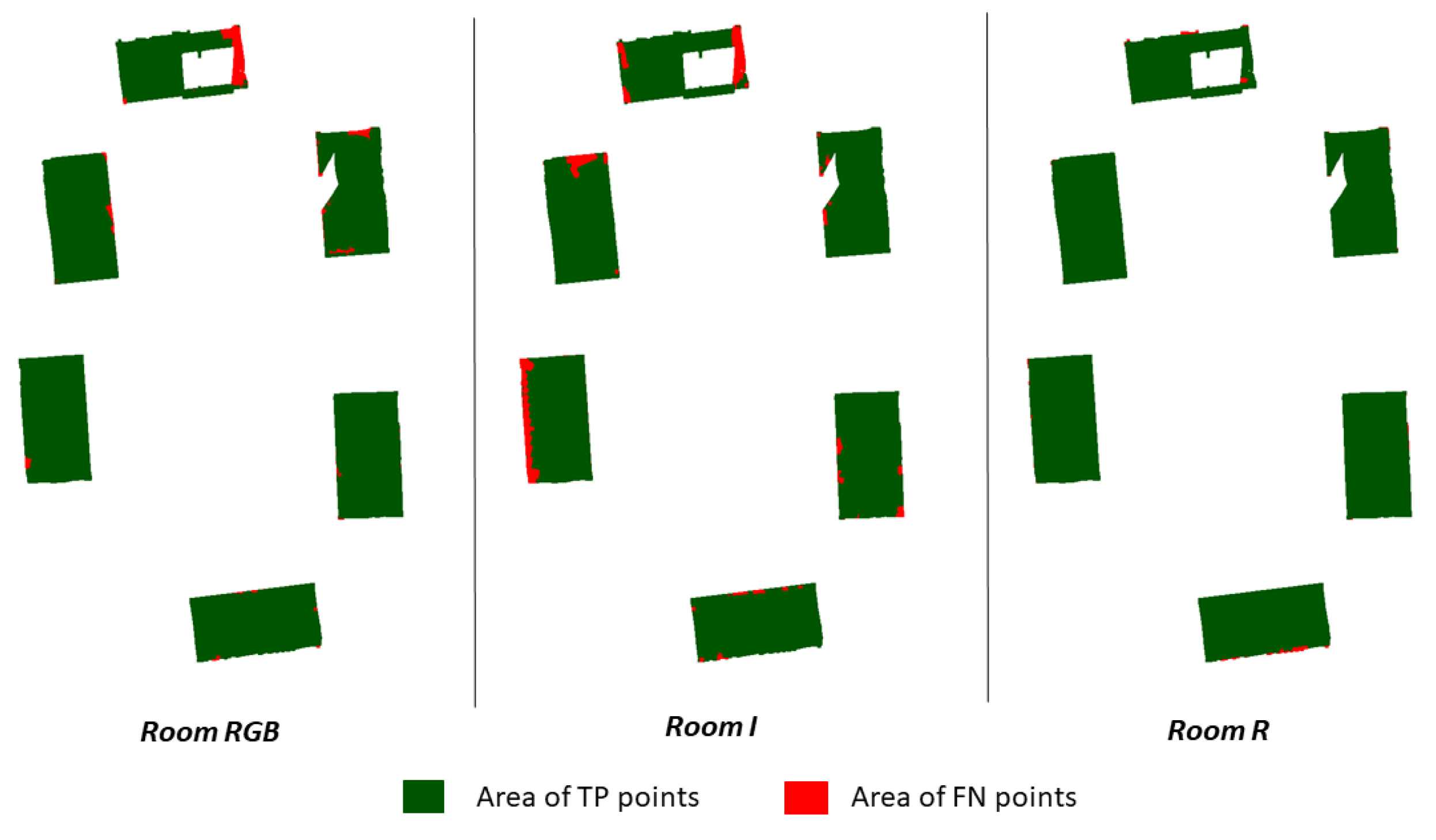
- If the point distance between both point clouds is less than a threshold, then a point in the point cloud under investigation has been correctly semantically segmented. These points are TP points.
- If a segmented point in the investigated point cloud is closer to a segment of another class, then it is an FP point of the selected class.
- The FP points are also FN points of the other classes. By comparing the GT point cloud segments of the other classes with the sub-point cloud of the investigated point cloud, the FN points can be determined.
4.1.3. Accuracy Characteristics
4.1.4. Descriptive Use for Multiple Annotations
4.1.5. Summary of the Descriptive Use
4.2. Quality Model to Evaluate Semantic Point Clouds
4.2.1. Point Cloud as Model
4.2.2. Point Cloud as a Basis for Modeling
4.2.3. Point Cloud as Training Data
4.2.4. Summary of the Evaluated Use
5. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
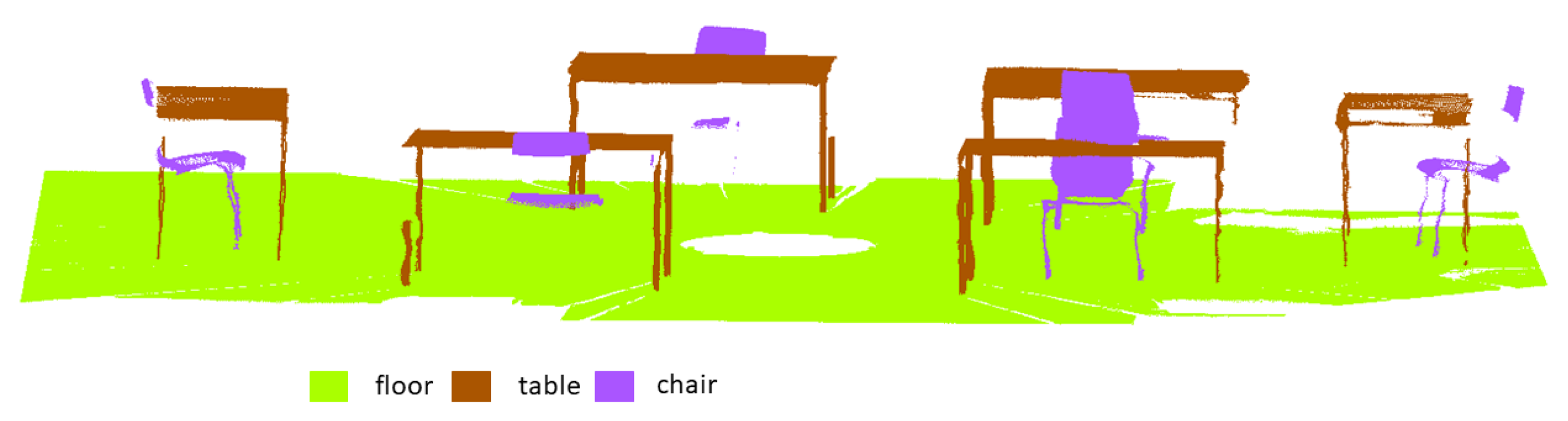
Appendix A. Class Definition
| Level | Class | Definition |
|---|---|---|
| L0 | furniture | Furniture includes objects that have contact with the floor and stand in the room. Objects that do not belong to the class chair or table cannot be furniture. The class can be further subdivided. |
| L1 | table | The table class consists of all the points that describe/contain the table legs, the lower frame of the table, the table top and the adjustable feet. |
| L1 | chair | The class chair consists of all the points that describe the seat, backrest, tubular frame and rubber feet. |
| L0 | floor | The floor class consists of all points describing the flat floor and small edges and floor inlets (maintenance flaps). The floor can be considered a plane with a deviation of 50 mm. |
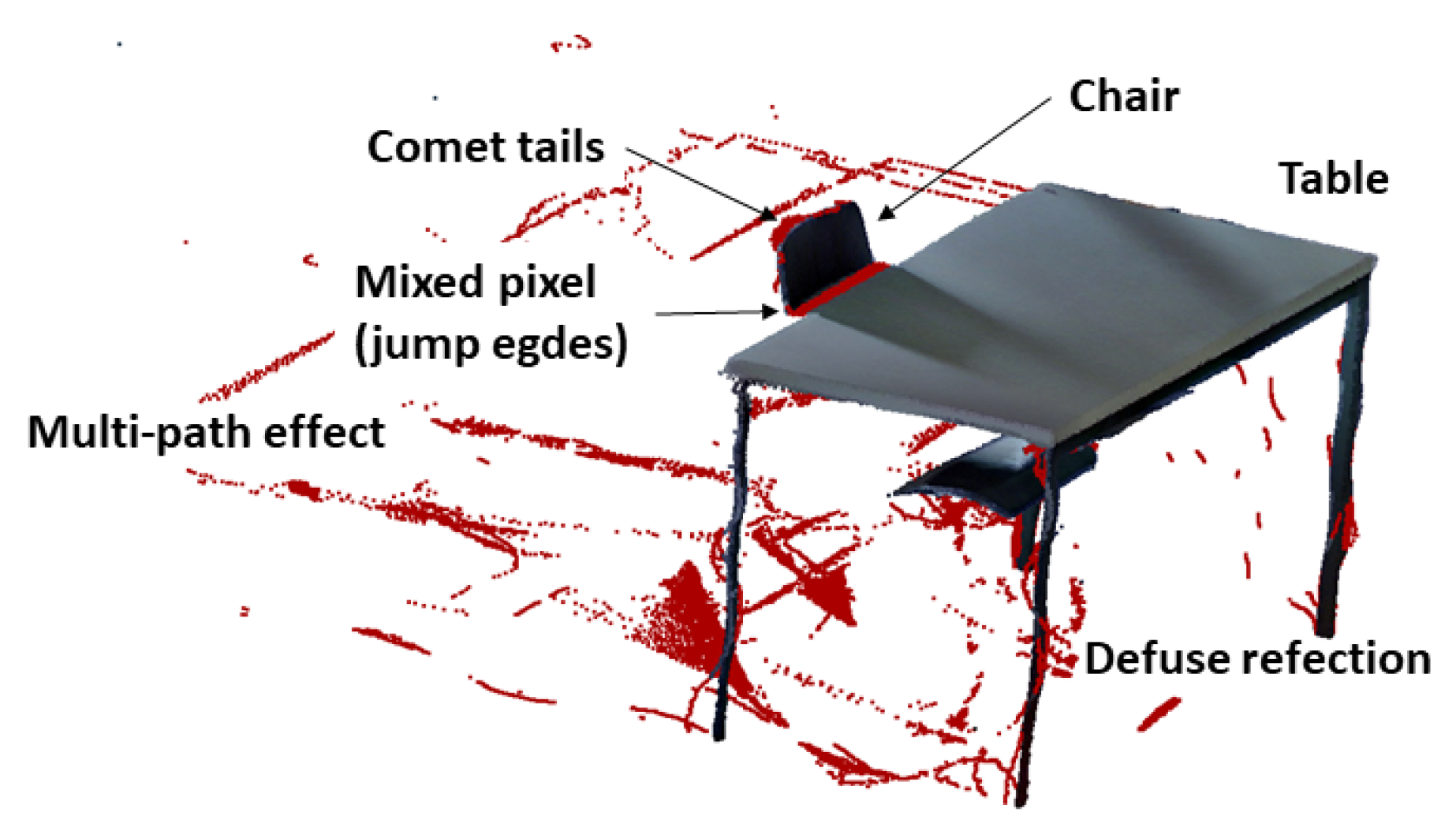
| L0 | scanning artifacts | The scanning artifacts class consists of all points that describe objects lying on the ground—for example, cables. Furthermore, this includes all points that are caused by measurement errors (phantom points), reflection of the objects and gap closures due to the evaluation software. Multiple reflections can also occur. |
Appendix B. Time Required for Semantic Segmentation
| Lab | Room | |||||
|---|---|---|---|---|---|---|
| No. | RGB | I | R | RGB | I | R |
| 1 | 12.5% | 12.5% | 41.7% | 41.2% | 46.4% | 49.0% |
| 2 | 14.2% | 11.7% | 64.2% | 27.8% | 33.5% | 34.0% |
| 3 | 12.5% | 12.5% | 100% | - | - | - |
| 4 | 10.0% | 10.8% | 94.2% | 32.5% | 42.3% | 100.0% |
| 5 | 9.2% | - | 35.8% | 33.5% | 51.5% | 46.4% |
| 6 | 19.2% | - | 37.5% | 23.2% | 30.9% | 30.9% |
| 7 | - | 12.5% | 75.0% | 61.9% | 61.9% | 61,9% |
| 8 | - | 15,8% | 25.0% | 46.1% | 46.4% | 15.5% |
| 9 | 10.8% | 13.3% | 20.8% | 41.2% | 43.8% | 51.5% |
| Avg. | 13.0% | 12.7% | 54.8% | 38.0% | 44.6% | 48.6% |
Appendix C. Correctness and Precision for Multiple Annotations
| Lab | Room | |||||||
|---|---|---|---|---|---|---|---|---|
| No. | Floor | Chair | Table | Scan. Artif. | Floor | Chair | Table | Scan. Artif. |
| 1 | 99.8% | 95.9% | 98.7% | 91.7% | 99.9% | 96.4% | 97.6% | 89.7% |
| 2 | 99.6% | 91.7% | 96.0% | 97.8% | 77.0% | 99.8% | 94.0% | 98.5% |
| 3 | 100.0% | 85.9% | 97.3% | 17.7% | - | - | - | - |
| 4 | 99.7% | 97.9% | 99.5% | 88.2% | 99.9% | 95.6% | 97.4% | 87.5% |
| 5 | 100.0% | 93.4% | 99.4% | 47.4% | 99.8% | 94.1% | 96.9% | 77.5% |
| 6 | 99.9% | 97.0% | 85.7% | 81.1% | 99.8% | 94.3% | 97.6% | 33.9% |
| 7 | 100.0% | 96.6% | 99.0% | 74.3% | 99.2% | 94.7% | 96.2% | 82.7% |
| 8 | 99.8% | 99.2% | 99.9% | 76.4% | 99.9% | 92.7% | 96.7% | 90.4% |
| 9 | 99.5% | 99.8% | 99.9% | 77.6% | 99.5% | 90.9% | 97.0% | 95.0% |
| Lab | Room | |||||||
|---|---|---|---|---|---|---|---|---|
| No. | Floor | Chair | Table | Scan. Artif. | Floor | Chair | Table | Scan. Artif. |
| 1 | 99.7% | 93.9% | 86.2% | 40.5% | 99.6% | 77.9% | 93.7% | 51.3% |
| 2 | 99.7% | 88.5% | 86.9% | 41.7% | 99.6% | 79.1% | 92.8% | 43.7% |
| 3 | 99.7% | 83.3% | 77.1% | 29.9% | - | - | - | - |
| 4 | 99.7% | 94.6% | 86.6% | 41.0% | 99.7% | 80.9% | 93.4% | 61.4% |
| 5 | 99.7% | 91.6% | 83.2% | 47.4% | 99.7% | 82.7% | 95.2% | 41.7% |
| 6 | 99.7% | 84.2% | 95.2% | 24.0% | 99.7% | 77.3% | 88.9% | 43.4% |
| 7 | - | - | - | - | 99.3% | 74.0% | 93.5% | 48.5% |
| 8 | - | - | - | - | 99.7% | 78.4% | 93.9% | 56.0% |
| 9 | 99.7% | 93.9% | 80.8% | 38.1% | 99.5% | 80.4% | 93.6% | 49.9% |
| Lab | Room | |||||||
|---|---|---|---|---|---|---|---|---|
| No. | Floor | Chair | Table | Scan. Artif. | Floor | Chair | Table | Scan. Artif. |
| 1 | 99.7% | 93.8% | 86.8% | 38.5% | 99.7% | 73.9% | 95.3% | 26.7% |
| 2 | 99.7% | 93.8% | 85.3% | 39.8% | 99.4% | 82.1% | 89.8% | 42.0% |
| 3 | 99.7% | 81.9% | 82.2% | 21.7% | - | - | - | - |
| 4 | 99.7% | 93.6% | 89.0% | 37.8% | 99.7% | 77.7% | 90.3% | 33.3% |
| 5 | - | - | - | - | 99.7% | 82.7% | 95.2% | 41.7% |
| 6 | - | - | - | - | 99.6% | 76.8% | 91.5% | 30.1% |
| 7 | 99.8% | 77.0% | 75.8% | 37.7% | 99.3% | 70.7% | 91.0% | 20.6% |
| 8 | 99.7% | 94.2% | 87.5% | 38.0% | 99.7% | 77.3% | 92.6% | 35.5% |
| 9 | 99.7% | 83.5% | 90.9% | 35.5% | 99.2% | 75.7% | 92.7% | 30.8% |
| Lab | Room | |||||||
|---|---|---|---|---|---|---|---|---|
| No. | Floor | Chair | Table | Scan. Artif. | Floor | Chair | Table | Scan. Artif. |
| 1 | 100.0% | 98.9% | 99.8% | 62.0% | 100.0% | 98.0% | 99.2% | 75.9% |
| 2 | 100.0% | 99.9% | 99.8% | 46.4% | 100.0% | 97.6% | 96.5% | 76.2% |
| 3 | 99.5 % | 90.7% | 94.0% | 80.1% | - | - | - | - |
| 4 | 100.0% | 98.3% | 99.7% | 67.0% | 100.0% | 99.0% | 99.4% | 74.0% |
| 5 | 99.6% | 98.5% | 99.0% | 69.8% | 99.9% | 99.1% | 97.1% | 66.7% |
| 6 | 99.9% | 70.4% | 99.8% | 74.8% | 100.0% | 49.6% | 98.7% | 71.1% |
| 7 | 99.8% | 97.8% | 99.8% | 79.1% | 100.0% | 97.9% | 98.3% | 42.3% |
| 8 | 100.0% | 96.4% | 99.2% | 77.1% | 99.9% | 99.3% | 99.6% | 64.4% |
| 9 | 100.0% | 96.0% | 99.1% | 57.2% | 100.0% | 99.4% | 99.5% | 51.1% |
| Lab | Room | |||||||
|---|---|---|---|---|---|---|---|---|
| No. | Floor | Chair | Table | Scan. Artif. | Floor | Chair | Table | Scan. Artif. |
| 1 | 99.9% | 80.5% | 96.0% | 26.3% | 99.8% | 83.0% | 88.6% | 54.4% |
| 2 | 99.9% | 84.6% | 95.4% | 19.3% | 99.8% | 68.2% | 92.7% | 46.6% |
| 3 | 99.9% | 83.6% | 95.6% | 20.4% | - | - | - | - |
| 4 | 99.9% | 84.8% | 95.6% | 22.2% | 99.8% | 80.4% | 94.2% | 55.9% |
| 5 | 99.8% | 84.6% | 95.2% | 18.1% | 99.8% | 50.8% | 91.7% | 64.0% |
| 6 | 99.7% | 93.5% | 87.3% | 32.6% | 99.8% | 69.7% | 96.2% | 29.2% |
| 7 | - | - | - | - | 99.8% | 68.2% | 91.9% | 44.2% |
| 8 | - | - | - | - | 99.8% | 87.1% | 91.5% | 52.7% |
| 9 | 99.9% | 84.8% | 95.0% | 15.2% | 99.8% | 77.2% | 91.2% | 49.4% |
| Lab | Room | |||||||
|---|---|---|---|---|---|---|---|---|
| No. | Floor | Chair | Table | Scan. Artif. | Floor | Chair | Table | Scan. Artif. |
| 1 | 99.9% | 83.8% | 96.1% | 22.0% | 99.8% | 46.2% | 88.5% | 54.7% |
| 2 | 99.9% | 83.2% | 96.6% | 20.0% | 99.8% | 57.1% | 90.6% | 45.3% |
| 3 | 99.8% | 85.1% | 90.0% | 29.6% | - | - | - | - |
| 4 | 99.9% | 84.3% | 95.8% | 23.6% | 99.8% | 80.4% | 86.4% | 39.0% |
| 5 | - | - | - | - | 99.8% | 74.7% | 90.6% | 52.0% |
| 6 | - | - | - | - | 99.8% | 65.4% | 87.7% | 38.0% |
| 7 | 99.0% | 84.0% | 95.5% | 15.1% | 99.8% | 56.4% | 85.8% | 26.5% |
| 8 | 99.9% | 83.7% | 96.2% | 21.6% | 99.8% | 81.4% | 85.8% | 43.5% |
| 9 | 99.9% | 87.6% | 95.5% | 24.3% | 99.8% | 61.4% | 86.2% | 37.6% |
Appendix D. Point Cloud Dataset Comparison

References
- Balangé, L.; Zhang, L.; Schwieger, V. First Step Towards the Technical Quality Concept for Integrative Computational Design and Construction. In Springer Proceedings in Earth and Environmental Sciences; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 118–127. [Google Scholar] [CrossRef]
- Frangez, V.; Salido-Monzú, D.; Wieser, A. Depth-Camera-Based In-line Evaluation of Surface Geometry and Material Classification For Robotic Spraying. In Proceedings of the 37th International Symposium on Automation and Robotics in Construction (ISARC), Kitakyushu, Japan, 27–28 October 2020; International Association for Automation and Robotics in Construction (IAARC): Berlin, Germany, 2020. [Google Scholar] [CrossRef]
- Placzek, G.; Brohmann, L.; Mawas, K.; Schwerdtner, P.; Hack, N.; Maboudi, M.; Gerke, M. A Lean-based Production Approach for Shotcrete 3D Printed Concrete Components. In Proceedings of the 38th International Symposium on Automation and Robotics in Construction (ISARC), Dubai, United Arab Emirates, 2–5 November 2021; International Association for Automation and Robotics in Construction (IAARC): Berlin, Germany, 2021. [Google Scholar] [CrossRef]
- Westphal, T.; Herrmann, E.M. (Eds.) Building Information Modeling I Management Band 2; Detail Business Information GmbH: München, Germany, 2018. [Google Scholar] [CrossRef]
- Hellweg, N.; Schuldt, C.; Shoushtari, H.; Sternberg, H. Potenziale für Anwendungsfälle des Facility Managements von Gebäuden durch die Nutzung von Bauwerksinformationsmodellen als Datengrundlage für Location-Based Services im 5G-Netz. In 21. Internationale Geodätische Woche Obergurgl 2021; Wichmann Herbert: Berlin, Germany; Offenbach, Germany, 2021. [Google Scholar]
- Willemsen, T. Fusionsalgorithmus zur Autonomen Positionsschätzung im Gebäude, Basierend auf MEMS-Inertialsensoren im Smartphone. Ph.D. Thesis, HafenCity Universität Hamburg, Hamburg, Germany, 2016. [Google Scholar]
- Schuldt, C.; Shoushtari, H.; Hellweg, N.; Sternberg, H. L5IN: Overview of an Indoor Navigation Pilot Project. Remote Sens. 2021, 13, 624. [Google Scholar] [CrossRef]
- Grieves, M.; Vickers, J. Digital Twin: Mitigating Unpredictable, Undesirable Emergent Behavior in Complex Systems. In Transdisciplinary Perspectives on Complex Systems; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 85–113. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; IEEE: New York, NY, USA, 2015; pp. 922–928. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.W.; Schindler, K. Fast Semantic Segmentation of 3D Point Clouds with Strongly Varying Densit. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 177–184. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep Learning on Point Sets for 3d Classification and Segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 77–85. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. Advances in Neural Information Processing Systems. 2017, pp. 5099–5108. Available online: https://arxiv.org/abs/1706.02413 (accessed on 15 December 2021).
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhu, J.; Gehrung, J.; Huang, R.; Borgmann, B.; Sun, Z.; Hoegner, L.; Hebel, M.; Xu, Y.; Stilla, U. TUM-MLS-2016: An Annotated Mobile LiDAR Dataset of the TUM City Campus for Semantic Point Cloud Interpretation in Urban Areas. Remote Sens. 2020, 12, 1875. [Google Scholar] [CrossRef]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3d.net: A New Large-scale Point Cloud Classification Benchmark. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, IV-1-W1, 91–98. [Google Scholar] [CrossRef] [Green Version]
- Khoshelham, K.; Vilariño, L.D.; Peter, M.; Kang, Z.; Acharya, D. The ISPRS Benchmark on Indoor Modelling. ISPRS- Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-2/W7, 367–372. [Google Scholar] [CrossRef] [Green Version]
- Padilla, R.; Passos, W.L.; Dias, T.L.B.; Netto, S.L.; da Silva, E.A.B. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Rangesh, A.; Trivedi, M.M. No Blind Spots: Full-Surround Multi-Object Tracking for Autonomous Vehicles using Cameras and LiDARs. IEEE Trans. Intell. Veh. 2018, 4, 588–599. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Qi, C.R.; Guibas, L.J. FlowNet3D: Learning Scene Flow in 3D Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Hou, S.; Wen, C.; Gong, Z.; Li, Q.; Sun, X.; Li, J. Semantic Line Framework-based Indoor Building Modeling Using Backpacked Laser Scanning Point Cloud. ISPRS J. Photogramm. Remote Sens. 2018, 143, 150–166. [Google Scholar] [CrossRef]
- Volk, R.; Luu, T.H.; Mueller-Roemer, J.S.; Sevilmis, N.; Schultmann, F. Deconstruction Project Planning of Existing Buildings Based on Automated Acquisition and Reconstruction of Building Information. Autom. Constr. 2018, 91, 226–245. [Google Scholar] [CrossRef]
- Wang, C.; Dai, Y.; Elsheimy, N.; Wen, C.; Retscher, G.; Kang, Z.; Lingua, A. ISPRS Benchmark on Multisensory Indoor Mapping and Positioning. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, V-5-2020, 117–123. [Google Scholar] [CrossRef]
- Bello, S.A.; Yu, S.; Wang, C. Review: Deep Learning on 3d Point Clouds. Remote Sens. 2020, 12, 1729. [Google Scholar] [CrossRef]
- Liu, W.; Sun, J.; Li, W.; Hu, T.; Wang, P. Deep Learning on Point Clouds and Its Application: A Survey. Sensors 2019, 19, 4188. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, Y.; Tian, J.; Zhu, X.X. Linking Points With Labels in 3D: A Review of Point Cloud Semantic Segmentation. IEEE Geosci. Remote Sens. Mag. 2020, 8, 38–59. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Zhou, B.; Shi, Y.; Chen, X.; Zhao, Q.; Xu, K. Shape2Motion: Joint Analysis of Motion Parts and Attributes from 3D Shapes. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Omata, K.; Furuya, T.; Ohbuchi, R. Annotating 3D Models and their Parts via Deep Feature Embedding. In Proceedings of the 2019 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shanghai, China, 8–12 July 2019; IEEE: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Mo, K.; Guerrero, P.; Yi, L.; Su, H.; Wonka, P.; Mitra, N.; Guibas, L.J. StructureNet: Hierarchical Graph Networks for 3D Shape Generation. ACM Trans. Graph. 2019, 38, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Luhmann, T.; Robson, S.; Kyle, S.; Boehm, J. Close-Range Photogrammetry and 3D Imaging; De Gruyter: Berlin, Germany, 2013. [Google Scholar] [CrossRef] [Green Version]
- Wasenmüller, O.; Stricker, D. Comparison of Kinect V1 and V2 Depth Images in Terms of Accuracy and Precision. In Computer Vision—ACCV 2016 Workshops; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 34–45. [Google Scholar] [CrossRef]
- Tölgyessy, M.; Dekan, M.; Chovanec, Ľ.; Hubinský, P. Evaluation of the Azure Kinect and Its Comparison to Kinect V1 and Kinect V2. Sensors 2021, 21, 413. [Google Scholar] [CrossRef]
- Schumann, O.; Hahn, M.; Dickmann, J.; Wohler, C. Semantic Segmentation on Radar Point Clouds. In Proceedings of the 2018 21st International Conference on Information Fusion, Cambridge, UK, 10–13 July 2018; IEEE: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Qian, K.; He, Z.; Zhang, X. 3D Point Cloud Generation with Millimeter-Wave Radar. Proc. ACM Interactive Mob. Wearable Ubiquitous Technol. 2020, 4, 1–23. [Google Scholar] [CrossRef]
- Shults, R.; Levin, E.; Habibi, R.; Shenoy, S.; Honcheruk, O.; Hart, T.; An, Z. Capability of Matterport 3D Camera for Industria Archaeolog Sites Inventory. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W11, 1059–1064. [Google Scholar] [CrossRef] [Green Version]
- Sarbolandi, H.; Lefloch, D.; Kolb, A. Kinect Range Sensing: Structured-Light versus Time-of-Flight Kinect. Comput. Vis. Image Underst. 2015, 139, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Luhmann, T. Nahbereichsphotogrammetrie Grundlagen-Methoden-Beispiele; Wichmann: Berlin, Germany; Offenbach, Germany, 2018. [Google Scholar]
- Freedman, B.; Shpunt, A.; Machline, M.; Arieli, Y. Depth Mapping Using Projected Patterns. U.S. Patent 2008/O2405O2A1, 3 October 2008. [Google Scholar]
- Landau, M.J.; Choo, B.Y.; Beling, P.A. Simulating Kinect Infrared and Depth Images. IEEE Trans. Cybern. 2016, 46, 3018–3031. [Google Scholar] [CrossRef]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3d Semantic Parsing of Large-scale Indoor Spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1534–1543. [Google Scholar] [CrossRef]
- Chang, A.; Dai, A.; Funkhouser, T.; Halber, M.; Nießner, M.; Savva, M.; Song, S.; Zeng, A.; Zhang, Y. Matterport3D: Learning from RGB-D Data in Indoor Environments. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; IEEE: New York, NY, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Matterport. Matterport Pro 3D Camera Specifications. Available online: https://support.matterport.com/s/articledetail?language=en_US&ardId=kA05d000001DX3DCAW (accessed on 23 September 2021).
- Hansard, M.; Lee, S.; Choi, O.; Horaud, R. Time-of-Flight Cameras; Springer: London, UK, 2013. [Google Scholar] [CrossRef] [Green Version]
- Keller, F. Entwicklung eines Forschungsorientierten Multi-Sensor-System zum Kinematischen Laserscannings Innerhalb von Gebäuden. Ph.D. Thesis, HafenCity Universität Hamburg, Hamburg, Germany, 2015. [Google Scholar]
- VelodyneLiDAR. Velodyne HDL-32E Data Sheet. Available online: https://www.mapix.com/wp-content/uploads/2018/07/97-0038_Rev-M_-HDL-32E_Datasheet_Web.pdf (accessed on 24 June 2021).
- Riegl. RIEGL VZ-400-Data Sheet. Available online: www.riegl.com/uploads/tx_pxpriegldownloads/10_DataSheet_VZ-400_2017-06-14.pdf (accessed on 24 June 2021).
- Lovas, T.; Hadzijanisz, K.; Papp, V.; Somogyi, A.J. Indoor Building Survey Assessment. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B1-2020, 251–257. [Google Scholar] [CrossRef]
- Kersten, T.P.; Lindstaedt, M.; Stange, M. Geometrische Genauigkeitsuntersuchungen aktueller terrestrischer Laserscanner im Labor und im Feld. AVN 2021, 2, 59–67. [Google Scholar]
- ISO17123-9; Optics and Optical Instruments. Field Procedures for Testing Geodetic and Surveying Instruments. Terrestrial Laser Scanners. British Standards Institution: London, UK, 2018.
- Kaartinen, H.; Hyyppä, J.; Kukko, A.; Jaakkola, A.; Hyyppä, H. Benchmarking the Performance of Mobile Laser Scanning Systems Using a Permanent Test Field. Sensors 2012, 12, 12814–12835. [Google Scholar] [CrossRef] [Green Version]
- Wujanz, D.; Burger, M.; Tschirschwitz, F.; Nietzschmann, T.; Neitzel, F.; Kersten, T. Determination of Intensity-Based Stochastic Models for Terrestrial Laser Scanners Utilising 3D-Point Clouds. Sensors 2018, 18, 2187. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neuer, H. Qualitätsbetrachtungen zu TLS-Daten. Qualitätssicherung geodätischer Mess-und Auswerteverfahren 2019. DVW-Arbeitskreis 3 Messmethoden und Systeme; Wißner-Verlag: Augsburg, Germany, 2019; Volume 95, pp. 69–89. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: New York, NY, USA, 2015. [Google Scholar] [CrossRef] [Green Version]
- Winiwarter, L.; Pena, A.M.E.; Weiser, H.; Anders, K.; Sánchez, J.M.; Searle, M.; Höfle, B. Virtual laser scanning with HELIOS++: A novel take on ray tracing-based simulation of topographic full-waveform 3D laser scanning. Remote Sens. Environ. 2022, 269, 112772. [Google Scholar] [CrossRef]
- Iqbal, J.; Xu, R.; Sun, S.; Li, C. Simulation of an Autonomous Mobile Robot for LiDAR-Based In-Field Phenotyping and Navigation. Robotics 2020, 9, 46. [Google Scholar] [CrossRef]
- Hua, B.S.; Pham, Q.H.; Nguyen, D.T.; Tran, M.K.; Yu, L.F.; Yeung, S.K. SceneNN: A Scene Meshes Dataset with aNNotations. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d Reconstructions of Indoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, US, 21–26 July 2017; IEEE: New York, NY, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Uy, M.A.; Pham, Q.H.; Hua, B.S.; Nguyen, D.T.; Yeung, S.K. Revisiting Point Cloud Classification: A New Benchmark Dataset and Classification Model on Real-World Data. In Proceedings of the IEEE/CVF International Conference on Computer Vision ( ICCV), Seoul, Korea, 27 October–2 November 2019; IEEE: New York, NY, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- CloudCompare. 3d Point Cloud and Mesh Processing Software Open-Source Project. Version 2.12. Available online: http://www.cloudcompare.org/ (accessed on 24 June 2021).
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Hua, B.S.; Yu, L.F.; Yeung, S.K. A Robust 3D-2D Interactive Tool for Scene Segmentation and Annotation. IEEE Trans. Vis. Comput. Graph. 2018, 24, 3005–3018. [Google Scholar] [CrossRef] [Green Version]
- Wada, K. labelme: Image Polygonal Annotation with Python. 2016. Available online: https://github.com/wkentaro/labelme (accessed on 15 December 2020).
- Hossain, M.; Ma, T.; Watson, T.; Simmers, B.; Khan, J.; Jacobs, E.; Wang, L. Building Indoor Point Cloud Datasets with Object Annotation for Public Safety. In Proceedings of the 10th International Conference on Smart Cities and Green ICT Systems, Online, 28–30 April 2021; SciTePRESS—Science and Technology Publications: Setubal, Portugal, 2021. [Google Scholar] [CrossRef]
- Roynard, X.; Deschaud, J.E.; Goulette, F. Paris-lille-3d: A Large and High-quality Ground-truth Urban Point Cloud Dataset for Automatic Segmentation and Classification. Int. J. Robot. Res. 2018, 37, 545–557. [Google Scholar] [CrossRef] [Green Version]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Yang, K.; Li, J. Toronto-3D: A Large-scale Mobile LiDAR Dataset for Semantic Segmentation of Urban Roadways. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Tong, G.; Li, Y.; Chen, D.; Sun, Q.; Cao, W.; Xiang, G. CSPC-Dataset: New LiDAR Point Cloud Dataset and Benchmark for Large-Scale Scene Semantic Segmentation. IEEE Access 2020, 8, 87695–87718. [Google Scholar] [CrossRef]
- Zimmer, W.; Rangesh, A.; Trivedi, M. 3D BAT: A Semi-Automatic, Web-based 3D Annotation Toolbox for Full-Surround, Multi-Modal Data Streams. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; IEEE: New York, NY, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, M.; Akhtar, N.; Wise, M.; Mian, A. Annotation Tool and Urban Dataset for 3D Point Cloud Semantic Segmentation. IEEE Access 2021, 9, 35984–35996. [Google Scholar] [CrossRef]
- Wirth, F.; Quehl, J.; Ota, J.; Stiller, C. PointAtMe: Efficient 3D Point Cloud Labeling in Virtual Reality. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; IEEE: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Monica, R.; Aleotti, J.; Zillich, M.; Vincze, M. Multi-label Point Cloud Annotation by Selection of Sparse Control Points. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; IEEE: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Autodesk-Recap. Youtube Channel. Available online: http://https://www.youtube.com/user/autodeskrecap/ (accessed on 24 June 2021).
- Barnefske, E.; Sternberg, H. PCCT: A Point Cloud Classification Tool To Create 3D Training Data To Adjust And Develop 3D ConvNet. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W16, 35–40. [Google Scholar] [CrossRef] [Green Version]
- ISO9000; Quality Management Systems—Fundamentals and Vocabulary. ISO: Geneva, Switzerland, 2015.
- DIN55350; Concepts for Quality Management and Statistics—Quality Management. DIN: Geneva, Switzerland, 2020.
- DIN18710; Engineering Survey. DIN: Geneva, Switzerland, 2010.
- Blankenbach, J. Bauaufnahme, Gebäudeerfassung und BIM. In Ingenieurgeodäsie: Handbuch der Geodäsie, Published by Willi Freeden and Reiner Rummel; Springer: Berlin/Heidelberg, Germany, 2017; pp. 23–53. [Google Scholar] [CrossRef]
- Joos, G. Zur Qualität von Objektstrukturierten Geodaten. Ph.D. Thesis, Universität der Bundeswehr München, Muenchen, Germany, 2000. [Google Scholar]
- Scharwächter, T.; Enzweiler, M.; Franke, U.; Roth, S. Efficient Multi-cue Scene Segmentation. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 435–445. [Google Scholar] [CrossRef]
- Miller, G.A.; Beckwith, R.; Fellbaum, C.; Gross, D.; Miller, K.J. Introduction to WordNet: An On-line Lexical Database. Int. J. Lexicogr. [CrossRef] [Green Version]
- buildingSMART. Industry Foundation Classes 4.0.2.1. Available online: https://standards.buildingsmart.org (accessed on 24 June 2021).
- BIM.Hamburg. BIM-Leitfaden für die FHH Hamburg; Technical Report; BIM: Hamburg, Germany, 2019. [Google Scholar]
- Kaden, R.; Clemen, C.; Seuß, R.; Blankenbach, J.; Becker, R.; Eichhorn, A.; Donaubauer, A.; Gruber, U. Leitfaden Geodäsie und BIM. Techreport 2.1, DVW e.V. und Runder Tisch GIS e.V. 2020. Available online: https://dvw.de/images/anhang/2757/leitfaden-geodaesie-und-bim2020onlineversion.pdf (accessed on 15 December 2021).
- BIM-Forum. Level of Development Specification Part1 & Commentary. 2020. Available online: https://bimforum.org/lod/ (accessed on 15 December 2021).
- Günther, M.; Wiemann, T.; Albrecht, S.; Hertzberg, J. Model-based furniture recognition for building semantic object maps. Artif. Intell. 2017, 247, 336–351. [Google Scholar] [CrossRef]
- Wiltscho, T. Sichere Information Durch Infrastrukturgestützte Fahrerassistenzsysteme zur Steigerung der Verkehrssicherheit an Straßenknotenpunkten. Ph.D. Thesis, University Stuttgart, Stuttgart, Germany, 2004. [Google Scholar]
- Torralba, A.; Efros, A.A. Unbiased Look at Dataset Bias. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: New York, NY, USA, 2011. [Google Scholar] [CrossRef] [Green Version]
- Niemeier, W. Ausgleichungsrechnung, 2nd ed.; De Gruyter: Berlin, Germany, 2008. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Powers, D.M.W. Evaluation: From Precision, Recall and F-measure to Roc, Informedness, Markedness and Correlation. Int. J. Mach. Learn. Technol. 2017, 2, 37–63. [Google Scholar]
- Becker, R.; Lublasser, E.; Martens, J.; Wollenberg, R.; Zhang, H.; Brell-Cokcan, S.; Blankenbach, J. Enabling BIM for Property Management of Existing Buildings Based on Automated As-is Capturing; Leitfaden Geodasie und BIM: Buehl, Germany; Muenchen, Germany, 2019. [Google Scholar] [CrossRef]
- Engelmann, F.; Kontogiannia, T.; Hermans, A.; Leibe, B. Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCV), Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Koguciuk, D.; Chechliński, Ł. 3D Object Recognition with Ensemble Learning—A Study of Point Cloud-Based Deep Learning Models. In Advances in Visual Computing; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 100–114. [Google Scholar] [CrossRef] [Green Version]
- Winiwarter, L.; Mandlburger, G.; Pfeifer, N. Klassifizierung von 3D ALS Punktwolken mit Neuronalen Netzen; 20. Internationale Geodätische Woche Obergurgl 2019; Wichmann Herbert: Berlin, Germany; Offenbach, Germany, 2019; Volume 20. [Google Scholar]
- Reiterer, A.; Wäschle, K.; Störk, D.; Leydecker, A.; Gitzen, N. Fully Automated Segmentation of 2D and 3D Mobile Mapping Data for Reliable Modeling of Surface Structures Using Deep Learning. Remote Sens. 2020, 12, 2530. [Google Scholar] [CrossRef]
- Zoller+Fröhlich-GmbH. Reaching New Levels, Z+F Imager5016, User Manual, V2.1; Zoller & Fröhlich GmbH: Wangen im Allgäu, Germany, 2019. [Google Scholar]
- Neitzel, F.; Gordon, B.; Wujanz, D. DVW-Merkblatt 7-2014, Verfahren zur Standardisierten Überprüfungvon Terrestrischen Laserscannern (TLS). Technical Report, DVW. Available online: https://dvw.de/veroeffentlichungen/standpunkte/1149-verfahren-zur-standardisierten-ueberpruefung-von-terrestrischen-laserscannern-tls (accessed on 28 October 2021).
- HexagonMetrology. Product Brochure Leica T-Scan TS 50-a. Available online: https://w3.leica-geosystems.com/downloads123/m1/metrology/t-scan/brochures/leica%20t-scan%20brochure_en.pdf (accessed on 24 June 2021).
- Bernardini, F.; Mittleman, J.; Rushmeier, H.; Silva, C.; Taubin, G. The Ball-pivoting Algorithm for Surface Reconstruction. IEEE Trans. Vis. Comput. Graph. 1999, 5, 349–359. [Google Scholar] [CrossRef]
- Zhou, Q.Y.; Park, J.; Koltun, V. Open3D: A Modern Library for 3D Data Processing. arXiv 2018, arXiv:1801.09847v1. [Google Scholar]
- Hodges, J.L. The Significance Probability of the Smirnov Two-sample Test. Ark. Mat. 1958, 3, 469–486. [Google Scholar] [CrossRef]





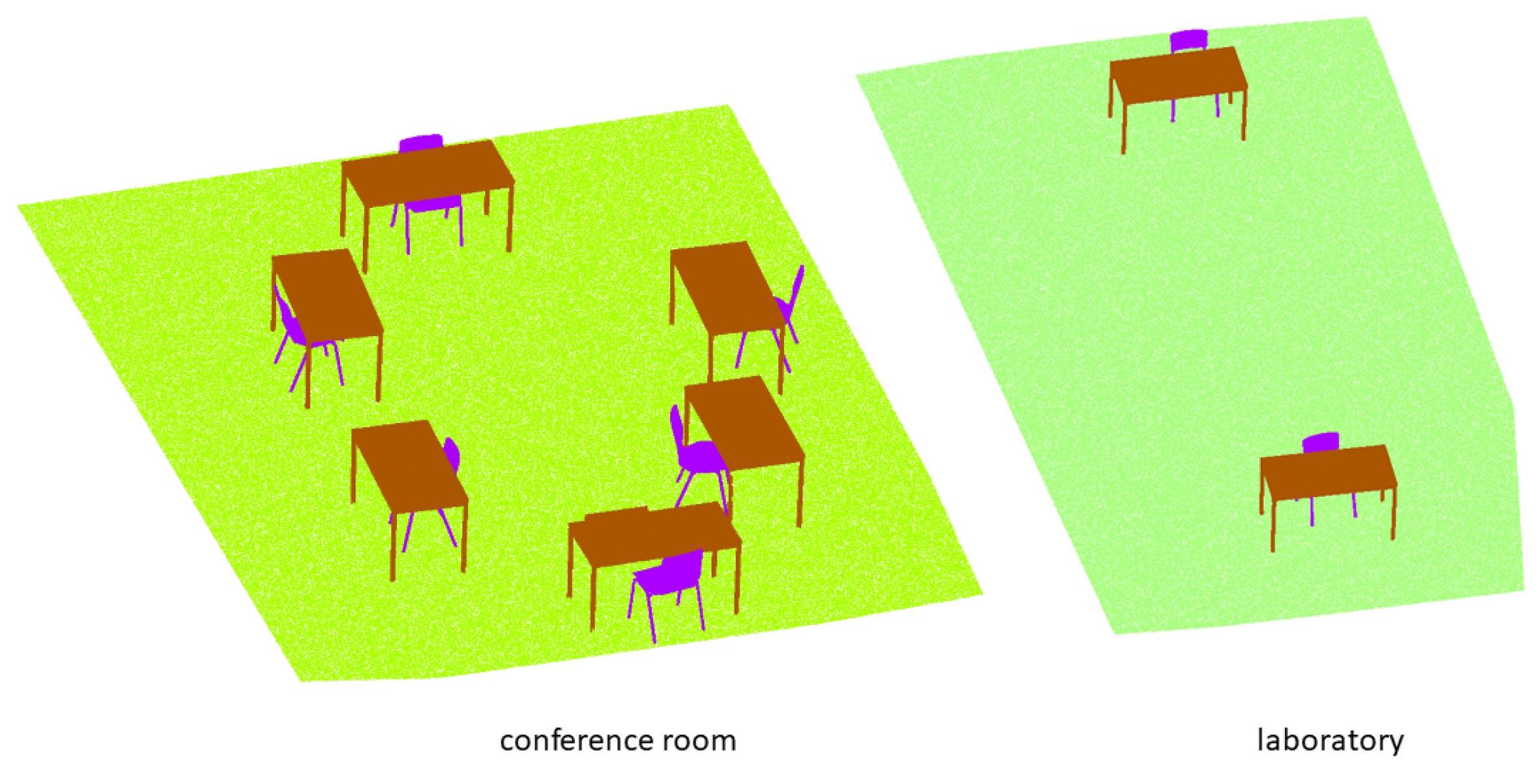

| Dataset | Year | Data Source | Separation Method | No. of Models | No. of Classes | Environment |
|---|---|---|---|---|---|---|
| ShapeNet [27] | 2015 | Trimble 3D Wareh., Yobi3D | Cls, SSeg | >220,000 | 3135 | In-/Outdoor |
| ModelNet [53] | 2015 | Trimble 3D Wareh., Yobi3D | Cls, ISeg | 151,128 | 660 | In-/Outdoor |
| Shape2Motion [26] | 2019 | ShapeNet, Trimble 3D Wareh. | ISeg Cls, SSeg | 2440 | 45 | In-/Outdoor |
| Dataset | Year | Sensor | Sensor Method | Separation Method | Surface Area Points | No. of Classes |
|---|---|---|---|---|---|---|
| SceneNN [56] | 2016 | Kinect v2 | ToF | Cls, SSeg | 7078 m² 1,450,748 | 19 |
| S3DIS [40] | 2016 | Matterport | SL | Cls, SSeg | 6020 m² | 12 |
| ScanNet [57] | 2017 | Occipial (iPad) | SL | ObjD, SSeg | 78,595 m² | 17 |
| Matterport3D [41] | 2017 | Matterport | SL | Cls, SSeg | 219,399 m² | 40 |
| ScanObjectNN [58] | 2019 | SceneNN, ScanNet | ToF, SL | Cls, SSeg | 2.971.648 | 15 |
| Tool | Instance | Semantic | Free Hand | Automatic | Bounding Box |
|---|---|---|---|---|---|
| Recap [71] | x | 3D | 3D | ||
| CloudCompare [59] | x | x | 3D | 3D | |
| SemanticKITTI [13] | x | x | 3D | ||
| PCCT [72] | x | 2D |
| P. No. | Parameter Name | Unit | Range | P/O |
|---|---|---|---|---|
| P1 | Availability | |||
| P1.1 | CD exists | yes/no | P | |
| P1.2 | Number of points | >0 | O | |
| P1.3 | Area size | m2 | >0 | O |
| P1.4 | Object charac. in | yes/no | O | |
| P1.5 | Object charac. out. | yes/no | O | |
| P1.6 | File format out | e.g., pts | O | |
| P1.7 | Use restriction | yes/no | O |
| P. No. | Parameter Name | Unit | Range | P/O |
|---|---|---|---|---|
| P2 | Reliability of Process | |||
| P2.1 | Number of segmentations | >1 | P | |
| P2.2 | Average time required | % | 0–100 | P |
| P. No. | Parameter Name | Unit | Range | P/O |
|---|---|---|---|---|
| P3 | Completeness | |||
| P3.1 | Semantic segmentation rate | % | 0–100 | O |
| P3.2 | Number of classes | >0 | O |
| P. No. | Parameter Name | Unit | Range | P/O |
|---|---|---|---|---|
| P4 | Consistency | |||
| P4.1 | Geometric Consistency (GC) of x, y, z | m | ≥0 | O |
| P4.2 | Spectral Consistency of RGB (SCRGB) | 0–255 | O | |
| P4.3 | Spectral Consistency of I (SCI) | 0–255 | O | |
| P4.4 | Class equality | 0–1 | O |
| P. No. | Parameter | Unit | Range | P/O |
|---|---|---|---|---|
| P5 | Correctness | |||
| P5.1 | Recall of points class x | % | 0–100 | O |
| P5.2 | Recall of area class x | % | 0–100 | O |
| P. No. | Parameter | Unit | Range | P/O |
|---|---|---|---|---|
| P6 | Precision | |||
| P6.1 | Precision class x | % | 0–100 | O |
| P6.2 | Precision area class x | % | 0–100 | O |
| P6.3 | MD of FP pts. class x | mm | ≥0 | O |
| P6.4 | SD of FP pts. class x | mm | ≥0 | O |
| P No. | Parameter | Unit | Range | P/O |
|---|---|---|---|---|
| P7 | Semantic Accuracy | |||
| P7.1 | CD applied | yes/no | P | |
| P7.2 | Hierarchical CD | yes/no | O | |
| P7.3 | class x used | yes/no | O |
| P. No. | Parameter Name | Lab RGB | Lab I | Lab R | Room RGB | Room I | Room R |
|---|---|---|---|---|---|---|---|
| P1 | Availability | ||||||
| P1.1 | CD exists | yes | yes | yes | yes | yes | yes |
| P1.2 | NoP | 2,790,352 points | 14,526,242 points | ||||
| P1.3 | Area size | 51 m | 61 m | ||||
| P1.4 | Object char. in. | x, y, z, I, R, G, B, xN*, yN*, zN* | |||||
| P1.5 | Object char. out. | x, y, z, I, R, G, B, Class | |||||
| P1.6 | File format out. | pts/csv | pts/csv | pts | pts/csv | pts /csv | pts |
| P1.7 | Use restriction | no | no | no | no | no | no |
| P2 | Reliability of Process | ||||||
| P2.1 | NoS | 7 | 7 | 9 | 8 | 8 | 8 |
| P2.2 | ATR | 13% | 13% | 55% | 38% | 45% | 49% |
| P. No. | Parameter Name | Lab RGB | Lab I | Lab R | Room RGB | Room I | Room R |
|---|---|---|---|---|---|---|---|
| P3 | Completeness | ||||||
| P3.1 | SSR | 1.000 | 1.000 | 0.739 | 1.000 | 1.000 | 0.409 |
| P3.2 | NoC | 5 | 5 | 5 | 5 | 5 | 5 |
| P4 | Consistency | ||||||
| P4.1 | GC x, y, z | 10.34, 8.56, 1.00 m | 8.07, 6.11, 0.82 m | ||||
| P4.2 | SCRGB | 0–255 | 0–255 | ||||
| P4.3 | SCI | 0–255 | 0–255 | ||||
| P4.4 | CE | 0.65 | 0.65 | 0.65 | 0.62 | 0.62 | 0.62 |
| P5 | Correctness | ||||||
| P5.1 | RP floor | 99.9% | 99.9% | 100.0% | 99.8% | 99.9% | 100.0% |
| P5.1 | RP chair | 96.1% | 95.7% | 99.2% | 81.6% | 66.0% | 99.7% |
| P5.1 | RP table | 89.6% | 89.6% | 99.8% | 94.5% | 87.8% | 99.7% |
| P5.1 | RP scan. artif. | 27.1% | 27.6% | 69.6% | 47.1% | 35.6% | 77.2% |
| P5.2 | RA floor | 100.0% | 100.0% | 100.0% | 99.8% | 99.8% | 100.0% |
| P5.2 | RA chair | 97.7% | 97.1% | 99.5% | 97.7% | 90.4% | 99.7% |
| P5.2 | RA table | 96.8% | 96.1% | 99.8% | 96.7% | 95.9% | 99.6% |
| P. No. | Parameter Name | Lab RGB | Lab I | Lab R | Room RGB | Room I | Room R |
|---|---|---|---|---|---|---|---|
| P6 | Precision | ||||||
| P6.1 | PP floor | 99.7% | 99.8% | 99.8% | 99.6% | 99.6% | 99.9% |
| P6.1 | PP chair | 78.5% | 78.2% | 95.8% | 77.9% | 67.3% | 95.5% |
| P6.1 | PP table | 92.1% | 93.1% | 98.2% | 93.2% | 93.6% | 97.5% |
| P6.1 | PP scan. artif. | 53.4% | 52.6% | 95.4% | 61.3% | 30.8% | 98.0% |
| P6.2 | PA floor | 99.8% | 100.0% | 100.0% | 99.5% | 99.5% | 99.5% |
| P6.2 | PA chair | 91.7% | 91.6% | 96.7% | 90.4% | 90.8% | 95.7% |
| P6.2 | PA table | 96.8% | 97.6% | 98.8% | 87.7% | 87.6% | 97.3% |
| mm | mm | mm | mm | mm | mm | ||
| P6.3 | MD FP pts floor | 249 | 666 | 83 | 131 | 884 | 92 |
| P6.3 | MD FP pts chair | 1278 | 1244 | 48 | 1699 | 1485 | 55 |
| P6.3 | MD FP pts table | 1237 | 1558 | 53 | 1906 | 1967 | 53 |
| mm | mm | mm | mm | mm | mm | ||
| P6.4 | SD FP pts. floor | 42 | 87 | 38 | 61 | 161 | 24 |
| P6.4 | SD FP pts. chair | 151 | 152 | 9 | 646 | 591 | 16 |
| P6.4 | SD FP pts. table | 207 | 214 | 14 | 279 | 443 | 14 |
| P7 | Semantic Accuracy | ||||||
| P7.1 | CD applied | yes | yes | yes | yes | yes | yes |
| P7.2 | Hier. CD | yes | yes | yes | yes | yes | yes |
| P7.3 | floor used | yes | yes | yes | yes | yes | yes |
| P7.3 | furniture used | no | no | no | no | no | no |
| P7.3 | chair used | yes | yes | yes | yes | yes | yes |
| P7.3 | table used | yes | yes | yes | yes | yes | yes |
| P7.3 | scan. artif. used | yes | yes | yes | yes | yes | yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barnefske, E.; Sternberg, H. Evaluating the Quality of Semantic Segmented 3D Point Clouds. Remote Sens. 2022, 14, 446. https://doi.org/10.3390/rs14030446
Barnefske E, Sternberg H. Evaluating the Quality of Semantic Segmented 3D Point Clouds. Remote Sensing. 2022; 14(3):446. https://doi.org/10.3390/rs14030446
Chicago/Turabian StyleBarnefske, Eike, and Harald Sternberg. 2022. "Evaluating the Quality of Semantic Segmented 3D Point Clouds" Remote Sensing 14, no. 3: 446. https://doi.org/10.3390/rs14030446
APA StyleBarnefske, E., & Sternberg, H. (2022). Evaluating the Quality of Semantic Segmented 3D Point Clouds. Remote Sensing, 14(3), 446. https://doi.org/10.3390/rs14030446