
Data-Driven Calibration Algorithm and Pre-Launch Performance Simulations for the SWOT Mission

 ,
,
Abstract
1. Introduction and Context
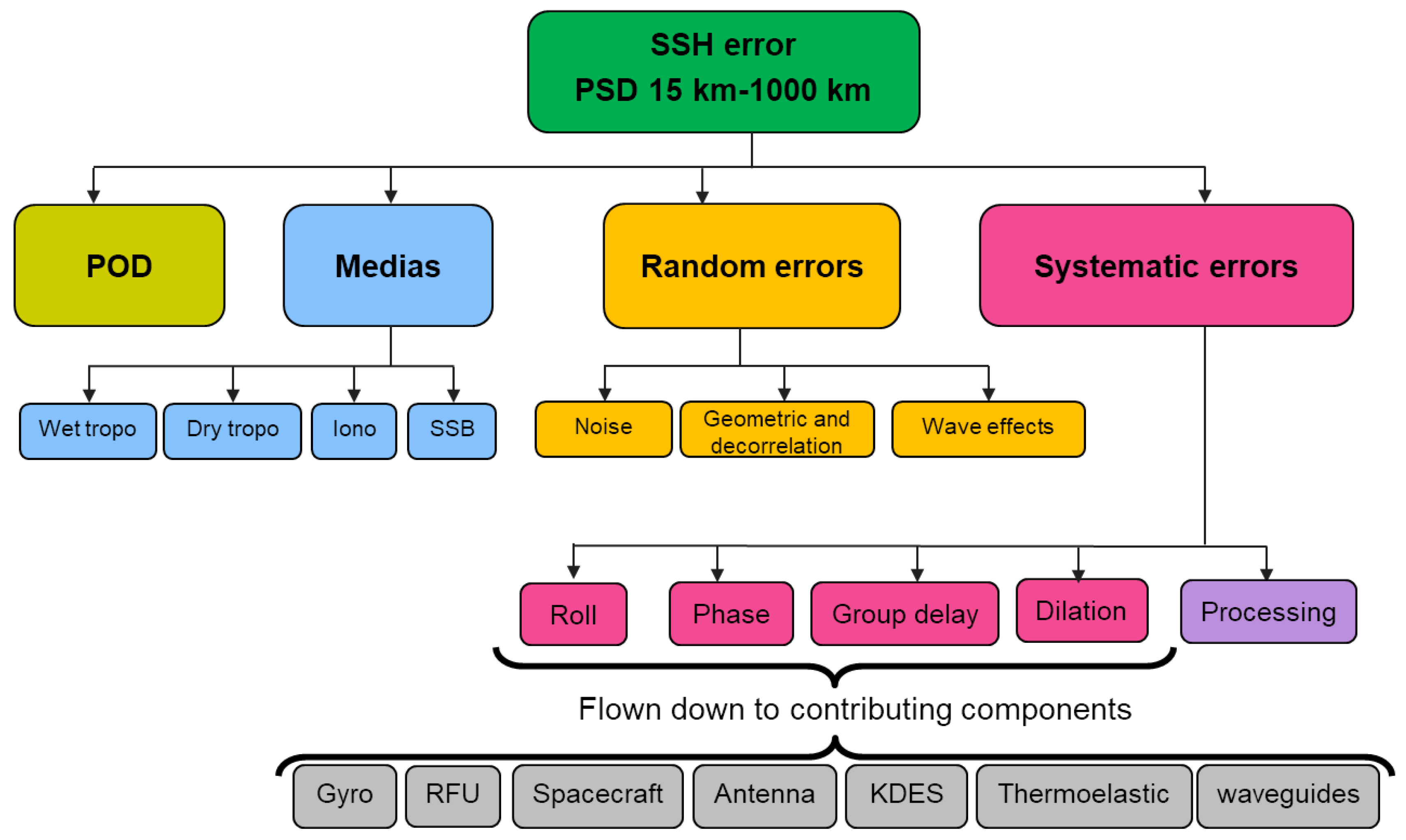
1.1. SWOT Error Budget and Systematic Errors
- SWOT’s error budget is required to be one order of magnitude below the ocean signal for wavelengths ranging from 15 to 1000 km (expressed as a power spectrum);
- KaRIn’s white noise must be less than 1.4 cm for 2 km pixels on ocean (or 2.7 cm for 1 km pixels);
- KaRIn measurement must have a 10 cm height accuracy and a 1.7 cm/1 km slope accuracy over 10 km of river flow distance (for river widths greater than 100 m);
- The topography requirements for the nadir altimeter are derived from Jason-class missions.
1.2. Data-Driven Calibration
1.3. Objective of This Paper
2. Input Data and Prelaunch Scenarios for SWOT
2.1. Input Data
- The GLORYS 1/12° model from Lellouche et al. [12], as it is the state-of-art operational system operated by Mercator Ocean International in the frame of the operational Copernicus Marine Service. This global model has a sufficient resolution to resolve large- and medium-mesoscale and is quite realistic when it comes to the global ocean circulation, including in polar regions. However, its relatively coarse resolution makes it unable to resolve small- to sub-mesoscale. Moreover, it does not have any forcing from tides, so the GLORYS topography does not contain any signature from internal tides.
- The Massachusetts Institute of Technology general circulation model (MITgcm) on a 1/48-degree nominal Latitude/Longitude-Cap horizontal grid (LLC4320). This is one of the latest iterations of the model initially presented by Marshall et al. [13] and discussed in Rocha et al. [14] among others. The strength of this model is the unprecedented resolution (horizontal and vertical) for a global simulation, which makes it possible to resolve small to sub-mesoscale features in the global surface topography snapshots. It is also forced with tides, thus adding important ocean features of interest for SWOT scientific objectives, and as well as more challenges for the data-driven calibration of KaRIn products (see Section 3.3).
- We also used the NEMO-eNATL60 regional model simulation of the North Atlantic at 1/60° from the Institut des Geosciences et de l’Environnement (IGE). Brodeau et al. [16] describe the configuration and the validation performed on this model. Despite its relatively limited geographical coverage (North Atlantic), this model complements our simulations because the topography snapshots compare extremely well with the observations at all scales (i.e., arguably more realistic than the global models above). The model also exists with and without tides, which is very useful to understand the impact of barotropic and baroclinic tides in our local inversions. For the sake of concision, we did not detail the analyses performed with this model as they were generally used to confirm or to modulate some findings from the global models.
2.2. Uncalibrated Error Scenarios
- A bias in each swath originating in the group delay of either antenna (timing error);
- A linear signature in each swath originating in the interferometric phase error;
- A linear signature in both swaths originating in imperfect roll angle knowledge (e.g., gyrometer error);
- A quadratic signature originating in the imperfect knowledge of the interferometric baseline length.
- There is a large non-zero mean for this one-year simulation. In practice, this yearly average might exhibit small inter-annual variations. To illustrate, the Sun controls the illumination and thermal conditions of the satellite. The Sun also has an 11-year cycle. This solar cycle might show up in SWOT as very slowly evolving conditions. In other words, our “non-zero mean” could actually be found to be a very slow signal from the natural variability of the Sun. This yearly time-scale indicates that any calibration performed on a temporal window of one 21-day cycle or less should yield a non-zero mean;
- Slow variations with time-scales of the order of a few weeks to a few months. These modulations are caused by changes in the beta angle of Figure 5. Note that the relationship with the beta-angle can be quite complex, hence the need of a sophisticated simulation such as STOP21. This time-scale indicates that any calibration performed on a temporal window of a few hours or less will observe a linear evolution of the uncalibrated errors;
- Repeating patterns with a time-scale of the order of 15 min to 2 h. These signatures are clearly harmonics of the orbital revolution period (e.g., thermal conditions changing along the orbit circle in a cyclic pattern). This time-scale indicates that the calibration algorithm can exploit the repeating nature of some error signatures using orbital harmonic interpolators rather than basic 1D interpolators;
- High-frequency components with a time-scale of a few minutes or less (essentially high-frequency noise or sharp discontinuities in the curves of Figure 7). These high-frequency components are also broadband because they are affecting many along-track wavelengths (as opposed to the harmonics of the repeating patterns). This time scale is important because it might affect the ocean error budget (requirement from 15 to 1000 km, i.e., 2.5–150 s), either globally if the error is ubiquitous, or locally at certain latitudes if the high-frequency error is limited to specific positions along the orbit circle.
3. Method: Data-Driven Calibration and Practical Implementation
3.1. Data-Driven Calibration: Basic Principles
- M1: One can use a first guess or prior for the true ocean topography (or sea surface height, SSH). The rationale is to remove as much ocean variability as possible with external data, in order to reduce the ambiguity with the systematic errors.
- M2: One can use image-to-image differences instead of a single KaRIn product. When the time lag between two images is shorter than correlation time scales of the ocean, using a difference between two pixels will cancel out a fraction of the ocean variability (the slow components). The closer in time the two images are, the more variability is removed with this process.
- M3: One can use a statistical knowledge of the problem to reduce the ambiguity. Qualitatively, most ocean features look very different from a 1000+ km bias between the left/right swaths of KaRIn, or a quadratic shape aligned with the satellite tracks, or the thin stripes of high-frequency systematic errors. From a numerical point of view, the 3D ocean decorrelation scales in space and time are very different from the covariance of swath-aligned systematic errors. Similarly, the SWOT errors have an along-track/temporal spectrum which is known from theory, hardware testing. It can also be measured from uncalibrated data (see Section 5.4). It is therefore possible to replace simple least square inversions by Gauss-Markov inversions or Kalman filters that exploit this statistical information. This was shown by [6] to reduce significantly the leakage of the ocean variability into the calibration parameters. The process can be used either during the local retrieval (M3a) such as in a crossover region, or it can be used to better interpolate between subsequent calibration zones (M3b).
3.2. Ground Segment Calibration Algorithm Sequence (Level-2)
3.3. Research Calibration Algorithm Sequence (Level-3)
4. Results: Prelaunch Performance Assessment
4.1. Performance of Level-2 Operational Calibration
4.1.1. SWOT’s 21-Day Orbit
4.1.2. SWOT’s One-Day Orbit
4.1.3. Spectral Metrics
4.2. Performance of Level-3 Research Calibration
4.3. Summary of Results
5. Discussions
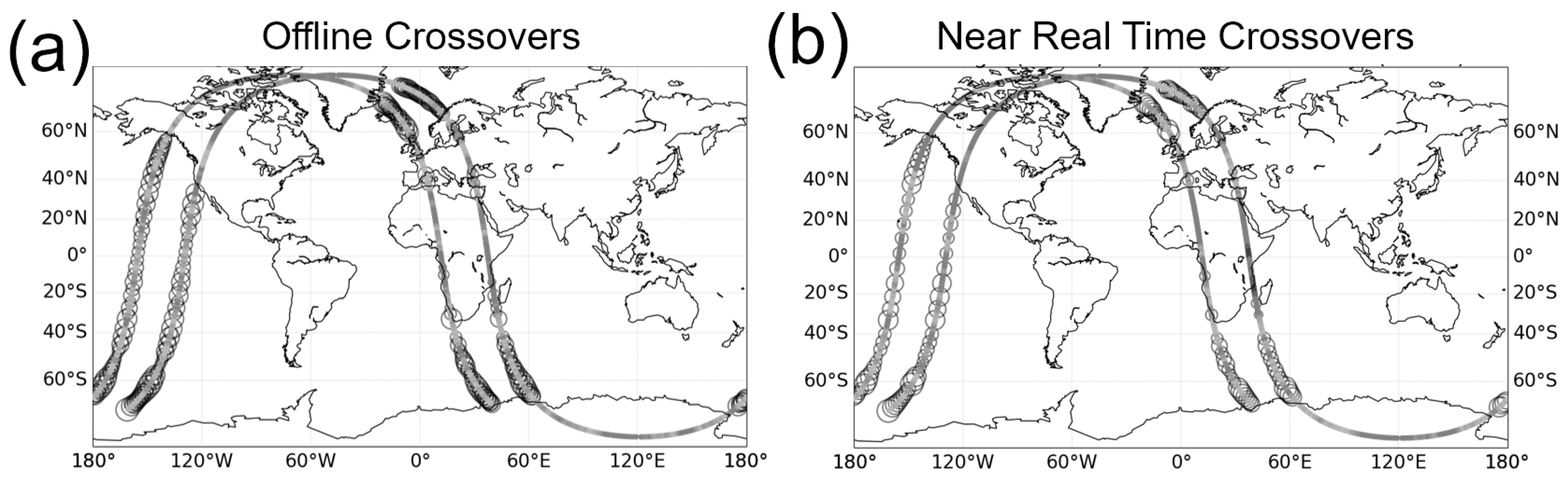
5.1. Near-Real Time Performance
5.2. Sensitivity to the Simulation Inputs
5.2.1. Simulated Ocean Reality
5.2.2. Simulated Orbital Harmonics
5.2.3. Data Gaps
5.3. Algorithm Limitations and Possible Improvements
5.3.1. Hydrology
5.3.2. Ocean
5.4. Validation of Flight Data
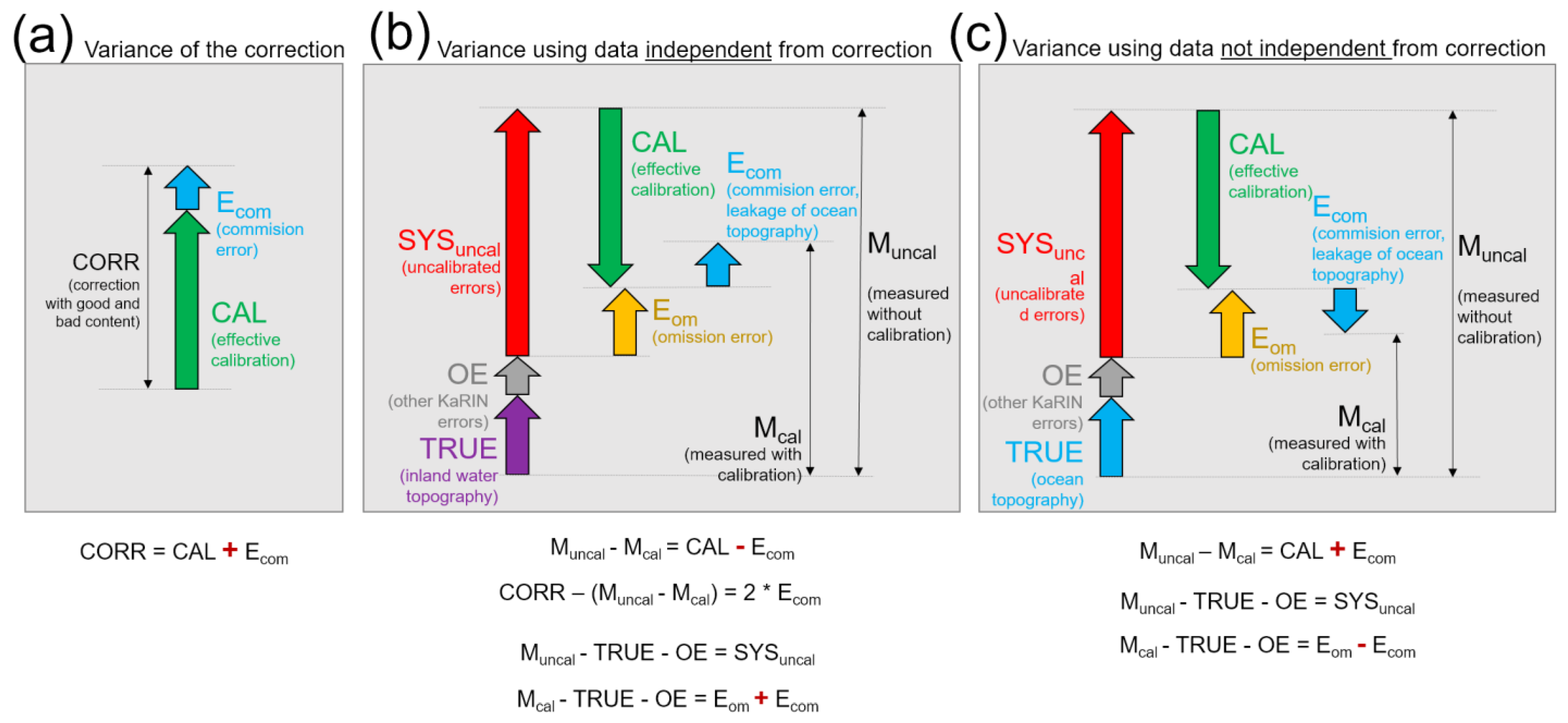
5.4.1. Validation Data: Independent VS. Correlated
- The commission error (Figure 21a) appears when the calibration introduces new errors from external sources (bad measurements, algorithm error, etc.). In our context, the primary source of commission error would be the leakage from ocean signals, and may be residual wet troposphere error or sea-state bias… In contrast, random noise barely affects the data-driven calibration: in our sensitivity studies, increasing random noise by a factor of 10 in variance, yields almost exactly the same results.
- The omission error (Figure 21b) appears when the calibration does not have enough measurements to retrieve the signal of interest (i.e., the uncalibrated systematic errors). In our context, the error primarily originates in the interpolation between crossovers or inland.
5.4.2. Cross-Spectra Validation Method
5.4.3. Other Methods
5.5. Application to Other Swath Altimeter Missions
6. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Morrow, R.; Fu, L.-L.; Ardhuin, F.; Benkiran, M.; Chapron, B.; Cosme, E.; D’Ovidio, F.; Farrar, J.T.; Gille, S.T.; Lapeyre, G.; et al. Global Observations of Fine-Scale Ocean Surface Topography with the Surface Water and Ocean Topography (SWOT) Mission. Front. Mar. Sci. 2019, 6, 232. [Google Scholar] [CrossRef]
- Fu, L.L.; Rodriguez, E. High-Resolution Measurement of Ocean Surface Topography by Radar Interferometry for Oceanographic and Geophysical Applications. In The State of the Planet: Frontiers and Challenges in Geophysics; IUGG Geophysical Monograph; American Geophysical Union: Washington, DC, USA, 2004; Volume 19, pp. 209–224. [Google Scholar]
- Esteban-Fernandez, D. SWOT Mission Performance and Error Budget; NASA/JPL Document (Reference: JPL D-79084); Jet Propulsion Laboratory: Pasadena, CA, USA, 2013. Available online: https://swot.jpl.nasa.gov/system/documents/files/2178_2178_SWOT_D-79084_v10Y_FINAL_REVA__06082017.pdf (accessed on 19 July 2022).
- Enjolras, V.; Vincent, P.; Souyris, J.-C.; Rodriguez, E.; Phalippou, L.; Cazenave, A. Performances study of interferometric radar altimeters: From the instrument to the global mission definition. Sensors 2006, 6, 164–192. [Google Scholar] [CrossRef]
- Dibarboure, G.; Labroue, S.; Ablain, M.; Fjortoft, R.; Mallet, A.; Lambin, J.; Souyris, J.-C. Empirical cross-calibration of coherent SWOT errors using external references and the altimetry constellation. IEEE Trans. Geosci. Remote Sens. 2012, 50, 2325–2344. [Google Scholar] [CrossRef]
- Dibarboure, G.; Ubelmann, C. Investigating the Performance of Four Empirical Cross-Calibration Methods for the Proposed SWOT Mission. Remote Sens. 2014, 6, 4831–4869. [Google Scholar] [CrossRef]
- Du, B.; Li, J.C.; Jin, T.Y.; Zhou, M.; Gao, X.W. Synthesis analysis of SWOT KaRIn-derived water surface heights and local cross-calibration of the baseline roll knowledge error over Lake Baikal. Earth Space Sci. 2021, 8, e2021EA001990. [Google Scholar] [CrossRef]
- Febvre, Q.; Fablet, R.; Le Sommer, J.; Ubelmann, C. Joint calibration and mapping of satellite altimetry data using trainable variational models. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1536–1540. [Google Scholar]
- CNES/JPL. SWOT Low Rate Simulated Products. 2022. [CrossRef]
- Gaultier, L.; Ubelmann, C.; Fu, L.-L. The Challenge of Using Future SWOT Data for Oceanic Field Reconstruction. J. Atmospheric Ocean. Technol. 2016, 33, 119–126. [Google Scholar] [CrossRef]
- Gaultier, L.; Ubelmann, C. SWOT Science Ocean Simulator Open Source Repository. 2019. Available online: https://github.com/SWOTsimulator/swotsimulator (accessed on 19 July 2022).
- Jean-Michel, L.; Eric, G.; Romain, B.-B.; Gilles, G.; Angélique, M.; Marie, D.; Clément, B.; Mathieu, H.; Olivier, L.G.; Charly, R.; et al. The Copernicus Global 1/12° Oceanic and Sea Ice GLORYS12 Reanalysis. Front. Earth Sci. 2021, 9, 698876. [Google Scholar] [CrossRef]
- Marshall, J.; Adcroft, A.; Hill, C.; Perelman, L.; Heisey, C. A finite-volume, incompressible Navier Stokes model for studies of the ocean on parallel computers. J. Geophys. Res. Oceans 1997, 102, 5753–5766. [Google Scholar] [CrossRef]
- Rocha, C.B.; Chereskin, T.K.; Gille, S.T.; Menemenlis, D. Mesoscale to Submesoscale Wavenumber Spectra in Drake Passage. J. Phys. Oceanogr. 2016, 46, 601–620. [Google Scholar] [CrossRef]
- Arbic, B.K.; Elipot, S.; Brasch, J.M.; Menemenlis, D.; Ponte, A.L.; Shriver, J.F.; Yu, X.; Zaron, E.D.; Alford, M.H.; Buijsman, M.C.; et al. Frequency dependence and vertical structure of ocean surface kinetic energy from global high-resolution models and surface drifter observations. arXiv 2022, arXiv:2202.08877. [Google Scholar]
- Brodeau, L.; Le Sommer, J.; Albert, A. Ocean-Next/eNATL60: Material Describing the Set-Up and the Assessment of NEMO-eNATL60 Simulations (Version v1), Zenodo [Code, Data Set]. 2020. Available online: https://zenodo.org/record/4032732 (accessed on 21 November 2022).
- Ubelmann, C.; Fu, L.-L.; Brown, S.; Peral, E.; Esteban-Fernandez, D. The Effect of Atmospheric Water Vapor Content on the Performance of Future Wide-Swath Ocean Altimetry Measurement. J. Atmos. Oceanic Technol. 2014, 31, 1446–1454. [Google Scholar] [CrossRef]
- Le Traon, P.Y.; Faugère, Y.; Hernandez, F.; Dorandeu, J.; Mertz, F.; Ablain, M. Can we merge GEOSAT follow-on with TOPEX/POSEIDON and ERS-2 for an improved description of the ocean circulation? J. Atmos. Ocean. Technol. 2003, 20, 889–895. [Google Scholar] [CrossRef]
- Bretherton, F.P.; Davis, R.E.; Fandry, C.B. A technique for objective analysis and design of oceanographic experiment applied to MODE-73. Deep-Sea Res. 1976, 23, 559–582. [Google Scholar] [CrossRef]
- Ballarotta, M.; Ubelmann, C.; Pujol, M.-I.; Taburet, G.; Fournier, F.; Legeais, J.-F.; Faugère, Y.; Delepoulle, A.; Chelton, D.; Dibarboure, G.; et al. On the resolutions of ocean altimetry maps. Ocean Sci. 2019, 15, 1091–1109. [Google Scholar] [CrossRef]
- Dibarboure, G.; Pujol, M.-I.; Briol, F.; Le Traon, P.-Y.; Larnicol, G.; Picot, N.; Mertz, F.; Ablain, M. Jason-2 in DUACS: Updated System Description, First Tandem Results and Impact on Processing and Products. Mar. Geodesy 2011, 34, 214–241. [Google Scholar] [CrossRef]
- Ponte, A.L.; Klein, P. Incoherent signature of internal tides on sea level in idealized numerical simulations. Geophys. Res. Lett. 2015, 42, 1520–1526. [Google Scholar] [CrossRef]
- Pascual, A.; Boone, C.; Larnicol, G.; Le Traon, P.Y. On the quality of real time altimeter gridded fields: Comparison with in situ data. J. Atmos. Ocean. Technol. 2009, 26, 556. [Google Scholar] [CrossRef]
- Dibarboure, G.; Pascual, A.; Pujol, M.-I. Using short scale content of OGDR data improve the Near Real Time products of Ssalto/Duacs. In Proceedings of the 2009 Ocean SurfaceTopography Science Team Meeting, Seattle, WA, USA, 22–24 June 2009; Available online: https://www.aviso.altimetry.fr/fileadmin/documents/OSTST/2009/oral/Dibarboure.pdf (accessed on 8 October 2022).
- Ubelmann, C.; Dibarboure, G.; Dubois, P. A cross-spectral approach to measure the error budget of the SWOT altimetry mission over the Ocean. J. Atmos. Ocean. Technol. 2018, 35, 845–857. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Stationary (>1 year) | β Angle Variations (1–2 Months) | Orbital Harmonics (0.25–2 h) | Broadband Spectrum (<3 min) |
|---|---|---|---|---|
| Offset | 300 | 1 | 1 | <0.1 |
| Linear | 500 | 200 | 8 | <0.1 |
| Quadratic | 20 | 2 | 1 | <0.1 |
| Residual | <1 | <0.1 | <0.1 | <0.1 |
| Ocean | Inland | |||||
|---|---|---|---|---|---|---|
| Algorithm | Scenario | Orbit | RMSE (cm) | λ Limit (km) | RMSE (cm) | Margins w.r.t Requirements (% Variance) |
| Level-2 | Allocations | SWOT (21d) | 2.2 | 1000 | 6.5 | 25% |
| Level-2 | Allocations | SWOT (1d) | 4.6 | 5000 | 7.8 | −8% |
| Level-2 | CBE2021 | SWOT (21d) | 1.5 | 2500 | 3.1 | 83% |
| Level-2 | CBE2021 | SWOT (1d) | 2.0 | 5000 | 3.1 | 83% |
| Ocean | Inland | ||||||
|---|---|---|---|---|---|---|---|
| Algorithm | Scenario | Orbit | RMSE (cm) | Gain w.r.t Level-2 (% of Variance) | λ Limit (km) | RMSE (cm) | Gain w.r.t Level-2 (% of Variance) |
| Level-3 | Allocations | SWOT (21d) | 1.3 | 65% | 400 | 6.1 | 13% |
| Level-3 | Allocations | SWOT (1d) | 1.1 | 94% | 400 | 5.9 | 43% |
| Level-3 | CBE2021 | SWOT (21d) | 0.9 | 62% | 700 | 2.8 | 21% |
| Level-3 | CBE2021 | SWOT (1d) | 0.9 | 79% | 700 | 2.7 | 22% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dibarboure, G.; Ubelmann, C.; Flamant, B.; Briol, F.; Peral, E.; Bracher, G.; Vergara, O.; Faugère, Y.; Soulat, F.; Picot, N. Data-Driven Calibration Algorithm and Pre-Launch Performance Simulations for the SWOT Mission. Remote Sens. 2022, 14, 6070. https://doi.org/10.3390/rs14236070
Dibarboure G, Ubelmann C, Flamant B, Briol F, Peral E, Bracher G, Vergara O, Faugère Y, Soulat F, Picot N. Data-Driven Calibration Algorithm and Pre-Launch Performance Simulations for the SWOT Mission. Remote Sensing. 2022; 14(23):6070. https://doi.org/10.3390/rs14236070
Chicago/Turabian StyleDibarboure, Gérald, Clément Ubelmann, Benjamin Flamant, Frédéric Briol, Eva Peral, Geoffroy Bracher, Oscar Vergara, Yannice Faugère, François Soulat, and Nicolas Picot. 2022. "Data-Driven Calibration Algorithm and Pre-Launch Performance Simulations for the SWOT Mission" Remote Sensing 14, no. 23: 6070. https://doi.org/10.3390/rs14236070
APA StyleDibarboure, G., Ubelmann, C., Flamant, B., Briol, F., Peral, E., Bracher, G., Vergara, O., Faugère, Y., Soulat, F., & Picot, N. (2022). Data-Driven Calibration Algorithm and Pre-Launch Performance Simulations for the SWOT Mission. Remote Sensing, 14(23), 6070. https://doi.org/10.3390/rs14236070